Chaque année, nous nous rappelons à votre bon souvenir pour vous inciter à soutenir financièrement nos actions. Vous voyez au fil du temps de nouveaux services et des campagnes ambitieuses se mettre en place. Mais peut-être voudriez-vous savoir en chiffres ce que nous avons réalisé jusqu’à présent. Voilà de quoi vous satisfaire.
Par souci de transparence, nos bilans financiers sont publiés chaque année et nous offrons en temps réel l’accès à certaines statistiques d’usage de nos services. Mais cela ne couvre pas l’ensemble de nos actions et nous nous sommes dit que vous pourriez en vouloir plus que ce qui se trouve sur Framastats.
Libre à vous de picorer un chiffre ou l’autre, d’en faire des quizz ou de les reprendre pour votre argumentaire afin de démontrer l’efficacité du monde associatif. Nous espérons que vous y verrez l’illustration de notre engagement à promouvoir le libre sous toutes ses formes.
1 : Depuis son lancement voilà un an, chaque heure un nouveau site naît sur Framasite.
2,5 : Les 5 000 utilisatrices de Framadrive utilisent 2,5 To de données pour leurs 3 millions de fichiers.
5 : Toutes les 5 secondes en moyenne, un utilisateur se connecte sur les services Framasoft.
10 : Toutes les 10 minutes à peine, une nouvelle visioconférence est créée sur Framatalk, qui accueille environ 400 participant⋅es par jour.
Framatalk, la vision-conférence Libre, vue par Pëhà
11 : C’est le nombre de pizzas, additionné aux 47 plateaux-repas et 25 couscous qu’ont avalé les 25 personnes présentes pendant les 4 jours de l’AG Framasoft 2018.
33 : Framasoft vous propose 33 services en ligne alternatifs, respectueux de vos données et sans publicité.
35 : Grâce aux 300 abonné·e·s à la liste Framalang, ce ne sont pas moins de 35 traductions qui ont été effectuées et publiées sur le Framablog en un an.
252 : http://joinpeertube.org , c’est une fédération de 252 instances (déclarées) affichant 23 017 vidéos libérées de YouTube
750 : Chaque mois, notre support répond à environ 750 demandes, questions et problèmes. Avec un seul salarié !
Framalibre, l’annuaire à l’origine de Framasoft
871 : Framalibre, l’annuaire du libre vous présente 871 projets, logiciels ou créations artistiques sous licence libre à l’aide de courtes notices.
1 000 : Framaforms c’est environ 1000 formulaires créés quotidiennement et plus de 44 000 formulaires hébergés.
1 800 : Chaque jour, ce sont près de 1 800 images qui viennent s’ajouter aux 770 000 déjà présentes sur les serveurs de Framapic.
2 236 : Le Framablog c’est 2 236 articles et 28 919 commentaires depuis 2006, faisant le lien entre logiciel libre et société/culture libres.
3 000 : 4 000 utilisatrices réparties en 250 groupes ont créé plus de 3 000 présentations et conférences grâce à Framaslides alors qu’il n’est encore qu’en beta !
6 000 : Framemo héberge 6 000 tableaux qui ont aidé des utilisateurs à mettre leurs idées au clair, sans avoir à s’inscrire.
Framacarte, pour ne pas se perdre en chemin
6 000 : Sur Framacarte ajoutez votre propre fond de carte aux 6 000 qui existent déjà, en partenariat avec OpenStreetMap.
6 579 : Framapiaf, c’est 6 579 utilisateurs ayant « pouetté » 734 500 messages sur cette instance Mastodon, elle-même fédérée avec près de 4 000 autres instances (totalisant environ 1,5 million de comptes).
11 000 : Avec Framanews, ce sont 500 lecteurs (limite qu’on a nous même fixée pour restreindre la charge du serveur) qui accèdent régulièrement à leurs 11 000 flux RSS.
13 000 : Près de 4 000 utilisatrices accèdent à leur 13 000 notes depuis n’importe quel navigateur, avec un accès sécurisé, sur Framanotes.
15 000 : Avec Framabag 15 000 personnes ont pu sauvegarder et classer 1,5 million d’articles.
Framagit, pour partager librement votre code
25 000 : Notre forge logicielle, Framagit, héberge plus de 25 000 projets (et autant d’utilisateurs).
35 000 : Avec MyFrama, 35 000 utilisatrices partagent librement leurs liens Internet.
43 000 : Accédez à une des 43 000 adresses Web abrégées ou créez-en une grâce au raccourcisseur d’URL Framalink qui ne traque pas vos visiteurs.
52 000 : Découvrez Framasphère, membre du réseau social libre et fédéré Diaspora*, où 52 000 utilisatrices ont échangé environ 600 000 messages et autant de commentaires.
75 000 : Près de 75 000 joueurs ont pu faire une petite pause ludique sans s’exposer à de la publicité sur Framagames.
Framadrop, le partage aisé de gros fichier, en sécurité
100 000 : Sur Framadrop plus de 100 000 fichiers ont pu être échangés en toute confidentialité.
130 000 : Framacalc accueille plus de 130 000 feuilles de calcul, où vos données ne sont pas espionnées ni revendues
142 600 : Sur Framapad, c’est en moyenne plus de 142 600 pads actifs chaque jour et presque 8 millions d’utilisateurs depuis ses débuts.
150 000 : Les serveurs de Framalistes adressent en moyenne 150 000 courriels chaque jour aux 280 000 inscrites à des listes de discussion.
200 000 : Êtes-vous l’une des 200 000 personnes à avoir consulté un des 23 000 messages chiffrés de Framabin ?
500 000 : Framadate c’est plus de 500 000 visites par mois et plus de 1 000 sondages créés chaque jour.
Framapiaf, notre instance Mastodon
2 500 000 : Plus de 2 millions et demi de personnes ont développé leurs idées, échafaudé des projets sur Framindmap depuis sa mise en place.
3 350 000 : Grâce à Framabook, 3 350 000 lecteurs ont pu télécharger en toute légalité un des 47 ouvrages librement publiés.
5 000 000 : Sur Framagenda environ 35 000 utilisateurs gèrent un million de contacts. Ils organisent et partagent près de cinq millions d’événements.
10 000 000 : Comme près de 40 000 personnes, travaillez en équipe sur Framateam et rejoignez un des 80 000 canaux avec presque 10 millions de messages !
Et le chiffre essentiel pour que tout cela soit possible, c’est celui de nos donatrices et donateurs (2381 en moyenne chaque année) : appuyez sur ce bouton pour le faire croître de 1
Voici déjà la traduction du quatrième chapitre de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà publiés. Il s’agit cette fois d’explorer les stratégies des régies publicitaires qui opèrent en arrière-plan : des opérations fort discrètes mais terriblement efficaces…
IV. Collecte de données par les outils des annonceurs et des diffuseurs
29. Une source majeure de collecte des données d’activité des utilisateurs provient des outils destinés au annonceurs et aux éditeurs tels que Google Analytics, DoubleClick, AdSense, AdWords et AdMob. Ces outils ont une portée énorme ; par exemple, plus d’un million d’applications mobiles utilisent AdMob1, plus d’un million d’annonceurs utilisent AdWords2, plus de 15 millions de sites internet utilisent AdSense3 et plus de 30 millions de sites utilisent Google Analytics4.
30. Au moment de la rédaction du présent rapport, Google a rebaptisé AdWords « Google Ads » et DoubleClick « Google Ad Manager« , mais aucune modification n’a été apportée aux fonctionnalités principales des produits, y compris la collecte d’informations par ces produits5. Par conséquent, pour les besoins du présent rapport, les premiers noms ont été conservés afin d’éviter toute confusion avec des noms de domaine connexes (tels que doubleclick.net).
31. Voici deux principaux groupes d’utilisateurs des outils de Google axés sur l’édition — et les annonces publicitaires :
Les éditeurs de sites web et d’applications, qui sont des organisations qui possèdent des sites web et créent des applications mobiles. Ces entités utilisent les outils de Google pour (1) gagner de l’argent en permettant l’affichage d’annonces aux visiteurs sur leurs sites web ou applications, et (2) mieux suivre et comprendre qui visite leurs sites et utilise leurs applications. Les outils de Google placent des cookies et exécutent des scripts dans les navigateurs des visiteurs du site web pour aider à déterminer l’identité d’un utilisateur et suivre son intérêt pour le contenu et son comportement en ligne. Les bibliothèques d’applications mobiles de Google suivent l’utilisation des applications sur les téléphones mobiles.
Les annonceurs, qui sont des organisations qui paient pour que des bannières, des vidéos ou d’autres publicités soient diffusées aux utilisateurs lorsqu’ils naviguent sur Internet ou utilisent des applications. Ces entités utilisent les outils de Google pour cibler des profils spécifiques de personnes pour que les publicités augmentent le retour sur leurs investissements marketing (les publicités mieux ciblées génèrent généralement des taux de clics et de conversion plus élevés). De tels outils permettent également aux annonceurs d’analyser leurs audiences et de mesurer l’efficacité de leur publicité numérique en regardant sur quelles annonces les utilisateurs cliquent et à quelle fréquence, et en donnant un aperçu du profil des personnes qui ont cliqué sur les annonces.
32. Ensemble, ces outils recueillent des informations sur les activités des utilisateurs sur les sites web et dans les applications, comme le contenu visité et les annonces cliquées. Ils travaillent en arrière-plan — en général imperceptibles par des utilisateurs. La figure 7 montre certains de ces outils clés, avec des flèches indiquant les données recueillies auprès des utilisateurs et les publicités qui leur sont diffusées.
Figure 7 : Produits Google destinés aux éditeurs et annonceurs6
33. Les informations recueillies par ces outils comprennent un identifiant non personnel que Google peut utiliser pour envoyer des publicités ciblées sans identifier les informations personnelles de la personne concernée. Ces identificateurs peuvent être spécifiques à l’appareil ou à la session, ainsi que permanents ou semi-permanents. Le tableau 1 liste un ensemble de ces identificateurs. Afin d’offrir aux utilisateurs un plus grand anonymat lors de la collecte d’informations pour le ciblage publicitaire, Google s’est récemment tourné vers l’utilisation d’identifiants uniques semi-permanents (par exemple, les GAID)7. Des sections ultérieures décrivent en détail la façon dont ces outils recueillent les données des utilisateurs et l’utilisation de ces identificateurs au cours du processus de collecte des données.
Tableau 1: Identificateurs transmis à Google
Identificateur
Type
Description
GAID/IDFA
Semi-permanent
Chaine de caractères alphanumériques pour appareils Android et iOS, pour permettre les publicités ciblées sur mobile. Réinitialisable par l’utilisateur.
ID client
Semi-permanent
ID créé la première fois qu’un cookie est stocké sur le navigateur. Utilisé pour relier les sessions de navigations. Réinitialisé lorsque les cookies du navigateur sont effacés.
Adresse IP
Semi-permanent
Une unique suite de nombre qui identifie le réseau par lequel un appareil accède à internet.
ID appareil Android
Semi-permanent
Nombre généré aléatoirement au premier démarrage d’un appareil. Utilisé pour identifier l’appareil. En retrait progressif pour la publicité. Réinitialisé lors d’une remise à zéro de l’appareil.
Google Services Framework (GSF)
Semi-permanent
Nombre assigné aléatoirement lorsqu’un utilisateur s’enregistre pour la première fois dans les services Google sur un appareil. Utilisé pour identifier un appareil unique. Réinitialisé lors d’une remise à zéro de l’appareil.
IEMI / MEID
Permanent
Identificateur utilisé dans les standards de communication mobile. Unique pour chaque téléphone portable.
Adresse MAC
Permanent
Identificateur unique de 12 caractères pour un élément matériel (ex. : routeur).
Numéro de série
Permanent
Chaine de caractères alphanumériques utilisée pour identifier un appareil.
A. Google Analytics et DoubleClick
34. DoubleClick et Google Analytics (GA) sont les produits phares de Google en matière de suivi du comportement des utilisateurs et d’analyse du trafic des pages Web sur les périphériques de bureau et mobiles. GA est utilisé par environ 75 % des 100 000 sites Web les plus visités8. Les cookies DoubleClick sont associés à plus de 1,6 million de sites Web9.
