Vous ne voyez pas le rapport ? Eh bien eux, si. La petite association allemande qui anime le projet Permaculture Commons a de modestes ambitions : changer le monde.
Nous voulons soutenir la transformation de la société vers une culture plus durable. En collaboration avec une vaste communauté, nous aimerions rendre les modes de vie durables et la permaculture aussi accessibles que possible. Nous croyons que la permaculture est la voie à suivre et que les outils numériques, les licences libres et la collaboration mondiale sont la voie à suivre pour diffuser le message.
Oui c’est rafraîchissant et un poil utopique diront les plus sceptiques. Mais après tout, chez Framasoft, nous voulons aussi changer le monde un octet à la fois et nous aimons présenter les CHATONS que nous sommes comme « des AMAP du logiciel libre ». De sorte qu’au-delà de l’analogie, ce rapprochement entre les militants écologistes et la culture libre a éveillé l’attention du groupe Framalang.
Ah et puis, vous avez vu le thème des Journées du Logiciel Libre cette année ? Oui, vous y verrez pas mal de membres de Framasoft — et la conférence de Pyg : Numérique et effondrement : est-il encore temps de faire du libre sans vision politique et écologique ? (non)
Voilà pourquoi nous avons traduit pour vous le rapide survol de deux domaines qui ont peut-être un intérêt mutuel à contribuer. Ce n’est pas une longue réflexion théorique mais quelques suggestions. Le prétexte à une réflexion que nous vous proposons d’entamer dans les commentaires, lesquels demeurent ouverts et modérés.
Page d’accueil du site Permaculture Commons : «Travailler à un patrimoine commun de connaissances pour les peuples du monde entier qui veulent mener une vie durable et autodéterminée.»
Le terme « permaculture » est un mot-valise qui vient de l’association des deux mots « permanente » et « agriculture ». Il décrit une agriculture soutenable et respectueuse de l’environnement.
La notion a progressivement évolué pour englober maintenant des domaines comme les systèmes économiques, l’habitat et beaucoup d’autres formes de « culture permanente ».
L’objectif de la permaculture est de faire en sorte que les êtres humains soient à nouveau en phase avec les processus et les cycles de la nature, pour que nous puissions faire un usage efficace de la nature sans lui causer de dommages, mais en y contribuant.
Contexte
Le concept a été développé par Bill Mollison et David Holmgren dans les années 70 et comprend trois règles essentielles et douze principes de conception.
La Permaculture est un terme fluide et vague. Il inclut une grande variété de techniques, d’outils de conception et de modes de vie qui sont liés aux mêmes idéaux.
La plupart des idées viennent de l’observation de la nature. Les écosystèmes naturels, comme les forêts, n’ont pas besoin de fertilisants et ne produisent aucun déchet. Tous les éléments du système collaborent étroitement et remplissent des missions importantes. De telles observations peuvent souvent être appliquées au systèmes agricoles.
Citations
« Je suis sûr que je ne sais pas ce qu’est la permaculture. C’est ce que j’aime ; ce n’est pas dogmatique. […]
La permaculture a pour philosophie le travail avec la nature, plutôt que contre elle ; l’observation prolongée et attentive plutôt que le travail de la terre prolongé et irréfléchi ; et une façon de voir les plantes et les animaux dans toutes leurs fonctions, plutôt que traiter chaque élément naturel comme un système mono-produit. »
Le droit d’auteur est une loi qui protège la propriété intellectuelle. Pour les auteurs c’était assez compliqué d’autoriser certains usages, tout en conservant d’autres droits. Les licences libres autorisent les auteurs à avoir plus de contrôle sur l’utilisation de leur contenu. Avec les licences bien connues Creative Commons les auteurs ont trois possibilités basiques :
Autoriser ou non les adaptations de leur travail pour qu’il soit partagé
Autoriser ou non les adaptations à la seule condition qu’elles soient sous la même licence
Autoriser ou non l’utilisation commerciale de leur travail
Avec l’aide de ce petit outil de sélection sur le site Creative Commons il ne faut que quelques secondes et trois clics pour choisir la licence valide la plus appropriée pour vous. Cette petite vidéo1 détaille la marche à suivre :
Donc les licences libres (ou permissives, domaine public, copyleft) sont facilement utilisables pour partager et utiliser les contenus. Wikipédia est l’un des succès typiques de l’utilisation des licences Creative Commons. La version anglophone dépasse les 5 millions d’articles et la version francophone propose plus de 2 millions d’articles sous licence CC-BY-SA
Cela semble logique puisque ces licences aident le grand public et les biens collectifs.
D’accord, mais comment le savoir libre et la permaculture sont-ils liés ?
La permaculture et le mouvement de la culture libre ont plus en commun qu’on ne pourrait le croire.
Par exemple :
* Les deux mouvements sont mondiaux, conduits par des convictions communes, très hétérogènes, décentralisés et travaillent fondamentalement pour le bien commun.
* Les deux mouvements se réfèrent à une série modeste de principes et règles (les 4 libertés), les 12 principes et 3 points éthiques. Au-delà, les projets peuvent être très différents.
* Les solutions ou réalisations sont testées de façon indépendante, adaptées aux conditions de chacun et constamment améliorées. Dans les deux mouvements les personnes font preuve de curiosité et d’inventivité.
En particulier dans la sphère de la coopération (grâce à Internet), la culture libre a nettement plus d’expérience, et le mouvement de la permaculture pourrait en profiter.
L’idée
Imaginez davantage de documents sur la permaculture en licences libres et une promotion du libre échange des connaissances. Imaginez les connaissances communes pour les personnes du monde entier qui voudraient vivre une vie durable et autodéterminée : les communs de la permaculture.
Fragments, photos, objets abandonnés, vieux livres… Internet et les bibliothèques débordent de contenus qui pourraient contribuer à des projets pratiques et vivants, mais qui tombent dans l’oubli.
Les licences libres peuvent aider à transformer les déchets en contribution. Si ces éléments oubliés peuvent être utilisés sans galère, ils seront utilisés. À vrai dire, les déchets ça n’existe pas.
« À plusieurs le travail est plus facile »
Écrire un livre : travail difficile. Coder un logiciel de planification pour la permaculture : pfff, c’est du lourd.
Commençons petit, travaillons ensemble. Les licences libres sont faites pour la coopération et rendent d’énormes projets possibles.
Le système d’exploitation GNU/Linux est un bon exemple. Commencé par une seule personne, amélioré par 100 000 autres et en fait utilisé par tous les internautes aujourd’hui. Une incroyable success story qui est rendue possible par les licences libres.
Au fait : le Permablitz permet à un groupe d’accomplir plus en un jour que vous ne pourriez réussir à faire seul en plusieurs semaines. Et cela a un équivalent direct dans le monde de la culture libre : dans un Book Sprint les auteurs se rassemblent et rédigent un livre entier en 3-5 jours, c’est assez excitant et des résultats sont de grande qualité.
Il est vrai que l’écriture est un travail solitaire, mais vous seriez surpris par toute l’amitié que peut offrir un groupe de personnages imaginaires une fois que vous vous êtes mis à les connaître.
– Anne Tyler
L’image de l’auteur solitaire est solidement ancrée dans notre culture. Mais les bénéfices de la collaboration de plusieurs personnes avec différentes approches, expertises et même fuseaux horaires sont énormes.
Pour atteindre de nombreuses personnes, vous avez besoin d’une variété de supports, langues et styles. La collaboration et les licences libres permettent une variété inattendue.
Quand le vent de changement souffle, certains construisent des murs de protection, d’autres fabriquent des éoliennes.
– Proverbe chinois
Le livre imprimé perd de son importance, les livres sont scannés, partagés et téléchargés illégalement. Les éditeurs et les auteurs ne gagnent pas assez d’argent. On le constate jour après jour.
Il semble hautement improbable que ces choses changeront dans un avenir proche. Des lois sur le droit d’auteur plus strictes et une protection de la copie élaborée pourraient ralentir ces tendances négatives, mais elles ne les arrêteront pas.
Les auteurs peuvent décider de lutter ou de reconnaître de nouvelles éventualités et les utiliser.
Windows 10 : plongée en eaux troubles
Vous avez sans doute remarqué que lorsque les médias grand public évoquent les entreprises dominantes du numérique on entend « les GAFA » et on a tendance à oublier le M de Microsoft. Et pourtant…On sait depuis longtemps à quel point Microsoft piste ses utilisateurs, mais des mesures précises faisaient défaut. Le bref article que Framalang vous propose évoque les données d’une analyse approfondie de tout ce que Windows 10 envoie vers ses serveurs pratiquement à l’insu de ses utilisateurs…
Selon les services allemands de cybersécurité, Windows 10 vous surveille de 534 façons
par Derek Zimmer
L’Office fédéral de la sécurité des technologies de l’information (ou BSI) a publié un rapport2 (PDF, 3,4 Mo) qui détaille les centaines de façons dont Windows 10 piste les utilisateurs, et montre qu’à moins d’avoir la version Entreprise de Windows, les multiples paramètres de confidentialité ne font pratiquement aucune différence.
