La bataille du libre, un documentaire contributopique !
Nous avons eu la chance de voir le nouveau documentaire de Philippe Borrel. Un conseil : ne le loupez pas, et surtout emmenez-y vos proches qui ne comprennent pas pourquoi vous les bassinez avec « vos trucs de libristes, là »…
Ce n’est pas de la publicité, c’est de la réclame
Avertissement : cet article de blog est enthousiaste sans être sponsorisé (et oui : nous vivons à une époque où ce genre de précision est devenue obligatoire -_-‘…), car en fait, il est simplement sincère.
Et c’est pas parce qu’on y voit apparaître tonton Richard (the Stallman himself), l’ami Calimaq, les potes de Mozilla ou notre Pyg à nous, hein… C’est parce que ce documentaire montre que la palette du Libre s’étend très largement au-delà du logiciel : agriculture, outils, santé, autogestion… Il montre combien le Libre concrétise dès aujourd’hui les utopies contributives de demain, et ça, bizarrement, ça nous parle.
Sans compter que sa bande annonce a le bon goût d’être présente et présentée sur PeerTube :
Ce qui est brillant, c’est que ce documentaire peut toucher les cœurs et les pensées de nos proches dont le regard divague au loin dès qu’on leur parle de « logiciels », « services », « clients » et autre « code-source »… et qui ne comprennent pas pourquoi certaines variétés de tomates anciennes ont circulé clandestinement dans leur AMAP, ou qui s’indignent de la montée du prix de l’insuline et des prothèses médicales.
Des avant-premières à Fontaine, Nantes et Paris… et sur Arte
Une version « condensée » du documentaire (55 minutes sur les 87 de la version cinéma) sera diffusée le mardi 19 février à 23h45 sur Arte, sous le titre « Internet ou la révolution du partage »… et disponible en accès libre et gratuit sur la plateforme VOD d’Arte jusqu’au 12 avril prochain.
Mais pour les plus chanceuxses d’entre nous, pour celles et ceux qui aiment les grandes toiles et les ciné-débats, il y a déjà quelques avant-premières :
Nous continuerons d’en parler sur nos médias sociaux, car nous considérons que ce documentaire est un bien bel outil dont on peut s’emparer pour se relier à ces communautés qui partagent les valeurs du Libre dans des domaines autre que le numérique… Et il n’est pas impossible que vous rencontriez certain·e·s de nos membres lors d’une projection 😉
Un navigateur pour diffuser votre site web en pair à pair
Les technologies qui permettent la décentralisation du Web suscitent beaucoup d’intérêt et c’est tant mieux. Elles nous permettent d’échapper aux silos propriétaires qui collectent et monétisent les données que nous y laissons.
Vous connaissez probablement Mastodon, peerTube, Pleroma et autres ressources qui reposent sur le protocole activityPub. Mais connaissez-vous les projets Aragon, IPFS, ou ScuttleButt ?
Aujourd’hui nous vous proposons la traduction d’un bref article introducteur à une technologie qui permet de produire et héberger son site web sur son ordinateur et de le diffuser sans le moindre serveur depuis un navigateur.
Nous sommes Blue Link Labs, une équipe de trois personnes qui travaillent à améliorer le Web avec le protocole Dat et un navigateur expérimental pair à pair qui s’appelle Beaker.
L’équipe Blue Link Labs
Nous travaillons sur Beaker car publier et partager est l’essence même du Web. Cependant pour publier votre propre site web ou seulement diffuser un document, vous avez besoin de savoir faire tourner un serveur ou de pouvoir payer quelqu’un pour le faire à votre place.
Nous nous sommes donc demandé « Pourquoi ne pas partager un site Internet directement depuis votre navigateur ? »
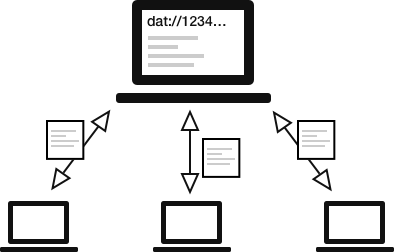
Un protocole pair-à-pair comme dat:// permet aux appareils des utilisateurs ordinaires d’héberger du contenu, donc nous utilisons dat:// dans Beaker pour pouvoir publier depuis le navigateur et donc au lieu d’utiliser un serveur, le site web d’un auteur et ses visiteurs l’aident à héberger ses fichiers. C’est un peu comme BitTorrent, mais pour les sites web !
Architecture
Beaker utilise un réseau pair-à-pair distribué pour publier des sites web et des jeux de données (parfois nous appelons ça des « dats »).
