Google, Yahoo, Microsoft (Outlook.com & Hotmail) voient forcément vos emails. Que vous soyez chez eux ou pas, nombre de vos correspondant·e·s y sont (c’est mathématique !), ce qui fait que vos échanges finissent forcément par passer sur leurs serveurs. Mais ce n’est pas là le seul problème.
Ça, c’est côté public : « Tout le monde est chez eux, alors au final, que j’y sois ou pas, qu’est-ce que ça change ? ». En coulisses, côté serveurs justement, ça change tout. La concentration des utilisateurs est telle qu’ils peuvent de fait imposer des pratiques aux « petits » fournisseurs d’emails, de listes de diffusion, etc. Ben oui : si vous ne respectez pas les exigences de Gmail, les emails que vous enverrez vers tou·te·s leurs utilisateurs et utilisatrices peuvent passer en spam, voire être tout bonnement bloqués.
Comme pour Facebook, on se trouve face à un serpent qui se mord la queue : « Tous mes amis sont dessus, alors je peux pas aller sur un autre réseau… » (phrase entendue lors des début de Twitter, Instagram, Snapchat, et Framasphère*…). Sauf qu’en perdurant chez eux, on devient aussi une part de la masse qui leur confère un pouvoir sur la gouvernance – de fait – d’Internet !
Il n’y a pas de solutions idéale (et, s’il vous plaît, ne jugeons pas les personnes qui participent à ces silos… elles sont souvent pas très loin dans le miroir 😄) ; mais nous pensons que prendre conscience des enjeux, c’est faire avancer sa réflexion et sa démarche vers plus de libertés.
Nous reprenons donc ici un article de Luc, notre administrateur-système, qui a partagé sur son blog son expérience de « petit » serveur d’email (à savoir Framasoft, principalement pour Framalistes) face à ces Léviathans. Luc ayant placé son blog dans le domaine public, nous nous sommes permis de remixer cet article avec des précisions qu’il a faites en commentaires et des simplifications/explications sur les parties les plus techniques (à grands coups de notes intempestives 😜 ).
Quand on pense aux GAFAM, on pense surtout à leur vilaine habitude d’aspirer les données de leurs utilisateurs (et des autres aussi d’ailleurs) mais on ne pense pas souvent à leur poids démesuré dans le domaine du mail.
Google, c’est gmail, Microsoft, c’est hotmail, live, msn et je ne sais quels autres domaines, etc. [Outlook.com. On l’oublie souvent. – Note du Framablog]
Tout ça représente un nombre plus que conséquent d’utilisateurs. Google revendiquait en 2015 900 millions de comptes Gmail. Bon OK, il y en a une part qui ne doit servir qu’à avoir un compte pour son téléphone Android, mais quand même. C’est énorme.
Ce qui nous ramène à une situation des plus déplaisantes où un petit nombre d’acteurs peut en em***er une multitude.
WARNING : la liste à puce qui suit contient des exemples techniques un poil velus. Nos notes vous aideront à y survivre, mais vous avez le droit de la passer pour lire la suite des réflexions de Luc. Ah, et puis il a son franc-parler, le loustic. ^^ – NdF.
Petits exemples vécus :
Microsoft bloque tout nouveau serveur mail qu’il ne connaît pas. C’est arrivé pour mon serveur perso, le serveur de mail de Framasoft que j’ai mis en place, sa nouvelle IP [l’adresse qui permet d’indiquer où trouver un serveur – NdF] quand je l’ai migré, le serveur de listes de Framasoft et sa nouvelle IP quand je l’ai migré. Ça me pétait une erreur 554 Message not allowed (de mémoire, je n’ai plus le message sous la main) [erreur qui fait que l’email est tout bonnement refusé – NdF]. Et pour trouver comment s’en débrouiller, bon courage : la page d’erreur de Microsoft n’indiquait rien. Je n’ai même pas trouvé tout seul (et pourtant j’ai cherché) : c’est un ami qui m’a trouvé la bonne adresse où se faire dé-blacklister (notez au passage qu’il est impossible de faire dé-blacklister une adresse ou un bloc d’adresses IPv6 [la nouvelle façon d’écrire les adresses IP, indispensable face à la croissance du nombre de machines connectées à Internet – NdF]).
Gmail qui, du jour au lendemain, décide de mettre tous les mails de mon domaine personnel en spam. Ce qui ne serait pas trop gênant (hé, les faux positifs, ça existe) si ce n’était pour une raison aberrante (ou alors c’est une sacrée coïncidence) : ça s’est passé à partir du moment où j’ai activé DNSSEC[une façon de sécuriser les échanges avec les serveurs DNS [ces serveurs sont les annuaires qui font correspondre une adresse web avec l’adresse IP difficile à retenir pour les humains – NdF²]] sur mon domaine. Et ça s’est terminé dès que j’ai ajouté un enregistrement SPF[une vérification que les emails envoyés ne sont pas usurpés – NdF] à ce domaine. Or le DNSSEC et le SPF n’ont rien à voir ! Surtout pas dans cet ordre-là ! Qu’on ne fasse confiance à un enregistrement SPF que dès lors que le DNS est de confiance (grâce à DNSSEC), soit, mais pourquoi nécessiter du SPF si on a du DNSSEC ? [Oui, pourquoi ? – NdF qui laisse cette question aux spécialistes]
Yahoo. Ah, Yahoo. Yahoo a décidé de renforcer la lutte contre le spam (bien) mais a de fait cassé le fonctionnement des listes de diffusion tel qu’il était depuis des lustres (pas bien). En effet, quand vous envoyez un mail à une liste de diffusion, le mail arrive dans les boîtes des abonnés avec votre adresse comme expéditeur, tout en étant envoyé par le serveur de listes [le serveur de listes se fait passer pour vous, puisque c’est bien vous qui l’avez envoyé par son intermédiaire… vous suivez ? – NdF]. Et Yahoo a publié un enregistrement DMARC[une sécurité de plus pour l’email… heureusement que Luc a mis des liens wikipédia, hein ? – NdF] indiquant que tout mail ayant pour expéditeur une adresse Yahoo doit impérativement provenir d’un serveur de Yahoo. C’est bien gentil, mais non seulement ça fout en l’air le fonctionnement des listes de diffusion, mais surtout ça met le bazar partout : les serveurs de mail qui respectent les enregistrements DMARC appliquent cette règle, pas que les serveurs de Yahoo. Notez qu’AOL fait la même chose.
Orange fait aussi son chieur à coup d’erreurs Too many connections, slow down. OFR004_104 [104][« trop de connexions, ralentissement », une erreur qui fait la joie des petits et des grands admin-sys – NdF]. C’est tellement connu que le moteur de recherche Google suggère de lui-même wanadoo quand on cherche Too many connections, slow down. Voici la solution que j’ai utilisée.
Pour s’en remettre, voici une image qui fait plaisir…
On peut le voir, le pouvoir de nuisance de ces silos est énorme. Et plus encore dans le cas de Yahoo qui n’impacte pas que les communications entre ses serveurs et votre serveur de listes de diffusion, mais entre tous les serveurs et votre serveur de listes, pour peu que l’expéditeur utilise une adresse Yahoo [on confirme : dès qu’une personne chez Yahoo utilisait Framalistes, ça devenait un beau bord… Bref, vous comprenez. Mais Luc a lutté et a fini par arranger tout cela. – NdF]. Et comme il y a encore pas mal de gens possédant une adresse Yahoo, il y a des chances que vous vous rencontriez le problème un jour ou l’autre.
Je sais bien que c’est pour lutter contre le spam, et que la messagerie propre devient si compliquée que ça pourrait limite devenir un champ d’expertise à part entière, mais le problème est que quand un de ces gros acteurs tousse, ce sont tous les administrateurs de mail qui s’enrhument.
Si ces acteurs étaient de taille modeste, l’ensemble de la communauté pourrait soit leur dire d’arrêter leurs bêtises, soit les laisser crever dans leurs forteresses injoignables. Mais ce n’est malheureusement pas le cas. 🙁 « À grand pouvoir, grandes responsabilités »… Je crois avoir montré leur pouvoir de nuisance, j’aimerais qu’ils prennent leurs responsabilités.
Ils peuvent dicter leur loi, de la même façon qu’Internet Explorer 6 le faisait sur le web il y a des années et que Chrome le fait aujourd’hui (n’ayez pas peur, le titre de la vidéo est en anglais, mais la vidéo est en français). C’est surtout ça qui me dérange.
Une seule solution pour faire cesser ce genre d’abus : la dégooglisation ! Une décentralisation du net, le retour à un Internet d’avant, fait de petites briques et pas d’immenses pans de béton.
PS : ne me lancez pas sur MailInBlack, ça me donne des envies de meurtre.
À force de les rencontrer sur des événements libristes comme les RMLL et POSS, nous avons demandé aux ambassadeurs français d’openSUSE de nous parler de leur distribution GNU/Linux.
Salut ! Présentez-vous. Comment justifiez-vous votre existence ?
Nicolas : Je viens d’un monde pur Windows. Un jour j’ai dû monter un petit serveur web où je devais installer une version Linux de mon choix sans rien y connaître. J’ai trouvé un tuto openSUSE 10.3 expliquant comment installer un serveur Apache + PhP en deux clics avec Yast-HTTP et je suis tombé dedans. Ensuite j’ai voulu tester sur mon PC pour virer mon Windows XP LSD (si, si…). J’ai commencé en 2005 avec un dual boot pour terminer exclusivement sous openSUSE depuis 2008. J’ai pris part à la communauté, puis à la création de l’association loi 1901 en 2012 en tant que secrétaire. L’an dernier j’ai repris le flambeau en devenant président.
Formaliser une association pour la promotion d’openSUSE en France était une nécessité pour faciliter la présence des membres et ambassadeurs openSUSE aux salons. Ils étaient reconnus par le programme openSUSE international mais pas forcément légitimes vis-à-vis des organisateurs locaux. On a un système d’adhésion qui couvre le budget hébergement. Quant aux goodies en version française et les clés USB, on vend à prix coûtant pour autofinancer les rééditions. Une année on était en galère mais on a eu la chance d’avoir du sponsoring de SUSE France qui nous soutient quand ils le peuvent, que ce soit financièrement ou matériellement au travers de goodies, etc. C’est appréciable de reproduire dans l’hexagone la synergie entre la communauté opensource et l’entreprise.
Antoine : openSUSE est la première distribution que j’ai utilisée. Je l’ai découverte en 2008, dans un magazine Linux. Des amis à moi utilisaient Ubuntu et m’avait convaincu d’essayer mais je n’avais trouvé que ce magazine, avec un DVD d’openSUSE (10.3) à l’intérieur. J’ai accroché : le changement, le vert, le caméléon comme logo. Bref, je l’ai installée (dual-boot), cassée, réinstallée, recassée, etc. J’ai appris plein de trucs, notamment grâce au forum Alionet. J’ai depuis essayé d’autres distributions, « en dur » mais aussi dans des machines virtuelles. Au final, je reviens toujours vers openSUSE, parce que c’est là où je me sens le mieux.
J’ai commencé à écrire des news sur Alionet en 2014, après la mort de jluce, un des admins du site qui en écrivait plein. Je trouvais dommage de ne pas essayer de continuer ce qu’il avait commencé. J’écris des articles sur openSUSE, pour informer de l’actualité du projet ; parfois des tutos, notamment quand je vois plusieurs personnes ayant une même difficulté sur le forum ; et enfin, sur tout ce qui touche au libre en général.
Qu’est-ce qui différencie openSUSE des autres distros ?
À mon sens, c’est une distribution qui s’adresse aussi bien aux débutants qu’aux utilisateurs avancés (powerusers) avec un certain nombre de qualités :
La distribution répond aussi bien à des besoins de poste de travail, d’ordinateur portable ou encore de serveur (elle partage le même core SUSE Linux Entreprise Server). Je l’utilise sur mes propres serveurs qu’ils soient physiques ou virtualisés, mes stations de travail fixes ou portables. Quelle que soit l’utilisation, ce qu’appréciera l’utilisateur, c’est sa stabilité. D’ailleurs, il existe également des images ARM pour les Raspberry Pi, Pi2 et Pi3.
L’ensemble des environnements graphiques proposés ont le même degré de finition et d’intégration dans la distribution que ce soit sur l’ISO de base : KDE (défaut), GNOME (mon bureau par défaut), LXQt, XFCE mais aussi via les dépôts en ligne pour MATE ou Cinnamon ou encore Enlightenment.
L’outil d’administration Yast est un atout indéniable pour administrer la machine que ce soit les dépôts en ligne, l’ajout/suppression de logiciel, la gestion des services, des utilisateurs, etc. De nombreux modules sont disponibles et de nouveaux arrivent régulièrement pour suivre les évolutions technologiques comme Snapper pour gérer les instantanés (snapshots) du système de fichiers Btrfs ou encore celui pour gérer des conteneurs Dockers.
Pour les utilisateurs débutants il est possible d’installer via Yast un serveur web, FTP ou email en quelques clics. Idéal pour avoir une base fonctionnelle et ensuite « mettre les mains dedans ». D’ailleurs l’édition manuelle, n’invalide pas l’utilisation de YaST dans la majorité des cas.
Si l’utilisateur avancé ne veut pas utiliser Yast, il est tout à fait en droit d’éditer les fichiers de configurations manuellement et d’utiliser Zypper pour la gestion des paquets (un équivalent robuste de apt-get des familles DEB). Les administrateurs systèmes apprécieront également le dernier projet né : Machinery, un outil pour GNU/Linux afin d’inspecter les configurations des machines.
Ce que j’apprécie justement dans la communauté openSUSE c’est que les outils ne sont pas élitistes et profitent également aux autres distributions. Prenons par exemple l’outil OpenBuildService (OBS) qui est une forge utilisée pour construire des packages. L’instance publique utilisée pour les différentes versions d’openSUSE (et de SLES) est ouverte aux contributions, actuellement l’openSUSE Build Service héberge 47 593 projets, pour un total de 402 280 paquets dans 77 223 dépôts et est utilisée par 45 616 personnes. Il est simple et ouvert à tous de se créer un compte et packager sur cette plate-forme sans pour autant se limiter à *SUSE seulement, ni aux plates-formes Intel. Votre paquet peut-être construit pour toutes les distributions majeures (RHEL, CentOS, Fedora, SLES, openSUSE, Debian, Ubuntu, Mageia, AchLinux, etc) avec le support matériel allant des processeurs ARM jusqu’au mainframe. D’ailleurs le projet VLC utilise sa propre instance de l’OBS pour packager l’ensemble des versions du célèbre logiciel. L’instance privée permettant également la construction de logiciels pour les plateformes Windows.
Pourquoi est-elle moins connue en France qu’en Allemagne ?
Elle n’est pas populaire qu’en Allemagne, de nombreux pays l’utilisent et ce n’est pas pour rien qu’elle est souvent entre la troisième et cinquième place sur DistroWatch.
En revanche, c’est indéniable, elle reste méconnue en France. Je pense qu’il y a plusieurs raisons à cela.
D’une part, c’était une distribution payante à la base, elle n’est devenue gratuite sous l’appellation openSUSE qu’à partir la version 10.
Quand j’ai démarré Linux en 2004, j’ai commencé avec Ubuntu car j’avais des problèmes de reconnaissance de matériel, ce qui s’est clairement amélioré par la suite. À présent, je ne rencontre plus de difficulté de support matériel que ce soit sur de l’assemblé ou du constructeur même si bien évidemment, je me documente avant d’acheter. Un autre manque était le nombre de logiciels disponibles mais là encore la communauté a largement rattrapé son retard.
Ensuite, il y a eu le « scandale » des accords Novell Microsoft alors que Novell possédait SUSE. Paradoxalement, même si tout le monde a crucifié la distribution, c’est cette collaboration qui a permis à l’ensemble des distributions Linux de s’insérer sur un réseau géré en active directory 100% Windows. Comme je me fais souvent troller sur les stands avec cela, je tiens d’ailleurs à préciser que suite au rachat de Novell par Microfocus, SUSE et Novell sont deux entités distinctes et les accords liaient spécifiquement Novell et Microsoft, SUSE n’est donc plus concerné.
Pour toutes ces raisons, je pense que la communauté francophone est en retrait par rapport aux autres mais dès que l’on franchit les frontières de l’Hexagone, ce n’est plus la même répartition. C’est d’autant plus frustrant que lors d’événements du type RMLL, Solutions Linux, Paris OpenSource Summit, Capitole du Libre, des personnes viennent nous revoir d’une année à l’autre en nous disant qu’elles ne regrettent pas d’avoir essayé notre caméléon. Elles n’ont pas eu besoin de venir sur le forum chercher de l’aide. Comme toujours, les personnes qui s’inscrivent ont généralement des problèmes à résoudre, il manque les autres pour qui tout s’est bien passé.
