Annoncé en juin 2020, [RÉSOLU] est un ensemble de fiches didactiques visant à favoriser et préparer l’adoption des logiciels libres. Elles sont destinées aux association d’éducation populaire et de manière générale à toutes les structures de l’Économie Sociale et Solidaire.
Les structures concernées par [RÉSOLU] n’existent évidemment pas uniquement en France. Et voici annoncée une version italienne qui trouvera sans conteste ses lecteurs et contributeurs ! Le projet de traduction a été initié par Nilocram qui suit et même propage de temps à autre les activités de Framasoft auprès de ses compatriotes italiens.
Nous lui laissons la parole pour l’annonce !
[RESOLU] Une traduction en italien très attendue
Par Nilocram
En décembre de l’année dernière, sur mon blog, j’ai présenté [RÉSOLU], un guide d’utilisation des logiciels libres s’adressant notamment aux organisations qui agissent pour l’économie sociale et solidaire.
Le guide a été créé par Framasoft en collaboration avec d’autres associations et publié en français, en format papier et numérique, par Framabook. Je l’ai trouvé très utile et intéressant. J’ai donc essayé d’en traduire un extrait (ici, en pdf).
Parfois ça m’arrive de traduire mes coups de cœur 🙂
J’ai conclu mon billet en constatant que vu l’intérêt et l’utilité du guide, il aurait été bien de le traduire de manière collaborative.
Reti Etiche e Soluzioni Aperte per Liberare i vostri Utilizzi
Ça peut paraître incroyable, mais cette fois c’est vraiment arrivé !
Les amis de l’association LinuxTrent ont décidé de relever le défi et de traduire l’intégralité du guide en italien.
LinuxTrent est une association qui rassemble un groupe important et actif d’utilisateurs de GNU Linux dans la province de Trente et ses environs. C’est une association à but non lucratif qui promeut le logiciel libre, l’hardware libre, les données ouvertes et les droits numériques des personnes dans la réalité de la région avec une attention particulière aux écoles et à l’administration publique.
Lorsque le président de l’association, Roberto Resoli, a lu l’extrait du guide, il a pensé qu’il s’agissait d’un travail de bonne qualité qui pourrait être d’une grande aide pour éveiller la conscience de ceux qui travaillent dans le domaine de l’économie sociale et solidaire. Il a demandè si quelqu’un avait envie d’aider, et il a obtenu une bonne réponse : c’est ainsi que la traduction a commencé.
Le travail de traduction a été organisé par LinuxTrent à l’aide des logiciels libres Nextcloud et Collabora Online (la version en ligne de LibreOffice).
Un grand merci à Ilario Quinson, Roberto Resoli, Danilo Spada, Daniele Zambelli qui avec leur travail ont permis l’achèvement de la traduction italienne à laquelle j’ai également apporté ma petite contribution.
Un an après la publication de l’édition française, voici enfin la traduction italienne !
[RÉSOLU] est téléchargeable à partir de cette page sur le site de LinuxTrent. Il est disponible en format .pdf et aussi en format .odt pour ceux qui veulent le modifier et le réutiliser, en améliorant peut-être la mise en page.
Note : la version italienne a tout récemment été retranscrite en markdown pour intégrer le dépôt GIT dédié au projet. La version web en italien ne saurait tarder.
À Quimper en juillet, entrée libre au carré
Partout en France, des personnes dynamiques s’investissent pour accompagner celles et ceux qui le désirent vers davantage de maîtrise et d’émancipation dans leurs usages numériques.
Framasoft a choisi de mettre en lumière et de soutenir l’activité exemplaire de celle qui se fait appeler « la Reine des Elfes » sur son média social favori. Si nous la connaissons bien et l’apprécions, c’est parce qu’au-delà de son activité régulière au Centre des Abeilles à Quimper, elle a organisé une première session d’Entrée libre, qui a réuni des intervenants du monde du Libre pour 3 jours en août 2019, un événement ouvert à toutes et gratuit « pour comprendre internet, découvrir les logiciels libres et protéger sa vie privée » (voir l’affiche 2019).
Eh bien voilà que notre chère « rainette » bretonne récidive cette année ! Voici dans l’interview ci-dessous les raisons qui la poussent à organiser et réussir un événement qui nous est cher. Et puis comme le budget est plus important cette année, elle a lancé un appel aux dons auquel nous vous invitons à répondre comme nous venons de le faire…
Mat ar jeu, Brigitte ?
Demat Framasoft. Tu te colles au brezhonneg ? Je ne te suivrai pas dans cette langue, car même si j’habite en terre bretonnante, je ne le maîtrise pas. Je te répondrais donc en Gallec : je vais bien ! 🙂
D’où est venue l’idée d’Entrée Libre ?
Ouh là ! Il faut revenir à la première édition en 2019. Je voulais faire un cadeau à mon pote @reunigkozh qui a initié les distributions gratuites d’ordinateurs au Centre des abeilles. Cela faisait 10 ans en 2019. Et je trouvais que nous devions fêter cela.
Mon expérience personnelle m’avait montré que tout le monde ne comprend pas ce qu’iel fait lors de l’utilisation d’un ordinateur. C’est compliqué de comprendre qu’alors que l’on est seul face à un écran, il se passe plein d’autres choses. De comprendre aussi qu’il peut y avoir aussi de l’éthique dans le numérique et qu’on peut choisir quoi utiliser, si on est suffisamment informé.
Le premier Entrée Libre était donc axé sur une présentation d’assos ou de logiciels qui pouvaient aider à prendre sa vie numérique en main.
Est-ce que c’est facile de faire venir des intervenant·e·s de qualitay à Quimper ? (question de Parisien-tête-de-chien qui se croit au centre du monde… libre 🙂 )
J’ai eu beaucoup de chance d’utiliser le Fédiverse, en l’occurrence, Mastodon. Avant, j’étais surtout sur Diaspora* et quand Framasoft a dit « ça vous dit d’essayer un nouvel outil de microblogging ? » ben, je suis allée tester !… et j’y ai rencontré des gens super, qui m’ont appris plein de trucs et qui répondaient à mes questions de noob. Alors, quand j’ai parlé de mon projet d’informer les gens de ce qui existait, Iels ont répondu présent. C’était très émouvant de voir que non seulement personne ne démontait ce projet mais qu’en plus il y avait du monde à répondre à mon appel. J’suis ni connue ni de ce monde-là… Et iels sont forcément de qualitay puisque ce sont mes mastopotes ! 😀
C’est le numéro 2, pourquoi ? Le 1 ne t’a pas suffi ? 😀
J’avais dit que je ne referai plus ! 😛 . C’est beaucoup de boulot mine de rien et beaucoup de stress ! Mais voilà, suite au premier confinement, j’ai rencontré beaucoup de gens « malades du numérique ». Je veux dire que beaucoup de personnes ont été obligées d’utiliser des outils qu’iels ne comprenaient pas. C’était devenu une obligation et iels ont galéré pensant que c’était de leur faute… « parce que je suis nul ! ». J’aimerais donc qu’iels comprennent que ce n’est pas le cas. Qu’il existe des outils plus accessibles que d’autres. Qu’iels ne vont pas casser Internet en allant « dessus ».
Quelles attentes est-ce que tu perçois lors des ateliers que tu réalises ? (je pense à la fois aux tiens et aux distributions d’ordis de LinuxQuimper)
Vaste question !
Pour les distributions, c’est facile. Les gens veulent s’équiper ! Leur besoin est simple, pouvoir accéder aux mails et pour beaucoup, pouvoir s’actualiser à Pôle Emploi. Mais nous n’avons pas beaucoup de retour quand à leur utilisation par la suite.
Pour les ateliers que j’anime, en tant que salariée maintenant, je mets bien les choses au clair. Je ne donne pas de cours, je fais un accompagnement. C’est-à-dire que je ne touche que très peu à la machine, sauf pour voir parfois où sont cachés les trucs (ben oui, n’utilisant qu’Ubuntu, je ne sais pas forcément utiliser un Windows ou un Mac.).
L’avantage de leur montrer cela, c’est que du coup, iels s’aperçoivent qu’il n’y a pas de science infuse et que non, l’apposition des mains ne leur fera pas venir le savoir. Quant à leurs attentes, une fois qu’iels ont compris cela , elles deviennent plus sympas. Les discussions sur la vie privée arrivent très vite, d’autant que j’ai accroché les belles affiches de la Quadrature du net dans la salle où je suis . Et une fois les angoisses passées, la curiosité arrive et tu les vois passer le curseur sur les icônes, pour savoir ce que c’est avant de cliquer. Et faire la différence entre Internet et leur machine. C’est génial !
Et puis ensuite, quand je les accompagne sur Internet, il y a plein de questions auxquelles je les force à trouver la réponse par rapport à leurs attentes. Notamment pour les cookies… Je leur explique que ce n’est pas à moi de décider pour elleux, cela leur semble étonnant au début, et puis je les vois décider, se demander pourquoi telle ou telle extension a été ajoutée la dernière fois qu’iels ont amené leur ordi à réparer… C’est très sympa !
D’où te vient cette curiosité pour apprendre et progresser en compétences dans un domaine qui ne t’était pas trop familier il y a peu d’années encore ?
Je crois que je suis curieuse par nature. Pas de cette curiosité pour savoir qui fait quoi. Mais de comment ça marche et du pourquoi, cela épuisait parfois mes instits même si elles aimaient bien cela.
J’ai toujours démonté mes machines, pas quand j’étais enfant, « les filles ne font pas ça » (déjà que je jouais au foot et que je grimpais aux arbres !), pour essayer de les réparer car souvent ce n’était pas grand-chose qui les empêchait de fonctionner (un tout petit jouet glissé dans le magnétoscope par exemple). Et on va dire que c’est grâce ou à cause de Windows que j’ai rencontré le Libre. Puisque j’en avais assez de le casser parce que je retirais des fichiers qui ne me semblaient pas clairs et de ces virus qui revenaient malgré les antivirus qu’ils soient gratuits ou payants. J’ai donc commencé par chercher sur internet « par quoi remplacer Windows ». À l’époque je ne connaissais pas le mot « système d’exploitation » et j’ai lu des trucs qui parlaient d’un bidule qui s’appelait Linux. J’ai fouillé, cherché, et au bout d’un an j’ai dit à un de mes fils : « tu te débrouilles mais je veux ça sur l’ordi ». Il a gravé un disque et la libération est arrivée. 😀
Puis j’ai vu qu’il existait un groupe LinuxQuimper (sur FB à l’époque où je l’utilisais) et qu’il y avait au centre social des Abeilles des gens de ce groupe (j’ai appris plus tard qu’on disait un GUL) distribuaient des ordis sous Linux. Je les ai donc contactés et je suis entrée dans l’équipe de distribution. Et j’ai recommencé à poser des questions ;-). Et un jour, ils m’ont parlé de Diaspora* où j’ai créé un compte…
Pour nous, tu es la figure de proue d’Entrée Libre, mais est-ce que tu es soutenue et aidée localement pour cette opération par une association ?
Le centre social est effectivement géré par une association « Centre des abeilles ».
Pour la prépa, je suis toute seule à bord, avec l’aval des intervenants et des aides ponctuelles sur les mises en forme. Je prépare cela bénévolement, et ensuite je me fais aider pour la diffusion et tous les petits détails pratiques.
Quand le projet prend forme, le directeur du centre le présente au conseil d’administration du Centre des Abeilles qui valide ou pas le projet. C.A où je suis convoquée pour le présenter aussi.
C’est donc toujours beaucoup d’incertitude et cette année j’ai trouvé cela plus compliqué que la première année. Un C.A. en visio manque de chaleur et d’interaction. En plus le budget est plus lourd que la dernière fois…
Le budget est/a été difficile à boucler, est-ce parce que les frais d’hébergement et déplacement de tous les invités sont trop importants cette fois-ci ?
