MobiliZon : reprendre le pouvoir sur ce qui nous rassemble
Nous voulons façonner les outils que les géants du Web ne peuvent ni ne veulent créer. Pour y parvenir, nous avons besoin de votre soutien.
Penser hors des sentiers battus par les actionnaires
Pauvre MeetUp ! Pauvre Facebook avec ses événements et ses groupes ! Vous imaginez combien c’est dur, d’être une des plus grandes capitalisations boursières au monde ? Non mais c’est que les actionnaires ils sont jamais contents, alors il faut les arracher avec les dents, ces dividendes !
Nos pauvres petits géants du Web sont o-bli-gés de coder des outils qui ne vous donnent que très peu de contrôle sur vos communautés (familiales, professionnelles, militantes, etc.). Parce qu’au fond, les centres d’intérêt que vous partagez avec d’autres, c’est leur fonds de commerce ! Nos pauvres vendeurs de temps de cerveau disponible sont trop-for-cés de vous enfermer dans leurs plateformes où tout ce que vous ferez sera retenu envers et contre vous. Parce qu’un profil publicitaire complet, ça se vend plus cher, et ça, ça compte, dans leurs actions…
Cliquez sur l’image pour aller voir la conférence « Comment internet a facilité l’organisation des révolutions sociales mais en a compromis la victoire » de Zeynep Tufekci sur TED Talk
Et nous, internautes prétentieuses, on voudrait qu’ils nous fassent en plus un outil complet, éthique et pratique pour nous rassembler…? Mais on leur en demande trop, à ces milliardaires du marketing digital !
Comme on est choubidou chez Framasoft, on s’est dit qu’on allait leur enlever une épine du pied. Oui, il faut un outil pour organiser ces moments où on se regroupe, que ce soit pour le plaisir ou pour changer le monde. Alors on accepte le défi et on se relève les manches.
On ne changera pas le monde depuis Facebook
Lors du lancement de la feuille de route Contributopia, nous avions annoncé une alternative à Meetup, nom de code Framameet. Au départ, nous imaginions vraiment un outil qui puisse servir à se rassembler autour de l’anniversaire du petit dernier, de l’AG de son asso ou de la compète de son club d’Aïkido… Un outil singeant les groupes et événements Facebook, mais la version libre, qui respecte nos sphères d’intimité.
Puis, nous avons vu comment les « Marches pour le climat » se sont organisées sur Facebook, et comment cet outil a limité les personnes qui voulaient s’organiser pour participer à ces manifestations. Cliquera-t-on vraiment sur «ça m’intéresse» si on sait que nos collègues, nos ami·e·s d’enfance et notre famille éloignée peuvent voir et critiquer notre démarche ? Quelle capacité pour les orgas d’envoyer une info aux participant·e·s quand tout le monde est enfermé dans des murs Facebook où c’est l’Algorithme qui décide de ce que vous verrez, de ce que vous ne verrez pas ?
L’outil dont nous rêvons, les entreprises du capitalisme de surveillance sont incapables de le produire, car elles ne sauraient pas en tirer profit. C’est l’occasion de faire mieux qu’elles, en faisant autrement.
Nous avons été contacté·e·s par des personnes des manifestations #OnVautMieuxQueÇa et contre la loi travail, des Nuits Debout, des Marches pour le climat, et des Gilets Jaunes… Et nous travaillons régulièrement avec les Alternatiba, l’association Résistance à l’Agression Publicitaire, le mouvement Colibris ou les CEMÉA (entre autres) : la plupart de ces personnes peinent à trouver des outils permettant de structurer leurs actions de mobilisation, sans perdre le contrôle de leur communauté, du lien qui est créé.
Cliquez sur cette image pour lire « Après avoir liké, les Gilets Jaunes iront-ils voter ? » d’Olivier Ertzschied.
Or « qui peut le plus peut le moins » : si on conçoit un outil qui peut aider un mouvement citoyen à s’organiser, à s’émanciper… cet outil peut servir, en plus, pour gérer l’anniversaire surprise de Tonton Roger !
Ce que MeetUp nous refuse, MobiliZon l’intègrera
Concevoir le logiciel MobiliZon (car ce sera son nom), c’est reprendre le pouvoir qui a été capté par les plateformes centralisatrices des géants du Web. Prendre le pouvoir aux GAFAM pour le remettre entre les mains de… de nous, des gens, des humains, quoi. Nous allons nous inspirer de l’aventure PeerTube, et penser un logiciel réellement émancipateur :
Ce sera un logiciel Libre : la direction que Framasoft lui donne ne vous convient pas ? Vous aurez le pouvoir de l’emmener sur une autre voie.
Comme Mastodon ou PeerTube, ce sera une plateforme fédérée (via ActivityPub). Vous aurez le pouvoir de choisir qui héberge vos données sans vous isoler du reste de la fédération, du « fediverse ».
L’effet « double rainbow » de la fédération, c’est qu’avec MobiliZon vous donnerez à vos événements le pouvoir d’interagir avec les pouets de Mastodon, les vidéosPeerTube, les musiques de FunkWhale…
Vous voulez cloisonner vos rassemblements familiaux de vos activités associatives ou de vos mobilisations militantes ? Vous aurez le pouvoir de créer plusieurs identités depuis le même compte, comme autant de masques sociaux.
Vous voulez créer des événements réellement publics ? Vous donnerez le pouvoir de cliquer sur « je participe » sans avoir à se créer de compte.
Il faut lier votre événement à des outils externes, par exemple (au hasard) à un Framapad ? Vous aurez le pouvoir d’intégrer des outils externes à votre communauté MobiliZon.
La route est longue, mais MobiliZon-nous pour que la voie soit libre !
Nous avons travaillé en amont pour poser des bases au projet, que nous vous présentons aujourd’hui sur JoinMobilizon.org. Au delà des briques logicielles et techniques, nous avons envie de penser à l’expérience utilisateur de l’application que les gens auront en main au final. Et qui, en plus, se doit d’être accessible et compréhensible par des néophytes.
Nous souhaitons éprouver ainsi une nouvelle façon de faire, en contribuant avec des personnes dont c’est le métier (designeurs et designeuses, on parlera très vite de Marie-Cécile et de Geoffrey !) pour œuvrer ensemble au service de causes qui veulent du bien à la société.
Le développement se fera par étapes et itérations, comme cela avait été le cas pour PeerTube, de façon à livrer rapidement (fin 2019) une version fonctionnelle qui soit aussi proche que possible des aspirations de celles et ceux qui ont besoin d’un tel outil pour se mobiliser.
Voilà notre déclaration d’intention. La question est : allez-vous nous soutenir ?
Pour notre campagne de dons de cette année, nous avons fait le choix de ne pas utiliser des outils invasifs qui jouent à vous motiver (genre la barre de dons qu’on a envie de voir se remplir). On a voulu rester sobre, et du coup c’est pas super la fête : on risque d’avoir du mal à ajouter MobiliZon dans notre budget 2019…
Alors si MobiliZon vous fait rêver autant que nous, et si vous le pouvez, pensez à soutenir Framasoft.
Voici déjà la traduction du quatrième chapitre de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà publiés. Il s’agit cette fois d’explorer les stratégies des régies publicitaires qui opèrent en arrière-plan : des opérations fort discrètes mais terriblement efficaces…
IV. Collecte de données par les outils des annonceurs et des diffuseurs
29. Une source majeure de collecte des données d’activité des utilisateurs provient des outils destinés au annonceurs et aux éditeurs tels que Google Analytics, DoubleClick, AdSense, AdWords et AdMob. Ces outils ont une portée énorme ; par exemple, plus d’un million d’applications mobiles utilisent AdMob1, plus d’un million d’annonceurs utilisent AdWords2, plus de 15 millions de sites internet utilisent AdSense3 et plus de 30 millions de sites utilisent Google Analytics4.
30. Au moment de la rédaction du présent rapport, Google a rebaptisé AdWords « Google Ads » et DoubleClick « Google Ad Manager« , mais aucune modification n’a été apportée aux fonctionnalités principales des produits, y compris la collecte d’informations par ces produits5. Par conséquent, pour les besoins du présent rapport, les premiers noms ont été conservés afin d’éviter toute confusion avec des noms de domaine connexes (tels que doubleclick.net).
31. Voici deux principaux groupes d’utilisateurs des outils de Google axés sur l’édition — et les annonces publicitaires :
Les éditeurs de sites web et d’applications, qui sont des organisations qui possèdent des sites web et créent des applications mobiles. Ces entités utilisent les outils de Google pour (1) gagner de l’argent en permettant l’affichage d’annonces aux visiteurs sur leurs sites web ou applications, et (2) mieux suivre et comprendre qui visite leurs sites et utilise leurs applications. Les outils de Google placent des cookies et exécutent des scripts dans les navigateurs des visiteurs du site web pour aider à déterminer l’identité d’un utilisateur et suivre son intérêt pour le contenu et son comportement en ligne. Les bibliothèques d’applications mobiles de Google suivent l’utilisation des applications sur les téléphones mobiles.
Les annonceurs, qui sont des organisations qui paient pour que des bannières, des vidéos ou d’autres publicités soient diffusées aux utilisateurs lorsqu’ils naviguent sur Internet ou utilisent des applications. Ces entités utilisent les outils de Google pour cibler des profils spécifiques de personnes pour que les publicités augmentent le retour sur leurs investissements marketing (les publicités mieux ciblées génèrent généralement des taux de clics et de conversion plus élevés). De tels outils permettent également aux annonceurs d’analyser leurs audiences et de mesurer l’efficacité de leur publicité numérique en regardant sur quelles annonces les utilisateurs cliquent et à quelle fréquence, et en donnant un aperçu du profil des personnes qui ont cliqué sur les annonces.
32. Ensemble, ces outils recueillent des informations sur les activités des utilisateurs sur les sites web et dans les applications, comme le contenu visité et les annonces cliquées. Ils travaillent en arrière-plan — en général imperceptibles par des utilisateurs. La figure 7 montre certains de ces outils clés, avec des flèches indiquant les données recueillies auprès des utilisateurs et les publicités qui leur sont diffusées.
Figure 7 : Produits Google destinés aux éditeurs et annonceurs6
33. Les informations recueillies par ces outils comprennent un identifiant non personnel que Google peut utiliser pour envoyer des publicités ciblées sans identifier les informations personnelles de la personne concernée. Ces identificateurs peuvent être spécifiques à l’appareil ou à la session, ainsi que permanents ou semi-permanents. Le tableau 1 liste un ensemble de ces identificateurs. Afin d’offrir aux utilisateurs un plus grand anonymat lors de la collecte d’informations pour le ciblage publicitaire, Google s’est récemment tourné vers l’utilisation d’identifiants uniques semi-permanents (par exemple, les GAID)7. Des sections ultérieures décrivent en détail la façon dont ces outils recueillent les données des utilisateurs et l’utilisation de ces identificateurs au cours du processus de collecte des données.
Tableau 1: Identificateurs transmis à Google
Identificateur
Type
Description
GAID/IDFA
Semi-permanent
Chaine de caractères alphanumériques pour appareils Android et iOS, pour permettre les publicités ciblées sur mobile. Réinitialisable par l’utilisateur.
ID client
Semi-permanent
ID créé la première fois qu’un cookie est stocké sur le navigateur. Utilisé pour relier les sessions de navigations. Réinitialisé lorsque les cookies du navigateur sont effacés.
Adresse IP
Semi-permanent
Une unique suite de nombre qui identifie le réseau par lequel un appareil accède à internet.
ID appareil Android
Semi-permanent
Nombre généré aléatoirement au premier démarrage d’un appareil. Utilisé pour identifier l’appareil. En retrait progressif pour la publicité. Réinitialisé lors d’une remise à zéro de l’appareil.
Google Services Framework (GSF)
Semi-permanent
Nombre assigné aléatoirement lorsqu’un utilisateur s’enregistre pour la première fois dans les services Google sur un appareil. Utilisé pour identifier un appareil unique. Réinitialisé lors d’une remise à zéro de l’appareil.
IEMI / MEID
Permanent
Identificateur utilisé dans les standards de communication mobile. Unique pour chaque téléphone portable.
Adresse MAC
Permanent
Identificateur unique de 12 caractères pour un élément matériel (ex. : routeur).
Numéro de série
Permanent
Chaine de caractères alphanumériques utilisée pour identifier un appareil.
A. Google Analytics et DoubleClick
34. DoubleClick et Google Analytics (GA) sont les produits phares de Google en matière de suivi du comportement des utilisateurs et d’analyse du trafic des pages Web sur les périphériques de bureau et mobiles. GA est utilisé par environ 75 % des 100 000 sites Web les plus visités8. Les cookies DoubleClick sont associés à plus de 1,6 million de sites Web9.
35. GA utilise de petits segments de code de traçage (appelés « balises de page ») intégrés dans le code HTML d’un site Web10. Après le chargement d’une page Web à la demande d’un utilisateur, le code GA appelle un fichier analytics.js qui se trouve sur les serveurs de Google. Ce programme transfère un instantané « par défaut » des données de l’utilisateur à ce moment, qui comprend l’adresse de la page web visitée, le titre de la page, les informations du navigateur, l’emplacement actuel (déduit de l’adresse IP), et les paramètres de langue de l’utilisateur. Les scripts de GA utilisent des cookies pour suivre le comportement des utilisateurs.
36. Le script de GA, la première fois qu’il est exécuté, génère et stocke un cookie spécifique au navigateur sur l’ordinateur de l’utilisateur. Ce cookie a un identificateur de client unique (voir le tableau 1 pour plus de détails)11 Google utilise l’identificateur unique pour lier les cookies précédemment stockés, qui capturent l’activité d’un utilisateur sur un domaine particulier tant que le cookie n’expire pas ou que l’utilisateur n’efface pas les cookies mis en cache dans son navigateur12
37. Alors qu’un cookie GA est spécifique au domaine particulier du site Web que l’utilisateur visite (appelé « cookie de première partie »), un cookie DoubleClick est généralement associé à un domaine tiers commun (tel que doubleclick.net). Google utilise de tels cookies pour suivre l’interaction de l’utilisateur sur plusieurs sites web tiers13 Lorsqu’un utilisateur interagit avec une publicité sur un site web, les outils de suivi de conversion de DoubleClick (par exemple, Floodlight) placent des cookies sur l’ordinateur de l’utilisateur et génèrent un identifiant client unique14 Par la suite, si l’utilisateur visite le site web annoncé, le serveur DoubleClick accède aux informations stockées dans le cookie, enregistrant ainsi la visite comme une conversion valide.