Les sites web dat:// sont joignables avec une clé publique faisant office d’URL, et chaque donnée ajoutée à un site web dat:// est attachée à un log signé.
Les visiteurs d’un site web dat:// peuvent se retrouver grâce à une table de hachage distribuée1, puis ils synchronisent les données entre eux, agissant à la fois comme téléchargeurs et téléverseurs, et vérifiant que les données n’ont pas été altérées pendant le transit.
Une illustration basique du réseau dat://
Techniquement, un site Web dat:// n’est pas tellement différent d’un site web https:// . C’est une collection de fichiers et de dossiers qu’un navigateur Internet va interpréter suivant les standards du Web. Mais les sites web dat:// sont spéciaux avec Beaker parce que nous avons ajouté une API (interface de programmation) qui permet aux développeurs de faire des choses comme lire, écrire, regarder des fichiers dat:// et construire des applications web pair-à-pair.
Créer un site Web pair-à-pair
Beaker rend facile pour quiconque de créer un nouveau site web dat:// en un clic (faire le tour des fonctionnalités). Si vous êtes familier avec le HTML, les CSS ou le JavaScript (même juste un peu !) alors vous êtes prêt⋅e à publier votre premier site Web dat://.
L’exemple ci-dessous montre comment fabriquer le site Web lui-même via la création et la sauvegarde d’un fichier JSON. Cet exemple est fictif mais fournit un modèle commun pour stocker des données, des profils utilisateurs, etc. pour un site Web dat:// : au lieu d’envoyer les données de l’application sur un serveur, elles peuvent être stockées sur le site web lui-même !
// index.js // first get an instance of the website's files var files = new DatArchive(window.location) document.getElementById('create-json-button').addEventListener('click', saveMessage) async function saveMessage () { var timestamp = Date.now() var filename = timestamp + '.json' var content = { timestamp, message: document.getElementById('message').value }
// write the message to a JSON file // this file can be read later using the DatArchive.readFile API await files.writeFile(filename, JSON.stringify(content)) }
Pour aller plus loin
Nous avons hâte de voir ce que les gens peuvent faire de dat:// et de Beaker. Nous apprécions tout spécialement quand quelqu’un crée un site web personnel ou un blog, ou encore quand on expérimente l’interface de programmation pour créer une application.
Beaucoup de choses sont à explorer avec le Web pair-à-pair !
Cela peut faire sourire car le meilleur moyen de ne pas être espionné par ce genre d’objet, c’est encore de s’en passer. La question qui se pose alors, c’est : doit-on accepter d’aller chez des gens qui ont ce genre d’objet chez eux ?
Allergie au Google Home
Se passer des GAFAM est un défi technique (surtout pour les néophytes), même si ça l’est de moins en moins.
Mais c’est souvent aussi un défi social.
On prend toujours les réseaux du genre Facebook comme exemple de site qui n’a aucun intérêt si vous êtes tout seul dessus…
Seulement, même les outils pour lesquels on peut se déGAFAMiser gentiment dans son coin deviennent problématiques si un tiers utilise du GAFAM.
Non contents de permettre la surveillance généralisée de nos vies numériques, les GAFAM se proposent maintenant de surveiller directement nos maisons par le biais d’enceintes connectées (objets qui colleraient des crises de priapisme à tout cadre de la Stasi).
Pour contrer ces dispositifs de surveillance (qui fileraient des crampes au poignet à tout agent de la DINA), un moyen simple existe :
NE PAS EN ACHETER.
Mais ça, vous le saviez déjà, et c’est relativement simple à appliquer.
Le problème se situe encore une fois dans nos relations sociales avec des gens moins prévenants : que faire si une de vos connaissances possédant un tel objet vous invite chez elle ? Doit-on se soumettre à la surveillance par pression sociale ?
Vous voyez, moi qui suis allergique aux poils de chats…
Bon.
Quand je dis allergique, c’est ALLERGIQUE.
Pour vous donner une idée, petit, je faisais des crises d’asthme quand j’étais assis à côté d’un camarade de classe qui avait un chat chez lui…
À ce niveau d’allergie, les antihistaminiques limitent la casse, mais faut pas rêver.
Donc.
Moi qui suis allergique aux poils de chats, je ne vais pas chez les possesseurs de chats. Tout simplement.
Ça fait rarement plaisir mais c’est une question de survie.
Eh bien, je me demande si je n’vais pas tout simplement me considérer comme allergique aux enceintes connectées. Ça simplifiera les choses.
Alors je sais ce que vous allez me dire : c’est un coup à se retrouver assez vite isolé.
Bah pas forcément.
Mettons qu’on ait tous une grosse poussée d’allergie anti-Google-Home, anti-Amazon-Echo, etc.
