Pour un monde avec un million de Netflix
À l’occasion du #DayAgainstDRM, attardons-nous sur un des géants du web.
Cette multinationale dont l’initiale n’est pas dans GAFAM a eu un rôle déterminant pour imposer des verrous numériques (les DRM) dans nos appareils, nos logiciels et jusque dans ce qui fait le web.
Merci à Sualtam, auteur de lectureaudio.fr pour cette contribution active.
Il est temps qu’on parle de Netflix.
Le péché originel : le droit d’auteur
La convention de Berne, initialement signée en 1886 par moins d’une dizaine d’états de la zone européenne, implique aujourd’hui 179 membres. Lire cette convention permet de reprendre la mesure des interdits qu’elle pose. Elle stipule notamment que le droit de communiquer au public la représentation d’une œuvre est soumise à l’autorisation de son auteur. C’est ce que l’on appelle le droit patrimonial : « l’auteur d’une œuvre de l’esprit jouit sur cette œuvre, du seul fait de sa création, d’un droit de propriété incorporelle exclusif et opposable à tous » (article L111-1 du code de la propriété intellectuelle français).

En France le droit patrimonial s’installe dans la loi en 1791, juste après la révolution, il est alors octroyé pour une durée couvrant la durée de la vie de l’auteur plus cinq ans. Petit à petit cette durée a été augmentée pour atteindre aujourd’hui 70 ans après la mort de l’auteur. Certaines exceptions font que c’est parfois un peu plus (je vous le mets quand même ?), parfois moins, notamment dans le cas des œuvres collectives (où ce n’est « que » 70 ans après la publication de l’œuvre). Dans d’autres pays c’est également parfois plus, parfois moins (c’est « seulement » 50 ans après la mort de l’auteur au Canada). On peut retenir qu’une œuvre publiée en 2020 ne pourra pas être reproduite sans autorisation de l’auteur au moins jusqu’en 2070, souvent 2090. Au XXIIe siècle quoi. C’est dans longtemps.
Oui, on sait, il faut bien que les industries culturelles vivent, que les auteurs soient rémunérés, etc. On aurait des choses à dire, mais ce n’est pas le sujet… Quand même, il faut garder en tête que ces lois ont été envisagées d’un point de vue industriel, de façon à garantir un retour sur investissement à des sociétés qui mobilisaient des moyens techniques lourds et onéreux. L’habillage sous terme de « droit d’auteur » n’est qu’une apparence sémantique : ce qui importe, c’est de sécuriser la filière de captation industrielle de la valeur.
En résumé, les créations ne sont pas librement exploitables en général et on parle d’ayant-droits pour désigner les personnes qui ont le contrôle d’une œuvre.

La gestion des droits numériques aka le DRM
La copie étant devenue plus facile — mais pas plus légale — avec les facilités ouvertes par la numérisation des œuvres, puis les facilités de circulation prolongées par Internet puis le Web, les ayants droit ont cherché des moyens de lutter contre ce qui profitait à presque tout le monde. Sauf eux donc. Notons qu’un ayant droit n’est en général pas un auteur. Celui-ci a généralement cédé ses droits patrimoniaux à l’ayant droit qui les exploite et lui reverse une partie des bénéfices. La répartition occasionne d’ailleurs régulièrement des négociations et souvent des conflits, comme lors de la grève des scénaristes américains, fortement syndiqués, qui bloqua une partie de la production audiovisuelle états-unienne en 2007-2008.
Les ayants droits, qui ont donc des droits à faire valoir même quand ils n’ont en rien contribué à l’œuvre — c’est le cas des héritiers des écrivains par exemple — ont déployé de nombreuses stratégies pour défendre leurs droits. Dont les DRM. Un DRM c’est un programme informatique dont l’objectif est de faire dysfonctionner la lecture d’un fichier dans le cas général. C’est un buggeur. Informatiquement c’est assez étonnant comme pratique, ça consiste à faire en sorte que les programmes fonctionnent moins bien. Donc si vous avez un contenu sous DRM, vous devez disposer du moyen technique (un logiciel non libre le plus souvent) fourni par celui qui gère l’accès au contenu pour le lire.
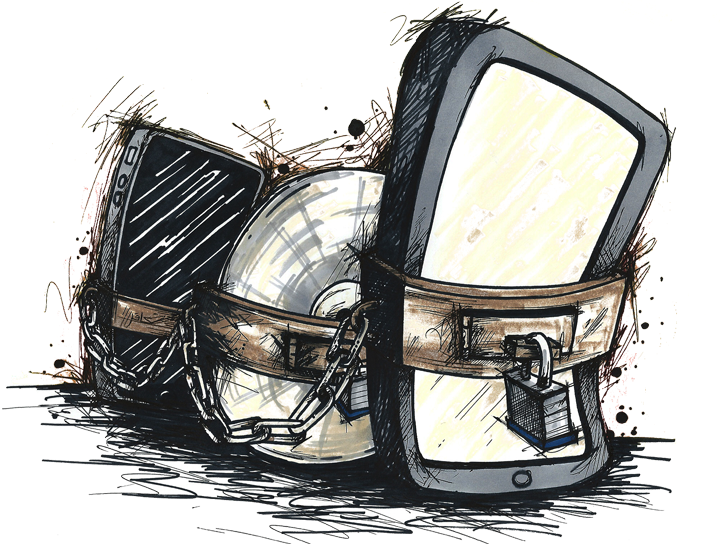
On pourrait aussi parler des nombreuses occasions où les DRM empêchent les programmes de fonctionner même dans le cas où a été légitimement acquis le contenu — parce que quand vous vous amusez à faire exprès de faire dysfonctionner des programmes, eh bien c’est plus facile que de les faire de nouveau fonctionner après — mais ce n’est pas non plus le sujet. On pourrait aussi expliquer que les DRM n’empêchent pas ceux qui veulent vraiment accéder aux contenus de le faire tout de même et donc qu’ils ont surtout comme conséquence de compliquer la vie de tout le monde sans rien résoudre en réalité. Mais ce n’est toujours pas notre sujet. Gardez néanmoins en tête que le vendeur peut ainsi effacer un de vos livres, même d’Orwell, avec toutes vos notes, voire votre bibliothèque complète car il ne trouve pas cette activité assez rentable.
En résumé il est illégal de diffuser le contenu de quelqu’un sans son accord et il existe des techniques pour compliquer la vie de ceux qui voudraient le faire quand même.

Quand les fabricants du Web ont laissé entrer les DRM
Le web n’a pas échappé aux DRM. Cela s’appelle les EME (Encrypted Media Extension). Il y a eu des oppositions, la FSF, l’Electronic Frontier Foundation, les associations militantes du libre. Et il y a eu aussi des acteurs, dont le W3C et Mozilla qui ont cédé devant la puissance des industriels souhaitant exploiter le droit d’auteur et devant les pratiques déjà en place. Ce fut certainement le processus de standardisation du web le plus controversé, et ce sont les promoteurs des DRM qui ont gagné.

Et aujourd’hui cela verrouille le web.
Le composant de gestion des DRM dans le navigateur n’est pas libre. Mozilla Firefox, ainsi que la majorité des autres navigateurs non libres utilisent Widevine de Google. Il est très difficile techniquement et totalement interdit légalement de chercher à en connaître les codes sources. Il est donc illégal de connaître le fonctionnement de l’un des outils que l’on utilise le plus au quotidien. Oui, même si c’est Firefox.
De plus le mécanisme DRM rend la construction de nouveaux navigateurs plus compliquée, voire même impossible selon Cory Doctorow. En fait il reste possible de fabriquer un nouveau navigateur mais il ne pourra pas lire les contenus sous DRM. Parce qu’un éventuel système DRM alternatif, c’est compliqué à faire, et que ça n’aurait de toutes façons pas la confiance des ayants droit. Et puis parce que Google, l’acteur dominant sur ce terrain (oui, sur ce terrain-là aussi) n’acceptera pas de licencier un lecteur Widevine libre.
Notez bien, même si vous avez bien acquis le droit d’accéder à ces contenus, que vous avez tout bien payé, vous ne pourrez pas les lire. Un tel navigateur libre a donc peu de chance de survivre, en dehors du cercle militant (c’est par exemple le cas du Tor Browser construit sur la base de Mozilla Firefox mais n’intégrant pas le composant propriétaire Widevine).
En résumé, il est aujourd’hui impossible de diffuser de la vidéo, et des médias en général, sous droit d’auteur sur le Web sans un accord avec un géant du numérique.

L’émergence du continent Netflix
Mettre en place un serveur d’accès libre à des fichiers ne coûte pas grand chose. En 2020, c’est vrai même pour des vidéos. Avec une machine solide qui coûtera quelques centaines d’euros par mois à amortir (accès Internet, disques, énergie, etc…), on peut diffuser quelques milliers de films à quelques milliers d’utilisateurs (peut être pas de la 4K en streaming à toute heure, mais ce serait tout de même une offre suffisante pour de nombreux utilisateurs relativement modestes dans leurs usages). Donc en théorie de nombreuses sociétés commerciales devraient être en mesure d’offrir un tel service. On devrait être en situation de concurrence forte.
Mais ce n’est pas ce que l’on observe. On observe une domination oligarchique avec Netflix qui confisque environ la moitié du marché en Europe et une vingtaine d’acteurs au dessus de 5% de parts de marché.

Pourquoi est-on dans cette situation ? Parce que la mise en place du service implique surtout d’acheter des droits. Et qu’il faut ensuite une infrastructure technique solide pour gérer les données, les chiffrer, les diffuser à ceux qui ont acquis le privilège d’y accéder et pas aux autres, etc. Sinon on risque d’être poursuivi en justice par les ayants droits.
Donc il faut des moyens. Beaucoup de moyens.
En résumé, c’est à cause de l’état du droit international qu’il est coûteux de diffuser la culture par des voies légales. Et c’est parce que c’est coûteux que l’on assiste à l’émergence de cet acteur proto-monopolistique qu’est Netflix.

Plus, c’est mieux
À noter que le monopole est une stratégie de développement industriel à part entière1, consciemment appliquée. Il signifie donc être et rester seul tout en haut. Cela implique une guerre commerciale permanente avec d’éventuels concurrents (guerre alimentée par la puissance financière des actionnaires).
Or le monopole pose problème. Il permet, une fois établi, des pratiques commerciales inégales, c’est donc un problème pour les consommateurs qui deviennent dépendants d’un système, sans alternative. C’est même pour ça qu’il est combattu depuis très longtemps2, même dans des zones où l’économie de marché n’est pas discutée3.

Mais, notamment quand il touche à la culture, le monopole pose d’autres problèmes, que d’aucuns considéreront comme plus importants.
Il engendre la concentration de la distribution. Qu’un diffuseur choisisse ce qu’il veut diffuser est légitime. C’est son business. Son catalogue c’est son business, s’il ne veut pas gérer de vieux films lents en noir et blanc, c’est son droit. S’il ne veut pas de film chinois ou français, il fait bien ce qu’il veut sur ses serveurs. S’il veut entraîner des IA à pousser des utilisateurs à regarder tout le temps les mêmes genres de trucs, c’est son problème (bon, et un peu celui des utilisateurs si c’est fait à leur insu, mais disons qu’ils donnent leur consentement, même moyennement éclairé, à un moteur de recommandation, donc qu’ils ne sont pas totalement innocents).
Mais dès lors qu’il n’y a plus qu’un seul diffuseur, c’est différent, car il décide alors de ce qui est diffusé. Tout court. Il acquiert le pouvoir de faire disparaître des pans entier de la culture. Et de décider de ce que sera celle de demain.
En résumé, la recherche du monopole est une stratégie économique des géants du web ; appliquée aux domaines culturels, elle engendre un contrôle de la culture.

Le pouvoir de fabriquer la culture
Mais ça ne s’arrête pas là. L’acteur monopolistique devient riche, très riche. Si c’est un vendeur de livres, il se met à commercialiser d’autres trucs rentables (comme des médicaments). Si c’est un diffuseur de films et de séries, il se met aussi à produire des films et des séries. C’est lui qui paye les acteurs, les scénaristes et qui choisit ce qu’il va diffuser. Il rachètera ou créera ensuite des écoles du cinéma qui expliqueront comment faire les choses comme il pense qu’il faut les faire. Il conçoit ses propres appareils pour imposer son format exclusif non-standard, en ne permettant pas la lecture d’autres formats, ouverts.
Bref il se déploie. Il acquiert le pouvoir de faire la culture. Il devient la culture. Mais ce n’est pas un être humain, un artiste, un poète, c’est un système industriel qui a pour but de grossir pour générer des profits financiers. Il va donc fourbir ses outils pour servir ces buts. Des recettes de storytelling sont définies, puis usées jusqu’à la trame tant qu’un retour sur investissement suffisant est réalisé. Un marketing de plus en plus précis va tenter de définir des communautés, des profils, à servir selon des algorithmes toujours plus précis, nourris d’informations collectées de façon pantagruélique. L’expérience utilisateur sera étudiée, affinée, optimisée afin de contraindre l’usager par des moyens détournés à demeurer dans l’écosystème contrôlé par l’industrie. Ses concurrents vont s’efforcer de le dépasser en y consacrant plus de moyens techniques et financiers, en appliquant le même genre de recettes, pour servir les mêmes objectifs.

Le but est désormais de s’arroger le plus de temps de cerveau disponible que possible.
C’est là que réside le véritable souci : la place hégémonique de ce modèle économique fait qu’il définit nos horizons d’une façon mondialisée uniforme. En cherchant à capter notre attention, cela définit nos protentions, notre attente de l’avenir d’une façon univoque. Il assèche notre écosystème symbolique des possibles. Il limite nos portes de sortie. Il renforce sa propre vision du monde. Le modèle dominant issu d’une société anglo-saxonne capitaliste, avec ses présupposés et ses valeurs, finit ainsi par être essentialisé.
En résumé, plus petit est le nombre d’acteurs qui font la culture et plus restreinte est cette culture, qui tend à l’uniforme.

Un monde sans Netflix ? Non, un monde avec un million de Netflix !
Est-il possible de faire autrement ? Is there an alternative ? Oui et non. On peut imaginer.

On peut imaginer le soutien par chaque état de sa propre industrie numérique de façon à disposer de, disons 100 Netflix, deux ou trois par pays qui aurait l’envie et les moyens4.
On pourrait aussi imaginer de réduire les contraintes législatives et techniques liées au droit d’auteur. On arriverait peut-être à 1000 Netflix en réduisant ainsi le coût d’entrée juridique. On garderait des interdits (la reproduction massive), des embargos (6 mois, 1 an, 3 ans, mais pas 70 ans), etc. On resterait globalement dans le cadre actuel, mais selon une équation plus équilibrée entre ayants droits et utilisateurs.
Et puis allons plus loin, imaginons un monde où la culture serait sous licences libres. Chacun pourrait librement créer une activité basée sur l’exploitation des œuvres. On ouvrirait un site de diffusion de musique ou de séries comme on ouvre un commerce de proximité ou un chaton. Ça ferait sûrement un million de Netflix. Un archipel de Netflix où chaque îlot aurait sa vision, avec des archipels qui ne pourraient pas se voir. Mais on s’en foutrait, s’il y avait un million de Netflix, il y en aurait bien un qui nous correspondrait (même si on est d’un naturel exigeant).
On peut donc imaginer. Mais on peut aussi commencer dès aujourd’hui à mettre les voiles.
Les auteurs peuvent déposer leurs œuvres sous licence libre, pour préparer le monde de demain. Ils peuvent le faire quelques mois, voire années, après une exploitation commerciale classique. Ça permettra à d’autres d’en vivre. À la culture de se diffuser. Et même ça les aidera peut-être en tant que créateurs et créatrices, à faire émerger d’autres modèles de financement de la culture, moins mortifères que ceux qui existent actuellement pour les créateurs et créatrices5.
Les utilisateurs de culture peuvent agir via leurs usages, c’est à dire avec leurs porte-monnaie comme le propose la FSF :

Cancel your subscription to Netflix, and tell them why. https://defectivebydesign.org/cancelnetflix.
Il est également possible de soutenir directement des créateurs et créatrices qui tentent de sortir de ces ornières, en proposant leur travail sous licences libres.
Les citoyens peuvent jouer de leur influence en interpellant les détenteurs du pouvoir politique, ou en soutenant les acteurs associatifs qui militent contre les DRM, comme la FSF ou La Quadrature Du Net.
En résumé ? Coupez votre abonnement Netflix et envoyez les sous à une asso, un·e artiste de votre choix, qui milite pour un truc chouette ou qui simplement produit des contenus à votre goût. Même si c’est juste pour un mois ou deux, histoire de voir comment ça fait…

Refuser les rapports et soutenances de stages confidentiels
Aujourd’hui, nous vous proposons de sortir un peu des sentiers (re)battus du libre et des communs pour explorer un peu plus ceux de l’éducation et du partage. Stéphane Crozat, membre de Framasoft et prof. à l’Université de Technologie de Compiègne, souhaite partager ici une réflexion autour des conditions de publication des rapports de stage. Profitons du fait que le Framablog est aussi le blog des membres de l’association Framasoft pour lui donner la parole.

