Let’s De-frama-tify the Internet !
Wait up before you yell at us! but yeah, we are here to announce the gradual closing down, spanning several years, of some services from the De-google-ify Internet campaign. We want to achieve this goal in a spirit of cooperation, so that we can focus on more decentralization and efficiency for people who are aiming to make a positive change in the world, no matter how small .
What’s going on?
We’ve said it time and time again: Framasoft is -and wishes to remain- a human scale organization, a team of enthusiasts DIY-ing their way through changing the world, one byte at a time. Our organization is made of 9 employees and about thirty members and every year, 700 to 800 volunteers help us (whether it be for one hour or throughout the year). Over 4000 patrons fund our projects (thank you <3), and every month, hundreds of thousands people benefit from those.
Yet Framasoft is more than all of this: dozens of blog articles, around a hundred of meetings, conferences & workshops every year, a publishing house for free-libre books, lots of responds to the requests of many media outlets and a collaborative directory of free-libre solutions. We currently develop two important softwares (PeerTube and Mobilizon), and we are working on so many cool partnerships and collaborative projects that we’re going to need three months to introduce you to all of them… (See y’all in October !)

One thing is for sure: we, at Framasoft, hold our not-for-profit status close to our hearts. We don’t want to become start-up nor replace Google. We want to preserve our identity without burning ourselves out (we’ll touch on that some more in the following weeks, as we have sometimes overworked ourselves in the past), and keep on experimenting with new things. If we want to achieve all of these goals, we have to reduce our (heavy) workload.
Why are we closing down some services?
From the start, we advertized the De-google-ify Internet project as an experiment, a proof of concept, which was set to stop at the end of 2017. What we had not foreseen was that the discourse about current web centralization (which only nerds like us cared about in 2014) would generate such enthusiasm, and that as a consequence, so many expectations would be placed on us. In plain English: De-google-ify Internet, and all of the services that come with it, was not meant to centralize so many users, nor to lock them up in frama-stuffs that would last to infinity (and beyond).
Apart from our « just for kicks » projects (Framatroll and Framadsense: still love you, fam), there are 38 services on the De-goole-ify Internet servers. That’s a lot. Like, seriously, a lot. This means 35 different softwares (each with its own update pace, active or dormant communities, etc.), written in 11 programming languages (and 5 types of databases), shared on 83 servers and virtual machines, all in need of monitoring, updating, adjusting, backing-up, debugging, promotion and support integration… It’s a lots of care and pampering, in the same vein as keeping hotel rooms visited by thousands of individuals every month.
Well, some services barely work anymore (Tonton Roger). Other started as experiments that we couldn’t carry on with (Framastory, Framaslides). Some services have such a large technical debt that even when we spent several days of development in them, we are only delaying their inevitable collapse (Framacalc). Other services could, left to their own devices, grow forever, limitless, which is unsustainable (Framasite, Framabag, Framabin, etc.). When you are as known as Framasoft in the French-speaking community (Framalink, Framapic), some service are extremely work-intensive in order to prevent and fight misuse. And don’t get us started on federated social medias (Framapiaf, Framasphere): they require a lot of moderation, and would operate much more fluidly had we not welcomed so many users.
And to top it all off… this is no healthy functioning! We all know how handy it is to be able to say « if you want alternative solutions, just look at Framastuffs! ». It is very reassuring to find everything in the same place, under the same name… We are aware of this phenomenon, and that’s why we decided to use « frama », in a way not dissimilar to a brand -though that is frankly not our cup of tea. Except internet centralization is unhealthy.
Internet centralization is risky, too. Not only was it not meant to become so centralized, but also putting all of our data in the same basket is just how you centralize power in the hands of hosts system administrators. Besides, this is precisely the slippery slope from which Google and Facebook emerged.
Therefore, de-frama-tifying is on the agenda.
Decentralization is one more click away
Let’s take time to exploit one of the great perks of free softwares over proprietary softwares. When (totally random example) Google burries its umpteenth project, the code is usually proprietary: Google deprives us from the freedom to take this code over and install it on our servers.
