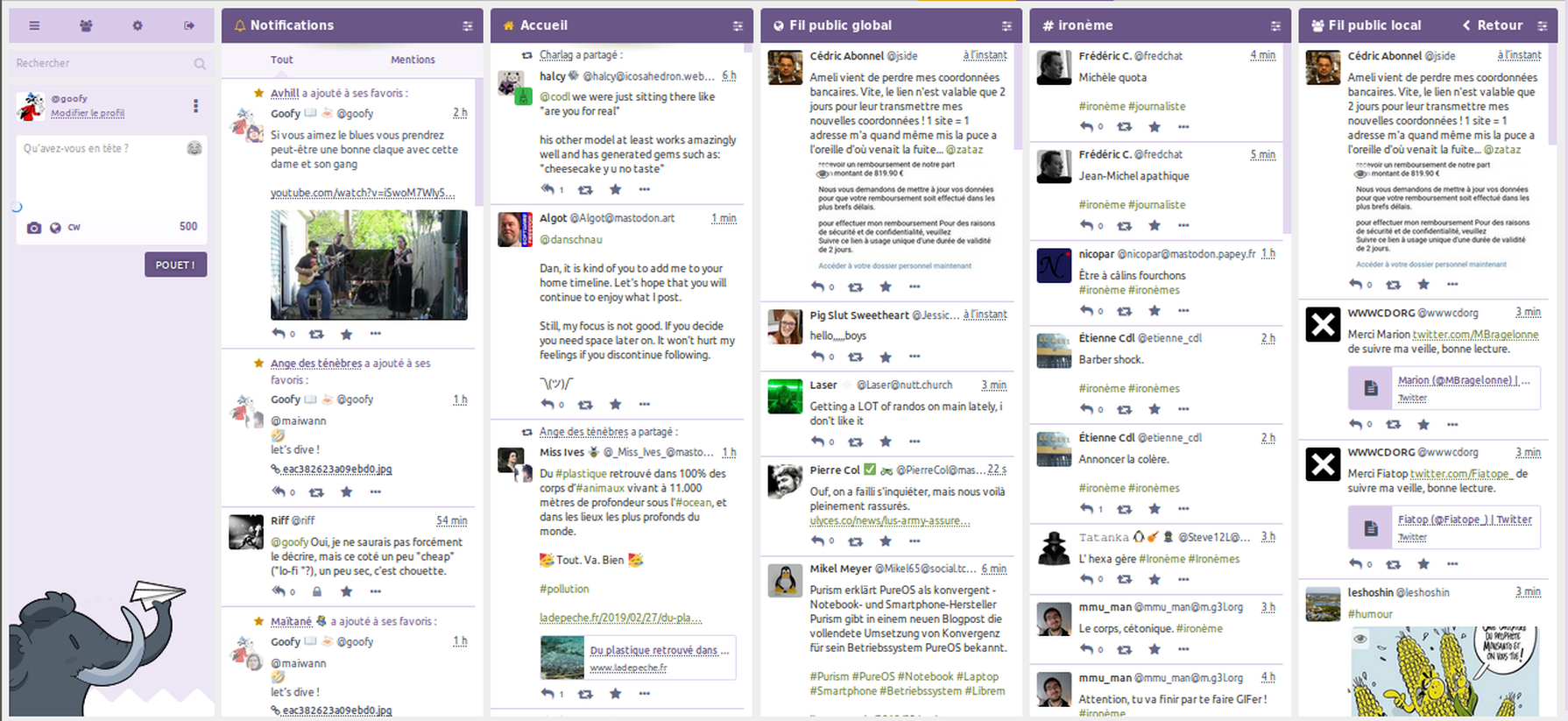
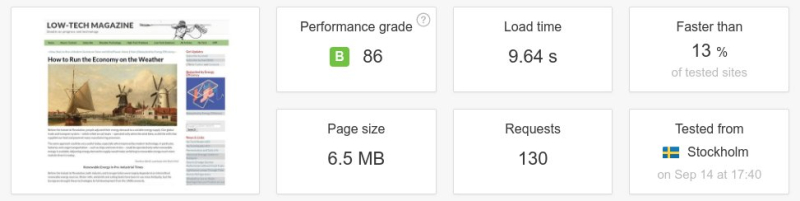
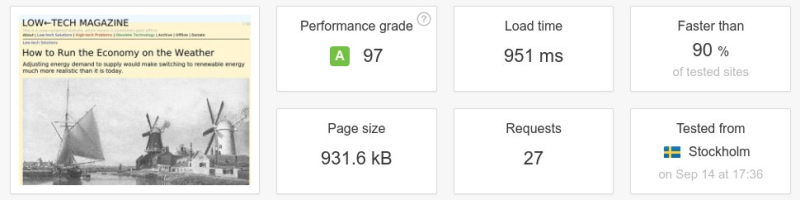
Dans un article assez lucide de son blog que nous reproduisons ici, Dada remue un peu le fer dans la plaie.
Faiblesse économique du Libre, faiblesse encore des communautés actives dans le développement et la maintenance des logiciels et systèmes, manque de visibilité hors du champ de perception de beaucoup de DSI. En face, les forces redoutables de l’argent investi à perte pour tuer la concurrence, les forces tout aussi redoutables des entreprises-léviathans qui phagocytent lentement mais sûrement les fleurons du Libre et de l’open source…
Lucide donc, mais aussi tout à fait convaincu depuis longtemps de l’intérêt des valeurs du Libre, Dada appelle de ses vœux l’émergence d’entreprises éthiques qui permettraient d’y travailler sans honte et d’y gagner sa vie décemment. Elles sont bien trop rares semble-t-il.
D’où ses interrogations, qu’il nous a paru pertinent de vous faire partager. Que cette question cruciale soit l’occasion d’un libre débat : faites-nous part de vos réactions, observations, témoignages dans les commentaires qui comme toujours sont ouverts et modérés. Et pourquoi pas dans les colonnes de ce blog si vous désirez plus longuement exposer vos réflexions.
Avec des projets plein la tête, ou plutôt des envies, et le temps libre que j’ai choisi de me donner en n’ayant pas de boulot depuis quelques mois, j’ai le loisir de m’interroger sur l’économie du numérique. Je lis beaucoup d’articles et utilise énormément Mastodon pour me forger des opinions.
Je vous invite à vraiment prendre le temps de l’écouter, c’est franchement passionnant. On y apprend, en gros, que l’économie des géants du numérique est, pour certains, basée sur une attitude extrêmement agressive : il faut être le moins cher possible, perdre de l’argent à en crever et lever des fonds à tire-larigot pour abattre ses concurrents avec comme logique un pari sur la quantité d’argent disponible à perdre par participants. Celui qui ne peut plus se permettre de vider les poches de ses actionnaires a perdu. Tout simplement. Si ces entreprises imaginent, un jour, remonter leurs prix pour envisager d’être à l’équilibre ou rentable, l’argument du « ce n’est pas possible puisque ça rouvrira une possibilité de concurrence » sortira du chapeau de ces génies pour l’interdire. Du capitalisme qui marche sur la tête.
L’investissement sécurisé
La deuxième grande technique des géants du numérique est basée sur la revente de statistiques collectées auprès de leurs utilisateurs. Ces données privées que vous fournissez à Google, Facebook Inc,, Twitter & co permettent à ces sociétés de disposer d’une masse d’informations telle que des entreprises sont prêtes à dégainer leurs portefeuilles pour en dégager des tendances.
Je m’amuse souvent à raconter que si les séries et les films se ressemblent beaucoup, ce n’est pas uniquement parce que le temps passe et qu’on se lasse des vieilles ficelles, c’est aussi parce que les énormes investissements engagés dans ces productions culturelles sont basés sur des dossiers mettant en avant le respect d’un certain nombre de « bonnes pratiques » captant l’attention du plus gros panel possible de consommateurs ciblés.
Avec toutes ces données, il est simple de savoir quel acteur ou quelle actrice est à la mode, pour quelle tranche d’âge, quelle dose d’action, de cul ou de romantisme dégoulinant il faut, trouver la période de l’année pour la bande annonce, sortie officielle, etc. Ça donne une recette presque magique. Comme les investisseurs sont friands de rentabilité, on se retrouve avec des productions culturelles calquées sur des besoins connus : c’est rassurant, c’est rentable, c’est à moindre risque. Pas de complot autour de l’impérialisme américain, juste une histoire de gros sous.
Cette capacité de retour sur investissement est aussi valable pour le monde politique, avec Barack OBAMA comme premier grand bénéficiaire ou encore cette histoire de Cambridge Analytica.
C’est ça, ce qu’on appelle le Big Data, ses divers intérêts au service du demandeur et la masse de pognon qu’il rapporte aux grands collecteurs de données.
La pub
Une troisième technique consiste à reprendre les données collectées auprès des utilisateurs pour afficher de la pub ciblée, donc plus efficace, donc plus cher. C’est une technique connue, alors je ne développe pas. Chose marrante, quand même, je ne retrouve pas l’étude (commentez si vous mettez la main dessus !) mais je sais que la capacité de ciblage est tellement précise qu’elle peut effrayer les consommateurs. Pour calmer l’angoisse des internautes, certaines pubs sans intérêt vous sont volontairement proposées pour corriger le tir.
Les hommes-sandwichs
Une autre technique est plus sournoise. Pas pour nous autres, vieux loubards, mais pour les jeunes : le placement produit. Même si certain Youtubeurs en font des blagues pas drôles (Norman…), ce truc est d’un vicieux.
Nos réseaux sociaux n’attirent pas autant de monde qu’espéré pour une raison assez basique : les influenceurs et influenceuses. Ces derniers sont des stars, au choix parce qu’ils sont connus de par leurs activités précédentes (cinéma, série, musique, sport, etc.) ou parce que ces personnes ont réussi à amasser un tel nombre de followers qu’un simple message sur Twitter, Youtube ou Instagram se cale sous les yeux d’un monstrueux troupeau. Ils gagnent le statut d’influenceur de par la masse de gens qui s’intéresse à leurs vies (lapsus, j’ai d’abord écrit vide à la place de vie). J’ai en tête l’histoire de cette jeune Léa, par exemple. Ces influenceurs sont friands de plateformes taillées pour leur offrir de la visibilité et clairement organisées pour attirer l’œil des Directeurs de Communication des marques. Mastodon, Pixelfed, diaspora* et les autres ne permettent pas de spammer leurs utilisateurs, n’attirent donc pas les marques, qui sont la cible des influenceurs, ces derniers n’y dégageant, in fine, aucun besoin d’y être présents.
Ces gens-là deviennent les nouveaux « hommes-sandwichs ». Ils ou elles sont contacté⋅e⋅s pour porter tel ou tel vêtement, boire telle boisson ou pour seulement poster un message avec le nom d’un jeu. Les marques les adorent et l’argent coule à flot.
On peut attendre
Bref, l’économie du numérique n’est pas si difficile que ça à cerner, même si je ne parle pas de tout. Ce qui m’intéresse dans toutes ces histoires est la stabilité de ces conneries sur le long terme et la possibilité de proposer autre chose. On peut attendre que les Uber se cassent la figure calmement, on peut attendre que le droit décide enfin de protéger les données des utilisateurs, on peut aussi attendre le jour où les consommateurs comprendront qu’ils sont les seuls responsables de l’inintérêt de ce qu’ils regardent à la télé, au cinéma, en photos ou encore que les mastodontes du numérique soient démantelés. Bref, on peut attendre. La question est : qu’aurons-nous à proposer quand tout ceci finira par se produire ?
La LowTech
Après la FinTech, la LegalTech, etc, faites place à la LowTech ou SmallTech. Je ne connaissais pas ces expressions avant de tomber sur cet article dans le Framablog et celui de Ubsek & Rica d’Aral. On y apprend que c’est un mouvement qui s’oppose frontalement aux géants, ce qui est fantastique. C’est une vision du monde qui me va très bien, en tant que militant du Libre depuis plus de 10 ans maintenant. On peut visiblement le rapprocher de l’initiative CHATONS.
Cependant, j’ai du mal à saisir les moyens qui pourraient être mis en œuvre pour sa réussite.
Les mentalités
Les mentalités actuelles sont cloisonnées : le Libre, même s’il s’impose dans quelques domaines, reste mal compris. Rien que l’idée d’utiliser un programme au code source ouvert donne des sueurs froides à bon nombre de DSI. Comment peut-on se protéger des méchants si tout le monde peut analyser le code et en sortir la faille de sécurité qui va bien ? Comment se démarquer des concurrents si tout le monde se sert du même logiciel ? Regardez le dernier changelog : il est plein de failles béantes : ce n’est pas sérieux !
Parlons aussi de son mode de fonctionnement : qui se souvient d’OpenSSL utilisé par tout le monde et abandonné pendant des années au bénévolat de quelques courageux qui n’ont pas pu empêcher l’arrivée de failles volontaires ? Certains projets sont fantastiques, vraiment, mais les gens ont du mal à réaliser qu’ils sont, certes, très utilisés mais peu soutenus. Vous connaissez beaucoup d’entreprises pour lesquelles vous avez bossé qui refilent une petite partie de leurs bénéfices aux projets libres qui les font vivre ?
Le numérique libre et la Presse
Les gens, les éventuels clients des LowTech, ont plus ou moins grandi dans une société du gratuit. L’autre jour, je m’amusais à comparer les services informatiques à la Presse. Les journaux ont du mal à se sortir du modèle gratuit. Certains y arrivent (Mediapart, Arrêts sur Image : abonnez-vous !), d’autres, largement majoritaires, non.
Il n’est pas difficile de retrouver les montants des subventions que l’État français offre à ces derniers. Libération en parle ici. Après avoir noué des partenariats tous azimuts avec les GAFAM, après avoir noyé leurs contenus dans de la pub, les journaux en ligne se tournent doucement vers le modèle payant pour se sortir du bourbier dans lequel ils se sont mis tout seuls. Le résultat est très moyen, si ce n’est mauvais. Les subventions sont toujours bien là, le mirage des partenariats avec les GAFAM aveugle toujours et les rares qui s’en sont sortis se comptent sur les doigts d’une main.
On peut faire un vrai parallèle entre la situation de la Presse en ligne et les services numériques. Trouver des gens pour payer l’accès à un Nextcloud, un Matomo ou que sais-je est une gageure. La seule différence qui me vient à l’esprit est que des services en ligne arrivent à s’en sortir en coinçant leurs utilisateurs dans des silos : vous avez un Windows ? Vous vous servirez des trucs de Microsoft. Vous avez un compte Gmail, vous vous servirez des trucs de Google. Les premiers Go sont gratuits, les autres seront payants. Là où les journaux généralistes ne peuvent coincer leurs lecteurs, les géants du numérique le peuvent sans trop de souci.
Et le libre ?
Profil de libriste sur Mastodon.
