Framaforms : n’offrez plus les réponses que vous collectez à Google !
Un formulaire d’inscription ? Une enquête en ligne ? Un questionnaire de satisfaction ? Bref : vous avez besoin de réaliser rapidement un questionnaire à diffuser en ligne et d’en collecter les réponses ?
Il existe plusieurs logiciels libres pour réaliser cela. Nous devons même reconnaître qu’aucun ne rivalise avec la redoutable efficacité de Google Forms (maintenant intégré à la « G(oogle) Suite » ). Mais ce dernier aspire vos données, et surtout celles des participants répondant innocemment à vos formulaires, en enregistrant leurs réponses dans Google Sheets, lui même enregistré dans Google Drive !

Alors, nous avons décidé de construire nous-mêmes une alternative : Framaforms !
Framaforms vous permet de réaliser simplement des formulaires, par glisser-déposer d’éléments (champs textes, cases à cocher, menu déroulant etc.). Il vous suffit alors de transmettre l’adresse de ce formulaire à qui bon vous semble par email, sur les réseaux sociaux, ou directement en l’intégrant sur votre site web… et de laisser les participants répondre. Les réponses seront anonymisées ; vous pourrez les visualiser et même les analyser, notamment à l’aide de graphes générés automatiquement pour vous faire gagner du temps. Et bien entendu vous pourrez les télécharger au format .csv, utilisable dans n’importe quel tableur.
Comme il faut parfois tâcher d’éviter les abus, l’outil comporte volontairement quelques limitations (durée d’hébergement du formulaire, ou nombre de réponses maximum par formulaire). Nous lèverons éventuellement ces contraintes suivant les usages, mais pour ne pas avoir à les subir, et surtout si vous avez des besoins spécifiques, le mieux est alors d’installer vous-même l’outil sur votre serveur. Vous pouvez aussi utiliser les services « premium » du site webform.com par l’auteur du module qui fait tourner Framaforms.
