Demain, une science citoyenne dans une société pair à pair ?
De simples citoyens ont-ils un rôle à jouer dans les sciences, où ils sont pour l’instant contingentés au mieux à des fonctions subalternes ?
On voit d’ici se lever d’inquiets sourcils à l’énoncé du simple terme de science citoyenne, tant la communauté scientifique se vit comme distincte de l’ensemble du corps social par ses missions, ses méthodes et son éthique. Pourtant un certain nombre d’expériences, de projets et même de réalisations montrent que la recherche scientifique universitaire peut tirer un profit important de sa collaboration avec les citoyens motivés, lesquels en retour élèveront leur niveau de connaissances tout en ayant un droit de regard sur la recherche.
Réconcilier citoyens et universitaires scientifiques, longtemps une utopie, est rendu aujourd’hui possible par des objets technologiques désormais beaucoup plus accessibles à chacun.
Cela ne va pas sans perplexité et crainte de dégrader les principes fondamentaux de méthode et d’éthique qui guident le travail scientifique, mais des systèmes de contrôle existent : de même que du code open source peut être révisé par des spécialistes du code, la science citoyenne peut être évaluée par des scientifiques (qui d’ailleurs ont eux-mêmes l’habitude d’être évalués par des pairs).
D’autres conditions sont également nécessaires : le partage mutuel des connaissances nécessite le pair à pair, des licences permissives, un élèvement du niveau de connaissances de la population et bien entendu l’extension des biens communs scientifiques.
Telles sont les problématiques explorées de façon approfondie par Diana Wildschut dans le long article universitaire que l’équipe Framalang vous propose.
Alors, pouvons-nous imaginer comme l’auteure un futur où au sein d’une société de pair à pair l’échange collaboratif mutuel fasse de la science un bien commun ?
La nécessité d’une science citoyenne pour aller vers une société de pair à pair durable
Article original de Diana Wildschut sur ScienceDirect : The need for citizen science in the transition to a sustainable peer-to-peer-society
Traduction Framalang : Bam92, dodosan, goofy, jaaf, lumpid, lyn, mo, Opsylac, simon
L’essentiel de l’article
Notre monde est en transition vers une société de pair à pair caractérisée par une nouvelle façon de produire les choses, des logiciels à l’alimentation, en passant par les villes et la connaissance scientifique. Cela nécessite un nouveau rôle pour la science.
Plutôt que de se focaliser sur la production de connaissances pour les ONG, les gouvernements et les entreprises, les scientifiques devraient prendre conscience que les citoyens seront les décideurs dans une future société de pair à pair (p2p), produire des connaissances durables et accessibles, et travailler ensemble aux côtés des scientifiques citoyens.
Les citoyens ont démontré leur capacité à définir leurs propres sujets de recherche, à monter leurs propres projets, à s’éduquer et à gérer des projets complexes. Il est temps pour eux d’être pris au sérieux.
Il existe toujours un grand fossé entre les citoyens et les scientifiques universitaires quand il est question de partage des connaissances. Les données collectées par des citoyens ne sont presque jamais utilisées par les scientifiques universitaires, et les résultats de la recherche scientifique restent en grande part cachés derrière des barrières de péage.
Si nous voulons qu’une transition durable prenne place, nous devons faire tomber les barrières entre la science et le public. Les préoccupations des citoyens doivent être prises au sérieux et leurs connaissances utilisées et valorisées.
1. Introduction
Notre monde est en cours de transition vers une société de pair à pair (p2p), caractérisée par une nouvelle façon de produire tout, des logiciels à l’alimentation, en passant par les villes et la connaissance scientifique (Bauwens 2012). Dans une société de pair à pair, des réseaux d’individus, ou de pairs, prennent en charge les tâches qui étaient précédemment entre les mains des institutions. Cela nécessite un nouveau rôle pour la science. Plutôt que de se focaliser sur la production de connaissances pour les ONG, les gouvernements et les entreprises, les scientifiques devraient prendre conscience que les citoyens seront les nouveaux décideurs dans une future société de pair à pair, produire des connaissances durables et accessibles et travailler ensemble avec des scientifiques citoyens.
Dans cet essai, quand je parle de citoyens, je parle des non-professionnels qui s’engagent dans ce qui les touche directement, qui peut être une ville, une rue, l’environnement, le système démocratique, etc. Quand je parle de scientifiques citoyens je parle des gens qui pratiquent la science en dehors d’un environnement universitaire ou du contexte industriel, et qui ont reçu ou non une formation scientifique réelle. Ma définition d’un système néolibéral est un système avec un marché libre, un petit gouvernement dans un monde globalisé.
En regardant autour de nous, nous voyons de vieilles structures échouer. L’efficacité des ONG est mise en doute (Edwards & Hulme, 1996) et elles semblent essentiellement préoccupées par leur propre survie. Elles en sont restées aux méthodes des années 80 ; elles se déguisent en porcs ou en abeilles, ou portent des masques à gaz et se présentent comme un petit groupe guère impressionnant dans le quartier général d’entreprises ou de gouvernements. Leurs causes sont légitimes et les problèmes qu’elles mettent à l’ordre du jour sont urgents, mais leurs méthodes sont complètement inadaptées au monde dans lequel nous vivons. L’attention des gouvernements néolibéraux n’est plus focalisée sur le bien-être des citoyens, elle s’est depuis longtemps déplacée vers les intérêts des entreprises (Chomsky,1999 ; von Werlhof, 2008). Les intérêts à long terme, y compris ceux de la science, en pâtissent (Saltelli & Giampietro, 2017). Les entreprises n’ont pas l’obligation légale d’agir dans l’intérêt public, et n’ont pas tendance à le faire si cela s’oppose à leurs intérêts économiques à court terme (Banerjee, 2008 ; Chomsky, 1999).
