Oubliez Framaforms-le-logiciel, faites de la place à Yakforms !
Après plusieurs années, Framasoft a décidé de ne plus prendre en charge les évolutions du logiciel Framaforms qui sert à vous offrir le service du même nom. Et pour que cesse la confusion entre le nom du logiciel et le nom du service Framaforms (qui reste ouvert, hein, ne vous inquiétez pas), on a décidé de donner un nouveau nom au logiciel : Yakforms. Petit retour sur ce qui a motivé cette décision.
À noter :
Découvrez la version en anglais de cet article réalisée par notre stagiaire Coraline
Framaforms, sa vie, son œuvre
Sorti officiellement le 5 octobre 2016 et présenté comme une alternative à Google Forms, Framaforms est un service en ligne qui permet à tou⋅tes les internautes de réaliser simplement des formulaires, par glisser-déposer d’éléments (champs textes, cases à cocher, menu déroulant, etc.), de les partager et d’analyser les réponses.
Contrairement à la majorité des services proposés dans le cadre de la campagne Dégooglisons Internet, celui-ci repose sur un logiciel développé en interne par l’un des salariés de l’association. Framasoft a toujours préféré proposer et mettre en valeur des logiciels libres déjà existants et disposant déjà d’une communauté, plutôt que de développer des solutions maison qu’il faut maintenir, faire évoluer, sans compter le support utilisateur à gérer. Mais aucun logiciel satisfaisant n’a été trouvé pour servir d’alternative à Google Forms : la plupart des logiciels libres existants n’étaient pas proposés comme services en ligne, ou lorsque c’était le cas, ils étaient assez complexes d’utilisation ou leurs tarifs étaient assez élevés.
Parfois, chez Framasoft, on doit faire des choix vraiment complexes :D
C’est donc pyg, à l’époque directeur général de l’association, qui s’est chargé de développer un outil simple et facile d’utilisation. Au regard de ses compétences techniques, il a fait le choix d’une solution utilisant Drupal (un des logiciels libres de création de sites web les plus installés au monde) et le module Webform (qui permet la création de formulaires). N’hésitez pas à consulter son interview parue à l’époque pour parler de ses choix.
4 ans et demi plus tard, Framaforms est l’un des services les plus utilisés parmi ceux proposés par l’association. En 2020, framaforms.org c’est plus de 36 millions de pages vues (une augmentation de 250% par rapport à 2019). Ne serait-ce que sur les douze derniers mois (mai 2020-avril 2021), presque 100 000 questionnaires ont été créés sur Framaforms et ils ont recueilli plus de 2 millions de réponses. Vous êtes plus de 1000 chaque semaine à créer plus de 3000 questionnaires. C’est vraiment impressionnant !
Parfois, on se demande pourquoi ce service rencontre un tel succès ! Bien sûr, on a fait de notre mieux pour le valoriser. Bien sûr, les internautes sont de plus en plus conscient·es de la nécessité de modifier leurs pratiques numériques afin de protéger leurs données personnelles. Bien sûr, on sait bien qu’il est de moins en moins répandu – et acceptable – de demander des informations sensibles, telles que l’identité de genre ou l’orientation sexuelle, via un Google Forms.
Mais il y a de fortes chances que la principale raison pour laquelle vous utilisez aujourd’hui Framaforms, c’est tout simplement parce qu’un jour, on vous a proposé de répondre à un questionnaire hébergé sur framaforms.org et qu’ainsi vous avez découvert l’outil. Les créateur·ices de formulaires deviennent indirectement auto-prescripteur·ices du service auprès de leur public. En répondant à un formulaire, vous avez une expérience active de l’outil et il est ainsi plus facile de passer le cap de devenir créateur·ice ensuite. Cela nous confirme que Framaforms est un outil qui a de l’avenir.
Le souci avec Framaforms
Cependant, Framaforms est un outil qui, depuis son développement en 2016, n’a que très peu évolué. Comme, vous pouvez le constater sur le dépôt git du logiciel, l’équipe a régulièrement fait les mises à jour de Drupal et des modules utilisés, amélioré les performances (notamment en passant à php7 et en changeant de machine) et corrigé les bugs identifiés, mais très peu de fonctionnalités ont été ajoutées (quelques-unes en 2017).
De plus, depuis 2016, Framasoft est devenu l’éditeur de nouveaux logiciels : PeerTube, puis Mobilizon. Avec Framadate et Framaforms, l’association se retrouve donc à gérer 4 logiciels différents, sans compter les très nombreuses contributions que notre association apporte à des projets existants. Et c’est beaucoup pour une petite structure comme la nôtre. Nous avons donc décidé que notre capacité de développement devait être mise en priorité sur PeerTube et Mobilizon, au détriment des deux autres outils.
Enfin, en raison de ses bases techniques, le logiciel Framaforms ne se prêtait pas à son installation par d’autres hébergeurs : le processus était ardu. Cela explique qu’il a très peu « essaimé », contrairement à d’autres logiciels qui ont rencontré un grand succès et sont actuellement portés par une large communauté. À ce jour, très peu d’instances sont installées, ce qui accroît la pression sur le service Framaforms, qui doit assumer la charge de la totalité des utilisateur⋅ices.
C’est l’une des principales raisons qui fait que nous avons accueilli Théo en stage de février à juillet 2020. Ses principales missions ont été :
améliorer le logiciel afin de le rendre plus fonctionnel ;
alléger la charge du support en participant activement à celui-ci ;
modifier le processus d’installation, afin de faciliter la multiplication des instances de Framaforms.
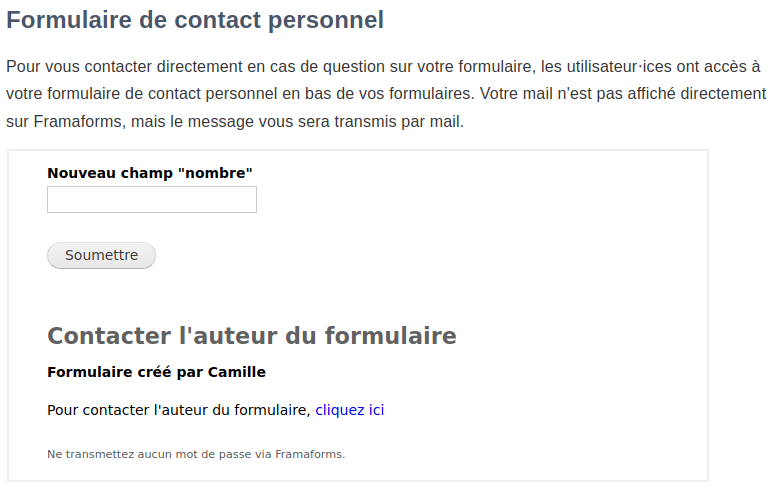
Théo a donc bûché dur sur de nouvelles fonctionnalités. Parmi les plus importantes : la mise en place d’un formulaire de contact direct, afin que les utilisateur⋅ices puissent directement contacter l’auteur·ice du formulaire sans passer par le support de Framasoft, la conception d’une page « Vue d’ensemble » qui permet aux administrateur⋅ices de Framaforms d’accéder facilement à un nombre de statistiques (nombre total de formulaires et d’utilisateur⋅ices, formulaires « abusifs », etc.) ou la suppression automatique des formulaires après une période d’expiration.
explications sur le formulaire de contact direct
Pour ce qui est du processus d’installation du logiciel, Théo a créé un profil d’installation Drupal pour Framaforms qui propose aux administrateur⋅ices d’instances les modules framaforms (enrichi) et webform sur lesquels repose le logiciel. L’installation de Framaforms se fait donc désormais directement via l’interface de Drupal plutôt qu’en manipulant des fichiers via un terminal. Le processus d’installation s’en trouve grandement simplifié, avec l’avantage notable qu’il se rapproche grandement du processus d’installation de Drupal.
Malgré ces améliorations, Framasoft est conscient que tant que le logiciel portera le même nom que le service associé, il y aura toujours une confusion qui laissera penser que c’est Framasoft qui a en charge le développement et la maintenance du logiciel.
Si nous n’envisageons pas la fermeture du service framaforms.org, nous ne souhaitons plus autant dédier d’énergie à l’évolution de cet outil. Du moins, nous ne souhaitons pas être les seuls à le faire et c’est pourquoi nous aimerions qu’une communauté de développement puisse émerger et s’emparer du logiciel Framaforms afin d’y apporter de nouvelles fonctionnalités.
Framaforms-le-logiciel est mort, vive Yakforms !
Faire émerger cette communauté est nécessaire afin de continuer à faire vivre le logiciel. Framaforms-le-logiciel a besoin, a minima, d’interventions sur des failles de sécurité et des bogues fonctionnels qui pourraient apparaître. Et ce logiciel mériterait aussi d’évoluer avec de nouvelles fonctionnalités, des améliorations d’interface et d’ergonomie, etc.
Afin de préparer ce projet de communauté autour du logiciel Framaforms, nous avons proposé à Théo de rejoindre l’équipe salariée pour quelques mois. Sa mission : travailler sur l’internationalisation (rendre le logiciel traduisible), permettre la customisation d’une instance (permettre aux administrateur⋅ices de paramétrer un certain nombre d’éléments tels que le nom de l’instance, sa mise en forme ou ses limitations), développer de nouvelles fonctionnalités (limitation du nombre de réponses par formulaire et du nombre de formulaires par compte) et créer un site web de présentation où tous les éléments concernant le logiciel seraient accessibles, que l’on soit simple utilisateur⋅ice, administrateur⋅ice ou développeur⋅se.
L’autre élément important pour nous a été de renommer le logiciel Framaforms afin d’éviter la confusion avec le service framaforms.org . Après de nombreux brainstorming internes, nous avons donc choisi le nom Yakforms pour remplacer Framaforms. Pourquoi Yakforms ? Et bien… c’est au final un choix qui relève à la fois d’une convergence de mauvais jeux de mots et de l’envie d’avoir une mascotte. Alors pourquoi un yak ? Le mystère reste entier, et nous nous engageons à inventer une réponse différente à chaque fois qu’on nous posera la question. Car la seule réponse qui compte, c’est celle que donnera la future communauté de développement qui se créera autour de ce logiciel (ou le copiera, ou le « forkera » pour lui offrir une toute nouvelle direction, et un nouveau nom).
Théo a aussi fait le nécessaire pour qu’une communauté puisse voir le jour autour de Yakforms. Pour cela, il a pris le temps de réfléchir aux différents espaces en ligne qui permettraient à une communauté d’échanger et de s’entraider. Il a créé une catégorie dédiée sur le forum Framacolibri et réalisé un site web qui vous présente le logiciel, ses principales fonctionnalités, comment installer une instance et comment contribuer à son développement.
Découvrez le nouveau site web de présentation de Yakforms ! http://yakforms.org/
On espère que vous serez nombreu⋅ses à le consulter pour en savoir plus sur les principales fonctionnalités, découvrir comment l’installer ou participer à son évolution. Car sans vous, ce logiciel n’évoluera pas. Rejoindre la communauté Yakforms, c’est participer à l’amélioration du logiciel : faire évaluer son code, repenser son ergonomie, traduire ses interfaces ou encore documenter son utilisation.
Emparez-vous de Yakforms ! Installez-le, traduisez-le, forkez-le, remettez-le en question ou proposez des retours d’expérience sur le forum, etc. En libérant ce projet du contrôle de Framasoft, nous espérons qu’une communauté diverse et forte saura s’en emparer et le mener plus loin que nous ne le pourrions. Yakforms est entre vos mains, et nous avons hâte de voir ce que vous allez en faire !
Et un grand merci à la #TeamMemes pour sa créativité !
Comment migrer son frama.site avant la fermeture du service le 6 juillet prochain ?
Nous avons annoncé pour le mardi 6 juillet 2021 la fermeture du service https://frama.site/. Pour rappel, frama.site héberge à la fois des sites (logiciel PrettyNoemieCMS), des blogs (logiciel Grav) et des wikis (logiciel Dokuwiki). Afin que les utilisateur⋅ices de ce service puissent continuer à héberger leurs sites et wikis, nous avons cherché si d’autres hébergeurs proposaient ce service.
Afin que vous puissiez choisir en toute transparence l’offre qui vous correspond le mieux, on s’est dit qu’il n’y avait rien de mieux à faire que d’interviewer ces structures afin qu’elles vous en disent plus sur qui elles sont, comment elles fonctionnent et qu’elles détaillent leur offre de migration.
Interview de Thomas Bourdon, de Bee-Home
Bonjour Thomas. Peux-tu te présenter ?
Je suis Thomas Bourdon, 38 ans, habitant dans l’Aisne, passionné d’informatique depuis toujours et utilisateur de GNU/Linux (et autres logiciels libres) depuis 2001. Mais ce n’est qu’en 2007 que j’ai réellement compris l’éthique du logiciel libre et du fonctionnement décentralisé (ou acentré) d’Internet. Depuis j’ai commencé à monter mes propres services à la maison (auto-hébergement) pour moi-même puis pour mes proches, et finalement pour des petites structures.
Tu nous parles de Bee-Home ? C’est quoi ? C’est qui ? Comment ça marche ?
