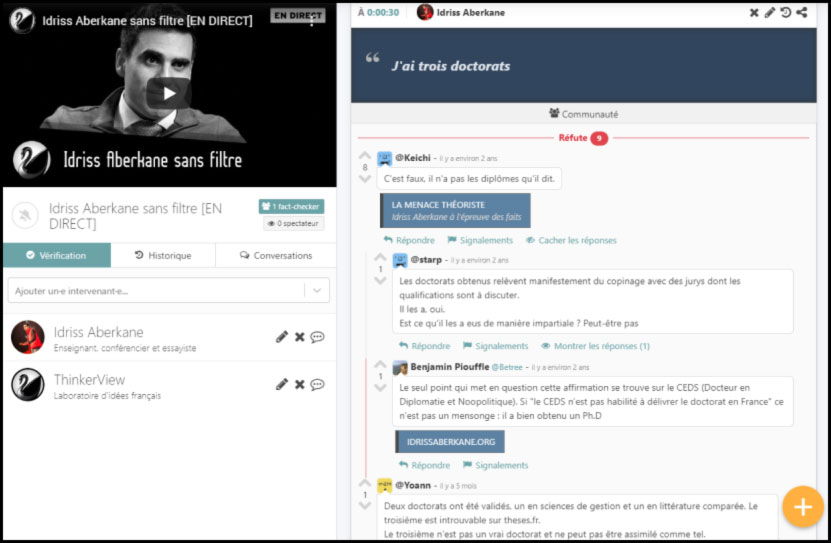
OpenKeys.science, des clés de détermination pour ouvrir les portes de la biodiversité
Nous avons rencontré les serruriers de la biodiversité, une fine équipe qui veut vous donner les clés du vivant pour apprendre à mieux le connaître…
… et qui veut vous apprendre aussi (vous allez voir, c’est facile et plutôt amusant) à contribuer vous-même à la création et l’enrichissement d’un vaste trousseau de « clés ». Libres, naturellement.
Merci à Sualtam, auteur de lectureaudio.fr pour cette contribution active.
Avant même de vous présenter, vous allez tout de suite nous expliquer ce qu’est une clé de détermination et à quoi ça sert, sinon, vous savez comme sont les lecteurs et les lectrices (exigeantes, intelligentes, attentionnées, etc.), ils et elles vont quitter cet article pour se précipiter sur Peertube afin de trouver une vidéo qui leur explique à notre place.
Sébastien Une clé de détermination, c’est un peu comme un livre dont on est le héros ! Une succession de questions vous permet d’aboutir à la détermination d’un être vivant. Au fil des questions et de vos réponses, la liste des espèces possibles se réduit progressivement jusqu’à ce qu’il ne reste qu’un seul candidat (ou une liste très réduite). Certaines questions font parfois appel à du vocabulaire spécialisé, pas de panique ! Une illustration et une définition sont systématiquement présentes pour vous guider.
À titre d’exemple, vous pouvez consulter cette clé de détermination des insectes pollinisateurs.
