Glyn Moody sur l’article 13 – Mensonges et mauvaise foi
Glyn Moody est un journaliste, blogueur et écrivain spécialisé dans les questions de copyright et droits numériques. Ses combats militants le placent en première ligne dans la lutte contre l’article 13 de la directive européenne sur le droit d’auteur, dont le vote final est prévu ce mois-ci. Cet article a été combattu par des associations en France telles que La Quadrature du Net, dénoncé pour ses effet délétères par de nombreuses personnalités (cette lettre ouverte par exemple, signée de Vinton Cerf, Tim Berners-lee, Bruce Schneier, Jimmy Wales…) et a fait l’objet de pétitions multiples.
Dans une suite d’articles en cours (en anglais) ou dans diverses autres interventions (celle-ci traduite en français) que l’on parcourra avec intérêt, Glyn Moody démonte un à un les éléments de langage des lobbyistes des ayants droit. Le texte que Framalang a traduit pour vous met l’accent sur la mauvaise foi des défenseurs de l’article 13 qui préparent des réponses biaisées aux objections qui leur viennent de toutes parts, et notamment de 4 millions d’Européens qui ont manifesté leur opposition.
Pour Glyn Moody, manifestement l’article 13 est conçu pour donner des pouvoirs exorbitants (qui vont jusqu’à une forme de censure automatisée) aux ayants droit au détriment des utilisateurs et utilisatrices « ordinaires »
L’article 13 n’est pas seulement un travail législatif dangereux, mais aussi foncièrement malhonnête
par Glyn Moody
La directive sur Copyright de l’Union Européenne est maintenant en phase d’achèvement au sein du système législatif européen. Étant donné la nature avancée des discussions, il est déjà très surprenant que le comité des affaires juridiques (JURI), responsable de son pilotage à travers le Parlement Européen, ait récemment publié une session de « Questions et Réponses » sur la proposition de « Directive au sujet du Copyright numérique ». Mais il n’est pas difficile de deviner pourquoi ce document a été publié maintenant. De plus en plus de personnes prennent conscience que la directive sur le Copyright en général, et l’Article 13 en particulier, vont faire beaucoup de tort à l’Internet en Europe. Cette session de Q & R tente de contrer les objections relevées et d’étouffer le nombre grandissant d’appels à l’abandon de l’Article 13.
La première question de cette session de Q & R, « En quoi consiste la directive sur le Copyright ? », souligne le cœur du problème de la loi proposée.
La réponse est la suivante : « La proposition de directive sur le Copyright dans le marché unique numérique » cherche à s’assurer que les artistes (en particulier les petits artistes, par exemple les musiciens), les éditeurs de contenu ainsi que les journalistes, bénéficient autant du monde connecté et d’Internet que du monde déconnecté. »
Il n’est fait mention nulle part des citoyens européens qui utilisent l’Internet, ou de leurs priorités. Donc, il n’est pas surprenant qu’on ne règle jamais le problème du préjudice que va causer la directive sur le Copyright à des centaines de millions d’utilisateurs d’Internet, car les défenseurs de la directive sur le Copyright ne s’en préoccupent pas. La session de Q & R déclare : « Ce qu’il est actuellement légal et permis de partager, restera légal et permis de partager. » Bien que cela soit sans doute correct au sens littéral, l’exigence de l’Article 13 concernant la mise en place de filtres sur la mise en ligne de contenus signifie en pratique que c’est loin d’être le cas. Une information parfaitement légale à partager sera bloquée par les filtres, qui seront forcément imparfaits, et parce que les entreprises devant faire face à des conséquences juridiques, feront toujours preuve d’excès de prudence et préféreront trop bloquer.
La question suivante est : « Quel impact aura la directive sur les utilisateurs ordinaires ? ».
Là encore, la réponse est correcte mais trompeuse : « Le projet de directive ne cible pas les utilisateurs ordinaires. »
Personne ne dit qu’elle cible les utilisateurs ordinaires, en fait, ils sont complètement ignorés par la législation. Mais le principal, c’est que les filtres sur les chargements de contenu vont affecter les utilisateurs ordinaires, et de plein fouet. Que ce soit ou non l’intention n’est pas la question.
« Est-ce que la directive affecte la liberté sur Internet ou mène à une censure d’Internet ? » demande la session de Q & R.
La réponse ici est « Un utilisateur pourra continuer d’envoyer du contenu sur les plateformes d’Internet et (…) ces plateformes / agrégateurs d’informations pourront continuer à héberger de tels chargements, tant que ces plateformes respectent les droits des créateurs à une rémunération décente. »
Oui, les utilisateurs pourront continuer à envoyer du contenu, mais une partie sera bloquée de manière injustifiable parce que les plateformes ne prendront pas le risque de diffuser du contenu qui ne sera peut-être couvert par l’une des licences qu’elles ont signées.
La question suivante concerne le mensonge qui est au cœur de la directive sur le Copyright, à savoir qu’il n’y a pas besoin de filtre sur les chargements. C’est une idée que les partisans ont mise en avant pendant un temps, et il est honteux de voir le Parlement Européen lui-même répéter cette contre-vérité. Voici l’élément de la réponse :
« La proposition de directive fixe un but à atteindre : une plateforme numérique ou un agrégateur de presse ne doit pas gagner d’argent grâce aux productions de tierces personnes sans les indemniser. Par conséquent, une plateforme ou un agrégateur a une responsabilité juridique si son site diffuse du contenu pour lequel il n’aurait pas correctement rémunéré le créateur. Cela signifie que ceux dont le travail est illégalement utilisé peuvent poursuivre en justice la plateforme ou l’agrégateur. Toutefois, le projet de directive ne spécifie pas ni ne répertorie quels outils, moyens humains ou infrastructures peuvent être nécessaires afin d’empêcher l’apparition d’une production non rémunérée sur leur site. Il n’y a donc pas d’obligation de filtrer les chargements.
Toutefois, si de grandes plateformes ou agrégateurs de presse ne proposent pas de solutions innovantes, ils pourraient finalement opter pour le filtrage. »
La session Q & R essaye d’affirmer qu’il n’est pas nécessaire de filtrer les chargements et que l’apport de « solutions innovantes » est à la charge des entreprises du web. Elle dit clairement que si une entreprise utilise des filtres sur les chargements, on doit lui reprocher de ne pas être suffisamment « innovante ». C’est une absurdité. D’innombrables experts ont signalé qu’il est impossible « d’empêcher la diffusion de contenu non-rémunéré sur un site » à moins de vérifier, un à un, chacun les fichiers et de les bloquer si nécessaire : il s’agit d’un filtrage des chargements. Aucune “innovation” ne permettra de contourner l’impossibilité logique de se conformer à la directive sur le Copyright, sans avoir recours au filtrage des chargements.
En plus de donner naissance à une législation irréfléchie, cette approche montre aussi la profonde inculture technique de nombreux politiciens européens. Ils pensent encore manifestement que la technologie est une sorte de poudre de perlimpinpin qui peut être saupoudrée sur les problèmes afin de les faire disparaître. Ils ont une compréhension médiocre du domaine numérique et sont cependant assez arrogants pour ignorer les meilleurs experts mondiaux en la matière lorsque ceux-ci disent que ce que demande la Directive sur le Copyright est impossible.
