Le site Dégooglisons Internet a servi, durant trois ans, à présenter une campagne d’information, d’actions, d’intentions de Framasoft tout en proposant un portail d’accès aux services qui venaient s’ajouter aux conquêtes de la communauté libriste.
Maintenant que nous avons conclu cette campagne, il va remplir une fonction unique : faciliter l’adoption de services éthiques, respectueux de ces données personnelles qui décrivent nos vies numériques. En trois ans, nous avons fait bien plus qu’héberger des services, et il était grand temps de vous présenter tout cela de manière claire et facile d’accès.
Dès l’accueil, nous vous invitons à faire feu des GAFAM (les géants du web que sont Google, Apple, Facebook, Amazon et Microsoft) en expliquant en trois bulles la problématique à laquelle nous essayons de répondre.
Bien vite, on arrive au cœur de la proposition : les services. Si vous ne pouvez pas les essayer, comment pourrez-vous les adopter ? Nous vous invitons donc à trouver le service que vous cherchez suivant deux entrées possibles (on y reviendra !)
Néanmoins, tester des services n’est qu’une première étape, et nous vous proposons ensuite d’aller plus loin :
savoir s’il n’y aurait pas un hébergeur éthique près de chez vous : l’un des CHATONS.
Seulement voilà, vous pouvez aussi vous poser des questions sur les raisons d’une telle démarche. C’est même très sain, puisque c’est ainsi que peut naître la confiance (ou la défiance, d’ailleurs) : ce sentiment qui nous pousse à confier nos données, nos vies numériques, à un hébergeur. Nous exposons donc :
Un espace final est réservé aux médias qui ont parlé de cette aventure, avec un lien vers notre espace médias, que chacun·e peut librement visiter et utiliser.
Chacun·e peut trouver service à son pied
Nous avons décidé de présenter de deux manières différentes les 32 services qui sont actuellement à votre disposition, car tout le monde ne cherche pas de la même manière.
La première démarche, lorsque l’on cherche selon un besoin précis, correspond à cette partie de la page d’accueil :
La deuxième démarche consiste à chercher un service alternatif au service propriétaire que l’on utilise et que l’on connaît.
Ici vous retrouverez d’abord la fameuse carte Dégooglisons, où il vous suffit de cliquer sur le camp romain du service qui vous intéresse pour en découvrir une alternative.
Mais il n’y a pas que les « Framachins » dans la vie. Très vite, vous trouverez en dessous de cette carte une liste bien plus complète d’alternatives en tous genres pour se dégoogliser plus complètement. Cette liste est inspirée de l’excellent site Prism-Break, un site à garder dans ses marque-pages !
Un exemple, totalement au hasard, pour les alternatives à l’email ;)
À vous de dégoogliser !
Vous l’avez saisi, l’idée du site degooglisons-internet.org, c’est qu’il vous soit utile. Que ce soit pour trouver des alternatives qui vous sont nécessaires, ou pour aider votre entourage à se dégoogliser, c’est désormais à vous de vous en emparer.
D’ailleurs, n’hésitez pas à aller visiter l’espace médias, qui s’est enrichi d’une fresque racontant ces trois années de Dégooglisons, ainsi que des dessins de Péhä, aux côtés de nombreux autres visuels libres… et à partager dans vos réseaux !
Nous espérons, sincèrement, que la refonte de ce site vous simplifiera la dégooglisation et même (soyons folles et fous) la vie !
Bienvenue au banquet concluant Dégooglisons Internet, par Péhä (CC-By)
Un cas de dopage : Gégé sous l’emprise du Dr Valvin
Quand un libriste s’amuse à reprendre et développer spectaculairement un petit Framaprojet, ça mérite bien une interview ! Voici Valvin, qui a dopé notre, – non, votre Geektionnerd Generator aux stéroïdes !
Gégé, le générateur de Geektionnerd, est un compagnon déjà ancien de nos illustrations plus ou moins humoristiques. Voilà 4 ans que nous l’avons mis à votre disposition, comme en témoigne cet article du Framablog qui vous invitait à vous en servir en toute occasion. Le rapide historique que nous mentionnions à l’époque, c’est un peu une chaîne des relais qui se sont succédé de William Carvalho jusqu’à Gee et ses toons en passant par l’intervention en coulisses de Cyrille et Quentin.
Vous le savez, hormis le frénétique Luc qu’on est obligés de piquer d’une flèche hypodermique pour l’empêcher de coder à toute heure, on développe peu à Framasoft. Aussi n’est-il guère surprenant que ce petit outil ludique soit resté en sommeil sans évolution particulière pendant ces dernières années où la priorité allait aux services de Dégooglisons.
Enfin Valvin vint, qui à l’occasion de l’ajout d’une tripotée de nouveaux personnages se mit à coder vite et bien, poursuivant avec la complicité de Framasky – ô Beauté du code libre ! – la chaîne amicale des contributeurs.
Mais faisons connaissance un peu avec celui qui vient d’ajouter généreusement des fonctionnalités sympathiques à Gégé.
Commençons par l’exercice rituel : peux-tu te présenter pour nos lecteurs et lectrices. Qui es-tu, Valvin ?
Salut Framasoft, je suis donc Valvin, originaire de Montélimar, j’habite maintenant dinch Nord avec ma petite famille. Je suis un peu touche-à-tout et il est vrai que j’ai une attirance particulière pour le Libre mais pas uniquement les logiciels.
Qu’est-ce qui t’a amené au Libre ? Tu es tombé dedans quand tu étais petit ou bien tu as eu droit à une potion magique ?
J’ai commencé en tant qu’ingénieur sur les technologies Microsoft (développement .NET, Active Directory, SQL Server…) J’avais bien commencé non ? Puis Pepper m’a concocté une potion et puis …. vous savez qu’elle ne réussit pas souvent ses potions ?
Plus sérieusement lors de mon parcours professionnel, j’ai travaillé dans une entreprise où Linux était largement déployé, ce qui m’a amené à rencontrer davidb2111, libriste convaincu depuis tout petit (il a dû tomber dans la marmite …). Et je pense que c’est lui qui m’a mis sur la voie du Libre…
Cependant ce qui m’a fait passer à l’action a été la 1re campagne « Dégooglisons Internet »… Elle a débuté juste après mon expérience de e-commerce, quand je gérais un petit site web de vente en ligne où j’ai découvert l’envers du décor : Google analytics, adwords, comparateurs de prix… et pendant que j’intégrais les premiers terminaux Android industriels.
Je suis maintenant un libriste convaincu mais surtout défenseur de la vie privée. Certains diront extrémiste mais je ne le pense pas.
Dans ta vie professionnelle, le Libre est-il présent ou bien est-ce compliqué de l’utiliser ou le faire utiliser ?
Aujourd’hui, je suis une sorte d’administrateur système mais pour les terminaux mobiles industriels (windows mobile/ce mais surtout Android). Pour ceux que ça intéresse, ça consiste à référencer du matériel, industrialiser les préparations, administrer le parc avec des outils MDM (Mobile Device Management), mais pas seulement !
Je suis en mission chez un grand compte (comme ils disent) où le Libre est présent mais pas majoritairement. On le retrouve principalement côté serveur avec Linux (CentOS), Puppet, Nagios/Centreon, PostgreSQL … (la liste est longue en fait). Après je travaille sur Android au quotidien mais j’ai un peu du mal à le catégoriser dans le Libre ne serait-ce qu’en raison de la présence des Google Play Services.
J’ai la chance d’avoir mon poste de travail sous Linux mais j’utilise beaucoup d’outils propriétaires au quotidien. (j’démarre même des fois une VM Windows … mais chuuuut !!).
Je suis assez content d’avoir mis en place une instance Kanboard (Framaboard) en passant par des chemins obscurs mais de nombreux utilisateurs ont pris en main l’outil ce qui en fait aujourd’hui un outil officiel.
On découvre des choses diverses sur ton blog, des articles sur le code et puis un Valvin fan de graphisme et surtout qui est prêt à contribuer dès qu’il y a passion ? Alors, tu as tellement de temps libre pour le Libre ?
Du temps quoi ?… Malheureusement, je n’ai pas beaucoup de temps libre entre le travail, les trajets quotidien (plus de 2 heures) et la famille. Du coup, une fois les enfants couchés, plutôt que regarder la télé, j’en profite (entre deux dessins). Mes contributions dans le libre sont principalement autour du projet de David Revoy, Pepper & Carrot. J’ai la chance de pouvoir vivre l’aventure à ses côtés ainsi que de sa communauté. Et dans l’univers de la BD, c’est inédit ! D’ailleurs je te remercie, Framasoft, de me l’avoir fait découvrir 🙂
Si je peux filer un petit coup de main avec mes connaissances sur un projet qui me tient à cœur, je n’hésite pas. Et même si ce n’est pas grand-chose, ça fait plaisir d’apporter une pierre à l’édifice et c’est ça aussi la magie du Libre !
J’ai eu parfois l’ambition de lancer moi même des projets libres mais j’ai bien souvent sous-estimé le travail que ça représentait …
Et maintenant, tu t’attaques au geektionnerd, pourquoi tout à coup une envie d’améliorer un projet/outil qui vivotait un peu ?
Je dois avouer que c’est par hasard. J’ai vu un message sur Mastodon qui m’a fait découvrir le projet. Il n’y a pas si longtemps, je m’étais intéressé au projet Bird’s Dessinés et j’avais trouvé le concept sympa. Mais tout était un peu verrouillé, notamment les droits sur les réalisations. J’aime bien le dessin et la bande dessinée, le projet du générateur de Geektionnerd m’a paru très simple à prendre en main… du coup, je me suis lancé !
Tu peux parler des problèmes du côté code qui se sont posés, comment les as-tu surmontés ?
Globalement, ça s’est bien passé jusqu’au moment où j’ai voulu ajouter des images distantes dans la bibliothèque. Le pire de l’histoire c’est que ça fonctionnait bien à première vue. On pouvait ajouter toutes les images que l’on voulait, les déplacer… Nickel ! Et puis j’ai cliqué sur « Enregistrer l’image » et là… j’ai découvert la magie de CORS !
CORS signifie Cross Origin Ressource Sharing et intervient donc lorsque le site web tente d’accéder à une ressource qui ne se situe pas sur son nom de domaine.
Il est possible de créer une balise image html qui pointe vers un site extérieur du type :
En revanche, récupérer cette image pour l’utiliser dans son code JavaScript, c’est possible mais dans certaines conditions uniquement. Typiquement, si j’utilise jquery et que je fais :
Cross-Origin Request Blocked: The Same Origin Policy disallows reading the remote resource at https://www.peppercarrot.com/extras/html/2016_cat-generator/avatar.php?seed=Linux. (Reason: CORS header 'Access-Control-Allow-Origin' missing).
En revanche, si on utilise une image hébergée sur un serveur qui autorise les requêtes Cross-Origin, il n’y a pas de souci :
Tout cela en raison de ce petit en-tête HTTP que l’on obtient du serveur distant :
Access-Control-Allow-Origin *
où `*` signifie tout le monde, mais il est possible de ne l’autoriser que pour certains domaines.
Avec les canvas, ça se passait bien jusqu’à la génération du fichier PNG car on arrivait au moment où l’on devait récupérer la donnée pour l’intégrer avec le reste de la réalisation. J’avais activé un petit paramètre dans la librairie JavaScript sur l’objet Image
image.crossOrigin = "Anonymous";
mais avec ce paramètre, seules les images dont le serveur autorisait le Cross-Origin s’affichaient dans le canvas et la génération du PNG fonctionnait. Mais c’était trop limitatif.
Bref, bien compliqué pour par grand-chose !
J’ai proposé de mettre en place un proxy CORS, un relais qui rajoute simplement les fameux en-têtes mais ça faisait un peu usine à gaz pour ce projet. Heureusement, framasky a eu une idée toute simple de téléchargement d’image qui a permis de proposer une alternative.
Tout cela a fini par aboutir, après plusieurs tentatives à ce Merge Request : https://framagit.org/framasoft/geektionnerd-generator/merge_requests/6
Et après tous ces efforts quelles sont les fonctionnalités que tu nous as apportées sur un plateau ?
Chaud devant !! Chaud !!!
Tout d’abord, j’ai ajouté le petit zoom sur les vignettes qui était trop petites à mon goût
Ensuite, j’ai agrandi la taille de la zone de dessin en fonction de la taille de l’écran. Mais tout en laissant la possibilité de choisir la dimension de la zone car dans certains cas, on ne souhaite qu’une petite vignette carrée et cela évite de ré-éditer l’image dans un second outil.
Et pour terminer, la possibilité d’ajouter un image depuis son ordinateur. Cela permet de compléter facilement la bibliothèque déjà bien remplie 🙂
D’autres développements pour Geektionnerd ? Euh oui, j’ai plein d’idées … mais est ce que j’aurai le temps ?
– intégration Lutim pour faciliter le partage des réalisations
– recherche dans la librairie de toons à partir de tags (nécessite un référencement de méta-data par image)
– séparation des toons des bulles et dialogues : l’idée serait de revoir la partie gauche de l’application et trouver facilement les différents types d’images. Notamment en découpant par type d’image : bulles / personnages / autres.
– ajout de rectangles SVG pour faire des cases de BD
– amélioration de la saisie de texte (multi-ligne) et sélection de la fonte pour le texte
– …
Je vais peut-être arrêter là 🙂
Sinon dans les cartons, j’aimerais poursuivre mon projet Privamics dont l’objectif est de réaliser des mini-BD sur le sujet de la vie privée de façon humoristique. Mais j’ai vu avec le premier épisode que ce n’était pas une chose si facile. Du coup, je privilégie mon apprentissage du dessin 🙂
Bien entendu, Pepper & Carrot reste le projet auquel je souhaite consacrer le plus de temps car je trouve que le travail que fait David est tout simplement fantastique !