1. Je réponds à des questions qui me sont proposées :
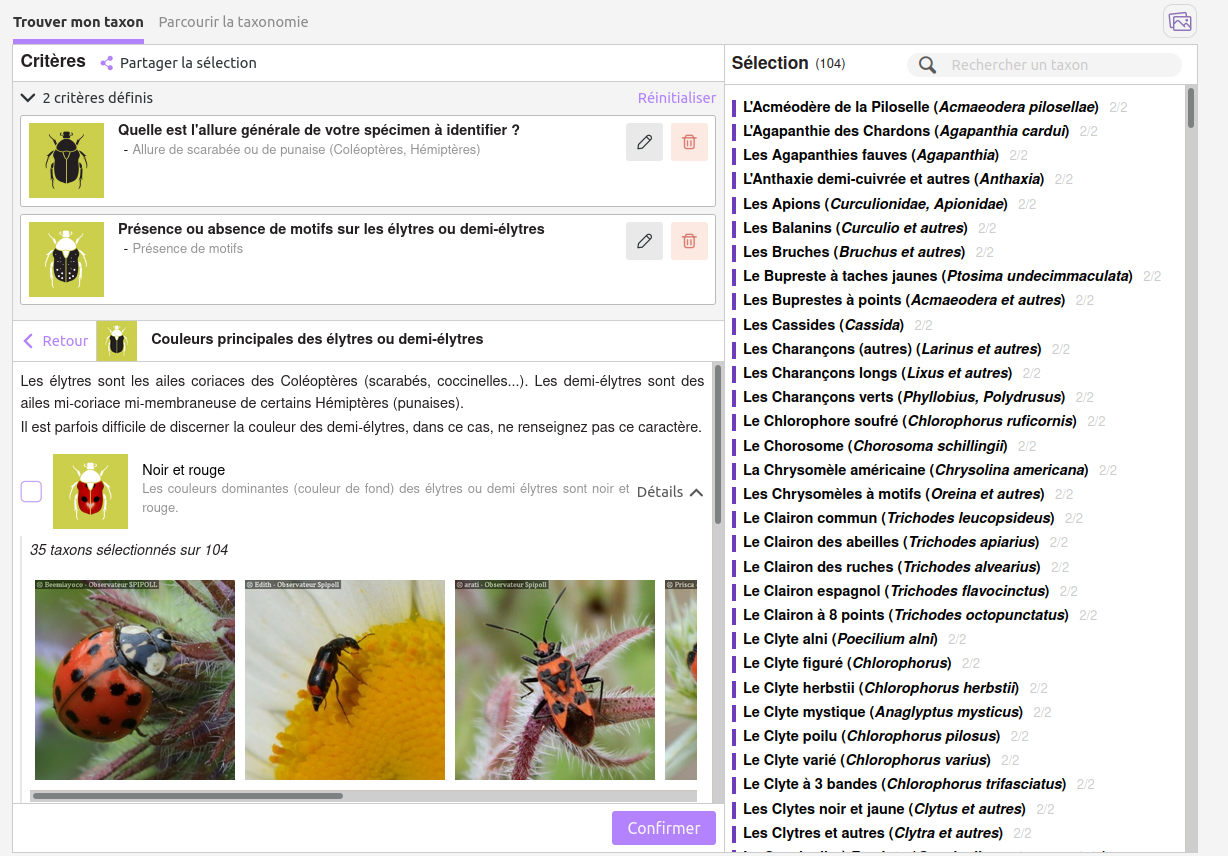
2. et ensuite visualiser les espèces candidates pour découvrir l’insecte que j’observe :
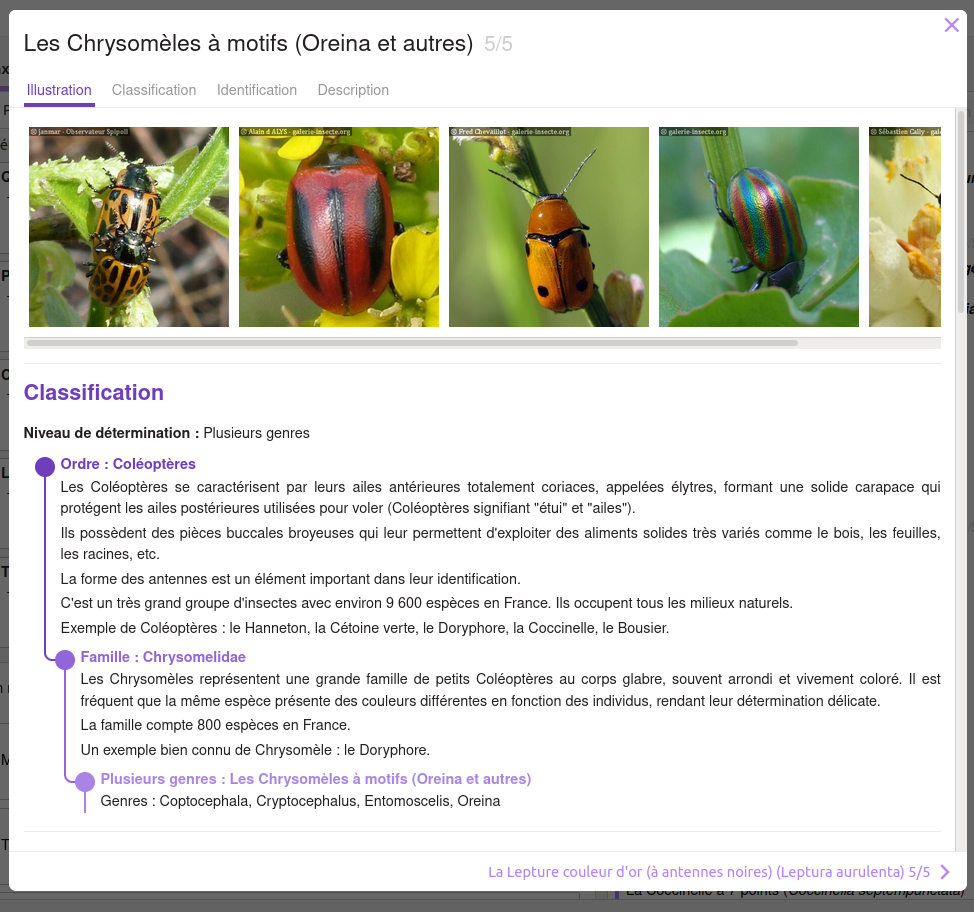
Donc si je dis qu’une clé de détermination c’est une liste de questions qui a pour objectif d’identifier à quelle espèce appartient un animal ou un végétal que j’observe, je simplifie un peu, mais j’ai bon ?
C’est l’idée oui.
Maintenant qu’on a compris de quoi on va parler, vous pouvez vous présenter !
Sébastien Turpin : Je suis enseignant de Sciences de la Vie et de la Terre et je travaille au Muséum national d’Histoire naturelle où je coordonne un programme de sciences participatives pour les scolaires. Et comme Thibaut, j’aime me balader dans la nature même si je n’arrive pas à y aller aussi souvent que je le souhaiterais !
Grégoire Loïs : Je suis naturaliste depuis toujours et j’ai la chance de travailler dans ce même établissement avec Sébastien, mais depuis un peu plus de 25 ans en ce qui me concerne. Je m’occupe comme lui de programmes de sciences participatives et plus particulièrement de bases de données.