Chaque semestre, une partie significative des entreprises qui accueillent des stagiaires de l’Université Technologique de Compiègne dont je suis suiveur font une demande de procédure de confidentialité concernant le rapport et/ou la soutenance de l’étudiant. Je suis opposé à cette pratique.
Récemment encore une grande société française impliquée notamment dans des activités en lien avec la défense m’a fait une telle demande.
Ce semestre, j’ai pris le temps de poser mes arguments à plat, à la suite de quoi la demande a été retirée. Le mail que j’ai reçu en réponse faisait état du bien-fondé de ces arguments. Je les partage donc afin de contribuer peut-être à rendre les demandes de confidentialité plus marginales.
Préambule : la confidentialité est un droit de l’entreprise
Je ne suis pas opposé aux besoins de confidentialité des entreprises. De nombreux contextes l’exigent. À titre personnel il est par exemple évident que les informations dont je dispose sur les étudiants ne sauraient être divulguées publiquement.
Il est à noter que :
- le principe de confidentialité est inclus par défaut dans le droit de travail :
« le contrat de travail est exécuté de bonne foi (article L1222–1 du Code du travail) »
ce qui implique notamment la loyauté, la non-concurrence ou la confidentialité ; - le stagiaire n’est pas complètement soumis au code du travail mais le principe de confidentialité reste présent dans la logique du stage et est communément explicité par une clause de non divulgation qui peut être ajoutée au contrat de travail ou à la convention de stage.
Donc, la confidentialité est une règle qui s’applique légitimement par défaut.
Argument 1 : Le rapport de l’étudiant est un élément de son CV, s’il est confidentiel, il ne pourra pas le produire.
Si un rapport est confidentiel, alors il ne pourra pas être produit pour faire valoir le travail réalisé, lors de la recherche d’un stage ultérieur ou lors de la recherche d’un emploi.
- Un mémoire de stage est un travail personnel significatif pour le stagiaire qui mérite de figurer au rang des choses dont il peut être fier et qu’il peut montrer. C’est le déposséder de quelque chose d’important que de lui interdire de produire le résultat de son travail.
- À défaut, c’est minorer l’importance de ce travail de restitution, ce qui peut conduire à des rapports sans intérêt, puisqu’en fin de compte personne ne les lira (à part peut-être à des fins d’évaluation, une fois, peut-être distraitement).
Proposition 1 : faire un rapport court et public
Je propose d’écrire un rapport synthétique et de bonne facture, non confidentiel et éventuellement de lui annexer un document confidentiel (qu’il n’est pas nécessaire de diffuser hors de l’entreprise).
On aura d’emblée l’ambition que ce rapport soit public, destiné à être diffusé sur le Web typiquement.
Le stagiaire cherchera à faire valoir les actions qu’il a pu mener sans divulguer d’information sensible. On peut pour cela procéder à de l’anonymisation, ou encore à la troncature d’information, sans nuire à la bonne compréhension du propos général. C’est en soi un bon exercice. La stagiaire pourra bien entendu mentionner en préambule qu’il a rédigé son rapport sous cette contrainte (un exemple d’approche : librecours.net/module/ing/rap).
Cette proposition a également le mérite de simplifier la gestion de la confidentialité et d’éviter les entre-deux inconfortables où personne ne sait exactement ce qu’il peut faire et laisser faire :
- un rapport public accessible à tous tout le temps,
- un rapport privé accessible à l’entreprise uniquement.
Argument 2 : La soutenance est un moment de mise en commun, cela ne peut pas fonctionner si tout le monde ne joue pas le jeu.
La soutenance est un moment d’échange entre étudiants, enseignants et entreprises. Les sessions sont organisées de telle façon que chacun profite des expériences des autres. Lorsque quelqu’un demande une soutenance confidentielle, il exclut de fait les autres de ce partage, c’est donc un appauvrissement de cette phase de restitution de stage. Si tout le monde procède ainsi, l’exercice perd tout intérêt, c’est en quelque sort un cas de dilemme du prisonnier6 : si personne ne se fait confiance, alors tout le monde perd.
Pour que la situation reste équitable, les soutenances confidentielles doivent se dérouler à part, en dehors de l’espace commun partagé par les autres. Ainsi ceux qui refusent de partager leur expérience se privent de la possibilité de profiter de l’expérience des autres.
C’est donc une dégradation de la situation d’apprentissage pour le stagiaire.
Proposition 2 : sélectionner ce qui est présenté en excluant ce qui est confidentiel
Je propose une soutenance non confidentielle sans information sensible. Il est possible qu’une soutenance ne porte pas sur l’ensemble du stage, c’est même souvent le cas, on peut donc se focaliser sur quelques-unes des tâches les moins sensibles et les exposer avec soin.
Le but d’une soutenance n’est pas de rendre compte dans le détail de tout ce qui a été fait, le temps ne le permettrait pas, mais de donner à voir une partie de ce que l’on a appris, ce que l’on sait faire, et, peut être en premier lieu : de communiquer des choses intéressantes au public.

Une bonne soutenance est pour moi une soutenance à l’issue de laquelle on a appris des choses que l’on ignorait grâce à la clarté de l’exposé du stagiaire.
Cela n’implique pas de révéler des secrets spécifiques, mais au contraire d’avoir été capable de monter en généralité pour présenter en dehors du contexte les compétences et connaissances acquises. C’est ce qui fait leur valeur pour le stagiaire et ses futurs collaborateurs.
Conclusion : un argument personnel complémentaire
Accepter un travail d’encadrement de stage correspond à la perspective d’instaurer un échange. On consacre un peu de temps, on fait éventuellement bénéficier un peu de son expérience lorsque c’est utile, et en échange on apprend des choses que l’on peut réinvestir dans sa propre pratique professionnelle.
Le métier d’un enseignant-chercheur consistant à publier de la connaissance au service de tous, les informations confidentielles lui sont mal utiles. Donc le bilan est négatif : on ne gagne rien et on perd un peu de ce temps si précieux pour tous.
Je refuse a priori tout engagement dans le suivi de stages comprenant des rapports ou soutenances confidentielles.
La dégooglisation de l’éditeur
Il y a quelques mois, avant que la covid19 ne vienne chambouler notre quotidien, Angie faisait le constat que nous n’avions finalement que très peu documenté sur ce blog les démarches de passage à des outils libres réalisées au sein des organisations. Celles-ci sont pourtant nombreuses à s’être questionnées et à avoir entamé une « degooglisation ». Il nous a semblé pertinent de les interviewer pour comprendre pourquoi et comment elles se sont lancées dans cette aventure. Ce retour d’expérience est, pour Framasoft, l’occasion de prouver que c’est possible, sans ignorer les difficultés et les freins rencontrés, les écueils et erreurs à ne pas reproduire, etc. Peut-être ces quelques témoignages parviendront-ils à vous convaincre de passer au libre au sein de votre structure et à la libérer des outils des géants du Web ?
La maison d’édition Pourpenser a attiré notre attention sur Mastodon avec ses prises de position libristes. En discutant un peu nous avons compris qu’elle a joint le geste à la parole en faisant évoluer ses outils informatiques. Ça n’est pas si fréquent, une entreprise qui se dégooglise. Nous lui avons demandé un retour d’expérience.
N’hésitez pas à consulter les autres articles de cette série consacrée à l’autonomisation numérique des organisations.
Bonjour, peux-tu te présenter brièvement ? Qui es-tu ? Quel est ton parcours ?
Albert, co-fondateur des éditions Pourpenser avec ma sœur Aline en 2002.
Petit je voulais être garde forestier ou cuisinier… autant dire que j’ai raté ma vocation 🙂 (même si j’adore toujours cuisiner).
En 1987 j’avais un voisin de palier qui travaillait chez Oracle. Après les cours je passais du temps sur un ordinateur qu’il me mettait à disposition : j’ai donc commencé avec un ordi sur MS-DOS et des tables SQL.
1987, c’était aussi le tout début de la PAO. Il y avait un logiciel dont j’ai perdu le nom dans lequel je mettais le texte en forme avec des balises du genre <A>ça fait du gras</A>, je trouvais ça beaucoup plus intéressant que PageMaker et lorsque j’ai découvert Ventura Publisher qui mariait les deux mondes, j’ai été conquis.

Par la suite j’ai travaillé une dizaine d’années dans la localisation de jeux vidéo et de CD-ROM : nous traduisions le contenu et le ré-intégrions dans le code. Ma première connexion à internet remonte à 1994 avec FranceNet, j’avais 25 ans. Je découvrais ce monde avec de grands yeux en m’intéressant au logiciel libre, à la gouvernance d’internet (je me rappelle notamment de l’ISOC et des rencontres d’Autrans) et ça bousculait pas mal de schémas que je pouvais avoir.
2000 : naissance de ma fille aînée, je quitte Paris, je prends un grand break : envie de donner plus de sens à ma vie.
2002 : naissance de mon fils et création de la maison d’édition avec ma sœur.
Tu nous parles de ton entreprise ?
Dans sa forme, Pourpenser est une SARL classique. Régulièrement, nous nous posons la question de revoir les statuts mais ça demande du temps et de l’argent que nous préférons mettre ailleurs. Finalement, le mode SARL est plutôt souple et dans les faits, nous avons une organisation très… anarchique. Même si avec Aline nous sentons bien qu’en tant que fondateurs notre voix compte un peu plus, l’organisation est très horizontale et les projets partent souvent dans tous les sens.

Que fait-elle ?
Dès le départ, nous avons eu à cœur de proposer des livres « avec du sens ». Aborder des questions existentielles, des questions de sociétés ou autour de notre relation au vivant. La notion d’empreinte nous interpelle régulièrement. Ne pas laisser d’empreinte est compliqué. Mais peut-être pouvons-nous choisir de laisser une empreinte aussi légère qu’utile ? La cohérence entre le contenu des livres que nous éditons et la manière dont nous produisons et amenons ces livres aux lecteurs et lectrices a toujours été centrale… même si rester cohérent est loin d’être toujours simple.
Nous aimons dire que notre métier n’est pas de faire des livres mais de transmettre du questionnement. Ceci dit, depuis 2002, nous avons édité environ 120 titres et une soixantaines d’auteur·e·s. Nous aimons éditer des contes, des romans, des BD, des jeux, des contes musicaux qui vont amener à une discussion, à une réflexion. Mais qui sait si un jour nous n’irons pas vers du spectacle vivant, de la chanson…
![]()
Combien êtes-vous ?
Normalement, nous sommes 8 personnes à travailler quasi-quotidiennement sur le catalogue de la maison et cela fait l’équivalent d’environ 5 temps plein, mais avec la crise actuelle nous avons nettement plus de temps libre… À côté de ça, nous accompagnons une soixantaine d’auteur·e·s, travaillons avec une centaine de points de vente en direct et avons quelques dizaines de milliers de contacts lecteurs.
Est-ce que tout le monde travaille au même endroit ?
L’équipe de huit est principalement située dans l’ouest, et l’une de nous est du côté de Troyes. Nous nous réunissons environ deux fois par an et utilisons donc beaucoup le réseau pour échanger. Le confinement de mars n’a fondamentalement rien changé à notre façon de travailler en interne. Par contre, les salons et les festivals ou nous aimons présenter les livres de la maison nous manquent et le fait que les librairies fonctionnent au ralenti ne nous aide pas.

Tu dirais que les membres de l’organisation sont plutôt à l’aise avec le numérique ? Pas du tout ? Ça dépend ? Kamoulox ?
Globalement, la culture « utilisateur du numérique » est bien présente dans toute l’équipe. Mais je dirais que nous sommes surtout deux : Dominique et moi, que la question de « jouer avec » amuse. Pour le reste de l’équipe, il faut que ça fonctionne et soit efficace sans prise de tête.
Avant de lancer cette démarche, vous utilisiez quels outils / services numériques ?
Lors de la création en 2002, j’ai mis en place un site que j’avais développé depuis un ensemble de scripts PHP liés à une base MySQL. Pour la gestion interne et la facturation, j’utilisais Filemaker (lorsque je ne suis pas sur Linux, je suis sur MacOS), et au fur et à mesure de l’arrivée des outils de Google (gmail, partage de documents…) nous les avons adoptés : c’était tellement puissant et pratique pour une mini structure éclatée comme la nôtre.
Par la suite, nous avons remplacé Filemaker par une solution ERP-CRM qui était proposée en version communautaire et que j’hébergeais chez OVH (LundiMatin – LMB) et le site internet a été séparé en 2 : un site B2C avec Emajine une solution locale mais sous licence propriétaire (l’éditeur Medialibs est basé à Nantes) et un site B2B sous Prestashop.

Pour les réseaux sociaux : Facebook, Instagram Twitter, Youtube.
En interne, tout ce qui est documents de travail léger passaient par Google Drive, Hubic (solution cloud de chez OVH) et les documents plus lourds (illustrations, livres mis en page) par du transfert de fichiers (FTP ou Wetransfer).
Qu’est-ce qui posait problème ?
La version communautaire de LMB n’a jamais vraiment décollé et au bout de 3 ans nous avons été contraints de migrer vers la solution SaS, et là, nous avons vraiment eu l’impression de nous retrouver enfermés. Impossible d’avoir accès à nos tables SQL, impossible de modifier l’interface. À côté de ça une difficulté grandissante à utiliser les outils de Google pour des raisons éthiques (alors que je les portais aux nues au début des années 2000…)
Vous avez entamé une démarche en interne pour migrer vers des outils numériques plus éthiques. Qu’est-ce qui est à l’origine de cette démarche ?
La démarche est en cours et bien avancée.
J’ai croisé l’existence de Framasoft au début des années 2000 et lorsque l’association a proposé des outils comme les Framapad, framacalc et toutes les framachoses ; j’en ai profité pour diffuser ces outils plutôt que ceux de Google auprès des associations avec lesquelles j’étais en contact. Mes activités associatives m’ont ainsi permis de tester petit à petit les outils avant de les utiliser au niveau de l’entreprise.

Des outils (LMB, Médialibs) propriétaires avec de grandes difficultés et/ou coûts pour disposer de fonctionnalités propre à notre métier d’éditeur. Des facturations pour utilisation des systèmes existants plutôt que pour du développement. Un sentiment d’impuissance pour répondre à nos besoins numériques et d’une non écoute de nos problématiques : c’est à nous de nous adapter aux solutions proposées… Aucune liberté.
« un besoin de cohérence »
Quelle était votre motivation ?
La motivation principale est vraiment liée à un besoin de cohérence.
Nous imprimons localement sur des papiers labellisés, nous calculons les droits d’auteurs sur les quantités imprimées, nos envois sont préparés par une entreprise adaptée, nous avons quitté Amazon dès 2013 (après seulement 1 an d’essai)…
À titre personnel j’ai quitté Gmail en 2014 et j’avais écrit un billet sur mon blog à ce sujet. Mais ensuite, passer du perso à l’entreprise, c’était plus compliqué, plus lent aussi.
Par ailleurs nous devions faire évoluer nos systèmes d’information et remettre tout à plat.
…et vos objectifs ?
Il y a clairement plusieurs objectifs dans cette démarche.
- Une démarche militante : montrer qu’il est possible de faire autrement.
- Le souhait de mieux maîtriser les données de l’entreprise et de nos clients.
- Le besoin d’avoir des outils qui répondent au mieux à nos besoins et que nous pouvons faire évoluer.
- Quitte à développer quelque chose pour nous autant que cela serve à d’autres.
- Les fonds d’aides publiques retournent au public sous forme de licence libre.
- Création d’un réseau d’acteurs et actrices culturelles autour de la question du numérique libre.
Quel lien avec les valeurs de votre maison d’édition ?
Les concepts de liberté et de responsabilité sont régulièrement présents dans les livres que nous éditons. Réussir à gagner petit à petit en cohérence est un vrai plaisir.
Partage et permaculture… Ce que je fais sert à autre chose que mon besoin propre…
Qui a travaillé sur cette démarche ?
Aujourd’hui ce sont surtout Dominique et moi-même qui travaillons sur les tests et la mise en place des outils.
Des entreprises associées : Symétrie sur Lyon, B2CK en Belgique , Dominique Chabort au début sur la question de l’hébergement.
Un des problèmes aujourd’hui est clairement le temps insuffisant que nous parvenons à y consacrer.
Aujourd’hui, la place du SI est pour nous primordiale pour prendre soin comme nous le souhaitons de nos contacts, lecteurs, pour diffuser notre catalogue et faire notre métier.
Vous avez les compétences pour faire ça dans l’entreprise ?
Il est clair que nous avons plus que des compétences basiques. Elles sont essentiellement liées à nos parcours et à notre curiosité : si Dominique a une expérience de dev et chef de projet que je n’ai pas, depuis 1987 j’ai eu le temps de comprendre les fonctionnements, faire un peu de code, et d’assemblages de briques 😉
Combien de temps ça vous a pris ?
Je dirais que la démarche est réellement entamée depuis 2 ans (le jour ou j’ai hébergé sauvagement un serveur NextCloud sur un hébergement mutualisé chez OVH). Et aujourd’hui il nous faudrait un équivalent mi-temps pour rester dans les délais que nous souhaitons.
Ça vous a coûté de l’argent ?
Aujourd’hui ça nous coûte plus car les systèmes sont un peu en parallèle et que nous sommes passés de Google « qui ne coûte rien » à l’hébergement sur un VPS pour 400 € l’année environ. Mais en fait ce n’est pas un coût, c’est réellement un investissement.
Nous ne pensons pas que nos systèmes nous coûteront moins chers qu’actuellement. Mais nous estimons que pour la moitié du budget, chaque année, les coûts seront en réalité des investissements.
Les coûts ne seront plus pour l’utilisation des logiciels, mais pour les développements. Ainsi nous pensons maîtriser les évolutions, pour qu’ils aillent dans notre sens, avec une grande pérennité.
Quelles étapes avez-vous suivi lors de cette démarche de dégooglisation ?
Ah… la méthodologie 🙂
Elle est totalement diffuse et varie au fil de l’eau.
Clairement, je n’ai AUCUNE méthode (c’est même très gênant par moment). Je dirais que je teste, je regarde si ça marche ou pas, et si ça marche moyen, je teste autre chose. Heureusement que Dominique me recadre un peu par moment.
Beaucoup d’échanges et de controverse. Surtout que le choix que nous faisons fait reposer la responsabilité sur nous si nous ni parvenons pas. Nous ne pouvons plus nous reposer sur « c’est le système qui ne fonctionne pas », « nous sommes bloqué·e·s par l’entreprise ». C’est ce choix qui est difficile à faire.
La démarche c’est les rencontres, les échanges, les témoignages d’expériences des uns et des autres…
Et puis surtout : qu’avons nous envie de faire, réellement…
Dans un premier cas, est-ce que cela me parle, me met en joie d’avoir un jolie SI tout neuf ? Ou cela nous aiderait au quotidien, mais aucune énergie de plus.
Dans l’option que nous prenons, l’idée de faire pour que cela aide aussi les autres éditeurs, que ce que nous créons participe à une construction globale est très réjouissant…
La stratégie est là : joie et partage.