Comme j’hébergeais de plus en plus de services pour de plus en plus de monde, il était temps que je quitte ma petite connexion ADSL pour prendre un serveur (puis deux) en datacenter. Comme je ne souhaitais pas payer de ma poche ces serveurs, j’ai décidé de monter l’auto-entreprise Bee Home dans ce but. Ce choix est aussi guidé par le fait que les structures que j’héberge ont besoin d’avoir des factures « officielles » et ne peuvent pas faire de don financier.
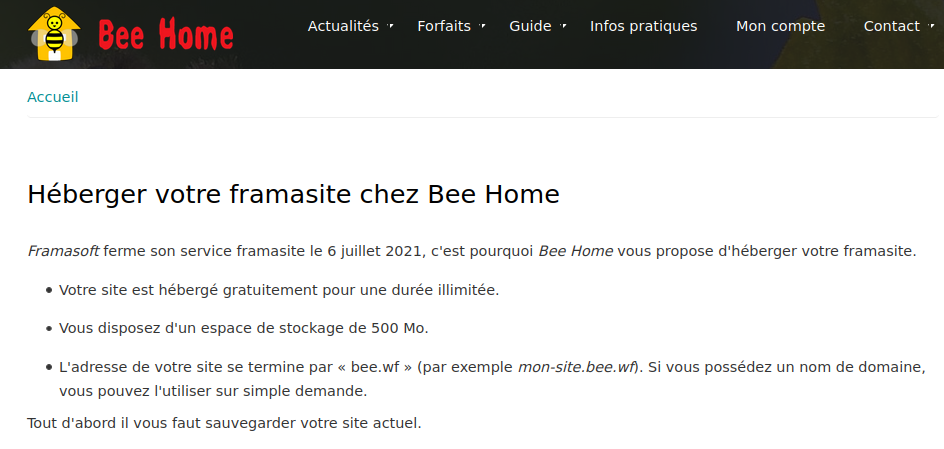
La page d’accueil du site web de Bee-Home
Les services que je fournis sont essentiellement du cloud – avec le logiciel Nextcloud (synchronisation de fichiers, agenda, carnet d’adresses, suite bureautique collaborative, discussion par texte ou visio et mail) – et l’hébergement de sites web. Pour cela je propose plusieurs outils que je maintiens (sauvegarde, mise à jour). Ainsi l’utilisateur·ice ne s’occupe que de publier du contenu. Évidemment il ou elle peut récupérer sur simple demande l’intégralité de son site pour l’héberger ailleurs par exemple.
Tous ces services sont payants et permettent aux utilisateur·ices d’avoir leur propre nom de domaine (sauf forfait de base) dont le coût est inclus dans le forfait. Même si je propose des forfaits pré-établis, il est tout à fait possible d’adapter le service et le tarif au besoin de la personne ou structure. Pour cela, il suffit de me contacter.
Bee-Home offre donc la possibilité de migrer son frama.site sous Grav / Dokuwiki. Ça se passe comment ? Ça coûte combien ?
J’ai décidé de proposer ce service gratuitement sans durée limitée sur simple demande. En revanche, j’impose un quota maximum de 500Mo d’espace disque. Au-delà de ce quota, je proposerai un tarif adapté. Chaque site sera accessible via une adresse se terminant par bee.wf (mon-site.bee.wf par exemple). Il est bien sûr possible d’utiliser son propre domaine pour celles et ceux qui en possèdent un.
Documentation sur la façon de migrer son framasite chez Bee-Home
Pourquoi ne pas permettre la migration des framasites réalisés avec le logiciel PrettyNoemieCMS ?
J’expliquais que je propose de maintenir moi-même les outils utilisés (WordPress, Grav, Dotclear, Piwigo…) pour les sites hébergés. C’est pourquoi je ne propose que des outils activement maintenus afin d’éviter l’usage d’outils obsolètes pouvant contenir des failles de sécurité qui ne seront jamais corrigées. PrettyNoemieCMS est justement un outil non maintenu, voilà pourquoi je ne le propose pas. Si un·e utilisateur·ice l’utilise, je peux toutefois proposer un hébergement sous Grav dans les mêmes conditions. Bien sûr il ou elle sera contraint de refaire son site entièrement.
Bee-Home fait partie du collectif CHATONS depuis fin 2018. Pourquoi avoir rejoint le collectif ?
D’une part parce que je partage complètement les valeurs de ce collectif, et d’autre part parce que cela m’a toujours plu de gérer et de proposer de l’hébergement de services.
Interview de l’équipe du directoire de Ouvaton
Bonjour l’équipe du directoire. Pouvez-vous vous présenter ?
Bonjour.
Nous sommes 3 personnes au « directoire » d’Ouvaton, actuellement :
– Claire, présidente, qui fait de l’informatique depuis le début des années 80 et chez Ouvaton depuis le début en 2001
– Matthieu, aussi informaticien et chez Ouvaton depuis 2006
– François, commercial, qui fait lui aussi de l’informatique, et chez Ouvaton depuis 2017
Vous nous parlez de Ouvaton ? C’est quoi ? C’est qui ? Comment ça marche ? Ouvaton a été créée en 2001, sous la forme d’une société anonyme « coopérative de consommation ». Cela veut dire que nos coopérateurs sont co-propriétaires et co-entrepreneurs de la coopérative. Grâce à cette structure, les utilisateurs sociétaires sont réellement des hébergés-hébergeurs. Donc Ouvaton, c’est plusieurs milliers de personnes qui décident. Et dans les faits, plusieurs dizaines qui ont « les mains dans le cambouis » au quotidien !
La coopérative se base sur un certain nombre de valeurs, que nous donnons sur notre site. Pour résumer à grands traits : indépendance et coopération, démocratie et protection de la vie privée.
Ouvaton fonctionne autour :
d’un conseil de surveillance de 9 membres élus pour des mandats de 3 années par l’Assemblée Générale
d’un directoire dont les membres sont nommés, pour des mandats renouvelables de 3 ans, par le conseil de surveillance
Page d’accueil du site https://ouvaton.coop/
Nous essayons aussi, dans la mesure des moyens de chacun, d’impliquer au quotidien un maximum de coopérateurs. Aucune obligation, mais une participation de chacun selon ses moyens (et ses envies !). Il y a toujours des chantiers en route dans un collectif comme Ouvaton et chacun peut y trouver sa place. Les Assemblées Générales sont l’occasion de présenter chaque année aux sociétaires l’état de la coopérative et de mettre aux votes les grandes orientations proposées par le conseil de surveillance et le directoire.
Ouvaton offre donc la possibilité de migrer son frama.site sous Grav / Dokuwiki. Ça se passe comment ? Ça coûte combien ?
Il faut commencer par créer son compte chez Ouvaton, sur notre interface de gestion Ouvadmin. L’adresse du site pourra être en *.ouvaton.org (https://monsite.ouvaton.org par exemple), et l’utilisation de son propre nom de domaine est bien sûr possible.
Notre documentation explique la procédure à suivre pour exporter puis importer son Framasite chez Ouvaton, et notre équipe d’assistance est là pour accompagner les utilisateurs en cas de difficultés.
Pour le prix, ce sera 12€ TTC la première année, et après ce sera 42€ TTC par an (le tarif « normal »). Ce tarif inclut des mails, de l’espace disque… On réfléchit sérieusement (et collectivement) à faire évoluer nos tarifs pour plusieurs offres selon les besoins. Pour ceux qui veulent vraiment rejoindre l’aventure, ils peuvent bien sûr devenir coopérateurs. La part sociale est à 16€ et permet d’être coopérateur « de plein droit ».
Pourquoi ne pas permettre la migration des framasites réalisés avec le logiciel PrettyNoemieCMS ?
Malheureusement ce logiciel n’est plus maintenu. Nous préférons nous concentrer sur Grav et Dokuwiki, qui disposent de solides équipes de développeurs pour les faire évoluer. Mais les personnes qui utilisent encore PrettyNoemieCMS peuvent reconstruire leur site sur un autre CMS aux mêmes conditions.
Je lis sur votre site web que vous comptez candidater pour rejoindre le collectif CHATONS fin 2021. Pourquoi souhaitez-vous rejoindre le collectif ?
Les valeurs affichées par le collectif sont concordantes avec les nôtres, nous avons donc souhaité le rejoindre au plus vite. Mais nous devons dans un premier temps assainir notre plateforme de quelques logiciels propriétaires qui étaient utilisés par notre ancien infogérant. C’est une tâche assez lourde qui, en plus du travail technique, a nécessité de nombreux échanges au sein de notre équipe. Nous sommes épaulés dans cette tâche par la super équipe de Octopuce, notre nouvel infogérant. Le train est en route et nous devrions pouvoir présenter notre candidature fin 2021 pour rejoindre les CHATONS.
Que vous utilisiez les services de frama.site ou que vous souhaitiez vous créer un nouvel espace sur internet, Framasoft vous encourage donc à aller étudier de près les offres de Ouvaton et Bee-Home.
Les médias sociaux ne sont pas des espaces démocratiques
On peut rêver d’une solution technologique ou juridique pour limiter ou interdire l’utilisation d’un logiciel à des groupes ou personnes qui ne partagent pas les valeurs auxquelles on tient ou pire veulent les détruire. L’entreprise est bien plus délicate qu’il n’y paraît, y compris pour les réseaux alternatifs décentralisés (ou plutôt acentrés) qu’on regroupe sous le terme de Fediverse. Il ne suffit pas en effet de dire que chaque instance décide de ses propres règles pour se débarrasser des difficultés.
Dans l’article qui suit, Christophe Masutti prend acte de la fin d’une illusion : l’idéal d’un grand espace de communication démocratique, égalitaire et ouvert à tous n’existe pas plus avec les Gafam qu’avec le Fediverse et ses réseaux alternatifs.
Face aux grandes plateformes centralisées de médias sociaux qui ne recherchent nullement à diffuser ou promouvoir le débat démocratique éclairé comme elles le prétendent mais à monétiser le spectacle d’un pseudo-débat, nous sommes confrontées au grand fourre-tout où distinguer le pire du meilleur renvoie chacun à une tâche colossale et indéfiniment renouvelée.
Cependant ce qui change la donne avec le Fediverse, c’est que la question de la fermeture à d’autres ne prend en compte ni le profit ni le facteur nombre : les instances sans objectif lucratif ont leurs qualités et leurs défauts propres, qu’elles aient deux ou deux cent mille utilisatrices. Et selon Christophe, les rapports entre les instances restent à écrire, à la manière dont les rapports variables entre les habitants d’un quartier déterminent leurs rapports individuels et collectifs…
Les médias sociaux ne sont pas des espaces démocratiques
par Christophe Masutti
Lors d’une récente interview avec deux autres framasoftiennes à propos du Fediverse et des réseaux sociaux dits « alternatifs », une question nous fut posée :
dans la mesure où les instances de service de micro-blogging (type Mastodon) ou de vidéo (comme Peertube) peuvent afficher des « lignes éditoriales » très différentes les unes des autres, comment gérer la modération en choisissant de se fédérer ou non avec une instance peuplée de fachos ou comment se comporter vis-à-vis d’une instance communautaire et exclusive qui choisit délibérément de ne pas être fédérée ou très peu ?
De manière assez libérale et pour peu que les conditions d’utilisation du service soient clairement définies dans chaque instance, on peut répondre simplement que la modération demande plus ou moins de travail, que chaque instance est tout à fait libre d’adopter sa propre politique éditoriale, et qu’il s’agit de choix individuels (ceux du propriétaire du serveur qui héberge l’instance) autant que de choix collectifs (si l’hébergeur entretient des relations diplomatiques avec les membres de son instance). C’est une évidence.
La difficulté consistait plutôt à expliquer pourquoi, dans la conception même des logiciels (Mastodon ou Peertube, en l’occurrence) ou dans les clauses de la licence d’utilisation, il n’y a pas de moyen mis en place par l’éditeur du logiciel (Framasoft pour Peertube, par exemple) afin de limiter cette possibilité d’enfermement de communautés d’utilisateurs dans de grandes bulles de filtres en particulier si elles tombent dans l’illégalité. Est-il légitime de faire circuler un logiciel qui permet à ♯lesgens de se réunir et d’échanger dans un entre-soi homogène tout en prétendant que le Fediverse est un dispositif d’ouverture et d’accès égalitaire ?
Une autre façon de poser la question pourrait être la suivante : comment est-il possible qu’un logiciel libre puisse permettre à des fachos d’ouvrir leurs propres instance de microblogging en déversant impunément sur le réseau leurs flots de haine et de frustrations ?1
Bien sûr nous avons répondu à ces questions, mais à mon avis de manière trop vague. C’est qu’en réalité, il y a plusieurs niveaux de compréhension que je vais tâcher de décrire ici.
Il y a trois aspects :
l’éthique du logiciel libre n’inclut pas la destination morale des logiciels libres, tant que la loyauté des usages est respectée, et la première clause des 4 libertés du logiciel libre implique la liberté d’usage : sélectionner les utilisateurs finaux en fonction de leurs orientations politique, sexuelles, etc. contrevient fondamentalement à cette clause…
… mais du point de vue technique, on peut en discuter car la conception du logiciel pourrait permettre de repousser ces limites éthiques2,
et la responsabilité juridique des hébergeurs implique que ces instances fachos sont de toute façon contraintes par l’arsenal juridique adapté ; ce à quoi on pourra toujours rétorquer que cela n’empêche pas les fachos de se réunir dans une cave (mieux : un local poubelle) à l’abri des regards.