Seules les versions Entreprise peuvent les arrêter
Les versions normales de Windows ont seulement trois niveaux différents de télémétrie. Le BSI a trouvé qu’entre la version Basic et la version Full on passe de 503 à 534 procédés de surveillance. La seule véritable réduction de télémétrie vient des versions Entreprise de Windows qui peuvent utiliser un réglage supplémentaire de « sécurité » pour leur télémétrie qui réduit le nombre de traqueurs actifs à 13.
C’est la première investigation approfondie dans les processus et dans la base de registre de Windows pour la télémétrie
L’analyse est très détaillée, et cartographie le système Event Tracing for Windows (ETW), la manière dont Windows enregistre les données de télémétrie, comment et quand ces données sont envoyées aux serveurs de Microsoft, ainsi que la différence entre les différents niveaux de paramétrage de la télémétrie.
Cette analyse va jusqu’à montrer où sont contrôlés les réglages pour modifier individuellement les composants d’enregistrement dans la base de registre de Windows, et comment ils initialisent Windows.
Voici quelques faits intéressants issus de ce document :
• Windows envoie vos données vers les serveurs Microsoft toutes les 30 minutes ;
• La taille des données enregistrées équivaut à 12 à 16 Ko par heure sur un ordinateur inactif (ce qui, pour donner une idée, représente chaque jour à peu près le volume de données d’un petit roman comme Le Vieil homme et la mer d’Hemingway) ;
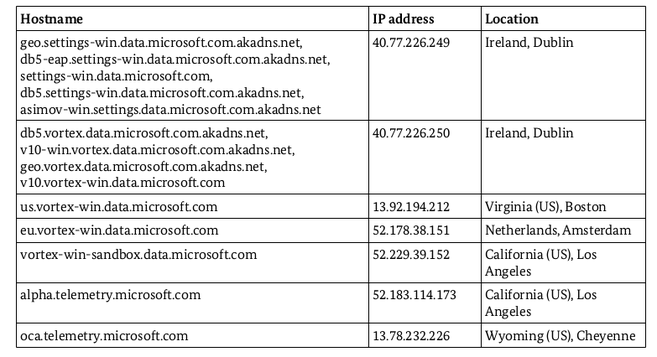
• Il envoie des informations à sept endroits différents, y compris l’Irlande, le Wyoming et la petite ville de Boston en Virginie. C’est la première « plongée en eaux profondes » que je voie où sont énumérés tous les enregistrements, ainsi que les endroits où va le trafic et à quelle fréquence.
Logiquement l’étape suivante consiste à découvrir ce qui figure dans ces 300 Ko de données quotidiennes. J’aimerais aussi savoir à quel point l’utilisation de Windows Media Player, Edge et les autres applications intégrées influe sur l’empreinte laissée par les données, ainsi que le nombre d’éléments actifs d’enregistrement.
Difficile de se prémunir
Au sein des communautés dédiées à l’administration des systèmes ou à la vie privée, la télémétrie Windows est l’objet de nombreuses discussions et il existe plusieurs guides sur les méthodes qui permettent de la désactiver complètement.
Comme toujours, la meilleure défense consiste à ne pas utiliser Windows. La deuxième meilleure défense semble être d’utiliser la version de Windows pour les entreprises où l’on peut désactiver la télémétrie d’une manière officielle. La troisième est d’essayer de la bloquer en changeant les paramètres et clefs de registre ainsi qu’en modifiant vos pare-feux (en dehors de Windows, parce que le pare-feu Windows ignorera les filtres qui bloquent les IP liées à la télémétrie Microsoft) ; en sachant que tout sera réactivé à chaque mise à jour majeure de Windows.
À propos de Derek Zimmer Derek est cryptanalyste, expert en sécurité et militant pour la protection de la vie privée. Fort de douze années d’expérience en sécurité et six années d’expérience en design et implémentation de systèmes respectant la vie privée, il a fondé le Open Source Technology Improvement Fund (OSTIF, Fond d’Amélioration des Technologies Open Source) qui vise à créer et améliorer les solutions de sécurité open source par de l’audit, du bug bounty, ainsi que par la collecte et la gestion de ressources.
Résistons à la pub sur Internet #bloquelapubnet
Aujourd’hui Framasoft (parmi d’autres) montre son soutien à l’association RAP (Résistance à l’Agression Publicitaire) ainsi qu’à la Quadrature du Net qui lancent une campagne de sensibilisation et d’action pour lutter contre les nuisances publicitaires non-consenties sur Internet.
#BloquelapubNet : un site pour expliquer comment se protéger
Cliquez sur l’image pour aller directement sur bloquelapub.net
Si vous, vous savez comment vous prémunir de cette pollution informationnelle… avez-vous déjà songé à aider vos proches, collègues et connaissances ? C’est compliqué de tout bien expliquer avec des mots simples, hein ? C’est justement à ça que sert le site bloquelapub.net : un tutoriel à suivre qui permet, en quelques clics, d’apprendre quelques gestes essentiels pour notre hygiène numérique. Voilà un site utile, à partager et communiquer autour de soi avec enthousiasme, sans modération et accompagné du mot clé #bloquelapubnet !
Pourquoi bloquer ? – Le communiqué
Nous reproduisons ci dessous le communiqué de presse des associations Résistance à l’Agression Publicitaire et La Quadrature du Net.
Internet est devenu un espace prioritaire pour les investissements des publicitaires. En France, pour la première fois en 2016, le marché de la publicité numérique devient le « premier média investi sur l’ensemble de l’année », avec une part de marché de 29,6%, devant la télévision. En 2017, c’est aussi le cas au niveau mondial. Ce jeune « marché » est principalement capté par deux géants de la publicité numérique. Google et Facebook. Ces deux géants concentrent à eux seuls autour de 50% du marché et bénéficient de la quasi-totalité des nouveaux investissements sur ce marché. « Pêché originel d’Internet », où, pour de nombreuses personnes et sociétés, il demeure difficile d’obtenir un paiement monétaire direct pour des contenus et services commerciaux et la publicité continue de s’imposer comme un paiement indirect.
Les services vivant de la publicité exploitent le « temps de cerveau disponible » des internautes qui les visitent, et qui n’en sont donc pas les clients, mais bien les produits. Cette influence est achetée par les annonceurs qui font payer le cout publicitaire dans les produits finalement achetés.
La publicité en ligne a plusieurs conséquences : en termes de dépendance vis-à-vis des annonceurs et des revenus publicitaires, et donc des limites sur la production de contenus et d’information, en termes de liberté de réception et de possibilité de limiter les manipulations publicitaires, sur la santé, l’écologie…
En ligne, ces problématiques qui concernent toutes les publicités ont de plus été complétées par un autre enjeu fondamental. Comme l’exprime parfaitement Zeynep Tufekci, une chercheuse turque, « on a créé une infrastructure de surveillance dystopique juste pour que des gens cliquent sur la pub ». De grandes entreprises telles que Google, Facebook et d’autres « courtiers en données » comme Criteo ont développés des outils visant à toujours mieux nous « traquer » dans nos navigations en ligne pour nous profiler publicitairement. Ces pratiques sont extrêmement intrusives et dangereuses pour les libertés fondamentales.
Il est plus temps que cette législation soit totalement respectée et que les publicitaires cessent de nous espionner en permanence en ligne.
Un sondage BVA-La Dépêche de 2018, révélait que 77% des Français·es se disent inquiet·es de l’utilisation que pouvaient faire des grandes entreprises commerciales de leurs données numériques personnelles. 83% des Français·es sont irrité·es par la publicité en ligne selon un sondage de l’institut CSA en mars 2016 et « seulement » 24% des personnes interrogées avaient alors installé un bloqueur de publicité.
Le blocage de la publicité en ligne apparait comme un bon outil de résistance pour se prémunir de la surveillance publicitaire sur Internet. Pour l’aider à se développer, nos associations lancent le site Internet :
Plusieurs opérations collectives ou individuelles de sensibilisation et blocages de la publicité auront lieu sur plusieurs villes du territoire français et sur Internet peu de temps avant et le jour du 28 janvier 2019, journée européenne de la « protection des données personnelles ». Le jour rêvé pour s’opposer à la publicité en ligne qui exploite ces données !
RAP et La Quadrature du Net demandent :
Le respect de la liberté de réception dans l’espace public et ailleurs, le droit et la possibilité de refuser d’être influencé par la publicité,
Le strict respect du règlement général pour la protection des données et l’interdiction de la collecte de données personnelles à des fins publicitaires sans le recueil d’un consentement libre (non-conditionnant pour l’accès au service), explicite et éclairé où les paramètres les plus protecteurs sont configurés par défaut. Les sites Internet et services en ligne ne doivent par défaut collecter aucune information à des fins publicitaires sans que l’internaute ne les y ait expressément autorisés.