Déjà on a plus du double d’intervenants. La dernière fois Entrée Libre finissait à 18h chaque soir sur 3 jours. Ce coup-ci , ça commence à la même heure mais ça va finir à 20h30, voire 21h le temps de tout ranger pour le lendemain, pour les bénévoles. Il y a donc un repas supplémentaire à prévoir.
Ce n’est pas tant les déplacements et l’hébergement (iels sont nombreux à ne pas vouloir de défraiement et d’hébergement, ouf !) qui vont coûter le plus mais bien les repas pour plus de trente personnes midi et soir (mon premier prévisionnel comptait tout le monde et arrivait à 9868,05€ t’imagines la tête des gens du CA 😛
Entrée Libre N°2 bénéficie d’une subvention du fonds de soutien à la vie associative, mais il reste de l’argent à trouver…
Est-ce qu’il y aura des crêpes ?
Au moins pour les intervenantes et intervenants ! Pourquoi vous croyez qu’iels viennent ? 😀
Mais je crois bien que j’ai un mastopote qui veut en faire pour le public aussi ! J’ai même prévu des repas et des crêpes véganes pour les bénévoles et le public.
On te laisse le mot de la fin !
Personnellement je trouve que c’est un beau projet que celui de permettre à des gens de s’émanciper, de pouvoir comprendre ce qui se passe avec leurs données numériques, de pouvoir choisir des outils respectueux. Mais pour pouvoir choisir il faut avoir du choix et sans informations on n’en a pas !
Parce que cette belle phrase « si tu ne sais pas demande, et si tu sais, partage » n’a de sens que si il y a du monde pour poser des questions et du monde pour recevoir les partages.
Si ce projet a du sens pour vous aussi n’hésitez pas, si vous le pouvez, à faire un don au « Centre des Abeilles » . Pour plus d’infos sur le programme n’hésitez pas à aller visiter sa page.
Merci à mes mastopotes et à Framasoft de m’avoir permis de tester plein de trucs et de croire en moi. Et bien sûr, un grand merci à celles et ceux qui ont déjà participé à la collecte de dons.
Pour assurer le succès de l’événement, Framasoft, qui animera plusieurs conférences et ateliers, a mis la main à la poche et contribué financièrement. Vous pouvez consulter le détail du budget prévisionnel.
Partagez l’inventaire de votre bibliothèque avec vos proches sur inventaire.io
Inventaire.io est une application web libre qui permet de faire l’inventaire de sa bibliothèque pour pouvoir organiser le don, le prêt ou la vente de livres physiques. Une sorte de méga-bibliothèque communautaire, si l’on veut. Ces derniers mois, Inventaire s’est doté de nouvelles fonctionnalités et on a vu là l’occasion de valoriser ce projet auprès de notre communauté. On a donc demandé à Maxlath et Jums qui travaillent sur le projet de répondre à quelques unes de nos questions.
Chez Framasoft, on a d’ailleurs créé notre inventaire où l’on recense les ouvrages qu’on achète pour se documenter. Cela permet aux membres de l’association d’avoir un accès facile à notre bibliothèque interne. On a aussi fait le choix de proposer ces documents en prêt, pour que d’autres puissent y accéder.
Salut Maxlath et Jums ! Pouvez-vous vous présenter ?
Nous sommes une association de deux ans d’existence, développant le projet Inventaire, centré autour de l’application web inventaire.io, en ligne depuis 2015. On construit Inventaire comme une infrastructure libre, se basant donc autant que possible sur des standards ouverts, et des logiciels et savoirs libres : Wikipédia, Wikidata, et plus largement le web des données ouvertes.
L’association ne compte aujourd’hui que deux membres, mais le projet ne serait pas où il en est sans les nombreu⋅ses contributeur⋅ices venu⋅es nous prêter main forte, notamment sur la traduction de l’interface, la contribution aux données bibliographiques, le rapport de bugs ou les suggestions des nouvelles fonctionnalités.
Vous pouvez nous en dire plus sur Inventaire.io ? Ça sert à quoi ? C’est pour qui ?
Inventaire.io se compose de deux parties distinctes :
D’une part, une application web qui permet à chacun⋅e de répertorier ses livres en scannant le code barre par exemple. Une fois constitué, cet inventaire est rendu accessible à ses ami⋅es et groupes, ou publiquement, en indiquant pour chaque livre si l’on souhaite le donner, le prêter, ou le vendre. Il est ensuite possible d’envoyer des demandes pour ces livres et les utilisateur⋅ices peuvent prendre contact entre elleux pour faire l’échange (en main propre, par voie postale, peu importe, Inventaire n’est plus concerné).
D’autre part, une base de données publique sur les auteurs, les œuvres, les maisons d’éditions, etc, qui permet à chacun⋅e de venir enrichir les données, un peu comme dans un wiki. Le tout organisé autour des communs de la connaissance (voir plus bas) que sont Wikipédia et Wikidata. Cette base de données bibliographiques permet d’adosser les inventaires à un immense graphe de données dont nous ne faisons encore qu’effleurer les possibilités (voir plus bas).
L’inventaire de Framasoft sur inventaire.io
Inventaire.io permettant de constituer des bibliothèques distribuées, le public est extrêmement large : tou⋅tes celleux qui ont envie de partager des livres ! On a donc très envie de dire que c’est un outil pour tout le monde ! Mais comme beaucoup d’outils numériques, l’outil d’inventaire peut être trop compliqué pour des personnes qui ne baignent pas régulièrement dans ce genre d’applications. C’est encore pire une fois que l’on rentre dans la contribution aux données bibliographiques, où on aimerait concilier richesse de la donnée et facilité de la contribution. Cela dit, on peut inventorier ses livres sans trop se soucier des données, et y revenir plus tard une fois qu’on se sent plus à l’aise avec l’outil.
Par ailleurs, on rêverait de pouvoir intégrer les inventaires des professionnel⋅les du livre, bibliothèques et librairies, à cette carte des ressources, mais cela suppose soit de l’interopérabilité avec leurs outils existants, soit de leur proposer d’utiliser notre outil (ce que font déjà de petites bibliothèques, associatives par exemple), mais inventaire.io nous semble encore jeune pour une utilisation à plusieurs milliers de livres.
Quelle est l’actualité du projet ? Vous prévoyez quoi pour les prochains mois / années ?
L’actualité de ces derniers mois, c’est tout d’abord de nouvelles fonctionnalités :
les étagères, qui permettent de grouper des livres en sous-catégories, et qui semble rencontrer un certain succès ;
la mise en place de rôles, qui va permettre notamment d’ouvrir les taches avancées d’administration des données bibliographiques (fusions/suppressions d’édition, d’œuvre, d’auteur etc.) ;
l’introduction des collections d’éditeurs, qui permettent de valoriser le travail de curation des maisons d’édition.
Pas mal de transitions techniques sous le capot aussi. On n’est pas du genre à changer de framework tous les quatre matins, mais certains choix techniques faits au départ du projet en 2014 – CoffeeScript, Brunch, Backbone – peuvent maintenant être avantageusement remplacés par des alternatives plus récentes – dernière version de Javascript (ES2020), Webpack, Svelte – ce qui augmente la maintenabilité et le confort, voire le plaisir de coder.
Autre transition en cours, notre wiki de documentation est maintenant une instance MediaWiki choisie entre autres pour sa gestion des traductions.
Le programme des prochains mois et années n’est pas arrêté, mais il y a des idées insistantes qu’on espère voir germer prochainement :
la décentralisation et la fédération (voir plus bas) ;
les recommandations entre lectrices : aujourd’hui on peut partager de l’information sur les livres que l’on possède, mais pas les livres que l’on apprécie, recommande ou recherche. Même si une utilisation détournée de l’outil est possible en ce sens et nous met aussi en joie (oui, c’est marrant de voir des humains détourner une utilisation), on devrait pouvoir proposer quelque chose pensé pour ;
des paramètres de visibilité d’un livre ou d’une étagère plus élaborés : aujourd’hui, les seuls modes de partage possible sont privé/amis et groupes/public, or amis et groupes ça peut être des personnes très différentes avec qui on n’a pas nécessairement envie de partager les mêmes choses.
Enfin tout ça c’est ce qu’on fait cachés derrière un écran, mais on aimerait bien aussi expérimenter avec des formats d’évènements, type BiblioParty : venir dans un lieu avec une belle bibliothèque et aider le lieu à en faire l’inventaire.
C’est quoi le modèle économique derrière inventaire.io ? Quelles sont/seront vos sources de financement ?
Pendant les premières années, l’aspect « comment on gagne de l’argent » était une question volontairement laissée de côté, on vivait avec quelques prestations en micro-entrepreneurs, notamment l’année dernière où nous avons réalisé une preuve de concept pour l’ABES (l’Agence bibliographique pour l’enseignement supérieur) et la Bibliothèque Nationale de France. Peu après, nous avons fondé une association loi 1901 à activité économique (voir les statuts), ce qui devrait nous permettre de recevoir des dons, que l’on pourra compléter si besoin par de la prestation de services. Pour l’instant, on compte peu sur les dons individuels car on est financé par NLNet via le NGI0 Discovery Fund.
Et sous le capot, ça fonctionne comment ? Vous utilisez quoi comme technos pour faire tourner le service ?
Le serveur est en NodeJS, avec une base de données CouchDB, synchronisé à un Elasticsearch pour la recherche, et LevelDB pour les données en cache. Ce serveur produit une API JSON (documentée sur https://api.inventaire.io) consommée principalement par le client : une webapp qui a la responsabilité de tout ce qui est rendu de l’application dans le navigateur. Cette webapp consiste en une bonne grosse pile de JS, de templates, et de CSS, initialement organisée autour des framework Backbone.Marionnette et Handlebars, lesquels sont maintenant dépréciés en faveur du framework Svelte. Une visualisation de l’ensemble de la pile technique peut être trouvée sur https://stack.inventaire.io.
Le nom est assez français… est-ce que ça ne pose pas de problème pour faire connaître le site et le logiciel à l’international ? Et d’ailleurs, est-ce que vous avez une idée de la répartition linguistique de vos utilisatrices ? (francophones, anglophones, germanophones, etc.)
Oui, le nom peut être un problème au début pour les non-francophones, lequel⋅les ne savent pas toujours comment l’écrire ou le prononcer. Cela fait donc un moment qu’on réfléchit à en changer, mais après le premier contact, ça ne semble plus poser de problème à l’utilisation (l’un des comptes les plus actifs étant par exemple une bibliothèque associative allemande), alors pour le moment on fait avec ce qu’on a.
Sticker inventaire.io
En termes de répartition linguistique, une bonne moitié des utilisateur⋅ices et contributeur⋅ices sont francophones, un tiers anglophones, puis viennent, en proportion beaucoup plus réduite (autour de 2%), l’allemand, l’espagnol, l’italien, suivi d’une longue traîne de langues européennes mais aussi : arabe, néerlandais, portugais, russe, polonais, danois, indonésien, chinois, suédois, turc, etc. À noter que la plupart de ces langues ne bénéficiant pas d’une traduction complète de l’interface à ce jour, il est probable qu’une part conséquente des utilisatrices utilisent l’anglais, faute d’une traduction de l’interface satisfaisante dans leur langue (malgré les 15 langues traduites à plus de 50%).
À ce que je comprends, vous utilisez donc des données provenant de Wikidata. Pouvez-vous expliquer à celles et ceux qui parmi nous ne sont pas très au point sur la notion de web de données quels sont les enjeux et les applications possibles de Wikidata ?
Tout comme le web a introduit l’hypertexte pour pouvoir lier les écrits humains entre eux (par exemple un article de blog renvoie vers un autre article de blog quelque part sur le web), le web des données ouvertes permet aux bases de données de faire des liens entre elles. Cela permet par exemple à des bibliothèques nationales de publier des données bibliographiques que l’on peut recouper : « Je connais cette auteure avec tel identifiant unique dans ma base. Je sais aussi qu’une autre base de données lui a donné cet autre identifiant unique ; vous pouvez donc aller voir là-bas s’ils en savent plus ». Beaucoup d’institutions s’occupent de créer ces liens, mais la particularité de Wikidata, c’est que, tout comme Wikipédia, tout le monde peut participer, discuter, commenter ce travail de production de données et de mise en relation.