Moralité : sauvons nos potes. Devenons allergiques aux enceintes connectées.
Nous avons souhaité partager avec vous ce texte, mi-fiction mi réflexion, de Neil Jomunsi. Et nous l’avons même invité à en publier d’autres ici s’il le souhaite. Bonne lecture.
C’était inéluctable, nous le savions, parce que rien en ce monde n’est éternel, mais nous ne pouvions pas nous empêcher d’espérer. On a beaucoup parlé, évoqué un temps un possible rachat collectif par tous les utilisateurs, mais le monde étant devenu complexe, il ne se satisfait plus de réponses simpl(ist)es. Ce jour du 29 avril 2026 est donc à marquer d’une pierre blanche : deux ans après Facebook, dont la fermeture de la branche « réseau social » avait provoqué le tollé que l’on sait, Twitter a officiellement annoncé qu’il fermait à son tour les portes de son service. Le bureau d’administration a tranché : plus assez rentable. Twitter venait tout juste de fêter son vingtième anniversaire.
Twitter avait pourtant connu une embellie dans le courant 2020, profitant de la démocratisation des technologies de contrôle vocal et d’intelligence artificielle, et offrant à ses utilisateurs des interfaces toujours plus personnalisées, à mi-chemin entre salon de discussion public et messagerie privée. Les critiques n’avaient pas été tendres lorsque le service de micro-blogging avait décidé de renforcer la part algorithmique des messages affichés aux utilisateurs, mais la tempête avait fini par passer ; car les utilisateurs ont fini, on le sait, par adhérer au concept de bulle de filtres, la vague du « webcare » étant passée par-là, popularisée par des livres de développement personnel tels que Le miroir du réseau ou Modelez le web à votre image.
Bien sûr, les défenseurs d’un web libre et décentralisé avaient prévenu : avec la concentration des données sur une poignée de grosses plateformes, c’était tout un pan de la réflexion et de la création du XXIe qui courait le risque de disparaître purement et simplement de l’histoire. Ils n’ont pas été démentis : avec Twitter qui ferme, ce sont 20 années d’échanges, de contradictions, de propos calomnieux, injurieux ou mensongers aussi, qui sombrent dans le néant. Twitter assure que les usagers pourront télécharger leur archive personnelle pendant encore un an à compter de la date de fermeture officielle, qui devrait être annoncée sous peu. Mais sans la connexion entre les différents comptes qui rendait lesdites archives dynamiques, et donc pertinentes, ces sauvegardes risquent fort de perdre tout intérêt documentaire pour les historiens. D’autant que peu d’internautes décideront d’en faire quelque chose, et la plupart finiront par pourrir dans un coin de cloud oublié.
Soixante-seize chercheurs et historiens ont publié lundi dans Le Monde une tribune invitant les états à se saisir du dossier et à négocier avec Twitter une pérennisation de la disponibilité en ligne du service, dans un souci de conservation. Il ne s’agirait pas de permettre aux utilisateurs de continuer à utiliser le service, mais de le garder en ligne en l’état, consultable librement par tous. On le sait, Twitter a été le lieu de toutes les discussions politiques des dix dernières années. Avec sa disparition, craignent les signataires, on risque de voir se créer « le plus grand trou noir de l’histoire moderne », comparable avec celui de la disparition des œuvres hors domaine public en déficit d’exploitation.
Alors bien sûr, tout ceci est une fiction.
Mais Twitter fermera ses portes un jour, vous pouvez en être assurés. Et il y a de bonnes chances pour que les choses se déroulent de cette façon. On l’aura encore vu avec Tumblr récemment : faire confiance à de grandes entreprises multinationales pour conserver notre patrimoine artistique, historique et politique est une grave erreur. Nous devons reprendre le contrôle sur nos publications, et a minima les héberger nous-mêmes, sur un blog sur lequel nous avons tout contrôle.
Sans quoi les mites troueront bientôt – et plus vite qu’on ne l’imagine – le tissu de notre mémoire collective.
Vous trouverez ci-dessous en un seul document sous deux formats (.odt et .pdf) non seulement l’ensemble des chapitres publiés précédemment mais aussi les copieuses annexes qui référencent les recherches menées par l’équipe ainsi que les éléments qui ne pouvaient être détaillés dans les chapitres précédents.
Traduction Framalang pour l’ensemble du document :
Nous avons fait de notre mieux, mais des imperfections de divers ordres peuvent subsister, n’hésitez pas à vous emparer de la version en .odt pour opérer les rectifications que vous jugerez nécessaires.
