Le Libre peut-il faire le poids ?
Dans un article assez lucide de son blog que nous reproduisons ici, Dada remue un peu le fer dans la plaie.
Faiblesse économique du Libre, faiblesse encore des communautés actives dans le développement et la maintenance des logiciels et systèmes, manque de visibilité hors du champ de perception de beaucoup de DSI. En face, les forces redoutables de l’argent investi à perte pour tuer la concurrence, les forces tout aussi redoutables des entreprises-léviathans qui phagocytent lentement mais sûrement les fleurons du Libre et de l’open source…
Lucide donc, mais aussi tout à fait convaincu depuis longtemps de l’intérêt des valeurs du Libre, Dada appelle de ses vœux l’émergence d’entreprises éthiques qui permettraient d’y travailler sans honte et d’y gagner sa vie décemment. Elles sont bien trop rares semble-t-il.
D’où ses interrogations, qu’il nous a paru pertinent de vous faire partager. Que cette question cruciale soit l’occasion d’un libre débat : faites-nous part de vos réactions, observations, témoignages dans les commentaires qui comme toujours sont ouverts et modérés. Et pourquoi pas dans les colonnes de ce blog si vous désirez plus longuement exposer vos réflexions.
L’économie du numérique et du Libre
par Dada
Republication de l’article original publié sur son blog

Avec des projets plein la tête, ou plutôt des envies, et le temps libre que j’ai choisi de me donner en n’ayant pas de boulot depuis quelques mois, j’ai le loisir de m’interroger sur l’économie du numérique. Je lis beaucoup d’articles et utilise énormément Mastodon pour me forger des opinions.
Ce billet a pour origine cet entretien de Frédéric Fréry sur France Culture : Plus Uber perd, plus Uber gagne.
Ubérisation d’Uber
Je vous invite à vraiment prendre le temps de l’écouter, c’est franchement passionnant. On y apprend, en gros, que l’économie des géants du numérique est, pour certains, basée sur une attitude extrêmement agressive : il faut être le moins cher possible, perdre de l’argent à en crever et lever des fonds à tire-larigot pour abattre ses concurrents avec comme logique un pari sur la quantité d’argent disponible à perdre par participants. Celui qui ne peut plus se permettre de vider les poches de ses actionnaires a perdu. Tout simplement. Si ces entreprises imaginent, un jour, remonter leurs prix pour envisager d’être à l’équilibre ou rentable, l’argument du « ce n’est pas possible puisque ça rouvrira une possibilité de concurrence » sortira du chapeau de ces génies pour l’interdire. Du capitalisme qui marche sur la tête.
L’investissement sécurisé
La deuxième grande technique des géants du numérique est basée sur la revente de statistiques collectées auprès de leurs utilisateurs. Ces données privées que vous fournissez à Google, Facebook Inc,, Twitter & co permettent à ces sociétés de disposer d’une masse d’informations telle que des entreprises sont prêtes à dégainer leurs portefeuilles pour en dégager des tendances.
Je m’amuse souvent à raconter que si les séries et les films se ressemblent beaucoup, ce n’est pas uniquement parce que le temps passe et qu’on se lasse des vieilles ficelles, c’est aussi parce que les énormes investissements engagés dans ces productions culturelles sont basés sur des dossiers mettant en avant le respect d’un certain nombre de « bonnes pratiques » captant l’attention du plus gros panel possible de consommateurs ciblés.
Avec toutes ces données, il est simple de savoir quel acteur ou quelle actrice est à la mode, pour quelle tranche d’âge, quelle dose d’action, de cul ou de romantisme dégoulinant il faut, trouver la période de l’année pour la bande annonce, sortie officielle, etc. Ça donne une recette presque magique. Comme les investisseurs sont friands de rentabilité, on se retrouve avec des productions culturelles calquées sur des besoins connus : c’est rassurant, c’est rentable, c’est à moindre risque. Pas de complot autour de l’impérialisme américain, juste une histoire de gros sous.
Cette capacité de retour sur investissement est aussi valable pour le monde politique, avec Barack OBAMA comme premier grand bénéficiaire ou encore cette histoire de Cambridge Analytica.
C’est ça, ce qu’on appelle le Big Data, ses divers intérêts au service du demandeur et la masse de pognon qu’il rapporte aux grands collecteurs de données.
La pub
Une troisième technique consiste à reprendre les données collectées auprès des utilisateurs pour afficher de la pub ciblée, donc plus efficace, donc plus cher. C’est une technique connue, alors je ne développe pas. Chose marrante, quand même, je ne retrouve pas l’étude (commentez si vous mettez la main dessus !) mais je sais que la capacité de ciblage est tellement précise qu’elle peut effrayer les consommateurs. Pour calmer l’angoisse des internautes, certaines pubs sans intérêt vous sont volontairement proposées pour corriger le tir.