En tout cas c’est moins facile d’avoir de l’aide… Moi aussi, je me suis battu avec une carte réseau récalcitrante et j’ai laissé tomber. Dommage, j’aimais bien. Comment on fait quand on galère ?
La communauté openSUSE francophone est clairement moins importante que celles d’autres distributions. C’est l’histoire de l’œuf ou la poule : est-ce que la communauté est petite à cause de sa popularité dans l’Hexagone ou est-ce l’inverse ?
Il existe néanmoins des moyens de trouver de l’aide sur openSUSE :
Bref, un éventail de plate-formes pour essayer de correspondre à chacun.
Vous avez tout le temps plein de goodies. Il y a des sous dans openSUSE ? Quel est le modèle économique ?
openSUSE est financée en majeure partie par SUSE, qui a lancé la distribution. L’entreprise encourage ses ingénieurs à participer à openSUSE. Du coup ils peuvent bosser sur la distribution sur une partie de leur temps de travail. Il y a aussi d’autres entreprises qui font des dons de matériel (notamment les machines pour l’openSUSE Build Service).
Concernant les goodies, lorsqu’on est ambassadeur openSUSE, il est possible via le wiki + email de prétendre à un kit stand. Il faut indiquer l’événement, le volume de personnes attendues, etc. openSUSE envoie alors un kit stand que nous devons redistribuer gratuitement. (nappe, 2 t-shirts, flyers en anglais).
En parallèle l’association Alionet a pris plusieurs initiatives :
Prendre contact avec SUSE France avec qui nous avons d’excellents contacts pour quelques goodies supplémentaires.
Éditer sur le budget de l’association propre des t-shirts et clés USB car nous n’en avions pas de la part de nos partenaires.
Nous prenons en charge l’impression de documents en français puisque openSUSE ne fournit que des informations en anglais.
Pourquoi est-elle passée en rolling release ?
En fait, elle n’est pas passée en rolling release. 😉
Le projet propose maintenant deux distributions : une « classique », openSUSE Leap, la distribution principale, l’héritière de l’openSUSE que l’on connaissait jusqu’à l’an dernier. La dénomination Leap souligne le fait qu’il y a eu un changement dans la façon de construire la distribution, en faisant une base commune avec SUSE Linux Enterprise (SLE) la distribution commerciale de SUSE. Un « saut » qui s’est traduit également dans le numéro de version : 13.2 -> 42.1.
Une en rolling release effectivement : openSUSE Tumbleweed (« virevoltant » en anglais). Elle, c’est l’héritière de « Factory », une base de code instable qui servait aux contributeurs du projet à mettre au point openSUSE ancienne formule (avant Leap). Cette base de code a évolué, s’est dotée de nouveaux outils pour finalement être considérée comme « stable » – dans le sens où ça ne casse pas, mais bien sûr ça bouge vite – et être appelée Tumbleweed.
Pourquoi faire ça ? Pour mieux répondre aux besoins de chacun : ceux qui ont besoin d’une grande stabilité ou ne veulent pas beaucoup de changements sur leur système peuvent utiliser Leap, ceux qui veulent des logiciels toujours plus récents (mais stables ; pas des préversions ou très peu) peuvent utiliser Tumbleweed.
Quoi de neuf dans la nouvelle version, justement ?
Une des nouvelles les plus intéressantes est l’arrivée de Plasma 5.8.1, la toute dernière version du bureau KDE. C’est une version estampillée LTS, c’est-à-dire que KDE va se focaliser sur la stabilité et la durée pour cette version, ce qui colle avec les objectifs de Leap. Pour la petite histoire, openSUSE et KDE se sont mis d’accord pour que leurs calendriers respectifs collent et que Leap 42.2 puisse intégrer dans de bonnes conditions cette nouvelle version de Plasma. Et pour la deuxième petite histoire : KDE chez openSUSE, c’est entièrement géré par la communauté (ça ne vient pas de SLE).
Pour les amateurs de cartes et d’embarqué, de nouveaux portages pour ARM sont disponibles.
Pour les amateurs de nouveaux systèmes de fichiers : Snapper peut utiliser les quotas Btrfs pour gérer le nettoyage des snapshots.
Pas à ma connaissance. Il y a peut être eu des signes en amont qui expliqueraient pourquoi openSUSE a revu son mode de fonctionnement en proposant deux versions : Leap et son rapprochement avec la version SUSE Linux Entreprise et la rolling release Tumbleweed face à la popularité d’Archlinux par exemple.
Ce que je constate en revanche, c’est le déclin de communauté d’entraide en général. La montée des réseaux sociaux a tué les bons vieux forums d’entraide et les mentalités ont changé. On peine à recruter des bonnes volontés mais ce n’est pas un problème exclusif à Alionet.
Comment peut-on aider au développement d’openSUSE ?
Une petite liste non-exhaustive de choses que l’on peut faire pour participer :
En parler à ses amis/ses collègues/son LUG pour mieux faire connaître les distribs ;
Demander, on trouvera quelque chose à vous faire faire ^^
Le mot de la fin est pour vous
openSUSE est un projet global vraiment passionnant avec une communauté internationale très ouverte. Sa communauté francophone bien que peu nombreuse n’en est pas moins réactive et les personnes ont toujours trouvé des réponses à leurs questions.
N’hésitez pas à tester cette distribution et à venir à notre rencontre. 🙂
Hé, en vrai, tu sais comment ça marche, toi, Wikipédia ?
Tout le monde connaît Wikipédia, chacun et chacune a son petit avis dessus, mais sait-on réellement comment cette encyclopédie collaborative fonctionne ?
Il y a 20 ans, lorsque, lors d’une soirée entre ami-e-s, on se posait une question du genre « Mais attends, comment on fait l’aspirine ? » le dialogue était souvent le même :
– Je sais pas, c’est pas avec de l’écorce de saule ?
– Oui mais ça doit être chimique, maintenant, non ?
– Je sais pas, t’as pas une encyclopédie ?
– Si, dans la bibliothèque, mais la raclette est prête.
– Bon, tant pis.
…et on en restait là. Aujourd’hui, on sort un ordiphone, on cherche la réponse sur Wikipédia, et on passe la raclette à se chamailler sur la fiabilité d’une encyclopédie où « tout le monde peut écrire n’importe quoi ».
(au fait, pour l’aspirine, on fait comme ça.) Par NEUROtiker — Travail personnel, Domaine public, Lien
En vrai, avez-vous déjà essayé d’écrire n’importe quoi sur Wikipédia… ? Savons-nous seulement comment ça marche ? Comment les articles sont-ils écrits, modifiés, corrigés, vérifiés, amendés… ?
Ça peut être impressionnant, la première fois qu’on se dit « tiens, et si moi aussi je participais à l’élaboration d’une encyclopédie ? » On peut se sentir un peu perdu·e, pas vraiment légitime, ou tout simplement ne pas savoir par quel bout commencer…
Heureusement, les membres de la communauté Wikipédia et Wikmédia France (l’association des contributeurs et contributrices à la Wikipédia francophone), ont créé un MOOC, un cours ouvert gratuit et en ligne, pour nous faire découvrir les rouages du cinquième site le plus visité au monde, et nous apprendre à nous en emparer.
L’an dernier plus de 6 000 personnes se sont inscrites à ce cours. Fort-e-s de cette expérience, l’équipe rempile pour une deuxième édition, l’occasion pour nous de les interroger et de découvrir ce que proposera ce cours.
Bonjour, avant toute chose, est-ce que vous pourriez nous présenter Wikimédia France et vos personnes ?
Jules : Bonjour ! Wikimédia France est une association française à but non-lucratif dont l’objet est « de soutenir en France la diffusion libre de la connaissance, notamment l’encyclopédie Wikipédia. » Il y a souvent des confusions à ce sujet, alors clarifions : Wikipédia est totalement rédigée par des internautes bénévoles, qui s’organisent de manière autonome et déterminent les règles du site. L’association Wikimédia France soutient les contributeurs et l’encyclopédie, mais ne participe pas à la rédaction et n’a aucun pouvoir sur la communauté ; ce n’est d’ailleurs pas la seule association à soutenir l’encyclopédie. Natacha, Alexandre, Valentin et moi-même sommes des contributrices et contributeurs bénévoles de Wikipédia ; nous faisons partie de la douzaine de bénévoles qui conçoivent le WikiMOOC. Je suis par ailleurs salarié de Wikimédia France, qui soutient l’initiative.
Une des missions de Wikimédia France, c’est justement d’inciter qui le veut à contribuer à la Wikipédia francophone… C’est pour cela que vous proposez ce MOOC ? Les cours massivement ouverts et en ligne sont un bon moyen d’inciter aux apports ?
Jules : Oui, les MOOC cumulent plusieurs avantages : bien souvent gratuits, ils sont en ligne et permettent donc de toucher un public plus nombreux qu’avec des formations en présentiel, mais aussi plus diversifié. Le MOOC s’adresse d’ailleurs à toute la francophonie, et près de la moitié des inscrits ne sont pas français.
Alexandre: Le WikiMOOC est effectivement réalisé de manière à donner envie de contribuer. Petit à petit, l’apprenant est guidé vers la rédaction d’un article. Mais il y a des façons très diverses de contribuer : ajouter des sources, des photos, corriger la mise en page, linkifier, améliorer des ébauches d’articles… Une des nouveautés de la deuxième session du WikiMOOC est de présenter des témoignages de contributeurs pour qu’ils racontent ce qu’ils font. Il est aussi plus aisé de contribuer si on ne se sent pas un étranger dans le monde de Wikipédia. Le but du WikiMOOC est aussi de faire mieux connaître ce monde aux apprenant-e-s.
Si je crains que « n’importe qui puisse écrire n’importe quoi dans Wikipédia », ce MOOC me rassurera-t-il ?
Jules : Nous l’espérons, car les choses ne sont pas aussi simples ! L’affirmation initiale, néanmoins, est exacte : n’importe qui peut écrire n’importe quoi sur Wikipédia. Mais le n’importe quoi a de fortes probabilités de ne rester sur Wikipédia qu’une vingtaine de secondes tout au plus. Car il faut étayer toute affirmation par des sources, et des sources de qualité, dont on sait qu’elles sont fiables (pas un obscur blog anonyme, donc). Pour vérifier que cette règle est bien respectée, il y a notamment un groupe de contributrices et contributeurs qui surveillent en temps réel les modifications effectuées sur les 1,8 million d’articles de Wikipédia : on les appelle avec un brin d’humour « les patrouilleurs ». C’est à ce stade que sont annulés la plupart des canulars, « vandalismes » (les dégradations volontaires d’articles) et ajouts d’opinions personnelles (totalement proscrits : on ne donne jamais son avis personnel dans un article). Certaines modifications passent évidemment entre les mailles du filet et ne seront annulées que plusieurs heures ou plusieurs jours après, par d’autres contributeurs – on manque de bras pour tout vérifier !
Finalement, à qui s’adresse ce MOOC ? Aux personnes qui veulent juste en savoir plus ? À celles qui veulent contribuer activement mais ne savent pas comment ?
Valentin : À tout le monde ! On peut effectivement s’inscrire juste pour comprendre comment Wikipédia fonctionne. Mais ce MOOC est surtout un outil permettant en quelques semaines d’assimiler l’essentiel de ce qu’il faut pour contribuer correctement. Nous voulons que de nombreuses personnes s’emparent de cet outil pour désacraliser la contribution à Wikipédia. Tout le monde utilise Wikipédia en tant que consommateur, mais trop peu de personnes viennent contribuer.
Jules : On peut se sentir un peu perdu quand on commence sur Wikipédia, seul⋅e. Le WikiMOOC est justement parfait pour être guidé dans sa découverte de l’encyclopédie, de son fonctionnement et de sa communauté.
Alexandre : Pour moi qui suis aussi universitaire, le WikiMOOC est un fabuleux point d’entrée pour un cours de Wikipédia. J’essaye donc de synchroniser mes cours avec le WikiMOOC ce semestre pour y inscrire mes étudiant-e-s, et j’encourage les collègues à faire de même !
Comme Framasoft, Wikimédia France est une association qui vit du don… Or créer un MOOC coûte cher… Comment avez-vous pu réussir ce tour de force ?
Jules : La création d’un MOOC, pour une université, se compte toujours en dizaines de milliers d’euros. Nous n’en avons dépensé « que » (ça nous paraît énorme, à vrai dire) 7 500 pour la première édition : 2 500 pour la plateforme, FUN, et 5 000 pour la réalisation des vidéos, via une association de vidéastes amateurs, beaucoup moins cher qu’avec un professionnel ! Et moitié moins pour cette seconde édition. Notre force, c’est qu’il y a une douzaine de bénévoles, contributeurs et contributrices francophones, qui bossent sur le projet ; c’est cet investissement bénévole, en temps, qui nous permet de ne pas dépenser trop. Nous réalisons nous-mêmes beaucoup de tâches (créer des visuels, tourner certaines vidéos, concevoir des tutoriels interactifs…) qui dans une université seraient sous-traitées. Nous bénéficions tout de même d’une partie importante de mon temps salarié chez Wikimédia France, même si je m’investis aussi sur du temps bénévole.
Quand il y a une personne face caméra, il y en a souvent plein en coulisses 😉 By English: Credits to Habib M’henni / Wikimedia Commons – Own work, CC BY-SA 4.0, Link
En passant, on lit de l’équipe pédagogique que « Ces trois présentateurs et présentatrices font partie d’une équipe pédagogique plus large, riche de treize wikipédiens et wikipédiennes expérimenté·e·s ». Le langage épicène, qui permet d’éviter la discrimination d’un genre, vous tient à cœur pour la wikipédia francophone ?
Natacha : Le langage épicène (ou langage non sexiste) est un langage inclusif qui tente de ne pas favoriser un genre par rapport à l’autre. Il est utilisé notamment en Suisse et au Québec, surtout dans la fonction publique. Par ailleurs, nous avons un fossé des genres sur Wikipédia – 75 000 articles sur des femmes contre 450 000 biographies d’hommes et moins de 20 % de personnes contribuant sont des femmes – ce qui introduit parfois des biais dans la façon dont les sujets sont traités. La fondation Wikimedia (qui participe au financement de Wikimédia France) en a fait un sujet de priorité depuis qu’un article du New York Times a relevé ce problème en 2011.
Par ailleurs le WikiMOOC cible toute la communauté francophone, et nommer explicitement le genre féminin peut avoir un impact sur la participation des femmes à ce dernier, alors même qu’on cherche à augmenter le nombre de contributrices ce détail peut avoir son importance !
Jules : Natacha a su nous convaincre d’utiliser le langage épicène dans le WikiMOOC ;-). Mais celui-ci n’est pas en usage systématique sur Wikipédia en français, notamment en raison de sa lourdeur visuelle, et car il n’est pas (encore ?) répandu dans les usages. Or Wikipédia a tendance (rien de systématique) à suivre les usages de la langue.
D’ailleurs, on peut parfois ne pas être d’accord avec les choix faits dans les règles que s’impose la communauté Wikipédia (éligibilité des articles, traitement des genres et des personnes trans, application du point de vue…). Quelle est la meilleure manière de faire évoluer ces positions ?
Jules : Le meilleur moyen de faire évoluer les règles de Wikipédia, ou bien les consensus qui ont émergé au coup par coup pour chaque article, c’est de s’investir dans la communauté. On voit souvent des internautes débarquer, parfois très bien intentionnés, mais très maladroits : ils arrivent et veulent tout changer. Or les contributeurs et contributrices sont souvent sur leurs gardes, notamment parce qu’il y a régulièrement des tentatives d’entrisme et de manipulation de Wikipédia à des fins idéologiques et politiques (en faveur d’une personnalité politique par exemple). Ce sont des internautes qui veulent utiliser la notoriété de Wikipédia pour faire et défaire les notoriétés, pour passer leurs idées… alors que ce n’est pas le lieu. Bref, quand on est bien intentionné, il est primordial dans un premier temps de se familiariser avec les règles ainsi que les us et usages relatifs qui guident le déroulement les discussions et les décisions. Cela évite les maladresses, et ça permet de parler le même langage que les autres contributeurs et contributrices bénévoles. Ça instaure une confiance mutuelle.
Wikipédia, c’est une encyclopédie, mais aussi nombre d’autres projets visant à partager le savoir collaborativement… vous en parlerez dans ce MOOC ?