Dans tout ça, les LowTech libres peuvent essayer de s’organiser pour subvenir aux besoins éthiques de leurs clients. Réflexion faite, cette dernière phrase n’a pas tant que ça de sens : comment une entreprise peut-elle s’en sortir alors que l’idéologie derrière cette mouvance favorise l’adhésion à des associations ou à rejoindre des collectifs ? Perso, je l’ai déjà dit, j’adhère volontiers à cette vision du monde horizontale et solidaire. Malgré tout, mon envie de travailler, d’avoir un salaire, une couverture sociale, une activité rentable, et peut-être un jour une retraite, me poussent à grimacer. Si les bribes d’idéologie LowTech orientent les gens vers des associations, comment fait-on pour sortir de terre une entreprise éthique, rentable et solidaire ?
On ne s’en sort pas, ou très difficilement, ou je n’ai pas réussi à imaginer comment. L’idée, connue, serait de s’attaquer au marché des entreprises et des collectivités pour laisser celui des particuliers aux associations sérieuses. Mais là encore, on remet un pied dans le combat pour les logiciels libres contre les logiciels propriétaires dans une arène encerclée par des DSI pas toujours à jour. Sans parler de la compétitivité, ce mot adoré par notre Président, et de l’état des finances de ces entités. Faire le poids face à la concurrence actuelle, même avec les mots « éthique, solidaire et responsable » gravés sur le front, n’est pas évident du tout.
Proie
Si je vous parle de tout ça, c’est parce que j’estime que nous sommes dans une situation difficile : celle d’une proie. Je ne vais pas reparler de l’achat de Nginx, de ce qu’il se passe avec ElasticSearch ou du comportement de Google qui forke à tout va pour ses besoins dans Chrome. Cette conférence vue au FOSDEM, The Cloud Is Just Another Sun, résonne terriblement en moi. L’intervenant y explique que les outils libres que nous utilisons dans le cloud sont incontrôlables. Qui vous certifie que vous tapez bien dans un MariaDB ou un ES quand vous n’avez accès qu’a une boite noire qui ne fait que répondre à vos requêtes ? Rien.
Nous n’avons pas trouvé le moyen de nous protéger dans le monde dans lequel nous vivons. Des licences ralentissent le processus de digestion en cours par les géants du numérique et c’est tout. Notre belle vision du monde, globalement, se fait bouffer et les poches de résistance sont minuscules.
Le Libre est-il sur une pente dangereuse ou en train de négocier brillamment un virage ? Page d’accueil du site d’entreprise https://befox.fr/
Pour finir
Pour finir, ne mettons pas complètement de côté l’existence réelle d’un marché : Nextcloud en est la preuve, tout comme Dolibarr et la campagne de financement réussie d’OpenDSI. Tout n’est peut-être pas vraiment perdu. C’est juste très compliqué.
La bonne nouvelle, s’il y en a bien une, c’est qu’en parlant de tout ça dans Mastodon, je vous assure que si une entreprise du libre se lançait demain, nous serions un bon nombre prêt à tout plaquer pour y travailler. À attendre d’hypothétiques clients, qu’on cherche toujours, certes, mais dans la joie et la bonne humeur.
Enfin voilà, des réflexions, des idées, beaucoup de questions. On arrive à plus de 1900 mots, de quoi faire plaisir à Cyrille BORNE.
Des bisous.
Un quatrième tome pour Ernaut de Jérusalem
Fin connaisseur du monde médiéval, Yann Kervran propose un nouveau volume des aventures d’Ernaut de Jérusalem. Son héros, qui a gagné en maturité, va affronter un nouveau mystère : un corps entièrement brûlé tandis que sa demeure est intacte autour de lui.
De là à y voir le souffle ardent du Malin…
Yann continue de ciseler tranquillement son univers. On peut lire ses romans comme d’habiles polars, ce qui ne serait déjà pas si mal, mais on peut s’attarder sur les liens qui se tissent au fil des ouvrages, l’incroyable précision des références historiques, la description minutieuse des mœurs d’une époque… et tout ça sous licence libre.
Nous lui avons posé quelques questions.
Le souffle du dragon… il y avait des dragons en Terre sainte ?
Forcément, vu que c’est là que saint Georges a tué le sien. Au-delà de la polysémie du titre, avec laquelle je joue chaque fois afin de laisser le public en faire sa propre lecture, c’est en référence à la basilique de Lydda où est conservé, justement, le corps de saint Georges. C’est là que se déroule la majeure partie de l’intrigue à laquelle est confronté Ernaut. C’est l’occasion d’évoquer bon nombre de dragons, des traditions orientales, qui viennent alors percoler dans les récits hagiographiques occidentaux. C’est aussi le nom d’une bannière issue de l’Antiquité romaine impériale…
Et c’est parfois, plus prosaïquement, le terme sous lequel on désigne les crocodiles, au Moyen Âge. Toutes ces définitions, ces évocations ont leur part de vérité dans la caractérisation du titre. D’ailleurs, c’est la même chose pour le second terme : le souffle n’est pas que le feu du dragon, il renvoie aussi à la tradition alchimique et ésotérique, avec laquelle le livre joue également, à plusieurs niveaux. Enfin, il y a des approches plus habituelles de ces termes, et cela peut aussi peut-être s’appliquer à certains points de vue sur le récit, un personnage ou l’autre.
Le quatrième tome, déjà ! On voit Ernaut gérer seul une enquête officielle. Peut-tu nous en dire plus sur les évolutions de notre héros ?
Cela fait désormais deux ans qu’il réside en Terre sainte et pratiquement un an et demi au service de l’hôtel du roi, en tant que sergent. Il commence à avoir des amis, un réseau de relations, une fiancée… Il n’est plus le garçon maladroit qui embarquait à bord du Falconus. C’est un jeune homme impatient d’embrasser la vie, qui voit son avenir se dessiner. J’ai conçu ce tome comme le dernier de son enfance, les choses sont en train de se placer pour lui tracer une voie.
Déjà quatre tomes ! (photo Yann Kervran CC-BY-SA)
Cela dit, s’il est en charge de l’enquête, ce n’est pas de façon aussi claire et formelle qu’il l’aurait peut-être souhaité. Je n’en dis pas trop pour ne pas gâcher le plaisir des lecteurs. Mais il est vrai qu’il se voit maître de son temps, de ses actions, dans une certaine mesure et dans un cadre général qui lui est imposé par des supérieurs.
Celui-ci a été écrit avec le concours du CNL, peut-tu nous présenter un peu ce que c’est ?
Le Centre National du Livre a, dans ses missions, la tâche de soutenir la création littéraire francophone avec, entre autres, l’existence de bourses d’écriture pour les auteurs. J’ai donc eu le bonheur de voir mon projet retenu parmi les 66 romans sélectionnés en 2017. J’avais deux ans pour voir le projet terminé et publié, c’est donc chose faite. En échange, il suffit d’indiquer que l’ouvrage a reçu leur soutien, ce que je fais avec plaisir. Je profite de cet entretien pour les remercier publiquement.
Ce qui pose aussi la question du modèle économique chez les auteurs. Alors, est-ce qu’être libre est plus rentable que l’édition traditionnelle ?
De façon générale, je ne sais pas, mais en ce qui me concerne la réponse est oui. Je n’ai pas encore les chiffres de vente pour mes autres ouvrages non romanesques, non libres, chez un autre éditeur, pour 2018. En partant du principe que c’est similaire à 2017, vu que je n’y ai rien sorti depuis deux ans, je vais gagner plus avec mes trois Framabooks. Mais cela reste dérisoire : mes revenus d’auteur non libre se sont effondrés au fil de la décennie, pour arriver à un peu moins de 300€ annuellement.
C’est le cas pour énormément d’écrivains et c’est une tendance globale :
Pour mon travail d’auteur libre, je dois percevoir à peu près le même montant pour 2018, mais s’y ajoutent les dons reçus en soutien de mon travail, ou en contre-don de la lecture des epub, pour environ 200€ sur l’année je dirais.
De toute évidence, cela ne permet pas d’en vivre. La bourse du CNL, de 7000€ brut, a beaucoup aidé, mais pour l’instant ce n’est pas viable pour moi. Je vais donc devoir surseoir à la rédaction du tome 5, n’ayant matériellement pas les moyens de m’y consacrer de façon sérieuse et sereine.
Quoiqu’il en soit, je suis très heureux d’avoir basculé mon travail sous licence libre car j’en garde la maîtrise et je sais que ce sera disponible pour qui veut y accéder. C’était un point essentiel pour moi. Ayant été contraint de garder des textes non publiés pendant des années, de me restreindre sur les productions liées directement ou indirectement, c’était extrêmement frustrant. Avec le libre, mes textes ne disparaissent pas au même rythme que mes revenus.
J’ai été ton éditeur pour ce tome, et c’était très enrichissant. Mais je ne sais pas comment tu fais pour t’en sortir avec les contraintes historiques. Ça me rendrait dingue, alors que tu navigues là-dedans avec une aisance incroyable. Bon sang, tu vérifies les phases de la Lune ! Comment arrives-tu à t’en sortir ?
C’est facile : j’ai une bibliothèque plus que conséquente sur le sujet et je me sers aussi beaucoup d’Internet. Il est désormais bien plus aisé d’accéder à la documentation que quand je faisais mes études (malgré de nombreux paywalls ici et là, qui enclosent parfois du savoir dans le domaine public).
C’est aussi plus simple de l’organiser : j’ai un wiki où je note pas mal de choses pour suivre la chronologie et conserver la cohérence de caractérisation de mes protagonistes. Par ailleurs je crains toujours l’effet carton pâte de certains récits où la documentation est plaquée sur une idée qui ne cadre pas avec le décor. Je m’efforce donc de lire régulièrement des ouvrages scientifiques sur le monde des croisades, des sources historiques, sans avoir de but en tête, juste pour m’imprégner. Et je note sur des feuilles des idées, des anecdotes, des envies, pour ensuite les exhumer quand je suis en recherche de motifs à développer.
Pour l’intégration de l’histoire au cycle romanesque, je commence toujours par voir comment la période historique peut offrir des sujets intéressants à traiter, par le biais de l’enquête principale, du décor ou des personnages annexes. Je bâtis ensuite là-dessus, en voyant comment je peux intégrer les personnages pour lesquels j’ai prévu de longs arcs narratifs au sein d’Hexagora. L’idée étant de nourrir les narrations les unes par les autres, de ne jamais rattacher une histoire à un seul arc, mais d’en faire un point de rencontre, de jonction, de friction.
Qu’est-ce qui est prévu pour la suite ?
Pour l’heure, je me focalise sur les Qit’a, histoires courtes dans le monde d’Ernaut. J’en ai rédigé presque une centaine qui vont être publiées en quatre recueils, j’espère avant l’été. Je continue aussi d’en écrire, mensuellement, car c’est une pratique régulière qui nourrit ma réflexion et fait avancer la façon dont je conçois mon métier d’écrivain. J’ai aussi quelques vieux projets que je dois finaliser, dans un tout autre style. Peut-être que j’utiliserai un pseudonyme pour ne pas induire mes lecteurs habituels en erreur. Mais ce qui est certain, c’est que ce sera sous licence libre.
Il n’est pas si fréquent que l’équipe Framalang traduise un article depuis la langue italienne, mais la récapitulation bien documentée de Cagizero était une bonne occasion de faire le point sur l’expansion de la Fediverse, un phénomène dont nous nous réjouissons et que nous souhaitons voir gagner plus d’amplitude encore, tant mieux si l’article ci-dessous est très lacunaire dans un an !
Mastodon, la Fediverse et l’avenir des réseaux décentralisés
par Cagizero
Peu de temps après une première vue d’ensemble de Mastodon il est déjà possible d’ajouter quelques observations nouvelles.
Tout d’abord, il faut noter que plusieurs personnes familières de l’usage des principaux médias sociaux commerciaux (Facebook, Twitter, Instagram…) sont d’abord désorientées par les concepts de « décentralisation » et de « réseau fédéré ».
En effet, l’idée des médias sociaux qui est répandue et bien ancrée dans les esprits est celle d’un lieu unique, indifférencié, monolithique, avec des règles et des mécanismes strictement identiques pour tous. Essentiellement, le fait même de pouvoir concevoir un univers d’instances séparées et indépendantes représente pour beaucoup de gens un changement de paradigme qui n’est pas immédiatement compréhensible.
Dans un article précédent où était décrit le média social Mastodon, le concept d’instance fédérée était comparé à un réseau de clubs ou cercles privés associés entre eux.
Certains aspects exposés dans l’article précédent demandent peut-être quelques éclaircissements supplémentaires pour celles et ceux qui abordent tout juste le concept de réseau fédéré.
1. On ne s’inscrit pas « sur Mastodon », mais on s’inscrit à une instance de Mastodon ! La comparaison avec un club ou un cercle s’avère ici bien pratique : adhérer à un cercle permet d’entrer en contact avec tous ceux et celles qui font partie du même réseau : on ne s’inscrit pas à une plateforme, mais on s’inscrit à l’un des clubs de la plateforme qui, avec les autres clubs, constituent le réseau. La plateforme est un logiciel, c’est une chose qui n’existe que virtuellement, alors qu’une instance qui utilise une telle plateforme en est l’aspect réel, matériel. C’est un serveur qui est physiquement situé quelque part, géré par des gens en chair et en os qui l’administrent. Vous vous inscrivez donc à une instance et ensuite vous entrez en contact avec les autres.
2. Les diverses instances ont la possibilité technique d’entrer en contact les unes avec les autres mais ce n’est pas nécessairement le cas. Supposons par exemple qu’il existe une instance qui regroupe 500 utilisateurs et utilisatrices passionné⋅e⋅s de littérature, et qui s’intitule mastodon.litterature : ces personnes se connaissent précisément parce en tant que membres de la même instance et chacun⋅e reçoit les messages publics de tous les autres membres.
Eh bien, chacun d’entre eux aura probablement aussi d’autres contacts avec des utilisateurs enregistrés sur difFerentes instances (nous avons tous des ami⋅e⋅s qui ne font pas partie de notre « cercle restreint », n’est-ce pas ?). Si chacun des 500 membres de maston.litterature suit par exemple 10 membres d’une autre instance, mastodon.litterature aurait un réseau local de 500 utilisateurs, mais aussi un réseau fédéré de 5000 utilisateurs !
Bien. Supposons que parmi ces 5000 il n’y ait même pas un seul membre de l’instance japonaise japan.nuclear.physics dont le thème est la physique nucléaire : cette autre instance pourrait avoir peut-être 800 membres et avoir un réseau fédéré de plus de 8000 membres, mais si entre les réseaux « littérature » et « physique nucléaire » il n’y avait pas un seul ami en commun, ses membres ne pourraient en théorie jamais se contacter entre eux.
En réalité, d’après la loi des grands nombres, il est assez rare que des instances d’une certaine taille n’entrent jamais en contact les unes avec les autres, mais l’exemple sert à comprendre les mécanismes sur lesquels repose un réseau fédéré (ce qui, en se basant justement sur la loi des grands nombres et les principes des degrés de séparation, confirme au contraire l’hypothèse que plus le réseau est grand, moins les utilisateurs et instances seront isolés sur une seule instance).
