Apple veut protéger les enfants mais met en danger le chiffrement
Apple vient de subir un tir de barrage nourri de la part des défenseurs de la vie privée alors que ce géant du numérique semble animé des intentions les plus louables…

... mais ce serait peut-être l'une des plus grandes opportunités manquées de notre époque si le logiciel libre ne libérait rien d'autre que du code
Apple vient de subir un tir de barrage nourri de la part des défenseurs de la vie privée alors que ce géant du numérique semble animé des intentions les plus louables…

La sécurité est pour Apple un argument marketing de poids, comme on le voit sur une page qui vante les mérites de la dernière version Big Sur de macOS :

Voici une troisième partie de l’essai que consacre Cory Doctorow au capitalisme de surveillance (parcourir sur le blog les épisodes précédents – parcourir les trois premiers épisodes en PDF : doctorow-1-2-3). Il s’attache ici à démonter les mécanismes utilisés par les … Lire la suite

« Ce dont nous avons besoin, c’est le contraire de la Big Tech. Nous avons besoin de Small Tech – des outils de tous les jours conçus pour augmenter le bien-être humain, et non les profits des entreprises. »

Voici déjà la traduction du cinquième chapitre de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà … Lire la suite
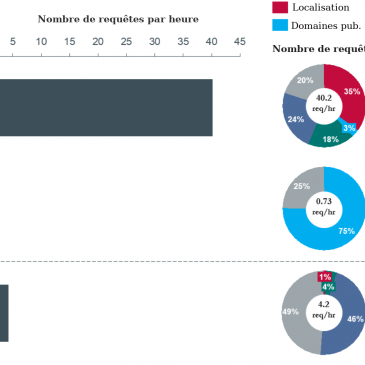
Voici déjà la traduction du troisième chapitre de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà … Lire la suite

Nos conversations dans la bulle privée de l’intimité familiale ne semblent plus vraiment à l’abri de l’espionnage par les objets dont nous acceptons de nous entourer.

Lundi, nous vous annoncions la refonte du site Dégooglisons Internet. Aujourd’hui, nous vous proposons un petit tour des co-propriétaires (ben oui : il est sous licence CC-By-SA !), afin que vous puissiez encore mieux vous emparer de cet outil pour vous dégoogliser, … Lire la suite