Thibaut Arribe : Je suis développeur dans une petite SCOP qui s’appelle Kelis. On édite des solutions documentaires open-source pour produire et diffuser des documents numériques (vous avez peut-être déjà entendu parler de Scenari ou Opale, deux logiciels édités par Kelis). Accessoirement, je suis accompagnateur en montagne. J’emmène des groupes et particuliers se balader dans la nature sauvage des Pyrénées et des Cévennes.
Entrons dans le vif du sujet, c’est quoi OpenKeys.science ?
Thibaut OpenKeys.science est un service en ligne qui permet de produire et diffuser des clés de détermination sous la forme de petit sites web autonomes.
Autonomes, ça veut dire qu’ils peuvent aller se promener tout seuls, sans attestation ?
Thibaut C’est exactement ça ! Pour tout un tas de bonnes et moins bonnes raisons, un site web est souvent dépendant de nombreux programmes à installer sur un serveur. Cette complexité rend bien service, mais l’installation de ce genre de site web en devient réservée à un public d’initiés.
Dans notre cas, une fois produit, rendre ce site “autonome” disponible sur le web est simple : n’importe quel espace web perso suffit (qu’il soit fourni par votre CHATON favori ou votre fournisseur d’accès à Internet).
Surtout, ça signifie qu’il est très simple d’en faire une copie pour l’emporter en balade dans la nature, et ça, c’est assez chouette.
Et donc produire des clés ? On a compris que c’était pas des vraies clés avec du métal, mais vous pouvez préciser en quoi ça consiste ?