.PDF Version 3.2 (2,6 Mo)
.ODT Version 3.2 (3,3 Mo)
Framasoft en 2019 pour les gens pressés
Vous avez aimé Dégooglisons Internet et pensez le plus grand bien de Contributopia ? Vous aimeriez savoir en quelques mots où notre feuille de route nous mènera en 2019 ? Cet article est fait pour vous, les décideurs pressés 🙂
Cet article présente de façon synthétique et ramassée ce que nous avons développé dans l’article de lancement de la campagne 2018-2019 : «Changer le monde, un octet à la fois».
Un octet à la fois, oui, parce qu’avec nos pattounes, ça prend du temps.
Depuis 4 ans, Framasoft montre qu’il est possible de décentraliser Internet avec l’opération « Dégooglisons Internet ». Le propos n’est ni de critiquer ni de culpabiliser, mais d’informer et de mettre en avant des alternatives qui existaient déjà, mais demeuraient difficiles d’accès ou d’usage.
De façon à ne pas devenir un nouveau nœud de centralisation, l’initiative CHATONS a été lancée, proposant de relier les hébergeurs de services en ligne qui partagent nos valeurs.
Depuis l’année dernière, avec sa feuille de route Contributopia, Framasoft a décidé d’affirmer clairement qu’il fallait aller au-delà du logiciel libre, qui n’était pas une fin en soi, mais un moyen de faire advenir un monde que nous appelons de nos vœux.
Il faut donc encourager la société de contribution et dépasser celle de la consommation, y compris en promouvant des projets qui ne soient plus seulement des alternatives aux GAFAM, mais qui soient porteurs d’une nouvelle façon de faire. Cela se fera aussi en se rapprochant de structures (y compris en dehors du mouvement traditionnel du libre) avec lesquelles nous partageons certaines valeurs, de façon à apprendre et diffuser nos savoirs.
Cette année a vu naître la version 1.0 de PeerTube, logiciel phare qui annonce une nouvelle façon de diffuser des médias vidéos, en conservant le contrôle de ses données sans se couper du monde, qu’on soit vidéaste ou spectateur.
Le monde des services de Contributopia. Illustration de David Revoy – Licence : CC-By 4.0
Avenir
La campagne de don actuelle est aussi l’occasion de de rappeler des éléments d’importance pour Framasoft : nous ne sommes pas une grosse multinationale, mais un petit groupe d’amis épaulé par quelques salarié·e·s, et une belle communauté de contributeurs et contributrices.
Cette petite taille et notre financement basé sur vos dons nous offrent souplesse et indépendance. Ils nous permettront de mettre en place de nouveaux projets comme MobilZon (mobilisation par le numérique), un Mooc CHATONS (tout savoir et comprendre sur pourquoi et comment devenir un chaton) ou encore Framapétitions (plateforme de pétitions n’exploitant pas les données des signataires).
Nous voulons aussi tenter d’en appeler à votre générosité sans techniques manipulatoires, en vous exposant simplement d’où nous venons et où nous allons. Nous espérons que cela vous motivera à nous faire un don.
Un article détaillé sur l’année 2019 de Contributopia (13mn de lecture)
La nouvelle page d’accueil de Framasoft, pour la campagne d’appel au don de cette fin d’année
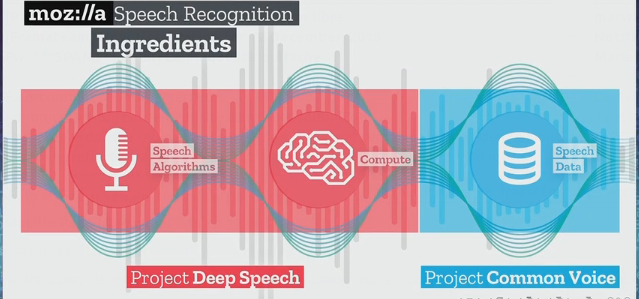
Projet Common Voice : pour que la voix soit libre
On nous demande souvent comment contribuer au Libre sans être un cador en informatique. Voici un projet utile, d’une grande importance et auquel il est très simple de contribuer : il suffit de savoir lire, parler et écouter. On vous explique tout.
On voit émerger à grande allure des objets avec lesquels l’interaction repose sur la reconnaissance vocale : smartphones, assistants connecté, dispositifs de réalité virtuelle…Selon les experts de ce marché, 50 % des recherches toutes plateformes confondues passeront par la voix d’ici 2 à 3 ans. Quant aux objets dits « intelligents », ils atteignent pour les pays favorisés un niveau de prix qui les rend accessibles à un nombre croissant de consommateurs. On peut trouver dès aujourd’hui dans la grande distribution des « enceintes connectées » à l’écoute de vos questions pour moins de 100 euros… Autant dire que ces produits sont en passe d’être des objets de consommation de masse.