L’éditeur de données, très facile d’utilisation, permet le partage vers wikidata.
Est-ce qu’il serait envisageable d’établir un lien vers la base de données de https://www.recyclivre.com/ quand l’ouvrage recherché ne figure dans aucun « inventaire » de participant⋅es ?
Ça pose au moins deux problèmes :
Ce service et d’autres qui peuvent être sympathiques, telles que les plateformes mutualisées de librairies indépendantes (leslibraires.fr, placedeslibraires.fr, librairiesindependantes.com, etc.), ne semblent pas intéressés par l’inter-connexion avec le reste du web, construisant leurs URL avec des identifiants à eux (seul le site librairiesindependantes.com semble permettre de construire une URL avec un ISBN, ex : https://www.librairiesindependantes.com/product/9782253260592/) et il n’existe aucune API publique pour interroger leurs bases de données : il est donc impossible, par exemple, d’afficher l’état des stocks de ces différents services.
D’autre part, recyclivre est une entreprise à but lucratif (SAS), sans qu’on leur connaisse un intérêt pour les communs (code et base de données propriétaires). Alors certes ça cartonne, c’est efficace, tout ça, mais ce n’est pas notre priorité : on aimerait être mieux connecté avec celleux qui, dans le monde du livre, veulent participer aux communs : les bibliothèques nationales, les projets libres comme OpenLibrary, lib.reviews, Bookwyrm, Readlebee, etc.
Cependant la question de la connexion avec des organisations à but lucratif pose un vrai problème : l’objectif de l’association Inventaire — cartographier les ressources où qu’elles soient — implique à un moment de faire des liens vers des organisations à but lucratif. En suivant l’esprit libriste, il n’y a aucune raison de refuser a priori l’intégration de ces liens, les développeuses de logiciels libres n’étant pas censé contraindre les comportements des utilisatrices ; mais ça pique un peu de travailler gratuitement, sans contrepartie pour les communs.
En quoi inventaire.io participe à un mouvement plus large qui est celui des communs de la connaissance ?
Inventaire, dans son rôle d’annuaire des ressources disponibles, essaye de valoriser les communs de la connaissance, en mettant des liens vers les articles Wikipédia, vers les œuvres dans le domaine public disponibles en format numérique sur des sites comme Wikisource, Gutenberg ou Internet Archive. En réutilisant les données de Wikidata, Inventaire contribue également à valoriser ce commun de la connaissance et à donner à chacun une bonne raison de l’enrichir.
Une interface simple pour ajouter un livre à son inventaire
Inventaire est aussi un commun en soi : le code est sous licence AGPL, les données bibliographiques sous licence CC0. L’organisation légale en association vise à ouvrir la gouvernance de ce commun à ses contributeur⋅ices. Le statut associatif garantit par ailleurs qu’il ne sera pas possible de transférer les droits sur ce commun à autre chose qu’une association poursuivant les mêmes objectifs.
Si je suis une organisation ou un particulier qui héberge des services en ligne, est-ce que je peux installer ma propre instance d’inventaire.io ?
C’est possible, mais déconseillé en l’état. Notamment car les bases de données bibliographiques de ces différentes instances ne seraient pas synchronisées, ce qui multiplie par autant le travail nécessaire à l’amélioration des données. Comme il n’y a pas encore de mécanisme de fédération des inventaires, les comptes de votre instance seraient donc isolés. Sur ces différents sujets, voir cette discussion : https://github.com/inventaire/inventaire/issues/187 (en anglais).
Cela dit, si vous ne souhaitez pas vous connecter à inventaire.io, pour quelque raison que ce soit, et malgré les mises en garde ci-dessus, vous pouvez vous rendre sur https://github.com/inventaire/inventaire-deploy/ pour déployer votre propre instance « infédérable ». On va travailler sur le sujet dans les mois à venir pour tendre vers plus de décentralisation.
A l’heure où il est de plus en plus urgent de décentraliser le web, envisagez-vous qu’à terme, il sera possible d’installer plusieurs instances d’inventaire.io et de les connecter les unes aux autres ?
Pour la partie réseau social d’inventaires, une décentralisation devrait être possible, même si cela pose des questions auquel le protocole ActivityPub ne semble pas proposer de solution. Ensuite, pour la partie base de données contributives, c’est un peu comme si on devait maintenir plusieurs instances d’OpenStreetMap en parallèle. C’est difficile et il semble préférable de garder cette partie centralisée, mais puisqu’il existe plein de services bibliographiques différents, il va bien falloir s’interconnecter un jour.
Vous savez sûrement que les Chevaliers Blancs du Web Libre sont à cran et vont vous le claironner : vous restez vraiment sur GitHub pour votre dépôt de code https://github.com/inventaire ou bien… ?
La pureté militante n’a jamais été notre modèle. Ce compte date de 2014, à l’époque Github avait peu d’alternatives… Cela étant, il est certain que nous ne resterons pas éternellement chez Microsoft, ni chez Transifex ou Trello, mais les solutions auto-hébergées c’est du boulot, et celles hébergées par d’autres peuvent se révéler instables.
Si on veut contribuer à Inventaire.io, on fait ça où ? Quels sont les différentes manière d’y contribuer ?
Il y a plein de manières de venir contribuer, et pas que sur du code, loin de là : on peut améliorer la donnée sur les livres, la traduction, la documentation et plus généralement venir boire des coups et discuter avec nous de la suite ! Rendez-vous sur https://wiki.inventaire.io/wiki/How_to_contribute/fr.
Est-ce que vous avez déjà eu vent d’outils tiers qui utilisent l’API ? Si oui, vous pouvez donner des noms ? À quoi servent-ils ? Readlebee et Bookwyrm sont des projets libres d’alternatives à GoodReads. Le premier tape régulièrement dans les données bibliographiques d’Inventaire. Le second vient de mettre en place un connecteur pour chercher de la donnée chez nous. A noter : cela apporte une complémentarité puisque ces deux services sont orientés vers les critiques de livres, ce qui reste très limité sur Inventaire.
Et comme toujours, sur le Framablog, on vous laisse le mot de la fin !
Inventaire est une app faite pour utiliser moins d’applications, pour passer du temps à lire des livres, papier ou non, et partager les dernières trouvailles. Pas de capture d’attention ici, si vous venez deux fois par an pour chiner des bouquins, ça nous va très bien ! Notre contributopie c’est un monde où l’information sur la disponibilité des objets qui nous entoure nous affranchit d’une logique de marché généralisée. Un monde où tout le monde peut contribuer à casser les monopoles de l’information sur les ressources que sont les géants du web et de la distribution. Pouvoir voir ce qui est disponible dans un endroit donné, sans pour autant dépendre ni d’un système cybernétique central, ni d’un marché obscur où les entreprises qui payent sont dorlotées par un algorithme de recommandations.
Merci beaucoup Maxlath et Jums pour ces explications et on souhaite longue vie à Inventaire. Et si vous aussi vous souhaitez mettre en commun votre bibliothèque, n’hésitez pas !
« Va te faire foutre, Twitter ! » dit Aral Balkan
Avec un ton acerbe contre les géants du numérique, Aral Balkan nourrit depuis plusieurs années une analyse lucide et sans concession du capitalisme de surveillance. Nous avons maintes fois publié des traductions de ses diatribes.
Ce qui fait la particularité de ce nouvel article, c’est qu’au-delà de l’adieu à Twitter, il retrace les étapes de son cheminement.
Sa trajectoire est mouvementée, depuis l’époque où il croyait (« quel idiot j’étais ») qu’il suffisait d’améliorer le système. Il revient donc également sur ses années de lutte contre les plateformes prédatrices et les startups .
Il explique quelle nouvelle voie constructive il a adoptée ces derniers temps, jusqu’à la conviction qu’il faut d’urgence « construire l’infrastructure technologique alternative qui sera possédée et contrôlée par des individus, pas par des entreprises ou des gouvernements ». Dans cette perspective, le Fediverse a un rôle important à jouer selon lui.
Sur le Fédiverse, ils ont un terme pour Twitter.
Ils l’appellent « le site de l’enfer ».
C’est très approprié.
Lorsque je m’y suis inscrit, il y a environ 15 ans, vers fin 2006, c’était un espace très différent. Un espace modeste, pas géré par des algorithmes, où on pouvait mener des discussions de groupe avec ses amis.
Ce que je ne savais pas à l’époque, c’est que Twitter, Inc. était une start-up financée avec du capital risque.
Même si j’avais su, ça n’aurait rien changé, vu que je n’avais aucune idée sur le financement ou les modèles commerciaux. Je pensais que tout le monde dans la tech essayait simplement de fabriquer les nouvelles choses du quotidien pour améliorer la vie des gens.
Même six ans après, en 2012, j’en étais encore à me concentrer sur l’amélioration de l’expérience des utilisateurs avec le système actuel :
« Les objets ont de la valeur non par ce qu’ils sont, mais par ce qu’ils nous permettent de faire. Et, en tant que personnes qui fabriquons des objets, nous avons une lourde responsabilité. La responsabilité de ne pas tenir pour acquis le temps limité dont chacun d’entre nous dispose en ce monde. La responsabilité de rendre ce temps aussi beau, aussi confortable, aussi indolore, aussi exaltant et aussi agréable que possible à travers les expériences que nous créons.
Parce que c’est tout ce qui compte.
Et il ne tient qu’à nous de le rendre meilleur. »
– C’est tout ce qui compte.
Quel idiot j’étais, pas vrai ?
Vous pouvez prendre autant de temps que nécessaire pour me montrer du doigt et ricaner.
Ok, c’est fait ? Continuons…
Privilège est simplement un autre mot pour dire qu’on s’en fiche
À cette époque, je tenais pour acquis que le système en général est globalement bon. Ou du moins je ne pensais pas qu’il était activement mauvais 1.
Bien sûr, j’étais dans les rues à Londres, avec des centaines de milliers de personnes manifestant contre la guerre imminente en Irak. Et bien sûr, j’avais conscience que nous vivions dans une société inégale, injuste, raciste, sexiste et classiste (j’ai étudié la théorie critique des médias pendant quatre ans, du coup j’avais du Chomsky qui me sortait de partout), mais je pensais, je ne sais comment, que la tech existait en dehors de cette sphère. Enfin, s’il m’arrivait de penser tout court.
Ce qui veut clairement dire que les choses n’allaient pas assez mal pour m’affecter personnellement à un point où je ressentais le besoin de me renseigner à ce sujet. Et ça, tu sais, c’est ce qu’on appelle privilège.
Il est vrai que ça me faisait bizarre quand l’une de ces start-ups faisait quelque chose qui n’était pas dans notre intérêt. Mais ils nous ont dit qu’ils avaient fait une erreur et se sont excusés alors nous les avons crus. Pendant un certain temps. Jusqu’à ce que ça devienne impossible.
Et, vous savez quoi, j’étais juste en train de faire des « trucs cools » qui « améliorent la vie des gens », d’abord en Flash puis pour l’IPhone et l’IPad…
Mais je vais trop vite.
Retournons au moment où j’étais complètement ignorant des modèles commerciaux et du capital risque. Hum, si ça se trouve, vous en êtes à ce point-là aujourd’hui. Il n’y a pas de honte à avoir. Alors écoutez bien, voici le problème avec le capital risque.
Ce qui se passe dans le Capital Risque reste dans le Capital Risque
Le capital risque est un jeu de roulette dont les enjeux sont importants, et la Silicon Valley en est le casino.
Un capital risqueur va investir, disons, 5 millions de dollars dans dix start-ups tout en sachant pertinemment que neuf d’entre elles vont échouer. Ce dont a besoin ce monsieur (c’est presque toujours un « monsieur »), c’est que celle qui reste soit une licorne qui vaudra des milliards. Et il (c’est presque toujours il) n’investit pas son propre argent non plus. Il investit l’argent des autres. Et ces personnes veulent récupérer 5 à 10 fois plus d’argent, parce que ce jeu de roulette est très risqué.
