« I don’t want any spam ! »
Traduction : « Je ne veux pas de spam ! »
Le spam est un problème qu’à Framasoft, nous connaissons bien. Mais savez-vous à quel point ?
Je vais, dans cet article, vous dresser le tableau des soucis de spam que nous rencontrons et des contre-mesures que nous avons mises en place.
Avant cela, un peu d’histoire…
Qu’est-ce que le spam ?
Avant l’ère d’Internet, le spam n’était qu’une marque de viande en conserve.
Les Monty Python, humoristes anglais à qui l’on doit notamment les hilarants Sacré Graal ! et La vie de Brian, ont réalisé un sketch (version textuelle) dans lequel un couple, dans un restaurant, demande ce qu’il y a à la carte pour le petit déjeuner et où la serveuse ne propose que des plats avec du spam (et pas qu’un peu : « Spam, spam, spam, spam, spam, spam, baked beans, spam, spam, spam and spam. »). La femme du couple ne peut avoir de petit déjeuner sans spam, la serveuse ne lui proposant qu’encore plus de spam… (le titre de cet article est une citation de la femme du couple).

De ce sketch découle l’utilisation du terme spam pour les courriels indésirables (et tout autre message indésirable, quelle que soit la plateforme comme nous allons le voir).
De nos jours, le spam représente 50% des courriels échangés sur la planète.
Que serait une marque sans #CopyrightMadness ? Hormel Foods, l’entreprise derrière le spam a tenté d’utiliser le droit des marques pour éviter que le nom de son produit soit utilisé pour quelque chose dont personne ne veut et pour essayer d’empêcher d’autres entreprises d’utiliser le terme (comme des éditeurs de solutions anti-spam). Je croyais qu’Hormel Foods avait cessé cette lutte inutile, mais il semblerait que non, allant jusqu’à embêter Gee pour un dessin qu’il proposait sur RedBubble.
Le spam dans les courriels
Chez Framasoft, nous sommes aux deux bouts de la chaîne : nous envoyons beaucoup de courriels (dans les 15 000 courriels par jour pour nos services – inscriptions, notifications, etc. – et plus de 200 000 courriels par jour pour Framalistes) et nous en recevons aussi, que ce soit au niveau de notre serveur de courriel interne ou sur Framalistes. Il y a aussi quelques autres services qui permettent d’interagir par courriel comme notre forum, Framavox et Framagit.

Nous devons donc nous assurer, d’un côté, de ne pas passer pour des spammeur·euses et de l’autre, de nous en protéger.
Se protéger des spams par courriel
Rien de bien fantastique à ce niveau. Nous utilisons l’antispam Rspamd qui vérifie la validité du courriel par rapport à sa signature DKIM, à l’enregistrement SPF et à la politique DMARC du domaine (voir sur NextINpact pour un bon article sur le sujet). Bien entendu, cela ne vaut que si le domaine en question met en place ces mécanismes… On notera que la plupart des FAI français, s’ils vérifient bien les courriels entrants de la même façon que nous, se tamponnent allègrement le coquillard de mettre en place ces mécanismes pour leurs propres courriels. J’aimerais qu’un jour, ceux-ci arrêtent de faire de la merde 🙄 (remarquez, il semblerait que ça avance… très lentement, mais ça avance).
En plus de ces vérifications, Rspamd effectue aussi une vérification par filtrage bayésien, interroge des listes de blocage (RBL) et utilise un mécanisme de liste grise.