Les services vocaux, au-delà des fonctions d’espionnage qui suscitent la méfiance, apporteront des avantages sensibles aux usages numériques du grand public. Ils abaisseront la barrière d’accès à des fonctionnalités utiles pour les personnes handicapées, en difficulté avec la lecture, dont les mains sont occupées ou pour celles qui ont besoin d’assistance immédiate. Dans bien des cas de figure il est ou sera plus efficace ou rapide d’utiliser la voix plutôt qu’une interface tactile ou souris/clavier2
Le problème hélas a un air de déjà-vu : aujourd’hui les systèmes de reconnaissance vocale sont essentiellement propriétaires et reposent sur 4 ou 5 bases de données vocales propriétaires : Cortana (Microsoft), Siri (Apple), Google Now (Google), Vocapia Research (VoxSigma suite)… En d’autres termes, tout est prêt pour assurer à quelques géants du numérique, toujours les mêmes, une suprématie commerciale et technologique. Et l’histoire récente prouve qu’ils n’hésiteront pas longtemps avant de capter les données les plus précieuses, celles de notre vie dans la bulle privée de notre habitation.
Il se trouve qu’un projet qui repose sur des ressources libres (données et code informatique) a été lancé par l’un des acteurs majeurs du monde du Libre : la fondation Mozilla.
Pourquoi Mozilla s’en mêle ?
Parmi les principes qui guident Mozilla et qu’on retrouve dans son manifeste, la santé d’un Web ouvert et l’inclusivité sont des valeurs essentielles. Cette ressource numérique dont l’usage est appelé à se développer rapidement doit être à la disposition du plus grand nombre, à commencer par les entreprises innovantes (déjà sur la brèche par exemple Mycroft et Snips) qui n’ont pas les moyens financiers d’accéder aux bases propriétaires et qui seraient tout simplement marginalisées par les grandes entreprises. Au-delà, bien sûr, c’est pour que des produits reposant sur la reconnaissance vocale soient accessibles à tous, quelle que soit leur langue, leur genre, leur accent local etc.
De quoi s’agit-il ?
De constituer la plus riche base possible d’échantillons sonores qui seront mis à la disposition des développeurs sous une licence libre (licence CC0). Le projet global s’appelle Deep Speech et Mozilla fait travailler des ingénieurs à traiter les données collectées avec des algorithmes, et ainsi alimenter un dispositif d’apprentissage machine.
Comment ça peut marcher ?
Ici nous tentons une description simple donc forcément approximative…
On donne à la machine des fichiers audio en entrée
On calcule la sortie, c’est-à-dire le texte
On compare au texte d’origine et… ben non c’est pas tout à fait ça.
On ajuste un petit peu des millions de paramètres internes pour essayer de se rapprocher de la sortie voulue
On répète sur des milliers d’heures…
Alexandre Lissy, ingénieur Mozilla qui travaille au bureau de Paris pour le projet Deep Speech. Les autres membres de l’équipe sont à Berlin, au Brésil et à San Francisco… (Photo de Samuel Nohra publiée dans Ouest France)
Pourquoi est-ce difficile à réaliser ?
L’entraînement des machines et la transcription nécessitent une grosse puissance de calcul.
Un nombre très important d’heures d’enregistrements valides est nécessaire pour que la reconnaissance vocale soit la plus efficace possible. C’est une somme d’environ 10 000 heures qui est considérée comme souhaitable pour obtenir un résultat.
Il existe peu de gros jeux de données publiquement accessibles en CC0 pour construire des modèles de reconnaissance 100% libres.
Les principes de Common Voice
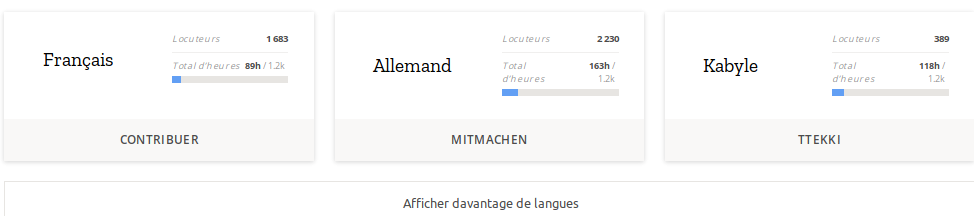
Tout d’abord le projet est mondial et vise à fonctionner pour le plus grand nombre de langues possible. Le projet est assez récent et pour l’instant, 16 langues seulement sont actives dont bien sûr le Français. On remarque que le projet a de l’importance pour les langues qui peuvent se sentir menacées : le Catalan, le Breton et le Kabyle par exemple sont déjà lancés !
