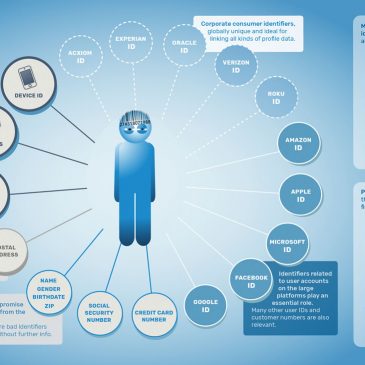
21 degrés de liberté – 02
Voici le deuxième article de la série écrite par Falkvinge. Ce militant des libertés numériques qui a porté son combat (notamment contre le copyright) sur le terrain politique en fondant le Parti Pirate suédois n’hésite pas à afficher des opinions tranchées … Lire la suite