Il y a toujours, bien évidemment des trous dans la raquette, mais le ratio spam intercepté/spam non détecté est assez haut et nous alimentons Rspamd avec les messages indésirables qui sont passés sous le radar.
Sur Framalistes, afin de ne pas risquer de supprimer de messages légitimes, nous avons forcé le passage des spams probables en modération : tout message considéré comme spam par Rspamd doit être approuvé (ou rejeté) par les modérateur·ices ou propriétaires de la liste.
Nous avons créé un scénario
spam_status.x-spam-status dans Sympa :
title.gettext test x-spam-status header
match([header->Subject][-1],/\*\*\*\*\*SPAM\*\*\*\*\*/) smtp,dkim,smime,md5 -> unsure
true() smtp,dkim,md5,smime -> hamEt nous avons ajouté cette ligne à tous les scenarii de type send :
match ([msg->spam_status], /unsure/) smtp,dkim,md5,smime -> editorkeyLe texte *****SPAM***** est ajouté au sujet du mail par Rspamd en cas de suspicion de spam. Si Rspamd est vraiment catégorique, le mail est directement rejeté.

Ne pas être considéré comme spammeur·euses
Là, c’est plus difficile. En effet, malgré notre respect de toutes les bonnes pratiques citées ci-dessus et d’autres (SPF, DKIM, DMARC…), nous restons à la merci de règles absurdes et non publiques mises en place par les autres services de courriel.
Vous mettez en place un nouveau serveur qui va envoyer des courriels ? Bon courage pour que les serveurs de Microsoft (hotmail.com, outlook.com…) l’acceptent. J’ai encore vécu ça il y a quelques mois et je ne sais toujours pas comment ça s’est débloqué (j’ai envoyé des courriels à des adresses chez eux que j’ai créées pour ça et je reclassais les courriels dans la catégorie « légitime », ça ne fonctionnait toujours pas mais quelques semaines plus tard, ça passait).

Votre serveur envoie beaucoup de courriels à Orange ? Pensez à limiter le nombre de courriels envoyés en même temps. Mais aussi à mettre en place un cache des connexions avec leurs serveurs. Eh oui : pas plus de X mails envoyés en même temps, mais pas plus de Y connexions par heure. Ou par minute. Ou par jour. C’est ça le problème : on n’en sait rien, on ne peut que poser la question à d’autres administrateurs de services de mail (pour cela, la liste de diffusion smtp-fr gagne à être connue. Le groupe des adminSys français, FRsAG est aussi à garder en tête).
Un autre problème est que nous ne sommes pas à l’origine du contenu de tous les courriels qui sortent de nos serveurs.
Par exemple, un spam arrivant sur une framaliste, s’il n’est pas détecté, sera envoyé à tou·tes les abonné·es de la liste, et ça peut vite faire du volume.
Les spams peuvent aussi passer de medium en medium : Framapiaf peut vous notifier par courriel d’une mention de votre identifiant dans un pouet (Ex. « Coucou @luc »). Si le pouet est un spam (« Coucou @luc, tu veux acheter une pierre magique contre les ondes 5G des reptiliens franc-maçons islamo-gauchistes partouzeurs de droite ? »), le spam se retrouve dans un courriel qui part de chez nous.