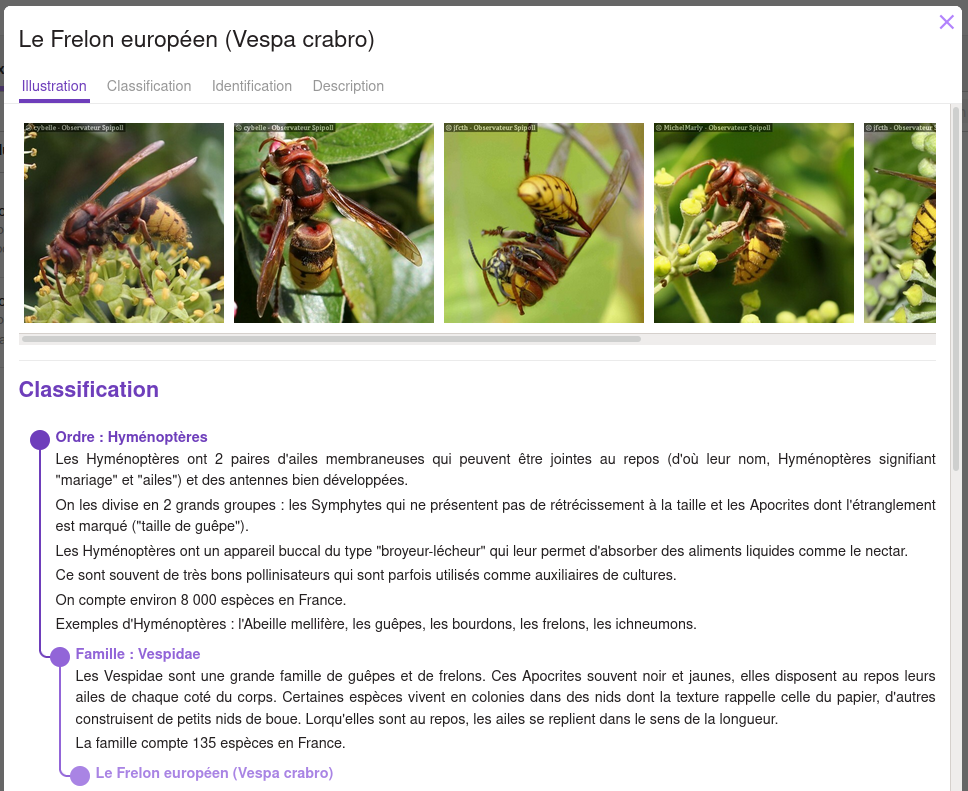
Thibaut Prenons un exemple simple : tu veux avoir un moyen de différencier à tous les coups un frelon européen (Vespa crabro pour les intimes) d’un frelon asiatique (le fameux Vespa velutina). C’est important de faire la différence, le frelon asiatique est une espèce invasive qui fait des dégats, par exemple dans l’apiculture… (il raffole des boulettes d’abeille à l’automne ! Chacun son truc…)
Bon, avec OpenKeys, je vais commencer par créer une belle fiche illustrée sur le frelon européen dans un éditeur adapté. Ça pourrait ressembler à ça :
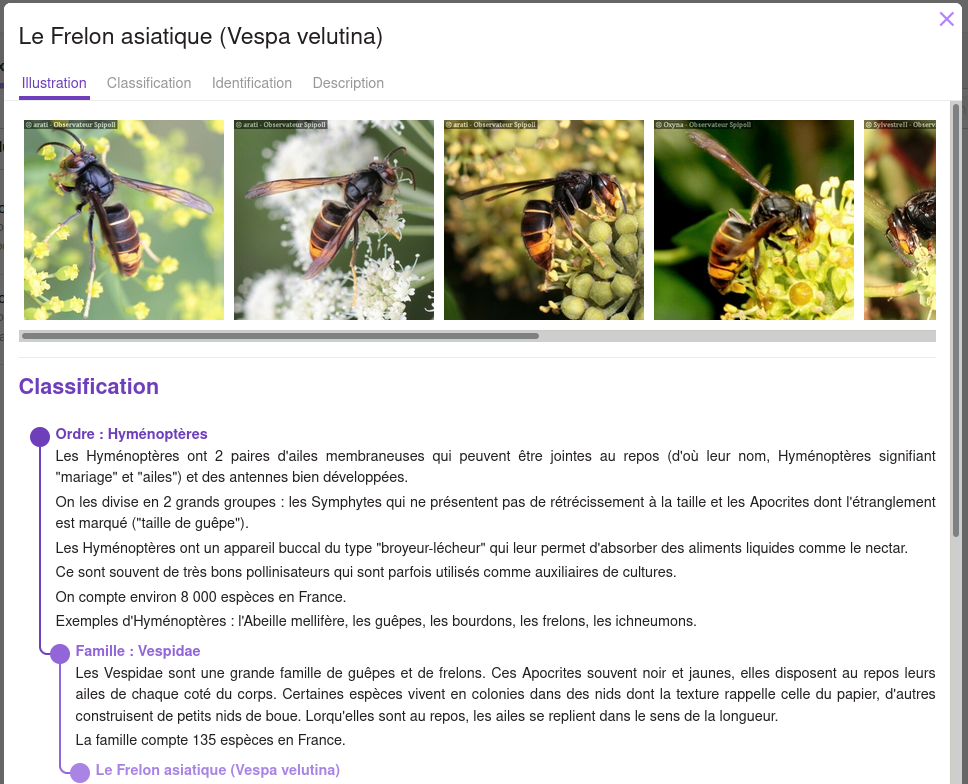
Ensuite, je fais la même pour son lointain cousin.
Voilà, toutes les espèces mentionnées par ma clé sont en place, je peux maintenant créer des critères qui vont m’aider à différencier ces deux espèces.
J’ai lu dans un bouquin que le critère le plus facile, c’est de regarder la couleur du thorax (la partie centrale du corps, entre la tête et l’abdomen). Pour les frelons asiatique, le thorax est de couleur unie (noire) et pour le frelon européen, c’est un mélange de bordeaux et noir.

J’associe chaque valeur à la fiche correspondante dans OpenKeys et le tour est joué. Je n’ai plus qu’à générer ma clé, la publier sur le Web et envoyer un email à la Fédération des apiculteurs pour les aider à faire connaître le frelon asiatique, ses risques sur les abeilles, et les moyens de le reconnaître.

Attends, je t’arrête, qui a envie de faire ça ?
Thibaut Très certainement plus de personnes que tu ne le crois ! Assez rapidement, on peut imaginer plusieurs publics :