Le mot de la fin est pour toi…
Un grand merci à toi Framasoft, tu m’as déjà beaucoup apporté et ton projet me tient particulièrement à cœur.
Prenons un peu des nouvelles des fameux GAFAM avec l’ami Gee qui nous synthétise les derniers exploits de ces entreprises aux pouvoirs de plus en plus larges et inquiétants… malheureusement, les quelques anecdotes racontées ici sont tirées de faits réels (les sources sont données après la BD).
La rentrée des GAFAM
Pendant que vous vous doriez la pilule en vacances ou que vous dégouliniez au travail sous une chaleur de plomb, les GAFAM n’ont pas chômé cet été…
On en avait déjà parlé, mais Microsoft s’invite s’impose à l’école dans le Grand Est en subventionnant l’achat de tablettes et ordinateurs portables désormais obligatoires pour les élèves…
L’opération, pour l’heure appliquée dans 50 lycées du Grand Est mais appelée à être généralisée par la suite, a pudiquement été appelée « lycée 4.0 ».
En parlant d’obsolescence programmée, parlons d’Apple qui se distingue toujours autant dans les championnats du monde de l’enfoirage la fourberie.
En effet, il a été montré que le capteur de foulées Nike+iPod cessait d’être reconnu par l’iPod après 1 000 heures d’utilisation, quel que soit l’état réel de l’appareil ou de sa batterie (une limitation artificielle volontairement ajoutée au niveau logiciel).
Ne tirons pas de conclusions hâtives, malgré tout : Apple a peut-être simplement voulu faire un placement de produit pour Mission Impossible.
Parlons enfin de Google Home, le mouchard à installer soi-même chez soi.
En même temps, comme l’heure est à la réduction de la dépense publique, ça permet de supprimer des postes devenus inutiles chez les services de renseignement, et ça, on n’en parle pas assez.
Google aurait d’ailleurs réussi à résoudre le problème de la consommation énergétique de ses petits appareils : en effet, ils seraient tous alimentés par une unique turbine branchée sur la dépouille de George Orwell qui n’a pas fini de se retourner dans sa tombe.
Personnage atypique dans notre galerie de portraits des dessinateur-ice-s qui publient sous licence libre, Antoine Moreau partage en copyleft des dessins réalisés par des personnes de rencontre. Entre autres activités.
Une démarche artistique hors normes, qui dure depuis super longtemps !
Je suis un artiste peut être. J’ai été à l’initiative et co-rédacteur de la Licence Art Libre en 2000. J’ai mis en place l’association Copyleft Attitude.
Raconte-nous comment est né ton projet, et depuis combien de temps tu fais ça ? (j’ai vu des dessins de 1982 !)
De 1982 à 1997 j’ai demandé à des personnes de rencontre de me dessiner quelque chose sur une feuille vierge A4. Elles signaient, je contresignais et conservais la feuille.
En février 2008 je reprends cette activité avec quelques changements :
La feuille comporte une mention légale copyleft selon les termes de la Licence Art Libre.
Je ne contresigne pas.
Le dessin est scanné ou photographié.
Il est restitué à son auteur.
J’en conserve une copie numérique et mets en ligne.
Je pense que si j’ai été amené à faire ces dessins c’est pour répondre à un problème simple : que dessiner et comment le faire ?
En confiant la réalisation du dessin à qui veut bien le faire à ma demande, je découvre ma part d’auteur excédant visiblement l’auteur que je suis censé être et reconnu comme tel par ce qu’il a en propre.
Aux RMLL en 2009 je présentais ainsi (avec une touche de Lao Tseu) ce que j’allais faire :
Antoine Moreau se promène avec des feuilles vierges copyleft selon les termes de la Licence Art Libre pour les offrir à qui veut dessiner dessus.
Il adopte la tactique du non-agir, et pratique l’enseignement sans parole.
Toutes choses du monde surgissent sans qu’il en soit l’auteur.
Il produit sans s’approprier, il agit sans rien attendre, son œuvre accomplie, il ne s’y attache pas.
Tu es vraiment à l’origine du copyleft ?
Non, c’est Don Hopkins, artiste et programmeur, ami de Richard Stallman qui, un jour de 1984, lui a envoyé une lettre avec noté sur l’enveloppe cette phrase : « Copyleft — all rights reversed ». « Copyleft » est alors devenu le mot qui allait désigner l’idée du logiciel libre tel qu’il a été formalisé par la General Public License.
Est-ce que tu es toi-même dessinateur ? J’ai vu des sculptures, aussi.
Je confie des sculptures à des personnes de rencontre en leur demandant de la confier également à quelqu’un d’autre et ainsi de suite, sans qu’il n’y ait de propriétaire définitif ni de point de chute final. Je demande simplement à ce qu’on m’informe de l’histoire de la sculpture :
à qui elle a été confiée, où elle se trouve et quand s’est passée la transmission, de façon à avoir un historique de l’œuvre itinérante.
Peinture : une peinture de peintres. Je propose à des peintres de se peindre les uns par dessus les autres sur une toile. Cette peinture n’aura pas de fin, pas d’image arrêtée. C’est la peinture sans fin par la fin de la peinture. Chaque couche de peinture d’un peintre différent fait disparaître, entièrement ou en partie la couche précédente.Des traces photo demeurent.
Tu as fait des expositions physiques, aussi. Beaucoup ?
Fatalement, un artiste est amené à montrer son travail. Je me suis appliqué à cette convenance.
Tu as besoin de contributeurices ? D’aide financière ? D’admiration ? De câlins ?
Après avoir soutenu ma thèse en 2011 « Le copyleft appliqué à la création hors logiciel. Une reformulation des données culturelles ? » il y a eu le projet d’en faire un framabook. Il y a eu enthousiasme et débat et tentative de passage à l’acte. Plutôt que de réviser moi-même le texte pour l’adapter au format livre j’avais proposé l’idée de laisser la communauté Framasoft le faire : couper dans le texte, choisir les passages à conserver, etc. en ayant, bien sûr, un droit de regard. Un wiki a été mis en place mais sans suite.
Eh bien je n’étais pas là à ce moment-là…
Ce Framabook serait semblable, dans son process, aux dessins dont je propose la réalisation. J’offre la matière, vous réalisez la forme que ça va prendre.
Comme d’habitude dans le Framablog, nous te laissons le mot de la fin.
Il n’y a pas de mot de la fin. L’infini est en cours. Tout se poursuit. D’une façon ou d’une autre.
Tous les dessins sont extraits de la collection d’Antoine.
Péhä : il lisait des Picsou, il dessine des gnous !
Des développeurs de logiciels libres, on en trouve presque à la pelle. Des artistes libres… ça se complique, mais on en trouve ! Bien évidemment, il y a Gee et vous avez déjà lu l’interview de David Revoy ici même à l’occasion de la sortie papier de Pepper & Carrot, mais d’autres se cachent encore dans les tréfonds des Internetz !
Nous passons l’été à les chercher pour vous les présenter. Samedi dernier, vous avez pu découvrir Nylnook et nous avons encore quelques surprises en prévision.
Voici Péhä ! Vous avez peut-être aperçu ses dessins ces derniers temps sur les réseaux sociaux via nos comptes. En effet, il a illustré les articles écrit par Emmabuntus et Arpinux dans L’Âge de faire à propos de certains de nos services.
Comme il a un joli coup de patte, nous avons décidé de lui poser quelques questions pour en savoir plus sur lui.
Bonjour Péhä. Est-ce que tu peux déjà te présenter ? (et d’où vient ton pseudo avec les accents extra-terrestres ?)
Hello Framasoft, je suis donc Péhä, j’ai 32 ans, je vis près d’Angers (c’est dans l’ouest de la France pour Pouhiou 🙂 ). Le pseudo avec les accents c’est un petit jeu de mot avec les initiales de mon prénom. Ça date d’il y a quelques années quand je faisais du volley, c’était pour rigoler mais comme tout mon entourage irl m’appelle comme ça depuis, j’ai gardé ce pseudo sur le net.
Qu’est-ce qui t’a amené au dessin ? Comment as-tu appris ?
Comme tous les gosses, j’ai pas mal dessiné étant gamin. J’ai fais arts plastiques comme tout le monde au collège/lycée (surtout parce qu’à l’époque le pc de la salle d’art était pas surveillé et que c’était une bonne bécane pour télécharger des roms de Mégadrive ni vu ni connu…), mais je n’ai jamais suivi de cours ou fait les beaux-arts. Je le regrette aujourd’hui un peu, car je fais pas mal d’erreurs (anatomie, proportions, perspectives) et je suis lent dans l’exécution d’un dessin.
Des sources d’inspiration ? Des dessinateurs qui t’ont donné envie de les égaler ?
Comme j’ai pas assez de bases, je m’inspire beaucoup de certains dessinateurs dont Moebius (Jean Giraud), Georges Herriman, Bill Watterson, Serre et bien sûr Franquin. Dans un genre tout autre, je voue un culte aux estampes d’Hiroshige, notamment les séries sur le tokaido ou les scènes de la vie quotidienne d’Edo.
Uderzo, aussi, manifestement…
Les tac au tac de Jean Frapat que j’ai découvert sur le site de l’INA m’inspirent également beaucoup.
Tu lisais quoi comme BD quand tu étais plus jeune ?
Ça va faire sourire mais j’ai commencé par Donald, les histoires de Carl Barks son créateur. Et puis La jeunesse de Picsou de Don Rosa qui a été une première claque pour moi. (j’avais dans les 8-9 ans.). Un soir une voisine m’a passé deux BD de sa collection. c’était des Gaston Lagaffe. J’avais 10 ans. J’ai lu la série d’une traite. Quelques jours plus tard ma mère m’abonnait à Spirou. J’ai essayé les mangas (Gunnm) mais sans trop accrocher. Je ne lis pas beaucoup de BD en fait, ou bien juste pour observer le dessin et les trucs et astuces des dessinateurs.
Pourquoi publier sous licence libre ?
Pour la liberté d’utilisation et de modification. Je veux que mes personnages puissent être repris par d’autres sans restriction. C’est ce que moi en tant que lecteur j’aurais aimé pouvoir faire avec Donald et Picsou (sans rire j’avais un scénario du tonnerre !). J’ai du mal avec l’idée même de propriété intellectuelle ou bien de création artistique. On ne crée rien, on adapte, on remixe, on ajoute son originalité rien de plus. Voilà pourquoi je publie sous licence libre car je ne possède rien, j’emprunte à tous donc je redonne.
Quelles sont les licences que tu utilises ?
J’ai commencé par la CC-BY-SA et la LAL et puis je suis passé en CC-BY lors de la publication de certains de mes dessins sur gnu.org. Mais rien n’est définitif ça peut changer.
Est-ce que tu arrives à vivre de ton art ou est-ce que tu as un vrai boulot honnête à côté ?
Je suis amateur. J’ai un travail culinaire, qui me sert à faire vivre ma petite tribu à côté gentiment. J’ai une page liberapay. (je remercie au passage mes 3 donateurs anonymes) avec le secret espoir de pouvoir couvrir mes dépenses pour le dessin avec les dons. Même si ce n’est pas beaucoup c’est toujours ça de moins sur le budget familial.
Comment t’es-tu retrouvé à faire les dessins des articles dont on parlait dans l’intro ? (et d’ailleurs, merci)
Ça c’est grâce à Patrick d’Emmabuntus qui est depuis un an notre manager/attaché de presse/impresario à Arpinux et moi. 😉
L’année dernière Patrick m’avait demandé une affiche pour la fête de l’Huma et en septembre avec Arpinux ils ont commencé à travailler sur les articles de l’âge de faire. Par charité ils m’ont proposé de faire des dessins en bas de leurs articles:) J’ai accepté et voilà. J’en profite pour les saluer eux et toute l’équipe, car bosser sur ces articles était vraiment très plaisant, un vrai travail d’équipe.
Parlons technique : comment dessines-tu ? Krita comme David ? Inkscape comme Gee ? Avec du charbon sur les murs d’une grotte comme les hommes de Cro-Magnon ? (eh oui, les dessins des hommes de Cro-Magnon sont dans le domaine public, donc sont libres 😉)
Ça dépend du moment, mais habituellement je fais mon crayonné/encrage sur papier au feutre calibré puis je fais les couleurs sous Krita (je suis nul pour faire les couleurs à l’aquarelle) et je découpe/cadre/ajoute du texte avec Gimp. J’utilise également un peu Inkscape mais pas au même niveau que Nylnook ou Gee ou bien Odysseus. J’utilise une tablette graphique qui m’a été offerte par le fondateur de PrimTux. J’ai également mes crayons de couleurs mais essentiellement pour des dessins qui n’ont pas vocation à être numérisés.
Un peu de satire ne peut pas faire de mal…
On peut te suivre quelque part ? Un blog peut-être ? (On pose la question pour la forme mais Tonton Roger a su te trouver)
Oui j’ai un blog mais super mal alimenté. Je suis surtout sur Framasphère (Mastodon aussi mais je galère). Le plus simple étant également de m’envoyer un e-mail ou de venir prendre un thé ou un café à la maison.
Et comme d’habitude, on te laisse le mot de la fin.
Je laisse mes deux compères conclure…
Allez, avant de partir je salue l’équipe historique d’Handylinux ( Fibi, Trefix, Starsheep, Thuban, Coyotus, Bruno Legrand, ceux que j’oublie (n’hésitez pas à m’envoyer des mails d’insultes) et bien sûr Arpinux. C’est grâce à eux et à leur confiance que mes dessins ont pu être diffusés lors des publications de version, un grand Merci.
Nylnook, le gentil lutin écolo-dessinateur
Cet été, nous vous proposons une série d’articles sur les dessinateur-ice-s libristes.
Nous vous avons déjà parlé de David Revoy. D’autres artistes talentueux partagent leur travail graphique sur Internet. Et certains en vivent !