Certes, les courriels partant de chez nous sont aussi analysés par Rspamd et certains sont bloqués avant envoi, mais ce n’est pas efficace à 100 %.
Il y a aussi les faux positifs : que faire si nos courriels sont incorrectement classés comme spam par leurs destinataires ? Comme quelqu’un abonné sur une framaliste sans en être averti et qui d’un coup se retrouve submergé de courriels venant d’un expéditeur inconnu ?
Nous nous sommes inscrits à une boucle de rétroaction : nous recevons des notifications pour chaque courriel classé comme indésirable par un certain nombre de fournisseurs de messagerie.
Cela nous a permis (et nous permet toujours. Quotidiennement.) d’envoyer un message à de nombreuses personnes au courriel @laposte.net abonnées à des framalistes pour leur demander de ne pas nous mettre en indésirable, mais de se désabonner de la liste (en leur indiquant la marche à suivre) si elles ne souhaitent pas en recevoir les messages.
Au niveau de Framalistes, nous vérifions que les comptes possédant plus qu’un certain nombre de listes, et que les listes avec beaucoup d’abonné⋅es ne soient pas utilisées pour envoyer des messages indésirables. En effet, nous avons déjà souffert de quelques vagues de spam, nous obligeant à l’époque à modérer la création de listes en dehors des heures de travail car nous ne souhaitions pas, le matin, nous rendre compte que le service était tombé ou s’était fait bloquer pendant la nuit : l’envoi massif de courriels comme le faisaient les spammeur·euses rencontrait souvent un goulot d’étranglement au niveau du serveur, incapable de gérer autant de courriels d’un coup, ce qui faisait tomber le service.
Cette modération n’est plus active aujourd’hui, mais nous avons toujours cet outil prêt à être utilisé en cas de besoin.
Framalistes, si vous l’utilisez, a besoin de vous pour lutter contre le spam !
Petit rappel : il y a un lien de désinscription en bas de chaque courriel des framalistes. Utilisez ce lien pour vous désinscrire si vous ne souhaitez plus recevoir les messages de la liste.
Rien de plus simple que de déclarer un courriel comme étant du spam, n’est-ce pas ? Un clic dans son client mail et hop !
Eh bien non, pas pour Framalistes.
En effet, en faisant cela, vous déclarez notre serveur comme émettant du spam et non pas le serveur originel : nous risquons d’être complètement bannis et de ne plus pouvoir envoyer de courriels vers votre service de messagerie. De plus, l’apprentissage du spam (si le service de messagerie que vous utilisez fait bien son travail, les messages déclarés manuellement comme étant du spam passent dans une moulinette pour mettre à jour les règles de filtrage anti-spam) ne se fait que sur votre service de messagerie, pas chez nous.

Si votre liste reçoit des spams, merci de le signaler à nom_de_la_liste-request@framalistes.org (l’adresse pour contacter les propriétaires de votre liste) : les propriétaires de la liste ont la possibilité, sur https://framalistes.org/sympa/arc/nom_de_la_liste, de supprimer un message des archives et de le signaler comme spam non détecté (n’hésitez pas à leur indiquer ce lien).
Le spam sur Framapiaf et Framasphère
Point d’antispam comme Rspamd possible sur Mastodon ou diaspora* (techniquement, il pourrait y avoir moyen de faire quelque chose, mais ça serait très compliqué).
Les serveurs Mastodon (pas que framapiaf.org, celui de Framasoft) font régulièrement l’objet de vagues d’inscription de spammeur·euses. Pour éviter l’épuisement de notre équipe de modération, nous avons décidé de modérer les inscriptions et donc d’accepter les comptes un à un.
Nous nous reposons sur les signalements des utilisateur·ices pour repérer les comptes de spam que nous aurions laissé passer et les supprimer (ce qui est très rare) ou les bloquer s’ils proviennent d’autres serveurs avec lesquels nous sommes fédérés.
Framasphère ne dispose pas, contrairement à Framapiaf de tels outils de modération : pas d’inscriptions modérées, pas de blocage de comptes distants… Nous ne pouvons que nous reposer sur les signalements et bloquer les comptes locaux.
Nous arrivons tout de même à bloquer les comptes distants, mais cela nécessite de modifier un enregistrement directement en base de données.
Voici comment nous bloquons les comptes distants sur Framasphère :
UPDATE people SET serialized_public_key = 'banned' WHERE guid = 'le_guid_du_compte';Le spam sur Framaforms
Framaforms a rapidement été victime de son succès : sa fréquentation a presque triplé entre 2019 et 2020 (et l’année n’est pas terminée !), devenant aujourd’hui le service le plus utilisé de notre réseau !
Nous n’avons donc pas remarqué la création de nombreux, trop nombreux formulaires proposant, par exemple, des liens vers des sites de téléchargement illégal de films. C’est d’ailleurs suite à une réclamation d’un ayant droit que nous avons pris conscience du problème (oui, nous avons fait suite à cette réclamation : quoi que nous pensions du droit d’auteur, nous nous devons de respecter la loi).
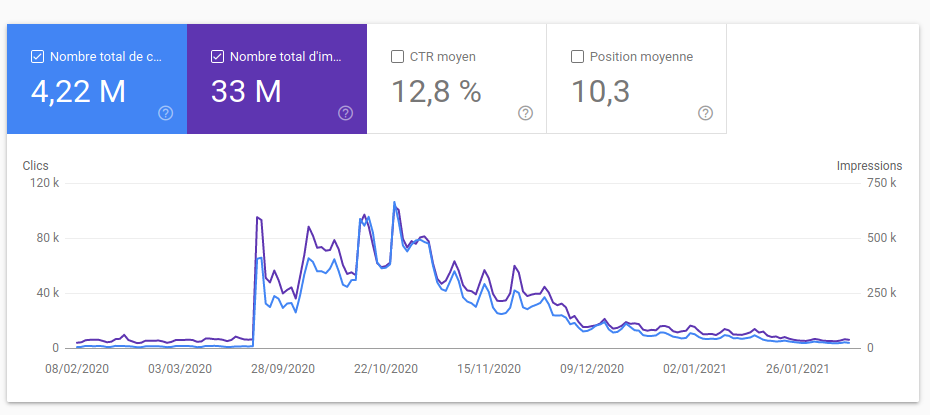
La lutte contre le spam a occupé une bonne partie du temps de Théo qui a temporairement rejoint notre équipe salariée pour prêter main forte sur Framaforms :
- détection de certains termes dans les formulaires avec mise en quarantaine (dépublication) en cas de suspicion de spam ;
- quarantaine des formulaires ne contenant aucune question (juste la description, quoi) ;
- interdiction de certains termes dans le titre des formulaires ;
- intégration d’Akismet (un service anti-spam en ligne, proposé par Automattic, la société derrière https://wordpress.com/, contributrice à WordPress) ;
- amélioration du système de CAPTCHA
- ajout de vues permettant une gestion plus aisée des formulaires par les administrateur·ices.
Les efforts de Theo ont porté leurs fruits : la détection automatique des spams et leur dépublication tout aussi automatique limitent la pollution présente sur Framaforms (ce qui évite les réclamations, donc de monopoliser l’attention d’un salarié pour y répondre) et l’interface de gestion des spams facilite grandement le travail des administrateur·ices.