B. AdSense, AdWords et AdMob
38. AdSense et AdWords sont des outils de Google qui diffusent des annonces sur les sites Web et dans les résultats de recherche Google, respectivement. Plus de 15 millions de sites Web ont installé AdSense pour afficher des annonces sponsorisées15 De même, plus de 2 millions de sites web et applications, qui constituent le réseau Google Display Network (GDN) et touchent plus de 90 % des internautes16 affichent des annonces AdWords.
39. AdSense collecte des informations indiquant si une annonce a été affichée ou non sur la page web de l’éditeur. Il recueille également la façon dont l’utilisateur a interagi avec l’annonce, par exemple en cliquant sur l’annonce ou en suivant le mouvement du curseur sur l’annonce17. AdWords permet aux annonceurs de diffuser des annonces de recherche sur Google Search, d’afficher des annonces sur les pages des éditeurs et de superposer des annonces sur des vidéos YouTube. Pour suivre les taux de clics et de conversion des utilisateurs, les publicités AdWords placent un cookie sur les navigateurs des utilisateurs pour identifier l’utilisateur s’il visite par la suite le site web de l’annonceur ou s’il effectue un achat18.
40. Bien qu’AdSense et AdWords recueillent également des données sur les appareils mobiles, leur capacité d’obtenir des renseignements sur les utilisateurs des appareils mobiles est limitée puisque les applications mobiles ne partagent pas de cookies entre elles, une technique d’isolement appelée « bac à sable »19 qui rend difficile pour les annonceurs de suivre le comportement des utilisateurs entre différentes applications mobiles.
41 Pour résoudre ce problème, Google et d’autres entreprises utilisent des « bibliothèques d’annonces » mobiles (comme AdMob) qui sont intégrées dans les applications par leurs développeurs pour diffuser des annonces dans les applications mobiles. Ces bibliothèques compilent et s’exécutent avec les applications et envoient à Google des données spécifiques à l’application à laquelle elles sont intégrées, y compris les emplacements GPS, la marque de l’appareil et le modèle de l’appareil lorsque les applications ont les autorisations appropriées. Comme on peut le voir dans les analyses de trafic de données (Figure 8), et comme on peut trouver confirmation sur les propres pages web des développeurs de Google20, de telles bibliothèques peuvent également envoyer des données personnelles de l’utilisateur, telles que l’âge et le genre, tout cela va vers Google à chaque fois que les développeurs d’applications envoient explicitement leurs valeurs numériques vers la bibliothèque.
Figure 8 : Aperçu des informations renvoyées à Google lorsqu’une application est lancée
C. Association de données recueillies passivement et d’informations à caractère personnel
42. Comme nous l’avons vu plus haut, Google recueille des données par l’intermédiaire de produits pour éditeurs et annonceurs, et associe ces données à une variété d’identificateurs semi-permanents et anonymes. Google a toutefois la possibilité d’associer ces identifiants aux informations personnelles d’un utilisateur. C’est ce qu’insinuent les déclarations faites dans la politique de confidentialité de Google, dont des extraits sont présentés à la figure 9. La zone de texte à gauche indique clairement que Google peut associer des données provenant de services publicitaires et d’outils d’analyse aux informations personnelles d’un utilisateur, en fonction des paramètres du compte de l’utilisateur. Cette disposition est activée par défaut, comme indiqué dans la zone de texte à droite.
Figure 9 : Page de confidentialité de Google pour la collecte de sites web tiers et l’association avec des informations personnelles2122.
43. De plus, une analyse du trafic de données échangé avec les serveurs de Google (résumée ci-dessous) a permis d’identifier deux exemples clés (l’un sur Android et l’autre sur Chrome) qui montrent la capacité de Google à corréler les données recueillies de façon anonyme avec les renseignements personnels des utilisateurs.
1) L’identificateur de publicité mobile peut être désanonymé grâce aux données envoyées à Google par Android.
44. Les analyses du trafic de données communiqué entre un téléphone Android et les domaines de serveur Google suggèrent un moyen possible par lequel des identifiants anonymes (GAID dans ce cas) peuvent être associés au compte Google d’un utilisateur. La figure 10 décrit ce processus en une série de trois étapes clés.
45. Dans l’étape 1, une donnée de check-in est envoyée à l’URL android.clients.google.com/checkin. Cette communication particulière fournit une synchronisation de données Android aux serveurs Google et contient des informations du journal Android (par exemple, du journal de récupération), des messages du noyau, des crash dumps, et d’autres identifiants liés au périphérique. Un instantané d’une demande d’enregistrement partiellement décodée envoyée au serveur de Google à partir d’Android est montré en figure 10.
Figure 10 : Les identifiants d’appareil sont envoyés avec les informations de compte dans les requêtes de vérification Android.
46. Comme l’indiquent les zones pointées, Android envoie à Google, au cours du processus d’enregistrement, une variété d’identifiants permanents importants liés à l’appareil, y compris l’adresse MAC de l’appareil, l’IMEI /MEID et le numéro de série du dispositif. En outre, ces demandes contiennent également l’identifiant Gmail de l’utilisateur Android, ce qui permet à Google de relier les informations personnelles d’un utilisateur aux identifiants permanents des appareils Android.
47. À l’étape 2, le serveur de Google répond à la demande d’enregistrement. Ce message contient un identifiant de cadre de services Google (GSF ID)23 qui est similaire à l’« Android ID »24 (voir le tableau 1 pour les descriptions).
48. L’étape 3 implique un autre cas de communication où le même identifiant GSF (de l’étape 2) est envoyé à Google en même temps que le GAID. La figure 10 montre l’une de ces transmissions de données à android.clients.google.com/fdfe/bulkDetails?au=1.
49. Grâce aux trois échanges de données susmentionnés, Google reçoit les informations nécessaires pour connecter un GAID avec des identifiants d’appareil permanents ainsi que les identifiants de compte Google des utilisateurs.
50. Ces échanges de données interceptés avec les serveurs de Google à partir d’un téléphone Android montrent comment Google peut connecter les informations anonymisées collectées sur un appareil mobile Android via les outils DoubleClick, Analytics ou AdMob avec l’identité personnelle de l’utilisateur. Au cours de la collecte de données sur 24 heures à partir d’un téléphone Android sans mouvement ni activité, deux cas de communications d’enregistrement avec des serveurs Google ont été observés. Une analyse supplémentaire est toutefois nécessaire pour déterminer si un tel échange d’informations a lieu avec une certaine périodicité ou s’il est déclenché par des activités spécifiques sur les téléphones.
2) L’ID du cookie DoubleClick est relié aux informations personnelles de l’utilisateur sur le compte Google.
51. La section précédente expliquait comment Google peut désanonymiser l’identité de l’utilisateur via les données passives et anonymisées qu’il collecte à partir d’un appareil mobile Android. Cette section montre comment une telle désanonymisation peut également se produire sur un ordinateur de bureau/ordinateur portable.
52. Les données anonymisées sur les ordinateurs de bureau et portables sont collectées par l’intermédiaire d’identifiants basés sur des cookies (par ex. Cookie ID), qui sont typiquement générés par les produits de publicité et d’édition de Google (par ex. DoubleClick) et stockés sur le disque dur local de l’utilisateur. L’expérience présentée ci-dessous a permis d’évaluer si Google peut établir un lien entre ces identificateurs (et donc les renseignements qui y sont associés) et les informations personnelles d’un utilisateur.
Cette expérience comportait les étapes ordonnées suivantes :
Ouverture d’une nouvelle session de navigation (Chrome ou autre) (pas de cookies enregistrés, par exemple navigation privée ou incognito) ;
Visite d’un site Web tiers qui utilisait le réseau publicitaire DoubleClick de Google ;
Visite du site Web d’un service Google largement utilisé (Gmail dans ce cas) ;
Connexion à Gmail.
53. Au terme des étapes 1 et 2, dans le cadre du processus de chargement des pages, le serveur DoubleClick a reçu une demande lorsque l’utilisateur a visité pour la première fois le site Web tiers. Cette demande faisait partie d’une série de reqêtes comprenant le processus d’initialisation DoubleClick lancé par le site Web de l’éditeur, qui a conduit le navigateur Chrome à installer un cookie pour le domaine DoubleClick. Ce cookie est resté sur l’ordinateur de l’utilisateur jusqu’à son expiration ou jusqu’à ce que l’utilisateur efface manuellement les cookies via les paramètres du navigateur.
54. Ensuite, à l’étape 3, lorsque l’utilisateur visite Gmail, il est invité à se connecter avec ses identifiants Google. Google gère l’identité à l’aide d’une architecture single sign on (SSO) [NdT : authentification unique], dans laquelle les identifiants sont fournis à un service de compte (ici accounts.google.com) en échange d’un « jeton d’authentification », qui peut ensuite être présenté à d’autres services Google pour identifier les utilisateurs. À l’étape 4, lorsqu’un utilisateur accède à son compte Gmail, il se connecte effectivement à son compte Google, qui fournit alors à Gmail un jeton d’autorisation pour vérifier l’identité de l’utilisateur.25 Ce processus est décrit à la figure 24 de la section IX.E de l’annexe.
55. Dans la dernière étape de ce processus de connexion, une requête est envoyée au domaine DoubleClick. Cette requête contient à la fois le jeton d’authentification fourni par Google et le cookie de suivi défini lorsque l’utilisateur a visité le site web tiers à l’étape 2 (cette communication est indiquée à la figure 11). Cela permet à Google de relier les informations d’identification Google de l’utilisateur à un cookie DoubleClick. Par conséquent, si les utilisateurs n’effacent pas régulièrement les cookies de leur navigateur, leurs informations de navigation sur les pages Web de tiers qui utilisent les services DoubleClick pourraient être associées à leurs informations personnelles sur Google Account.
Figure 11 : La requête à DoubleClick.net inclut le jeton d’authentification Google et les cookies passés.
56. Il est donc établi à présent que Google recueille une grande variété de données sur les utilisateurs par l’intermédiaire de ses outils d’éditeur et d’annonceur, sans que l’utilisateur en ait une connaissance directe. Bien que ces données soient collectées à l’aide d’identifiants anonymes, Google a la possibilité de relier ces informations collectées aux identifiants personnels de l’utilisateur stockés sur son compte Google.
57. Il convient de souligner que la collecte passive de données d’utilisateurs de Google à partir de pages web tierces ne peut être empêchée à l’aide d’outils populaires de blocage de publicité26, car ces outils sont conçus principalement pour empêcher la présence de publicités pendant que les utilisateurs naviguent sur des pages web tierces27. La section suivante examine de plus près l’ampleur de cette collecte de données.
Ce que peut faire votre Fournisseur d’Accès à l’Internet
Nous sommes ravis et honorés d’accueillir Stéphane Bortzmeyer qui allie une compétence de haut niveau sur des questions assez techniques et une intéressante capacité à rendre assez claires des choses complexes. Nous le remercions de nous expliquer dans cet article quelles pratiques douteuses tentent certains fournisseurs d’accès à l’Internet, quelles menaces cela représente pour la confidentialité comme pour la neutralité du Net, et pourquoi la parade du chiffrement fait l’objet d’attaques répétées de leur part.
Pour vous connecter à l’Internet, vous avez besoin d’un FAI (Fournisseur d’Accès à l’Internet), une entreprise ou une association dont le métier est de relier des individus ou des organisations aux autres FAI. En effet, l’Internet est une coalition de réseaux, chaque FAI a le sien, et ce qui constitue l’Internet global, c’est la connexion de tous ces FAI entre eux. À part devenir soi-même FAI, la seule façon de se connecter à l’Internet est donc de passer par un de ces FAI. La question de la confiance est donc cruciale : qu’est-ce que mon FAI fait sans me le dire ?
Outre son travail visible (vous permettre de regarder Wikipédia, et des vidéos avec des chats mignons), le FAI peut se livrer à des pratiques plus contestables, que cet article va essayer d’expliquer. L’article est prévu pour un vaste public et va donc simplifier une réalité parfois assez compliquée.
Notons déjà tout de suite que je ne prétends pas que tous les FAI mettent en œuvre les mauvaises pratiques décrites ici. Il y a heureusement des FAI honnêtes. Mais toutes ces pratiques sont réellement utilisées aujourd’hui, au moins par certains FAI.
La langue française a un seul verbe, « pouvoir », pour désigner à la fois une possibilité technique (« ma voiture peut atteindre 140 km/h ») et un droit (« sur une route ordinaire, je peux aller jusqu’à 80 km/h »). Cette confusion des deux possibilités est très fréquente dans les discussions au sujet de l’Internet. Ici, je parlerais surtout des possibilités techniques. Les règles juridiques et morales encadrant les pratiques décrites ici varient selon les pays et sont parfois complexes (et je ne suis ni juriste ni moraliste) donc elles seront peu citées dans cet article.
Au sujet du numérique
Pour résumer les possibilités du FAI (Fournisseur d’Accès à l’Internet), il faut se rappeler de quelques propriétés essentielles du monde numérique :
Modifier des données numériques ne laisse aucune trace. Contrairement à un message physique, dont l’altération, même faite avec soin, laisse toujours une trace, les messages envoyés sur l’Internet peuvent être changés sans que ce changement ne se voit.
Copier des données numériques, par exemple à des fins de surveillance des communications, ne change pas ces données, et est indécelable. Elle est très lointaine, l’époque où (en tout cas dans les films policiers), on détectait une écoute à un « clic » entendu dans la communication ! Les promesses du genre « nous n’enregistrons pas vos données » sont donc impossibles à vérifier.
Modifier les données ou bien les copier est très bon marché, avec les matériels et logiciels modernes. Le FAI qui voudrait le faire n’a même pas besoin de compétences pointues : les fournisseurs de matériel et de logiciel pour FAI ont travaillé pour lui et leur catalogue est rempli de solutions permettant modification et écoute des données, solutions qui ne sont jamais accompagnées d’avertissements légaux ou éthiques.
Une publicité pour un logiciel d’interception des communications, même chiffrées. Aucun avertissement légal ou éthique dans la page.
