Framaslides : reprenez en main votre Power, Point !
Pour le meilleur ou pour le pire, les diaporamas, slides et autres présentations font partie de notre quotidien. Quitte à devoir en faire et en voir, seul·e ou en groupe, autant disposer d’un outil en ligne pratique et respectueux de nos vies numériques, non ?
Ceci n’est pas un Powerpoint®
Commençons par un point vocabulaire : demander un diaporama en prononçant les mots « Tu me fais un Powerpoint ? » c’est un peu comme si on disait « Tu me fais un Subway ? » lorsqu’on veut un sandwich. Non seulement on fait de la pub gratos à une marque (si encore Microsoft vous payait…) ; mais en plus on court le risque de se polluer les cerveaux en apprenant à nos subconscients que sandwich = Subway.
Et puis il faut être francs, le format de documents .ppt ou .pptx (utilisé par Microsoft pour enchaîner vos diaporamas à leur logiciel Powerpoint), ben c’est une plaie. Un format fermé, difficilement compatible avec d’autres logiciels, et dépassé. Et cher, en plus, si vous voulez l’utiliser en ligne avec la suite « Office 365 »…

C’est payant et je suis quand même le produit ?
Microsoft, vous êtes des génies.
Car aujourd’hui, les langages qui permettent de faire des sites web (le HTML, bien sûr, mais aussi ses copaings CSS et Javascript), permettent de produire et de lire hyper facilement des présentations (même complexes), sans toucher à une seule ligne de code, sans installer de logiciel ni d’application, juste à l’intérieur de nos navigateurs web.
C’est justement, ce que permet le logiciel libre Strut. C’est donc à ce logiciel que nous avons contribué afin qu’il ait toutes les fonctionnalités dont nous rêvions pour mieux vous proposer Framaslides !
Framaslides présenté en une framaslide !
Nous pourrions énumérer les fonctionnalités qu’offre Strut : formatage de texte et choix de couleurs, intégration d’images, vidéos, sites web et formes, transitions, etc. Mais le plus simple, c’est encore de vous les montrer, non ?
Cliquez sur le cadre ci dessous et naviguez grâce aux flèches droite et gauche (ou haut et bas) de votre clavier ;).
Cliquez, puis faites défiler les slides avec ↑ ↓ → ←
Déjà, vous allez nous dire, c’est beau (et on vous remercie de nous le dire). Oui. Le seul souci c’est que Struts a été conçu comme un logiciel « perso ». On l’installe sur son ordinateur ou sur un coin de serveur (une brique inter.net, par exemple), on l’utilise, et il enregistre notre ou nos présentation(s) dans le cache de notre navigateur web. Mais si on change d’ordinateur, de navigateur, ou si on nettoie l’historique et le cache de son navigateur web, pfuiiit ! Tout est perdu !
Tout ceci est normal : Strut a été conçu comme cela, et il faut rendre grâce à Matt Crinklaw-Vogt, son développeur, pour le travail fourni. En revanche, si vous voulons que ce logiciel ait de nouvelles fonctionnalités permettant d’autres utilisations, on fait comme tout·e libriste qui se respecte : on se relève les manches et on contribue au code 😉 !
Framaslides, un service collaboratif
Nous avons donc demandé à Thomas (que nous avons embauché suite à son stage où il a mené à bien Framagenda) de relever le défi ! Un peu comme une liste au père Noël, qui s’allonge au fur et à mesure que la date approche…

Dis, Thomas, ce serait pas génial si on pouvait…
- … enregistrer ses diaporamas en ligne ?
- … du coup envoyer nos images à Framaslides ?
- … pour ça il me faut un compte, non ? Tu nous fais le gestionnaire de compte ?
- … ben alors il nous permettra de gérer nos présentations ?
- … genre de créer un lien public pour celle-ci ?
- … ou de proposer celle-là comme modèle ?
- … ah mais j’aime pas ce que j’ai changé, tu peux nous faire un système de révisions, hein, hein ?
- … obah si on peut revenir en arrière, ce serait bien de pouvoir collaborer ensemble, s’te plééééé ???
