Le Web est-il devenu trop compliqué ?
Le Web, tout le monde s’en sert et beaucoup en sont très contents. Mais, même parmi ceux et celles qui sont ravi·es de l’utiliser, il y a souvent des critiques. Elles portent sur de nombreux aspects et je ne vais pas essayer de lister ici toutes ces critiques. Je vais parler d’un problème souvent ressenti : le Web n’est-il pas devenu trop compliqué ?
Merci à Sualtam, auteur de lectureaudio.fr pour cette contribution active.

Je ne parle pas de la complexité pour l’utilisateur, par exemple des problèmes qu’il ou elle peut avoir avec telle ou telle application Web, ou tel formulaire incompréhensible ou excluant. Non, je parle de la complexité des nombreuses technologies sous-jacentes. Alors, si vous n’êtes pas technicien·ne, vous avez peut-être envie d’arrêter votre lecture ici en pensant qu’on ne parlera que de technique. Mais ce n’est pas le cas, cet article est pour tous et toutes. (Ceci dit, si vous arrêtez votre lecture pour jouer avec le chat, manger un bon plat, lire un livre passionnant ou faire des câlins à la personne appropriée, cela ne me dérange pas et je vous souhaite un agréable moment.)
Mais revenons à l’objection « OK, les techniques utilisées dans le Web sont compliquées mais cela ne concerne que les développeuses et développeurs, non ? » Eh bien non car cette complication a des conséquences pour tous et toutes. Elle se traduit par des logiciels beaucoup plus complexes, donc elle réduit la concurrence, très peu d’organisations pouvant aujourd’hui développer un navigateur Web. Elle a pour conséquence de rendre l’utilisation du Web plus lente : bien que les machines et les réseaux aient nettement gagné en performance, le temps d’affichage d’une page ne cesse d’augmenter. Passer à la fibre ou à la 5G ne se traduira pas forcément par un gain de temps, puisque ce sont souvent les calculs nécessaires à l’affichage qui ralentissent la navigation. Et enfin cette complication augmente l’empreinte environnementale du Web, en imposant davantage d’opérations aux machines, ce qui pousse au remplacement plus rapide des terminaux.
L’insoutenable lourdeur du Web
Une page Web d’aujourd’hui n’est en effet pas une simple description d’un contenu. Elle inclut la « feuille de style », rédigée dans le langage CSS, qui va indiquer comment présenter la page, du JavaScript, un langage de programmation qui va être exécuté pour faire varier le contenu de la page, des vidéos, et d’autres choses qui souvent distraient du contenu lui-même. Je précise que je ne parle pas ici des applications tournant sur le Web (comme une application d’accès au courrier électronique, ou une application de gestion des évènements ou l’application maison utilisée par les employés d’une organisation pour gérer leur travail), non, je parle des pages Web de contenu, qui ne devraient pas avoir besoin de toute cette artillerie.
Du fait de cette complexité, il n’existe aujourd’hui que quatre ou cinq navigateurs Web réellement distincts. Écrire un navigateur Web aujourd’hui est une tâche colossale, hors de portée de la très grande majorité des organisations. La concurrence a diminué sérieusement. La complexité technique a donc des conséquences stratégiques pour le Web. Et ceci d’autant plus qu’il n’existe derrière ces navigateurs que deux moteurs de rendu, le cœur du navigateur, la partie qui interprète le langage HTML et le CSS et dessine la page. Chrome, Edge et Safari utilisent le même moteur de rendu, WebKit (ou l’une de ses variantes).
Et encore tout ne tourne pas sur votre machine. Derrière votre écran, l’affichage de la moindre page Web va déclencher d’innombrables opérations sur des machines que vous ne voyez pas, comme les calculs des entreprises publicitaires qui vont, en temps réel, déterminer les « meilleures » publicités à vous envoyer dans la figure ou comme l’activité de traçage des utilisateurs, notant en permanence ce qu’ils font, d’où elles viennent et de nombreuses autres informations, dont beaucoup sont envoyées automatiquement par votre navigateur Web, qui travaille au moins autant pour l’industrie publicitaire que pour vous. Pas étonnant que la consommation énergétique du numérique soit si importante. Et ces calculs côté serveur ont une grande influence sur la capacité du serveur à tenir face à une charge élevée, comme on l’a vu pendant les confinements Covid-19. Les sites Web de l’Éducation Nationale ne tenaient pas le coup, même quand il s’agissait uniquement de servir du contenu statique.