- les chercheuses et chercheurs qui s’intéressent à la biodiversité comme ceux de Vigie-nature
- les enseignantes et enseignants (à l’école, en SVT au collège ou à l’université) pour un usage en classe
- les médiatrices et médiateurs de l’environnement, des gardiens des parcs nationaux aux intervenants nature en passant par les agents de l’Office National des Forêts (ONF) ou l’Office Français pour la Biodiversité (OFB)
- et au final, toutes les contemplatrices et contemplateurs de la nature et de la biodiversité, qui s’intéressent aux plantes, aux oiseaux, aux insectes, aux champignons… ou juste à ce qu’on peut observer à proximité de la maison.
OK, je vois. Et, une fois les clés produites, qu’en font ces structures et ces gens ?
Thibaut Ça dépend des profils… Le laboratoire Vigie-Nature utilise la clé des insectes pollinisateurs dans son observatoire de sciences participatives SPIPOLL par exemple.
Un⋅e enseignant⋅e va produire une ressource éducative pour sa classe (par exemple ici).
Un⋅e médiateur⋅rice de l’environnement va produire des clés pour le grand public (comme le fait l’ONF ici)
On voit aussi des naturalistes amateur⋅ices mettre leurs connaissances à disposition : le site Champ Yves en est un bon exemple.
De mon côté, j’utilise des clés pour progresser et identifier de nouvelles espèces dans mon activité en montagne. J’en propose aussi aux groupes que j’accompagne pour identifier les espèces de montagne qui les entoureront au cours leurs prochaines randonnées.