Alexandre : Le mouvement Wikimedia contient de nombreux projets en plus de Wikipédia, comme Wikimedia Commons qui est l’endroit où les fichiers multimédia Wikipédia-compatibles sont déposés. Comment ajouter une photo est une question qui revient souvent donc le sujet est abordé. Au delà, Wikipédia et les projets « sœurs » sont une excellente école pour comprendre les enjeux du copyright et de ses abus, ce que sont les licences Creative Commons et ce qu’elles représentent politiquement. La famille des projets Wikimedia correspond au seul projet libre (libre comme dans libre discours, pas comme dans libre bière 🙂 ) accessible au et connu du grand public. À ce titre, il est une sorte de porte étendard et pour moi, le WikiMOOC a aussi pour vocation de le promouvoir.
Bon c’est bien gentil tout ça, mais ça va me demander quoi de participer à ce MOOC ? Des milliers d’heures de travail ? Un ordi surpuissant dernier cri ? Une connaissance infaillible de la calcification des hydrogénocarbonates ?
Alexandre : le point commun de tous les MOOC, c’est qu’on peut se sentir libre de les aborder à sa manière : regarder seulement les vidéos, faire les exercices ou pas, s’intéresser à une semaine mais pas à l’autre. Dans le WikiMOOC, des mécanismes pédagogiques sont prévus pour inciter les apprenant-e-s à aller le plus en profondeur possible mais tout le monde doit se sentir libre (sauf mes étudiant-e-s qui seront noté-e-s, évidemment !).
Jules : Pour rebondir sur votre question, pas besoin d’ordi surpuissant, un navigateur web à jour suffit amplement. Pour suivre la totalité du cours, il faut compter au moins trois heures de travail par semaine, mais c’est très variable d’une personne à une autre !
Du coup, si je suis convaincu, qu’est-ce que je dois faire pour m’inscrire ?
Et, comme d’habitude sur le Framablog, on vous laisse le mot de la fin !
Jules : Soyez nombreux et nombreuses à vous inscrire pour aider à donner accès à la connaissance au plus grand nombre !
Si on laissait tomber Facebook ?
Le travail de Salim Virani que nous vous invitons à parcourir est remarquable parce qu’il a pris la peine de réunir et classer le très grand nombre de « petites » atteintes de Facebook à notre vie privée. Ce n’est donc pas ici une révélation fracassante mais une patiente mise en série qui constitue une sorte de dossier accablant sur Facebook et ses pratiques avouées ou inavouables. Vous trouverez donc de nombreux liens dans l’article et au bas de l’article, qui sont autant de sources.
Si comme nous le souhaitons, vous avez déjà renoncé à Facebook, il est temps d’en libérer vos proches : les références et les faits évoqués ici par Salim Virani seront pour vous un bon réservoir d’arguments.
Par quoi remplacer Facebook lorsqu’on va supprimer son compte ? Telle est la question qui reste le point bloquant pour un certain nombre de personnes. Bien sûr il existe entre autres Diaspora et ses divers pods (dont Framasphère bien sûr), mais Salim Virani répond plutôt : par de vrais contacts sociaux ! Avons-nous vraiment besoin de Facebook pour savoir qui sont nos véritables amis et pouvoir échanger avec eux ?
N’hésitez pas à nous faire part de votre expérience de Facebook et de ses dangers, dont le moindre n’est pas l’addiction. Saurons-nous nous dé-facebook-iser ?
Dites à ceux que vous aimez de laisser tomber Facebook
par Salim Virani
J’ai écrit ce qui suit pour ma famille et mes proches, afin de leur expliquer pourquoi les dernières clauses de la politique de confidentialité de Facebook sont vraiment dangereuses. Cela pourra peut-être vous aider aussi. Une série de références externes, et des suggestions pour en sortir correctement, se trouvent au bas de cet article.
Mise à jour 2017 : beaucoup des inquiétudes que j’avais se sont avérées fondées. Facebook a persévéré dans sa logique de mépris envers ses utilisateurs. J’ai actualisé cet article en y ajoutant quelques liens et arguments supplémentaires.
« Ah au fait, j’avais envie de te demander pourquoi tu quittes Facebook », telle est la question embarrassée qu’on me pose du bout des lèvres très fréquemment ces temps-ci. Genre vous savez plus ou moins que Facebook c’est mal, mais vous n’avez pas trop envie de savoir jusqu’à quel point.
J’ai été un grand supporter de Facebook – un des premiers utilisateurs de mon entourage à défendre ce moyen génial de rester en contact, c’était en 2006. J’ai fait s’inscrire ma mère et mes frères, ainsi qu’environ vingt autres personnes. J’ai même enseigné le marketing de Facebook à l’un des plus prestigieux programmes technologiques du Royaume-Uni, la Digital Business Academy. Je suis un technico-commercial – donc je peux voir les implications – et jusqu’à maintenant elles ne m’avaient pas inquiété plus que ça. Je ne prenais pas au sérieux les personnes qui hésitaient en invoquant des questions de vie privée.
Juste pour vérifier…
Pendant les vacances 2014/2015, j’ai voulu passer quelques minutes à vérifier les prochains changements dans la politique de confidentialité, avec une attitude prudente en me demandant « et si… ? ». Certaines éventualités étaient inquiétantes, en particulier concernant nos informations financières et de localisation, sans oublier tout le reste. En fait, ce que je soupçonnais a déjà eu lieu il y a deux ans, depuis 2011 ! Ces quelques minutes se sont changées en quelques jours de lecture. J’ai ignoré beaucoup d’affirmationspas qui, selon moi, peuvent être expliquées comme des accidents (« techniquement plausibles » ou « techniquement fainéantes »).
Après tout, je suis moi-même le fondateur d’une start-up, et je sais à quel point les questions techniques peuvent être complexes. Par exemple, les droits d’accès excessifs demandés par l’application Facebook pour Android proviennent d’un problème technique étroitement lié à Android. Mais il restait encore beaucoup de préoccupations concernant la protection de la vie privée, et j’ai croisé ces faits avec des techniques que je sais être standards dans le marketing basé sur les données.
Avec ces derniers changements de confidentialité le 30 janvier 2015, j’ai peur.
Facebook a toujours été légèrement pire que toutes les autres entreprises technologiques avec une gestion louche de la confidentialité ; mais maintenant, on est passé à un autre niveau. Quitter Facebook n’est plus simplement nécessaire pour vous protéger vous-même, c’est devenu aussi nécessaire pour protéger vos amis et votre famille. Cela pourrait être le point de non-retour – mais il n’est pas encore trop tard pour reprendre le contrôle.
Une petite liste de pratiques de Facebook
Il ne s’agit plus simplement des informations que Facebook dit qu’il va prendre et ce qu’il va en faire ; il s’agit de tout ce qu’il ne dit pas, et qu’il fait tout de même grâce aux failles qu’ils se sont créées dans les Conditions de Service, et la facilité avec laquelle ils reviennent sur leurs promesses. Nous n’avons même plus besoin de cliquer sur « J’accepte ». Ils modifient simplement la politique de confidentialité, et en restant sur Facebook, vous acceptez. Et hop !
Aucune de vos données sur Facebook n’est sécurisée ni anonyme, quels que soient vos paramètres de confidentialité. Ces réglages sont juste des diversions. Il y a des violations de confidentialité très sérieuses, comme la vente de listes des produits que vous recommandez à des annonceurs et des politiciens, le pistage de tout ce que vous lisez sur Internet, ou l’utilisation des données de vos amis pour apprendre des informations privées sur vous – aucune de ces pratiques n’a de bouton « off ». Pire encore, Facebook agit ainsi sans vous le dire, et sans vous révéler les dommages que vous subissez, même si vous le demandez.
Facebook donne vos données à des « tiers » via les applications que vous utilisez, puis il affirme que c’est vous qui le faites, pas eux. À chaque fois que vous utilisez une application connectée à Facebook, vous autorisez Facebook à échapper à sa propre politique de confidentialité avec vous et vos amis. C’est comme quand mon frère me forçait à me frapper moi-même, puis me demandait « Pourquoi tu te frappes tout seul ? ». Et il allait dire à ma mère que ce n’était pas de sa faute.
En creusant un peu, j’ai découvert tout le pistage que fait Facebook – et je l’ai vérifié avec des articles de sources connues et réputées, ainsi qu’avec des études qui ont été examinées minutieusement. Les liens sont dans la section Source à la fin de ce post.
Ça semble fou quand on met le tout bout à bout !
Facebook crée de fausses recommandations de produits venant de vous pour vos amis – et ils ne vous le disent jamais.
Quand vous voyez un bouton « J’aime » sur le web, Facebook est en train de repérer que vous êtes en train de lire cette page. Il parcourt les mots-clés de cette page et les associe avec vous. Il sait combien de temps vous passez sur les différents sites et les différents sujets.
Ils repèrent votre localisation et l’utilisent pour trouver des informations sur vous, si par exemple vous êtes malade (si vous êtes chez un médecin ou un spécialiste), avec qui vous couchez (qui est à vos côtés pendant la nuit), où vous travaillez, si vous êtes en recherche d’emploi (un rendez-vous d’une heure dans les bureaux de la concurrence), etc.
Ils ont organisé des campagnes de quasi-dénonciation pour inciter par la ruse les amis des gens à révéler des informations sur eux, alors qu’ils avaient décidé de les garder secrètes.
Ils utilisent l’énorme quantité de données qu’ils ont sur vous (avec vos « J’aime », ce que vous lisez, ce que vous écrivez mais que vous ne publiez pas) pour créer des profils très précis de qui vous êtes – même si vous faites tout pour garder ces choses secrètes. Il y a des techniques statistiques, qui existent depuis des décennies en marketing, pour trouver des modèles comportementaux en corrélant les actions et les caractéristiques d’une personne. Même si vous n’avez jamais publié quoi que ce soit, ils peuvent facilement déduire vos âge, sexe, orientation sexuelle et opinions politiques. Quand vous publiez, ils en déduisent beaucoup plus. Puis ils le révèlent aux banques, aux compagnies d’assurances, aux gouvernements et, évidemment, aux annonceurs.
« Je n’ai rien à cacher »
Pourtant, beaucoup de gens ne s’en inquiètent pas, estimant qu’ils n’ont rien à cacher. Pourquoi s’intéresseraient-ils à ma petite personne ? Pourquoi devrais-je m’inquiéter de cela alors que je ne fais rien de mal ?
L’histoire est désormais célèbre : une adolescente enceinte a vu sa grossesse révélée au grand jour par le magasin Target, après que ce dernier a analysé ses données d’achat (sacs à main plus grands, pilules contre le mal de tête, mouchoirs…) et a envoyé par erreur un message de félicitations à son père, qui n’était pas au courant. Oups !
Il arrive la même chose à vos données, qui sont révélées à n’importe quelle entreprise sans contrôle de votre part. Et cela se traduit par les différentes manières dont vos données peuvent révéler des choses vous concernant à des entités que vous ne souhaitez pas mettre au courant.
L’un des problèmes les plus évidents ici concerne les compagnies d’assurance. Les données qu’elles récoltent sur vous sont exploitées pour prédire votre futur. Aimeriez-vous qu’on vous refuse une assurance santé sous prétexte qu’un algorithme a prédit à tort que vous aviez commencé à consulter un cardiologue ?
Et si votre employeur ou futur employeur savait que vous êtes peut-être enceinte ?
Aimeriez-vous que votre patron soit au courant quand vous n’êtes pas réellement cloué au lit, ou quand vous cherchez un autre job ?
Aimeriez-vous que n’importe qui soit au courant si vous avez des difficultés à payer votre prêt ? Si vous vendez votre maison, les acheteurs sauront qu’ils sont en position de force.
Même si nous avons pour la plupart d’entre nous le sentiment que nous n’avons rien à cacher, nous nous retrouvons tous parfois dans des situations où nous avons besoin que certaines choses restent secrètes, au moins pendant un temps. Mais nous renonçons à cela – et pour quelle raison ?
Extraits des « Conditions d’utilisation » (et non « Politique de confidentialité », vous voyez l’astuce ?)
Vous nous donnez permission d’utiliser votre nom, image de votre profil, le contenu et les informations en lien avec des activités commerciales, soutiens sponsorisés et autres contenus (comme les marques que vous aimez), proposés ou mis en avant par nos soins.
Plus bas :
Par « information » nous voulons dire les données et autres informations qui vous concernent, ce qui inclut les faits et gestes des utilisateurs et des non-utilisateurs qui interagissent avec Facebook.
Donc cela inclut tout ce qu’ils collectent sur vous mais sans vous le dire. Tout ce que vous lisez sur Internet, tout ce qu’on a jamais publié à votre propos, toutes vos transactions financières privées.
De plus, vos données commencent à être combinées avec les données de vos amis pour faire un modèle encore plus précis. Il ne s’agit pas que de vos données, mais ce que l’on obtient quand on combine tout ensemble.
Le problème n’est pas ce que nous avons à cacher, il s’agit de garantir le droit fondamental à notre liberté – lequel est notre droit à la vie privée
Nul ne sera l’objet d’immixtions arbitraires dans sa vie privée, sa famille, son domicile ou sa correspondance, ni d’atteintes à son honneur et à sa réputation.
Nous avons le droit de dire un mot sur la façon dont ces informations seront utilisées. Mais en utilisant Facebook, nous les abandonnons volontairement, pas seulement les nôtres mais aussi celle de nos amis, de notre famille !
Si vous admettez avoir commis quelque chose d’illégal dans les messages privés de Facebook, ou si vous avez simplement mentionné un soutien à une action politique, cela pourra être utilisé contre vous à l’avenir, tout particulièrement par un gouvernement étranger. Vous pouvez être arrêté simplement parce que vous étiez au mauvais endroit au mauvais moment, ou être mis à l’écart à l’aéroport un jour, pour risquer de la prison car vous avez révélé que vous avez fait quelque chose d’illégal il y a 5 ans. Un comédien New Yorkais a vu une équipe SWAT (un groupe d’intervention policière américaine musclé) entrer dans son appartement pour une blague sur Facebook. Les forces de l’ordre commettent souvent des erreurs, et vous leur donnez plus de pouvoir et plus de chance d’être dans l’erreur. Vous rechargez le fusil, le pointez sur votre tempe, et le donnez à n’importe quel « applicateur de la loi » à la gâchette facile capable d’acheter vos données personnelles.
Pas besoin de parler d’une hypothétique surveillance gouvernementale ici. L’un des premiers investisseurs de Facebook, Greylock, a un conseil d’administration en lien avec la CIA via une entreprise appelée In-Q-Tel. Selon leur site web, ils « identifient les technologies de pointe pour aider la CIA et plus largement l’intelligence américaine à poursuivre leur mission ». Et si vous n’êtes toujours pas au courant, il a été révélé que les données de Facebook ont été livrées directement au programme PRISM.
Les courtiers en données commerciales
Et comme je l’explique plus loin, ces informations se retrouvent de toute façon en grande partie publiquement accessible. Pas besoin des programmes de la NSA, les entreprises de données marketing s’en occupent, en dés-anonymisant toutes vos données pour les vendre encore et encore. C’est fait systématiquement et automatiquement. Il y a toute une industrie autour de ça. Il y a des places de marché pour acheter et vendre les données des consommateurs, qui étaient bâties originellement autour des agences de crédit et des entreprises de publipostage, puis qui ont évolué avec l’industrie de la barre d’outil de navigateur, quand Internet Explorer était répandu – maintenant il y a encore plus d’informations qu’avant. Un exemple récent est RapLeaf qui a collecté et publié des informations identifiables personnellement, y compris des identifiants Facebook et MySpace.
Ils ont arrêté suite à une sérieuse controverse, mais non seulement le mal avait été fait, mais il y a eu d’autres entreprises qui ont échappé à cette mauvaise publicité et ont continué ces pratiques. Il ne s’agit pas de la façon dont les commerciaux vous adressent des publicités ciblées : le problème, c’est que vos données sont achetées et vendues pour cela.
Dans quel pays envisagez-vous de partir en voyage ? Êtes-vous d’accord pour confier toutes ces informations sur vous aux forces de l’ordre de ce pays ? Parce que, sachez-le : elles les achètent.
Le truc, c’est qu’il n’y a pas besoin d’approuver une théorie du complot pour être concerné. Mark Zuckerburg lui-même a été très clair publiquement avec ses investisseurs à propos de ses intentions :
1) Être l’intermédiaire de toutes les communications personnelles.