La surveillance coûte cher
La complexité du Web cache en effet également cette activité de surveillance, pratiquée aussi bien par les entreprises privées que par les États. Autrefois, acheter un journal à un kiosque et le lire étaient des activités largement privées. Aujourd’hui, toute activité sur le Web est enregistrée et sert à nourrir les bases de données du monde de la publicité, ou les fichiers des États. Comme exemple des informations envoyées par votre navigateur, sans que vous en ayez clairement connaissance, on peut citer bien sûr les fameux cookies. Ce sont des petits fichiers choisis par le site Web et envoyés à votre navigateur. Celui-ci les stockera et, lors d’une visite ultérieure au même site Web, renverra le cookie. C’est donc un outil puissant de suivi de l’utilisateur. Et ne croyez pas que, si vous visitez un site Web, seule l’organisation derrière ce site pourra vous pister. La plupart des pages Web incluent en effet des ressources extérieures (images, vidéos, boutons de partage), pas forcément chargés depuis le site Web que vous visitez et qui ont eux aussi leurs cookies. La loi Informatique et Libertés (et, aujourd’hui, le RGPD) impose depuis longtemps que les utilisateurs soient prévenus de ce pistage et puissent s’y opposer, mais il a fallu très longtemps pour que la CNIL tape sur la table et impose réellement cette information des utilisateurs, le « bandeau cookies ». Notez qu’il n’est pas obligatoire. D’abord, si le site Web ne piste pas les utilisateurs, il n’y a pas d’obligation d’un tel bandeau, ensuite, même en cas de pistage, de nombreuses exceptions sont prévues.

Les bandeaux cookies sont en général délibérément conçus pour qu’il soit difficile de refuser. Le but est que l’utilisateur clique rapidement sur « Accepter » pour en être débarrassé, permettant ainsi à l’entreprise qui gère le site Web de prétendre qu’il y a eu consentement.
Désolé de la longueur de ce préambule, d’autant plus qu’il est très possible que, en tant que lectrice ou lecteur du Framablog, vous soyez déjà au courant. Mais il était nécessaire de revenir sur ces problèmes du Web pour mieux comprendre les projets qui visent à corriger le tir. Notez que les évolutions néfastes du Web ne sont pas qu’un problème technique. Elles sont dues à des raisons économiques et politiques et donc aucune approche purement technique ne va résoudre complètement le problème. Cela ne signifie pas que les techniciens et techniciennes doivent rester les bras croisés. Ils et elles peuvent apporter des solutions partielles au problème.

Bloquer les saletés