Au début ?
Un peu perdu, peur de la complexité, comment trouver les partenaires qui ont la même philosophie que nous…
Mais finalement le monde libre n’est pas si grand, et les contacts se font bien.
Ensuite ?
Trouver les financements, et se lancer.
Et à ce jour, où en êtes-vous ?
À ce jour nous avons totalement remplacé les GoogleDrive, Hubic et Wetransfer par Nextcloud ; remplacé également GoogleHangout par Talk sur Nextcloud.
Facebook, Instagram et Twitter sont toujours là… Mais nous avons un compte sur Mastodon !
Youtube est toujours là… Mais le serveur Peertube est en cours de création et Funkwhale pour l’audio également.
Concernant l’administration de ces outils, je suis devenu un grand fan de Yunohost : une solution qui permet l’auto-hébergement de façon assez simple et avec communauté très dynamique.
Notre plus gros projet est dans le co-développement d’un ERP open source : Oplibris
Ce projet est né en 2018 après une étude du Coll.LIBRIS (l’association des éditeurs en Pays de la Loire) auprès d’une centaine d’éditeurs de livres. Nous avons constaté qu’il n’existait à ce jour aucune solution plébiscité par les éditeurs indépendants qui ont entre 10 et 1000 titres au catalogue. Nous avons rencontré un autre éditeur (Symétrie, sur Lyon) qui avait de son côté fait le même constat et commencé à utiliser Tryton. (je profite de l’occasion pour lancer un petit appel : si des dev flask et des designers ont envie de travailler ensemble sur ce projet, nous sommes preneurs !)
Migrer LMB, notre ERP actuel, vers Oplibris est vraiment notre plus gros chantier.
À partir de là, nous pourrons revoir nos sites internet qui viendront se nourrir dans ses bases et le nourrir en retour.
Combien de temps entre la décision et le début des actions ?
Entre la décision et le début des actions : environ 15 secondes. Par contre, entre le début des actions et les premières mise en place utilisateur environ 6 mois. Ceci dit, de nombreuses graines plantées depuis des années ne demandaient qu’à germer.
« Nous mettons de grosses contraintes éthiques »
Avant de migrer, avez-vous testé plusieurs outils au préalable ?
J’ai l’impression d’être toujours en test. Par exemple, Talk/Discussion sur Nextcloud ne répond qu’imparfaitement à notre besoin. Je préférerais Mattermost, mais le fait que Talk/Discussion soit inclus dans Nextcloud est un point important côté utilisateurs.
Nous mettons de grosses contraintes éthiques, de ce fait les choix se réduisent d’eux-mêmes, il ne reste plus beaucoup de solutions. Lorsqu’on en trouve une qui nous correspond c’est déjà énorme !
Avez-vous organisé un accompagnement des utilisateur⋅ices ?
L’équipe est assez réduite et plutôt que de prévoir de la documentation avec des captures écran ou de la vidéo, je préfère prendre du temps au téléphone ou en visio.
Prévoyez-vous des actions plus élaborées ?
Nous n’en sommes pas à ce stade, probablement que si le projet se développe et est apprécié par d’autres, des formations entre nous seront nécessaires.
Quels ont été les retours ?
Il y a régulièrement des remarques du genre : « Ah mais pourquoi je ne peux plus faire ça » et il faut expliquer qu’il faut faire différemment. Compliqué le changement des habitudes, ceci dit l’équipe est bien consciente de l’intérêt de la démarche.
Comment est constituée « l’équipe projet » ?
Dominique, B2CK, Symétrie.
Quelles difficultés avez-vous rencontrées ?
La difficulté majeure est de trouver le bon équilibre entre la cohérence des outils et l’efficacité nécessaire dans le cadre d’une entreprise.
Le frein majeur côté utilisateurs est de faire migrer les personnes qui utilisent encore Gmail pour le traitement de leur courriel. L’interface est si pratique et la recherche tellement puissante et rapide qu’il est compliqué de le quitter.
Une autre difficulté est d’ordre comptable et financier : comment contribuer financièrement à ce monde du logiciel libre ? Comment donner ? A quelles structures ? (aujourd’hui nos financements vont principalement au développement de Tryton).
Et l’avenir ? Envisagez-vous de continuer cette démarche pour l’appliquer à d’autres aspects de votre organisation ?
Côté création, j’aimerais beaucoup que nous puissions utiliser des outils libres tels que Scribus, Inkscape, Krita ou GIMP plutôt que la suite Adobe. Mais aujourd’hui ces outils ne sont pas adoptés par l’équipe de création car trop compliqués d’utilisation et pas nativement adaptés à l’impression en CMJN. Une alternative serait d’utiliser la suite Affinity (mais qui n’est pas open source…)

Quels conseils donneriez-vous à d’autres organisations qui se lanceraient dans la même démarche ?
Y prendre du plaisir ! Mine de rien, la démarche demande du temps et de l’attention. Il faut confier ça à des personnes qui prennent ça comme un jeu. Oubliez la notion de temps et de délais, optez pour les valeurs qui soient plus la finalité et le plaisir. Au pied de la montagne entre prendre le téléphérique ou le chemin à pied ce n’est pas le même projet, vous n’avez pas besoin des même moyens.
Le mot de la fin, pour donner envie de migrer vers les outils libres ?
Sommes-nous les outils que nous utilisons ? Libres ?
Quitter les réseaux sociaux centralisés est extrêmement complexe. Je manque encore de visibilité à ce sujet et ça risque d’être encore très long. J’ai proposé à l’équipe une migration totale sans clore les comptes mais avec un mot régulièrement posté pour dire « rejoignez-nous ici plutôt que là ». Mon rêve serait d’embarquer au moins une centaine d’entreprises dans une telle démarche pour tous faire sécession le même jour. Des volontaires ? 🙂
Aller plus loin
- Fair-play, Albert ne nous l’a jamais demandé, il sait qu’on est
un peuallergique à la pub, mais on vous donne quand même le lien vers le site des Éditions Pourpenser
Crédits
- Illustrations réalisées par Albert sur Gégé à partir de dessins de Gee
- Photo de l’équipe avec des illustrations d’Aline de Pétigny et Laura Edon
- Logo de pourpenser mis en couleurs par Galou
« I don’t want any spam ! »
Traduction : « Je ne veux pas de spam ! »
Le spam est un problème qu’à Framasoft, nous connaissons bien. Mais savez-vous à quel point ?
Je vais, dans cet article, vous dresser le tableau des soucis de spam que nous rencontrons et des contre-mesures que nous avons mises en place.
Avant cela, un peu d’histoire…
Qu’est-ce que le spam ?
Avant l’ère d’Internet, le spam n’était qu’une marque de viande en conserve.
Les Monty Python, humoristes anglais à qui l’on doit notamment les hilarants Sacré Graal ! et La vie de Brian, ont réalisé un sketch (version textuelle) dans lequel un couple, dans un restaurant, demande ce qu’il y a à la carte pour le petit déjeuner et où la serveuse ne propose que des plats avec du spam (et pas qu’un peu : « Spam, spam, spam, spam, spam, spam, baked beans, spam, spam, spam and spam. »). La femme du couple ne peut avoir de petit déjeuner sans spam, la serveuse ne lui proposant qu’encore plus de spam… (le titre de cet article est une citation de la femme du couple).

De ce sketch découle l’utilisation du terme spam pour les courriels indésirables (et tout autre message indésirable, quelle que soit la plateforme comme nous allons le voir).
De nos jours, le spam représente 50% des courriels échangés sur la planète.
Que serait une marque sans #CopyrightMadness ? Hormel Foods, l’entreprise derrière le spam a tenté d’utiliser le droit des marques pour éviter que le nom de son produit soit utilisé pour quelque chose dont personne ne veut et pour essayer d’empêcher d’autres entreprises d’utiliser le terme (comme des éditeurs de solutions anti-spam). Je croyais qu’Hormel Foods avait cessé cette lutte inutile, mais il semblerait que non, allant jusqu’à embêter Gee pour un dessin qu’il proposait sur RedBubble.
Le spam dans les courriels
Chez Framasoft, nous sommes aux deux bouts de la chaîne : nous envoyons beaucoup de courriels (dans les 15 000 courriels par jour pour nos services – inscriptions, notifications, etc. – et plus de 200 000 courriels par jour pour Framalistes) et nous en recevons aussi, que ce soit au niveau de notre serveur de courriel interne ou sur Framalistes. Il y a aussi quelques autres services qui permettent d’interagir par courriel comme notre forum, Framavox et Framagit.

Nous devons donc nous assurer, d’un côté, de ne pas passer pour des spammeur·euses et de l’autre, de nous en protéger.
Se protéger des spams par courriel
Rien de bien fantastique à ce niveau. Nous utilisons l’antispam Rspamd qui vérifie la validité du courriel par rapport à sa signature DKIM, à l’enregistrement SPF et à la politique DMARC du domaine (voir sur NextINpact pour un bon article sur le sujet). Bien entendu, cela ne vaut que si le domaine en question met en place ces mécanismes… On notera que la plupart des FAI français, s’ils vérifient bien les courriels entrants de la même façon que nous, se tamponnent allègrement le coquillard de mettre en place ces mécanismes pour leurs propres courriels. J’aimerais qu’un jour, ceux-ci arrêtent de faire de la merde 🙄 (remarquez, il semblerait que ça avance… très lentement, mais ça avance).
En plus de ces vérifications, Rspamd effectue aussi une vérification par filtrage bayésien, interroge des listes de blocage (RBL) et utilise un mécanisme de liste grise.

Il y a toujours, bien évidemment des trous dans la raquette, mais le ratio spam intercepté/spam non détecté est assez haut et nous alimentons Rspamd avec les messages indésirables qui sont passés sous le radar.
Sur Framalistes, afin de ne pas risquer de supprimer de messages légitimes, nous avons forcé le passage des spams probables en modération : tout message considéré comme spam par Rspamd doit être approuvé (ou rejeté) par les modérateur·ices ou propriétaires de la liste.
Nous avons créé un scénario
spam_status.x-spam-status dans Sympa :
title.gettext test x-spam-status header
match([header->Subject][-1],/\*\*\*\*\*SPAM\*\*\*\*\*/) smtp,dkim,smime,md5 -> unsure
true() smtp,dkim,md5,smime -> hamEt nous avons ajouté cette ligne à tous les scenarii de type send :
match ([msg->spam_status], /unsure/) smtp,dkim,md5,smime -> editorkeyLe texte *****SPAM***** est ajouté au sujet du mail par Rspamd en cas de suspicion de spam. Si Rspamd est vraiment catégorique, le mail est directement rejeté.

Ne pas être considéré comme spammeur·euses
Là, c’est plus difficile. En effet, malgré notre respect de toutes les bonnes pratiques citées ci-dessus et d’autres (SPF, DKIM, DMARC…), nous restons à la merci de règles absurdes et non publiques mises en place par les autres services de courriel.
Vous mettez en place un nouveau serveur qui va envoyer des courriels ? Bon courage pour que les serveurs de Microsoft (hotmail.com, outlook.com…) l’acceptent. J’ai encore vécu ça il y a quelques mois et je ne sais toujours pas comment ça s’est débloqué (j’ai envoyé des courriels à des adresses chez eux que j’ai créées pour ça et je reclassais les courriels dans la catégorie « légitime », ça ne fonctionnait toujours pas mais quelques semaines plus tard, ça passait).

Votre serveur envoie beaucoup de courriels à Orange ? Pensez à limiter le nombre de courriels envoyés en même temps. Mais aussi à mettre en place un cache des connexions avec leurs serveurs. Eh oui : pas plus de X mails envoyés en même temps, mais pas plus de Y connexions par heure. Ou par minute. Ou par jour. C’est ça le problème : on n’en sait rien, on ne peut que poser la question à d’autres administrateurs de services de mail (pour cela, la liste de diffusion smtp-fr gagne à être connue. Le groupe des adminSys français, FRsAG est aussi à garder en tête).
Un autre problème est que nous ne sommes pas à l’origine du contenu de tous les courriels qui sortent de nos serveurs.
Par exemple, un spam arrivant sur une framaliste, s’il n’est pas détecté, sera envoyé à tou·tes les abonné·es de la liste, et ça peut vite faire du volume.
Les spams peuvent aussi passer de medium en medium : Framapiaf peut vous notifier par courriel d’une mention de votre identifiant dans un pouet (Ex. « Coucou @luc »). Si le pouet est un spam (« Coucou @luc, tu veux acheter une pierre magique contre les ondes 5G des reptiliens franc-maçons islamo-gauchistes partouzeurs de droite ? »), le spam se retrouve dans un courriel qui part de chez nous.

Certes, les courriels partant de chez nous sont aussi analysés par Rspamd et certains sont bloqués avant envoi, mais ce n’est pas efficace à 100 %.
Il y a aussi les faux positifs : que faire si nos courriels sont incorrectement classés comme spam par leurs destinataires ? Comme quelqu’un abonné sur une framaliste sans en être averti et qui d’un coup se retrouve submergé de courriels venant d’un expéditeur inconnu ?
Nous nous sommes inscrits à une boucle de rétroaction : nous recevons des notifications pour chaque courriel classé comme indésirable par un certain nombre de fournisseurs de messagerie.
Cela nous a permis (et nous permet toujours. Quotidiennement.) d’envoyer un message à de nombreuses personnes au courriel @laposte.net abonnées à des framalistes pour leur demander de ne pas nous mettre en indésirable, mais de se désabonner de la liste (en leur indiquant la marche à suivre) si elles ne souhaitent pas en recevoir les messages.
Au niveau de Framalistes, nous vérifions que les comptes possédant plus qu’un certain nombre de listes, et que les listes avec beaucoup d’abonné⋅es ne soient pas utilisées pour envoyer des messages indésirables. En effet, nous avons déjà souffert de quelques vagues de spam, nous obligeant à l’époque à modérer la création de listes en dehors des heures de travail car nous ne souhaitions pas, le matin, nous rendre compte que le service était tombé ou s’était fait bloquer pendant la nuit : l’envoi massif de courriels comme le faisaient les spammeur·euses rencontrait souvent un goulot d’étranglement au niveau du serveur, incapable de gérer autant de courriels d’un coup, ce qui faisait tomber le service.
Cette modération n’est plus active aujourd’hui, mais nous avons toujours cet outil prêt à être utilisé en cas de besoin.
Framalistes, si vous l’utilisez, a besoin de vous pour lutter contre le spam !
Petit rappel : il y a un lien de désinscription en bas de chaque courriel des framalistes. Utilisez ce lien pour vous désinscrire si vous ne souhaitez plus recevoir les messages de la liste.
Rien de plus simple que de déclarer un courriel comme étant du spam, n’est-ce pas ? Un clic dans son client mail et hop !
Eh bien non, pas pour Framalistes.
En effet, en faisant cela, vous déclarez notre serveur comme émettant du spam et non pas le serveur originel : nous risquons d’être complètement bannis et de ne plus pouvoir envoyer de courriels vers votre service de messagerie. De plus, l’apprentissage du spam (si le service de messagerie que vous utilisez fait bien son travail, les messages déclarés manuellement comme étant du spam passent dans une moulinette pour mettre à jour les règles de filtrage anti-spam) ne se fait que sur votre service de messagerie, pas chez nous.

Si votre liste reçoit des spams, merci de le signaler à nom_de_la_liste-request@framalistes.org (l’adresse pour contacter les propriétaires de votre liste) : les propriétaires de la liste ont la possibilité, sur https://framalistes.org/sympa/arc/nom_de_la_liste, de supprimer un message des archives et de le signaler comme spam non détecté (n’hésitez pas à leur indiquer ce lien).
Le spam sur Framapiaf et Framasphère
Point d’antispam comme Rspamd possible sur Mastodon ou diaspora* (techniquement, il pourrait y avoir moyen de faire quelque chose, mais ça serait très compliqué).
Les serveurs Mastodon (pas que framapiaf.org, celui de Framasoft) font régulièrement l’objet de vagues d’inscription de spammeur·euses. Pour éviter l’épuisement de notre équipe de modération, nous avons décidé de modérer les inscriptions et donc d’accepter les comptes un à un.
Nous nous reposons sur les signalements des utilisateur·ices pour repérer les comptes de spam que nous aurions laissé passer et les supprimer (ce qui est très rare) ou les bloquer s’ils proviennent d’autres serveurs avec lesquels nous sommes fédérés.
Framasphère ne dispose pas, contrairement à Framapiaf de tels outils de modération : pas d’inscriptions modérées, pas de blocage de comptes distants… Nous ne pouvons que nous reposer sur les signalements et bloquer les comptes locaux.
Nous arrivons tout de même à bloquer les comptes distants, mais cela nécessite de modifier un enregistrement directement en base de données.
Voici comment nous bloquons les comptes distants sur Framasphère :
UPDATE people SET serialized_public_key = 'banned' WHERE guid = 'le_guid_du_compte';Le spam sur Framaforms
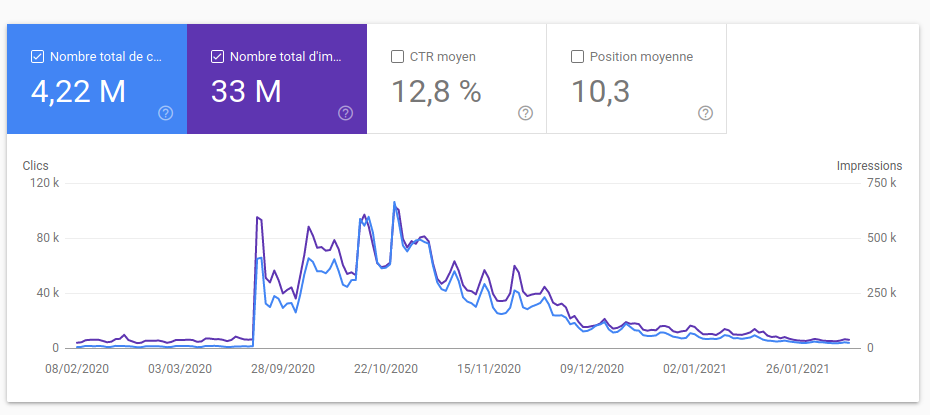
Framaforms a rapidement été victime de son succès : sa fréquentation a presque triplé entre 2019 et 2020 (et l’année n’est pas terminée !), devenant aujourd’hui le service le plus utilisé de notre réseau !
Nous n’avons donc pas remarqué la création de nombreux, trop nombreux formulaires proposant, par exemple, des liens vers des sites de téléchargement illégal de films. C’est d’ailleurs suite à une réclamation d’un ayant droit que nous avons pris conscience du problème (oui, nous avons fait suite à cette réclamation : quoi que nous pensions du droit d’auteur, nous nous devons de respecter la loi).
La lutte contre le spam a occupé une bonne partie du temps de Théo qui a temporairement rejoint notre équipe salariée pour prêter main forte sur Framaforms :
- détection de certains termes dans les formulaires avec mise en quarantaine (dépublication) en cas de suspicion de spam ;
- quarantaine des formulaires ne contenant aucune question (juste la description, quoi) ;
- interdiction de certains termes dans le titre des formulaires ;
- intégration d’Akismet (un service anti-spam en ligne, proposé par Automattic, la société derrière https://wordpress.com/, contributrice à WordPress) ;
- amélioration du système de CAPTCHA
- ajout de vues permettant une gestion plus aisée des formulaires par les administrateur·ices.
Les efforts de Theo ont porté leurs fruits : la détection automatique des spams et leur dépublication tout aussi automatique limitent la pollution présente sur Framaforms (ce qui évite les réclamations, donc de monopoliser l’attention d’un salarié pour y répondre) et l’interface de gestion des spams facilite grandement le travail des administrateur·ices.