Pour couronner le tout, la réponse à la question : « Pourquoi y a-t-il eu de nombreuses contestations à l’encontre de cette directive ? » constitue un terrible affront pour le public européen. La réponse reconnaît que : « Certaines statistiques au sein du Parlement Européen montrent que les parlementaires ont rarement, voire jamais, été soumis à un tel niveau de lobbying (appels téléphoniques, courriels, etc.). » Mais elle écarte ce niveau inégalé de contestation de la façon suivante :
« De nombreuses campagnes antérieures de lobbying ont prédit des conséquences désastreuses qui ne se sont jamais réalisées.
Par exemple, des entreprises de télécommunication ont affirmé que les factures téléphoniques exploseraient en raison du plafonnement des frais d’itinérance ; les lobbies du tabac et de la restauration ont prétendu que les personnes allaient arrêter d’aller dans les restaurants et dans les bars suite à l’interdiction d’y fumer à l’intérieur ; des banques ont dit qu’elles allaient arrêter de prêter aux entreprises et aux particuliers si les lois devenaient plus strictes sur leur gestion, et le lobby de la détaxe a même argué que les aéroports allaient fermer, suite à la fin des produits détaxés dans le marché intérieur. Rien de tout ceci ne s’est produit. »
Il convient de remarquer que chaque « contre-exemple » concerne des entreprises qui se plaignent de lois bénéficiant au public. Mais ce n’est pas le cas de la vague de protestation contre la directive sur le Copyright, qui vient du public et qui est dirigée contre les exigences égoïstes de l’industrie du copyright. La session de Q & R tente de monter un parallèle biaisé entre les pleurnichements intéressés des industries paresseuses et les attentes d’experts techniques inquiets, ainsi que de millions de citoyens préoccupés par la préservation des extraordinaires pouvoirs et libertés de l’Internet ouvert.
Voici finalement la raison pour laquelle la directive sur le Copyright est si pernicieuse : elle ignore totalement les droits des usagers d’Internet. Le fait que la nouvelle session de Q & R soit incapable de répondre à aucune des critiques sérieuses sur la loi autrement qu’en jouant sur les mots, dans une argumentation pitoyable, est la confirmation que tout ceci n’est pas seulement un travail législatif dangereux, mais aussi profondément malhonnête. Si l’Article 13 est adopté, il fragilisera l’Internet dans les pays de l’UE, entraînera la zone dans un marasme numérique et, par le refus réitéré de l’Union Européenne d’écouter les citoyens qu’elle est censée servir, salira le système démocratique tout entier.
Aujourd’hui Framasoft (parmi d’autres) montre son soutien à l’association RAP (Résistance à l’Agression Publicitaire) ainsi qu’à la Quadrature du Net qui lancent une campagne de sensibilisation et d’action pour lutter contre les nuisances publicitaires non-consenties sur Internet.
#BloquelapubNet : un site pour expliquer comment se protéger
Cliquez sur l’image pour aller directement sur bloquelapub.net
Si vous, vous savez comment vous prémunir de cette pollution informationnelle… avez-vous déjà songé à aider vos proches, collègues et connaissances ? C’est compliqué de tout bien expliquer avec des mots simples, hein ? C’est justement à ça que sert le site bloquelapub.net : un tutoriel à suivre qui permet, en quelques clics, d’apprendre quelques gestes essentiels pour notre hygiène numérique. Voilà un site utile, à partager et communiquer autour de soi avec enthousiasme, sans modération et accompagné du mot clé #bloquelapubnet !
Pourquoi bloquer ? – Le communiqué
Nous reproduisons ci dessous le communiqué de presse des associations Résistance à l’Agression Publicitaire et La Quadrature du Net.
Internet est devenu un espace prioritaire pour les investissements des publicitaires. En France, pour la première fois en 2016, le marché de la publicité numérique devient le « premier média investi sur l’ensemble de l’année », avec une part de marché de 29,6%, devant la télévision. En 2017, c’est aussi le cas au niveau mondial. Ce jeune « marché » est principalement capté par deux géants de la publicité numérique. Google et Facebook. Ces deux géants concentrent à eux seuls autour de 50% du marché et bénéficient de la quasi-totalité des nouveaux investissements sur ce marché. « Pêché originel d’Internet », où, pour de nombreuses personnes et sociétés, il demeure difficile d’obtenir un paiement monétaire direct pour des contenus et services commerciaux et la publicité continue de s’imposer comme un paiement indirect.
Les services vivant de la publicité exploitent le « temps de cerveau disponible » des internautes qui les visitent, et qui n’en sont donc pas les clients, mais bien les produits. Cette influence est achetée par les annonceurs qui font payer le cout publicitaire dans les produits finalement achetés.
La publicité en ligne a plusieurs conséquences : en termes de dépendance vis-à-vis des annonceurs et des revenus publicitaires, et donc des limites sur la production de contenus et d’information, en termes de liberté de réception et de possibilité de limiter les manipulations publicitaires, sur la santé, l’écologie…
En ligne, ces problématiques qui concernent toutes les publicités ont de plus été complétées par un autre enjeu fondamental. Comme l’exprime parfaitement Zeynep Tufekci, une chercheuse turque, « on a créé une infrastructure de surveillance dystopique juste pour que des gens cliquent sur la pub ». De grandes entreprises telles que Google, Facebook et d’autres « courtiers en données » comme Criteo ont développés des outils visant à toujours mieux nous « traquer » dans nos navigations en ligne pour nous profiler publicitairement. Ces pratiques sont extrêmement intrusives et dangereuses pour les libertés fondamentales.
Il est plus temps que cette législation soit totalement respectée et que les publicitaires cessent de nous espionner en permanence en ligne.
Un sondage BVA-La Dépêche de 2018, révélait que 77% des Français·es se disent inquiet·es de l’utilisation que pouvaient faire des grandes entreprises commerciales de leurs données numériques personnelles. 83% des Français·es sont irrité·es par la publicité en ligne selon un sondage de l’institut CSA en mars 2016 et « seulement » 24% des personnes interrogées avaient alors installé un bloqueur de publicité.
Le blocage de la publicité en ligne apparait comme un bon outil de résistance pour se prémunir de la surveillance publicitaire sur Internet. Pour l’aider à se développer, nos associations lancent le site Internet :
Plusieurs opérations collectives ou individuelles de sensibilisation et blocages de la publicité auront lieu sur plusieurs villes du territoire français et sur Internet peu de temps avant et le jour du 28 janvier 2019, journée européenne de la « protection des données personnelles ». Le jour rêvé pour s’opposer à la publicité en ligne qui exploite ces données !
RAP et La Quadrature du Net demandent :
Le respect de la liberté de réception dans l’espace public et ailleurs, le droit et la possibilité de refuser d’être influencé par la publicité,
Le strict respect du règlement général pour la protection des données et l’interdiction de la collecte de données personnelles à des fins publicitaires sans le recueil d’un consentement libre (non-conditionnant pour l’accès au service), explicite et éclairé où les paramètres les plus protecteurs sont configurés par défaut. Les sites Internet et services en ligne ne doivent par défaut collecter aucune information à des fins publicitaires sans que l’internaute ne les y ait expressément autorisés.