Mais est-ce suffisant ? se réfugier derrière une prétendue neutralité de la technique (qui n’est jamais neutre), les limites éthiques ou la loi, ce n’est pas une bonne solution. Il faut se poser la question : que fait-on concrètement non pour interdire certains usages du Fediverse, mais pour en limiter l’impact social négatif ?
La principale réponse, c’est que le modèle économique du Fediverse ne repose pas sur la valorisation lucrative des données, et que se détacher des modèles centralisés implique une remise en question de ce que sont les « réseaux » sociaux. La vocation d’un dispositif technologique comme le Fediverse n’est pas d’éliminer les pensées fascistes et leur expression, pas plus que la vocation des plateformes Twitter et Facebook n’est de diffuser des modèles démocratiques, malgré leur prétention à cet objectif. La démocratie, les échanges d’idées, et de manière générale les interactions sociales ne se décrètent pas par des modèles technologiques, pas plus qu’elles ne s’y résument.
Prétendre le contraire serait les restreindre à des modèles et des choix imposés (et on voit bien que la technique ne peut être neutre). Si Facebook, Twitter et consorts ont la prétention d’être les gardiens de la liberté d’expression, c’est bien davantage pour exploiter les données personnelles à des fins lucratives que pour mettre en place un débat démocratique.
Exit le vieux rêve du global village ? En fait, cette vieille idée de Marshall McLuhan ne correspond pas à ce que la plupart des gens en ont retenu. En 1978, lorsque Murray Turoff et Roxanne Hiltz publient The Network Nation, ils conceptualisent vraiment ce qu’on entend par « Communication médiée par ordinateur » : échanges de contenus (volumes et vitesse), communication sociale-émotionnelle (les émoticônes), réduction des distances et isolement, communication synchrone et asynchrone, retombées scientifiques, usages domestiques de la communication en ligne, etc. Récompensés en 1994 par l’EFF Pioneer Award, Murray Turoff et Roxanne Hiltz sont aujourd’hui considérés comme les « parents » des systèmes de forums et de chat massivement utilisés aujourd’hui. Ce qu’on a retenu de leurs travaux, et par la suite des nombreuses applications, c’est que l’avenir du débat démocratique, des processus de décision collective (M. Turoff travaillait pour des institutions publiques) ou de la recherche de consensus, reposent pour l’essentiel sur les technologies de communication. C’est vrai en un sens, mais M. Turoff mettait en garde3 :
Dans la mesure où les communications humaines sont le mécanisme par lequel les valeurs sont transmises, tout changement significatif dans la technologie de cette communication est susceptible de permettre ou même de générer des changements de valeur.
Communiquer avec des ordinateurs, bâtir un système informatisé de communication sociale-émotionnelle ne change pas seulement l’organisation sociale, mais dans la mesure où l’ordinateur se fait de plus en plus le support exclusif des communications (et les prédictions de Turoff s’avéreront très exactes), la communication en réseau fini par déterminer nos valeurs.
Aujourd’hui, communiquer dans un espace unique globalisé, centralisé et ouvert à tous les vents signifie que nous devons nous protéger individuellement contre les atteintes morales et psychiques de celleux qui s’immiscent dans nos échanges. Cela signifie que nos écrits puissent être utilisés et instrumentalisés plus tard à des fins non souhaitées. Cela signifie qu’au lieu du consensus et du débat démocratique nous avons en réalité affaire à des séries de buzz et des cancans. Cela signifie une mise en concurrence farouche entre des contenus discursifs de qualité et de légitimités inégales mais prétendument équivalents, entre une casserole qui braille La donna è mobile et la version Pavarotti, entre une conférence du Collège de France et un historien révisionniste amateur dans sa cuisine, entre des contenus journalistiques et des fake news, entre des débats argumentés et des plateaux-télé nauséabonds.
Tout cela ne relève en aucun cas du consensus et encore moins du débat, mais de l’annulation des chaînes de valeurs (quelles qu’elles soient) au profit d’une mise en concurrence de contenus à des fins lucratives et de captation de l’attention. Le village global est devenu une poubelle globale, et ce n’est pas brillant.
Là où les médias sociaux centralisés impliquaient une ouverture en faveur d’une croissance lucrative du nombre d’utilisateurs, le Fediverse se fout royalement de ce nombre, pourvu qu’il puisse mettre en place des chaînes de confiance.
Dans cette perspective, le Fediverse cherche à inverser la tendance. Non par la technologie (le protocole ActivityPub ou autre), mais par le fait qu’il incite à réfléchir sur la manière dont nous voulons conduire nos débats et donc faire circuler l’information.
On pourrait aussi bien affirmer qu’il est normal de se voir fermer les portes (ou du moins être exclu de fait) d’une instance féministe si on est soi-même un homme, ou d’une instance syndicaliste si on est un patron, ou encore d’une instance d’un parti politique si on est d’un autre parti. C’est un comportement tout à fait normal et éminemment social de faire partie d’un groupe d’affinités, avec ses expériences communes, pour parler de ce qui nous regroupe, d’actions, de stratégies ou simplement un partage d’expériences et de subjectivités, sans que ceux qui n’ont pas les mêmes affinités ou subjectivités puissent s’y joindre. De manière ponctuelle on peut se réunir à l’exclusion d’autre groupes, pour en sortir à titre individuel et rejoindre d’autre groupes encore, plus ouverts, tout comme on peut alterner entre l’intimité d’un salon et un hall de gare.
Dans ce texte paru sur le Framablog, A. Mansoux et R. R. Abbing montrent que le Fediverse est une critique de l’ouverture. Ils ont raison. Là où les médias sociaux centralisés impliquaient une ouverture en faveur d’une croissance lucrative du nombre d’utilisateurs, le Fediverse se fout royalement de ce nombre, pourvu qu’il puisse mettre en place des chaînes de confiance.
Un premier mouvement d’approche consiste à se débarrasser d’une conception complètement biaisée d’Internet qui fait passer cet ensemble de réseaux pour une sorte de substrat technique sur lequel poussent des services ouverts aux publics de manière égalitaire. Évidemment ce n’est pas le cas, et surtout parce que les réseaux ne se ressemblent pas, certains sont privés et chiffrés (surtout dans les milieux professionnels), d’autres restreints, d’autres plus ouverts ou complètement ouverts. Tous dépendent de protocoles bien différents. Et concernant les médias sociaux, il n’y a aucune raison pour qu’une solution technique soit conçue pour empêcher la première forme de modération, à savoir le choix des utilisateurs. Dans la mesure où c’est le propriétaire de l’instance (du serveur) qui reste in fine responsable des contenus, il est bien normal qu’il puisse maîtriser l’effort de modération qui lui incombe. Depuis les années 1980 et les groupes usenet, les réseaux sociaux se sont toujours définis selon des groupes d’affinités et des règles de modération clairement énoncées.
À l’inverse, avec des conditions générales d’utilisation le plus souvent obscures ou déloyales, les services centralisés tels Twitter, Youtube ou Facebook ont un modèle économique tel qu’il leur est nécessaire de drainer un maximum d’utilisateurs. En déléguant le choix de filtrage à chaque utilisateur, ces médias sociaux ont proposé une représentation faussée de leurs services :
Faire croire que c’est à chaque utilisateur de choisir les contenus qu’il veut voir alors que le système repose sur l’économie de l’attention et donc sur la multiplication de contenus marchands (la publicité) et la mise en concurrence de contenus censés capter l’attention. Ces contenus sont ceux qui totalisent plus ou moins d’audience selon les orientations initiales de l’utilisateur. Ainsi on se voit proposer des contenus qui ne correspondent pas forcément à nos goûts mais qui captent notre attention parce de leur nature attrayante ou choquante provoquent des émotions.
Faire croire qu’ils sont des espaces démocratiques. Ils réduisent la démocratie à la seule idée d’expression libre de chacun (lorsque Trump s’est fait virer de Facebook les politiques se sont sentis outragés… comme si Facebook était un espace public, alors qu’il s’agit d’une entreprise privée).
Les médias sociaux mainstream sont tout sauf des espaces où serait censée s’exercer la démocratie bien qu’ils aient été considérés comme tels, dans une sorte de confusion entre le brouhaha débridé des contenus et la liberté d’expression. Lors du « printemps arabe » de 2010, par exemple, on peut dire que les révoltes ont beaucoup reposé sur la capacité des réseaux sociaux à faire circuler l’information. Mais il a suffi aux gouvernements de censurer les accès à ces services centralisés pour brider les révolutions. Ils se servent encore aujourd’hui de cette censure pour mener des négociations diplomatiques qui tantôt cherchent à attirer l’attention pour obtenir des avantages auprès des puissances hégémoniques tout en prenant la « démocratie » en otage, et tantôt obligent les GAFAM à se plier à la censure tout en facilitant la répression. La collaboration est le sport collectif des GAFAM. En Turquie, Amnesty International s’en inquiète et les exemples concrets ne manquent pas comme au Vietnam récemment.
Si les médias sociaux comme Twitter et Facebook sont devenus des leviers politiques, c’est justement parce qu’ils se sont présentés comme des supports technologiques à la démocratie. Car tout dépend aussi de ce qu’on entend par « démocratie ». Un mot largement privé de son sens initial comme le montre si bien F. Dupuis-Déri4. Toujours est-il que, de manière très réductrice, on tient pour acquis qu’une démocratie s’exerce selon deux conditions : que l’information circule et que le débat public soit possible.
Même en réduisant la démocratie au schéma techno-structurel que lui imposent les acteurs hégémoniques des médias sociaux, la question est de savoir s’il permettent la conjonction de ces conditions. La réponse est non. Ce n’est pas leur raison d’être.
Alors qu’Internet et le Web ont été élaborés au départ pour être des dispositifs égalitaires en émission et réception de pair à pair, la centralisation des accès soumet l’émission aux conditions de l’hébergeur du service. Là où ce dernier pourrait se contenter d’un modèle marchand basique consistant à faire payer l’accès et relayer à l’aveugle les contenus (ce que fait La Poste, encadrée par la loi sur les postes et télécommunications), la salubrité et la fiabilité du service sont fragilisés par la responsabilisation de l’hébergeur par rapport à ces contenus et la nécessité pour l’hébergeur à adopter un modèle économique de rentabilité qui repose sur la captation des données des utilisateurs à des fins de marketing pour prétendre à une prétendue gratuité du service5. Cela implique que les contenus échangés ne sont et ne seront jamais indépendants de toute forme de censure unilatéralement décidée (quoi qu’en pensent les politiques qui entendent légiférer sur l’emploi des dispositifs qui relèveront toujours de la propriété privée), et jamais indépendants des impératifs financiers qui justifient l’économie de surveillance, les atteintes à notre vie privée et le formatage comportemental qui en découlent.
Paradoxalement, le rêve d’un espace public ouvert est tout aussi inatteignable pour les médias sociaux dits « alternatifs », où pour des raisons de responsabilité légale et de choix de politique éditoriale, chaque instance met en place des règles de modération qui pourront toujours être considérées par les utilisateurs comme abusives ou au moins discutables. La différence, c’est que sur des réseaux comme le Fediverse (ou les instances usenet qui reposent sur NNTP), le modèle économique n’est pas celui de l’exploitation lucrative des données et n’enferme pas l’utilisateur sur une instance en particulier. Il est aussi possible d’ouvrir sa propre instance à soi, être le seul utilisateur, et néanmoins se fédérer avec les autres.
De même sur chaque instance, les règles d’usage pourraient être discutées à tout moment entre les utilisateurs et les responsables de l’instance, de manière à créer des consensus. En somme, le Fediverse permet le débat, même s’il est restreint à une communauté d’utilisateurs, là où la centralisation ne fait qu’imposer un état de fait tout en tâchant d’y soumettre le plus grand nombre. Mais dans un pays comme le Vietnam où l’essentiel du trafic Internet passe par Facebook, les utilisateurs ont-ils vraiment le choix ?
Ce sont bien la centralisation et l’exploitation des données qui font des réseaux sociaux comme Facebook, YouTube et Twitter des instruments extrêmement sensibles à la censure d’État, au service des gouvernements totalitaires, et parties prenantes du fascisme néolibéral.
L’affaire Cambridge Analytica a bien montré combien le débat démocratique sur les médias sociaux relève de l’imaginaire, au contraire fortement soumis aux effets de fragmentation discursive. Avant de nous demander quelles idéologies elles permettent de véhiculer nous devons interroger l’idéologie des GAFAM. Ce que je soutiens, c’est que la structure même des services des GAFAM ne permet de véhiculer vers les masses que des idéologies qui correspondent à leurs modèles économiques, c’est-à-dire compatibles avec le profit néolibéral.