C’est Camille Bissuel qui inaugure cette respiration estivale, à l’occasion de la sortie du premier épisode de sa BD Mokatori.
Nous avons craqué pour son style graphique, mais aussi pour son bagout.
Bonjour Camille. Est-ce que tu peux te présenter ?
Photo par Elisa de Castro Guerra
Alors, je suis un Camille (♂), 33 ans, illustrateur et graphiste, je travaille de chez moi, dans les Hautes-Alpes, près de Gap. Mon pseudo est Nylnook, le nom d’un petit lutin du pôle nord que j’ai imaginé.
Dans mes activités libristes, j’ai participé à l’écriture de quelques livres avec Flossmanuals Francophone. J’utilise des logiciels libres exclusivement pour mon travail depuis que je suis devenu indépendant en 2008 : par exemple Krita, Inkscape, Scribus, Blender, et beaucoup d’autres… Il m’arrive de former des gens à ces logiciels, et je publie mes travaux personnels sous licence libre également (souvent la Creative Commons by-sa).
Tu sors le premier épisode d’une belle BD sur le réchauffement climatique. Tu es militant écolo ?
Je n’ai pas l’impression d’être très pénible sur ce sujet avec mes proches ou avec les gens que je rencontre, mais oui je suis convaincu qu’il y a vraiment du boulot sur l’écologie, comme sur celui du libre ! Et c’est devenu le sujet de beaucoup de mes travaux artistiques. Donc je dois être une sorte de militant pervers qui ne va pas vous baratiner ou vous reprocher de ne pas avoir éteint la lumière, mais qui avance un peu caché pour vous montrer des images choquantes de notre futur ! Ça m’est venu en auto-construisant ma maison, j’ai été forcé de comprendre l’ampleur des dégâts.
La différence avec le militantisme pour (grand sac) le logiciel libre, la culture libre et la vie privée numérique, c’est l’urgence. Si dans 100 ans, tout le monde n’est pas passé sur Linux, ce sera dommage, mais on devrait survivre. Si on est plus capable de s’auto-héberger ou de rester anonyme sur Internet, ça sera déjà plus embêtant. Mais pour le changement climatique, si on ne fait rien de radicalement différent avant 2020, dans moins de 3 ans, on est sûr que le réchauffement dépassera 2°C. Et la plupart des gens n’ont aucune idée de ce que cela signifie. Désolé chers libristes, oui c’est plus grave que d’utiliser Gmail. D’où la BD, que j’ai titrée « Mokatori », le mot pour changement climatique chez les indiens d’Amazonie. Mais je ne suis pas sûr d’avoir fini tous les épisodes prévus d’ici là, alors il ne faut pas compter que sur moi !
En tout cas c’est à la fois très élégant et hyper documenté. À mon avis Gee est devenu accro instantanément. Tu as une formation scientifique ?
Merci pour les compliments, j’espère bien que Gee succombera à la tentation, comme pleins d’autres geeks. 😉
Non, je n’ai pas de formation scientifique, sauf si on compte les sciences humaines, car j’ai fait des études de philosophie avant de devenir graphiste. Mais par contre je me suis bien tapé l’intégralité du 5e rapport du GIEC, et j’ai lu beaucoup de livres sur le sujet depuis fin 2014, quand le projet est né dans ma tête.
Si je ne dois citer que trois livres à lire sur le changement climatique je dirais « Voyage à travers les climats de la terre » de Gilles Ramstein, « L’âge des low tech » de Philippe Bihouix, et « Vandana Shiva pour une désobéissance créatrice » de Lionel Astruc. Bon ok, ils ne sont pas libres, mais ça vaut vraiment le coup. 😉
Qu’est-ce qui t’a amené au dessin ? Comment as-tu appris ?
Je dessine depuis tout petit, ça m’a toujours plu. Et puis j’étais timide, je ne faisais pas beaucoup de bruit, ça me convenait bien. J’ai appris en extra-scolaire dans les MJC, en prenant des cours de modèle vivant le soir aux Beaux-Arts, et je continue à le faire près de chez moi, c’est le meilleur exercice que je connaisse. Et devenir illustrateur (en 2013), ça permet de beaucoup pratiquer, et c’est surtout ça qui compte !
Après je ne me lève pas le matin avec un crayon à la main comme certains dessinateurs, je n’ai pas ce rapport fusionnel au dessin mais c’est quelque chose que j’aime et que je veux continuer à faire.
Des sources d’inspiration ? Des artistes qui t’ont donné envie de les égaler ? (on a noté les hommages à Franquin et au Douanier Rousseau)
Et bien David Revoy bien sûr, parce qu’il partage tellement ses astuces que c’est difficile de ne pas s’en inspirer au moins un peu ! D’ailleurs j’ai trouvé mon style BD quand j’ai arrêté d’utiliser ses brosses et que j’ai fait les miennes. 😉
Mais je crois que c’est surtout tous les auteurs de BD que j’ai lus et les films que j’ai vus. Dans l’Olympe il y a Franquin, Moebius, Miyazaki, Keith Haring, Loisel, Terry Pratchett, Tolkien, Franck Herbert, Terry Gilliam et George R. R. Martin. Dans les auteurs actuels Massimiliano Frezzato, Jean-David Morvan pour ses scénarios et les auteurs de l’OuBaPo. Les techniques de Jason Brubaker m’ont aidé aussi. Mais la liste est trop longue, presque tout est inspirant !
Pourquoi publier sous licence libre ? Est-ce que cela est lié selon toi à ta démarche de sensibilisation à l’écologie ?
C’est sûr que choisir une licence Creative Commons by-sa et publier gratuitement ou à prix libre, c’est aussi pour ne pas mettre de frein à la diffusion et encourager à faire passer le message.
Je crois qu’il y a deux raisons principales :
La première c’est que personne n’est vraiment original quand il fait de l’art : consciemment ou inconsciemment on copie toujours les autres pour refaire à notre main. Ou on détourne le travail d’un autre, ou fait le contraire du travail d’un autre. Donc si je copie, je ne me permets pas d’essayer d’empêcher les autres de me copier. D’ailleurs quand on sait qu’Internet est une machine à copier mondiale, on abandonne tout de suite le combat. 😉
La deuxième c’est que je veux être lu et que je respecte la liberté et le porte-monnaie de mes lecteurs, donc je ne vais surtout pas leur interdire de donner une copie à leur voisin ! Dans ma petite expérience le droit d’auteur ne rapporte quasiment rien, des solutions comme le financement participatif et surtout le mécénat participatif (Patreon, Tipeee, Liberapay) me semblent beaucoup plus adaptées à l’ère numérique. Alors autant mettre les choses au clair avec une bonne licence libre.
Est-ce que tu arrives à vivre de ton art ou est-ce que tu as un vrai travail sérieux à côté ? 🙂
Et bien, puisque vous en parlez, j’ai une page Tipeee et une page Liberapay, à vot’ bon cœur. 😉
Non je n’arrive pas à vivre de la BD, loin de là, mais par contre je vis de mon travail d’illustrateur indépendant, en faisant aussi des travaux de graphisme, de la formation professionnelle, et que je suis parfois modèle vivant. Bref, si je ne roule pas sur l’or je fais ce que j’aime !
La BD, je l’avance sur les temps libres, quand je n’ai pas de contrat sur mon temps de travail, car je suis jeune papa aussi et donc le soir et les week-ends sont pris.
Ça explique aussi pourquoi je voulais publier cet épisode 1 en janvier et que je le publie en août… Merci infiniment à mes patients tipeurs !
Parlons technique. Comment dessines-tu ?
J’ai une technique très spéciale qui consiste à utiliser un crayon. 😉
Non, souvent c’est le stylet de la tablette graphique, je fais presque tout en numérique, sauf quand je fais des exercices en technique traditionnels ou que je veux faire des croquis et que je n’ai pas de tablette sous la main.
J’ai donc un ordinateur sous Linux (distribution Antergos, Archlinux pour les humains), Gnome, une tablette graphique Wacom, et le stylet que je préfère c’est le Art Pen, car il supporte la rotation, donc on peut dessiner facilement des pleins et des déliés, que j’utilise abondamment dans mes encrages (les traits noirs). Le logiciel pour dessiner c’est Krita. J’utilise Inkscape pour les bulles, le texte et les quelques graphiques, et un script bash maison pour assembler les pages et en faire des ebooks. J’ai fait un petit tutoriel à ce sujet.
Occasionnellement je fais quelques décors en 3D avec Blender. J’ai un trait large, semi-réaliste, qui est la plupart du temps noir mais que je peux inverser en blanc ou exceptionnellement mettre en couleur. De plus je rajoute des textures à ma couleur pour des effets de matière qui cassent l’aspect trop lisse du dessin numérique.
D12 à Paris, le samedi 12 décembre 2015 : la manifestation des militants pour la justice climatique à la fin de la COP21, d’après des photos de Adriana Karpinska et de Camille Bissuel. Ces anges se font appeler des gardiennes du climat.
On peut te suivre quelque part ? Un blog, les réseaux sociaux ?
Mon site web, qui contient un blog (et des flux RSS), mes BD, un portfolio de mes illustrations.
Pour les réseaux sociaux, et la newsletter, tout est résumé ici : http://nylnook.art/fr/suivre/
J’essaye de poster un peu partout, surtout sur le web libre (Framasphere et Framapiaf depuis peu) mais le plus sûr si vous voulez ne rien rater c’est quand même le site web, les flux RSS et la newsletter. 😉
Et comme d’habitude sur le Framablog, on te laisse le mot de la fin.
Alors merci pour cette interview, c’est un honneur d’être sur le Framablog, j’espère que vous aimerez la BD, que vous la diffuserez pour sauver notre monde (rien de moins), et que vous m’inonderez de commentaires. 😉
Si je peux faire mon militant chimère libriste/écolo je dirais « La route est longue, mais la voie est libre, et n’oubliez pas de planter des arbres sur le chemin… »
Les nouveaux Leviathans III. Du capitalisme de surveillance à la fin de la démocratie ?
Une chronique de Xavier De La Porte1 sur le site de la radio France Culture pointe une sortie du tout nouveau président Emmanuel Macron parue sur le compte Twitter officiel : « Une start-up nation est une nation où chacun peut se dire qu’il pourra créer une startup. Je veux que la France en soit une ». Xavier De La Porte montre à quel point cette conception de la France en « start-up nation » est en réalité une vieille idée, qui reprend les archaïsmes des penseurs libéraux du XVIIe siècle, tout en provoquant un « désenchantement politique ». La série des Nouveaux Léviathans, dont voici le troisième numéro, part justement de cette idée et cherche à en décortiquer les arguments.
Note : voici le troisième volet de la série des Nouveaux (et anciens) Léviathans, initiée en 2016, par Christophe Masutti, alias Framatophe. Pour retrouver les articles précédents, une liste vous est présentée à la fin de celui-ci.
Dans cet article nous allons voir comment ce que Shoshana Zuboff nomme Big Other (cf. article précédent) trouve dans ces archaïques conceptions de l’État un lieu privilégié pour déployer une nouvelle forme d’organisation sociale et politique. L’idéologie-Silicon ne peut plus être aujourd’hui analysée comme un élan ultra-libéral auquel on opposerait des valeurs d’égalité ou de solidarité. Cette dialectique est dépassée car c’est le Contrat Social qui change de nature : la légitimité de l’État repose désormais sur des mécanismes d’expertise2 par lesquels le capitalisme de surveillance impose une logique de marché à tous les niveaux de l’organisation socio-économique, de la décision publique à l’engagement politique. Pour comprendre comment le terrain démocratique a changé à ce point et ce que cela implique dans l’organisation d’une nation, il faut analyser tour à tour le rôle des monopoles numériques, les choix de gouvernance qu’ils impliquent, et comprendre comment cette idéologie est non pas théorisée, mais en quelque sorte auto-légitimée, rendue presque nécessaire, parce qu’aucun choix politique ne s’y oppose. Le capitalisme de surveillance impliquerait-il la fin de la démocratie ?
Dans Les Nouveaux Leviathans II, j’abordais la question du capitalisme de surveillance sous l’angle de la fin du modèle économique du marché libéral. L’utopie dont se réclame ce dernier, que ce soit de manière rhétorique ou réellement convaincue, suppose une auto-régulation du marché, théorie maintenue en particulier par Friedrich Hayek3. À l’opposé de cette théorie qui fait du marché la seule forme (auto-)équilibrée de l’économie, on trouve des auteurs comme Karl Polanyi4 qui, à partir de l’analyse historique et anthropologique, démontre non seulement que l’économie n’a pas toujours été organisée autour d’un marché libéral, mais aussi que le capitalisme « désencastre » l’économie des relations sociales, et provoque un déni du contrat social.
Or, avec le capitalisme de surveillance, cette opposition (qui date tout de même de la première moitié du XXe siècle) a vécu. Lorsque Shoshana Zuboff aborde la genèse du capitalisme de surveillance, elle montre comment, à partir de la logique de rationalisation du travail, on est passé à une société de marché dont les comportements individuels et collectifs sont quantifiés, analysés, surveillés, grâce aux big data, tout comme le (un certain) management d’entreprise quantifie et rationalise les procédures. Pour S. Zuboff, tout ceci concourt à l’avènement de Big Other, c’est-à-dire un régime socio-économique régulé par des mécanismes d’extraction des données, de marchandisation et de contrôle. Cependant, ce régime ne se confronte pas à l’État comme on pourrait le dire du libertarisme sous-jacent au néolibéralisme qui considère l’État au pire comme contraire aux libertés individuelles, au mieux comme une instance limitative des libertés. Encore pourrait-on dire qu’une dialectique entre l’État et le marché pourrait être bénéfique et aboutirait à une forme d’équilibre acceptable. Or, avec le capitalisme de surveillance, le politique lui-même devient un point d’appui pour Big Other, et il le devient parce que nous avons basculé d’un régime politique à un régime a-politique qui organise les équilibres sociaux sur les principes de l’offre marchande. Les instruments de cette organisation sont les big datas et la capacité de modeler la société sur l’offre.