Rendez-vous sur bloquelapub.net et sur Internet toute la journée du 28 janvier 2019
Les associations soutiens de cette mobilisation : Framasoft, Le CECIL, Globenet, Le Creis-Terminal
Pour un Web frugal ?
Sites lourds, sites lents, pages web obèses qui exigent pour être consultées dans un délai raisonnable une carte graphique performante, un processeur rapide et autant que possible une connexion par fibre optique… tel est le quotidien de l’internaute ordinaire.
Nul besoin de remonter aux débuts du Web pour comparer : c’est d’une année sur l’autre que la taille moyenne des pages web s’accroît désormais de façon significative.
Quant à la consommation en énergie de notre vie en ligne, elle prend des proportions qui inquiètent à juste titre : des lointains datacenters aux hochets numériques dont nous aimons nous entourer, il y a de quoi se poser des questions sur la nocivité environnementale de nos usages collectifs et individuels.
Bien sûr, les solutions économes à l’échelle de chacun sont peut-être dérisoires au regard des gigantesques gaspillages d’un système consumériste insatiable et énergivore.
Cependant nous vous invitons à prendre en considération l’expérience de l’équipe barcelonaise de Low-Tech Magazine dont nous avons traduit pour vous un article. Un peu comme l’association Framasoft l’avait fait en ouverture de la campagne dégooglisons… en se dégooglisant elle-même, les personnes de Low-tech Magazine ont fait de leur mieux pour appliquer à leur propre site les principes de frugalité qu’elles défendent : ce ne sont plus seulement les logiciels mais aussi les matériels qui ont fait l’objet d’une cure d’amaigrissement au régime solaire.
En espérant que ça donnera des idées à tous les bidouilleurs…
article original : How to build a Low-tech website Traduction Framalang : Khrys, Mika, Bidouille, Penguin, Eclipse, Barbara, Mannik, jums, Mary, Cyrilus, goofy, simon, xi, Lumi, Suzy + 2 auteurs anonymes
Comment créer un site web basse technologie
Low-tech Magazine a été créé en 2007 et n’a que peu changé depuis. Comme une refonte du site commençait à être vraiment nécessaire, et comme nous essayons de mettre en œuvre ce que nous prônons, nous avons décidé de mettre en place une version de Low Tech Magazine en basse technologie, auto-hébergée et alimentée par de l’énergie solaire. Le nouveau blog est conçu pour réduire radicalement la consommation d’énergie associée à l’accès à notre contenu.
Premier prototype du serveur alimenté à l’énergie solaire sur lequel tourne le nouveau site.
Pour éviter les conséquences négatives d’une consommation énergivore, les énergies renouvelables seraient un moyen de diminuer les émissions des centres de données. Par exemple, le rapport annuel ClickClean de Greenpeace classe les grandes entreprises liées à Internet en fonction de leur consommation d’énergies renouvelables.
Cependant, faire fonctionner des centres de données avec des sources d’énergie renouvelables ne suffit pas à compenser la consommation d’énergie croissante d’Internet. Pour commencer, Internet utilise déjà plus d’énergie que l’ensemble des énergies solaire et éolienne mondiales. De plus, la réalisation et le remplacement de ces centrales électriques d’énergies renouvelables nécessitent également de l’énergie, donc si le flux de données continue d’augmenter, alors la consommation d’énergies fossiles aussi.
Cependant, faire fonctionner les centres de données avec des sources d’énergie renouvelables ne suffit pas à combler la consommation d’énergie croissante d’Internet.
Enfin, les énergies solaire et éolienne ne sont pas toujours disponibles, ce qui veut dire qu’un Internet fonctionnant à l’aide d’énergies renouvelables nécessiterait une infrastructure pour le stockage de l’énergie et/ou pour son transport, ce qui dépend aussi des énergies fossiles pour sa production et son remplacement. Alimenter les sites web avec de l’énergie renouvelable n’est pas une mauvaise idée, mais la tendance vers l’augmentation de la consommation d’énergie doit aussi être traitée.
Des sites web qui enflent toujours davantage
Tout d’abord, le contenu consomme de plus en plus de ressources. Cela a beaucoup à voir avec l’importance croissante de la vidéo, mais une tendance similaire peut s’observer sur les sites web.
La taille moyenne d’une page web (établie selon les pages des 500 000 domaines les plus populaires) est passée de 0,45 mégaoctets en 2010 à 1,7 mégaoctets en juin 2018. Pour les sites mobiles, le poids moyen d’une page a décuplé, passant de 0,15 Mo en 2011 à 1,6 Mo en 2018. En utilisant une méthode différente, d’autres sources évoquent une moyenne autour de 2,9 Mo en 2018.
La croissance du transport de données surpasse les avancées en matière d’efficacité énergétique (l’énergie requise pour transférer 1 mégaoctet de données sur Internet), ce qui engendre toujours plus de consommation d’énergie. Des sites plus « lourds » ou plus « gros » ne font pas qu’augmenter la consommation d’énergie sur l’infrastructure du réseau, ils raccourcissent aussi la durée de vie des ordinateurs, car des sites plus lourds nécessitent des ordinateurs plus puissants pour y accéder. Ce qui veut dire que davantage d’ordinateurs ont besoin d’être fabriqués, une production très coûteuse en énergie.
Être toujours en ligne ne fait pas bon ménage avec des sources d’énergies renouvelables telles que l’éolien ou le solaire, qui ne sont pas toujours disponibles.
La deuxième raison de l’augmentation de la consommation énergétique d’Internet est que nous passons de plus en plus de temps en ligne. Avant l’arrivée des ordinateurs portables et du Wi-Fi, nous n’étions connectés au réseau que lorsque nous avions accès à un ordinateur fixe au bureau, à la maison ou à la bibliothèque. Nous vivons maintenant dans un monde où quel que soit l’endroit où nous nous trouvons, nous sommes toujours en ligne, y compris, parfois, sur plusieurs appareils à la fois.
Un accès Internet en mode « toujours en ligne » va de pair avec un modèle d’informatique en nuage, permettant des appareils plus économes en énergie pour les utilisateurs au prix d’une dépense plus importante d’énergie dans des centres de données. De plus en plus d’activités qui peuvent très bien se dérouler hors-ligne nécessitent désormais un accès Internet en continu, comme écrire un document, remplir une feuille de calcul ou stocker des données. Tout ceci ne fait pas bon ménage avec des sources d’énergies renouvelables telles que l’éolien ou le solaire, qui ne sont pas disponibles en permanence.
Conception d’un site internet basse technologie
La nouvelle mouture de notre site répond à ces deux problématiques. Grâce à une conception simplifiée de notre site internet, nous avons réussi à diviser par cinq la taille moyenne des pages du blog par rapport à l’ancienne version, tout en rendant le site internet plus agréable visuellement (et plus adapté aux mobiles). Deuxièmement, notre nouveau site est alimenté à 100 % par l’énergie solaire, non pas en théorie, mais en pratique : il a son propre stockage d’énergie et sera hors-ligne lorsque le temps sera couvert de manière prolongée.
