700 organisations already up in the (free) clouds : Framaspace’s first year in review
The aim of this long article is to take stock of the Framaspace project (an associative cloud based on Nextcloud) a little over a year after its announcement.
🦆 VS 😈: Let’s take back some ground from the tech giants!
Thanks to your donations to our not-for-profit, Framasoft is taking action to advance the ethical, user-friendly web. Find a summary of our progress in 2023 on our Support Framasoft page.
➡️ Read the series of articles from this campaign (Nov. – Dec. 2023)
Once upon a time there was Frama.space
Remember, a year ago we announced (in French, sorry!) one of Framasoft’s most ambitious projects: Frama.space.
For those of you who weren’t there, or who don’t remember, the desire to set up Frama.space was based on three things.
The first is that things are fucked. Politically, socially, geopolitically, ecologically and so on. Of course, you may think otherwise, but we don’t think the world is going very well…
The second observation is that civil society, caricatured here as associations and trade unions, is under attack from all sides. The pressure to depoliticise associations, the reduction of their funding in favour of « impact companies » or the start-up nation, the attacks on freedom of association… All this is eroding the capacity of the voluntary sector to respond to needs that the market cannot meet. It is becoming increasingly difficult to balance a social contract that is being undermined by both business and government.

Finally, closer to Framasoft, digital technology has become a tool for organising people, but also for taking action. However, this rather positive observation is countered by two more negative observations. Firstly, digital technology is a tool for surveillance and alienation. And secondly, associations are lagging behind both in terms of use and consistency (The report in the link is in French, sorry!). Associations working for an ecological transition, for example, will use the tools and services of GAFAM, which play a large part in the problem they are trying to solve.
Frama.space: (Next)cloud for non-profit organisations
A year ago we announced a new Framasoft service: Frama.space.
Its mission? To equip the ‘contributing society’. In other words, to digitally equip « off-market » associations and groups. Whether it’s the AMAP in FarFarAway-town, the community café in Bernache-sur-Yvette or the queer theatre collective in Cygne-lès-Lavaur.
We believe that these associations and collectives need (and even want) to rediscover the coherence between their values, their actions and their tools. It seems contradictory to us, for example, to be an association committed to « zero waste » and still use Google or Microsoft tools.
Please note that this is not a value judgement on our part. We fully understand that there may be contradictions and legitimate objections (it is perfectly possible to be concerned about the fate of the planet and still drive your children to a weekly sports activity 20km away).
However, we believe it is important that these structures have the choice to have easy access to tools that are not based on the mechanisms of surveillance capitalism.
Nextcloud: an imperfect solution (but a solution nonetheless)
The software has a lot of room for improvement (in terms of UX, technical debt, performance, etc.), but… it’s still the best horse in the stable.
What’s more, its community is large (over 60 million users worldwide) and quite active, which gives us hope for the future.
We have therefore decided to base our Framaspace offering on this software, proposing a technically ambitious offering capable of eventually hosting up to 10,000 Framaspace spaces (and therefore as many instances of the Nextcloud software). To achieve this, we have built a substantial technical infrastructure (the video link is in French, sorry!) and developed homemade software tools (free of charge, of course) to validate registration requests and automatically provision new spaces very quickly, with just a few clicks.
But enough of reminiscing: if you want to know more about the ambitions behind Framaspace, you can watch two videos:
- The political presentation of the project (in French), by Pierre-Yves Gosset, project coordinator, at the Capitole du Libre (November 2022);
- The technical presentation of the project (in French), by Luc Didry and Thomas Citharel, technical managers of the project, at the ESUP Nextcloud Day (June 2023).
Taking stock, calmly
Frama.space becomes Framaspace.org
- Facilitate access to Nextcloud/Framaspace
- Raise awareness of Nextcloud/Framaspace
- Contribute to the creation of a French-speaking Nextcloud/Framaspace community
- Use Nextcloud/Framaspace as an empowerment tool
This first anniversary is therefore a good time to take stock of each of these objectives.
Functional assessment: does it work or not?
Yes, it does!
While you are reading these lines, more than 700 spaces are active. This means that Framasoft provides tools to 700 associations and groups. And the feedback is very positive!
We have been able to carry out complex operations without too much difficulty. For example, we’ve carried out major upgrades of Nextcloud (from version 25 to version 26) with very limited downtime (less than 2 minutes per space).
As far as the technical infrastructure is concerned, there are occasional potholes, but the infrastructure is holding up!
For example, at the end of 2022 we noticed that there was a problem with our office suite management system. With the year-end holidays just around the corner, followed by intense preparations for the Framasoft AGM, we decided to suspend registration and take the time needed to develop a long-term solution. We reopened the registration in March 2023. So, in case you missed the news: it’s perfectly possible to register your association or collective on https://framaspace.org!
The fact that it’s Framasoft that manages the technical aspects can have certain disadvantages (we limit the number of accounts, disk space or Nextcloud plugins you can use). However, this outsourcing makes life much easier for the users (who, in most cases, would find it very difficult to maintain over time an instance of Nextcloud software that they would have installed ‘manually’).
In one year, we have gone from 0 to more than 700 spaces managed by Framasoft. We therefore consider this functional assessment to be more than satisfactory.

Public awareness
One of Framaspace’s objectives is also to raise awareness of Nextcloud and the Framaspace offer (or similar offers elsewhere, in particular at CHATONS).
To this end, in 2023 we will:
- 3 conferences: Capitole du Libre 2022, Capitole du Libre 2023, OSXP;
- 2 interviews: NextINpact, Techologie;
- published 3 articles about Framaspace: Association Mode d’Emploi, NextINpact, ZDNet;
- participated in 1 workshop/webinar: « Collaborate effectively with Nextcloud« , at Solidatech, in partnership with Arawa;
- 1 newsletter distributed: Lettre d’information Framaspace #1.
On a report card, we could write: « Not bad, but can do better ».
« Community » review
This concerns our desire to build a community of French-speaking Nextcloud users in the long term.
To this end, we have:
- Opened a community-based help forum: 148 accounts created and 542 messages exchanged
- published a series of tutorials on the forum
- carried out a survey on satisfaction and expectations about Framaspace (presented at the CHATONS camp and results to be published soon).
This part of the project got off to a rather slow start, but that’s quite logical, because for various reasons we were not able to devote as much time to this part of the project in 2023 as we would have liked.