Rendez-vous sur bloquelapub.net et sur Internet toute la journée du 28 janvier 2019
Les associations soutiens de cette mobilisation : Framasoft, Le CECIL, Globenet, Le Creis-Terminal
Pour un Web frugal ?
Sites lourds, sites lents, pages web obèses qui exigent pour être consultées dans un délai raisonnable une carte graphique performante, un processeur rapide et autant que possible une connexion par fibre optique… tel est le quotidien de l’internaute ordinaire.
Nul besoin de remonter aux débuts du Web pour comparer : c’est d’une année sur l’autre que la taille moyenne des pages web s’accroît désormais de façon significative.
Quant à la consommation en énergie de notre vie en ligne, elle prend des proportions qui inquiètent à juste titre : des lointains datacenters aux hochets numériques dont nous aimons nous entourer, il y a de quoi se poser des questions sur la nocivité environnementale de nos usages collectifs et individuels.
Bien sûr, les solutions économes à l’échelle de chacun sont peut-être dérisoires au regard des gigantesques gaspillages d’un système consumériste insatiable et énergivore.
Cependant nous vous invitons à prendre en considération l’expérience de l’équipe barcelonaise de Low-Tech Magazine dont nous avons traduit pour vous un article. Un peu comme l’association Framasoft l’avait fait en ouverture de la campagne dégooglisons… en se dégooglisant elle-même, les personnes de Low-tech Magazine ont fait de leur mieux pour appliquer à leur propre site les principes de frugalité qu’elles défendent : ce ne sont plus seulement les logiciels mais aussi les matériels qui ont fait l’objet d’une cure d’amaigrissement au régime solaire.
En espérant que ça donnera des idées à tous les bidouilleurs…
article original : How to build a Low-tech website Traduction Framalang : Khrys, Mika, Bidouille, Penguin, Eclipse, Barbara, Mannik, jums, Mary, Cyrilus, goofy, simon, xi, Lumi, Suzy + 2 auteurs anonymes
Comment créer un site web basse technologie
Low-tech Magazine a été créé en 2007 et n’a que peu changé depuis. Comme une refonte du site commençait à être vraiment nécessaire, et comme nous essayons de mettre en œuvre ce que nous prônons, nous avons décidé de mettre en place une version de Low Tech Magazine en basse technologie, auto-hébergée et alimentée par de l’énergie solaire. Le nouveau blog est conçu pour réduire radicalement la consommation d’énergie associée à l’accès à notre contenu.
Premier prototype du serveur alimenté à l’énergie solaire sur lequel tourne le nouveau site.
Pour éviter les conséquences négatives d’une consommation énergivore, les énergies renouvelables seraient un moyen de diminuer les émissions des centres de données. Par exemple, le rapport annuel ClickClean de Greenpeace classe les grandes entreprises liées à Internet en fonction de leur consommation d’énergies renouvelables.
Cependant, faire fonctionner des centres de données avec des sources d’énergie renouvelables ne suffit pas à compenser la consommation d’énergie croissante d’Internet. Pour commencer, Internet utilise déjà plus d’énergie que l’ensemble des énergies solaire et éolienne mondiales. De plus, la réalisation et le remplacement de ces centrales électriques d’énergies renouvelables nécessitent également de l’énergie, donc si le flux de données continue d’augmenter, alors la consommation d’énergies fossiles aussi.
Cependant, faire fonctionner les centres de données avec des sources d’énergie renouvelables ne suffit pas à combler la consommation d’énergie croissante d’Internet.
Enfin, les énergies solaire et éolienne ne sont pas toujours disponibles, ce qui veut dire qu’un Internet fonctionnant à l’aide d’énergies renouvelables nécessiterait une infrastructure pour le stockage de l’énergie et/ou pour son transport, ce qui dépend aussi des énergies fossiles pour sa production et son remplacement. Alimenter les sites web avec de l’énergie renouvelable n’est pas une mauvaise idée, mais la tendance vers l’augmentation de la consommation d’énergie doit aussi être traitée.
Des sites web qui enflent toujours davantage
Tout d’abord, le contenu consomme de plus en plus de ressources. Cela a beaucoup à voir avec l’importance croissante de la vidéo, mais une tendance similaire peut s’observer sur les sites web.
La taille moyenne d’une page web (établie selon les pages des 500 000 domaines les plus populaires) est passée de 0,45 mégaoctets en 2010 à 1,7 mégaoctets en juin 2018. Pour les sites mobiles, le poids moyen d’une page a décuplé, passant de 0,15 Mo en 2011 à 1,6 Mo en 2018. En utilisant une méthode différente, d’autres sources évoquent une moyenne autour de 2,9 Mo en 2018.
La croissance du transport de données surpasse les avancées en matière d’efficacité énergétique (l’énergie requise pour transférer 1 mégaoctet de données sur Internet), ce qui engendre toujours plus de consommation d’énergie. Des sites plus « lourds » ou plus « gros » ne font pas qu’augmenter la consommation d’énergie sur l’infrastructure du réseau, ils raccourcissent aussi la durée de vie des ordinateurs, car des sites plus lourds nécessitent des ordinateurs plus puissants pour y accéder. Ce qui veut dire que davantage d’ordinateurs ont besoin d’être fabriqués, une production très coûteuse en énergie.
Être toujours en ligne ne fait pas bon ménage avec des sources d’énergies renouvelables telles que l’éolien ou le solaire, qui ne sont pas toujours disponibles.
La deuxième raison de l’augmentation de la consommation énergétique d’Internet est que nous passons de plus en plus de temps en ligne. Avant l’arrivée des ordinateurs portables et du Wi-Fi, nous n’étions connectés au réseau que lorsque nous avions accès à un ordinateur fixe au bureau, à la maison ou à la bibliothèque. Nous vivons maintenant dans un monde où quel que soit l’endroit où nous nous trouvons, nous sommes toujours en ligne, y compris, parfois, sur plusieurs appareils à la fois.
Un accès Internet en mode « toujours en ligne » va de pair avec un modèle d’informatique en nuage, permettant des appareils plus économes en énergie pour les utilisateurs au prix d’une dépense plus importante d’énergie dans des centres de données. De plus en plus d’activités qui peuvent très bien se dérouler hors-ligne nécessitent désormais un accès Internet en continu, comme écrire un document, remplir une feuille de calcul ou stocker des données. Tout ceci ne fait pas bon ménage avec des sources d’énergies renouvelables telles que l’éolien ou le solaire, qui ne sont pas disponibles en permanence.
Conception d’un site internet basse technologie
La nouvelle mouture de notre site répond à ces deux problématiques. Grâce à une conception simplifiée de notre site internet, nous avons réussi à diviser par cinq la taille moyenne des pages du blog par rapport à l’ancienne version, tout en rendant le site internet plus agréable visuellement (et plus adapté aux mobiles). Deuxièmement, notre nouveau site est alimenté à 100 % par l’énergie solaire, non pas en théorie, mais en pratique : il a son propre stockage d’énergie et sera hors-ligne lorsque le temps sera couvert de manière prolongée.
Internet n’est pas une entité autonome. Sa consommation grandissante d’énergie est la résultante de décisions prises par des développeurs logiciels, des concepteurs de site internet, des départements marketing, des annonceurs et des utilisateurs d’internet. Avec un site internet poids plume alimenté par l’énergie solaire et déconnecté du réseau, nous voulons démontrer que d’autres décisions peuvent être prises.
Avec 36 articles en ligne sur environ une centaine, le poids moyen d’une page sur le site internet alimenté par énergie solaire est environ cinq fois inférieur à celui de la version précédente.
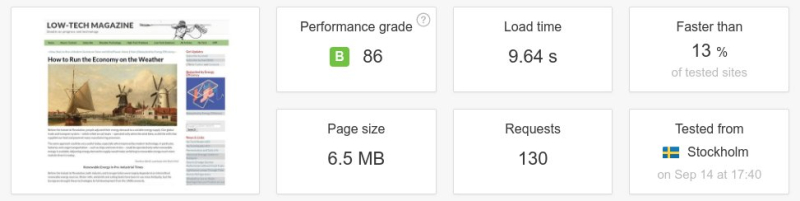
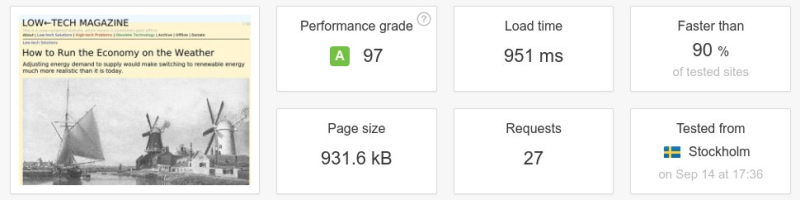
Pour commencer, la nouvelle conception du site va à rebours de la tendance à des pages plus grosses. Sur 36 articles actuellement en ligne sur environ une centaine, le poids moyen d’une page sur le site internet alimenté par énergie solaire est 0,77 Mo – environ cinq fois inférieur à celui de la version précédente, et moins de la moitié du poids moyen d’une page établi sur les 500 000 blogs les plus populaires en juin 2018.