C’est que je précisais en 2016 dans un ouvrage coordonné par Tristan Nitot, Nina Cercy, Numérique : reprendre le contrôle5, en ces termes :
(L)es firmes mettent en œuvre des pratiques d’extraction de données qui annihilent toute réciprocité du contrat avec les utilisateurs, jusqu’à créer un marché de la quotidienneté (nos données les plus intimes et à la fois les plus sociales). Ce sont nos comportements, notre expérience quotidienne, qui deviennent l’objet du marché et qui conditionne même la production des biens industriels (dont la vente dépend de nos comportements de consommateurs). Mieux : ce marché n’est plus soumis aux contraintes du hasard, du risque ou de l’imprédictibilité, comme le pensaient les chantres du libéralisme du XXe siècle : il est devenu malléable parce que ce sont nos comportements qui font l’objet d’une prédictibilité d’autant plus exacte que les big data peuvent être analysées avec des méthodes de plus en plus fiables et à grande échelle.
Si j’écris que nous sommes passés d’un régime politique à un régime a-politique, cela ne signifie pas que cette transformation soit radicale, bien entendu. Il existe et il existera toujours des tensions idéologiques à l’intérieur des institutions de l’État. C’est plutôt une question de proportions : aujourd’hui, la plus grande partie des décisions et des organes opérationnels sont motivés et guidés par des considérations relevant de situations déclarées impératives et non par des perspectives politiques. On peut citer par exemple le grand mouvement de « rigueur » incitant à la « maîtrise » des dépenses publiques imposée par les organismes financiers européens ; des décisions motivées uniquement par le remboursement des dettes et l’expertise financière et non par une stratégie du bien-être social. On peut citer aussi, d’un point de vue plus local et français, les contrats des institutions publiques avec Microsoft, à l’instar de l’Éducation Nationale, à l’encontre de l’avis d’une grande partie de la société civile, au détriment d’une offre différente (comme le libre et l’open source) et dont la justification est uniquement donnée par l’incapacité de la fonction publique à envisager d’autres solutions techniques, non par ignorance, mais à cause du détricotage massif des compétences internes. Ainsi « rationaliser » les dépenses publiques revient en fait à se priver justement de rationalité au profit d’une simple adaptation de l’organisation publique à un état de fait, un déterminisme qui n’est pas remis en question et condamne toute idéologie à être non pertinente.
Ce n’est pas pour autant qu’il faut ressortir les vieilles théories de la fin de l’histoire. Qui plus est, les derniers essais du genre, comme la thèse de Francis Fukuyama6, se sont concentrés justement sur l’avènement de la démocratie libérale conçue comme le consensus ultime mettant fin aux confrontations idéologiques (comme la fin de la Guerre Froide). Or, le capitalisme de surveillance a minima repousse toute velléité de consensus, au-delà du libéralisme, car il finit par définir l’État tout entier comme un instrument d’organisation, quelle que soit l’idéologie : si le nouveau régime de Big Other parvient à organiser le social, c’est aussi parce que ce dernier a désengagé le politique et relègue la décision publique au rang de validation des faits, c’est-à-dire l’acceptation des contrats entre les individus et les outils du capitalisme de surveillance.
Les mécanismes ne sont pas si nombreux et tiennent en quatre points :
le fait que les firmes soient des multinationales et surfent sur l’offre de la moins-disance juridique pour s’établir dans les pays (c’est la pratique du law shopping),
le fait que l’utilisation des données personnelles soit déloyale envers les individus-utilisateurs des services des firmes qui s’approprient les données,
le fait que les firmes entre elles adoptent des processus loyaux (pactes de non-agression, partage de marchés, acceptation de monopoles, rachats convenus, etc.) et passent des contrats iniques avec les institutions, avec l’appui de l’expertise, faisant perdre aux États leur souveraineté numérique,
le fait que les monopoles « du numérique » diversifient tellement leurs activités vers les secteurs industriels qu’ils finissent par organiser une grande partie des dynamiques d’innovation et de concurrence à l’échelle mondiale.
Pour résumer les trois conceptions de l’économie dont il vient d’être question, on peut dresser ce tableau :
Économie
Forme
Individus
État
Économie spontanée
Diversité et créativité des formes d’échanges, du don à la financiarisation
Régulent l’économie par la démocratie ; les échanges sont d’abord des relations sociales
Garant de la redistribution équitable des richesses ; régulateur des échanges et des comportements
Marché libéral
Auto-régulation, défense des libertés économiques contre la décision publique (conception libérale de la démocratie : liberté des échanges et de la propriété)
Agents consommateurs décisionnaires dans un milieu concurrentiel
Réguler le marché contre ses dérives inégalitaires ; maintient une démocratie plus ou moins forte
Capitalisme de surveillance
Les monopoles façonnent les échanges, créent (tous) les besoins en fonction de leurs capacités de production et des big data
Sont exclusivement utilisateurs des biens et services
Automatisation du droit adapté aux besoins de l’organisation économique ; sécurisation des conditions du marché
Il est important de comprendre deux aspects de ce tableau :
il ne cherche pas à induire une progression historique et linéaire entre les différentes formes de l’économie et des rapports de forces : ces rapports sont le plus souvent diffus, selon les époques, les cultures. Il y a une économie spontanée à l’Antiquité comme on pourrait par exemple, comprendre les monnaies alternatives d’aujourd’hui comme des formes spontanées d’organisation des échanges.
aucune de ces cases ne correspond réellement à des conceptions théorisées. Il s’agit essentiellement de voir comment le capitalisme de surveillance induit une distorsion dans l’organisation économique : alors que dans des formes classiques de l’organisation économique, ce sont les acteurs qui produisent l’organisation, le capitalisme de surveillance induit non seulement la fin du marché libéral (vu comme place d’échange équilibrée de biens et services concurrentiels) mais exclut toute possibilité de régulation par les individus / citoyens : ceux-ci sont vus uniquement comme des utilisateurs de services, et l’État comme un pourvoyeur de services publics. La décision publique, elle, est une affaire d’accord entre les monopoles et l’État.
Pour sa première visite en Europe, Sundar Pichai qui était alors en février 2016 le nouveau CEO de Google Inc. , choisit les locaux de Sciences Po. Paris pour tenir une conférence de presse7, en particulier devant les élèves de l’école de journalisme. Le choix n’était pas anodin, puisqu’à ce moment-là Google s’est présenté en grand défenseur de la liberté d’expression (par un ensemble d’outils, de type reverse-proxy que la firme est prête à proposer aux journalistes pour mener leurs investigations), en pourvoyeur de moyens efficaces pour lutter contre le terrorisme, en proposant à qui veut l’entendre des partenariats avec les éditeurs, et de manière générale en s’investissant dans l’innovation numérique en France (voir le partenariat Numa / Google). Tout cela démontre, s’il en était encore besoin, à quel point la firme Google (et Alphabet en général) est capable de proposer une offre si globale qu’elle couvre les fonctions de l’État : en réalité, à Paris lors de cette conférence, alors que paradoxalement elle se tenait dans les locaux où étudient ceux qui demain sont censés remplir des fonctions régaliennes, Sundar Pichai ne s’adressait pas aux autorités de l’État mais aux entreprises (éditeurs) pour leur proposer des instruments qui garantissent leurs libertés. Avec comme sous-entendu : vous évoluez dans un pays dont la liberté d’expression est l’un des fleurons, mais votre gouvernement n’est pas capable de vous le garantir mieux que nous, donc adhérez à Google. Les domaines de la santé, des systèmes d’informations et l’éducation en sont pas exempts de cette offre « numérique ».
Du côté du secteur public, le meilleur moyen de ne pas perdre la face est de monter dans le train suivant l’adage « Puisque ces mystères nous dépassent, feignons d’en être l’organisateur ». Par exemple, si Google et Facebook ont une telle puissance capable de mener efficacement une lutte, au moins médiatique, contre le terrorisme, à l’instar de leurs campagnes de propagande8, il faut créer des accords de collaboration entre l’État et ces firmes9, quitte à les faire passer comme une exigence gouvernementale (mais quel État ne perdrait pas la face devant le poids financier des GAFAM ?).
… Et tout cela crée un marché de la gouvernance dans lequel on ne compte plus les millions d’investissement des GAFAM. Ainsi, la gouvernance est un marché pour Microsoft, qui lance un Office 2015 spécial « secteur public », ou, mieux, qui sait admirablement se situer dans les appels d’offre en promouvant des solutions pour tous les besoins d’organisation de l’État. Par exemple, la présentation des activités de Microsoft dans le secteur public sur son site comporte ces items :
Stimulez la transformation numérique du secteur public
Optimisez l’administration publique
Transformez des services du secteur public
Améliorez l’efficacité des employés du secteur public
Mobilisez les citoyens
Microsoft dans le secteur public
Microsoft Office pour le secteur public
D’aucuns diraient que ce que font les GAFAM, c’est proposer un nouveau modèle social. Par exemple dans une enquête percutante sur les entreprises de la Silicon Valley, Philippe Vion-Dury définit ce nouveau modèle comme « politiquement technocratique, économiquement libéral, culturellement libertaire, le tout nimbé de messianisme typiquement américain »10. Et il a entièrement raison, sauf qu’il ne s’agit pas d’un modèle social, c’est justement le contraire, c’est un modèle de gouvernance sans politique, qui considère le social comme la juxtaposition d’utilisateurs et de groupes d’utilisateurs. Comme le montre l’offre de Microsoft, si cette firme est capable de fournir un service propre à « mobiliser les citoyens » et si en même temps, grâce à ce même fournisseur, vous avez les outils pour transformer des services du secteur public, quel besoin y aurait-il de voter, de persuader, de discuter ? si tous les avis des citoyens sont analysés et surtout anticipés par les big datas, et si les seuls outils efficaces de l’organisation publique résident dans l’offre des GAFAM, quel besoin y aurait-il de parler de démocratie ?
En réalité, comme on va le voir, tout cette nouvelle configuration du capitalisme de surveillance n’est pas seulement rendue possible par la puissance novatrice des monopoles du numérique. C’est peut-être un biais : penser que leur puissance d’innovation est telle qu’aucune offre concurrente ne peut exister. En fait, même si l’offre était moindre, elle n’en serait pas moins adoptée car tout réside dans la capacité de la décision publique à déterminer la nécessité d’adopter ou non les services des GAFAM. C’est l’aménagement d’un terrain favorable qui permet à l’offre de la gouvernance numérique d’être proposée. Ce terrain, c’est la décision par l’expertise.
L’accueil favorable au capitalisme de surveillance
Dans son livre The united states of Google11, Götz Haman fait un compte-rendu d’une conférence durant laquelle interviennent Eric Schmidt, alors président du conseil d’administration de Google, et son collègue Jared Cohen. Ces derniers ont écrit un ouvrage (The New Digital Age) qu’ils présentent dans les grandes lignes. Götz Haman le résume en ces termes : « Aux yeux de Google, les États sont dépassés. Ils n’ont rien qui permette de résoudre les problèmes du XXIe siècle, tels le changement climatique, la pauvreté, l’accès à la santé. Seules les inventions techniques peuvent mener vers le Salut, affirment Schmidt et son camarade Cohen. »
Une fois cette idéologie — celle du capitalisme de surveillance12 — évoquée, il faut s’interroger sur la raison pour laquelle les États renvoient cette image d’impuissance. En fait, les sociétés occidentales modernes ont tellement accru leur consommation de services que l’offre est devenue surpuissante, à tel point, comme le montre Shoshanna Zuboff, que les utilisateurs eux-mêmes sont devenus à la fois les pourvoyeurs de matière première (les données) et les consommateurs. Or, si nous nous plaçons dans une conception de la société comme un unique marché où les relations sociales peuvent être modelées par l’offre de services (ce qui se cristallise aujourd’hui par ce qu’on nomme dans l’expression-valise « Uberisation de la société »), ce qui relève de la décision publique ne peut être motivé que par l’analyse de ce qu’il y a de mieux pour ce marché, c’est-à-dire le calcul de rentabilité, de rendement, d’efficacité… d’utilité. Or cette analyse ne peut être à son tour fournie par une idéologie visionnaire, une utopie ou simplement l’imaginaire politique : seule l’expertise de l’état du monde pour ce qu’il est à un instant T permet de justifier l’action publique. Il faut donc passer du concept de gouvernement politique au concept de gouvernance par les instruments. Et ces instruments doivent reposer sur les GAFAM.
Pour comprendre au mieux ce que c’est que gouverner par les instruments, il faut faire un petit détour conceptuel.
L’expertise et les instruments
Prenons un exemple. La situation politique qu’a connue l’Italie après novembre 2011 pourrait à bien des égards se comparer avec la récente élection en France d’Emmanuel Macron et les élections législatives qui ont suivi. En effet, après le gouvernement de Silvio Berlusconi, la présidence italienne a nommé Mario Monti pour former un gouvernement dont les membres sont essentiellement reconnus pour leurs compétences techniques appliquées en situation de crise économique. La raison du soutien populaire à cette nomination pour le moins discutable (M. Monti a été nommé sénateur à vie, reconnaissance habituellement réservée aux anciens présidents de République Italienne) réside surtout dans le désaveu de la casta, c’est-à-dire le système des partis qui a dominé la vie politique italienne depuis maintes années et qui n’a pas réussi à endiguer les effets de la crise financière de 2008. Si bien que le gouvernement de Mario Monti peut être qualifié de « gouvernement des experts », non pas un gouvernement technocratique noyé dans le fatras administratif des normes et des procédures, mais un gouvernement à l’image de Mario Monti lui-même, ex-commissaire européen au long cours, motivé par la nécessité technique de résoudre la crise en coopération avec l’Union Européenne. Pour reprendre les termes de l’historien Peppino Ortoleva, à propos de ce gouvernement dans l’étude de cas qu’il consacre à l’Italie13 en 2012 :
Le « gouvernement des experts » se présente d’un côté comme le gouvernement de l’objectivité et des chiffres, celui qui peut rendre compte à l’Union européenne et au système financier international, et d’un autre côté comme le premier gouvernement indépendant des partis.