Pour en savoir plus sur l’outil Framaforms, notamment sur pourquoi et comment nous avons décidé de le faire nous-mêmes, nous vous invitons à lire l’interview de Pierre-Yves, qui a réalisé cet outil pour vous : entretien avec Pierre-Yves, pour en savoir (un peu) plus sur Framaforms.
Donnez-moi un exemple simple à comprendre !
Tristan[1] a des choses à dire sur ce qu’il pense des GAFAM (Google, Apple, Amazon, Facebook, Microsoft), et de l’utilisation qu’ils font de nos données personnelles. D’ailleurs il est régulièrement invité pour en parler car son expertise sur le sujet est reconnue. Il a donc décidé de rassembler ses idées dans un livre. Après plusieurs mois de rédaction et avoir pris bonne note des retours qui lui ont été faits par les lectrices et lecteurs de son blog, il a trouvé une maison d’édition proche de ses valeurs prête à publier son livre. Le jour tant attendu du lancement de son ouvrage approche, mais afin de pouvoir s’organiser, il décide de créer un formulaire en ligne invitant à s’inscrire les personnes qui souhaitent venir.
Framaforms à la rescousse
Première étape, l’inscription.
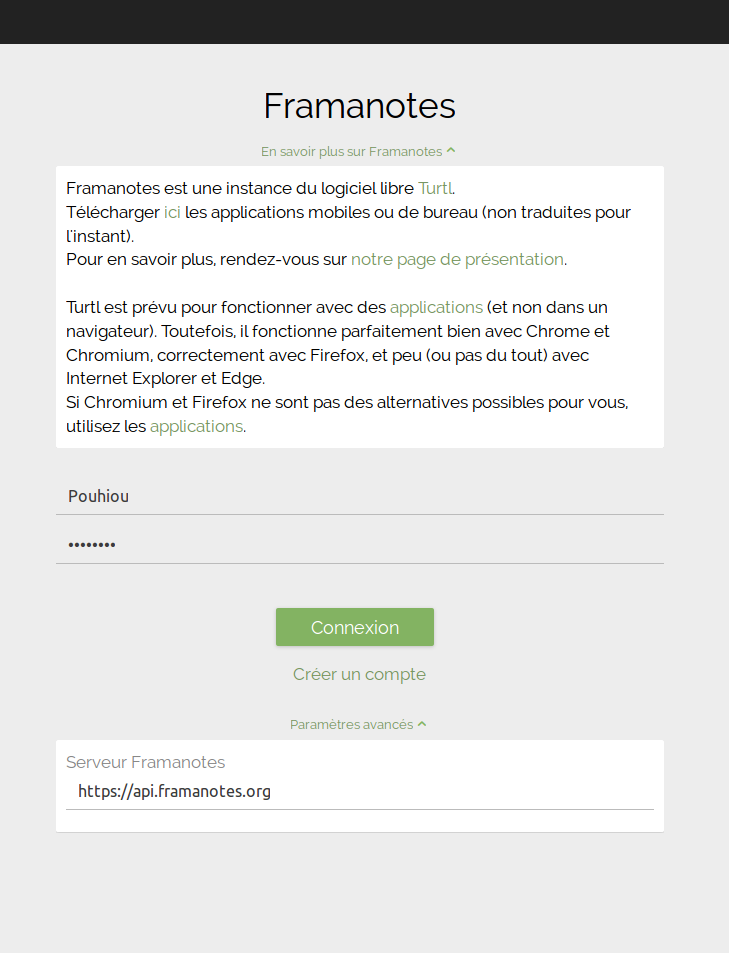
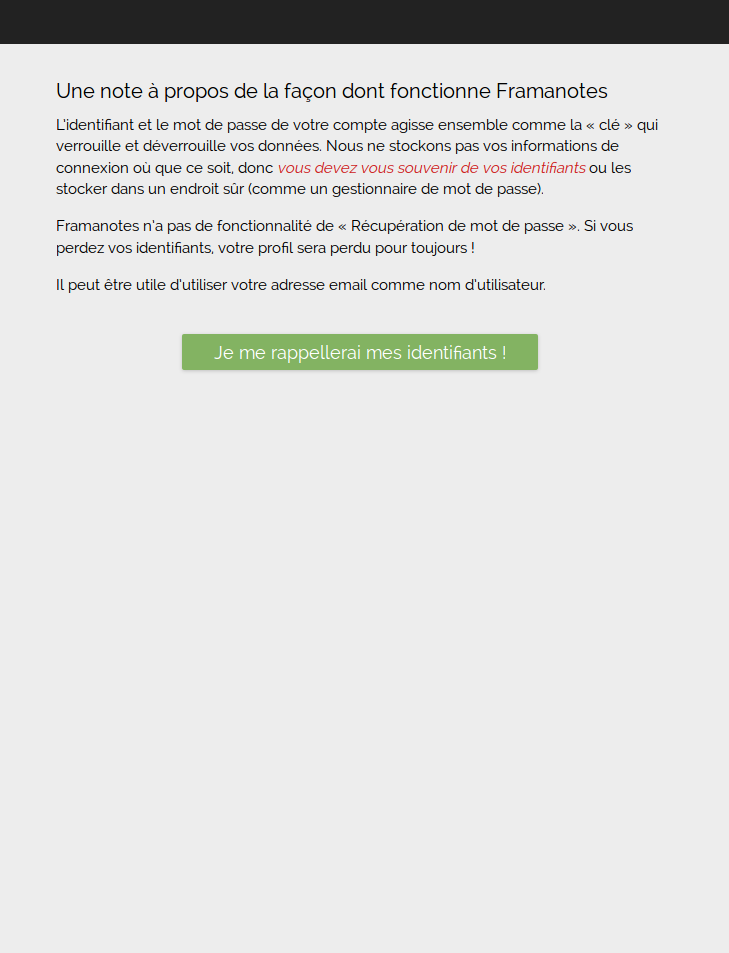
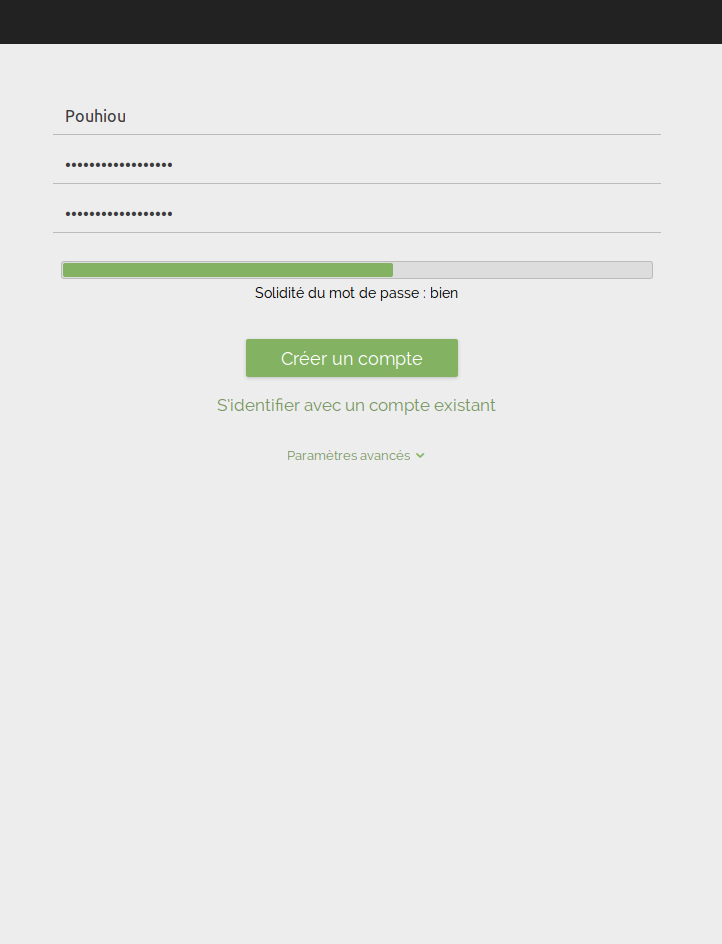
Rien d’extraordinaire de ce côté-là. Tristan se rend sur https://framaforms.org et clique sur « Créer un compte ». Il saisit alors un login, son adresse email, et répond à la question servant à s’assurer qu’il n’est pas un robot-spammeur (pour info, la réponse est « framaforms » 😛 )
Il reçoit quelques secondes plus tard un email provenant du site lui demandant de cliquer sur un lien pour terminer son inscription. Il clique dessus et peut alors choisir son mot de passe et quelques informations complémentaires.
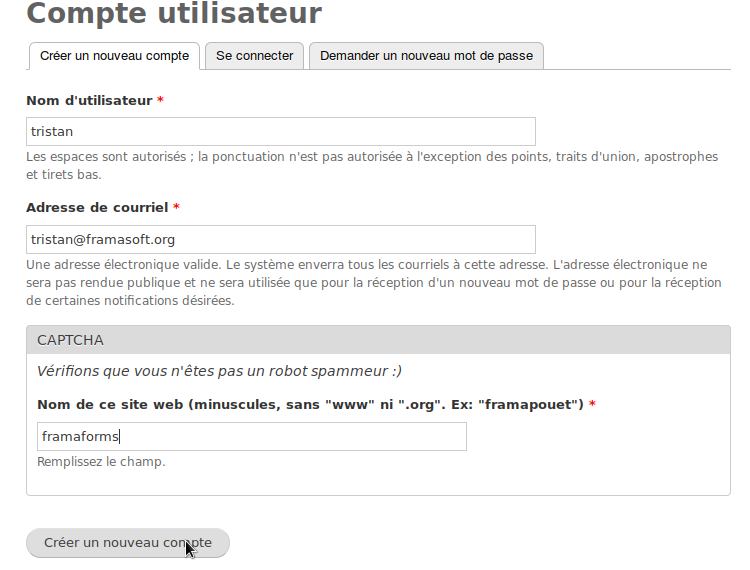
Voilà, son compte est créé et validé, il peut commencer son formulaire !
Création du formulaire
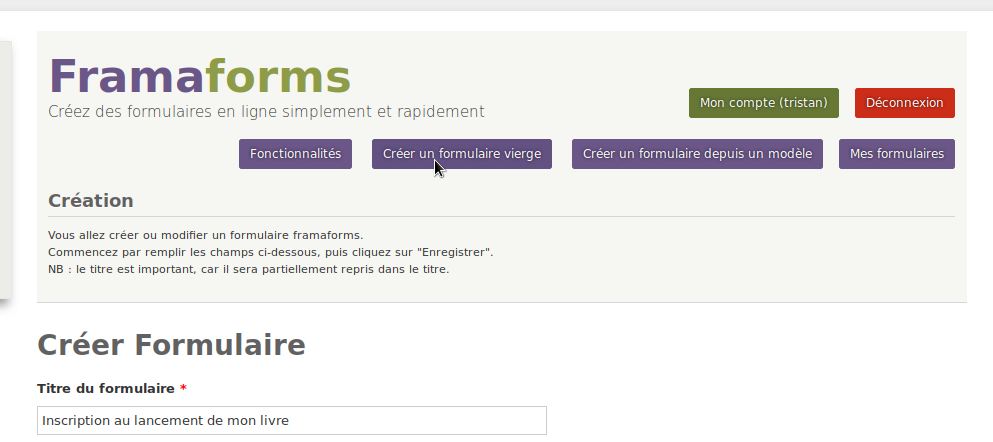
Il clique sur « Créer un formulaire ». Le site lui demande alors de remplir les informations de base, comme l’intitulé (« Inscription au lancement de mon livre »).