Internet n’est pas une entité autonome. Sa consommation grandissante d’énergie est la résultante de décisions prises par des développeurs logiciels, des concepteurs de site internet, des départements marketing, des annonceurs et des utilisateurs d’internet. Avec un site internet poids plume alimenté par l’énergie solaire et déconnecté du réseau, nous voulons démontrer que d’autres décisions peuvent être prises.
Avec 36 articles en ligne sur environ une centaine, le poids moyen d’une page sur le site internet alimenté par énergie solaire est environ cinq fois inférieur à celui de la version précédente.
Pour commencer, la nouvelle conception du site va à rebours de la tendance à des pages plus grosses. Sur 36 articles actuellement en ligne sur environ une centaine, le poids moyen d’une page sur le site internet alimenté par énergie solaire est 0,77 Mo – environ cinq fois inférieur à celui de la version précédente, et moins de la moitié du poids moyen d’une page établi sur les 500 000 blogs les plus populaires en juin 2018.
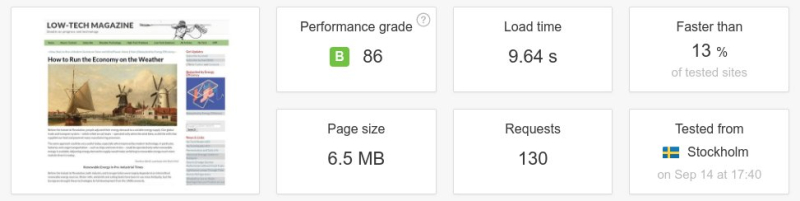
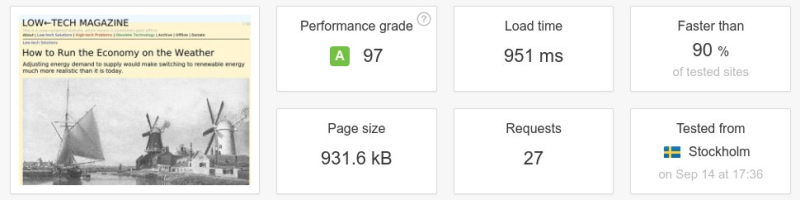
Ci-dessous : un test de vitesse d’une page web entre l’ancienne et la nouvelle version du magazine Low-Tech. La taille de la page a été divisée par plus de six, le nombre de requêtes par cinq, et la vitesse de téléchargement a été multipliée par dix. Il faut noter que l’on n’a pas conçu le site internet pour être rapide, mais pour une basse consommation d’énergie. La vitesse aurait été supérieure si le serveur avait été placé dans un centre de données et/ou à une position plus centrale de l’infrastructure d’Internet.
Ci-dessous sont détaillées plusieurs des décisions de conception que nous avons faites pour réduire la consommation d’énergie. Des informations plus techniques sont données sur une page distincte. Nous avons aussi libéré le code source pour la conception de notre site internet.
Site statique
Un des choix fondamentaux que nous avons faits a été d’élaborer un site internet statique. La majorité des sites actuels utilisent des langages de programmation côté serveur qui génèrent la page désirée à la volée par requête à une base de données. Ça veut dire qu’à chaque fois que quelqu’un visite une page web, elle est générée sur demande.
Au contraire, un site statique est généré une fois pour toutes et existe comme un simple ensemble de documents sur le disque dur du serveur. Il est toujours là, et pas seulement quand quelqu’un visite la page. Les sites internet statiques sont donc basés sur le stockage de fichiers quand les sites dynamiques dépendent de calculs récurrents. En conséquence, un site statique nécessite moins de puissance de calcul, donc moins d’énergie.
Le choix d’un site statique nous permet d’opérer la gestion de notre site de manière économique depuis notre bureau de Barcelone. Faire la même chose avec un site web généré depuis une base de données serait quasiment impossible, car cela demanderait trop d’énergie. Cela présenterait aussi des risques importants de sécurité. Bien qu’un serveur avec un site statique puisse toujours être piraté, il y a significativement moins d’attaques possibles et les dommages peuvent être plus facilement réparés.
Images optimisées pour en réduire le « poids »
Le principal défi a été de réduire la taille de la page sans réduire l’attractivité du site. Comme les images consomment l’essentiel de la bande passante il serait facile d’obtenir des pages très légères et de diminuer l’énergie nécessaire en supprimant les images, en réduisant leur nombre ou en réduisant considérablement leur taille. Néanmoins, les images sont une part importante de l’attractivité de Low-tech Magazine et le site ne serait pas le même sans elles.
Par optimisation, on peut rendre les images dix fois moins gourmandes en ressources, tout en les affichant bien plus largement que sur l’ancien site.
Nous avons plutôt choisi d’appliquer une ancienne technique de compression d’image appelée « diffusion d’erreur ». Le nombre de couleurs d’une image, combiné avec son format de fichier et sa résolution, détermine la taille de cette image. Ainsi, plutôt que d’utiliser des images en couleurs à haute résolution, nous avons choisi de convertir toutes les images en noir et blanc, avec quatre niveaux de gris intermédiaires.
Ces images en noir et blanc sont ensuite colorées en fonction de la catégorie de leur contenu via les capacités de manipulation d’image natives du navigateur. Compressées par ce module appelé dithering, les images présentées dans ces articles ajoutent beaucoup moins de poids au contenu ; par rapport à l’ancien site web, elles sont environ dix fois moins consommatrices de ressources.
Police de caractère par défaut / Pas de logo
Toutes les ressources chargées, y compris les polices de caractères et les logos, le sont par une requête supplémentaire au serveur, nécessitant de l’espace de stockage et de l’énergie. Pour cette raison, notre nouveau site web ne charge pas de police personnalisée et enlève toute déclaration de liste de polices de caractères, ce qui signifie que les visiteurs verront la police par défaut de leur navigateur.
Une page du magazine en version basse consommation
Nous utilisons une approche similaire pour le logo. En fait, Low-tech Magazine n’a jamais eu de véritable logo, simplement une bannière représentant une lance, considérée comme une arme low-tech (technologie sobre) contre la supériorité prétendue des « high-tech » (hautes technologies).
Au lieu d’un logo dessiné, qui nécessiterait la production et la distribution d’image et de polices personnalisées, la nouvelle identité de Low-Tech Magazine consiste en une unique astuce typographique : utiliser une flèche vers la gauche à la place du trait d’union dans le nom du blog : LOW←TECH MAGAZINE.
Pas de pistage par un tiers, pas de services de publicité, pas de cookies
Les logiciels d’analyse de sites tels que Google Analytics enregistrent ce qui se passe sur un site web, quelles sont les pages les plus vues, d’où viennent les visiteurs, etc. Ces services sont populaires car peu de personnes hébergent leur propre site. Cependant l’échange de ces données entre le serveur et l’ordinateur du webmaster génère du trafic de données supplémentaire et donc de la consommation d’énergie.
Avec un serveur auto-hébergé, nous pouvons obtenir et visualiser ces mesures de données avec la même machine : tout serveur génère un journal de ce qui se passe sur l’ordinateur. Ces rapports (anonymes) ne sont vus que par nous et ne sont pas utilisés pour profiler les visiteurs.
Avec un serveur auto-hébergé, pas besoin de pistage par un tiers ni de cookies.
