Pour un Web frugal ?
Sites lourds, sites lents, pages web obèses qui exigent pour être consultées dans un délai raisonnable une carte graphique performante, un processeur rapide et autant que possible une connexion par fibre optique… tel est le quotidien de l’internaute ordinaire.
Nul besoin de remonter aux débuts du Web pour comparer : c’est d’une année sur l’autre que la taille moyenne des pages web s’accroît désormais de façon significative.
Quant à la consommation en énergie de notre vie en ligne, elle prend des proportions qui inquiètent à juste titre : des lointains datacenters aux hochets numériques dont nous aimons nous entourer, il y a de quoi se poser des questions sur la nocivité environnementale de nos usages collectifs et individuels.
Bien sûr, les solutions économes à l’échelle de chacun sont peut-être dérisoires au regard des gigantesques gaspillages d’un système consumériste insatiable et énergivore.
Cependant nous vous invitons à prendre en considération l’expérience de l’équipe barcelonaise de Low-Tech Magazine dont nous avons traduit pour vous un article. Un peu comme l’association Framasoft l’avait fait en ouverture de la campagne dégooglisons… en se dégooglisant elle-même, les personnes de Low-tech Magazine ont fait de leur mieux pour appliquer à leur propre site les principes de frugalité qu’elles défendent : ce ne sont plus seulement les logiciels mais aussi les matériels qui ont fait l’objet d’une cure d’amaigrissement au régime solaire.
En espérant que ça donnera des idées à tous les bidouilleurs…
article original : How to build a Low-tech website
Traduction Framalang : Khrys, Mika, Bidouille, Penguin, Eclipse, Barbara, , jums, Mary, Cyrilus, goofy, simon, xi, Lumi, Suzy + 2 auteurs anonymes
Comment créer un site web basse technologie
Low-tech Magazine a été créé en 2007 et n’a que peu changé depuis. Comme une refonte du site commençait à être vraiment nécessaire, et comme nous essayons de mettre en œuvre ce que nous prônons, nous avons décidé de mettre en place une version de Low Tech Magazine en basse technologie, auto-hébergée et alimentée par de l’énergie solaire. Le nouveau blog est conçu pour réduire radicalement la consommation d’énergie associée à l’accès à notre contenu.

* Voir cet article (en anglais) dans une version frugale donc moins énergivore
Pourquoi un site web basse technologie ?
On nous avait dit qu’Internet permettrait de « dématérialiser » la société et réduire la consommation d’énergie. Contrairement à cette projection, Internet est en fait lui-même devenu un gros consommateur d’énergie de plus en plus vorace. Selon les dernières estimations, le réseau tout entier représente 10 % de la consommation mondiale d’électricité et la quantité de données échangées double tous les deux ans.
Pour éviter les conséquences négatives d’une consommation énergivore, les énergies renouvelables seraient un moyen de diminuer les émissions des centres de données. Par exemple, le rapport annuel ClickClean de Greenpeace classe les grandes entreprises liées à Internet en fonction de leur consommation d’énergies renouvelables.
Cependant, faire fonctionner des centres de données avec des sources d’énergie renouvelables ne suffit pas à compenser la consommation d’énergie croissante d’Internet. Pour commencer, Internet utilise déjà plus d’énergie que l’ensemble des énergies solaire et éolienne mondiales. De plus, la réalisation et le remplacement de ces centrales électriques d’énergies renouvelables nécessitent également de l’énergie, donc si le flux de données continue d’augmenter, alors la consommation d’énergies fossiles aussi.
Cependant, faire fonctionner les centres de données avec des sources d’énergie renouvelables ne suffit pas à combler la consommation d’énergie croissante d’Internet.
Enfin, les énergies solaire et éolienne ne sont pas toujours disponibles, ce qui veut dire qu’un Internet fonctionnant à l’aide d’énergies renouvelables nécessiterait une infrastructure pour le stockage de l’énergie et/ou pour son transport, ce qui dépend aussi des énergies fossiles pour sa production et son remplacement. Alimenter les sites web avec de l’énergie renouvelable n’est pas une mauvaise idée, mais la tendance vers l’augmentation de la consommation d’énergie doit aussi être traitée.