Modifier le trafic réseau
Commençons avec la possibilité technique de modification des données numériques. On a vu qu’elle était non seulement faisable, mais en outre facile. Citons quelques exemples où l’internaute ne recevait pas les données qui avaient été réellement envoyées, mais une version modifiée :
de 2011 à 2013 (et peut-être davantage), en France, le FAI SFR modifiait les images envoyées via son réseau, pour en diminuer la taille. Une image perdait donc ainsi en qualité. Si la motivation (diminuer le débit) était compréhensible, le fait que les utilisateurs n’étaient pas informés indique bien que SFR était conscient du caractère répréhensible de cette pratique.
en 2018 (et peut-être avant), Orange Tunisie modifiait les pages Web pour y insérer des publicités. La modification avait un intérêt financier évident pour le FAI, et aucun intérêt pour l’utilisateur. On lit parfois que la publicité sur les pages Web est une conséquence inévitable de la gratuité de l’accès à cette page mais, ici, bien qu’il soit client payant, l’utilisateur voit des publicités qui ne rapportent qu’au FAI. Comme d’habitude, l’utilisateur n’avait pas été notifié, et le responsable du compte Twitter d’Orange, sans aller jusqu’à nier la modification (qui est interdite par la loi tunisienne), la présentait comme un simple problème technique.
en 2015 (et peut-être avant), Verizon Afrique du Sud modifiait les échanges effectués entre le téléphone et un site Web pour ajouter aux demandes du téléphone des informations comme l’IMEI (un identificateur unique du téléphone) ou bien le numéro de téléphone de l’utilisateur. Cela donnait aux gérants des sites Web des informations que l’utilisateur n’aurait pas donné volontairement. On peut supposer que le FAI se faisait payer par ces gérants de sites en échange de ce service.
Il s’agit uniquement des cas connus, c’est-à-dire de ceux où des experts ont décortiqué ce qui se passait et l’ont documenté. Il y a certainement de nombreux autres cas qui passent inaperçus. Ce n’est pas par hasard si la majorité de ces manipulations se déroulent dans les pays du Sud, où il y a moins d’experts disponibles pour l’analyse, et où l’absence de démocratie politique n’encourage pas les citoyens à regarder de près ce qui se passe. Il n’est pas étonnant que ces modifications du trafic qui passe dans le réseau soient la règle en Chine. Ces changements du trafic en cours de route sont plus fréquents sur les réseaux de mobiles (téléphone mobile) car c’est depuis longtemps un monde plus fermé et davantage contrôlé, où les FAI ont pris de mauvaises habitudes.
Quelles sont les motivations des FAI pour ces modifications ? Elles sont variées, souvent commerciales (insertion de publicités) mais peuvent être également légales (obligation de censure passant techniquement par une modification des données).
Mais ces modifications sont une violation directe du principe de neutralité de l’intermédiaire (le FAI). La « neutralité de l’Internet » est parfois présentée à tort comme une affaire financière (répartition des bénéfices entre différents acteurs de l’Internet) alors qu’elle est avant tout une protection des utilisateurs : imaginez si la Poste modifiait le contenu de vos lettres avant de les distribuer !
Les FAI qui osent faire cela le savent très bien et, dans tous les cas cités, aucune information des utilisateurs n’avait été faite. Évidemment, « nous changerons vos données au passage, pour améliorer nos bénéfices » est plus difficile à vendre aux clients que « super génial haut débit, vos vidéos et vos jeux plus rapides ! » Parfois, même une fois les interférences avec le trafic analysées et publiées, elles sont niées, mais la plupart du temps, le FAI arrête ces pratiques temporairement, sans explications ni excuses.
Surveiller le trafic réseau
De même que le numérique permet de modifier les données en cours de route, il rend possible leur écoute, à des fins de surveillance, politique ou commerciale. Récolter des quantités massives de données, et les analyser, est désormais relativement simple. Ne croyez pas que vos données à vous sont perdues dans la masse : extraire l’aiguille de la botte de foin est justement ce que les ordinateurs savent faire le mieux.
Grâce au courage du lanceur d’alerte Edward Snowden, la surveillance exercée par les États, en exploitant ces possibilités du numérique, est bien connue. Mais il n’y a pas que les États. Les grands intermédiaires que beaucoup de gens utilisent comme médiateurs de leurs communications (tels que Google ou Facebook) surveillent également massivement leurs utilisateurs, en profitant de leur position d’intermédiaire. Le FAI est également un intermédiaire, mais d’un type différent. Il a davantage de mal à analyser l’information reçue, car elle n’est pas structurée pour lui. Mais par contre, il voit passer tout le trafic réseau, alors que même le plus gros des GAFA (Google, Apple, Facebook, Amazon) n’en voit qu’une partie.
L’existence de cette surveillance par les FAI ne fait aucun doute, mais est beaucoup plus difficile à prouver que la modification des données. Comme pour la modification des données, c’est parfois une obligation légale, où l’État demande aux FAI leur assistance dans la surveillance. Et c’est parfois une décision d’un FAI.
Les données ainsi récoltées sont parfois agrégées (regroupées en catégories assez vastes pour que l’utilisateur individuel puisse espérer qu’on ne trouve pas trace de ses activités), par exemple quand elles sont utilisées à des fins statistiques. Elles sont dans ce cas moins dangereuses que des données individuelles. Mais attention : le diable est dans les détails. Il faut être sûr que l’agrégation a bien noyé les détails individuels. Quand un intermédiaire de communication proclame bien fort que les données sont « anonymisées », méfiez-vous. Le terme est utilisé à tort et à travers, et désigne souvent des simples remplacements d’un identificateur personnel par un autre, tout aussi personnel.
La solution du chiffrement
Ces pratiques de modification ou de surveillance des données sont parfois légales et parfois pas. Même quand elles sont illégales, on a vu qu’elles étaient néanmoins pratiquées, et jamais réprimées par la justice. Il est donc nécessaire de ne pas compter uniquement sur les protections juridiques mais également de déployer des protections techniques contre la modification et l’écoute. Deux catégories importantes de protections existent : minimiser les données envoyées, et les chiffrer. La minimisation consiste à envoyer moins de données, et elle fait partie des protections imposées par le RGPD (Règlement [européen] Général sur la Protection des Données). Combinée au chiffrement, elle protège contre la surveillance. Le chiffrement, lui, est la seule protection contre la modification des données.
Mais c’est quoi, le chiffrement ? Le terme désigne un ensemble de techniques, issues de la mathématique, et qui permet d’empêcher la lecture ou la modification d’un message. Plus exactement, la lecture est toujours possible, mais elle ne permet plus de comprendre le message, transformé en une série de caractères incompréhensibles si on ne connait pas la clé de déchiffrement. Et la modification reste possible mais elle est détectable : au déchiffrement, on voit que les données ont été modifiées. On ne pourra pas les lire mais, au moins, on ne recevra pas des données qui ne sont pas les données authentiques.
Dans le contexte du Web, la technique de chiffrement la plus fréquente se nomme HTTPS (HyperText Transfer Protocol Secure). C’est celle qui est utilisée quand une adresse Web commence par https:// , ou quand vous voyez un cadenas vert dans votre navigateur, à gauche de l’adresse. HTTPS sert à assurer que les pages Web que vous recevez sont exactement celles envoyées par le serveur Web, et il sert également à empêcher des indiscrets de lire au passage vos demandes et les réponses. Ainsi, dans le cas de la manipulation faite par Orange Tunisie citée plus haut, HTTPS aurait empêché cet ajout de publicités.
Pour toutes ces raisons, HTTPS est aujourd’hui massivement déployé. Vous le voyez de plus en plus souvent par exemple sur ce blog que vous êtes en train de lire.
Tous les sites Web sérieux ont aujourd’hui HTTPS
Le chiffrement n’est pas utilisé que par HTTPS. Si vous utilisez un VPN (Virtual Private Network, « réseau privé virtuel »), celui-ci chiffre en général les données, et la motivation des utilisateurs de VPN est en effet en général d’échapper à la surveillance et à la modification des données par les FAI. C’est particulièrement important pour les accès publics (hôtels, aéroports, Wifi du TGV) où les manipulations et filtrages sont quasi-systématiques.
Comme toute technique de sécurité, le chiffrement n’est pas parfait, et il a ses limites. Notamment, la communication expose des métadonnées (qui communique, quand, même si on n’a pas le contenu de la communication) et ces métadonnées peuvent être aussi révélatrices que la communication elle-même. Le système « Tor », qui peut être vu comme un type de VPN particulièrement perfectionné, réduit considérablement ces métadonnées.
Le chiffrement est donc une technique indispensable aujourd’hui. Mais il ne plait pas à tout le monde. Lors du FIC (Forum International de la Cybersécurité) en 2015, le représentant d’un gros FAI français déplorait en public qu’en raison du chiffrement, le FAI ne pouvait plus voir ce que faisaient ses clients. Et ce raisonnement est apparu dans un document d’une organisation de normalisation, l’IETF (Internet Engineering Task Force). Ce document, nommé « RFC 8404 »28 décrit toutes les pratiques des FAI qui peuvent être rendues difficiles ou impossibles par le chiffrement. Avant le déploiement massif du chiffrement, beaucoup de FAI avaient pris l’habitude de regarder trop en détail le trafic qui circulait sur leur réseau. C’était parfois pour des motivations honorables, par exemple pour mieux comprendre ce qui passait sur le réseau afin de l’améliorer. Mais, aujourd’hui, compte-tenu de ce qu’on sait sur l’ampleur massive de la surveillance, il est urgent de changer ses pratiques, au lieu de simplement regretter que ce qui était largement admis autrefois soit maintenant rejeté.
Cette liste de pratiques de certains FAI est une information intéressante mais il est dommage que ce document de l’IETF les présente comme si elles étaient toutes légitimes, alors que beaucoup sont scandaleuses et ne devraient pas être tolérées. Si le chiffrement les empêche, tant mieux !
Conclusion
Le déploiement massif du chiffrement est en partie le résultat des pratiques déplorables de certains FAI. Il est donc anormal que ceux-ci se plaignent des difficultés que leur pose le chiffrement. Ils sont les premiers responsables de la méfiance des utilisateurs !
La guerre contre les pratiques douteuses, déjà au XIe siècle… – Image retrouvée sur ce site.
J’ai surtout parlé ici des risques que le FAI écoute les messages, ou les modifie. Mais la place cruciale du FAI dans la communication fait qu’il existe d’autres risques, comme celui de censure de certaines activités ou certains services, ou de coupure d’accès. À l’heure où la connexion à l’Internet est indispensable pour tant d’activités, une telle coupure serait très dommageable.
Quelles sont les solutions, alors ? Se passer de FAI n’est pas réaliste. Certes, des bricoleurs peuvent connecter quelques maisons proches en utilisant des techniques fondées sur les ondes radio, mais cela ne s’étend pas à tout l’Internet. Par contre, il ne faut pas croire qu’un FAI est forcément une grosse entreprise commerciale. Ce peut être une collectivité locale, une association, un regroupement de citoyens. Dans certains pays, des règles très strictes imposées par l’État limitent cette activité de FAI, afin de permettre le maintien du contrôle des citoyens. Heureusement, ce n’est pas (encore ?) le cas en France. Par exemple, la FFDN (Fédération des Fournisseurs d’Accès Internet Associatifs) regroupe de nombreux FAI associatifs en France. Ceux-ci se sont engagés à ne pas recourir aux pratiques décrites plus haut, et notamment à respecter le principe de neutralité.
Bien sûr, monter son propre FAI ne se fait pas en cinq minutes dans son garage. Mais c’est possible en regroupant un collectif de bonnes volontés.
Et, si on n’a pas la possibilité de participer à l’aventure de la création d’un FAI, et pas de FAI associatif proche, quelles sont les possibilités ? Peut-on choisir un bon FAI commercial, en tout cas un qui ne viole pas trop les droits des utilisateurs ? Il est difficile de répondre à cette question. En effet, aucun FAI commercial ne donne des informations détaillées sur ce qui est possible et ne l’est pas. Les manœuvres comme la modification des images dans les réseaux de mobiles sont toujours faites en douce, sans information des clients. Même si M. Toutlemonde était prêt à passer son week-end à comparer les offres de FAI, il ne trouverait pas l’information essentielle « est-ce que ce FAI s’engage à rester strictement neutre ? » En outre, contrairement à ce qui existe dans certains secteurs économiques, comme l’agro-alimentaire, il n’existe pas de terminologie standardisée sur les offres des FAI, ce qui rend toute comparaison difficile.
Dans ces conditions, il est difficile de compter sur le marché pour réguler les pratiques des FAI. Une régulation par l’État n’est pas forcément non plus souhaitable (on a vu que c’est parfois l’État qui oblige les FAI à surveiller les communications, ainsi qu’à modifier les données transmises). À l’heure actuelle, la régulation la plus efficace reste la dénonciation publique des mauvaises pratiques : les FAI reculent souvent, lorsque des modifications des données des utilisateurs sont analysées et citées en public. Cela nécessite du temps et des efforts de la part de ceux et celles qui font cette analyse, et il faut donc saluer leur rôle.
Il s’agit aujourd’hui de mesurer ce que les plateformes les plus populaires recueillent de nos smartphones
Traduction Framalang : Côme, goofy, Khrys, Mika, Piup. Remerciements particuliers à badumtss qui a contribué à la traduction de l’infographie.
La collecte des données par les plateformes Android et Chrome
11. Android et Chrome sont les plateformes clés de Google qui facilitent la collecte massive de données des utilisateurs en raison de leur grande portée et fréquence d’utilisation. En janvier 2018, Android détenait 53 % du marché américain des systèmes d’exploitation mobiles (iOS d’Apple en détenait 45 %)29 et, en mai 2017, il y avait plus de 2 milliards d’appareils Android actifs par mois dans le monde.30
12. Le navigateur Chrome de Google représentait plus de 60 % de l’utilisation mondiale de navigateurs Internet avec plus d’un milliard d’utilisateurs actifs par mois, comme l’indiquait le rapport Q4 10K de 201731. Les deux plateformes facilitent l’usage de contenus de Google et de tiers (p.ex. applications et sites tiers) et fournissent donc à Google un accès à un large éventail d’informations personnelles, d’activité web, et de localisation.
A. Collecte d’informations personnelles et de données d’activité
13. Pour télécharger et utiliser des applications depuis le Google Play Store sur un appareil Android, un utilisateur doit posséder (ou créer) un compte Google, qui devient une passerelle clé par laquelle Google collecte ses informations personnelles, ce qui comporte son nom d’utilisateur, son adresse de messagerie et son numéro de téléphone. Si un utilisateur s’inscrit à des services comme Google Pay32, Android collecte également les données de la carte bancaire, le code postal et la date de naissance de l’utilisateur. Toutes ces données font alors partie des informations personnelles de l’utilisateur associées à son compte Google.