Première approche possible vers un Web plus léger, tenter de bloquer les services néfastes. Tout bon navigateur Web permet ainsi un certain contrôle de l’usage des cookies. C’est par exemple ce que propose Firefox dans une rubrique justement nommée « Vie privée et sécurité ».
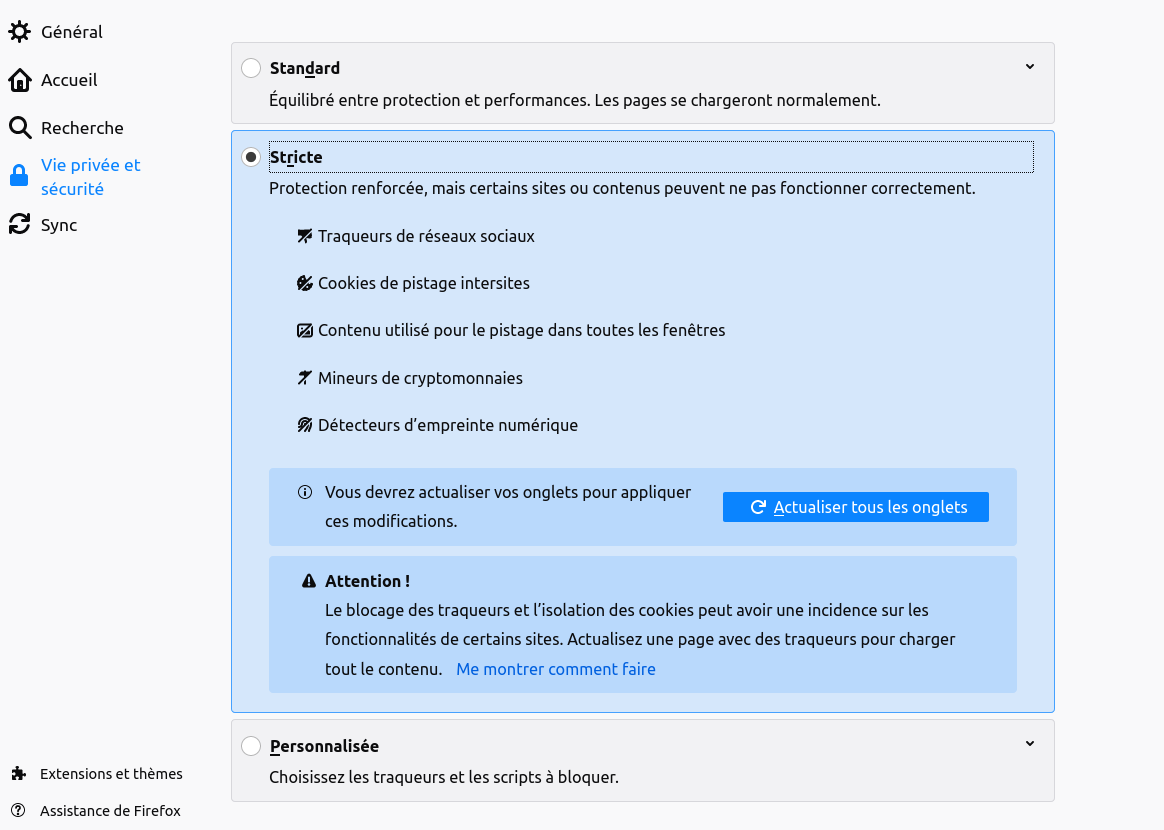
On peut ainsi bloquer une partie du système de surveillance. Cette approche est très recommandée mais notez que Firefox vous avertit que cela risque d’ « empêcher certains sites de fonctionner ». Cet avertissement peut faire hésiter certains utilisateurs, d’autant plus qu’avec les sites en question, il n’y aura aucun message clair, uniquement des dysfonctionnements bizarres. La plupart des sites Web commerciaux sont en effet développés sans tenir compte de la possibilité que le visiteur ait activé ces options. Si le site de votre banque ne marche plus après avoir changé ces réglages, ne comptez pas sur le support technique de la banque pour vous aider à analyser le problème, on vous dira probablement uniquement d’utiliser Google Chrome et de ne pas toucher aux réglages. D’un côté, les responsables du Web de surveillance disent qu’on a le choix, qu’on peut changer les réglages, d’un autre côté ils exercent une pression sociale intense pour qu’on ne le fasse pas. Et puis, autant on peut renoncer à regarder le site Web d’un journal lorsqu’il ne marche pas sans cookies, autant on ne peut guère en faire autant lorsqu’il s’agit de sa banque.
De même qu’on peut contrôler, voire débrayer les cookies, on peut supprimer le code Javascript. À ma connaissance, Firefox ne permet pas en standard de le faire, mais il existe une extension nommée NoScript pour le faire. Comme avec les cookies, cela posera des problèmes avec certains sites Web et, pire, ces problèmes ne se traduiront pas par des messages clairs mais par des dysfonctionnements. Là encore, peu de chance que le logiciel que l’entreprise en question a chargé de répondre aux questions sur Twitter vous aide.
Enfin, un troisième outil pour limiter les divers risques du Web est le bloqueur de publicité. (Personnellement, j’utilise uBlock Origin.)
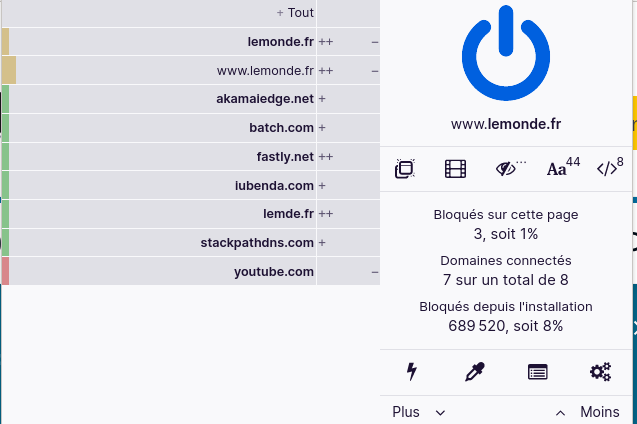
Absolument indispensable à la fois pour éviter de consacrer du temps de cerveau à regarder les publicités, pour la sécurité (les réseaux de distribution de la publicité sont l’endroit idéal pour diffuser du logiciel malveillant) et aussi pour l’empreinte environnementale, le bloqueur empêchant le chargement de contenus qui feront travailler votre ordinateur pour le profit des agences de publicité et des annonceurs.