Alors, comment une start-up devient-elle une licorne ? Eh bien, il y a un modèle commercial testé sur le terrain qui est connu pour fonctionner : l’exploitation des personnes.
Voici comment ça fonctionne:
1. Rendez les gens accros
Offrez votre service gratuitement à vos « utilisateurs » et essayez de rendre dépendants à votre produit le plus de gens possible.
Pourquoi?
Parce qu’il vous faut croître de manière exponentielle pour obtenir l’effet de réseau, et vous avez besoin de l’effet de réseau pour enfermer les gens que vous avez attirés au début.
Bon dieu, des gens très importants ont même écrit des guides pratiques très vendus sur cette étape, comme Hooked : comment créer un produit ou un service qui ancre des habitudes.
Voilà comment la Silicon Valley pense à vous.
2. Exploitez-les
Collectez autant de données personnelles que possible sur les gens.
Pistez-les sur votre application, sur toute la toile et même dans l’espace physique, pour créer des profils détaillés de leurs comportements. Utilisez cet aperçu intime de leurs vies pour essayer de les comprendre, de les prédire et de les manipuler.
Monétisez tout ça auprès de vos clients réels, qui vous paient pour ce service.
C’est ce que certains appellent le Big Data, et que d’autres appellent le capitalisme de surveillance.
3. Quittez la scène (vendez)
Une start-up est une affaire temporaire, dont le but du jeu est de se vendre à une start-up en meilleure santé ou à une entreprise existante de la Big Tech, ou au public par le biais d’une introduction en Bourse.
Si vous êtes arrivé jusque-là, félicitations. Vous pourriez fort bien devenir le prochain crétin milliardaire et philanthrope en Bitcoin de la Silicon Valley.
De nombreuses start-ups échouent à la première étape, mais tant que le capital risque a sa précieuse licorne, ils sont contents.
Des conneries (partie 1)
Je ne savais donc pas que le fait de disposer de capital risque signifiait que Twitter devait connaître une croissance exponentielle et devenir une licorne d’un milliard de dollars. Je n’avais pas non plus saisi que ceux d’entre nous qui l’utilisaient – et contribuaient à son amélioration à ce stade précoce – étaient en fin de compte responsables de son succès. Nous avons été trompés. Du moins, je l’ai été et je suis sûr que je ne suis pas le seul à ressentir cela.
Tout cela pour dire que Twitter était bien destiné à devenir le Twitter qu’il est aujourd’hui dès son premier « investissement providentiel » au tout début.
C’est ainsi que se déroule le jeu du capital risque et des licornes dans la Silicon Valley. Voilà ce que c’est. Et c’est tout ce à quoi j’ai consacré mes huit dernières années : sensibiliser, protéger les gens et construire des alternatives à ce modèle.
Voici quelques enregistrements de mes conférences datant de cette période, vous pouvez regarder :
Dans le cadre de la partie « sensibilisation », j’essayais également d’utiliser des plateformes comme Twitter et Facebook à contre-courant.
Comme je l’ai écrit dans Spyware vs Spyware en 2014 : « Nous devons utiliser les systèmes existants pour promouvoir nos alternatives, si nos alternatives peuvent exister tout court. » Même pour l’époque, c’était plutôt optimiste, mais une différence cruciale était que Twitter, au moins, n’avait pas de timeline algorithmique.
Les timelines algorithmiques (ou l’enfumage 2.0)
Qu’est-ce qu’une timeline algorithmique ? Essayons de l’expliquer.
Ce que vous pensez qu’il se passe lorsque vous tweetez: « j’ai 44 000 personnes qui me suivent. Quand j’écris quelque chose, 44 000 personnes vont le voir ».
Ce qui se passe vraiment lorsque vous tweetez : votre tweet pourrait atteindre zéro, quinze, quelques centaines, ou quelques milliers de personnes.
Et ça dépend de quoi?
Dieu seul le sait, putain.
(Ou, plus exactement, seul Twitter, Inc. le sait.)
Donc, une timeline algorithmique est une boîte noire qui filtre la réalité et décide de qui voit quoi et quand, sur la base d’un lot de critères complètement arbitraires déterminés par l’entreprise à laquelle elle appartient.
En d’autres termes, une timeline algorithmique est simplement un euphémisme pour parler d’un enfumage de masse socialement acceptable. C’est de l’enfumage 2.0.
L’algorithme est un trouduc
La nature de l’algorithme reflète la nature de l’entreprise qui en est propriétaire et l’a créé.
Étant donné que les entreprises sont sociopathes par nature, il n’est pas surprenant que leurs algorithmes le soient aussi. En bref, les algorithmes d’exploiteurs de personnes comme Twitter et Facebook sont des connards qui remuent la merde et prennent plaisir à provoquer autant de conflits et de controverses que possible.
Hé, qu’attendiez-vous exactement d’un milliardaire qui a pour bio #Bitcoin et d’un autre qui qualifie les personnes qui utilisent sont utilisées par son service de « pauvres cons » ?
Ces salauds se délectent à vous montrer des choses dont ils savent qu’elles vont vous énerver dans l’espoir que vous riposterez. Ils se délectent des retombées qui en résultent. Pourquoi ? Parce que plus il y a d’« engagement » sur la plateforme – plus il y a de clics, plus leurs accros («utilisateurs») y passent du temps – plus leurs sociétés gagnent de l’argent.
Eh bien, ça suffit, merci bien.
Des conneries (partie 2)
Certes je considère important de sensibiliser les gens aux méfaits des grandes entreprises technologiques, et j’ai probablement dit et écrit tout ce qu’il y a à dire sur le sujet au cours des huit dernières années. Rien qu’au cours de cette période, j’ai donné plus d’une centaine de conférences, sans parler des interviews dans la presse écrite, à la radio et à la télévision.
Voici quelques liens vers une poignée d’articles que j’ai écrits sur le sujet au cours de cette période :
Est-ce que ça a servi à quelque chose ?
Je ne sais pas.
J’espère que oui.
J’ai également interpellé d’innombrables personnes chez les capitalistes de la surveillance comme Google et Facebook sur Twitter et – avant mon départ il y a quelques années – sur Facebook, et ailleurs. (Quelqu’un se souvient-il de la fois où j’ai réussi à faire en sorte que Samuel L. Jackson interpelle Eric Schmidt sur le fait que Google exploite les e-mails des gens?) C’était marrant. Mais je m’égare…
Est-ce que tout cela a servi à quelque chose ?
Je ne sais pas.
J’espère que oui.
Mais voici ce que je sais :
Est-ce que dénoncer les gens me rend malheureux ? Oui.
Est-ce que c’est bien ? Non.
Est-ce que j’aime les conflits ? Non.
Alors, trop c’est trop.
Les gens viennent parfois me voir pour me remercier de « parler franchement ». Eh bien, ce « parler franchement » a un prix très élevé. Alors peut-être que certaines de ces personnes peuvent reprendre là où je me suis arrêté. Ou pas. Dans tous les cas, j’en ai fini avec ça.
Dans ta face
Une chose qu’il faut comprendre du capitalisme de surveillance, c’est qu’il s’agit du courant dominant. C’est le modèle dominant. Toutes les grandes entreprises technologiques et les startups en font partie2. Et être exposé à leurs dernières conneries et aux messages hypocrites de personnes qui s’y affilient fièrement tout en prétendant œuvrer pour la justice sociale n’est bon pour la santé mentale de personne.
C’est comme vivre dans une ferme industrielle appartenant à des loups où les partisans les plus bruyants du système sont les poulets qui ont été embauchés comme chefs de ligne.
J’ai passé les huit dernières années, au moins, à répondre à ce genre de choses et à essayer de montrer que la Big Tech et le capitalisme de surveillance ne peuvent pas être réformés.
Et cela me rend malheureux.
J’en ai donc fini de le faire sur des plates-formes dotées d’algorithmes de connards qui s’amusent à m’infliger autant de misère que possible dans l’espoir de m’énerver parce que cela «fait monter les chiffres».
Va te faire foutre, Twitter !
J’en ai fini avec tes conneries.
« fuck twitter » par mowl.eu, licence CC BY-NC-ND 2.0
Et après ?
À bien des égards, cette décision a été prise il y a longtemps. J’ai créé mon propre espace sur le fediverse en utilisant Mastodon il y a plusieurs années et je l’utilise depuis. Si vous n’avez jamais entendu parler du fediverse, imaginez-le de la manière suivante :
Imaginez que vous (ou votre groupe d’amis) possédez votre propre copie de twitter.com. Mais au lieu de twitter.com, le vôtre se trouve sur votre-place.org. Et à la place de Jack Dorsey, c’est vous qui fixez les règles.
Vous n’êtes pas non plus limité à parler aux gens sur votre-place.org.
Je possède également mon propre espace sur mon-espace.org (disons que je suis @moi@mon-espace.org). Je peux te suivre @toi@ton-espace.org et aussi bien @eux@leur.site et @quelquun-dautre@un-autre.espace. Ça marche parce que nous parlons tous un langage commun appelé ActivityPub.
Donc imaginez un monde où il y a des milliers de twitter.com qui peuvent tous communiquer les uns avec les autres et Jack n’a rien à foutre là-dedans.
Eh bien, c’est ça, le Fediverse.
Et si Mastodon n’est qu’un moyen parmi d’autres d’avoir son propre espace dans le Fediverse, joinmastodon.org est un bon endroit pour commencer à se renseigner sur le sujet et mettre pied à l’étrier de façon simple sans avoir besoin de connaissances techniques. Comme je l’ai déjà dit, je suis sur le Fediverse depuis les débuts de Mastodon et j’y copiais déjà manuellement les posts sur Twitter.
Maintenant j’ai automatisé le processus via moa.party et, pour aller de l’avant, je ne vais plus me connecter sur Twitter ou y répondre3.
Vu que mes posts sur Mastodon sont maintenant automatiquement transférés là-bas, vous pouvez toujours l’utiliser pour me suivre, si vous en avez envie. Mais pourquoi ne pas utiliser cette occasion de rejoindre le Fediverse et vous amuser ?
Small is beautiful
Si je pense toujours qu’avoir des bonnes critiques de la Big Tech est essentiel pour peser pour une régulation efficace, je ne sais pas si une régulation efficace est même possible étant donné le niveau de corruption institutionnelle que nous connaissons aujourd’hui (lobbies, politique des chaises musicales, partenariats public-privé, captation de réglementation, etc.)
Ce que je sais, c’est que l’antidote à la Big Tech est la Small Tech.
Nous devons construire l’infrastructure technologique alternative qui sera possédée et contrôlée par des individus, pas par des entreprises ou des gouvernements. C’est un prérequis pour un futur qui respecte la personne humaine, les droits humains, la démocratie et la justice sociale.
Dans le cas contraire, nous serons confrontés à des lendemains sombres où notre seul recours sera de supplier un roi quelconque, de la Silicon Valley ou autre, « s’il vous plaît monseigneur, soyez gentil ».
Je sais aussi que travailler à la construction de telles alternatives me rend heureux alors que désespérer sur l’état du monde ne fait que me rendre profondément malheureux. Je sais que c’est un privilège d’avoir les compétences et l’expérience que j’ai, et que cela me permet de travailler sur de tels projets. Et je compte bien les mettre à contribution du mieux possible.
Pour aller de l’avant, je prévois de concentrer autant que possible de mon temps et de mon énergie à la construction d’un Small Web.
Si vous avez envie d’en parler (ou d’autre chose), vous pouvez me trouver sur le Fediverse.
Vous pouvez aussi discuter avec moi pendant mes live streams S’update et pendant nos live streams Small is beautiful avec Laura.
Des jours meilleurs nous attendent…
Prenez soin de vous.
Portez-vous bien.
Aimez-vous les uns les autres.