C’est pour cela qu’ils ont conçu Messenger et acheté WhatsApp, mais n’oubliez pas qu’ils ont essayé pire. Quand ils ont lancé les emails Facebook, ils ont profité des utilisateurs qui avaient synchronisé leurs contacts Facebook. Ils ont fait en sorte que l’adresse @facebook.com soit l’adresse par défaut pour tout le monde. Pourquoi ? Pour que vos amis vous envoient des e-mails sur votre adresse @facebook.com au lieu de votre adresse normale, ce qui leur permettra de lire vos correspondances.
2) Rendre publiques toutes les communications privées au fil du temps.
C’est pour cela qu’ils ont lentement changé les paramètres de vie privée par défaut vers public, rendu les configurations de la vie privée de plus en plus difficiles à utiliser, et prétendent maintenant que leur outil d’aide à la vie privée va changer cela.
En réalité, il y a une foule de violations de la vie privée qui ne peuvent être désactivées, comme permettre aux publicitaires d’utiliser votre liste de contacts, couper la façon dont Facebook suit ce que vous lisez sur Internet, ou empêcher Facebook de collecter d’autres informations sur vous. Vous ne pouvez pas les désactiver !
Facebook ne vous laisse pas partager ce que vous voulez
Même si vous n’avez rien à cacher, inquiétez-vous du contraire, ce que Facebook choisit de cacher quand vous souhaitez le partager. Ils vous filtrent.
« Je voulais te demander pourquoi tu quittes Facebook » arrive généralement après quelque chose comme « Tu n’as pas vu mon post la semaine dernière ? ».
Si vous avez déjà eu cette conversation, vous aurez noté qu’il y a une grande différence entre vos attentes lorsque vous communiquez sur Facebook et ce qui arrive réellement. En gros, Facebook filtre vos posts suivant que les utilisateurs utiliseront plus Facebook ou non s’ils ne le voient pas.
On a l’impression que Facebook est la seule manière de rester en contact. Avec les photos et les commentaires. On a l’impression que tout le monde y est et qu’on y voit une bonne partie de leur vie.
En fait, un grand nombre de vos messages ne sont jamais vus par personne !
Et vous en manquez plein aussi. Même si ceux de vos amis vous arrivent, cela ne veut pas dire que les vôtres leur parviennent.
Les messages privés puent aussi. Combien de messages Facebook envoyés sans réponse ? À combien de messages Facebook pensez-vous avoir oublié de revenir plus tard, combien en manquez-vous simplement ? Est-ce comme ça que vous voulez traiter vos amis ?
Facebook est un moyen vraiment peu fiable pour rester en contact.
Le mois dernier (NdT : en 2015), j’ai simplement cessé d’utiliser Facebook. Quelque chose d’incroyable est arrivé. Les gens m’ont téléphoné, et on s’est vraiment donné de nos nouvelles. Ma famille était plus en contact. Mon frère m’a envoyé des courriels avec des nouvelles. Des amis sont venus chez moi me dire bonjour.
C’était, disons, social.
Censure politique
Facebook bloque des publications s’il y a du contenu politique qu’il n’aime pas. Ils ont bloqué des publications concernant Ferguson et d’autres manifestations politiques. Quand Zuckerberg a prétendument pété un câble et a banni les mots « vie privée » des réunions à Facebook, cela a aussi été censuré dans toutes les publications Facebook. Vous aviez juste un message d’erreur à propos de « contenu inapproprié ». Ouais, c’est ça ! Inapproprié pour qui ?
Pourtant, nous ne devrions pas être surpris. Facebook n’est pas une plate-forme neutre – nous devons être conscients des objectifs des gens qui sont derrière. Zuckerberg a révélé ses intentions publiquement. Le premier membre du conseil de Facebook aussi, Peter Thiel, un conservateur. Quand il était plus jeune, il a écrit un livre remettant en question le multiculturalisme à Stanford, et il soutient maintenant une théorie appelée le « Désir Mimétique » qui, parmi d’autres choses positives, peut utiliser les groupes sociaux des gens pour manipuler leurs désirs et leurs intentions (je suis un fan de Thiel quand il parle des startups – mais on oublie souvent que beaucoup de gens ne connaissent pas tout ceci).
Facebook va jusqu’à laisser des organisations politiques bloquer vos communications. Il suffit de quelques personnes pour classer comme offensant un article d’actualité, et il est supprimé du flux de tout le monde. Cette fonctionnalité est souvent détournée. Je peux bloquer n’importe quel article sur Facebook en convainquant quelques amis de le classer comme offensant. C’est de la censure facile et pas chère.
Mise à jour de 2017 : on a vu combien cela a affecté les élections des États-Unis. Les fils d’actualité des gens qui avaient des idées opposées étaient souvent filtrés, et pourtant des fausses actualités se sont facilement répandues facilement, parce que ces faux gros-titres renforcent nos convictions et nous sommes contents de les partager.
Tout cela confirme que c’est une mauvaise idée de compter sur Facebook pour communiquer avec des gens qui sont importants pour vous. Votre habitude d’utiliser Facebook implique que d’autres personnes doivent utiliser Facebook.
C’est un cercle vicieux.
En fait, cela nuit à vos relations avec beaucoup de gens, parce que vous pensez que vous êtes en contact avec eux, mais vous ne l’êtes pas. Au mieux, vous êtes en contact avec une version filtrée de vos amis. Ces relations s’affaiblissent, alors que vos relations avec des personnes qui publient du contenu qui plaît à Facebook prennent leur place.
Non seulement Facebook veut lire toutes vos communications, mais il veut aussi les contrôler.
Vous balancez vos amis
Même si vous pensez que tout ça ne vous pose pas trop de problèmes, en utilisant Facebook, vous forcez vos amis et votre famille à accepter la même chose. Même ceux qui ne sont pas sur Facebook, ou qui vont jusqu’à utiliser des faux noms.
Si vous avez déjà utilisé la synchronisation des contacts Facebook, ou si vous avez déjà utilisé Facebook sur votre téléphone, alors Facebook a récupéré la totalité de votre liste de contacts. Les noms, les numéros de téléphone, les adresses, les adresses électroniques, tout. Puis ils utilisent tout ça pour créer des « profils fantômes » des gens que vous connaissez et qui ne sont pas sur Facebook. Les internautes qui n’utilisent pas Facebook s’en aperçoivent souvent en recevant des e-mails qui contiennent leurs informations personnelles de la part de Facebook. Les internautes qui utilisent Facebook s’en aperçoivent aussi quand ils publient une photo d’un ami qui n’est pas sur Facebook, et qu’elle se retrouve automatiquement taguée. Mon ami n’est pas sur Facebook, mais comme d’autres amis et moi avons utilisé Facebook sur nos téléphones, Facebook connaît son nom et ses informations de contact, et sait aussi qui sont ses amis, puisqu’il peut le voir dans leur liste de contacts et leur journal d’appel. Il suffit de publier quelques photos avec son visage (ils peuvent l’identifier sur des photos), et voilà, ils peuvent ajouter les données de géolocalisation tirées des photos à son profil fantôme. Beaucoup d’autres techniques de Facebook fonctionnent aussi avec les profils fantômes. Et par-dessus le marché, ils peuvent déduire beaucoup de choses sur lui très précisément en s’appuyant sur des similitudes statistiques avec ses amis.
Donc en gros, on a tous balancé accidentellement nos amis qui voulaient préserver leur vie privée. Facebook nous a piégés.
Mais les pièges de Facebook vont encore plus loin.
La « vie privée » ne s’applique pas à ce que Facebook déterre
Tout comme les profils fantômes des gens, Facebook peut « deviner un like » en fonction d’autres informations qu’il possède sur vous, comme ce que vous lisez sur Internet ou ce que vous faites dans les applications quand vous vous y authentifiez avec Facebook ou ce qu’il y a sur votre facture de carte bleue (j’en parlerai davantage plus loin). Appelez cela un « like fantôme ». Cela leur permet de vous vendre à plus d’annonceurs.
Il y a déjà une vaste documentation sur la collecte de ces informations par Facebook. La technique du « like fantôme » est simplement une utilisation standard des techniques statistiques en marketing de base de données. Si vous lisez beaucoup sur ce sujet, vous l’aimez probablement. Ce genre de chose. Ces techniques sont utilisées en marketing depuis les années 80 et vous pouvez embaucher des étudiants en statistiques pour le faire, même si bien sûr, Facebook embauche les meilleurs du domaine et cherchent à faire avancer l’état de l’art en intelligence artificielle pour cela. En Europe, Facebook est légalement obligé de partager toutes les informations qu’il a sur vous, mais il refuse. Donc il y a encore une autre action en justice contre eux.
Les permissions
Au travers de son labyrinthe de redéfinitions des mots comme « information », « contenu » et « données », vous permettez à Facebook de collecter toutes sortes d’informations sur vous et de les donner à des annonceurs. Avec votre permission seulement, disent-ils, mais la définition de « permission » contient l’utilisation d’une application ou qui sait quoi d’autre.
Et vous pensiez que ces requêtes Farmville étaient embêtantes. À chaque fois que vous en voyez une, cet ami révèle vos informations à des « tiers ».
Vous voyez comment ça marche ? Vous dites à Facebook que c’est « uniquement pour vos amis », mais vos amis peuvent le révéler à un « tiers ». Et la plupart des applications qu’ils utilisent sont des « tiers ».
Donc en fait, tout ce que vous marquiez en « amis seulement » n’a pas grande importance. En étant sur Facebook, il y a bien plus d’informations à votre propos qui sont collectées, combinées, partagées et utilisées.
Ils disent qu’ils « anonymisent » ça, mais en réalité il n’y a qu’une étape pour le dés-anonymiser. Beaucoup de données anonymes, comme ce que vous postez et quand, vos photos, votre localisation à tel moment est suffisant pour un grand nombre d’entreprises qui relient ces données anonymes à vous – et les revendent (c’est pour cela que ça n’a pas d’importance que vous utilisiez un faux nom sur Facebook, vos données sont comme une empreinte digitale et permettront de vous associer à votre vrai nom).
En plus, ils permettent à toutes les applications Facebook d’avoir un accès complet à vos informations – avec votre nom et tout. Et même si vous n’utilisez jamais d’application sur Facebook, vos amis le font. Lorsqu’ils utilisent ces applications, ces amis partagent toutes vos informations pour vous. Il y a toute une industrie derrière.
Certaines choses ont bien un bouton « off », mais rappelez-vous que c’est temporaire, et comme Facebook l’a fait dans le passé, ils les réactiveront sans vous en avertir. Lorsque Facebook a démarré (et sans doute quand vous vous êtes inscrit) c’était clairement un endroit sûr pour partager avec vos amis. C’était leur grande promesse. Avec le temps, ils ont passé les paramètres de confidentialité à « public par défaut ». De cette façon, si vous vouliez toujours garder Facebook mais seulement pour vos amis, vous deviez trouver manuellement plus d’une centaine de paramètres sur d’innombrables pages cachées. Ensuite, ils ont abandonné ces paramètres pour forcer les informations à être publiques de toute façon.
Pourquoi est-ce que vous vous frappez tout seul ? 🙂
Vente de vos recommandations sans votre accord
Vous avez sûrement déjà remarqué des publicités Facebook avec une recommandation de vos amis en dessous. En gros, Facebook donne aux annonceurs le droit d’utiliser vos recommandations, mais vous n’avez aucun contrôle dessus. Cela ne concerne pas simplement quand vous cliquez sur un bouton « J’aime ». Il y a des cas connus de végétariens qui recommandent McDonald’s, d’une femme mariée heureuse qui recommande des sites de rencontres, et même un jeune garçon qui recommande un sex club à sa propre mère !
Ces cas étaient si embarrassants que les personnes concernées s’en sont rendu compte. Les gens les ont appelées. Mais dans la plupart des cas, ces « recommandations » ne sont pas découvertes – les gens pensent qu’elles sont vraies. C’est encore plus effrayant, car Facebook est largement utilisé pour la promotion politique, et la recommandation de produits. Les gens savent que j’ai déjà collecté des fonds pour le soutien d’enfants malades du cancer, donc cela ne les étonnera peut-être pas de voir une publicité où je recommande un programme chrétien d’aide aux enfants pauvres en Afrique. Mais je ne soutiens absolument pas les programmes qui ont une tendance religieuse, car ils sont connus pour favoriser les gens qui se convertissent. Pire, des gens pourraient s’imaginer des choses fausses sur mes convictions religieuses à partir de ces fausses recommandations. Et je passe sur tous les trucs à la mode sur les startups que je ne cautionne pas !
Ils profitent de la confiance que vos proches ont en vous
Nous n’avons aucun moyen de savoir si notre cautionnement a été utilisé pour vendre des conneries ineptes en notre nom. Je n’ai pas envie d’imaginer ma mère gâcher son argent en achetant quelque chose qu’elle pensait que je cautionnais, ou les investisseurs financiers de ma startup voir des publicités pour des produits inutiles avec mon visage en dessous.
Utiliser Facebook signifie que ce genre de chose se produit à tout moment. Les publicitaires peuvent acheter votre cautionnement sur Facebook et vos informations à des revendeurs de données extérieurs. Vous n’êtes jamais mis au courant de ça et vous ne pouvez pas le désactiver.
Les derniers changements en matière de vie privée
Finalement, je veux expliquer comment ce dernier changement dans nos vies privées engendre des choses encore pires, et la manière dont vous continuerez à en perdre le contrôle si vous restez sur Facebook.
L’usage de Facebook exige de vous suivre à la trace, de connaître ce que vous achetez, vos informations financières comme les comptes bancaires et les numéros de carte de crédit. Vous avez donné votre accord dans les nouvelles « conditions de service ». Ils ont déjà commencé à partager des données avec Mastercard. Ils utiliseront le fait que vous êtes restés sur Facebook comme « la permission » d’échanger avec toutes sortes de banques et institutions financières afin d’obtenir vos données d’eux. Ils diront que c’est anonyme, mais comme ils dupent vos amis pour qu’ils dévoilent vos données aux tiers avec des applications, ils créeront des échappatoires ici aussi.
Facebook insiste aussi pour suivre à la trace votre emplacement via le GPS de votre téléphone, partout et tout le temps. Il saura exactement avec qui vous passez votre temps. Il connaîtra vos habitudes, il saura quand vous appelez au travail pour vous déclarer malade, alors que vous êtes au bowling. « Machin a aimé : « bowling à Secret Lanes a 14h. » ». Ils sauront si vous faites partie d’un groupe d’entraide de toxicomanes, ou allez chez un psychiatre, ou un médium, ou votre maîtresse. Ils sauront combien de fois vous êtes allé chez le médecin ou à l’hôpital et peuvent le partager avec d’éventuels assureurs ou employeurs. Ils sauront quand vous serez secrètement à la recherche d’un travail, et vendront votre intérêt pour des sites de recherche de travail à vos amis et collègues – vous serez dévoilé.
Ils sauront tout ce qui peut être révélé par votre emplacement et ils l’utiliseront pour faire de l’argent.
Et – tout sera fait rétrospectivement. Si vous restez sur Facebook après le 30 janvier, il n’y a rien qui empêchera tout vos emplacements et vos données financières passés d’être utilisées. Ils obtiendront vos localisations passées avec vos amis vérifiés – donc avec vous, et les données GPS stockées dans les photos ou vous êtes identifiés ensemble. Ils extrairont vos vieux relevés financiers – ce médicament embarrassant que vous avez acheté avec votre carte de crédit il y a 5 ans sera ajouté à votre profil pour être utilisé selon les choix de Facebook. Il sera vendu à maintes reprises et probablement utilisé contre vous. Il sera partagé avec des gouvernements et sera librement disponible pour des tas d’entreprises « tierces » qui ne vendent rien que de données personnelles et éliminent irréversiblement votre vie privée.
Désormais c’est irréversible.
Les données relatives à votre géolocalisation et vos moyens financiers ne sont pas seulement sensibles, elles permettent à des entreprises tierces (extérieures à Facebook) de dés-anonymiser des informations vous concernant. Cela permet de récolter toutes sortes d’informations disponibles sur vous, y compris des informations recoupées que vous n’avez pas spécifiées. C’est un fait que même Facebook lui-même ne parvient pas à maintenir totalement le caractère privé des données – on ne peut pas dire que ça les préoccupe, d’ailleurs.
C’est sans précédent, et de même que vous n’avez jamais pensé que Facebook puisse revendre vos libertés lorsque vous vous êtes inscrits en 2009, il est trop difficile de prédire quels revenus Facebook et les vendeurs de données tiers vont tirer de cette nouvelle énergie dormante.
