La communication, sur Internet et ses médias sociaux comme dans la vie, doit rester dans le cadre des lois. Mais est-il normal qu’un puissant média comme Facebook s’arroge le droit de décider, le plus souvent sans explication ni recours, de quels sujets on parle de façon privée ?
Voici déjà le 15e article de la série écrite par Rick Falkvinge. Le fondateur du Parti Pirate suédois prend ici l’exemple de la censure exercée par Facebook, qui en quelque sorte se substitue aux lois en imposant la sienne et bride la liberté d’expression.
Le fil directeur de la série de ces 21 articles, comme on peut le voir clairement dans les épisodes précédents que nous vous avons déjà livrés, c’est la perte de certaines libertés dont nous disposions encore assez récemment, avant que le passage au tout-numérique ne nous en prive.
Les médias numériques interdisent à nos enfants d’aborder certains sujets.
Traduction Framalang : wyatt, draenog, goofy, et un⋅e anonyme
Dans le pire des cas il pouvait être interdit à nos parents de se rencontrer. Mais aujourd’hui, on empêche nos enfants de parler de certains sujets, une fois la conversation en cours. Cette évolution est effrayante.
Lorsqu’un lien vers The Pirate Bay est publié sur Facebook par nos enfants, une petite fenêtre fait son apparition à l’écran avec pour message « Le lien que vous venez de publier n’est pas approprié. Veuillez ne plus publier de tels liens ».
Oui, même dans les conversations privées. Particulièrement dans les conversations privées.
Cela peut paraître anodin, c’est véritablement inouï. Les discussions de nos enfants ne sont pas restreintes en soi, mais elles sont en revanche contrôlées si elles abordent les sujets sensibles dont le régime ne souhaite pas qu’on discute et on les empêche d’en discuter. C’est bien pire que de simplement interdire à certaines personnes de se rencontrer.
L’équivalent analogique de cette pratique serait une conversation téléphonique classique de nos parents dans laquelle une troisième voix menaçante interviendrait, parlant lentement sur un ton assez doux pour être perçu comme une menace : « Vous avez fait mention d’un sujet interdit. Veuillez ne plus discuter de sujets interdits à l’avenir. »
Nos parents auraient été effrayés si cela s’était produit — et à juste raison !
Mais dans le monde numérique de nos enfants, au lieu d’être conspuée, cette pratique est acclamée par les mêmes personnes qui la réprouveraient si elles venaient à en être les victimes.
Dans le cas de notre exemple bien sûr, n’importe lequel des liens vers The Pirate Bay est considéré comme sujet interdit, selon le postulat — le postulat ! — qu’ils mènent à la production de copies qui seraient décrétées en violation du droit d’auteur par un tribunal.
La première fois que j’ai vu la fenêtre Facebook m’enjoignant à ne pas discuter de sujets interdits, je tentais de partager via The Pirate Bay du contenu à caractère politique que j’avais créé. Cette façon de faire s’est avérée très efficace pour partager des gros fichiers, c’est exactement la raison pour laquelle le site est très utilisé (qui aurait pensé à ça, hein ?), notamment par des personnes qui comme moi veulent partager de vastes séries de documents politiques.
Il existe des canaux de communications privés, mais très peu de personnes les utilisent, et les politiciens (oui, nos parents analogiques inclus) s’en réjouissent, à cause du « terrorisme » et autres épouvantails.
Module agenda avec une insertion de votre Framagenda ou Google agenda (oui, si vous n’avez pas encore dégooglisé votre vie, c’est pas grave, on vous accepte)
Module réseaux sociaux (et même ceux qu’on n’aime pas)
Module lecteur audio (SoundCloud) si vous souhaitez faire le site de votre groupe de musique
Module avec lecteur vidéo et vidéo d’arrière plan
Un formulaire d’initialisation pour installer votre site sur un serveur personnel
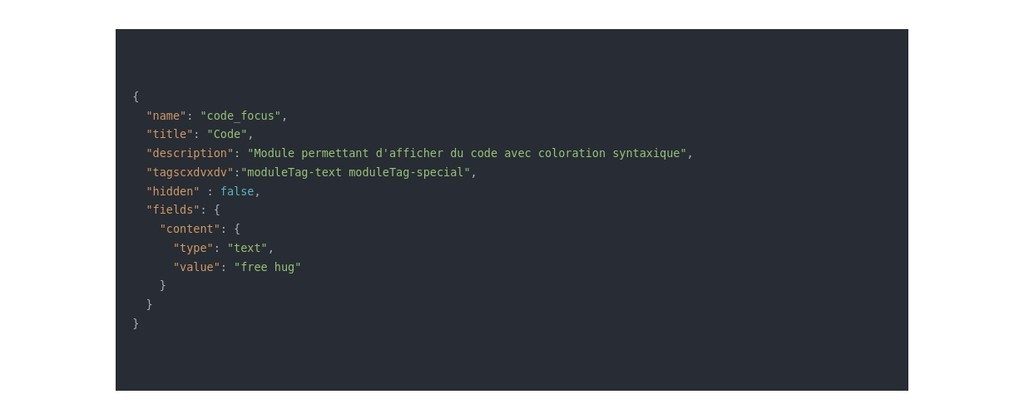
Module de code avec coloration syntaxique, comme les pros
Du zouli design !