![]()
On the contrary, free softwares allow anyone to take the reigns. For example, Framapic doesn’t belong to Framasoft: everyone is legally entitled to install the Lutim software somewhere on their server and let anyone they see fit benefit from it… Actually, this spirit of decentralization is the reason why we have worked with self hosting-easing tools (like Yunohost), as well as with CHATONS (collective of independant, transparent, open, neutral and ethical hosters).
Our goal with this early announcements (concerning, for example, Framapic) is twofold.
Firstly, we hope this will incentivize many hosts to open their Lutim instances, aka the same service (looking at you, fellow CHATONS). Secondly, this gives us time to pick hosting offers and to display them on the Framapic landing page, redirecting you in one click to the same service, except with a different host. All of this will be implemented as soon as we announce Framapic’s close down (one year before it actually happens).
So, what happens next?
Smoothly, and over two years! at the very least. (Might take longer if we stumble on our keyboards and sprain our phalanxes! You never know until you know).
Now that we can all catch our breath, reassured that free and ethical services are SWAG, it is (high) time we start transitionning from the « everything Framasoft » instinct. Less frama services means all of you can explore elsewhere. It’s kinda as if we said:
Our digital CSA is at full capacity, but we are not leaving you with an empty basket: our network of CSAs and other network members will be delighted to welcome you.
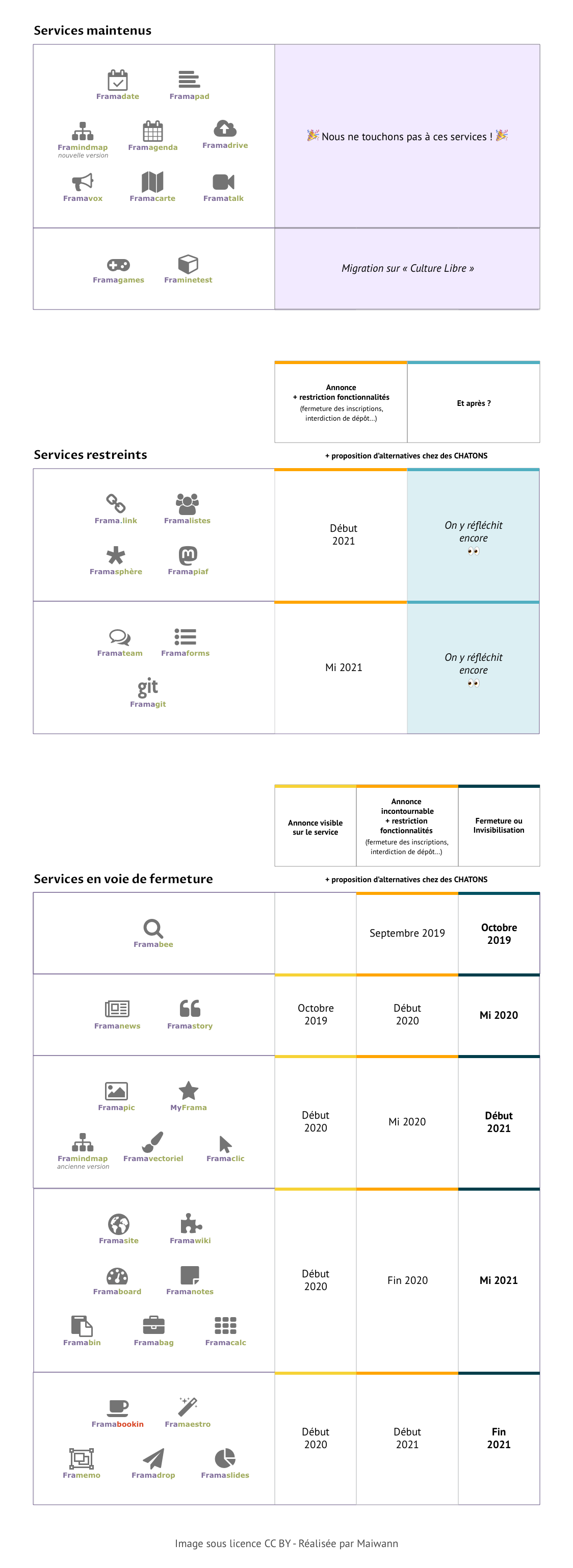
We are laying the groundwork for y’all. In a spirit of transparency, you can dowload this spreadsheet [FR] that shows in detail our estimated closing down schedule. And if you prefer to have a general look, here is our we plan this closing down:
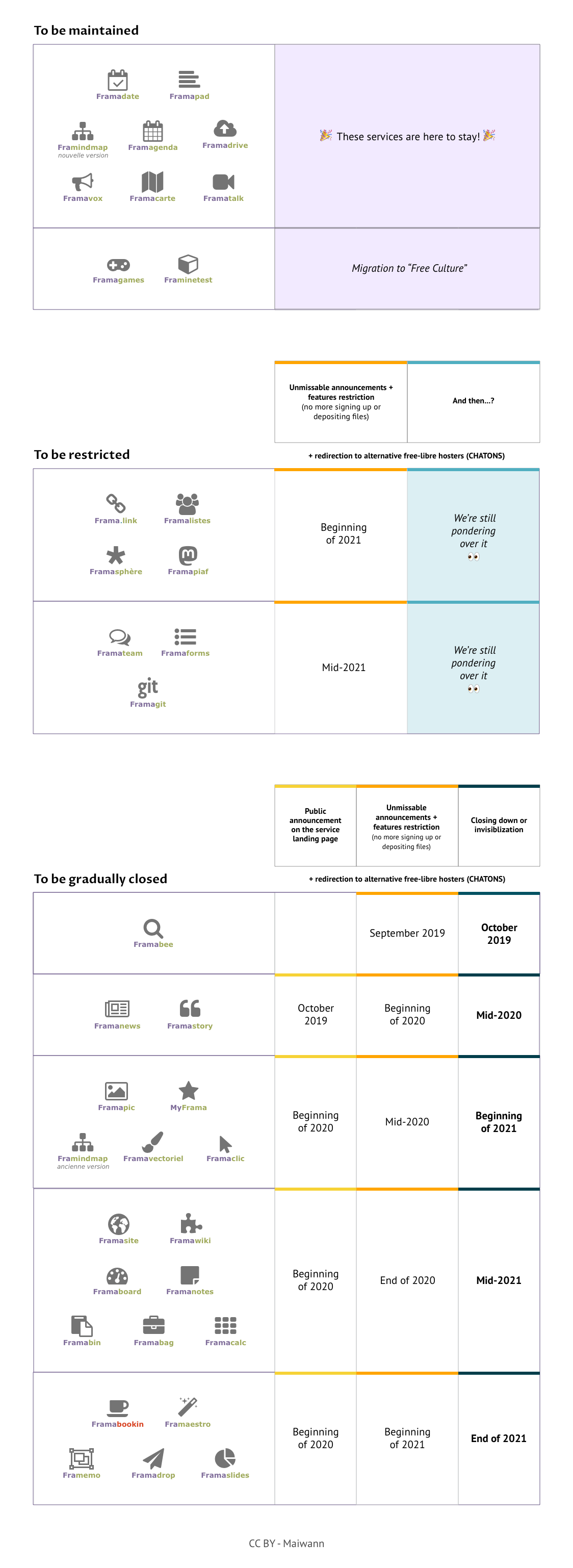
If we take a closer look, there’s a similar pattern for each service involved:
- Then, we announce on each concerned service that it will be first restricted, then closed down (1rst column). We will display on the landing page a link to hand-picked alternative hosts (same software or similar one).
- Afterwards, we limit the service use (2nd column). The goal here is to close the door to newcomers (they won’t be able to create a new account, a new calc, or to upload a new file). We will advise them on alternatives solutions, all the while giving existing users time to migrate their account and personal data if they still up on our services.
- At last, we close down the service whenever possible (last column on the board) or we make it invisible when maintaining a certain amount of continuity is necessary (e.g. existing frama.link will still redirect to the right web address).