C’est simplement une conséquence de leurs nouveaux modèles économiques. Facebook vous vend au plus offrant, parce que c’est comme cela qu’ils font leur beurre. Et ils subissent des pressions monstrueuses de leurs investisseurs pour en faire plus.
Qu’est-ce que vous pouvez faire de plus à ce sujet ? Facebook vous offre deux possibilités : accepter tout cela ou sauter du bus Facebook.
Pour être honnête, ce bus est de plus en plus fou et pue un peu, n’est-ce pas ? Il y a de plus en plus de problèmes qui prennent des proportions sidérantes. Entre vous et moi, je doute que les choses s’orientent vers quelque chose de rationnel un jour…
Comment se tirer de ce pétrin
Image par Kvarki1 (CC BY-SA 3.0 ), via Wikimedia Commons
D’après la décision de justice rendue il y a quelques années par le FTC (Federal Trade Commission, NdT), après que Facebook a été poursuivi par le gouvernement des États-Unis pour ses pratiques en matière de vie privée, Facebook est « tenu d’empêcher que quiconque puisse accéder aux informations d’un utilisateur plus de 30 jours après que cet utilisateur a supprimé son compte ».
On peut l’interpréter de différentes façons. Certains disent qu’il faut supprimer chacune de vos publications, une par une ; d’autres disent qu’il faut supprimer votre compte, et d’autres disent qu’ils garderont vos données quand même – tout ce que vous pouvez faire, c’est arrêter de leur donner plus d’informations. Et puis, il y a les courtiers en données qui travaillent avec Facebook, qui ont déjà récupéré vos informations.
Donc supprimer votre compte Facebook (pas simplement le désactiver) est nécessaire pour arrêter tout ça, puis il y a quelques autres étapes à suivre pour tenter de réparer les dégâts :
Récupérez vos photos. J’ai utilisé cette application Android puisque l’outil Facebook ne vous permet pas de récupérer toutes vos photos, ni dans leur résolution maximale (j’ai aussi téléchargé la page avec ma liste d’amis, simplement en faisant défiler la page jusqu’en bas pour charger tout le monde, puis en cliquant sur Fichier -> Enregistrer. Honnêtement, je n’ai pas eu besoin du fichier jusqu’à présent. Il s’avère que je n’ai pas besoin d’un ordinateur pour savoir qui sont mes amis).
Ensuite, il y a toutes les applications que vous avez utilisées. C’est l’une des plus grosses failles de Facebook, car cela leur permet de dire qu’ils ne peuvent pas contrôler ce que les applications font avec vos données une fois que vous les leur avez données. Du coup, j’ai sauvegardé sur mon disque dur la page de paramètres qui montre quelles applications j’ai utilisées, et j’ai désactivé l’accès de chacune d’elles manuellement. Chacune de ces applications a sa propre politique de confidentialité – la plupart sont une cause perdue et prétendent avoir des droits illimités sur mes informations, donc je les coupe simplement et je passe à autre chose.
Facebook pourra toujours vous pister avec un « compte fantôme », mais cela peut-être bloqué.
Pour empêcher Facebook (et consort) de surveiller ce que je lis sur internet (ils le font même si vous n’avez pas de compte), j’utilise Firefox avec l’option « Ne pas me pister » activée.
Si vous n’utilisez pas Firefox, EFF a un plugin pour votre navigateur appelé Privacy Badger (et pendant que l’on y est, l’EEF a fait en sorte que ce plugin génial choisisse automatiquement le serveur qui dispose de la connexion la plus sécurisée, cela rend plus difficile d’intercepter votre activité numérique pour l’industrie de l’information).
Mise à jour 2017 : au début, je pensais essayer des alternatives à Facebook. Je ressentais un besoin de remplacer Facebook par quelque chose de similaire comme Diaspora, mais l’e-mail et le téléphone se sont révélés bien meilleurs ! Après un mois sans Facebook, je n’ai plus ressenti le besoin de le remplacer. Les coups de téléphone ont suffi, figurez-vous. Tout le monde en a déjà un, et on oublie combien ils sont super faciles et pratiques à utiliser. Je vois moins de photos, mais je parle à des gens pour de vrai. Plus récemment, nous sommes tous allés sur un grand salon de messagerie instantanée. Je recommande actuellement Signal pour faire ça. Vous pouvez faire des appels, chatter et partager des photos de façon chiffrée, et très peu de choses sont stockées sur leurs serveurs. En fait, c’est bien mieux que Facebook, puisque c’est plus instantané et personnel.
Si vous avez d’autres idées ou conseils, merci de me joindre. Je considère ceci comme une étape responsable pour éviter qu’on me prive de ma liberté, et celle de ma famille et mes amis, et que nos relations personnelles en pâtissent.
Gardez bien à l’esprit que ce n’est pas juste une question technique. En restant sur Facebook, vous leur donnez l’autorisation de collecter et d’utiliser des informations sur vous, même si vous n’utilisez pas Internet. Et en y restant, les données qu’ils collectent sur vous sont utilisées pour créer des modèles sur vos amis proches et votre famille, même ceux qui ont quitté Facebook.
Internet est libre et ouvert, mais ça ne veut pas dire que nous acceptons d’être espionnés
Pour finir, le monde est rempli de gens qui disent « ça n’arrivera jamais », et quand cela finit par arriver, cela se change en « on ne peut rien y faire ». Si, on peut. Internet a été décentralisé pendant 50 ans, et contient un tas de fonctionnalités faites pour nous aider à protéger nos vies privées. Nous avons notre mot à dire sur le monde dans lequel nous voulons vivre – si nous commençons par agir à notre niveau. Et en plus, nous pouvons aider tout le monde à comprendre, et faire en sorte que chacun puisse faire son propre choix éclairé.
Cet article a maintenant été lu par 1 000 000 personnes. C’est un signe fort que nous pouvons nous informer et nous éduquer nous-mêmes !
Merci de partager ceci avec les gens qui vous sont importants. Mais honnêtement, même si cet article est vraiment populaire, il est clair que beaucoup de gens pensent savoir ce qu’il contient. Partager un lien n’est jamais aussi efficace que de parler aux gens.
Si vous avez lu jusqu’ici et que vous voulez partager avec un proche, je vous suggère de faire ce que j’ai fait – décrochez votre téléphone.
Une question pour vous
Cet article a été écrit en réaction à la politique de confidentialité de janvier 2015, il y a 2 ans. Ça a toujours été un article populaire, mais en janvier 2017, il a connu un pic de popularité. Je me demande bien pourquoi, et ça serait sympa si vous pouviez me dire ce que vous en pensez, par Twitter ou par e-mail.
Je me demande pourquoi mon article sur la vie privée sur Facebook (qui date de plusieurs années) subit une vague de popularité depuis la semaine dernière. Des idées ?
– Salim Virani (@SaintSal) 8 janvier 2017
Sources
Une petite note sur la qualité de ces sources : j’ai essayé de trouver des références dans des médias majeurs, avec tout un échantillon de biais politiques. Ces articles sont moins précis techniquement, mais on peut s’attendre à ce qu’ils soient plus rigoureux que les blogs pour vérifier leurs sources. Pour les aspects plus techniques, d’autres sources comme The Register sont certainement plus crédibles, et Techcrunch est notoirement peu fiable en matière de fact-checking. J’ai toutefois inclus certains de leurs articles, parce qu’ils sont doués pour expliquer les choses.
Articles en anglais
Facebook likes reveal sensitive personal information eff.org
Private traits and attributes are predictable from digital records of human behavior pnas.org table of top likes
New Facebook Policies Sell Your Face And Whatever It Infers forbes.com
Des routes et des ponts (18) – À la croisée des chemins
Le 12 septembre dernier, Framalang commençait la traduction de l’ouvrage de Nadia Eghbal Des routes et des ponts. Aujourd’hui, nous vous proposons le dernier chapitre de ce livre.
Ce chapitre s’interroge sur la marche à suivre pour continuer les avancées technologiques et sociales des cultures open source et libres. Cette conclusion rappelle qu’à l’heure de l’information, tout le monde est concerné par les technologies ouvertes, bien que nous n’en ayons souvent que peu conscience. Ainsi, afin de pouvoir continuer d’utiliser cette infrastructure qui a été mise à notre disposition, nous devons nous mobiliser pour en garantir la pérennité.
L’état actuel de notre infrastructure numérique est un des problèmes les moins bien compris de notre temps. Il est vital de le comprendre.
En s’investissant bénévolement dans notre structure sous-jacente, les développeurs ont facilité la construction de logiciels pour autrui. En la fournissant gratuitement plutôt qu’en la facturant, ils ont alimenté une révolution de l’information.
Les développeurs n’ont pas fait cela pour être altruistes. Ils l’ont fait car c’était la meilleure manière de résoudre leurs propres problèmes. L’histoire du logiciel open source est l’un des grands triomphes de nos jours pour le bien public.
Nous avons de la chance que les développeurs aient limité les coûts cachés de ces investissements. Mais leurs investissements initiaux ne nous ont amenés que là où nous sommes aujourd’hui.
Nous ne sommes qu’au commencement de l’histoire de la transformation de l’humanité par le logiciel. Marc Andreessen, co-fondateur de Netscape et reconnu comme capital-risqueur derrière la société Andreessen Horowitz, remarque en 2011 que «le logiciel dévore le monde» (source). Depuis lors, cette pensée est devenue un mantra pour l’ère moderne.
Le logiciel touche tout ce que l’on fait : non seulement les frivolités et les loisirs, mais aussi les choses obligatoires et critiques. OpenSSL, le projet décrit au début de cet essai, le démontre bien. Dans une interview téléphonique, Steve Marquess explique qu’OpenSSL n’était pas utilisé seulement par les utilisateurs de sites web, mais aussi par les gouvernements, les drones, les satellites et tous «les gadgets que vous entendez bipper dans les hôpitaux» [Entretien téléphonique avec Steve Marquess, NdA.].
Le Network Time Protocol [protocole de temps par le réseau, NdT], maintenu par Harlan Stenn, synchronise les horloges utilisées par des milliards de périphériques connectés et touche tout ce qui contient un horodatage. Pas seulement les applications de conversations ou les courriels, mais aussi les marchés financiers, les enregistrements médicaux et la production de produits chimiques.
Et pourtant, Harlan note:
Il y a un besoin de soutenir l’infrastructure publique libre. Mais il n’y a pas de source de revenu disponible à l’heure actuelle. Les gens se plaignent lorsque leurs horloges sont décalées d’une seconde. Ils disent, «oui nous avons besoin de vous, mais nous ne pouvons pas vous donner de l’argent». (source)
Durant ces cinq dernières années, l’infrastructure open source est devenue une couche essentielle de notre tissu social. Mais tout comme les startups ou la technologie elle-même, ce qui a fonctionné pour les 30 premières années de l’histoire de l’open source n’aidera plus à avancer. Pour maintenir notre rythme de progression, nous devons réinvestir dans les outils qui nous aident à construire des projets plus importants et de meilleure qualité.
Trouver un moyen de soutenir l’infrastructure numérique peut sembler intimidant, mais il y a de multiples raisons de voir le chemin à parcourir comme une opportunité.
Premièrement, l’infrastructure est déjà là, avec une valeur clairement démontrée. Ce rapport ne propose pas d’investir dans une idée sans plus-value. L’énorme contribution sociale de l’infrastructure numérique actuelle ne peut être ignorée ni mise de côté, comme cela est déjà arrivé dans des débats tout aussi importants sur les données, la vie privée, la neutralité du net, ou l’opposition entre investissement privé et investissement public. Il est dès lors plus facile de faire basculer les débats vers les solutions.
Deuxièmement, il existe déjà des communautés open source engagées et prospères avec lesquelles travailler. De nombreux développeurs s’identifient par le langage de programmation qu’ils utilisent (tels que Python ou JavaScript), la fonction qu’ils apportent (telles qu’analyste ou développeur opérationnels), ou un projet important (tels que Node.js ou Rails). Ce sont des communautés fortes, visibles, et enthousiastes.
Les constructeurs de notre infrastructure numérique sont connectés les uns aux autres, attentifs à leurs besoins, et techniquement talentueux. Ils ont déjà construit notre ville ; nous avons seulement besoin d’aider à maintenir les lumières allumées, de telle sorte qu’ils puissent continuer à faire ce qu’ils font de mieux.
Les infrastructures, qu’elles soient physiques ou numériques, ne sont pas faciles à comprendre, et leurs effets ne sont pas toujours visibles, mais cela doit nous encourager à les suivre plus en détail, pas moins. Quand une communauté a parlé si ouvertement et si souvent de ses besoins, tout ce que nous devons faire est d’écouter.
Remerciements
Merci à tous ceux qui ont courageusement accepté d’être mentionnés dans cet ouvrage, ainsi qu’à ceux dont les réponses honnêtes et réféléchies m’ont aidée à affiner ma pensée pendant la phase de recherche :
André Arko, Brian Behlendorf, Adam Benayoun, Juan Benet, Cory Benfield, Kris Borchers, John Edgar, Maciej Fijalkowski, Karl Fogel, Brian Ford, Sue Graves, Eric Holscher, Brandon Keepers, Russell Keith-Magee, Kyle Kemp, Jan Lehnardt, Jessica Lord, Steve Marquess, Karissa McKelvey, Heather Meeker, Philip Neustrom, Max Ogden, Arash Payan, Stormy Peters, Andrey Petrov, Peter Rabbitson, Mikeal Rogers, Hynek Schlawack, Boaz Sender, Quinn Slack, Chris Soghoian, Charlotte Spencer, Harlan Stenn, Diane Tate, Max Veytsman, Christopher Allan Webber, Chad Whitacre, Meredith Whittaker, Doug Wilson.
Merci à tous ceux qui ont écrit quelque chose de public qui a été référencé dans cet essai. C’était une partie importante de la recherche, et je remercie ceux dont les idées sont publiques pour que d’autres s’en inspirent.
Merci à Franz Nicolay pour la relecture et Brave UX pour le design de ce rapport.
Enfin, un très grand merci à Jenny Toomey et Michael Brennan pour m’avoir aidée à conduire ce projet avec patience et enthousiasme, à Lori McGlinchey et Freedman Consulting pour leur retours et à Ethan Zuckerman pour que la magie opère.
Framasoft remercie chaleureusement les 40 traducteurs et traductrices du groupe Framalang qui depuis septembre ont contribué à vous proposer cet ouvrage (qui sera disponible en Framabook… quand il sera prêt) :
Des routes et des ponts (13) – Des mécènes pour les projets open source
Chaque semaine, l’équipe Framalang vous propose la traduction d’un chapitre de Roads and Bridges de Nadia Eghbal, une enquête fouillée qui explore les problématiques des infrastructures numériques, et en particulier leur intrication avec l’écosystème open source.
Après avoir exploré dans le précédent chapitre différents types de modèles économiques adaptés aux projets open source (retrouvez ici tous les chapitres antérieurs), l’auteure examine ici les cas de projets s’appuyant sur les dons ou le mécénat : du financement participatif au soutien institutionnalisé d’une entreprise, elle analyse les avantages et les limites de chaque solution, et livre les témoignages de nombreux porteurs de projets ou contributeurs qui relatent leur expérience au cœur de projets aussi divers qu’OpenSSL, jQuery ou encore Node.js.
La deuxième option pour financer des projets d’infrastructure numérique consiste à trouver des mécènes ou des donateurs. Il s’agit d’une pratique courante dans les cas de figure suivants :
Il n’existe pas de demande client facturable pour les services proposés par le projet.
Rendre l’accès payant empêcherait l’adoption (on ne pourrait pas, par exemple, faire payer l’utilisation d’un langage de programmation comme Python, car personne ne l’utiliserait ; ce serait comme si parler anglais étant payant).
Le projet n’a pas les moyens de financer des emplois rémunérés, ou bien il n’y a pas de volonté de la part du développeur de s’occuper des questions commerciales.
La neutralité et le refus de la commercialisation sont considérés comme des principes importants en termes de gouvernance.
Dans ce type de situation, un porteur de projet cherchera des mécènes qui croient en la valeur de son travail et qui sont disposés à le soutenir financièrement. À l’heure actuelle, il existe deux sources principales de financement : les entreprises de logiciel et les autres développeurs.
Le financement participatif
Certains travaux de développement obtiennent des fonds grâce à des campagnes de financement participatif (« crowdfunding ») via des plateformes telles que Kickstarter ou Indiegogo. Bountysource, le site de récompenses dont nous parlions dans un chapitre précédent, possède également une plateforme appelée Salt dédiée au financement participatif de projets open source.