Low-tech Magazine a utilisé des publicités Google Adsense depuis ses débuts en 2007. Bien qu’il s’agisse d’une ressource financière importante pour maintenir le blog, elles ont deux inconvénients importants. Le premier est la consommation d’énergie : les services de publicité augmentent la circulation des données, ce qui consomme de l’énergie.
Deuxièmement, Google collecte des informations sur les visiteurs du blog, ce qui nous contraint à développer davantage les déclarations de confidentialité et les avertissements relatifs aux cookies, qui consomment aussi des données et agacent les visiteurs. Nous avons donc remplacé Adsense par d’autres sources de financement (voir ci-dessous pour en savoir plus). Nous n’utilisons absolument aucun cookie.
À quelle fréquence le site web sera-t-il hors-ligne ?
Bon nombre d’entreprises d’hébergement web prétendent que leurs serveurs fonctionnent avec de l’énergie renouvelable. Cependant, même lorsqu’elles produisent de l’énergie solaire sur place et qu’elles ne se contentent pas de « compenser » leur consommation d’énergie fossile en plantant des arbres ou autres, leurs sites Web sont toujours en ligne.
Cela signifie soit qu’elles disposent d’un système géant de stockage sur place (ce qui rend leur système d’alimentation non durable), soit qu’elles dépendent de l’énergie du réseau lorsqu’il y a une pénurie d’énergie solaire (ce qui signifie qu’elles ne fonctionnent pas vraiment à 100 % à l’énergie solaire).
Le panneau photo-voltaïque solaire de 50 W. Au-dessus, un panneau de 10 W qui alimente un système d’éclairage.
En revanche, ce site web fonctionne sur un système d’énergie solaire hors réseau avec son propre stockage d’énergie et hors-ligne pendant les périodes de temps nuageux prolongées. Une fiabilité inférieure à 100 % est essentielle pour la durabilité d’un système solaire hors réseau, car au-delà d’un certain seuil, l’énergie fossile utilisée pour produire et remplacer les batteries est supérieure à l’énergie fossile économisée par les panneaux solaires.
Reste à savoir à quelle fréquence le site sera hors ligne. Le serveur web est maintenant alimenté par un nouveau panneau solaire de 50 Wc et une batterie plomb-acide (12V 7Ah) qui a déjà deux ans. Comme le panneau solaire est à l’ombre le matin, il ne reçoit la lumière directe du soleil que 4 à 6 heures par jour. Dans des conditions optimales, le panneau solaire produit ainsi 6 heures x 50 watts = 300 Wh d’électricité.
Le serveur web consomme entre 1 et 2,5 watts d’énergie (selon le nombre de visiteurs), ce qui signifie qu’il consomme entre 24 et 60 Wh d’électricité par jour. Dans des conditions optimales, nous devrions donc disposer de suffisamment d’énergie pour faire fonctionner le serveur web 24 heures sur 24. La production excédentaire d’énergie peut être utilisée pour des applications domestiques.
Nous prévoyons de maintenir le site web en ligne pendant un ou deux jours de mauvais temps, après quoi il sera mis hors ligne.
Cependant, par temps nuageux, surtout en hiver, la production quotidienne d’énergie pourrait descendre à 4 heures x 10 watts = 40 watts-heures par jour, alors que le serveur nécessite entre 24 et 60 Wh par jour. La capacité de stockage de la batterie est d’environ 40 Wh, en tenant compte de 30 % des pertes de charge et de décharge et de 33 % de la profondeur ou de la décharge (le régulateur de charge solaire arrête le système lorsque la tension de la batterie tombe à 12 V).
Par conséquent, le serveur solaire restera en ligne pendant un ou deux jours de mauvais temps, mais pas plus longtemps. Cependant, il s’agit d’estimations et nous pouvons ajouter une deuxième batterie de 7 Ah en automne si cela s’avère nécessaire. Nous visons un uptime, c’est-à-dire un fonctionnement sans interruption, de 90 %, ce qui signifie que le site sera hors ligne pendant une moyenne de 35 jours par an.
Premier prototype avec batterie plomb-acide (12 V 7 Ah) à gauche et batterie Li-Po UPS (3,7V 6600 mA) à droite. La batterie au plomb-acide fournit l’essentiel du stockage de l’énergie, tandis que la batterie Li-Po permet au serveur de s’arrêter sans endommager le matériel (elle sera remplacée par une batterie Li-Po beaucoup plus petite).
Quel est la période optimale pour parcourir le site ?
L’accessibilité à ce site internet dépend de la météo à Barcelone en Espagne, endroit où est localisé le serveur. Pour aider les visiteurs à « planifier » leurs visites à Low-tech Magazine, nous leur fournissons différentes indications.
Un indicateur de batterie donne une information cruciale parce qu’il peut indiquer au visiteur que le site internet va bientôt être en panne d’énergie – ou qu’on peut le parcourir en toute tranquillité. La conception du site internet inclut une couleur d’arrière-plan qui indique la charge de la batterie qui alimente le site Internet grâce au soleil. Une diminution du niveau de charge indique que la nuit est tombée ou que la météo est mauvaise.
Outre le niveau de batterie, d’autres informations concernant le serveur du site web sont affichées grâce à un tableau de bord des statistiques. Celui-ci inclut des informations contextuelles sur la localisation du serveur : heure, situation du ciel, prévisions météorologiques, et le temps écoulé depuis la dernière fois où le serveur s’est éteint à cause d’un manque d’électricité.
SERVEUR : Ce site web fonctionne sur un ordinateur Olimex A20. Il est doté de 2 GHz de vitesse de processeur, 1 Go de RAM et 16 Go d’espace de stockage. Le serveur consomme 1 à 2,5 watts de puissance.
SOFTWARE DU SERVEUR : le serveur web tourne sur Armbian Stretch, un système d’exploitation Debian construit sur un noyau SUNXI. Nous avons rédigé une documentation technique sur la configuration du serveur web.
LOGICIEL DE DESIGN : le site est construit avec Pelican, un générateur de sites web statiques. Nous avons publié le code source de « solar », le thème que nous avons développé.
CONNEXION INTERNET. Le serveur est connecté via une connexion Internet fibre 100 MBps. Voici comment nous avons configuré le routeur. Pour l’instant, le routeur est alimenté par le réseau électrique et nécessite 10 watts de puissance. Nous étudions comment remplacer ce routeur gourmand en énergie par un routeur plus efficace qui pourrait également être alimenté à l’énergie solaire.
SYSTÈME SOLAIRE PHOTOVOLTAÏQUE. Le serveur fonctionne avec un panneau solaire de 50 Wc et une batterie plomb-acide 12 V 7 Ah. Cependant, nous continuons de réduire la taille du système et nous expérimentons différentes configurations. L’installation photovoltaïque est gérée par un régulateur de charge solaire 20A.
Qu’est-il arrivé à l’ancien site ?
Le site Low-tech Magazine alimenté par énergie solaire est encore en chantier. Pour le moment, la version alimentée par réseau classique reste en ligne. Nous encourageons les lecteurs à consulter le site alimenté par énergie solaire, s’il est disponible. Nous ne savons pas trop ce qui va se passer ensuite. Plusieurs options se présentent à nous, mais la plupart dépendront de l’expérience avec le serveur alimenté par énergie solaire.