En reprenant des méthodes d’analyse des années 1970-80, le marketing psychographique et la socio-démographie6, Cambridge Analytica illustre parfaitement les trente dernières années de perfectionnement de l’analyse des données comportementales des individus en utilisant le big data. Ce qui intéresse le marketing, ce ne sont plus les causes, les déterminants des choix des individus, mais la possibilité de prédire ces choix, peu importent les causes. La différence, c’est que lorsqu’on applique ces principes, on segmente la population par stéréotypage dont la granularité est d’autant plus fine que vous disposez d’un maximum de données. Si vous voulez influencer une décision, dans un milieu où il est possible à la fois de pomper des données et d’en injecter (dans les médias sociaux, donc), il suffit de voir quels sont les paramètres à changer. À l’échelle de millions d’individus, changer le cours d’une élection présidentielle devient tout à fait possible derrière un écran.
C’est la raison pour laquelle les politiques du moment ont surréagi face au bannissement de Trump des plateformes comme Twitter et Facebook (voir ici ou là). Si ces plateformes ont le pouvoir de faire taire le président des États-Unis, c’est que leur capacité de caisse de résonance accrédite l’idée qu’elles sont les principaux espaces médiatiques réellement utiles aux démarches électoralistes. En effet, nulle part ailleurs il n’est possible de s’adresser en masse, simultanément et de manière segmentée (ciblée) aux populations. Ce faisant, le discours politique ne s’adresse plus à des groupes d’affinité (un parti parle à ses sympathisants), il ne cherche pas le consensus dans un espace censé servir d’agora géante où aurait lieu le débat public. Rien de tout cela. Le discours politique s’adresse désormais et en permanence à chaque segment électoral de manière assez fragmentée pour que chacun puisse y trouver ce qu’il désire, orienter et conforter ses choix en fonction de ce que les algorithmes qui scandent les contenus pourront présenter (ou pas). Dans cette dynamique, seul un trumpisme ultra-libéral pourra triompher, nulle place pour un débat démocratique, seules triomphent les polémiques, la démagogie réactionnaire et ce que les gauches ont tant de mal à identifier7 : le fascisme.
Face à cela, et sans préjuger de ce qu’il deviendra, le Fediverse propose une porte de sortie sans toutefois remettre au goût du jour les vieilles représentations du village global. J’aime à le voir comme une multiplication d’espaces (d’instances) plus où moins clos (ou plus ou moins ouverts, c’est selon) mais fortement identifiés et qui s’affirment les uns par rapport aux autres, dans leurs différences ou leurs ressemblances, en somme dans leurs diversités.
C’est justement cette diversité qui est à la base du débat et de la recherche de consensus, mais sans en constituer l’alpha et l’oméga. Les instances du Fediverse, sont des espaces communs d’immeubles qui communiquent entre eux, ou pas, ni plus ni moins. Ils sont des lieux où l’on se regroupe et où peuvent se bâtir des collectifs éphémères ou non. Ils sont les supports utilitaires où des pratiques d’interlocution non-concurrentielles peuvent s’accomplir et s’inventer : microblog, blog, organiseur d’événement, partage de vidéo, partage de contenus audio, et toute application dont l’objectif consiste à outiller la liberté d’expression et non la remplacer.
Angélisme ? Peut-être. En tout cas, c’est ma manière de voir le Fediverse aujourd’hui. L’avenir nous dira ce que les utilisateurs en feront.
On peut se référer au passage de la plateforme suprémaciste Gab aux réseaux du Fediverse, mais qui finalement fut bloquée par la plupart des instances du réseau.↩
Par exemple, sans remplacer les outils de modération par du machine learning plus ou moins efficace, on peut rendre visible davantage les procédures de reports de contenus haineux, mais à condition d’avoir une équipe de modérateurs prête à réceptionner le flux : les limites deviennent humaines.↩
Turoff, Murray, and Starr Roxane Hiltz. 1994. The Network Nation: Human Communication via Computer. Cambridge: MIT Press, p. 401.↩
Dupuis-Déri, Francis. Démocratie, histoire politique d’un mot: aux États-Unis et en France. Montréal (Québec), Canada: Lux, 2013.↩
Et même si le service était payant, l’adhésion supposerait un consentement autrement plus poussé à l’exploitation des données personnelles sous prétexte d’une qualité de service et d’un meilleur ciblage marketing ou de propagande. Pire encore s’il disposait d’une offre premium ou de niveaux d’abonnements qui segmenteraient encore davantage les utilisateurs.↩
J’en parlerai dans un article à venir au sujet du courtage de données et de la société Acxiom.↩
…pas faute d’en connaître les symptômes depuis longtemps. Comme ce texte de Jacques Ellul paru dans la revue Esprit en 1937, intitulé « Le fascisme fils du libéralisme », dont voici un extrait : « [Le fascisme] s’adresse au sentiment et non à l’intelligence, il n’est pas un effort vers un ordre réel mais vers un ordre fictif de la réalité. Il est précédé par tout un courant de tendances vers le fascisme : dans tous les pays nous retrouvons ces mesures de police et de violence, ce désir de restreindre les droits du parlement au profit du gouvernement, décrets-lois et pleins pouvoirs, affolement systématique obtenu par une lente pression des journaux sur la mentalité courante, attaques contre tout ce qui est pensée dissidente et expression de cette pensée, limitation de liberté de parole et de droit de réunion, restriction du droit de grève et de manifester, etc. Toutes ces mesures de fait constituent déjà le fascisme. ».↩
Nextcloud pour l’enseignement ? Ça se tente !
La maîtrise des outils numériques pour l’éducation est un enjeu important pour les personnels, qui confrontés aux « solutions » Microsoft et Google cherchent et commencent à adopter des alternatives crédibles et plus respectueuses.
C’est dans cet esprit que nous vous invitons à découvrir la décision prise par de nombreux établissements scolaires en Allemagne sous l’impulsion de Thomas Mayer : ils ont choisi et promu Nextcloud et son riche « écosystème » de fonctionnalités. Dans l’interview que nous avons traduite et que Nexcloud met évidemment en vitrine, Thomas Mayer évoque rapidement ce qui l’a motivé et les avantages des solutions choisies. Bien sûr, nous sommes conscients que NextCloud, qui fait ici sa promotion avec un témoignage convaincant, n’est pas sans défauts ni problème. L’interface pour partager les fichiers par exemple, n’est pas des plus intuitives…
Mais sans être LA solution miraculeuse adaptée à toutes les pratiques de l’enseignement assisté par l’outil numérique, Nextcloud… – est un logiciel libre respectueux des utilisatrices et utilisateurs – permet l’hébergement et le partage de fichiers distants – est une plateforme de collaboration C’est déjà beaucoup ! Si l’on ajoute un grand nombre de fonctionnalités avec plus de 200 applications, vous disposerez de quoi libérer les pratiques pédagogiques de Google drive et d’Office365 sans parler des autres qui se pressent au portillon pour vous convaincre…
Qui plus est, au plan institutionnel, Nextcloud a été adopté officiellement par le ministère de l’Intérieur français en substitution des solutions de cloud computing1 américaines et il est même (roulement de tambour)… disponible au sein de notre Éducation Nationale ! Si vous ne l’avez pas encore repéré, c’est sur la très enthousiasmante initiative Apps.Education.fr. En principe, les personnels de l’Éducation nationale peuvent s’en emparer — dans toutes les académies ? Mais oui. Et les enseignantes françaises semblent déjà nombreuses à utiliser Nextcloud : rien qu’au mois d’avril dernier, 1,2 millions de fichiers ont été déposés, nous souffle-t-on. C’est un bon début, non ?
À vous de jouer : testez, évaluez, mettez en pratique, faites remonter vos observations, signalez les problèmes, partagez votre enthousiasme ou vos réticences, et ce qui vous manque aujourd’hui sera peut-être implémenté demain par Nextcloud. Mais pour commencer, jetons un œil de l’autre côté du Rhin…
Les écoles de Bavière essaient Nextcloud : les bénéfices sont immenses !
Nous avons interviewé Thomas Mayer, qui est administrateur système d’une école secondaire en Bavière mais aussi un médiateur numérique pour les écoles secondaires bavaroises à l’institut pour la qualité pédagogique et la recherche en didactique de Munich. Thomas nous a fait part de son expérience de l’usage et du déploiement de Nextcloud dans les écoles, les multiples bénéfices qui en découlent. C’est un message important pour les décideurs qui cherchent des solutions collaboratives en milieu scolaire.
Les écoles peuvent en tirer d’immenses avantages ! Les élèves et les collègues bénéficient d’un système complet et moderne qu’ils peuvent également utiliser à la maison. De plus, utiliser Nextcloud leur donne des compétences importantes sur le numérique au quotidien et les technologies informatiques. Les étudiants apprennent beaucoup de choses en utilisant Nextcloud qui seront aussi pertinentes dans leurs études et leur vie professionnelle.
Administrateur système, Thomas a pu déployer un environnement autour de Nextcloud qui est documenté sur le site schulnetzkonzept.de. Outre Nextcloud, le site décrit l’installation et la configuration de Collabora, Samba, Freeradius, Debian comme système d’exploitation de base, Proxmox comme système de virtualisation, etc.
Plusieurs centaines de milliers d’élèves utilisent déjà Nextcloud, y compris par exemple dans des écoles en Saxe, Rhénanie du Nord-Westphalie, Saxe-Anhalt, à Berne en Suisse et bien d’autres. Il est possible d’ajouter des fonctionnalités supplémentaires avec des extensions Nextcloud ou bien des plateformes d’apprentissage comme Moodle ou HPI School Cloud, qui sont open source et conformes au RGPD.
Quand et pourquoi avez-vous décidé d’utiliser Nextcloud ?
Nous avions déjà Nextcloud dans notre école, quand il s’appelait encore Owncloud. Avec l’introduction du système en 2014, nous avons voulu innover en prenant nos distances avec les usages habituels des domaines de Microsoft et les ordinateurs toujours installés en classe pour aller vers un usage plus naturel de fichiers accessibles aussi par mobile ou par les appareils personnels utilisés quotidiennement par les élèves et les professeurs.
Dans le même temps, Nextcould a mûri, et nous aussi avons évolué dans nos usages. Il ne s’agit plus uniquement de manipuler fichiers et répertoires, il existe désormais des outils de communication, d’organisation, de collaboration, et des concepts pour imaginer l’école et les solutions numériques. Nextcloud est devenu un pilier utile et important de notre école.
Quels sont les bénéfices pour les écoles depuis que vous avez lancé l’usage de Nextcloud ?
Les écoles qui reposent sur Nextcloud disposent d’une solution économique, qui ouvre la voie vers l’école numérique à travers de nombreuses fonctions, dans l’esprit de la protection des données et de l’open source ! Malheureusement, ses nombreux avantages n’ont pas encore été identifiés par les décideurs du ministère de l’Éducation. Là-bas, les gens considèrent encore que les bonnes solutions viennent forcément de Microsoft ou assimilés. Afin que les avantages de l’infrastructure Nextcloud deviennent plus visibles pour les écoles, davantage de travail de lobbying devrait être fait en ce sens. De plus, nous avons besoin de concepts qui permettent à CHAQUE école d’utiliser une infrastructure Nextcloud.
« computer class » par woodleywonderworks, licence CC BY 2.0
Quel message souhaitez-vous transmettre aux décideurs qui recherchent des solutions collaboratives pour l’enseignement ?
Une solution étendue à toutes les écoles d’Allemagne serait souhaitable. Si vous ne voulez pas réinventer la roue lorsque vous devez collaborer, et que vous voulez être attentif à la protection des données, vous ne pouvez pas contourner Nextcloud ! Mais ce n’est pas uniquement aux responsables des ministères de l’Éducation de faire des progrès ici : j’espère que les personnes responsables de Nextcloud vont amener leurs produits dans les écoles avec un lobbying approprié et des concepts convaincants !
Les décideurs des ministères de l’Éducation devraient chercher les meilleures solutions sans biais, et ne devraient pas être effrayés par l’open source lors de ces recherches : l’utilisation de logiciels open source est la seule manière concrète d’utiliser du code de qualité !
Quelles ont été vos motivations pour créer le Schulnetzkonzept2 ?
Dans ma vie, j’ai pu bénéficier de nombreux logiciels open source, et de formidables tutoriels gratuits. Avec le concept de réseau éducatif, je voudrais aussi contribuer à quelque chose dans la philosophie de l’open source, et rendre mon expérience disponible. Même si mon site est destiné à des gens calés en informatique, la réponse est relativement importante et toujours positive.
Quels retours avez-vous des élèves et des professeurs ?
Le retour est essentiellement très positif. Les gens sont heureux que nous ayons une communication fiable et un système collaboratif entre les mains, particulièrement en ces temps d’école à la maison.
« computer class » par woodleywonderworks, licence CC BY 2.0
Quelles sont les fonctionnalités que vous préférez utiliser et quelles sont celles qui vous manquent encore peut-être ?
Pas facile de répondre. Beaucoup de composants ont une grande valeur et nous sont utiles. Nous utilisons principalement les fonctionnalités autour des fichiers et Collabora. Bien sûr, les applications mobiles jouent aussi un rôle important !
Ce qui serait le plus profitable aux écoles actuellement serait que le backend haute-performance pour les conférences vidéos soit plus facilement disponible. Cela contrecarrait aussi les sempiternelles visios avec Microsoft Teams de nombreux ministres de l’éducation.