Empowerment assessment
This part of the project is planned for 2025. There were no plans to work on it in 2023. So it’s logical that we haven’t made any progress on it.

Project stats
Here are some numbers to give you a more objective view of the first year. If you’re not interested, you can skip to the « Review of the review » section 🙂
Typology of the structures
Breakdown by type of structure
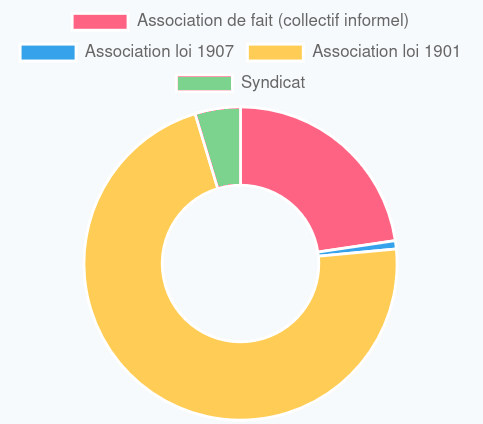
Description :
- 72% associations under the law of 1901(yellow);
- 22% informal groups (pink);
- 5% trade unions (green);
- 1% associations under the 1907 law (mixed/cultural associations) (blue).
Breakdown by activity
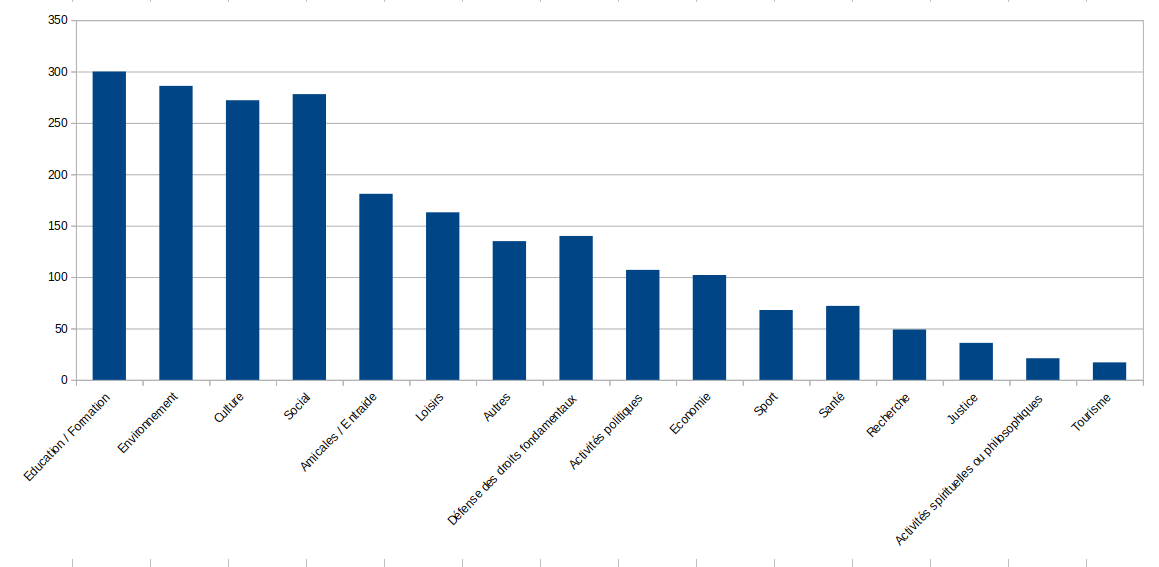
Description (note: organisations could choose more than one topic):
- A first « block » of more than 250 organisations in the following sectors or themes Education/training, environment, culture, social affairs;
- a second « block » of more than 100 organisations claiming to be active in the following sectors or themes: Friendship/Mutual Aid, Leisure, Defence of Fundamental Rights, Political Activities, Economy and Social Affairs: Amicale / Entraide, Loisirs, Défense des droits fondamentaux, Activités politiques, Économie ;
- a final « block » of less than 100 organisations claiming to be active in the following sectors or themes: Sport, Health, Research, Justice, Spiritual or philosophical activities, Tourism.
Breakdown by year in which the structure was created
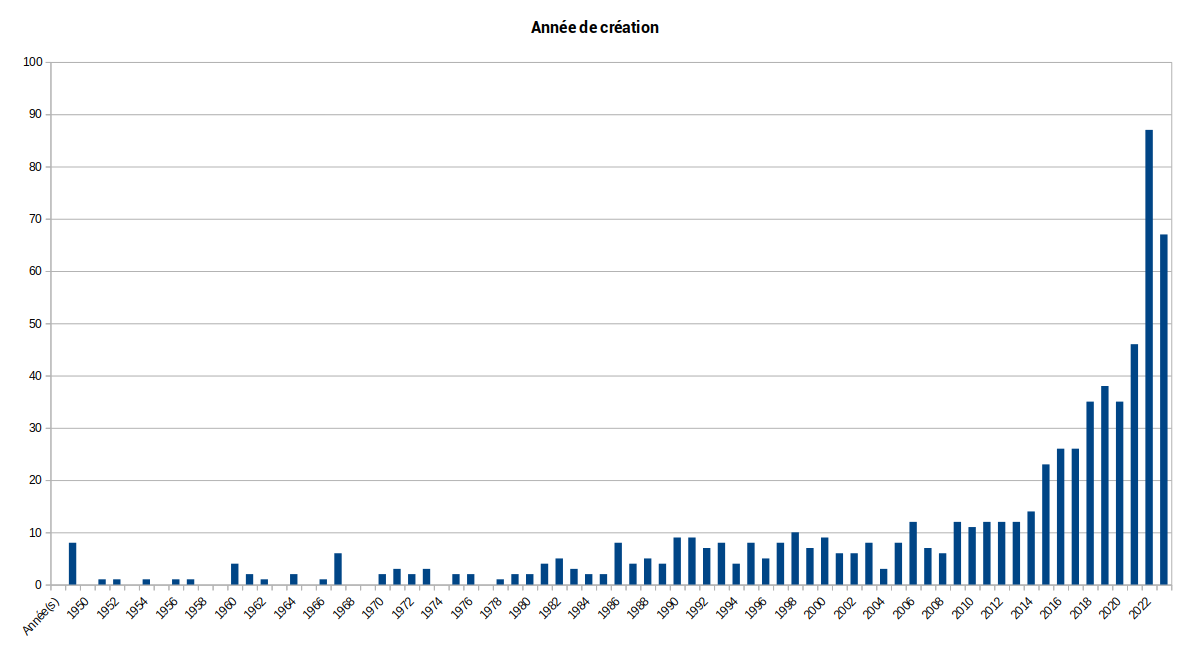
Description: 50% of the 700 spaces correspond to structures created in 2017 or later. Even if a dozen structures existed before 1950, we can deduce that the Framaspace public as a whole represents rather recent structures.