Tant que nous n’avons pas déterminé la manière d’intégrer l’ancien et le nouveau site, il ne sera possible d’écrire et lire des commentaires que sur notre site internet alimenté par réseau, qui est toujours hébergé chez TypePad. Si vous voulez envoyer un commentaire sur le serveur web alimenté en énergie solaire, vous pouvez en commentant cette page ou en envoyant un courriel à solar (at) lowtechmagazine (dot) com.
Est-ce que je peux aider ?
Bien sûr, votre aide est la bienvenue.
D’une part, nous recherchons des idées et des retours d’expérience pour améliorer encore plus le site web et réduire sa consommation d’énergie. Nous documenterons ce projet de manière détaillée pour que d’autres personnes puissent aussi faire des sites web basse technologie.
D’autre part, nous espérons recevoir des contributions financières pour soutenir ce projet. Les services publicitaires qui ont maintenu Low-tech Magazine depuis ses débuts en 2007 sont incompatibles avec le design de notre site web poids plume. C’est pourquoi nous cherchons d’autres moyens de financer ce site :
1. Nous proposerons bientôt un service de copies du blog imprimées à la demande. Grâce à ces publications, vous pourrez lire le Low-tech Magazine sur papier, à la plage, au soleil, où vous voulez, quand vous voulez.
2. Vous pouvez nous soutenir en envoyant un don sur PayPal, Patreon ou LiberaPay.
3. Nous restons ouverts à la publicité, mais nous ne pouvons l’accepter que sous forme d’une bannière statique qui renvoie au site de l’annonceur. Nous ne travaillons pas avec les annonceurs qui ne sont pas en phase avec notre mission.
Vous avez aimé Dégooglisons Internet et pensez le plus grand bien de Contributopia ? Vous aimeriez savoir en quelques mots où notre feuille de route nous mènera en 2019 ? Cet article est fait pour vous, les décideurs pressés 🙂
Cet article présente de façon synthétique et ramassée ce que nous avons développé dans l’article de lancement de la campagne 2018-2019 : «Changer le monde, un octet à la fois».
Un octet à la fois, oui, parce qu’avec nos pattounes, ça prend du temps.
Depuis 4 ans, Framasoft montre qu’il est possible de décentraliser Internet avec l’opération « Dégooglisons Internet ». Le propos n’est ni de critiquer ni de culpabiliser, mais d’informer et de mettre en avant des alternatives qui existaient déjà, mais demeuraient difficiles d’accès ou d’usage.
De façon à ne pas devenir un nouveau nœud de centralisation, l’initiative CHATONS a été lancée, proposant de relier les hébergeurs de services en ligne qui partagent nos valeurs.
Depuis l’année dernière, avec sa feuille de route Contributopia, Framasoft a décidé d’affirmer clairement qu’il fallait aller au-delà du logiciel libre, qui n’était pas une fin en soi, mais un moyen de faire advenir un monde que nous appelons de nos vœux.
Il faut donc encourager la société de contribution et dépasser celle de la consommation, y compris en promouvant des projets qui ne soient plus seulement des alternatives aux GAFAM, mais qui soient porteurs d’une nouvelle façon de faire. Cela se fera aussi en se rapprochant de structures (y compris en dehors du mouvement traditionnel du libre) avec lesquelles nous partageons certaines valeurs, de façon à apprendre et diffuser nos savoirs.
Cette année a vu naître la version 1.0 de PeerTube, logiciel phare qui annonce une nouvelle façon de diffuser des médias vidéos, en conservant le contrôle de ses données sans se couper du monde, qu’on soit vidéaste ou spectateur.
Le monde des services de Contributopia. Illustration de David Revoy – Licence : CC-By 4.0
Avenir
La campagne de don actuelle est aussi l’occasion de de rappeler des éléments d’importance pour Framasoft : nous ne sommes pas une grosse multinationale, mais un petit groupe d’amis épaulé par quelques salarié·e·s, et une belle communauté de contributeurs et contributrices.
Cette petite taille et notre financement basé sur vos dons nous offrent souplesse et indépendance. Ils nous permettront de mettre en place de nouveaux projets comme MobilZon (mobilisation par le numérique), un Mooc CHATONS (tout savoir et comprendre sur pourquoi et comment devenir un chaton) ou encore Framapétitions (plateforme de pétitions n’exploitant pas les données des signataires).
Nous voulons aussi tenter d’en appeler à votre générosité sans techniques manipulatoires, en vous exposant simplement d’où nous venons et où nous allons. Nous espérons que cela vous motivera à nous faire un don.
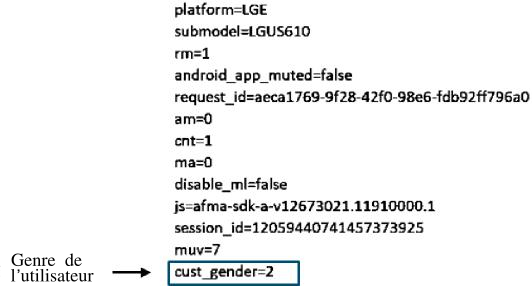
Il s’agit cette fois de comprendre comment Google complète les données collectées avec les données provenant des applications et des comptes connectés des utilisateurs.
VI. Données collectées par les applications clés de Google destinées aux particuliers
67. Google a des dizaines de produits et services qui évoluent en permanence (une liste est disponible dans le tableau 4, section IX.B de l’annexe). On accède souvent à ces produits grâce à un compte Google (ou on l’y associe), ce qui permet à Google de relier directement les détails des activités de l’utilisateur de ses produits et services à un profil utilisateur. En plus des données d’usage de ses produits, Google collecte également des identificateurs et des données de localisation liés aux appareils lorsqu’on accède aux services Google. 1
68. Certaines applications de Google (p.ex. YouTube, Search, Gmail et Maps) occupent une place centrale dans les tâches de base qu’une multitude d’utilisateurs effectuent quotidiennement sur leurs appareils fixes ou mobiles. Le tableau 2 décrit la portée de ces produits clés. Cette section explique comment chacune de ces applications majeures collecte les informations des utilisateurs.
Tableau 2 : Portée mondiale des principales applications Google
Produits
Utilisateurs actifs
Search
Plus d’un milliard d’utilisateurs actifs par mois, 90.6 % de part de marché des moteurs de recherche 2
Youtube
Plus de 1,8 milliard d’utilisateurs inscrits et actifs par mois 3
Maps
Plus d’un milliard d’utilisateurs actifs par mois 4
69. Google Search est le moteur de recherche sur internet le plus populaire au monde 6, avec plus de 11 milliards de requêtes par mois aux États-Unis 7. En plus de renvoyer un classement de pages web en réponse aux requêtes globales des utilisateurs, Google exploite d’autres outils basés sur la recherche, tels que Google Finance, Flights (vols), News (actualités), Scholar (recherche universitaire), Patents (brevets), Books (livres), Images, Videos et Hotels. Google utilise ses applications de recherche afin de collecter des données liées aux recherches, à l’historique de navigation ainsi qu’aux activités d’achats et de clics sur publicités. Par exemple, Google Finance collecte des informations sur le type d’actions que les utilisateurs peuvent suivre, tandis que Google Flight piste leurs réservations et recherches de voyage.