3. Chaque instance peut décider volontairement de ne pas entrer en contact avec une autre, sur la base des choix, des règles et politiques internes qui lui sont propres. Ce point est évidemment peu compris des différents commentateurs qui ne parviennent pas à sortir de l’idée du « réseau social monolithique ». S’il y avait sur Mastodon une forte concentration de suprémacistes blancs en deuil de Gab, ou de blogueurs porno en deuil de Tumblr, cela ne signifie pas que ce serait l’ensemble du réseau social appelé Mastodon qui deviendrait un « réseau social pour suprémacistes blancs et porno », mais seulement quelques instances qui n’entreraient probablement jamais en contact avec des instances antifascistes ou ultra-religieuses. Comme il est difficile de faire comprendre un tel concept, il est également difficile de faire comprendre les potentialités d’une structure de ce type. Dans un réseau fédéré, une fois donnée la possibilité technique d’interagir entre instances et utilisateurs, chaque instance et chaque utilisateur peut ensuite choisir de façon indépendante l’utilisation qui en sera faite.
Supposons qu’il existe par exemple :
Une instance écologiste, créée, maintenue et soutenue financièrement par un groupe de passionnés qui veulent avoir un lieu où échanger sur la nature et l’écologie, qui pose comme principe qu’on n’y poste ni liens externes ni images pornographiques.
Une instance commerciale, créée par une petite entreprise qui dispose d’un bon serveur et d’une bande passante très confortable, et celui ou celle qui s’y inscrit en payant respecte les règles fixées auparavant par l’entreprise elle-même.
Une instance sociale, créée par un centre social et dont les utilisateurs sont surtout les personnes qui fréquentent ledit centre et se connaissent aussi personnellement.
Une instance vidéoludique, qui était à l’origine une instance interne des employés d’une entreprise de technologie mais qui dans les faits est ouverte à quiconque s’intéresse aux jeux vidéos.
Avec ce scénario à quatre instances, on peut déjà décrire quelques interactions intéressantes : l’instance écologiste pourrait consulter ses utilisateurs et utilisatrices et décider de bannir l’instance commerciale au motif qu’on y diffuse largement une culture contraire à l’écologie, tandis que l’instance sociale pourrait au contraire maintenir le lien avec l’instance commerciale tout en choisissant préventivement de la rendre muette dans son propre fil, laissant le choix personnel à ses membres d’entrer ou non en contact avec les membres de l’instance commerciale. Cependant, l’instance sociale pourrait bannir l’instance de jeu vidéo à cause de la mentalité réactionnaire d’une grande partie de ses membres.
En somme, les contacts « insupportables/inacceptables » sont spontanément limités par les instances sur la base de leurs différentes politiques. Ici, le cadre d’ensemble commence à devenir très complexe, mais il suffit de l’observer depuis une seule instance, la nôtre, pour en comprendre les avantages : les instances qui accueillent des trolls, des agitateurs et des gens avec qui on n’arrive vraiment pas à discuter, nous les avons bannies, alors que celles avec lesquelles on n’avait pas beaucoup d’affinités mais pas non plus de motif de haine, nous les avons rendues muettes. Ainsi, si quelqu’un parmi nous veut les suivre, il n’y a pas de problème, mais ce sera son choix personnel.
4. Chaque utilisateur peut décider de rendre muets d’autres utilisateurs, mais aussi des instances entières. Si vous voulez particulièrement éviter les contenus diffusés par les utilisateurs et utilisatrices d’une certaine instance qui n’est cependant pas bannie par l’instance qui vous accueille (mettons que votre instance ne ferme pas la porte à une instance appelée meme.videogamez.lulz, dont la communauté tolère des comportements excessifs et une ambiance de moquerie lourde que certains trouvent néanmoins amusante), vous êtes libres de la rendre muette pour vous seulement. En principe, en présence de groupes d’utilisateurs indésirables venant d’une même instance/communauté, il est possible de bloquer plusieurs dizaines ou centaines d’utilisateurs à la fois en bloquant (pour vous) l’instance entière. Si votre instance n’avait pas un accord unanime sur la manière de traiter une autre instance, vous pourriez facilement laisser le choix aux abonnés qui disposent encore de ce puissant outil. Une instance peut également choisir de modérer seulement ses utilisateurs ou de ne rien modérer du tout, laissant chaque utilisateur complètement libre de faire taire ou d’interdire qui il veut sans jamais interférer ou imposer sa propre éthique.
La Fediverse
logo de la Fediverse
Maintenant que nous nous sommes mieux concentrés sur ces aspects, nous pouvons passer à l’étape suivante. Comme déjà mentionné dans le post précédent, Mastodon fait partie de quelque chose de plus vaste appelé la Fediverse (Fédération + Univers).
En gros, Mastodon est un réseau fédéré qui utilise certains outils de communication (il existe plusieurs protocoles mais les principaux sont ActivityPub, Ostatus et Diaspora*, chacun ayant ses avantages, ses inconvénients, ses partisans et ses détracteurs), utilisés aussi par et d’autres réalités fédérées (réseaux sociaux, plateformes de blogs, etc.) qui les mettent en contact pour former une galaxie unique de réseaux fédérés.
Pour vous donner une idée, c’est comme si Mastodon était un système planétaire qui tourne autour d’une étoile (Mastodon est l’étoile et chaque instance est une planète), cependant ce système planétaire fait partie d’un univers dans lequel existent de nombreux systèmes planétaires tous différents mais qui communiquent les uns avec les autres.
Toutes les planètes d’un système planétaire donné (les instances, comme des « clubs ») tournent autour d’un soleil commun (la plate-forme logicielle). L’utilisateur peut choisir la planète qu’il préfère mais il ne peut pas se poser sur le soleil : on ne s’inscrit pas à la plateforme, mais on s’inscrit à l’un des clubs qui, avec tous les autres, forme le réseau.
Dans cet univers, Mastodon est tout simplement le « système planétaire » le plus grand (celui qui a le plus de succès et qui compte le plus grand nombre d’utilisateurs) mais il n’est pas certain qu’il en sera toujours ainsi : d’autres « systèmes planétaires » se renforcent et grandissent.
[NB : chaque plate-forme évoquée ici utilise ses propres noms pour définir les serveurs indépendants sur lesquels elle est hébergée. Mastodon les appelle instances, Hubzilla les appelle hubs et Diaspora* les appelle pods. Toutefois, par souci de simplicité et de cohérence avec l’article précédent, seul le terme « instance » sera utilisé pour tous dans l’article]
La structure d’ensemble de la Fediverse
Les interactions de Mastodon avec les autres médias
Sur Kumu.io on peut trouver une représentation interactive de la Fediverse telle qu’elle apparaît actuellement. Chaque « nœud » représente un réseau différent (ou « système planétaire »). Ce sont les différentes plateformes qui composent la fédération. Mastodon n’est que l’une d’entre elles, la plus grande, en bas au fond. Sur la capture d’écran qui illustre l’article, Mastodon est en bas.
En sélectionnant Mastodon il est possible de voir avec quels autres médias ou systèmes de la Fediverse il est en mesure d’interagir. Comme on peut le voir, il interagit avec la plupart des autres médias mais pas tout à fait avec tous.
Les interactions de Gnu social avec les autres médias
En sélectionnant un autre réseau social comme GNU Social, on observe qu’il a différentes interactions : il en partage la majeure partie avec Mastodon mais il en a quelques-unes en plus et d’autres en moins.
Cela dépend principalement du type d’outils de communication (protocoles) que chaque média particulier utilise. Un média peut également utiliser plus d’un protocole pour avoir le plus grand nombre d’interactions, mais cela rend évidemment leur gestion plus complexe. C’est, par exemple, la voie choisie par Friendica et GNU Social.
En raison des différents protocoles utilisés, certains médias ne peuvent donc pas interagir avec tous les autres. Le cas le plus important est celui de Diaspora*, qui utilise son propre protocole (appelé lui aussi Diaspora), qui ne peut interagir qu’avec Friendica et Gnu Social mais pas avec des médias qui reposent sur ActivityPub tels que Mastodon.
Au sein de la Fediverse, les choses sont cependant en constante évolution et l’image qui vient d’être montrée pourrait avoir besoin d’être mise à jour prochainement. En ce moment, la plupart des réseaux semblent s’orienter vers l’adoption d’ActivityPub comme outil unique. Ce ne serait pas mal du tout d’avoir un seul protocole de communication qui permette vraiment tout type de connexion !
Mais revenons un instant à l’image des systèmes planétaires. Kumu.io montre les connexions techniquement possibles entre tous les « systèmes planétaires » et, pour ce faire, relie génériquement les différents soleils. Mais comme nous l’avons bien vu, les vraies connexions ont lieu entre les planètes et non entre les soleils ! Une carte des étoiles montrant les connexions réelles devrait montrer pour chaque planète (c’est-à-dire chaque « moustache » des nœuds de Kum.io), des dizaines ou des centaines de lignes de connexion avec autant de planètes/moustaches, à la fois entre instances de sa plateforme et entre instances de différentes plateformes ! La quantité et la complexité des connexions, comme on peut l’imaginer, formeraient un enchevêtrement qui donnerait mal à la tête serait graphiquement illisible. Le simple fait de l’imaginer donne une idée de la quantité et de la complexité des connexions possibles.
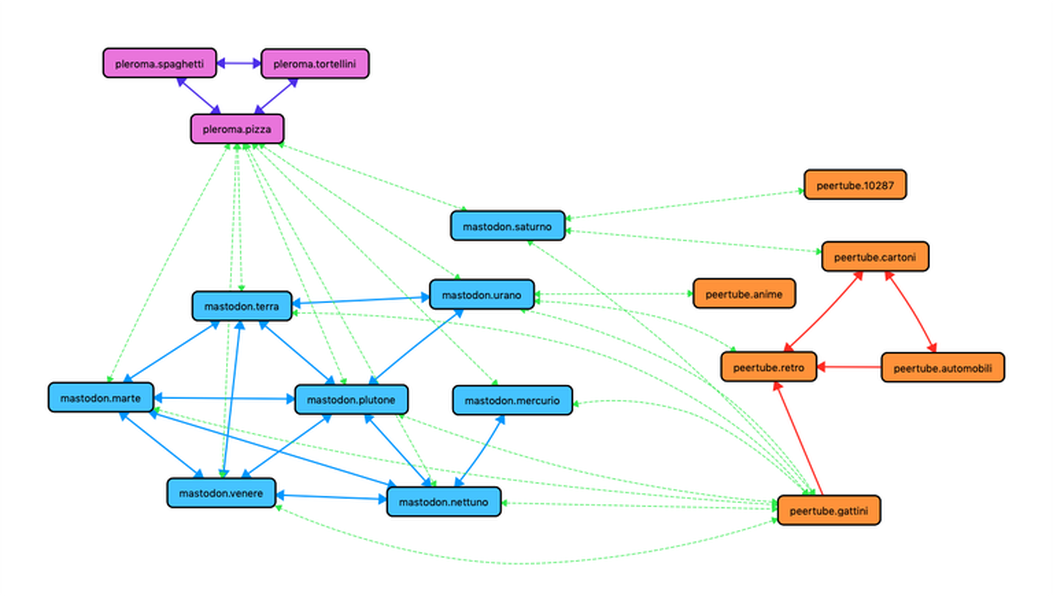
Et cela ne s’arrête pas là : chaque planète peut établir ou interrompre ses contacts avec les autres planètes de son système solaire (c’est-à-dire que l’instance Mastodon A peut décider de ne pas avoir de contact avec l’instance Mastodon B), et de la même manière elle peut établir ou interrompre les contacts avec des planètes de différents systèmes solaires (l’instance Mastodon A peut établir ou interrompre des contacts avec l’instance Pleroma B). Pour donner un exemple radical, nous pouvons supposer que nous avons des cousins qui sont des crétins, mais d’authentiques crétins, que nous avons chassés de notre planète (mastodon.terre) et qu’ensuite ils ont construit leur propre instance (mastodon.saturne) dans notre voisinage parce que ben, ils aiment bien notre soleil « Mastodon ». Nous décidons de nous ignorer les uns les autres tout de suite. Ces cousins, cependant, sont tellement crétins que même nos parents et amis proches des planètes voisines (mastodon.jupiter, mastodon.venus, etc.) ignorent les cousins crétins de mastodon.saturne.
Aucune planète du système Mastodon ne les supporte. Les cousins, cependant, ne sont pas entièrement sans relations et, au contraire, ils ont beaucoup de contacts avec les planètes d’autres systèmes solaires. Par exemple, ils sont en contact avec certaines planètes du système planétaire PeeeTube: peertube.10287, peertube.chatons, peertube.anime, mais aussi avec pleroma.pizza du système Pleroma et friendica.jardinage du système Friendica. En fait, les cousins crétins sont d’accord pour vivre sur leur propre petite planète dans le système Mastodon, mais préfèrent avoir des contacts avec des planètes de systèmes différents.
Nous qui sommes sur mastodon.terre, nous ne nous soucions pas moins des planètes qui leur sont complaisantes : ce sont des crétins tout autant que nos cousins et nous les avons bloquées aussi. Sauf un. Sur pleroma.pizza, nous avons quelques ami⋅e⋅s qui sont aussi des ami⋅e⋅s de certains cousins crétins de mastodon.saturne. Mais ce n’est pas un problème. Oh que non ! Nous avons des connexions interstellaires et nous devrions nous inquiéter d’une chose pareille ? Pas du tout ! Le blocage que nous avons activé sur mastodon.saturne est une sorte de barrière énergétique qui fonctionne dans tout le cosmos ! Si nous étions impliqués dans une conversation entre un ami de pleroma.pizza et un cousin de mastodon.saturne, simplement, ce dernier ne verrait pas ce qui sort de notre clavier et nous ne verrions pas ce qui sort du sien. Chacun d’eux saura que l’autre est là, mais aucun d’eux ne pourra jamais lire l’autre. Bien sûr, nous pourrions déduire quelque chose de ce que notre ami commun de pleroma.pizza dira, mais bon, qu’est-ce qu’on peut en espérer ? 😉
Cette image peut donner une idée de la façon dont les instances (planètes) se connectent entre elles. Si l’on considère qu’il existe des milliers d’instances connues de la Fediverse, on peut imaginer la complexité de l’image. Un aspect intéressant est le fait que les connexions entre une instance et une autre ne dépendent pas de la plateforme utilisée. Sur l’image on peut voir l’instance mastodon.mercure : c’est une instance assez isolée par rapport au réseau d’instances Mastodon, dont les seuls contacts sont mastodon.neptune, peertube.chatons et pleroma.pizza. Rien n’empêche mastodon.mercure de prendre connaissance de toutes les autres instances de Mastodon non par des échanges de messages avec mastodon.neptune, mais par des commentaires sur les vidéos de peertube.chatons. En fait, c’est d’autant plus probable que mastodon.neptune n’est en contact qu’avec trois autres instances Mastodon, alors que peertube.chatons est en contact avec toutes les instances Mastodon.
Essayer d’imaginer comment les différentes instances de cette image qui « ne se connaissent pas » peuvent entrer en contact nous permet d’avoir une idée plus précise du niveau de complexité qui peut être atteint. Dans un système assez grand, avec un grand nombre d’utilisateurs et d’instances, isoler une partie de celui-ci ne compromettra en aucune façon la richesse des connexions possibles.
Une fois toutes les connexions possibles créées, il est également possible de réaliser une expérience différente, c’est-à-dire d’imaginer interrompre des connexions jusqu’à la formation de deux ou plusieurs réseaux parfaitement séparés, contenant chacune des instances Mastodon, Pleroma et Peertube.