Breakdown by number of persons employed
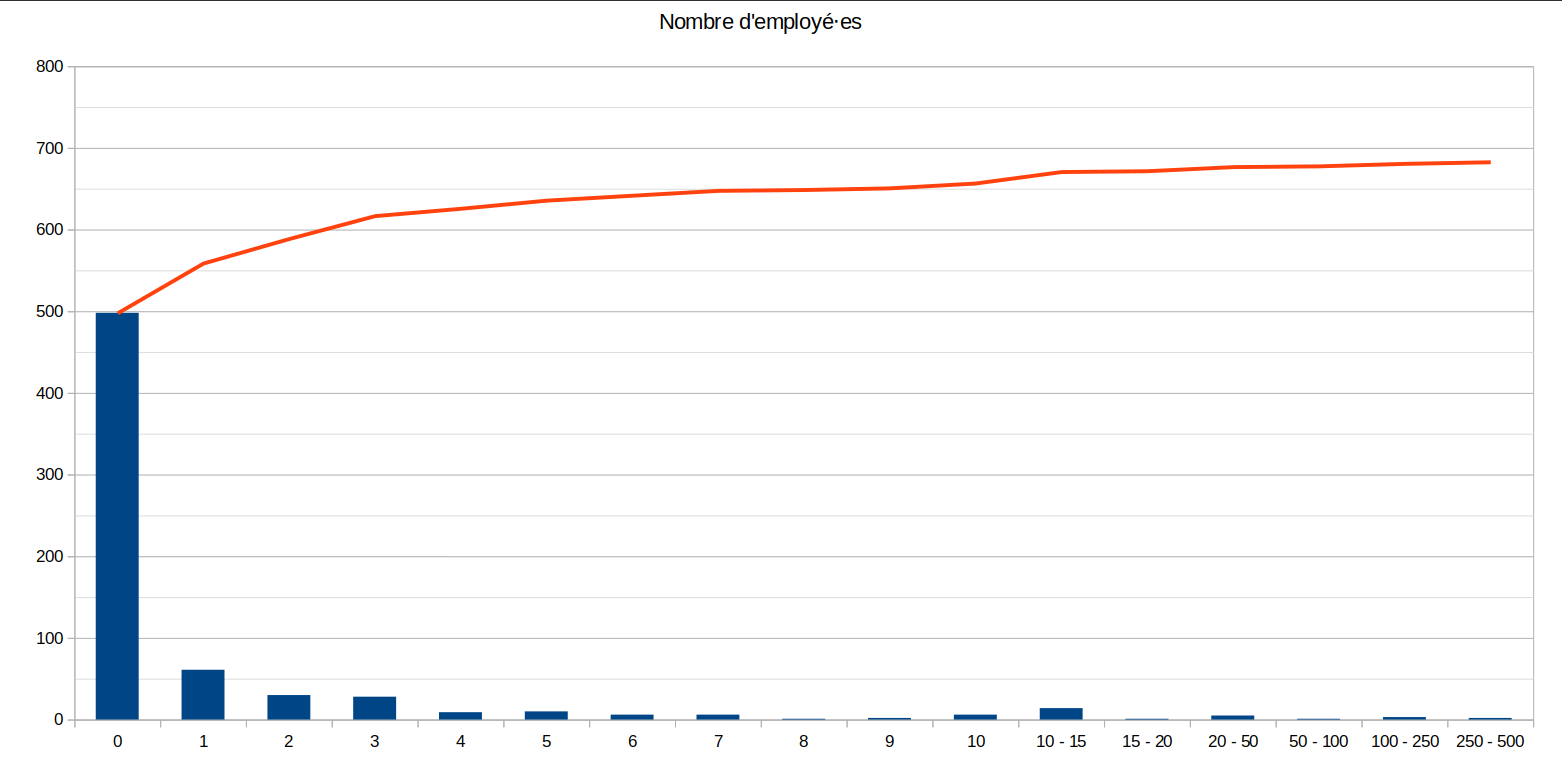
Description and comments: 500 of the spaces (71% of the total) are structures with no employees. There are a few structures with more than 20 employees, but these are often « anomalies » (for example, the space is created for a local trade union group, which indicates the number of employees of the national trade union).