L’avenir de la planète pourrait bien se retrouver entre les mains de petits groupes de citoyens ou d’individus qui bâtissent une nouvelle société à côté de l’existante en jetant les bases d’initiatives durables qui seraient interconnectées en réseaux de pair à pair. Dès à présent, la science procure des technologies qui donnent aux gens le pouvoir de faire leurs propres recherches, en utilisant leurs smartphones, leurs webcams et leurs ordinateurs portables (Bonney et al., 2014). Mais il y a toujours un large fossé entre les citoyens et les scientifiques universitaires quand on en arrive au partage des connaissances. Les connaissances collectées par les citoyens sont très peu utilisées par les scientifiques universitaires, et les résultats de la recherche scientifique sont le plus souvent cachés derrières des barrières de péage.
Si nous voulons qu’une transition durable prenne place, nous devons abaisser ces barrières entre la science et le public. Les préoccupations des citoyens doivent être prises au sérieux et leurs connaissances utilisées et jugées à leur juste valeur (Irwin, 1995).
Dans cet essai je soutiens que les citoyens sont prêts à produire une science valable, et à utiliser et comprendre la science produite par les scientifiques universitaires. Ils sont prêts à utiliser la science pour combler certains fossés existants que les gouvernements, les entreprises et les ONG laissent à l’abandon.

2. La science citoyenne
Au début de la révolution scientifique, quiconque ayant du temps libre pouvait regarder les étoiles, accumuler des données et faire des prévisions. On n’avait pas besoin d’équipements ou de compétences mathématiques. Les scientifiques étaient souvent des fermiers, artistes ou hommes d’État. Ce n’était pas des spécialistes mais plutôt des généralistes.
À partir de la seconde moitié du 19e siècle, la science est devenue une affaire de spécialistes, qui utilise des équipements de pointe ainsi que les mathématiques, et nécessite des années d’études universitaires. La science n’était plus quelque chose que n’importe qui pouvait pratiquer (Vermij, 2006).
Ces dernières décennies, les ordinateurs sont devenus bon marché et puissants. Internet permet à tous d’accéder à des données ainsi qu’à des formations. Le développement de microcontrôleurs programmables bon marché a permis à de nombreux profanes de créer leur propre électronique. La popularité de ces microcontrôleurs peut être attribuée principalement à Arduino, une carte microcontrôleur, open source, bon marché, avec un environnement de programmation en ligne.
Programmer de telles cartes est facile grâce à l’abondance d’exemples, tutoriels et codes fournis par la communauté. Les cartes peuvent être connectées à un circuit, en respectant des schémas disponibles en ligne. La communauté Arduino maintient une excellente documentation pour les débutants et les experts sur www.arduino.cc.
La possibilité de se procurer des capteurs peu coûteux est le prochain problème à résoudre. L’utilisation de capteurs combinée avec ATMegas (les microcontrôleurs utilisés sur les cartes Arduino) est très populaire. Les gens peuvent mesurer autour d’eux tout ce qui leur passe par la tête. Ils collectent toutes les données et cherchent à les comparer à celles d’autres personnes. Cela crée un besoin de plate-formes open data permettant de partager ces données en ligne. Des communautés se forment non seulement autour du matériel, mais aussi autour de sujets de recherche. Par exemple, spectralworkbench.org, où les personnes partagent leurs analyses spectrales de différentes sources lumineuses. Ils utilisent un spectromètre fait d’un morceau de carton et d’un morceau de CD connecté à une webcam. Ils déposent leurs spectres dans la base de données, qui contient des résultats venant à la fois de spectrographes professionnels et amateurs. Il s’agit d’un mélange de spectres utiles et d’images floues. La base de données est alimentée essentiellement par des passionnés curieux, et à mesure que sa taille augmente, elle devient une ressource précieuse pour déterminer des éléments chimiques. Dans la section « Apprendre » du site internet, on peut découvrir l’usage qui est fait des données. Des citoyens l’utilisent pour mesurer la contamination de la nourriture, la présence d’OGM (Critical Art Ensemble, 2003), la quantité d’azote dans des terres agricoles, le niveau de pollution de l’air, etc. Cela les amène à porter un regard critique sur les informations obtenues depuis des sources officielles, comme les gouvernements et les industriels.

Une avancée récente est le Lab-on-a-Chip (Ndt : littéralement, laboratoire-sur-une-puce), un petit laboratoire qui peut être utilisé pour des analyses de fluides. Le Lab-on-a-Chip est bon marché et facile à utiliser. Le but est d’en faire un labo si facile à utiliser que n’importe qui puisse s’en servir sans connaissances préalables. Dans le domaine médical, il permet aux patients de faire leur propre diagnostic in vitro. Il permet aussi de raccourcir le temps nécessaire pour prendre une décision car le patient qui possède déjà le laboratoire à la maison n’a pas à attendre un rendez-vous (von Lode, 2005).
Un Lab-on-a-Chip est une petite plaque de verre sur laquelle sont gravés de minuscules canaux fluides. Elle est montée accolée à un capteur semi-conducteur, connecté à un microcontrôleur qui effectue les analyses ou envoie les données à un outil d’analyse.
Le boom récent des Fablabs et des ateliers ouverts pour la fabrication numérique, qui trouvent leur origine au MIT (Gershenfeld, 2012), a permis au citoyen scientifique de graver ses propres systèmes Lab-on-a-Chip, en lui donnant accès à des ciseaux lasers et des imprimantes 3D. En utilisant Arduino et du logiciel open source pour l’analyse, il peut maintenant effectuer lui-même des analyses de fluides chimiques complexes.
Ces nouvelles technologies sont désormais à la disposition de tous, pour autant qu’on ne soit pas effrayé par la technologie. De nouveaux outils voient le jour sous forme d’outils pour jeux vidéo et il faut un peu de temps avant que des gens les rendent accessibles à un public plus large en les dotant d’interfaces conviviales. Ce processus est déjà entamé et de nombreux outils deviennent utiles à ceux qui sont intéressés à les utiliser plutôt qu’à les faire fonctionner.