14. Alors que Chrome n’oblige pas le partage d’informations personnelles supplémentaires recueillies auprès des utilisateurs, il a la possibilité de récupérer de telles informations. Par exemple, Chrome collecte toute une gamme d’informations personnelles avec la fonctionnalité de remplissage automatique des formulaires, qui incluent typiquement le nom d’utilisateur, l’adresse, le numéro de téléphone, l’identifiant de connexion et les mots de passe.33 Chrome stocke les informations saisies dans les formulaires sur le disque dur de l’utilisateur. Cependant, si l’utilisateur se connecte à Chrome avec un compte Google et active la fonctionnalité de synchronisation, ces informations sont envoyées et stockées sur les serveurs de Google. Chrome pourrait également apprendre la ou les langues que parle la personne avec sa fonctionnalité de traduction, activée par défaut.34
15. En plus des données personnelles, Chrome et Android envoient tous deux à Google des informations concernant les activités de navigation et l’emploi d’applications mobiles, respectivement. Chaque visite de page internet est automatiquement traquée et collectée par Google si l’utilisateur a un compte Chrome. Chrome collecte également son historique de navigation, ses mots de passe, les permissions particulières selon les sites web, les cookies, l’historique de téléchargement et les données relatives aux extensions.35
16. Android envoie des mises à jour régulières aux serveurs de Google, ce qui comprend le type d’appareil, le nom de l’opérateur, les rapports de bug et des informations sur les applications installées36. Il avertit également Google chaque fois qu’une application est ouverte sur le téléphone (ex. Google sait quand un utilisateur d’Android ouvre son application Uber).
B. Collecte des données de localisation de l’utilisateur
17. Android et Chrome collectent méticuleusement la localisation et les mouvements de l’utilisateur en utilisant une variété de sources, représentées sur la figure 3. Par exemple, un accès à la « localisation approximative » peut être réalisé en utilisant les coordonnées GPS sur un téléphone Android ou avec l’adresse IP sur un ordinateur. La précision de la localisation peut être améliorée (« localisation précise ») avec l’usage des identifiants des antennes cellulaires environnantes ou en scannant les BSSID (’’Basic Service Set IDentifiers’’), identifiants assignés de manière unique aux puces radio des points d’accès Wi-Fi présents aux alentours37. Les téléphones Android peuvent aussi utiliser les informations des balises Bluetooth enregistrées dans l’API Proximity Beacon de Google38. Ces balises non seulement fournissent les coordonnées de géolocalisation de l’utilisateur, mais pourraient aussi indiquer à quel étage exact il se trouve dans un immeuble.39
Figure 3 : Android et Chrome utilisent diverses manières de localiser l’utilisateur d’un téléphone.
18. Il est difficile pour un utilisateur de téléphone Android de refuser le traçage de sa localisation. Par exemple, sur un appareil Android, même si un utilisateur désactive le Wi-Fi, la localisation est toujours suivie par son signal Wi-Fi. Pour éviter un tel traçage, le scan Wi-Fi doit être explicitement désactivé par une autre action de l’utilisateur, comme montré sur la figure 4.
Figure 4 : Android collecte des données même si le Wi-Fi est éteint par l’utilisateur
19. L’omniprésence de points d’accès Wi-Fi a rendu le traçage de localisation assez fréquent. Par exemple, durant une courte promenade de 15 minutes autour d’une résidence, un appareil Android a envoyé neuf requêtes de localisation à Google. Les requêtes contenaient au total environ 100 BSSID de points d’accès Wi-Fi publics et privés.
20. Google peut vérifier avec un haut degré de confiance si un utilisateur est immobile, s’il marche, court, fait du vélo, ou voyage en train ou en car. Il y parvient grâce au traçage à intervalles de temps réguliers de la localisation d’un utilisateur Android, combiné avec les données des capteurs embarqués (comme l’accéléromètre) sur les téléphones mobiles. La figure 5 montre un exemple de telles données communiquées aux serveurs de Google pendant que l’utilisateur marchait.
Figure 5 : capture d’écran d’un envoi de localisation d’utilisateur à Google.
C. Une évaluation de la collecte passive de données par Google via Android et Chrome
21. Les données actives que les plateformes Android ou Chrome collectent et envoient à Google à la suite des activités des utilisateurs sur ces plateformes peuvent être évaluées à l’aide des outils MyActivity et Takeout. Les données passives recueillies par ces plateformes, qui vont au-delà des données de localisation et qui restent relativement méconnues des utilisateurs, présentent cependant un intérêt potentiellement plus grand. Afin d’évaluer plus en détail le type et la fréquence de cette collecte, une expérience a été menée pour surveiller les données relatives au trafic envoyées à Google par les téléphones mobiles (Android et iPhone) en utilisant la méthode décrite dans la section IX.D de l’annexe. À titre de comparaison, cette expérience comprenait également l’analyse des données envoyées à Apple via un appareil iPhone.
22. Pour des raisons de simplicité, les téléphones sont restés stationnaires, sans aucune interaction avec l’utilisateur. Sur le téléphone Android, une seule session de navigateur Chrome restait active en arrière-plan, tandis que sur l’iPhone, le navigateur Safari était utilisé. Cette configuration a permis une analyse systématique de la collecte de fond que Google effectue uniquement via Android et Chrome, ainsi que de la collecte qui se produit en l’absence de ceux-ci (c’est-à-dire à partir d’un appareil iPhone), sans aucune demande de collecte supplémentaire générée par d’autres produits et applications (par exemple YouTube, Gmail ou utilisation d’applications).
23. La figure 6 présente un résumé des résultats obtenus dans le cadre de cette expérience. L’axe des abscisses indique le nombre de fois où les téléphones ont communiqué avec les serveurs Google (ou Apple), tandis que l’axe des ordonnées indique le type de téléphone (Android ou iPhone) et le type de domaine de serveur (Google ou Apple) avec lequel les paquets de données ont été échangés par les téléphones. La légende en couleur décrit la catégorisation générale du type de demandes de données identifiées par l’adresse de domaine du serveur. Une liste complète des adresses de domaine appartenant à chaque catégorie figure dans le tableau 5 de la section IX.D de l’annexe.
24. Au cours d’une période de 24 heures, l’appareil Android a communiqué environ 900 échantillons de données à une série de terminaux de serveur Google. Parmi ceux-ci, environ 35 % (soit environ 14 par heure) étaient liés à la localisation. Les domaines publicitaires de Google n’ont reçu que 3 % du trafic, ce qui est principalement dû au fait que le navigateur mobile n’a pas été utilisé activement pendant la période de collecte. Le reste (62 %) des communications avec les domaines de serveurs Google se répartissaient grosso modo entre les demandes adressées au magasin d’applications Google Play, les téléchargements par Android de données relatives aux périphériques (tels que les rapports de crash et les autorisations de périphériques), et d’autres données — principalement de la catégorie des appels et actualisations de fond des services Google.
Figure 6 : Données sur le trafic envoyées par les appareils Andoid et les iPhones en veille.
25. La figure 6 montre que l’appareil iPhone communiquait avec les domaines Google à une fréquence inférieure de plus d’un ordre de grandeur (50 fois) à celle de l’appareil Android, et que Google n’a recueilli aucun donnée de localisation utilisateur pendant la période d’expérience de 24 heures via iPhone. Ce résultat souligne le fait que les plateformes Android et Chrome jouent un rôle important dans la collecte de données de Google.
26. De plus, les communications de l’appareil iPhone avec les serveurs d’Apple étaient 10 fois moins fréquentes que les communications de l’appareil Android avec Google. Les données de localisation ne représentaient qu’une très faible fraction (1 %) des données nettes envoyées aux serveurs Apple à partir de l’iPhone, Apple recevant en moyenne une fois par jour des communications liées à la localisation.
27. En termes d’amplitude, les téléphones Android communiquaient 4,4 Mo de données par jour (130 Mo par mois) avec les serveurs Google, soit 6 fois plus que ce que les serveurs Google communiquaient à travers l’appareil iPhone.
28. Pour rappel, cette expérience a été réalisée à l’aide d’un téléphone stationnaire, sans interaction avec l’utilisateur. Lorsqu’un utilisateur commence à bouger et à interagir avec son téléphone, la fréquence des communications avec les serveurs de Google augmente considérablement. La section V du présent rapport résume les résultats d’une telle expérience.
Impôts et dons à Framasoft : le prélèvement à la source en 2019
De nombreux donateurs s’inquiètent de savoir comment cela va se passer l’année prochaine pour les dons effectués à Framasoft en 2018 et le prélèvement à la source à partir de 2019. Pour une fois les choses sont très simples : rien ne change pour votre réduction d’impôt.
En 2019, les impôts seront prélevés à la source. Pour autant, la réduction fiscale demeure inchangée si vous faites un don à Framasoft : un don de 100 € en 2018 peut vous donner droit à 66 € de réduction fiscale, qui vous seront remboursés en août 2019.
Illustration du processus de don
Le déroulement en détail
Jusqu’à présent, vous faisiez votre déclaration au printemps en indiquant votre don ouvrant droit à une réduction d’impôt de 66%, dans la limite de 20 % du revenu imposable. En fin d’année, les services fiscaux vous indiquaient le montant à régler en tenant compte d’une éventuelle mensualisation demandée de votre part.
À partir de 2019, vous allez faire des règlements mensuels dès le mois de janvier en fonction d’un taux déterminé par l’administration fiscale et des paramètres que vous leur aurez fournis. Ceux qui ont fait un don en 2017 recevront, dès le 15 janvier 2019, un acompte de 60% de la réduction d’impôt dont ils ont bénéficié en 2018 au titre des dons effectués en 2017.
Vous ferez, comme chaque année, votre déclaration au printemps, vers mai-juin. Vous indiquerez alors le montant des dons faits à Framasoft en 2018 et pourrez, si demandé, joindre le justificatif que nous vous aurons fait parvenir vers mars-avril. C’est vers la fin de l’été que les impôts vous enverront votre avis, en tenant compte de ce don et d’un éventuel acompte versé de leur part en janvier. C’est alors que l’administration procédera à un recalcul de vos mensualités ou un remboursement, selon le cas et les montants. Les prélèvements mensuels se poursuivront ensuite pour ajuster vos paiements au montant de l’impôt dont vous devrez vous acquitter.
Et c’est tout. En gros, rien ne change pour votre réduction d’impôt pour les dons faits à Framasoft.
En mars 2018, Framasoft lui a envoyé un reçu fiscal pour ce don de 100€.
En mai 2018, Camille a déclaré ses revenus 2017, en précisant qu’elle avait fait un don de 100€ à Framasoft dans la case 7UF «Dons versés à d’autres organismes d’intérêt général».
En août 2018, Camille a reçu son avis d’imposition, qui indiquait prendre en compte une déduction de 66€ (100€ x 66%).
En mars 2019, Framasoft lui envoie son reçu fiscal pour un don de 100€.
En mai 2019, Camille reçoit des impôts sa déclaration de revenus 2018. Elle déclare alors (sur papier ou en ligne) ses revenus 2018, et indique (toujours dans la case « Dons versés à d’autres organismes d’intérêt général ») un montant de 100€.
En août/septembre 2019 (environ), les impôts envoient à Camille son avis d’imposition indiquant prendre en compte sa déduction de 66€ (100 € x 66%).
Son don de 100€ à Framasoft, après déduction, ne lui aura coûté que 34€ (100€ de don – 66€ de déduction).
Son don de 100€ à Framasoft, après déduction, ne lui aura coûté que 34€ (100€ de don – 66€ de déduction).
Maintenant que vous voilà rassurés, nous ne pouvons que vous encourager à faire un don pour soutenir nos actions 🙂
Paris, Lyon, Toulouse, Bordeaux… et quelques autres métropoles régionales sont animées par des associations libristes actives et efficaces : réunions régulières, actions de terrain, conférences et rencontres… Mais dans les villes moyennes ça bouge aussi.
À l’ouest par exemple, entre Nantes, Quimper ou Brest, beaucoup de projets et d’initiatives sont déjà en place et parfois depuis longtemps. Mais ce sont les habitants de Lannion qui ont récemment pu bénéficier d’un premier Café Vie Privée, un événement qui a connu un beau succès (oui, l’évènement était accueilli au Truc café, ça ne s’invente pas…). Bravo aux organisateurs et organisatrices !
… et puis il y avait aussi la conférence de Clochix, dont il avait préparé le détail sur son blog Gribouillis dans les marges et que nous reprenons ici avec son accord.
Comme il est modeste, il nous signalait ne rien mentionner d’original, et en effet on retrouvera ici des indications et recommandations dont sont familiers les conférenciers libristes. Cependant, il nous a semblé qu’il abordait une question cruciale classique (comment protéger sa vie privée numérique) selon une démarche plus originale : il commence en effet par tracer les contours de notre intimité numérique avant de définir le « modèle de menace » auquel chacun⋅e s’expose potentiellement. La liste de ses exemples est assez riche… C’est seulement alors que peuvent venir les mesures ou plutôt contre-mesures dont nous pouvons disposer, et pas seulement à titre individuel, en ayant pleine conscience de leurs limites.
Hygiène et écologisme numérique
Avatar de Clochix
Remarque liminaire : je préfère parler plutôt d’intimitéque de vie privée. On a parfois l’impression que la vie privée ne concerne que les personnes publiques ou les gens qui ont des choses à cacher. En parlant d’intimité, j’espère que davantage de gens se sentent concerné·e·s.
En réfléchissant à ce que j’allais conseiller pour protéger son intimité, je me suis rendu compte que j’abordais le problème à l’envers. Parler de techniques et d’outils pour protéger son intimité n’est que la dernière étape du processus, avant d’en arriver là, il faut d’abord réfléchir à ce que l’on veut protéger et de qui ou quoi on veut le protéger.
Qu’est-ce que l’intimité numérique et pourquoi la protéger ?
L’intime est ce qui nous définit en tant qu’individus et motive une grande partie de nos actes.
L’intimité, c’est un endroit où l’on est seul avec soi-même (ou avec un nombre très restreint de personnes en qui on a confiance), et qui nous permet, à l’abri de tout regard, de tout jugement externe, de se construire, d’exister, de prendre des décisions, etc.