35. GA utilise de petits segments de code de traçage (appelés « balises de page ») intégrés dans le code HTML d’un site Web10. Après le chargement d’une page Web à la demande d’un utilisateur, le code GA appelle un fichier analytics.js qui se trouve sur les serveurs de Google. Ce programme transfère un instantané « par défaut » des données de l’utilisateur à ce moment, qui comprend l’adresse de la page web visitée, le titre de la page, les informations du navigateur, l’emplacement actuel (déduit de l’adresse IP), et les paramètres de langue de l’utilisateur. Les scripts de GA utilisent des cookies pour suivre le comportement des utilisateurs.
36. Le script de GA, la première fois qu’il est exécuté, génère et stocke un cookie spécifique au navigateur sur l’ordinateur de l’utilisateur. Ce cookie a un identificateur de client unique (voir le tableau 1 pour plus de détails)11 Google utilise l’identificateur unique pour lier les cookies précédemment stockés, qui capturent l’activité d’un utilisateur sur un domaine particulier tant que le cookie n’expire pas ou que l’utilisateur n’efface pas les cookies mis en cache dans son navigateur12
37. Alors qu’un cookie GA est spécifique au domaine particulier du site Web que l’utilisateur visite (appelé « cookie de première partie »), un cookie DoubleClick est généralement associé à un domaine tiers commun (tel que doubleclick.net). Google utilise de tels cookies pour suivre l’interaction de l’utilisateur sur plusieurs sites web tiers13 Lorsqu’un utilisateur interagit avec une publicité sur un site web, les outils de suivi de conversion de DoubleClick (par exemple, Floodlight) placent des cookies sur l’ordinateur de l’utilisateur et génèrent un identifiant client unique14 Par la suite, si l’utilisateur visite le site web annoncé, le serveur DoubleClick accède aux informations stockées dans le cookie, enregistrant ainsi la visite comme une conversion valide.
B. AdSense, AdWords et AdMob
38. AdSense et AdWords sont des outils de Google qui diffusent des annonces sur les sites Web et dans les résultats de recherche Google, respectivement. Plus de 15 millions de sites Web ont installé AdSense pour afficher des annonces sponsorisées15 De même, plus de 2 millions de sites web et applications, qui constituent le réseau Google Display Network (GDN) et touchent plus de 90 % des internautes16 affichent des annonces AdWords.
39. AdSense collecte des informations indiquant si une annonce a été affichée ou non sur la page web de l’éditeur. Il recueille également la façon dont l’utilisateur a interagi avec l’annonce, par exemple en cliquant sur l’annonce ou en suivant le mouvement du curseur sur l’annonce17. AdWords permet aux annonceurs de diffuser des annonces de recherche sur Google Search, d’afficher des annonces sur les pages des éditeurs et de superposer des annonces sur des vidéos YouTube. Pour suivre les taux de clics et de conversion des utilisateurs, les publicités AdWords placent un cookie sur les navigateurs des utilisateurs pour identifier l’utilisateur s’il visite par la suite le site web de l’annonceur ou s’il effectue un achat18.
40. Bien qu’AdSense et AdWords recueillent également des données sur les appareils mobiles, leur capacité d’obtenir des renseignements sur les utilisateurs des appareils mobiles est limitée puisque les applications mobiles ne partagent pas de cookies entre elles, une technique d’isolement appelée « bac à sable »19 qui rend difficile pour les annonceurs de suivre le comportement des utilisateurs entre différentes applications mobiles.
41 Pour résoudre ce problème, Google et d’autres entreprises utilisent des « bibliothèques d’annonces » mobiles (comme AdMob) qui sont intégrées dans les applications par leurs développeurs pour diffuser des annonces dans les applications mobiles. Ces bibliothèques compilent et s’exécutent avec les applications et envoient à Google des données spécifiques à l’application à laquelle elles sont intégrées, y compris les emplacements GPS, la marque de l’appareil et le modèle de l’appareil lorsque les applications ont les autorisations appropriées. Comme on peut le voir dans les analyses de trafic de données (Figure 8), et comme on peut trouver confirmation sur les propres pages web des développeurs de Google20, de telles bibliothèques peuvent également envoyer des données personnelles de l’utilisateur, telles que l’âge et le genre, tout cela va vers Google à chaque fois que les développeurs d’applications envoient explicitement leurs valeurs numériques vers la bibliothèque.
Figure 8 : Aperçu des informations renvoyées à Google lorsqu’une application est lancée
C. Association de données recueillies passivement et d’informations à caractère personnel
42. Comme nous l’avons vu plus haut, Google recueille des données par l’intermédiaire de produits pour éditeurs et annonceurs, et associe ces données à une variété d’identificateurs semi-permanents et anonymes. Google a toutefois la possibilité d’associer ces identifiants aux informations personnelles d’un utilisateur. C’est ce qu’insinuent les déclarations faites dans la politique de confidentialité de Google, dont des extraits sont présentés à la figure 9. La zone de texte à gauche indique clairement que Google peut associer des données provenant de services publicitaires et d’outils d’analyse aux informations personnelles d’un utilisateur, en fonction des paramètres du compte de l’utilisateur. Cette disposition est activée par défaut, comme indiqué dans la zone de texte à droite.
Figure 9 : Page de confidentialité de Google pour la collecte de sites web tiers et l’association avec des informations personnelles2122.
43. De plus, une analyse du trafic de données échangé avec les serveurs de Google (résumée ci-dessous) a permis d’identifier deux exemples clés (l’un sur Android et l’autre sur Chrome) qui montrent la capacité de Google à corréler les données recueillies de façon anonyme avec les renseignements personnels des utilisateurs.
1) L’identificateur de publicité mobile peut être désanonymé grâce aux données envoyées à Google par Android.
44. Les analyses du trafic de données communiqué entre un téléphone Android et les domaines de serveur Google suggèrent un moyen possible par lequel des identifiants anonymes (GAID dans ce cas) peuvent être associés au compte Google d’un utilisateur. La figure 10 décrit ce processus en une série de trois étapes clés.
45. Dans l’étape 1, une donnée de check-in est envoyée à l’URL android.clients.google.com/checkin. Cette communication particulière fournit une synchronisation de données Android aux serveurs Google et contient des informations du journal Android (par exemple, du journal de récupération), des messages du noyau, des crash dumps, et d’autres identifiants liés au périphérique. Un instantané d’une demande d’enregistrement partiellement décodée envoyée au serveur de Google à partir d’Android est montré en figure 10.
Figure 10 : Les identifiants d’appareil sont envoyés avec les informations de compte dans les requêtes de vérification Android.
46. Comme l’indiquent les zones pointées, Android envoie à Google, au cours du processus d’enregistrement, une variété d’identifiants permanents importants liés à l’appareil, y compris l’adresse MAC de l’appareil, l’IMEI /MEID et le numéro de série du dispositif. En outre, ces demandes contiennent également l’identifiant Gmail de l’utilisateur Android, ce qui permet à Google de relier les informations personnelles d’un utilisateur aux identifiants permanents des appareils Android.
47. À l’étape 2, le serveur de Google répond à la demande d’enregistrement. Ce message contient un identifiant de cadre de services Google (GSF ID)23 qui est similaire à l’« Android ID »24 (voir le tableau 1 pour les descriptions).
48. L’étape 3 implique un autre cas de communication où le même identifiant GSF (de l’étape 2) est envoyé à Google en même temps que le GAID. La figure 10 montre l’une de ces transmissions de données à android.clients.google.com/fdfe/bulkDetails?au=1.
49. Grâce aux trois échanges de données susmentionnés, Google reçoit les informations nécessaires pour connecter un GAID avec des identifiants d’appareil permanents ainsi que les identifiants de compte Google des utilisateurs.
50. Ces échanges de données interceptés avec les serveurs de Google à partir d’un téléphone Android montrent comment Google peut connecter les informations anonymisées collectées sur un appareil mobile Android via les outils DoubleClick, Analytics ou AdMob avec l’identité personnelle de l’utilisateur. Au cours de la collecte de données sur 24 heures à partir d’un téléphone Android sans mouvement ni activité, deux cas de communications d’enregistrement avec des serveurs Google ont été observés. Une analyse supplémentaire est toutefois nécessaire pour déterminer si un tel échange d’informations a lieu avec une certaine périodicité ou s’il est déclenché par des activités spécifiques sur les téléphones.
2) L’ID du cookie DoubleClick est relié aux informations personnelles de l’utilisateur sur le compte Google.
51. La section précédente expliquait comment Google peut désanonymiser l’identité de l’utilisateur via les données passives et anonymisées qu’il collecte à partir d’un appareil mobile Android. Cette section montre comment une telle désanonymisation peut également se produire sur un ordinateur de bureau/ordinateur portable.
52. Les données anonymisées sur les ordinateurs de bureau et portables sont collectées par l’intermédiaire d’identifiants basés sur des cookies (par ex. Cookie ID), qui sont typiquement générés par les produits de publicité et d’édition de Google (par ex. DoubleClick) et stockés sur le disque dur local de l’utilisateur. L’expérience présentée ci-dessous a permis d’évaluer si Google peut établir un lien entre ces identificateurs (et donc les renseignements qui y sont associés) et les informations personnelles d’un utilisateur.
Cette expérience comportait les étapes ordonnées suivantes :
Ouverture d’une nouvelle session de navigation (Chrome ou autre) (pas de cookies enregistrés, par exemple navigation privée ou incognito) ;
Visite d’un site Web tiers qui utilisait le réseau publicitaire DoubleClick de Google ;
Visite du site Web d’un service Google largement utilisé (Gmail dans ce cas) ;
Connexion à Gmail.
53. Au terme des étapes 1 et 2, dans le cadre du processus de chargement des pages, le serveur DoubleClick a reçu une demande lorsque l’utilisateur a visité pour la première fois le site Web tiers. Cette demande faisait partie d’une série de reqêtes comprenant le processus d’initialisation DoubleClick lancé par le site Web de l’éditeur, qui a conduit le navigateur Chrome à installer un cookie pour le domaine DoubleClick. Ce cookie est resté sur l’ordinateur de l’utilisateur jusqu’à son expiration ou jusqu’à ce que l’utilisateur efface manuellement les cookies via les paramètres du navigateur.
54. Ensuite, à l’étape 3, lorsque l’utilisateur visite Gmail, il est invité à se connecter avec ses identifiants Google. Google gère l’identité à l’aide d’une architecture single sign on (SSO) [NdT : authentification unique], dans laquelle les identifiants sont fournis à un service de compte (ici accounts.google.com) en échange d’un « jeton d’authentification », qui peut ensuite être présenté à d’autres services Google pour identifier les utilisateurs. À l’étape 4, lorsqu’un utilisateur accède à son compte Gmail, il se connecte effectivement à son compte Google, qui fournit alors à Gmail un jeton d’autorisation pour vérifier l’identité de l’utilisateur.25 Ce processus est décrit à la figure 24 de la section IX.E de l’annexe.
55. Dans la dernière étape de ce processus de connexion, une requête est envoyée au domaine DoubleClick. Cette requête contient à la fois le jeton d’authentification fourni par Google et le cookie de suivi défini lorsque l’utilisateur a visité le site web tiers à l’étape 2 (cette communication est indiquée à la figure 11). Cela permet à Google de relier les informations d’identification Google de l’utilisateur à un cookie DoubleClick. Par conséquent, si les utilisateurs n’effacent pas régulièrement les cookies de leur navigateur, leurs informations de navigation sur les pages Web de tiers qui utilisent les services DoubleClick pourraient être associées à leurs informations personnelles sur Google Account.
Figure 11 : La requête à DoubleClick.net inclut le jeton d’authentification Google et les cookies passés.
56. Il est donc établi à présent que Google recueille une grande variété de données sur les utilisateurs par l’intermédiaire de ses outils d’éditeur et d’annonceur, sans que l’utilisateur en ait une connaissance directe. Bien que ces données soient collectées à l’aide d’identifiants anonymes, Google a la possibilité de relier ces informations collectées aux identifiants personnels de l’utilisateur stockés sur son compte Google.