Ce ne sont pas seulement les données collectées par les citoyens, mais aussi leurs connaissances, leur intelligence, leur créativité et les réseaux sociaux, qui ont de la valeur pour les scientifiques universitaires. Dans beaucoup de projets de science citoyenne menés par des scientifiques universitaires, seul le temps du participant et la puissance de traitement de son ordinateur sont utilisés. Généralement, le participant n’est utilisé que pour la collecte des données et leur classement. L’intelligence du participant ou sa créativité sont rarement nécessaires et le projet n’offre que des opportunités très limitées pour une amélioration personnelle (Rotman et al., 2012). Parfois, une formation est disponible qui permet au participant d’apprendre à reconnaître des motifs, des espèces et des types de galaxies, mais il n’est presque jamais invité à participer à la conception de la recherche.
Les citoyens ont de précieuses connaissances souvent hors de portée des scientifiques universitaires (voir aussi Pereira et Saltelli). Ils disposent d’une connaissance locale que Warren (Warren, 1991) décrit comme
« une connaissance qui est particulière à une culture ou à une société donnée). […] C’est le fondement de la prise de décision à un niveau local en agriculture, pour les soins médicaux, la préparation alimentaire, l’éducation, la gestion des ressources naturelles, et une foultitude d’autres activités dans les communautés rurales. »
Mais bien sûr, il n’y a pas que dans les communautés rurales que la connaissance locale est importante. Les citoyens sont bien plus capables de participer qu’il ne leur est permis de le montrer (Fischer, 2000). De nombreux gouvernements locaux réalisent maintenant qu’ils ont besoin de l’apport de leurs citoyens pour gouverner leur cité à la satisfaction de ceux-ci. Commencer à travailler avec des citoyens critiques n’est pas une étape facile à franchir, mais dès que les citoyens sont impliqués dans la fourniture des connaissances qui permettront la prise de décision, ils sont plus enclins à accepter les conséquences et les mesures qui en résultent.
Dans la ville néerlandaise d’Amersfoot, le gouvernement local avait besoin de données sur les impacts du changement climatique à une échelle très locale, où seulement des données globales étaient disponibles. Après avoir assisté à une conférence sur la science citoyenne, il a décidé de ne pas confier le travail à un consultant, mais de trouver un groupe de citoyens intéressés par l’investigation sur les changements climatiques dans leur voisinage. Le groupe a été chargé de mettre en place la recherche, de décider quels indicateurs devaient être mesurés, qui faire participer et comment publier les résultats. Ils ont maintenant démarré leur projet dont les résultats sont visibles sur www.meetjestad.net (Meet je Stad, 2015).
Les scientifiques universitaires voient les avantages à coopérer avec les citoyens, non seulement pour la valeur qualitative de leurs connaissances locales, mais aussi pour leurs réseaux sociaux étendus. Les citoyens actifs savent ce qui se passe dans leur communauté et peuvent dire quels investisseurs devraient être impliqués. Aussi doivent-ils être impliqués au tout début d’un projet de recherche, sinon il sera trop tard pour tirer profit de cette partie de leurs connaissances. Il y a vingt ans, Alan Irwin (Irwin, 1995) prônait la réunion des mondes de la science universitaire et de la science citoyenne. Aujourd’hui le besoin et les possibilités se sont accrus. Les scientifiques citoyens disposent de plus d’outils pour créer de la connaissance, l’infrastructure existe pour la partager et nous avons quelques gros problèmes à résoudre pour lesquels nous avons besoin de toute l’aide disponible.
Et Cash et al. (2003) de conclure que « […] les efforts pour mobiliser la science et la technologie pour la durabilité ont plus de chances d’être efficaces si on gère les frontières entre la connaissance et l’action d’une façon qui améliore à la fois l’importance, la crédibilité et la légitimité de l’information produite. » De nombreux citoyens sont prêts à l’action ou déjà actifs. Ils ont besoin de connaissances scientifiques.

Stockholm Public Library CC-BY Samantha Marx
3. Accès libre
Pour cet essai, j’avais prévu de n’utiliser que des références à des articles disponibles en accès libre, juste pour le principe. Le fait que cela se soit avéré impossible est en soi encore plus parlant que je ne l’aurais voulu. Pour être en mesure de rédiger un essai comme celui-ci, un scientifique citoyen serait obligé de contacter par e-mail des amis travaillant dans des universités, d’utiliser le hashtag Twitter #icanhazpdf (lepdfsivouplé) et d’écrire des mails à des auteurs, en espérant recevoir leurs articles en retour.
Certains des articles en accès restreint, comme celui-ci, parlent de la science citoyenne, dont certains pourraient directement intéresser les citoyens. Mais les citoyens qui luttent pour construire leurs propres projets scientifiques sans budget ont peu de chances de pouvoir investir 41,95 $ dans un article dont ils ne sont même pas certains qu’il leur sera utile. Dans la plupart des cas, la science qui traite de science citoyenne n’atteindra pas des citoyens pratiquant les sciences, ni des citoyens ayant besoin d’un apport scientifique.
Dans la société de pair à pair, il est tacitement convenu que quiconque utilise les services d’une autre personne, restitue quelque chose à la communauté dont il se nourrit. Aussi, faire de la recherche en se basant sur de la science citoyenne et ne pas en partager les résultats serait une violation de ces règles tacites.