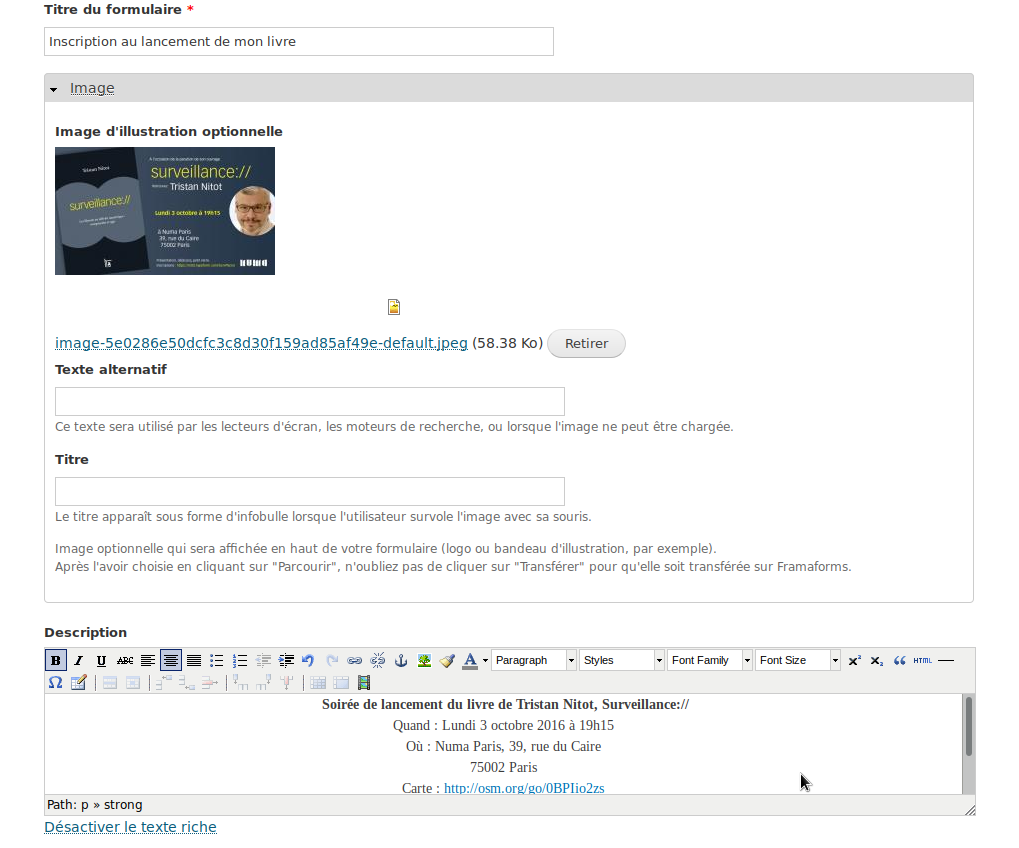
Il choisit aussi de mettre en ligne une description et une image qui rappelleront aux gens de quoi il s’agit.
Comme date d’expiration, Tristan choisit une date 15 jours après l’événement. Il aura de toutes façons récupéré toutes les informations d’ici là, et inutile d’encombrer les serveurs avec un formulaire dont les informations n’auront plus d’intérêt quelques jours plus tard.
Comme Tristan est un type sympa, il se dit que son formulaire pourra servir à d’autres plus tard, et décide donc de faire de son formulaire un « modèle ». Cela signifie que son formulaire se retrouvera parmi les multiples modèles de formulaires dont d’autres utilisateurs pourront s’inspirer et qu’ils pourront surtout « cloner » d’un seul clic, leur faisant gagner un temps précieux. Il décide de nommer ce formulaire « Modèle de formulaire d’inscription à un événement ».
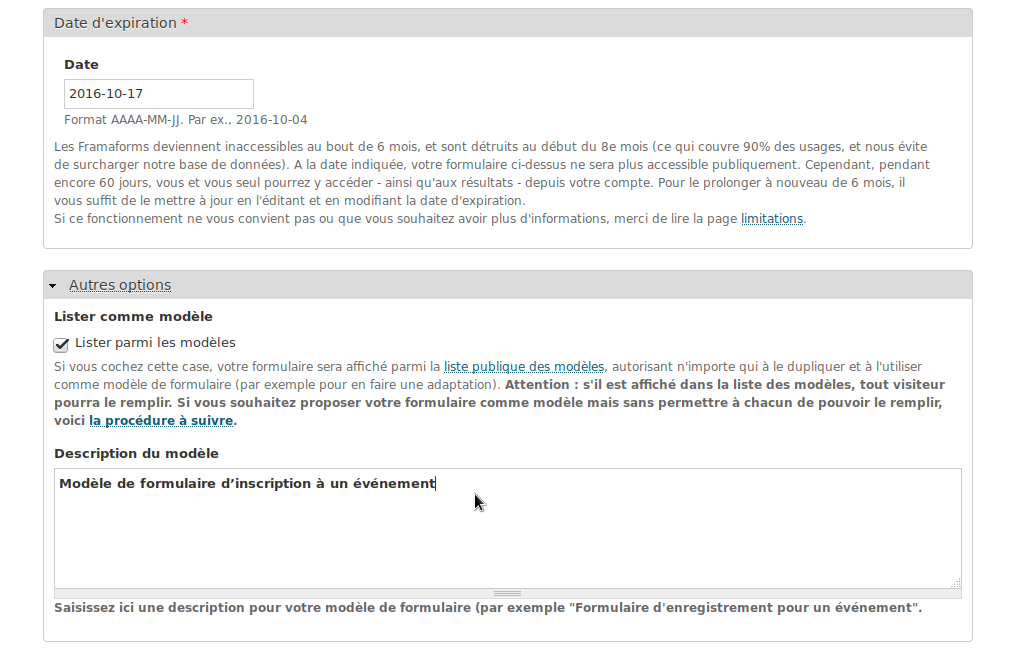
Il passe alors à l’étape de la construction de son formulaire.