Andrew Godwin, un développeur du noyau Django résidant à Londres, a ainsi réussi à récolter sur Kickstarter 17952£ (environ 21000€) de la part de 507 contributeurs, afin de financer des travaux de base de données pour Django. Le projet a été entièrement financé en moins de quatre heures.
Pour expliquer sa décision de lever des fonds pour un projet open source, Godwin écrit :
« Une quantité importante de code open source est écrit gratuitement. Cependant, mon temps libre est limité. Je dispose actuellement d’une seule journée libre par semaine pour travailler, et j’adorerais la consacrer à l’amélioration de Django, plutôt qu’à du conseil ou à de la sous-traitance.
L’objectif est double : d’une part, garantir au projet un temps de travail conséquent et au moins 80 heures environ de temps de codage ; et d’autre part prouver au monde que les logiciels open source peuvent réellement rémunérer le temps de travail des développeurs. »
À l’instar des récompenses, le financement participatif s’avère utile pour financer de nouvelles fonctionnalités, ou des développements aboutissant à un résultat clair et tangible. Par ailleurs, le financement participatif a moins d’effets pervers que les récompenses, notamment parce qu’organiser une campagne de financement demande plus d’efforts que de poster une offre de récompense, et parce que le succès du financement repose en grande partie sur la confiance qu’a le public dans la capacité du porteur de projet à réaliser le travail annoncé. Dans le cas de Godwin, il était l’un des principaux contributeurs au projet Django depuis six ans et était largement reconnu dans la communauté.
Toutefois, le financement participatif ne répond pas à la nécessité de financer les frais de fonctionnement et les frais généraux. Ce n’est pas une source de capital régulière. En outre, planifier et mettre en œuvre une campagne de financement participatif demande à chaque fois un investissement important en temps et en énergie. Enfin, les donateurs pour ces projets sont souvent eux-mêmes des développeurs ou des petites entreprises – et un porteur de projet ne peut pas éternellement aller toquer à la même porte pour financer ses projets.
Avec le recul, Godwin a commenté sa propre expérience :
« Je ne suis pas sûr que le financement participatif soit totalement compatible avec le développement open source en général ; non seulement c’est un apport ponctuel, mais en plus l’idée de rétribution est souvent inadéquate car elle nécessite de promettre quelque chose que l’on puisse garantir et décrire a priori.
S’en remettre uniquement à la bonne volonté du public, cela ne fonctionnera pas. On risque de finir par s’appuyer de manière disproportionnée sur des développeurs, indépendants ou non, à un niveau personnel – et je ne pense pas que ce soit viable. »
À côté des campagnes de financement participatif, plusieurs plateformes ont émergé pour encourager la pratique du « pourboire » (tipping en anglais) pour les contributeurs open source : cela consiste à verser une petite somme de revenu régulier à un contributeur, en signe de soutien à son travail. Deux plateformes populaires se distinguent : Patreon (qui ne se limite pas exclusivement aux contributeurs open source) et Gratipay (qui tend à fédérer une communauté plus technique).
L’idée d’un revenu régulier est alléchante, mais souffre de certains problèmes communs avec le financement participatif. On remarque notamment que les parrains (patrons ou tippers en anglais) sont souvent eux-mêmes des développeurs, avec une quantité limitée de capital à se promettre les uns aux autres. Les dons ont généralement la réputation de pouvoir financer une bière, mais pas un loyer. Gratipay rassemble 122 équipes sur sa plateforme, qui reçoivent collectivement 1000 $ par semaine, ce qui signifie qu’un projet touche en moyenne moins de 40$ par mois.
Même les très gros projets tels que OpenSSL ne généraient que 2000$ de dons annuels avant la faille Heartbleed. Comme expliqué précédemment, après Heartbleed, Steve Marquess, membre de l’équipe, a remarqué « un déferlement de soutien de la part de la base de la communauté OpenSSL » : la première vague de dons a rassemblé environ 200 donateurs pour un total de 9000$.
Marquess a remercié la communauté pour son soutien mais a également ajouté :
« Même si ces donations continuent à arriver au même rythme indéfiniment (ce ne sera pas le cas), et même si chaque centime de ces dons allait directement aux membres de l’équipe OpenSSL, nous serions encore loin de ce qu’il faudrait pour financer correctement le niveau de main-d’œuvre humaine nécessaire à la maintenance d’un projet aussi complexe et aussi crucial. Même s’il est vrai que le projet « appartient au peuple », il ne serait ni réaliste ni correct d’attendre de quelques centaines, ou même de quelques milliers d’individus seulement, qu’ils le financent à eux seuls. Ceux qui devraient apporter les vraies ressources, ce sont les entreprises lucratives et les gouvernements qui utilisent OpenSSL massivement et qui le considèrent comme un acquis. »
(À l’appui de l’argument de Marquess, les dons de la part des entreprises furent par la suite plus importants, les sociétés ayant davantage à donner que les particuliers. La plus grosse donation provint d’un fabricant de téléphone chinois, Smartisan, pour un montant de 160000$. Depuis, Smartisan a continué de faire des dons substantiels au projet OpenSSL.)
Au bout du compte, la réalité est la suivante : il y a trop de projets, tous qualitatifs ou cruciaux à leur manière, et pas assez de donateurs, pour que la communauté technique (entreprises ou individus) soit en mesure de prêter attention et de contribuer significativement à chacun d’eux.
Le mécénat d’entreprises pour les projets d’infrastructure
À plus grande échelle, dans certains cas, la valeur d’un projet devient si largement reconnue qu’une entreprise finit par recruter un contributeur pour travailler à plein temps à son développement.
John Resig est l’auteur de jQuery, une bibliothèque de programmation JavaScript qui est utilisée par près des 2/3 du million de sites web les plus visités au monde. John Resig a développé et publié jQuery en 2006, sous la forme d’un projet personnel. Il a rejoint Mozilla en 2007 en tant que développeur évangéliste, se spécialisant notamment dans les bibliothèques JavaScript.
La popularité de jQuery allant croissante, il est devenu clair qu’en plus des aspects liés au développement technique, il allait falloir formaliser certains aspects liés à la gouvernance du projet. Mozilla a alors proposé à John de travailler à plein temps sur jQuery entre 2009 et 2011, ce qu’il a fait.
À propos de cette expérience, John Resig a écrit :
« Pendant l’année et demi qui vient de s’écouler, Mozilla m’a permis de travailler à plein temps sur jQuery. Cela a abouti à la publication de 9 versions de jQuery… et à une amélioration drastique de l’organisation du projet (nous appartenons désormais à l’organisation à but non lucratif Software Freedom Conservancy, nous avons des réunions d’équipe régulières, des votes publics, fournissons des états des lieux publics et encourageons activement la participation au projet). Heureusement, le projet jQuery se poursuit sans encombre à l’heure actuelle, ce qui me permet de réduire mon implication à un niveau plus raisonnable et de participer à d’autres travaux de développement. »
Après avoir passé du temps chez Mozilla pour donner à jQuery le support organisationnel dont il avait besoin, John a annoncé qu’il rejoindrait la Khan Academy afin de se concentrer sur de nouveaux projets.
Cory Benfield, développeur Python, a suivi un chemin similaire. Après avoir contribué à plusieurs projets open source sur son temps libre, il est devenu un développeur-clé pour une bibliothèque essentielle de Python intitulée Requests. Cory Benfield note que :
« Cette bibliothèque a une importance comparable à celle de Django, dans la mesure où les deux sont des « infrastructures critiques » pour les développeurs Python. Et pourtant, avant que j’arrive sur le projet, elle était essentiellement maintenue par une seule personne. »
Benfield estime qu’il a travaillé bénévolement sur le projet environ 12 heures par semaine pendant presque quatre ans, en plus de son travail à plein temps. Personne n’était payé pour travailler sur Requests.
Pendant ce temps, HP embauchait un employé, Donald Stufft, pour se consacrer spécifiquement aux projets en rapport avec Python, un langage qu’il considère comme indispensable à ses logiciels. (Donald est le développeur cité précédemment qui est payé à plein temps pour travailler sur le packaging Python). Donald a alors convaincu son supérieur d’embaucher Cory pour qu’il travaille à temps plein sur des projets Python. Il y travaille toujours.
Les entreprises sont des acteurs tout désignés pour soutenir financièrement les projets bénévoles qu’elles considèrent comme indispensables à leurs activités, et quand des cas comme ceux de John Resig ou de Cory Benfield surviennent, ils sont chaleureusement accueillis. Cependant, il y a des complications.
Premièrement, aucune entreprise n’est obligée d’embaucher quelqu’un pour travailler sur des projets en demande de soutien ; ces embauches ont tendance à advenir par hasard de la part de mécènes bienveillants. Et même une fois qu’un employé est embauché, il y a toujours la possibilité de perdre ce financement, notamment parce que l’employé ne contribue pas directement au résultat net de l’entreprise. Une telle situation est particulièrement périlleuse si la viabilité d’un projet dépend entièrement d’un seul contributeur employé à plein temps. Dans le cas de Requests, Cory est le seul contributeur à plein temps (on compte deux autres contributeurs à temps partiel, Ian Cordasco et Kenneth Reitz).
Une telle situation s’est déjà produite dans le cas de « rvm », un composant critique de l’infrastructure Ruby. Michal Papis, son auteur principal, a été engagé par Engine Yard entre 2011 et 2013 pour soutenir le développement de rvm. Mais quand ce parrainage s’est terminé, Papis a dû lancer une campagne de financement participatif pour continuer de financer le développement de rvm.
Le problème, c’est que cela ne concernait pas seulement rvm. Engine Yard avait embauché plusieurs mainteneurs de projets d’infrastructure Ruby, qui travaillaient notamment sur JRuby, Ruby on Rails 3 et bundler. Quand les responsables d’Engine Yard ont été obligés de faire le choix réaliste qui s’imposait pour la viabilité de leur entreprise, c’est-à-dire réduire leur soutien financier, tous ces projets ont perdu leurs mainteneurs à temps plein, et presque tous en même temps.
L’une des autres craintes est qu’une entreprise unique finisse par avoir une influence disproportionnée sur un projet, puisqu’elle en est de facto le seul mécène. Cory Benfield note également que le contributeur ou la contributrice lui-même peut avoir une influence disproportionnée sur le projet, puisqu’il ou elle dispose de beaucoup plus de temps que les autres pour faire des contributions. De fait, une telle décision peut même être prise par une entreprise et un mainteneur, sans consulter le reste de la communauté du projet.
On peut en voir un exemple avec le cas d’Express.js, un framework important pour l’écosystème Node.js. Quand l’auteur du projet a décidé de passer à autre chose, il en a transféré les actifs (en particulier le dépôt du code source et le nom de domaine) à une société appelée StrongLoop dont les employés avaient accepté de continuer à maintenir le projet. Cependant StrongLoop n’a pas fourni le soutien qu’attendait la communauté, et comme les employés de StrongLoop étaient les seuls à avoir un accès administrateur, il est devenu difficile pour la communauté de faire des contributions. Doug Wilson, l’un des principaux mainteneurs (non-affilié à StrongLoop), disposait encore d’un accès commit et a continué de traiter la charge de travail du projet, essayant tant bien que mal de tout gérer à lui seul.
Après l’acquisition de StrongLoop par IBM, Doug déclara que StrongLoop avait bel et bien tué la communauté des contributeurs.
« Au moment où on est passé à StrongLoop, il y avait des membres actifs comme @Fishrock123 qui travaillaient à créer… de la documentation. Et puis tout à coup, je me suis retrouvé tout seul à faire ça sur mon temps libre alors que les demandes de support ne faisaient que se multiplier… et pendant tout ce temps, je me suis tué à la tâche, je me suis engagé pour le compte StrongLoop. Quoi qu’il arrive, jamais plus je ne contribuerai à aucun dépôt logiciel appartenant à StrongLoop. »
Finalement, le projet Express.js a été transféré de StrongLoop à la fondation Node.js, qui aide à piloter des projets appartenant à l’écosystème technologique Node.js.
En revanche, pour les projets open source qui ont davantage d’ampleur et de notoriété, il n’est pas rare d’embaucher des développeurs. La Fondation Linux a fait savoir, par exemple, que 80% du développement du noyau Linux est effectué par des développeurs rémunérés pour leur travail. La fondation Linux emploie également des Fellows [« compagnons » selon un titre consacré, NdT] payés pour travailler à plein temps sur les projets d’infrastructure, notamment Greg Kroah-Hartman, un développeur du noyau Linux, et Linus Torvalds lui-même, le créateur de Linux.
Pourquoi Framasoft n’ira plus prendre le thé au ministère de l’Éducation Nationale
Cet article vise à clarifier la position de Framasoft, sollicitée à plusieurs reprises par le Ministère de l’Éducation Nationale ces derniers mois. Malgré notre indignation, il ne s’agit pas de claquer la porte, mais au contraire d’en ouvrir d’autres vers des acteurs qui nous semblent plus sincères dans leur choix du libre et ne souhaitent pas se cacher derrière une « neutralité et égalité de traitement » complètement biaisée par l’entrisme de Google, Apple ou Microsoft au sein de l’institution.
Pour commencer
Une technologie n’est pas neutre, et encore moins celui ou celle qui fait des choix technologiques. Contrairement à l’affirmation de la Ministre de l’Éducation Mme Najat Vallaud-Belkacem, une institution publique ne peut pas être « neutre technologiquement », ou alors elle assume son incompétence technique (ce qui serait grave). En fait, la position de la ministre est un sophisme déjà bien ancien ; c’est celui du Gorgias de Platon qui explique que la rhétorique étant une technique, il n’y en a pas de bon ou de mauvais usage, elle ne serait qu’un moyen.
Or, lui oppose Socrate, aucune technique n’est neutre : le principe d’efficacité suppose déjà d’opérer des choix, y compris économiques, pour utiliser une technique plutôt qu’une autre ; la possession d’une technique est déjà en soi une position de pouvoir ; enfin, rappelons l’analyse qu’en faisait Jacques Ellul : la technique est un système autonome qui impose des usages à l’homme qui en retour en devient addict. Même s’il est consternant de rappeler de tels fondamentaux à ceux qui nous gouvernent, tout choix technologique suppose donc une forme d’aliénation. En matière de logiciels, censés servir de supports dans l’Éducation Nationale pour la diffusion et la production de connaissances pour les enfants, il est donc plus qu’évident que choisir un système plutôt qu’un autre relève d’une stratégie réfléchie et partisane.
Le tweet confondant neutralité logicielle et choix politique.
Un système d’exploitation n’est pas semblable à un autre, il suffit pour cela de comparer les deux ou trois principaux OS du marché (privateur) et les milliers de distributions GNU/Linux, pour comprendre de quel côté s’affichent la créativité et l’innovation. Pour les logiciels en général, le constat est le même : choisir entre des logiciels libres et des logiciels privateurs implique une position claire qui devrait être expliquée. Or, au moins depuis 1997, l’entrisme de Microsoft dans les organes de l’Éducation Nationale a abouti à des partenariats et des accords-cadres qui finirent par imposer les produits de cette firme dans les moindres recoins, comme s’il était naturel d’utiliser des solutions privatrices pour conditionner les pratiques d’enseignement, les apprentissages et in fine tous les usages numériques. Et ne parlons pas des coûts que ces marchés publics engendrent, même si les solutions retenues le sont souvent, au moins pour commencer, à « prix cassé ».
Depuis quelque temps, au moins depuis le lancement de la première vague de son projet Degooglisons Internet, Framasoft a fait un choix stratégique important : se tourner vers l’éducation populaire, avec non seulement ses principes, mais aussi ses dynamiques propres, ses structures solidaires et les valeurs qu’elle partage. Nous ne pensions pas que ce choix pouvait nous éloigner, même conceptuellement, des structures de l’Éducation Nationale pour qui, comme chacun le sait, nous avons un attachement historique. Et pourtant si… Une rétrospective succincte sur les relations entre Microsoft et l’Éducation Nationale nous a non seulement donné le tournis mais a aussi occasionné un éclair de lucidité : si, malgré treize années d’(h)activisme, l’Éducation Nationale n’a pas bougé d’un iota sa préférence pour les solutions privatrices et a même radicalisé sa position récemment en signant un énième partenariat avec Microsoft, alors nous utiliserions une partie des dons, de notre énergie et du temps bénévole et salarié en pure perte dans l’espoir qu’il y ait enfin une position officielle et des actes concrets en faveur des logiciels libres. Finalement, nous en sommes à la fois indignés et confortés dans nos choix.