Les droits d’auteur et les brevets empêchent la mise à disposition et le développement de la connaissance. On pense souvent que les droits d’auteur sont le seul moyen de protéger les auteurs, mais il existe d’autres moyens de protéger les droits des auteurs et des développeurs de produits logiciels open source. Certaines institutions développent leurs propres licences pour les logiciels open source (MIT Public License, 1988) ou pour le matériel open source (CERN Open Hardware License, 2011). Elles utilisent leurs connaissances des droits d’auteur et de la propriété intellectuelle pour aider les gens qui veulent ajouter leurs données, idées, conceptions et produits au domaine public. Une fois là, cela pourra être utilisé comme base par n’importe qui (selon la licence), mais ne pourra jamais être réclamé, breveté ou sorti du domaine public. Chacune des licences propose ses propres solutions, laissant au développeur le choix de qui peut utiliser son produit et dans quelles conditions. Certaines licences permettent une utilisation commerciale du produit, d’autres non. Certaines demandent l’attribution à l’auteur original. D’autres demandent que les sous-produits soient publiés sous la même licence que l’original.
Concevoir ces licences et les rendre disponibles est une manière très appréciée pour les institutions de restituer quelque chose aux biens communs.

4. Éducation
L’existence de citoyens instruits est une condition nécessaire pour avoir une démocratie qui fonctionne (Hils Hauge et Barwell), et ça l’est tout autant dans une société de pair à pair. Néanmoins, aux Pays-Bas par exemple [ndt : l’auteure est néerlandaise], les études universitaires ne sont pas facilement accessibles à tous les citoyens qui pourraient y prétendre. Les gens qui ont déjà un diplôme payent des frais d’inscription très élevés. Étudier à temps partiel est déconseillé et dans la majorité des disciplines ce n’est même pas possible. Cela entre en conflit avec l’idéal « d’éducation tout au long de la vie » qui est diffusé par les institutions éducatives, et cela ne permet pas d’avoir des citoyens ouverts à tout et bien informés. Cependant, nous comptons sur eux pour faire des choix éclairés au moment de voter (Westheimer et Kahne, 2000). Pour les gouvernements, la mode est de vouloir des citoyens impliqués, mais très peu d’efforts sont faits pour leur donner les outils et informations nécessaires.
Mais maintenant, une part croissante des citoyens est en train de trouver le chemin vers des études plus accessibles et moins structurées. De nouvelles méthodes de partage des connaissances sont inventées, le plus souvent en utilisant Internet. Les cours magistraux de certaines universités sont disponibles en streaming. Cela peut aider pour compléter une formation, mais sans exercices cela reste incomplet. Khan Academy.org est un site web où vous pouvez vous former vous-mêmes dans n’importe quelle matière du lycée à l’université. Il utilise un algorithme intelligent qui permet aux étudiants de garder la trace de leur progrès. Néanmoins la Khan Academy fonctionne essentiellement du sommet vers la base, une personne donne un cours et un étudiant consomme cette connaissance. OpenTOKO (http://web.archive.org/web/20140927205928/http://www.opentoko.org/) a une approche différente.
Un thème est proposé en ligne, des experts et des novices s’y inscrivent, créant un groupe de connaissances partagées qui se réunit pour un après-midi. La dynamique est très variable, parfois un TOKO est planifié largement à l’avance, parfois dans un délai très court. Les thèmes peuvent être populaires ou ésotériques ; on peut être très nombreux ou seulement deux ou trois. Souvent, il s’avère que les experts apprennent des compétences, des connaissances ou des questions des débutants. Les experts acquièrent une meilleure compréhension du thème, et cela donne au débutant un bon départ sur le sujet. OpenTOKO doit encore être amélioré. Un système de référencement automatique doit être créé, permettant à chacun de suggérer un thème, de s’inscrire comme expert ou novice, de proposer un lieu ou une date. Quand toutes les conditions sont réunies, un OpenTOKO est automatiquement créé.
L’inscription est gratuite, tout le monde en profite en améliorant ses connaissances. Les thèmes abordés sont divers : langage de programmation, électronique, mathématiques et statistiques mais aussi comment tricoter des chaussettes ou faire pousser des légumes, tout dépend de ce que souhaitent les participants. Les scientifiques qui souhaitent faire participer des citoyens à leurs cours, n’ont pas besoin de simplifier leurs résultats ou leur langage. Les citoyens peuvent apprendre eux-mêmes et devenir familiers de la terminologie utilisée dans les différents domaines scientifiques.
Wikipédia peut être utilisée comme point de départ de collecte d’informations sur pratiquement tous les sujets. À partir de là, il est facile de trouver des publications scientifiques, mais à nouveau les citoyens se heurtent souvent à des ressources payantes.

5. Vers une société de pair à pair
On constate, au cours de la dernière décennie, une tendance au partage sur un mode de p2p : d’un individu vers les autres. En 1999, un adolescent a créé le logiciel Napster, qui permettait à tout le monde de partager des fichiers numériques (Carlsson et Gustavsson, 2001). Napster utilisait un serveur central. À cause de cela, l’industrie du disque, via des poursuites judiciaires, a pu fermer Napster. Les outils d’échange de musique de la génération suivante sont les réseaux P2P, dans lesquels les utilisateurs échangent directement leurs fichiers avec d’autres personnes. Ces réseaux ne sont pas hiérarchisés et sont difficiles à fermer. Brafman et Beckstrom (2006) compare ces organisations sans leader à des étoiles de mer, et les organisations hiérarchiques à des araignées ; si vous coupez la tête d’une araignée, elle meurt. L’étoile de mer, elle, n’a pas de tête. Coupez un bras et un nouveau bras se formera. Coupez l’étoile de mer en deux et vous obtiendrez deux étoiles de mer. Les réseaux P2P semblent indestructibles aussi longtemps qu’ils ont la volonté d’exister.