L’intimité, ce sont aussi nos rêves, et les carnets où parfois on les note. Ce sont nos projets fous que l’on élabore dans notre tête longtemps avant d’oser en parler à quiconque. Et qui ne pourraient pas naître à la lumière.
L’intimité n’a rien à voir avec des actions illicites.
L’intimité, ce sont aussi des choses sans conséquence mais dont on a un peu honte. Se curer le nez, roter, ce sont des choses que l’on s’autorise lorsqu’on est seul chez soi, mais qu’on peut avoir honte de voir exposer sur la place publique. Imaginez l’inconfort d’être dans une cellule de prison où vous devez faire vos besoins au vu et au su de vos co-détenu·e·s. Être privé⋅e d’intimité déshumanise, affecte l’image que l’on a de soi.
Dernier exemple de lieu intime : l’isoloir. Il est depuis longtemps acquis que le secret du vote est important dans une démocratie. Il est vital d’avoir la possibilité que certaines choses restent secrètes.
L’intimité numérique, ce sont toutes les traces de notre intimité sur des outils numériques. C’est naturellement notre correspondance, les informations qui révèlent directement nos pensées intimes. Mais c’est aussi tout ce qui, de manière plus large, permet indirectement, par des recoupements, d’accéder à notre intimité. Nos recherches en ligne, nos achats, nos rendez-vous médicaux, nos errances dans la rue (« tiens, il fait souvent un détour pour passer dans la rue où habite X, cherche-t-il à lae croiser ? »). Nos téléphones qui suivent chacune de nos activités permettent de savoir si nous fréquentons un lieu de culte, un local syndical ou un bar, et à quelle fréquence…
L’intimité est un besoin vital pour les humains, en être privé nous prive d’une partie de notre humanité. En être privé, être toujours sous la menace du regard et du jugement d’autrui, c’est perdre la capacité de penser par soi-même, d’exister, de se comporter en tant qu’individu indépendant, autonome. Priver les citoyen·ne·s d’intimité est une des caractéristiques des régimes totalitaires qui cherchent à nier les individualités pour ne gérer que des robots déshumanisés.
Protéger son intimité est donc essentiel. Mais il faut aussi veiller à ce que la société garantisse à chacun et chacune le droit à l’intimité.
Ok, mais de qui ou de quoi faut-il la protéger ?
Les menaces sur notre droit à l’intimité sont très nombreuses, selon les contextes. Attention, il ne faut pas croire que sont uniquement le fait de gens qui cherchent explicitement à nous nuire. En fait, l’essentiel des risques n’est pas lié à la malveillance, mais à la simple utilisation de nos données pour influencer notre vie. Petite liste non exhaustive :
votre employeur actuel : pour avoir certaines conversations avec des collègues, mieux vaut éviter d’utiliser les outils internes de l’entreprise ;
vos futurs employeurs : celleux-ci pourraient apprécier de différentes manières de découvrir sur notre fil Facebook que l’on participe à toutes les journées de grève et applaudit aux actions des syndicats 😉
vos proches : compagnon ou compagne qui pourrait être blessé·e de découvrir que l’on discute encore avec ses « ex ». Ados ne souhaitant pas que leurs parents écoutent leurs conversations avec leurs potes ou connaissent les sites qu’ils consultent (« pourquoi as-tu fait des recherches sur la contraception ??? ») ;
le harcèlement : le phénomène est de plus en plus courant, dans les cours de récréation comme parmi les adultes. Si pour une raison quelconque vous devenez la cible de harcèlement, toutes les informations disponibles en ligne sur vous pourront être utilisées contre vous. Votre adresse, pour vous menacer. Vos proches, pour s’en prendre à elleux… Personne n’est à l’abri, et ça peut être très violent ;
des escrocs : les informations que l’on peut trouver en ligne sur nous peuvent permettre à des escrocs d’usurper notre identité, pour nous faire payer leurs amendes, pour souscrire des services à notre place, pour escroquer nos proches en se faisant passer pour nous, etc ;
du marketing : plus quelqu’un nous connait, plus iel sera en mesure d’influencer nos actes, voire nos opinions, par exemple pour nous pousser à acheter une marchandise dont on n’avait pas forcément besoin, ou à voter pour un·e candidat·e dont on n’avait pas forcément besoin ;
des décisions nous concernant prises en se fondant sur ce que l’on sait ou croit savoir de nous (« gouvernance algorithmique »). Si vous avez été malade et avez évoqué cette maladie sur Internet, une banque pourra des années plus tard vous refuser un prêt, une assurance pourra vous faire payer des primes supérieures… Imaginez qu’un site collecte l’ensemble de nos rendez-vous médicaux, imaginez le nombre de décisions qui pourraient être prises à notre insu à partir de ces informations par un employeur (« elle vient de tomber enceinte, ne lui proposons pas de CDI »), un banquier (« il consulte un psy donc n’est pas stable, refusons-lui ce prêt »)…
de l’état : avoir un aéroport ou une usine chimique qui veut s’installer dans notre jardin, ça peut arriver à tout le monde. Tout le monde peut avoir un jour ou l’autre besoin de devenir ZADiste et de s’organiser contre le pouvoir en place, pas besoin d’habiter en Chine pour cela ;
…
Chacun de ces exemples appelle une réponse particulière et certaines réponses sont parfois contradictoires. Par exemple, GMail offre un bon niveau de protection des correspondances contre les attaques de gens de notre entourage, employeur, conjoint·e, etc. En revanche, il sera obligé de répondre aux demandes de la justice. Héberger ses courriels chez des potes peut-être une bonne idée si on participe à une ZAD. Par contre selon leurs compétences en informatique, la sécurité sera peut-être moindre. Et en cas d’embrouille avec elleux, iels pourraient accéder à nos informations.
Donner de fausses informations en ligne peut relativement nous protéger des tentatives d’influencer nos actes. Mais peut aussi nous nuire le jour où des décisions nous concernant seront prises en se basant sur ces informations.
Et pour protéger son intimité, il faut adopter quelques règles d’hygiène. Mais pour cela il faut d’abord définir son « modèle de menace », c’est à dire ce qui selon vous menace le plus votre intimité, afin de choisir des solutions qui répondent à vos besoins.
Hygiène pour vous… et pour les autres
L’hygiène n’est pas qu’une pratique égoïste. On ne se lave pas les mains juste pour éviter de tomber malade, mais aussi pour éviter de contaminer les autres. Il en va de même pour l’hygiène numérique. Même si vous ne vous sentez pas concerné·e, peut-être aurez-vous envie d’adopter certaines règles d’hygiène par respect ou affection pour vos proches qui se sentent concerné. Par exemple, si vous permettez à une application ou un site Web d’accéder à votre carnet d’adresse, vous divulguez sans leur consentement des données personnelles sur vos proches. Si un·e ami⋅e m’a référencé dans son répertoire téléphonique en tant que Clochix et un·e autre en tant que Papa-de-XXXX, un site accédant à ces deux répertoires pourra faire le lien entre mes différentes identités et anéantir les efforts que je fais pour me protéger.
Si vous mettez en ligne des photos de vos proches, vous perdez le contrôle sur ces photos et ne savez pas quels usages pourront en être faits demain.
Avoir de l’hygiène, c’est donc aussi protéger ses proches, ses collègues…
De l’hygiène individuelle à l’écologisme
Parmi les risques évoqués plus haut, certains nous concernent directement. D’autres affectent plus globalement la société dans son ensemble, par exemple lorsque nos informations sont utilisées à grande échelle pour influencer nos votes. Il est possible que les élections d’Obama et de Trump, entre autres, aient été influencées par des outils se basant sur la masse d’informations que nous laissons en ligne.
La surveillance de masse, qu’elle soit réelle ou supposée, nous pousse à l’auto-censure. Est-ce que si je cherche « Daesh » sur Internet, je ne vais pas devenir suspect ? Est-ce qu’une opinion exprimée aujourd’hui sur Twitter dans un certain contexte ne pourra pas être exhumée demain, dans un autre contexte, et me nuire ? Tout cela pousse à l’auto-censure et sclérose peu à peu le débat démocratique.
Un autre risque est ce que l’on appelle les bulles de filtres, même si leur existence fait débat. Une bulle de filtres, c’est lorsque tous les sites que nous consultons détectent les informations qui nous plaisent et ne nous affichent plus que celles-ci. Cela nous donne du monde une vision biaisée.
Ces enjeux dépassent donc largement nos situations individuelles.
Lorsqu’on parle d’hygiène, on pense d’abord à des mesures de protection individuelles, comme se laver les mains ou bloquer les cookies. Mais il ne faut pas oublier que l’hygiène est aussi un enjeu collectif : « l’hygiène est un enjeu de santé publique, l’accès à un environnement propre et sain étant une condition première du développement durable. » (Wikipédia). L’hygiène numérique ne peut donc se limiter à des actions reposant sur les individus, ça n’est pas seulement de notre responsabilité. Il faut aussi penser ces questions et prendre des mesures au niveau de la collectivité. Et, de manière plus globale, il faudrait réfléchir à la notion d’écologisme numérique. L’espace numérique fait partie intégrante de l’environnement dans lequel évolue l’espèce humaine, et comme tel doit être protégé.
Ok et à présent, qu’est-ce qu’on fait ?
Il n’y a pas d’outils magiques. Utiliser des outils sans avoir un minimum de compréhension du contexte technique, c’est se tirer pratiquement à coup sûr une balle dans le pied. Un faux sentiment de sécurité incite à l’imprudence. C’est comme croire qu’une fois la porte fermée on peut se promener à poil chez soi, parce qu’on ignore l’existence des fenêtres.
La meilleure des protections, c’est l’éducation. C’est acquérir une compréhension du fonctionnement des outils numériques. Connaître les techniques qui permettent de porter atteinte à notre intimité. Les techniques qui, à partir de nos informations intimes, permettent de nous influencer ou de décider de nos vies. Donc : éduquons-nous !
Il ne faut pas se le cacher, se protéger demande une vigilance de tous les instants, souvent épuisante. Il faut donc être convaincu·e de l’importance d’adopter une certaine discipline.
La seule information qui ne pourra pas être utilisée, c’est celle qui n’existe pas (et encore…). Il faut donc selon moi essayer de réduire au maximum son empreinte, les traces que l’on laisse. Le numérique permet de compiler une foule d’informations insignifiantes pour en extraire du sens. Avoir accès à un de vos tickets de caisse ne dit pas forcément grand-chose de vous. Avoir accès à tous vos tickets de caisse permet de connaître votre situation familiale (« tiens, iel achète des gâteaux pour enfants une semaine sur deux ») ou financière, vos convictions (« iel a arrêté d’acheter de la viande de porc et de l’alcool, signe de radicalisation… »). C’est donc une gymnastique quotidienne pour essayer de réduire au maximum ce que l’on dévoile : bloquer systématiquement tous les cookies sauf pour les sites sur lesquels c’est indispensable (et c’est là qu’on en vient à la nécessaire compréhension du fonctionnement), refuser si possible les cartes de fidélité, désactiver le Wifi et le Bluetooth sur son téléphone lorsqu’on ne les utilise pas… C’est une gymnastique contraignante.
Essayez aussi de compartimenter : si vous tenez un carnet Web sur un sujet polémique, essayez d’éviter qu’on puisse faire le lien avec notre état civil (sur le long terme, c’est très très difficile à tenir). A minima, avoir plusieurs profils / plusieurs adresses mail, etc, et ne pas les lier entre elles permet de réduire les risques. Quelqu’un qui vous ciblera pourra faire le lien, mais les programmes de collecte automatique de données ne chercheront pas forcément à recouper.
Compartimentez aussi vos outils : par exemple, utilisez deux navigateurs différents (ou un navigateur avec deux profils) : dans l’un, bloquez tout ce qui permet de vous pister et accédez aux sites qui n’ont pas besoin de savoir qui vous êtes. Utilisez l’autre, moins protégé, uniquement pour les sites nécessitant une connexion (webmail, réseaux sociaux, etc.).
Méfiez-vous comme de la peste des photos et des vidéos. De vous, de vos proches, de quiconque. Demain, en cherchant votre nom, il sera possible de vous identifier sur cette photo prise voilà 20 ans où vous montriez vos fesses. Avez-vous vraiment envie que vos enfants vous voient ainsi ? Demain, en cherchant le nom de votre enfant, ses camarades de classe pourront retrouver une vidéo de ellui à deux ans sur le pot. Hier vous trouviez cette photo adorable, aujourd’hui elle va lui valoir des torrents de moqueries.
Contre la malveillance, il faut naturellement utiliser des pratiques et outils qui relèvent davantage de la sécurité informatique : par exemple des mots de passe complexes, différents pour chaque service.
Pour aller plus loin, je vous encourage à vous renseigner sur le chiffrement : de vos communications, de vos données. Attention, le chiffrement est un sujet relativement complexe, ça n’est à utiliser qu’en ayant une idée précise de ce que vous faites.
Et, naturellement, portez en toutes circonstances un chandail à capuche noir et une cagoule, histoire de rester discret.
Et pour terminer, parce que nous ne sommes que des nains sur l’épaule de géants, une citation que je vous laisse méditer :
« la solution est forcément dans une articulation entre politique (parce que c’est un problème de société) et technique (parce que les outils actuels le permettent). Et il faut bien les deux volets, un seul, ça ne sert à rien. »
(Benjamin Bayart).
Changer le monde, un octet à la fois
Cette année, comme les précédentes, Framasoft fait appel à votre générosité afin de poursuivre ses actions.
Depuis 14 ans : promouvoir le logiciel libre et la culture libre
L’association Framasoft a 14 ans. Durant nos 10 premières années d’existence, nous avons créé l’annuaire francophone de référence des logiciels libres, ouvert une maison d’édition ne publiant que des ouvrages sous licences libres, répondu à d’innombrables questions autour du libre, participé à plusieurs centaines d’événements en France ou à l’étranger, promu le logiciel libre sur DVD puis clé USB, accompagné la compréhension de la culture libre, ou plutôt des cultures libres, au travers de ce blog, traduit plus de 1 000 articles ainsi que plusieurs ouvrages, des conférences, et bien d’autres choses encore !
Depuis 4 ans, décentraliser Internet
En 2014, l’association prenait un virage en tentant de sensibiliser non seulement à la question du libre, mais aussi à celle de la problématique de la centralisation d’Internet. En déconstruisant les types de dominations exercées par les GAFAM (dominations technique, économique, mais aussi politique et culturelle), nous avons pendant plusieurs années donné à voir en quoi l’hyperpuissance de ces acteurs mettait en place une forme de féodalité.