Et pour ajouter encore un degré de complexité, on peut faire encore une autre expérience, en raisonnant non plus à l’échelle des instances mais à celle des utilisateurs⋅rices individuel⋅le⋅s des instances (faire l’hypothèse de cinq utilisateurs⋅rices par instance pourrait suffire pour recréer les différentes situations). Quelques cas qu’on peut imaginer :
1) Nous sommes sur une instance de Mastodon et l’utilisatrice Anna vient de découvrir par le commentaire d’une vidéo sur Peertube l’existence d’une nouvelle instance de Pleroma, donc maintenant elle connaît son existence mais, choisissant de ne pas la suivre, elle ne fait pas réellement connaître sa découverte aux autres membres de son instance.
2) Sur cette même instance de Mastodon l’utilisateur Ludo bloque la seule instance Pleroma connue. Conséquence : si cette instance Pleroma devait faire connaître d’autres instances Pleroma avec lesquelles elle est en contact, Ludo devrait attendre qu’un autre membre de son instance les fasse connaître, car il s’est empêché lui-même d’être parmi les premiers de son instance à les connaître.
3) En fait, la première utilisatrice de l’instance à entrer en contact avec les autres instances Pleroma sera Marianne. Mais elle ne les connaît pas de l’instance Pleroma (celle que Ludo a bloquée) avec laquelle ils sont déjà en contact, mais par son seul contact sur GNU Social.
Cela semble un peu compliqué mais en réalité ce n’est rien de plus qu’une réplique de mécanismes humains auxquels nous sommes tellement habitué⋅e⋅s que nous les tenons pour acquis. On peut traduire ainsi les différents exemples qui viennent d’être exposés :
1) Notre amie Anna, habituée de notre bar, rencontre dans la rue une personne qui lui dit fréquenter un nouveau bar dans une ville proche. Mais Anna n’échange pas son numéro de téléphone avec le type et elle ne pourra donc pas donner d’informations à ses amis dans son bar sur le nouveau bar de l’autre ville.
2) Dans le bar habituel, Ludo de Nancy évite Laura de Metz. Quand Laura amène ses autres amies Solène et Louise de Metz au bar, elle ne les présente pas à Ludo. Ce n’est que plus tard que les amis du bar, devenus amis avec Solène et Louise, pourront les présenter à Ludo indépendamment de Laura.
3) En réalité Marianne avait déjà rencontré Solène et Louise, non pas grâce à Laura, mais grâce à Stéphane, son seul ami à Villers.
Pour avoir une idée de l’ampleur de la Fediverse, vous pouvez jeter un coup d’œil à plusieurs sites qui tentent d’en fournir une image complète. Outre Kumu.io déjà mentionné, qui essaie de la représenter avec une mise en page graphique élégante qui met en évidence les interactions, il y a aussi Fediverse.network qui essaie de lister chaque instance existante en indiquant pour chacune d’elles les protocoles utilisés et le statut du service, ou Fediverse.party, qui est un véritable portail où choisir la plate-forme à utiliser et à laquelle s’enregistrer. Switching.software, une page qui illustre toutes les alternatives gratuites aux médias sociaux et propriétaires, indique également quelques réseaux fédérés parmi les alternatives à Twitter et Facebook.
Pour être tout à fait complet : au début, on avait tendance à diviser tout ce mégaréseau en trois « univers » superposés : celui de la « Fédération » pour les réseaux reposant sur le protocole Diaspora, La « Fediverse » pour ceux qui utilisent Ostatus et « ActivityPub » pour ceux qui utilisent… ActivityPub. Aujourd’hui, au contraire, ils sont tous considérés comme faisant partie de la Fediverse, même si parfois on l’appelle aussi la Fédération.
Tant de réseaux…
Examinons donc les principales plateformes/réseaux et leurs différences. Petites précisions : certaines de ces plateformes sont pleinement actives alors que d’autres sont à un stade de développement plus ou moins avancé. Dans certains cas, l’interaction entre les différents réseaux n’est donc pas encore pleinement fonctionnelle. De plus, en raison de la nature libre et indépendante des différents réseaux, il est possible que des instances apportent des modifications et des personnalisations « non standard » (un exemple en est la limite de caractères sur Mastodon : elle est de 500 caractères par défaut, mais une instance peut décider de définir la limite qu’elle veut ; un autre exemple est l’utilisation des fonctions de mise en favori ou de partage, qu’une instance peut autoriser et une autre interdire). Dans ce paragraphe, ces personnalisations et différences ne sont pas prises en compte.
Mastodon (semblable à : Twitter)
Copie d’écran, une instance de Mastodon, Framapiaf
Mastodon est une plateforme de microblogage assez semblable à Twitter parce qu’elle repose sur l’échange de messages très courts. C’est le réseau le plus célèbre de la Fediverse. Il est accessible sur smartphone à travers un certain nombre d’applications tant pour Android que pour iOS. Un de ses points forts est le design bien conçu et le fait qu’il a déjà un « parc d’utilisateurs⋅rices » assez conséquent (presque deux millions d’utilisateurs⋅rices dans le monde, dont quelques milliers en France). En version bureau, il se présente comme une série de colonnes personnalisables, qui montrent les différents « fils », sur le modèle de Tweetdeck. Pour le moment, Mastodon est la seule plateforme sociale fédérée accessible par des applications sur Android et iOS.
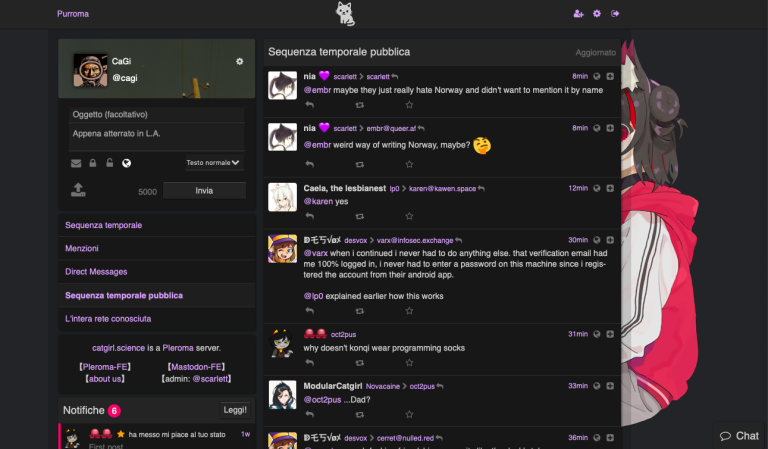
Pleroma (semblable à : Twitter et DeviantArt)
Copie d’écran, Pleroma
Pleroma est le réseau « sœur » de Mastodon : fondamentalement, c’est la même chose dans deux versions un peu différentes. Pleroma offre quelques fonctionnalités supplémentaires concernant la gestion des images et permet par défaut des messages plus longs. À la différence de Mastodon, Pleroma montre en version bureau une colonne unique avec le fil sélectionné, ce qui le rend beaucoup plus proche de Twitter. Actuellement, de nombreuses instances Pleroma ont un grand nombre d’utilisateurs⋅rices qui s’intéressent à l’illustration et au manga, ce qui, comme ambiance, peut vaguement rappeler l’ambiance de DeviantArt. Les applications pour smartphone de Mastodon peuvent également être utilisées pour accéder à Pleroma.
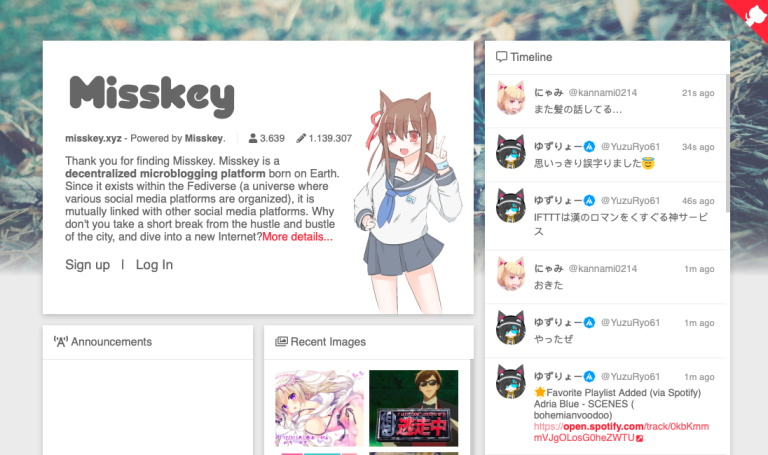
Misskey (semblable à : un mélange entre Twitter et DeviantArt)
Copie d’écran, Misskey
Misskey est une sorte de Twitter qui tourne principalement autour d’images. Il offre un niveau de personnalisation supérieur à Mastodon et Pleroma, et une plus grande attention aux galeries d’images. C’est une plateforme qui a eu du succès au Japon et parmi les passionnés de manga (et ça se voit !).
Friendica (semblable à : Facebook)
Friendica est un réseau extrêmement intéressant. Il reprend globalement la structure graphique de Facebook (avec les ami⋅e⋅s, les notifications, etc.), mais il permet également d’interagir avec plusieurs réseaux commerciaux qui ne font pas partie de la Fediverse. Il est donc possible de connecter son compte Friendica à Facebook, Twitter, Tumblr, WordPress, ainsi que de générer des flux RSS, etc. Bref, Friendica se présente comme une sorte de nœud pour diffuser du contenu sur tous les réseaux disponibles, qu’ils soient fédérés ou non. En somme, Friendica est le passe-partout de la Fediverse : une instance Friendica au maximum de ses fonctions se connecte à tout et dialogue avec tout le monde.
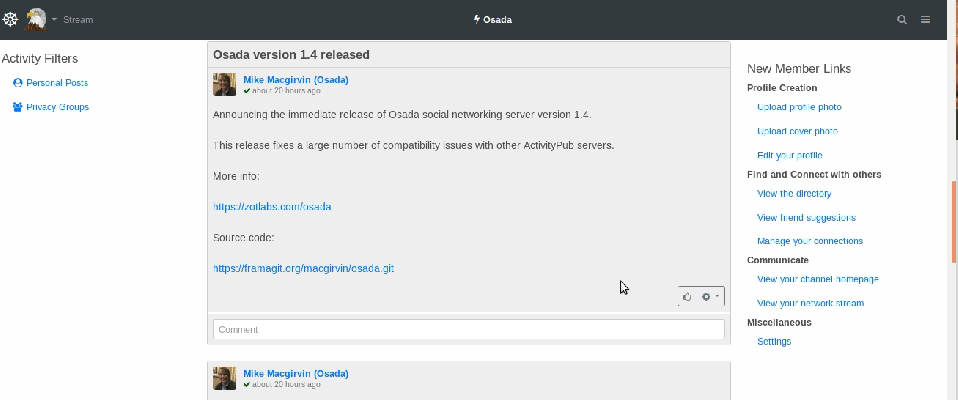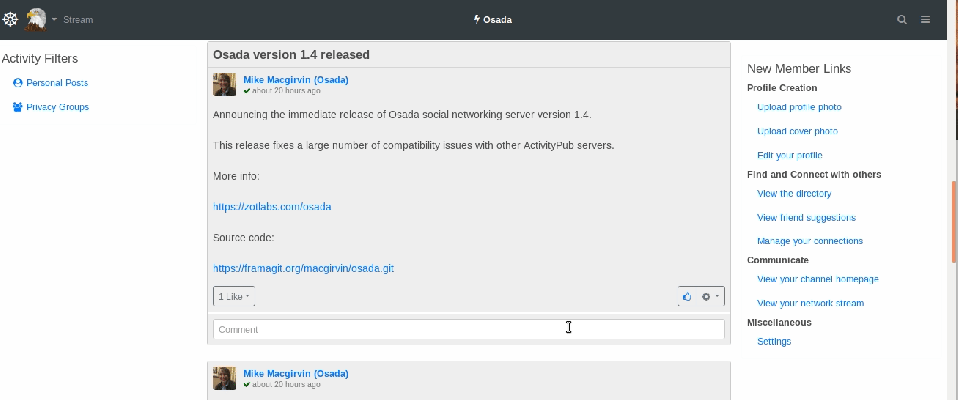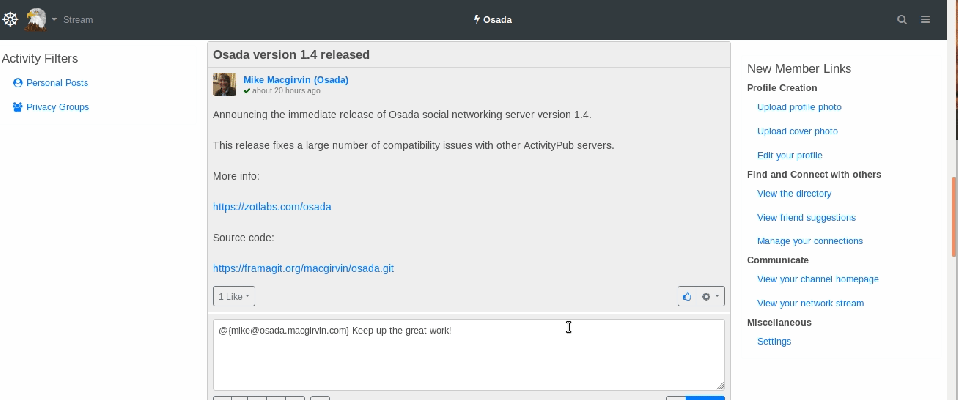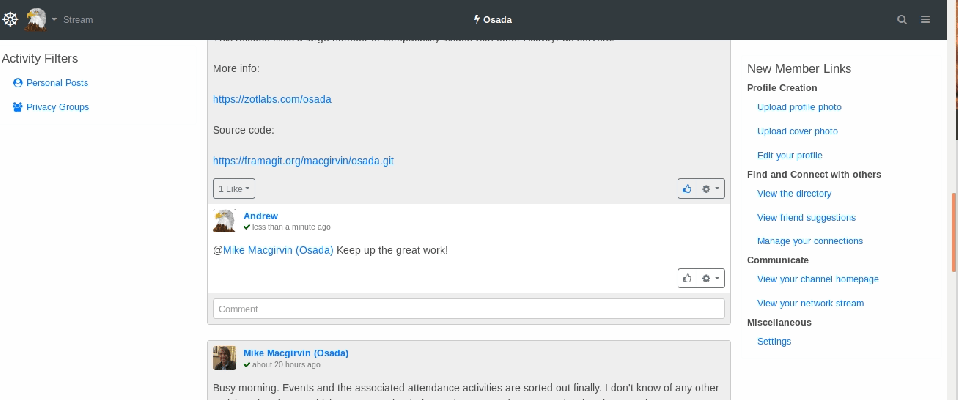
Osada (semblable à : un mélange entre Twitter et Facebook)
Image animée, réponse à un commentaire sur Osada
Osada est un autre réseau dont la configuration peut faire penser à un compromis entre Twitter et Facebook. De toutes les plateformes qui rappellent Facebook, c’est celle dont le design est le plus soigné.