Sébastien et Grégoire, pouvez-vous nous expliquer ce qu’est Vigie-nature ?
Sébastien Vigie-Nature est un programme de sciences participatives ouvert à tous. En s’appuyant sur des protocoles simples et rigoureux, il propose à chacun de contribuer à la recherche en découvrant la biodiversité qui nous entoure. Initié il y a plus de 30 ans avec le Suivi Temporel des Oiseaux Communs (STOC), le programme Vigie-Nature s’est renforcé depuis avec le suivi de nouveaux groupes : les papillons, chauves-souris, escargots, insectes pollinisateurs, libellules, plantes sauvages des villes…. En partageant avec les scientifiques des données de terrain essentielles les participants contribuent à l’amélioration des connaissances sur la biodiversité ordinaire et sur ses réponses face aux changements globaux (urbanisation, changement climatique…). Chacun peut y participer qu’il s’y connaisse ou non. À vous de jouer !
Grégoire En participant, on découvre un monde. Nous avons des échanges avec des participants qui se sont pris au jeu et sont devenus de véritables experts passionnés en quelques années alors qu’ils ne prêtaient pas attention aux plantes et aux animaux qui les entouraient. D’autres ont découvert cet univers puis ont butiné de programmes participatifs en programmes participatifs, au gré des découvertes. Enfin, il faut souligner que toute l’année, en ville comme à la campagne, on peut s’impliquer et contribuer à la recherche scientifique en s’enrichissant d’expériences de nature.
Donc si je veux, je peux observer des papillons et des abeilles dans mon jardin, utiliser les clés de détermination pour les identifier correctement, et remonter les résultats à Vigie-Nature ? C’est un peu comme améliorer les cartes d’OpenStreetMap, avec des êtres vivants à la place des bâtiments, mon analogie est bonne ?
Grégoire Oui en quelque sorte. Mais on pourrait même dire que ça va un peu plus loin qu’Open Street Map. C’est un peu comme si l’amélioration permanente d’Open Street Map était cadrée. Comme si, en participant, vous vous engagiez à faire une contribution régulière à Open Street Map, en revenant sur les mêmes lieux et dans les mêmes conditions. La différence est ténue mais elle est importante. En faisant de la sorte, vous pourriez suivre de manière rigoureuse les changements d’occupation du sol. Et en multipliant le nombre de personnes agissant de la sorte, il serait possible de modéliser puis d’extrapoler les divers changements, voire d’en faire des prédictions pour le futur.
Vous nous avez aussi parlé de SPIPOLL, c’est pour espionner les insectes ? (mais espion, ça prend un Y en anglais…)
Grégoire Ici, Spipoll signifie Suivi Photographique des Insectes POLLinisteurs.
De quoi s’agit-il ? La pollinisation de laquelle dépend la reproduction des plantes à fleurs peut se faire de plusieurs manières.
Ainsi les graminées ou encore certains arbres profitent du vent pour faire circuler le pollen. C’est malheureusement à l’origine des allergies qu’on regroupe sous le nom de rhume des foins.
Mais pour beaucoup d’espèces, un bénéfice mutuel s’est mis en place entre plantes et insectes il y a un peu plus de 100 millions d’années (sous notre latitude, dans les tropiques, oiseaux et chauves-souris s’en mêlent). La plante fournit en abondance pollen et même nectar, un liquide sucré qui n’a d’autre rôle que d’attirer les insectes. Ces derniers viennent consommer ces deux ressources et passent de fleurs en fleurs chargés de minuscules grains de pollen. Ils assurent ainsi la reproduction sexuée des plantes et tirent bénéfice de ce service sous forme de ressources alimentaires.
Dans certains cas même, la plante ensorcelle littéralement l’insecte puisqu’elle l’attire et se fait passer pour un partenaire sexuel, trompant ainsi les mâles qui passent de fleurs en fleurs en transportant de petits sacs de pollens mais sans bénéficier de victuailles.