57. Il convient de souligner que la collecte passive de données d’utilisateurs de Google à partir de pages web tierces ne peut être empêchée à l’aide d’outils populaires de blocage de publicité26, car ces outils sont conçus principalement pour empêcher la présence de publicités pendant que les utilisateurs naviguent sur des pages web tierces27. La section suivante examine de plus près l’ampleur de cette collecte de données.
Il s’agit aujourd’hui de mesurer ce que les plateformes les plus populaires recueillent de nos smartphones
Traduction Framalang : Côme, goofy, Khrys, Mika, Piup. Remerciements particuliers à badumtss qui a contribué à la traduction de l’infographie.
La collecte des données par les plateformes Android et Chrome
11. Android et Chrome sont les plateformes clés de Google qui facilitent la collecte massive de données des utilisateurs en raison de leur grande portée et fréquence d’utilisation. En janvier 2018, Android détenait 53 % du marché américain des systèmes d’exploitation mobiles (iOS d’Apple en détenait 45 %)28 et, en mai 2017, il y avait plus de 2 milliards d’appareils Android actifs par mois dans le monde.29
12. Le navigateur Chrome de Google représentait plus de 60 % de l’utilisation mondiale de navigateurs Internet avec plus d’un milliard d’utilisateurs actifs par mois, comme l’indiquait le rapport Q4 10K de 201730. Les deux plateformes facilitent l’usage de contenus de Google et de tiers (p.ex. applications et sites tiers) et fournissent donc à Google un accès à un large éventail d’informations personnelles, d’activité web, et de localisation.
A. Collecte d’informations personnelles et de données d’activité
13. Pour télécharger et utiliser des applications depuis le Google Play Store sur un appareil Android, un utilisateur doit posséder (ou créer) un compte Google, qui devient une passerelle clé par laquelle Google collecte ses informations personnelles, ce qui comporte son nom d’utilisateur, son adresse de messagerie et son numéro de téléphone. Si un utilisateur s’inscrit à des services comme Google Pay31, Android collecte également les données de la carte bancaire, le code postal et la date de naissance de l’utilisateur. Toutes ces données font alors partie des informations personnelles de l’utilisateur associées à son compte Google.
14. Alors que Chrome n’oblige pas le partage d’informations personnelles supplémentaires recueillies auprès des utilisateurs, il a la possibilité de récupérer de telles informations. Par exemple, Chrome collecte toute une gamme d’informations personnelles avec la fonctionnalité de remplissage automatique des formulaires, qui incluent typiquement le nom d’utilisateur, l’adresse, le numéro de téléphone, l’identifiant de connexion et les mots de passe.32 Chrome stocke les informations saisies dans les formulaires sur le disque dur de l’utilisateur. Cependant, si l’utilisateur se connecte à Chrome avec un compte Google et active la fonctionnalité de synchronisation, ces informations sont envoyées et stockées sur les serveurs de Google. Chrome pourrait également apprendre la ou les langues que parle la personne avec sa fonctionnalité de traduction, activée par défaut.33
15. En plus des données personnelles, Chrome et Android envoient tous deux à Google des informations concernant les activités de navigation et l’emploi d’applications mobiles, respectivement. Chaque visite de page internet est automatiquement traquée et collectée par Google si l’utilisateur a un compte Chrome. Chrome collecte également son historique de navigation, ses mots de passe, les permissions particulières selon les sites web, les cookies, l’historique de téléchargement et les données relatives aux extensions.34
16. Android envoie des mises à jour régulières aux serveurs de Google, ce qui comprend le type d’appareil, le nom de l’opérateur, les rapports de bug et des informations sur les applications installées35. Il avertit également Google chaque fois qu’une application est ouverte sur le téléphone (ex. Google sait quand un utilisateur d’Android ouvre son application Uber).
B. Collecte des données de localisation de l’utilisateur
17. Android et Chrome collectent méticuleusement la localisation et les mouvements de l’utilisateur en utilisant une variété de sources, représentées sur la figure 3. Par exemple, un accès à la « localisation approximative » peut être réalisé en utilisant les coordonnées GPS sur un téléphone Android ou avec l’adresse IP sur un ordinateur. La précision de la localisation peut être améliorée (« localisation précise ») avec l’usage des identifiants des antennes cellulaires environnantes ou en scannant les BSSID (’’Basic Service Set IDentifiers’’), identifiants assignés de manière unique aux puces radio des points d’accès Wi-Fi présents aux alentours36. Les téléphones Android peuvent aussi utiliser les informations des balises Bluetooth enregistrées dans l’API Proximity Beacon de Google37. Ces balises non seulement fournissent les coordonnées de géolocalisation de l’utilisateur, mais pourraient aussi indiquer à quel étage exact il se trouve dans un immeuble.38
Figure 3 : Android et Chrome utilisent diverses manières de localiser l’utilisateur d’un téléphone.
18. Il est difficile pour un utilisateur de téléphone Android de refuser le traçage de sa localisation. Par exemple, sur un appareil Android, même si un utilisateur désactive le Wi-Fi, la localisation est toujours suivie par son signal Wi-Fi. Pour éviter un tel traçage, le scan Wi-Fi doit être explicitement désactivé par une autre action de l’utilisateur, comme montré sur la figure 4.
Figure 4 : Android collecte des données même si le Wi-Fi est éteint par l’utilisateur
19. L’omniprésence de points d’accès Wi-Fi a rendu le traçage de localisation assez fréquent. Par exemple, durant une courte promenade de 15 minutes autour d’une résidence, un appareil Android a envoyé neuf requêtes de localisation à Google. Les requêtes contenaient au total environ 100 BSSID de points d’accès Wi-Fi publics et privés.
20. Google peut vérifier avec un haut degré de confiance si un utilisateur est immobile, s’il marche, court, fait du vélo, ou voyage en train ou en car. Il y parvient grâce au traçage à intervalles de temps réguliers de la localisation d’un utilisateur Android, combiné avec les données des capteurs embarqués (comme l’accéléromètre) sur les téléphones mobiles. La figure 5 montre un exemple de telles données communiquées aux serveurs de Google pendant que l’utilisateur marchait.
Figure 5 : capture d’écran d’un envoi de localisation d’utilisateur à Google.
C. Une évaluation de la collecte passive de données par Google via Android et Chrome
21. Les données actives que les plateformes Android ou Chrome collectent et envoient à Google à la suite des activités des utilisateurs sur ces plateformes peuvent être évaluées à l’aide des outils MyActivity et Takeout. Les données passives recueillies par ces plateformes, qui vont au-delà des données de localisation et qui restent relativement méconnues des utilisateurs, présentent cependant un intérêt potentiellement plus grand. Afin d’évaluer plus en détail le type et la fréquence de cette collecte, une expérience a été menée pour surveiller les données relatives au trafic envoyées à Google par les téléphones mobiles (Android et iPhone) en utilisant la méthode décrite dans la section IX.D de l’annexe. À titre de comparaison, cette expérience comprenait également l’analyse des données envoyées à Apple via un appareil iPhone.
22. Pour des raisons de simplicité, les téléphones sont restés stationnaires, sans aucune interaction avec l’utilisateur. Sur le téléphone Android, une seule session de navigateur Chrome restait active en arrière-plan, tandis que sur l’iPhone, le navigateur Safari était utilisé. Cette configuration a permis une analyse systématique de la collecte de fond que Google effectue uniquement via Android et Chrome, ainsi que de la collecte qui se produit en l’absence de ceux-ci (c’est-à-dire à partir d’un appareil iPhone), sans aucune demande de collecte supplémentaire générée par d’autres produits et applications (par exemple YouTube, Gmail ou utilisation d’applications).
23. La figure 6 présente un résumé des résultats obtenus dans le cadre de cette expérience. L’axe des abscisses indique le nombre de fois où les téléphones ont communiqué avec les serveurs Google (ou Apple), tandis que l’axe des ordonnées indique le type de téléphone (Android ou iPhone) et le type de domaine de serveur (Google ou Apple) avec lequel les paquets de données ont été échangés par les téléphones. La légende en couleur décrit la catégorisation générale du type de demandes de données identifiées par l’adresse de domaine du serveur. Une liste complète des adresses de domaine appartenant à chaque catégorie figure dans le tableau 5 de la section IX.D de l’annexe.
24. Au cours d’une période de 24 heures, l’appareil Android a communiqué environ 900 échantillons de données à une série de terminaux de serveur Google. Parmi ceux-ci, environ 35 % (soit environ 14 par heure) étaient liés à la localisation. Les domaines publicitaires de Google n’ont reçu que 3 % du trafic, ce qui est principalement dû au fait que le navigateur mobile n’a pas été utilisé activement pendant la période de collecte. Le reste (62 %) des communications avec les domaines de serveurs Google se répartissaient grosso modo entre les demandes adressées au magasin d’applications Google Play, les téléchargements par Android de données relatives aux périphériques (tels que les rapports de crash et les autorisations de périphériques), et d’autres données — principalement de la catégorie des appels et actualisations de fond des services Google.
Figure 6 : Données sur le trafic envoyées par les appareils Andoid et les iPhones en veille.
25. La figure 6 montre que l’appareil iPhone communiquait avec les domaines Google à une fréquence inférieure de plus d’un ordre de grandeur (50 fois) à celle de l’appareil Android, et que Google n’a recueilli aucun donnée de localisation utilisateur pendant la période d’expérience de 24 heures via iPhone. Ce résultat souligne le fait que les plateformes Android et Chrome jouent un rôle important dans la collecte de données de Google.
26. De plus, les communications de l’appareil iPhone avec les serveurs d’Apple étaient 10 fois moins fréquentes que les communications de l’appareil Android avec Google. Les données de localisation ne représentaient qu’une très faible fraction (1 %) des données nettes envoyées aux serveurs Apple à partir de l’iPhone, Apple recevant en moyenne une fois par jour des communications liées à la localisation.
27. En termes d’amplitude, les téléphones Android communiquaient 4,4 Mo de données par jour (130 Mo par mois) avec les serveurs Google, soit 6 fois plus que ce que les serveurs Google communiquaient à travers l’appareil iPhone.
28. Pour rappel, cette expérience a été réalisée à l’aide d’un téléphone stationnaire, sans interaction avec l’utilisateur. Lorsqu’un utilisateur commence à bouger et à interagir avec son téléphone, la fréquence des communications avec les serveurs de Google augmente considérablement. La section V du présent rapport résume les résultats d’une telle expérience.
Impôts et dons à Framasoft : le prélèvement à la source en 2019
De nombreux donateurs s’inquiètent de savoir comment cela va se passer l’année prochaine pour les dons effectués à Framasoft en 2018 et le prélèvement à la source à partir de 2019. Pour une fois les choses sont très simples : rien ne change pour votre réduction d’impôt.
En 2019, les impôts seront prélevés à la source. Pour autant, la réduction fiscale demeure inchangée si vous faites un don à Framasoft : un don de 100 € en 2018 peut vous donner droit à 66 € de réduction fiscale, qui vous seront remboursés en août 2019.
Illustration du processus de don
Le déroulement en détail
Jusqu’à présent, vous faisiez votre déclaration au printemps en indiquant votre don ouvrant droit à une réduction d’impôt de 66%, dans la limite de 20 % du revenu imposable. En fin d’année, les services fiscaux vous indiquaient le montant à régler en tenant compte d’une éventuelle mensualisation demandée de votre part.
À partir de 2019, vous allez faire des règlements mensuels dès le mois de janvier en fonction d’un taux déterminé par l’administration fiscale et des paramètres que vous leur aurez fournis. Ceux qui ont fait un don en 2017 recevront, dès le 15 janvier 2019, un acompte de 60% de la réduction d’impôt dont ils ont bénéficié en 2018 au titre des dons effectués en 2017.
Vous ferez, comme chaque année, votre déclaration au printemps, vers mai-juin. Vous indiquerez alors le montant des dons faits à Framasoft en 2018 et pourrez, si demandé, joindre le justificatif que nous vous aurons fait parvenir vers mars-avril. C’est vers la fin de l’été que les impôts vous enverront votre avis, en tenant compte de ce don et d’un éventuel acompte versé de leur part en janvier. C’est alors que l’administration procédera à un recalcul de vos mensualités ou un remboursement, selon le cas et les montants. Les prélèvements mensuels se poursuivront ensuite pour ajuster vos paiements au montant de l’impôt dont vous devrez vous acquitter.