Le spam sur Framagit
Nous avons beaucoup d’utilisateur⋅ices sur Framagit : nous avons dépassé les 90 000 inscrit⋅es. Mais pour notre malheur, la grande majorité d’entre elleux est constituée de comptes de spam !
Après des mois de ménage, nous sommes redescendus à un peu moins de 34 000 comptes, mais nous ne sommes pas dupes : il y a encore beaucoup de comptes illégitimes.
À noter cependant : ces comptes de spam ne semblent pas être dommageables pour les utilisateur⋅ices de Framagit. En effet, leur nuisance se limite généralement à mettre des liens vers un site de poker en ligne, de rencontres voire… de plombiers à Dubaï (je ne comprends pas non plus 😅).
Ceci explique en partie pourquoi nous n’avons pas lutté très activement contre le spam sur Framagit (l’autre raison étant que nous n’avions tout simplement pas de temps à y consacrer).
Nous avions déjà eu une vague de spams lors de l’ouverture de Framagit et nous avions dû interdire l’accès de notre forge logicielle à l’Inde, à l’Indonésie et au Viêt Nam, restriction active jusqu’à la semaine dernière.
Cela n’est pas dans nos habitudes mais s’il faut choisir entre ça et le risque d’épuisement professionnel d’un membre de l’équipe, Framasoft préfère faire passer l’humain avant tout (🤗).
Une grande vague de nettoyage a eu lieu en juin, où j’ai recherché des critères communs aux comptes de spam afin de les supprimer en masse… ce qui a donné lieu à une vilaine boulette lorsque j’ai choisi des critères bien trop larges, conduisant à la suppression de nombreux comptes légitimes (rétablis depuis).
Depuis, j’ai vérifié manuellement chaque compte remonté par mes recherches… soit plus de 18 000 comptes depuis septembre. Parmi ceux-ci, il devait y en avoir, à la louche (parce que mes souvenirs me trahissent), une ou deux dizaines de comptes légitimes. Heureusement ! Je crois que j’aurais assez mal pris le fait d’avoir vérifié chaque compte pour rien 😅
Nous avons désormais un script qui supprime automatiquement les comptes qui ne se sont jamais connectés dans les 10 jours suivant leur inscription : ce sont visiblement des comptes de spam qui ne reçoivent pas les mails de confirmation et donc ne se sont jamais connectés.
Ce script nous remonte aussi les comptes dont la biographie ou les liens contiennent certains termes usités par les spammeur·euses.
Nous avons recherché une solution de CAPTCHA pour Framagit, mais celui-ci ne supporte que reCaptcha, la solution d’Alphabet/Google… et il était hors de question de faire fuiter les informations (adresse IP, caractéristiques du navigateur…) et permettre le tracking de nos utilisateurs vers les services de l’infâme bête aux multiples têtes que nous combattons !