Conception du formulaire
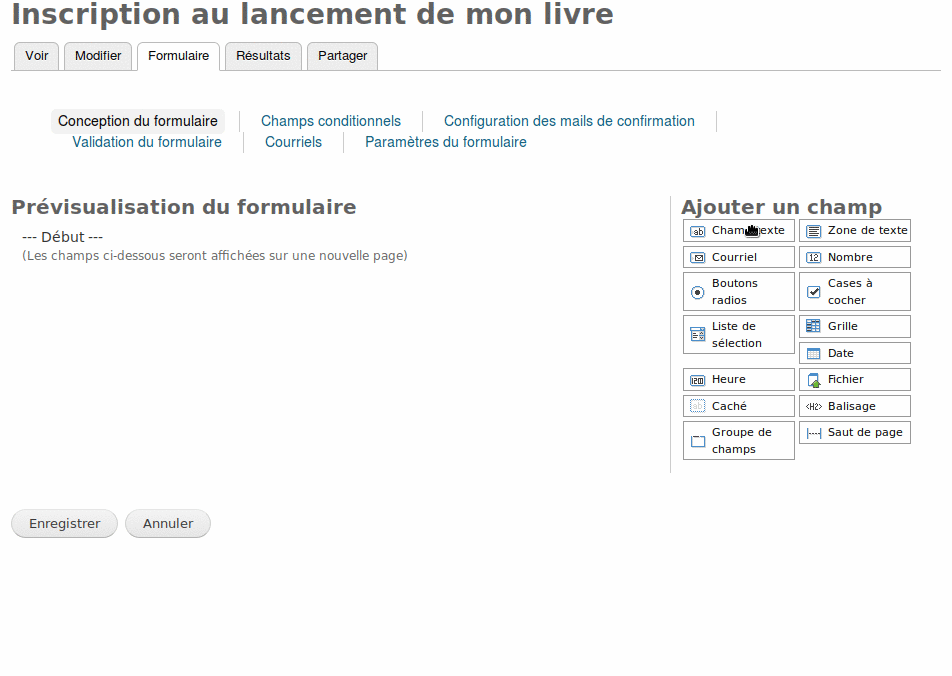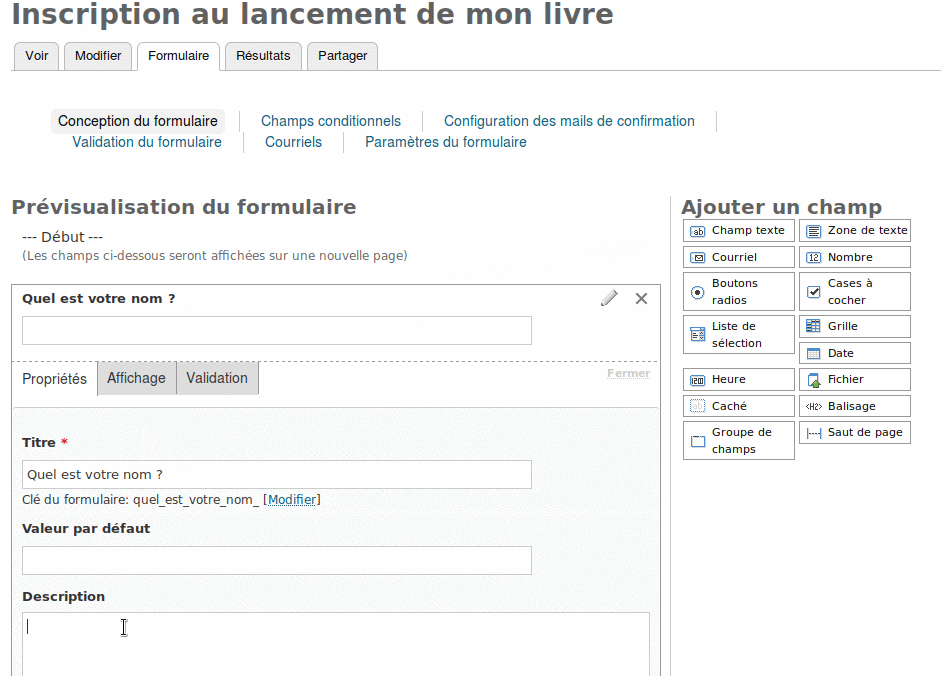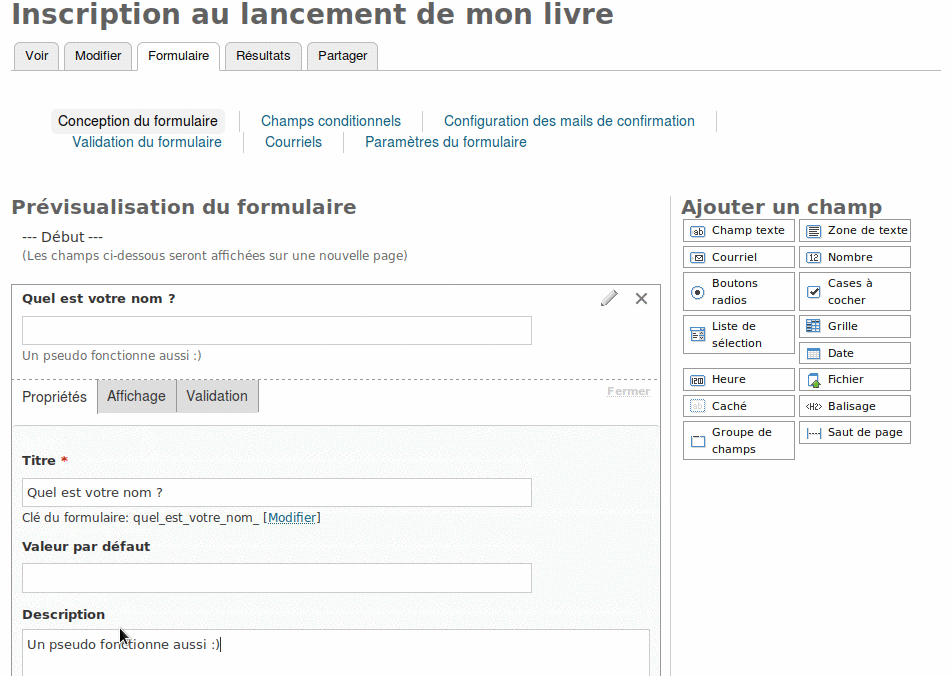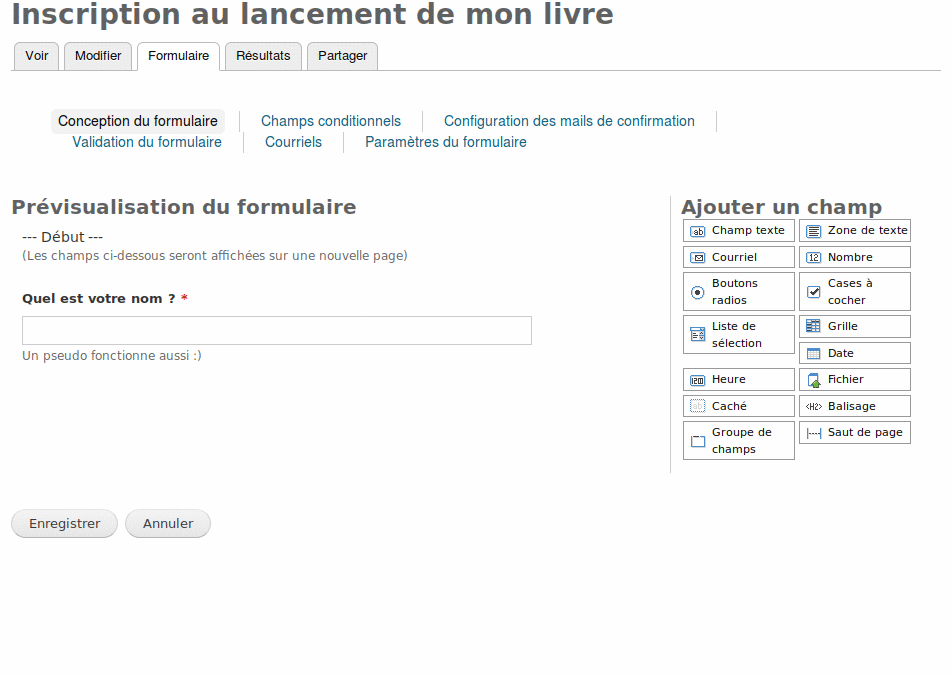
C’est simple et rapide : il suffit de glisser-déposer les champs, puis de cliquer dessus pour éditer les informations qui seront affichées.