Des sites web qui enflent toujours davantage
Tout d’abord, le contenu consomme de plus en plus de ressources. Cela a beaucoup à voir avec l’importance croissante de la vidéo, mais une tendance similaire peut s’observer sur les sites web.
La taille moyenne d’une page web (établie selon les pages des 500 000 domaines les plus populaires) est passée de 0,45 mégaoctets en 2010 à 1,7 mégaoctets en juin 2018. Pour les sites mobiles, le poids moyen d’une page a décuplé, passant de 0,15 Mo en 2011 à 1,6 Mo en 2018. En utilisant une méthode différente, d’autres sources évoquent une moyenne autour de 2,9 Mo en 2018.
La croissance du transport de données surpasse les avancées en matière d’efficacité énergétique (l’énergie requise pour transférer 1 mégaoctet de données sur Internet), ce qui engendre toujours plus de consommation d’énergie. Des sites plus « lourds » ou plus « gros » ne font pas qu’augmenter la consommation d’énergie sur l’infrastructure du réseau, ils raccourcissent aussi la durée de vie des ordinateurs, car des sites plus lourds nécessitent des ordinateurs plus puissants pour y accéder. Ce qui veut dire que davantage d’ordinateurs ont besoin d’être fabriqués, une production très coûteuse en énergie.
Être toujours en ligne ne fait pas bon ménage avec des sources d’énergies renouvelables telles que l’éolien ou le solaire, qui ne sont pas toujours disponibles.
La deuxième raison de l’augmentation de la consommation énergétique d’Internet est que nous passons de plus en plus de temps en ligne. Avant l’arrivée des ordinateurs portables et du Wi-Fi, nous n’étions connectés au réseau que lorsque nous avions accès à un ordinateur fixe au bureau, à la maison ou à la bibliothèque. Nous vivons maintenant dans un monde où quel que soit l’endroit où nous nous trouvons, nous sommes toujours en ligne, y compris, parfois, sur plusieurs appareils à la fois.
Un accès Internet en mode « toujours en ligne » va de pair avec un modèle d’informatique en nuage, permettant des appareils plus économes en énergie pour les utilisateurs au prix d’une dépense plus importante d’énergie dans des centres de données. De plus en plus d’activités qui peuvent très bien se dérouler hors-ligne nécessitent désormais un accès Internet en continu, comme écrire un document, remplir une feuille de calcul ou stocker des données. Tout ceci ne fait pas bon ménage avec des sources d’énergies renouvelables telles que l’éolien ou le solaire, qui ne sont pas disponibles en permanence.
Conception d’un site internet basse technologie
La nouvelle mouture de notre site répond à ces deux problématiques. Grâce à une conception simplifiée de notre site internet, nous avons réussi à diviser par cinq la taille moyenne des pages du blog par rapport à l’ancienne version, tout en rendant le site internet plus agréable visuellement (et plus adapté aux mobiles). Deuxièmement, notre nouveau site est alimenté à 100 % par l’énergie solaire, non pas en théorie, mais en pratique : il a son propre stockage d’énergie et sera hors-ligne lorsque le temps sera couvert de manière prolongée.
Internet n’est pas une entité autonome. Sa consommation grandissante d’énergie est la résultante de décisions prises par des développeurs logiciels, des concepteurs de site internet, des départements marketing, des annonceurs et des utilisateurs d’internet. Avec un site internet poids plume alimenté par l’énergie solaire et déconnecté du réseau, nous voulons démontrer que d’autres décisions peuvent être prises.
Avec 36 articles en ligne sur environ une centaine, le poids moyen d’une page sur le site internet alimenté par énergie solaire est environ cinq fois inférieur à celui de la version précédente.