Et c’est tout. En gros, rien ne change pour votre réduction d’impôt pour les dons faits à Framasoft.
En mars 2018, Framasoft lui a envoyé un reçu fiscal pour ce don de 100€.
En mai 2018, Camille a déclaré ses revenus 2017, en précisant qu’elle avait fait un don de 100€ à Framasoft dans la case 7UF «Dons versés à d’autres organismes d’intérêt général».
En août 2018, Camille a reçu son avis d’imposition, qui indiquait prendre en compte une déduction de 66€ (100€ x 66%).
En mars 2019, Framasoft lui envoie son reçu fiscal pour un don de 100€.
En mai 2019, Camille reçoit des impôts sa déclaration de revenus 2018. Elle déclare alors (sur papier ou en ligne) ses revenus 2018, et indique (toujours dans la case « Dons versés à d’autres organismes d’intérêt général ») un montant de 100€.
En août/septembre 2019 (environ), les impôts envoient à Camille son avis d’imposition indiquant prendre en compte sa déduction de 66€ (100 € x 66%).
Son don de 100€ à Framasoft, après déduction, ne lui aura coûté que 34€ (100€ de don – 66€ de déduction).
Son don de 100€ à Framasoft, après déduction, ne lui aura coûté que 34€ (100€ de don – 66€ de déduction).
Maintenant que vous voilà rassurés, nous ne pouvons que vous encourager à faire un don pour soutenir nos actions 🙂
Mastodon a déjà deux ans, et il est toujours vivant, n’en déplaise aux oiseaux de mauvais augure. Il est inadéquat de le comparer aux plateformes sociales, et Peter 0’Shaughnessy nous explique bien pourquoi…
Pourquoi Mastodon se moque de la « masse critique »
C’est une erreur de juger la Fediverse comme s’il s’agissait d’une startup de la Silicon Valley.
Mastodon a maintenant plus de deux ans et (pour emprunter une expression à Terry Pratchett), il n’est toujours pas mort. D’une manière ou d’une autre, il a réussi à défier les premiers critiques qui disaient qu’il « ne survivrait pas » et qu’il était « mort dans l’œuf ». Même certains de ceux qui postaient sur Mastodon à ses débuts doutaient de sa longévité :
Plus récemment, un article sur l’écosystème plus vaste qui comprend Mastodon, appelé La Fediverse, a fait la une de Hacker News : Qu’est-ce que ActivityPub, et comment changera-t-il l’Internet ? par Jeremy Dormitzer. C’est un bon argument en faveur de l’importance de la norme ActivityPub, sur laquelle reposent Mastodon et d’autres plateformes sociales. Cependant, il commet toujours la même erreur que ces premiers prophètes de malheur :
Le plus gros problème à l’heure actuelle, c’est l’adoption par les utilisateurs. Le réseau ActivityPub n’est viable que si les gens l’utilisent, et pour concurrencer de manière significative Facebook et Twitter, nous avons besoin de beaucoup de gens pour l’utiliser. Pour rivaliser avec les grands, nous avons besoin de beaucoup d’argent…
Des arguments similaires ont été présentés dans de nombreux articles au cours des derniers mois. Ils impliquent :
que la valeur du réseau n’est proportionnelle qu’au nombre d’utilisateurs ;
que ce ne sera vraiment un succès que s’il devient un remplacement massif pour Twitter et Facebook ;
que si vous ne le rejoignez pas, il ne survivra pas.
Mais tout cela est faux. Voici pourquoi…
1. La Fediverse n’est pas une startup
Nous sommes tellement conditionnés de nos jours par le monde du capital-risque et des startups que nous pensons intuitivement que toutes les nouvelles entreprises technologiques doivent réussir ou faire faillite. Mais ce n’est pas la nature du modèle économique qui se cache derrière le Fediverse, qui est déjà durable, tout en continuant de fonctionner comme si de rien n’était.
Nous devons cesser de juger la Fediverse comme s’il s’agissait d’une startup de la Silicon Valley en concurrence avec Twitter et Facebook.
Jeremy a raison de dire que la plupart des instances sont « créées et administrées par des bénévoles avec des budgets minuscules », mais il implique que cela doit changer, alors que la plupart des administrateurs et utilisateurs de Mastodon que je connais sont très satisfaits de ce modèle, qui nous libère des intérêts acquis et contradictoires des régies publicitaires.
C’est facile à dire pour moi, car je n’héberge pas ma propre instance et mon administrateur a gentiment refusé les offres de dons jusqu’ici. Cependant, dans la plupart des cas, il semble que tout se passe très bien, la plupart du temps grâce au financement participatif. Même si certaines instances ont été fermées à un moment donné (et c’est malheureusement le cas), il y en a d’autres qui se présentent à leur place. Malgré les fortes fluctuations à chaque nouvelle vague d’utilisateurs venant de Twitter, la trajectoire globale est à la hausse, et c’est ce qui importe — pas la vitesse de la croissance, ni l’atteinte d’un certain niveau de masse critique. Michael Mahemoff l’a bien dit :
« Mastodon est déjà « assez bon » dans sa forme initiale pour satisfaire plusieurs besoins de niche (les personnes qui veulent plus ou moins de modération ou des critères différents de modération, celles qui ne veulent pas de publicités, celles qui veulent des participant⋅e⋅s qui sont libres d’innover, celles qui veulent posséder et/ou héberger leur propre contenu, etc.). Comme Mastodon a un modèle de mécénat durable, il peut se développer au fil du temps et être capable de continuer à innover. »
En fait, si Mastodon se développait trop rapidement, cela pourrait avoir des conséquences plus négatives que positives. La croissance progressive permet aux instances existantes de mieux faire face à la charge et permet à de nouvelles instances d’émerger et de faire face à une partie du flux.
2. C’est aussi une question de qualité (d’expérience), pas seulement de quantité (d’utilisateurs et utilisatrices)
Lorsque j’ai rejoint Mastodon pour la première fois, j’ai été enthousiasmé par chaque nouvelle vague d’utilisateurs et utilisatrices venant de Twitter. Je voulais prêcher à ce sujet à autant de gens que possible et essayer d’amener autant d’amis que possible à « déménager ». Au bout d’un moment, j’ai pris conscience que je me concentrais trop sur la comparaison avec Twitter et que j’essayais d’en faire un remplaçant de Twitter. En fait, j’avais déjà un réseau précieux là-bas et suffisamment de raisons de le visiter régulièrement, même si j’ai continué à utiliser Twitter aussi.
Mastodon s’articule autour des communautés. Ces communautés peuvent être des réseaux spécialisés selon les sujets qui vous intéressent. Vous n’avez pas besoin de tous vos amis pour être au sein de ces communautés, pour trouver des gens intéressants, du contenu utile et des interactions intéressantes.
Comme Vee Satayamas l’a noté, si vous êtes un utilisateur de Twitter, vous le trouverez peut-être utile même si peu de membres de votre famille ou d’amis réels sont présents. Vous n’avez pas besoin que tout le monde soit disponible sur chaque réseau. J’ai récemment quitté Facebook et j’ai quand même pu entrer en contact avec mes amis, par courriel ou par texto. Ce serait bien mieux si davantage de mes amis étaient sur Mastodon, mais ce n’est pas un gros problème.
En réalité, il y a quelque chose de positif dans la petite taille de mon réseau sur Mastodon. Je peux suivre ma chronologie, mon « fil », sans me sentir dépassé. C’est moins stressant d’y poster, comparé à Twitter, où chaque message que vous envoyez risque d’être republié par une horde géante ! Je suppose que c’est comparable à l’effet ressenti par les YouTubers, tel que détaillé dans cet intéressant article du Guardian, qui cite Matt Lees :
« Le cerveau humain n’est pas vraiment conçu pour interagir avec des centaines de personnes chaque jour… Lorsque des milliers de personnes vous envoient des commentaires directs sur votre travail, vous avez vraiment l’impression que quelque chose vous vient à l’esprit. Nous ne sommes pas faits pour gérer l’empathie et la sympathie à cette échelle. »
Pour moi, Mastodon offre un moyen terme heureux entre les conversations intimes des groupes WhatsApp, par exemple, et le potentiel sans limites de Twitter pour découvrir de nouvelles personnes et de nouveaux contenus.
D’après mon expérience, la plupart des utilisateurs actifs de Mastodon ne veulent pas qu’il ressemble davantage à Twitter — et ne ressentent pas le besoin que tous ceux qui sont sur Twitter les rejoignent. Par exemple, ces personnes apprécient le fait qu’il n’y a pas de publicitaires et très peu de marques. Pour les gens qui ne s’inquiètent que de leur « influence », alors c’est sûr, Mastodon n’aura pas autant de valeur. Mais la plupart de celles et ceux qui sont sur Mastodon ne regretteront pas trop de ce genre de personnes venues de Twitter !
Nous devons cesser de considérer Mastodon comme un substitut potentiel de Twitter. C’est différent, et c’est délibéré. Je comprends qu’on se plaise à imaginer que la Fediverse pourrait un jour écraser Twitter et Facebook, mais je ne pense pas que ce soit réaliste (du moins pas dans un avenir proche). Je pense que ce sera toujours l’outsider et c’est très bien ainsi, d’une certaine façon.
3. C’est un écosystème ouvert
La Fediverse ne gagne pas seulement de la valeur à partir de la quantité d’utilisateurs, elle en gagne aussi à partir de la quantité de services. S’appuyer sur le standard ActivityPub implique que nous pouvons utiliser Mastodon, PeerTube (un service semblable à YouTube), PixelFed (un service semblable à Instagram) et beaucoup d’autres, qui peuvent tous interopérer. Cela donne à la Fediverse un avantage d’échelle par rapport aux plateformes propriétaires closes. C’est un point que l’article de Jeremy a bien fait ressortir :
« Parce qu’il parle le même « langage », un utilisateur de Mastodon peut suivre un utilisateur de PeerTube. Si l’utilisateur de PeerTube envoie une nouvelle vidéo, elle apparaîtra dans le flux de l’utilisateur Mastodon. L’utilisatrice de Mastodon peut commenter la vidéo PeerTube directement depuis Mastodon. Pensez-y une seconde. Toute application qui implémente ActivityPub fait partie d’un réseau social étendu, qui conserve le choix de l’utilisateur et pulvérise les jardins propriétaires clos. Imaginez que vous puissiez vous connecter à Facebook et voir les messages de vos amis sur Instagram et Twitter, sans avoir besoin de compte Instagram ni de compte Twitter. »
Cela signifie également que si nous avons l’impression que le service que nous utilisons ne va pas dans la direction qui nous convient (coucou, utilisateurs de Twitter 👋), alors nous pouvons passer à une autre instance et conserver l’accès à l’écosystème global.
La Fediverse s’accroît et c’est une bonne chose. Mais elle n’a pas besoin de davantage d’utilisatrices. Transmettre l’idée qu’on pourrait échouer sans une migration massive à partir d’autres plateformes sociales est une perspective trompeuse. Et défendre cette idée donnerait aux gens la fausse impression, lorsqu’ils rejoindront ce réseau social, qu’on devrait rechercher la quantité d’utilisateurs et utilisatrices, plutôt que la qualité de l’expérience.
Alors ne comptons pas trop le nombre d’inscrit⋅e⋅s sur Mastodon. Allons doucement en le comparant à Twitter. Arrêtons de le traiter comme s’il s’agissait d’une situation à la Highlander où « il n’y a de la place que pour un seul ». Et commençons à profiter de la Fediverse pour ce qu’elle est — quelque chose de différent.
Merci à Jeremy Dormit d’avoir été très gentil avec moi en critiquant cette partie de son billet de blog (qui m’a beaucoup plu par ailleurs) – voici sa réponse à mon pouet qui a mené à ce billet. Merci aussi à mes anciens collègues de Samsung Internet qui ont jeté un coup d’œil à une version antérieure de ce post.