Peppino Ortoleva conclut alors que cet exemple italien ne représente que les prémices pour d’autres gouvernements du même acabit dans d’autres pays, avec tous les questionnements que cela suppose en termes de débat politique et démocratique : si en effet la décision publique n’est mue que par la nécessité (ici la crise financière et la réponse aux injonctions de la Commission européenne) quelle place peut encore tenir le débat démocratique et l’autonomie décisionnaire des peuples ?
En son temps déjà le « There is no alternative » de Margaret Thatcher imposait par la force des séries de réformes au nom de la nécessité et de l’expertise économiques. On ne compte plus, en Europe, les gouvernements qui nomment des groupes d’expertise, conseils et autres comités censés répondre aux questions techniques que pose l’environnement économique changeant, en particulier en situation de crise.
Cette expertise a souvent été confondue avec la technocratie, à l’instar de l’ouvrage de Vincent Dubois et Delphine Dulong publié en 2000, La question technocratique14. Lorsqu’en effet la décision publique se justifie exclusivement par la nécessité, cela signifie que cette dernière est définie en fonction d’une certaine compréhension de l’environnement socio-économique. Par exemple, si l’on part du principe que la seule réponse à la crise financière est la réduction des dépenses publiques, les technocrates inventeront les instruments pour rendre opérationnelle la décision publique, les experts identifieront les méthodes et l’expertise justifiera les décisions (on remet en cause un avis issu d’une estimation de ce que devrait être le monde, mais pas celui issu d’un calcul d’expert).
La technocratie comme l’expertise se situent hors des partis, mais la technocratie concerne surtout l’organisation du gouvernement. Elle répond souvent aux contraintes de centralisation de la décision publique. Elle crée des instruments de surveillance, de contrôle, de gestion, etc. capables de permettre à un gouvernement d’imposer, par exemple, une transformation économique du service public. L’illustration convaincante est le gouvernement Thatcher, qui dès 1979 a mis en place plusieurs instruments de contrôle visant à libéraliser le secteur public en cassant les pratiques locales et en imposant un système concurrentiel. Ce faisant, il démontrait aussi que le choix des instruments suppose aussi des choix d’exercice du pouvoir, tels ceux guidés par la croyance en la supériorité des mécanismes de marché pour organiser l’économie15.
Gouverner par l’expertise ne signifie donc pas que le gouvernement manque de compétences en son sein pour prendre les (bonnes ou mauvaises) décisions publiques. Les technocrates existent et sont eux aussi des experts. En revanche, l’expertise permet surtout de justifier les choix, les stratégies publiques, en interprétant le monde comme un environnement qui contraint ces choix, sans alternative.
En parlant d’alternative, justement, on peut s’interroger sur celles qui relèvent de la société civile et portées tant bien que mal à la connaissance du gouvernement. La question du logiciel libre est, là encore, un bon exemple.
En novembre 2016, Framasoft publiait un billet retentissant intitulé « Pourquoi Framasoft n’ira plus prendre le thé au ministère de l’Éducation Nationale ». La raison de ce billet est la prise de conscience qu’après plus de treize ans d’efforts de sensibilisation au logiciel libre envers les autorités publiques, et en particulier l’Éducation Nationale, Framasoft ne pouvait plus dépenser de l’énergie à coopérer avec une telle institution si celle-ci finissait fatalement par signer contrats sur contrats avec Microsoft ou Google. En fait, le raisonnement va plus loin et j’y reviendrai plus tard dans ce texte. Mais il faut comprendre que ce à quoi Framasoft s’est confronté est exactement ce gouvernement par l’expertise. En effet, les communautés du logiciel libre n’apportent une expertise que dans la mesure où elles proposent de changer de modèle : récupérer une autonomie numérique en développant des compétences et des initiatives qui visent à atteindre un fonctionnement idéal (des données protégées, des solutions informatiques modulables, une contribution collective au code, etc.). Or, ce que le gouvernement attend de l’expertise, ce n’est pas un but à atteindre, c’est savoir comment adapter l’organisation au modèle existant, c’est-à-dire celui du marché.
Dans le cadre des élections législatives, l’infatigable association APRIL (« promouvoir et défendre le logiciel libre ») lance sa campagne de promotion de la priorité au logiciel libre dans l’administration publique. À chaque fois, la campagne connaît un certain succès et des députés s’engagent réellement dans cette cause qu’ils plaident même à l’intérieur de l’Assemblée Nationale. Sous le gouvernement de F. Hollande, on a entendu des députés comme Christian Paul ou Isabelle Attard avancer les arguments les plus pertinents et sans ménager leurs efforts, convaincus de l’intérêt du Libre. À leur image, il serait faux de dire que la sphère politique est toute entière hermétique au logiciel libre et aux équilibres numériques et économiques qu’il porte en lui. Peine perdue ? À voir les contrats passés entre le gouvernement et les GAFAM, c’est un constat qu’on ne peut pas écarter et sans doute au profit d’une autre forme de mobilisation, celle du peuple lui-même, car lui seul est capable de porter une alternative là où justement la politique a cédé la place : dans la décision publique.
La rencontre entre la conception du marché comme seule organisation gouvernementale des rapports sociaux et de l’expertise qui détermine les contextes et les nécessités de la prise de décision a permis l’émergence d’un terrain favorable à l’État-GAFAM. Pour s’en convaincre il suffit de faire un tour du côté de ce qu’on a appelé la « modernisation de l’État ».
Les firmes à la gouvernance numérique
Anciennement la Direction des Systèmes d’Information (DSI), la DINSIC (Direction Interministérielle du Numérique et du Système d’Information et de Communication) définit les stratégies et pilote les structures informationnelles de l’État français. Elle prend notamment part au mouvement de « modernisation » de l’État. Ce mouvement est en réalité une cristallisation de l’activité de réforme autour de l’informatisation commencée dans les années 1980. Cette activité de réforme a généré des compétences et assez d’expertise pour être institutionnalisée (DRB, DGME, aujourd’hui DIATP — Direction interministérielle pour l’accompagnement des transformations publiques). On se perd facilement à travers les acronymes, les ministères de rattachement, les changements de noms au rythme des fusions des services entre eux. Néanmoins, le concept même de réforme n’a pas évolué depuis les grandes réformes des années 1950 : il faut toujours adapter le fonctionnement des administrations publiques au monde qui change, en particulier le numérique.
La différence, aujourd’hui, c’est que cette adaptation ne se fait pas en fonction de stratégies politiques, mais en fonction d’un cadre de productivité, dont on dit qu’il est un « contrat de performance » ; cette performance étant évaluée par des outils de contrôle : augmenter le rendement de l’administration en « rationalisant » les effectifs, automatiser les services publics (par exemple déclarer ses impôts en ligne, payer ses amendes en lignes, etc.), expertiser (accompagner) les besoins des systèmes d’informations selon les offres du marché, limiter les instances en adaptant des méthodes agiles de prise de décision basées sur des outils numériques de l’analyse de data, maîtrise des coûts….
Continuer à faire évoluer les systèmes d’information est nécessaire pour répondre aux enjeux publics de demain : il s’agit d’un outil de production de l’administration, qui doit délivrer des services plus performants aux usagers, faciliter et accompagner les réformes de l’État, rendre possible les politiques publiques transverses à plusieurs administrations, s’intégrer dans une dimension européenne.
Cette feuille de route concerne en fait deux grandes orientations : l’amélioration de l’organisation interne aux institutions gouvernementales et les interfaces avec les citoyens. Il est flagrant de constater que, pour ce qui concerne la dimension interne, certains projets que l’on trouve mentionnés dans le Panorama des grands projets SI de l’Etat font appel à des solutions open source et les opérateurs sont publics, notamment par souci d’efficacité, comme c’est le cas, par exemple pour le projet VITAM, relatif à l’archivage. En revanche, lorsqu’il s’agit des relations avec les citoyens-utilisateurs, c’est-à-dires les « usagers », ce sont des entreprises comme Microsoft qui entrent en jeu et se substituent à l’État, comme c’est le cas par exemple du grand projet France Connect, dont Microsoft France est partenaire.
En effet, France Connect est une plateforme centralisée visant à permettre aux citoyens d’effectuer des démarches en ligne (pour les particuliers, pour les entreprises, etc.). Pour permettre aux collectivités et aux institutions qui mettent en place une « offre » de démarche en ligne, Microsoft propose en open source des « kit de démarrage », c’est à dire des modèles, qui vont permettre à ces administrations d’offrir ces services aux usagers. En d’autres termes, c’est chaque collectivité ou administration qui va devenir fournisseur de service, dans un contexte de développement technique mutualisé (d’où l’intérêt ici de l’open source). Ce faisant, l’État n’agit plus comme maître d’œuvre, ni même comme arbitre : c’est Microsoft qui se charge d’orchestrer (par les outils techniques choisis, et ce n’est jamais neutre) un marché de l’offre de services dont les acteurs sont les collectivités et administrations. De là, il est tout à fait possible d’imaginer une concurrence, par exemple entre des collectivités comme les mairies, entre celles qui auront une telle offre de services permettant d’attirer des contribuables et des entreprises sur son territoire, et celles qui resteront coincées dans les procédures administratives réputées archaïques.
Microsoft : contribuer à FranceConnect
En se plaçant ainsi non plus en prestataire de produits mais en tuteur, Microsoft organise le marché de l’offre de service public numérique. Mais la firme va beaucoup plus loin, car elle bénéficie désormais d’une grande expérience, reconnue, en matière de service public. Ainsi, lorsqu’il s’agit d’anticiper les besoins et les changements, elle est non seulement à la pointe de l’expertise mais aussi fortement enracinée dans les processus de la décision publique. Sur le site Econocom en 2015, l’interview de Raphaël Mastier16, directeur du pôle Santé de Microsoft France, est éloquent sur ce point. Partant du principe que « historiquement le numérique n’a pas été considéré comme stratégique dans le monde hospitalier », Microsoft propose des outils « d’analyse et de pilotage », et même l’utilisation de l’analyse prédictive des big data pour anticiper les temps d’attentes aux urgences : « grâce au machine learning, il sera possible de s’organiser beaucoup plus efficacement ». Avec de tels arguments, en effet, qui irait à l’encontre de l’expérience microsoftienne dans les services publics si c’est un gage d’efficacité ? on comprend mieux alors, dans le monde hospitalier, l’accord-cadre CAIH-Microsoft qui consolide durablement le marché Microsoft avec les hôpitaux.
Au-delà de ces exemples, on voit bien que cette nouvelle forme de gouvernance à la Big Other rend ces instruments légitimes car ils produisent le marché et donc l’organisation sociale. Cette transformation de l’État est parfaitement assumée par les autorités, arguant par exemple dans un billet sur gouvernement.fr intitulé « Le numérique : instrument de la transformation de l’État », en faveur de l’allégement des procédures, de la dématérialisation, de la mise à disposition des bases de données (qui va les valoriser ?), etc. En somme autant d’arguments dont il est impossible de nier l’intérêt collectif et qui font, en règle générale, l’objet d’un consensus.
Le groupe canadien CGI, l’un des leaders mondiaux en technologies et gestion de l’information, œuvre aussi en France, notamment en partenariat avec l’UGAP (Union des Groupements d’Achats Publics). Sur son blog, dans un Billet du 2 mai 201717, CGI résume très bien le discours dominant de l’action publique dans ce domaine (et donc l’intérêt de son offre de services), en trois points :
Réduire les coûts. Le sous-entendu consiste à affirmer que si l’État organise seul sa transformation numérique, le budget sera trop conséquent. Ce qui reste encore à prouver au vu des montants en jeu dans les accords de partenariat entre l’État et les firmes, et la nature des contrats (on peut souligner les clauses concernant les mises à jour chez Microsoft) ;
Le secteur public accuse un retard numérique. C’est l’argument qui justifie la délégation du numérique sur le marché, ainsi que l’urgence des décisions, et qui, par effet de bord, contrevient à la souveraineté numérique de l’État.
Il faut améliorer « l’expérience citoyen ». C’est-à-dire que l’objectif est de transformer tous les citoyens en utilisateurs de services publics numériques et, comme on l’a vu plus haut, organiser une offre concurrentielle de services entre les institutions et les collectivités.
Du côté des décideurs publics, les choix et les décisions se justifient sur un mode Thatchérien (il n’y a pas d’alternative). Lorsqu’une alternative est proposée, tel le logiciel libre, tout le jeu consiste à donner une image politique positive pour ensuite orienter la stratégie différemment.
Sur ce point, l’exemple de Framasoft est éloquent et c’est quelque chose qui n’a pas forcément été perçu lors de la publication de la déclaration « Pourquoi Framasoft n’ira plus prendre le thé…» (citée précédemment). Il s’agit de l’utilisation de l’alternative libriste pour légitimer l’appel à une offre concurrentielle sur le marché des firmes. En effet, les personnels de l’Éducation Nationale utilisent massivement les services que Framasoft propose dans le cadre de sa campagne « Degooglisons Internet ». Or, l’institution pourrait très bien, sur le modèle promu par Framasoft, installer ces mêmes services, et ainsi offrir ces solutions pour un usage généralisé dans les écoles, collèges et lycées. C’est justement le but de la campagne de Framasoft que de proposer une vaste démonstration pour que des organisations retrouvent leur autonomie numérique. Les contacts que Framasoft a noué à ce propos avec différentes instances de l’Éducation Nationale se résumaient finalement soit à ce que Framasoft et ses bénévoles proposent un service à la carte dont l’ambition est bien loin d’une offre de service à l’échelle institutionnelle, soit participe à quelques comités d’expertise sur le numérique à l’école. L’idée sous-jacente est que l’Éducation Nationale ne peut faire autrement que de demander à des prestataires de mettre en place une offre numérique clé en main et onéreuse, alors même que Framasoft propose tous ses services au grand public avec des moyens financiers et humains ridiculement petits.