Un peu envie de voir tout de suite à quoi ça ressemble ? Allez sur la démo en ligne et vous avez 60 minutes pour explorer en vrai la suite Nextcloud : https://try.nextcloud.com/
Une vidéo de 4 minutes de Apps.education.fr vous montre comment créer une ressource partagée avec paramétrage des permissions, la mettre à disposition des élèves et récolter les documents qu’ils et elles envoient.
Régulièrement, un accident qui entraine la perte de données importantes nous rappelle l’importance des sauvegardes. L’incendie du centre de données d’OVH à Strasbourg le 10 mars dernier a été particulièrement spectaculaire, car de nombreuses personnes et organisations ont été touchées, mais des incidents de ce genre sont fréquents, quoique moins médiatisés. Un ami vient de m’écrire pour me demander mon numéro de téléphone car il a perdu son ordiphone avec son carnet d’adresses, un étudiant a perdu son ordinateur portable dans le métro, avec tout son mémoire de master dessus, et met une petite annonce dans la station de métro, une graphiste s’aperçoit que son ordinateur, avec tous ses travaux dessus, ne démarre plus un matin, une ville a perdu ses données suite au passage d’un rançongiciel, une utilisatrice de Facebook demande de l’aide car son compte a été piraté et elle ne peut plus accéder à ses photos de famille… Des appels au secours sur les réseaux sociaux comme celui-ci ou celui-là sont fréquents. Dans tous ces cas, le problème était l’absence de sauvegardes. Mais c’est quoi, les sauvegardes, et comment faut-il les faire ?
Le principe est simple : une sauvegarde (backup, en anglais) est une copie des données effectuée sur un autre support. Le but est de pouvoir récupérer ses données en cas de perte. Les causes de perte sont innombrables : vol de l’ordinateur portable ou de l’ordiphone (ces engins, étant mobiles, sont particulièrement exposés à ces risques), effacement par un logiciel malveillant ou par une erreur humaine, panne matérielle. Les causes possibles sont trop nombreuses pour être toutes citées. Retenons plutôt ce principe : les données peuvent devenir inaccessibles du jour au lendemain. Même si vous n’utilisez qu’un ordinateur fixe, parfaitement sécurisé, dans un local à l’abri des incendies (qui peut vraiment prétendre avoir une telle sécurité ?), un composant matériel peut toujours lâcher, vous laissant dans l’angoisse face à vos fichiers irrécupérables. Ne pensons donc pas aux causes de perte, pensons aux précautions à prendre.
(Au passage, saviez-vous que Lawrence d’Arabie avait perdu lors d’un voyage en train un manuscrit qu’il avait dû retaper complètement ? Il n’avait pas de sauvegardes. À sa décharge, avant le numérique, faire des sauvegardes était long et compliqué.)
La règle est simple : il faut sauvegarder ses données. Ou, plus exactement, ce qui n’est pas sauvegardé peut être perdu à tout instant, sans préavis. Si vous êtes absolument certain ou certaine que vos données ne sont pas importantes, vous pouvez vous passer de sauvegardes. À l’inverse, si vous êtes en train d’écrire l’œuvre de votre vie et que dix ans de travail sont sur votre ordinateur, arrêter de lire cet article et aller faire tout de suite une sauvegarde est impératif. Entre les deux, c’est à vous de juger de l’importance de vos données, mais l’expérience semble indiquer que la plupart des utilisateurices sous-estiment le risque de panne, de vol ou de perte. Dans le doute, il vaut donc mieux sauvegarder.
Comment on sauvegarde ?
Là, je vais vous décevoir, je ne vais pas donner de mode d’emploi tout fait. D’abord, cela dépend beaucoup de votre environnement informatique. On n’utilisera pas les mêmes logiciels sur macOS et sur Ubuntu. Je ne connais pas tous les environnements et je ne peux donc pas vous donner des procédures exactes. (Mais, connaissant les lecteurices du Framablog, je suis certain qu’ielles vont ajouter dans les commentaires plein de bons conseils pratiques.) Ensuite, une autre raison pour laquelle je ne donne pas de recettes toutes faites est que la stratégie de sauvegarde va dépendre de votre cas particulier. Par exemple, si vous travaillez sur des données confidentielles (données personnelles, par exemple), certaines stratégies ne pourront pas être appliquées.
Je vais plutôt me focaliser sur quelques principes souvent oubliés. Le premier est d’éviter de mettre tous ses œufs dans le même panier. J’ai déjà vu le cas d’une étudiante ayant bien mis sa thèse en cours de rédaction sur une clé USB mais qui avait la clé et l’ordinateur portable dans le même sac… qui fut volé à l’arrachée dans la rue. Dans ce cas, il n’y a pas de réelle sauvegarde, puisque le même problème (le vol) entraîne la perte du fichier et de la sauvegarde. Même chose si la sauvegarde est accessible depuis la machine principale, par exemple parce qu’elle est sur un serveur de fichiers. Certes, dans ce cas, une panne matérielle de la machine n’entrainerait pas la perte des données sauvegardées sur le serveur, en revanche, une fausse manœuvre (destruction accidentelle des fichiers) ou une malveillance (rançongiciel chiffrant tout ce qu’il trouve, pour le rendre inutilisable) frapperait la sauvegarde aussi bien que l’original. Enfin, si vous travaillez à la maison, et que la sauvegarde est chez vous, rappelez-vous que le même incendie peut détruire les deux. (Il n’est pas nécessaire que tout brûle pour que tous les fichiers soient perdus ; un simple début de fumée peut endommager le matériel au point de rendre les données illisibles.) Rappelez-vous : il y a plusieurs causes de pertes de données, pas juste la panne d’un disque dur, et la stratégie de sauvegarde doit couvrir toutes ces causes. On parle parfois de « règle 3-2-1 » : les données doivent être sauvegardées en trois exemplaires, sur au moins deux supports physiques différents, et au moins une copie doit être dans un emplacement séparé. Bref, il faut être un peu paranoïaque et imaginer tout ce qui pourrait aller mal.
Donc, pensez à séparer données originelles et sauvegardes. Si vous utilisez un disque dur externe pour vos sauvegardes, débranchez-le physiquement une fois la sauvegarde faite. Si vous utilisez un serveur distant, déconnectez-vous après la copie.
(Si vous êtes programmeureuse, les systèmes de gestion de versions gardent automatiquement les précédentes versions de vos programmes, ce qui protège contre certaines erreurs humaines, comme d’effacer un fichier. Et, si ce système de gestion de versions est décentralisé, comme git, cela permet d’avoir facilement des copies en plusieurs endroits. Toutefois, tous ces endroits sont en général accessibles et donc vulnérables à, par exemple, un logiciel malveillant. Le système de gestion de versions ne dispense pas de sauvegardes.)
Ensuite, ne faites pas d’économies : il est très probable que vos données valent davantage que les quelques dizaines d’euros que coûte un disque dur externe ou une clé USB. Toutefois, il vaut mieux des sauvegardes imparfaites que pas de sauvegardes du tout. Simplement envoyer un fichier par courrier électronique à un autre compte (par exemple celui d’un ami) est simple, rapide et protège mieux que de ne rien faire du tout.
Enfin, faites attention à ce que la sauvegarde elle-même peut faire perdre des données, si vous copiez sur un disque ou une clé où se trouvent déjà des fichiers. C’est une des raisons pour lesquelles il est recommandé d’automatiser les sauvegardes, ce que permettent la plupart des outils. L’automatisation n’a pas pour but que de vous fatiguer moins, elle sert aussi à limiter les risques de fausse manœuvre.
« Five Days’ Backup » par daryl_mitchell, licence CC BY-SA 2.0
À quel rythme ?
La règle est simple : si vous faites des sauvegardes tous les jours, vous pouvez perdre une journée de travail. Si vous en faites toutes les semaines, vous pouvez perdre une semaine de travail. À vous de voir quel rythme vous préférez.
Et le cloud magique qui résout tout ?
Quand on parle de sauvegardes, beaucoup de gens répondent tout de suite « ah, mais pas de problème, moi, tout est sauvegardé dans le cloud ». Mais ce n’est pas aussi simple. D’abord, le cloud n’existe pas : il s’agit d’ordinateurs comme les autres, susceptibles des mêmes pannes, comme l’a tristement démontré l’incendie d’OVH. Il est d’ailleurs intéressant de noter que beaucoup de clients d’OVH supposaient acquis que leurs données étaient recopiées sur plusieurs centres de données, pour éviter la perte, malgré les conditions d’utilisation d’OVH qui disaient clairement que la sauvegarde était de la responsabilité du client. (Mais qui lit les conditions d’utilisation ?)
Parfois, la croyance dans la magie du cloud va jusqu’à dire que leurs centres de données ne peuvent pas brûler, que des copies sont faites, bref que ce qui est stocké dans le nuage ne peut pas être perdu. Mais rappelez-vous qu’il existe d’innombrables causes de perte de données. Combien d’utilisateurs d’un service en ligne ont eu la mauvaise surprise de découvrir un matin qu’ils n’avaient plus accès à leur compte parce qu’un pirate avait deviné leur mot de passe (ou détourné leur courrier ou leurs SMS) ou parce que la société gestionnaire avait délibérément fermé le compte, en raison d’un changement de politique de leur part ou tout simplement parce que le logiciel qui contrôle automatiquement les accès a décidé que votre compte était problématique ? Il n’est pas nécessaire que la société qui contrôle vos fichiers perde les données pour que vous n’y ayez plus accès. Là aussi, c’est une histoire fréquente (témoignage en anglais) et elle l’est encore plus en cas d’hébergement gratuit où vous n’êtes même pas un client.
Ah, et un autre problème avec la sous-traitance (le terme correct pour cloud), la confidentialité. Si vous travaillez avec des données confidentielles (s’il s’agit de données personnelles, vous avez une responsabilité légale, n’oubliez pas), il n’est pas prudent de les envoyer à l’extérieur sans précautions, surtout vers les fournisseurs états-uniens (ou chinois, mais ce cas est plus rare). Une bonne solution est de chiffrer vos fichiers avant l’envoi. Mais comme rien n’est parfait dans le monde cruel où nous vivons, il faut se rappeler que c’est moins pratique et surtout que cela introduit un risque de perte : si vous perdez ou oubliez la clé de chiffrement, vos sauvegardes ne serviront à rien.
Tester
Un adage ingénierie classique est que ce qui n’a pas été testé ne marche jamais, quand on essaie de s’en servir. Appliqué aux sauvegardes, cela veut dire qu’il faut tester que la sauvegarde fonctionne, en essayant une restauration (le contraire d’une sauvegarde : mettre les fichiers sur l’ordinateur, à partir de la copie).
Une bonne discipline, par exemple, est de profiter de l’achat d’une nouvelle machine pour essayer de restaurer les fichiers à partir de la copie. Vous serez peut-être surpris·e de constater à ce moment qu’il manque des fichiers importants, qui avaient été négligés lors de la sauvegarde, ou bien que la sauvegarde la plus récente n’est… pas très récente. Ou bien tout simplement que la clé USB où vous aviez fait la sauvegarde a disparu, ou bien ne fonctionne plus.
Conclusion
Il faut sauvegarder. Je l’ai déjà dit, non ? Pour vous motiver, posez-vous les questions suivantes :
Si, un matin, mon ordinateur fait entendre un bruit de casserole et ne démarre pas, saurais-je facilement restaurer des données sauvegardées ?
Si toutes mes données sont chez un hébergeur extérieur et que je perds l’accès à mon compte, comment restaurerais-je mes données ?
Si je travaille sur un ordinateur portable que je trimballe souvent, et qu’il est volé ou perdu, où et comment restaurer les données ?
Si vous préférez les messages en vidéo, j’ai bien aimé cette vidéo qui, en dépit de son nom, n’est pas faite que pour les geeks.
J’enseigne, je code et je partage : une série de portraits-entretiens à la rencontre des enseignant⋅es développeur·euses
J’enseigne, je code et je partage est une série de portraits-entretiens à la rencontre des enseignant⋅es développeur·euses réalisée par Hervé Baronnet (enseignant) et Jean-Marc Adolphe (journaliste culture et humanités) pour l’association Faire École Ensemble. Déjà 3 de ces portraits-entretiens ont été publiés et on s’est dit que ça pourrait être chouette d’en savoir un peu plus sur cette initiative. Alors, on a demandé aux interviewers s’ils acceptaient d’être interviewés à leur tour.
Bonjour Hervé et Jean-Marc ! Pouvez-vous vous présenter ?
Bonjour,
Hervé Baronnet, je suis enseignant en maternelle depuis 25 ans, toujours en zone d’éducation prioritaire. Utilisateurs des TICE, notamment de logiciels éducatifs libres mais pas exclusivement. J’ai contribué au projet AbulÉdu en tant que bêta-testeur et auteur de documentations pédagogiques. Je suis actuellement membre du conseil collégial de FÉE.
Bonjour,
Jean-Marc Adolphe, journaliste et conseiller artistique, ex-militant FCPE. Je m’intéresse depuis longtemps à l’éducation aux médias, à mes yeux insuffisamment enseignée à l’école. Et en tant que citoyen, l’école m’engage. La question des « biens communs numériques » me semble essentielle dans tout ce qui ressort du service public, particulièrement au sein de l’Éducation nationale.