Libre adaptation avec le Geektionerd generator d’un mastodon dessiné par Peter O’Saughnessy
Ce que récolte Google : revue de détail
Le temps n’est plus où il était nécessaire d’alerter sur la prédation opérée par Google et ses nombreux services sur nos données personnelles. Il est fréquent aujourd’hui d’entendre dire sur un ton fataliste : « de toute façon, ils espionnent tout »
Si beaucoup encore proclament à l’occasion « je n’ai rien à cacher » c’est moins par conviction réelle que parce que chacun en a fait l’expérience : « on ne peut rien cacher » dans le monde numérique. Depuis quelques années, les mises en garde, listes de précautions à prendre et solutions alternatives ont été largement exposées, et Framasoft parmi d’autres y a contribué.
Il manquait toutefois un travail de fond pour explorer et comprendre, une véritable étude menée suivant la démarche universitaire et qui, au-delà du jugement global approximatif, établisse les faits avec précision.
C’est à quoi s’est attelée l’équipe du professeur Douglas C. Schmidt, spécialiste depuis longtemps des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt, qui livre au public une étude d’une cinquantaine de pages intitulée Google Data Collection. Cette étude, qui nous semble pouvoir servir de référence, a retenu l’attention du groupe Framalang qui vous en livre ci-dessous l’executive summary, c’est-à-dire une sorte de résumé initial, qui en donne un aperçu programmatique.
Si vous trouvez un intérêt à cette traduction et souhaitez que Framalang vous propose la suite nous ferons de notre mieux…
1.
Google est la plus grosse agence de publicité numérique du monde 39. Elle fournit aussi le leader des navigateurs web 40, la première plateforme mobile 41 ainsi que le moteur de recherche le plus utilisé au monde 42. La plateforme vidéo de Google, ses services de mail et de cartographie comptent 1 milliard d’utilisateurs mensuels actifs chacun 43. Google utilise l’immense popularité de ses produits pour collecter des données détaillées sur le comportement des utilisateurs en ligne comme dans la vie réelle, données qu’il utilisera ensuite pour cibler ses utilisateurs avec de la publicité payante. Les revenus de Google augmentent significativement en fonction de la finesse des technologies de ciblage des données.
2.
Google collecte les données utilisateurs de diverses manières. Les plus évidentes sont « actives », celles dans lesquelles l’utilisateur donne
directement et consciemment des informations à Google, par exemple en s’inscrivant à des applications très populaires telles que YouTube, Gmail, ou le moteur de recherche. Les voies dites « passives » utilisées par Google pour collecter des données sont plus discrètes, quand une application devient pendant son utilisation l’instrument de la collecte des données, sans que l’utilisateur en soit conscient. On trouve ces méthodes de collecte dans les plateformes (Android, Chrome), les applications (le moteur de recherche, YouTube, Maps), des outils de publication (Google Analytics, AdSense) et de publicité (AdMob, AdWords). L’étendue et l’ampleur de la collecte passive de données de Google ont été en grande partie négligées par les études antérieures sur le sujet 44.
3.
Pour comprendre les données que Google collecte, cette étude s’appuie sur quatre sources clefs :
a. Les outils Google « Mon activité » (My Activity) 45 et « Téléchargez vos données » (Takeout) 46, qui décrivent aux utilisateurs l’information collectée lors de l’usage des outils Google.
b. Les données interceptées lors de l’envoi aux serveurs de Google pendant l’utilisation des produits Google ou d’autres sociétés associées.
c. Les règles concernant la vie privée (des produits Google spécifiquement ou en général).
d. Des recherches tierces qui ont analysé les collectes de données opérées par Google.
Histoire naturelle, générale et particulière, des mollusques, animaux sans vertèbres et à sang blanc. T.2. Paris,L’Imprimerie de F. Dufart,An X-XIII [1802-1805]. biodiversitylibrary.org/page/35755415
4.
Au travers de la combinaison des sources ci-dessus, cette étude montre une vue globale et exhaustive de l’approche de Google concernant la collecte des données et aborde en profondeur certains types d’informations collectées auprès des utilisateurs et utilisatrices.
Cette étude met en avant les éléments clés suivants :
a. Dans une journée d’utilisation typique, Google en apprend énormément sur les intérêts personnels de ses utilisateurs. Dans ce scénario d’une journée « classique », où un utilisateur réel avec un compte Google et un téléphone Android (avec une nouvelle carte SIM) suit sa routine quotidienne, Google collecte des données tout au long des différentes activités, comme la localisation, les trajets empruntés, les articles achetés et la musique écoutée. De manière assez surprenante, Google collecte ou infère plus de deux tiers des informations via des techniques passives. Au bout du compte, Google a identifié les intérêts des utilisateurs avec une précision remarquable.
b. Android joue un rôle majeur dans la collecte des données pour Google, avec plus de 2 milliards d’utilisateurs actifs mensuels dans le monde 47. Alors que le système d’exploitation Android est utilisé par des fabricants d’équipement d’origine (FEO) partout dans le monde, il est étroitement connecté à l’écosystème Google via le service Google Play. Android aide Google à récolter des informations personnelles sur les utilisateurs (nom, numéro de téléphone, date de naissance, code postal et dans beaucoup de cas le numéro de carte bancaire), les activités réalisées sur le téléphone (applications utilisées, sites web consultés) et les coordonnées de géolocalisation. En coulisses, Android envoie fréquemment la localisation de l’utilisateur ainsi que des informations sur l’appareil lui-même, comme sur l’utilisation des applications, les rapports de bugs, la configuration de l’appareil, les sauvegardes et différents identifiants relatifs à l’appareil.
c. Le navigateur Chrome aide Google à collecter des données utilisateurs depuis à la fois le téléphone et l’ordinateur de bureau, grâce à quelque 2 milliards d’installations dans le monde 48. Le navigateur Chrome collecte des informations personnelles (comme lorsqu’un utilisateur remplit un formulaire en ligne) et les envoie à Google via le processus de synchronisation. Il liste aussi les pages visitées et envoie les données de géolocalisation à Google.
d. Android comme Chrome envoient des données à Google même en l’absence de toute interaction de l’utilisateur. Nos expériences montrent qu’un téléphone Android dormant et stationnaire (avec Chrome actif en arrière-plan) a communiqué des informations de localisation à Google 340 fois pendant une période de 24 heures, soit en moyenne 14 communications de données par heure. En fait, les informations de localisation représentent 35 % de l’échantillon complet de données envoyés à Google. À l’opposé, une expérience similaire a montré que sur un appareil iOS d’Apple avec Safari (où ni Android ni Chrome n’étaient utilisés), Google ne pouvait pas collecter de données notables (localisation ou autres) en absence d’interaction de l’utilisateur avec l’appareil.
e. Une fois qu’un utilisateur ou une utilisatrice commence à interagir avec un téléphone Android (par exemple, se déplace, visite des pages web, utilise des applications), les communications passives vers les domaines de serveurs Google augmentent considérablement, même dans les cas où l’on n’a pas utilisé d’applications Google majeures (c.-à-d. ni recherche Google, ni YouTube, pas de Gmail ni Google Maps). Cette augmentation s’explique en grande partie par l’activité sur les données de l’éditeur et de l’annonceur de Google (Google Analytics, DoubleClick, AdWords) 49. Ces données représentaient 46 % de l’ensemble des requêtes aux serveurs Google depuis le téléphone Android. Google a collecté la localisation à un taux 1,4 fois supérieur par rapport à l’expérience du téléphone fixe sans interaction avec l’utilisateur. En termes d’amplitude, les serveurs de Google ont communiqué 11,6 Mo de données par jour (ou 0,35 Go / mois) avec l’appareil Android. Cette expérience suggère que même si un utilisateur n’interagit avec aucune application phare de Google, Google est toujours en mesure de recueillir beaucoup d’informations par l’entremise de ses produits d’annonce et d’éditeur.
f. Si un utilisateur d’appareil sous iOS décide de renoncer à l’usage de tout produit Google (c’est-à-dire sans Android, ni Chrome, ni applications Google) et visite exclusivement des pages web non-Google, le nombre de fois où les données sont communiquées aux serveurs de Google demeure encore étonnamment élevé. Cette communication est menée exclusivement par des services de l’annonceur/éditeur. Le nombre d’appels de ces services Google à partir d’un appareil iOS est similaire à ceux passés par un appareil Android. Dans notre expérience, la quantité totale de données communiquées aux serveurs Google à partir d’un appareil iOS est environ la moitié de ce qui est envoyé à partir d’un appareil Android.
g. Les identificateurs publicitaires (qui sont censés être « anonymisés » et collectent des données sur l’activité des applications et les visites des pages web tierces) peuvent être associés à l’identité d’un utilisateur ou utilisatrice de Google. Cela se produit par le transfert des informations d’identification depuis l’appareil Android vers les serveurs de Google. De même, le cookie ID DoubleClick (qui piste les activités des utilisateurs et utilisatrices sur les pages web d’un tiers) constitue un autre identificateur censé être anonymisé que Google peut associer à celui d’un compte personnel Google, si l’utilisateur accède à une application Google avec le navigateur déjà utilisé pour aller sur la page web externe. En définitive, nos conclusions sont que Google a la possibilité de connecter les données anonymes collectées par des moyens passifs avec les données personnelles de l’utilisateur.
Framinetest Edu, et maintenant ?
Deux ans après son lancement, il est temps de dresser un premier bilan de l’aventure Framinetest. Souvenez-vous, le jour de la rentrée des enseignants, septembre 2016, nous écrivions ceci :
Combien d’utilisateurs se sont connectés ? Notre initiative a-t-elle réussi à faire ses chatons ? Autant de questions auxquelles nous vous proposons de répondre dans ce premier bilan public. Et avouons-le, si nous avons attendu avant de partager, c’est avant tout parce que nous n’avons pas eu une seconde à nous. Mais que d’aventures et de chemin parcourus depuis son lancement !
Commençons par un nombre
Forcément, lorsqu’on parle de bilan et d’une plateforme en ligne, vient à un moment la question : « c’est qui qui y va, sur ton bouzin ? Et combien c’est-y qui sont à y aller ? »
Voici la réponse… Le nombre total d’utilisateurs qui se sont connectés au moins une fois est de (tadaaa) : plus de 10 000. Après, on a arrêté de compter.
Qui se connecte, ou s’est connecté pour découvrir le jeu ?
Des élèves du premier et du second degré, des étudiants, des enseignants du premier et du second degré de toutes disciplines, des universitaires, des inspecteurs et des parents ! Oui, vous avez bien lu, des parents aussi. Et pourquoi pas, après tout ? Personnellement, j’y vois à minima un intérêt : la transparence des outils et de l’enseignement.
Autant dire que Framinetest a été un franc succès ! Mais alors que se passe-t-il en ce moment ?
Dans ce contexte, le premier, et non le moindre, des défis était de trouver une solution de modération qui ne demanderait pas aux modérateurs de rester en ligne 24h/24 et 7j/7. La solution que nous avons donc choisie est celle des privilèges différenciés entre les joueurs. En résumé, plus on est sérieux, attentif aux autres et actif, plus on gagne de privilèges. Solution simple mais particulièrement efficace puisque dès que les élèves sont arrivés sur la plateforme, le nombre de modérateurs a tout simplement triplé !
Le second défi à relever fut assez rapidement celui de l’entrée dans le jeu. En effet, lorsqu’on utilise un serveur Minetest public, le nombre de joueurs (français comme étrangers) peut rapidement devenir un problème, en particulier lorsque se glissent parmi eux quelques petits plaisantins aimant jouer avec le feu et la lave (« Ah, cool, j’y suis, je vais pouvoir jou… » Froutch !).
C’est la raison pour laquelle nous avons mis en place un quiz d’entrée. En résumé, chaque nouveau joueur arrivant dans le jeu possède des privilèges très limités (qui ne permettent pas le grief) et est invité à passer le quiz s’il veut en gagner davantage. Simple, mais particulièrement efficace !
Souvenez-vous : améliorations, évolutions…
Septembre 2016 : l’entrée dans le jeu est (donc) modifiée (construction du quiz, mise en place du spawn).
Décembre 2016 : l’accès aux blocs de lave devient un privilège (a pus, froutch).
Octobre-janvier : les mods utilisés sont adaptés et traduits.
Janvier : le serveur est mis à jour de la version 0.4.14 vers 0.4.15, ce qui ajoute de nouvelles fonctionnalités et corrige de nombreux bogues.
Janvier-février : les élèves testent et installent la « prison » de ré-éducation (on en reparle plus bas).