Nous avons alors recherché quelqu’un·e qui saurait développer, contre rémunération, une solution de type honeypot.
Dans le ticket que nous avons, sans aucune honte, squatté pour poser notre petite annonce, on nous a aiguillés vers une fonctionnalité d’honeypot expérimentale et cachée de Gitlab que je me suis empressé d’activer.
Il faut bien le dire : c’est très efficace ! Le nombre de comptes automatiquement supprimés par le script évoqué plus haut est descendu de près de 100 par jour à entre 0 et 2 comptes, ce qui montre bien que les scripts des spammeur·euses pour s’inscrire ne fonctionnent plus aussi bien.
Bien évidemment, il reste encore beaucoup de spam sur Framagit, et de nombreux comptes de spam sont créés chaque jour (10 ? 15 ? 20 ? Ça dépend des jours…), mais nous ne comptons pas en rester là. Le honeypot pourrait être amélioré, ou nous pourrions voir pour une intégration d’Akismet à Gitlab (il y en a déjà une, mais elle n’est pas utilisée pour vérifier les biographies des comptes).
Gitlab permet maintenant de modérer les inscriptions en les acceptant une à une (comme nous le faisons sur Framapiaf) : nous avons récemment activé cette fonctionnalité, pour voir si la charge de modération était acceptable et si cela avait un effet bénéfique.