Vous êtes tous les deux adhérents de l’association Faire École Ensemble. C’est quoi cette asso ?
L’association Faire École Ensemble est une association collégiale qui facilite les collaborations entre les citoyens et la communauté éducative tout au long de la pandémie. Fée engage des projets collaboratifs en s’appuyant sur 3 spécificités : la convivialité, la documentation et le recours par défaut aux licences ouvertes.
Concrètement, à l’annonce de la fermeture des écoles et de la mise en place généralisée de l’enseignement à distance en mars 2020, nous avons mobilisé 1000 citoyennes et citoyens pour aider les professeurs peu à l’aise avec le numérique. S’en sont suivies d’autres actions autour de la réouverture progressive des écoles avec un protocole sanitaire drastique, les possibilités de faire école à l’extérieur, la préparation d’une rentrée apaisée en passant une nuit à l’école et une action réflexive sur la place du numérique dans l’enseignement (recherche-action ; états généraux du numérique libre et des communs pédagogiques).
Ce que nous faisons avec Faire École Ensemble relève d’une configuration tiers-lieux telle que définie par Antoine Burret (« le tiers-lieu peut-être défini conceptuellement comme : une configuration sociale où la rencontre entre des entités individuées engage intentionnellement à la conception de représentations communes »). Nos projets réunissent des communautés de personnes diverses (parents, profs, designers, chercheurs, élèves, architectes, juristes, militants associatifs, artistes…) autour d’une intention commune (réaménager sa classe, organiser une nuit à l’école, penser la pédagogique en période de crise…). Nous documentons les conversations (formelles et informelles) pour faire émerger un patrimoine informationnel commun, nous prenons soin des liens entre les personnes, sommes garants de la convivialité et accompagnons celles et ceux qui le souhaitent dans le passage à l’action (nous ne faisons pas à leur place).
J’ai cru comprendre que FÉE souhaitait développer une communauté d’enseignant⋅es développeur·euses en informatique. Quel est l’objectif ? Ça s’organise où et comment ? Quelles sont les modalités pour y participer ?
Des webinaires « le logiciel libre par des acteurs de l’éducation pour l’éducation » dans le cadre du cycle sur le libre et les communs sont proposés régulièrement. Les enseignant⋅es développeur·euses sont invité⋅es à y participer.
Il est important de souligner que les « enseignant⋅es développeur·euses » ne sont pas nécessairement des spécialistes en informatique. Ce sont avant tout des enseignant⋅es, soucieu⋅ses de trouver des ressources pédagogiques et « techniques » adaptées à leurs élèves.
Dans ce cadre, vous vous êtes lancés dans une série d’interviews d’enseignant⋅es développeur·euses. Quel est l’objectif de ces interviews ?
Le premier objectif de cette série d’entretiens-portraits est de faire connaître l’existence de ces personnes, de les valoriser elleux ainsi que les projets sur lesquels ielles travaillent. Ensuite, un portrait type présentant leurs spécificités va pouvoir naître en croisant les réponses.
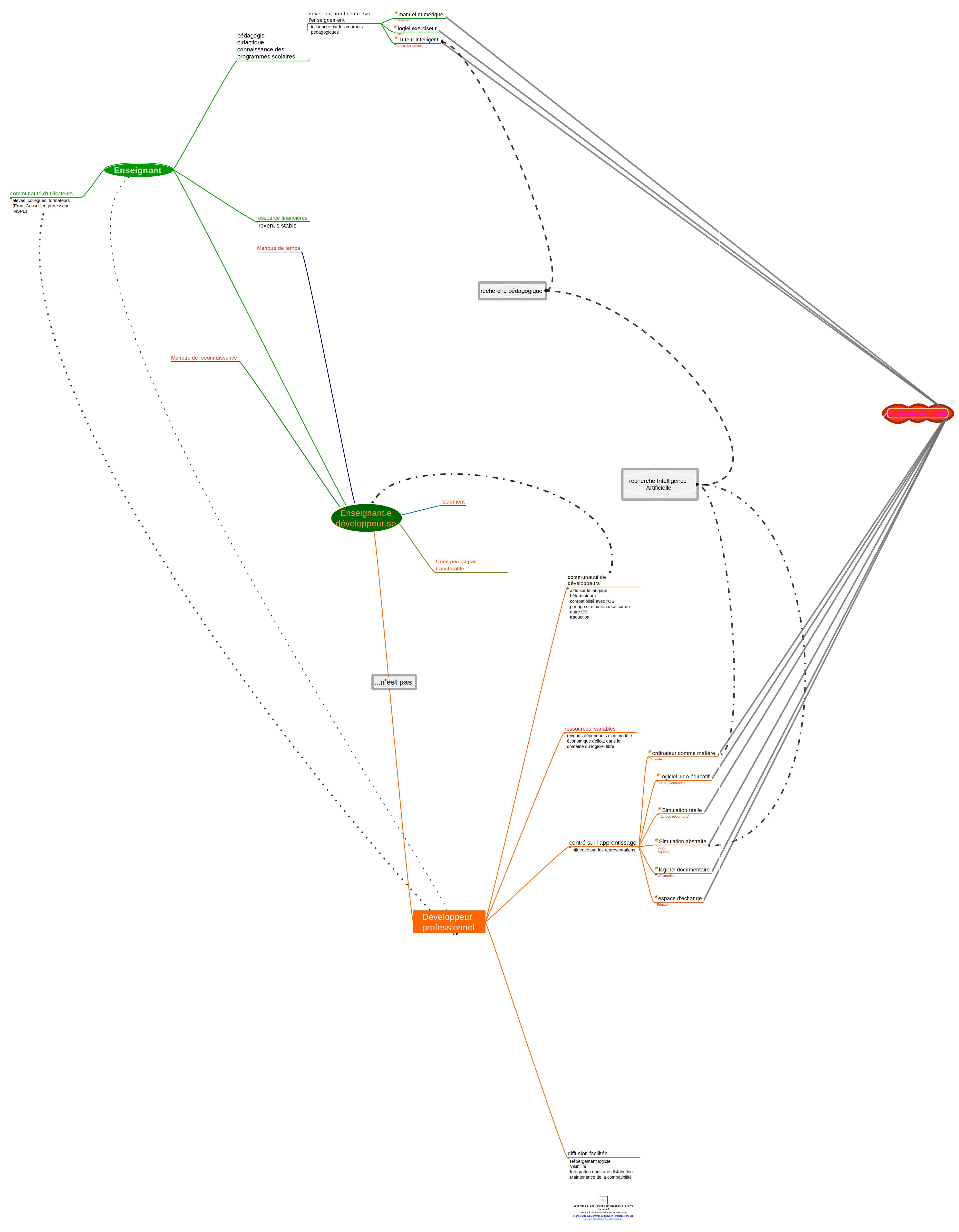
Carte heuristique pour mettre en évidence les spécificités des enseignant⋅es développeur·euses.
Il s’agit de faire savoir à d’autres enseignant⋅es développeur·euses qu’ielles ne sont pas seul⋅es. À plus long terme, il s’agit de faire prendre conscience de la valeur de ces acteur⋅ices et de lister les freins et les besoins pour aboutir à un soutien institutionnel.
Sur quels critères sélectionnez-vous les enseignant⋅es développeur·euses pour votre série de portraits ?
Nous avons sollicité dans un premier temps des enseignant⋅es qui s’étaient inscrit⋅es sur le forum de FÉE. Puis nous avons réalisé des portraits de personnes au profil plus étendu, avec la double casquette enseignant et développeur au sens large. Le fait de développer ou de contribuer à des logiciels libres est privilégié dans le choix des entretiens.
#ModeTroll : il y a à ce jour 3 entretiens sur le blog et uniquement des hommes. C’est volontaire de ne pas valoriser la gent féminine ?
Il y en a 3 et bientôt 6, tous des hommes, en effet ! FÉE n’y est pour rien (le conseil collégial de l’association devrait être bientôt à parité hommes / femmes). Il se trouve que seuls des enseignants-hommes se sont manifestés à ce jour. Mais nous profitons de cet entretien pour lancer un appel à des enseignantes-développeuses afin qu’elles participent à cette série d’entretiens et qu’elles puissent rejoindre la communauté qui est en train de se former.
Quelle est la place du logiciel libre dans les pratiques des enseignant⋅es développeur·euses ?
La place du logiciel libre est centrale, car la priorité a été donnée aux enseignant⋅es développeur·euses libristes, cette action étant dans la continuité des États Généraux du Numérique Libre organisés par FÉE.
Des développeur·euses qui utilisent des outils non libres ou développant des applications gratuites propriétaires pourront aussi être sollicité⋅es pour mieux définir ce qui les empêche de basculer vers le libre.
Et comme toujours, sur le Framablog, on vous laisse le mot de la fin !
À partir de ces entretiens des caractéristiques communes aux enseignant⋅es développeur·euses peuvent être extraites.
Parmi les points positifs :
+ la motivation à aider les élèves
+ l’éthique comme moteur
+ la valeur ajoutée de leur projet en tant qu’outil métier
Parmi les aspects négatifs :
– le temps, la non-reconnaissance du travail
– le code « amateur » peu ou pas documenté
– l’aspect chronophage des questions des utilisateur⋅ices qui augmente avec le succès des logiciels
Notre contributopie serait de limiter ces freins par l’impulsion de solutions :
Que les institutions qui emploient ces enseignant⋅es développeur·euses reconnaissent l’intérêt de leur travail et leur permettent d’y consacrer du temps. Les enseignant⋅es ne veulent pas devenir développeur·euses à temps plein, le côté passion est leur moteur et les expériences de « professionnalisation » ont été des échecs.
Que la communauté du libre les aide pour améliorer le code sous forme, par exemple, de formations menées par des développeur·euses professionnel⋅les.
La mise en place d’une communauté d’usage permettant de répondre aux questions des utilisateur⋅ices et de créer de la documentation pédagogique.
Merci beaucoup pour vos précisions Hervé et Jean-Marc. Et on espère que de nombreu⋅ses enseignant⋅es et libristes rejoindront votre communauté.
Développeurs, développeuses, nettoyez le Web !
Voici la traduction d’une nouvelle initiative d’Aral Balkan intitulée : Clean up the web! : et si on débarrassait les pages web de leurs nuisances intrusives ?
En termes parfois fleuris (mais il a de bonnes raisons de hausser le ton) il invite toutes les personnes qui font du développement web à agir pour en finir avec la soumission aux traqueurs des GAFAM. Pour une fois, ce n’est pas seulement aux internautes de se méfier de toutes parts en faisant des choix éclairés, mais aussi à celles et ceux qui élaborent les pages web de faire face à leurs responsabilités, selon lui…
Développeurs, développeuses, c’est le moment de choisir votre camp : voulez-vous contribuer à débarrasser le Web du pistage hostile à la confidentialité, ou bien allez-vous en être complices ?
Que puis-je faire ?
🚮️ Supprimer les scripts tiers de Google, Facebook, etc.
Ces scripts permettent à des éleveurs de moutons numériques comme Google et Facebook de pister les utilisatrices d’un site à l’autre sur tout le Web. Si vous les incorporez à votre site, vous êtes complice en permettant ce pistage par des traqueurs.
Face à la pression montante des mécontents, Google a annoncé qu’il allait à terme bloquer les traqueurs tiers dans son navigateur Chrome. Ça a l’air bien non ? Et ça l’est, jusqu’à ce que l’on entende que l’alternative proposée est de faire en sorte que Chrome lui-même traque les gens sur tous les sites qu’ils visitent…sauf si les sites lui demandent de ne pas le faire, en incluant le header suivant dans leur réponse :
Permissions-Policy: interest-cohort=()
Bon, maintenant, si vous préférez qu’on vous explique à quel point c’est un coup tordu…
Aucune page web au monde ne devrait avoir à supplier Google : « s’il vous plaît, monsieur, ne violez pas la vie privée de la personne qui visite mon site » mais c’est exactement ce que Google nous oblige à faire avec sa nouvelle initiative d’apprentissage fédéré des cohortes (FLoC).
Si jamais vous avez du mal à retenir le nom, n’oubliez pas que « flock » veut dire « troupeau » en anglais, comme dans « troupeau de moutons, » parce que c’est clairement l’image qu’ils se font de nous chez Google s’ils pensent qu’on va accepter cette saloperie.
Donc c’est à nous, les développeurs, de coller ce header dans tous les serveurs web (comme nginx, Caddy, etc.), tous les outils web (comme WordPress, Wix, etc.)… bref dans tout ce qui, aujourd’hui, implique une réponse web à une requête, partout dans le monde.
Notre petit serveur web, Site.js, l’a déjà activé par défaut.
Si jamais il y a des politiciens qui ont les yeux ouverts en ce 21e siècle et qui ne sont pas trop occupés à se frotter les mains ou à saliver à l’idée de fricoter, voire de se faire embaucher par Google et Facebook, c’est peut-être le moment de faire attention et de faire votre putain de taf pour changer.
🚮️ Arrêter d’utiliser Chrome et conseiller aux autres d’en faire autant, si ça leur est possible.