Redimensionnement d’images
Bouton « haut de page »
La page d’accueil est encore plus cool
Le menu réapparaît lorsqu’on scrolle vers le haut
Une version mobile pour le menu
Les fenêtres sont plus sympas (il y a eu un coup de main d’un designer)
On va glisser sur les nombreuses corrections de bugs.
Un tuto vidéo pour faire son CV
Et comme il restait du temps, hop, Robin a concocté une petite vidéo pour fabriquer son CV sur Framasite.
Vous pouvez le mettre sur un média social propriétaire appartenant à un GAFAM, hein. No problemo. C’est cool.
Mais bon, votre CV hébergé par Framasoft, ça fait toujours son petit effet :p !
Le 16 avril dernier, la Quadrature du Net a lancé un appel inédit en France pour une action de groupe contre les GAFAM. Cette action s’appuiera sur l’application prochaine du Règlement général sur la protection des données (RGPD).
Sans attendre la date d’entrée en vigueur du RGPD (le 15 mai 2018), la Quadrature du Net propose à tous les utilisateurs des services numériques des GAFAM de souscrire en masse en vue de déposer une plainte auprès de la CNIL et obliger implicitement celle-ci à agir.
En effet, l’article 80 du RGPD permet aux associations « actives dans le domaine de la protection des droits et libertés des personnes » à entreprendre des actions collectives dans le cadre de la protection des données.
La personne concernée a le droit de mandater un organisme, une organisation ou une association à but non lucratif, qui a été valablement constitué conformément au droit d’un État membre, dont les objectifs statutaires sont d’intérêt public et est actif dans le domaine de la protection des droits et libertés des personnes concernées dans le cadre de la protection des données à caractère personnel les concernant, pour qu’il introduise une réclamation en son nom, exerce en son nom les droits visés aux articles 77, 78 et 79 et exerce en son nom le droit d’obtenir réparation visé à l’article 82 lorsque le droit d’un État membre le prévoit. (extrait de l’art. 80)
À ce titre, la Quadrature du Net se propose d’agir en tant que mandataire pour tous les citoyens-utilisateurs qui le désirent par l’intermédiaire d’un formulaire simple et rapide à remplir.
Pour permettre de comprendre les arguments sur lesquels repose la plainte, la Quadrature met à disposition un texte très clair. En résumé, il repose sur l’aspect illicite de l’échange de services contre le consentement systématique des utilisateurs permettant à ces entreprises d’extraire et inférer leurs données personnelles. Ce consentement est en effet soit déduit du silence de l’utilisateur (le fait d’utiliser le service impliquerait ce consentement) soit littéralement extorqué par une action « positive » (cliquer sur un bouton « j’accepte ») sous contrainte de ne pas accéder au service.
Les conséquences de l’extraction des données des utilisateurs sont connues et l’affaire Cambridge Analytica en a donné récemment une illustration convaincante. Le fait d’utiliser et vendre les données des utilisateurs dans un cadre qui n’a pas de lien direct avec le service pour lequel ils ont été contraint de les céder n’est pas le seul grief que la Quadrature du Net expose. Cette action collective vise aussi à mettre en lumière le lien évident entre le droit à ne pas monétiser les données personnelles et la liberté de conscience menacée par le traitement des informations relatives à la vie privée des citoyens, véritable porte ouverte à la segmentation sociale et la manipulation de l’information.
Pendant les 40 jours qui nous séparent de l’entrée en vigueur du RGPD, la Quadrature du Net publiera chaque semaine sur son site des documents et vidéos visant à expliquer les tenants et aboutissants de ce recours collectif.
La réforme européenne du droit d’auteur ? – une menace pour le logiciel libre selon Glyn Moody
Comme vous l’avez peut-être lu dans l’appel de Julia Reda que nous avons publié hier, l’heure est à la mobilisation contre une proposition de directive européenne qui pourrait avoir des effets dévastateurs.
Non, les GAFAM ne seraient pas les premiers impactés, mais plutôt des entreprises moins bien armées et aussi des sites comme Wikipédia, ainsi que des plateformes de dépôt et partage de code qui constituent des ressources précieuses pour la communauté du logiciel libre.
De tels sites risquent d’être contraints à des dispositifs coûteux et difficiles à mettre en œuvre pour filtrer les contenus sous droits. C’est ce que détaille aujourd’hui Glyn Moody à propos des effets de l’article 13 de cette proposition de directive, contre laquelle a déjà alerté l’April depuis septembre dernier.