Décembre-février : de nouveaux mods sont testés, et parfois installés (dont « shérif » et véhicules).
Février-mars 2017 : l’entrée dans le jeu est encore améliorée avec la mise en place d’un nouveau quiz.
Année 2 : on a montré que c’était possible, maintenant il faut faire des chatons !
OK, c’est cool, mais un tel serveur, avec autant de joueurs, est-ce viable sur le long terme ? La question mérite d’être posée, en particulier après quelques nuits blanches à éteindre des incendies (j’en ris tout seul derrière mon clavier ; seuls les joueurs de la première heure et amis comprendront !).
Il fallait poser les choses : Framinetest n’a pas vocation à accueillir toutes les demandes ! Car elles étaient nombreuses et très diverses, pour ne pas dire toutes différentes. Oui, il faut que je vous explique : quand on vient de l’univers Minecraft, on a la fâcheuse tendance à imaginer son monde à soi, sans penser nécessairement qu’on n’est pas le seul joueur en ligne… CQFD. C’est là que la décentralisation trouve son intérêt, afin que chacun trouve chaussure à son pied.
Et puis soyons honnêtes, ce n’était pas humainement possible, franchement déraisonnable. Il fallait décentraliser ! Bref, peut-être encore plus que pour les autres framachins, le discours se devait d’être clair : « on vous a montré la voie, maintenant, à vous de jouer ! ».
Bien entendu, nous avons guidé aidé, conseillé… Et Framinetest est retourné à sa source : un bac à sable, un lieu d’essai où l’erreur est humaine, mais où on se fait plaisir ! Et des essais, des bugs… il y en a eu un paquet !
Octobre 2017 : nous participons au hackathon du Gamixlab !
Octobre 2017 à aujourd’hui : nous accompagnons des projets pédagogiques proposés par les enseignants sur Framinetest.
Souvenirs, anecdotes et retours d’expérience
Framinetest est basé sur Minetest, un logiciel libre, moteur de l’innovation pédagogique et favorisant l’élargissement du champ des possibles pour les utilisateurs.
Les administrateurs du serveur ont la possibilité d’ajouter, modifier, optimiser, l’ensemble du jeu : autant dire qu’un enseignant pourra s’y sentir libre, d’un point de vue pédagogique ! Les élèves deviennent force de proposition et d’amélioration du jeu ; c’est motivant et formateur.
Le jeu est une société miniature, avec ses évolutions, de l’idée à la réalisation… en passant par l’utopie ! Quelques exemples :
EnzoJP et sa prison, où comment rééduquer les joueurs ne respectant pas les règles ! Devant les joueurs les moins sérieux, enzoJP, jeune modérateur et accessoirement l’un de mes élèves, nous a un jour fait part de son idée au cours d’une partie : « monsieur Sangokuss, plutôt que de bannir ces joueurs-là, je pense qu’il serait mieux de les mettre en prison et d’essayer de les ré-éduquer. Est-ce que vous êtes d’accord ? » Bon, là, j’avoue, il y a un moment d’absence dans mon cerveau… Mais après réflexion, je lui dis que c’est envisageable s’il argumente et qu’il respecte la règle du « c’est celui qui dit qui fait ». Réponse d’enzoJP : « monsieur, ne vous inquiétez pas, on ne les tapera pas ! Mais quand ils font une bêtise, on les envoie en prison et un modérateur-psychologue s’en occupe pour le ré-éduquer ». Intérieurement, je me dis que cela devient intéressant (de quoi philosopher et débattre pendant longtemps…) et je réponds « OK, on essaie ». Quinze jours plus tard, la prison est construite et les premiers prisonniers y sont enfermés. Reste à savoir s’ils ressortiront un jour… Bref, restez sérieux !
Reproduire la vraie vie : travailler, dormir, faire ses courses, se cultiver.
« Promis monsieur, on ne se bat pas ! Mais on stocke des armes au cas où… ». Euh, ouais, il va falloir en parler, quand même.
Le lâcher prise : une posture pas si simple pour l’enseignant, et pourtant une nécessité.
L’apprentissage de la démocratie, les scrutins, les décisions communes.
Au fond, c’est une véritable réflexion sur notre société que le jeu permet et facilite pour les joueurs. Sans pour autant aboutir à un résultat idéal, il y a là des pistes intéressantes, parfois surprenantes ou amusantes, parfois politiquement incorrectes, mais toujours dans un esprit de co-construction et d’ouverture.
Je l’ai déjà évoqué, mais travailler l’entrée dans le jeu est une absolue nécessité ! En effet, lorsqu’un tel serveur est ouvert 24h/24, on remarque inévitablement des problèmes apparaître, plus particulièrement l’arrivée d’intrus qu’il convient de filtrer / cadrer… Mais il y a encore plus important dans un contexte pédagogique : faire prendre conscience aux joueurs (ici, des élèves), de l’importance de respecter certaines règles élémentaires. Et voici les solutions et pistes de réflexions qui ont été proposées par les intervenants eux-mêmes :
Forcer les joueurs à lire la charte ! D’où l’idée lancée de construire un labyrinthe dont seul le joueur qui lira les articles de la charte trouvera la sortie. Simple, mais très efficace !
Limiter les privilèges au minimum à l’entrée dans le jeu, tout en expliquant qu’il y a moyen d’en gagner, sous condition de respecter les règles du serveur.
Avantage important : cela libère du temps au(x) modérateur(s) ou enseignant(s) qui gèrent le serveur puisque l’entrée dans le jeu se fait en autonomie, alors qu’auparavant il fallait prêter une grande attention à cette étape cruciale..
Sur un serveur ouvert, au delà de l’entrée dans le jeu, un autre point de vigilance doit être abordé : l’encadrement. D’où la logique des privilèges croissants.
Ne deviennent « modo » que ceux qui disposent des privilèges associés, donc ceux qui respectent les règles.
Les déplacements sont également facilités par les téléporteurs qui permettent aux participants de se rendre rapidement d’un point à un autre de la map sans pour autant avoir le privilège dédié.
La responsabilisation progressive permet d’apprendre la coopération.
Retour vers le futur : le privilège du roll-back, c’est-à-dire pouvoir revenir à une situation précédente (soit restaurer le jeu à un point de sauvegarde).
Shérif, fait moi peur ! Ou tout simplement l’idée d’un élève de développer une police dans le jeu. Simple à dire, mais si difficile à mettre en place si l’on souhaite que cela se fasse avec calme et légitimité. D’où la notion de vote. Les participants ont, s’ils le souhaitent, la possibilité d’élire un (ou plusieurs) shérif dont les privilèges seront différenciés en fonction de son nombre de bulletins !
L’usage de surnom et le respect ne sont pas antagonistes, ce qui surprend parfois les collègues.
Le rôle des modérateurs est indispensable pour favoriser le développement de l’autonomie : accueillir, expliquer, former, faciliter les échanges, et si nécessaire… sanctionner. Comme dans la vraie vie, sauf que dans le jeu certains modérateurs sont eux aussi des participants, parfois plus jeunes que les joueurs « modérés ».
De nouveaux usages, ou plutôt des usages inattendus, ont vu le jour :
L’inauguration ;
L’organisation d’évènements festifs : pour Noël…etc. ;
La photo de classe.
Pourquoi pousser le libre dans l’éducation ?
Au-delà du discours libriste global, la fermeture du logiciel Minecraft rend difficile, pour ne pas dire impossible toutes personnalisation profonde du jeu par l’enseignant et donc encore moins par les élèves ! Jouer, dans un tel contexte, c’est davantage être utilisé qu’être utilisateur, pour reprendre une expression de Richard M. Stallman à propos de Facebook. Par conséquent, comment imaginer une démarche pédagogique de formation au numérique ? Car oui, former au numérique c’est former des utilisateurs éclairés, capables (ou du moins ayant la possibilité) de plier l’outil pour répondre à leurs besoins. Or, dans Minetest, cette voie est ouverte aux utilisateurs et les élèves ne s’y trompent pas ; à partir du moment où ils comprennent que tout n’est que dossiers et fichiers, ils personnalisent, adaptent, et créent même leurs propres serveurs.
Bref, ils deviennent indépendants. Libres. Et le devoir de l’école est accompli !
Et demain ?
Framinetest restera. Le projet se poursuit et nous sommes loin d’avoir épuisé l’imagination de nos joueurs et modérateurs ! Figurez-vous que pas plus tard que le week-end dernier, de grosses mises à jour ont été poussées sur Framinetest !
Mais les serveurs doivent se multiplier… Et de fait ils le font, avec de nouvelles expérimentations qu’il est toujours passionnant de suivre tant le jeu est riche de libertés. Si j’en crois ce que j’observe sur les médias sociaux, nous avons fait déjà un joli bout de chemin !
Tout est résumé dans un mot : Contributopia ! Il s’agit d’encourager les nouveaux serveurs pédagogiques et de les accompagner.
Le succès de Framinetest n’est pas passé inaperçu et mon petit doigt me dit que cette histoire n’est pas terminée…
Rendez-vous prochainement pour le troisième volet de l’aventure Framinetest.
Cette année, comme les précédentes, Framasoft fait appel à votre générosité afin de poursuivre ses actions.
Depuis 14 ans : promouvoir le logiciel libre et la culture libre
L’association Framasoft a 14 ans. Durant nos 10 premières années d’existence, nous avons créé l’annuaire francophone de référence des logiciels libres, ouvert une maison d’édition ne publiant que des ouvrages sous licences libres, répondu à d’innombrables questions autour du libre, participé à plusieurs centaines d’événements en France ou à l’étranger, promu le logiciel libre sur DVD puis clé USB, accompagné la compréhension de la culture libre, ou plutôt des cultures libres, au travers de ce blog, traduit plus de 1 000 articles ainsi que plusieurs ouvrages, des conférences, et bien d’autres choses encore !
Depuis 4 ans, décentraliser Internet
En 2014, l’association prenait un virage en tentant de sensibiliser non seulement à la question du libre, mais aussi à celle de la problématique de la centralisation d’Internet. En déconstruisant les types de dominations exercées par les GAFAM (dominations technique, économique, mais aussi politique et culturelle), nous avons pendant plusieurs années donné à voir en quoi l’hyperpuissance de ces acteurs mettait en place une forme de féodalité.
Et comme montrer du doigt n’a jamais mené très loin, il a bien fallu initier un chemin en prouvant que le logiciel libre était une réponse crédible pour s’émanciper des chaînes de Google, Facebook & co. En 3 ans, nous avons donc agencé plus de 30 services alternatifs, libres, éthiques, décentralisables et solidaires. Aujourd’hui, ces services accueillent 400 000 personnes chaque mois. Sans vous espionner. Sans revendre vos données. Sans publicité. Sans business plan de croissance perpétuelle.
Parfois, Framasoft se met au vert. Parce qu’il y a un monde par-delà les ordinateurs…
Mais Framasoft, c’est une bande de potes, pas la #startupnation. Et nous ne souhaitions pas devenir le « Google du libre ». Nous avons donc en 2016 impulsé le collectif CHATONS, afin d’assurer la résilience de notre démarche, mais aussi afin de « laisser de l’espace » aux expérimentations, aux bricolages, à l’inventivité, à l’enthousiasme, aux avis divergents du nôtre. Aujourd’hui, une soixantaine de chatons vivent leurs vies, à leurs rythmes, en totale indépendance.
Il y a un an : penser au-delà du code libre
Il y a un an, nous poursuivions notre virage en faisant 3 constats :
L’open source se porte fort bien. Mais le logiciel libre (c-à-d. opensource + valeurs éthiques) lui, souffre d’un manque de contributions exogènes.
Dégoogliser ne suffit pas ! Le logiciel libre n’est pas une fin en soi, mais un moyen (nécessaire, mais pas suffisant) de transformation de la société.
Il existe un ensemble de structures et de personnes partageant nos valeurs, susceptibles d’avoir besoin d’outils pour faire advenir le type de monde dont nous rêvons. C’est avec elles qu’il nous faut travailler en priorité.