Extrait de l’accord-Cadre MS-EN novembre 2015
L’Éducation Nationale et Microsoft, une (trop) longue histoire
En France, les rapports qu’entretient le secteur de l’enseignement public avec Microsoft sont assez anciens. On peut remonter à la fin des années 1990 où eurent lieu les premiers atermoiements à l’heure des choix entre des solutions toutes faites, clés en main, vendues par la société Microsoft, et des solutions de logiciels libres, nécessitant certes des efforts de développement mais offrant à n’en pas douter, des possibilités créatrices et une autonomie du service public face aux monopoles économiques. Une succession de choix délétères nous conduisent aujourd’hui à dresser un tableau bien négatif.
Dans un article paru dans Le Monde du 01/10/1997, quelques mois après la réception médiatisée de Bill Gates par René Monory, alors président du Sénat, des chercheurs de l’Inria et une professeure au CNAM dénonçaient la mainmise de Microsoft sur les solutions logicielles retenues par l’Éducation Nationale au détriment des logiciels libres censés constituer autant d’alternatives fiables au profit de l’autonomie de l’État face aux monopoles américains. Les mots ne sont pas tendres :
(…) Microsoft n’est pas la seule solution, ni la meilleure, ni la moins chère. La communauté internationale des informaticiens développe depuis longtemps des logiciels, dits libres, qui sont gratuits, de grande qualité, à la disposition de tous, et certainement beaucoup mieux adaptés aux objectifs, aux besoins et aux ressources de l’école. Ces logiciels sont largement préférés par les chercheurs, qui les utilisent couramment dans les contextes les plus divers, et jusque dans la navette spatiale. (…) On peut d’ailleurs, de façon plus générale, s’étonner de ce que l’administration, et en particulier l’Éducation Nationale, préfère acheter (et imposer à ses partenaires) des logiciels américains, plutôt que d’utiliser des logiciels d’origine largement européenne, gratuits et de meilleure qualité, qui préserveraient notre indépendance technologique.
D’autres témoignages mettent en lumière des tensions entre logiciels libres et logiciels privateurs dans les décisions d’équipement et dans les intentions stratégiques de l’Éducation Nationale au tout début des années 2000. En revanche, en décembre 2003, l’accord-cadre1 Microsoft et le Ministère de l’Éducation Nationale change radicalement la donne et propose des solutions clés en main intégrant trois aspects :
tous les établissements de l’Éducation Nationale sont concernés, des écoles primaires à l’enseignement supérieur ;
le développement des solutions porte à la fois sur les systèmes d’exploitation et la bureautique, c’est-à-dire l’essentiel des usages ;
la vente des logiciels se fait avec plus de 50% de remise, c’est-à-dire avec des prix résolument tirés vers le bas.
Depuis lors, des avenants à cet accord-cadre sont régulièrement signés. Comme si cela ne suffisait pas, certaines institutions exercent leur autonomie et établissent de leur côté des partenariats « en surplus », comme l’Université Paris Descartes le 9 juillet 2009, ou encore les Villes, comme Mulhouse qui signe un partenariat Microsoft dans le cadre de « plans numériques pour l’école », même si le budget est assez faible comparé au marché du Ministère de l’Éducation.
Il serait faux de prétendre que la société civile ne s’est pas insurgée face à ces accords et à l’entrisme de la société Microsoft dans l’enseignement. On ne compte plus les communiqués de l’April (souvent conjoints avec d’autres associations du Libre) dénonçant ces pratiques. Bien que des efforts financiers (discutables) aient été faits en faveur des logiciels libres dans l’Éducation Nationale, il n’en demeure pas moins que les pratiques d’enseignement et l’environnement logiciel des enfants et des étudiants sont soumis à la microsoftisation des esprits, voire une Gafamisation car la firme Microsoft n’est pas la seule à signer des partenariats dans ce secteur. Le problème ? Il réside surtout dans le coût cognitif des outils logiciels qui, sous couvert d’apprentissage numérique, enferme les pratiques dans des modèles privateurs : « Les enfants qui ont grandi avec Microsoft, utiliseront Microsoft ».
Et si c’était MacDonald’s qui rentrait dans les cantines scolaires…? Les habitudes malsaines peuvent se prendre dès le plus jeune âge.
On ne saurait achever ce tableau sans mentionner le plus récent partenariat Microsoft-EN signé en novembre 2015 et vécu comme une véritable trahison par, entre autres, beaucoup d’acteurs du libre. Il a en effet été signé juste après la grande consultation nationale pour le Projet de Loi Numérique porté par la ministre Axelle Lemaire. La consultation a fait ressortir un véritable plébiscite en faveur du logiciel libre dans les administrations publiques et des amendements ont été discutés dans ce sens, même si le Sénat a finalement enterré l’idée. Il n’en demeure pas moins que les défenseurs du logiciel libre ont cru déceler chez nombre d’élus une oreille attentive, surtout du point de vue de la souveraineté numérique de l’État. Pourtant, la ministre Najat Vallaud-Belkacem a finalement décidé de montrer à quel point l’Éducation Nationale ne saurait être réceptive à l’usage des logiciels libre en signant ce partenariat, qui constitue, selon l’analyse par l’April des termes de l’accord, une « mise sous tutelle de l’informatique à l’école » par Microsoft.
Entre libre-washing et méthodes douteuses
Pour être complète, l’analyse doit cependant rester honnête : il existe, dans les institutions de l’Éducation Nationale des projets de production de ressources libres. On peut citer par exemple le projet EOLE (Ensemble Ouvert Libre Évolutif), une distribution GNU/Linux basée sur Ubuntu, issue du Pôle de compétence logiciel libre, une équipe du Ministère de l’Éducation Nationale située au rectorat de l’académie de Dijon. On peut mentionner le projet Open Sankoré, un projet de développement de tableau interactif au départ destiné à la coopération auprès de la Délégation Interministérielle à l’Éducation Numérique en Afrique (DIENA), repris par la nouvelle Direction du numérique pour l’éducation (DNE) du Ministère de l’EN, créée en 2014. En ce qui concerne l’information et la formation des personnels, on peut souligner certaines initiatives locales comme le site Logiciels libres et enseignement de la DANE (Délégation Académique au Numérique Éducatif) de l’académie de Versailles. D’autres projets sont parfois maladroits comme la liste de « logiciels libres et gratuits » de l’académie de Strasbourg, qui mélange allègrement des logiciels libres et des logiciels privateurs… pourvus qu’ils soient gratuits.
Les initiatives comme celles que nous venons de recenser se comptent néanmoins sur les doigts des deux mains. En pratique, l’environnement des salles informatiques des lycées et collèges reste aux couleurs Microsoft et les tablettes (réputées inutiles) distribuées çà et là par villes et départements, sont en majorité produites par la firme à la pomme2. Les enseignants, eux, n’ayant que très rarement voix au chapitre, s’épuisent souvent à des initiatives en classe fréquemment isolées bien que créatives et efficaces. Au contraire, les inspecteurs de l’Éducation Nationale sont depuis longtemps amenés à faire la promotion des logiciels privateurs quand ils ne sont pas carrément convoqués chez Microsoft.
Convocation Inspecteurs de l’EN chez Microsoft
L’interprétation balance entre deux possibilités. Soit l’Éducation Nationale est composée exclusivement de personnels incohérents prêts à promouvoir le logiciel libre partout mais ne faisant qu’utiliser des suites Microsoft. Soit des projets libristes au sein de l’Éducation Nationale persistent à exister, composés de personnels volontaires et motivés, mais ne s’affichent que pour mieux mettre en tension les solutions libres et les solutions propriétaires. Dès lors, comme on peut s’attendre à ce que le seul projet EOLE ne puisse assurer toute une migration de tous les postes de l’EN à un système d’exploitation libre, il est logique de voir débouler Microsoft et autres sociétés affiliées présentant des solutions clés en main et économiques. Qu’a-t-on besoin désormais de conserver des développeurs dans la fonction publique puisque tout est pris en charge en externalisant les compétences et les connaissances ? Pour que cela ne se voie pas trop, on peut effectivement s’empresser de mettre en avant les quelques deniers concédés pour des solutions libres, parfois portées par des sociétés à qui on ne laisse finalement aucune chance, telle RyXéo qui proposait la suite Abulédu.
Finalement, on peut en effet se poser la question : le libre ne serait-il pas devenu un alibi, voire une caution bien mal payée et soutenue au plus juste, pour légitimer des solutions privatrices aux coûts exorbitants ? Les décideurs, DSI et autres experts, ne préfèrent-ils pas se reposer sur un contrat Microsoft plutôt que sur le management de développeurs et de projets créatifs ? Les solutions les plus chères sont surtout les plus faciles.
Plus faciles, mais aussi plus douteuses ! On pourra en effet se pencher à l’envi sur les relations discutables entre certains cadres de Microsoft France et leurs postes occupés aux plus hautes fonctions de l’État, comme le montrait le Canard Enchaîné du 30 décembre 2015. Framasoft se fait depuis longtemps l’écho des manœuvres de Microsoft sans que cela ne soulève la moindre indignation chez les décideurs successifs au Ministère3. On peut citer, pêle-mêle :
la stratégie sournoise d’introduction des produits à l’école, selon la technique « embrace and extend », ce qui flirte dangereusement avec les règlements en vigueur, à commencer par le droit des marchés publics (opposé régulièrement pour contrecarrer la préférence donnée au Libre dans les appels d’offres) ;
les frontières imprécises entre promotion marketing et innovation pédagogique, voilant à peine les intentions réelles de Microsoft…
Cette publicité est un vrai tweet Microsoft. Oui. Cliquez sur l’image pour lire l’article de l’APRIL à ce sujet.
Du temps et de l’énergie en pure perte
« Vous n’avez qu’à proposer », c’est en substance la réponse balourde par touittes interposés de Najat Vallaud-Belkacem aux libristes qui dénonçaient le récent accord-cadre signé entre Microsoft et le Ministère. Car effectivement, c’est bien la stratégie à l’œuvre : alors que le logiciel libre suppose non seulement une implication forte des décideurs publics pour en adopter les usages, son efficience repose également sur le partage et la contribution. Tant qu’on réfléchit en termes de pure consommation et de fournisseur de services, le logiciel libre n’a aucune chance. Il ne saurait être adopté par une administration qui n’est pas prête à développer elle-même (ou à faire développer) pour ses besoins des logiciels libres et pertinents, pas plus qu’à accompagner leur déploiement dans des milieux qui ne sont plus habitués qu’à des produits privateurs prêts à consommer.
Au lieu de cela, les décideurs s’efforcent d’oublier les contreparties du logiciel libre, caricaturent les désavantages organisationnels des solutions libres et légitiment la Microsoft-providence pour qui la seule contrepartie à l’usage de ses logiciels et leur « adaptation », c’est de l’argent… public. Les conséquences en termes de hausses de tarifs des mises à jour, de sécurité, de souveraineté numérique et de fiabilité, par contre, sont des sujets laissés vulgairement aux « informaticiens », réduits à un débat de spécialistes dont les décideurs ne font visiblement pas partie, à l’instar du Ministère de la défense lui aussi aux prises avec Microsoft.
Comme habituellement il manque tout de même une expertise d’ordre éthique, et pour peu que des compétences libristes soient nécessaires pour participer au libre-washing institutionnel, c’est vers les associations que certains membres de l’Éducation Nationale se tournent. Framasoft a bien souvent été démarchée soit au niveau local pour intervenir dans des écoles / collèges / lycées afin d’y sensibiliser au Libre, soit pour collaborer à des projets très pertinents, parfois même avec des possibilités de financement à la clé. Ceci depuis les débuts de l’association qui se présente elle-même comme issue du milieu éducatif.
Témoignage : usage de Framapad à l’école
Depuis plus de dix ans Framasoft intervient sur des projets concrets et montre par l’exemple que les libristes sont depuis longtemps à la fois forces de proposition et acteurs de terrain, et n’ont rien à prouver à ceux qui leur reprocheraient de se contenter de dénoncer sans agir. Depuis deux décennies des associations comme l’April ont impulsé des actions, pas seulement revendicatrices mais aussi des conseils argumentés, de même que l’AFUL (mentionnée plus haut). Las… le constat est sans appel : l’Éducation Nationale a non seulement continué à multiplier les relations contractuelles avec des firmes comme Microsoft, barrant la route aux solutions libres, mais elle a radicalisé sa position en novembre 2015 en un ultime pied de nez à ces impertinentes communautés libristes.
Nous ne serons pas revanchards, mais il faut tout de même souligner que lorsque des institutions publiques démarchent des associations composées de membres bénévoles, les tâches demandées sont littéralement considérées comme un dû, voire avec des obligations de rendement. Cette tendance à amalgamer la soi-disant gratuité du logiciel libre et la soi-disant gratuité du temps bénévole des libristes, qu’il s’agisse de développement ou d’organisation, est particulièrement détestable.
Discuter au lieu de faire
À quelles demandes avons-nous le plus souvent répondu ? Pour l’essentiel, il s’agit surtout de réunions, de demandes d’expertises dont les résultats apparaissent dans des rapports, de participation plus ou moins convaincante (quand il s’agit parfois de figurer comme caution) à des comités divers, des conférences… On peut discuter de la pertinence de certaines de ces sollicitations tant les temporalités de la réflexion et des discours n’ont jamais été en phase avec les usages et l’évolution des pratiques numériques.
Le discours de Framasoft a évolué en même temps que grandissait la déception face au décalage entre de timides engagements en faveur du logiciel libre et des faits attestant qu’à l’évidence le marché logiciel de l’Éducation Nationale était structuré au bénéfice des logiques privatrices. Nous en sommes venus à considérer que…
si, en treize ans de sensibilisation des enseignants et des décideurs, aucune décision publique n’a jamais assumé de préférence pour le logiciel libre ;
si, en treize ans, le discours institutionnel s’est même radicalisé en défaveur du Libre : en 2003, le libre n’est « pas souhaitable » ; en 2013 le libre et les formats ouverts pourraient causer des « difficultés juridiques » ; en 2016, le libre ne pourra jamais être prioritaire malgré le plébiscite populaire4…
…une association comme Framasoft ne peut raisonnablement continuer à utiliser l’argent de ses donateurs pour dépenser du temps bénévole et salarié dans des projets dont les objectifs ne correspondent pas aux siens, à savoir la promotion et la diffusion du Libre.
Par contre, faire la nique à Microsoft en proposant du Serious Gaming éducatif, ça c’est concret !
L’éducation populaire : pas de promesses, des actes
Framasoft s’est engagée depuis quelque temps déjà dans une stratégie d’éducation populaire. Elle repose sur les piliers suivants :
social : le mouvement du logiciel libre est un mouvement populaire où tout utilisateur est créateur (de code, de valeur, de connaissance…) ;
technique : par le logiciel libre et son développement communautaire, le peuple peut retrouver son autonomie numérique et retrouver savoirs et compétences qui lui permettront de s’émanciper ;
solidaire : le logiciel libre se partage, mais aussi les compétences, les connaissances et même les ressources. Le projet CHATONS démontre bien qu’il est possible de renouer avec des chaînes de confiance en mobilisant des structures au plus proche des utilisateurs, surtout si ces derniers manquent de compétences et/ou d’infrastructures.
Quelles que soient les positions institutionnelles, nous sommes persuadés qu’en collaborant avec de petites ou grandes structures de l’économie sociale et solidaire (ESS), avec le monde culturel en général, nous touchons bien plus d’individus. Cela sera également bien plus efficace qu’en participant à des projets avec le Ministère de l’Éducation Nationale, qui se révèlent n’avoir au final qu’une portée limitée. Par ailleurs, nous sommes aussi convaincus que c’est là le meilleur moyen de toucher une grande variété de publics, ceux-là mêmes qui s’indigneront des pratiques privatrices de l’Éducation Nationale.
Néanmoins, il est vraiment temps d’agir, car même le secteur de l’ESS commence à se faire « libre-washer » et noyauter par Microsoft : par exemple la SocialGoodWeek a pour partenaires MS et Facebook ; ou ADB Solidatech qui équipe des milliers d’ordinateurs pour associations avec des produits MS à prix cassés.
Page SocialGoodWeek, sponsors
Ce positionnement du « faire, faire sans eux, faire malgré eux » nous a naturellement amenés à développer notre projet Degooglisons Internet. Mais au-delà, nous préférons effectivement entrer en relation directe avec des enseignants éclairés qui, plutôt que de perdre de l’énergie à convaincre la pyramide hiérarchique kafkaïenne, s’efforcent de créer des projets concrets dans leurs (minces) espaces de libertés. Et pour cela aussi le projet Degooglisons Internet fait mouche.