Et le plus beau, c’est que le résultat est là. Autour de l’outil d’édition de présentations qu’offre Strut, Thomas a conçu un outil permettant de créer, présenter et collaborer sur ses présentations, en gérant aisément son compte, ses images, ses groupes, et bien entendu ses Framaslides !
Pour les plus techos d’entre nous, Thomas a même pris le temps de faire un code propre, facile d’accès, documenté et de le déposer sur un Git aux petits oignons avec les tags et issues kivonbien… bref : un code qui est un appel aux contributions et collaborations ! Du coup, si vous maîtrisez du ImpressJS, du BackboneJS et du Handlebars (qui font tourner Strut) ; ou si vous êtes virtuose du Symphony3 (qui se trouve derrière la surcouche « Framaslides » de Thomas), vos contributions seront grandement appréciées 😉 !
Manuel change le monde avec Framaslides
Manuel Dupuis-Morizeau veut changer le monde. Il se dit que la première étape, c’est de convaincre d’autres personnes de le rejoindre dans son envie… Et pour cela, rien de tel qu’une présentation de derrière les fagots ! Ne voulant pas que ses idées soient confiées aux mains de Google Slides ou Microsoft Powerpoint 365, Manuel décide de se lancer sur Framaslides.
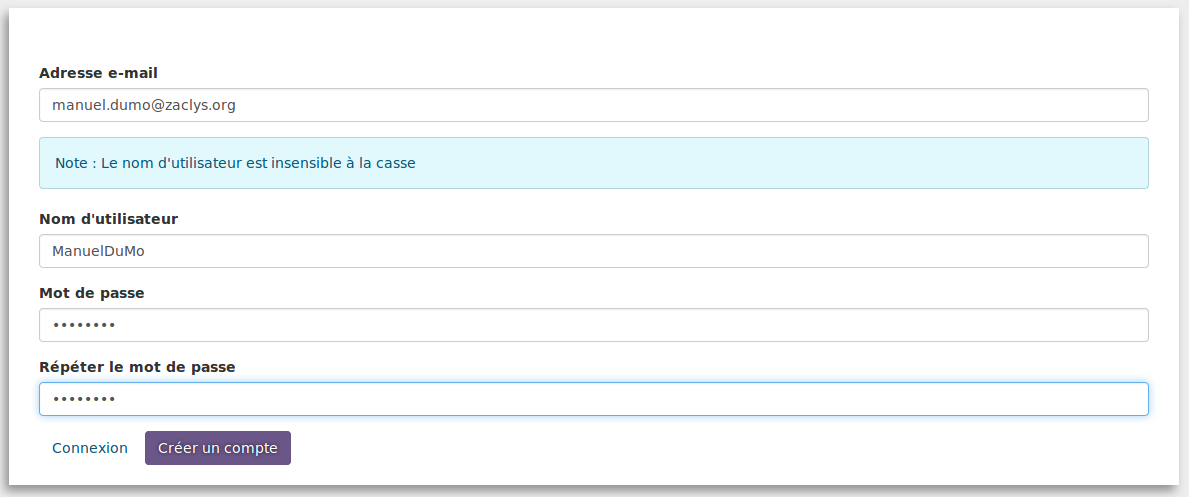
Pour cela, il lui faut un compte Framaslides. C’est facile : dès la page d’accueil, il clique sur le bouton « Se créer un compte », remplit le formulaire assez classique, puis attend l’email de confirmation (en vérifiant de temps en temps dans son dossier courriers indésirables, sait-on jamais)
Une fois son compte validé, Manuel est impatient de s’y mettre, il clique donc directement sur « Créer une présentation ». Là, il découvre l’interface d’édition des diaporama de Struts.