Est-ce une victoire pour les valeurs du Libre que d’équiper un appareil tel que le drone militaire MQ-8C Fire Scout ? Nous ne le pensons pas. Cliché Domaine public – Wikimedia
Face à ces constats, notre feuille de route Contributopia vise à proposer des solutions. Sur 3 ans (on aime bien les plans triennaux), Framasoft porte l’ambition de participer à infléchir la situation.
D’une part en mettant la lumière sur la faiblesse des contributions, et en tentant d’y apporter différentes réponses. Par exemple en abaissant la barrière à la contribution. Ou, autre exemple, en généralisant les pratiques d’ouvertures à des communautés non-dev.
D’autre part, en mettant en place des projets qui ne soient pas uniquement des alternatives à des services de GAFAM (aux moyens disproportionnés), mais bien des projets engagés, militants, qui seront des outils au service de celles et ceux qui veulent changer le monde. Nous sommes en effet convaincu·es qu’un monde où le logiciel libre serait omniprésent, mais où le réchauffement climatique, la casse sociale, l’effondrement, la précarité continueraient à nous entraîner dans leur spirale mortifère n’aurait aucun sens pour nous. Nous aimons le logiciel libre, mais nous aimons encore plus les êtres humains. Et nous voulons agir dans un monde où notre lutte pour le libre et les communs est en cohérence avec nos aspirations pour un monde plus juste et durable.
Aujourd’hui : publier Peertube et nouer des alliances
Aujourd’hui, l’association Framasoft n’est pas peu fière d’annoncer la publication de la version 1.0 de PeerTube, notre alternative libre et fédérée à YouTube. Si vous souhaitez en savoir plus sur PeerTube, ça tombe bien : nous venons de publier un article complet à ce sujet !
Ce n’est pas la première fois que Framasoft se retrouve en position d’éditeur de logiciel libre, mais c’est la première fois que nous publions un logiciel d’une telle ambition (et d’une telle complexité). Pour cela, nous avons fait le pari l’an passé d’embaucher à temps plein son développeur, afin d’accompagner PeerTube de sa version alpha (octobre 2017) à sa version bêta (mars 2018), puis à sa version 1.0 (octobre 2018).
Le crowdfunding effectué cet été comportait un palier qui nous engageait à poursuivre le contrat de Chocobozzz, le développeur de PeerTube, afin de vous assurer que le développement ne s’arrêterait pas à une version 1.0 forcément perfectible. Ce palier n’a malheureusement pas été atteint, ce qui projetait un flou sur l’avenir de PeerTube à la fin du contrat de Chocobozzz.
Nous avons cependant une excellente nouvelle à vous annoncer ! Bien que le palier du crowdfunding n’ait pas été atteint, l’association Framasoft a fait le choix d’embaucher définitivement Chocobozzz (en CDI) afin de pérenniser PeerTube et de lui donner le temps et les moyens de construire une communauté solide et autonome. Cela représente un investissement non négligeable pour notre association, mais nous croyons fermement non seulement dans le logiciel PeerTube, mais aussi et surtout dans les valeurs qu’il porte (liberté, décentralisation, fédération, émancipation, indépendance). Sans parler des compétences de Chocobozzz lui-même qui apporte son savoir-faire à l’équipe technique dans d’autres domaines.
Nous espérons que vos dons viendront confirmer que vous approuvez notre choix.
D’ici la fin de l’année, annoncer de nouveaux projets… et une campagne de don
Comme vous l’aurez noté (ou pas encore !), nous avons complètement modifié notre page d’accueil « framasoft.org ». D’une page portail plutôt institutionnelle, décrivant assez exhaustivement « Qu’est-ce que Framasoft ? », nous l’avons recentrée sur « Que fait Framasoft ? » mettant en lumière quelques éléments clefs. En effet, l’association porte plus d’une cinquantaine de projets en parallèle et présenter d’emblée la Framagalaxie nous semblait moins pertinent que de « donner à voir » des actions choisies, tout en laissant la possibilité de tirer le fil pour découvrir l’intégralité de nos actions.
Nous y rappelons brièvement que Framasoft n’est pas une multinationale, mais une micro-association de 35 membres et 8 salarié⋅es (bientôt 9 : il reste quelques jours pour candidater !). Que nous sommes à l’origine de la campagne « Dégooglisons Internet » (plus de 30 services en ligne)… Mais pas seulement ! Certain⋅es découvriront peut-être l’existence de notre maison d’édition Framabook, ou de notre projet historique Framalibre. Nous y mettons en avant LE projet phare de cette année 2018 : PeerTube. D’autres projets à court terme sont annoncés sur cette page (en mode teasing), s’intégrant dans notre feuille de route Contributopia.
Framasoft n’est pas une multinationale, mais une micro-association
Enfin, nous vous invitons à faire un don pour soutenir ces actions. Car c’est aussi l’occasion de rappeler que l’association ne vit quasiment que de vos dons ! Ce choix fort, volontaire et assumé, nous insuffle notre plus grande force : notre indépendance. Que cela soit dans le choix des projets, dans le calendrier de nos actions, dans la sélection de nos partenaires, dans nos prises de paroles et avis publics, nous sommes indépendant⋅es, libres, et non-soumis⋅es à certaines conventions que nous imposerait le système de subventions ou de copinage avec les ministères ou toute autre institution.
Ce sont des milliers de donatrices et donateurs qui valident nos actions par leur soutien financier. Ce qu’on a fait vous a plu ? Vous pensez que nous allons dans le bon sens ? Alors, si vous en avez l’envie et les moyens, nous vous invitons à faire un don. C’est par ce geste que nous serons en mesure de verser les salaires des salarié⋅es de l’association, de payer les serveurs qui hébergent vos services préférés ou de continuer à intervenir dans des lieux ou devant des publics qui ont peu de moyens financiers (nous intervenons plus volontiers en MJC que devant l’Assemblée Nationale, et c’est un choix assumé). Rappelons que nos comptes sont publics et validés par un commissaire aux comptes indépendant.
En 2019, proposer des outils pour la société de contribution
Fin 2018, nous vous parlerons du projet phare que nous souhaitons développer pendant l’année 2019, dont le nom de code est Mobilizon. Au départ pensé comme une simple alternative à Meetup.com (ou aux événements Facebook, si vous préférez), nous avons aujourd’hui la volonté d’emmener ce logiciel bien plus loin afin d’en faire un véritable outil de mobilisation destiné à celles et ceux qui voudraient se bouger pour changer le monde, et s’organiser à 2 ou à 100 000, sans passer par des systèmes certes efficaces, mais aussi lourds, centralisés, et peu respectueux de la vie privée (oui, on parle de Facebook, là).
Évidemment, ce logiciel sera libre, mais aussi fédéré (comme Mastodon ou PeerTube), afin d’éviter de faire d’une structure (Framasoft ou autre), un point d’accès central, et donc de faiblesse potentielle du système. Nous vous donnerons plus de nouvelles dans quelques semaines, restez à l’écoute !
Éviter de faire d’une structure (Framasoft ou autre), un point d’accès central
D’autres projets sont prévus pour 2019 :
la sortie du (apparemment très attendu) Framapétitions ;
la publication progressive du MOOC CHATONS (cours en ligne gratuit et ouvert à toutes et tous), en partenariat avec la Ligue de l’Enseignement et bien d’autres. Ce MOOC, nous l’espérons, permettra à celles et ceux qui le souhaitent, de comprendre les problématiques de la concentration des acteurs sur Internet, et donc les enjeux de la décentralisation. Mais il donnera aussi de précieuses informations en termes d’organisation (création d’une association, modèle économique, gestion des usager⋅es, gestion communautaire, …) ainsi qu’en termes techniques (quelle infrastructure technique ? Comment la sécuriser ? Comment gérer les sauvegardes, etc.) ;
évidemment, bien d’autres projets en ligne (on ne va pas tout vous révéler maintenant, mais notre feuille de route donne déjà de bons indices)
Bref, on ne va pas chômer !
Dans les années à venir : se dédier à toujours plus d’éducation populaire, et des alliances
Nous avions coutume de présenter Framasoft comme « un réseau à géométrie variable ». Il est certain en tout cas que l’association est en perpétuelle mutation. Nous aimons le statut associatif (la loi de 1901 nous paraît l’une des plus belles au monde, rien que ça !), et nous avons fait le choix de rester en mode « association de potes » et de refuser — en tout cas jusqu’à nouvel ordre — une transformation en entreprise/SCOP/SCIC ou autre. Mais même si nous avons choisi de ne pas être des super-héro⋅ïnes et de garder l’association à une taille raisonnable (moins de 10 salarié⋅es), cela ne signifie pas pour autant que nous ne pouvons pas faire plus !
La seconde année de Contributopia Illustration de David Revoy – Licence : CC-By 4.0
Pour cela, de la même façon que nous proposons de mettre nos outils « au service de celles et ceux qui veulent changer le monde », nous sommes en train de créer des ponts avec de nombreuses structures qui n’ont pas de rapport direct avec le libre, mais avec lesquelles nous partageons un certain nombre de valeurs et d’objectifs.
Ainsi, même si leurs objets de militantisme ou leurs moyens d’actions ne sont pas les mêmes, nous aspirons à mettre les projets, ressources et compétences de Framasoft au service d’associations œuvrant dans des milieux aussi divers que ceux de : l’éducation à l’environnement, l’économie sociale et solidaire et écologique, la transition citoyenne, les discriminations et oppressions, la précarité, le journalisme citoyen, la défense des libertés fondamentales, etc. Bref, mettre nos compétences au service de celles et ceux qui luttent pour un monde plus juste et plus durable, afin qu’ils et elles puissent le faire avec des outils cohérents avec leurs valeurs et modulables selon leurs besoins.
Seul on va plus vite, ensemble on va plus loin. Nous pensons que le temps est venu de faire ensemble.
Framasoft est une association d’éducation populaire (qui a soufflé « d’éducation politique » ?), et nous n’envisageons plus de promouvoir ou de faire du libre « dans le vide ». Il y a quelques années, nous évoquions l’impossibilité chronique et structurelle d’échanger de façon équilibrée avec les institutions publiques nationales. Cependant, en nous rapprochant de réseaux d’éducation populaire existants (certains ont plus de cent ans), nos positions libristes et commonistes ont été fort bien accueillies. À tel point qu’aujourd’hui nous avons de nombreux projets en cours avec ces réseaux, qui démultiplieront l’impact de nos actions, et qui permettront — nous l’espérons — que le milieu du logiciel libre ne reste pas réservé à une élite de personnes maîtrisant le code et sachant s’y retrouver dans la jungle des licences.
Seul on va plus vite, ensemble on va plus loin. Nous pensons que le temps est venu de faire ensemble.
Nous avons besoin de vous !
Un des paris que nous faisons pour cette campagne est « d’informer sans sur-solliciter ». Et l’équilibre n’est pas forcément simple à trouver. Nous sommes en effet bien conscient⋅es qu’en ce moment, toutes les associations tendent la main et sollicitent votre générosité.
Nous ne souhaitons pas mettre en place de « dark patterns » que nous dénonçons par ailleurs. Nous pouvions jouer la carte de l’humour (si vous êtes détendu⋅es, vous êtes plus en capacité de faire des dons), celle de la gamification (si on met une jauge avec un objectif de dons, vous êtes plus enclin⋅es à participer), celle du chantage affectif (« Donnez, sinon… »), etc.
Le pari que nous prenons, que vous connaissiez Framasoft ou non, c’est qu’en prenant le temps de vous expliquer qui nous sommes, ce que nous avons fait, ce que nous sommes en train de faire, et là où nous voulons vous emmener, nous parlerons à votre entendement et non à vos pulsions. Vous pourrez ainsi choisir de façon éclairée si nos actions méritent d’être soutenues.
« Si tu veux construire un bateau, ne rassemble pas tes hommes et femmes pour leur donner des ordres, pour expliquer chaque détail, pour leur dire où trouver chaque chose. Si tu veux construire un bateau, fais naître dans le cœur de tes hommes et femmes le désir de la mer. » — Antoine de Saint-Exupéry
Nous espérons, à la lecture de cet article, vous avoir donné le désir de co-construire avec nous le Framasoft de demain, et que vous embarquerez avec nous.