Suite aux incroyables bouleversement qu’ont subis les milieux naturels notamment depuis la révolution industrielle, on a pu constater des déclins d’insectes et des difficultés pour les plantes à échanger leurs gamètes. C’est crucial : sans cet échange, pas de fruits, et par exemple, aux États-Unis, les plantations d’orangers ont de grandes difficultés à fructifier. Dans ce cas, les arboriculteurs installent des ruches d’abeilles domestiques mais il semble que la situation soit tout de même critique. Les chercheurs en Écologie fondamentale se posent donc beaucoup de questions sur les communautés de pollinisateurs. On parle ici de communautés parce qu’on estime à entre cinq et dix mille le nombre d’espèces d’invertébrés impliqués dans la pollinisation en France ! Aucun spécialiste des insectes n’est à même d’étudier un si vaste nombre d’espèces, surtout qu’elles appartiennent à des groupes très variés (mouches, guêpes, abeilles et fourmis, coléoptères, papillons diurnes et nocturnes, punaises, etc.).
L’idée du Spipoll est de solliciter les personnes intéressées pour collecter des informations sur les réseaux d’interaction entre plantes et insectes partout sur le territoire. Il s’agit de prendre des photos de tout ce qui s’active sur les parties florales d’une espèce de plante dans un rayon de 5 mètres, puis de trier ces photos pour n’en garder qu’une par “bestiole différente” puis de tenter de ranger ces bestioles au sein d’une simplification taxonomique comptant quand même 630 branches !!! Et c’est là qu’une clé se révèle indispensable…
Vous avez mentionné au début de l’article que vous aimiez contempler la nature, ça fait envie, vous pouvez me décrire concrètement en quoi OpenKeys.science va m’y aider ?
Thibaut Savoir nommer les espèces qui nous entourent, c’est ouvrir une porte sur la complexité du vivant. De découverte en découverte, les paysages que nous contemplons nous apparaissent comme des lieux de vies ou cohabitent des milliers d’espèces. La diversité des espèces, des milieux et des relations entre ces espèces donne le vertige (et une soif d’en découvrir toujours plus).
En fournissant des clés à utiliser chez soi ou à emmener en balade, OpenKeys met le pied à l’étrier pour changer son regard sur la nature et pour découvrir tout ce qui se cache autour de nous.
Avec une clé de détermination dans la poche, je peux prendre le temps de m’arrêter, d’observer les alentours et d’identifier ce qui m’entoure. De découverte en découverte, c’est toute cette richesse de la nature qui s’offrira à vous…
Entre deux confinements, on va pouvoir retourner se balader, quelles clés sont disponibles sur OpenKeys.science pour une débutante ou un débutant ?
Sébastien Une clé des insectes pollinisateurs est déjà disponible, avec laquelle vous devriez pouvoir nommer la plupart des insectes que vous verrez dans votre jardin !
Nous travaillons également à proposer rapidement une clé pour :
des oiseaux communs ![]() ,
,
des chauve-souris ![]()
et des escargots ![]() …
…
Thibaut Depuis la liste des domaines sur OpenKeys.science, on peut aller se balader sur chacun des domaines et y consulter les clés qui y seront publiées. On y retrouve par exemple une clé pour identifier certains arbres à partir de leurs feuilles.
Cet interview est aussi l’occasion de faire un appel… Vous voulez partager vos connaissances, venez faire un tour sur OpenKeys.science et créez votre clé. Par exemple, j’adorerais avoir une clé pour progresser dans l’identification des champignons.
Est-ce que vous ne seriez pas en train d’essayer de googliser la clé de détermination ? Et après vous allez capter toutes les données, les monétiser, disrupter, on connaît la suite…
Thibaut Hé hé ! Non, ce n’est pas du tout l’idée. Les contenus sources sont dans des formats libres et ouverts. Il est possible d’importer et exporter ses productions. Le service OpenKeys.science est construit avec des technologies libres (la suite logicielle Scenari et le modèle associé IDKey). Il est donc possible d’héberger ce genre de service ailleurs…
On peut considérer OpenKeys.science comme une îlot en interaction avec d’autres dans l’archipel des connaissances libres. Chez nous, on fabrique et diffuse des ressources pour comprendre la nature qui nous entoure. On utilise des technologies open source et les ressources produites sont sous licence libre pour favoriser la circulation des connaissances.