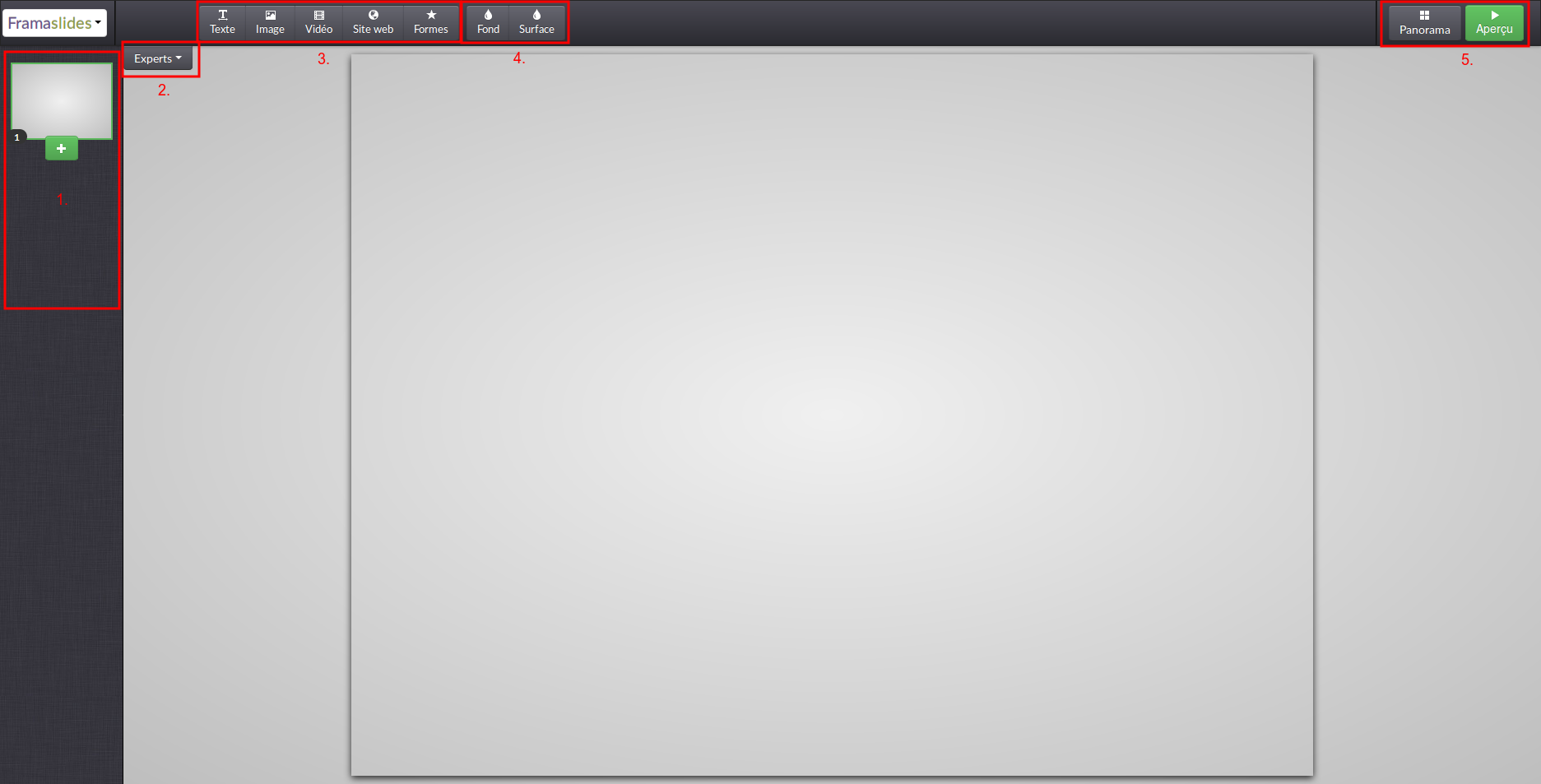
- La colonne des diapositives (1) ;
- Le mode expert (2) (s’il veut trifouiller du code) ;
- Les boutons d’ajout de contenu (3) ;
- Les boutons de choix des couleurs (4) ;
- Les vues panorama et aperçu (5).
Il décide donc de créer ses premières diapositives, ou slides, comme on dit !
