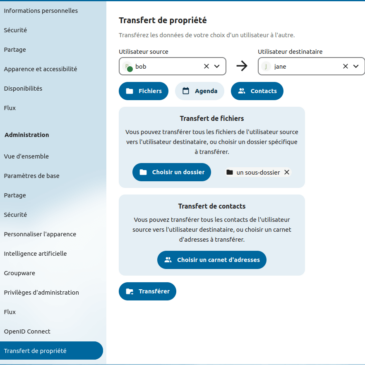
Reprenons le contrôle de notre vie numérique dès maintenant !
J’ai écrit ce texte il y a un an, peu après la ré-élection de Trump. Il est resté en attente de publication car je voulais lui ajouter des illustrations, mais je ne suis pas graphiste. Finalement, la situation géopolitique est … Lire la suite