Pour commencer, la nouvelle conception du site va à rebours de la tendance à des pages plus grosses. Sur 36 articles actuellement en ligne sur environ une centaine, le poids moyen d’une page sur le site internet alimenté par énergie solaire est 0,77 Mo – environ cinq fois inférieur à celui de la version précédente, et moins de la moitié du poids moyen d’une page établi sur les 500 000 blogs les plus populaires en juin 2018.
Ci-dessous : un test de vitesse d’une page web entre l’ancienne et la nouvelle version du magazine Low-Tech. La taille de la page a été divisée par plus de six, le nombre de requêtes par cinq, et la vitesse de téléchargement a été multipliée par dix. Il faut noter que l’on n’a pas conçu le site internet pour être rapide, mais pour une basse consommation d’énergie. La vitesse aurait été supérieure si le serveur avait été placé dans un centre de données et/ou à une position plus centrale de l’infrastructure d’Internet.
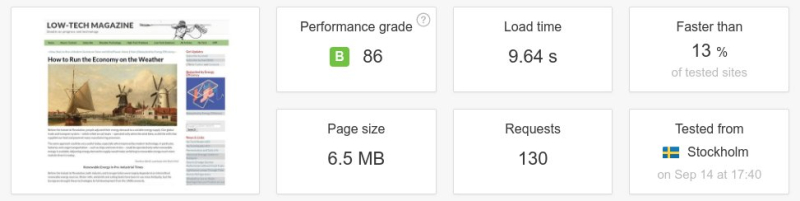
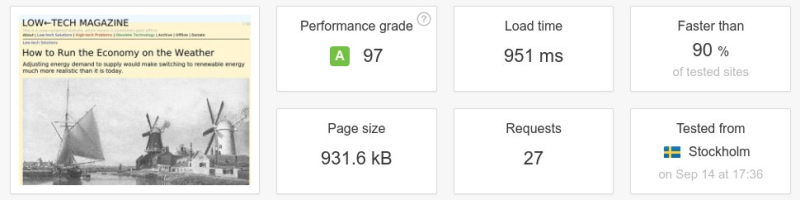 Source : Pingdom
Source : Pingdom
Ci-dessous sont détaillées plusieurs des décisions de conception que nous avons faites pour réduire la consommation d’énergie. Des informations plus techniques sont données sur une page distincte. Nous avons aussi libéré le code source pour la conception de notre site internet.
Site statique
Un des choix fondamentaux que nous avons faits a été d’élaborer un site internet statique. La majorité des sites actuels utilisent des langages de programmation côté serveur qui génèrent la page désirée à la volée par requête à une base de données. Ça veut dire qu’à chaque fois que quelqu’un visite une page web, elle est générée sur demande.
Au contraire, un site statique est généré une fois pour toutes et existe comme un simple ensemble de documents sur le disque dur du serveur. Il est toujours là, et pas seulement quand quelqu’un visite la page. Les sites internet statiques sont donc basés sur le stockage de fichiers quand les sites dynamiques dépendent de calculs récurrents. En conséquence, un site statique nécessite moins de puissance de calcul, donc moins d’énergie.
Le choix d’un site statique nous permet d’opérer la gestion de notre site de manière économique depuis notre bureau de Barcelone. Faire la même chose avec un site web généré depuis une base de données serait quasiment impossible, car cela demanderait trop d’énergie. Cela présenterait aussi des risques importants de sécurité. Bien qu’un serveur avec un site statique puisse toujours être piraté, il y a significativement moins d’attaques possibles et les dommages peuvent être plus facilement réparés.

Le principal défi a été de réduire la taille de la page sans réduire l’attractivité du site. Comme les images consomment l’essentiel de la bande passante il serait facile d’obtenir des pages très légères et de diminuer l’énergie nécessaire en supprimant les images, en réduisant leur nombre ou en réduisant considérablement leur taille. Néanmoins, les images sont une part importante de l’attractivité de Low-tech Magazine et le site ne serait pas le même sans elles.
Par optimisation, on peut rendre les images dix fois moins gourmandes en ressources, tout en les affichant bien plus largement que sur l’ancien site.