Breakdown by number of members
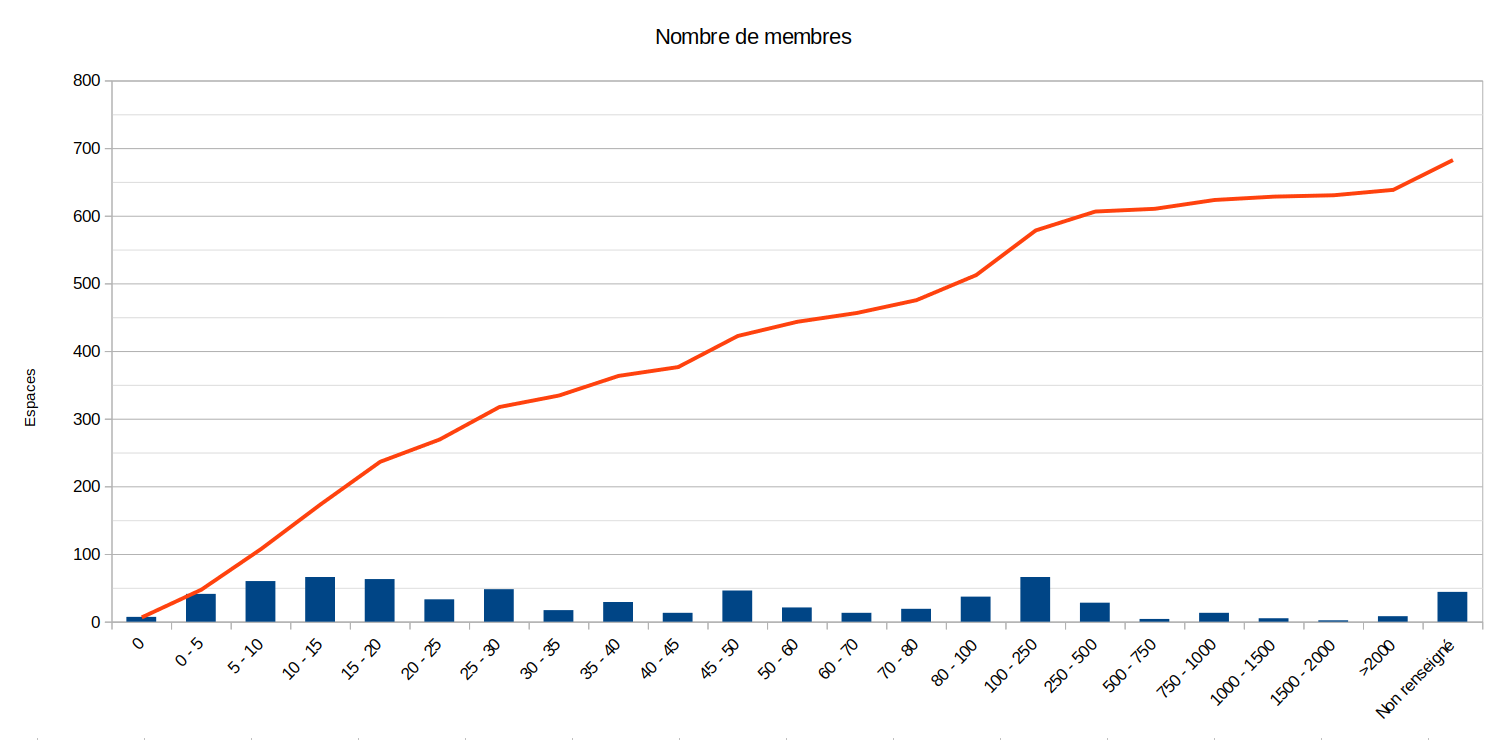 Description: Half of the spaces represent organisations with less than 30 members. 75% say they have 100 members or less.
Description: Half of the spaces represent organisations with less than 30 members. 75% say they have 100 members or less.
Breakdown by number of beneficiaries
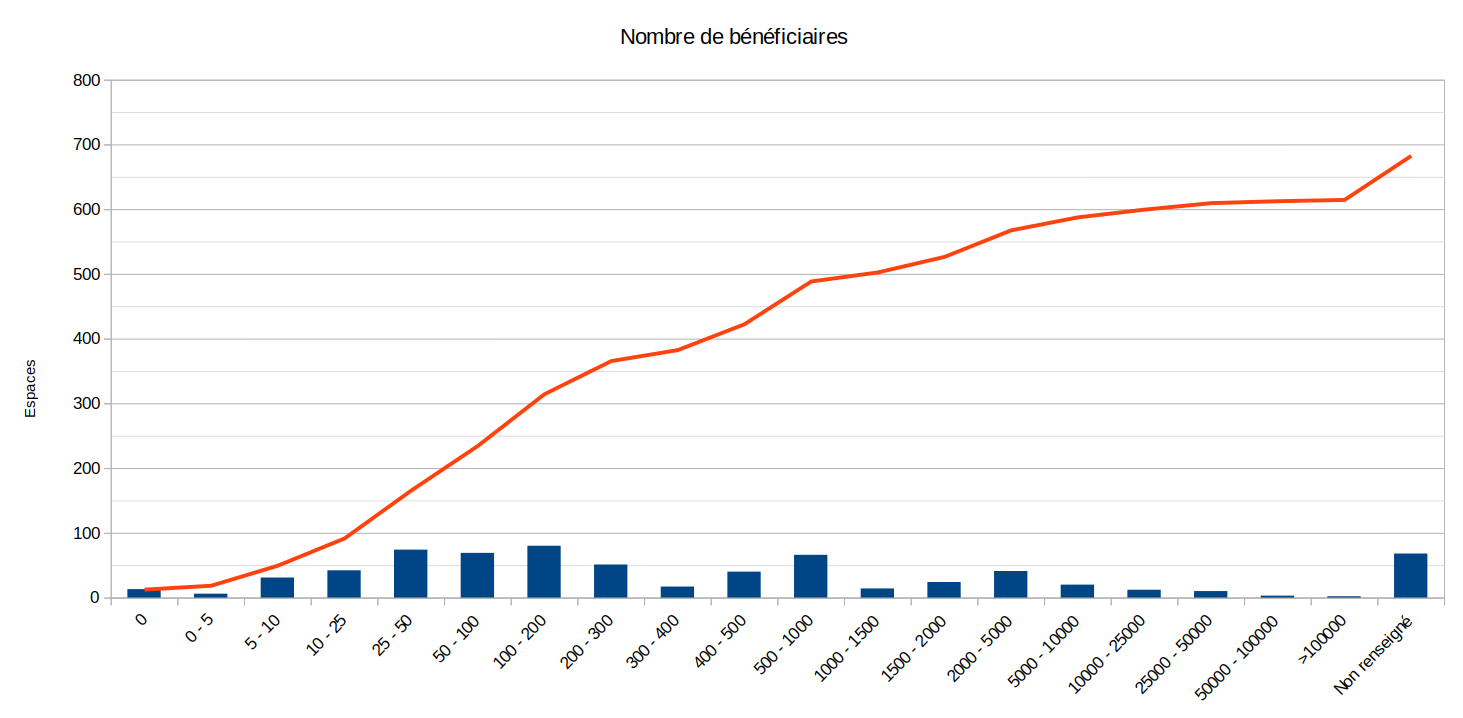
Description: Half of the spaces represent organisations claiming to reach 100 people or more. There are a few organisations claiming to reach more than 25,000 people, but these are often « anomalies » (for example, the space is created for a local trade union group, which indicates the number of beneficiaries of the national trade union).
