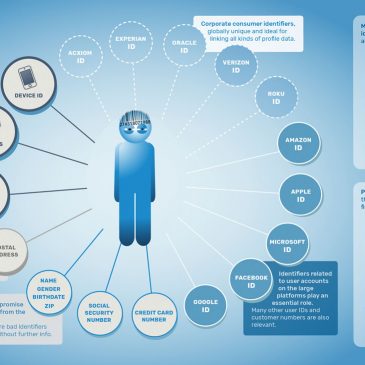
La nouvelle dystopie, c’est maintenant
Classé dans : Contributopia (2018-2022), Dégooglisons Internet (2014-2017), Enjeux du numérique, G.A.F.A.M. |
4
L’article qui suit n’est pas une traduction intégrale mais un survol aussi fidèle que possible de la conférence TED effectuée par la sociologue des technologies Zeynep Tufecki. Cette conférence intitulée : « Nous créons une dystopie simplement pour obliger les gens à … Lire la suite