Dès lors, après la signature du partenariat entre le MEN et Microsoft, le message a été clairement formulé à Framasoft (et aux communautés du Libre en général), par un Tweet de la Ministre Najat Vallaud-Belkacem exprimant en substance la « neutralité technologique » du ministère (ce qui justifie donc le choix de Microsoft comme objectivement la meilleure offre du marché) et l’idée que les « éditeurs de logiciels libres » devraient proposer eux aussi leurs solutions, c’est-à-dire entrer sur le marché concurrentiel. Cette distorsion dans la compréhension de ce que sont les alternatives libres (non pas un produit mais un engagement) a été confirmée à plusieurs reprises par la suite : les solutions libres et leurs usages à l’Éducation Nationale peuvent être utilisées pour « mettre en tension » le marché et négocier des tarifs avec les firmes comme Microsoft, ou du moins servir d’épouvantail (dont on peut s’interroger sur l’efficacité réelle devant la puissance promotionnelle et lobbyiste des firmes en question).
On peut conclure de cette histoire que si la décision publique tient à ce point à discréditer les solutions alternatives qui échappent au marché des monopoles, c’est qu’une idéologie est à l’œuvre qui empêche toute forme d’initiative qui embarquerait le gouvernement dans une dynamique différente. Elle peut par exemple placer les décideurs devant une incapacité structurelle18 de choisir des alternatives proposant des logiciels libres, invoquant par exemple le droit des marchés publics voire la Constitution, alors que l’exclusion du logiciel libre n’est pas réglementaire19.
Ministre de l’Éducation Nationale et Microsoft
L’idéologie de Silicon
En février 2017, quelques jours à peine après l’élection de Donald Trump à présidence des États-Unis, le PDG de Facebook, Mark Zuckerberg, publie sur son blog un manifeste20 remarquable à l’encontre de la politique isolationniste et réactionnaire du nouveau président. Il cite notamment tous les outils que Facebook déploie au service des utilisateurs et montre combien ils sont les vecteurs d’une grande communauté mondiale unie et solidaire. Tous les concepts de la cohésion sociale y passent, de la solidarité à la liberté de l’information, c’est-à-dire ce que le gouvernement est, aux yeux de Zuckerberg, incapable de garantir correctement à ses citoyens, et ce que les partisans de Trump en particulier menacent ouvertement.
Au moins, si les idées de Mark Zuckerberg semblent pertinentes aux yeux des détracteurs de Donald Trump, on peut néanmoins s’interroger sur l’idéologie à laquelle se rattache, de son côté, le PDG de Facebook. En réalité, pour lui, Donald Trump est la démonstration évidente que l’État ne devrait occuper ni l’espace social ni l’espace économique et que seul le marché et l’offre numérique sont en mesure d’intégrer les relations sociales.
Cette idéologie a déjà été illustrée par Fred Tuner, dans son ouvrage Aux sources de l’utopie numérique21. À propos de ce livre, j’écrivais en 201622 :
(…) Fred Turner montre comment les mouvements communautaires de contre-culture ont soit échoué par désillusion, soit se sont recentrés (surtout dans les années 1980) autour de techno-valeurs, en particulier portées par des leaders charismatiques géniaux à la manière de Steve Jobs un peu plus tard. L’idée dominante est que la revendication politique a échoué à bâtir un monde meilleur ; c’est en apportant des solutions techniques que nous serons capables de résoudre nos problèmes.
Cette analyse un peu rapide passe sous silence la principale clé de lecture de Fred Tuner : l’émergence de nouveaux modes d’organisation économique du travail, en particulier le freelance et la collaboration en réseau. Comme je l’ai montré, le mouvement de la contre-culture californienne des années 1970 a permis la création de nouvelles pratiques d’échanges numériques utilisant les réseaux existants, comme le projet Community Memory, c’est-à-dire des utopies de solidarité, d’égalité et de liberté d’information dans une Amérique en proie au doute et à l’autoritarisme, notamment au sortir de la Guerre du Vietnam. Mais ce faisant, les années 1980, elles, ont développé à partir de ces idéaux la vision d’un monde où, en réaction à un État conservateur et disciplinaire, ce dernier se trouverait dépossédé de ses prérogatives de régulation, au profit de l’autonomie des citoyens dans leurs choix économiques et leurs coopérations. C’est l’avènement des principes du libertarisme grâce aux outils numériques. Et ce que montre Fred Turner, c’est que ce mouvement contre-culturel a ainsi paradoxalement préparé le terrain aux politiques libérales de dérégulation économique des années 1980-1990. C’est la volonté de réduire au strict minimum le rôle de l’État, garant des libertés individuelles, afin de permettre aux individus d’exercer leurs droits de propriété (sur leurs biens et sur eux-mêmes) dans un ordre social qui se définit uniquement comme un marché. À ce titre, pour ce qu’il est devenu, ce libertarisme est une résurgence radicale du libéralisme à la Hayek (la société démocratique libérale est un marché concurrentiel) doublé d’une conception utilitaire des individus et de leurs actions.
Néanmoins, tels ne sont pas exactement les principes du libertarisme, mais ceux-ci ayant cours dans une économie libérale, ils ne peuvent qu’aboutir à des modèles économiques basés sur une forme de collaboration dérégulée, anti-étatique, puisque la forme du marché, ici, consiste à dresser la liberté des échanges et de la propriété contre un État dont les principes du droit sont vécus comme arbitrairement interventionnistes. Les concepts tels la solidarité, l’égalité, la justice sont remplacés par l’utilité, le choix, le droit.
Un exemple intéressant de ce renversement concernant le droit, est celui du droit de la concurrence appliqué à la question de la neutralité des plateformes, des réseaux, etc. Regardons les plateformes de service. Pourquoi assistons-nous à une forme de schizophrénie entre une Commission européenne pour qui la neutralité d’internet et des plateformes est une condition d’ouverture de l’économie numérique et la bataille contre cette même neutralité appliquée aux individus censés être libres de disposer de leurs données et les protéger, notamment grâce au chiffrement ? Certes, les mesures de lutte contre le terrorisme justifient de s’interroger sur la pertinence d’une neutralité absolue (s’interroger seulement, car le chiffrement ne devrait jamais être remis en cause), mais la question est surtout de savoir quel est le rôle de l’État dans une économie numérique ouverte reposant sur la neutralité d’Internet et des plateformes. Dès lors, nous avons d’un côté la nécessité que l’État puisse intervenir sur la circulation de l’information dans un contexte de saisie juridique et de l’autre celle d’une volontaire absence du Droit dans le marché numérique.
Pour preuve, on peut citer le président de l’Autorité de la concurrence en France, Bruno Lassere, auditionné à l’Assemblée Nationale le 7 juillet 201523. Ce dernier cite le Droit de la Concurrence et ses applications comme un instrument de lutte contre les distorsions du marché, comme les monopoles à l’image de Google/Alphabet. Mais d’un autre côté, le Droit de la Concurrence est surtout vu comme une solution d’auto-régulation dans le contexte de la neutralité des plates-formes :
(…) Les entreprises peuvent prendre des engagements par lesquels elles remédient elles-mêmes à certains dysfonctionnements. Il me semble important que certains abus soient corrigés à l’intérieur du marché et non pas forcément sur intervention législative ou régulatrice. C’est ainsi que Booking, Expedia et HRS se sont engagées à lever la plupart des clauses de parité tarifaire qui interdisent une véritable mise en compétition de ces plateformes de réservation hôtelières. Comment fonctionnent ces clauses ? Si un hôtel propose à Booking douze nuitées au prix de 100 euros la chambre, il ne peut offrir de meilleures conditions – en disponibilité ou en tarif – aux autres plateformes. Il ne peut pas non plus pratiquer un prix différent à ses clients directs. Les engagements signés pour lever ces contraintes sont gagnants-gagnants : ils respectent le modèle économique des plateformes, et donc l’incitation à investir et à innover, tout en rétablissant plus de liberté de négociation. Les hôtels pourront désormais mettre les plateformes en concurrence.
Sur ce point, il ne faut pas s’interroger sur le mécanisme de concurrence qu’il s’agit de promouvoir mais sur l’implication d’une régulation systématique de l’économie numérique par le Droit de la Concurrence. Ainsi le rapport Numérique et libertés présenté Christian Paul et Christiane Féral-Schuhl, propose un long développement sur la question des données personnelles mais cite cette partie de l’audition de Bruno Lasserre à propos du Droit de la Concurrence sans revenir sur la conception selon laquelle l’alpha et l’omega du Droit consiste à aménager un environnement concurrentiel « sain » à l’intérieur duquel les mécanismes de concurrence suffisent à eux-seuls à appliquer des principes de loyauté, d’équité ou d’égalité.
Cette absence de questionnement politique sur le rôle du Droit dans un marché où la concentration des services abouti à des monopoles finit par produire immanquablement une forme d’autonomie absolue de ces monopoles dans les mécanismes concurrentiels, entre une concurrence acceptable et une concurrence non-souhaitable. Tel est par exemple l’objet de multiples pactes passés entre les grandes multinationales du numérique, ainsi entre Microsoft et AOL, entre AOL / Yahoo et Microsoft, entre Intertrust et Microsoft, entre Apple et Google (pacte géant), entre Microsoft et Android, l’accord entre IBM et Apple en 1991 qui a lancé une autre vague d’accords du côté de Microsoft tout en définissant finalement l’informatique des années 1990, etc.
La liste de tels accords peut donner le tournis à n’importe quel juriste au vu de leurs implications en termes de Droit, surtout lorsqu’ils sont déclinés à de multiples niveaux nationaux. L’essentiel est de retenir que ce sont ces accords entre monopoles qui définissent non seulement le marché mais aussi toutes nos relations avec le numérique, à tel point que c’est sur le même modèle qu’agit le politique aujourd’hui.
Ainsi, face à la puissance des GAFAM et consorts, les gouvernements se placent en situation de demandeurs. Pour prendre un exemple récent, à propos de la lutte anti-terroriste en France, le gouvernement ne fait pas que déléguer une partie de ses prérogatives (qui pourraient consister à mettre en place lui-même un système anti-propagande efficace), mais se repose sur la bonne volonté des Géants, comme c’est le cas de l’accord avec Google, Facebook, Microsoft et Twitter, conclu par le Ministre Bernard Cazeneuve, se rendant lui-même en Californie en février 2015. On peut citer, dans un autre registre, celui de la maîtrise des coûts, l’accord-cadre CAIH-Microsoft cité plus haut, qui finalement ne fait qu’entériner la mainmise de Microsoft sur l’organisation hospitalière, et par extension à de multiples secteurs de la santé.
Certes, on peut arguer que ce type d’accord entre un gouvernement et des firmes est nécessaire dans la mesure où ce sont les opérateurs les mieux placés pour contribuer à une surveillance efficace des réseaux ou modéliser les échanges d’information. Cependant, on note aussi que de tels accords relèvent du principe de transfert du pouvoir du politique aux acteurs numériques. Tel est la thèse que synthétise Mark Zuckerberg dans son plaidoyer de février 2017. Elle est acceptée à de multiples niveaux de la décision et de l’action publique.
C’est par une analyse du rôle et de l’emploi du Droit aujourd’hui, en particulier dans ce contexte où ce sont les firmes qui définissent le droit (par exemple à travers leurs accords de loyauté) que Alain Supiot démontre comment le gouvernement par les nombres, c’est-à-dire ce mode de gouvernement par le marché (celui des instruments, de l’expertise, de la mesure et du contrôle) et non plus par le Droit, est en fait l’avènement du Big Other de Shoshanna Zuboff, c’est-à-dire un monde où ce n’est plus le Droit qui règle l’organisation sociale, mais c’est le contrat entre les individus et les différentes offres du marché. Alain Supiot l’exprime en deux phrases24 :
Référée à un nouvel objet fétiche – non plus l’horloge, mais l’ordinateur –, la gouvernance par les nombres vise à établir un ordre qui serait capable de s’autoréguler, rendant superflue toute référence à des lois qui le surplomberaient. Un ordre peuplé de particules contractantes et régi par le calcul d’utilité, tel est l’avenir radieux promis par l’ultralibéralisme, tout entier fondé sur ce que Karl Polanyi a appelé le solipsisme économique.
Le rêve de Mark Zuckerberg et, avec lui, les grands monopoles du numérique, c’est de pouvoir considérer l’État lui-même comme un opérateur économique. C’est aussi ce que les tenants new public management défendent : appliquer à la gestion de l’État les mêmes règles que l’économie privée. De cette manière, ce sont les acteurs privés qui peuvent alors prendre en charge ce qui était du domaine de l’incalculable, c’est-à-dire ce que le débat politique est normalement censé orienter mais qui finit par être approprié par des mécanismes privés : la protection de l’environnement, la gestion de l’état-civil, l’organisation de la santé, la lutte contre le terrorisme, la régulation du travail, etc.
Conclusion : l’État est-il soluble dans les GAFAM ?
Nous ne perdons pas seulement notre souveraineté numérique mais nous changeons de souveraineté. Pour appréhender ce changement, on ne peut pas se limiter à pointer les monopoles, les effets de la concentration des services numériques et l’exploitation des big data. Il faut aussi se questionner sur la réception de l’idéologie issue à la fois de l’ultra-libéralisme et du renversement social qu’impliquent les techniques numériques à l’épreuve du politique. Le terrain favorable à ce renversement est depuis longtemps prêt, c’est l’avènement de la gouvernance par les instruments (par les nombres, pour reprendre Alain Supiot). Dès lors que la décision publique est remplacée par la technique, cette dernière est soumise à une certaine idéologie du progrès, celle construite par les firmes et structurée par leur marché.