Bauwens et Lievens (2013) voient la transition vers une société de pair à pair comme l’inévitable prochaine étape du développement humain. Leur présentation de l’histoire de la société occidentale commence à l’époque romaine. À cette époque, 80 % des gens étaient des esclaves. La société romaine dépendait entièrement de ces esclaves, et en avait un besoin toujours plus important. Pour continuer d’augmenter le nombre d’esclaves, ils devaient continuer d’étendre leur empire. Finalement, cela devint plus cher que des solutions alternatives comme le métayage. Ils commencèrent donc à affranchir des esclaves, leur laissant cultiver la terre en échange d’un partage des récoltes. Cette pratique a évolué vers le système féodal qui a perduré plusieurs siècles.
L’industrialisation, au 19e siècle, a déplacé les travailleurs vers les villes, ces derniers achetant alors leur nourriture au lieu de la faire pousser. Les travailleurs ont reçu un salaire, le moment du capitalisme était venu. Dans le même temps, les gens prirent une place précise dans de grandes structures hiérarchisées.
Maintenant, l’automatisation a réduit la quantité de travail humain nécessaire à la production des besoins indispensables à nos sociétés. Et le spécialiste d’économie politique Skidelsky(2012) de conclure : « La vérité est que nous ne pouvons pas continuer à automatiser efficacement nos productions sans remettre en cause nos attitudes envers la consommation, le travail, les loisirs et la distribution des revenus. » Dans les sociétés occidentales, seule une petite part de notre travail sert à fournir les besoins fondamentaux de la société. La majorité des gens a un travail qui n’est pas vraiment indispensable (Graeber, 2013). La plupart d’entre eux en ont conscience, ce qui a souvent un impact négatif sur leur santé morale et physique.
On constate aussi une augmentation du nombre de personnes sans emploi pour qui l’ancien système est un échec. Ils ont été virés par leur ancien employeur, souvent après des décennies de travail dévoué et de loyauté. Une grande partie des gens virés sont devenus trop chers à cause de leur ancienneté. Les employeurs ont tendance à choisir des employés moins chers, plutôt que plus expérimentés. Ici, l’argent prime sur la qualité ou l’humanité.
Certains chômeurs choisissent désormais de faire les choses différemment, et se mettent à chercher un nouveau système plus respectueux des personnes et valorisant la qualité. Comme les esclaves affranchis, ils sont un nombre croissant dans nos sociétés à avoir l’énergie nécessaire pour commencer à travailler dans un nouveau système. Bauwens et Lievens appelle ce système « l’économie P2P », celle-ci est basée sur les échanges entre individus.
La combinaison d’un savoir disponible et d’une insatisfaction croissante face à la manière dont les gouvernements traitent les questions écologiques encourage les personnes à s’impliquer dans des expériences à l’échelle locale pour produire de l’énergie et de la nourriture, pour recycler les déchets et pour plus de démocratie et d’innovation sociale. Certaines de ces expériences échouent, mais d’autres sont des succès et rendent stables des alternatives locales et modestes qui peuvent inspirer les autres. Tout ne peut pas se faire facilement au niveau local. Il vaut mieux que la médecine spécialisée soit exercée dans un hôpital dédié. Les experts sont les plus à même de traiter les questions de droit, bien que le système des jurys populaires soit un peu plus P2P que les systèmes judiciaires avec uniquement des juges, et qu’il soit considéré comme juste dans de nombreux pays. Les processus de production que l’on dit plus efficaces à grande échelle, ne le sont peut-être pas tant que ça si tous les coûts réels relatifs au transport, aux infrastructures, aux ressources naturelles et aux déchets sont inclus dans le calcul. Souvent, ces « externalités » comme on les appelle, ne sont pas financées par les multinationales (Mansfield, 2011 ; Scherhorn, 2005).

6. Quand les systèmes se percutent
La société de pair à pair peut cohabiter avec la société capitaliste dans de nombreux cas, tout comme les scientifiques citoyens cohabitent avec les scientifiques universitaires. Il peut y avoir des conflits de nature financière, comme dans le cas des maisons de disques avec les réseaux p2p pour la distribution de musique, où les deux cotés essayent de maximiser leurs profits. Les situations les plus intéressantes, cependant, sont celles où les deux points de vue sont valables, mais incompatibles.
La société de pair à pair est basée sur la confiance acquise lors de travaux préalables. Si vous contribuez à la communauté, vous obtenez en retour du respect et de la confiance. Cependant, dans la société capitaliste, la confiance se base sur les diplômes. Si vous voulez un travail en tant qu’ingénieur informaticien, il vous faut avoir des diplômes et des qualifications pour prouver que vous pouvez écrire du code. Dans la société de pair à pair, vous prouvez que vous pouvez écrire du code en écrivant du code. Le code est open source afin que les utilisateurs puissent vérifier s’il fonctionne et que les experts puissent vérifier qu’il est bien écrit et ne contient pas de virus. Quand les deux mondes se rencontrent, ils sont souvent sceptiques sur l’approche de l’autre.
Certaines personnes voient les forces et faiblesses de chaque système, et un ingénieur informaticien peut avoir un emploi sans diplôme, s’il rencontre le bon responsable des ressources humaines. Le lien entre les deux mondes vient de ceux qui reconnaissent les possibilités de coopérer et ont un statut qui leur permet de s’écarter des règles en usage. Dans tous les cas, la manière pair à pair d’assurer la qualité ou la fiabilité d’un pair demandera plus d’efforts que pour un scientifique universitaire par exemple. Il faudra faire des recherches sur la personne, soit à travers un contact personnel, soit en regardant à sa réputation auprès de ses pairs et son travail. Pour des nouveaux venus, il s’agit de deux situations complètement différentes.
Mais que peut-on dire des autres différences entre les scientifiques citoyens et les scientifiques universitaires ? Pour faire de la vraie science, il faut travailler selon un certain nombre de règles, mais les citoyens peuvent n’en faire qu’à leur tête. Comment se positionnent-ils vis-à-vis de l’éthique ou de la qualité ? C’est ce qui inquiète de nombreux scientifiques universitaires. Les motivations des citoyens et la qualité de leur travail sont suspectes (Show, 2015). Même les projets montés et gérés par des scientifiques universitaires qui utilisent des données collectées par des volontaires ont du mal à se faire publier (Bonney et al, 2014).