70. Dès lors que Search est utilisé, Google collecte les données de localisation par différents biais, sur ordinateur ou sur mobile, comme décrit dans les sections précédentes. Google enregistre toute l’activité de recherche d’un utilisateur ou utilisatrice et la relie à son compte Google si cette personne est connectée. L’illustration 13 montre un exemple d’informations collectées par Google sur une recherche utilisateur par mot-clé et la navigation associée.
Illustration 13 : Un exemple de collecte de données de recherche extrait de la page My Activity (Mon Activité) d’un utilisateur
71. Non seulement c’est le moteur de recherche par défaut sur Chrome et les appareils Google, mais Google Search est aussi l’option par défaut sur d’autres navigateurs internet et applications grâce à des arrangements de distribution. Ainsi, Google est récemment devenu le moteur de recherche par défaut sur le navigateur internet Mozilla Firefox 8 dans des régions clés (dont les USA et le Canada), une position occupée auparavant par Yahoo. De même, Apple est passé de Microsoft Bing à Google pour les résultats de recherche via Siri sur les appareils iOS et Mac 9. Google a des accords similaires en place avec des OEM (fabricants d’équipement informatique ou électronique) 10, ce qui lui permet d’atteindre les consommateurs mobiles.
B. YouTube
72. YouTube met à disposition des utilisateurs et utilisatrices une plateforme pour la mise en ligne et la visualisation de contenu vidéo. Il attire plus de 180 millions de personnes rien qu’aux États-Unis et a la particularité d’être le deuxième site le plus visité des États-Unis 11, juste derrière Google Search. Au sein des entreprises de streaming multimédia, YouTube possède près de 80 % de parts de marché en termes de visites mensuelles (comme décrit dans l’illustration 14). La quantité de contenu mis en ligne et visualisé sur YouTube est conséquente : 400 heures de vidéo sont mises en ligne chaque minute 12 et 1 milliard d’heures de vidéo sont visualisées quotidiennement sur la plateforme YouTube.13
Illustration 14 : Comparaison d’audiences mensuelles des principaux sites multimédia aux États-Unis 14
73. Les utilisateurs peuvent accéder à YouTube sur l’ordinateur (navigateur internet), sur leurs appareils mobiles (application et/ou navigateur internet) et sur Google Home (via un abonnement payant appelé YouTube Red). Google collecte et sauvegarde l’historique de recherche, l’historique de visualisation, les listes de lecture, les abonnements et les commentaires aux vidéos. La date et l’horaire de chaque activité sont ajoutés à ces informations.
74. Si un utilisateur se connecte à son compte Google pour accéder à n’importe quelle application Google via un navigateur internet (par ex. Chrome, Firefox, Safari), Google reconnaît l’identité de l’utilisateur, même si l’accès à la vidéo est réalisé par un site hors Google (ex. : vidéos YouTube lues sur cnn.com). Cette fonctionnalité permet à Google de pister l’utilisation YouTube d’un utilisateur à travers différentes plateformes tierces. L’illustration 15 montre un exemple de données YouTube collectées.
Illustration 15 : Exemple de collecte de données YouTube dans My Activity (Mon Activité)
75. Google propose également un produit YouTube différencié pour les enfants, appelé YouTube Kids, dans l’intention d’offrir une version « familiale » de YouTube avec des fonctionnalités de contrôle parental et de filtres vidéos. Google collecte des informations de YouTube Kids, notamment le type d’appareil, le système d’exploitation, l’identifiant unique de l’appareil, les informations de journalisation et les détails d’utilisation du service. Google utilise ensuite ces informations pour fournir des annonces publicitaires limitées, qui ne sont pas cliquables et dont le format, la durée et le site sont limités.15.
C. Maps
76. Maps est l’application phare de navigation routière de Google. Google Maps peut déterminer les trajets et la vitesse d’un utilisateur et ses lieux de fréquentation régulière (ex. : domicile, travail, restaurants et magasins). Cette information donne à Google une idée des intérêts (ex. : préférences d’alimentation et d’achats), des déplacements et du comportement de l’utilisateur.
77. Maps utilise l’adresse IP, le GPS, le signal cellulaire et les points d’accès au Wi-Fi pour calculer la localisation d’un appareil. Les deux dernières informations sont collectées par le biais de l’appareil où Maps est utilisé, puis envoyées à Google pour évaluer la localisation via son interface de localisation (Location API). Cette interface fournit de nombreux détails sur un utilisateur, dont les coordonnées géographiques, son état stationnaire ou en mouvement, sa vitesse et la détermination probabiliste de son mode de transport (ex. : en vélo, voiture, train, etc.).
78. Maps sauvegarde un historique des lieux qu’un utilisateur connecté à Maps par son compte Googe a visités. L’illustration 16. montre un exemple d’un tel historique 16. Les points rouges indiquent les coordonnées géographiques recueillies par Maps lorsque l’utilisateur se déplace ; les lignes bleues représentent les projections de Maps sur le trajet réel de l’utilisateur.
Illustration 16 : Exemple d’un historique Google Maps (« Timeline ») d’un utilisateur réel
79. La précision des informations de localisation recueillies par les applications de navigation routière permet à Google de non seulement cibler des audiences publicitaires, mais l’aide aussi à fournir des annonces publicitaires aux utilisateurs lorsqu’ils s’approchent d’un magasin 17. Google Maps utilise de plus ces informations pour générer des données de trafic routier en temps réel.18
D. Gmail
80. Gmail sauvegarde tous les messages (envoyés et reçus), le nom de l’expéditeur, son adresse email et la date et l’heure des messages envoyés ou reçus. Puisque Gmail représente pour beaucoup un répertoire central pour la messagerie électronique, il peut déterminer leurs intérêts en scannant le contenu de leurs courriels, identifier les adresses de commerçants grâce à leurs courriels publicitaires ou les factures envoyées par message électronique, et connaître l’agenda d’un utilisateur (ex. : réservations à dîner, rendez-vous médicaux…). Étant donné que les utilisateurs utilisent leur identifiant Gmail pour des plateformes tierces (Facebook, LinkedIn…), Google peut analyser tout contenu qui leur parvient sous forme de courriel (ex. : notifications, messages).
81. Depuis son lancement en 2004 jusqu’à la fin de l’année 2017 (au moins), Google peut avoir analysé le contenu des courriels Gmail pour améliorer le ciblage publicitaire et les résultats de recherche ainsi que ses filtres de pourriel. Lors de l’été 2016, Google a franchi une nouvelle étape et a modifié sa politique de confidentialité pour s’autoriser à fusionner les données de navigation, autrefois anonymes, de sa filiale DoubleClick (qui fournit des publicités personnalisées sur internet) avec les données d’identification personnelles qu’il amasse à travers ses autres produits, dont Gmail 19. Le résultat : « les annonces publicitaires DoubleClick qui pistent les gens sur Internet peuvent maintenant leur être adaptées sur mesure, en se fondant sur les mots-clés qu’ils ont utilisés dans leur messagerie Gmail. Cela signifie également que Google peut à présent reconstruire le portrait complet d’une utilisatrice ou utilisateur par son nom, en fonction de tout ce qui est écrit dans ses courriels, sur tous les sites visités et sur toutes les recherches menées. » 20
82. Vers la fin de l’année 2017, Google a annoncé qu’il arrêterait la personnalisation des publicités basées sur les messages Gmail 21. Cependant, Google a annoncé récemment qu’il continue à analyser les messages Gmail pour certaines raisons 22.