Mais euh… On n’en est que là nous autres les francophones ? Vous avez compris : il est temps de nous y mettre tous ! (copie d’écran de la page des langues)
C’est aussi un projet inclusif pour lequel les intonations diverses sont bienvenues, avec une insistance particulière des ingénieurs responsables du projet pour qu’il y ait une grande diversité de voix : locuteurs et locutrices, de tous âges, avec tous les accents régionaux (oui les accents du sud, du nord etc. sont tout à fait bienvenus, une trentaine d’accents sont retenus), car les machines devront traiter la voix pour le plus grand nombre et pas exclusivement pour une prononciation standard appliquée. il est important de prononcer distinctement, mais le projet n’a pas besoin de textes déclamés professionnellement par des acteurs.
C’est surtout un projet communautaire et collaboratif. Il s’est construit dès le départ avec la communauté Mozilla et ses contributeurs et contributrices. Il fait maintenant appel à la communauté plus large de… tous les francophones. Car comme vous allez le voir, tout le monde 3 peut y participer !
et enregistrer tour à tour une série de 5 brèves phrases
Pas d’inquiétude : on peut choisir « passer » avec un bouton dédié si on rencontre une difficulté de compréhension, prononciation ou autre. Et bien entendu si en se réécoutant on constate que ça peut être mieux, un simple clic permet de recommencer.
2. ÉCOUTER
pour valider ou non une série de 5 phrases
Vous vous demandez peut-être d’où viennent tous ces textes parfois bizarres qu’on doit lire à haute voix ou écouter. Eh bien ce sont des textes dont la licence permet l’utilisation, qui viennent de transcriptions de débats de l’assemblée Nationale, de quelques livres du projet Gutenberg, de quelques pièces de théâtre, d’adresses françaises… Ah tiens, mais s’il faut enrichir la base, les romans de Pouhiou et celui de Frédéric Urbain publiés chez Framabook sont en CC0 ! Ça pourrait donner des phrases de test assez rigolotes.
Quand t’as eu des hémorroïdes, tu peux plus croire à la réincarnation.
Vingt-cinq ans, j’ai été bignole. Vous pensez si je retapisse un poulet.
Le coin des pas contents
Ah et puis ça ne va pas rater, les chevaliers blancs du Libre ne vont pas manquer d’agiter leur drapeau immaculé, donc on vous le dit d’avance : oui malheureusement la page de Common Voice contient du Google Analytics. Et oui encore, amis sourcilleux sur les licences libres, la CC0 va permettre la réutilisation commerciale des voix enregistrées bénévolement. C’est dommage ou pas de placer un travail collectif sous une licence très permissive ?
Cliquez sur l’image pour parcourir la page d’informations sur la CC0
À vous de jouer !
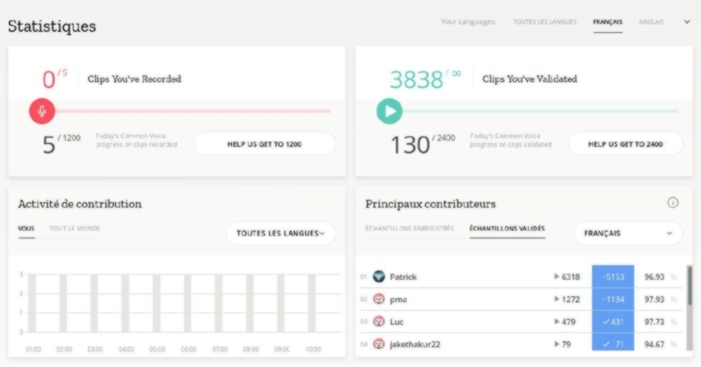
Chaque contribution est précieuse, surtout si elle est réitérée un grand nombre de fois 😉 Pour s’encourager, on peut suivre la progression des objectifs quotidiens, et certain⋅e⋅s ne manquent pas de se prendre au jeu…
Vous l’avez compris, ce projet réclame une participation massive pour avancer, alors si chacun y contribue ne serait-ce que modestement, nous pourrons dire que la voix est libre !
Il s’agit cette fois de comprendre comment Google complète les données collectées avec les données provenant des applications et des comptes connectés des utilisateurs.