Il commence donc par un champ texte pour le nom ou le pseudo.
Il clique sur le crayon et complète les informations souhaitées. Il en profite d’ailleurs pour rendre ce champ obligatoire.
Comme il souhaite savoir comment les inscrits ont entendu parler de son ouvrage, il utilise alors un champ « boutons radio ». Et remplit 3 champs « Par l’auteur », « Par l’éditeur »,
« Autre ».
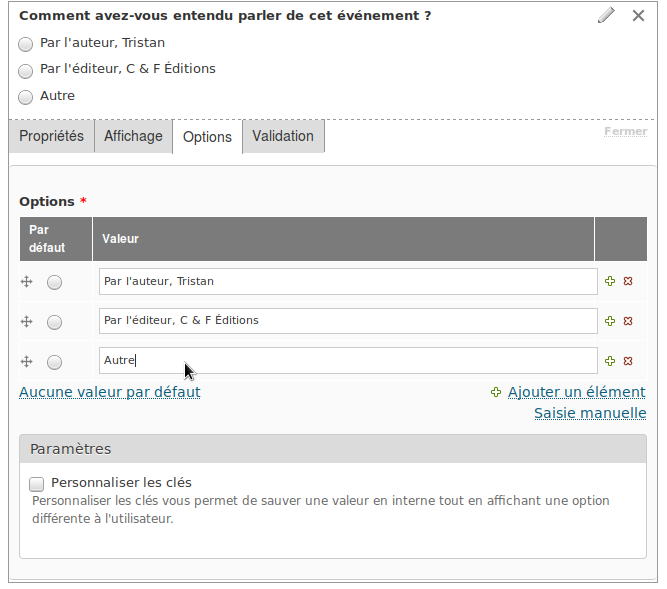
Afin de savoir avec combien de livres son éditeur doit venir le jour J, il décide de poser la question sous forme d’une simple case à cocher.
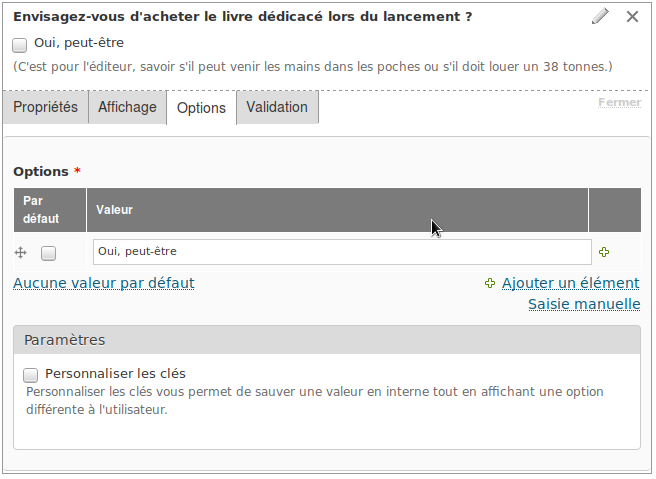
Enfin, il décide d’ajouter, à la demande de son éditeur, un champ email pour les personnes qui souhaiteraient être tenues au courant de l’actualité de ce dernier. Aucun problème, un dernier glisser-déposer et c’est réglé.
Et voilà, il enregistre, et son formulaire est prêt à être diffusé !
Il peut le visualiser et le tester en cliquant sur « Voir »
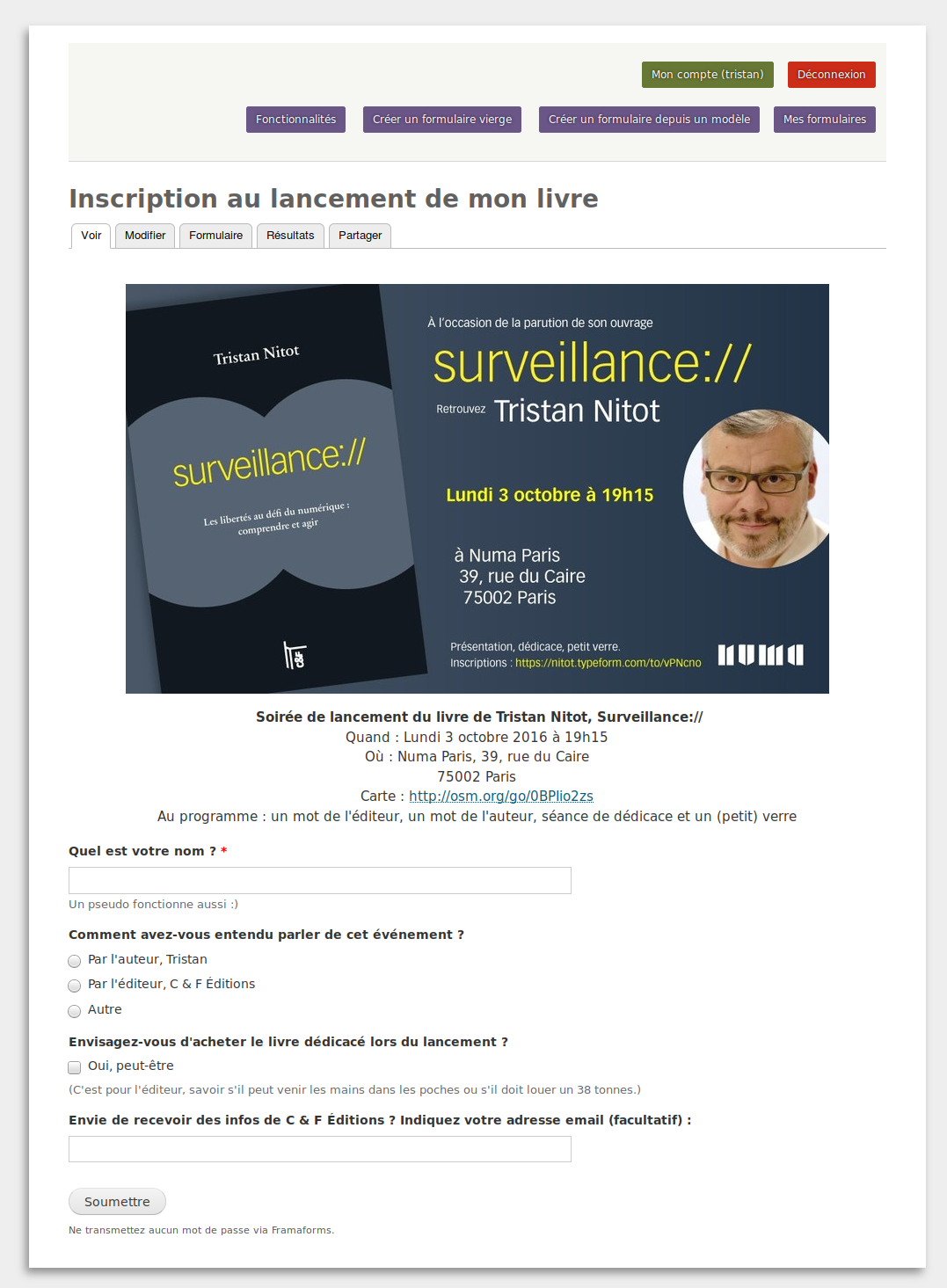
Options
Bon, jusqu’ici ça ne lui a pris que 5 minutes chrono, mais Tristan se dit que ça mérite un peu de peaufinage. C’est un jour important après tout !