Breakdown by annual budget
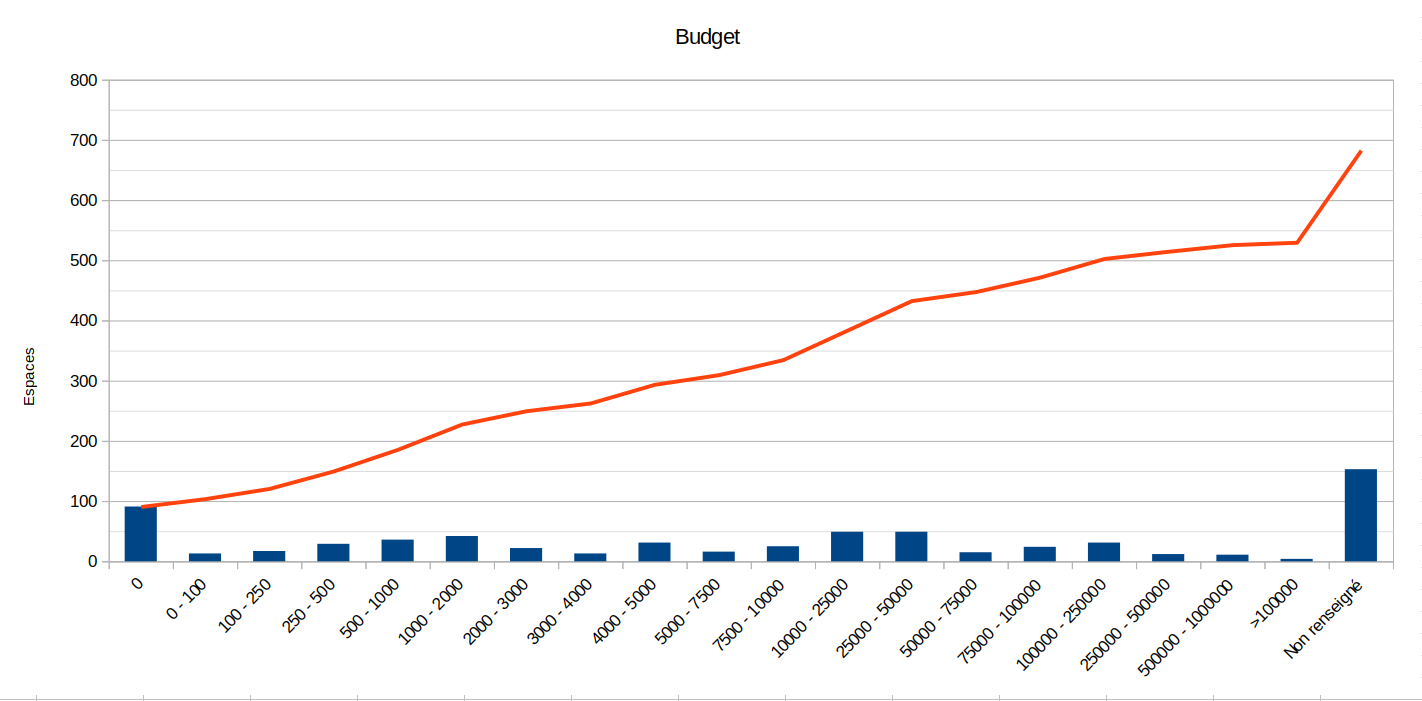
Description: 150 organisations did not wish to answer this question. Of the remaining 550 organisations, half said they had an annual budget of less than €4,000 (around a hundred organisations even said they had a budget of €0). About 25% of the organisations reported having a budget between €4,000 and €50,000 (which can be correlated with organisations having at least one⋅e employee⋅e). A handful of organisations report a budget of more than €50,000/year, but again these are mostly ‘statistical anomalies’.
Examples of structures
NB: These associations have presented themselves publicly on the Framaspace forum, so we have no problem with their identity or purpose being made public.
For example:
« Hello. We’re the « Les petits pois sont verts » association in Clamart. Our aim is to imagine and build a way of life based on solidarity and respect for the environment by ..:
- Bringing together people in Clamart who share the same motivations,
- encouraging local dynamism
- supporting projects,
- gathering and disseminating information.
We are only a few years old and we advocate the use of free and sober digital technology.
We use the following Framasoft tools Framapad, Framadate and recently Frama.space. »
Or again:
« The Association des Cavaliers Au Long Cours (CALC) is a French-speaking association with about 200 members from all over the world (our most distant member is in Kyrgyzstan!), but mainly from Western European countries. Our aim is to develop long-distance travel with a mounted and/or covered animal (horse, donkey, mule, etc.). We also help would-be travellers with their organisation and provide assistance to travellers in difficulty ».
Other examples:
- Plan B – Breton Pop Education Association (Rennes)
- AMAP of St Vallier de Thiey (Alpes Maritimes)
- La Gonette – local currency for citizens (Lyon)
- Les amis du Portique – Journal of Philosophy and Human Sciences
- Les Pieds à Terre – environmental education (Haute-Loire)
- Family planning in the Aude
- …
Use of structures
Office suites used
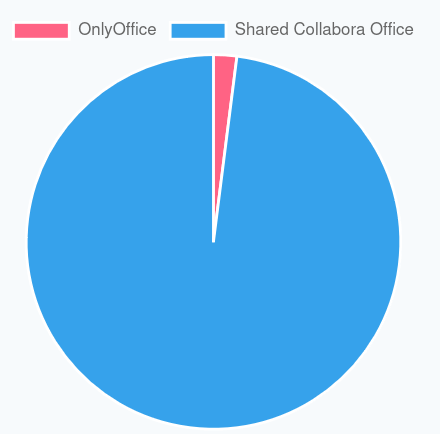
NB: The overrepresentation of Collabora Online is due to the fact that it is the office suite offered by default. The administrator of the instance can switch to OnlyOffice if they wish, but very few do.