Il est vrai que la science citoyenne n’a pas nécessairement un ensemble fixe de règles sur l’éthique ou les méthodes. Bien qu’il y ait quantité d’exemples de réseaux qui partagent une charte éthique ou une liste de méthodes [29], comme certains diy-biolabs (ndt : littéralement labo-bio à faire soi-même) (Diybio,2016) et makerspaces (espaces collaboratifs) (Fablab.nl), beaucoup n’y ont jamais pensé, n’en ont jamais discuté, ou même, ne s’y sont simplement pas intéressés. Mais tout comme n’importe quel programmeur peut vérifier du code informatique ouvert, n’importe quel scientifique universitaire peut vérifier si un projet de science citoyenne est bien fait, à l’aune des normes universitaires. Pour moi, cela ne veut pas dire que les normes universitaires doivent être celles qu’il faut utiliser pour évaluer la science citoyenne, mais qu’il est possible de le faire. Dans certains cas, les normes universitaires sont moins strictes que celle utilisées dans la science citoyenne.
Par exemple, dans la science conventionnelle, il n’est pas courant d’ouvrir l’ensemble des données, alors que c’est le cas dans la science citoyenne. De ce point de vue, la science citoyenne et plus reproductible et la fraude est plus facile à détecter. Les expériences des scientifiques citoyens sont souvent répétées et améliorées. Les scientifiques citoyens ne sont pas soumis à la pression de la publication (Saltelli et Giampetro, traitent du déchirement entre publier ou périr comme d’un ingrédient clé de la crise de la recherche scientifique), ils publient quand ils pensent avoir trouvé quelque chose d’intéressant. Le travail est ouvert au regard des pairs de la première tentative aux conclusions finales.
![]()
Les scientifiques citoyens publient plus facilement des résultats négatifs. Ils ne sont pas gênés par leurs erreurs. Les publications de résultats positifs contiennent aussi un chapitre sur les tentatives précédentes qui ont échoué, et un retour sur la cause de l’échec. Ces résultats négatifs sont, à mon avis, aussi valables que des résultats positifs, bien que dans la recherche scientifique conventionnelle il existe une forte propension à ne publier que des résultats positifs, ce qui rend la recherche scientifique universitaire incomplète (Dwan et al., 2008).
Les scientifiques citoyens sont souvent suspectés d’avoir des partis pris, des motivations ou des ordres du jour cachés. Nous savons désormais que les professionnels de la science ont aussi des partis pris. Les scientifiques citoyens sont même moins susceptibles d’avoir certains partis pris, comme ceux relatifs au prestige ou au financement, et ce goût pour les résultats positifs. Mais le fait que les scientifiques universitaires ne soient pas forcément meilleurs que n’importe quel scientifique citoyen ne signifie pas que nous devons ignorer les problèmes potentiels liés à la qualité des scientifiques citoyens. Afin de permettre plus de coopération entre les scientifiques citoyens et universitaires, nous devons insister sur la totale transparence concernant les conflits d’intérêt, tant pour les scientifiques universitaires que citoyens. Dans la recherche scientifique universitaire, il existe une saine discussion sur la qualité, les partis pris et les conflits d’intérêt. Dans la science citoyenne le sujet est difficilement évoqué, ce qui est une honte puisque certains partis pris sont moins susceptibles d’exister quand leur propriétaire en a conscience.
La qualité est souvent décrite comme être « adapté à la fonction ». Parfois, nous pouvons avoir besoin de données précises issues de capteurs onéreux. Dans de tels cas, la recherche universitaire pourrait aboutir à une meilleure qualité. Mais dans d’autre cas, nous pouvons avoir besoin d’une haute définition et ici de vastes groupes de citoyens sont plus à même de fournir de la haute qualité. La connaissance n’est adaptée au besoin que si elle est ouverte à ceux qui en ont besoin. Il est par conséquent important que les connaissances relatives au changement climatique et aux autres problèmes mondiaux soient totalement ouvertes.
Je pense qu’il serait bon que les scientifiques universitaires et citoyens aient un débat sur les raisons pour lesquelles des résultats de qualité sont utiles aux autres citoyens, aux décideurs politiques locaux et aux scientifiques universitaires suivant la fonction retenue. Si nous voulons partager les données entre les scientifiques citoyens et universitaires, ou entre les scientifiques citoyens et les décideurs, quelles sont les barrières et comment peut-on les dépasser ? Devons-nous trouver un ensemble de critères définissant la qualité (y compris l’accessibilité) qui soit satisfaisant pour les chercheurs scientifiques et gérable par les citoyens ?
7. Les biens communs
La plupart des enjeux soulevés dans les paragraphes précédents nous amènent à la notion de biens communs. Les biens communs incluent tout ce qui appartient à tout le monde, par exemple l’atmosphère, l’écosystème planétaire, la culture et les connaissances humaines.
La majeure partie de la richesse mondiale privée existe parce que les biens ou les services qui appartiennent aux biens communs peuvent souvent être accaparés sans payer, et qu’il n’y a pas d’obligation de restituer quelque chose aux biens communs.
Cela concerne les entreprises qui polluent ou s’approprient des ressources, les sociétés de divertissement commerciales qui prennent des contes traditionnels dans le domaine public pour les placer sous droits d’auteur, les entreprises qui brevètent des gènes qui sont en grande partie naturels, ainsi que les recherches scientifiques qui utilisent des contributions en provenance des biens communs, sans jamais restituer leurs résultats aux biens communs (Barnes, 2006).