Ci-dessous : un test de vitesse d’une page web entre l’ancienne et la nouvelle version du magazine Low-Tech. La taille de la page a été divisée par plus de six, le nombre de requêtes par cinq, et la vitesse de téléchargement a été multipliée par dix. Il faut noter que l’on n’a pas conçu le site internet pour être rapide, mais pour une basse consommation d’énergie. La vitesse aurait été supérieure si le serveur avait été placé dans un centre de données et/ou à une position plus centrale de l’infrastructure d’Internet.
Ci-dessous sont détaillées plusieurs des décisions de conception que nous avons faites pour réduire la consommation d’énergie. Des informations plus techniques sont données sur une page distincte. Nous avons aussi libéré le code source pour la conception de notre site internet.
Site statique
Un des choix fondamentaux que nous avons faits a été d’élaborer un site internet statique. La majorité des sites actuels utilisent des langages de programmation côté serveur qui génèrent la page désirée à la volée par requête à une base de données. Ça veut dire qu’à chaque fois que quelqu’un visite une page web, elle est générée sur demande.
Au contraire, un site statique est généré une fois pour toutes et existe comme un simple ensemble de documents sur le disque dur du serveur. Il est toujours là, et pas seulement quand quelqu’un visite la page. Les sites internet statiques sont donc basés sur le stockage de fichiers quand les sites dynamiques dépendent de calculs récurrents. En conséquence, un site statique nécessite moins de puissance de calcul, donc moins d’énergie.
Le choix d’un site statique nous permet d’opérer la gestion de notre site de manière économique depuis notre bureau de Barcelone. Faire la même chose avec un site web généré depuis une base de données serait quasiment impossible, car cela demanderait trop d’énergie. Cela présenterait aussi des risques importants de sécurité. Bien qu’un serveur avec un site statique puisse toujours être piraté, il y a significativement moins d’attaques possibles et les dommages peuvent être plus facilement réparés.
Images optimisées pour en réduire le « poids »
Le principal défi a été de réduire la taille de la page sans réduire l’attractivité du site. Comme les images consomment l’essentiel de la bande passante il serait facile d’obtenir des pages très légères et de diminuer l’énergie nécessaire en supprimant les images, en réduisant leur nombre ou en réduisant considérablement leur taille. Néanmoins, les images sont une part importante de l’attractivité de Low-tech Magazine et le site ne serait pas le même sans elles.
Par optimisation, on peut rendre les images dix fois moins gourmandes en ressources, tout en les affichant bien plus largement que sur l’ancien site.
Nous avons plutôt choisi d’appliquer une ancienne technique de compression d’image appelée « diffusion d’erreur ». Le nombre de couleurs d’une image, combiné avec son format de fichier et sa résolution, détermine la taille de cette image. Ainsi, plutôt que d’utiliser des images en couleurs à haute résolution, nous avons choisi de convertir toutes les images en noir et blanc, avec quatre niveaux de gris intermédiaires.
Ces images en noir et blanc sont ensuite colorées en fonction de la catégorie de leur contenu via les capacités de manipulation d’image natives du navigateur. Compressées par ce module appelé dithering, les images présentées dans ces articles ajoutent beaucoup moins de poids au contenu ; par rapport à l’ancien site web, elles sont environ dix fois moins consommatrices de ressources.
Police de caractère par défaut / Pas de logo
Toutes les ressources chargées, y compris les polices de caractères et les logos, le sont par une requête supplémentaire au serveur, nécessitant de l’espace de stockage et de l’énergie. Pour cette raison, notre nouveau site web ne charge pas de police personnalisée et enlève toute déclaration de liste de polices de caractères, ce qui signifie que les visiteurs verront la police par défaut de leur navigateur.
Une page du magazine en version basse consommation
Nous utilisons une approche similaire pour le logo. En fait, Low-tech Magazine n’a jamais eu de véritable logo, simplement une bannière représentant une lance, considérée comme une arme low-tech (technologie sobre) contre la supériorité prétendue des « high-tech » (hautes technologies).
Au lieu d’un logo dessiné, qui nécessiterait la production et la distribution d’image et de polices personnalisées, la nouvelle identité de Low-Tech Magazine consiste en une unique astuce typographique : utiliser une flèche vers la gauche à la place du trait d’union dans le nom du blog : LOW←TECH MAGAZINE.
Pas de pistage par un tiers, pas de services de publicité, pas de cookies
Les logiciels d’analyse de sites tels que Google Analytics enregistrent ce qui se passe sur un site web, quelles sont les pages les plus vues, d’où viennent les visiteurs, etc. Ces services sont populaires car peu de personnes hébergent leur propre site. Cependant l’échange de ces données entre le serveur et l’ordinateur du webmaster génère du trafic de données supplémentaire et donc de la consommation d’énergie.
Avec un serveur auto-hébergé, nous pouvons obtenir et visualiser ces mesures de données avec la même machine : tout serveur génère un journal de ce qui se passe sur l’ordinateur. Ces rapports (anonymes) ne sont vus que par nous et ne sont pas utilisés pour profiler les visiteurs.
Avec un serveur auto-hébergé, pas besoin de pistage par un tiers ni de cookies.
Low-tech Magazine a utilisé des publicités Google Adsense depuis ses débuts en 2007. Bien qu’il s’agisse d’une ressource financière importante pour maintenir le blog, elles ont deux inconvénients importants. Le premier est la consommation d’énergie : les services de publicité augmentent la circulation des données, ce qui consomme de l’énergie.
Deuxièmement, Google collecte des informations sur les visiteurs du blog, ce qui nous contraint à développer davantage les déclarations de confidentialité et les avertissements relatifs aux cookies, qui consomment aussi des données et agacent les visiteurs. Nous avons donc remplacé Adsense par d’autres sources de financement (voir ci-dessous pour en savoir plus). Nous n’utilisons absolument aucun cookie.
À quelle fréquence le site web sera-t-il hors-ligne ?
Bon nombre d’entreprises d’hébergement web prétendent que leurs serveurs fonctionnent avec de l’énergie renouvelable. Cependant, même lorsqu’elles produisent de l’énergie solaire sur place et qu’elles ne se contentent pas de « compenser » leur consommation d’énergie fossile en plantant des arbres ou autres, leurs sites Web sont toujours en ligne.
Cela signifie soit qu’elles disposent d’un système géant de stockage sur place (ce qui rend leur système d’alimentation non durable), soit qu’elles dépendent de l’énergie du réseau lorsqu’il y a une pénurie d’énergie solaire (ce qui signifie qu’elles ne fonctionnent pas vraiment à 100 % à l’énergie solaire).
Le panneau photo-voltaïque solaire de 50 W. Au-dessus, un panneau de 10 W qui alimente un système d’éclairage.
En revanche, ce site web fonctionne sur un système d’énergie solaire hors réseau avec son propre stockage d’énergie et hors-ligne pendant les périodes de temps nuageux prolongées. Une fiabilité inférieure à 100 % est essentielle pour la durabilité d’un système solaire hors réseau, car au-delà d’un certain seuil, l’énergie fossile utilisée pour produire et remplacer les batteries est supérieure à l’énergie fossile économisée par les panneaux solaires.
Reste à savoir à quelle fréquence le site sera hors ligne. Le serveur web est maintenant alimenté par un nouveau panneau solaire de 50 Wc et une batterie plomb-acide (12V 7Ah) qui a déjà deux ans. Comme le panneau solaire est à l’ombre le matin, il ne reçoit la lumière directe du soleil que 4 à 6 heures par jour. Dans des conditions optimales, le panneau solaire produit ainsi 6 heures x 50 watts = 300 Wh d’électricité.
Le serveur web consomme entre 1 et 2,5 watts d’énergie (selon le nombre de visiteurs), ce qui signifie qu’il consomme entre 24 et 60 Wh d’électricité par jour. Dans des conditions optimales, nous devrions donc disposer de suffisamment d’énergie pour faire fonctionner le serveur web 24 heures sur 24. La production excédentaire d’énergie peut être utilisée pour des applications domestiques.
Nous prévoyons de maintenir le site web en ligne pendant un ou deux jours de mauvais temps, après quoi il sera mis hors ligne.
Cependant, par temps nuageux, surtout en hiver, la production quotidienne d’énergie pourrait descendre à 4 heures x 10 watts = 40 watts-heures par jour, alors que le serveur nécessite entre 24 et 60 Wh par jour. La capacité de stockage de la batterie est d’environ 40 Wh, en tenant compte de 30 % des pertes de charge et de décharge et de 33 % de la profondeur ou de la décharge (le régulateur de charge solaire arrête le système lorsque la tension de la batterie tombe à 12 V).