Le spam sur Framagit
Nous avons beaucoup d’utilisateur⋅ices sur Framagit : nous avons dépassé les 90 000 inscrit⋅es. Mais pour notre malheur, la grande majorité d’entre elleux est constituée de comptes de spam !
Après des mois de ménage, nous sommes redescendus à un peu moins de 34 000 comptes, mais nous ne sommes pas dupes : il y a encore beaucoup de comptes illégitimes.
À noter cependant : ces comptes de spam ne semblent pas être dommageables pour les utilisateur⋅ices de Framagit. En effet, leur nuisance se limite généralement à mettre des liens vers un site de poker en ligne, de rencontres voire… de plombiers à Dubaï (je ne comprends pas non plus 😅).
Ceci explique en partie pourquoi nous n’avons pas lutté très activement contre le spam sur Framagit (l’autre raison étant que nous n’avions tout simplement pas de temps à y consacrer).
Nous avions déjà eu une vague de spams lors de l’ouverture de Framagit et nous avions dû interdire l’accès de notre forge logicielle à l’Inde, à l’Indonésie et au Viêt Nam, restriction active jusqu’à la semaine dernière.
Cela n’est pas dans nos habitudes mais s’il faut choisir entre ça et le risque d’épuisement professionnel d’un membre de l’équipe, Framasoft préfère faire passer l’humain avant tout (🤗).
Une grande vague de nettoyage a eu lieu en juin, où j’ai recherché des critères communs aux comptes de spam afin de les supprimer en masse… ce qui a donné lieu à une vilaine boulette lorsque j’ai choisi des critères bien trop larges, conduisant à la suppression de nombreux comptes légitimes (rétablis depuis).
Depuis, j’ai vérifié manuellement chaque compte remonté par mes recherches… soit plus de 18 000 comptes depuis septembre. Parmi ceux-ci, il devait y en avoir, à la louche (parce que mes souvenirs me trahissent), une ou deux dizaines de comptes légitimes. Heureusement ! Je crois que j’aurais assez mal pris le fait d’avoir vérifié chaque compte pour rien 😅
Nous avons désormais un script qui supprime automatiquement les comptes qui ne se sont jamais connectés dans les 10 jours suivant leur inscription : ce sont visiblement des comptes de spam qui ne reçoivent pas les mails de confirmation et donc ne se sont jamais connectés.
Ce script nous remonte aussi les comptes dont la biographie ou les liens contiennent certains termes usités par les spammeur·euses.
Nous avons recherché une solution de CAPTCHA pour Framagit, mais celui-ci ne supporte que reCaptcha, la solution d’Alphabet/Google… et il était hors de question de faire fuiter les informations (adresse IP, caractéristiques du navigateur…) et permettre le tracking de nos utilisateurs vers les services de l’infâme bête aux multiples têtes que nous combattons !

Nous avons alors recherché quelqu’un·e qui saurait développer, contre rémunération, une solution de type honeypot.
Dans le ticket que nous avons, sans aucune honte, squatté pour poser notre petite annonce, on nous a aiguillés vers une fonctionnalité d’honeypot expérimentale et cachée de Gitlab que je me suis empressé d’activer.
Il faut bien le dire : c’est très efficace ! Le nombre de comptes automatiquement supprimés par le script évoqué plus haut est descendu de près de 100 par jour à entre 0 et 2 comptes, ce qui montre bien que les scripts des spammeur·euses pour s’inscrire ne fonctionnent plus aussi bien.
Bien évidemment, il reste encore beaucoup de spam sur Framagit, et de nombreux comptes de spam sont créés chaque jour (10 ? 15 ? 20 ? Ça dépend des jours…), mais nous ne comptons pas en rester là. Le honeypot pourrait être amélioré, ou nous pourrions voir pour une intégration d’Akismet à Gitlab (il y en a déjà une, mais elle n’est pas utilisée pour vérifier les biographies des comptes).
Gitlab permet maintenant de modérer les inscriptions en les acceptant une à une (comme nous le faisons sur Framapiaf) : nous avons récemment activé cette fonctionnalité, pour voir si la charge de modération était acceptable et si cela avait un effet bénéfique.

Framalink
Nous recevons de temps à autre (bien moins ces derniers temps, fort heureusement) des mails indiquant que Framalink est utilisé pour dissimuler des liens de hameçonnage dans des mails.
Lorsque la vague d’utilisation malveillante s’est intensifiée, j’ai développé (et amélioré au fil du temps) quelques fonctionnalités dans Lstu (le logiciel derrière Framalink) : une commande pour supprimer des raccourcis, pour rechercher les raccourcis contenant une chaîne de caractères ou provenant d’une certaine adresse IP, un système de bannissement d’adresse IP, un système de domaines interdits, empêchant le raccourcissement d’URL de tels domaines, une vérification des URL dans la base de données Google Safe Browsing (lien en anglais) avant raccourcissement et même a posteriori (je vous rassure, aucune donnée n’est envoyée à Google, la base de données est copiée et utilisée en local).
Ces efforts n’ont pas été suffisamment efficaces et nous avons été obligés de couper l’accès à l’API de Framalink, ce qui n’est pas une panacée, mais tout cela a fortement réduit nos problèmes de spam (ou pas, mais en tout cas, on a beaucoup moins de mails nous alertant de l’utilisation de Framalink pour du hameçonnage).
Notez que c’est à cause de l’utilisation de Framalink à des fins malveillantes que ce service est souvent persona non grata chez Facebook, Twitter et consorts.
Framasite
Des framasites avec de jeunes filles dénudées qui jouent au poker avec des plombiers de contrées lointaines ? Eh bien non, même pas. Les spammeurs se contentent de créer des comptes dont le nom d’utilisateur·ice est du genre « Best adult dating site, register on… ».
Et tout comme sur Framagit, beaucoup de comptes créés ne sont jamais validés (vous savez, avec l’email qui dit « cliquez sur ce lien pour finaliser votre inscription » ?).
Heureusement que ce n’est que cela, Framasite n’ayant pas d’interface d’administration permettant la suppression propre d’utilisateur·ices (« propre » voulant dire avec suppression des sites créés). Une simple suppression des comptes illégitimes en base de données suffit à faire le ménage.
Framalibre
Framalibre est aussi sujet aux spams, mais il s’agit généralement là de notices de logiciels non libres. Soit les personnes créant ces notices n’ont pas compris que Framalibre n’était dédié qu’aux logiciels libres, soit elles ont essayé d’améliorer leur référencement en ajoutant leurs logiciels.
Pour une fois, ce n’est pas bien méchant, pas bien violent (cela n’arrive pas souvent) et la vigilance de l’équipe de modération permet de supprimer (manuellement) ces notices indésirables très rapidement.
WordPress (commentaires)
Les spams dans les commentaires d’un blog sont un graaaaand classique ! Nous avons opté, sur nos sites wordpress, pour les extensions Antispam Bee et Spam Honey Pot.
C’est plutôt efficace, il est rare qu’un spam passe à travers ce système.
Drupal (inscriptions)
Nous avons quelques autres installations de Drupal autres que Framaforms et Framalibre. Les spammeurs s’inscrivent, voient qu’ils ne peuvent rien publier facilement : les Drupal en question ont les inscriptions ouvertes pour une bonne raison, mais ne permettent pas de créer des articles comme ça, hop !
Ce n’est donc, à l’heure actuelle, pas gênant.
Notre formulaire de contact
« Un formulaire de contact ? Oh chic ! » se disent les spammeurs. Là aussi, nous recevons un certain nombre de spams, tous les jours, toutes les semaines (une quarantaine par semaine), ou par une ancienne adresse de contact.
Nous nous contentons de répondre « #spam » en commentaire du ticket créé dans notre RequestTracker : cela supprime le message et empêche son expéditeur·ice de nous envoyer d’autres messages (voir sur mon wiki personnel pour commander son RequestTracker par mail).
Les faux positifs

Je n’ai pas encore parlé des faux positifs : des messages légitimes détectés à tort comme étant du spam. Cela arrive forcément, quel que soit le type de plateforme, quels que soient les moyens déployés : statistiquement, il y aura toujours, un jour, une erreur du système ou des humain·es derrière (cf la boulette évoquée dans la partie « Framagit »).
Et dans l’autre sens, on aura toujours des spams qui arriveront à passer. Il est généralement difficile voire impossible de durcir les règles de détection de spam sans augmenter la proportion de faux positifs.
Conclusion
Il n’y en pas vraiment. La lutte contre le spam est un combat sans fin, un jeu du chat et de la souris qui ne se termine jamais. On tente de se protéger du mieux qu’on peut, on trouve des astuces, ça va mieux pendant un temps et ça recommence.
Il faut pas se le cacher : plus un hébergeur « grossit », plus il prend de la renommée sur Internet, plus il y a de chances que des personnes malveillantes repèrent son service et l’utilisent pour leur spam. Il y a donc un paradoxe de l’hébergement : trop petit, on est vite seul·e et débordé·e par la multiplicité des tâches à accomplir pour faire les choses correctement…
Mais trop gros, on centralise les attentions, dont celles des personnes malveillantes qui auront peu de scrupules à parasiter les ressources que vous mettez en commun. Ce qui induit encore plus de travail pour se protéger des spams et les nettoyer.
Ça vous paraît pessimiste ? Ça l’est un peu, sans doute ¯\_(ツ)_/¯

Ce que Framasoft a fait durant le (premier) confinement
Entre mars et mai 2020, les membres de Framasoft ont mouillé la chemise pour partager des savoirs, des outils et des actions en espérant qu’elles fassent sens alors qu’une pandémie bouleversait nos repères.
Retour sur une période pas comme les autres, ainsi que sur les outils et les leçons qu’on en tire aujourd’hui.
À noter : lorsque nous avons commencé l’écriture de cette… disons « longue synthèse », nous ignorions qu’il faudrait préciser dans le titre qu’il s’agit du premier confinement.
Endiguer le flot
Nous l’avions un peu vu venir. Une semaine avant l’annonce du #RestezChezVous français, l’Italie et l’Espagne étaient déjà confinées. C’est alors que Framatalk (visioconférence) et Framapad (écriture collaborative) ont vu leurs nombres de visites multipliés par 8, et que nos serveurs ont montré des signes de surcharge. Nous avons alors compris que des familles, des écoles et des entreprises de nos voisines européennes venaient utiliser nos services pour continuer de communiquer ensemble.

Mais pas demain : demain, y’a mise à jour.
Nous avons aussi un peu pressenti qu’on allait en prendre pour notre grade lorsque le gouvernement français décida enfin un confinement qui semblait inéluctable. Et cela n’a pas manqué. Ça a pris exactement un week-end. Lorsque le PDG de la startup nation est passé de « Nous ne renoncerons à rien » à « Nous sommes en guerre ! » c’est un tsunami d’impréparation numérique qui est venu se réfugier sur nos serveurs.
Nous l’avons —sérieusement— senti passer. Pratiquant déjà le télétravail pour des activités qui se font principalement en ligne, il n’y eut aucun moment d’inactivité. Nous, les membres de Framasoft, avons trimé comme jamais pour accompagner (à notre petite échelle d’association loi 1901 financée par les dons) des centaines de milliers de confiné·es qui avaient besoin d’outils numériques pour maintenir leurs liens avec les autres.
Il est fort probable que nombre de ces actions, souvent expérimentales, parfois improvisées, soient passées inaperçues. D’où notre besoin de faire le point aujourd’hui sur le travail effectué.

Informer / éduquer / accompagner
Le mémo sur le télétravail n’est pas simplement une liste de logiciels et services libres, c’est surtout un ensemble d’astuces, de réflexes pour réhumaniser les relations lorsqu’on travaille à distance. C’est enfin le partage de plus de 10 ans d’expérience de télétravail que Pyg a eue au sein de Framasoft.
Le dossier StopCovid est un ensemble d’articles que nous avons écrits, traduits ou repris pour les publier sur le Framablog. L’objectif, double, était à la fois d’informer sur ce que peuvent impliquer les choix technologiques et sociétaux de créer une telle application ; et aussi d’alerter, en tant que passionnées du numérique, sur la toxicité du solutionnisme technologique effréné.

Plus que jamais, le Framablog s’est fait le relais d’informations et de savoirs partagés. Qu’il s’agisse de publier l’appel d’un collectif pour la continuité pédagogique, de lancer les librecours sur la culture libre, de publier un témoignage de directeur d’école primaire en temps de pandémie… Nous avons fait de notre mieux pour accompagner voire favoriser la publication de nombreux articles.
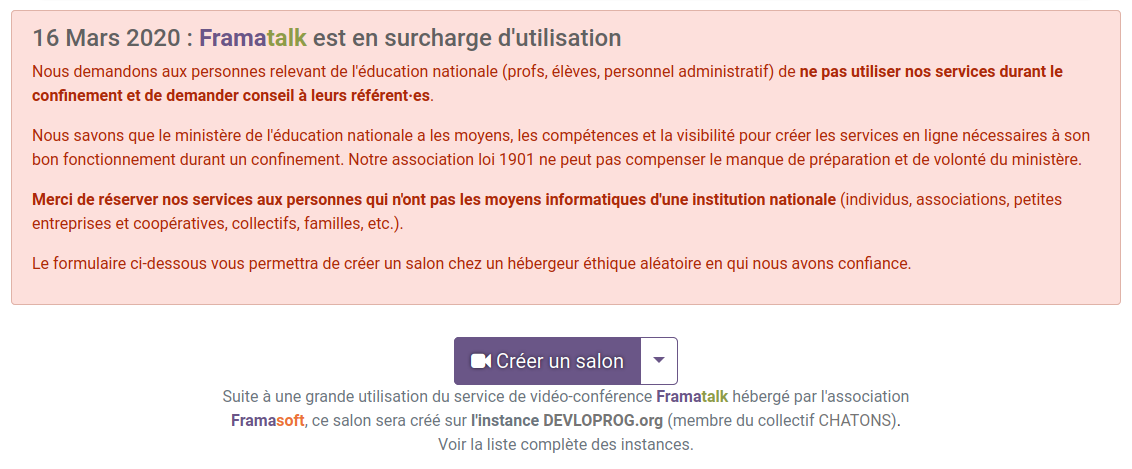
Afficher, en pages d’accueils de Framapad ou de Framatalk, notre refus d’être le « service informatique de secours » des Ministères de l’Éducation Nationale et de celui de l’Enseignement Supérieur et de la Recherche fut un réel crève-cœur. Car cela signifiait refuser nos services aux profs, au personnel encadrant et aux étudiant·es. Même si nous avons pris nos distances, Framasoft vient de l’Éducation Nationale. Et pourtant, notre petite association n’a pas à compenser l’incurie et l’impréparation numérique de ces ministères, dont dépendent des centaines de milliers d’employé·es et des millions d’élèves.
Nous remercions les profs et leurs élèves qui ont joué le jeu de la restriction volontaire pour laisser l’usage de nos services aux collectifs, familles, associations etc. qui n’ont pas les moyens de l’État à leur disposition. Nous espérons que notre refus a au moins eu l’effet d’un coup de pied dans la fourmilière pour favoriser l’émancipation numérique de nos académies par des initiatives libres et auto-hébergées telles que apps.education.fr
Tenir régulièrement les journaux de confinement de Framasoft fut un travail supplémentaire, certes, mais dont nous croyons aujourd’hui encore qu’il était essentiel. D’une part, cela nous a permis de mettre des mots sur les moments d’adrénaline comme sur les coups de fatigue ou les coups de colère. D’autre part, ces journaux montrent combien Framasoft, c’est avant tout des personnes qui œuvrent sur des outils numériques pour favoriser une société de contribution. À l’heure où nombre de personnes découvraient Framasoft par la petite lorgnette des services en ligne, nous trouvions essentiel de rappeler que derrière les machines, il y a des humain·es.
Enfin, et dans un second temps, nous avons aussi pris le soin de répondre aux médias qui sont venus nous interroger sur notre position et nos actions durant ce confinement. De Reporterre à l’Âge de Faire en passant par Le Monde et Politis, la liste est longue mais nous essayons de la tenir à jour sur cette page de notre wiki.
Maintenir /proposer
Le confinement de la France a mécaniquement induit une violente augmentation des outils numériques pour communiquer et collaborer à distance. Cependant, la ruée sur des services libres et éthiques indique qu’une grande partie du public recherche activement des alternatives aux outils prédateurs des entreprises du capitalisme de surveillance.
C’est Framatalk, notre outil de visioconférence, qui a été submergé en premier. Très vite, les Framapad (rédaction collaborative) ou un service comme Framadrop (partage de gros fichiers par un simple lien) ont aussi été pris d’assaut. Nous avons donc commencé par migrer les logiciels sur des serveurs plus puissants (que nous avions réservés la semaine précédant le confinement français), quitte à ventiler la charge d’un seul service sur plusieurs serveurs (pour Framatalk, par exemple).

En même temps, nos salariés techniciens se sont plongés dans la documentation des logiciels libres derrière ces services (Jitsi Meet pour Framatalk, Etherpad pour Framapad, etc.), afin de trouver toutes les astuces qui permettraient d’optimiser leur installation et de réduire la charge. En gros, nos techniciens ont finement ajusté de nombreux paramètres sur les ordinateurs-serveurs qui font tourner ces logiciels, pour que les processeurs travaillent moins et donc travaillent mieux.
Dès la deuxième semaine de confinement, nous avons mis en place de nouveaux services. Lorsqu’on voit qu’il y a un moyen simple de faire de l’audio-conférence avec Mumble (sans installation logicielle pour les participant·es, sauf pour qui organise la réunion), et qu’un serveur bien paramétré peut accueillir 1200 personnes en même temps, nous n’hésitons pas.
Lorsque des personnels soignants nous demandent un outil provisoire pour la prise de rendez-vous médicaux en ligne… Nous n’hésitons que le temps de nous renseigner sur l’encadrement légal (qui fut allégé provisoirement et exceptionnellement). C’est ainsi que nous avons installé l’application Rendez-vous sur un NextCloud pour leur fournir rdv-medecins.org. L’outil est passé hors ligne depuis la fin du confinement, mais il a inspiré d’autres usages (par exemple en bibliothèques).
Car même si l’on parle de (et agit pour) Déframasoftiser Internet, nous avions simplement la volonté d’être utiles là où on peut et on sait le faire. Lorsque nous installons un service, nous faisons de notre mieux pour donner un maximum d’autonomie aux personnes qui vont l’utiliser. Cela signifie un travail technique d’installation et d’administration, mais aussi une production de tutoriels, guides et astuces (ici pour les audio-conférences et là pour les prises de rendez-vous en ligne), ainsi qu’un accompagnement sur notre support (dont on reparle plus bas).

