Déjà 2 500 Framaspaces pour renforcer les structures qui changent le monde
Comme chaque année (2022, 2023, 2024), Framasoft fait le bilan de son projet de « cloud associatif et militant » : Framaspace.

... mais ce serait peut-être l'une des plus grandes opportunités manquées de notre époque si le logiciel libre ne libérait rien d'autre que du code
Le logiciel s’est envolé dans les nuages (c’est à dire sur les ordinateurs des autres). Ces services, applications web et autres outils en lignes connaissent un succès croissant… et le libre, dans tout ça ?

Comme chaque année (2022, 2023, 2024), Framasoft fait le bilan de son projet de « cloud associatif et militant » : Framaspace.

Nous l’annoncions il y a quelques semaines, nous avons ouvert quatre nouveaux services ! La semaine dernière nous vous proposions de découvrir les coulisses du nouveau Framadate et aujourd’hui, nous souhaitons vous présenter le deuxième service de la liste : Framatoolbox. Pour … Lire la suite

Vous voulez produire du mème libre, artisanal et remixé ? Framasoft sort (vraiment) le service Framamèmes. Vraiment. Promis.

Quel est l’impact concret des actions de notre association ? C’est la question à laquelle nous aimons répondre en fin d’année (cf. chiffres 2022, chiffres 2023) : prendre le temps de chiffrer nos actions est essentiel pour réaliser le service que l’on … Lire la suite
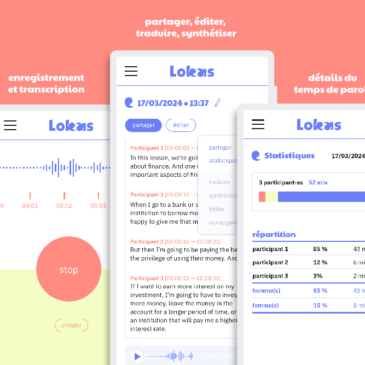
Framasoft vous propose d’essayer le prototype de Lokas, une nouvelle application de transcription « speech to text » qui respecte votre vie privée. Cette démo fonctionnelle est aussi une expérimentation de Framasoft dans le domaine de l’IA, accompagnée du site Framamia, que … Lire la suite
Framasoft invites you to try out the prototype of Lokas, a new speech-to-text transcription application that respects your privacy. This functional demo is also an experiment by Framasoft in the field of AI, accompanied by the Framamia website, which we … Lire la suite

Ce sont les 20 ans de Framasoft, mais c’est aussi l’anniversaire de Framaspace, notre cloud gratuit à destination des associations et petits collectifs militants. Deux ans après son annonce, c’est l’occasion de faire le bilan de l’année écoulée, et de … Lire la suite
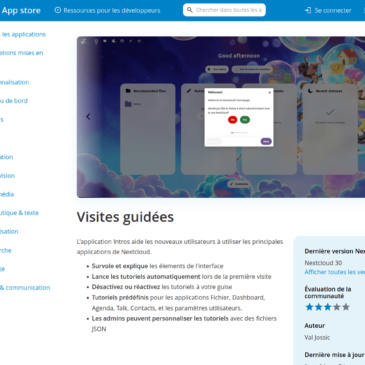
The Framaspace project currently hosts a cloud environment (files, calendars, contacts, wiki, kanban, etc.) for more than 1,200 associations and groups. That’s as many instances of the Nextcloud free software. Unfortunately, it’s not always easy to get to grips with … Lire la suite