Aujourd’hui, la mobilisation de plus de 80 organisations et la mise en place du site https://savethememe.net/en constituent des formes d’action militante auxquelles le plus grand nombre doit contribuer. Diffusons largement la traduction des articles de Julia Reda et de Glyn Moody. Signons la lettre ouverte Save Code Share! Opposons le groupe de pression de la communauté du libre au lobby du droit d’auteur qui est sans cesse à la manœuvre dans les institutions européennes.
Le logiciel libre subit l’offensive des nouvelles lois européennes sur le droit d’auteur
Glyn Moody, photo Zaizi Ltd (CC BY-SA 2.0)
Le logiciel libre et le droit d’auteur sont étroitement liés. C’est grâce au détournement (hack) habile de la loi sur le droit d’auteur par Richard Stallman qu’a pu être créée la General Public License (GPL) et, par conséquent, le logiciel libre. La GPL requiert de la part des personnes copiant ou modifiant un logiciel publié sous cette licence qu’elles préservent les quatre libertés. Si cela n’est pas le cas, elles enfreignent alors les clauses de la GPL et perdent ainsi toute protection juridique de leurs copies et modifications. En d’autres termes, la sévérité des sanctions pour une violation du droit d’auteur est ce qui permet d’assurer la liberté de partage.
Malgré l’utilisation du droit d’auteur pour faire respecter la GPL et toutes les autres licences du logiciel libre ou open source, le droit d’auteur n’est généralement pas si inoffensif. Ce n’est pas étonnant : le droit d’auteur est un monopole intellectuel. En règle générale, il cherche à empêcher le partage — pas à le promouvoir. Ainsi, les ambitions de l’industrie du droit d’auteur vont généralement à l’encontre des aspirations du monde du logiciel libre.
C’est en Europe que l’on retrouve l’une des preuves les plus évidentes du désintérêt du monde du droit d’auteur envers les préoccupations de la communauté du logiciel libre. Les propositions actuelles de réforme du droit d’auteur au niveau de l’Union européenne contiennent un élément qui aurait des effets dévastateurs pour le codage du logiciel libre. L’article 13 de la pompeusement titrée « Directive du Parlement européen et du Conseil sur le droit d’auteur dans le marché unique numérique » contient la disposition clef suivante :
Les prestataires de services de la société de l’information qui stockent un grand nombre d’œuvres ou d’autres objets protégés chargés par leurs utilisateurs et qui donnent accès à ces œuvres et autres objets prennent, en coopération avec les titulaires de droits, des mesures destinées à assurer le bon fonctionnement des accords conclus avec les titulaires de droits en ce qui concerne l’utilisation de leurs œuvres ou autres objets protégés ou destinées à empêcher la mise à disposition, par leurs services, d’œuvres ou d’autres objets protégés identifiés par les titulaires de droits en coopération avec les prestataires de services. Ces mesures, telles que le recours à des techniques efficaces de reconnaissance des contenus, doivent être appropriées et proportionnées.
Cela signifie concrètement que les sites détenant une (très) importante base de fichiers téléversés par les utilisateurs et utilisatrices seront forcés de filtrer tous les fichiers avant de les publier. Les problèmes posés par cette proposition sont clairs. Une surveillance constante de l’activité des internautes sur lesdits sites, avec tout ce que cela induit en termes de perte de vie privée. Les faux-positifs sont inévitables, particulièrement parce que les complexités du droit d’auteur ne peuvent pas se voir réduites à de simples algorithmes qui pourront être appliqués automatiquement. Ajouté à l’effet dissuasif que cela aura sur la volonté des internautes de publier des contenus, cela impactera négativement la liberté d’expression et affaiblira le domaine public (article en anglais).
Le coût élevé de la mise en place des filtres de contenus — le système ContentID de Google a nécessité 50 000 heures de codage (page en anglais) et coûté 60 millions de dollars — signifie qu’un nombre restreint de sociétés finiront par contrôler le marché des systèmes de censure. Leur pouvoir d’oligopole leur donne la possibilité de faire payer très cher leurs services, ce qui imposerait de lourdes charges aux entreprises de l’Union européenne et conduirait à une diminution des startups dans la région. Un autre problème, parmi d’autres, avec cette idée : le fait non-négligeable que cela pourrait être contraire au droit de l’UE en vigueur (en anglais).