#gallery-1 { margin: auto; } #gallery-1 .gallery-item { float: left; margin-top: 10px; text-align: center; width: 33%; } #gallery-1 img { border: 2px solid #cfcfcf; } #gallery-1 .gallery-caption { margin-left: 0; } /* see gallery_shortcode() in wp-includes/media.php */
-
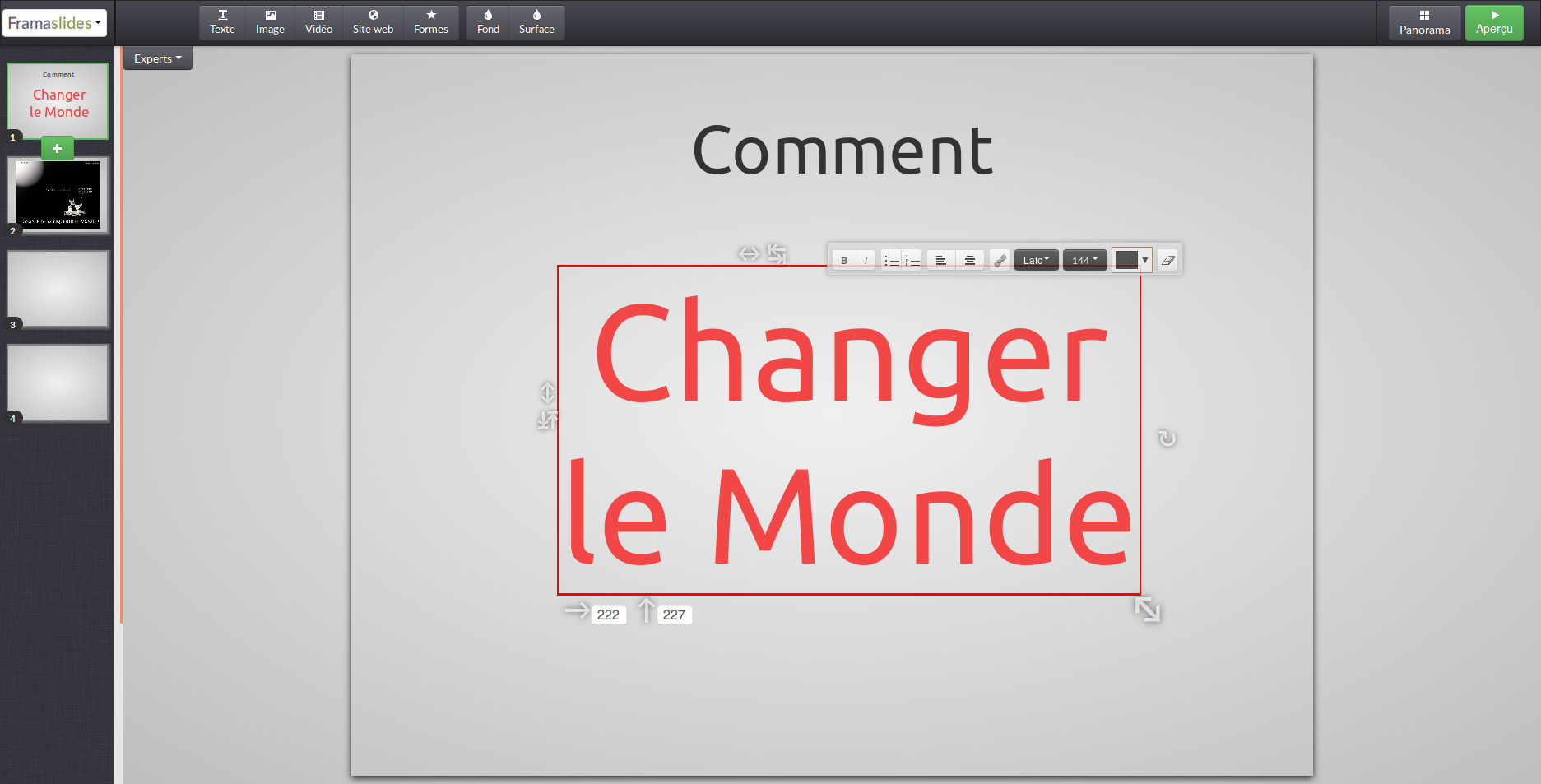
- 1ère slide : texte titre.
-
- En copiant/collant l’adresse web d’un image…
-

- …elle s’insère dans sa 2e slide.