VI. Données collectées par les applications clés de Google destinées aux particuliers
67. Google a des dizaines de produits et services qui évoluent en permanence (une liste est disponible dans le tableau 4, section IX.B de l’annexe). On accède souvent à ces produits grâce à un compte Google (ou on l’y associe), ce qui permet à Google de relier directement les détails des activités de l’utilisateur de ses produits et services à un profil utilisateur. En plus des données d’usage de ses produits, Google collecte également des identificateurs et des données de localisation liés aux appareils lorsqu’on accède aux services Google. 4
68. Certaines applications de Google (p.ex. YouTube, Search, Gmail et Maps) occupent une place centrale dans les tâches de base qu’une multitude d’utilisateurs effectuent quotidiennement sur leurs appareils fixes ou mobiles. Le tableau 2 décrit la portée de ces produits clés. Cette section explique comment chacune de ces applications majeures collecte les informations des utilisateurs.
Tableau 2 : Portée mondiale des principales applications Google
Produits
Utilisateurs actifs
Search
Plus d’un milliard d’utilisateurs actifs par mois, 90.6 % de part de marché des moteurs de recherche 5
Youtube
Plus de 1,8 milliard d’utilisateurs inscrits et actifs par mois 6
Maps
Plus d’un milliard d’utilisateurs actifs par mois 7
69. Google Search est le moteur de recherche sur internet le plus populaire au monde 9, avec plus de 11 milliards de requêtes par mois aux États-Unis 10. En plus de renvoyer un classement de pages web en réponse aux requêtes globales des utilisateurs, Google exploite d’autres outils basés sur la recherche, tels que Google Finance, Flights (vols), News (actualités), Scholar (recherche universitaire), Patents (brevets), Books (livres), Images, Videos et Hotels. Google utilise ses applications de recherche afin de collecter des données liées aux recherches, à l’historique de navigation ainsi qu’aux activités d’achats et de clics sur publicités. Par exemple, Google Finance collecte des informations sur le type d’actions que les utilisateurs peuvent suivre, tandis que Google Flight piste leurs réservations et recherches de voyage.
70. Dès lors que Search est utilisé, Google collecte les données de localisation par différents biais, sur ordinateur ou sur mobile, comme décrit dans les sections précédentes. Google enregistre toute l’activité de recherche d’un utilisateur ou utilisatrice et la relie à son compte Google si cette personne est connectée. L’illustration 13 montre un exemple d’informations collectées par Google sur une recherche utilisateur par mot-clé et la navigation associée.
Illustration 13 : Un exemple de collecte de données de recherche extrait de la page My Activity (Mon Activité) d’un utilisateur
71. Non seulement c’est le moteur de recherche par défaut sur Chrome et les appareils Google, mais Google Search est aussi l’option par défaut sur d’autres navigateurs internet et applications grâce à des arrangements de distribution. Ainsi, Google est récemment devenu le moteur de recherche par défaut sur le navigateur internet Mozilla Firefox 11 dans des régions clés (dont les USA et le Canada), une position occupée auparavant par Yahoo. De même, Apple est passé de Microsoft Bing à Google pour les résultats de recherche via Siri sur les appareils iOS et Mac 12. Google a des accords similaires en place avec des OEM (fabricants d’équipement informatique ou électronique) 13, ce qui lui permet d’atteindre les consommateurs mobiles.
B. YouTube
72. YouTube met à disposition des utilisateurs et utilisatrices une plateforme pour la mise en ligne et la visualisation de contenu vidéo. Il attire plus de 180 millions de personnes rien qu’aux États-Unis et a la particularité d’être le deuxième site le plus visité des États-Unis 14, juste derrière Google Search. Au sein des entreprises de streaming multimédia, YouTube possède près de 80 % de parts de marché en termes de visites mensuelles (comme décrit dans l’illustration 14). La quantité de contenu mis en ligne et visualisé sur YouTube est conséquente : 400 heures de vidéo sont mises en ligne chaque minute 15 et 1 milliard d’heures de vidéo sont visualisées quotidiennement sur la plateforme YouTube.16
Illustration 14 : Comparaison d’audiences mensuelles des principaux sites multimédia aux États-Unis 17
73. Les utilisateurs peuvent accéder à YouTube sur l’ordinateur (navigateur internet), sur leurs appareils mobiles (application et/ou navigateur internet) et sur Google Home (via un abonnement payant appelé YouTube Red). Google collecte et sauvegarde l’historique de recherche, l’historique de visualisation, les listes de lecture, les abonnements et les commentaires aux vidéos. La date et l’horaire de chaque activité sont ajoutés à ces informations.
74. Si un utilisateur se connecte à son compte Google pour accéder à n’importe quelle application Google via un navigateur internet (par ex. Chrome, Firefox, Safari), Google reconnaît l’identité de l’utilisateur, même si l’accès à la vidéo est réalisé par un site hors Google (ex. : vidéos YouTube lues sur cnn.com). Cette fonctionnalité permet à Google de pister l’utilisation YouTube d’un utilisateur à travers différentes plateformes tierces. L’illustration 15 montre un exemple de données YouTube collectées.