L’article 13 a été spécifiquement rédigé pour satisfaire le désir à peine déguisé de l’industrie européenne du droit d’auteur d’attaquer des entreprises états-uniennes prospères comme Google ou Facebook. Mais le filtrage des contenus mis en ligne est une arme grossière et va en affecter beaucoup d’autres qui, ironiquement, vont être moins capables que les géants d’Internet de se conformer aux onéreuses exigences de la censure. Par exemple, il est fort probable que Wikipédia rentrera dans le périmètre de la nouvelle règle. Après tout, le projet héberge un grand nombre d’ « objets protégés » chargés par des utilisateurs et utilisatrices. Comme le montre un billet sur le blog de Wikimedia (en anglais), « il serait absurde de demander à la Fondation Wikimedia de mettre en place des systèmes automatisés coûteux et technologiquement défaillants pour détecter des violations de droit d’auteur. »
Le point de l’article 13 qui est peut être le plus inquiétant pour les lecteurs du Linux Journal concerne les conséquences pour le logiciel libre. Une autre catégorie de sites web qui donnent accès « à des œuvres ou d’autres objets protégés chargés par leurs utilisateurs » : les plateformes de développement collaboratif et les dépôts de code [informatique]. Comme l’explique le site Savecodeshare.eu (Note de traduction : en anglais, voir l’article de l’April qui soutient cette campagne), créé par la Free Software Foundation Europe et OpenForum Europe (note de transparence : je suis un membre bénévole de OpenForum Academy) :
Si cette réforme du droit d’auteur devait être votée, chaque utilisateur ou utilisatrice d’une plateforme de partage de code, qu’il ou elle soit une personne physique, une entreprise ou une administration publique, serait traité comme un potentiel contrevenant au droit d’auteur : tous ses contenus, incluant des dépôts entiers de code, seraient contrôlés et empêchés d’être partagés en ligne à n’importe quel moment. Cela restreindrait la liberté des développeurs et développeuses d’utiliser des composants et outils logiciels spécifiques, ce qui, en retour, conduirait à moins de compétition et d’innovation. Finalement, cela pourrait conduire à des logiciels moins fiables et à une infrastructure logicielle moins résiliente pour tout le monde.
Comme l’explique en détail un livre blanc (PDF en anglais) de la même organisation, des sites web majeurs tels que Software Heritage, GitHub, GitLab, GNU Savannah et SourceForge sont menacés. Il met en exergue le fait que si cette proposition de loi venait à être adoptée, ces sites seraient directement responsables d’un grand nombre d’actions de leurs utilisateurs et utilisatrices, ce qui inclut le téléversement de copies non autorisées de logiciels et l’utilisation de code contraire à la licence initiale. Du fait de la difficulté, voire de l’impossibilité pour la plupart de ces sites d’éviter que cela se produise, il est fort probable que certains d’entre eux bloquent l’accès à leur site aux utilisateurs et utilisatrices européen⋅nes et arrêtent leur activité au sein de l’UE. Les projets de logiciels libres pourraient alors être forcés de faire la même chose. Dans le livre blanc, Thomas Pfeiffer, membre du conseil d’administration de KDE, est cité ainsi :
Pour savoir à quel point KDE est directement touché par le règlement proposé, il faut se demander si la configuration ci-dessus ferait de nous des « fournisseurs de services de la société de l’information stockant et distribuant de grandes quantités d’œuvres ou d’autres objets téléchargés par leurs utilisateurs ». Si c’est le cas, nous devrions probablement déplacer la majeure partie de notre infrastructure et de notre organisation en dehors de l’UE.
Le potentiel impact de l’Article 13 de la directive sur le droit d’auteur sur la façon dont le logiciel libre est créé tout autour du globe est clairement considérable. La bonne nouvelle est que cette loi européenne n’a pas encore été finalisée et est toujours amenée à évoluer ; la mauvaise est qu’elle n’évolue actuellement pas dans le bon sens.
Par exemple, le responsable politique supervisant l’adoption de cette nouvelle loi par le Parlement européen a récemment proposé un amendement qui exonérerait les grands sites de filtrer les contenus mis en ligne à condition que ceux-ci signent des accords avec l’ensemble des titulaires de droits d’auteur sur les contenus qu’ils hébergent. Ce qui est impossible pour les dépôts de code [informatique], étant donné le volume de fichiers téléversés — il n’existe pas de sociétés de perception pour les développeurs et développeuses, comme on peut en trouver chez les musicien⋅nes ou auteur⋅es, pouvant par exemple accorder une licence globale sur l’ensemble du contenu hébergé. L’article 13, qu’il s’agisse de filtre automatisé ou d’accord de licence obligatoire, est inconciliable avec la manière de fonctionner des principaux sites dans le domaine du logiciel libre.
Ses défauts fondamentaux impliquent que l’article 13 doit être retiré de la directive sur le droit d’auteur. Un site multilingue baptisé Savethememe.net (en anglais) a été mis en place pour faciliter la prise de contact direct avec les membres du Parlement européen, qui auront un vote décisif sur les propositions. Un autre moyen d’action est de faire connaître la nocivité de l’article 13 pour l’ensemble de l’écosystème du logiciel libre, et sur les effets secondaires négatifs que cela aurait pour l’innovation en général et pour la société.
Plus les programmeurs et programmeuses sont conscient⋅es du problème et le font savoir partout, plus les dépôts de code les plus affectés se joignent à la vague globale d’inquiétude grandissante sur les conséquences des filtres de contenus, plus grand sera l’impact de leur appel à complètement abandonner l’article 13.