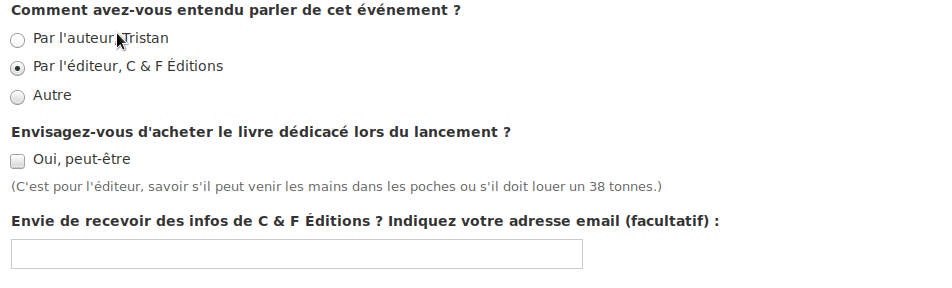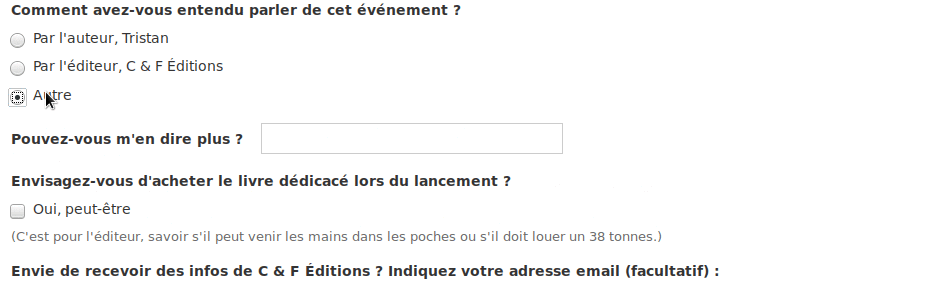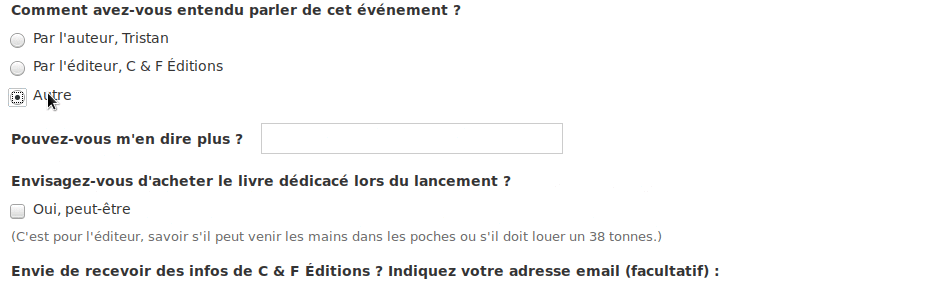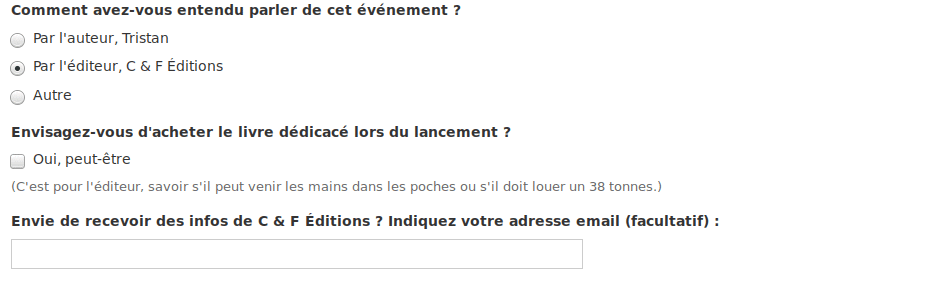
D’abord, il retourne modifier son formulaire et décide de rajouter un champ texte « Pouvez-vous m’en dire plus ? » qui ne s’affichera QUE si le participant coche la case « Autre ».
Il ajoute ce champ sous les boutons radio et enregistre son formulaire.
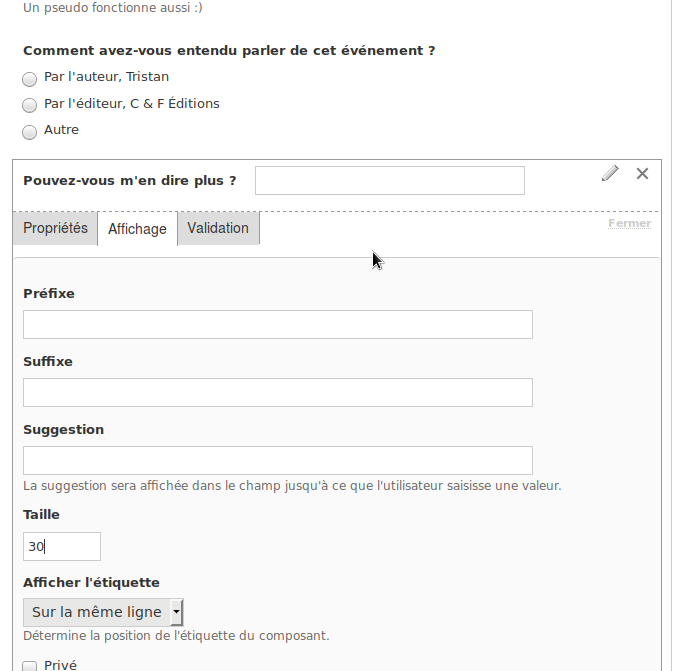
Puis, il clique sur « champs conditionnels » et sélectionne les menus de façon à formuler la phrase « Si Comment avez-vous entendu parler de cet événement est Autre alors Pouvez-vous m’en dire plus ? est affiché », puis enregistre. Simple !