À 23 ans, cURL se rend utile partout
Non, ce n’est pas une marque de biscuits apéritifs aux cacahuètes, mais un outil logiciel méconnu qui mérite pourtant de faire partie de notre culture numérique. On révise ?
Bien qu’ignoré de la plupart des internautes, il est d’un usage familier pour celles et ceux qui travaillent en coulisses pour le Web. L’adage : « si un site web n’est pas « curlable », ce n’est pas du Web » fait de curl un outil majeur pour définir ce qu’est le Web aujourd’hui.
Son développeur principal suédois Daniel Stenberg retrace ici la genèse de cURL, son continu développement et surtout, ce qui devrait intéresser les moins geeks de nos lecteurs, son incroyable diffusion, à travers sa bibliothèque libcurl, au cœur de tant d’objets et appareils familiers. Après des débuts fort modestes, « la quasi-totalité des appareils connectés à Internet exécutent curl » !
Si vous n’êtes pas développeur et que les caractéristiques techniques de curl sont pour vous un peu obscures, allez directement à la deuxième partie de l’article pour en comprendre facilement l’importance.
Article original sur le blog de l’auteur : curl is 23 years old today
Traduction : Fabrice, Goofy, Julien/Sphinx, jums, NGFChristian, tTh,
curl fête son 23e anniversaire
par Daniel Stenberg La date de naissance officielle de curl, le 20 mars 1998, marque le jour de la toute première archive tar qui pouvait installer un outil nommé curl. Je l’ai créé et nommé curl 4.0 car je voulais poursuivre la numérotation de versions que j’avais déjà utilisée pour les noms précédents de l’outil. Ou plutôt, j’ai fait un saut depuis la 3.12, qui était la dernière version que j’avais utilisée avec le nom précédent : urlget.
Bien sûr, curl n’a pas été créé à partir de rien ce jour-là. Son histoire commence une petite année plus tôt : le 11 novembre 1996 a été publié un outil appelé httpget, développé par Rafael Sagula. C’est un projet j’avais trouvé et auquel j’avais commencé à contribuer. httpget 0.1 était un fichier de code C de moins de 300 lignes. (La plus ancienne version dont j’aie encore le code source est httpget 1.3, retrouvée ici)
Comme je l’ai évoqué à de multiples reprises, j’ai commencé à m’attaquer à ce projet parce que je voulais avoir un petit outil pour télécharger des taux de change régulièrement depuis un site internet et les fournir via mon petit bot4 de taux de change sur IRC5.
Ces petites décisions prises rapidement à cette époque allaient avoir plus tard un impact significatif et influencer ma vie. curl a depuis toujours été l’un de mes passe-temps principaux. Et bien sûr il s’agit aussi d’un travail à plein temps depuis quelques années désormais.
En ce même jour de novembre 1996 a été distribué pour la première fois le programme Wget(1.4.0). Ce projet existait déjà sous un autre nom avant d’être distribué, et je crois me souvenir que je ne le connaissais pas, j’utilisais httpget pour mon robogiciel. Peut-être que j’avais vu Wget et que je ne l’utilisais pas à cause de sa taille : l’archive tar de Wget 1.4.0 faisait 171 ko.
Peu de temps après, je suis devenu le responsable de httpget et j’ai étendu ses fonctionnalités. Il a ensuite été renommé urlget quand je lui ai ajouté le support de Gopher et de FTP (ce que j’ai fait parce que j’avais trouvé des taux de change sur des serveurs qui utilisaient ces protocoles). Au printemps 1998, j’ai ajouté le support de l’envoi par FTP et comme le nom du programme ne correspondait plus clairement à ses fonctionnalités j’ai dû le renommer une fois de plus6.
Nommer les choses est vraiment difficile. Je voulais un nom court dans le style d’Unix. Je n’ai pas planché très longtemps puisque j’ai trouvé un mot marrant assez rapidement. L’outil fonctionne avec des URL, et c’est un client Internet. « c » pour client et URL ont fait que « cURL » semblait assez pertinent et marrant. Et court. Bien dans de style d’Unix.
J’ai toujours voulu que curl soit un citoyen qui s’inscrive dans la tradition Unix d’utiliser des pipes7, la sortie standard, etc. Je voulais que curl fonctionne comme la commande cat, mais avec des URL. curl envoie donc par défaut le contenu de l’URL sur la sortie standard dans le terminal. Tout comme le fait cat. Il nous permettra donc de « voir » le contenu de l’URL. La lettre C se prononce si (Ndt : ou see, « voir » en anglais) donc « see URL » fonctionne aussi. Mon esprit blagueur n’en demande pas plus, mais je dis toujours « kurl ».
Le logo original, créé en 1998 par Henrik Hellerstedt
J’ai créé le paquet curl 4.0 et l’ai rendu public ce vendredi-là. Il comprenait alors 2 200 lignes de code. Dans la distribution de curl 4.8 que j’ai faite quelques mois plus tard, le fichier THANKS mentionnait 7 contributeurs[Note] Daniel Stenberg, Rafael Sagula, Sampo Kellomaki, Linas Vepstas, Bjorn Reese, Johan Anderson, Kjell Ericson[/note]. Ça nous a pris presque sept ans pour atteindre une centaine de contributeurs. Aujourd’hui, ce fichier liste plus de 2 300 noms et nous ajoutons quelques centaines de noms chaque année. Ce n’est pas un projet solo !
Il ne s’est rien passé de spécial
curl n’a pas eu un succès massif. Quelques personnes l’ont découvert et deux semaines après cette première distribution, j’ai envoyé la 4.1 avec quelques corrections de bugs et une tradition de plusieurs décennies a commencé : continuer à publier des mises à jour avec des corrections de bug. « Distribuer tôt et souvent » est un mantra auquel nous nous sommes conformés.
Plus tard en 1998, après plus de quinze distributions, notre page web présentait cette excellente déclaration :
Capture d’écran : Liste de diffusion. Pour cause de grande popularité, nous avons lancé une liste de diffusion pour parler de cet outil. (La version 4.8.4 a été téléchargée à elle seule plus de 300 fois depuis ce site.)
Trois cents téléchargements !
Je n’ai jamais eu envie de conquérir le monde ou nourri de visions idylliques pour ce projet et cet outil. Je voulais juste que les transferts sur Internet soient corrects, rapides et fiables, et c’est ce sur quoi j’ai travaillé.
Afin de mieux procurer au monde entier de quoi réaliser de bons transferts sur Internet, nous avons lancé la bibliothèque libcurl, publiée pour la première fois à l’été 2000. Cela a permis au projet de se développer sous un autre angle 8. Avec les années, libcurl est devenue de facto une API de transfert Internet.
Aujourd’hui, alors qu’il fête son 23e anniversaire, c’est toujours principalement sous cet angle que je vois le cœur de mon travail sur curl et ce que je dois y faire. Je crois que si j’ai atteint un certain succès avec curl avec le temps, c’est principalement grâce à une qualité spécifique. En un mot :
Persistance
Nous tenons bon. Nous surmontons les problèmes et continuons à perfectionner le produit. Nous sommes dans une course de fond. Il m’a fallu deux ans (si l’on compte à partir des précurseurs) pour atteindre 300 téléchargements. Il en a fallu dix ou presque pour qu’il soit largement disponible et utilisé.
En 2008, le site web pour curl a servi 100 Go de données par mois. Ce mois-ci, c’est 15 600 Go (soit fait 156 fois plus en 156 mois) ! Mais bien entendu, la plupart des utilisatrices et utilisateurs ne téléchargent rien depuis notre site, c’est leur distribution ou leur système d’exploitation qui leur met à disposition curl.
curl a été adopté au sein de Red Hat Linux à la fin de l’année 1998, c’est devenu un paquet Debian en mai 1999 et faisait partie de Mac OS X 10.1 en août 2001. Aujourd’hui, il est distribué par défaut dans Windows 10 et dans les appareils iOS et Android. Sans oublier les consoles de jeux comme la Nintendo Switch, la Xbox et la PS5 de Sony.
Ce qui est amusant, c’est que libcurl est utilisé par les deux principaux systèmes d’exploitation mobiles mais que ces derniers n’exposent pas d’API pour ses fonctionnalités. Aussi, de nombreuses applications, y compris celles qui sont largement diffusées, incluent-elles leur propre version de libcurl : YouTube, Skype, Instagram, Spotify, Google Photos, Netflix, etc. Cela signifie que la plupart des personnes qui utilisent un smartphone ont curl installé plusieurs fois sur leur téléphone.
Par ailleurs, libcurl est utilisé par certains des jeux vidéos les plus populaires : GTA V, Fortnite, PUBG mobile, Red Dead Redemption 2, etc.
libcurl alimente les fonctionnalités de lecteurs média ou de box comme Roku, Apple TV utilisés par peut-être un demi milliard de téléviseurs.
curl et libcurl sont pratiquement intégrés dans chaque serveur Internet, c’est le moteur de transfert par défaut de PHP qui est lui-même utilisé par environ 80% des deux milliards de sites web.
Maintenant que les voitures sont connectées à Internet, libcurl est utilisé dans presque chaque voiture moderne pour le transfert de données depuis et vers les véhicules.
À cela s’ajoutent les lecteurs média, les appareils culinaires ou médicaux, les imprimantes, les montres intelligentes et les nombreux objets « intelligents » connectés à Internet. Autrement dit, la quasi-totalité des appareils connectés à Internet exécutent curl.
Je suis convaincu que je n’exagère pas quand je déclare que curl existe sur plus de dix milliards d’installations sur la planète.
Seuls et solides
À plusieurs reprises lors de ces années, j’ai essayé de voir si curl pouvait rejoindre une organisation cadre mais aucune n’a accepté et, en fin de compte, je pense que c’est mieux ainsi. Nous sommes complètement seuls et indépendants de toute organisation ou entreprise. Nous faisons comme nous l’entendons et nous ne suivons aucune règle édictée par d’autres. Ces dernières années, les dons et les soutiens financiers se sont vraiment accélérés et nous sommes désormais en situation de pouvoir confortablement payer des récompenses pour la chasse aux bugs de sécurité par exemple.
Le support commercial que nous proposons, wolfSSL et moi-même, a je crois renforcé curl : cela me laisse encore plus de temps pour travailler sur curl, et permet à davantage d’entreprises d’utiliser curl sereinement, ce qui en fin de compte le rend meilleur pour tous.
Ces 300 lignes de code fin 1996 sont devenues 172 000 lignes en mars 2021.
L’avenir
Notre travail le plus important est de ne pas « faire chavirer le navire ». Fournir la meilleure et la plus solide bibliothèque de transfert par Internet, sur le plus de plateformes possible.
Mais pour rester attractifs, nous devons vivre avec notre temps, c’est à dire de nous adapter aux nouveaux protocoles et aux nouvelles habitudes au fur et à mesure qu’ils apparaissent. Prendre en charge de nouvelles versions de protocoles, permettre de meilleures manières de faire les choses et, au fur et à mesure, abandonner les mauvaises choses de manière responsable pour ne pas nuire aux personnes qui utilisent le logiciel.
À court terme je pense que nous voulons travailler à nous assurer du fonctionnement d’HTTP/3, faire de Hyper 9 une brique de très bonne qualité et voir ce que devient la brique rustls.
Après 23 ans, nous n’avons toujours pas de vision idéale ni de feuille de route pour nous guider. Nous allons là où Internet et nos utilisatrices nous mènent. Vers l’avant, toujours plus haut !
La feuille de route de curl 😉
23 ans de curl en 23 nombres
Pendant les jours qui ont précédé cet anniversaire, j’ai tweeté 23 « statistiques de curl » en utilisant le hashtag #curl23. Ci-dessous ces vingt-trois nombres et faits.