Rappelons qui est le méchant ici : c’est Google (Alphabet, Inc.), pas les gens qui pour de multiples raisons pourraient être obligés d’utiliser le navigateur web de Google (par exemple, ils ne savent pas forcément comment télécharger et installer un nouveau navigateur, ou peuvent être obligés de l’utiliser au travail, etc.)
Donc, attention de ne pas vous retrouver à blâmer la victime, mais faites comprendre aux gens quel est le problème avec Google (« c’est une ferme industrielle pour les êtres humains ») et conseillez-leur d’utiliser, s’ils le peuvent, un navigateur différent.
C’est décourageant de voir les tentacules de ce foutu monstre marin s’étendre partout et s’il a jamais été temps de créer une organisation indépendante financée par des fonds publics pour mettre au point un navigateur sans cochonnerie, c’est le moment.
🚮️ Protégez-vous et montrez aux autres comment en faire autant
Pointez vers cette page avec les hashtags #CleanUpTheWeb et#FlocOffGoogle.
🚮️ Choisissez un autre business model
En fin de compte, on peut résumer les choses ainsi : si votre business model est fondé sur le pistage et le profilage des gens, vous faites partie du problème.
Les mecs de la tech dans la Silicon Valley vous diront qu’il n’y a pas d’autre façon de faire de la technologie que la leur.
C’est faux.
Ils vous diront que votre « aventure extraordinaire » commence par une startup financée par des business angels et du capital risque et qu’elle se termine soit quand vous êtes racheté par un Google ou un Facebook, soit quand vous en devenez un vous-même. Licornes et compagnie…
Vous pouvez créer de petites entreprises durables. Vous pouvez créer des coopératives. Vous pouvez créer des associations à but non lucratif, comme nous.
Si vous vous demandez ce qui vous rend heureux, est-ce que ce n’est pas ça, par hasard ?
Est-ce que vous voulez devenir milliardaire ? Est-ce que vous avez envie de traquer, de profiler, de manipuler les gens ? Ou est-ce que vous avec juste envie de faire de belles choses qui améliorent la vie des gens et rendent le monde plus équitable et plus sympa ?
Nous faisons le pari que vous préférez la seconde solution.
Si vous manquez d’inspiration, allez voir ce qui se fait chez Plausible, par exemple, et comment c’est fait, ou chez HEY, Basecamp, elementary OS, Owncast, Pine64, StarLabs, Purism, ou ce à quoi nous travaillons avec Site.js et le Small Web… vous n’êtes pas les seuls à dire non aux conneries de la Silicon Valley
On existe en partie grâce au soutien de gens comme vous. Si vous partagez notre vision et désirez soutenir notre travail, faites une don aujourd’hui et aidez-nous à continuer à exister.
Google chante le requiem pour les cookies, mais le grand chœur du pistage résonnera encore
Google va cesser de nous pister avec des cookies tiers ! Une bonne nouvelle, oui mais… Regardons le projet d’un peu plus près avec un article de l’EFF.
La presse en ligne s’en est fait largement l’écho : par exemple siecledigital, generation-nt ou lemonde. Et de nombreux articles citent un éminent responsable du tout-puissant Google :
Chrome a annoncé son intention de supprimer la prise en charge des cookies tiers et que nous avons travaillé avec l’ensemble du secteur sur le Privacy Sandbox afin de mettre au point des innovations qui protègent l’anonymat tout en fournissant des résultats aux annonceurs et aux éditeurs. Malgré cela, nous continuons à recevoir des questions pour savoir si Google va rejoindre d’autres acteurs du secteur des technologies publicitaires qui prévoient de remplacer les cookies tiers par d’autres identifiants de niveau utilisateur. Aujourd’hui, nous précisons qu’une fois les cookies tiers supprimés, nous ne créerons pas d’identifiants alternatifs pour suivre les individus lors de leur navigation sur le Web et nous ne les utiliserons pas dans nos produits.
David Temkin, Director of Product Management, Ads Privacy and Trust (source)
« Pas d’identifiants alternatifs » voilà de quoi nous réjouir : serait-ce la fin d’une époque ?
Comme d’habitude avec Google, il faut se demander où est l’arnaque lucrative. Car il semble bien que le Béhémoth du numérique n’ait pas du tout renoncé à son modèle économique qui est la vente de publicité.
Dans cet article de l’Electronic Frontier Foundation, que vous a traduit l’équipe de Framalang, il va être question d’un projet déjà entamé de Google dont l’acronyme est FLoC, c’est-à-dire Federated Learning of Cohorts. Vous le trouverez ici traduit AFC pour « Apprentissage Fédéré de Cohorte » (voir l’article de Wikipédia Apprentissage fédéré).
Pour l’essentiel, ce dispositif donnerait au navigateur Chrome la possibilité de créer des groupes de milliers d’utilisateurs ayant des habitudes de navigation similaires et permettrait aux annonceurs de cibler ces « cohortes ».
Les cookies tiers se meurent, mais Google essaie de créer leur remplaçant.
Personne ne devrait pleurer la disparition des cookies tels que nous les connaissons aujourd’hui. Pendant plus de deux décennies, les cookies tiers ont été la pierre angulaire d’une obscure et sordide industrie de surveillance publicitaire sur le Web, brassant plusieurs milliards de dollars ; l’abandon progressif des cookies de pistage et autres identifiants tiers persistants tarde à arriver. Néanmoins, si les bases de l’industrie publicitaire évoluent, ses acteurs les plus importants sont déterminés à retomber sur leurs pieds.
Google veut être en première ligne pour remplacer les cookies tiers par un ensemble de technologies permettant de diffuser des annonces ciblées sur Internet. Et certaines de ses propositions laissent penser que les critiques envers le capitalisme de surveillance n’ont pas été entendues. Cet article se concentrera sur l’une de ces propositions : l’Apprentissage Fédéré de Cohorte (AFC, ou FLoC en anglais), qui est peut-être la plus ambitieuse – et potentiellement la plus dangereuse de toutes.
L’AFC est conçu comme une nouvelle manière pour votre navigateur d’établir votre profil, ce que les pisteurs tiers faisaient jusqu’à maintenant, c’est-à-dire en retravaillant votre historique de navigation récent pour le traduire en une catégorie comportementale qui sera ensuite partagée avec les sites web et les annonceurs. Cette technologie permettra d’éviter les risques sur la vie privée que posent les cookies tiers, mais elle en créera de nouveaux par la même occasion. Une solution qui peut également exacerber les pires attaques sur la vie privée posées par les publicités comportementales, comme une discrimination accrue et un ciblage prédateur.
La réponse de Google aux défenseurs de la vie privée a été de prétendre que le monde de demain avec l’AFC (et d’autres composants inclus dans le « bac à sable de la vie privée » sera meilleur que celui d’aujourd’hui, dans lequel les marchands de données et les géants de la tech pistent et profilent en toute impunité. Mais cette perspective attractive repose sur le présupposé fallacieux que nous devrions choisir entre « le pistage à l’ancienne » et le « nouveau pistage ». Au lieu de réinventer la roue à espionner la vie privée, ne pourrait-on pas imaginer un monde meilleur débarrassé des problèmes surabondants de la publicité ciblée ?
Nous sommes à la croisée des chemins. L’ère des cookies tiers, peut-être la plus grande erreur du Web, est derrière nous et deux futurs possibles nous attendent.
Dans l’un d’entre eux, c’est aux utilisateurs et utilisatrices que revient le choix des informations à partager avec chacun des sites avec lesquels il ou elle interagit. Plus besoin de s’inquiéter du fait que notre historique de navigation puisse être utilisé contre nous-mêmes, ou employé pour nous manipuler, lors de l’ouverture d’un nouvel onglet.
Dans l’autre, le comportement de chacune et chacun est répercuté de site en site, au moyen d’une étiquette, invisible à première vue mais riche de significations pour celles et ceux qui y ont accès. L’historique de navigation récent, concentré en quelques bits, est « démocratisé » et partagé avec les dizaines d’interprètes anonymes qui sont partie prenante des pages web. Les utilisatrices et utilisateurs commencent chaque interaction avec une confession : voici ce que j’ai fait cette semaine, tenez-en compte.
Les utilisatrices et les personnes engagées dans la défense des droits numériques doivent rejeter l’AFC et les autres tentatives malvenues de réinventer le ciblage comportemental. Nous exhortons Google à abandonner cette pratique et à orienter ses efforts vers la construction d’un Web réellement favorable aux utilisateurs.
Qu’est-ce que l’AFC ?
En 2019, Google présentait son bac à sable de la vie privée qui correspond à sa vision du futur de la confidentialité sur le Web. Le point central de ce projet est un ensemble de protocoles, dépourvus de cookies, conçus pour couvrir la multitude de cas d’usage que les cookies tiers fournissent actuellement aux annonceurs. Google a soumis ses propositions au W3C, l’organisme qui forge les normes du Web, où elles ont été principalement examinées par le groupe de commerce publicitaire sur le Web, un organisme essentiellement composé de marchands de technologie publicitaire. Dans les mois qui ont suivi, Google et d’autres publicitaires ont proposé des dizaines de standards techniques portant des noms d’oiseaux : pigeon, tourterelle, moineau, cygne, francolin, pélican, perroquet… et ainsi de suite ; c’est très sérieux ! Chacune de ces propositions aviaires a pour objectif de remplacer différentes fonctionnalités de l’écosystème publicitaire qui sont pour l’instant assurées par les cookies.
L’AFC est conçu pour aider les annonceurs à améliorer le ciblage comportemental sans l’aide des cookies tiers. Un navigateur ayant ce système activé collecterait les informations sur les habitudes de navigation de son utilisatrice et les utiliserait pour les affecter à une « cohorte » ou à un groupe. Les utilisateurs qui ont des habitudes de navigations similaires – reste à définir le mot « similaire » – seront regroupés dans une même cohorte. Chaque navigateur partagera un identifiant de cohorte, indiquant le groupe d’appartenance, avec les sites web et les annonceurs. D’après la proposition, chaque cohorte devrait contenir au moins plusieurs milliers d’utilisatrices et utilisateurs (ce n’est cependant pas une garantie).
Si cela vous semble complexe, imaginez ceci : votre identifiant AFC sera comme un court résumé de votre activité récente sur le Web.
La démonstration de faisabilité de Google utilisait les noms de domaines des sites visités comme base pour grouper les personnes. Puis un algorithme du nom de SimHash permettait de créer les groupes. Il peut tourner localement sur la machine de tout un chacun, il n’y a donc pas besoin d’un serveur central qui collecte les données comportementales. Toutefois, un serveur administrateur central pourrait jouer un rôle dans la mise en œuvre des garanties de confidentialité. Afin d’éviter qu’une cohorte soit trop petite (c’est à dire trop caractéristique), Google propose qu’un acteur central puisse compter le nombre de personnes dans chaque cohorte. Si certaines sont trop petites, elles pourront être fusionnées avec d’autres cohortes similaires, jusqu’à ce qu’elles représentent suffisamment d’utilisateurs.
Pour que l’AFC soit utile aux publicitaires, une cohorte d’utilisateurs ou utilisatrices devra forcément dévoiler des informations sur leur comportement.
Selon la proposition formulée par Google, la plupart des spécifications sont déjà à l’étude. Le projet de spécification prévoit que l’identification d’une cohorte sera accessible via JavaScript, mais on ne peut pas savoir clairement s’il y aura des restrictions, qui pourra y accéder ou si l’identifiant de l’utilisateur sera partagé par d’autres moyens. L’AFC pourra constituer des groupes basés sur l’URL ou le contenu d’une page au lieu des noms domaines ; également utiliser une synergie de « système apprentissage » (comme le sous-entend l’appellation AFC) afin de créer des regroupements plutôt que de se baser sur l’algorithme de SimHash. Le nombre total de cohortes possibles n’est pas clair non plus. Le test de Google utilise une cohorte d’utilisateurs avec des identifiants sur 8 bits, ce qui suppose qu’il devrait y avoir une limite de 256 cohortes possibles. En pratique, ce nombre pourrait être bien supérieur ; c’est ce que suggère la documentation en évoquant une « cohorte d’utilisateurs en 16 bits comprenant 4 caractères hexadécimaux ». Plus les cohortes seront nombreuses, plus elles seront spécialisées – plus les identifiants de cohortes seront longs, plus les annonceurs en apprendront sur les intérêts de chaque utilisatrice et auront de facilité pour cibler leur empreinte numérique.
Mais si l’un des points est déjà clair c’est le facteur temps. Les cohortes AFC seront réévaluées chaque semaine, en utilisant chaque fois les données recueillies lors de la navigation de la semaine précédente.
Ceci rendra les cohortes d’utilisateurs moins utiles comme identifiants à long terme, mais les rendra plus intrusives sur les comportements des utilisatrices dans la durée.
De nouveaux problèmes pour la vie privée.
L’AFC fait partie d’un ensemble qui a pour but d’apporter de la publicité ciblée dans un futur où la vie privée serait préservée. Cependant la conception même de cette technique implique le partage de nouvelles données avec les annonceurs. Sans surprise, ceci crée et ajoute des risques concernant la donnée privée.
Le Traçage par reconnaissance d’ID.