Usage stats
- Number of active
- Active: 700
- Rejected: 14
- Deactivated (by their administrators) 10
- Accounts (admins + users): 3,356
- Average: 4.8 accounts; Median: 2 accounts
- Hosted user files: 760,939 for 860 GB (excluding revisions and recycle bin)
- 131 GB in recycle bin
- 99% of spaces have created at least one file
- Connections:
- 198 rooms connected in the last 3 days
- 390 rooms connected in the last 15 days
Number of accounts
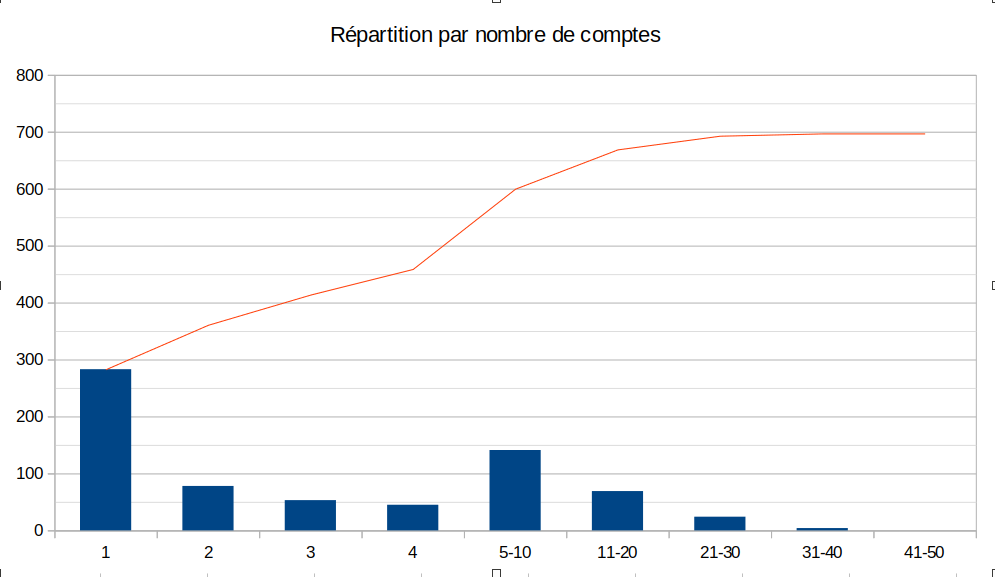 Description: almost 300 rooms have only one account (necessarily the « admin » account). This means that 40% of the spaces have no collaborative use with other users. However, we did find cases where the space admin did have collaborative uses with other people in his or her association (for example, by using shared folders, with or without passwords). This means – all the same – that 60% of the spaces have several users. 42% even have 5 or more users.
Description: almost 300 rooms have only one account (necessarily the « admin » account). This means that 40% of the spaces have no collaborative use with other users. However, we did find cases where the space admin did have collaborative uses with other people in his or her association (for example, by using shared folders, with or without passwords). This means – all the same – that 60% of the spaces have several users. 42% even have 5 or more users.
Used disk space
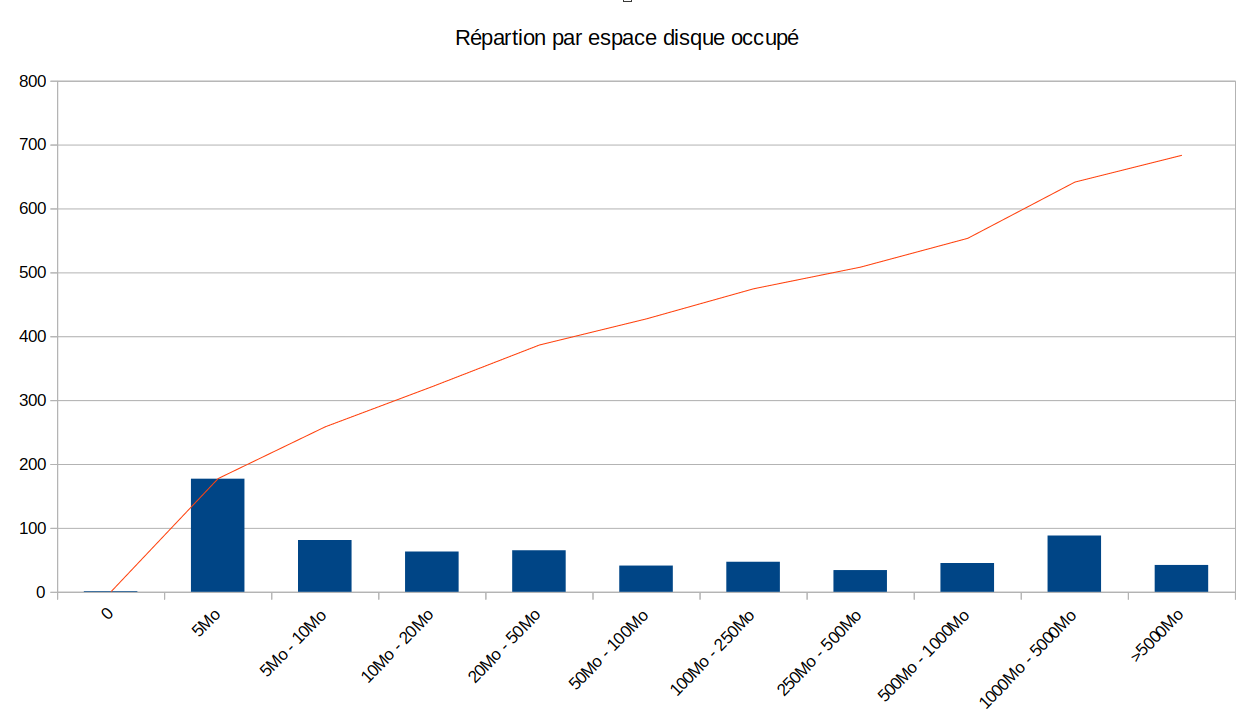
Description: almost all spaces have used their file space (only 2% have never created a file). It is interesting to note that less than 20% of the spaces use more than 1 GB (out of a maximum of 40 GB per space).