Le changement climatique, la pollution et l’épuisement des ressources sont le problème de tout le monde. Ces problèmes font autant partie des biens communs que les solutions. Leur résolution n’a pas à dépendre d’une initiative privée. En partageant le savoir entre scientifiques universitaires et citoyens, nous pouvons travailler ensemble sur ces questions.
8. Débat et conclusion
Les scientifiques citoyens ne sont pas des anges envoyés de l’au-delà pour sauver la science. Ils ne sont pas là non plus pour détruire les institutions universitaires et prendre le pouvoir. Ils ont leurs propres programmes, imperfections et partis pris, comme les scientifiques universitaires. Une meilleure prise de conscience de ces partis pris peut améliorer la qualité de leur travail. Chaque débat sur la qualité doit être respectueux et ouvert, et tenir compte des limites de la science citoyenne et de ses pratiquants. Nous savons que les citoyens ne prennent pas toujours la bonne décision quand ils votent, ne votent pas ou achètent quelque chose. Donc pourquoi devrait-on compter sur eux pour résoudre les problèmes de la société ? On ne doit rien attendre de personne, mais nous devons impliquer toute l’aide disponible, et si les gens sont intrinsèquement motivés, nous ne devons pas les marginaliser
Bien que les groupes qui utilisent la science citoyenne pour résoudre les problèmes, dont à leur avis les institutions ne s’occupent pas, soient encore petits, l’intérêt qu’ils reçoivent des autres et la disponibilité des outils et des infrastructures faciles à utiliser peuvent conduire à des groupes plus nombreux et plus grands, et à un réseau plus fort d’individus. Ce que nous voyons actuellement est une tendance à l’indépendance des personnes qui pensent et qui font. Ils développeront peut-être un jour leurs propres institutions, mais risquent aussi de rester des groupes faiblement liés d’individus isolés.
C’est la même chose en ce qui concerne la transition vers une société de pair à pair. La transition est en cours. Elle n’a pas besoin d’une révolution mais elle croît à côté du système actuel. Elle accélère là où le système actuel échoue. Elle a besoin de cet élan, et si le système actuel résout soudain les problèmes, ou si le système P2P n’y arrive pas, cette tendance pourrait s’arrêter. Pour le moment, ça grandit.
Les citoyens ont envie de contribuer à trouver des solutions aux problèmes que le système néo-libéral échoue à résoudre, comme les problèmes d’environnement, de représentation démocratique (publiclab.org). Les citoyens partagent de plus en plus pour la prise de décision à mesure que notre société évolue vers un modèle P2P (Public Laboratory, 2016).
Les citoyens ont prouvé qu’ils étaient capables de formuler leurs propres thèmes de recherche, de monter leurs propres projets, de se former et de gérer des projets complexes. Il est temps de les prendre au sérieux.
Les scientifiques contribuent déjà à l’émancipation des citoyens en développant par exemple de nouvelles technologies et licences, mais celles-ci découlent de la connaissance scientifique. Il est aussi nécessaire de partager la connaissance elle-même. Si les scientifiques veulent que leurs résultats soient utiles, ils doivent les rendre accessibles aux citoyens.
Les connaissances créées par les citoyens peuvent être très utiles aux chercheurs universitaires. Néanmoins, l’initiative de donner quelque chose en retour à la communauté doit être prise par les chercheurs universitaires qui s’engagent dans des projets de science citoyenne.
Nous ne sommes pas loin de nous débarrasser de tout ce qui entrave la voie de la production collaborative de connaissances utiles. Il faudra des ajustements de part et d’autre pour rassembler la science citoyenne et la science universitaire, mais nous pouvons joindre nos efforts afin de rendre possible cette transition durable.

Bibliographie
Banerjee, S. B. (2008). « Corporate Social Responsibility: The Good, the Bad and the Ugly ». Critical Sociology, 34(1), 51‑79. Accessible en ligne.
Barnes, P. (2006). « Capitalism 3.0: A Guide to Reclaiming the Commons ». San Francisco: Berrett-Koehler Publishers.
Bauwens, M. (2012). « Blueprint for P2P Society: The Partner State & Ethical Economy ». Consulté 30 mars 2017, à l’adresse http://www.shareable.net/blog/blueprint-for-p2p-society-the-partner-state-ethical-economy
Bauwens, M., & Lievens, J. (2016). « De wereld redden: met peer-to-peer naar een postkapitalistische samenleving ». Antwerpen: VBK – Houtekiet.
Bonney, R., et al. (2014). « Next Steps for Citizen Science ». Science, 343(6178), 1436‑1437. accessible en ligne.
Brafman, O., & Beckstrom, R. A. (2006). « The Starfish and the Spider: The Unstoppable Power of Leaderless Organizations ». Penguin.
Carlsson, B., & Gustavsson, R. (2001). « The Rise and Fall of Napster – An Evolutionary Approach ». Dans Active Media Technology (p. 347‑354). Springer, Berlin, Heidelberg. accessible en ligne
Cash, et al. (2003). « Knowledge systems for sustainable development ». Proceedings of the National Academy of Sciences, 100(14), 8086–8091.
CERN. (2011). « CERN releases new version of open hardware licence » | CERN. Consulté le 16 aout 2015, à l’adresse http://home.cern/about/updates/2013/09/cern-releases-new-version-open-hardware-licence
Chomsky, N. (1999). « Profit Over People: Neoliberalism and Global Order ». Seven Stories Press.
Diybio.org (2013). « Code of Ethics for diybio labs in Europe ». Consulté le 31 aout 2016 à l’adresse https://diybio.org/codes/draft-diybio-code-of-ethics-from-european-congress/
Dwan, K., et al. (2008). « Systematic Review of the Empirical Evidence of Study Publication Bias and Outcome Reporting Bias ». PLoS ONE, 3(8), e3081. accessible en ligne
Edwards, M., & Hulme, D. (1995). « Non-governmental Organisations: Performance and Accountability Beyond the Magic Bullet ». Earthscan publications LTD
Fablab. (2016). « Rules for use of Fablabs in Belgium, Luxembourg and the Netherlands ». Consulté le 31 aout 2016, à l’adresse http://fablab.nl/wat-is-een-fablab/fabcharter/
Fischer, F. (2000). « Citizens, Experts, and the Environment: The Politics of Local Knowledge ». Duke University Press.
