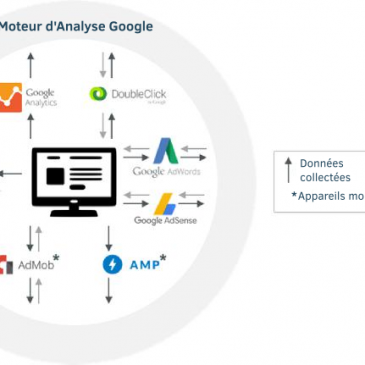
Google et son robot pipoteur(*), selon Doctorow
Source de commentaires alarmants ou sarcastiques, les robots conversationnels qui reposent sur l’apprentissage automatique ne provoquent pas seulement l’intérêt du grand public, mais font l’objet d’une course de vitesse chez les GAFAM.