2 200 lignes de code en mars 1998 sont devenues 170 000 lignes en 2021 alors que curl fête ses 23 ans
14 bibliothèques TLS différentes sont prises en charge par curl alors qu’il fête ses 23 ans
2 348 contributrices et contributeurs ont participé au développement de curl alors qu’il fête ses 23 ans
197 versions de curl ont été publiées alors que curl fête ses 23 ans
6 787 correctifs de bug ont été enregistrés alors que curl fête ses 23 ans
10 000 000 000 d’installations dans le monde font que curl est l’un des jeunes hommes de 23 ans des plus distribués au monde
871 personnes ont contribué au code de curl pour en faire un projet vieux de 23 ans
935 000 000 récupérations pour l’image docker officielle de curl (83 récupérations par seconde) alors que curl fête ses 23 ans
22 marques de voitures, au moins, exécutent curl dans leurs véhicules alors que curl fête ses 23 ans
100 tâches d’intégration continue sont exécutées pour chaque commit et pull request sur le projet curl alors qu’il fête ses 23 ans
15 000 heures de son temps libre ont été passés sur le projet curl par Daniel alors qu’il fête ses 23 ans
2 systèmes d’exploitation mobile les plus utilisés intègrent et utilisent curl dans leur architecture alors que curl fête ses 23 ans
86 systèmes d’exploitation différents font tourner curl alors qu’il fête ses 23 ans
250 000 000 de télévisions utilisent curl alors qu’il fête ses 23 ans
26 protocoles de transport sont pris en charge alors que curl fête ses 23 ans
36 bibliothèques tierces différentes peuvent être compilées afin d’être utilisées par curl alors qu’il fête ses 23 ans
22 architectures différentes de processeurs exécutent curl alors qu’il fête ses 23 ans
4 400 dollars américains ont été payés au total pour la découverte de bugs alors que curl fête ses 23 ans
240 options de ligne de commandes existent lorsque curl fête ses 23 ans
15 600 Go de données sont téléchargées chaque mois depuis le site web de curl alors que curl fête ses 23 ans
60 passerelles vers d’autres langages existent pour permettre aux programmeurs de transférer des données facilement en utilisant n’importe quel langage alors que curl fête ses 23 ans
1 327 449 mots composent l’ensemble des RFC pertinentes qu’il faut lire pour les opérations effectuées par curl alors que curl fête ses 23 ans
1 fondateur et développeur principal est resté dans les parages du projet alors que curl fête ses 23 ans
Forget about Framaforms-the-software, make room for Yakforms !
After several years, Framasoft has decided to stop the developments of its software Framaforms, which provides you the same name service. And to avoid any confusion between the software’s name and the service named Framaforms (which remains open, don’t worry), we have decided to give it a new name: Yakforms. Let’s see what motivated this decision.
Officially released on October 5, 2016 as an alternative to Google Forms, Framaforms is an online service that allows internet users to simply create forms, by dragging and dropping elements (text fields, checkboxes, drop-down menu, etc.), to share them and analyze the answers.
Unlike most of the services presented in the De-google-ify internet campaign, Framaforms is based on a software developed by one of the association’s employees. Framasoft has always preferred to offer and promote existing free-libre softwares that have their own community, rather than developing homemade solutions that need to be maintained and developed, not to mention user support. But no satisfying software was found to provide an alternative to Google Forms: most of the existing free-libre softwares were not online services, or were pretty hard to use or too expensive.
Sometimes at Framasoft, we have to make very difficult choices.
Also, Pyg, the general director of Framasoft at the time, decided to develop a simple and user-friendly tool. Considering his technical skills, he chose a solution using Drupal (one of the most intalled free-libre Content Management Software – or CMS – in the world) and the Webform module (for creating forms). Feel free to read his interview published at the time where he talked about his choices.
Four years and a half later, Framaforms is one of the most used services of Framasoft. In 2020, framaforms.org represented more than 36 million page views (a 250% increase compared to 2019). In the last twelve months (May 2020 to April 2021) alone, almost 100,000 forms were created on Framaforms where they collected over 2 million responses. Every week more than 1,000 of you create more than 3,000 forms. That’s really impressive!
Sometimes, we wonder why this service is so successfull! Of course, we did our best to promote it. Of course, internet users are more and more aware of the need to change their digital practices to protect their privacy. Of course, we know that asking for sensitive information, such as gender identity or sexual orientation, via a Google Forms is less and less common and acceptable.
But it seems that the main reason why you use Framaforms is just because one day, you were asked to submit a form hosted on framaforms.org and therefore you discovered the tool. Form creators indirectly become self-prescribers of the service to their audience. Submitting to a form gives you an active experience of the tool and then allows you to become a creator more easily. That confirms that Framaforms is a tool with a future.
The issue with Framaforms
However, since its development in 2016, Framaforms is a tool that hasn’t much evolved. As you can notice on the software’s repository, the team has regularly updated Drupal and the modules used, improved performances (especially by switching to php7 and changing servers), fixed identified bugs but added very few features (some in 2017).
Besides, since 2016, Framasoft is the new editor of two softwares: PeerTube and Mobilizon. With Framadate and Framaforms, Framasoft finds itself managing 4 different softwares, not to mention all the existing projects to which our association contributes. And it’s a lot for a small not-for-profit like ours. We decided that our capacity to develop should be focused on PeerTube and Mobilizon, at the cost of the two other tools.
Finally, because of its technical bases, Framaforms software wasn’t suitable for installation by other hosting companies: the process was arduous. This explains why Framaforms didn’t become much of a « swarm », unlike other successful softwares currently supported by a large community. So far, very few instances are installed, which increases the pressure on the Framaforms service that has to take care of all users’ burden.
That’s one of the main reasons why we welcomed Théo as an intern from February to July 2020. His main missions were to:
improve the software to make it more functional;
reduce the support load by actively participating in it;
simplify the installation process, in order to increase Framaforms instances’ number.
Théo worked very hard on new features. Among the most important ones:
creation of a direct contact form so that users can directly contact the form creator without using Framasoft support
design of an « Overview » page allowing Framaforms administrators to easily access statistics (total number of forms and users, « abusive » forms, etc.)
forms automatic deletion after an expiration period.
Details about the direct contact form.
Concerning the software installation process, Théo has created a Drupal installation profile for Framaforms offering instance administrators Framaforms module (enriched), and webform modules on which the software is based. Framaforms can now be installed directly via the Drupal interface rather than by manipulating files via a terminal. This simplifies the installation process, with the significant advantage that it’s very similar to the Drupal installation process.
Despite these improvements, Framasoft knows that, as long as the software has the same name than the associated service, people would always think that Framasoft is responsible for developing and maintaining the software.
Even though we don’t consider closing down the framaforms.org service, we don’t want to dedicate as much energy developing this tool. At least, we don’t want to be the only ones to do it, therefore we would like a development community to emerge who will take over Framaforms software to bring it new features.
Framaforms-the-software is dead, long live Yakforms!
The emergence of this community is needed to keep the software alive. Framaforms needs, at least, interventions on security flaws and functional bugs that may appear. And this software would also deserve new features, interface and ergonomy improvements, etc.
In order to prepare this community, we offered Théo to join the salaried team for a few months. His missions: to work on the internationalization (making the software translatable), to provide instances customization (allowing administrators to configure some elements such as the instance name, its formatting or its limitations) and to develop new features (limiting the number of answers per form and the number of forms per account). He also had to create a presentation website where everything about the software would be accessible, whether you are a simple user, an administrator or a developer.
The other important thing for us was to rename Framaforms to avoid any confusion with the framaforms.org service. After many brainstormings, we chose the name Yakforms to replace Framaforms. Why Yakforms? Well… this choice is both a combination of bad puns and the desire to have a mascot. So why a yak? The mystery remains, and we are committed to inventing a different answer every time we are asked. Because the only answer that matters, is the one given by the future development community created around this software (or that will copy it, « fork » it to give it a brand new direction, and a new name).
Théo also did his best to create a community around Yakforms. Therefore he thought a lot about different online spaces that would allow a community to exchange and pull together. He created a dedicated category on the Framacolibri forum and a website presenting the software: its main features, how to install an instance and how to contribute to its development.
We hope that many of you will browse through it to learn more about the main features, to find out how to install it or participate in its development. Because this software won’t evolve without you. Joining the Yakforms community means participating in the software development: improving its code, rethinking its ergonomics, translating its interfaces or documenting its use.
So get hold of Yakforms! Install it, translate it, fork it, challenge it or offer feedback on the forum, etc. By releasing this project from Framasoft’s control, we hope that a diverse and strong community will take it further than we did. Yakforms is in your hands, and we look forward to seeing what you will do with it!
And a huge thanks to the #MemesTeam for their creativity!
Oubliez Framaforms-le-logiciel, faites de la place à Yakforms !
Après plusieurs années, Framasoft a décidé de ne plus prendre en charge les évolutions du logiciel Framaforms qui sert à vous offrir le service du même nom. Et pour que cesse la confusion entre le nom du logiciel et le nom du service Framaforms (qui reste ouvert, hein, ne vous inquiétez pas), on a décidé de donner un nouveau nom au logiciel : Yakforms. Petit retour sur ce qui a motivé cette décision.
À noter :
Découvrez la version en anglais de cet article réalisée par notre stagiaire Coraline
Framaforms, sa vie, son œuvre
Sorti officiellement le 5 octobre 2016 et présenté comme une alternative à Google Forms, Framaforms est un service en ligne qui permet à tou⋅tes les internautes de réaliser simplement des formulaires, par glisser-déposer d’éléments (champs textes, cases à cocher, menu déroulant, etc.), de les partager et d’analyser les réponses.
Contrairement à la majorité des services proposés dans le cadre de la campagne Dégooglisons Internet, celui-ci repose sur un logiciel développé en interne par l’un des salariés de l’association. Framasoft a toujours préféré proposer et mettre en valeur des logiciels libres déjà existants et disposant déjà d’une communauté, plutôt que de développer des solutions maison qu’il faut maintenir, faire évoluer, sans compter le support utilisateur à gérer. Mais aucun logiciel satisfaisant n’a été trouvé pour servir d’alternative à Google Forms : la plupart des logiciels libres existants n’étaient pas proposés comme services en ligne, ou lorsque c’était le cas, ils étaient assez complexes d’utilisation ou leurs tarifs étaient assez élevés.
Parfois, chez Framasoft, on doit faire des choix vraiment complexes :D
C’est donc pyg, à l’époque directeur général de l’association, qui s’est chargé de développer un outil simple et facile d’utilisation. Au regard de ses compétences techniques, il a fait le choix d’une solution utilisant Drupal (un des logiciels libres de création de sites web les plus installés au monde) et le module Webform (qui permet la création de formulaires). N’hésitez pas à consulter son interview parue à l’époque pour parler de ses choix.
4 ans et demi plus tard, Framaforms est l’un des services les plus utilisés parmi ceux proposés par l’association. En 2020, framaforms.org c’est plus de 36 millions de pages vues (une augmentation de 250% par rapport à 2019). Ne serait-ce que sur les douze derniers mois (mai 2020-avril 2021), presque 100 000 questionnaires ont été créés sur Framaforms et ils ont recueilli plus de 2 millions de réponses. Vous êtes plus de 1000 chaque semaine à créer plus de 3000 questionnaires. C’est vraiment impressionnant !
Parfois, on se demande pourquoi ce service rencontre un tel succès ! Bien sûr, on a fait de notre mieux pour le valoriser. Bien sûr, les internautes sont de plus en plus conscient·es de la nécessité de modifier leurs pratiques numériques afin de protéger leurs données personnelles. Bien sûr, on sait bien qu’il est de moins en moins répandu – et acceptable – de demander des informations sensibles, telles que l’identité de genre ou l’orientation sexuelle, via un Google Forms.
Mais il y a de fortes chances que la principale raison pour laquelle vous utilisez aujourd’hui Framaforms, c’est tout simplement parce qu’un jour, on vous a proposé de répondre à un questionnaire hébergé sur framaforms.org et qu’ainsi vous avez découvert l’outil. Les créateur·ices de formulaires deviennent indirectement auto-prescripteur·ices du service auprès de leur public. En répondant à un formulaire, vous avez une expérience active de l’outil et il est ainsi plus facile de passer le cap de devenir créateur·ice ensuite. Cela nous confirme que Framaforms est un outil qui a de l’avenir.