Framalink
Nous recevons de temps à autre (bien moins ces derniers temps, fort heureusement) des mails indiquant que Framalink est utilisé pour dissimuler des liens de hameçonnage dans des mails.
Lorsque la vague d’utilisation malveillante s’est intensifiée, j’ai développé (et amélioré au fil du temps) quelques fonctionnalités dans Lstu (le logiciel derrière Framalink) : une commande pour supprimer des raccourcis, pour rechercher les raccourcis contenant une chaîne de caractères ou provenant d’une certaine adresse IP, un système de bannissement d’adresse IP, un système de domaines interdits, empêchant le raccourcissement d’URL de tels domaines, une vérification des URL dans la base de données Google Safe Browsing (lien en anglais) avant raccourcissement et même a posteriori (je vous rassure, aucune donnée n’est envoyée à Google, la base de données est copiée et utilisée en local).
Ces efforts n’ont pas été suffisamment efficaces et nous avons été obligés de couper l’accès à l’API de Framalink, ce qui n’est pas une panacée, mais tout cela a fortement réduit nos problèmes de spam (ou pas, mais en tout cas, on a beaucoup moins de mails nous alertant de l’utilisation de Framalink pour du hameçonnage).
Notez que c’est à cause de l’utilisation de Framalink à des fins malveillantes que ce service est souvent persona non grata chez Facebook, Twitter et consorts.
Framasite
Des framasites avec de jeunes filles dénudées qui jouent au poker avec des plombiers de contrées lointaines ? Eh bien non, même pas. Les spammeurs se contentent de créer des comptes dont le nom d’utilisateur·ice est du genre « Best adult dating site, register on… ».
Et tout comme sur Framagit, beaucoup de comptes créés ne sont jamais validés (vous savez, avec l’email qui dit « cliquez sur ce lien pour finaliser votre inscription » ?).
Heureusement que ce n’est que cela, Framasite n’ayant pas d’interface d’administration permettant la suppression propre d’utilisateur·ices (« propre » voulant dire avec suppression des sites créés). Une simple suppression des comptes illégitimes en base de données suffit à faire le ménage.
Framalibre
Framalibre est aussi sujet aux spams, mais il s’agit généralement là de notices de logiciels non libres. Soit les personnes créant ces notices n’ont pas compris que Framalibre n’était dédié qu’aux logiciels libres, soit elles ont essayé d’améliorer leur référencement en ajoutant leurs logiciels.
Pour une fois, ce n’est pas bien méchant, pas bien violent (cela n’arrive pas souvent) et la vigilance de l’équipe de modération permet de supprimer (manuellement) ces notices indésirables très rapidement.
WordPress (commentaires)
Les spams dans les commentaires d’un blog sont un graaaaand classique ! Nous avons opté, sur nos sites wordpress, pour les extensions Antispam Bee et Spam Honey Pot.
C’est plutôt efficace, il est rare qu’un spam passe à travers ce système.
Drupal (inscriptions)
Nous avons quelques autres installations de Drupal autres que Framaforms et Framalibre. Les spammeurs s’inscrivent, voient qu’ils ne peuvent rien publier facilement : les Drupal en question ont les inscriptions ouvertes pour une bonne raison, mais ne permettent pas de créer des articles comme ça, hop !
Ce n’est donc, à l’heure actuelle, pas gênant.
Notre formulaire de contact
« Un formulaire de contact ? Oh chic ! » se disent les spammeurs. Là aussi, nous recevons un certain nombre de spams, tous les jours, toutes les semaines (une quarantaine par semaine), ou par une ancienne adresse de contact.
Nous nous contentons de répondre « #spam » en commentaire du ticket créé dans notre RequestTracker : cela supprime le message et empêche son expéditeur·ice de nous envoyer d’autres messages (voir sur mon wiki personnel pour commander son RequestTracker par mail).
Les faux positifs

Je n’ai pas encore parlé des faux positifs : des messages légitimes détectés à tort comme étant du spam. Cela arrive forcément, quel que soit le type de plateforme, quels que soient les moyens déployés : statistiquement, il y aura toujours, un jour, une erreur du système ou des humain·es derrière (cf la boulette évoquée dans la partie « Framagit »).
Et dans l’autre sens, on aura toujours des spams qui arriveront à passer. Il est généralement difficile voire impossible de durcir les règles de détection de spam sans augmenter la proportion de faux positifs.
Conclusion
Il n’y en pas vraiment. La lutte contre le spam est un combat sans fin, un jeu du chat et de la souris qui ne se termine jamais. On tente de se protéger du mieux qu’on peut, on trouve des astuces, ça va mieux pendant un temps et ça recommence.
Il faut pas se le cacher : plus un hébergeur « grossit », plus il prend de la renommée sur Internet, plus il y a de chances que des personnes malveillantes repèrent son service et l’utilisent pour leur spam. Il y a donc un paradoxe de l’hébergement : trop petit, on est vite seul·e et débordé·e par la multiplicité des tâches à accomplir pour faire les choses correctement…
Mais trop gros, on centralise les attentions, dont celles des personnes malveillantes qui auront peu de scrupules à parasiter les ressources que vous mettez en commun. Ce qui induit encore plus de travail pour se protéger des spams et les nettoyer.
Ça vous paraît pessimiste ? Ça l’est un peu, sans doute ¯\_(ツ)_/¯




{kind=link}