Enfin, maintenir des services (encore plus de trente à ce jour) implique d’en assurer un entretien régulier. Durant les quelques semaines de confinement, nos équipes techniques ont donc procédé à des résolutions de bug sur Framacalc, une mise à jour majeure de Framavox, et même à de gros développements sur Framaforms qui ont mené à sa première version majeure au début de l’été.
Faire jouer la contribution
Le monde du Libre, encore une fois, nous a prouvé que solidarité et organisation collective sont bien plus efficaces que la simple puissance brute. Alors que nous migrions Framapad, Framatalk et Framadrop sur des machines plus puissantes (voire sur un lot de machines pour Framatalk) tout en affinant leurs paramétrages, de nombreuxses ami·es de la communauté ont proposé de l’aide pour accueillir les besoins numériques des confiné·es.
Si seul on va plus vite, ensemble on va carrément plus loin. Mais moins vite. Il a fallu prendre le temps de rassembler les bonnes volontés et de discuter ensemble pour trouver la marche à suivre. Mais au bout de quelques jours, nous avons pu faire en sorte que la création d’un nouveau pad (ou d’un nouveau talk) sur les pages d’accueil de nos services puisse être redirigée, sans accrocs, vers l’un des serveurs des libristes se portant volontaires pour porter la charge ensemble.
La majeure partie de ces bonnes volontés qui ont mis leurs serveurs et leurs services dans le pot commun sont des membres du Collectif des Hébergeurs Alternatifs CHATONS (avec un « S » comme « Solidaires »). Leur présence et leur entraide était déjà un magnifique cadeau en soit (et encore merci à vous, les ami·es !), cela aurait pu s’arrêter là. Sauf que comme nous avions développé l’outil permettant de rediriger la demande de création d’un pad (par exemple) vers un des sites de pads disponibles, les CHATONS y ont vu une belle opportunité !
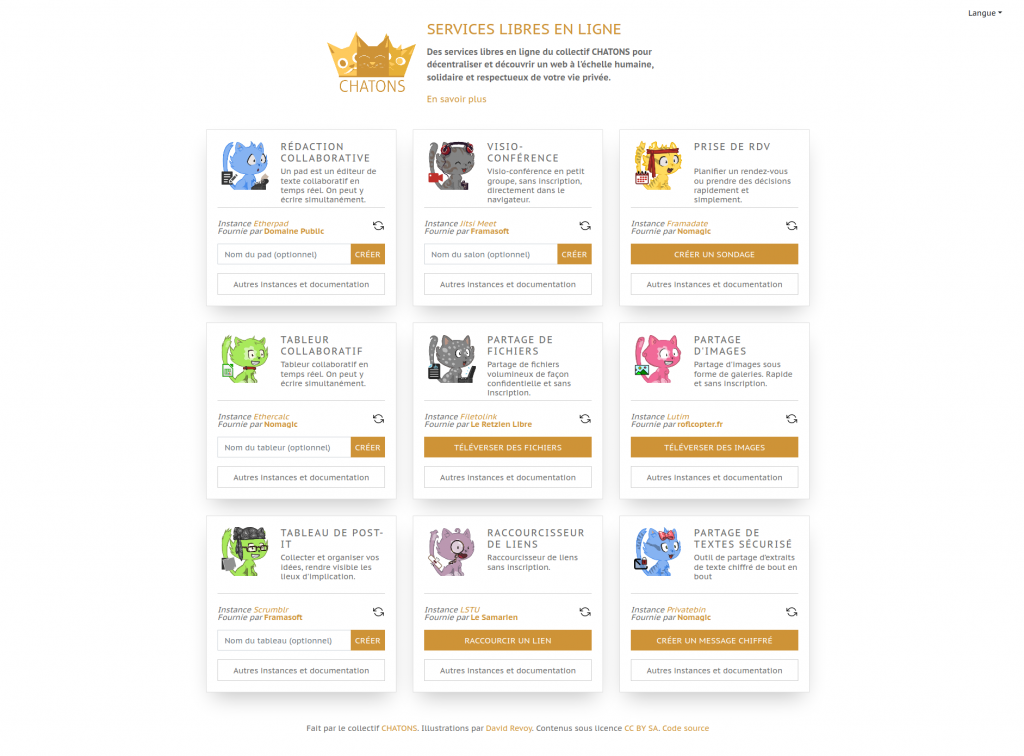
C’est ainsi qu’est né le site entraide.chatons.org. Une adresse, 9 services essentiels, éthiques et sans inscription (tableau de post-it, visioconf, écriture collaborative, hébergement d’images, etc.). Mais en plus de cela, ce site va rediriger votre usage vers un des membres du collectif CHATONS qui peut et veut l’accueillir. Concrètement, pour vous ça ne change rien. Mais pour vos données, ça change tout : elles ne sont pas hébergées au même endroit… Elles sont, au contraire, décentralisées. Une bonne manière de ne pas mettre toutes ses données dans le même panier (non parce qu’après ça crée des Google et des Facebook, et le monde n’a pas besoin de nouveaux géants du web !)
De nombreuses personnes, pas forcément spécialisées en hébergements de services, nous ont spontanément proposé de l’aide. C’est ainsi que nous avons pu demander à ce que les demandes de support pour nos services passent en priorité sur le forum, où des bénévoles ont contribué à répondre dans une entraide communautaire. D’autres ont rejoint le groupe de traductions Framalang, qui n’a pas chômé durant cette période et a notamment produit des traductions nourrissant notre dossier StopCOVID.
Enfin, le groupe des Contribateliers a expérimenté une formule en ligne, le Confinatelier. Grâce au logiciel BigBlueButton, près de 80 personnes se sont retrouvées le 6 juin 2020 sur plus de 11 salons visio pour contribuer au Libre sans forcément faire du code. Merci au groupe d’avoir publié leur retour d’expérience et d’avoir continué à faire des confinateliers encore récemment.
Le monde d’après ne ressemblera pas au monde d’avant
Bien entendu, la pandémie a grandement influé le fonctionnement interne de l’association Framasoft. Le « Framacamp 2020 » (un temps estival de convivialité et de travail collectif des membres) a finalement eu lieu sous forme d’ateliers en visioconf tout au long d’un week-end. Nous craignions vraiment que le fait de ne pas pouvoir se faire des câlins et trinquer ne vide ce Framacamp de son intérêt, et finalement, même si ce n’est pas pareil, ce fut un moment de retrouvailles agréable, productif et essentiel à la vie de l’association.
Il nous a aussi fallu repenser le reste de notre année. D’une part, nous avons annoncé un retard d’un trimestre pour la sortie de Mobilizon. D’autre part, nous avons complètement repensé la collecte que nous avions commencé à imaginer pour financer la v3 de PeerTube. Exit les mécaniques du crowdfunding ou « si vous ne payez pas, alors on ne fait pas » ! Nous avons choisi d’annoncer que nous développerions cette version, que l’on reçoive les 60 000 € de dons nécessaires ou non.
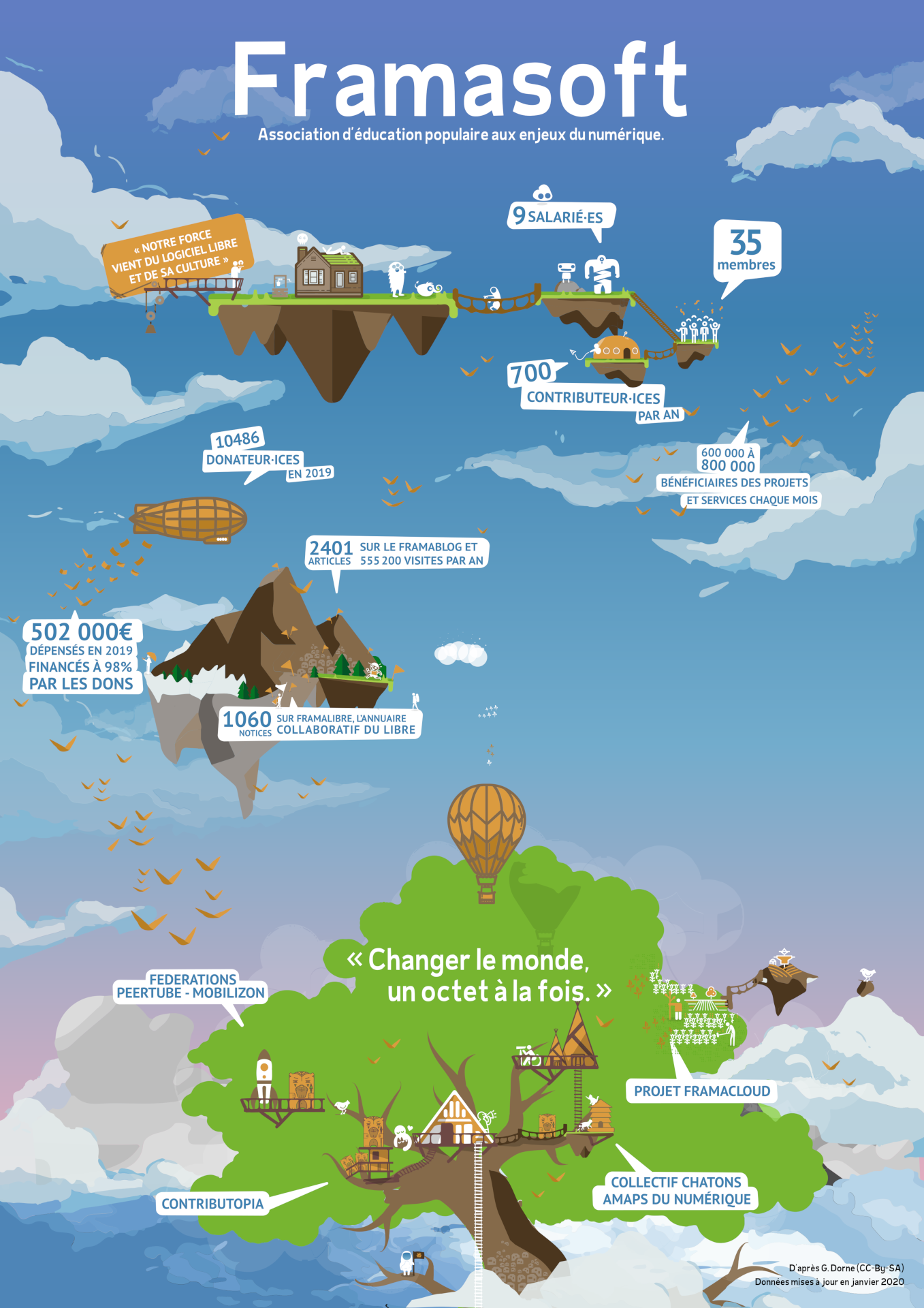
D’après une infographie de Geoffrey Dorne, CC-By-SA.
C’est une chose que nous nous n’avons réalisée qu’après coup : vous avez été très généreuxses dans votre soutien à Framasoft durant ce premier confinement. C’était important : nos actions sont financées (à plus de 95 %) par vos dons. Si nous avons pu tout mettre en pause, prendre des libertés, expérimenter des contributions et retarder, voire modifier des projets, c’est parce que les seules personnes à qui nous avons des comptes à rendre, c’est vous. Vous nous avez offert cette liberté, merci.
Pour qui le peut, nous rappelons que Framasoft est une association reconnue d’intérêt général, et qu’à ce titre elle donne droit à des réductions fiscales pour les contribuables français·es. Concrètement, un don de 100 € à Framasoft revient, après déduction des impôts sur le revenu, à 34 €. Si vous le pouvez et le voulez, merci de contribuer à nos actions.
Et le reste de 2020…?
Nous raconterons, dans un prochain article, ce que nous avons fait hors de cette parenthèse étrange et intense. Entre le 17 mars et le 11 mai, il y a eu moins de deux mois : nous avons eu l’impression que cela a duré un an !
L’avantage, si l’on peut dire, c’est que ce premier confinement nous a préparé⋅es au suivant. Aujourd’hui nos services ont beaucoup mieux encaissé la sérieuse montée en charge due au reconfinement. Du coup, nous, nous avons pu nous détendre, et faire des frama-prouts !
Framaprout : ceci est une Prout-révolution
Plus qu’un service, Framasoft lance aujourd’hui un mouvement, un art de vivre, un programme politique qui se résume en un mot : prout.
« Alors ça y est, Framasoft a prouté un câble…? »
Oui.
Il faut dire qu’entre un reconfinement mi-figue mimolette (dont les règles oscillent entre Kamoulox et chante-sloubi), des drames affreux récupérés de manière cynique et morbide par des obsédé·es du solutionnisme compulsif, la théâtralisation de jeux électoraux dont les conséquences risquent de n’amuser personne… Comment garder l’esprit sain ?
La solution est apparue au petit Pierre-Yves, 42 ans, alors que l’application Twitter l’entraînait dans un scroll infini. Les tweets anxiogènes défilaient sous ses yeux jusqu’à ce que : Prout.
J’ai alors un peu craqué nerveusement, témoigne-t-il. Je trouvais ça tellement génial que le site la RTBF (l’équivalent Belge de France Télévision) se retrouve avec des dizaines de milliers de pages terminant par « Prout ».

Justice nulle part…? Prout partout !
On pourrait vous pondre un essai long, intelligent et académique sur les vertus du Prout face au capitalisme de surveillance. (attention, ceci est une menace : ne nous poussez pas ou on l’écrit, hein !)
Nous y évoquerions à coup sûr la loi de Brandolini, qui explique qu’il est toujours moins fatiguant de dire une connerie que de démentir la connerie qui vient d’être dite. Vous aussi vous trouvez que c’est usant de répondre à une personne qui dénie le réchauffement climatique, dit que la terre est plate et que toutes les opinions -même les nazies- se valent…? Prout.

Notre éloge du Prout mentionnerait forcément la fenêtre d’Overton. Lorsque des partis, médias, groupes, etc. laissent certains membres dire des énormités choquantes, c’est pour que leur idée nauséabonde pue un peu moins en comparaison. Des politiques se lancent dans un nouveau concours Lépine des idées extrêmes ? Prout, prout et re-prout !
« Le prout n’est-il pas nihiliste, dépolitisant ou aquoiboniste ? » Non ! Sa matière, si tant est qu’on puisse parler de matière, est tellement éthérée, qu’elle ne porte pas d’autres poids que celui d’affirmer la fa(r)tuité de celui qui le génère. On peut même compléter en paraphrasant Victor Hugo dans un de ses plus beaux discours : « Le prout, comme épiphonème, appartient à son auteur, mais comme acte, il appartient — le mot n’est pas trop vaste — au genre humain. ».
Enfin, le prout est in-censurable. « Prout » n’est pas une insulte, c’est une fonction naturelle. Prout.

Du prout comme arme d’auto-défense sociale
C’est une phrase connue sur Internet : argumenter avec des trolls, c’est comme jouer aux échecs contre un pigeon. Peu importe votre niveau, le pigeon va juste renverser toutes les pièces, chier sur le plateau et se pavaner fièrement comme s’il avait gagné.
Le meilleur moyen de s’en sortir c’est de s’écrier : « Aha ! Je te vois ! Tu es un pigeon ! Et les pigeons ne jouent pas aux échecs, donc je ne joue pas avec toi ! ». Mais, dans notre expérience, un tel recul est rare. Et s’il advient, le pigeon vous entraîne dans un nouveau débat d’un « mais pourquoi tu me traites de troll ? ». Donc : prout.

Le prout est un moyen de faire tomber les masques, de s’écrier ce « je te vois ! » au pigeon qui voulait nous mettre en échec. Notre paysage médiatique (qui inclut les médias sociaux) est rempli de postures d’autorité ballonnées, de rhétoriques foireuses, de techniques de manipulation nauséabondes et de vents de désinformation. Celles et ceux qui en pètent d’avoir tout le temps un avis : on vous voit. Prout.
Le monde n’a jamais eu autant besoin de Prouts. Parce qu’en fait, on n’a aucune place dans le débat en tant qu’individu. Parce que les médias sociaux sont des places où tout le monde crie et personne n’écoute. Parce que, pire encore, à gueuler et à voir que rien ne bouge alors qu’on est des milliers (millions) à être en désaccord ne fait qu’exacerber la haine de « l’autre », de cellelui qui n’entend pas. Mieux vaut prouter.

Framaprout, des outils numériques pour prouter en liberté
Nous, quand on commence à péter du casque, on le fait bien. Sur Framaprout.org, vous avez à votre disposition :
Proutify, l’extension navigateur qui va vous prouter le web
Proutify est une extension pour votre navigateur que vous retrouverez ici. L’installation est facilitée sur Firefox, mais elle reste manuelle pour Chrome (parce que plutôt prouter que de créer un compte dev Google !). Une fois installée, Proutify remplacera toute une série de noms et d’expressions par leur version Proutesque. Parce que la vie est absurde.
Avant, la lecture des actualités me déprimait. Désormais, grâce à Proutify, je vois des Prouts partout !
Les prouts de la Team Mème
La #TeamMémé a encore frappé. Ou Prouté. À vrai dire, la team est au bord du surmenage. Ses membres ont plus prouté qu’un Ariégeois venant de remporter un concours de dégustation de Mounjetada.
Nous ne pouvions pas tous les utiliser pour illustrer cet article, donc on vous a préparé une galerie de mèmes gastriques à télécharger et à prouter partout autour de vous.

Le prout-o-mètre, pour compter les prouts
Une personne vient de lâcher une grosse caisse et vous voulez identifier en quoi son prout pue ? Il y a un Framachin pour ça, un « bingo du prout » inspiré de notre Bingo du Troll.
Sur le prout-o-mètre, vous pouvez cocher les cases qui correspondent à ses flatulences. Et donnez lui son score en partageant avec lui le lien en bas de ce « bingo du prout ».

Le bon vieux prout artisanal
Il y a des moments où on n’en peut plus de répondre. Où on est fatigué·e de se prendre l’écume des jours dans les dents, ressassée par chaque nouvelle vague d’indignation. Si ça vous arrive, répondez simplement : prout.
Le bon vieux prout artisanal, n’y a que ça de vrai. C’est cinq touches sur votre clavier. Six si vous en faites un hashtag. Allez-y, lâchez-vous, vous verrez : ça soulage.

Voulez-vous prouter avec nous, ce soir ?
Nous serrons les fesses à l’idée de votre réponse. Du fond de l’internet, la Raie Publique se fraiera-t-elle un chemin vers la sortie du tunnel ?
Notre argument, vous l’aurez senti, c’est que ça sent le gaz. Et qu’on a besoin de se (dé)ballonner un peu.
Une action burlesco-dadaïste pour mettre le web en odorama, vous la sentez comment ?

Hommage à Laurent Séguin
Hier, nous apprenions le décès de Laurent Séguin, à l’âge de 44 ans.
Pour reprendre le communiqué du CNLL, après une première carrière au sein de la Marine Nationale, Laurent s’était investi dans les communautés du logiciel libre en France. Il avait été notamment:
- Président de l’AFUL
- Vice-président de l’ADULLACT
- Responsable du GT Logiciel Libre du Pôle Systematic
- Entrepreneur
- Directeur commercial et marketing de plusieurs entreprises du logiciel libre
- Créateur de musiques électroniques (libres)
Les membres de Framasoft et Laurent se sont côtoyés régulièrement pendant près de 15 ans sur différents événements autour du logiciel libre. Forcément, cela crée des liens.
Nous lui serons éternellement reconnaissant⋅es d’avoir aussi été l’une des premières personnes à soutenir financièrement Framasoft, par le biais d’entreprises successives pour lesquelles il a travaillé. Sans lui, nous n’en serions peut-être pas là où nous en sommes.
Peu de gens hors de ses proches le savaient, mais Laurent était aussi musicien (sous licence libre). Au mois d’avril dernier, nous recevions par e-mail une « auto-interview » signée de son pseudonyme. Étant en pleine phase de confinement, et peu disponibles, nous ne lui avions pas répondu alors. Puis le temps est passé…
Nous publions donc aujourd’hui cette interview à titre posthume, chargée d’émotions pour nous, en hommage au militant plein d’énergie qu’il était, et au compagnon de la route longue – mais libre – qu’il fut pour nous.
Nous présentons à sa famille, ses proches, ses amis, ses collègues d’Entr’ouvert, nos plus sincères condoléances.