Et comme montrer du doigt n’a jamais mené très loin, il a bien fallu initier un chemin en prouvant que le logiciel libre était une réponse crédible pour s’émanciper des chaînes de Google, Facebook & co. En 3 ans, nous avons donc agencé plus de 30 services alternatifs, libres, éthiques, décentralisables et solidaires. Aujourd’hui, ces services accueillent 400 000 personnes chaque mois. Sans vous espionner. Sans revendre vos données. Sans publicité. Sans business plan de croissance perpétuelle.
Parfois, Framasoft se met au vert. Parce qu’il y a un monde par-delà les ordinateurs…
Mais Framasoft, c’est une bande de potes, pas la #startupnation. Et nous ne souhaitions pas devenir le « Google du libre ». Nous avons donc en 2016 impulsé le collectif CHATONS, afin d’assurer la résilience de notre démarche, mais aussi afin de « laisser de l’espace » aux expérimentations, aux bricolages, à l’inventivité, à l’enthousiasme, aux avis divergents du nôtre. Aujourd’hui, une soixantaine de chatons vivent leurs vies, à leurs rythmes, en totale indépendance.
Il y a un an : penser au-delà du code libre
Il y a un an, nous poursuivions notre virage en faisant 3 constats :
L’open source se porte fort bien. Mais le logiciel libre (c-à-d. opensource + valeurs éthiques) lui, souffre d’un manque de contributions exogènes.
Dégoogliser ne suffit pas ! Le logiciel libre n’est pas une fin en soi, mais un moyen (nécessaire, mais pas suffisant) de transformation de la société.
Il existe un ensemble de structures et de personnes partageant nos valeurs, susceptibles d’avoir besoin d’outils pour faire advenir le type de monde dont nous rêvons. C’est avec elles qu’il nous faut travailler en priorité.
Est-ce une victoire pour les valeurs du Libre que d’équiper un appareil tel que le drone militaire MQ-8C Fire Scout ? Nous ne le pensons pas. Cliché Domaine public – Wikimedia
Face à ces constats, notre feuille de route Contributopia vise à proposer des solutions. Sur 3 ans (on aime bien les plans triennaux), Framasoft porte l’ambition de participer à infléchir la situation.
D’une part en mettant la lumière sur la faiblesse des contributions, et en tentant d’y apporter différentes réponses. Par exemple en abaissant la barrière à la contribution. Ou, autre exemple, en généralisant les pratiques d’ouvertures à des communautés non-dev.
D’autre part, en mettant en place des projets qui ne soient pas uniquement des alternatives à des services de GAFAM (aux moyens disproportionnés), mais bien des projets engagés, militants, qui seront des outils au service de celles et ceux qui veulent changer le monde. Nous sommes en effet convaincu·es qu’un monde où le logiciel libre serait omniprésent, mais où le réchauffement climatique, la casse sociale, l’effondrement, la précarité continueraient à nous entraîner dans leur spirale mortifère n’aurait aucun sens pour nous. Nous aimons le logiciel libre, mais nous aimons encore plus les êtres humains. Et nous voulons agir dans un monde où notre lutte pour le libre et les communs est en cohérence avec nos aspirations pour un monde plus juste et durable.
Aujourd’hui : publier Peertube et nouer des alliances
Aujourd’hui, l’association Framasoft n’est pas peu fière d’annoncer la publication de la version 1.0 de PeerTube, notre alternative libre et fédérée à YouTube. Si vous souhaitez en savoir plus sur PeerTube, ça tombe bien : nous venons de publier un article complet à ce sujet !
Ce n’est pas la première fois que Framasoft se retrouve en position d’éditeur de logiciel libre, mais c’est la première fois que nous publions un logiciel d’une telle ambition (et d’une telle complexité). Pour cela, nous avons fait le pari l’an passé d’embaucher à temps plein son développeur, afin d’accompagner PeerTube de sa version alpha (octobre 2017) à sa version bêta (mars 2018), puis à sa version 1.0 (octobre 2018).
Le crowdfunding effectué cet été comportait un palier qui nous engageait à poursuivre le contrat de Chocobozzz, le développeur de PeerTube, afin de vous assurer que le développement ne s’arrêterait pas à une version 1.0 forcément perfectible. Ce palier n’a malheureusement pas été atteint, ce qui projetait un flou sur l’avenir de PeerTube à la fin du contrat de Chocobozzz.
Nous avons cependant une excellente nouvelle à vous annoncer ! Bien que le palier du crowdfunding n’ait pas été atteint, l’association Framasoft a fait le choix d’embaucher définitivement Chocobozzz (en CDI) afin de pérenniser PeerTube et de lui donner le temps et les moyens de construire une communauté solide et autonome. Cela représente un investissement non négligeable pour notre association, mais nous croyons fermement non seulement dans le logiciel PeerTube, mais aussi et surtout dans les valeurs qu’il porte (liberté, décentralisation, fédération, émancipation, indépendance). Sans parler des compétences de Chocobozzz lui-même qui apporte son savoir-faire à l’équipe technique dans d’autres domaines.
Nous espérons que vos dons viendront confirmer que vous approuvez notre choix.
D’ici la fin de l’année, annoncer de nouveaux projets… et une campagne de don
Comme vous l’aurez noté (ou pas encore !), nous avons complètement modifié notre page d’accueil « framasoft.org ». D’une page portail plutôt institutionnelle, décrivant assez exhaustivement « Qu’est-ce que Framasoft ? », nous l’avons recentrée sur « Que fait Framasoft ? » mettant en lumière quelques éléments clefs. En effet, l’association porte plus d’une cinquantaine de projets en parallèle et présenter d’emblée la Framagalaxie nous semblait moins pertinent que de « donner à voir » des actions choisies, tout en laissant la possibilité de tirer le fil pour découvrir l’intégralité de nos actions.
Nous y rappelons brièvement que Framasoft n’est pas une multinationale, mais une micro-association de 35 membres et 8 salarié⋅es (bientôt 9 : il reste quelques jours pour candidater !). Que nous sommes à l’origine de la campagne « Dégooglisons Internet » (plus de 30 services en ligne)… Mais pas seulement ! Certain⋅es découvriront peut-être l’existence de notre maison d’édition Framabook, ou de notre projet historique Framalibre. Nous y mettons en avant LE projet phare de cette année 2018 : PeerTube. D’autres projets à court terme sont annoncés sur cette page (en mode teasing), s’intégrant dans notre feuille de route Contributopia.
Framasoft n’est pas une multinationale, mais une micro-association
Enfin, nous vous invitons à faire un don pour soutenir ces actions. Car c’est aussi l’occasion de rappeler que l’association ne vit quasiment que de vos dons ! Ce choix fort, volontaire et assumé, nous insuffle notre plus grande force : notre indépendance. Que cela soit dans le choix des projets, dans le calendrier de nos actions, dans la sélection de nos partenaires, dans nos prises de paroles et avis publics, nous sommes indépendant⋅es, libres, et non-soumis⋅es à certaines conventions que nous imposerait le système de subventions ou de copinage avec les ministères ou toute autre institution.
Ce sont des milliers de donatrices et donateurs qui valident nos actions par leur soutien financier. Ce qu’on a fait vous a plu ? Vous pensez que nous allons dans le bon sens ? Alors, si vous en avez l’envie et les moyens, nous vous invitons à faire un don. C’est par ce geste que nous serons en mesure de verser les salaires des salarié⋅es de l’association, de payer les serveurs qui hébergent vos services préférés ou de continuer à intervenir dans des lieux ou devant des publics qui ont peu de moyens financiers (nous intervenons plus volontiers en MJC que devant l’Assemblée Nationale, et c’est un choix assumé). Rappelons que nos comptes sont publics et validés par un commissaire aux comptes indépendant.
En 2019, proposer des outils pour la société de contribution
Fin 2018, nous vous parlerons du projet phare que nous souhaitons développer pendant l’année 2019, dont le nom de code est Mobilizon. Au départ pensé comme une simple alternative à Meetup.com (ou aux événements Facebook, si vous préférez), nous avons aujourd’hui la volonté d’emmener ce logiciel bien plus loin afin d’en faire un véritable outil de mobilisation destiné à celles et ceux qui voudraient se bouger pour changer le monde, et s’organiser à 2 ou à 100 000, sans passer par des systèmes certes efficaces, mais aussi lourds, centralisés, et peu respectueux de la vie privée (oui, on parle de Facebook, là).
Évidemment, ce logiciel sera libre, mais aussi fédéré (comme Mastodon ou PeerTube), afin d’éviter de faire d’une structure (Framasoft ou autre), un point d’accès central, et donc de faiblesse potentielle du système. Nous vous donnerons plus de nouvelles dans quelques semaines, restez à l’écoute !
Éviter de faire d’une structure (Framasoft ou autre), un point d’accès central
D’autres projets sont prévus pour 2019 :
la sortie du (apparemment très attendu) Framapétitions ;
la publication progressive du MOOC CHATONS (cours en ligne gratuit et ouvert à toutes et tous), en partenariat avec la Ligue de l’Enseignement et bien d’autres. Ce MOOC, nous l’espérons, permettra à celles et ceux qui le souhaitent, de comprendre les problématiques de la concentration des acteurs sur Internet, et donc les enjeux de la décentralisation. Mais il donnera aussi de précieuses informations en termes d’organisation (création d’une association, modèle économique, gestion des usager⋅es, gestion communautaire, …) ainsi qu’en termes techniques (quelle infrastructure technique ? Comment la sécuriser ? Comment gérer les sauvegardes, etc.) ;
évidemment, bien d’autres projets en ligne (on ne va pas tout vous révéler maintenant, mais notre feuille de route donne déjà de bons indices)
Bref, on ne va pas chômer !
Dans les années à venir : se dédier à toujours plus d’éducation populaire, et des alliances
Nous avions coutume de présenter Framasoft comme « un réseau à géométrie variable ». Il est certain en tout cas que l’association est en perpétuelle mutation. Nous aimons le statut associatif (la loi de 1901 nous paraît l’une des plus belles au monde, rien que ça !), et nous avons fait le choix de rester en mode « association de potes » et de refuser — en tout cas jusqu’à nouvel ordre — une transformation en entreprise/SCOP/SCIC ou autre. Mais même si nous avons choisi de ne pas être des super-héro⋅ïnes et de garder l’association à une taille raisonnable (moins de 10 salarié⋅es), cela ne signifie pas pour autant que nous ne pouvons pas faire plus !
La seconde année de Contributopia Illustration de David Revoy – Licence : CC-By 4.0
Pour cela, de la même façon que nous proposons de mettre nos outils « au service de celles et ceux qui veulent changer le monde », nous sommes en train de créer des ponts avec de nombreuses structures qui n’ont pas de rapport direct avec le libre, mais avec lesquelles nous partageons un certain nombre de valeurs et d’objectifs.
Ainsi, même si leurs objets de militantisme ou leurs moyens d’actions ne sont pas les mêmes, nous aspirons à mettre les projets, ressources et compétences de Framasoft au service d’associations œuvrant dans des milieux aussi divers que ceux de : l’éducation à l’environnement, l’économie sociale et solidaire et écologique, la transition citoyenne, les discriminations et oppressions, la précarité, le journalisme citoyen, la défense des libertés fondamentales, etc. Bref, mettre nos compétences au service de celles et ceux qui luttent pour un monde plus juste et plus durable, afin qu’ils et elles puissent le faire avec des outils cohérents avec leurs valeurs et modulables selon leurs besoins.
Seul on va plus vite, ensemble on va plus loin. Nous pensons que le temps est venu de faire ensemble.
Framasoft est une association d’éducation populaire (qui a soufflé « d’éducation politique » ?), et nous n’envisageons plus de promouvoir ou de faire du libre « dans le vide ». Il y a quelques années, nous évoquions l’impossibilité chronique et structurelle d’échanger de façon équilibrée avec les institutions publiques nationales. Cependant, en nous rapprochant de réseaux d’éducation populaire existants (certains ont plus de cent ans), nos positions libristes et commonistes ont été fort bien accueillies. À tel point qu’aujourd’hui nous avons de nombreux projets en cours avec ces réseaux, qui démultiplieront l’impact de nos actions, et qui permettront — nous l’espérons — que le milieu du logiciel libre ne reste pas réservé à une élite de personnes maîtrisant le code et sachant s’y retrouver dans la jungle des licences.
Seul on va plus vite, ensemble on va plus loin. Nous pensons que le temps est venu de faire ensemble.
Nous avons besoin de vous !
Un des paris que nous faisons pour cette campagne est « d’informer sans sur-solliciter ». Et l’équilibre n’est pas forcément simple à trouver. Nous sommes en effet bien conscient⋅es qu’en ce moment, toutes les associations tendent la main et sollicitent votre générosité.
Nous ne souhaitons pas mettre en place de « dark patterns » que nous dénonçons par ailleurs. Nous pouvions jouer la carte de l’humour (si vous êtes détendu⋅es, vous êtes plus en capacité de faire des dons), celle de la gamification (si on met une jauge avec un objectif de dons, vous êtes plus enclin⋅es à participer), celle du chantage affectif (« Donnez, sinon… »), etc.
Le pari que nous prenons, que vous connaissiez Framasoft ou non, c’est qu’en prenant le temps de vous expliquer qui nous sommes, ce que nous avons fait, ce que nous sommes en train de faire, et là où nous voulons vous emmener, nous parlerons à votre entendement et non à vos pulsions. Vous pourrez ainsi choisir de façon éclairée si nos actions méritent d’être soutenues.
« Si tu veux construire un bateau, ne rassemble pas tes hommes et femmes pour leur donner des ordres, pour expliquer chaque détail, pour leur dire où trouver chaque chose. Si tu veux construire un bateau, fais naître dans le cœur de tes hommes et femmes le désir de la mer. » — Antoine de Saint-Exupéry
Nous espérons, à la lecture de cet article, vous avoir donné le désir de co-construire avec nous le Framasoft de demain, et que vous embarquerez avec nous.
PeerTube 1.0 : la plateforme de vidéos libre et fédérée
Ce qui nous fait du bien, chez Framasoft, c’est quand nous arrivons à tenir nos engagements. On a beau faire les marioles, se dire qu’on est dans l’associatif, que la pression n’est pas la même, tu parles !