À propos de l’auteur
Glyn Moody écrit au sujet d’Internet depuis 1994, et au sujet des logiciels libres depuis 1995. En 1997, il a écrit le premier article grand public sur GNU/Linux et le logiciel libre, paru dans Wired (en anglais). En 2001, son livre Rebel Code: Linux And The Open Source Revolution a été publié. Depuis, il a très souvent écrit sur le logiciel libre et les libertés informatiques. Il a un blog et il est actif sur des réseaux sociaux : @glynmoody sur Twitter ou identi.ca, et +glynmoody sur Google+.
Julia Reda, eurodéputée du Parti Pirate, lance un appel
Le projet de réforme du droit d’auteur provoque une forte inquiétude au sein des communautés de développeurs et développeuses de logiciels libres. Que restera-t-il de leur liberté de partager et modifier si obligation est faite aux forges logicielles de mettre en place des filtres de contenus ? L’eurodéputée Julia Reda nous indique les façons dont nous pouvons tous agir, dès maintenant.
« Les machines à censurer arrivent : il est temps que la communauté du logiciel libre prenne conscience de son impact politique »
Le développement du logiciel libre tel que nous le connaissons est menacé par les projets de réforme du droit d’auteur de l’Union européenne.
La bataille continue autour de la proposition de réforme du droit d’auteur dans l’UE, se concentrant autour du projet de filtrer les contenus au moment de leur téléversement (en anglais). En résumé, on demanderait aux plateformes en ligne de contrôler les contenus chargés par leurs utilisateurs et utilisatrices afin de tenter de prévenir les violations du droit d’auteur par des filtres automatiques. Puisque la plupart des communications en ligne consistent en un dépôt de fichiers sur différentes plateformes, de telles « machines à censurer » auraient de larges conséquences, y compris pour les dépôts de logiciels libres et open source.
Sur ces plateformes, des développeurs et développeuses du monde entier travaillent de concert sur des projets de logiciels que quiconque peut librement utiliser et adapter. À coup sûr, ces filtres automatiques feraient état de nombreux faux-positifs. La suppression automatique de contenus signifierait que les personnes ayant contribué seraient présumées coupables jusqu’à prouver leur innocence : des contributions légitimes se verraient bloquées.
Les récentes levées de boucliers à ce sujet au sein de la communauté du logiciel libre/open-source commencent à porter leurs fruits : nos préoccupations sont en train d’attirer l’attention des porteurs de lois. Malheureusement cependant, la plupart comprennent mal les enjeux et tirent de mauvaises conclusions. Maintenant que nous savons quelle est la force de la voix de la communauté, il est d’autant plus important de continuer à la faire entendre !
Pourquoi cela ?
Le point de départ de cette législation a été une bataille entre de grosses entreprises, l’industrie musicale et YouTube, à propos d’argent. L’industrie musicale s’est plainte de moins percevoir chaque fois qu’un morceau de leur catalogue est joué sur une plateforme vidéo comme YouTube que lorsqu’il est diffusé sur des services d’abonnement comme Spotify, qualifiant la différence de « manque-à-gagner ». Elle s’est alors lancée, avec succès, dans une campagne de lobbying : la loi sur le filtrage des contenus vise principalement à lui donner un atout afin de demander plus d’argent à Google au moment des négociations. Pendant ce temps, toutes les autres plateformes se retrouvent au milieu de cette bagarre, y compris les communautés de partage de code.
Le lobbying a ancré dans l’esprit de nombreux législateurs la fausse idée que les plateformes d’hébergement à but lucratif exploitent nécessairement les créateurs et créatrices.
Partage de code
Il y a cependant beaucoup d’exemples où il existe une relation symbiotique entre la plateforme et les créateurs et créatrices. Les développeurs et développeuses utilisent et versent volontairement dans les dépôts logiciels parce que les plateformes ajoutent de la valeur. GitHub est une société à but lucratif qui soutient des projets sans but lucratif – elle finance l’hébergement gratuit de projets libres et open source en facturant l’utilisation commerciale des services du site. Ainsi, des travaux libres et open source seront affectés par une loi destinée à réguler un différend entre quelques grandes sociétés.
Dans un récent billet (en anglais), GitHub a tiré la sonnette d’alarme, indiquant trois raisons pour lesquelles le filtrage automatique des contenus constitue une terrible attaque contre les forges logicielles :
la loi impose que le code soit filtré parce qu’il est soumis au droit d’auteur – mais de nombreux développeurs et développeuses souhaitent que leur code source soit partagé sous une licence libre et open source ;
le risque de faux positifs est très élevé parce que les différentes parties d’un logiciel peuvent être soumises à des licences différentes, ce qui est très difficile à traiter de manière automatisée ;
le fait de supprimer automatiquement un code suspecté de porter atteinte au droit d’auteur peut avoir des conséquences désastreuses pour les développeurs et développeuses de logiciels qui s’appuient sur des ressources communes risquant de disparaître à tout moment.