Nous continuerons d’entretenir des relations de proximité et peut-être même d’établir des projets communs avec les associations qui, déjà, font un travail formidable dans le secteur de l’Éducation Nationale, y compris avec ses institutions, telles AbulEdu, Sésamath et bien d’autres. Il s’agit là de relations naturelles, logiques et même souhaitables pour l’avancement du Libre. Fermons-nous définitivement la porte à l’Éducation Nationale ? Non… nous inversons simplement les rôles.
Pour autant, il est évident que nous imposons implicitement des conditions : les instances de l’Éducation Nationale doivent considérer que le logiciel libre n’est pas un produit mais que l’adopter, en plus de garantir une souveraineté numérique, implique d’en structurer les usages, de participer à son développement et de généraliser les compétences en logiciels libres. Dans un système déjà noyauté (y compris financièrement) par les produits Microsoft, la tâche sera rude, très rude, car le coût cognitif est déjà cher payé, dissimulé derrière le paravent brumeux du droit des marchés publics (même si en la matière des procédures négociées peuvent très bien être adaptées au logiciel libre). Ce n’est pas (plus) notre rôle de redresser la barre ou de cautionner malgré nous plus d’une décennie de mauvaises décisions pernicieuses.
Si l’Éducation Nationale décide finalement et officiellement de prendre le bon chemin, avec force décrets et positions de principe, alors, ni partisans ni vindicatifs, nous l’accueillerons volontiers à nos côtés car « la route est longue, mais la voie est libre… ».
— L’association Framasoft
En revanche, si c’est juste pour prendre le thé… merci de se référer à l’erreur 418.
Certes, on pourrait aussi ajouter que, bien qu’il soit le plus familier, Microsoft n’est pas le seul acteur dans la place: Google est membre fondateur de la « Grande École du Numérique » et Apple s’incruste aussi à l’école avec ses tablettes.↩
On pourra aussi noter le rôle joué par l’AFDEL et Syntec Numérique dans cette dernière décision, mais aussi, de manière générale, par les lobbies dans les couloirs de l’Assemblée et du Sénat. Ceci n’est pas un scoop.↩
10 trucs que j’ignorais sur Internet et mon ordi (avant de m’y intéresser…)
Disclaimer : Cet article est sous licence CC-0 car les petits bouts de savoir qu’il contient sont autant d’armes d’auto-défense numérique qu’il faut diffuser. En gros, j’espère vraiment que certains d’entre vous en feront un top youtube, une buzzfeederie, une BD, un truc que j’ai même pas encore imaginé, ce que vous voulez… Mais que vous ferez passer les messages.
À noter : cet article bénéficie désormais d’une version audio.
Merci à Sualtam, auteur de lectureaudio.fr pour cette contribution active.
1) Tu ne consultes pas une page Internet, tu la copies
Toute ressemblance avec les métaphores de Terry Pratchett n’est que pure admiration de ma part ;)
Un site web, c’est pas une espèce de journal qu’on aurait mis dans le pays magique d’internet pour que ton navigateur aille le consulter comme tu consulterais le quotidien de ton jour de naissance à la médiathèque du coin.
Pour voir une page web, ton navigateur la copie sur ton ordi. Les textes, les images, les sons : tout ce que tu vois ou entends sur ton écran a été copié sur ton ordinateur (vilain pirate !)
Un ordinateur est un photocopieur dont la trieuse serait une méga fourmilière qui peut faire plein de trucs. La bonne nouvelle, c’est que copier permet de multiplier, que ça ne vole rien à personne, parce que si je te copie un fichier tu l’as toujours.
2) Mon navigateur web ne cuisine pas la même page web que le tien.
Sérieux, imagine qu’une page web, c’est une recette de cuisine :
Mettez un titre en gros, en gris et en gras.
Réduisez l’image afin qu’elle fasse un quart de la colonne d’affichage, réservez.
Placez le texte, agrémenté d’une jolie police, aligné à gauche, puis l’image à droite.
Servez chaud.
Le navigateur web (Firefox, Chrome, Safari, Internet Explorer…), c’est le cuisinier. Il va télécharger les ingrédients, et suivre la recette. T’as déjà vu quand on donne la même recette avec les mêmes ingrédients à 4 cuisiniers différents ? Ben ouais, c’est comme dans Top Chef, ça fait 4 plats qui sont pas vraiment pareils.
Surtout quand les assiettes ne sont pas de la même taille (genre l’écran de ton téléphone et celui de ton ordi…) et que pour cuire l’un utilise le four et l’autre un micro-ondes (je te laisse trouver une correspondance métaphorique dans ton esprit, tu peux y arriver, je crois en toi :p !).
Bref : l’article que tu lis aura peu de chance d’avoir la même gueule pour toi et la personne à qui tu le feras passer 😉
Préfère Firefox si t’as pas envie de filer tes données à Google-Chrome, Apple-Safari ou Microsoft-Edge
Ou sinon Chromium c’est Chrome sans du Google dedans 😉
3) Le streaming n’existe pas
Nope. Le streaming, c’est du téléchargement qui s’efface au fur et à mesure. Parce qu’un ordinateur est une machine à copier.
Le streaming, c’est du téléchargement que tu ne peux (ou ne sais) pas récupérer, donc tu downloades une vidéo ou un son mais juste pour une seule fois, et si tu veux en profiter à nouveau, il faut encore les télécharger et donc encombrer les tuyaux d’internet.
Tu vois les précieux mégas du forfait data de ton téléphone qui te ruinent chaque mois ? Ce sont des textes, images sons, vidéos et informations qui viennent jusqu’à ton ordi (ordinateur ou ordiphone, hein, c’est pareil). La taille de ces mégas, c’est un peu les litres d’eau que tu récupères au robinet d’internet.
Regarder ou écouter deux fois le même truc en streaming, sur YouTube ou Soundcloud par exemple, c’est comme si tu prenais deux fois le même verre d’eau au robinet.
4) Quand tu regardes une page web, elle te regarde aussi.
Mon livre ne me dit pas de le sortir du tiroir de la table de nuit. Il ne sait pas où je suis lorsque je le lis, quand je m’arrête, quand je saute des pages ni vers quel chapitre, quand je le quitte et si c’est pour aller lire un autre livre.
Sur Internet, les tuyaux vont dans les deux sens. Une page web sait déjà plein de choses sur toi juste lorsque tu cliques dessus et la vois s’afficher. Elle sait où tu te trouves, parce qu’elle connaît l’adresse de la box internet à laquelle tu t’es connecté. Elle sait combien de temps tu restes. Quand est-ce que tu cliques sur une autre page du même site. Quand et où tu t’en vas.
Netflix, par exemple, est une application web, donc un site web hyper complexe, genre QI d’intello plus plus plus. Netflix sait quel type de film tu préfères voir lors de tes soirées d’insomnie. À partir de quel épisode tu accroches vraiment à la saison d’une série. Ils doivent même pouvoir déterminer quand tu fais ta pause pipi !
Ouaip : Internet te regarde juste pour pouvoir fonctionner, et souvent plus. Ne t’y trompe pas : il prend des notes sur toi.
5) Pas besoin d’un compte Facebook/Google/etc pour qu’ils aient un dossier sur toi.
Dès qu’on te parle de « service personnalisé » c’est qu’on te vend ça -_-…
Si Internet peut te regarder, ceux qui y gagnent le plus d’argent ont les moyens d’en profiter (logique : ils peuvent se payer les meilleurs spécialistes !)
Tu vois le petit bouton « like » (ou « tweet » ou « +1 » ou…) sur tous les articles web que tu lis ? Ces petits boutons sont des espions, des trous de serrures. Ils donnent à Facebook (ou Twitter ou Google ou…) toutes les infos sur toi dont on parlait juste au dessus. Si tu n’as pas de compte, qu’ils n’ont pas ton nom, ils mettront cela sur l’adresse de ta machine. Le pire, c’est que cela fonctionne aussi avec des choses que tu vois moins (les polices d’écriture fournies par Google et très utilisées par les sites, les framework javascript, les vidéos YouTube incrustées sur un blog…)
Une immense majorité de sites utilisent aussi « Google Analytics » pour analyser tes comportements et mieux savoir quelles pages web marchent bien et comment. Mais du coup, ces infos ne sont pas données qu’à la personne qui a fait le site web : Google les récupère au passage. Là où ça devient marrant, c’est quand on se demande qui décide qu’un site marche « bien » ? C’est quoi ce « bien » ? C’est bien pour qui…?
Oui : avec le blog rank comme avec la YouTube money, Google décide souvent de comment nous devons créer nos contenus.
On a tendance à comparer les emails (et les SMS) à des lettres, le truc sous enveloppe. Sauf que non : c’est une carte postale. Tout le monde (la poste, le centre de tri, ceux qui gèrent le train ou l’avion, l’autre centre de tri, le facteur…), tous ces gens peuvent lire ton message. J’ai même des pros qui me disent que c’est carrément un poster affiché sur tous les murs de ces intermédiaires, puisque pour transiter par leurs ordis, ton email se… copie. Oui, même si c’est une photo de tes parties intimes…
Si tu veux une enveloppe, il faut chiffrer tes emails (ou tes sms).
Gamin, j’adorais déchiffrer les messages codés dans la page jeux du journal de Mickey. Y’avait une phrase faite d’étoiles, carrés, et autre symboles, et je devais deviner que l’étoile c’est la lettre A, le cœur la lettre B, etc. Lorsque j’avais trouvé toutes les correspondances c’était le sésame magique : j’avais trouvé la clé pour déchiffrer la phrase dans la mystérieuse bulle de Mickey.
Imagine la même chose version calculatrice boostée aux amphètes. C’est ça, le chiffrement. Une petit logiciel prend ton email/SMS, applique la clé des correspondances bizarres pour le chiffrer en un brouillard de symboles, et l’envoie à ton pote. Comme vos logiciels se sont déjà échangé les clés, ton pote peut le déchiffrer. Mais comme il est le seul à avoir la clé, lui seul peut le déchiffrer.
Ben ça, ça te fait une enveloppe en plomb que même le regard laser de Superman il peut pas passer au travers pour lire ta lettre.
Mettre sur le cloud ses fichiers (icloud), ses emails (gmail), ses outils (Office365)… c’est les mettre sur l’ordinateur d’Apple, de Google, de Microsoft.
Alors OK, on parle pas d’un petit PC qui prend la poussière, hein. On parle d’une grosse ferme de serveurs, de milliers d’ordinateurs qui chauffent tellement que des climatiseurs tournent à fond.
Mais c’est le même principe : un serveur, c’est un ordinateur-serviteur en mode Igor, qui est tout le temps allumé, qu’on a enchaîné au plus gros tuyau internet possible. Dès qu’on lui demande une page web, un fichier, un email, une application… on le fouette et il doit répondre au plus vite « Ouiiiiii, Mestre ! »
Tout le truc est de savoir si tu fais confiance aux Igors de savants fous dont le but est de devenir les plus riches et les maîtres du monde, ou au petit Igor du gentil nerd du coin… Voire si tu te paierais pas le luxe d’avoir ton propre Igor, ton propre serveur à la maison.
Moi, après quelques minutes de Facebook (allégorie.)
Ouais, je suis faible. J’ai, encore aujourd’hui, le réflexe « je clique sur facebook entre deux trucs à faire ». Ou Twitter. Ou Tumblr. Ou l’autre truc à la con, OSEF, c’est pareil.
Cinq minutes plus tard, je finis dans état de semi zombie, à scroller de la mollette en voyant mon mur défiler des informations devant mes yeux hypnotisés. Je finis par faire ce qu’on attend de moi : cliquer sur un titre putassier, liker, retwetter une notification et répondre à des trucs dont je n’aurais rien à foutre si une vague connaissance venait m’en parler dans un bar.
Ce n’est pas que je manque de volonté : c’est juste que Facebook (et ses collègues de bureau) m’ont bien étudié. Enfin, ils ont plus étudié l’humain que moi, mais pas de bol : j’en fais partie. Du coup ils ont construit leurs sites, leurs applications, etc. de façon à me piéger, à ce que je reste là (afin de bouffer leur pub), et à ce que j’y retourne.
Ces techniques de design qui hackent notre esprit (genre le « scroll infini », le « bandit manchot des notifications » et les « titres clickbait » dont je parle juste au dessus) sont volontaires, étudiées et documentées. Elles utilisent simplement des failles de notre esprit (subconscient, inconscient, biais cognitifs… je laisse les scientifiques définir tout cela) qui court-circuitent nos volontés. Ce n’est pas en croyant qu’on est maître de soi-même qu’on l’est vraiment. C’est souvent le contraire : le code fait la loi jusque dans nos esprits.
Bref, je suis faible, parce que je suis humain, et donc je suis pas le seul. Et ça, les géants du web l’ont bien compris.
Si je veux voir d’autres choses dans ma vie numérique, j’ai le choix : attendre que les autres le fassent jusqu’à ce que des toiles d’araignées collent mes phalanges aux touches de mon clavier, en mode squelette… ou bien je peux bouger mes doigts.
Alors ouais, j’ai pas appris à conduire en vingt heures de cours, j’ai raté plein de gâteaux avant de m’acheter les bons ustensiles et la première écharpe que j’ai faite avait pleins de trous. Mais aujourd’hui, je sais conduire, faire des pâtisseries pas dégueu et même me tricoter un pull.
Ben créer et diffuser des contenus sur Internet, c’est pareil, ça s’apprend. On trouve même facilement les infos et les outils sur Internet (dont des cours de tricot !).
Une fois qu’on sait, on peut proposer autre chose : c’est la mode des articles courts, creux et aux titres putassiers ? Tiens, et si je gardais le coup du titre pour faire un top, mais cette fois-ci dans un article blog long, dense, et condensant une tonne de sujets épars…?
Oh, wait.
Zeste de savoir, un site pour apprendre et partager de tout.
Quand on voit à quel point on a perdu la maîtrise de l’informatique, de nos vies numériques, de notre capacité à simplement imaginer comment on pourrait faire autrement… y’a de quoi déprimer.
Mais avant que tu demandes à ce qu’on t’apporte une corde, une pierre et une rivière, regarde juste un truc : le numérique est une révolution toute jeune dans notre Histoire. C’est comme quand tu découvres le chocolat, le maquillage, ou une fucking nouvelle série qui déboîte : tu t’en fous plein la gueule.
Sociétalement, on vient de se gaver d’ordinateurs (jusqu’à en mettre dans nos poches, ouais, de vrais ordis avec option téléphone !) et de numérique, et là les plus gros marchands de chocolat/maquillage/séries se sont gavés sur notre dos en nous fourguant un truc sucré, gras et qui nous laisse parfois l’estomac au bord des lèvres.
Mais on commence tout juste, et il est encore temps d’apprendre à devenir gourmet, à savoir se maquiller avec finesse, et même à écrire une fan fiction autour de cette nouvelle série.
Il est temps de revenir vers une informatique-amie, à échelle humaine, vers un outil que l’on maîtrise nous ! (et pas l’inverse, parce que moi j’aime pas que mon lave-linge me donne des ordres, nanmého !)
Des gens plus intelligents et spécialistes que moi m’ont dit qu’avec le trio « logiciel libres + chiffrement + services décentralisés », on tenait une bonne piste. J’ai tendance à les croire, et si ça te botte, tu peux venir explorer cette voie avec nous. Cela ne nous empêchera pas d’en cheminer d’autres, ensemble et en même temps, car nous avons un vaste territoire à découvrir.







 J’ai écrit ce qui suit pour ma famille et mes proches, afin de leur expliquer pourquoi les dernières clauses de la politique de confidentialité de Facebook sont vraiment dangereuses. Cela pourra peut-être vous aider aussi. Une série de références externes, et des suggestions pour en sortir correctement, se trouvent au bas de cet article.
J’ai écrit ce qui suit pour ma famille et mes proches, afin de leur expliquer pourquoi les dernières clauses de la politique de confidentialité de Facebook sont vraiment dangereuses. Cela pourra peut-être vous aider aussi. Une série de références externes, et des suggestions pour en sortir correctement, se trouvent au bas de cet article.

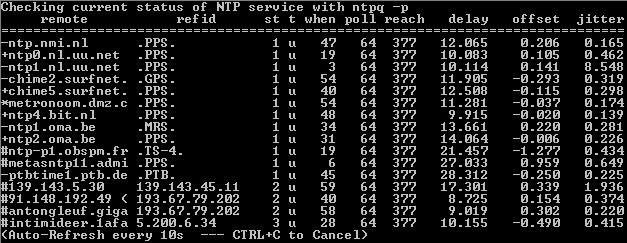
















{kind=link}
{kind=link}
{kind=link}
{kind=link}