Gershenfeld, N. (2012). « How to Make Almost Anything: The Digital Fabrication Revolution ». Foreign Affairs, 91, 43.
Graeber, D. (2013). « On the Phenomenon of Bullshit Jobs », Strike! Magazine, Summer, pp.201310-20133411.
Hauge, K. H., & Barwell, R. (2017). « Post-normal science and mathematics education in uncertain times: Educating future citizens for extended peer communities ». Futures. accessible en ligne
Irwin, A. (1995). « Citizen Science: A Study of People, Expertise and Sustainable Development ». Psychology Press.
Mansfield, B. (2011). « « Modern » industrial fisheries and the crisis of overfishing ». Global political ecology, 84-99.
Meet je Stad. (2015). « Guidelines for data collection by the flora observation group of Meet je Stad ». Consulté le 31 aout 2016, à l’adresse http://meetjestad.net/flora/?info
MIT. (1988). « GNU Public License ». Consulté le 9 avril 2014, à l’adresse http://web.mit.edu/drela/Public/web/gpl.txt
Pereira, Â., & Saltelli, A. (2017). « Post-normal institutional identities: Quality assurance, reflexivity and ethos of care ». Futures. accessible en ligne
Public Laboratory (2016). « Public Lab: a DIY environmental science community ». Consulté le 18 octobre 2016, à l’adresse https://publiclab.org/
Rotman, D. et al. (2012). « Dynamic Changes in Motivation in Collaborative Citizen-science Projects ». Dans Proceedings of the ACM 2012 Conference on Computer Supported Cooperative Work (p. 217–226). New York, NY, USA: ACM. accessible en ligne.
Saltelli, A., & Giampietro, M. (2017). « What is wrong with evidence based policy, and how can it be improved? » Futures. Consulté à l’adresse http://www.sciencedirect.com/science/article/pii/S0016328717300472.
Scherhorn, G. (2005). « Sustainability, Consumer Sovereignty, and the Concept of the Market ». Dans K. G. Grunert & J. Thøgersen (Éd.), Consumers, Policy and the Environment A Tribute to Folke Ölander (p. 301‑310). Springer US. accessible en ligne
Show (2015). « Rise of the citizen scientist ». Nature, 524(7565), 265‑265. accessible en ligne
Skidelsky (2012). « Return to capitalism « red in tooth and claw » spells economic madness ». The Guardian. Consulté le 05 avril 2014, à l’adresse https://www.theguardian.com/business/economics-blog/2012/jun/21/capitalism-red-tooth-claw-keynes?commentpage=2%26fb=native#post-area
Vermij, R. H. (2006). « Kleine geschiedenis van de wetenschap ». Uitgeverij Nieuwezijds.
Von Lode, P. (2005). « Point-of-care immunotesting: Approaching the analytical performance of central laboratory methods ». Clinical Biochemistry, 38(7), 591‑606. accessible en ligne.
Werlhof, C. von. (2008). « The Globalization of Neoliberalism, its Consequences, and Some of its Basic Alternatives ». Capitalism Nature Socialism, 19(3), 94‑117. accessible en ligne
Westheimer, J., & Kahne, J. (1998). « Education for action: Preparing youth for participatory democracy ». Press and Teachers College Press.







 J’utilise Twitter tous les jours. Pour moi qui suis consultant en cybersécurité, c’est de loin un des meilleurs outils pour rester informé des dernières actualités et pour partager des informations qu’on estime pertinentes pour d’autres. Avec la récente investiture de Donald Trump, les
J’utilise Twitter tous les jours. Pour moi qui suis consultant en cybersécurité, c’est de loin un des meilleurs outils pour rester informé des dernières actualités et pour partager des informations qu’on estime pertinentes pour d’autres. Avec la récente investiture de Donald Trump, les 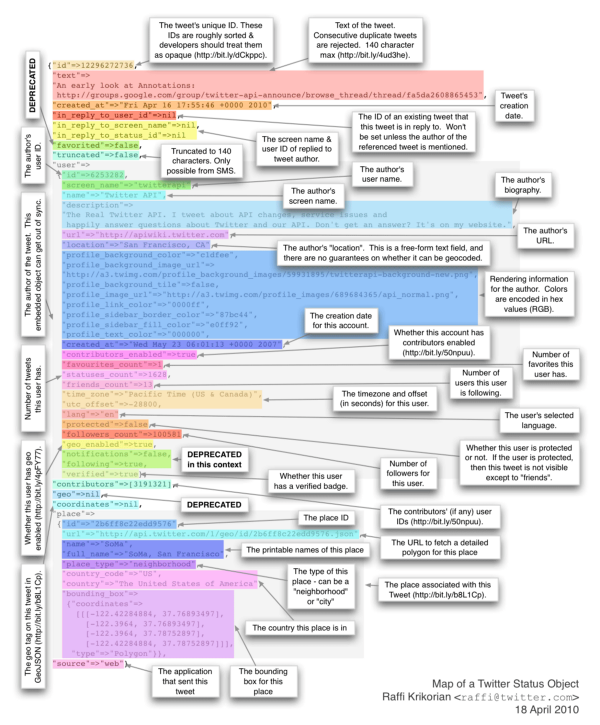



 Ça paraît une bonne affaire : vos applis favorites pour mobile sont gratuites et en contrepartie vous regardez des pubs agaçantes.
Ça paraît une bonne affaire : vos applis favorites pour mobile sont gratuites et en contrepartie vous regardez des pubs agaçantes.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}