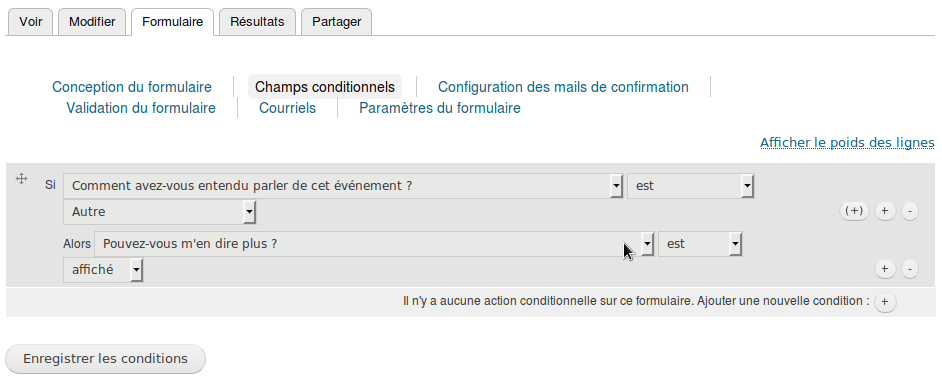
Le résultat est concluant :
Par ailleurs, il se dit qu’il aimerait bien recevoir un mail à chaque réponse.
Il se rend dans l’onglet « courriels » et ajoute un « courriel standard ». Pour adresse courriel du destinataire, il met la sienne.
Il parcourt les autres champs, mais les valeurs par défaut lui conviennent, et il décide donc de valider.

Dernière modification, cosmétique, dans l’onglet « Modifier », tout en bas, il choisit un autre thème, plus adapté aux smartphones que le thème par défaut (il faut dire que les amis de Tristan sont très connectés). Il enregistre encore une fois.
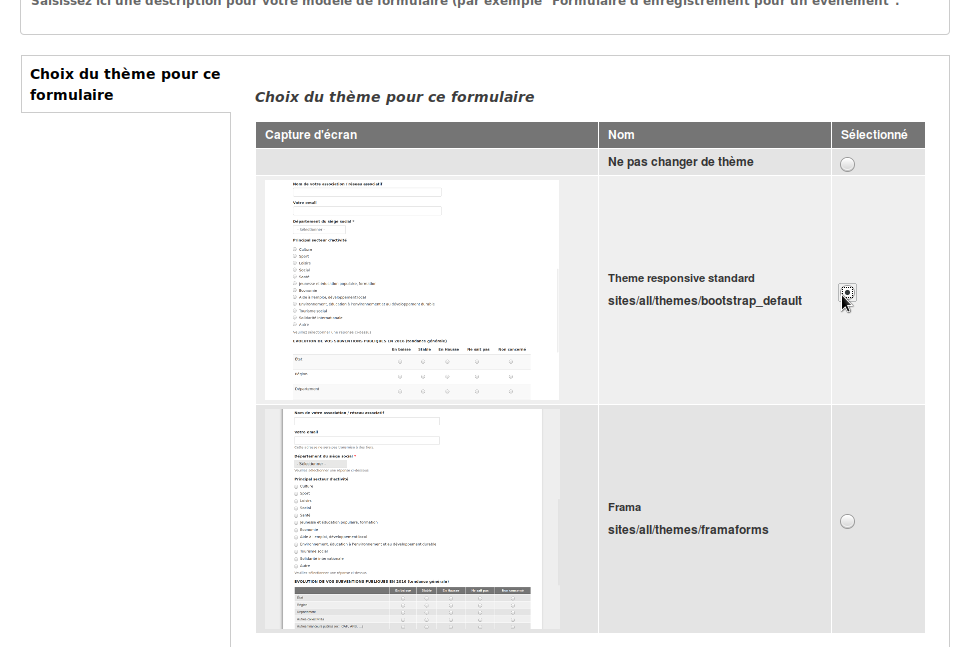
Voilà, son formulaire peut être diffusé !
Diffusion
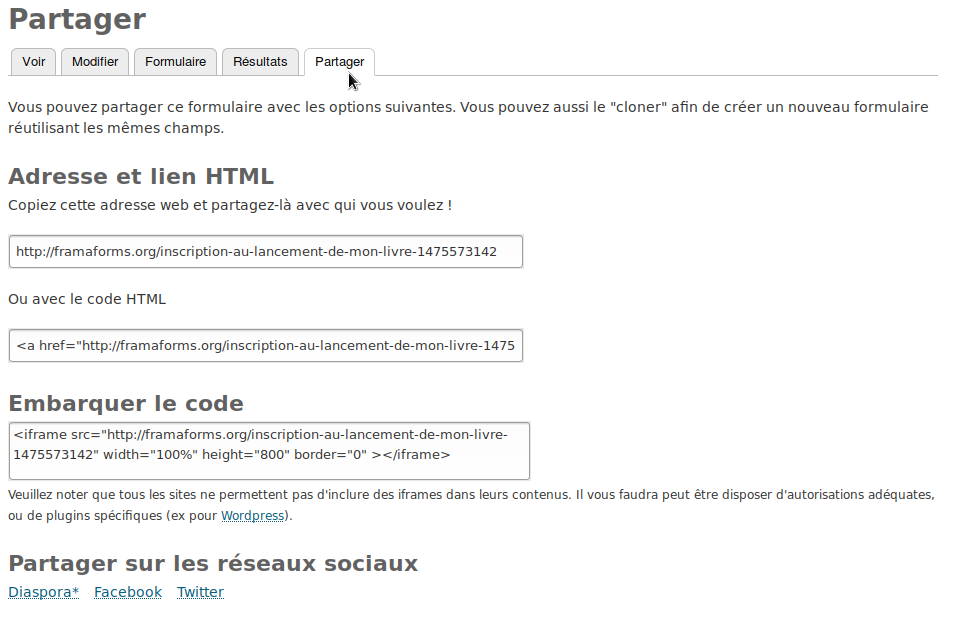
En se rendant sur l’onglet « Partager », Tristan voit une option pour partager son formulaire sur les réseaux sociaux.
Il a supprimé son compte Facebook il y a très longtemps, parce que l’entreprise modifiait sans cesse ses conditions d’utilisation, de plus en plus abusives. Par contre Tristan a un compte diaspora* sur Framasphère, le pod du réseau social loyal et respectueux de vos données, géré par l’association Framasoft (le pod, pas le réseau :P). Et il est aussi très présent sur Twitter (100 000 abonnés tout de même). Il publie donc l’annonce du lancement de son livre sur ces deux réseaux. Il a même le code HTML qui lui permet d’afficher ce formulaire directement embarqué sur son site. Il envoie aussi l’adresse de son formulaire à ses contacts par email.
Les dés sont jetés.
Collecte, analyse et téléchargement des données
Quelques jours plus tard, Tristan se connecte sur Framaforms et peut retrouver son formulaire via le bouton « Mes formulaires ».
Il clique sur son formulaire, puis sur « Résultats ». Il peut alors voir le nombre de réponses et visualiser chacune d’entre elles en situation (et supprimer les tests qu’il avait faits au début).