Le premier enjeu, c’est le pistage des navigateurs, une pratique qui consiste à collecter de multiples données distinctes afin de créer un identifiant unique, personnalisé et stable lié à un navigateur en particulier. Le projet Cover Your Tracks (Masquer Vos Traces) de l’Electronic Frontier Foundation (EFF) montre comment ce procédé fonctionne : pour faire simple, plus votre navigateur paraît se comporter ou agir différemment des autres, plus il est facile d’en identifier l’empreinte unique.
Google a promis que la grande majorité des cohortes AFC comprendrait chacune des milliers d’utilisatrices, et qu’ainsi on ne pourra vous distinguer parmi le millier de personnes qui vous ressemblent. Mais rien que cela offre un avantage évident aux pisteurs. Si un pistage commence avec votre cohorte, il doit seulement identifier votre navigateur parmi le millier d’autres (au lieu de plusieurs centaines de millions). En termes de théorie de l’information, les cohortes contiendront quelques bits d’entropie jusqu’à 8, selon la preuve de faisabilité. Cette information est d’autant plus éloquente sachant qu’il est peu probable qu’elle soit corrélée avec d’autres informations exposées par le navigateur. Cela va rendre la tâche encore plus facile aux traqueurs de rassembler une empreinte unique pour les utilisateurs de l’AFC.
Google a admis que c’est un défi et s’est engagé à le résoudre dans le cadre d’un plan plus large, le « Budget vie privée » qui doit régler le problème du pistage par l’empreinte numérique sur le long terme. Un but admirable en soi, et une proposition qui va dans le bon sens ! Mais selon la Foire Aux Questions, le plan est « une première proposition, et n’a pas encore d’implémentation dans un navigateur ». En attendant, Google a commencé à tester l’AFC dès ce mois de mars.
Le pistage par l’empreinte numérique est évidemment difficile à arrêter. Des navigateurs comme Safari et Tor se sont engagés dans une longue bataille d’usure contre les pisteurs, sacrifiant une grande partie de leurs fonctionnalités afin de réduire la surface des attaques par traçage. La limitation du pistage implique généralement des coupes ou des restrictions sur certaines sources d’entropie non nécessaires. Il ne faut pas que Google crée de nouveaux risques d’être tracé tant que les problèmes liés aux risques existants subsistent.
L’exposition croisée
Un second problème est moins facile à expliquer : la technologie va partager de nouvelles données personnelles avec des pisteurs qui peuvent déjà identifier des utilisatrices. Pour que l’AFC soit utile aux publicitaires, une cohorte devra nécessairement dévoiler des informations comportementales.
La page Github du projet aborde ce sujet de manière très directe :
Cette API démocratise les accès à certaines informations sur l’historique de navigation général des personnes (et, de fait, leurs intérêts principaux) à tous les sites qui le demandent… Les sites qui connaissent les Données à Caractère Personnel (c’est-à-dire lorsqu’une personne s’authentifie avec son adresse courriel) peuvent enregistrer et exposer leur cohorte. Cela implique que les informations sur les intérêts individuels peuvent éventuellement être rendues publiques.
Comme décrit précédemment, les cohortes AFC ne devraient pas fonctionner en tant qu’identifiant intrinsèque. Cependant, toute entreprise capable d’identifier un utilisateur d’une manière ou d’une autre – par exemple en offrant les services « identifiez-vous via Google » à différents sites internet – seront à même de relier les informations qu’elle apprend de l’AFC avec le profil de l’utilisateur.
Deux catégories d’informations peuvent alors être exposées :
1. Des informations précises sur l’historique de navigation. Les pisteurs pourraient mettre en place une rétro-ingénierie sur l’algorithme d’assignation des cohortes pour savoir si une utilisatrice qui appartient à une cohorte spécifique a probablement ou certainement visité des sites spécifiques.
2. Des informations générales relatives à la démographie ou aux centres d’intérêts. Par exemple, une cohorte particulière pourrait sur-représenter des personnes jeunes, de sexe féminin, ou noires ; une autre cohorte des personnes d’âge moyen votant Républicain ; une troisième des jeunes LGBTQ+, etc.
Cela veut dire que chaque site que vous visitez se fera une bonne idée de quel type de personne vous êtes dès le premier contact avec ledit site, sans avoir à se donner la peine de vous suivre sur le Net. De plus, comme votre cohorte sera mise à jour au cours du temps, les sites sur lesquels vous êtes identifié⋅e⋅s pourront aussi suivre l’évolution des changements de votre navigation. Souvenez-vous, une cohorte AFC n’est ni plus ni moins qu’un résumé de votre activité récente de navigation.
Vous devriez pourtant avoir le droit de présenter différents aspects de votre identité dans différents contextes. Si vous visitez un site pour des informations médicales, vous pourriez lui faire confiance en ce qui concerne les informations sur votre santé, mais il n’y a pas de raison qu’il ait besoin de connaître votre orientation politique. De même, si vous visitez un site de vente au détail, ce dernier n’a pas besoin de savoir si vous vous êtes renseigné⋅e récemment sur un traitement pour la dépression. L’AFC érode la séparation des contextes et, au contraire, présente le même résumé comportemental à tous ceux avec qui vous interagissez.
Au-delà de la vie privée
L’AFC est conçu pour éviter une menace spécifique : le profilage individuel qui est permis aujourd’hui par le croisement des identifiants contextuels. Le but de l’AFC et des autres propositions est d’éviter de laisser aux pisteurs l’accès à des informations qu’ils peuvent lier à des gens en particulier. Alors que, comme nous l’avons montré, cette technologie pourrait aider les pisteurs dans de nombreux contextes. Mais même si Google est capable de retravailler sur ses conceptions et de prévenir certains risques, les maux de la publicité ciblée ne se limitent pas aux violations de la vie privée. L’objectif même de l’AFC est en contradiction avec d’autres libertés individuelles.
Pouvoir cibler c’est pouvoir discriminer. Par définition, les publicités ciblées autorisent les annonceurs à atteindre certains types de personnes et à en exclure d’autres. Un système de ciblage peut être utilisé pour décider qui pourra consulter une annonce d’emploi ou une offre pour un prêt immobilier aussi facilement qu’il le fait pour promouvoir des chaussures.
Au fur et à mesure des années, les rouages de la publicité ciblée ont souvent été utilisés pour l’exploitation, la discrimination et pour nuire. La capacité de cibler des personnes en fonction de l’ethnie, la religion, le genre, l’âge ou la compétence permet des publicités discriminatoires pour l’emploi, le logement ou le crédit. Le ciblage qui repose sur l’historique du crédit – ou des caractéristiques systématiquement associées – permet de la publicité prédatrice pour des prêts à haut taux d’intérêt. Le ciblage basé sur la démographie, la localisation et l’affiliation politique aide les fournisseurs de désinformation politique et la suppression des votants. Tous les types de ciblage comportementaux augmentent les risques d’abus de confiance.
Au lieu de réinventer la roue du pistage, nous devrions imaginer un monde sans les nombreux problèmes posés par les publicités ciblées.
Google, Facebook et beaucoup d’autres plateformes sont en train de restreindre certains usages sur de leur système de ciblage. Par exemple, Google propose de limiter la capacité des annonceurs de cibler les utilisatrices selon des « catégories de centres d’intérêt à caractère sensible ». Cependant, régulièrement ces tentatives tournent court, les grands acteurs pouvant facilement trouver des compromis et contourner les « plateformes à usage restreint » grâce à certaines manières de cibler ou certains types de publicité.
Même un imaginant un contrôle total sur quelles informations peuvent être utilisées pour cibler quelles personnes, les plateformes demeurent trop souvent incapables d’empêcher les usages abusifs de leur technologie. Or l’AFC utilisera un algorithme non supervisé pour créer ses propres cohortes. Autrement dit, personne n’aura un contrôle direct sur la façon dont les gens seront regroupés.
Idéalement (selon les annonceurs), les cohortes permettront de créer des regroupements qui pourront avoir des comportements et des intérêts communs. Mais le comportement en ligne est déterminé par toutes sortes de critères sensibles : démographiques comme le genre, le groupe ethnique, l’âge ou le revenu ; selon les traits de personnalités du « Big 5 »; et même la santé mentale. Ceci laisse à penser que l’AFC regroupera aussi des utilisateurs parmi n’importe quel de ces axes.
L’AFC pourra aussi directement rediriger l’utilisatrice et sa cohorte vers des sites internet qui traitent l’abus de substances prohibées, de difficultés financières ou encore d’assistance aux victimes d’un traumatisme.
Google a proposé de superviser les résultats du système pour analyser toute corrélation avec ces catégories sensibles. Si l’on découvre qu’une cohorte spécifique est étroitement liée à un groupe spécifique protégé, le serveur d’administration pourra choisir de nouveaux paramètres pour l’algorithme et demander aux navigateurs des utilisateurs concernés de se constituer en un autre groupe.
Cette solution semble à la fois orwellienne et digne de Sisyphe. Pour pouvoir analyser comment les groupes AFC seront associés à des catégories sensibles, Google devra mener des enquêtes gigantesques en utilisant des données sur les utilisatrices : genre, race, religion, âge, état de santé, situation financière. Chaque fois que Google trouvera qu’une cohorte est associée trop fortement à l’un de ces facteurs, il faudra reconfigurer l’ensemble de l’algorithme et essayer à nouveau, en espérant qu’aucune autre « catégorie sensible » ne sera impliquée dans la nouvelle version. Il s’agit d’une variante bien plus compliquée d’un problème que Google s’efforce déjà de tenter de résoudre, avec de fréquents échecs.
Dans un monde numérique doté de l’AFC, il pourrait être plus difficile de cibler directement les utilisatrices en fonction de leur âge, genre ou revenu. Mais ce ne serait pas impossible. Certains pisteurs qui ont accès à des informations secondaires sur les utilisateurs seront capables de déduire ce que signifient les groupes AFC, c’est-à-dire quelles catégories de personnes appartiennent à une cohorte, à force d’observations et d’expérimentations. Ceux qui seront déterminés à le faire auront la possibilité de la discrimination. Pire, les plateformes auront encore plus de mal qu’aujourd’hui à contrôler ces pratiques. Les publicitaires animés de mauvaises intentions pourront être dans un déni crédible puisque, après tout, ils ne cibleront pas directement des catégories protégées, ils viseront seulement les individus en fonction de leur comportement. Et l’ensemble du système sera encore plus opaque pour les utilisatrices et les régulateurs.
Avec Google les instruments changent, mais c’est toujours la même musique…
Google, ne faites pas ça, s’il vous plaît
Nous nous sommes déjà prononcés sur l’AFC et son lot de propositions initiales lorsque tout cela a été présenté pour la première fois, en décrivant l’AFC comme une technologie « contraire à la vie privée ». Nous avons espéré que les processus de vérification des standards mettraient l’accent sur les défauts de base de l’AFC et inciteraient Google à renoncer à son projet. Bien entendu, plusieurs problèmes soulevés sur leur GitHub officiel exposaient exactement les mêmespréoccupations que les nôtres. Et pourtant, Google a poursuivi le développement de son système, sans pratiquement rien changer de fondamental. Ils ont commencé à déployer leur discours sur l’AFC auprès des publicitaires, en vantant le remplacement du ciblage basé sur les cookies par l’AFC « avec une efficacité de 95 % ». Et à partir de la version 89 de Chrome, depuis le 2 mars, la technologie est déployée pour un galop d’essai. Une petite fraction d’utilisateurs de Chrome – ce qui fait tout de même plusieurs millions – a été assignée aux tests de cette nouvelle technologie.
Ne vous y trompez pas, si Google poursuit encore son projet d’implémenter l’AFC dans Chrome, il donnera probablement à chacun les « options » nécessaires. Le système laissera probablement le choix par défaut aux publicitaires qui en tireront bénéfice, mais sera imposé par défaut aux utilisateurs qui en seront affectés. Google se glorifiera certainement de ce pas en avant vers « la transparence et le contrôle par l’utilisateur », en sachant pertinemment que l’énorme majorité de ceux-ci ne comprendront pas comment fonctionne l’AFC et que très peu d’entre eux choisiront de désactiver cette fonctionnalité. L’entreprise se félicitera elle-même d’avoir initié une nouvelle ère de confidentialité sur le Web, débarrassée des vilains cookies tiers, cette même technologie que Google a contribué à développer bien au-delà de sa date limite, engrangeant des milliards de dollars au passage.
Ce n’est pas une fatalité. Les parties les plus importantes du bac-à-sable de la confidentialité comme l’abandon des identificateurs tiers ou la lutte contre le pistage des empreintes numériques vont réellement améliorer le Web. Google peut choisir de démanteler le vieil échafaudage de surveillance sans le remplacer par une nouveauté nuisible.
Nous rejetons vigoureusement le devenir de l’AFC. Ce n’est pas le monde que nous voulons, ni celui que méritent les utilisatrices. Google a besoin de tirer des leçons pertinentes de l’époque du pistage par des tiers et doit concevoir son navigateur pour l’activité de ses utilisateurs et utilisatrices, pas pour les publicitaires.
Remarque : nous avons contacté Google pour vérifier certains éléments exposés dans ce billet ainsi que pour demander davantage d’informations sur le test initial en cours. Nous n’avons reçu aucune réponse à ce jour.