Le souci avec Framaforms
Cependant, Framaforms est un outil qui, depuis son développement en 2016, n’a que très peu évolué. Comme, vous pouvez le constater sur le dépôt git du logiciel, l’équipe a régulièrement fait les mises à jour de Drupal et des modules utilisés, amélioré les performances (notamment en passant à php7 et en changeant de machine) et corrigé les bugs identifiés, mais très peu de fonctionnalités ont été ajoutées (quelques-unes en 2017).
De plus, depuis 2016, Framasoft est devenu l’éditeur de nouveaux logiciels : PeerTube, puis Mobilizon. Avec Framadate et Framaforms, l’association se retrouve donc à gérer 4 logiciels différents, sans compter les très nombreuses contributions que notre association apporte à des projets existants. Et c’est beaucoup pour une petite structure comme la nôtre. Nous avons donc décidé que notre capacité de développement devait être mise en priorité sur PeerTube et Mobilizon, au détriment des deux autres outils.
Enfin, en raison de ses bases techniques, le logiciel Framaforms ne se prêtait pas à son installation par d’autres hébergeurs : le processus était ardu. Cela explique qu’il a très peu « essaimé », contrairement à d’autres logiciels qui ont rencontré un grand succès et sont actuellement portés par une large communauté. À ce jour, très peu d’instances sont installées, ce qui accroît la pression sur le service Framaforms, qui doit assumer la charge de la totalité des utilisateur⋅ices.
C’est l’une des principales raisons qui fait que nous avons accueilli Théo en stage de février à juillet 2020. Ses principales missions ont été :
améliorer le logiciel afin de le rendre plus fonctionnel ;
alléger la charge du support en participant activement à celui-ci ;
modifier le processus d’installation, afin de faciliter la multiplication des instances de Framaforms.
Théo a donc bûché dur sur de nouvelles fonctionnalités. Parmi les plus importantes : la mise en place d’un formulaire de contact direct, afin que les utilisateur⋅ices puissent directement contacter l’auteur·ice du formulaire sans passer par le support de Framasoft, la conception d’une page « Vue d’ensemble » qui permet aux administrateur⋅ices de Framaforms d’accéder facilement à un nombre de statistiques (nombre total de formulaires et d’utilisateur⋅ices, formulaires « abusifs », etc.) ou la suppression automatique des formulaires après une période d’expiration.
explications sur le formulaire de contact direct
Pour ce qui est du processus d’installation du logiciel, Théo a créé un profil d’installation Drupal pour Framaforms qui propose aux administrateur⋅ices d’instances les modules framaforms (enrichi) et webform sur lesquels repose le logiciel. L’installation de Framaforms se fait donc désormais directement via l’interface de Drupal plutôt qu’en manipulant des fichiers via un terminal. Le processus d’installation s’en trouve grandement simplifié, avec l’avantage notable qu’il se rapproche grandement du processus d’installation de Drupal.
Malgré ces améliorations, Framasoft est conscient que tant que le logiciel portera le même nom que le service associé, il y aura toujours une confusion qui laissera penser que c’est Framasoft qui a en charge le développement et la maintenance du logiciel.
Si nous n’envisageons pas la fermeture du service framaforms.org, nous ne souhaitons plus autant dédier d’énergie à l’évolution de cet outil. Du moins, nous ne souhaitons pas être les seuls à le faire et c’est pourquoi nous aimerions qu’une communauté de développement puisse émerger et s’emparer du logiciel Framaforms afin d’y apporter de nouvelles fonctionnalités.
Framaforms-le-logiciel est mort, vive Yakforms !
Faire émerger cette communauté est nécessaire afin de continuer à faire vivre le logiciel. Framaforms-le-logiciel a besoin, a minima, d’interventions sur des failles de sécurité et des bogues fonctionnels qui pourraient apparaître. Et ce logiciel mériterait aussi d’évoluer avec de nouvelles fonctionnalités, des améliorations d’interface et d’ergonomie, etc.
Afin de préparer ce projet de communauté autour du logiciel Framaforms, nous avons proposé à Théo de rejoindre l’équipe salariée pour quelques mois. Sa mission : travailler sur l’internationalisation (rendre le logiciel traduisible), permettre la customisation d’une instance (permettre aux administrateur⋅ices de paramétrer un certain nombre d’éléments tels que le nom de l’instance, sa mise en forme ou ses limitations), développer de nouvelles fonctionnalités (limitation du nombre de réponses par formulaire et du nombre de formulaires par compte) et créer un site web de présentation où tous les éléments concernant le logiciel seraient accessibles, que l’on soit simple utilisateur⋅ice, administrateur⋅ice ou développeur⋅se.
L’autre élément important pour nous a été de renommer le logiciel Framaforms afin d’éviter la confusion avec le service framaforms.org . Après de nombreux brainstorming internes, nous avons donc choisi le nom Yakforms pour remplacer Framaforms. Pourquoi Yakforms ? Et bien… c’est au final un choix qui relève à la fois d’une convergence de mauvais jeux de mots et de l’envie d’avoir une mascotte. Alors pourquoi un yak ? Le mystère reste entier, et nous nous engageons à inventer une réponse différente à chaque fois qu’on nous posera la question. Car la seule réponse qui compte, c’est celle que donnera la future communauté de développement qui se créera autour de ce logiciel (ou le copiera, ou le « forkera » pour lui offrir une toute nouvelle direction, et un nouveau nom).
Théo a aussi fait le nécessaire pour qu’une communauté puisse voir le jour autour de Yakforms. Pour cela, il a pris le temps de réfléchir aux différents espaces en ligne qui permettraient à une communauté d’échanger et de s’entraider. Il a créé une catégorie dédiée sur le forum Framacolibri et réalisé un site web qui vous présente le logiciel, ses principales fonctionnalités, comment installer une instance et comment contribuer à son développement.
Découvrez le nouveau site web de présentation de Yakforms ! http://yakforms.org/
On espère que vous serez nombreu⋅ses à le consulter pour en savoir plus sur les principales fonctionnalités, découvrir comment l’installer ou participer à son évolution. Car sans vous, ce logiciel n’évoluera pas. Rejoindre la communauté Yakforms, c’est participer à l’amélioration du logiciel : faire évaluer son code, repenser son ergonomie, traduire ses interfaces ou encore documenter son utilisation.
Emparez-vous de Yakforms ! Installez-le, traduisez-le, forkez-le, remettez-le en question ou proposez des retours d’expérience sur le forum, etc. En libérant ce projet du contrôle de Framasoft, nous espérons qu’une communauté diverse et forte saura s’en emparer et le mener plus loin que nous ne le pourrions. Yakforms est entre vos mains, et nous avons hâte de voir ce que vous allez en faire !
Et un grand merci à la #TeamMemes pour sa créativité !
Comment migrer son frama.site avant la fermeture du service le 6 juillet prochain ?
Nous avons annoncé pour le mardi 6 juillet 2021 la fermeture du service https://frama.site/. Pour rappel, frama.site héberge à la fois des sites (logiciel PrettyNoemieCMS), des blogs (logiciel Grav) et des wikis (logiciel Dokuwiki). Afin que les utilisateur⋅ices de ce service puissent continuer à héberger leurs sites et wikis, nous avons cherché si d’autres hébergeurs proposaient ce service.
Afin que vous puissiez choisir en toute transparence l’offre qui vous correspond le mieux, on s’est dit qu’il n’y avait rien de mieux à faire que d’interviewer ces structures afin qu’elles vous en disent plus sur qui elles sont, comment elles fonctionnent et qu’elles détaillent leur offre de migration.
Interview de Thomas Bourdon, de Bee-Home
Bonjour Thomas. Peux-tu te présenter ?
Je suis Thomas Bourdon, 38 ans, habitant dans l’Aisne, passionné d’informatique depuis toujours et utilisateur de GNU/Linux (et autres logiciels libres) depuis 2001. Mais ce n’est qu’en 2007 que j’ai réellement compris l’éthique du logiciel libre et du fonctionnement décentralisé (ou acentré) d’Internet. Depuis j’ai commencé à monter mes propres services à la maison (auto-hébergement) pour moi-même puis pour mes proches, et finalement pour des petites structures.
Tu nous parles de Bee-Home ? C’est quoi ? C’est qui ? Comment ça marche ?
Comme j’hébergeais de plus en plus de services pour de plus en plus de monde, il était temps que je quitte ma petite connexion ADSL pour prendre un serveur (puis deux) en datacenter. Comme je ne souhaitais pas payer de ma poche ces serveurs, j’ai décidé de monter l’auto-entreprise Bee Home dans ce but. Ce choix est aussi guidé par le fait que les structures que j’héberge ont besoin d’avoir des factures « officielles » et ne peuvent pas faire de don financier.
La page d’accueil du site web de Bee-Home
Les services que je fournis sont essentiellement du cloud – avec le logiciel Nextcloud (synchronisation de fichiers, agenda, carnet d’adresses, suite bureautique collaborative, discussion par texte ou visio et mail) – et l’hébergement de sites web. Pour cela je propose plusieurs outils que je maintiens (sauvegarde, mise à jour). Ainsi l’utilisateur·ice ne s’occupe que de publier du contenu. Évidemment il ou elle peut récupérer sur simple demande l’intégralité de son site pour l’héberger ailleurs par exemple.
Tous ces services sont payants et permettent aux utilisateur·ices d’avoir leur propre nom de domaine (sauf forfait de base) dont le coût est inclus dans le forfait. Même si je propose des forfaits pré-établis, il est tout à fait possible d’adapter le service et le tarif au besoin de la personne ou structure. Pour cela, il suffit de me contacter.
Bee-Home offre donc la possibilité de migrer son frama.site sous Grav / Dokuwiki. Ça se passe comment ? Ça coûte combien ?
J’ai décidé de proposer ce service gratuitement sans durée limitée sur simple demande. En revanche, j’impose un quota maximum de 500Mo d’espace disque. Au-delà de ce quota, je proposerai un tarif adapté. Chaque site sera accessible via une adresse se terminant par bee.wf (mon-site.bee.wf par exemple). Il est bien sûr possible d’utiliser son propre domaine pour celles et ceux qui en possèdent un.
Documentation sur la façon de migrer son framasite chez Bee-Home
Pourquoi ne pas permettre la migration des framasites réalisés avec le logiciel PrettyNoemieCMS ?
J’expliquais que je propose de maintenir moi-même les outils utilisés (WordPress, Grav, Dotclear, Piwigo…) pour les sites hébergés. C’est pourquoi je ne propose que des outils activement maintenus afin d’éviter l’usage d’outils obsolètes pouvant contenir des failles de sécurité qui ne seront jamais corrigées. PrettyNoemieCMS est justement un outil non maintenu, voilà pourquoi je ne le propose pas. Si un·e utilisateur·ice l’utilise, je peux toutefois proposer un hébergement sous Grav dans les mêmes conditions. Bien sûr il ou elle sera contraint de refaire son site entièrement.
Bee-Home fait partie du collectif CHATONS depuis fin 2018. Pourquoi avoir rejoint le collectif ?
D’une part parce que je partage complètement les valeurs de ce collectif, et d’autre part parce que cela m’a toujours plu de gérer et de proposer de l’hébergement de services.
Interview de l’équipe du directoire de Ouvaton
Bonjour l’équipe du directoire. Pouvez-vous vous présenter ?
Bonjour.
Nous sommes 3 personnes au « directoire » d’Ouvaton, actuellement :
– Claire, présidente, qui fait de l’informatique depuis le début des années 80 et chez Ouvaton depuis le début en 2001
– Matthieu, aussi informaticien et chez Ouvaton depuis 2006
– François, commercial, qui fait lui aussi de l’informatique, et chez Ouvaton depuis 2017
Vous nous parlez de Ouvaton ? C’est quoi ? C’est qui ? Comment ça marche ? Ouvaton a été créée en 2001, sous la forme d’une société anonyme « coopérative de consommation ». Cela veut dire que nos coopérateurs sont co-propriétaires et co-entrepreneurs de la coopérative. Grâce à cette structure, les utilisateurs sociétaires sont réellement des hébergés-hébergeurs. Donc Ouvaton, c’est plusieurs milliers de personnes qui décident. Et dans les faits, plusieurs dizaines qui ont « les mains dans le cambouis » au quotidien !