Un navigateur Web léger ?
Une solution plus radicale est de changer de navigateur Web. On peut ainsi préférer le logiciel Dillo, explicitement conçu pour la légèreté, les performances et la vie privée. Dillo marche parfaitement avec des sites Web bien conçus, mais ceux-ci ne sont qu’une infime minorité. La plupart du temps, le site sera affiché de manière bizarre. Et on ne peut pas le savoir à l’avance ; naviguer sur le Web avec Dillo, c’est avoir beaucoup de mauvaises surprises et seulement quelques bonnes (le Framablog, que vous lisez en ce moment, marche très bien avec Dillo).
Autre navigateur « alternatif », le Tor Browser. C’est un Firefox modifié, avec NoScript inclus et qui, surtout, ne se connecte pas directement au site Web visité mais passe par plusieurs relais du réseau Tor, supprimant ainsi un moyen de pistage fréquent, l’adresse IP de votre ordinateur. Outre que certains sites ne réagissent pas bien aux réglages du Tor Browser, le passage par le réseau Tor se traduit par des performances décrues.
Toutes ces solutions techniques, du bloqueur de publicités au navigateur léger et protecteur de la vie privée, ont un problème commun : elles sont perçues par les sites Web comme « alternatives » voire « anormales ». Non seulement le site Web risque de ne pas fonctionner normalement mais surtout, on n’est pas prévenu à l’avance, et même après on n’a pas de diagnostic clair. Le Web, pourtant devenu un écosystème très complexe, n’a pas de mécanismes permettant d’exprimer des préférences et d’être sûr qu’elles sont suivies. Certes, il existe des techniques comme l’en-tête « Do Not Track » où votre navigateur annonce qu’il ne souhaite pas être pisté mais il est impossible de garantir qu’il sera respecté et, vu le manque d’éthique de la grande majorité des sites Web, il vaut mieux ne pas compter dessus.
Gemini, une solution de rupture
Cela a mené à une approche plus radicale, sur laquelle je souhaitais terminer cet article, le projet Gemini. Gemini est un système complet d’accès à l’information, alternatif au Web, même s’il en reprend quelques techniques. Gemini est délibérément très simple : le protocole, le langage parlé entre le navigateur et le serveur, est très limité, afin d’éviter de transmettre des informations pouvant servir au pistage (comme l’en-tête User-Agent du Web) et il n’est pas extensible. Contrairement au Web, aucun mécanisme n’est prévu pour ajouter des fonctions, l’expérience du Web ayant montré que ces fonctions ne sont pas forcément dans l’intérêt de l’utilisateur. Évidemment, il n’y a pas l’équivalent des cookies. Et le format des pages est également très limité, à la fois pour permettre des navigateurs simples (pas de CSS, pas de Javascript), pour éviter de charger des ressources depuis un site tiers et pour diminuer la consommation de ressources informatiques par le navigateur. Il n’y a même pas d’images. Voici deux exemples de navigateurs Gemini :