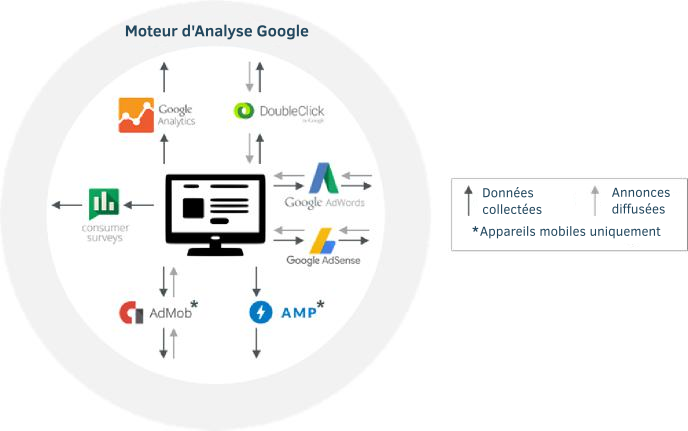
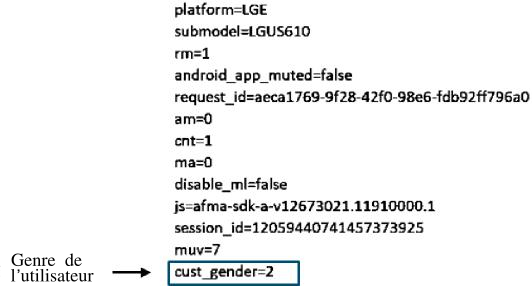
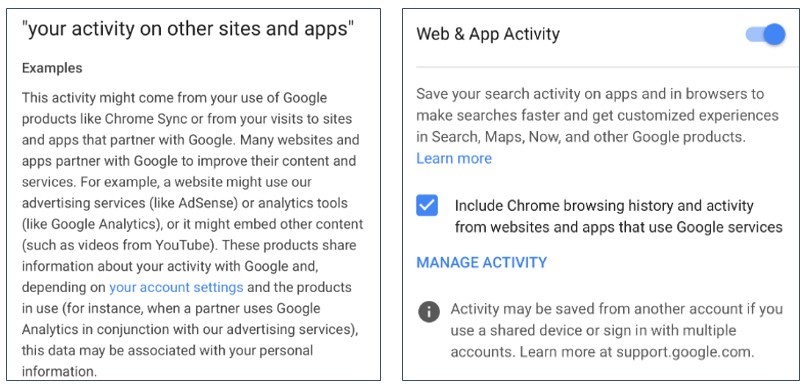

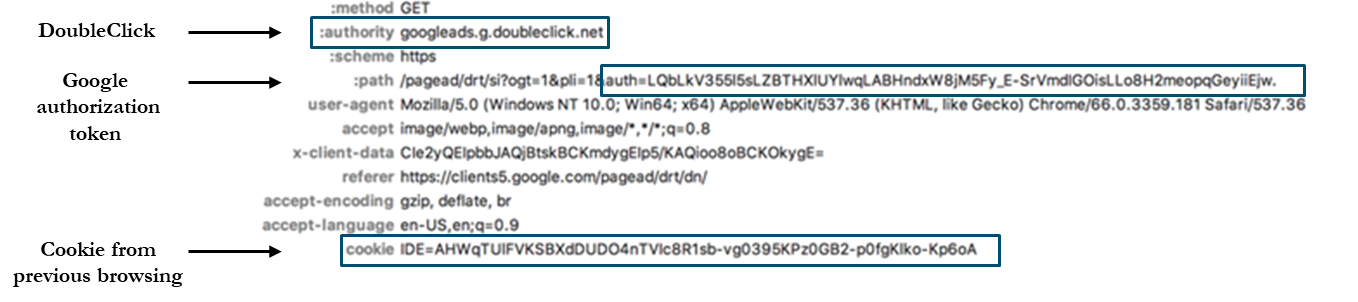

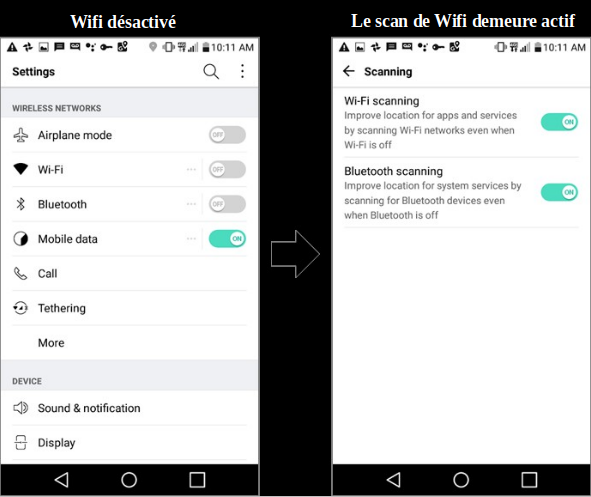

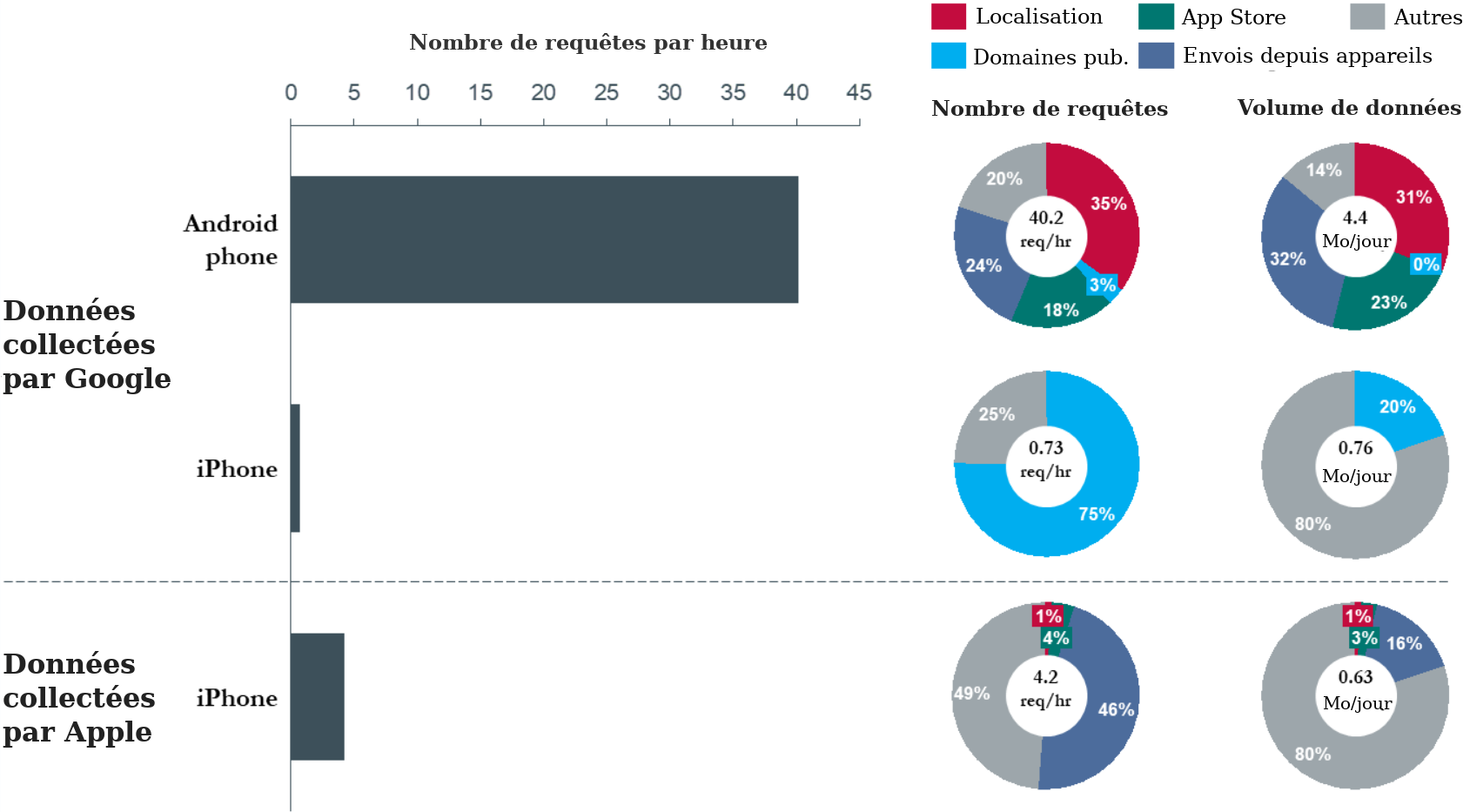






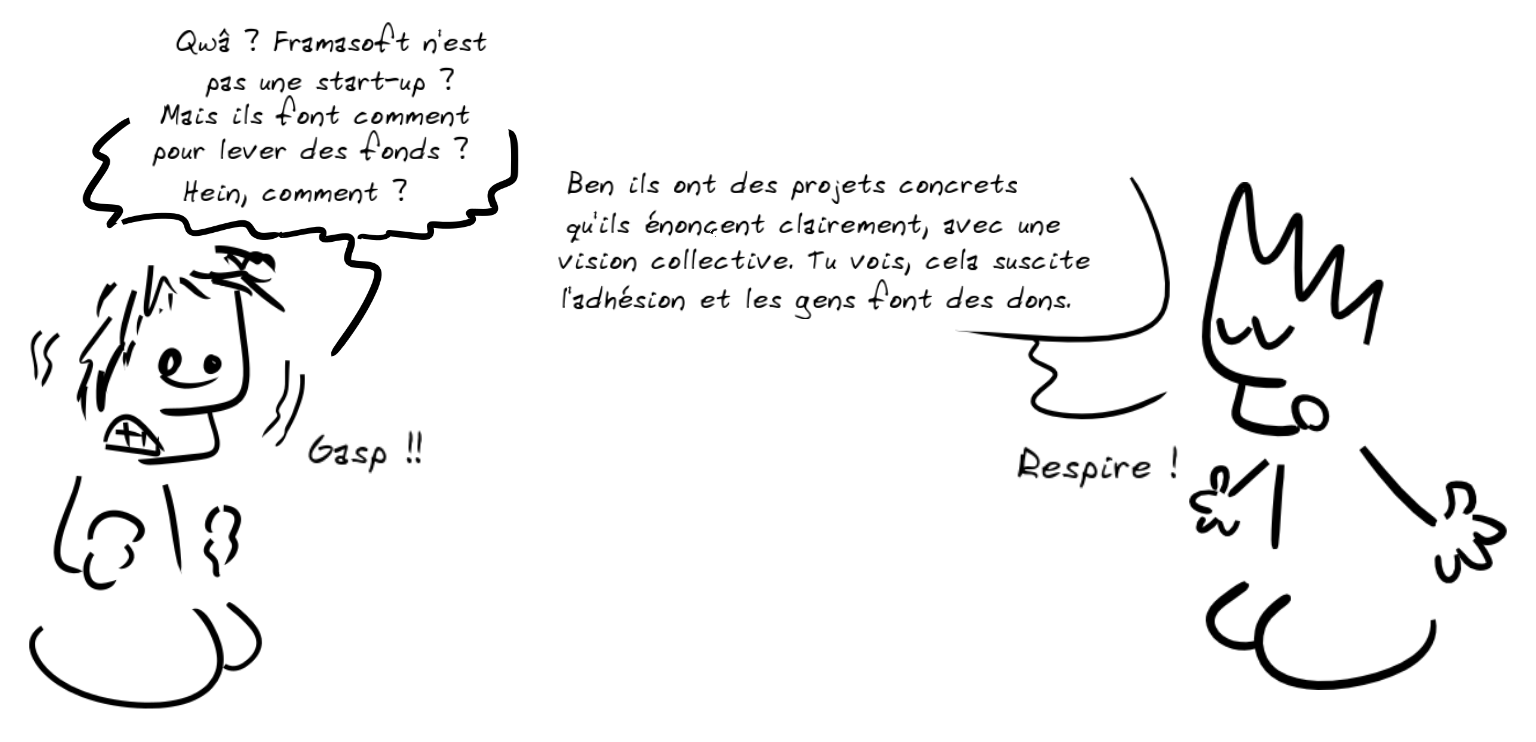

{kind=link}
{kind=link}