-
- Cela fonctionne aussi avec les vidéos (3e slide)
-
- Et même les pages web/articles de blog (4e Slide)
-
- Changer la couleur de fond des slides ? Easy.
Alors c’est bien gentil tout cela, mais il ne voit toujours pas comment faire les transitions… C’est là qu’il active le mode Panorama. Cela demande une petite gymnastique mentale, mais il voit vite comment ça peut marcher !

Bon, après avoir regardé un aperçu, ce début semble prometteur à Manuel, alors faut-il le sauvegarder en utilisant le menu en haut à gauche.
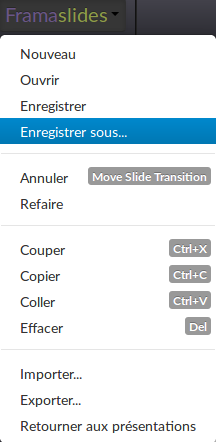
Puis clique sur « retourner aux présentations », dans ce même menu.
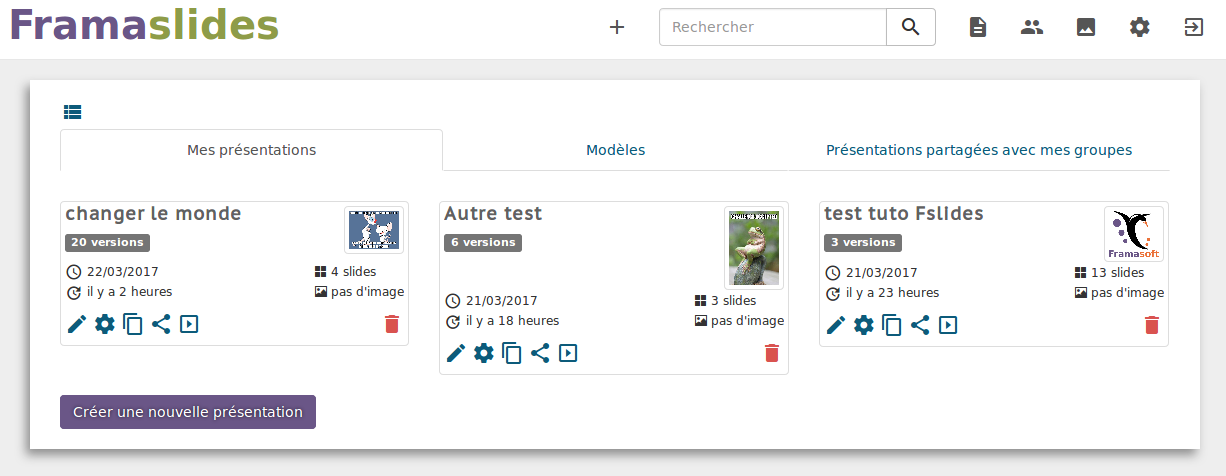
Manuel se retrouve alors devant l’interface de gestion de ses Framaslides. L’outil a l’air assez explicite, en fait…
Au centre, il retrouve ses présentations, ses modèles et ses collaborations, chacun sous leur onglet.
Et en haut à droite une barre de recherche et d’outils qui lui permet de :
- créer une nouvelle présentation ;
- voir ses présentations (donc retourner à l’écran principal de son compte) ;
- gérer ses groupes de collaboration ;
- gérer les images qu’il a téléversées en utilisant Framaslides ;
- gérer les paramètres de son compte (mot de passe, etc.) ;
- et se déconnecter.
Tout cela rend Manuel assez curieux, il va donc aller voir son gestionnaire d’images, mais comme il n’en a téléchargé qu’une, cela ne lui sert pas encore beaucoup. Il est quand même rassuré de savoir qu’il peut en effacer à tout moment et garder la maîtrise de ses fichiers.
Par contre, Manuel a une idée brillante… se faire aider pour commencer à changer le monde. Il décide d’aller directement créer un nouveau groupe afin d’y inviter toute la famille Dupuis Morizeau !