Les hommes-sandwichs
Une autre technique est plus sournoise. Pas pour nous autres, vieux loubards, mais pour les jeunes : le placement produit. Même si certain Youtubeurs en font des blagues pas drôles (Norman…), ce truc est d’un vicieux.
Nos réseaux sociaux n’attirent pas autant de monde qu’espéré pour une raison assez basique : les influenceurs et influenceuses. Ces derniers sont des stars, au choix parce qu’ils sont connus de par leurs activités précédentes (cinéma, série, musique, sport, etc.) ou parce que ces personnes ont réussi à amasser un tel nombre de followers qu’un simple message sur Twitter, Youtube ou Instagram se cale sous les yeux d’un monstrueux troupeau. Ils gagnent le statut d’influenceur de par la masse de gens qui s’intéresse à leurs vies (lapsus, j’ai d’abord écrit vide à la place de vie). J’ai en tête l’histoire de cette jeune Léa, par exemple. Ces influenceurs sont friands de plateformes taillées pour leur offrir de la visibilité et clairement organisées pour attirer l’œil des Directeurs de Communication des marques. Mastodon, Pixelfed, diaspora* et les autres ne permettent pas de spammer leurs utilisateurs, n’attirent donc pas les marques, qui sont la cible des influenceurs, ces derniers n’y dégageant, in fine, aucun besoin d’y être présents.
Ces gens-là deviennent les nouveaux « hommes-sandwichs ». Ils ou elles sont contacté⋅e⋅s pour porter tel ou tel vêtement, boire telle boisson ou pour seulement poster un message avec le nom d’un jeu. Les marques les adorent et l’argent coule à flot.
On peut attendre
Bref, l’économie du numérique n’est pas si difficile que ça à cerner, même si je ne parle pas de tout. Ce qui m’intéresse dans toutes ces histoires est la stabilité de ces conneries sur le long terme et la possibilité de proposer autre chose. On peut attendre que les Uber se cassent la figure calmement, on peut attendre que le droit décide enfin de protéger les données des utilisateurs, on peut aussi attendre le jour où les consommateurs comprendront qu’ils sont les seuls responsables de l’inintérêt de ce qu’ils regardent à la télé, au cinéma, en photos ou encore que les mastodontes du numérique soient démantelés. Bref, on peut attendre. La question est : qu’aurons-nous à proposer quand tout ceci finira par se produire ?
La LowTech
Après la FinTech, la LegalTech, etc, faites place à la LowTech ou SmallTech. Je ne connaissais pas ces expressions avant de tomber sur cet article dans le Framablog et celui de Ubsek & Rica d’Aral. On y apprend que c’est un mouvement qui s’oppose frontalement aux géants, ce qui est fantastique. C’est une vision du monde qui me va très bien, en tant que militant du Libre depuis plus de 10 ans maintenant. On peut visiblement le rapprocher de l’initiative CHATONS.
Cependant, j’ai du mal à saisir les moyens qui pourraient être mis en œuvre pour sa réussite.
Les mentalités
Les mentalités actuelles sont cloisonnées : le Libre, même s’il s’impose dans quelques domaines, reste mal compris. Rien que l’idée d’utiliser un programme au code source ouvert donne des sueurs froides à bon nombre de DSI. Comment peut-on se protéger des méchants si tout le monde peut analyser le code et en sortir la faille de sécurité qui va bien ? Comment se démarquer des concurrents si tout le monde se sert du même logiciel ? Regardez le dernier changelog : il est plein de failles béantes : ce n’est pas sérieux !
Parlons aussi de son mode de fonctionnement : qui se souvient d’OpenSSL utilisé par tout le monde et abandonné pendant des années au bénévolat de quelques courageux qui n’ont pas pu empêcher l’arrivée de failles volontaires ? Certains projets sont fantastiques, vraiment, mais les gens ont du mal à réaliser qu’ils sont, certes, très utilisés mais peu soutenus. Vous connaissez beaucoup d’entreprises pour lesquelles vous avez bossé qui refilent une petite partie de leurs bénéfices aux projets libres qui les font vivre ?
Le numérique libre et la Presse
Les gens, les éventuels clients des LowTech, ont plus ou moins grandi dans une société du gratuit. L’autre jour, je m’amusais à comparer les services informatiques à la Presse. Les journaux ont du mal à se sortir du modèle gratuit. Certains y arrivent (Mediapart, Arrêts sur Image : abonnez-vous !), d’autres, largement majoritaires, non.
Il n’est pas difficile de retrouver les montants des subventions que l’État français offre à ces derniers. Libération en parle ici. Après avoir noué des partenariats tous azimuts avec les GAFAM, après avoir noyé leurs contenus dans de la pub, les journaux en ligne se tournent doucement vers le modèle payant pour se sortir du bourbier dans lequel ils se sont mis tout seuls. Le résultat est très moyen, si ce n’est mauvais. Les subventions sont toujours bien là, le mirage des partenariats avec les GAFAM aveugle toujours et les rares qui s’en sont sortis se comptent sur les doigts d’une main.