Par conséquent, le serveur solaire restera en ligne pendant un ou deux jours de mauvais temps, mais pas plus longtemps. Cependant, il s’agit d’estimations et nous pouvons ajouter une deuxième batterie de 7 Ah en automne si cela s’avère nécessaire. Nous visons un uptime, c’est-à-dire un fonctionnement sans interruption, de 90 %, ce qui signifie que le site sera hors ligne pendant une moyenne de 35 jours par an.
Premier prototype avec batterie plomb-acide (12 V 7 Ah) à gauche et batterie Li-Po UPS (3,7V 6600 mA) à droite. La batterie au plomb-acide fournit l’essentiel du stockage de l’énergie, tandis que la batterie Li-Po permet au serveur de s’arrêter sans endommager le matériel (elle sera remplacée par une batterie Li-Po beaucoup plus petite).
Quel est la période optimale pour parcourir le site ?
L’accessibilité à ce site internet dépend de la météo à Barcelone en Espagne, endroit où est localisé le serveur. Pour aider les visiteurs à « planifier » leurs visites à Low-tech Magazine, nous leur fournissons différentes indications.
Un indicateur de batterie donne une information cruciale parce qu’il peut indiquer au visiteur que le site internet va bientôt être en panne d’énergie – ou qu’on peut le parcourir en toute tranquillité. La conception du site internet inclut une couleur d’arrière-plan qui indique la charge de la batterie qui alimente le site Internet grâce au soleil. Une diminution du niveau de charge indique que la nuit est tombée ou que la météo est mauvaise.
Outre le niveau de batterie, d’autres informations concernant le serveur du site web sont affichées grâce à un tableau de bord des statistiques. Celui-ci inclut des informations contextuelles sur la localisation du serveur : heure, situation du ciel, prévisions météorologiques, et le temps écoulé depuis la dernière fois où le serveur s’est éteint à cause d’un manque d’électricité.
SERVEUR : Ce site web fonctionne sur un ordinateur Olimex A20. Il est doté de 2 GHz de vitesse de processeur, 1 Go de RAM et 16 Go d’espace de stockage. Le serveur consomme 1 à 2,5 watts de puissance.
SOFTWARE DU SERVEUR : le serveur web tourne sur Armbian Stretch, un système d’exploitation Debian construit sur un noyau SUNXI. Nous avons rédigé une documentation technique sur la configuration du serveur web.
LOGICIEL DE DESIGN : le site est construit avec Pelican, un générateur de sites web statiques. Nous avons publié le code source de « solar », le thème que nous avons développé.
CONNEXION INTERNET. Le serveur est connecté via une connexion Internet fibre 100 MBps. Voici comment nous avons configuré le routeur. Pour l’instant, le routeur est alimenté par le réseau électrique et nécessite 10 watts de puissance. Nous étudions comment remplacer ce routeur gourmand en énergie par un routeur plus efficace qui pourrait également être alimenté à l’énergie solaire.
SYSTÈME SOLAIRE PHOTOVOLTAÏQUE. Le serveur fonctionne avec un panneau solaire de 50 Wc et une batterie plomb-acide 12 V 7 Ah. Cependant, nous continuons de réduire la taille du système et nous expérimentons différentes configurations. L’installation photovoltaïque est gérée par un régulateur de charge solaire 20A.
Qu’est-il arrivé à l’ancien site ?
Le site Low-tech Magazine alimenté par énergie solaire est encore en chantier. Pour le moment, la version alimentée par réseau classique reste en ligne. Nous encourageons les lecteurs à consulter le site alimenté par énergie solaire, s’il est disponible. Nous ne savons pas trop ce qui va se passer ensuite. Plusieurs options se présentent à nous, mais la plupart dépendront de l’expérience avec le serveur alimenté par énergie solaire.
Tant que nous n’avons pas déterminé la manière d’intégrer l’ancien et le nouveau site, il ne sera possible d’écrire et lire des commentaires que sur notre site internet alimenté par réseau, qui est toujours hébergé chez TypePad. Si vous voulez envoyer un commentaire sur le serveur web alimenté en énergie solaire, vous pouvez en commentant cette page ou en envoyant un courriel à solar (at) lowtechmagazine (dot) com.
Est-ce que je peux aider ?
Bien sûr, votre aide est la bienvenue.
D’une part, nous recherchons des idées et des retours d’expérience pour améliorer encore plus le site web et réduire sa consommation d’énergie. Nous documenterons ce projet de manière détaillée pour que d’autres personnes puissent aussi faire des sites web basse technologie.
D’autre part, nous espérons recevoir des contributions financières pour soutenir ce projet. Les services publicitaires qui ont maintenu Low-tech Magazine depuis ses débuts en 2007 sont incompatibles avec le design de notre site web poids plume. C’est pourquoi nous cherchons d’autres moyens de financer ce site :
1. Nous proposerons bientôt un service de copies du blog imprimées à la demande. Grâce à ces publications, vous pourrez lire le Low-tech Magazine sur papier, à la plage, au soleil, où vous voulez, quand vous voulez.
2. Vous pouvez nous soutenir en envoyant un don sur PayPal, Patreon ou LiberaPay.
3. Nous restons ouverts à la publicité, mais nous ne pouvons l’accepter que sous forme d’une bannière statique qui renvoie au site de l’annonceur. Nous ne travaillons pas avec les annonceurs qui ne sont pas en phase avec notre mission.
Les données que récolte Google – Ch.7 et conclusion
Voici déjà la traduction du septième chapitre et de la brève conclusion de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà publiés.
Il s’agit cette fois-ci de tous les récents produits de Google (ou plutôt Alphabet) qui investissent nos pratiques et nos habitudes : des pages AMP aux fournisseurs de services tiers en passant par les assistants numériques, tout est prétexte à collecte de données directement ou non.
VII. Des produits avec un haut potentiel futur d’agrégation de données
83. Google a d’autres produits qui pourraient être adoptés par le marché et pourraient bientôt servir à la collecte de données, tels que AMP, Photos, Chromebook Assistant et Google Pay. Il faut ajouter à cela que Google est capable d’utiliser les données provenant de partenaires pour collecter les informations de l’utilisateur. La section suivante les décrit plus en détail.
84. Il existe également d’autres applications Google qui peuvent ne pas être largement utilisées. Toutefois, par souci d’exhaustivité, la collecte de données par leur intermédiaire est présentée dans la section VIIII.B de l’annexe.
A. Pages optimisées pour les mobiles (AMP)
85. Les Pages optimisées pour les mobiles (AMP) sont une initiative open source menée par Google pour réduire le temps de chargement des sites Web et des publicités. AMP convertit le HTML standard et le code JavaScript en une version simplifiée développée par Google3 qui stocke les pages validées dans un cache des serveurs du réseau Google pour un accès plus rapide4. AMP fournit des liens vers les pages grâce aux résultats de la recherche Google mais également via des applications tierces telles que LinkedIn et Twitter. D’après AMP : « L’ecosystème AMP compte 25 millions de domaines, plus de 100 fournisseurs de technologie et plateformes de pointe qui couvrent les secteurs de la publication de contenu, les publicités, le commerce en ligne, les petits commerces, le commerce local etc. »5
86. L’illustration 17a décrit les étapes menant à la fourniture d’une page AMP accessible via la recherche Google. Merci de noter que le fournisseur de contenu à travers AMP n’a pas besoin de fournir ses propres caches serveur, car c’est quelque chose que Google fournit pour garantir un délai optimal de livraison aux utilisateurs. Dans la mesure où le cache AMP est hébergé sur les serveurs de Google, lors d’un clic sur un lien AMP produit par la recherche Google, le nom de domaine vient du domaine google.com et non pas du domaine du fournisseur. Ceci est montré grâce aux captures prises lors d’un exemple de recherche de mots clés dans l’illustration 17b.
Illustration 17 : une page web normale qui devient une page AMP.
87. Les utilisateurs peuvent accéder au contenu depuis de multiples fournisseurs dont les articles apparaissent dans les résultats de recherche pendant qu’ils naviguent dans le carrousel AMP, tout en restant dans le domaine de Google. En effet, le cache AMP opère comme un réseau de distribution de contenu (RDC, ou CDN en anglais) appartenant à Google et géré par Google.
88. En créant un outil open source, complété avec un CDN, Google a attiré une large base d’utilisateurs à qui diffuser les sites mobiles et la publicité et cela constitue une quantité d’information significative (p.ex. le contenu lui-même, les pages vues, les publicités, et les informations de celui à qui ce contenu est fourni). Toutes ces informations sont disponibles pour Google parce qu’elles sont collectées sur les serveurs CDN de Google, fournissant ainsi à Google beaucoup plus de données que par tout autre moyen d’accès.