CyberSDF, drôle de pseudo, qui es-tu en vrai ?
Oui c’est stupide comme pseudo. Il date d’il y a très longtemps (les années 2000 n’existaient pas encore). J’ai utilisé ce pseudo pour les jeux vidéo et je ne sais pas vraiment pourquoi je l’ai utilisé comme nom d’artiste.
Quant à qui je suis, ce n’est pas secret, on va dire que je suis discret. Beaucoup (trop) de gens connaissent ma réelle identité, mais si vous ne savez pas qui je suis, gardez cette part de mystère qui a son charme.
NB : Je suis GNU-Linuxien depuis plus de 20 ans, donc libriste 😉
Tu es donc musicien ?
On va dire que non. Adolescent, j’ai été pendant assez longtemps (mauvais) batteur et (mauvais) bassiste en groupe et j’ai toujours aimé appuyer sur les touches d’un piano. Même si j’ai le goût de la musique depuis tout petit et que j’ai touché à pas mal d’instruments je ne me considère pas comme un musicien qui maîtrise un instrument.
Je me vois plutôt comme un manipulateur du travail des autres. Avec un bon enregistrement d’une guitare ou d’un piano, sur plusieurs gammes, je peux exploiter ce travail pour le mélanger à d’autres instruments pour en faire une œuvre originale. Si je n’ai pas cette matière première, on a les logiciels qu’il faut pour générer ces sons. Je travaille principalement avec des boucles de deux ou quatre mesures sur un tempo dans les 120 bpm la plupart du temps (bien que j’ai publié des titres allant de 90 à 140 bpm).
Pourquoi tu as commencé à publier de la musique ?
Lors d’une table ronde dont le sujet portait sur la création musicale et la loi Hadopi (oui ça date), je défendais un point de vue de diffusion sous licence libre face à un représentant de la SACEM qui ne comprenait visiblement de quoi je parlais tellement c’était éloigné de son schéma de pensée. Vexé de mes arguments à un moment il me sort « vous ne pouvez pas comprendre, vous n’êtes pas créateur de musique ».
Je me renseigne sur le mec, pensant avoir eu affaire avec un grand compositeur, eh bien non. Le type de toute sa vie n’avait composé qu’une pauvre musique d’un film qui n’a pas eu un fort succès, mais il en était tellement imbu de lui-même que cela m’avait énervé. Quelque temps plus tard j’ai commencé à créer mes propres musiques que j’ai finalement décidé de partager pour démontrer que la création musicale sous licence libre était pertinente.
Donc tu continues à créer pour lui en mettre plein les dents ?
Non. En vrai je crée d’abord pour moi. Je fais ce que j’ai envie d’écouter, et comme je suis très éclectique, je passe d’un style musical à un autre assez facilement. Une fois que je suis content de mon travail, il m’arrive de le publier pour le partager avec les gens. Je ne publie pas tout, même si parfois je publie trop vite…
Ce n’est donc pas une activité professionnelle ?
Pas du tout. Je crée mes musiques quand j’ai le temps et l’envie, sans pression. Bien évidement, j’ai des coûts de production. Par exemple, je protège l’antériorité de mes créations sur safecreative.org et cela me coûte 72€ par an. Pour les diffuser sur Soundcoud, cela me coûte 8,25 €/mois (parce que je prends à l’année). À cela il faut ajouter les coûts des sons que j’achète pour créer mes morceaux, souvent à prix d’or pour pouvoir diffuser en CC-BY (un chant par exemple, va me coûter les yeux de la tête alors qu’un rif de guitare ne me coûtera que quelques euros ; bon j’ai aussi des contres exemples avec mes deux titres de flamenco).
Mais j’accepte les dons. Si le système de don a bien fonctionné les premières années où créer et publier ne me coûtait presque rien d’autre que du temps, cela a énormément baissé et là cela devient compliqué d’être à l’équilibre financier. Comme je vois ma création musicale comme un passe-temps et non pas une activité rémunératrice pour subvenir à mes besoins, j’accepte que cela me coûte de l’argent, mais comme pour tout loisir pas trop non plus.
Avec quoi tu composes ?
Avec un peu tout ce qui tombe sous la main. Au début j’aimais beaucoup manipuler Music Maker Jam sous Android, mais ils ont changé leur interface et c’est devenu moins puissant pour composer. Ils ont ajouté trop de fioritures qui tuent le vrai travail de création.
Étant aussi Gamer à l’occasion, j’ai un Windows dans le Cloud avec Shadow.tech ce qui me donne accès à des logiciels de création musicales assez puissants, notamment dans les générateurs de son. Après je manipule un peu tout et n’importe quoi comme son, et il n’est pas rare que je sorte mon smartphone pour enregistrer un son de la rue qui me plaît afin de l’isoler et le retravailler à la maison pour l’intégrer dans un morceau (même si vous ne l’entendez pas vraiment, il est là). Il m’est aussi arrivé de demander à des artistes de rue de jouer sur leur instrument une mélodie que j’avais en tête pour obtenir un son plus naturel et moins « parfait ».
Quel est ton plus gros défaut d’artiste ?
Je ne remastérise pas mes titres. Après avoir passé des heures à sortir un FLAC correct, je n’ai plus l’énergie pour repasser dessus et réarranger les niveaux des pistes du morceau.
J’ai aussi une grosse flemme pour faire du marketing. Parfois je fais des campagnes aux USA pour attirer des auditeurs, mais en vrai ça me saoule. J’aimerais que les auditeurs qui aiment ce que je fais partagent plus (ça motive), mais (d’après les stats Soundcloud) ils ne le font pas et se gardent « le bon plan ».
J’ai été longtemps naïf aussi en pensant que d’autres musiciens allaient améliorer mes morceaux ou créer des œuvres dérivées des miennes, un peu à l’image du logiciel, mais non. Cela explique pourquoi mes créations dans les deux premières année ont ce goût de « c’est pas fini ». Parce que oui, c’était fait exprès…
Quelles sont les difficultés de publier en CC-BY ?
La première ce sont les vrais prédateurs. Ces gens qui vont prendre ta musique, éventuellement la modifier un peu et la faire diffuser par un service du genre CD Baby (https://en.wikipedia.org/wiki/CD_Baby). L’écueil c’est que ce genre de service est totalement automatisé et va envoyer des violations de copyright à l’œuvre originale et toutes ses utilisations. C’est pour cela que j’ai été contraint de publier sur Youtube, car pas mal de youtubeurs utilisent ma musique puisque ma licence est compatible avec leur propre monétisation.
Le second ce sont les « promoteurs » qui vont publier sous leur nom ma musique et ainsi noyer la source de création, et donc pour moi perdre de l’attention. Il y a des chaînes Youtube russes avec presque que mes créations qui ont plus d’abonnés que la mienne.
Enfin la dernière, majoritaire, ce sont ceux qui utilisent mes musiques sans créditer. Ce n’est quand même pas compliqué de donner le nom de l’artiste et le titre de la musique…
Quels sont tes titres préférés ?
J’ai publié 169 musiques, j’en ai donc pas mal 😉
Je peux vous donner les plus écoutées par plateforme :
– Sur Souncloud : Welcome, suivi de Burneco
– Sur Youtube : Flame and Go, suivi de Aventurine
– Sur Bandcamp : Sunday, suivi de CyberBeats
Et je trouve que beaucoup d’autres méritent plus de succès que ces six-là 😛
As-tu une chose surprenante à nous dire ?
Plusieurs ! Mais je n’en garderai que quelques-unes, significatives.
1/ J’ai composé Persepolis dans une chambre aux Arc 1800 en 3h de travail non stop
2/ J’ai rencontré une fille totalement en dehors de mes univers à qui je faisais écouter ma dernière création du moment pour voir sa réaction, juste en donnant le nom de l’artiste et sans préciser que c’était moi, elle m’a répondu « de lui, je préfère Welcome »
3/ Une Suisse m’a fait un don de 200€ d’un coup via Bandcamp
4/ Arched Cellar est un résumé d’un live mix d’environ une demi-heure lors d’une free party dans les catacombes de Paris
5/ L’UNRIC et BFMTV ont, à un an d’intervalle, utilisé ma même musique
Détruire le capitalisme de surveillance (3)
Voici une troisième partie de l’essai que consacre Cory Doctorow au capitalisme de surveillance (parcourir sur le blog les épisodes précédents – parcourir les trois premiers épisodes en PDF : doctorow-1-2-3). Il s’attache ici à démonter les mécanismes utilisés par les Gafam pour lutter contre nos facultés à échapper aux messages publicitaires, mais aussi pour faire croire aux publicitaires que leurs techniques sont magiquement efficaces. Il insiste également sur la quasi-impunité dont bénéficient jusqu’à présent les géants de la Tech…
Billet original sur le Medium de OneZero : How To Destroy Surveillance Capitalism
Traduction Framalang : Claire, Fabrice, Gangsoleil, Goofy, Jums, Laure, Retrodev
Si les données sont le nouvel or noir, alors les forages du capitalisme de surveillance ont des fuites
par Cory Doctorow

La faculté d’adaptation des internautes explique l’une des caractéristiques les plus alarmantes du capitalisme de surveillance : son insatiable appétit de données et l’expansion infinie de sa capacité à collecter des données au travers de la diffusion de capteurs, de la surveillance en ligne, et de l’acquisition de flux de données de tiers.
Zuboff étudie ce phénomène et conclut que les données doivent valoir très cher si le capitalisme de surveillance en est aussi friand (selon ses termes : « Tout comme le capitalisme industriel était motivé par l’intensification continue des moyens de production, le capitalisme de surveillance et ses acteurs sont maintenant enfermés dans l’intensification continue des moyens de modification comportementale et dans la collecte des instruments de pouvoir. »). Et si cet appétit vorace venait du fait que ces données ont une demi-vie très courte, puisque les gens s’habituent très vite aux nouvelles techniques de persuasion fondées sur les données au point que les entreprises sont engagées dans un bras de fer sans fin avec notre système limbique ? Et si c’était une course de la Reine rouge d’Alice dans laquelle il faut courir de plus en plus vite collecter de plus en plus de données, pour conserver la même place ?
Bien sûr, toutes les techniques de persuasion des géants de la tech travaillent de concert les unes avec les autres, et la collecte de données est utile au-delà de la simple tromperie comportementale.
Si une personne veut vous recruter pour acheter un réfrigérateur ou participer à un pogrom, elle peut utiliser le profilage et le ciblage pour envoyer des messages à des gens avec lesquels elle estime avoir de bonnes perspectives commerciales. Ces messages eux-mêmes peuvent être mensongers et promouvoir des thèmes que vous ne connaissez pas bien (la sécurité alimentaire, l’efficacité énergétique, l’eugénisme ou des affirmations historiques sur la supériorité raciale). Elle peut recourir à l’optimisation des moteurs de recherche ou à des armées de faux critiques et commentateurs ou bien encore au placement payant pour dominer le discours afin que toute recherche d’informations complémentaires vous ramène à ses messages. Enfin, elle peut affiner les différents discours en utilisant l’apprentissage machine et d’autres techniques afin de déterminer quel type de discours convient le mieux à quelqu’un comme vous.
Chacune des phases de ce processus bénéficie de la surveillance : plus ils possèdent de données sur vous, plus leur profilage est précis et plus ils peuvent vous cibler avec des messages spécifiques. Pensez à la façon dont vous vendriez un réfrigérateur si vous saviez que la garantie de celui de votre client potentiel venait d’expirer et qu’il allait percevoir un remboursement d’impôts le mois suivant.
De plus, plus ils ont de données, mieux ils peuvent élaborer des messages trompeurs. Si je sais que vous aimez la généalogie, je n’essaierai pas de vous refourguer des thèses pseudo-scientifiques sur les différences génétiques entre les « races », et je m’en tiendrai plutôt aux conspirationnistes habituels du « grand remplacement ».
Facebook vous aide aussi à localiser les gens qui ont les mêmes opinions odieuses ou antisociales que vous. Il permet de trouver d’autres personnes avec qui porter des torches enflammées dans les rues de Charlottesville déguisé en Confédéré. Il peut vous aider à trouver d’autres personnes qui veulent rejoindre votre milice et aller à la frontière pour terroriser les migrants illégaux. Il peut vous aider à trouver d’autres personnes qui pensent aussi que les vaccins sont un poison et que la Terre est plate.
La publicité ciblée profite en réalité uniquement à ceux qui défendent des causes socialement inacceptables car elle est invisible. Le racisme est présent sur toute la planète, et il y a peu d’endroits où les racistes, et seulement eux, se réunissent. C’est une situation similaire à celle de la vente de réfrigérateurs là où les clients potentiels sont dispersés géographiquement, et où il y a peu d’endroits où vous pouvez acheter un encart publicitaire qui sera principalement vu par des acheteurs de frigo. Mais acheter un frigo est acceptable socialement, tandis qu’être un nazi ne l’est pas, donc quand vous achetez un panneau publicitaire ou quand vous faites de la pub dans la rubrique sports d’un journal pour vendre votre frigo, le seul risque c’est que votre publicité soit vue par beaucoup de gens qui ne veulent pas de frigo, et vous aurez jeté votre argent par la fenêtre.
Mais même si vous vouliez faire de la pub pour votre mouvement nazi sur un panneau publicitaire, à la télé en première partie de soirée ou dans les petites annonces de la rubrique sports, vous auriez du mal à trouver quelqu’un qui serait prêt à vous vendre de l’espace pour votre publicité, en partie parce qu’il ne serait pas d’accord avec vos idées, et aussi parce qu’il aurait peur des retombées négatives (boycott, mauvaise image, etc.) de la part de ceux qui ne partagent pas vos opinions.
Ce problème disparaît avec les publicités ciblées : sur Internet, les encarts de publicité peuvent être personnalisés, ce qui veut dire que vous pouvez acheter des publicités qui ne seront montrées qu’à ceux qui semblent être des nazis et pas à ceux qui les haïssent. Quand un slogan raciste est diffusé à quelqu’un qui hait le racisme, il en résulte certaines conséquences, et la plateforme ou la publication peut faire l’objet d’une dénonciation publique ou privée de la part de personnes outrées. Mais la nature des risques encourus par l’acheteur de publicités en ligne est bien différente des risques encourus par un éditeur ou un propriétaire de panneaux publicitaires classiques qui pourrait vouloir publier une pub nazie.
Les publicités en ligne sont placées par des algorithmes qui servent d’intermédiaires entre un écosystème diversifié de plateformes publicitaires en libre-service où chacun peut acheter une annonce. Ainsi, les slogans nazis qui s’immiscent sur votre site web préféré ne doivent pas être vus comme une atteinte à la morale mais plutôt comme le raté d’un fournisseur de publicité lointain. Lorsqu’un éditeur reçoit une plainte pour une publicité gênante diffusée sur un de ses sites, il peut engager une procédure pour bloquer la diffusion de cette publicité. Mais les nazis pourraient acheter une publicité légèrement différente auprès d’un autre intermédiaire qui diffuse aussi sur ce site. Quoi qu’il en soit, les internautes comprennent de plus en plus que quand une publicité s’affiche sur leur écran, il est probable que l’annonceur n’a pas choisi l’éditeur du site et que l’éditeur n’a pas la moindre idée de qui sont ses annonceurs.
Ces couches d’indétermination entre les annonceurs et les éditeurs tiennent lieu de tampon moral : il y a aujourd’hui un large consensus moral selon lequel les éditeurs ne devraient pas être tenus pour responsables des publicités qui apparaissent sur leurs pages car ils ne choisissent pas directement de les y placer. C’est ainsi que les nazis peuvent surmonter d’importants obstacles pour organiser leur mouvement.
Les données entretiennent une relation complexe avec la domination. La capacité à espionner vos clients peut vous alerter sur leurs préférences pour vos concurrents directs et vous permettre par la même occasion de prendre l’ascendant sur eux.
Mais surtout, si vous pouvez dominer l’espace informationnel tout en collectant des données, alors vous renforcez d’autres stratégies trompeuses, car il devient plus difficile d’échapper à la toile de tromperie que vous tissez. Ce ne sont pas les données elles-mêmes mais la domination, c’est-à-dire le fait d’atteindre, à terme, une position de monopole, qui rend ces stratégies viables, car la domination monopolistique prive votre cible de toute alternative.
Si vous êtes un nazi qui veut s’assurer que ses cibles voient en priorité des informations trompeuses, qui vont se confirmer à mesure que les recherches se poursuivent, vous pouvez améliorer vos chances en leur suggérant des mots-clefs à travers vos communications initiales. Vous n’avez pas besoin de vous positionner sur les dix premiers résultats de la recherche décourager électeurs de voter si vous pouvez convaincre vos cibles de n’utiliser que les mots clefs voter fraud (fraude électorale), qui retourneront des résultats de recherche très différents.
Les capitalistes de la surveillance sont comme des illusionnistes qui affirment que leur extraordinaire connaissance des comportements humains leur permet de deviner le mot que vous avez noté sur un bout de papier plié et placé dans votre poche, alors qu’en réalité ils s’appuient sur des complices, des caméras cachées, des tours de passe-passe et de leur mémoire développée pour vous bluffer.
Ou peut-être sont-ils des comme des artistes de la drague, cette secte misogyne qui promet d’aider les hommes maladroits à coucher avec des femmes en leur apprenant quelques rudiments de programmation neurolinguistique, des techniques de communication non verbale et des stratégies de manipulation psychologique telles que le « negging », qui consiste à faire des commentaires dévalorisant aux femmes pour réduire leur amour-propre et susciter leur intérêt.
Certains dragueurs parviennent peut-être à convaincre des femmes de les suivre, mais ce n’est pas parce que ces hommes ont découvert comment court-circuiter l’esprit critique des femmes. Le « succès » des dragueurs vient plutôt du fait qu’ils sont tombés sur des femmes qui n’étaient pas en état d’exprimer leur consentement, des femmes contraintes, des femmes en état d’ébriété, des femmes animées d’une pulsion autodestructrice et de quelques femmes qui, bien que sobres et disposant de toutes leurs facultés, n’ont pas immédiatement compris qu’elles fréquentaient des hommes horribles mais qui ont corrigé cette erreur dès qu’elles l’ont pu.
Les dragueurs se figurent qu’ils ont découvert une formule secrète qui court-circuite les facultés critiques des femmes, mais ce n’est pas le cas. La plupart des stratégies qu’ils déploient, comme le negging, sont devenues des sujets de plaisanteries (tout comme les gens plaisantent à propos des mauvaises campagnes publicitaires) et il est fort probable que ceux qui mettent en pratique ces stratégies avec les femmes ont de fortes chances d’être aussitôt démasqués, jetés et considérés comme de gros losers.
Les dragueurs sont la preuve que les gens peuvent croire qu’ils ont développé un système de contrôle de l’esprit même s’il ne marche pas. Ils s’appuient simplement sur le fait qu’une technique qui fonctionne une fois sur un million peut finir par se révéler payante si vous l’essayez un million de fois. Ils considèrent qu’ils ont juste mal appliqué la technique les autres 999 999 fois et se jurent de faire mieux la prochaine fois. Seul un groupe de personnes trouve ces histoires de dragueurs convaincantes, les aspirants dragueurs, que l’anxiété et l’insécurité rend vulnérables aux escrocs et aux cinglés qui les persuadent que, s’ils payent leur mentorat et suivent leurs instructions, ils réussiront un jour. Les dragueurs considèrent que, s’ils ne parviennent pas à séduire les femmes, c’est parce qu’ils ne sont pas de bons dragueurs, et non parce que les techniques de drague sont du grand n’importe quoi. Les dragueurs ne parviennent pas à se vendre auprès des femmes, mais ils sont bien meilleurs pour se vendre auprès des hommes qui payent pour apprendre leurs prétendues techniques de séduction.
« Je sais que la moitié des sommes que je dépense en publicité l’est en pure perte mais je ne sais pas de quelle moitié il s’agit. » déplorait John Wanamaker, pionnier des grands magasins.
Le fait que Wanamaker considérait que la moitié seulement de ses dépenses publicitaires avait été gaspillée témoigne de la capacité de persuasion des cadres commerciaux, qui sont bien meilleurs pour convaincre de potentiels clients d’acheter leurs services que pour convaincre le grand public d’acheter les produits de leurs clients.