Illustration 15 : Exemple de collecte de données YouTube dans My Activity (Mon Activité)
75. Google propose également un produit YouTube différencié pour les enfants, appelé YouTube Kids, dans l’intention d’offrir une version « familiale » de YouTube avec des fonctionnalités de contrôle parental et de filtres vidéos. Google collecte des informations de YouTube Kids, notamment le type d’appareil, le système d’exploitation, l’identifiant unique de l’appareil, les informations de journalisation et les détails d’utilisation du service. Google utilise ensuite ces informations pour fournir des annonces publicitaires limitées, qui ne sont pas cliquables et dont le format, la durée et le site sont limités.18.
C. Maps
76. Maps est l’application phare de navigation routière de Google. Google Maps peut déterminer les trajets et la vitesse d’un utilisateur et ses lieux de fréquentation régulière (ex. : domicile, travail, restaurants et magasins). Cette information donne à Google une idée des intérêts (ex. : préférences d’alimentation et d’achats), des déplacements et du comportement de l’utilisateur.
77. Maps utilise l’adresse IP, le GPS, le signal cellulaire et les points d’accès au Wi-Fi pour calculer la localisation d’un appareil. Les deux dernières informations sont collectées par le biais de l’appareil où Maps est utilisé, puis envoyées à Google pour évaluer la localisation via son interface de localisation (Location API). Cette interface fournit de nombreux détails sur un utilisateur, dont les coordonnées géographiques, son état stationnaire ou en mouvement, sa vitesse et la détermination probabiliste de son mode de transport (ex. : en vélo, voiture, train, etc.).
78. Maps sauvegarde un historique des lieux qu’un utilisateur connecté à Maps par son compte Googe a visités. L’illustration 16. montre un exemple d’un tel historique 19. Les points rouges indiquent les coordonnées géographiques recueillies par Maps lorsque l’utilisateur se déplace ; les lignes bleues représentent les projections de Maps sur le trajet réel de l’utilisateur.
Illustration 16 : Exemple d’un historique Google Maps (« Timeline ») d’un utilisateur réel
79. La précision des informations de localisation recueillies par les applications de navigation routière permet à Google de non seulement cibler des audiences publicitaires, mais l’aide aussi à fournir des annonces publicitaires aux utilisateurs lorsqu’ils s’approchent d’un magasin 20. Google Maps utilise de plus ces informations pour générer des données de trafic routier en temps réel.21
D. Gmail
80. Gmail sauvegarde tous les messages (envoyés et reçus), le nom de l’expéditeur, son adresse email et la date et l’heure des messages envoyés ou reçus. Puisque Gmail représente pour beaucoup un répertoire central pour la messagerie électronique, il peut déterminer leurs intérêts en scannant le contenu de leurs courriels, identifier les adresses de commerçants grâce à leurs courriels publicitaires ou les factures envoyées par message électronique, et connaître l’agenda d’un utilisateur (ex. : réservations à dîner, rendez-vous médicaux…). Étant donné que les utilisateurs utilisent leur identifiant Gmail pour des plateformes tierces (Facebook, LinkedIn…), Google peut analyser tout contenu qui leur parvient sous forme de courriel (ex. : notifications, messages).
81. Depuis son lancement en 2004 jusqu’à la fin de l’année 2017 (au moins), Google peut avoir analysé le contenu des courriels Gmail pour améliorer le ciblage publicitaire et les résultats de recherche ainsi que ses filtres de pourriel. Lors de l’été 2016, Google a franchi une nouvelle étape et a modifié sa politique de confidentialité pour s’autoriser à fusionner les données de navigation, autrefois anonymes, de sa filiale DoubleClick (qui fournit des publicités personnalisées sur internet) avec les données d’identification personnelles qu’il amasse à travers ses autres produits, dont Gmail 22. Le résultat : « les annonces publicitaires DoubleClick qui pistent les gens sur Internet peuvent maintenant leur être adaptées sur mesure, en se fondant sur les mots-clés qu’ils ont utilisés dans leur messagerie Gmail. Cela signifie également que Google peut à présent reconstruire le portrait complet d’une utilisatrice ou utilisateur par son nom, en fonction de tout ce qui est écrit dans ses courriels, sur tous les sites visités et sur toutes les recherches menées. » 23
82. Vers la fin de l’année 2017, Google a annoncé qu’il arrêterait la personnalisation des publicités basées sur les messages Gmail 24. Cependant, Google a annoncé récemment qu’il continue à analyser les messages Gmail pour certaines raisons 25.