Nous avons plutôt choisi d’appliquer une ancienne technique de compression d’image appelée « diffusion d’erreur ». Le nombre de couleurs d’une image, combiné avec son format de fichier et sa résolution, détermine la taille de cette image. Ainsi, plutôt que d’utiliser des images en couleurs à haute résolution, nous avons choisi de convertir toutes les images en noir et blanc, avec quatre niveaux de gris intermédiaires.
Ces images en noir et blanc sont ensuite colorées en fonction de la catégorie de leur contenu via les capacités de manipulation d’image natives du navigateur. Compressées par ce module appelé dithering, les images présentées dans ces articles ajoutent beaucoup moins de poids au contenu ; par rapport à l’ancien site web, elles sont environ dix fois moins consommatrices de ressources.
Police de caractère par défaut / Pas de logo
Toutes les ressources chargées, y compris les polices de caractères et les logos, le sont par une requête supplémentaire au serveur, nécessitant de l’espace de stockage et de l’énergie. Pour cette raison, notre nouveau site web ne charge pas de police personnalisée et enlève toute déclaration de liste de polices de caractères, ce qui signifie que les visiteurs verront la police par défaut de leur navigateur.

Nous utilisons une approche similaire pour le logo. En fait, Low-tech Magazine n’a jamais eu de véritable logo, simplement une bannière représentant une lance, considérée comme une arme low-tech (technologie sobre) contre la supériorité prétendue des « high-tech » (hautes technologies).
Au lieu d’un logo dessiné, qui nécessiterait la production et la distribution d’image et de polices personnalisées, la nouvelle identité de Low-Tech Magazine consiste en une unique astuce typographique : utiliser une flèche vers la gauche à la place du trait d’union dans le nom du blog : LOW←TECH MAGAZINE.
Pas de pistage par un tiers, pas de services de publicité, pas de cookies
Les logiciels d’analyse de sites tels que Google Analytics enregistrent ce qui se passe sur un site web, quelles sont les pages les plus vues, d’où viennent les visiteurs, etc. Ces services sont populaires car peu de personnes hébergent leur propre site. Cependant l’échange de ces données entre le serveur et l’ordinateur du webmaster génère du trafic de données supplémentaire et donc de la consommation d’énergie.
Avec un serveur auto-hébergé, nous pouvons obtenir et visualiser ces mesures de données avec la même machine : tout serveur génère un journal de ce qui se passe sur l’ordinateur. Ces rapports (anonymes) ne sont vus que par nous et ne sont pas utilisés pour profiler les visiteurs.
Avec un serveur auto-hébergé, pas besoin de pistage par un tiers ni de cookies.
Low-tech Magazine a utilisé des publicités Google Adsense depuis ses débuts en 2007. Bien qu’il s’agisse d’une ressource financière importante pour maintenir le blog, elles ont deux inconvénients importants. Le premier est la consommation d’énergie : les services de publicité augmentent la circulation des données, ce qui consomme de l’énergie.
Deuxièmement, Google collecte des informations sur les visiteurs du blog, ce qui nous contraint à développer davantage les déclarations de confidentialité et les avertissements relatifs aux cookies, qui consomment aussi des données et agacent les visiteurs. Nous avons donc remplacé Adsense par d’autres sources de financement (voir ci-dessous pour en savoir plus). Nous n’utilisons absolument aucun cookie.
À quelle fréquence le site web sera-t-il hors-ligne ?
Bon nombre d’entreprises d’hébergement web prétendent que leurs serveurs fonctionnent avec de l’énergie renouvelable. Cependant, même lorsqu’elles produisent de l’énergie solaire sur place et qu’elles ne se contentent pas de « compenser » leur consommation d’énergie fossile en plantant des arbres ou autres, leurs sites Web sont toujours en ligne.
Cela signifie soit qu’elles disposent d’un système géant de stockage sur place (ce qui rend leur système d’alimentation non durable), soit qu’elles dépendent de l’énergie du réseau lorsqu’il y a une pénurie d’énergie solaire (ce qui signifie qu’elles ne fonctionnent pas vraiment à 100 % à l’énergie solaire).

