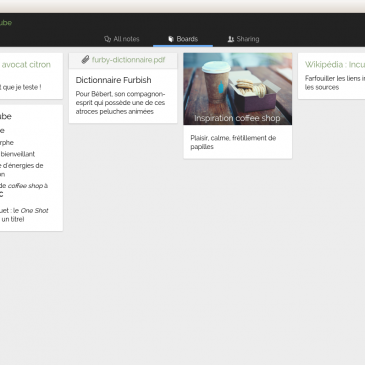
Framanotes : vos notes vous appartiennent. For ever.
Framanotes vous permettra de chiffrer (et de retrouver) sans effort vos listes de courses, de tâches à faire, schémas et photos inspirantes, fichiers perso et marque-pages qui en racontent bien plus sur vous que ce que vous voudriez en dire !