On peut faire un vrai parallèle entre la situation de la Presse en ligne et les services numériques. Trouver des gens pour payer l’accès à un Nextcloud, un Matomo ou que sais-je est une gageure. La seule différence qui me vient à l’esprit est que des services en ligne arrivent à s’en sortir en coinçant leurs utilisateurs dans des silos : vous avez un Windows ? Vous vous servirez des trucs de Microsoft. Vous avez un compte Gmail, vous vous servirez des trucs de Google. Les premiers Go sont gratuits, les autres seront payants. Là où les journaux généralistes ne peuvent coincer leurs lecteurs, les géants du numérique le peuvent sans trop de souci.
Et le libre ?
Dans tout ça, les LowTech libres peuvent essayer de s’organiser pour subvenir aux besoins éthiques de leurs clients. Réflexion faite, cette dernière phrase n’a pas tant que ça de sens : comment une entreprise peut-elle s’en sortir alors que l’idéologie derrière cette mouvance favorise l’adhésion à des associations ou à rejoindre des collectifs ? Perso, je l’ai déjà dit, j’adhère volontiers à cette vision du monde horizontale et solidaire. Malgré tout, mon envie de travailler, d’avoir un salaire, une couverture sociale, une activité rentable, et peut-être un jour une retraite, me poussent à grimacer. Si les bribes d’idéologie LowTech orientent les gens vers des associations, comment fait-on pour sortir de terre une entreprise éthique, rentable et solidaire ?
On ne s’en sort pas, ou très difficilement, ou je n’ai pas réussi à imaginer comment. L’idée, connue, serait de s’attaquer au marché des entreprises et des collectivités pour laisser celui des particuliers aux associations sérieuses. Mais là encore, on remet un pied dans le combat pour les logiciels libres contre les logiciels propriétaires dans une arène encerclée par des DSI pas toujours à jour. Sans parler de la compétitivité, ce mot adoré par notre Président, et de l’état des finances de ces entités. Faire le poids face à la concurrence actuelle, même avec les mots « éthique, solidaire et responsable » gravés sur le front, n’est pas évident du tout.
Proie
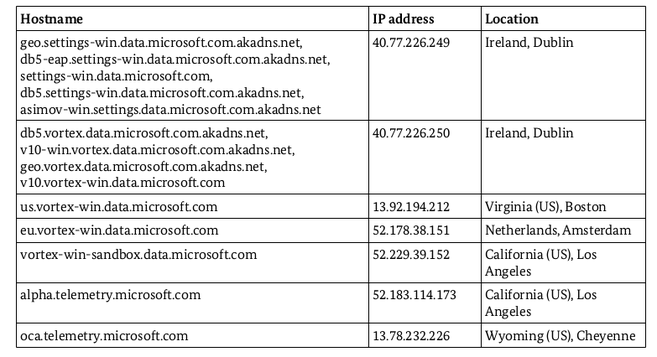
Si je vous parle de tout ça, c’est parce que j’estime que nous sommes dans une situation difficile : celle d’une proie. Je ne vais pas reparler de l’achat de Nginx, de ce qu’il se passe avec ElasticSearch ou du comportement de Google qui forke à tout va pour ses besoins dans Chrome. Cette conférence vue au FOSDEM, The Cloud Is Just Another Sun, résonne terriblement en moi. L’intervenant y explique que les outils libres que nous utilisons dans le cloud sont incontrôlables. Qui vous certifie que vous tapez bien dans un MariaDB ou un ES quand vous n’avez accès qu’a une boite noire qui ne fait que répondre à vos requêtes ? Rien.
Nous n’avons pas trouvé le moyen de nous protéger dans le monde dans lequel nous vivons. Des licences ralentissent le processus de digestion en cours par les géants du numérique et c’est tout. Notre belle vision du monde, globalement, se fait bouffer et les poches de résistance sont minuscules.

Pour finir
Pour finir, ne mettons pas complètement de côté l’existence réelle d’un marché : Nextcloud en est la preuve, tout comme Dolibarr et la campagne de financement réussie d’OpenDSI. Tout n’est peut-être pas vraiment perdu. C’est juste très compliqué.
La bonne nouvelle, s’il y en a bien une, c’est qu’en parlant de tout ça dans Mastodon, je vous assure que si une entreprise du libre se lançait demain, nous serions un bon nombre prêt à tout plaquer pour y travailler. À attendre d’hypothétiques clients, qu’on cherche toujours, certes, mais dans la joie et la bonne humeur.
Enfin voilà, des réflexions, des idées, beaucoup de questions. On arrive à plus de 1900 mots, de quoi faire plaisir à Cyrille BORNE.
Des bisous.