89. L’AMP est très centré sur l’utilisateur, c’est-à-dire qu’il offre aux utilisateurs une expérience de navigation beaucoup plus rapide et améliorée sans l’encombrement des fenêtres pop-up et des barres latérales. Bien que l’AMP représente un changement majeur dans la façon dont le contenu est mis en cache et transmis aux utilisateurs, la politique de confidentialité de Google associée à l’AMP est assez générale6. En particulier, Google est en mesure de recueillir des informations sur l’utilisation des pages Web (par exemple, les journaux de serveur et l’adresse IP) à partir des requêtes envoyées aux serveurs de cache AMP. De plus, les pages standards sont converties en AMP via l’utilisation des API AMP7. Google peut donc accéder à des applications ou à des sites Web (« clients API ») et utiliser toute information soumise par le biais de l’API conformément à ses politiques générales8.
90. Comme les pages Web ordinaires, les pages Web AMP pistent les données d’utilisation via Google Analytics et DoubleClick. En particulier, elles recueillent des informations sur les données de page (par exemple : domaine, chemin et titre de page), les données d’utilisateur (par exemple : ID client, fuseau horaire), les données de navigation (par exemple : ID et référence de page uniques), l’information du navigateur et les données sur les interactions et les événements9. Bien que les modes de collecte de données de Google n’aient pas changé avec l’AMP, la quantité de données recueillies a augmenté puisque les visiteurs passent 35 % plus de temps sur le contenu Web qui se charge avec Google AMP que sur les pages mobiles standard.10
B. Google Assistant
91. Google Assistant est un assistant personnel virtuel auquel on accède par le biais de téléphones mobiles et d’appareils dits intelligents. C’est un assistant virtuel populaire, comme Siri d’Apple, Alexa d’Amazon et Cortana de Microsoft. 11 Google Assistant est accessible via le bouton d’accueil des appareils mobiles sous Android 6.0 ou versions ultérieures. Il est également accessible via une application dédiée sur les appareils iOS12, ainsi que par l’intermédiaire de haut-parleurs intelligents, tel Google Home, qui offre de nombreuses fonctions telles que l’envoi de textes, la recherche de courriels, le contrôle de la musique, la recherche de photos, les réponses aux questions sur la météo ou la circulation, et le contrôle des appareils domestiques intelligents13.
92. Google collecte toutes les requêtes de Google Assistant, qu’elles soient audio ou saisies au clavier. Il collecte également l’emplacement où la requête a été effectuée. L’illustration 18 montre le contenu d’une requête enregistrée par Google. Outre son utilisation via les haut-parleurs de Google Home, Google Assistant est activé sur divers autres haut-parleurs produits par des tiers (par exemple, les casques sans fil de Bose). Au total, Google Assistant est disponible sur plus de 400 millions d’appareils14. Google peut collecter des données via l’ensemble de ces appareils puisque les requêtes de l’Assistant passent par les serveurs de Google.
Figure 18 : Exemple de détails collectés à partir de la requête Google Assistant.
C. Photos
93. Google Photos est utilisé par plus de 500 millions de personnes dans le monde et stocke plus de 1,2 milliard de photos et vidéos chaque jour15. Google enregistre l’heure et les coordonnées GPS de chaque photo prise.Google télécharge des images dans le Google cloud et effectue une analyse d’images pour identifier un large éventail d’objets, tels que les modes de transport, les animaux, les logos, les points de repère, le texte et les visages16. Les capacités de détection des visages de Google permettent même de détecter les états émotionnels associés aux visages dans les photos téléchargées et stockées dans leur cloud17.
94. Google Photos effectue cette analyse d’image par défaut lors de l’utilisation du produit, mais ne fera pas de distinction entre les personnes, sauf si l’utilisateur donne l’autorisation à l’application18. Si un utilisateur autorise Google à regrouper des visages similaires, Google identifie différentes personnes à l’aide de la technologie de reconnaissance faciale et permet aux utilisateurs de partager des photos grâce à sa technologie de « regroupement de visages »1920. Des exemples des capacités de classification d’images de Google avec et sans autorisation de regroupement des visages de l’utilisateur sont présentés dans l’illustration 19. Google utilise Photos pour assembler un vaste ensemble d’informations d’identifications faciales, qui a récemment fait l’objet de poursuites judiciaires21 de la part de certains États.
Illustration : Exemple de reconnaissance d’images dans Google Photos.
D. Chromebook
95. Chromebook est la tablette-ordinateur de Google qui fonctionne avec le système d’exploitation Chrome (Chrome OS) et permet aux utilisateurs d’accéder aux applications sur le cloud. Bien que Chromebook ne détienne qu’une très faible part du marché des PC, il connaît une croissance rapide, en particulier dans le domaine des appareils informatiques pour la catégorie K-12, où il détenait 59,8 % du marché au deuxième trimestre 201722. La collecte de données de Chromebook est similaire à celle du navigateur Google Chrome, qui est décrite dans la section II.A. Chromebooks permet également aux cookies de Google et de domaines tiers de pister l’activité de l’utilisateur, comme pour tout autre ordinateur portable ou PC.
96. De nombreuses écoles de la maternelle à la terminale utilisent des Chromebooks pour accéder aux produits Google via son service GSuite for Education. Google déclare que les données recueillies dans le cadre d’une telle utilisation ne sont pas utilisées à des fins de publicité ciblée23. Toutefois, les étudiants reçoivent des publicités s’ils utilisent des services supplémentaires (tels que YouTube ou Blogger) sur les Chromebooks fournis par leur établissement d’enseignement.
E. Google Pay
97. Google Pay est un service de paiement numérique qui permet aux utilisateurs de stocker des informations de carte de crédit, de compte bancaire et de PayPal pour effectuer des paiements en magasin, sur des sites Web ou dans des applications utilisant Google Chrome ou un appareil Android connecté24. Pay est le moyen par lequel Google collecte les adresses et numéros de téléphone vérifiés des utilisateurs, car ils sont associés aux comptes de facturation. En plus des renseignements personnels, Pay recueille également des renseignements sur la transaction, comme la date et le montant de la transaction, l’emplacement et la description du marchand, le type de paiement utilisé, la description des articles achetés, toute photo qu’un utilisateur choisit d’associer à la transaction, les noms et adresses électroniques du vendeur et de l’acheteur, la description du motif de la transaction par l’utilisateur et toute offre associée à la transaction25. Google traite ses informations comme des informations personnelles en fonction de sa politique générale de confidentialité. Par conséquent il peut utiliser ces informations sur tous ses produits et services pour fournir de la publicité très ciblée26. Les paramètres de confidentialité de Google l’autorisent par défaut à utiliser ces données collectées27.
F. Données d’utilisateurs collectées auprès de fournisseurs de données tiers
98. Google collecte des données de tiers en plus des informations collectées directement à partir de leurs services et applications. Par exemple, en 2014, Google a annoncé qu’il commencerait à suivre les ventes dans les vrais commerces réels en achetant des données sur les transactions par carte de crédit et de débit. Ces données couvraient 70 % de toutes les opérations de crédit et de débit aux États-Unis28. Elles contenaient le nom de l’individu, ainsi que l’heure, le lieu et le montant de son achat29.
99. Les données de tiers sont également utilisées pour aider Google Pay, y compris les services de vérification, les informations résultant des transactions Google Pay chez les commerçants, les méthodes de paiement, l’identité des émetteurs de cartes, les informations concernant l’accès aux soldes du compte de paiement Google, les informations de facturation des opérateurs et transporteurs et les rapports des consommateurs30. Pour les vendeurs, Google peut obtenir des informations des organismes de crédit aux particuliers ou aux entreprises.
100. Bien que l’information des utilisateurs tiers que Google reçoit actuellement soit de portée limitée, elle a déjà attiré l’attention des autorités gouvernementales. Par exemple, la FTC a annoncé une injonction contre Google en juillet 2017 concernant la façon dont la collecte par Google de données sur les achats des consommateurs porte atteinte à la vie privée électronique31. L’injonction conteste l’affirmation de Google selon laquelle il peut protéger la vie privée des consommateurs tout au long du processus en utilisant son algorithme. Bien que d’autres mesures n’aient pas encore été prises, l’injonction de la FTC est un exemple des préoccupations du public quant à la quantité de données que Google recueille sur les consommateurs.
VIII. CONCLUSION
101. Google compte un pourcentage important de la population mondiale parmi ses clients directs, avec de multiples produits en tête de leurs marchés mondiaux et de nombreux produits qui dépassent le milliard d’utilisateurs actifs par mois. Ces produits sont en mesure de recueillir des données sur les utilisateurs au moyen d’une variété de techniques qui peuvent être difficiles à comprendre pour un utilisateur moyen. Une grande partie de la collecte de données de Google a lieu lorsque l’utilisateur n’utilise aucun de ses produits directement. L’ampleur d’une telle collecte est considérable, en particulier sur les appareils mobiles Android. Et bien que ces informations soient généralement recueillies sans identifier un utilisateur unique, Google a la possibilité d’utiliser les données recueillies auprès d’autres sources pour désanonymiser une telle collecte.