[Short version of this article in English available here]
Après le financement participatif réussi du mois de juin 2018, nous avions fait la promesse de sortir la version 1 de Peertube en octobre 2018. Et alors, où en sommes-nous ? Le suspense est insoutenable.
Nous étions confiants. Le salaire du développeur principal, Chocobozzz, était assuré jusqu’à la fin de l’année, nous avions déjà recensé des contributions de qualité, nous avions fait un peu de bruit dans la presse… Cependant, nous avions aussi pris un engagement ferme vis-à-vis de nos donateur·ices, ainsi qu’auprès d’un large public international qui ne nous connaissait pas aussi bien que nos soutiens francophones habituels.
Ne vous faisons pas languir plus longtemps, cette version 1.0, elle est là, elle sort à l’heure dite et elle tient ses promesses, elle aussi. C’est l’occasion de dérouler pour vous un récapitulatif des épisodes précédents, ce qui vous évitera de farfouiller dans le blog pour retrouver vos petits. On sait que c’est pénible, on l’a fait. 🙂
C’est quoi, PeerTube ? Une révolte ? Non, Sire, une révolution
[Vidéo de présentation de PeerTube, en anglais, avec les sous-titres français, sur Framatube. Pour la vidéo avec les sous-titres en anglais, cliquez ici. Réalisation : Association LILA (CC by-sa)]
« Dégooglisons Internet ! » avons-nous crié partout pendant trois ans, sur l’air de « Delenda Carthago ! »
Ça, c’était une révolte. Un cri du cœur. Déjà un défi fou : proposer une alternative aux services des géants du web, les GAFAM et leurs petits copains (Twitter, par exemple). Un par un, les services étaient sortis, à un rythme insensé. Ils sont toujours là. Il faut les maintenir. Heureusement, les (désormais 60) CHATONS permettent de répartir un peu la charge. L’offre de mail mise de côté, il restait un gros morceau : proposer une alternative crédible au géant Youtube, rien que ça ! Pas facile de briser l’hégémonie des plateformes de diffusion vidéo !
Les fichiers vidéo sont lourds, c’est le principal inconvénient. Donc il faut de gros serveurs, beaucoup de bande passante, ce qui représente un coût astronomique, sans parler de l’administration technique de tout ça.
Non seulement impensable au regard de nos moyens, mais surtout complètement à l’opposé des principes du Libre : indépendance, décentralisation, partage. Pour répondre au défi financier, Youtube et ses clones utilisent toutes les ressources du capitalisme de surveillance : en captant l’attention des internautes dans des boucles sans fin, en profilant leurs goûts, en les assaillant de publicité, en leur proposant des recommandations parfois toxiques…
C’est là que nous avons pris connaissance du logiciel (libre !) d’un jeune homme sympathique caché derrière le pseudo Chocobozzz, qui travaillait dans son coin à proposer une manière innovante de diffuser et visionner de la vidéo sur Internet.
Quand vous visionnez une vidéo, votre ordinateur participe à sa diffusion
PeerTube utilise les ressources du Web (WebRTC et BitTorrent, des technologies permettant le partage de diffusion, qui est un concept fondamental d’Internet) pour alléger la charge des sites qui hébergent du contenu. Avec un principe on ne peut plus simple : quand vous visionnez une vidéo, votre ordinateur participe à sa diffusion. Si beaucoup de personnes regardent la même vidéo, au lieu de tirer sur les ressources du serveur, on demande un petit effort à chaque machine et à chaque connexion. Les flux se répartissent, le réseau est optimisé. L’Internet comme il doit être. Comme il aurait dû le rester !
Pas besoin d’héberger tous les contenus que vous souhaitez diffuser : il suffit de se fédérer avec des instances amies qui proposent ces contenus pour les référencer sur sa propre instance. Sans dupliquer les fichiers. Et ça marche ! Quand les copains de Datagueule ont mis en ligne leur documentaire Démocratie, le logiciel a encaissé les milliers de visionnages sans broncher. Nous vous avons alors soumis l’idée d’embaucher Chocobozzz pour lui permettre de travailler sereinement à son projet, avec pour objectif de produire une version bêta du logiciel en mars 2018. Grâce à vos dons et à votre confiance, nous avons franchi cette première étape.
Nous avons entre-temps peaufiné notre nouvelle feuille de route Contributopia, dans laquelle PeerTube s’inscrivait parfaitement. Avec la recommandation du protocole ActivityPub par le W3C, qui renforçait le principe de fédération déjà initié par des logiciels sociaux (comme Mastodon), PeerTube est même devenu une brique majeure de Contributopia. Heureusement, la fédération, c’est facile à expliquer, parce que tout le monde l’utilise déjà : on a tou⋅tes des adresses mails, fournies par des tas de serveurs différents, et pourtant on arrive à s’écrire ! Avec PeerTube, lorsque plusieurs instances sont fédérées, il est possible de faire des recherches sur toutes ces instances, sans quitter celle sur laquelle vous êtes, ou de commenter des vidéos d’une instance distante sans avoir besoin de vous créer un compte dessus.
L’étape suivante allait de soi : continuer. La communication autour de PeerTube, via nos réseaux habituels, nous avait déjà permis d’attirer les contributions, des vidéastes avaient manifesté leur intérêt, les forums bruissaient de questions.
C’est pourquoi, rompant avec nos usages habituels, bousculant notre tempo, nous avons décidé de pousser les feux en prenant définitivement le rôle d’éditeur du logiciel de Chocobozzz, avec son accord, évidemment. Et surtout en soumettant une demande de financement participatif à l’international, en anglais, pour pérenniser son embauche, sans forcément vous solliciter à nouveau directement (mais on sait qu’une partie d’entre vous a tenu à participer quand même, et ça fait chaud au cœur, vraiment).
Cette fois encore, ce fut un joli succès, alors que franchement on n’en menait pas large, et voilà ce qui nous amène à cette version 1.0.
Mais alors, elle embarque quoi, cette version 1.0 ?
Avant tout, et pour éviter les mécompréhensions, rappelons que PeerTube n’est pas une seule plateforme centralisée (comme peuvent l’être YouTube, Dailymotion ou Viméo), mais un logiciel permettant de rassembler de nombreuses instances PeerTube (c’est-à-dire différentes installations du logiciel PeerTube, thématiques ou communautaires) au sein de ce que l’on appelle une fédération. Il vous faut donc chercher l’instance PeerTube qui vous convient pour visionner ou mettre en ligne vos vidéos ou, à défaut, mettre en place votre propre instance PeerTube, sur lequel vous aurez tous les droits.
PeerTube n’est pas une seule plateforme centralisée, mais un logiciel
Fonctionnalités de base
Peertube permet de regarder des vidéos avec WebTorrent, pour ne pas saturer les serveurs de diffusion. Si plusieurs personnes regardent la même vidéo, elles téléchargent de petits morceaux de la vidéo depuis votre serveur, mais aussi depuis les machines des autres personnes qui regardent la même vidéo !
Fédération entre instances PeerTube. Si l’instance PeerTube A s’abonne aux instances PeerTube B et C, depuis une recherche sur A, on peut trouver et visionner les vidéos de B et C, sans quitter A.
Le logiciel dispose de réglages assez fins qui permettent d’ajuster la gouvernance : chaque instance s’organise comme elle le souhaite. Ainsi, l’administrateur·ice de l’instance peut définir :
un quota d’espace disque pour chaque vidéaste ;
le nombre de comptes acceptés ;
le rôle des utilisateur·ices (administration, modération, utilisation, upload de vidéos).
PeerTube peut fonctionner sur un petit serveur. Vous pouvez par exemple l’installer sur un matériel type VPS ayant deux cœurs et 2Go de RAM. L’espace de stockage requis dépend évidemment du nombre de vidéos que vous souhaitez héberger personnellement.
PeerTube dispose d’un code stable et robuste, testé et éprouvé sur de nombreux systèmes, ce qui le rend performant. Ainsi, une page PeerTube se charge souvent bien plus vite qu’une page YouTube.
Vos vidéos peuvent être automatiquement converties dans différentes définitions (par exemple 240p, 720p ou 1080p. voire le 4K) pour s’adapter au débit et matériel des visiteur·euses. Cette étape s’appelle le transcodage.
Un mode «Théâtre» ainsi qu’un mode «nuit» sont disponibles pour un meilleur confort de visionnage.
PeerTube ne vous espionne pas et ne vous enferme pas : en effet, l’application ne collecte pas d’informations personnelles à des fins d’exploitation commerciale, et surtout PeerTube ne vous enferme pas dans une « bulle de filtre ». Par ailleurs, il n’utilise pas d’algorithme de recommandation biaisé pour vous faire rester indéfiniment en ligne. C’est peut-être un détail (ou une faiblesse) pour vous, mais pour nous c’est une force qui veut dire beaucoup !
Il n’existe pas – encore – d’application smartphone dédiée. Cependant, la version web de PeerTube fonctionne rapidement sur smartphone et s’adapte parfaitement à votre appareil.
Les visiteur⋅euses peuvent commenter les vidéos. Cette fonctionnalité peut être désactivée soit par l’administrateur·ice de l’instance sur n’importe quelle vidéo, soit localement par la personne qui met en ligne les vidéos.
PeerTube utilisant le protocole d’échanges ActivityPub, il est possible d’interagir avec d’autres logiciels utilisant ce même protocole. Par exemple, la plateforme de vidéo PeerTube peut interagir avec le réseau social Mastodon, alternative à Twitter. Ainsi, il est possible de « suivre » un utilisateur PeerTube depuis Mastodon, ou même de commenter une vidéo directement depuis votre compte Mastodon.
Un bouton permet d’apporter votre soutien à l’auteur d’une vidéo. Ainsi, les vidéastes peuvent mettre en place le mode de financement qui leur convient.
Nous n’avons peut-être pas insisté sur ce point, mais PeerTube est bien évidemment un logiciel libre 🙂 Cela signifie que son code source (sa recette de cuisine) est disponible et ouverte à tou⋅tes. Ainsi, vous pouvez contribuer au code ou, si vous pensez que le logiciel ne va pas dans la bonne direction, le copier et y apporter les modifications qui correspondent à vos besoins.
Image du crowdfunding réussi ayant financé une large partie des fonctionnalités les plus attendues.
Fonctionnalités financées par le crowdfunding
Le sous-titrage : possibilité d’ajouter de multiples fichiers de langue (au format .srt) pour proposer les sous-titrages des vidéos.
La redondance d’instance : il est possible « d’aider » une instance désignée en activant la redondance de tout ou partie de ses vidéos (qui seront alors dupliquées sur votre instance). Ainsi, si l’instance liée est surchargée parce que trop de monde regarde les vidéos qu’elle héberge, votre instance pourra la soutenir en mettant sa bande passante à disposition.
L’import depuis d’autres plateformes vidéo par simple copier-coller : YouTube, Viméo, Dailymotion, etc. Depuis certaines plateformes, la récupération du titre, de la description ou des mots clés est même automatique. Il est bien entendu possible d’importer aussi des vidéos par lien direct ou depuis une autre instance PeerTube. Enfin, PeerTube permet aussi l’import depuis les fichiers .torrent.
Plusieurs flux RSS s’offrent à vous selon vos besoins : un pour les vidéos de manière globale, un autre pour celles d’une chaîne et un dernier pour les commentaires d’une vidéo.
Peertube s’est internationalisé et parle maintenant 13 langues dont le chinois. Des traductions vers d’autres langues sont en cours.
La recherche est plus pertinente. Elle prend en compte certaines fautes de frappe et propose l’utilisation de filtres.
Fonctionnalités à venir
Nous avons une excellente nouvelle : bien que le troisième palier du crowdfunding n’ait pas été atteint, Framasoft a décidé d’embaucher Chocobozzz en CDI afin de pérenniser le développement de Peertube. D’autres fonctionnalités sont donc prévues au cours de l’année 2019.
Un système de plugins pour personnaliser Peertube. Il s’agit là d’un développement essentiel, car il permettra à chacun⋅e de développer ses propres plugins pour adapter PeerTube à ses besoins. Par exemple il deviendra possible de proposer des plugins de recommandations avec des algorithmes spécifiques ou des thèmes graphiques complètement différents.
Nous développerons éventuellement une application mobile (ou bien des contributeur⋅ices motivé⋅e⋅s le feront)
Il sera rapidement possible d’améliorerl’outil d’importation de vidéos, de façon à pouvoir «synchroniser» votre chaîne YouTube avec votre chaîne PeerTube (PeerTube sera en capacité de vérifier si de nouvelles vidéos ont été ajoutées et pourra automatiquement les ajouter à votre compte PeerTube, titre et descriptions compris). Dans les faits, cette fonctionnalité fonctionne déjà pour celles et ceux qui hébergent leur instance PeerTube et maîtrisent la ligne de commande.
Des statistiques par instance ou par compte pourront être mises à disposition.
L’amélioration des outils de modération.
[Exemple de la fonction d’import de vidéo]
PeerTube répare Internet
La campagne « Dégooglisons Internet » était un cri, une réaction, un rejet. Rejet des GAFAM et de leur vision centralisatrice, fermée, toute tournée vers le fric et le contrôle. Lutter contre les GAFAM, c’est mener un combat disproportionné. Mais la prise de conscience est faite. Nous n’avons plus besoin de rabâcher notre couplet sur leur façon de nier nos libertés, de s’approprier nos données personnelles, de prendre le pouvoir dans nos vies. Et puis il faut dire qu’à force de scandales, ils nous ont bien aidés à accélérer dans l’opinion publique cette prise de conscience. Nous revendiquons fièrement notre participation à cette évolution des esprits, au milieu d’autres acteurs tout aussi importants (LQDN, la CNIL, l’APRIL, etc.). Il est temps maintenant de passer à autre chose.
https://framalab.org/gknd-creator/
Chez Framasoft, incorrigibles bavards que nous sommes, nous avons produit beaucoup d’écrits, et nous avons finalement, proportionnellement, assez peu de contenus vidéos à proposer, alors que c’est un média qui est devenu à la fois plus facile à élaborer et plus demandé par le public. Ce virage vers la vidéo nous a été confisqué par les plateformes centralisatrices, Youtube en tête. Elles ont installé un standard, une norme, avec des pratiques révoltantes comme la censure aveugle et l’appropriation des contenus.
Le principe de fédération impulsé par le protocole ActivityPub et les logiciels qui l’utilisent (Peertube, Mastodon, Funkwhale, PixelFed, Plume… la liste s’allonge chaque mois) est en train, ni plus ni moins, de corriger le tir, de (re)construire le futur d’Internet. Celui que nous appelons de nos vœux.