Les inquiétudes commencent à être entendues
Dans sa dernière proposition, le Conseil de l’Union européenne cherche à exclure « les plateformes de développement open source à but non lucratif » de l’obligation de filtrer les contenus chargés par les utilisateurs et utilisatrices. Cet amendement est la conséquence directe de la levée de boucliers par la communauté FLOSS. Cependant, cette exception ne couvre pas les plateformes à but lucratif comme GitHub et bien d’autres, même si une partie seulement de leur activité est à but lucratif.
Plutôt que de remettre en cause le principe de base de la loi, les politiciens essayent d’étouffer les critiques en proposant de plus en plus d’exceptions à celles et ceux qui peuvent démontrer de façon crédible que la loi va les affecter négativement. Créer une telle liste d’exceptions est une tâche titanesque vouée à rester inachevée. Le filtrage des contenus devrait être rejeté dans son ensemble car c’est une mesure disproportionnée mettant en danger le droit fondamental de la liberté d’expression en ligne.
Nous pouvons y arriver !
Pour y parvenir, nous avons besoin de votre aide. La communauté FLOSS ne peut pas résoudre ces problèmes simplement avec du code : elle a un impact politique, la force du nombre et des allié⋅e⋅s au Parlement (européen). Nous avons déjà provoqué certains changements. Voici comment vous pouvez agir dès maintenant :
utilisez l’outil gratuit de Mozilla pour appeler les membres du Parlement européen ;
tweetez aux principaux acteurs de la Commission des affaires légales du Parlement européen via FixCopyright (en anglais).
Note technique :
Trois acteurs sont impliqués dans le processus législatif. La Commission émet une première proposition de loi, à laquelle le Parlement européen et le Conseil de l’Union européenne peuvent proposer des amendements. Au sein du Parlement, la loi est d’abord discutée en Commission des affaires légales dans laquelle chaque groupe politique nomme un négociateur. Une fois que la Commission aura voté le compromis élaboré par les négociateurs, le texte sera soumis au vote en séance plénière du Parlement, avant que les négociations ne commencent avec les autres institutions. Le parcours législatif exact est disponible ici (en anglais).
Dans la mesure du possible et conformément à la loi, l’auteur [Julia Reda] renonce à tous les droits d’auteur et droits voisins sur ce texte.
21 degrés de liberté – 14
Vos rendez-vous amoureux, votre orientation sexuelle, les sites « pour adultes » que vous visitez selon vos préférences… un ensemble de données confidentielles on ne peut plus personnelles, qui pourtant font aussi l’objet de repérage et classements dans notre monde numérique…
Voici déjà le 14e article de la série écrite par Rick Falkvinge. Le fondateur du Parti Pirate suédois examine aujourd’hui la captation des données les plus sensibles à nos yeux, celles qui concernent notre vie amoureuse.
Le fil directeur de la série de ces 21 articles, comme on peut le voir clairement dans les épisodes précédents que nous vous avons déjà livrés, c’est la perte de certaines libertés dont nous disposions encore assez récemment, avant que le passage au tout-numérique ne nous en prive.
Les préférences amoureuses de nos parents n’étaient pas pistées, enregistrées et cataloguées
Traduction Framalang : draenog, wan, goofy et un anonyme
Les préférences amoureuses de nos parents de l’ère analogique étaient considérées comme un sujet des plus intimes. Pour nos enfants du numérique, ces préférences sont une occasion de collecte à grande échelle à des fins de marketing. Comment cette dérive terrifiante a-t-elle pu se produire ?
Chatelaine et Tropea, photo d’Helena Jacoba (CC-BY-2.0)
Je crois que le premier gros collecteur de préférences amoureuses était le site à l’apparence innocente hotornot.com, il y a 18 ans, un site qui évoquait plus l’emploi de son temps libre par un lycéen frustré qu’une fine stratégie marketing. Il permettait simplement aux gens de noter la beauté d’une personne à partir d’une photographie, et de mettre en ligne des photographies pour obtenir des notes. (Les deux fondateurs de ce prétendu projet amateur de lycéen ont gagné 10 millions de dollars chacun lorsque le site a été vendu.)
Le marché a ensuite connu une expansion phénoménale, avec des sites de rencontre financés soit par des publicités, soit par les utilisateurs, chacun de ces sites stockant les préférences amoureuses de ses membres dans les moindres détails.
Les sites de pornographie à grande échelle, comme Pornhub, se sont également mis à cataloguer les préférences en matière de porno de leurs utilisateurs et utilisatrices, produisant des infographies intéressantes à propos des différences régionales entre celles-ci. Vous pouvez par exemple consulter (sans risques) la page https://www.inverse.com/article/26011-pornhub-post-popular-porn-report-2016, il s’agit seulement de données et de cartes dans un article sur Inverse, ce n’est pas un lien vers Pornhub. C’est particulièrement intéressant, car on se rend compte que Pornhub est capable de détailler plutôt précisément les préférences des gens par âge, lieu, sexe, niveau de revenus, et ainsi de suite.