Framasoft en 2019 pour les gens pressés
Vous avez aimé Dégooglisons Internet et pensez le plus grand bien de Contributopia ? Vous aimeriez savoir en quelques mots où notre feuille de route nous mènera en 2019 ? Cet article est fait pour vous, les décideurs pressés 🙂
Cet article présente de façon synthétique et ramassée ce que nous avons développé dans l’article de lancement de la campagne 2018-2019 : «Changer le monde, un octet à la fois».
Un octet à la fois, oui, parce qu’avec nos pattounes, ça prend du temps.
Depuis 4 ans, Framasoft montre qu’il est possible de décentraliser Internet avec l’opération « Dégooglisons Internet ». Le propos n’est ni de critiquer ni de culpabiliser, mais d’informer et de mettre en avant des alternatives qui existaient déjà, mais demeuraient difficiles d’accès ou d’usage.
De façon à ne pas devenir un nouveau nœud de centralisation, l’initiative CHATONS a été lancée, proposant de relier les hébergeurs de services en ligne qui partagent nos valeurs.
Depuis l’année dernière, avec sa feuille de route Contributopia, Framasoft a décidé d’affirmer clairement qu’il fallait aller au-delà du logiciel libre, qui n’était pas une fin en soi, mais un moyen de faire advenir un monde que nous appelons de nos vœux.
Il faut donc encourager la société de contribution et dépasser celle de la consommation, y compris en promouvant des projets qui ne soient plus seulement des alternatives aux GAFAM, mais qui soient porteurs d’une nouvelle façon de faire. Cela se fera aussi en se rapprochant de structures (y compris en dehors du mouvement traditionnel du libre) avec lesquelles nous partageons certaines valeurs, de façon à apprendre et diffuser nos savoirs.
Cette année a vu naître la version 1.0 de PeerTube, logiciel phare qui annonce une nouvelle façon de diffuser des médias vidéos, en conservant le contrôle de ses données sans se couper du monde, qu’on soit vidéaste ou spectateur.
Le monde des services de Contributopia. Illustration de David Revoy – Licence : CC-By 4.0
Avenir
La campagne de don actuelle est aussi l’occasion de de rappeler des éléments d’importance pour Framasoft : nous ne sommes pas une grosse multinationale, mais un petit groupe d’amis épaulé par quelques salarié·e·s, et une belle communauté de contributeurs et contributrices.
Cette petite taille et notre financement basé sur vos dons nous offrent souplesse et indépendance. Ils nous permettront de mettre en place de nouveaux projets comme MobilZon (mobilisation par le numérique), un Mooc CHATONS (tout savoir et comprendre sur pourquoi et comment devenir un chaton) ou encore Framapétitions (plateforme de pétitions n’exploitant pas les données des signataires).
Nous voulons aussi tenter d’en appeler à votre générosité sans techniques manipulatoires, en vous exposant simplement d’où nous venons et où nous allons. Nous espérons que cela vous motivera à nous faire un don.
Un article détaillé sur l’année 2019 de Contributopia (13mn de lecture)
La nouvelle page d’accueil de Framasoft, pour la campagne d’appel au don de cette fin d’année
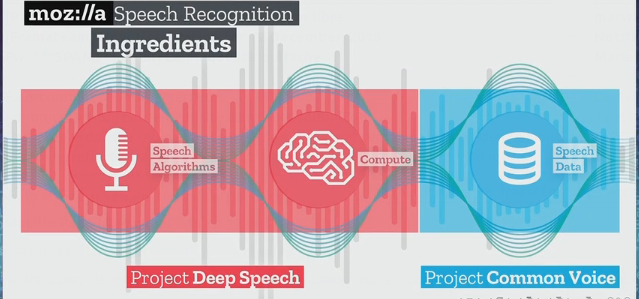
Projet Common Voice : pour que la voix soit libre
On nous demande souvent comment contribuer au Libre sans être un cador en informatique. Voici un projet utile, d’une grande importance et auquel il est très simple de contribuer : il suffit de savoir lire, parler et écouter. On vous explique tout.
On voit émerger à grande allure des objets avec lesquels l’interaction repose sur la reconnaissance vocale : smartphones, assistants connecté, dispositifs de réalité virtuelle…Selon les experts de ce marché, 50 % des recherches toutes plateformes confondues passeront par la voix d’ici 2 à 3 ans. Quant aux objets dits « intelligents », ils atteignent pour les pays favorisés un niveau de prix qui les rend accessibles à un nombre croissant de consommateurs. On peut trouver dès aujourd’hui dans la grande distribution des « enceintes connectées » à l’écoute de vos questions pour moins de 100 euros… Autant dire que ces produits sont en passe d’être des objets de consommation de masse.
Les services vocaux, au-delà des fonctions d’espionnage qui suscitent la méfiance, apporteront des avantages sensibles aux usages numériques du grand public. Ils abaisseront la barrière d’accès à des fonctionnalités utiles pour les personnes handicapées, en difficulté avec la lecture, dont les mains sont occupées ou pour celles qui ont besoin d’assistance immédiate. Dans bien des cas de figure il est ou sera plus efficace ou rapide d’utiliser la voix plutôt qu’une interface tactile ou souris/clavier32
Le problème hélas a un air de déjà-vu : aujourd’hui les systèmes de reconnaissance vocale sont essentiellement propriétaires et reposent sur 4 ou 5 bases de données vocales propriétaires : Cortana (Microsoft), Siri (Apple), Google Now (Google), Vocapia Research (VoxSigma suite)… En d’autres termes, tout est prêt pour assurer à quelques géants du numérique, toujours les mêmes, une suprématie commerciale et technologique. Et l’histoire récente prouve qu’ils n’hésiteront pas longtemps avant de capter les données les plus précieuses, celles de notre vie dans la bulle privée de notre habitation.
Il se trouve qu’un projet qui repose sur des ressources libres (données et code informatique) a été lancé par l’un des acteurs majeurs du monde du Libre : la fondation Mozilla.
Pourquoi Mozilla s’en mêle ?
Parmi les principes qui guident Mozilla et qu’on retrouve dans son manifeste, la santé d’un Web ouvert et l’inclusivité sont des valeurs essentielles. Cette ressource numérique dont l’usage est appelé à se développer rapidement doit être à la disposition du plus grand nombre, à commencer par les entreprises innovantes (déjà sur la brèche par exemple Mycroft et Snips) qui n’ont pas les moyens financiers d’accéder aux bases propriétaires et qui seraient tout simplement marginalisées par les grandes entreprises. Au-delà, bien sûr, c’est pour que des produits reposant sur la reconnaissance vocale soient accessibles à tous, quelle que soit leur langue, leur genre, leur accent local etc.
De quoi s’agit-il ?
De constituer la plus riche base possible d’échantillons sonores qui seront mis à la disposition des développeurs sous une licence libre (licence CC0). Le projet global s’appelle Deep Speech et Mozilla fait travailler des ingénieurs à traiter les données collectées avec des algorithmes, et ainsi alimenter un dispositif d’apprentissage machine.
Comment ça peut marcher ?
Ici nous tentons une description simple donc forcément approximative…
On donne à la machine des fichiers audio en entrée
On calcule la sortie, c’est-à-dire le texte
On compare au texte d’origine et… ben non c’est pas tout à fait ça.
On ajuste un petit peu des millions de paramètres internes pour essayer de se rapprocher de la sortie voulue
On répète sur des milliers d’heures…
Alexandre Lissy, ingénieur Mozilla qui travaille au bureau de Paris pour le projet Deep Speech. Les autres membres de l’équipe sont à Berlin, au Brésil et à San Francisco… (Photo de Samuel Nohra publiée dans Ouest France)
Pourquoi est-ce difficile à réaliser ?
L’entraînement des machines et la transcription nécessitent une grosse puissance de calcul.
Un nombre très important d’heures d’enregistrements valides est nécessaire pour que la reconnaissance vocale soit la plus efficace possible. C’est une somme d’environ 10 000 heures qui est considérée comme souhaitable pour obtenir un résultat.
Il existe peu de gros jeux de données publiquement accessibles en CC0 pour construire des modèles de reconnaissance 100% libres.