GNUsocial (semblable à : un mélange entre Twitter et Facebook)
Copie d’écran : GNUsocial avec une interface en suédois.
GNUsocial est un peu le « grand-père » des médias sociaux listés ici, en particulier de Friendica et d’Osada, dont il est le prédécesseur.
Aardwolf (semblable à : Twitter, éventuellement)
Copie d’écran : logo et slogan d’Aardwolf
Aardwolf n’est pas encore prêt, mais il est annoncé comme une sorte d’alternative à Twitter. On attend de voir.
PeerTube (semblable à : YouTube)
Capture d’écran, une instance de PeerTube, aperi.tube
PeerTube est le réseau fédéré d’hébergement de vidéo vraiment, mais vraiment très semblable à YouTube, Vimeo et d’autres services de ce genre. Avec un catalogue en cours de construction, Peertube apparaît déjà comme un projet très solide.
Pixelfed (semblable à : Instagram)
Copie d’écran, Pixelfed
Pixelfed est essentiellement l’Instagram de la Fédération. Il est en phase de développement mais semble être plutôt avancé. Il lui manque seulement des applications pour smartphone pour être adopté à la place d’Instagram. Pixelfed a le potentiel pour devenir un membre extrêmement important de la Fédération !
NextCloud (semblable à : iCloud, Dropbox, GDrive)
Logo de Owncloud
NextCloud, né du projet plus ancien ownCloud, est un service d’hébergement de fichiers assez semblable à Dropbox. Tout le monde peut faire tourner NextCloud sur son propre serveur. NextCloud offre également des services de partage de contacts (CardDAV) ou de calendriers (CalDAV), de streaming de médias, de marque-page, de sauvegarde, et d’autres encore. Il tourne aussi sur Window et OSX et est accessible sur smartphone à travers des applications officielles. Il fait partie de la Fediverse dans la mesure où il utilise ActivityPub pour communiquer différentes informations à ses utilisateurs, comme des changements dans les fichiers, les activités du calendrier, etc.
Diaspora* (semblable à : Facebook, et aussi un peu Tumblr)
Copie d’écran, un « pod » de Diaspora*, Framasphere
Diaspora* est un peu le « cousin » de la Fediverse. Il fonctionne avec un protocole bien à lui et dialogue avec le reste de la Fediverse principalement via GNU social et Friendica, le réseau passe-partout, même s’il semble qu’il circule l’idée de faire utiliser à Diaspora* (l’application) aussi bien son propre protocole qu’ActivityPub. Il s’agit d’un grand et beau projet, avec une base solide d’utilisateurs⋅rices fidèles. Au premier abord, il peut faire penser à une version extrêmement minimaliste de Facebook, mais son attention aux images et son système intéressant d’organisation des posts par tag permet également de le comparer, d’une certaine façon, à Tumblr.
Funkwhale (semblable à : SoundCloud et Grooveshark)
Copie d’écran, Funkwhale
Funkwhale ressemble à SoundCloud, Grooveshark et d’autre services semblables. Comme une sorte de YouTube pour l’audio, il permet de partager des pistes audio mais au sein d’un réseau fédéré. Avec quelques fonctionnalités en plus, il pourrait devenir un excellent service d’hébergement de podcasts audio.
Plume, Write Freely et Write.as (plateformes de blog)
Copie d’écran, Write freely
Plume, Write Freely et Write.as sont des plateformes de blog assez minimalistes qui font partie de la Fédération. Elles n’ont pas toute la richesse, les fonctions, les thèmes et la personnalisation de WordPress ou de Blogger, mais elles font leur travail avec légèreté.
Hubzilla (semblable à : …TOUT !!)
Page d’accueil de Hubzilla
Hubzilla est un projet très riche et complexe qui permet de gérer aussi bien des médias sociaux que de l’hébergement de fichiers, des calendriers partagés, de l’hébergement web, et le tout de manière décentralisée. En bref, Hubzilla se propose de faire tout à la fois ce que font plusieurs des services listés ici. C’est comme avoir une seule instance qui fait à la fois Friendica, Peertube et NextCloud. Pas mal ! Un projet à surveiller !
GetTogether (semblable à : MeetUp)
Copie d’écran, GetTogether
GetTogether est une plateforme servant à planifier des événements. Semblable à MeetUp, elle sert à mettre en relation des personnes différentes unies par un intérêt commun, et à amener cet intérêt dans le monde réel. Pour le moment, GetTogether ne fait pas encore partie de la Fediverse, mais il est en train de mettre en place ActivityPub et sera donc bientôt des nôtres.
Mobilizon (semblable à : MeetUp)
Mobilizon est une nouvelle plateforme en cours de développement, qui se propose comme une alternative libre à MeetUp et à d’autres logiciels servant à organiser des réunions et des rencontres en tout genre. Dès le départ, le projet naît avec l’intention d’utiliser ActivityPub et de faire partie de la Fediverse, en conformité avec les valeurs de Framasoft, association française née avec l’objectif de diffuser l’usage des logiciels libres et des réseaux décentralisés. Voir la présentation de Mobilizon en italien.
Prismo est une application encore en phase de développement, qui se propose de devenir un sorte de version décentralisée de Reddit, c’est-à-dire un média social centré sur le partage de liens, mais qui pourrait potentiellement évoluer en quelque chose qui ressemble à Pocket ou Evernote. Les fonctions de base sont déjà opérationnelles.
Socialhome
Capture d’écran, Socialhome
Socialhome est un média social qui utilise une interface par « blocs », affichant les messages comme dans un collage de photos de Pinterest. Pour le moment, il communique seulement via le protocole de Diaspora, mais il devrait bientôt mettre en place ActivityPub.
Et ce n’est pas tout !
Les recommandations du W3C pour ActivityPub, page d’accueil
Il existe encore d’autres applications et médias sociaux qui adoptent ou vont adopter ActivityPub, ce qui rendra la Fediverse encore plus structurée. Certains sont assez semblables à ceux déjà évoqués, alors que d’autres sont encore en phase de développement, on ne peut donc pas encore les conseiller pour remplacer des systèmes commerciaux plus connus. Il y a cependant des plateformes déjà prêtes et fonctionnelles qui pourraient entrer dans la Fediverse en adoptant ActivityPub : NextCloud en est un exemple (il était déjà constitué quand il a décidé d’entrer dans la Fediverse) ; le plugin de WordPress est pour sa part un outil qui permet de fédérer une plateforme qui existe déjà ; GetTogether est un autre service qui est en train d’être fédéré. Des plateformes déjà en place (je pense à Gitter, mais c’est juste un exemple parmi tant d’autres) pourraient trouver un avantage à se fédérer et à entrer dans une grande famille élargie. Bref : ça bouge dans la Fediverse et autour d’elle !
… un seul Grand Réseau !
Jusqu’ici, nous avons vu de nombreuses versions alternatives d’outils connus qui peuvent aussi être intéressant pris individuellement, mais qui sont encore meilleurs quand ils collaborent. Voici maintenant le plus beau : le fait qu’ils partagent les mêmes protocoles de communication élimine l’effet « cage dorée » de chaque réseau !
Maintenant qu’on a décrit chaque plateforme, on peut donner quelques exemples concrets :
Je suis sur Mastodon, où apparaît le message d’une personne que je « suis ». Rien d’étrange à cela, si ce n’est que cette personne n’est pas utilisatrice de Mastodon, mais de Peertube ! En effet, il s’agit de la vidéo d’un panorama. Toujours depuis Mastodon, je commente en écrivant « joli » et cette personne verra apparaître mon commentaire sous sa vidéo, sur Peertube.
Je suis sur Osada et je poste une réflexion ouverte un peu longue. Cette réflexion est lue par une de mes amies sur Friendica, qui la partage avec ses followers, dont certains sont sur Friendica, mais d’autres sont sur d’autres plateformes. Par exemple, l’un d’eux est sur Pleroma, il me répond et nous commençons à dialoguer.
Je publie une photo sur Pixelfed qui est vue et commentée par un de mes abonnés sur Mastodon.
En somme, chacun peut garder contact avec ses ami⋅e⋅s/abonné⋅e⋅s depuis son réseau préféré, mêmes si ces personnes en fréquentent d’autres.
Pour établir une comparaison avec les réseaux commerciaux, c’est comme si l’on pouvait recevoir sur Facebook les tweets d’un ami qui est sur Twitter, les images postées par quelqu’un d’autre sur Instagram, les vidéos d’une chaîne YouTube, les pistes audio sur SoundCloud, les nouveaux posts de divers blogs et sites personnels, et commenter et interagir avec chacun d’eux parce que tous ces réseaux collaborent et forment un seul grand réseau !
Chacun de ces réseaux pourra choisir la façon dont il veut gérer ces interactions : par exemple, si je voulais une vie sociale dans un seul sens, je pourrais choisir une instance Pixelfed où les autres utilisateurs⋅rices peuvent me contacter seulement en commentant les photos que je publie, ou bien je pourrais choisir une instance Peertube et publier des vidéos qui ne pourraient pas être commentées mais qui pourraient tourner dans toute la Fediverse, ou choisir une instance Mastodon qui oblige mes interlocuteurs à communiquer avec moi de manière concise.
Certains détails sont encore à définir (par exemple : je pourrais envoyer un message direct depuis Mastodon vers une plateforme qui ne permet pas à ses utilisateurs⋅rices de recevoir des messages directs, sans jamais être averti du fait que le/la destinataire n’aura aucun moyen de savoir que je lui ai envoyé quelque chose). Il s’agit de situations bien compréhensibles à l’intérieur d’un écosystème qui doit s’adapter à des réalités très diverses, mais dans la majorité des cas il s’agit de détails faciles à gérer. Ce qui compte, c’est que les possibilités d’interactions sont potentiellement infinies !
Connectivité totale, exposition dosée
Toute cette connectivité partagée doit être observée en gardant à l’esprit que, même si par simplicité les différents réseaux ont été traités ici comme des réseaux centralisés, ce sont en réalité des réseaux d’instances indépendantes qui interagissent directement avec les instances des autres réseaux : mon instance Mastodon filtrera les instances Peertube qui postent des vidéos racistes mais se connectera à toutes les instances Peertube qui respectent sa politique ; si je suis un certain ami sur Pixelfed je verrai seulement ses posts, sans que personne m’oblige à voir toutes les photos de couchers de soleil et de chatons de ses ami⋅e⋅s sur ce réseau.
La combinaison entre autonomie des instances, grande interopérabilité entre celles-ci et liberté de choix permet une série de combinaisons extrêmement intéressantes dont les réseaux commerciaux ne peuvent même pas rêver : ici, l’utilisateur⋅rice est membre d’un seul grand réseau où chacun⋅e peut choisir :
Son outil d’accès préféré (Mastodon, Pleroma, Friendica) ;
La communauté dans laquelle il ou elle se sent le plus à l’aise (l’instance) ;
La fermeture aux communautés indésirables et l’ouverture aux communautés qui l’intéressent.
Tout cela sans pour autant renoncer à être connecté à des utilisateurs⋅rices qui ont choisi des outils et des communautés différents. Par exemple, je peux choisir une certaine instance Pleroma parce que j’aime son design, la communauté qu’elle accueille, ses règles et la sécurité qu’elle procure mais, à partir de là, suivre et interagir principalement avec des utilisateurs⋅rices d’une instance Pixelfed particulière et en importer les contenus et l’esthétique dans mon instance.
À cela on peut ajouter que des instances individuelles peuvent littéralement être installées et administrées par chaque utilisateur individuel sur ses propres machines, ce qui permet un contrôle total du contenu. Les instances minuscules auto-hébergées « à la maison » et les instances de travail plus robustes, les instances scolaires et les instances collectives, les instances avec des milliers d’utilisateurs et les instances avec un seul utilisateur, les instances à l’échelle d’un quartier ou d’un immeuble, toutes sont unies pour former un réseau complexe et personnalisable, qui vous permet de vous connecter pratiquement à n’importe qui mais aussi de vous éviter la surcharge d’information.
C’est une sorte de retour aux origines d’Internet, mais un retour à un âge de maturité, celui du Web 2.0, qui a tiré les leçons de l’expérience : être passé par la centralisation de la communication entre les mains de quelques grands acteurs internationaux a renforcé la conviction que la structure décentralisée est la plus humaine et la plus enrichissante.
Rejoignez la fédération !
Nous devons nous passer de Chrome
Chrome, de navigateur internet novateur et ouvert, est devenu au fil des années un rouage essentiel de la domination d’Internet par Google. Cet article détaille les raisons pour lesquelles Chrome asphyxie le Web ouvert et pourquoi il faudrait passer sur un autre navigateur tel Vivaldi ou Firefox.
Il y a dix ans, nous avons eu besoin de Google Chrome pour libérer le Web de l’hégémonie des entreprises, et nous avons réussi à le faire pendant une courte période. Aujourd’hui, sa domination étouffe la plateforme même qu’il a autrefois sauvée des griffes de Microsoft. Et personne, à part Google, n’a besoin de ça.
Nous sommes en 2008. Microsoft a toujours une ferme emprise sur le marché des navigateurs web. Six années se sont écoulées depuis que Mozilla a sorti Firefox, un concurrent direct d’Internet Explorer. Google, l’entreprise derrière le moteur de recherche que tout le monde aimait à ce moment-là, vient d’annoncer qu’il entre dans la danse. Chrome était né.
Au bout de deux ans, Chrome représentait 15 % de l’ensemble du trafic web sur les ordinateurs fixes — pour comparer, il a fallu 6 ans à Firefox pour atteindre ce niveau. Google a réussi à fournir un navigateur rapide et judicieusement conçu qui a connu un succès immédiat parmi les utilisateurs et les développeurs Web. Les innovations et les prouesses d’ingénierie de leur produit étaient une bouffée d’air frais, et leur dévouement à l’open source la cerise sur le gâteau. Au fil des ans, Google a continué à montrer l’exemple en adoptant les standards du Web.
Avançons d’une décennie. Le paysage des navigateurs Web est très différent. Chrome est le navigateur le plus répandu de la planète, faisant de facto de Google le gardien du Web, à la fois sur mobile et sur ordinateur fixe, partout sauf dans une poignée de régions du monde. Le navigateur est préinstallé sur la plupart des téléphones Android vendus hors de Chine, et sert d’interface utilisateur pour Chrome OS, l’incursion de Google dans les systèmes d’exploitation pour ordinateurs fixe et tablettes. Ce qui a commencé comme un navigateur d’avant-garde respectant les standards est maintenant une plateforme tentaculaire qui n’épargne aucun domaine de l’informatique moderne.
Bien que le navigateur Chrome ne soit pas lui-même open source, la plupart de ses composantes internes le sont. Chromium, la portion non-propriétaire de Chrome, a été rendue open source très tôt, avec une licence laissant de larges marges de manœuvre, en signe de dévouement à la communauté du Web ouvert. En tant que navigateur riche en fonctionnalités, Chromium est devenu très populaire auprès des utilisateurs de Linux. En tant que projet open source, il a de nombreux adeptes dans l’écosystème open source, et a souvent été utilisé comme base pour d’autres navigateurs ou applications.