La fédération, avec ActivityPub, c’est s’allier aux autres sans perdre son identité
Oui, cette fois, c’est une révolution. Avec Contributopia, nous annonçons une étape de construction, basée sur le partage, les communs, l’éducation populaire.
Nous avons aussi pris conscience, en avançant, que nous ne pouvions plus nier la dimension politique de cette vision. Alors quand on dit «politique», on convoque l’étymologie du mot, hein. C’est pas demain qu’on verra Pyg, notre délégué général, à l’Assemblée Nationale. Il n’empêche ! La culture du libre, ça va bien au-delà de l’hébergement d’agendas ou de l’ouverture d’un pad pour rédiger le présent article à plusieurs.
Nous travaillons, dans le cadre qui est le nôtre, à fournir des outils numériques aux utopistes qui, comme nous, pensent qu’il y a encore moyen de sauver les meubles. On se disait que ce n’était pas super vendeur, mais nous avons pu voir, lors de nos fréquentes interventions à droite et à gauche, que la démarche rencontrait de l’écho. Nous avons encore quelques jolies cartes à jouer pour la suite (même si pour certaines on ne sait pas encore comment ça se passera ^^), comme toujours dans la bonne humeur et le houblon doré.
Nous espérons que vous nous suivrez, encore, dans cette voie.
Longue vie à PeerTube.
L’équipe de Framasoft.
Pour aller plus loin
À vous de jouer ! PeerTube vous appartient, emparez-vous de ses possibilités. Déposez des vidéos de qualité (de préférence sous licence libre, ou pour laquelle vous avez les droits de diffusion ou un accord explicite) sur l’une des instances déjà existantes. Faites connaître PeerTube à vos contacts et aux YouTubeur⋅euses auxquels vous êtes abonné⋅e. Et si vous le pouvez, installez votre propre instance pour agrandir encore le réseau fédéré !

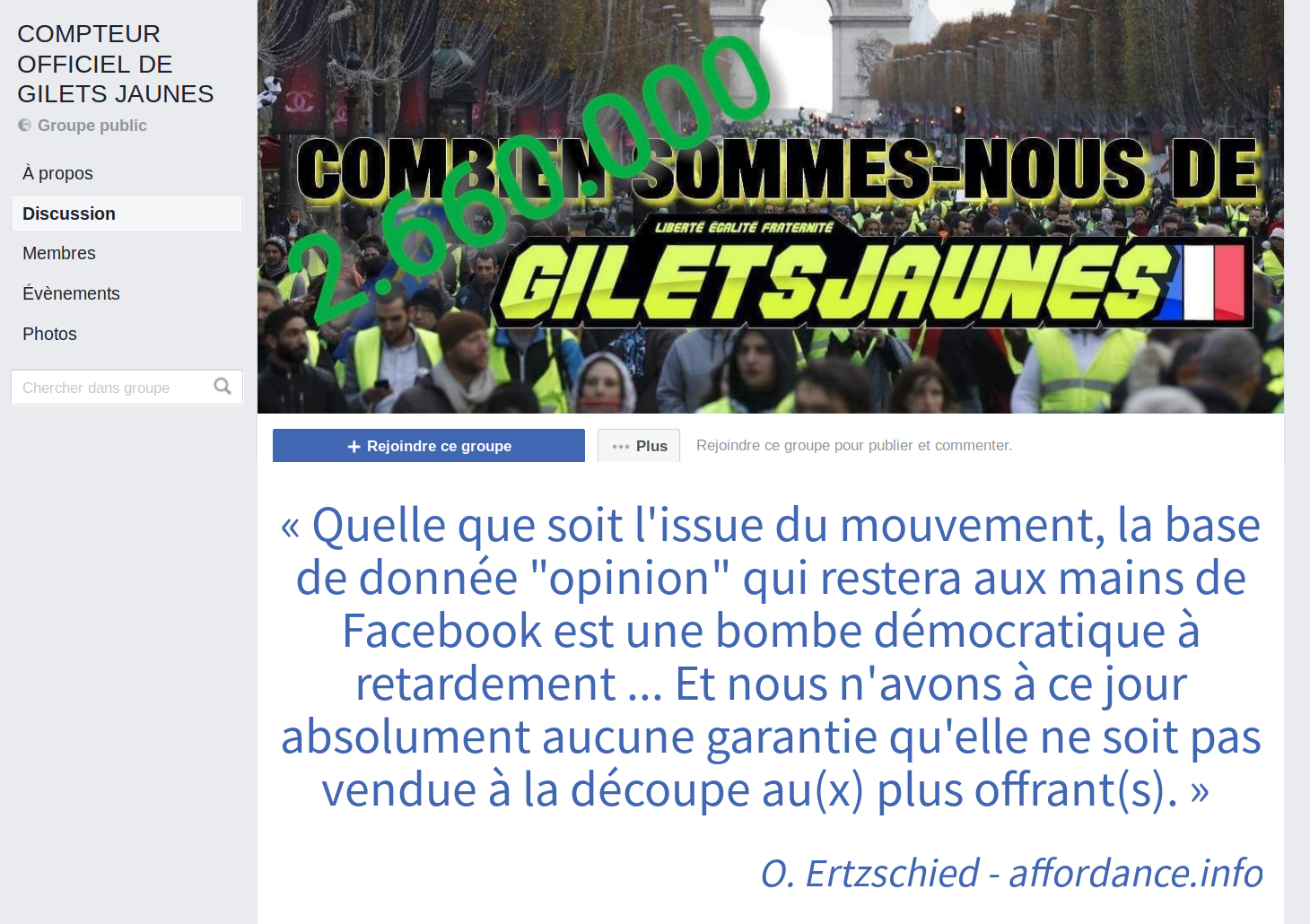

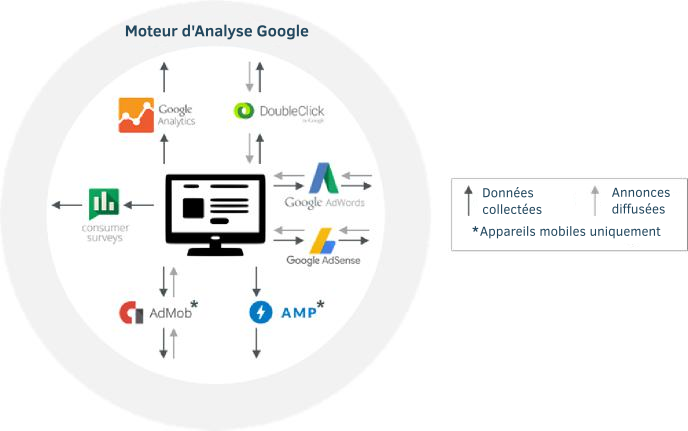
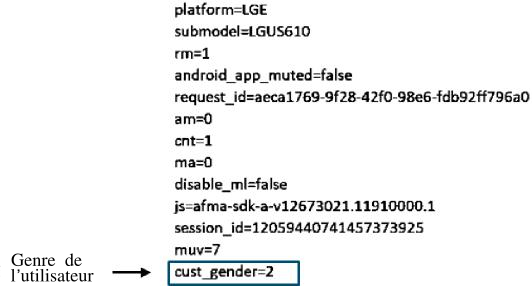
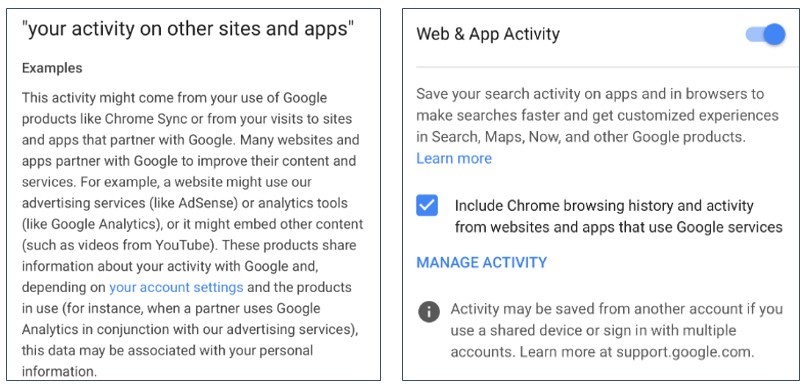

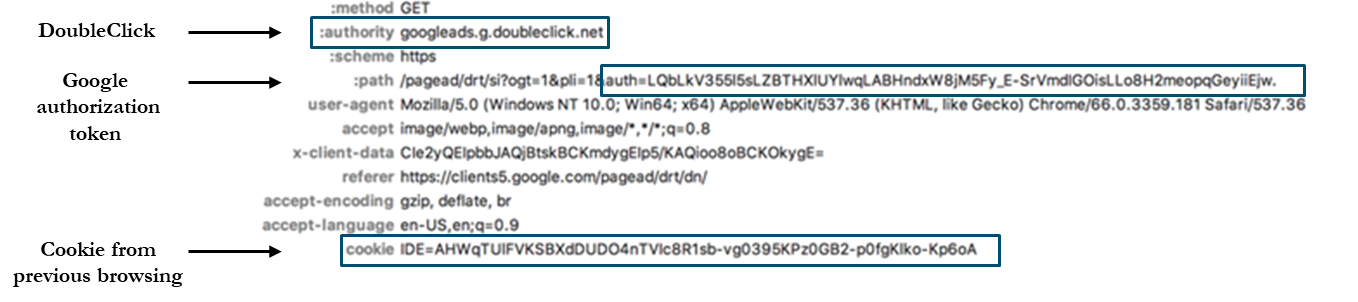



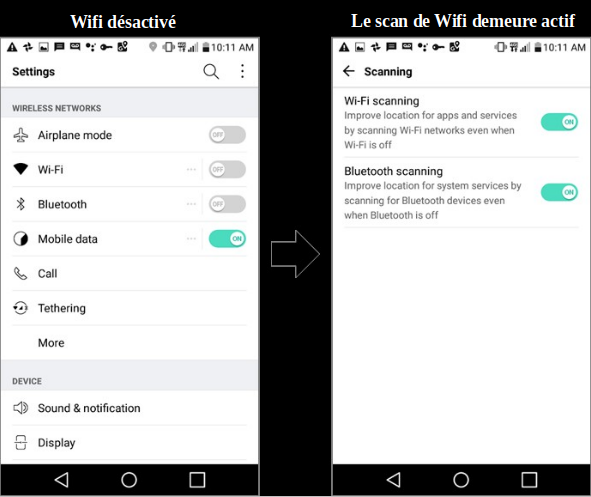

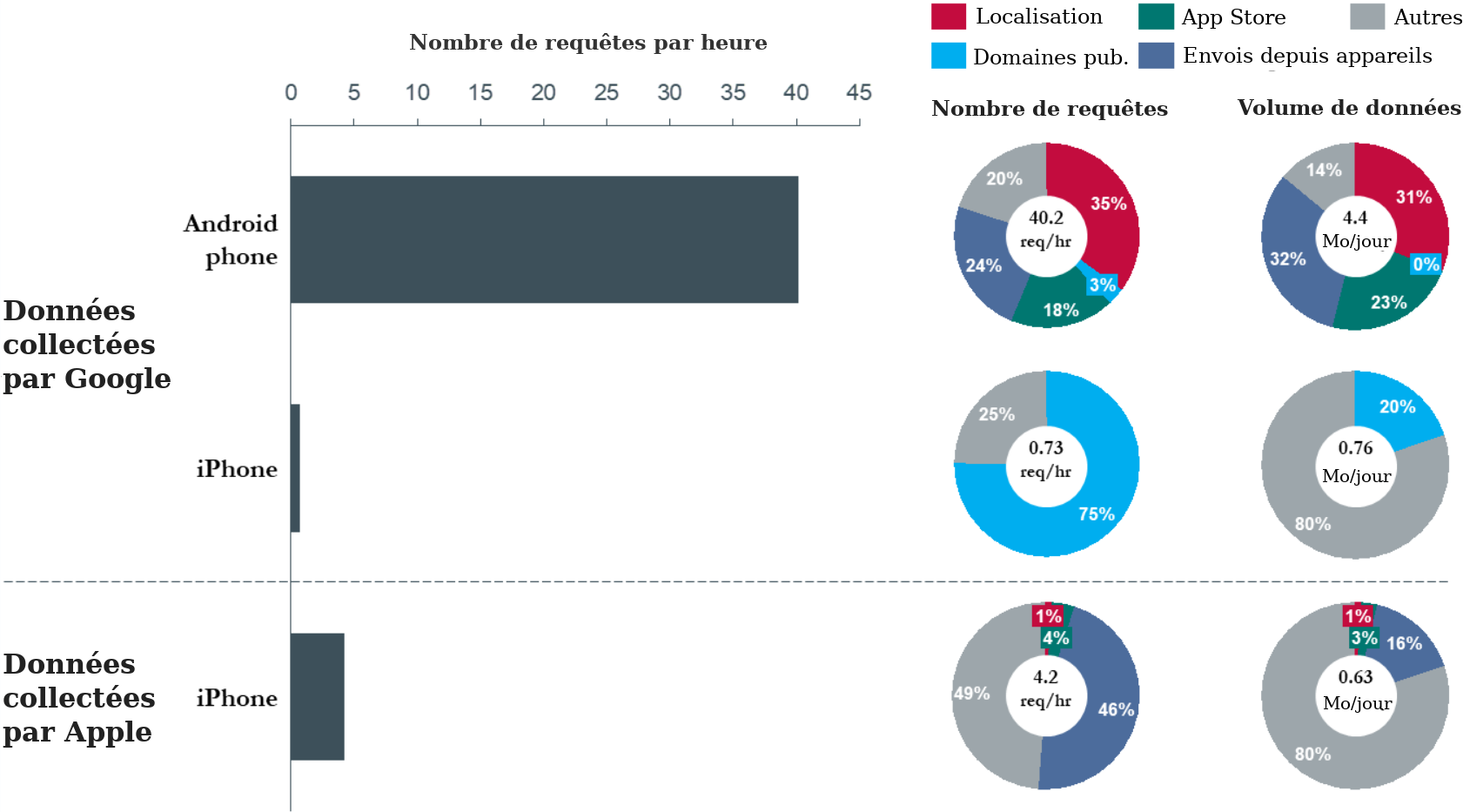










{kind=link}
{kind=link}