Les principes de Common Voice
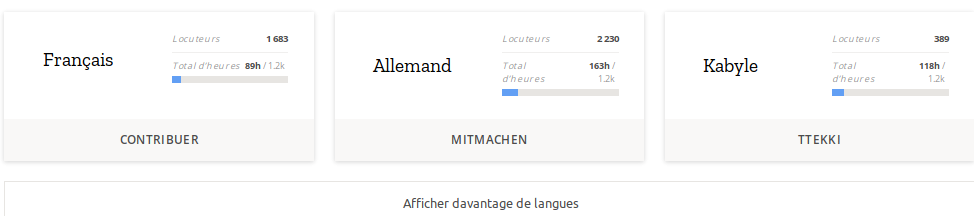
Tout d’abord le projet est mondial et vise à fonctionner pour le plus grand nombre de langues possible. Le projet est assez récent et pour l’instant, 16 langues seulement sont actives dont bien sûr le Français. On remarque que le projet a de l’importance pour les langues qui peuvent se sentir menacées : le Catalan, le Breton et le Kabyle par exemple sont déjà lancés !
Mais euh… On n’en est que là nous autres les francophones ? Vous avez compris : il est temps de nous y mettre tous ! (copie d’écran de la page des langues)
C’est aussi un projet inclusif pour lequel les intonations diverses sont bienvenues, avec une insistance particulière des ingénieurs responsables du projet pour qu’il y ait une grande diversité de voix : locuteurs et locutrices, de tous âges, avec tous les accents régionaux (oui les accents du sud, du nord etc. sont tout à fait bienvenus, une trentaine d’accents sont retenus), car les machines devront traiter la voix pour le plus grand nombre et pas exclusivement pour une prononciation standard appliquée. il est important de prononcer distinctement, mais le projet n’a pas besoin de textes déclamés professionnellement par des acteurs.
C’est surtout un projet communautaire et collaboratif. Il s’est construit dès le départ avec la communauté Mozilla et ses contributeurs et contributrices. Il fait maintenant appel à la communauté plus large de… tous les francophones. Car comme vous allez le voir, tout le monde 33 peut y participer !
et enregistrer tour à tour une série de 5 brèves phrases
Pas d’inquiétude : on peut choisir « passer » avec un bouton dédié si on rencontre une difficulté de compréhension, prononciation ou autre. Et bien entendu si en se réécoutant on constate que ça peut être mieux, un simple clic permet de recommencer.
2. ÉCOUTER
pour valider ou non une série de 5 phrases
Vous vous demandez peut-être d’où viennent tous ces textes parfois bizarres qu’on doit lire à haute voix ou écouter. Eh bien ce sont des textes dont la licence permet l’utilisation, qui viennent de transcriptions de débats de l’assemblée Nationale, de quelques livres du projet Gutenberg, de quelques pièces de théâtre, d’adresses françaises… Ah tiens, mais s’il faut enrichir la base, les romans de Pouhiou et celui de Frédéric Urbain publiés chez Framabook sont en CC0 ! Ça pourrait donner des phrases de test assez rigolotes.
Quand t’as eu des hémorroïdes, tu peux plus croire à la réincarnation.
Vingt-cinq ans, j’ai été bignole. Vous pensez si je retapisse un poulet.
Le coin des pas contents
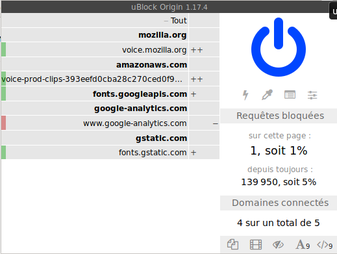
Ah et puis ça ne va pas rater, les chevaliers blancs du Libre ne vont pas manquer d’agiter leur drapeau immaculé, donc on vous le dit d’avance : oui malheureusement la page de Common Voice contient du Google Analytics. Et oui encore, amis sourcilleux sur les licences libres, la CC0 va permettre la réutilisation commerciale des voix enregistrées bénévolement. C’est dommage ou pas de placer un travail collectif sous une licence très permissive ?
Cliquez sur l’image pour parcourir la page d’informations sur la CC0
À vous de jouer !
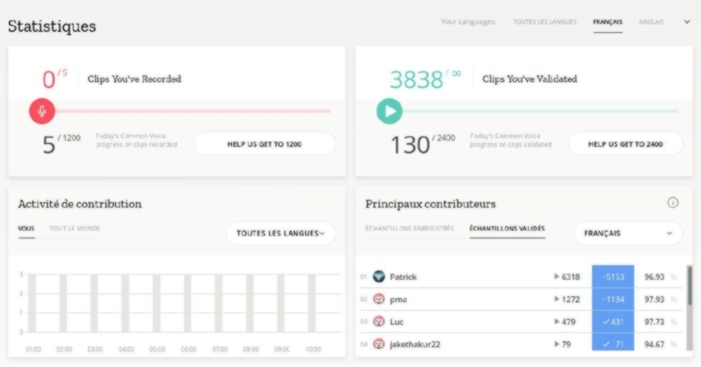
Chaque contribution est précieuse, surtout si elle est réitérée un grand nombre de fois 😉 Pour s’encourager, on peut suivre la progression des objectifs quotidiens, et certain⋅e⋅s ne manquent pas de se prendre au jeu…
Vous l’avez compris, ce projet réclame une participation massive pour avancer, alors si chacun y contribue ne serait-ce que modestement, nous pourrons dire que la voix est libre !
Voici déjà la traduction du cinquième chapitre de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà publiés. Il s’agit cette fois d’explorer la quantité de données que Google collecte lorsque l’on a désactivé tout ce qui pouvait l’être…
V. Quantité de données collectées lors d’une utilisation minimale des produits Google
58. Cette section montre les détails de la collecte de données par Google à travers ses services de publication et d’annonces. Afin de comprendre une telle collecte de données, une expérience est réalisée impliquant un utilisateur qui se sert de son téléphone dans sa vie de tous les jours mais qui évite délibérément d’utiliser les produits Google (Search, Gmail, YouTube, Maps, etc.), exception faite du navigateur Chrome.
59. Pour que l’expérience soit aussi réaliste que possible, plusieurs études sur les usages de consommateurs34, 35 ont été utilisées pour créer le profil d’usage journalier d’un utilisateur lambda. Ensuite, toutes les interactions directes avec les services Google ont été retirées du profil. La section IX.F dans les annexes liste les sites internet et applications utilisés pendant l’expérience.
60. L’expérience a été reproduite sur des appareils Android et iOS et les données HTTPS envoyées aux serveurs Google et Apple ont été tracées et analysées en utilisant une méthode similaire à celle expliquée dans la section précédente. Les résultats sont résumés dans la figure 12. Pendant la période de 24 h (qui inclut la période de repos nocturne), la majorité des appels depuis le téléphone Android ont été effectués vers les services Google de localisation et de publication de publicités (DoubleClick, Analytics). Google a enregistré la géolocalisation de l’utilisateur environ 450 fois, ce qui représente 1,4 fois le volume de l’expérience décrite dans la section III.C, qui se basait sur un téléphone immobile.
Figure 12 : Requêtes du téléphone portable durant une journée typique d’utilisation
61. Les serveurs de Google communiquent significativement moins souvent avec un appareil iPhone qu’avec Android (45 % moins). En revanche, le nombre d’appels aux régies publicitaires de Google reste les mêmes pour les deux appareils — un résultat prévisible puisque l’utilisation de pages web et d’applications tierces était la même sur chacun des périphériques. À noter, une différence importante est que l’envoi de données de géolocalisation à Google depuis un appareil iOS est pratiquement inexistant. En absence des plateformes Android et Chrome — ou de l’usage d’un des autres produits de Google — Google perd significativement sa capacité à pister la position des utilisateurs.
62. Le nombre total d’appels aux serveurs Apple depuis un appareil iOS était bien moindre, seulement 19 % des appels aux serveurs de Google depuis l’appareil Android. De plus, il n’y a pas d’appels aux serveurs d’Apple liés à la publicité, ce qui pourrait provenir du fait que le modèle économique d’Apple ne dépend pas autant de la publicité que celui de Google. Même si Apple obtient bien certaines données de localisation des utilisateurs d’appareil iOS, le volume de données collectées est bien moindre (16 fois moins) que celui collecté par Google depuis Android.
63. Au total, les téléphones Android ont communiqué 11.6 Mo de données par jour (environ 350 Mo par mois) avec les serveurs de Google. En comparaison, l’iPhone n’a envoyé que la moitié de ce volume. La quantité de données spécifiques aux régies publicitaires de Google est restée pratiquement identique sur les deux appareils.
64. L’appareil iPhone a communiqué bien moins de données aux serveurs Apple que l’appareil Android n’a échangé avec les serveurs Google.
65. De manière générale, même en l’absence d’interaction utilisateur avec les applications Google les plus populaires, un utilisateur de téléphone Android muni du navigateur Chrome a tout de même tendance à envoyer une quantité non négligeable de données à Google, dont la majorité est liée à la localisation et aux appels aux serveurs de publicité. Bien que, dans le cadre limité de cette expérience, un utilisateur d’iPhone soit protégé de la collecte des données de localisation par Google, Google recueille tout de même une quantité comparable de données liées à la publicité.
66. La section suivante décrit les données collectées par les applications les plus populaires de Google, telles que Gmail, Youtube, Maps et la recherche.