En revanche, ce site web fonctionne sur un système d’énergie solaire hors réseau avec son propre stockage d’énergie et hors-ligne pendant les périodes de temps nuageux prolongées. Une fiabilité inférieure à 100 % est essentielle pour la durabilité d’un système solaire hors réseau, car au-delà d’un certain seuil, l’énergie fossile utilisée pour produire et remplacer les batteries est supérieure à l’énergie fossile économisée par les panneaux solaires.
Reste à savoir à quelle fréquence le site sera hors ligne. Le serveur web est maintenant alimenté par un nouveau panneau solaire de 50 Wc et une batterie plomb-acide (12V 7Ah) qui a déjà deux ans. Comme le panneau solaire est à l’ombre le matin, il ne reçoit la lumière directe du soleil que 4 à 6 heures par jour. Dans des conditions optimales, le panneau solaire produit ainsi 6 heures x 50 watts = 300 Wh d’électricité.
Le serveur web consomme entre 1 et 2,5 watts d’énergie (selon le nombre de visiteurs), ce qui signifie qu’il consomme entre 24 et 60 Wh d’électricité par jour. Dans des conditions optimales, nous devrions donc disposer de suffisamment d’énergie pour faire fonctionner le serveur web 24 heures sur 24. La production excédentaire d’énergie peut être utilisée pour des applications domestiques.
Nous prévoyons de maintenir le site web en ligne pendant un ou deux jours de mauvais temps, après quoi il sera mis hors ligne.
Cependant, par temps nuageux, surtout en hiver, la production quotidienne d’énergie pourrait descendre à 4 heures x 10 watts = 40 watts-heures par jour, alors que le serveur nécessite entre 24 et 60 Wh par jour. La capacité de stockage de la batterie est d’environ 40 Wh, en tenant compte de 30 % des pertes de charge et de décharge et de 33 % de la profondeur ou de la décharge (le régulateur de charge solaire arrête le système lorsque la tension de la batterie tombe à 12 V).
Par conséquent, le serveur solaire restera en ligne pendant un ou deux jours de mauvais temps, mais pas plus longtemps. Cependant, il s’agit d’estimations et nous pouvons ajouter une deuxième batterie de 7 Ah en automne si cela s’avère nécessaire. Nous visons un uptime, c’est-à-dire un fonctionnement sans interruption, de 90 %, ce qui signifie que le site sera hors ligne pendant une moyenne de 35 jours par an.
 Premier prototype avec batterie plomb-acide (12 V 7 Ah) à gauche et batterie Li-Po UPS (3,7V 6600 mA) à droite. La batterie au plomb-acide fournit l’essentiel du stockage de l’énergie, tandis que la batterie Li-Po permet au serveur de s’arrêter sans endommager le matériel (elle sera remplacée par une batterie Li-Po beaucoup plus petite).
Premier prototype avec batterie plomb-acide (12 V 7 Ah) à gauche et batterie Li-Po UPS (3,7V 6600 mA) à droite. La batterie au plomb-acide fournit l’essentiel du stockage de l’énergie, tandis que la batterie Li-Po permet au serveur de s’arrêter sans endommager le matériel (elle sera remplacée par une batterie Li-Po beaucoup plus petite).
Quel est la période optimale pour parcourir le site ?
L’accessibilité à ce site internet dépend de la météo à Barcelone en Espagne, endroit où est localisé le serveur. Pour aider les visiteurs à « planifier » leurs visites à Low-tech Magazine, nous leur fournissons différentes indications.
Un indicateur de batterie donne une information cruciale parce qu’il peut indiquer au visiteur que le site internet va bientôt être en panne d’énergie – ou qu’on peut le parcourir en toute tranquillité. La conception du site internet inclut une couleur d’arrière-plan qui indique la charge de la batterie qui alimente le site Internet grâce au soleil. Une diminution du niveau de charge indique que la nuit est tombée ou que la météo est mauvaise.