Tant Chrome que Chromium se basent sur Blink, le moteur de rendu qui a démarré comme un fork de WebKit en 2013, lorsque l’insatisfaction de Google grandissait envers le projet mené par Apple. Blink a continué de croître depuis lors, et va continuer de prospérer lorsque Microsoft commencera à l’utiliser pour son navigateur Edge.
La plateforme Chrome a profondément changé le Web. Et plus encore. L’adoption des technologies web dans le développement des logiciels PC a connu une augmentation sans précédent dans les 5 dernières années, avec des projets comme Github Electron, qui s’imposent sur chaque OS majeur comme les standards de facto pour des applications multiplateformes. ChromeOS, quoique toujours minoritaire comparé à Windows et MacOS, s’installe dans les esprits et gagne des parts de marché.
Chrome est, de fait, partout. Et c’est une mauvaise nouvelle
Don’t Be Evil
L’hégémonie de Chrome a un effet négatif majeur sur le Web en tant que plateforme ouverte : les développeurs boudent de plus en plus les autres navigateurs lors de leurs tests et de leurs débogages. Si cela fonctionne comme prévu sur Chrome, c’est prêt à être diffusé. Cela engendre en retour un afflux d’utilisateurs pour le navigateur puisque leurs sites web et applications favorites ne marchent plus ailleurs, rendant les développeurs moins susceptibles de passer du temps à tester sur les autres navigateurs. Un cercle vicieux qui, s’il n’est pas brisé, entraînera la disparition de la plupart des autres navigateurs et leur oubli. Et c’est exactement comme ça que vous asphyxiez le Web ouvert.
Quand il s’agit de promouvoir l’utilisation d’un unique navigateur Web, Google mène la danse. Une faible assurance de qualité et des choix de conception discutables sont juste la surface visible de l’iceberg quand on regarde les applications de Google et ses services en dehors de l’écosystème Chrome. Pour rendre les choses encore pires, le blâme retombe souvent sur les autres concurrents car ils « retarderaient l’avancée du Web ». Le Web est actuellement le terrain de jeu de Google ; soit vous faites comme ils disent, soit on vous traite de retardataire.
Sans une compétition saine et équitable, n’importe quelle plateforme ouverte régressera en une organisation dirigiste. Pour le Web, cela veut dire que ses points les plus importants — la liberté et l’accessibilité universelle — sont sapés pour chaque pour-cent de part de marché obtenu par Chrome. Rien que cela est suffisant pour s’inquiéter. Mais quand on regarde de plus près le modèle commercial de Google, la situation devient beaucoup plus effrayante.
La raison d’être de n’importe quelle entreprise est de faire du profit et de satisfaire les actionnaires. Quand la croissance soutient une bonne cause, c’est considéré comme un avantage compétitif. Dans le cas contraire, les services marketing et relations publiques sont mis au travail. Le mantra de Google, « Don’t be evil« , s’inscrivait parfaitement dans leur récit d’entreprise quand leur croissance s’accompagnait de rendre le Web davantage ouvert et accessible.
Hélas, ce n’est plus le cas.
Logos de Chrome
L’intérêt de l’entreprise a dérivé petit à petit pour transformer leur domination sur le marché des navigateurs en une croissance du chiffre d’affaires. Il se trouve que le modèle commercial de Google est la publicité sur leur moteur de recherche et Adsense. Tout le reste représente à peine 10 % de leur revenu annuel. Cela n’est pas forcément un problème en soi, mais quand la limite entre navigateur, moteur de recherche et services en ligne est brouillée, nous avons un problème. Et un gros.
Les entreprises qui marchent comptent sur leurs avantages compétitifs. Les moins scrupuleuses en abusent si elles ne sont pas supervisées. Quand votre navigateur vous force à vous identifier, à utiliser des cookies que vous ne pouvez pas supprimer et cherche à neutraliser les extensions de blocage de pub et de vie privée, ça devient très mauvais1. Encore plus quand vous prenez en compte le fait que chaque site web contient au moins un bout de code qui communique avec les serveurs de Google pour traquer les visiteurs, leur montrer des publicités ou leur proposer des polices d’écriture personnalisées.
En théorie, on pourrait fermer les yeux sur ces mauvaises pratiques si l’entreprise impliquée avait un bon bilan sur la gestion des données personnelles. En pratique cependant, Google est structurellement flippant, et ils n’arrivent pas à changer. Vous pouvez penser que vos données personnelles ne regardent que vous, mais ils ne semblent pas être d’accord.
Le modèle économique de Google requiert un flot régulier de données qui puissent être analysées et utilisées pour créer des publicités ciblées. Du coup, tout ce qu’ils font a pour but ultime d’accroître leur base utilisateur et le temps passé par ces derniers sur leurs outils. Même quand l’informatique s’est déplacée de l’ordinateur de bureau vers le mobile, Chrome est resté un rouage important du mécanisme d’accumulation des données de Google. Les sites web que vous visitez et les mots-clés utilisés sont traqués et mis à profit pour vous offrir une expérience plus « personnalisée ». Sans une limite claire entre le navigateur et le moteur de recherche, il est difficile de suivre qui connaît quoi à votre propos. Au final, on accepte le compromis et on continue à vivre nos vies, exactement comme les ingénieurs et concepteurs de produits de Google le souhaitent.
En bref, Google a montré à plusieurs reprises qu’il n’avait aucune empathie envers ses utilisateurs finaux. Sa priorité la plus claire est et restera les intérêts des publicitaires.
Voir au-delà
Une compétition saine centrée sur l’utilisateur est ce qui a provoqué l’arrivée des meilleurs produits et expériences depuis les débuts de l’informatique. Avec Chrome dominant 60 % du marché des navigateurs et Chromium envahissant la bureautique sur les trois plateformes majeures, on confie beaucoup à une seule entreprise et écosystème. Un écosystème qui ne semble plus concerné par la performance, ni par l’expérience utilisateur, ni par la vie privée, ni par les progrès de l’informatique.
Mais on a encore la possibilité de changer les choses. On l’a fait il y a une décennie et on peut le faire de nouveau.
Mozilla et Apple font tous deux un travail remarquable pour combler l’écart des standards du Web qui s’est élargi dans les premières années de Chrome. Ils sont même sensiblement en avance sur les questions de performance, utilisation de la batterie, vie privée et sécurité.
Si vous êtes coincés avec des services de Google qui ne marchent pas sur d’autres navigateurs, ou comptez sur Chrome DevTools pour faire votre travail, pensez à utiliser Vivaldi2 à la place. Ce n’est pas l’idéal —Chromium appartient aussi à Google—, mais c’est un pas dans la bonne direction néanmoins. Soutenir des petits éditeurs et encourager la diversité des navigateurs est nécessaire pour renverser, ou au moins ralentir, la croissance malsaine de Chrome.
Je me suis libéré de Chrome en 2014, et je n’y ai jamais retouché. Il est probable que vous vous en tirerez aussi bien que moi. Vous pouvez l’apprécier en tant que navigateur. Et vous pouvez ne pas vous préoccuper des compromissions en termes de vie privée qui viennent avec. Mais l’enjeu est bien plus important que nos préférences personnelles et nos affinités ; une plateforme entière est sur le point de devenir un nouveau jardin clos. Et on en a déjà assez. Donc, faisons ce que nous pouvons, quand nous le pouvons, pour éviter ça.
Glyn Moody sur l’article 13 – Mensonges et mauvaise foi
Glyn Moody est un journaliste, blogueur et écrivain spécialisé dans les questions de copyright et droits numériques. Ses combats militants le placent en première ligne dans la lutte contre l’article 13 de la directive européenne sur le droit d’auteur, dont le vote final est prévu ce mois-ci. Cet article a été combattu par des associations en France telles que La Quadrature du Net, dénoncé pour ses effet délétères par de nombreuses personnalités (cette lettre ouverte par exemple, signée de Vinton Cerf, Tim Berners-lee, Bruce Schneier, Jimmy Wales…) et a fait l’objet de pétitions multiples.
Dans une suite d’articles en cours (en anglais) ou dans diverses autres interventions (celle-ci traduite en français) que l’on parcourra avec intérêt, Glyn Moody démonte un à un les éléments de langage des lobbyistes des ayants droit. Le texte que Framalang a traduit pour vous met l’accent sur la mauvaise foi des défenseurs de l’article 13 qui préparent des réponses biaisées aux objections qui leur viennent de toutes parts, et notamment de 4 millions d’Européens qui ont manifesté leur opposition.
Pour Glyn Moody, manifestement l’article 13 est conçu pour donner des pouvoirs exorbitants (qui vont jusqu’à une forme de censure automatisée) aux ayants droit au détriment des utilisateurs et utilisatrices « ordinaires »
L’article 13 n’est pas seulement un travail législatif dangereux, mais aussi foncièrement malhonnête
par Glyn Moody
La directive sur Copyright de l’Union Européenne est maintenant en phase d’achèvement au sein du système législatif européen. Étant donné la nature avancée des discussions, il est déjà très surprenant que le comité des affaires juridiques (JURI), responsable de son pilotage à travers le Parlement Européen, ait récemment publié une session de « Questions et Réponses » sur la proposition de « Directive au sujet du Copyright numérique ». Mais il n’est pas difficile de deviner pourquoi ce document a été publié maintenant. De plus en plus de personnes prennent conscience que la directive sur le Copyright en général, et l’Article 13 en particulier, vont faire beaucoup de tort à l’Internet en Europe. Cette session de Q & R tente de contrer les objections relevées et d’étouffer le nombre grandissant d’appels à l’abandon de l’Article 13.
La première question de cette session de Q & R, « En quoi consiste la directive sur le Copyright ? », souligne le cœur du problème de la loi proposée.
La réponse est la suivante : « La proposition de directive sur le Copyright dans le marché unique numérique » cherche à s’assurer que les artistes (en particulier les petits artistes, par exemple les musiciens), les éditeurs de contenu ainsi que les journalistes, bénéficient autant du monde connecté et d’Internet que du monde déconnecté. »
Il n’est fait mention nulle part des citoyens européens qui utilisent l’Internet, ou de leurs priorités. Donc, il n’est pas surprenant qu’on ne règle jamais le problème du préjudice que va causer la directive sur le Copyright à des centaines de millions d’utilisateurs d’Internet, car les défenseurs de la directive sur le Copyright ne s’en préoccupent pas. La session de Q & R déclare : « Ce qu’il est actuellement légal et permis de partager, restera légal et permis de partager. » Bien que cela soit sans doute correct au sens littéral, l’exigence de l’Article 13 concernant la mise en place de filtres sur la mise en ligne de contenus signifie en pratique que c’est loin d’être le cas. Une information parfaitement légale à partager sera bloquée par les filtres, qui seront forcément imparfaits, et parce que les entreprises devant faire face à des conséquences juridiques, feront toujours preuve d’excès de prudence et préféreront trop bloquer.
La question suivante est : « Quel impact aura la directive sur les utilisateurs ordinaires ? ».
Là encore, la réponse est correcte mais trompeuse : « Le projet de directive ne cible pas les utilisateurs ordinaires. »
Personne ne dit qu’elle cible les utilisateurs ordinaires, en fait, ils sont complètement ignorés par la législation. Mais le principal, c’est que les filtres sur les chargements de contenu vont affecter les utilisateurs ordinaires, et de plein fouet. Que ce soit ou non l’intention n’est pas la question.
« Est-ce que la directive affecte la liberté sur Internet ou mène à une censure d’Internet ? » demande la session de Q & R.
La réponse ici est « Un utilisateur pourra continuer d’envoyer du contenu sur les plateformes d’Internet et (…) ces plateformes / agrégateurs d’informations pourront continuer à héberger de tels chargements, tant que ces plateformes respectent les droits des créateurs à une rémunération décente. »
Oui, les utilisateurs pourront continuer à envoyer du contenu, mais une partie sera bloquée de manière injustifiable parce que les plateformes ne prendront pas le risque de diffuser du contenu qui ne sera peut-être couvert par l’une des licences qu’elles ont signées.
La question suivante concerne le mensonge qui est au cœur de la directive sur le Copyright, à savoir qu’il n’y a pas besoin de filtre sur les chargements. C’est une idée que les partisans ont mise en avant pendant un temps, et il est honteux de voir le Parlement Européen lui-même répéter cette contre-vérité. Voici l’élément de la réponse :
« La proposition de directive fixe un but à atteindre : une plateforme numérique ou un agrégateur de presse ne doit pas gagner d’argent grâce aux productions de tierces personnes sans les indemniser. Par conséquent, une plateforme ou un agrégateur a une responsabilité juridique si son site diffuse du contenu pour lequel il n’aurait pas correctement rémunéré le créateur. Cela signifie que ceux dont le travail est illégalement utilisé peuvent poursuivre en justice la plateforme ou l’agrégateur. Toutefois, le projet de directive ne spécifie pas ni ne répertorie quels outils, moyens humains ou infrastructures peuvent être nécessaires afin d’empêcher l’apparition d’une production non rémunérée sur leur site. Il n’y a donc pas d’obligation de filtrer les chargements.
Toutefois, si de grandes plateformes ou agrégateurs de presse ne proposent pas de solutions innovantes, ils pourraient finalement opter pour le filtrage. »
La session Q & R essaye d’affirmer qu’il n’est pas nécessaire de filtrer les chargements et que l’apport de « solutions innovantes » est à la charge des entreprises du web. Elle dit clairement que si une entreprise utilise des filtres sur les chargements, on doit lui reprocher de ne pas être suffisamment « innovante ». C’est une absurdité. D’innombrables experts ont signalé qu’il est impossible « d’empêcher la diffusion de contenu non-rémunéré sur un site » à moins de vérifier, un à un, chacun les fichiers et de les bloquer si nécessaire : il s’agit d’un filtrage des chargements. Aucune “innovation” ne permettra de contourner l’impossibilité logique de se conformer à la directive sur le Copyright, sans avoir recours au filtrage des chargements.
En plus de donner naissance à une législation irréfléchie, cette approche montre aussi la profonde inculture technique de nombreux politiciens européens. Ils pensent encore manifestement que la technologie est une sorte de poudre de perlimpinpin qui peut être saupoudrée sur les problèmes afin de les faire disparaître. Ils ont une compréhension médiocre du domaine numérique et sont cependant assez arrogants pour ignorer les meilleurs experts mondiaux en la matière lorsque ceux-ci disent que ce que demande la Directive sur le Copyright est impossible.
Pour couronner le tout, la réponse à la question : « Pourquoi y a-t-il eu de nombreuses contestations à l’encontre de cette directive ? » constitue un terrible affront pour le public européen. La réponse reconnaît que : « Certaines statistiques au sein du Parlement Européen montrent que les parlementaires ont rarement, voire jamais, été soumis à un tel niveau de lobbying (appels téléphoniques, courriels, etc.). » Mais elle écarte ce niveau inégalé de contestation de la façon suivante :
« De nombreuses campagnes antérieures de lobbying ont prédit des conséquences désastreuses qui ne se sont jamais réalisées.