Number of files
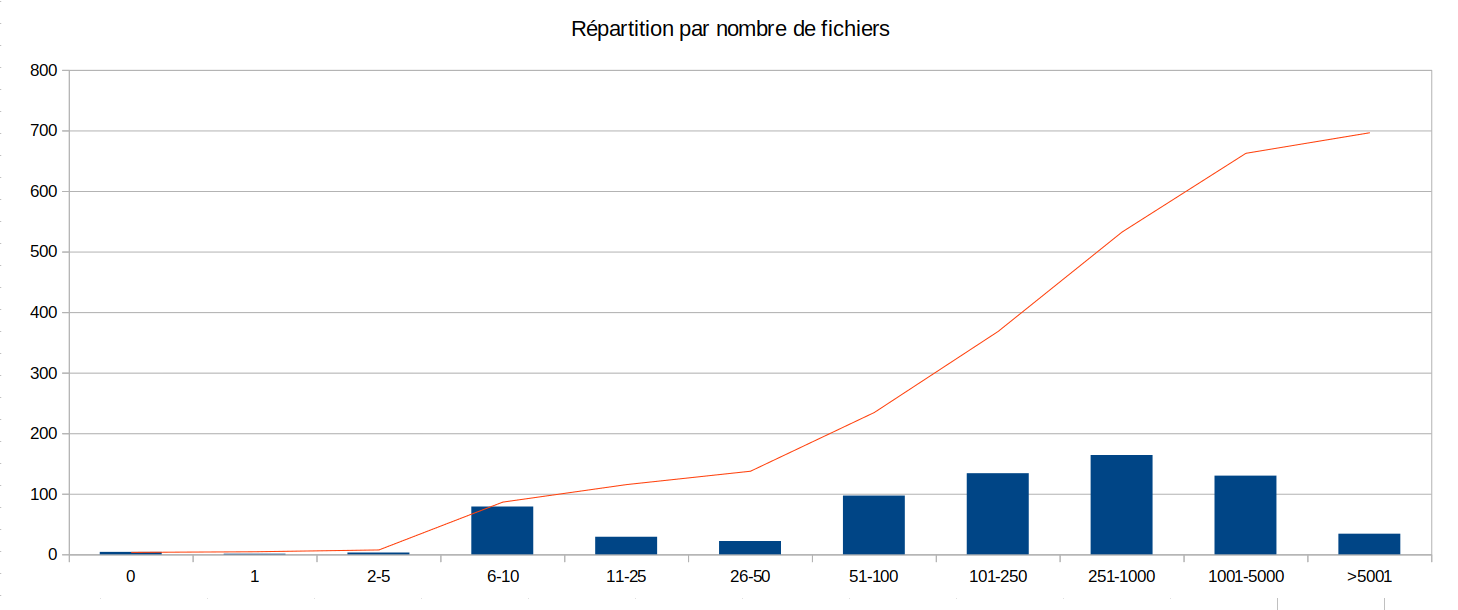
Description: 50% of the rooms have more than 250 user files. This is a good « surprise » in our opinion: it means that Framaspace is quite useful (either for storing or sharing files).
Balance sheet
Expenses
At present, the technical infrastructure (computer servers) of Framaspace costs us about 1,200 € per month (i.e. about 15,000 € per year). The cost of the work, estimated by the very inaccurate LaLouche Institute, is around €20,000 of investment before the launch of the project. Since the start of the project, we’ve been able to estimate this figure at around €2,000 per month (3 people involved, working very, very part-time on this project). So, roughly speaking, Framaspace has cost Framasoft around €60,000.
Income
The income side is a bit more complex.
Framaspace is a project reserved for small associations and solidarity groups, and it is deliberately free. We don’t want the price to be a barrier to access. And we don’t want to set a « free price », because a price means a service sold, a service provided, an invoice and obligations (contractual, accounting and fiscal). We voluntarily choose to donate without expecting any financial compensation (which does not mean that we cannot hope for it 😉 ).
It is likely that some members of the associations we host have made a donation to Framasoft. However, we do not want to earmark donations for Framasoft projects. For accounting purposes, a donation earmarked for a project must go into a dedicated fund that must be used for that project. However, we would like donations to Framasoft to be able to finance « loss-making » projects, which is exactly what Framaspace is doing in this first year.
For the sake of simplicity we can say that the income is… €0! 😱
Cost per space
From the above data, we can deduce that the cost of a space (so far) is €86 per year (or €7 per month, of which €1.8 per month is infrastructure costs).
However, the infrastructure costs are not expected to change too much and the labour costs are expected to increase slightly by 2024, while the number of spaces could triple or quadruple. Let us assume a total cost of €60,000 (for 2023) + €15,000 for the servers in 2024 + €36,000 in labour costs. This gives a total of €111,000 by the end of 2024. Assuming 2,500 active spaces at the end of 2024, the total cost would be €45 per space per year (i.e. €3.7 per month, including €1/month for infrastructure costs). These costs could fall further in 2025.
It’s a significant cost, and few associations can afford this type of project, which does not aim to be profitable or even break even.
However, we believe that the political importance of this project means that we have to take this risk. We hope (more from experience than naivety) that the associations that can afford it will support Framasoft (and indirectly Framaspace) financially.
Review of the review
The news is pretty good!

First of all, Framaspace works 🙂
Managing 700 Nextcloud instances in one year isn’t bad, is it? Especially since outsourcing is going pretty well (for now!).
Secondly, we’ve managed to reach the audience we wanted to reach: associations (registered or de facto) that are fairly small, with small budgets. Most of them focus on education, the environment, social or cultural issues. Which is hardly surprising given Framasoft’s target audience.
Finally, Framaspace is used. More than half the spaces have regular connections. And people handle quite a lot of files (rather small files, which explains why very few spaces use more than one GB of the maximum 40 GB allowed).
We feel that our 2023 goals have been more than adequately met in terms of actions 🎉 We could even say that it’s a success given the resources we’ve invested.
Offering « locked » spaces (for example, you can’t install the Nextcloud plugins of your choice on Framaspace, and only small associations or collectives can open a Framaspace) has had the expected frustrating effect. In fact, we have regularly referred people frustrated by these limitations to friendly structures such as Zaclys, IndieHosters, Cloud Girofle, Paquerette, Arawa, etc. This shows that we’re not taking a « slice of the cake », but helping to make it bigger.

Framaspace in 2024 (and 2025)
As you may have read in our ‘assessment of the assessment’, Framaspace is meeting a need, and Framasoft believes the response is pretty good. It’s far from perfect, of course, but for a small association that wants to get out of the box and align its values with its digital tools, Framaspace could be the answer.
But we’re not going to stop there! Framaspace is still in beta testing (and will probably be until the end of 2025!) and many improvements are still to come 😀.
Support
First of all, we’re going to keep hosting spaces. Now that Framaspace is more stable, we think we can pick up the pace and host 2,500 spaces by the end of 2024 (i.e. more than triple the current number. Don’t worry!).