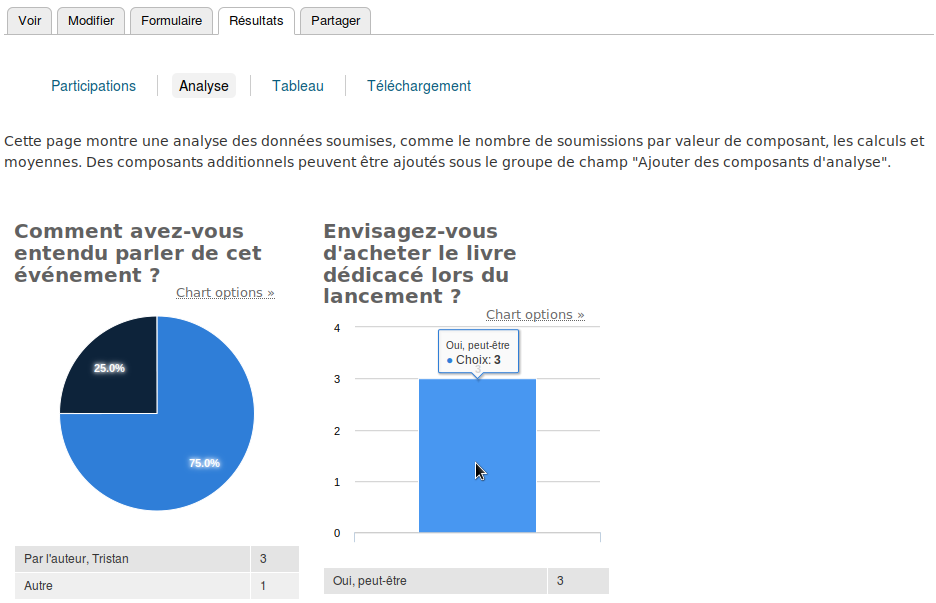
Il peut aussi sélectionner l’onglet « Analyse » pour afficher des graphiques des réponses.
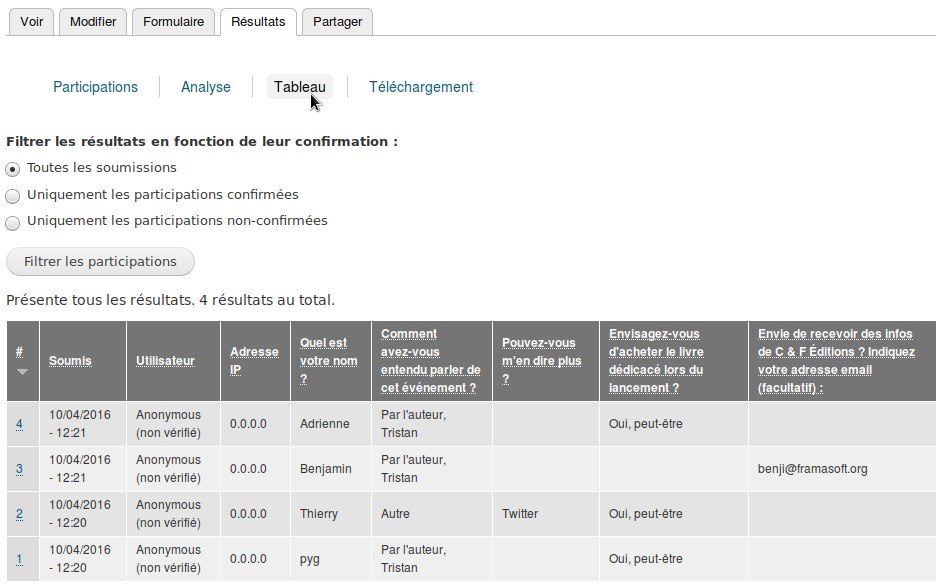
L’onglet « Tableau » permet, lui, d’avoir une vision globale des réponses (pratique pour les formulaires ne comportant pas trop d’éléments.
Enfin, il peut bien entendu télécharger les résultats au format .csv pour importer les informations brutes dans, par exemple, LibreOffice Calc (son tableur préféré).
Conclusion
Tristan a donc créé un formulaire en quelques minutes, qui plus est en étant certain que les données des réponses des participants n’iront pas nourrir l’ogre Google.

Il n’en a pas eu l’utilité, mais de nombreuses autres options étaient disponibles. Par exemple il aurait pu ajouter un champ pour demander l’âge des participants, avec une vérification automatique que la valeur saisie était bien un nombre compris entre 7 et 97 ans. Ou renvoyer automatiquement le participant sur une page de remerciements sur son blog une fois le formulaire rempli. Ou limiter le nombre de places aux 100 premiers répondants. Ou …
Pour aller plus loin :
- Découvrir la liste des modèles (à vous d’en créer !)
- Le site de Drupal, moteur de Framaforms
- Webform.com : une alternative très proche de Framaforms, partiellement libre – par l’auteur du module Webform (gratuit avec quelques limitations, mais avec une offre payante si vous ne voulez pas de contraintes)
- Installer Framaforms sur votre site (sera publié le 20 octobre 2016)
[1] – oui, cet exemple est tiré d’une histoire vraie que certain-e-s d’entre-vous reconnaîtront sûrement 😉 Cependant, notez que la soirée de Tristan est intervenue avant la sortie de Framaforms ! Il ne pouvait donc pas l’utiliser. Mais que ça ne vous empêche pas d’acheter son (excellent) bouquin !





 Le problème exposé dans cet ouvrage m’est apparu sur une intuition. Pour avoir travaillé dans des startups puis dans des sociétés de capital-risque, j’ai pu constater que des sommes d’argent considérables affluaient dans les entreprises de logiciel. Par ailleurs, en tant que développeuse de logiciel en amateur, j’étais bien consciente que je n’aurais rien pu produire toute seule. J’utilisais du code gratuit et public (plus connu sous le nom de code open source) dont j’assemblais des éléments afin de répondre à des objectifs personnels ou commerciaux. Et franchement, les personnes impliquées dans ces projets avaient, quel que soit leur rôle, fait le plus gros du travail.
Le problème exposé dans cet ouvrage m’est apparu sur une intuition. Pour avoir travaillé dans des startups puis dans des sociétés de capital-risque, j’ai pu constater que des sommes d’argent considérables affluaient dans les entreprises de logiciel. Par ailleurs, en tant que développeuse de logiciel en amateur, j’étais bien consciente que je n’aurais rien pu produire toute seule. J’utilisais du code gratuit et public (plus connu sous le nom de code open source) dont j’assemblais des éléments afin de répondre à des objectifs personnels ou commerciaux. Et franchement, les personnes impliquées dans ces projets avaient, quel que soit leur rôle, fait le plus gros du travail.
 la position et l’expérimentation d’artistes comme
la position et l’expérimentation d’artistes comme