Par exemple, des entreprises de télécommunication ont affirmé que les factures téléphoniques exploseraient en raison du plafonnement des frais d’itinérance ; les lobbies du tabac et de la restauration ont prétendu que les personnes allaient arrêter d’aller dans les restaurants et dans les bars suite à l’interdiction d’y fumer à l’intérieur ; des banques ont dit qu’elles allaient arrêter de prêter aux entreprises et aux particuliers si les lois devenaient plus strictes sur leur gestion, et le lobby de la détaxe a même argué que les aéroports allaient fermer, suite à la fin des produits détaxés dans le marché intérieur. Rien de tout ceci ne s’est produit. »
Il convient de remarquer que chaque « contre-exemple » concerne des entreprises qui se plaignent de lois bénéficiant au public. Mais ce n’est pas le cas de la vague de protestation contre la directive sur le Copyright, qui vient du public et qui est dirigée contre les exigences égoïstes de l’industrie du copyright. La session de Q & R tente de monter un parallèle biaisé entre les pleurnichements intéressés des industries paresseuses et les attentes d’experts techniques inquiets, ainsi que de millions de citoyens préoccupés par la préservation des extraordinaires pouvoirs et libertés de l’Internet ouvert.
Voici finalement la raison pour laquelle la directive sur le Copyright est si pernicieuse : elle ignore totalement les droits des usagers d’Internet. Le fait que la nouvelle session de Q & R soit incapable de répondre à aucune des critiques sérieuses sur la loi autrement qu’en jouant sur les mots, dans une argumentation pitoyable, est la confirmation que tout ceci n’est pas seulement un travail législatif dangereux, mais aussi profondément malhonnête. Si l’Article 13 est adopté, il fragilisera l’Internet dans les pays de l’UE, entraînera la zone dans un marasme numérique et, par le refus réitéré de l’Union Européenne d’écouter les citoyens qu’elle est censée servir, salira le système démocratique tout entier.
Aujourd’hui Framasoft (parmi d’autres) montre son soutien à l’association RAP (Résistance à l’Agression Publicitaire) ainsi qu’à la Quadrature du Net qui lancent une campagne de sensibilisation et d’action pour lutter contre les nuisances publicitaires non-consenties sur Internet.
#BloquelapubNet : un site pour expliquer comment se protéger
Cliquez sur l’image pour aller directement sur bloquelapub.net
Si vous, vous savez comment vous prémunir de cette pollution informationnelle… avez-vous déjà songé à aider vos proches, collègues et connaissances ? C’est compliqué de tout bien expliquer avec des mots simples, hein ? C’est justement à ça que sert le site bloquelapub.net : un tutoriel à suivre qui permet, en quelques clics, d’apprendre quelques gestes essentiels pour notre hygiène numérique. Voilà un site utile, à partager et communiquer autour de soi avec enthousiasme, sans modération et accompagné du mot clé #bloquelapubnet !
Pourquoi bloquer ? – Le communiqué
Nous reproduisons ci dessous le communiqué de presse des associations Résistance à l’Agression Publicitaire et La Quadrature du Net.
Internet est devenu un espace prioritaire pour les investissements des publicitaires. En France, pour la première fois en 2016, le marché de la publicité numérique devient le « premier média investi sur l’ensemble de l’année », avec une part de marché de 29,6%, devant la télévision. En 2017, c’est aussi le cas au niveau mondial. Ce jeune « marché » est principalement capté par deux géants de la publicité numérique. Google et Facebook. Ces deux géants concentrent à eux seuls autour de 50% du marché et bénéficient de la quasi-totalité des nouveaux investissements sur ce marché. « Pêché originel d’Internet », où, pour de nombreuses personnes et sociétés, il demeure difficile d’obtenir un paiement monétaire direct pour des contenus et services commerciaux et la publicité continue de s’imposer comme un paiement indirect.
Les services vivant de la publicité exploitent le « temps de cerveau disponible » des internautes qui les visitent, et qui n’en sont donc pas les clients, mais bien les produits. Cette influence est achetée par les annonceurs qui font payer le cout publicitaire dans les produits finalement achetés.
La publicité en ligne a plusieurs conséquences : en termes de dépendance vis-à-vis des annonceurs et des revenus publicitaires, et donc des limites sur la production de contenus et d’information, en termes de liberté de réception et de possibilité de limiter les manipulations publicitaires, sur la santé, l’écologie…
En ligne, ces problématiques qui concernent toutes les publicités ont de plus été complétées par un autre enjeu fondamental. Comme l’exprime parfaitement Zeynep Tufekci, une chercheuse turque, « on a créé une infrastructure de surveillance dystopique juste pour que des gens cliquent sur la pub ». De grandes entreprises telles que Google, Facebook et d’autres « courtiers en données » comme Criteo ont développés des outils visant à toujours mieux nous « traquer » dans nos navigations en ligne pour nous profiler publicitairement. Ces pratiques sont extrêmement intrusives et dangereuses pour les libertés fondamentales.
Il est plus temps que cette législation soit totalement respectée et que les publicitaires cessent de nous espionner en permanence en ligne.
Un sondage BVA-La Dépêche de 2018, révélait que 77% des Français·es se disent inquiet·es de l’utilisation que pouvaient faire des grandes entreprises commerciales de leurs données numériques personnelles. 83% des Français·es sont irrité·es par la publicité en ligne selon un sondage de l’institut CSA en mars 2016 et « seulement » 24% des personnes interrogées avaient alors installé un bloqueur de publicité.
Le blocage de la publicité en ligne apparait comme un bon outil de résistance pour se prémunir de la surveillance publicitaire sur Internet. Pour l’aider à se développer, nos associations lancent le site Internet :
Plusieurs opérations collectives ou individuelles de sensibilisation et blocages de la publicité auront lieu sur plusieurs villes du territoire français et sur Internet peu de temps avant et le jour du 28 janvier 2019, journée européenne de la « protection des données personnelles ». Le jour rêvé pour s’opposer à la publicité en ligne qui exploite ces données !
RAP et La Quadrature du Net demandent :
Le respect de la liberté de réception dans l’espace public et ailleurs, le droit et la possibilité de refuser d’être influencé par la publicité,
Le strict respect du règlement général pour la protection des données et l’interdiction de la collecte de données personnelles à des fins publicitaires sans le recueil d’un consentement libre (non-conditionnant pour l’accès au service), explicite et éclairé où les paramètres les plus protecteurs sont configurés par défaut. Les sites Internet et services en ligne ne doivent par défaut collecter aucune information à des fins publicitaires sans que l’internaute ne les y ait expressément autorisés.
Rendez-vous sur bloquelapub.net et sur Internet toute la journée du 28 janvier 2019
Les associations soutiens de cette mobilisation : Framasoft, Le CECIL, Globenet, Le Creis-Terminal
Pour un Web frugal ?
Sites lourds, sites lents, pages web obèses qui exigent pour être consultées dans un délai raisonnable une carte graphique performante, un processeur rapide et autant que possible une connexion par fibre optique… tel est le quotidien de l’internaute ordinaire.
Nul besoin de remonter aux débuts du Web pour comparer : c’est d’une année sur l’autre que la taille moyenne des pages web s’accroît désormais de façon significative.
Quant à la consommation en énergie de notre vie en ligne, elle prend des proportions qui inquiètent à juste titre : des lointains datacenters aux hochets numériques dont nous aimons nous entourer, il y a de quoi se poser des questions sur la nocivité environnementale de nos usages collectifs et individuels.
Bien sûr, les solutions économes à l’échelle de chacun sont peut-être dérisoires au regard des gigantesques gaspillages d’un système consumériste insatiable et énergivore.
Cependant nous vous invitons à prendre en considération l’expérience de l’équipe barcelonaise de Low-Tech Magazine dont nous avons traduit pour vous un article. Un peu comme l’association Framasoft l’avait fait en ouverture de la campagne dégooglisons… en se dégooglisant elle-même, les personnes de Low-tech Magazine ont fait de leur mieux pour appliquer à leur propre site les principes de frugalité qu’elles défendent : ce ne sont plus seulement les logiciels mais aussi les matériels qui ont fait l’objet d’une cure d’amaigrissement au régime solaire.
En espérant que ça donnera des idées à tous les bidouilleurs…
article original : How to build a Low-tech website Traduction Framalang : Khrys, Mika, Bidouille, Penguin, Eclipse, Barbara, Mannik, jums, Mary, Cyrilus, goofy, simon, xi, Lumi, Suzy + 2 auteurs anonymes
Comment créer un site web basse technologie
Low-tech Magazine a été créé en 2007 et n’a que peu changé depuis. Comme une refonte du site commençait à être vraiment nécessaire, et comme nous essayons de mettre en œuvre ce que nous prônons, nous avons décidé de mettre en place une version de Low Tech Magazine en basse technologie, auto-hébergée et alimentée par de l’énergie solaire. Le nouveau blog est conçu pour réduire radicalement la consommation d’énergie associée à l’accès à notre contenu.
Premier prototype du serveur alimenté à l’énergie solaire sur lequel tourne le nouveau site.
Pour éviter les conséquences négatives d’une consommation énergivore, les énergies renouvelables seraient un moyen de diminuer les émissions des centres de données. Par exemple, le rapport annuel ClickClean de Greenpeace classe les grandes entreprises liées à Internet en fonction de leur consommation d’énergies renouvelables.
Cependant, faire fonctionner des centres de données avec des sources d’énergie renouvelables ne suffit pas à compenser la consommation d’énergie croissante d’Internet. Pour commencer, Internet utilise déjà plus d’énergie que l’ensemble des énergies solaire et éolienne mondiales. De plus, la réalisation et le remplacement de ces centrales électriques d’énergies renouvelables nécessitent également de l’énergie, donc si le flux de données continue d’augmenter, alors la consommation d’énergies fossiles aussi.
Cependant, faire fonctionner les centres de données avec des sources d’énergie renouvelables ne suffit pas à combler la consommation d’énergie croissante d’Internet.
Enfin, les énergies solaire et éolienne ne sont pas toujours disponibles, ce qui veut dire qu’un Internet fonctionnant à l’aide d’énergies renouvelables nécessiterait une infrastructure pour le stockage de l’énergie et/ou pour son transport, ce qui dépend aussi des énergies fossiles pour sa production et son remplacement. Alimenter les sites web avec de l’énergie renouvelable n’est pas une mauvaise idée, mais la tendance vers l’augmentation de la consommation d’énergie doit aussi être traitée.
Des sites web qui enflent toujours davantage
Tout d’abord, le contenu consomme de plus en plus de ressources. Cela a beaucoup à voir avec l’importance croissante de la vidéo, mais une tendance similaire peut s’observer sur les sites web.
La taille moyenne d’une page web (établie selon les pages des 500 000 domaines les plus populaires) est passée de 0,45 mégaoctets en 2010 à 1,7 mégaoctets en juin 2018. Pour les sites mobiles, le poids moyen d’une page a décuplé, passant de 0,15 Mo en 2011 à 1,6 Mo en 2018. En utilisant une méthode différente, d’autres sources évoquent une moyenne autour de 2,9 Mo en 2018.
La croissance du transport de données surpasse les avancées en matière d’efficacité énergétique (l’énergie requise pour transférer 1 mégaoctet de données sur Internet), ce qui engendre toujours plus de consommation d’énergie. Des sites plus « lourds » ou plus « gros » ne font pas qu’augmenter la consommation d’énergie sur l’infrastructure du réseau, ils raccourcissent aussi la durée de vie des ordinateurs, car des sites plus lourds nécessitent des ordinateurs plus puissants pour y accéder. Ce qui veut dire que davantage d’ordinateurs ont besoin d’être fabriqués, une production très coûteuse en énergie.
Être toujours en ligne ne fait pas bon ménage avec des sources d’énergies renouvelables telles que l’éolien ou le solaire, qui ne sont pas toujours disponibles.
La deuxième raison de l’augmentation de la consommation énergétique d’Internet est que nous passons de plus en plus de temps en ligne. Avant l’arrivée des ordinateurs portables et du Wi-Fi, nous n’étions connectés au réseau que lorsque nous avions accès à un ordinateur fixe au bureau, à la maison ou à la bibliothèque. Nous vivons maintenant dans un monde où quel que soit l’endroit où nous nous trouvons, nous sommes toujours en ligne, y compris, parfois, sur plusieurs appareils à la fois.
Un accès Internet en mode « toujours en ligne » va de pair avec un modèle d’informatique en nuage, permettant des appareils plus économes en énergie pour les utilisateurs au prix d’une dépense plus importante d’énergie dans des centres de données. De plus en plus d’activités qui peuvent très bien se dérouler hors-ligne nécessitent désormais un accès Internet en continu, comme écrire un document, remplir une feuille de calcul ou stocker des données. Tout ceci ne fait pas bon ménage avec des sources d’énergies renouvelables telles que l’éolien ou le solaire, qui ne sont pas disponibles en permanence.
Conception d’un site internet basse technologie
La nouvelle mouture de notre site répond à ces deux problématiques. Grâce à une conception simplifiée de notre site internet, nous avons réussi à diviser par cinq la taille moyenne des pages du blog par rapport à l’ancienne version, tout en rendant le site internet plus agréable visuellement (et plus adapté aux mobiles). Deuxièmement, notre nouveau site est alimenté à 100 % par l’énergie solaire, non pas en théorie, mais en pratique : il a son propre stockage d’énergie et sera hors-ligne lorsque le temps sera couvert de manière prolongée.
Internet n’est pas une entité autonome. Sa consommation grandissante d’énergie est la résultante de décisions prises par des développeurs logiciels, des concepteurs de site internet, des départements marketing, des annonceurs et des utilisateurs d’internet. Avec un site internet poids plume alimenté par l’énergie solaire et déconnecté du réseau, nous voulons démontrer que d’autres décisions peuvent être prises.
Avec 36 articles en ligne sur environ une centaine, le poids moyen d’une page sur le site internet alimenté par énergie solaire est environ cinq fois inférieur à celui de la version précédente.
Pour commencer, la nouvelle conception du site va à rebours de la tendance à des pages plus grosses. Sur 36 articles actuellement en ligne sur environ une centaine, le poids moyen d’une page sur le site internet alimenté par énergie solaire est 0,77 Mo – environ cinq fois inférieur à celui de la version précédente, et moins de la moitié du poids moyen d’une page établi sur les 500 000 blogs les plus populaires en juin 2018.
Ci-dessous : un test de vitesse d’une page web entre l’ancienne et la nouvelle version du magazine Low-Tech. La taille de la page a été divisée par plus de six, le nombre de requêtes par cinq, et la vitesse de téléchargement a été multipliée par dix. Il faut noter que l’on n’a pas conçu le site internet pour être rapide, mais pour une basse consommation d’énergie. La vitesse aurait été supérieure si le serveur avait été placé dans un centre de données et/ou à une position plus centrale de l’infrastructure d’Internet.
Ci-dessous sont détaillées plusieurs des décisions de conception que nous avons faites pour réduire la consommation d’énergie. Des informations plus techniques sont données sur une page distincte. Nous avons aussi libéré le code source pour la conception de notre site internet.
Site statique
Un des choix fondamentaux que nous avons faits a été d’élaborer un site internet statique. La majorité des sites actuels utilisent des langages de programmation côté serveur qui génèrent la page désirée à la volée par requête à une base de données. Ça veut dire qu’à chaque fois que quelqu’un visite une page web, elle est générée sur demande.