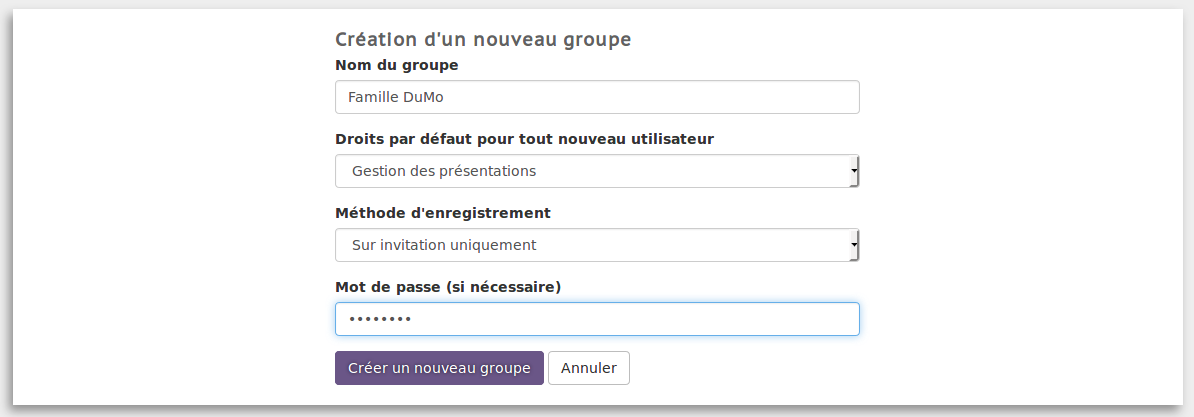
Bon, l’histoire ne dit pas si Manuel réussira à changer le monde, mais on peut croire qu’il réussira facilement à créer sa présentation avec d’autres membres de la famille et à la partager le plus largement possible 😉
Pour aller plus loin :
- Essayer Framaslides
- Découvrir Strut, la brique logicielle originelle
- Participer au développement de Framaslides
- Un service proposé dans le projet Dégooglisons Internet
- Son développement a été financé grâce à vos dons.






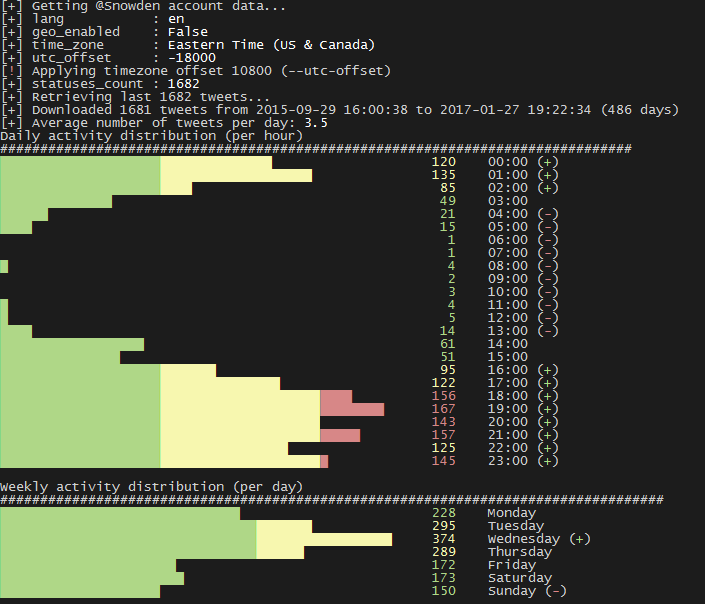
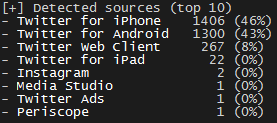
 J’utilise Twitter tous les jours. Pour moi qui suis consultant en cybersécurité, c’est de loin un des meilleurs outils pour rester informé des dernières actualités et pour partager des informations qu’on estime pertinentes pour d’autres. Avec la récente investiture de Donald Trump, les
J’utilise Twitter tous les jours. Pour moi qui suis consultant en cybersécurité, c’est de loin un des meilleurs outils pour rester informé des dernières actualités et pour partager des informations qu’on estime pertinentes pour d’autres. Avec la récente investiture de Donald Trump, les 






{kind=link}
{kind=link}
{kind=link}
{kind=link}