Qu’on ne s’y méprenne pas : la transformation progressive de la gouvernance et cette idéologie-silicone sont l’objet d’une convergence plus que d’un enchaînement logique et intentionnel. La convergence a des causes multiples, de la crise financière en passant par la formation des décideurs, les conjonctures politiques… autant de potentielles opportunités par lesquelles des besoins nouveaux structurels et sociaux sont nés sans pour autant trouver dans la décision publique de quoi les combler, si bien que l’ingéniosité des GAFAM a su configurer un marché où les solutions s’imposent d’elles-mêmes, par nécessité.
Le constat est particulièrement sombre. Reste-t-il malgré tout une possibilité à la fois politique et technologique capable de contrer ce renversement ? Elle réside évidemment dans le modèle du logiciel libre. Premièrement parce qu’il renoue technique et Droit (par le droit des licences, avant tout), établit des chaînes de confiance là où seules des procédures régulent les contrats, ne construit pas une communauté mondiale uniforme mais des groupes sociaux en interaction impliqués dans des processus de décision, induit une diversité numérique et de nouveaux équilibres juridiques. Deuxièmement parce qu’il suppose des apprentissages à la fois techniques et politiques et qu’il est possible par l’éducation populaire de diffuser les pratiques et les connaissances pour qu’elles s’imposent à leur tour non pas sur le marché mais sur l’économie, non pas sur la gouvernance mais dans le débat public.
C’est ce que montre, d’un point de vue sociologique Corinne Delmas, dans Sociologie politique de l’expertise, Paris : La Découverte, 2011. Alain Supiot, dans La gouvernance par les nombres (cité plus loin), choisit quant à lui une approche avec les clés de lecture du Droit.↩
Voir Friedrich Hayek, La route de la servitude, Paris : PUF, (réed.) 2013.↩
Voir Karl Polanyi, La Grande Transformation, Paris : Gallimard, 2009.↩
Christophe Masutti, « du software au soft power », dans : Tristan Nitot, Nina Cercy (dir.), Numérique : reprendre le contrôle, Lyon : Framasoft, 2016, pp. 99-107.↩
Francis Fukuyama, La Fin de l’Histoire et le dernier homme, Paris : Flammarion, 1992.↩
Philippe Vion-Dury, La nouvelle servitude volontaire, Enquête sur le projet politique de la Silicon Valley, Editions FYP, 2016.↩
Götz Hamman, The United States of Google, Paris : Premier Parallèle, 2015.↩
On pourrait ici affirmer que ce qui est en jeu ici est le solutionnisme technologique, tel que le critique Evgeny Morozov. Certes, c’est aussi ce que Götz Haman démontre : à vouloir adopter des solutions web-centrées et du data mining pour mécaniser les interactions sociales, cela revient à les privatiser par les GAFAM. Mais ce que je souhaite montrer ici, c’est que la racine du capitalisme de surveillance est une idéologie dont le solutionnisme technologique n’est qu’une résurgence (un rhizome, pour filer la métaphore végétale). Le phénomène qu’il nous faut comprendre, c’est que l’avènement du capitalisme de surveillance n’est pas dû uniquement à cette tendance solutionniste, mais il est le résultat d’une convergence entre des renversements idéologiques (fin du libéralisme classique et dénaturation du néo-libéralisme), des nouvelles organisations (du travail, de la société, du droit), des innovations technologiques (le web, l’extraction et l’exploitation des données), de l’abandon du politique. On peut néanmoins lire avec ces clés le remarquable ouvrage de Evgeny Morozov, Pour tout résoudre cliquez ici : L’aberration du solutionnisme technologique, Paris : FYP éditions, 2014.↩
Peppino Ortoleva, « Qu’est-ce qu’un gouvernement d’experts ? Le cas italien », dans : Hermès, 64/3, 2012, pp. 137-144.↩
Vincent Dubois et Delphine Dulong, La question technocratique. De l’invention d’une figure aux transformations de l’action publique, Strasbourg : Presses Universitaires de Strasbourg, 2000.↩
Pierre Lascoumes et Patrick Le Galès (dir.), Gouverner par les instruments, Paris : Les Presses de Sciences Po., 2004, chap. 6, pp. 237 sq.↩
Fred Tuner, Aux sources de l’utopie numérique. De la contre-culture à la cyberculture. Stewart Brand, un homme d’influence, Caen : C&F Éditions, 2013.↩
Compte-rendu de l’audition deBruno Lasserre, président de l’Autorité de la concurrence, sur la régulation et la loyauté des plateformes numériques, devant la Commission de réflexion et de propositions sur le droit et les libertés à l’âge du numérique, Mardi 7 juillet 2015 (lien).↩
Alain Supiot, La gouvernance par les nombres. Cours au Collège de France (2012-2014), Paris : Fayard, 2015, p. 206.↩
Firefox Night-club, entrée libre !
Aujourd’hui c’est un peu spécial copinage, mais pourquoi pas ? Ils ne sont pas si nombreux les navigateurs web à la fois open source, grand public et à la pointe des technologies, respectueux des personnes qui les utilisent et de leurs données, distribués en langue locale à peu près partout dans le monde, pour toutes les plateformes, etc.
Il est temps de considérer que c’est une ressource précieuse pour tous (et pas seulement pour la communauté du libre).
– D’accord, mais comment y contribuer lorsqu’on est seulement utilisateur ou utilisatrice?
Pascal Chevrel qui répond aujourd’hui à nos questions nous présente une version de Firefox trop peu connue mais qui mérite toute notre attention et même notre implication : Firefox Nightly
Bonjour Pascal ! Commençons par le début : peux-tu te présenter ? Bonjour, Parisien, 45 ans, je suis impliqué dans le projet Mozilla depuis pratiquement sa création et je travaille à plein temps pour Mozilla depuis 11 ans. De formation plutôt économique et linguistique, j’ai longtemps travaillé sur l’internationalisation des sites web de Mozilla, l’animation de communautés de traducteurs et le développement d’outils de suivi et d’assurance qualité de nos traductions. Depuis un an, j’ai quitté mes précédentes fonctions pour rejoindre l’équipe Release Management qui est chargée d’organiser et de planifier les livraisons de Firefox. Dans ce nouveau contexte, au sein du département Product Integrity, je suis maintenant responsable du canal Nightly de Firefox.
L’équipe de Release Management chez Mozilla. Tiens, il n’y a pas que des mecs ;-)
Alors, je doute que beaucoup des personnes qui nous lisent sachent ce qu’est exactement Nightly, tu peux nous en dire plus ?
Nightly est la version alpha de Firefox, chaque jour nous compilons Firefox avec les modifications apportées par les développeurs la veille à notre code source et nous proposons cette version de Firefox au téléchargement afin de recevoir des retours sur l’état de qualité du logiciel.
Quel est l’intérêt pour moi, péquin moyen, d’utiliser Nightly ?
Pour un internaute lambda, pas forcément à l’aise avec l’informatique, il n’y a effectivement aucun intérêt à utiliser Nightly. Les utilisateurs « ordinaires » sont encouragés à utiliser le canal Release qui est la version finale grand public et pas une version alpha ou bêta de Firefox.
Pour un utilisateur averti, utiliser Nightly signifie avoir accès à une version de Firefox qui plusieurs mois de développement d’avance sur la version finale et donc de pouvoir utiliser des fonctionnalités auxquelles n’ont pas encore accès les utilisateurs de Firefox. Depuis plusieurs mois, nous faisons un gros travail de modernisation et de nettoyage du code source de Firefox afin d’améliorer ses performances, les utilisateurs de Nightly ont donc accès à un navigateur beaucoup plus performant que la version grand public.
Pour un utilisateur averti et sensible aux valeurs véhiculées par Mozilla et par le logiciel libre, c’est aussi le meilleur moyen de participer à un projet de logiciel libre lorsque l’on a pas de temps à investir dans des activités de bénévolat. Le simple fait d’utiliser Nightly est une aide plus que précieuse au développement de Firefox car Nightly envoie par défaut des données de télémétrie et les rapports de plantage à nos développeurs qui peuvent ainsi repérer immédiatement toute nouvelle régression.
Attends ! Ça veut dire que vous préparez toutes les nuits une nouvelle version de Firefox ?! Elle doit être pleine de bogues ! Ça marche vraiment ton machin ?
Toutes les nuits en effet (d’où son nom de Nightly), nous compilons Firefox avec le code de la veille, dans toutes les langues, pour tous les systèmes d’exploitations que nous supportons, en 32 comme en 64 bits. Toutes ces versions (builds) doivent passer notre batterie de tests automatisés qui valident un niveau de qualité minimal. Évidemment, c’est une version alpha, donc moins stable, elle peut planter plus facilement qu’une version destinée au grand public…
Ceci dit c’est très utilisable, j’utilise des nightlies depuis 2002 et les véritables problèmes sont rares. Lorsqu’un vrai problème passe entre nos filets, en général la télémétrie nous en informe en quelques heures et nous livrons une deuxième nightly dans la journée pour le régler ou fournir une solution d’atténuation de l’impact causé par le bug (retour arrière sur le patch fautif, désactivation temporaire d’une nouvelle fonctionnalité si le retour arrière n’est pas possible).
Et si j’installe Nightly, ça veut dire que ça me remplace mon Firefox habituel ? Et mes favoris et mots de passe enregistrés ?
Déjà, on dit marque-page, « favori » c’est de la terminologie Microsoft, je peux avoir dans mes marque-pages le site des impôts, ça ne veut pas dire que ce soit un des mes sites favoris 😉
On peut tout à fait installer Nightly à côté d’un Firefox classique, la chose importante est de ne pas leur faire partager le même profil de données. Le plus simple est d’installer Nightly dans un nouveau profil et de synchroniser les données (marque-pages, historiques, mots de passe…) entre les deux versions via Firefox Sync, notre service de synchronisation de données.
Histoire de bien comprendre : je dois télécharger Nightly tous les matins pour profiter des dernières mises à jour ?
Non, Nightly se met à jour en arrière-plan tout seul, lorsque la nouvelle version est disponible et peut être installée, une petite flèche verte apparaît sur l’icône de menu et il suffit de cliquer dans ce menu sur un bouton qui appliquera la mise à jour, ce qui se traduit concrètement par la fenêtre qui se ferme et se rouvre en quelques secondes.
Allez, fais-nous rêver : c’est quoi les nouvelles fonctionnalités attendues ?
En novembre, nous allons sortir une mise à jour majeure de Firefox, la plus grosse mise à jour du logiciel depuis 2011. Nous travaillons à une modernisation importante du moteur de rendu des pages (Gecko) en intégrant des parties mûres de notre autre moteur de rendu en R&D, Servo. Ce moteur est écrit dans un nouveau langage informatique très performant, Rust, les gains attendus en termes de performances sont importants. Ce projet de modernisation des fondations s’appelle Quantum. Il s’agit d’un projet proprement titanesque sur lequel plusieurs équipes de développeurs travaillent à plein temps depuis plusieurs mois, la version de novembre intégrera les premiers fruits de ce travail.
Nous travaillons aussi à une modernisation de l’interface actuelle de Firefox avec notre équipe d’ergonomes et de designers afin d’améliorer aussi l’interaction avec l’utilisateur, ce projet s’appelle Photon. Tu peux voir à quoi ressemblera Firefox d’ici quelques mois en parcourant ce diaporama illustré d’aperçus de la future interface.
La mascotte du projet Photon/Quantum
Tous les travaux en cours sur Quantum et Photon ne sont disponibles que sur Nightly, les amateurs de performances et de design peuvent donc avoir accès en avant première à ces avancées.
En termes de fonctionnalités spécifiques à Nightly, la gestion d’identité multiples dans une même session (qui permet d’avoir des onglets « boulot » et des onglets « perso » par exemple) semble être la nouveauté la plus appréciée de nos utilisateurs sur ce canal.
Bon si c’est pour avoir une version toute en anglais, merci bien !
Nous proposons Nightly dans toutes nos langues, il est donc disponible au téléchargement en français. Évidemment, pour les nouvelles fonctionnalités, il faut parfois attendre quelques jours pour voir celles-ci en français dans l’interface, il arrive donc parfois que certaines phrases ou items de menu soient en anglais. Mais c’est rare, les traducteurs veillent au grain.
Cliquez sur l’image pour avoir le grand poster (attention gros fichier de 4,2 Mo)
Notre wiki contient des informations détaillées (mais en anglais) sur l’installation de Nightly selon son système d’exploitation, dont un screencast pour Windows.
Mais au fait, ça fait quand même beaucoup, beaucoup d’énergie dépensée par Mozilla pour une version de Firefox plutôt méconnue. C’est quoi votre intérêt ?
Pour développer Firefox qui est un projet de grande envergure (des centaines de développeurs, une base de code très importante, près de 100 langues et 4 systèmes d’exploitation pris en charge…), il faut le compiler tous les jours et avoir une infrastructure d’intégration continue en place, il était donc logique de proposer ces versions (que nous utilisons déjà en interne) à nos utilisateurs afin de pouvoir bénéficier d’un bêta test externe qio réponde à des questions comme : est-ce que le site de ma banque en Belgique fonctionne avec ? Est-ce que la traduction est bonne ? Est-ce qu’il est stable sur ma configuration ?…
Cela représente donc un investissement mais avoir une version dédiée au bêta-test communautaire est fait partie (ou devrait faire partie) de tout projet de logiciel libre communautaire.
Au fait, beaucoup de gens l’utilisent ?