Est-ce que vous connaissez qui que ce soit qui aurait donné à Pornhub ce genre de données ? Non, et moi non plus. Et pourtant, ils sont capables d’identifier qui aime quoi avec une certaine précision, précision qui doit bien venir de quelque part.
Et ensuite, bien sûr, nous avons les réseaux sociaux (qui peuvent ou non être responsables de ce pistage, d’ailleurs).
On a pu dire1 que Facebook est capable de savoir si vous êtes homosexuel⋅le ou non avec seulement trois « J’aime ». Trois. Et ces « Like » ne sont pas forcément liés aux préférences amoureuses ni au mode de vie ; elles peuvent cibler des choses complètement anodines qui vont juste être associées à des motifs plus généraux.
C’est déjà une mauvaise chose en soi, dans la mesure où ce sont des informations privées. Au strict minimum, les préférences de nos enfants de l’ère numérique devraient leur appartenir, comme leur parfum de glace préféré.
Mais les affinités amoureuses sont des informations plus sensibles que notre parfum de glace préféré, n’est-ce pas ? Cela devrait être le cas, mais aujourd’hui ça ne l’est pas. Ces informations pourraient toucher aussi quelque chose d’inné. Des choses pour lesquelles des personnes risquent jusqu’à la mort si elles sont nées2 avec la « mauvaise » préférence…
Il est toujours illégal d’être né homosexuel⋅le dans 73 pays sur 192, et dans ces 73, onze prévoient la peine de mort pour être né⋅e ainsi. À peine 23 pays sur 192 permettent pleinement le mariage pour tous.
De plus, bien que l’évolution des mœurs aille de manière assez nette vers plus de tolérance, d’acceptation et d’inclusion à l’heure actuelle, cela ne veut pas dire que nous soyons à l’abri d’une régression, pour diverses raisons, la plupart d’entre elles très mauvaises. Des personnes qui se sont senties suffisamment solides pour s’exprimer sur elles-mêmes peuvent à nouveau être persécutées.
Le génocide prend presque toujours appui sur des données publiques collectées avec de bonnes intentions.
C’est pourquoi le respect de la vie privée est la dernière ligne de défense, non pas la première. Et cette dernière ligne de défense, qui a tenu bon pour nos parents analogiques, a été rompue pour nos enfants numériques. Ce problème n’est certainement pas assez pris au sérieux.
La vie privée demeure de votre responsabilité.
Les Léviathans V. Vie privée, informatique et marketing dans le monde d’avant Google
Dans notre ère désormais numérique il nous arrive parfois d’être pris d’un léger vertige tant le flux tourbillonnant de l’actualité porte des coups brutaux à notre représentation du monde. C’est alors qu’un pas de côté est salutaire.
Apprendre avec Meltdown et Spectre que même le matériel, en l’occurrence le processeur, comporte des failles critiques, ou plus récemment que par dizaines de millions des profils Facebook ont été exploités pour manipuler l’opinion à des fins politiques, voilà le genre d’affaires qui défraient la chronique, mais qui nous demandent un peu de recul.
Dans la continuité de sa série des Léviathans, Christophe Masutti nous propose aujourd’hui avec Léviathans V de prendre un peu de distance avec le capitalisme de surveillance pour mieux en appréhender et déconstruire le mode opératoire.
Pour commencer, il nous invite à remonter aux années 1960 aux États-Unis et découvrir que l’exploitation des données personnelles par le marketing numérique (certes moins sophistiqué qu’aujourd’hui) était une réalité dès la constitution des premières banques de données. Au point que très tôt des mouvements d’opinion sont apparus pour s’opposer aux dangers des atteintes à la vie privée. On verra donc à quel point ni la collecte de données personnelles à des fins marchandes ni les légitimes oppositions qu’elle soulève ne sont dans leur principe des phénomènes nouveaux.
Historiquement, c’est l’informatique bancaire qui s’est trouvée comme à l’avant-garde de cette collecte structurée qui va constituer les bases de données. Mais entre le climat de la Guerre froide et la méfiance des citoyens américains alors jaloux de leur liberté, les protestations sont vives. Dès le début des années 1970 certains déjà redoutent un monde où l’individu serait sous totale surveillance grâce aux technologies informatiques.
Les tentatives pour contenir par un cadre juridique l’exploitation des données privées étaient trouées d’exceptions dont les entreprises commerciales ont évidemment profité. Grâce à l’informatisation croissante du traitement de données, il leur devenait facile de déterminer des types de consommateurs et d’anticiper sur leurs désirs d’achat : dès avant 1980, le profilage était né.
Christophe Masutti retrace le chemin parcouru depuis : comment les données vont devenir une ressource monnayable, comment dès le début des années 1990 on peut proposer un modèle économique où chacun vendrait ses données (ça ne vous rappelle rien ?), comment s’est développé le business juteux du commerce des données, au point d’alimenter les méga-corporations que nous connaissons aujourd’hui, et quelles voix se sont élevées, opposant la liberté au profilage et à la segmentation sociale qu’impose cette économie de la surveillance.