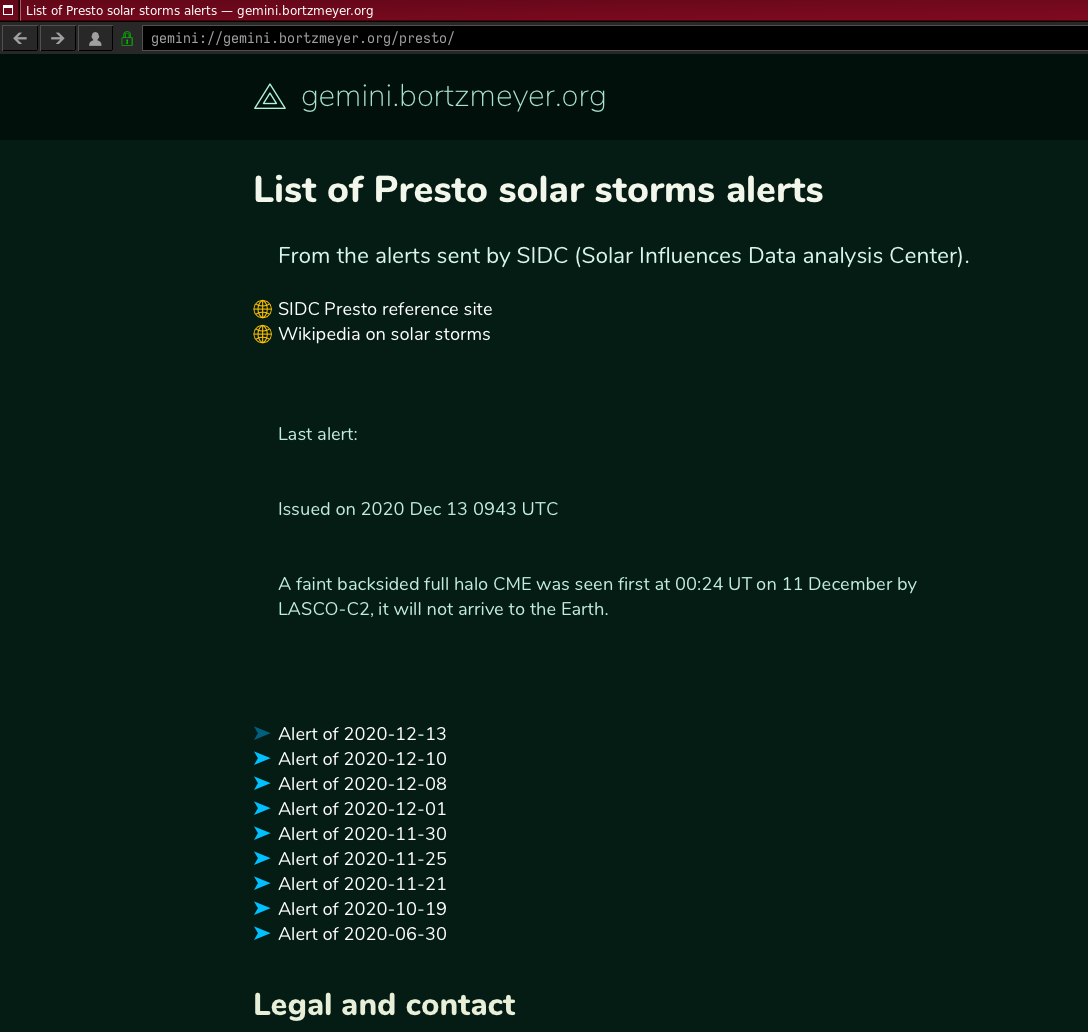
Gemini est un système récent, s’inspirant à la fois de systèmes anciens (comme le Web des débuts) et de choses plus récentes (ainsi, contrairement au Web, le chiffrement du trafic, pour compliquer la surveillance, est systématique). Il reprend notamment le concept d’URL donc par exemple le site d’informations sur les alertes de tempêtes solaires utilisé plus haut à titre d’exemple est gemini://gemini.bortzmeyer.org/presto/. Gemini est actuellement en cours de développement, de manière très ouverte, notamment sur la liste de diffusion publique du projet. Tout le monde peut participer à sa définition. (Mais, si vous voulez le faire, merci de lire la FAQ d’abord, pour ne pas recommencer une question déjà discutée.) Conformément aux buts du projet, écrire un client ou un serveur Gemini est facile et des dizaines de logiciels existent déjà. Le nom étant une allusion aux missions spatiales étatsuniennes Gemini, mais signifiant également « jumeaux » en latin, beaucoup de ces logiciels ont un nom qui évoque le spatial ou la gémellité. Pour la même raison spatiale, les sites Gemini se nomment des capsules, et il y en a actuellement quelques centaines opérationnelles. (Mais, en général, avec peu de contenu original. Gemini ressemble pour l’instant au Web des débuts, avec du contenu importé automatiquement d’autres services, et du contenu portant sur Gemini lui-même.)
On a vu que Gemini est une solution très disruptive et qui ne sera pas facilement adoptée, tant le marketing a réussi à convaincre que, sans vidéos incluses dans la page, on ne peut pas être vraiment heureux. Gemini ne prétend pas à remplacer le Web pour tous ses usages. Par exemple, un CMS, logiciel de gestion de contenu, comme le WordPress utilisé pour cet article, ne peut pas être fait avec Gemini, et ce n’est pas son but. Son principal intérêt est de nous faire réfléchir sur l’accès à l’information : de quoi avons-nous besoin pour nous informer ?
— — —
- Pour en savoir plus sur Gemini, cet autre article un peu plus technique du même auteur : Le protocole Gemini, revenir à du simple et sûr pour distribuer l’information en ligne ?