Trop peu de gens utilisent Nightly, essentiellement les employés Mozilla et notre communauté de bénévoles les plus impliqués dans le projet Mozilla, quelques dizaines de milliers de personnes dans le monde. Cela peut sembler beaucoup dans l’absolu mais c’est en réalité assez faible car le Web est immense, les configurations matérielles sur lesquelles tournent Firefox sont des plus diverses dans le monde et nous n’avons pas aujourd’hui assez de retours d’utilisation (que ce soit la télémétrie ou des rapports de bugs plus formels) afin de prendre les meilleures décisions de développement.
Nous recherchons donc des utilisateurs mais bien sûr nous sommes très clairs sur le fait que Nightly est destiné à un public plus à l’aise avec l’informatique que la moyenne et prêt à accepter des changements de comportement ou d’interface du logiciel au jour le jour avec en contrepartie l’accès en avant-première à des fonctionnalités innovantes.
Si vous voulez aider Mozilla, que vous êtes à l’aise avec l’informatique, utiliser Nightly à la place ou à côté de votre navigateur actuel (qui n’a pas à être Firefox) est probablement le moyen le plus simple de participer au projet.
Donc, même si je n’y connais rien de rien en logiciel libre, en code, et tous les autres trucs techniques, rien qu’en utilisant Nightly, je fais avancer le schmilblick ?
Si vous êtes à l’aise avec l’informatique (en gros, si vous savez installer et désinstaller un logiciel sans faire appel à la cousine en école d’ingénieur), simplement utiliser Nightly aide énormément Mozilla et les développeurs de Firefox.
Nous avons aujourd’hui une qualité de Nightly qui est suffisante pour de très nombreux utilisateurs sans connaissances techniques particulières.
Si je vois des trucs qui clochent, je le signale où et comment ? Parce que moi le bugzilla, comment dire…
Pour les francophones, le plus simple est d’expliquer ce qui cloche dans nos forums de mozfr à cette adresse : https://forums.mozfr.org/viewforum.php?f=24
S’il s’avère que c’est effectivement un problème dont nous n’avons pas connaissance, nos modérateurs les plus anglophiles se chargeront d’ouvrir un ticket sur Bugzilla et d’agir comme intermédiaires avec les développeurs. Je passe sur le forum moi-même deux fois par semaine.
Et si je suis un développeur, et que les mots « code source », « mercurial », « bugzilla » ou « RTFM » me parlent, je peux aider quand même ?
Si vous êtes développeur non seulement vous pourrez rapporter des bugs directement dans Bugzilla mais on peut aussi vous aider à écrire le patch pour résoudre ce bug ! Il y a d’ailleurs une vingtaine de développeurs Firefox qui sont francophones si l’anglais vous fait un peu peur.
Les développeurs mais aussi les utilisateurs les plus techniques peuvent ouvrir des bugs et faire une recherche du patch qui a causé une régression grâce à l’outil mozregression
Tiens une question qu’on nous pose souvent, qui peut paraître hors sujet, mais en fait pas du tout : qu’est-ce que je peux dire à mon cousin qui utilise Google Chrome, afin qu’il envisage de passer à Firefox ?
Il n’y a pas de réponse unique à cette question car pour cela il faudrait savoir pourquoi il utilise Chrome. Si ton cousin est sensible au respect de sa vie privée, utiliser Firefox va probablement de soi. Si ce qui importe pour lui ce sont les performances, alors Nightly est certainement dans la course avec Chrome, voire plus performant sur certaines activités, ce n’a pas toujours été le cas donc c’est important à souligner. S’il est un utilisateur compulsif d’onglets, la gestion des onglets de Nightly est certainement plus riche et performante que celle de Chrome ; avoir une session avec plusieurs centaines d’onglets ouverts sur une machine récente ne pose aucun problème sous Nightly.
Je pense que de nombreux utilisateurs qui sont passés de Firefox à Chrome il y a quelques années seraient très surpris des avancées (performances, ergonomies, fonctionnalités) que nous avons intégrées dans Firefox. C’est encore plus vrai pour Nightly et je reçois quasiment quotidiennement du feedback d’utilisateurs Chrome passés avec bonheur à Nightly, C’est très encourageant pour notre grosse livraison 57 en novembre évidemment. Le magazine en ligne américain CNET a publié en juin un article intitulé « New speed boost means maybe it’s time to try Firefox again » plus qu’élogieux et ils n’ont testé que la version grand public 54. Nightly qui est en 56 est déjà bien plus performant.
Merci Pascal ! Un dernier mot ? Ou une question que tu aurais aimé qu’on te pose ?
Un grand merci à toi pour l’intérêt que tu portes à Firefox, Mozilla et mon travail sur Firefox Nightly ! Merci aussi pour le travail de vulgarisation que fait Framasoft en ce qui concerne le logiciel et la culture libre. Firefox est l’outil qui permet à Mozilla d’avoir un impact sur le Web. Étant donné le travail que fait Framasoft sur la décentralisation et de dégooglisation du web, les lecteurs de cet article seront peut être intéressés par cette récente annonce de Mozilla dans laquelle nous annonçons un budget de 2 millions de dollars dédié à financer les projets de décentralisation du Web.
… et le slogan du blog de Nightly pour le mot de la fin : Améliorons ensemble la qualité, version après version (Let’s improve quality, build after build!)






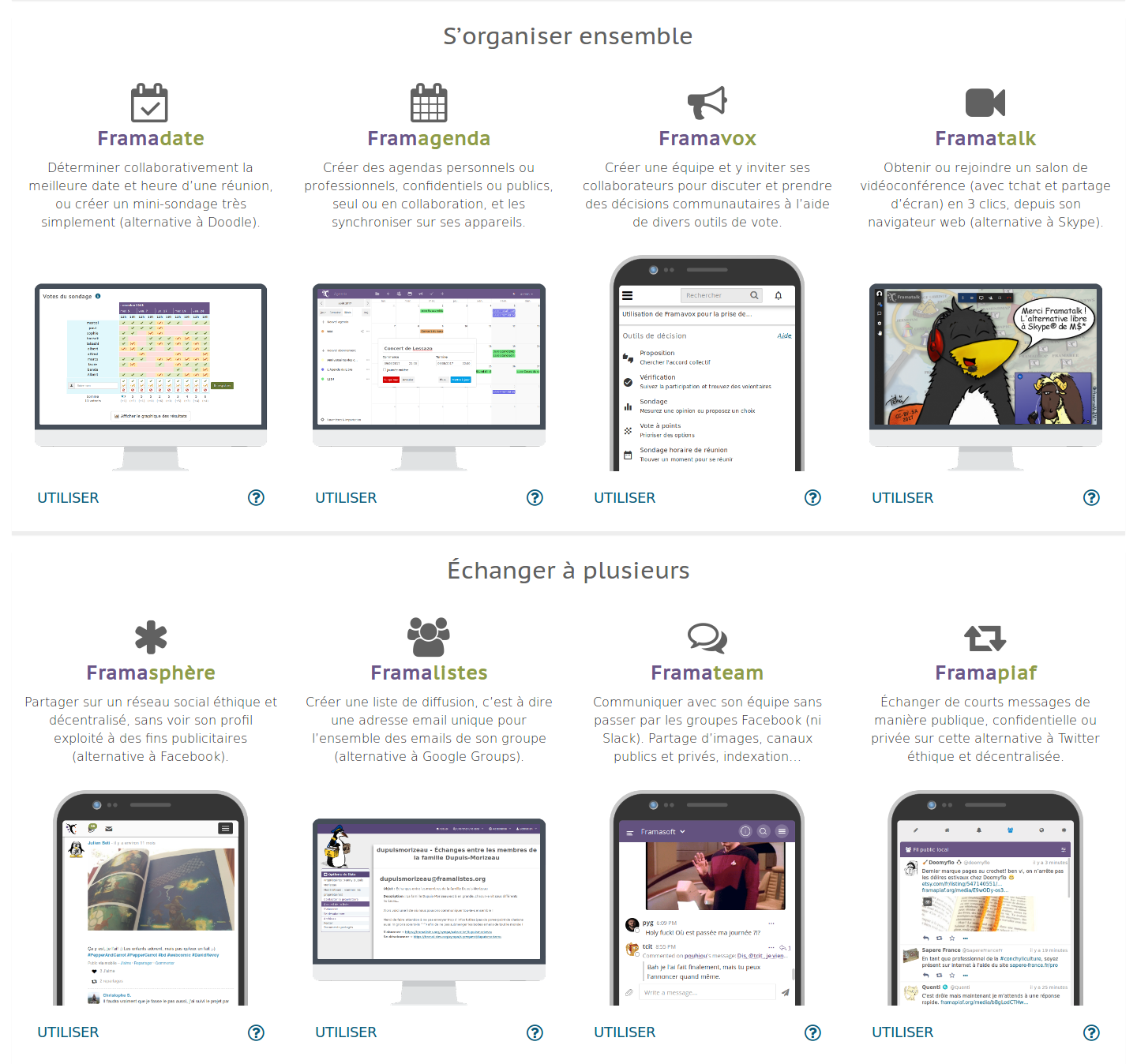

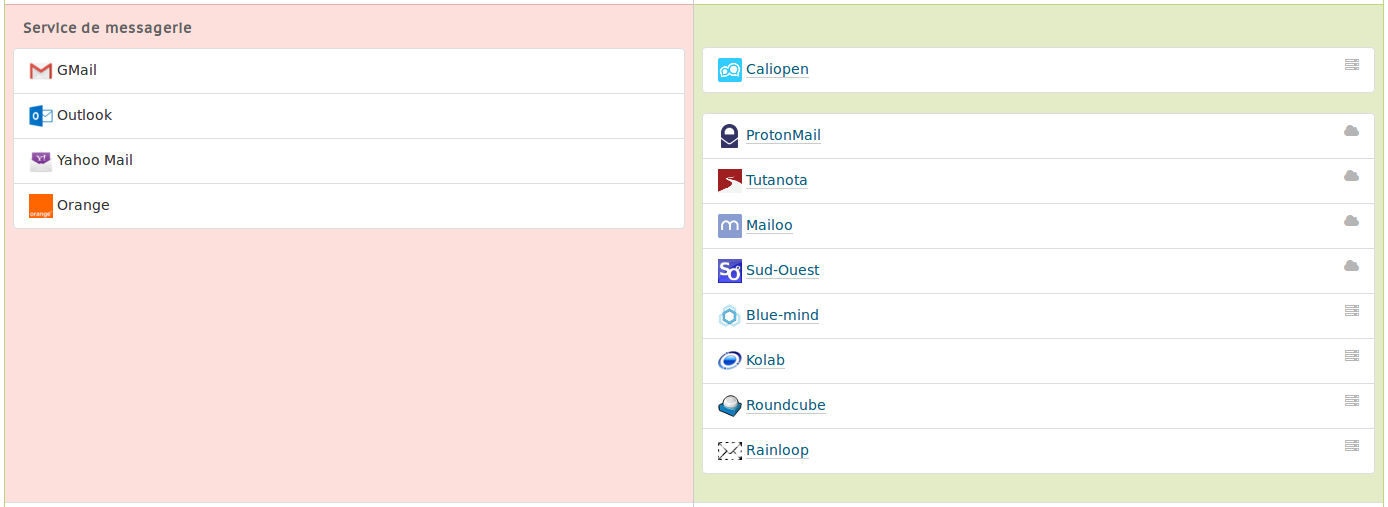
































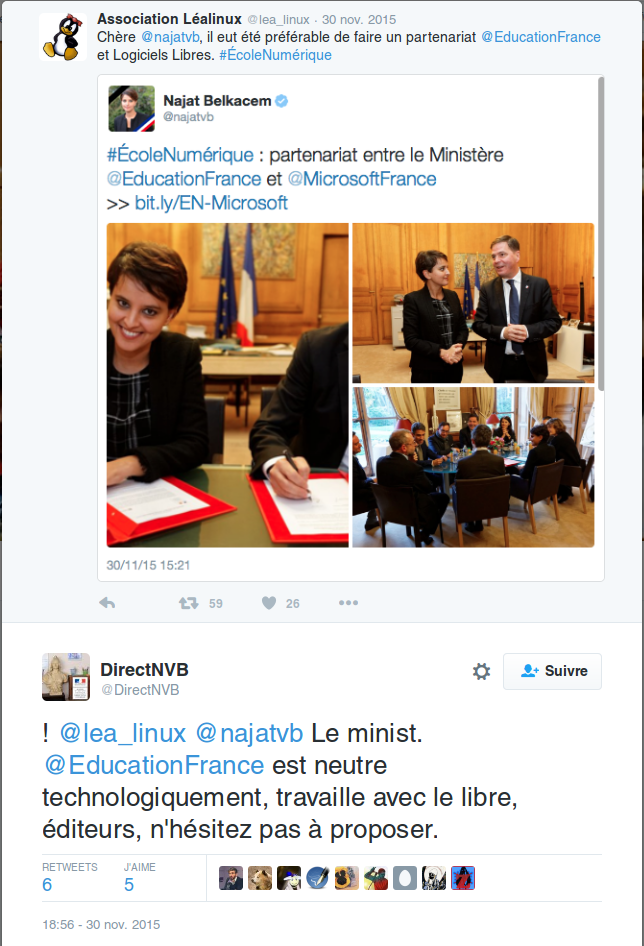

 Bonjour, Parisien, 45 ans, je suis impliqué dans le projet Mozilla depuis pratiquement sa création et je travaille à plein temps pour Mozilla depuis 11 ans. De formation plutôt économique et linguistique, j’ai longtemps travaillé sur l’
Bonjour, Parisien, 45 ans, je suis impliqué dans le projet Mozilla depuis pratiquement sa création et je travaille à plein temps pour Mozilla depuis 11 ans. De formation plutôt économique et linguistique, j’ai longtemps travaillé sur l’


{kind=link}