En définitive, le parcours historique et analytique que vous allez lire est à la fois surprenant – puisque tout était déjà là, et éclairant – car c’est ainsi que nous en sommes arrivés là.
* * *
Comme le texte de l’article est un peu long (une trentaine de pages au format A4 plus une abondante bibliographie), nous vous en proposons la lecture hors-ligne en téléchargeant ci-dessous le fichier .pdf (avec liens actifs pour le parcourir)
Cliquez sur l’image pour télécharger Léviathans V de Christophe Masutti au format .pdf (210 Ko) (ou sur Hal-shs)
Nos comportements font désormais l’objet d’une surveillance de plus en plus intrusive de la part du commerce, qu’il soit ou non virtuel, au point de surveiller même les achats que nous ne faisons pas…
Voici déjà le 13e article de la série écrite par Rick Falkvinge. Le fondateur du Parti Pirate suédois. Il attire aujourd’hui notre attention sur une forme inattendue du pistage à caractère commercial.
Le fil directeur de la série de ces 21 articles, comme on peut le voir clairement dans les épisodes précédents que nous vous avons déjà livrés, c’est la perte de certaines libertés dont nous disposions encore assez récemment, avant que le passage au tout-numérique ne nous en prive.
On espionne non seulement tout ce que nos enfants achètent, mais également tout ce qu’ils N’ACHÈTENT PAS
Traduction Framalang : draenog, dodosan, goofy et un anonyme
Nous avons vu comment les achats de nos enfants, que ce soit en liquide ou par carte, sont surveillés au mépris de leur vie privée, d’une manière qui aurait fait frémir nos parents. Pire encore : la vie privée de nos enfants est également violée par l’espionnage des achats qu’ils ne font pas, qu’ils les refusent sciemment ou qu’ils passent simplement leur chemin.
Amazon vient d’ouvrir son premier magasin Amazon Go, où il est possible de mettre des articles dans son sac et de partir, sans avoir à passer par une caisse. Pour présenter ce concept3, Amazon indique qu’il est possible de prendre un article, qui sera inscrit dans vos achats, puis de changer d’avis et de le reposer, auquel cas le système enregistre que l’article n’a pas été acheté.
Évidemment, on ne paie pas pour un article à propos duquel on a changé d’avis, ce qui est le message de la vidéo. Mais il ne s’agit pas seulement d’enlever un article du total à payer : Amazon sait que quelqu’un a envisagé de l’acheter et ne l’a au final pas fait, et l’entreprise utilisera cette information.
Nos enfants sont espionnés de cette manière chaque jour, si ce n’est à chaque heure. Nos parents n’ont jamais connu cela.
Lorsque nous faisons des achats en ligne, nous rencontrons même des plugins simples pour les solutions commerciales les plus courantes, qui réalisent ce qu’on nomme, par un barbarisme commercial, une « analyse en entonnoir » ou « analyse d’abandon de panier », qui détermine à quel moment nos enfants décident d’abandonner le processus d’achat.
On ne peut même plus quitter un achat en cours de route sans qu’il soit enregistré, consigné et catalogué pour un usage futur.
Mais cet « abandon de panier » n’est qu’une partie d’un plus vaste problème, à savoir le pistage de ce qui nous intéresse, à l’ère de nos enfants du numérique, sans pour autant que nous l’achetions. On ne manque pas aujourd’hui de personnes qui jureraient avoir tout juste discuté d’un type de produit au téléphone (disons, « jupe noire en cuir ») pour voir, tout à coup, des publicités spécifiques pour ce type de produit surgir de tous les côtés sur les pubs Facebook et/ou Amazon. Est-ce qu’il s’agit vraiment d’entreprises à l’écoute de mots-clés via notre téléphone ? Peut-être, peut-être pas. Tout ce qu’on sait depuis Snowden, c’est que s’il est techniquement possible de faire intrusion dans notre vie privée, alors c’est déjà en place.
(On peut supposer que ces personnes n’ont pas encore appris à installer un simple bloqueur de publicités… Mais bon.)
Dans les endroits les plus surchargés en pubs, comme les aéroports (mais pas seulement là), on trouve des traqueurs de mouvements oculaires pour déterminer quelles publicités vous regardez. Elles ne changent pas encore pour s’adapter à vos intérêts, comme dans Minority Report, mais puisque c’est déjà le cas sur votre téléphone et votre ordinateur, il ne serait pas surprenant que cela arrive bientôt dans l’espace public.
Dans le monde analogique de nos parents, nous n’étions pas enregistrés ni pistés quand nous achetions quelque chose.
Dans le monde numérique de nos enfants, nous sommes enregistrés et suivis même quand nous n’achetons pas quelque chose.











{kind=link}