On a découvert qu’il existait plusieurs clés de détermination sur le site de TelaBotanica. Qu’est-ce que la vôtre aura de plus ?
Thibaut On peut discuter sur le plan technique. Les clés produites sur OpenKeys.science sont plus ergonomiques (ça, c’est pas moi, c’est Anna, l’ergonome qui a travaillé avec moi sur ces clés qui le dit). Elles s’adaptent mieux à l’affichage sur grand et petit écran. Elles utilisent des standards récents du Web pour être installées sur son ordinateur ou téléphone. Elles peuvent donc fonctionner sans Internet…
Après, ce n’est pas vraiment le sujet, je crois. Il ne s’agit pas de concurrencer des sites de référence comme TelaBotanica ou MycoDB par exemple. J’insiste, on ne souhaite pas centraliser les connaissances sur les clés ni challenger le reste du monde. L’idée est plutôt d’aider ces communautés de passionnés à partager. Je serai ravi de donner un coup de main aux autrices et auteurs de ces sites pour migrer techniquement leur contenu et ainsi leur permettre de générer leur clé sur OpenKeys.science ou ailleurs avec les mêmes technologies open-source. Elles ou ils y gagnent une clé plus facile à utiliser et à installer sur leur site ainsi qu’un outil pour mettre à jour et enrichir cette clé facilement.
Je suis nul en smartphone, mais un pote m’a parlé de Pl@ntnet, ça va pas vous couper l’herbe sous le pied ? Est-ce que des IA dans la blockchain avec des drones autonomes connectés 5.0 ne seraient pas plus efficaces que des humains qui se promènent avec des sites statiques ? C’est pas un peu old tech votre histoire ?
Sébastien Mais non 🙂 ! Ce n’est juste pas du tout les mêmes approches ! Une clé de détermination permet de guider le regard, d’apprendre à observer, de prendre son temps, bref de s’intéresser et de découvrir un être vivant… c’est certainement un peu plus long que de prendre une photo et d’attendre qu’une IA du Web 3.0 fasse tout le travail mais tellement plus valorisant !
Et puis, quand on a pris le temps d’observer à fond une espèce, lors de la prochaine rencontre vous vous en rappellerez tout seul et sans aide !
Thibaut Côté technique, plutôt que old tech, je revendiquerais plutôt le terme low tech. Oui, c’est volontairement un objet technique simple. Ça a plein d’avantages. Par exemple, c’est bien moins consommateur d’énergie, ça marchera encore bien après la fin d’un projet comme Pl@ntnet…

Votre projet démontre que logiciel libre et biodiversité peuvent aller de pair, et ça c’est une bonne nouvelle pour les gens qui se préoccupent de l’un et l’autre, et on est pas mal dans ce cas à Framasoft. Est-ce que vous avez d’autres idées dans le genre ?
Thibaut Je crois que OpenKeys.science est un bon exemple d’interactions super positives entre ces deux mondes ! Disons que ça valide complètement l’intuition de départ… Oui, mettre en relation l’univers de l’informatique libre et la recherche en biodiversité nous profite à tous.
Je vais donc continuer d’explorer cette piste. D’un côté, rencontrer des chercheurs pour discuter des difficultés technologiques dans leurs travaux. De l’autre, identifier des développeurs qui pourraient les aider. Je pense que ça intéresserait du monde, par exemple pour prendre le temps de découvrir une nouvelle techno en menant un projet sympa, ou une organisation qui cherche un sujet pour créer un démonstrateur de son savoir-faire, ou encore des étudiants et enseignants à la recherche de projets à mener dans un cadre universitaire… les contextes ne manquent pas.
Et pourquoi pas, si tout ça fonctionne et rend service, fédérer la démarche dans une association ou une fondation.
(image d’illustration : CC BY-SA Dominik Stodulski, Wikipédia, https://fr.wikipedia.org/wiki/Coccinellidae)