Outre le niveau de batterie, d’autres informations concernant le serveur du site web sont affichées grâce à un tableau de bord des statistiques. Celui-ci inclut des informations contextuelles sur la localisation du serveur : heure, situation du ciel, prévisions météorologiques, et le temps écoulé depuis la dernière fois où le serveur s’est éteint à cause d’un manque d’électricité.
Matériel & Logiciel
Nous avons écrit un article plus détaillé d’un point de vue technique : Comment faire un site web basse technologie : logiciels et matériel.
SERVEUR : Ce site web fonctionne sur un ordinateur Olimex A20. Il est doté de 2 GHz de vitesse de processeur, 1 Go de RAM et 16 Go d’espace de stockage. Le serveur consomme 1 à 2,5 watts de puissance.
SOFTWARE DU SERVEUR : le serveur web tourne sur Armbian Stretch, un système d’exploitation Debian construit sur un noyau SUNXI. Nous avons rédigé une documentation technique sur la configuration du serveur web.
LOGICIEL DE DESIGN : le site est construit avec Pelican, un générateur de sites web statiques. Nous avons publié le code source de « solar », le thème que nous avons développé.
CONNEXION INTERNET. Le serveur est connecté via une connexion Internet fibre 100 MBps. Voici comment nous avons configuré le routeur. Pour l’instant, le routeur est alimenté par le réseau électrique et nécessite 10 watts de puissance. Nous étudions comment remplacer ce routeur gourmand en énergie par un routeur plus efficace qui pourrait également être alimenté à l’énergie solaire.
SYSTÈME SOLAIRE PHOTOVOLTAÏQUE. Le serveur fonctionne avec un panneau solaire de 50 Wc et une batterie plomb-acide 12 V 7 Ah. Cependant, nous continuons de réduire la taille du système et nous expérimentons différentes configurations. L’installation photovoltaïque est gérée par un régulateur de charge solaire 20A.

Qu’est-il arrivé à l’ancien site ?
Le site Low-tech Magazine alimenté par énergie solaire est encore en chantier. Pour le moment, la version alimentée par réseau classique reste en ligne. Nous encourageons les lecteurs à consulter le site alimenté par énergie solaire, s’il est disponible. Nous ne savons pas trop ce qui va se passer ensuite. Plusieurs options se présentent à nous, mais la plupart dépendront de l’expérience avec le serveur alimenté par énergie solaire.
Tant que nous n’avons pas déterminé la manière d’intégrer l’ancien et le nouveau site, il ne sera possible d’écrire et lire des commentaires que sur notre site internet alimenté par réseau, qui est toujours hébergé chez TypePad. Si vous voulez envoyer un commentaire sur le serveur web alimenté en énergie solaire, vous pouvez en commentant cette page ou en envoyant un courriel à solar (at) lowtechmagazine (dot) com.
Est-ce que je peux aider ?
Bien sûr, votre aide est la bienvenue.
D’une part, nous recherchons des idées et des retours d’expérience pour améliorer encore plus le site web et réduire sa consommation d’énergie. Nous documenterons ce projet de manière détaillée pour que d’autres personnes puissent aussi faire des sites web basse technologie.
D’autre part, nous espérons recevoir des contributions financières pour soutenir ce projet. Les services publicitaires qui ont maintenu Low-tech Magazine depuis ses débuts en 2007 sont incompatibles avec le design de notre site web poids plume. C’est pourquoi nous cherchons d’autres moyens de financer ce site :
1. Nous proposerons bientôt un service de copies du blog imprimées à la demande. Grâce à ces publications, vous pourrez lire le Low-tech Magazine sur papier, à la plage, au soleil, où vous voulez, quand vous voulez.
2. Vous pouvez nous soutenir en envoyant un don sur PayPal, Patreon ou LiberaPay.
3. Nous restons ouverts à la publicité, mais nous ne pouvons l’accepter que sous forme d’une bannière statique qui renvoie au site de l’annonceur. Nous ne travaillons pas avec les annonceurs qui ne sont pas en phase avec notre mission.
Le serveur alimenté par énergie solaire est un projet de Kris De Decker, Roel Roscam Abbing et Marie Otsuka.