Next, we’ll continue our outsourcing initiatives. For example, by moving from Nextcloud 26 to Nextcloud 27 in late 2023 or early 2024. Each version brings a host of new features (see our friends at Arawa who give a summary presentation here and here).
On the support side, we want to produce a bit of a special tutorial. In fact, many tutorials already exist (we highlight the Coopaname one, produced by La Dérivation). But this type of tutorial doesn’t meet everyone’s needs. That’s why we want to produce a more narrative and immersive tutorial. A « tutorial in which you are the hero » (or « tricks in which you are the heroine », if you prefer). Inspired by « Books in which you are the hero« , the user⋅ice will embody a character who has to carry out various missions with his or her Framaspace room. The special feature is that certain « quests » can either be bypassed (for example, if the user⋅ice already knows how to create a user⋅ice account) or explored in more depth (for example, on file sharing).
We also want to provide documentation (and facilitation tools) to facilitate migration from OneDrive, Dropbox or GoogleDrive, and to simplify import/export between Nextcloud instances. For example, an association that has reached the 50 account limit on its Framaspace space and wants to migrate to a more powerful Nextcloud with our friends at IndieHosters would be able to transfer its data – files, calendars, contacts, etc. – in a more automated way.
Finally, we are aware that one of the major weaknesses of Nextcloud (and by extension Framaspace) is the difficulty of « onboarding » novices to a (too?) rich and sometimes (very?) confusing interface. That’s why we want to integrate the free IntroJS tool into Nextcloud to highlight certain parts of the software and make it easier to learn. See the video below.
Video demonstration of how IntroJS has been integrated into Nextcloud to make it easier to learn.
Still on the subject of getting started, we’re working with designer Marie-Cécile Godwin, who teaches at the Strate design school, to get her students thinking about how Nextcloud could be improved from a UX and UI perspective.
Raising awareness of Nextcloud
In 2024, we will of course continue our efforts to make Nextcloud better known in the French-speaking world.
For example, we have already subtitled a number of Nextcloud presentation videos in French. But we’d like to go further. For example, we’d like to redo the voice-overs or translate the documentation (flyers, brochures, etc.).
Video of a Nextcloud promotional video, originally in English only and subtitled by Framasoft.
Framasoft will also continue to promote Nextcloud and Framaspace through conferences, webinars, interviews, etc.
We will also continue to share our experience and feedback with the CHATONS community, many of whose members offer services based on Nextcloud. We think we’ve acquired a certain amount of knowledge and know-how around Nextcloud, but above all we know that we still have a lot to learn.
Finally, we’re going to start getting in touch with the heads of associative networks (Collectif Associations Citoyennes, Mouvement Associatif, popular education networks, but also networks such as Associations Mode d’Emploi, Solidatech, Associathèque, etc.) to present Framaspace, and highlight what Nextcloud can do (or can’t do!) in terms of collaborative ethical digital technology. The ultimate aim is to assess its relevance as a « digital commons of general interest » for associations.
Framaspace & Nextcloud user community
In 2024, we will continue our work to promote, animate and coordinate a community of Nextcloud software users on the Framaspace forum.
We will also publish a website for the OPEN-L Observatory (« Observatory of Free Digital Practices and Experiences »), which will publicly host the various surveys (and their results!) that Framasoft will have conducted among its audiences. This site will be open to other organisations wishing to share their feedback. The aim is not to reinvent the wheel, but to make it easier to objectify the needs (and frustrations) of users.
Of course, we will continue to improve both Framaspace and Nextcloud. We’re lucky (and happy) to have Thomas, one of the world’s leading contributors from outside Nextcloud GmbH, on our staff.
- His contributions to the heart of Nextcloud
- Its contributions to the Nextcloud calendar app
- The applications that Framasoft maintains for the Nextcloud community:
- https://github.com/nextcloud/registration/
- https://framagit.org/framasoft/nextcloud/csp_editor
- https://framagit.org/framasoft/nextcloud/login-notes
- https://framagit.org/framasoft/nextcloud/drop_account
- https://framagit.org/framasoft/nextcloud/holiday_calendars (now abandoned as it has been integrated into the calendar app)
This means that Framasoft (through Framadrive, Framagenda and now Framaspace) is taking a very active part in this digital commons that is the Nextcloud software.
On a more ‘internal’ note, in the coming months we should be increasing our capacity to work on the Framaspace project within Framasoft: Thomas, currently the lead developer on Mobilizon, will shift up to 50% of his time to Framaspace, and Pierre-Yves, currently co-director of Framasoft, will leave this role to concentrate on the association’s digital services (including Framaspace, of course).
Empowering ‘off-market’ structures
We have many policy ambitions for the Framaspace project (see our launch article – only in French, sorry!).
To achieve this, we will use surveys to gather information about the needs (both functional and more political) of the structures we host. Depending on the results, and if resources allow, we will be able to adapt Framaspace to the needs of its users.
We have noticed that in the associations we support, the issue of digital tools often lies with one or two volunteers, who sometimes struggle to implement a change management policy or convince their board. So we also want to produce « practical information sheets » to make life easier for these key people. « For example, we’ll look at how to carry out a digital diagnosis of my association, or how to convince my board to switch from Gdrive or Dropbox to Framaspace.
Finally, and we are aware of the high demand for this item, we would like to pool funding for new features in Framaspace.
We will focus on :
- The possibility of managing your members in Framaspace (members, categories, identity card, subscriptions, membership reminders, etc.) using the (fabulous) free association management software Paheko;
- The possibility of managing your association’s accounts (data entry, balance sheet, profit and loss, choice of chart of accounts, etc.), again thanks to Paheko;
- the possibility of quickly creating visual communication tools using the Aktivisda software (see the example of the Alternatiba association);
- allow associations that wish to do so to publish pages presenting their structure and activities. To do this, we want to make it possible to publish a mini-website presenting the organisation (written in Framaspace’s « Collectives » application).

Moulaga needed!
As you can see, the Framaspace 2024 roadmap is already very full!
Please note: none of the items below are firm commitments on our part. They’re just our wishes, what we want to implement in the coming year. It’s all very ambitious. And like any ambition, we need to know what resources we can devote to it.

If we are to balance our budget for 2024, we have six weeks to raise €183,478: we can’t do it without your help!

























{kind=link}