La coopérative se base sur un certain nombre de valeurs, que nous donnons sur notre site. Pour résumer à grands traits : indépendance et coopération, démocratie et protection de la vie privée.
Ouvaton fonctionne autour :
d’un conseil de surveillance de 9 membres élus pour des mandats de 3 années par l’Assemblée Générale
d’un directoire dont les membres sont nommés, pour des mandats renouvelables de 3 ans, par le conseil de surveillance
Page d’accueil du site https://ouvaton.coop/
Nous essayons aussi, dans la mesure des moyens de chacun, d’impliquer au quotidien un maximum de coopérateurs. Aucune obligation, mais une participation de chacun selon ses moyens (et ses envies !). Il y a toujours des chantiers en route dans un collectif comme Ouvaton et chacun peut y trouver sa place. Les Assemblées Générales sont l’occasion de présenter chaque année aux sociétaires l’état de la coopérative et de mettre aux votes les grandes orientations proposées par le conseil de surveillance et le directoire.
Ouvaton offre donc la possibilité de migrer son frama.site sous Grav / Dokuwiki. Ça se passe comment ? Ça coûte combien ?
Il faut commencer par créer son compte chez Ouvaton, sur notre interface de gestion Ouvadmin. L’adresse du site pourra être en *.ouvaton.org (https://monsite.ouvaton.org par exemple), et l’utilisation de son propre nom de domaine est bien sûr possible.
Notre documentation explique la procédure à suivre pour exporter puis importer son Framasite chez Ouvaton, et notre équipe d’assistance est là pour accompagner les utilisateurs en cas de difficultés.
Pour le prix, ce sera 12€ TTC la première année, et après ce sera 42€ TTC par an (le tarif « normal »). Ce tarif inclut des mails, de l’espace disque… On réfléchit sérieusement (et collectivement) à faire évoluer nos tarifs pour plusieurs offres selon les besoins. Pour ceux qui veulent vraiment rejoindre l’aventure, ils peuvent bien sûr devenir coopérateurs. La part sociale est à 16€ et permet d’être coopérateur « de plein droit ».
Pourquoi ne pas permettre la migration des framasites réalisés avec le logiciel PrettyNoemieCMS ?
Malheureusement ce logiciel n’est plus maintenu. Nous préférons nous concentrer sur Grav et Dokuwiki, qui disposent de solides équipes de développeurs pour les faire évoluer. Mais les personnes qui utilisent encore PrettyNoemieCMS peuvent reconstruire leur site sur un autre CMS aux mêmes conditions.
Je lis sur votre site web que vous comptez candidater pour rejoindre le collectif CHATONS fin 2021. Pourquoi souhaitez-vous rejoindre le collectif ?
Les valeurs affichées par le collectif sont concordantes avec les nôtres, nous avons donc souhaité le rejoindre au plus vite. Mais nous devons dans un premier temps assainir notre plateforme de quelques logiciels propriétaires qui étaient utilisés par notre ancien infogérant. C’est une tâche assez lourde qui, en plus du travail technique, a nécessité de nombreux échanges au sein de notre équipe. Nous sommes épaulés dans cette tâche par la super équipe de Octopuce, notre nouvel infogérant. Le train est en route et nous devrions pouvoir présenter notre candidature fin 2021 pour rejoindre les CHATONS.
Que vous utilisiez les services de frama.site ou que vous souhaitiez vous créer un nouvel espace sur internet, Framasoft vous encourage donc à aller étudier de près les offres de Ouvaton et Bee-Home.






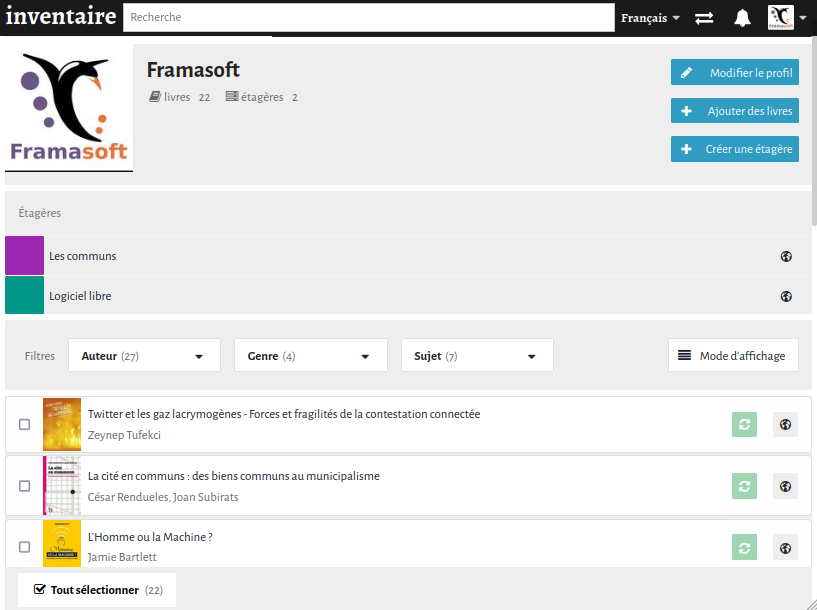


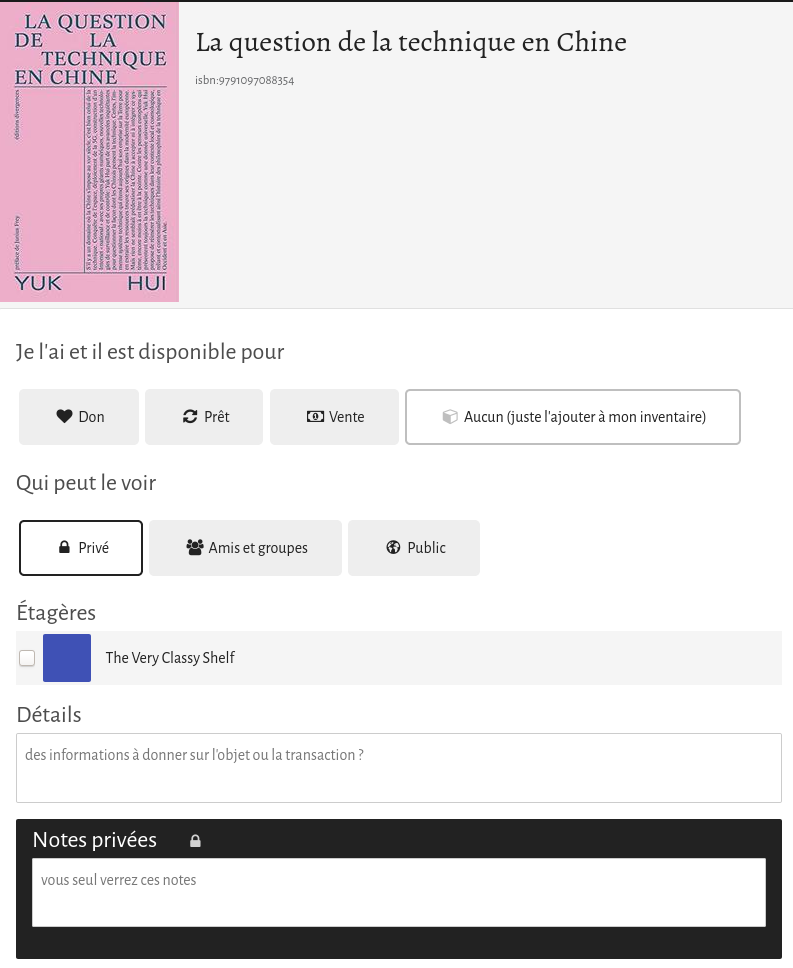
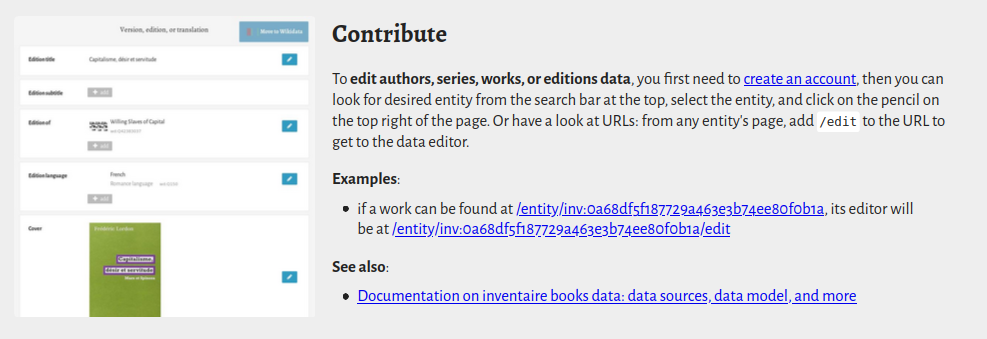







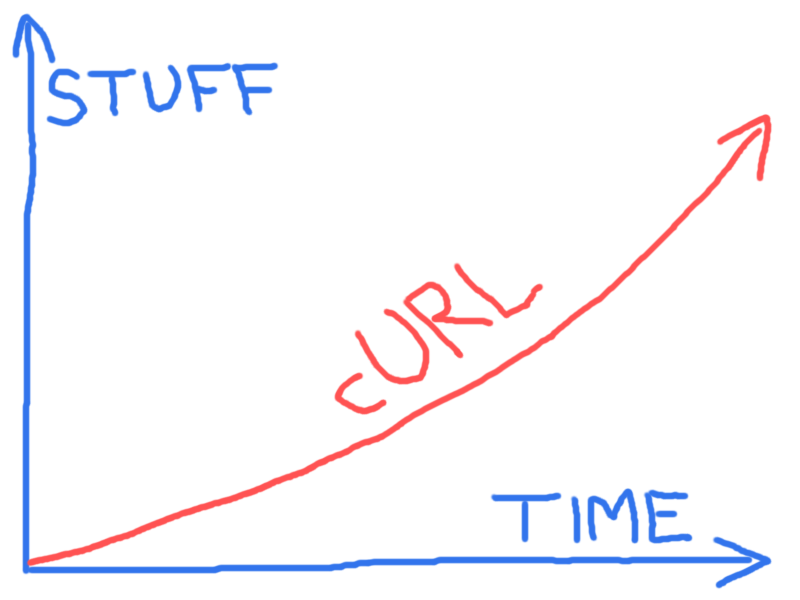




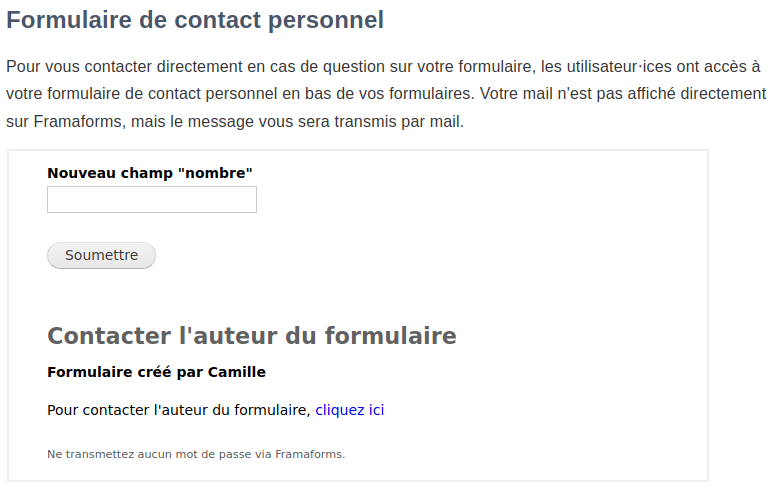






{kind=link}