We are not closing down everything, and certainly not now (save for one)
Framastory and Framanews pose a lot of technical issues, forcing us to act quickly. They will be the first services impacted. They will be restricted at the start of 2020, and closed down a semester later. For all of the other services we talked about earlier, restrictions will only start during summer 2020 (even summer 2021 for some), and the first closing downs will not happen before 2021 – in some cases, not before 2022!
Simply put, the only exceptions to this rule will be the service we won’t close down, (Framadate, Framapads and MyPads, Framavox, Framagenda, Framatalk, the collaborative Framindmap, Framacarte), as well as those we are just moving to our « free-libre culture » project (Framagames and Framinetest). This includes Framadrive, which now has been on limited access for a while because of how popular it became, with 5000 accounts created. This is the limit we had set from the start, and we intend on keeping things that way.
And then, there’s Framabee, aka good old Tonton Roger, our meta search engine that no longer quite works. Some might say we should just finish it off, other would prefer for the landing page to state « killed by Google » . Indeed, no matter how much we hacked, Google & Co received too many queries from us and started refusing them en masse… which proves further that centralizing uses, even here at Framasoft, just won’t cut it! We’ll let Tonton Roger retire early: next month, we’ll wave him goodbye and gift him a pair of slippers.

Spring cleaning so we can more forwards together
We have learnt a lot. The “de-google-ify” campaign showed us that users don’t have to follow the « the client is king » model, or to behave like Karen « I wanna speak to the manager » Von Soccer Mom. Yall have gracefully dealt with week-end server crashes (our system administrators don’t have to work on week-ends), slightly less fancy-looking tools, and limitations on service use so as to give space for other users… In short: there is room in our lives for hand-crafted digital tech, aka small techs, in the most noble sense of the term.
Everything we have learnt since 2014 leads us to think we need a change. Clearly, we don’t want to let people (i.e. y’all!) high and dry, or give you the impression that free culture and softwares is an unkept promise. Quite the opposite: we were happy to introduce you to FLOSS solutions and to help you take them on (thanks for your efforts!). Your trust in and craving for for ethical digital tools are precious: we don’t want to make anyone lose their mojo, only to take you all one step further.

And by the way, we are taking the time to do something GAFAMs & Co have never cared to do: announcing way ahead of time our closing down plans and helping our users in the road towards de-google-ifying. We are getting rid of what no longer sparks joy, putting some order in the tools and experiment we have accumulated over the years in our backpacks. This will give space and availability for what’s next.
PeerTube and Mobilizon are proof of our desire to move away from the « just-like-Google-but-with-ethics » software model. Starting this October and spanning three months, we will be reviewing our « Contributopia » roadmap, and y’all will see that there is a lot to talk about. You’ll discover many more projects we hadn’t seen at the bottom of our digital backpack.
We are very excited for the next steps, as we have many announcements and contribution stories to share… see you in mid-October, we can’t wait!
One year to offer you a new proposition
Drawing on what we learnt from De-google-ify Internet, we sense that it’s possible to build a new, simpler, and handier offer for a range of services, both for users and hosts.
Through observing your uses of those services and listening to your expectations, we (along with many other people!) believe that Nextcloud, rich in many applications, is one way to go. We believe this software could fulfill most of the needs of people trying to change the world.
We’re giving ourselves a year to contribute (once again) to this software, stir in it, experiment with buddies and offer you a new proposition, which hopefully will make de-google-ifiying even easier… just like de-frama-tifying!
Key points:
- We refuse to become the « default » solution and to monopolize your uses and attention (that’s how we empowered GAFAM & Co)
- 38 services, it’s way too complex for you to adopt and for us to host
- We wish to stay an organization of a human scale, and retain our human warmth… a sort of digital CSA;
- We propose to take the next step towards data decentralization:
- By gradually closing-down some frama-services so their landing-pages can become gateways to other hosters
- By taking the time to offer a new simpler range of services for users (through a single sign-on account for example)


























{kind=link}