Qu’est-ce que Facebook ?
On considère Facebook comme l’origine de tous nos fléaux actuels, et il n’est pas difficile de comprendre pourquoi. Certaines entreprises technologiques cherchent à enfermer leurs utilisateurs mais font leur beurre en gardant le monopole sur l’accès aux applications pour leurs appareils et en abusant largement sur leurs tarifs plutôt qu’en espionnant leurs clients (c’est le cas d’Apple). D’autres ne cherchent pas à enfermer leurs utilisateurs et utilisatrices parce que ces entreprises ont bien compris comment les espionner où qu’ils soient et quoi qu’elles fassent, et elles gagnent de l’argent avec cette surveillance (Google). Seul Facebook, parmi les géants de la tech, fait reposer son business à la fois sur le verrouillage de ses utilisateurs et leur espionnage constant.
Le type de surveillance qu’exerce Facebook est véritablement sans équivalent dans le monde occidental. Bien que Facebook s’efforce de se rendre le moins visible possible sur le Web public, en masquant ce qui s’y passe aux yeux des gens qui ne sont pas connectés à Facebook, l’entreprise a disposé des pièges sur la totalité du Web avec des outils de surveillance, sous forme de boutons « J’aime » que les producteurs de contenus insèrent sur leur site pour doper leur profil Facebook. L’entreprise crée également diverses bibliothèques logicielles et autres bouts de code à l’attention des développeurs qui fonctionnent comme des mouchards sur les pages où on les utilise (journaux parcourus, sites de rencontres, forums…), transmettant à Facebook des informations sur les visiteurs du site.
Les géants de la tech peuvent surveiller, non seulement parce qu’ils font de la tech mais aussi parce que ce sont des géants.
Facebook offre des outils du même genre aux développeurs d’applications, si bien que les applications que vous utilisez, que ce soit des jeux, des applis pétomanes, des services d’évaluation des entreprises ou du suivi scolaire enverront des informations sur vos activités à Facebook même si vous n’avez pas de compte Facebook, et même si vous n’utilisez ni ne téléchargez aucune application Facebook. Et par-dessus le marché, Facebook achète des données à des tiers pour connaître les habitudes d’achat, la géolocalisation, l’utilisation de cartes de fidélité, les transactions bancaires, etc., puis croise ces données avec les dossiers constitués d’après les activités sur Facebook, avec les applications et sur le Web général.
S’il est simple d’intégrer des éléments web dans Facebook – faire un lien vers un article de presse, par exemple – les produits de Facebook ne peuvent en général pas être intégrés sur le Web. Vous pouvez inclure un tweet dans une publication Facebook, mais si vous intégrez une publication Facebook dans un tweet, tout ce que vous obtiendrez est un lien vers Facebook qui vous demande de vous authentifier avant d’y accéder. Facebook a eu recours à des contre-mesures techniques et légales radicales pour que ses concurrents ne puissent pas donner la possibilité à leurs utilisateurs d’intégrer des fragments de Facebook dans des services rivaux, ou de créer des interfaces alternatives qui fusionneraient votre messagerie Facebook avec celle des autres services que vous utilisez.
Et Facebook est incroyablement populaire, avec 2,3 milliards d’utilisateurs annoncés (même si beaucoup considèrent que ce nombre est exagéré). Facebook a été utilisé pour organiser des pogroms génocidaires, des émeutes racistes, des mouvements antivaccins, des théories de la Terre plate et la carrière politique des autocrates les plus horribles et les plus autoritaires au monde. Des choses réellement alarmantes se produisent dans le monde et Facebook est impliqué dans bon nombre d’entre elles, il est donc assez facile de conclure que ces choses sont le résultat du système de contrôle mental de Facebook, mis à disposition de toute personne prête à y dépenser quelques dollars.
Pour comprendre le rôle joué par Facebook dans l’élaboration et la mobilisation des mouvements nuisibles à la société, nous devons comprendre la double nature de Facebook.
Parce qu’il a beaucoup d’utilisateurs et beaucoup de données sur ces utilisateurs, l’outil Facebook est très efficace pour identifier des personnes avec des caractéristiques difficiles à trouver, le genre de caractéristiques qui sont suffisamment bien disséminées dans la population pour que les publicitaires aient toujours eu du mal à les atteindre de manière rentable.
Revenons aux réfrigérateurs. La plupart d’entre nous ne remplaçons notre gros électro-ménager qu’un petit nombre de fois dans nos vies. Si vous êtes un fabricant ou un vendeur de réfrigérateurs, il n’y a que ces brèves fenêtres temporelles dans la vie des consommateurs au cours desquelles ils réfléchissent à un achat, et vous devez trouver un moyen pour les atteindre. Toute personne ayant déjà enregistré un changement de titre de propriété après l’achat d’une maison a pu constater que les fabricants d’électroménager s’efforcent avec l’énergie du désespoir d’atteindre quiconque pourrait la moindre chance d’être à la recherche d’un nouveau frigo.
Facebook rend la recherche d’acheteurs de réfrigérateurs beaucoup plus facile. Il permet de cibler des publicités à destination des personnes ayant enregistré l’achat d’une nouvelle maison, des personnes qui ont cherché des conseils pour l’achat de réfrigérateurs, de personnes qui se sont plaintes du dysfonctionnement de leur frigo, ou n’importe quelle combinaison de celles-ci. Il peut même cibler des personnes qui ont récemment acheté d’autres équipements de cuisine, en faisant l’hypothèse que quelqu’un venant de remplacer son four et son lave-vaisselle pourrait être d’humeur à acheter un frigo. La grande majorité des personnes qui sont ciblées par ces publicités ne seront pas à la recherche d’un nouveau frigo mais – et c’est le point crucial – le pourcentage de personnes à la recherche de frigo que ces publicités atteignent est bien plus élevé que celui du groupe atteint par les techniques traditionnelles de ciblage marketing hors-ligne.
Facebook rend également beaucoup plus simple le fait de trouver des personnes qui ont la même maladie rare que vous, ce qui aurait été peut-être impossible avant, le plus proche compagnon d’infortune pouvant se trouver à des centaines de kilomètres. Il rend plus simple de retrouver des personnes qui sont allées dans le même lycée que vous, bien que des décennies se soient écoulées et que vos anciens camarades se soient disséminés aux quatre coins de la planète.
Facebook rend également beaucoup plus simple de trouver des personnes ayant les mêmes opinions politiques minoritaires que vous. Si vous avez toujours eu une affinité secrète pour le socialisme, sans jamais oser la formuler à voix haute de peur de vous aliéner vos voisins, Facebook peut vous aider à découvrir d’autres personnes qui pensent la même chose que vous (et cela pourrait vous démontrer que votre affinité est plus commune que vous ne l’auriez imaginée). Il peut rendre plus facile de trouver des personnes qui ont la même identité sexuelle que vous. Et, à nouveau, il peut vous aider à comprendre que ce que vous considériez comme un secret honteux qui ne regarde que vous est en réalité un trait répandu, vous donnant ainsi le réconfort et le courage nécessaire pour en parler à vos proches.
Tout cela constitue un dilemme pour Facebook : le ciblage rend les publicités de la plateforme plus efficaces que les publicités traditionnelles, mais il permet également aux annonceurs de savoir précisément à quel point leurs publicités sont efficaces. Si les annonceurs sont satisfaits d’apprendre que les publicités de Facebook sont plus efficaces que celles de systèmes au ciblage moins perfectionné, les annonceurs peuvent aussi voir que, dans presque tous les cas, les personnes qui voient leurs publicités les ignorent. Ou alors, tout au mieux, que leurs publicités ne fonctionnent qu’à un niveau inconscient, créant des effets nébuleux impossibles à quantifier comme la « reconnaissance de marque ». Cela signifie que le prix par publicité est très réduit dans la quasi-totalité des cas.
Pour ne rien arranger, beaucoup de groupes Facebook n’hébergent que très peu de discussions. Votre équipe de football locale, les personnes qui ont la même maladie rare que vous et ceux dont vous partagez l’orientation politique peuvent échanger des rafales de messages dans les moments critiques forts mais, dans la vie de tous les jours, il n’y a pas grand-chose à raconter à vos anciens camarades de lycée et autres collectionneurs de vignettes de football.
S’il n’y avait que des discussions « saines », Facebook ne générerait pas assez de trafic pour vendre des publicités et amasser ainsi les sommes nécessaires pour continuellement se développer en rachetant ses concurrents, tout en reversant de coquettes sommes à ses investisseurs.
Facebook doit donc augmenter le trafic tout en détournant ses propres forums de discussion : chaque fois que l’algorithme de Facebook injecte de la matière à polémiques dans un groupe – brûlots politiques, théories du complot, faits-divers révoltants – il peut détourner l’objectif initial de ce groupe avec des discussions affligeantes et gonfler ainsi artificiellement ces échanges en les transformant en interminables disputes agressives et improductives. Facebook est optimisé pour l’engagement, pas pour le bonheur, et il se trouve que les systèmes automatisés sont plutôt performants pour trouver des choses qui vont mettre les gens en colère.
Facebook peut modifier notre comportement mais seulement en suivant quelques modalités ordinaires. Tout d’abord, il peut vous enfermer avec vos amis et votre famille pour que vous passiez votre temps à vérifier sans cesse sur Facebook ce qu’ils sont en train de faire. Ensuite, il peut vous mettre en colère ou vous angoisser. Il peut vous forcer à choisir entre être constamment interrompu par des mises à jour, un processus qui vous déconcentre et vous empêche de réfléchir, et rester indéfiniment en contact avec vos amis. Il s’agit donc d’une forme de contrôle mental très limitée, qui ne peut nous rendre que furieux, déprimés et angoissés.
C’est pourquoi les systèmes de ciblage de Facebook – autant ceux qu’il montre aux annonceurs que ceux qui permettent aux utilisateurs de trouver des personnes qui partagent les mêmes centres d’intérêt – sont si modernes, souples et faciles à utiliser, tandis que ses forums de discussion ont des fonctionnalités qui paraissent inchangées depuis le milieu des années 2000. Si Facebook offrait à ses utilisateurs un système de lecture de messages tout aussi souple et sophistiqué, ceux-ci pourraient se défendre contre les gros titres polémiques sur Donald Trump qui leur font saigner des yeux.
Plus vous passez de temps sur Facebook, plus il a de pubs à vous montrer. Comme les publicités sur Facebook ne marchent qu’une fois sur mille, leur solution est de tenter de multiplier par mille le temps que vous y passez. Au lieu de considérer Facebook comme une entreprise qui a trouvé un moyen de vous montrer la bonne publicité en obtenant de vous exactement ce que veulent les annonceurs publicitaires, considérez que c’est une entreprise qui sait parfaitement comment vous noyer dans un torrent permanent de controverses, même si elles vous rendent malheureux, de sorte que vous passiez tellement de temps sur le site que vous finissiez par voir au moins une pub qui va fonctionner pour vous.