Au contraire, un site statique est généré une fois pour toutes et existe comme un simple ensemble de documents sur le disque dur du serveur. Il est toujours là, et pas seulement quand quelqu’un visite la page. Les sites internet statiques sont donc basés sur le stockage de fichiers quand les sites dynamiques dépendent de calculs récurrents. En conséquence, un site statique nécessite moins de puissance de calcul, donc moins d’énergie.
Le choix d’un site statique nous permet d’opérer la gestion de notre site de manière économique depuis notre bureau de Barcelone. Faire la même chose avec un site web généré depuis une base de données serait quasiment impossible, car cela demanderait trop d’énergie. Cela présenterait aussi des risques importants de sécurité. Bien qu’un serveur avec un site statique puisse toujours être piraté, il y a significativement moins d’attaques possibles et les dommages peuvent être plus facilement réparés.
Images optimisées pour en réduire le « poids »
Le principal défi a été de réduire la taille de la page sans réduire l’attractivité du site. Comme les images consomment l’essentiel de la bande passante il serait facile d’obtenir des pages très légères et de diminuer l’énergie nécessaire en supprimant les images, en réduisant leur nombre ou en réduisant considérablement leur taille. Néanmoins, les images sont une part importante de l’attractivité de Low-tech Magazine et le site ne serait pas le même sans elles.
Par optimisation, on peut rendre les images dix fois moins gourmandes en ressources, tout en les affichant bien plus largement que sur l’ancien site.
Nous avons plutôt choisi d’appliquer une ancienne technique de compression d’image appelée « diffusion d’erreur ». Le nombre de couleurs d’une image, combiné avec son format de fichier et sa résolution, détermine la taille de cette image. Ainsi, plutôt que d’utiliser des images en couleurs à haute résolution, nous avons choisi de convertir toutes les images en noir et blanc, avec quatre niveaux de gris intermédiaires.
Ces images en noir et blanc sont ensuite colorées en fonction de la catégorie de leur contenu via les capacités de manipulation d’image natives du navigateur. Compressées par ce module appelé dithering, les images présentées dans ces articles ajoutent beaucoup moins de poids au contenu ; par rapport à l’ancien site web, elles sont environ dix fois moins consommatrices de ressources.
Police de caractère par défaut / Pas de logo
Toutes les ressources chargées, y compris les polices de caractères et les logos, le sont par une requête supplémentaire au serveur, nécessitant de l’espace de stockage et de l’énergie. Pour cette raison, notre nouveau site web ne charge pas de police personnalisée et enlève toute déclaration de liste de polices de caractères, ce qui signifie que les visiteurs verront la police par défaut de leur navigateur.
Une page du magazine en version basse consommation
Nous utilisons une approche similaire pour le logo. En fait, Low-tech Magazine n’a jamais eu de véritable logo, simplement une bannière représentant une lance, considérée comme une arme low-tech (technologie sobre) contre la supériorité prétendue des « high-tech » (hautes technologies).
Au lieu d’un logo dessiné, qui nécessiterait la production et la distribution d’image et de polices personnalisées, la nouvelle identité de Low-Tech Magazine consiste en une unique astuce typographique : utiliser une flèche vers la gauche à la place du trait d’union dans le nom du blog : LOW←TECH MAGAZINE.
Pas de pistage par un tiers, pas de services de publicité, pas de cookies
Les logiciels d’analyse de sites tels que Google Analytics enregistrent ce qui se passe sur un site web, quelles sont les pages les plus vues, d’où viennent les visiteurs, etc. Ces services sont populaires car peu de personnes hébergent leur propre site. Cependant l’échange de ces données entre le serveur et l’ordinateur du webmaster génère du trafic de données supplémentaire et donc de la consommation d’énergie.
Avec un serveur auto-hébergé, nous pouvons obtenir et visualiser ces mesures de données avec la même machine : tout serveur génère un journal de ce qui se passe sur l’ordinateur. Ces rapports (anonymes) ne sont vus que par nous et ne sont pas utilisés pour profiler les visiteurs.
Avec un serveur auto-hébergé, pas besoin de pistage par un tiers ni de cookies.
Low-tech Magazine a utilisé des publicités Google Adsense depuis ses débuts en 2007. Bien qu’il s’agisse d’une ressource financière importante pour maintenir le blog, elles ont deux inconvénients importants. Le premier est la consommation d’énergie : les services de publicité augmentent la circulation des données, ce qui consomme de l’énergie.
Deuxièmement, Google collecte des informations sur les visiteurs du blog, ce qui nous contraint à développer davantage les déclarations de confidentialité et les avertissements relatifs aux cookies, qui consomment aussi des données et agacent les visiteurs. Nous avons donc remplacé Adsense par d’autres sources de financement (voir ci-dessous pour en savoir plus). Nous n’utilisons absolument aucun cookie.
À quelle fréquence le site web sera-t-il hors-ligne ?
Bon nombre d’entreprises d’hébergement web prétendent que leurs serveurs fonctionnent avec de l’énergie renouvelable. Cependant, même lorsqu’elles produisent de l’énergie solaire sur place et qu’elles ne se contentent pas de « compenser » leur consommation d’énergie fossile en plantant des arbres ou autres, leurs sites Web sont toujours en ligne.
Cela signifie soit qu’elles disposent d’un système géant de stockage sur place (ce qui rend leur système d’alimentation non durable), soit qu’elles dépendent de l’énergie du réseau lorsqu’il y a une pénurie d’énergie solaire (ce qui signifie qu’elles ne fonctionnent pas vraiment à 100 % à l’énergie solaire).
Le panneau photo-voltaïque solaire de 50 W. Au-dessus, un panneau de 10 W qui alimente un système d’éclairage.
En revanche, ce site web fonctionne sur un système d’énergie solaire hors réseau avec son propre stockage d’énergie et hors-ligne pendant les périodes de temps nuageux prolongées. Une fiabilité inférieure à 100 % est essentielle pour la durabilité d’un système solaire hors réseau, car au-delà d’un certain seuil, l’énergie fossile utilisée pour produire et remplacer les batteries est supérieure à l’énergie fossile économisée par les panneaux solaires.
Reste à savoir à quelle fréquence le site sera hors ligne. Le serveur web est maintenant alimenté par un nouveau panneau solaire de 50 Wc et une batterie plomb-acide (12V 7Ah) qui a déjà deux ans. Comme le panneau solaire est à l’ombre le matin, il ne reçoit la lumière directe du soleil que 4 à 6 heures par jour. Dans des conditions optimales, le panneau solaire produit ainsi 6 heures x 50 watts = 300 Wh d’électricité.
Le serveur web consomme entre 1 et 2,5 watts d’énergie (selon le nombre de visiteurs), ce qui signifie qu’il consomme entre 24 et 60 Wh d’électricité par jour. Dans des conditions optimales, nous devrions donc disposer de suffisamment d’énergie pour faire fonctionner le serveur web 24 heures sur 24. La production excédentaire d’énergie peut être utilisée pour des applications domestiques.
Nous prévoyons de maintenir le site web en ligne pendant un ou deux jours de mauvais temps, après quoi il sera mis hors ligne.
Cependant, par temps nuageux, surtout en hiver, la production quotidienne d’énergie pourrait descendre à 4 heures x 10 watts = 40 watts-heures par jour, alors que le serveur nécessite entre 24 et 60 Wh par jour. La capacité de stockage de la batterie est d’environ 40 Wh, en tenant compte de 30 % des pertes de charge et de décharge et de 33 % de la profondeur ou de la décharge (le régulateur de charge solaire arrête le système lorsque la tension de la batterie tombe à 12 V).
Par conséquent, le serveur solaire restera en ligne pendant un ou deux jours de mauvais temps, mais pas plus longtemps. Cependant, il s’agit d’estimations et nous pouvons ajouter une deuxième batterie de 7 Ah en automne si cela s’avère nécessaire. Nous visons un uptime, c’est-à-dire un fonctionnement sans interruption, de 90 %, ce qui signifie que le site sera hors ligne pendant une moyenne de 35 jours par an.
Premier prototype avec batterie plomb-acide (12 V 7 Ah) à gauche et batterie Li-Po UPS (3,7V 6600 mA) à droite. La batterie au plomb-acide fournit l’essentiel du stockage de l’énergie, tandis que la batterie Li-Po permet au serveur de s’arrêter sans endommager le matériel (elle sera remplacée par une batterie Li-Po beaucoup plus petite).
Quel est la période optimale pour parcourir le site ?
L’accessibilité à ce site internet dépend de la météo à Barcelone en Espagne, endroit où est localisé le serveur. Pour aider les visiteurs à « planifier » leurs visites à Low-tech Magazine, nous leur fournissons différentes indications.
Un indicateur de batterie donne une information cruciale parce qu’il peut indiquer au visiteur que le site internet va bientôt être en panne d’énergie – ou qu’on peut le parcourir en toute tranquillité. La conception du site internet inclut une couleur d’arrière-plan qui indique la charge de la batterie qui alimente le site Internet grâce au soleil. Une diminution du niveau de charge indique que la nuit est tombée ou que la météo est mauvaise.
Outre le niveau de batterie, d’autres informations concernant le serveur du site web sont affichées grâce à un tableau de bord des statistiques. Celui-ci inclut des informations contextuelles sur la localisation du serveur : heure, situation du ciel, prévisions météorologiques, et le temps écoulé depuis la dernière fois où le serveur s’est éteint à cause d’un manque d’électricité.
SERVEUR : Ce site web fonctionne sur un ordinateur Olimex A20. Il est doté de 2 GHz de vitesse de processeur, 1 Go de RAM et 16 Go d’espace de stockage. Le serveur consomme 1 à 2,5 watts de puissance.
SOFTWARE DU SERVEUR : le serveur web tourne sur Armbian Stretch, un système d’exploitation Debian construit sur un noyau SUNXI. Nous avons rédigé une documentation technique sur la configuration du serveur web.
LOGICIEL DE DESIGN : le site est construit avec Pelican, un générateur de sites web statiques. Nous avons publié le code source de « solar », le thème que nous avons développé.
CONNEXION INTERNET. Le serveur est connecté via une connexion Internet fibre 100 MBps. Voici comment nous avons configuré le routeur. Pour l’instant, le routeur est alimenté par le réseau électrique et nécessite 10 watts de puissance. Nous étudions comment remplacer ce routeur gourmand en énergie par un routeur plus efficace qui pourrait également être alimenté à l’énergie solaire.
SYSTÈME SOLAIRE PHOTOVOLTAÏQUE. Le serveur fonctionne avec un panneau solaire de 50 Wc et une batterie plomb-acide 12 V 7 Ah. Cependant, nous continuons de réduire la taille du système et nous expérimentons différentes configurations. L’installation photovoltaïque est gérée par un régulateur de charge solaire 20A.
Qu’est-il arrivé à l’ancien site ?
Le site Low-tech Magazine alimenté par énergie solaire est encore en chantier. Pour le moment, la version alimentée par réseau classique reste en ligne. Nous encourageons les lecteurs à consulter le site alimenté par énergie solaire, s’il est disponible. Nous ne savons pas trop ce qui va se passer ensuite. Plusieurs options se présentent à nous, mais la plupart dépendront de l’expérience avec le serveur alimenté par énergie solaire.
Tant que nous n’avons pas déterminé la manière d’intégrer l’ancien et le nouveau site, il ne sera possible d’écrire et lire des commentaires que sur notre site internet alimenté par réseau, qui est toujours hébergé chez TypePad. Si vous voulez envoyer un commentaire sur le serveur web alimenté en énergie solaire, vous pouvez en commentant cette page ou en envoyant un courriel à solar (at) lowtechmagazine (dot) com.
Est-ce que je peux aider ?
Bien sûr, votre aide est la bienvenue.
D’une part, nous recherchons des idées et des retours d’expérience pour améliorer encore plus le site web et réduire sa consommation d’énergie. Nous documenterons ce projet de manière détaillée pour que d’autres personnes puissent aussi faire des sites web basse technologie.
D’autre part, nous espérons recevoir des contributions financières pour soutenir ce projet. Les services publicitaires qui ont maintenu Low-tech Magazine depuis ses débuts en 2007 sont incompatibles avec le design de notre site web poids plume. C’est pourquoi nous cherchons d’autres moyens de financer ce site :
1. Nous proposerons bientôt un service de copies du blog imprimées à la demande. Grâce à ces publications, vous pourrez lire le Low-tech Magazine sur papier, à la plage, au soleil, où vous voulez, quand vous voulez.
2. Vous pouvez nous soutenir en envoyant un don sur PayPal, Patreon ou LiberaPay.
3. Nous restons ouverts à la publicité, mais nous ne pouvons l’accepter que sous forme d’une bannière statique qui renvoie au site de l’annonceur. Nous ne travaillons pas avec les annonceurs qui ne sont pas en phase avec notre mission.
La bataille du libre, un documentaire contributopique !
Nous avons eu la chance de voir le nouveau documentaire de Philippe Borrel. Un conseil : ne le loupez pas, et surtout emmenez-y vos proches qui ne comprennent pas pourquoi vous les bassinez avec « vos trucs de libristes, là »…
Ce n’est pas de la publicité, c’est de la réclame
Avertissement : cet article de blog est enthousiaste sans être sponsorisé (et oui : nous vivons à une époque où ce genre de précision est devenue obligatoire -_-‘…), car en fait, il est simplement sincère.
Et c’est pas parce qu’on y voit apparaître tonton Richard (the Stallman himself), l’ami Calimaq, les potes de Mozilla ou notre Pyg à nous, hein… C’est parce que ce documentaire montre que la palette du Libre s’étend très largement au-delà du logiciel : agriculture, outils, santé, autogestion… Il montre combien le Libre concrétise dès aujourd’hui les utopies contributives de demain, et ça, bizarrement, ça nous parle.
Sans compter que sa bande annonce a le bon goût d’être présente et présentée sur PeerTube :
Ce qui est brillant, c’est que ce documentaire peut toucher les cœurs et les pensées de nos proches dont le regard divague au loin dès qu’on leur parle de « logiciels », « services », « clients » et autre « code-source »… et qui ne comprennent pas pourquoi certaines variétés de tomates anciennes ont circulé clandestinement dans leur AMAP, ou qui s’indignent de la montée du prix de l’insuline et des prothèses médicales.
Des avant-premières à Fontaine, Nantes et Paris… et sur Arte
Une version « condensée » du documentaire (55 minutes sur les 87 de la version cinéma) sera diffusée le mardi 19 février à 23h45 sur Arte, sous le titre « Internet ou la révolution du partage »… et disponible en accès libre et gratuit sur la plateforme VOD d’Arte jusqu’au 12 avril prochain.
Mais pour les plus chanceuxses d’entre nous, pour celles et ceux qui aiment les grandes toiles et les ciné-débats, il y a déjà quelques avant-premières :
Nous continuerons d’en parler sur nos médias sociaux, car nous considérons que ce documentaire est un bien bel outil dont on peut s’emparer pour se relier à ces communautés qui partagent les valeurs du Libre dans des domaines autre que le numérique… Et il n’est pas impossible que vous rencontriez certain·e·s de nos membres lors d’une projection 😉