Les monopoles et le droit au futur
Mme Zuboff et ceux qui la suivent sont particulièrement alarmés par l’influence de la surveillance des entreprises sur nos décisions. Cette influence nous prive de ce qu’elle appelle poétiquement « le droit au futur », c’est-à-dire le droit de décider par vous-même de ce que vous ferez à l’avenir.
Il est vrai que la publicité peut faire pencher la balance d’une manière ou d’une autre : lorsque vous envisagez d’acheter un frigo, une publicité pour un frigo qui vient juste à point peut mettre fin tout de suite à vos recherches. Mais Zuboff accorde un poids énorme et injustifié au pouvoir de persuasion des techniques d’influence basées sur la surveillance. La plupart d’entre elles ne fonctionnent pas très bien, et celles qui le font ne fonctionneront pas très longtemps. Les concepteurs de ces outils sont persuadés qu’ils les affineront un jour pour en faire des systèmes de contrôle total, mais on peut difficilement les considérer comme des observateurs sans parti-pris, et les risques que leurs rêves se réalisent sont très limités. En revanche, Zuboff est plutôt optimiste quant aux quarante années de pratiques antitrust laxistes qui ont permis à une poignée d’entreprises de dominer le Web, inaugurant une ère de l’information avec, comme l’a fait remarquer quelqu’un sur Twitter, cinq portails web géants remplis chacun de captures d’écran des quatre autres.
Cependant, si l’on doit s’inquiéter parce qu’on risque de perdre le droit de choisir nous-mêmes de quoi sera fait notre avenir, alors les préjudices tangibles et immédiats devraient être au cœur de nos débats sur les politiques technologiques, et non les préjudices potentiels décrit par Zuboff.
Commençons avec la « gestion des droits numériques ». En 1998, Bill Clinton promulgue le Digital Millennium Copyright Act (DMCA). Cette loi complexe comporte de nombreuses clauses controversées, mais aucune ne l’est plus que la section 1201, la règle « anti-contournement ».
Il s’agit d’une interdiction générale de modifier les systèmes qui limitent l’accès aux œuvres protégées par le copyright. L’interdiction est si stricte qu’elle interdit de retirer le verrou de copyright même si aucune violation de copyright n’a eut lieu. C’est dans la conception même du texte : les activités, que l’article 1201 du DMCA vise à interdire, ne sont pas des violations du copyright ; il s’agit plutôt d’activités légales qui contrarient les plans commerciaux des fabricants.
Par exemple, la première application majeure de la section 1201 a visé les lecteurs de DVD comme moyen de faire respecter le codage par « région » intégré dans ces appareils. Le DVD-CCA, l’organisme qui a normalisé les DVD et les lecteurs de DVD, a divisé le monde en six régions et a précisé que les lecteurs de DVD doivent vérifier chaque disque pour déterminer dans quelles régions il est autorisé à être lu. Les lecteurs de DVD devaient avoir leur propre région correspondante (un lecteur de DVD acheté aux États-Unis serait de la région 1, tandis qu’un lecteur acheté en Inde serait de la région 5). Si le lecteur et la région du disque correspondent, le lecteur lira le disque ; sinon, il le rejettera.
Pourtant, regarder un DVD acheté légalement dans un autre pays que celui dans lequel vous vous situez n’est pas une violation de copyright – bien au contraire. Les lois du copyright n’imposent qu’une seule obligation aux consommateurs de films : vous devez aller dans un magasin, trouver un DVD autorisé, et payer le prix demandé. Si vous faites cela – et rien de plus – tout ira bien.
Le fait qu’un studio de cinéma veuille faire payer les Indiens moins cher que les Américains, ou sortir un film plus tard en Australie qu’au Royaume-Uni n’a rien à voir avec les lois sur le copyright. Une fois que vous avez légalement acquis un DVD, ce n’est pas une violation du copyright que de le regarder depuis l’endroit où vous vous trouvez.
Donc les producteurs de DVD et de lecteurs de disques ne pourraient pas employer les accusations de complicité de violations du copyright pour punir les producteurs de lecteurs lisant des disques de n’importe quelle région, ou les ateliers de réparation qui ont modifié les lecteurs pour vous laisser regarder des disques achetés hors de votre région, ou encore les développeurs de logiciels qui ont créé des programmes pour vous aider à le faire.
C’est là que la section 1201 du DCMA entre en jeu : en interdisant de toucher aux contrôles d’accès, la loi a donné aux producteurs et aux ayants droit la possibilité de poursuivre en justice leurs concurrents qui produisent des produits supérieurs avec des caractéristiques très demandées par le marché (en l’occurrence, des lecteurs de disques sans restriction de région).
C’est une arnaque ignoble contre les consommateurs, mais, avec le temps, le champ de la section 1201 s’est étendu pour inclure toute une constellation grandissante d’appareils et de services, car certains producteurs malins ont compris un certain nombre de choses :
- Tout appareil doté d’un logiciel contient une « œuvre protégée par copyright » (le logiciel en question).
- Un appareil peut être conçu pour pouvoir reconfigurer son logiciel et contourner le « moyen de contrôle d’accès à une œuvre protégée par copyright », un délit d’après la section 1201.
- Par conséquent, les entreprises peuvent contrôler le comportement de leurs consommateurs après qu’ils ont rapporté leurs achats à la maison. Elles peuvent en effet concevoir des produits pour que toutes les utilisations interdites demandent des modifications qui tombent sous le coup de la section 1201.
Cette section devient alors un moyen pour tout fabricant de contraindre ses clients à agir au profit de leurs actionnaires plutôt que dans l’intérêt des clients.
Cela se manifeste de nombreuses façons : une nouvelle génération d’imprimantes à jet d’encre utilisant des contre-mesures qui empêchent l’utilisation d’encre d’autres marques et qui ne peuvent être contournées sans risques juridiques, ou des systèmes similaires dans les tracteurs qui empêchent les réparateurs d’échanger les pièces du fabricant, car elles ne sont pas reconnues par le système du tracteur tant qu’un code de déverrouillage du fabricant n’est pas saisi.
Plus proches des particuliers, les iPhones d’Apple utilisent ces mesures pour empêcher à la fois les services de tierce partie et l’installation de logiciels tiers. Cela permet à Apple, et non à l’acheteur de l’iPhone, de décider quand celui-ci est irréparable et doit être réduit en pièces et jeté en déchetterie (l’entreprise Apple est connue pour sa politique écologiquement catastrophique qui consiste à détruire les vieux appareils électroniques plutôt que de permettre leur recyclage pour en récupérer les pièces). C’est un pouvoir très utile à exercer, surtout à la lumière de l’avertissement du PDG Tim Cook aux investisseurs en janvier 2019 : les profits de la société sont en danger si les clients choisissent de conserver leur téléphone plutôt que de le remplacer.
L’utilisation par Apple de verrous de copyright lui permet également d’établir un monopole sur la manière dont ses clients achètent des logiciels pour leurs téléphones. Les conditions commerciales de l’App Store garantissent à Apple une part de tous les revenus générés par les applications qui y sont vendues, ce qui signifie qu’Apple gagne de l’argent lorsque vous achetez une application dans son magasin et continue à gagner de l’argent chaque fois que vous achetez quelque chose en utilisant cette application. Cette situation retombe au final sur les développeurs de logiciels, qui doivent soit facturer plus cher, soit accepter des profits moindres sur leurs produits.
Il est important de comprendre que l’utilisation par Apple des verrous de copyright lui donne le pouvoir de prendre des décisions éditoriales sur les applications que vous pouvez ou ne pouvez pas installer sur votre propre appareil. Apple a utilisé ce pouvoir pour rejeter les dictionnaires qui contiennent des mots obscènes ; ou pour limiter certains discours politiques, en particulier les applications qui diffusent des propos politiques controversés, comme cette application qui vous avertit chaque fois qu’un drone américain tue quelqu’un quelque part dans le monde ; ou pour s’opposer à un jeu qui commente le conflit israélo-palestinien.
Apple justifie souvent son pouvoir monopolistique sur l’installation de logiciels au nom de la sécurité, en arguant que le contrôle des applications de sa boutique lui permet de protéger ses utilisateurs contre les applications qui contiennent du code qui surveille les utilisateurs. Mais ce pouvoir est à double tranchant. En Chine, le gouvernement a ordonné à Apple d’interdire la vente d’outils de protection de vie privée, comme les VPN, à l’exception de ceux dans lesquels des failles de sécurité ont délibérément été introduites pour permettre à l’État chinois d’écouter les utilisateurs. Étant donné qu’Apple utilise des contre-mesures technologiques – avec des mesures de protection légales – pour empêcher les clients d’installer des applications non autorisées, les propriétaires chinois d’iPhone ne peuvent pas facilement (ou légalement) se connecter à des VPN qui les protégeraient de l’espionnage de l’État chinois.
Zuboff décrit le capitalisme de surveillance comme un « capitalisme voyou ». Les théoriciens du capitalisme prétendent que sa vertu est d’agréger des informations relatives aux décisions des consommateurs, produisant ainsi des marchés efficaces. Le prétendu pouvoir du capitalisme de surveillance, de priver ses victimes de leur libre‑arbitre grâce à des campagnes d’influence surchargées de calculs, signifie que nos marchés n’agrègent plus les décisions des consommateurs parce que nous, les clients, ne décidons plus – nous sommes aux ordres des rayons de contrôle mental du capitalisme de surveillance.
Si notre problème c’est que les marchés cessent de fonctionner lorsque les consommateurs ne peuvent plus faire de choix, alors les verrous du copyright devraient nous préoccuper au moins autant que les campagnes d’influence. Une campagne d’influence peut vous pousser à acheter une certaine marque de téléphone, mais les verrous du copyright sur ce téléphone déterminent où vous pouvez l’utiliser, quelles applications peuvent fonctionner dessus et quand vous devez le jeter plutôt que le réparer.
Le classement des résultats de recherche et le droit au futur
Les marchés sont parfois présentés comme une sorte de formule magique : en découvrant des informations qui pourraient rester cachées mais sont transmises par le libre choix des consommateurs, les connaissances locales de ces derniers sont intégrées dans un système auto‑correcteur qui améliore les correspondances entre les résultats – de manière plus efficace que ce qu’un ordinateur pourrait calculer. Mais les monopoles sont incompatibles avec ce processus. Lorsque vous n’avez qu’un seul magasin d’applications, c’est le propriétaire du magasin, et non le consommateur, qui décide de l’éventail des choix. Comme l’a dit un jour Boss Tweed « peu importe qui gagne les élections, du moment que c’est moi qui fais les nominations ». Un marché monopolistique est une élection dont les candidats sont choisis par le monopole.
Ce trucage des votes est rendu plus toxique par l’existence de monopoles sur le classement des résultats. La part de marché de Google dans le domaine de la recherche est d’environ 90 %. Lorsque l’algorithme de classement de Google place dans son top 10 un résultat pour un terme de recherche populaire, cela détermine le comportement de millions de personnes. Si la réponse de Google à la question « Les vaccins sont-ils dangereux ? » est une page qui réfute les théories du complot anti-vax, alors une partie non négligeable du grand public apprendra que les vaccins sont sûrs. Si, en revanche, Google envoie ces personnes sur un site qui met en avant les conspirations anti-vax, une part non-négligeable de ces millions de personnes ressortira convaincue que les vaccins sont dangereux.
L’algorithme de Google est souvent détourné pour fournir de la désinformation comme principal résultat de recherche. Mais dans ces cas-là, Google ne persuade pas les gens de changer d’avis, il ne fait que présenter quelque chose de faux comme une vérité alors même que l’utilisateur n’a aucune raison d’en douter.
C’est vrai peu importe que la recherche porte sur « Les vaccins sont-ils dangereux ? » ou bien sur « meilleurs restaurants près de chez moi ». La plupart des utilisateurs ne regarderont jamais au-delà de la première page de résultats de recherche, et lorsque l’écrasante majorité des gens utilisent le même moteur de recherche, l’algorithme de classement utilisé par ce moteur de recherche aura déterminé une myriade de conséquences (adopter ou non un enfant, se faire opérer du cancer, où dîner, où déménager, où postuler pour un emploi) dans une proportion qui dépasse largement les résultats comportementaux dictés par les techniques de persuasion algorithmiques.
Beaucoup des questions que nous posons aux moteurs de recherche n’ont pas de réponses empiriquement correctes : « Où pourrais-je dîner ? » n’est pas une question objective. Même les questions qui ont des réponses objectives (« Les vaccins sont-ils dangereux ? ») n’ont pas de source empiriquement supérieure pour ces réponses. De nombreuses pages confirment l’innocuité des vaccins, alors laquelle afficher en premier ? Selon les règles de la concurrence, les consommateurs peuvent choisir parmi de nombreux moteurs de recherche et s’en tenir à celui dont le verdict algorithmique leur convient le mieux, mais en cas de monopole, nos réponses proviennent toutes du même endroit.
La domination de Google dans le domaine de la recherche n’est pas une simple question de mérite : pour atteindre sa position dominante, l’entreprise a utilisé de nombreuses tactiques qui auraient été interdites en vertu des normes antitrust classiques d’avant l’ère Reagan. Après tout, il s’agit d’une entreprise qui a développé deux produits majeurs : un très bon moteur de recherche et un assez bon clone de Hotmail. Tous ses autres grands succès, Android, YouTube, Google Maps, etc., ont été obtenus grâce à l’acquisition d’un concurrent naissant. De nombreuses branches clés de l’entreprise, comme la technologie publicitaire DoubleClick, violent le principe historique de séparation structurelle de la concurrence, qui interdisait aux entreprises de posséder des filiales en concurrence avec leurs clients. Les chemins de fer, par exemple, se sont vus interdire la possession de sociétés de fret qui auraient concurrencé les affréteurs dont ils transportent le fret.
Si nous craignons que les entreprises géantes ne détournent les marchés en privant les consommateurs de leur capacité à faire librement leurs choix, alors une application rigoureuse de la législation antitrust semble être un excellent remède. Si nous avions refusé à Google le droit d’effectuer ses nombreuses fusions, nous lui aurions probablement aussi refusé sa domination totale dans le domaine de la recherche. Sans cette domination, les théories, préjugés et erreurs (et le bon jugement aussi) des ingénieurs de recherche et des chefs de produits de Google n’auraient pas eu un effet aussi disproportionné sur le choix des consommateurs..
Cela vaut pour beaucoup d’autres entreprises. Amazon, l’entreprise type du capitalisme de surveillance, est évidemment l’outil dominant pour la recherche sur Amazon, bien que de nombreuses personnes arrivent sur Amazon après des recherches sur Google ou des messages sur Facebook. Évidemment, Amazon contrôle la recherche sur Amazon. Cela signifie que les choix éditoriaux et intéressés d’Amazon, comme la promotion de ses propres marques par rapport aux produits concurrents de ses vendeurs, ainsi que ses théories, ses préjugés et ses erreurs, déterminent une grande partie de ce que nous achetons sur Amazon. Et comme Amazon est le détaillant dominant du commerce électronique en dehors de la Chine et qu’elle a atteint cette domination en rachetant à la fois de grands rivaux et des concurrents naissants au mépris des règles antitrust historiques, nous pouvons reprocher à ce monopole de priver les consommateurs de leur droit à l’avenir et de leur capacité à façonner les marchés en faisant des choix raisonnés.
Tous les monopoles ne sont pas des capitalistes de surveillance, mais cela ne signifie pas qu’ils ne sont pas capables de façonner les choix des consommateurs de multiples façons. Zuboff fait l’éloge d’Apple pour son App Store et son iTunes Store, en insistant sur le fait qu’afficher le prix des fonctionnalités de ses plateformes était une recette secrète pour résister à la surveillance et ainsi créer de nouveaux marchés. Mais Apple est le seul détaillant autorisé à vendre sur ses plateformes, et c’est le deuxième plus grand vendeur d’appareils mobiles au monde. Les éditeurs de logiciels indépendants qui vendent sur le marché d’Apple accusent l’entreprise des mêmes vices de surveillance qu’Amazon et autres grands détaillants : espionner ses clients pour trouver de nouveaux produits lucratifs à lancer, utiliser efficacement les éditeurs de logiciels indépendants comme des prospecteurs de marché libre, puis les forcer à quitter tous les marchés qu’ils découvrent.
Avec l’utilisation des verrous de copyright, les clients qui possèdent un iPhone ne sont pas légalement autorisés à changer de distributeurs d’applications. Apple, évidemment, est la seule entité qui peut décider de la manière dont elle classe les résultats de recherche sur son store. Ces décisions garantissent que certaines applications sont souvent installées (parce qu’elles apparaissent dès la première page) et d’autres ne le sont jamais (parce qu’elles apparaissent sur la millionième page). Les décisions d’Apple en matière de classement des résultats de recherche ont un impact bien plus important sur les comportements des consommateurs que les campagnes d’influence des robots publicitaires du capitalisme de surveillance.

Les monopoles ont les moyens d’endormir les chiens de garde
Les idéologues du marché les plus fanatiques sont les seuls à penser que les marchés peuvent s’autoréguler sans contrôle de l’État. Pour rester honnêtes, les marchés ont besoin de chiens de garde : régulateurs, législateurs et autres représentants du contrôle démocratique. Lorsque ces chiens de garde s’endorment sur la tâche, les marchés cessent d’agréger les choix des consommateurs parce que ces choix sont limités par des activités illégitimes et trompeuses dont les entreprises peuvent se servir sans risques parce que personne ne leur demande des comptes.
Mais ce type de tutelle réglementaire a un coût élevé. Dans les secteurs concurrentiels, où la concurrence passe son temps à grappiller les marges des autres, les entreprises individuelles n’ont pas les excédents de capitaux nécessaires pour faire pression efficacement en faveur de lois et de réglementations qui serviraient leurs objectifs.
Beaucoup des préjudices causés par le capitalisme de surveillance sont le résultat d’une réglementation trop faible ou même inexistante. Ces vides réglementaires viennent du pouvoir des monopoles qui peuvent s’opposer à une réglementation plus stricte et adapter la réglementation existante pour continuer à exercer leurs activités telles quelles.
Voici un exemple : quand les entreprises collectent trop de données et les conservent trop longtemps, elles courent un risque accru de subir une fuite de données. En effet, vous ne pouvez pas divulguer des données que vous n’avez jamais collectées, et une fois que vous avez supprimé toutes les copies de ces données, vous ne pouvez plus risquer de les fuiter. Depuis plus d’une décennie, nous assistons à un festival ininterrompu de fuites de données de plus en plus graves, plus effrayantes les unes que les autres de par l’ampleur des violations et la sensibilité des données concernées.
Mais les entreprises persistent malgré tout à moissonner et conserver en trop grand nombre nos données pour trois raisons :
1. Elles sont enfermées dans cette course aux armements émotionnels (évoquée plus haut) avec notre capacité à renforcer nos systèmes de défense attentionnelle pour résister à leurs nouvelles techniques de persuasion. Elles sont également enfermées dans une course à l’armement avec leurs concurrents pour trouver de nouvelles façons de cibler les gens. Dès qu’elles découvrent un point faible dans nos défenses attentionnelles (une façon contre-intuitive et non évidente de cibler les acheteurs potentiels de réfrigérateurs), le public commence à prendre conscience de la tactique, et leurs concurrents s’y mettent également, hâtant le jour où tous les acheteurs potentiels de réfrigérateurs auront été initiés à cette tactique.
2. Elles souscrivent à cette belle croyance qu’est le capitalisme de surveillance. Les données sont peu coûteuses à agréger et à stocker, et les partisans, tout comme les opposants, du capitalisme de surveillance ont assuré aux managers et concepteurs de produits que si vous collectez suffisamment de données, vous pourrez pratiquer la sorcellerie du marketing pour contrôler les esprits ce qui fera grimper vos ventes. Même si vous ne savez pas comment tirer profit de ces données, quelqu’un d’autre finira par vous proposer de vous les acheter pour essayer. C’est la marque de toutes les bulles économiques : acquérir un bien en supposant que quelqu’un d’autre vous l’achètera à un prix plus élevé que celui que vous avez payé, souvent pour le vendre à quelqu’un d’autre à un prix encore plus élevé.
3. Les sanctions pour fuite de données sont négligeables. La plupart des pays limitent ces pénalités aux dommages réels, ce qui signifie que les consommateurs dont les données ont fuité doivent prouver qu’ils ont subi un préjudice financier réel pour obtenir réparation. En 2014, Home Depot a révélé qu’ils avaient perdu les données des cartes de crédit de 53 millions de ses clients, mais a réglé l’affaire en payant ces clients environ 0,34 $ chacun – et un tiers de ces 0,34 $ n’a même pas été payé en espèces. Cette réparation s’est matérialisée sous la forme d’un crédit pour se procurer un service de contrôle de crédit largement inefficace.
Mais les dégâts causés par les fuites sont beaucoup plus importants que ce que peuvent traiter ces règles sur les dommages réels. Les voleurs d’identité et les fraudeurs sont rusés et infiniment inventifs. Toutes les grandes fuites de données de notre époque sont continuellement recombinées, les ensembles de données sont fusionnés et exploités pour trouver de nouvelles façons de s’en prendre aux propriétaires de ces données. Toute politique raisonnable, fondée sur des preuves, de la dissuasion et de l’indemnisation des violations ne se limiterait pas aux dommages réels, mais permettrait plutôt aux utilisateurs de réclamer compensation pour ces préjudices à venir.
Quoi qu’il en soit, même les réglementations les plus ambitieuses sur la protection de la vie privée, telles que le règlement général de l’UE sur la protection des données, sont loin de prendre en compte les conséquences négatives de la collecte et de la conservation excessives et désinvoltes des données par les plateformes, et les sanctions qu’elles prévoient ne sont pas appliquées de façon assez agressive par ceux qui doivent les appliquer.
Cette tolérance, ou indifférence, à l’égard de la collecte et de la conservation excessives des données peut être attribuée en partie à la puissance de lobbying des plateformes. Ces plateformes sont si rentables qu’elles peuvent facilement se permettre de détourner des sommes gigantesques pour lutter contre tout changement réel – c’est-à-dire un changement qui les obligerait à internaliser les coûts de leurs activités de surveillance.
Et puis il y a la surveillance d’État, que l’histoire du capitalisme de surveillance rejette comme une relique d’une autre époque où la grande inquiétude était d’être emprisonné pour un discours subversif, et non de voir son libre‑arbitre dépouillé par l’apprentissage machine.
Mais la surveillance d’État et la surveillance privée sont intimement liées. Comme nous l’avons vu lorsque Apple a été enrôlé par le gouvernement chinois comme collaborateur majeur de la surveillance d’État. La seule manière abordable et efficace de mener une surveillance de masse à l’échelle pratiquée par les États modernes, qu’ils soient « libres » ou autocratiques, est de mettre sous leur coupe les services commerciaux.
Toute limitation stricte du capitalisme de surveillance paralyserait la capacité de surveillance d’État, qu’il s’agisse de l’utilisation de Google comme outil de localisation par les forces de l’ordre locales aux États-Unis ou du suivi des médias sociaux par le Département de la sécurité intérieure pour constituer des dossiers sur les participants aux manifestations contre la politique de séparation des familles des services de l’immigration et des douanes (ICE).
Sans Palantir, Amazon, Google et autres grands entrepreneurs technologiques, les flics états-uniens ne pourraient pas espionner la population noire comme ils le font, l’ICE ne pourrait pas gérer la mise en cage des enfants à la frontière américaine et les systèmes d’aides sociales des États ne pourraient pas purger leurs listes en déguisant la cruauté en empirisme et en prétendant que les personnes pauvres et vulnérables n’ont pas droit à une aide. On peut attribuer à cette relation symbiotique une partie de la réticence des États à prendre des mesures significatives pour réduire la surveillance. Il n’y a pas de surveillance d’État de masse sans surveillance commerciale de masse.
Le monopole est la clé du projet de surveillance massive d’État. Il est vrai que les petites entreprises technologiques sont susceptibles d’être moins bien défendues que les grandes, dont les experts en sécurité font partie des meilleurs dans leur domaine, elles disposent également d’énormes ressources pour sécuriser et surveiller leurs systèmes contre les intrusions. Mais les petites entreprises ont également moins à protéger : moins d’utilisateurs, des données plus fragmentées sur un plus grand nombre de systèmes et qui doivent être demandées une par une par les acteurs étatiques.
Un secteur technologique centralisé qui travaille avec les autorités est un allié beaucoup plus puissant dans le projet de surveillance massive d’État qu’un secteur fragmenté composé d’acteurs plus petits. Le secteur technologique états-unien est suffisamment petit pour que tous ses cadres supérieurs se retrouvent autour d’une seule table de conférence dans la Trump Tower en 2017, peu après l’inauguration de l’immeuble. La plupart de ses plus gros acteurs candidatent pour remporter le JEDI, le contrat à 10 milliards de dollars du Pentagone pour mettre en place une infrastructure de défense commune dans le cloud. Comme d’autres industries fortement concentrées, les géants de la tech font pantoufler leurs employés clés dans le service public. Ils les envoient servir au Ministère de la Défense et à la Maison Blanche, puis engagent des cadres et des officiers supérieurs de l’ex-Pentagone et de l’ex-DOD pour travailler dans leurs propres services de relations avec les gouvernements.
Ils ont même de bons arguments pour ça : après tout, quand il n’existe que quatre ou cinq grandes entreprises dans un secteur industriel, toute personne qualifiée pour contrôler la réglementation de ces entreprises a occupé un poste de direction dans au moins deux d’entre elles. De même, lorsqu’il n’y a que cinq entreprises dans un secteur, toute personne qualifiée pour occuper un poste de direction dans l’une d’entre elles travaille par définition dans l’une des autres.