Les données que récolte Google – Ch.4
Voici déjà la traduction du quatrième chapitre de Google Data Collection, l’étude élaborée par l’équipe du professeur Douglas C. Schmidt, spécialiste des systèmes logiciels, chercheur et enseignant à l’Université Vanderbilt. Si vous les avez manqués, retrouvez les chapitres précédents déjà publiés. Il s’agit cette fois d’explorer les stratégies des régies publicitaires qui opèrent en arrière-plan : des opérations fort discrètes mais terriblement efficaces…
IV. Collecte de données par les outils des annonceurs et des diffuseurs
29. Une source majeure de collecte des données d’activité des utilisateurs provient des outils destinés au annonceurs et aux éditeurs tels que Google Analytics, DoubleClick, AdSense, AdWords et AdMob. Ces outils ont une portée énorme ; par exemple, plus d’un million d’applications mobiles utilisent AdMob23, plus d’un million d’annonceurs utilisent AdWords24, plus de 15 millions de sites internet utilisent AdSense25 et plus de 30 millions de sites utilisent Google Analytics26.
30. Au moment de la rédaction du présent rapport, Google a rebaptisé AdWords « Google Ads » et DoubleClick « Google Ad Manager« , mais aucune modification n’a été apportée aux fonctionnalités principales des produits, y compris la collecte d’informations par ces produits27. Par conséquent, pour les besoins du présent rapport, les premiers noms ont été conservés afin d’éviter toute confusion avec des noms de domaine connexes (tels que doubleclick.net).
31. Voici deux principaux groupes d’utilisateurs des outils de Google axés sur l’édition — et les annonces publicitaires :
Les éditeurs de sites web et d’applications, qui sont des organisations qui possèdent des sites web et créent des applications mobiles. Ces entités utilisent les outils de Google pour (1) gagner de l’argent en permettant l’affichage d’annonces aux visiteurs sur leurs sites web ou applications, et (2) mieux suivre et comprendre qui visite leurs sites et utilise leurs applications. Les outils de Google placent des cookies et exécutent des scripts dans les navigateurs des visiteurs du site web pour aider à déterminer l’identité d’un utilisateur et suivre son intérêt pour le contenu et son comportement en ligne. Les bibliothèques d’applications mobiles de Google suivent l’utilisation des applications sur les téléphones mobiles.
Les annonceurs, qui sont des organisations qui paient pour que des bannières, des vidéos ou d’autres publicités soient diffusées aux utilisateurs lorsqu’ils naviguent sur Internet ou utilisent des applications. Ces entités utilisent les outils de Google pour cibler des profils spécifiques de personnes pour que les publicités augmentent le retour sur leurs investissements marketing (les publicités mieux ciblées génèrent généralement des taux de clics et de conversion plus élevés). De tels outils permettent également aux annonceurs d’analyser leurs audiences et de mesurer l’efficacité de leur publicité numérique en regardant sur quelles annonces les utilisateurs cliquent et à quelle fréquence, et en donnant un aperçu du profil des personnes qui ont cliqué sur les annonces.
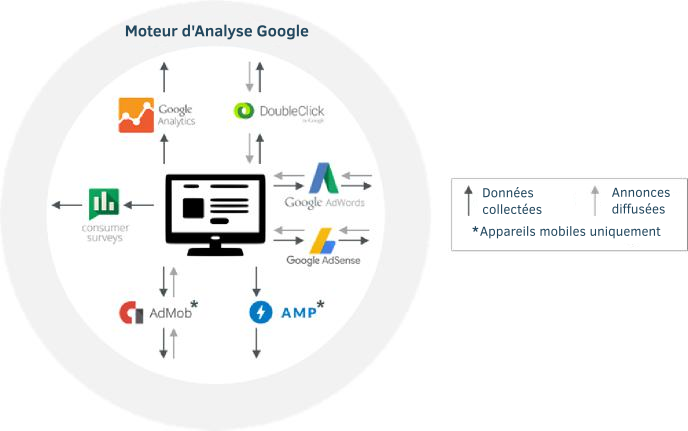
32. Ensemble, ces outils recueillent des informations sur les activités des utilisateurs sur les sites web et dans les applications, comme le contenu visité et les annonces cliquées. Ils travaillent en arrière-plan — en général imperceptibles par des utilisateurs. La figure 7 montre certains de ces outils clés, avec des flèches indiquant les données recueillies auprès des utilisateurs et les publicités qui leur sont diffusées.
Figure 7 : Produits Google destinés aux éditeurs et annonceurs28
33. Les informations recueillies par ces outils comprennent un identifiant non personnel que Google peut utiliser pour envoyer des publicités ciblées sans identifier les informations personnelles de la personne concernée. Ces identificateurs peuvent être spécifiques à l’appareil ou à la session, ainsi que permanents ou semi-permanents. Le tableau 1 liste un ensemble de ces identificateurs. Afin d’offrir aux utilisateurs un plus grand anonymat lors de la collecte d’informations pour le ciblage publicitaire, Google s’est récemment tourné vers l’utilisation d’identifiants uniques semi-permanents (par exemple, les GAID)29. Des sections ultérieures décrivent en détail la façon dont ces outils recueillent les données des utilisateurs et l’utilisation de ces identificateurs au cours du processus de collecte des données.
Tableau 1: Identificateurs transmis à Google
Identificateur
Type
Description
GAID/IDFA
Semi-permanent
Chaine de caractères alphanumériques pour appareils Android et iOS, pour permettre les publicités ciblées sur mobile. Réinitialisable par l’utilisateur.
ID client
Semi-permanent
ID créé la première fois qu’un cookie est stocké sur le navigateur. Utilisé pour relier les sessions de navigations. Réinitialisé lorsque les cookies du navigateur sont effacés.
Adresse IP
Semi-permanent
Une unique suite de nombre qui identifie le réseau par lequel un appareil accède à internet.
ID appareil Android
Semi-permanent
Nombre généré aléatoirement au premier démarrage d’un appareil. Utilisé pour identifier l’appareil. En retrait progressif pour la publicité. Réinitialisé lors d’une remise à zéro de l’appareil.
Google Services Framework (GSF)
Semi-permanent
Nombre assigné aléatoirement lorsqu’un utilisateur s’enregistre pour la première fois dans les services Google sur un appareil. Utilisé pour identifier un appareil unique. Réinitialisé lors d’une remise à zéro de l’appareil.
IEMI / MEID
Permanent
Identificateur utilisé dans les standards de communication mobile. Unique pour chaque téléphone portable.
Adresse MAC
Permanent
Identificateur unique de 12 caractères pour un élément matériel (ex. : routeur).
Numéro de série
Permanent
Chaine de caractères alphanumériques utilisée pour identifier un appareil.
A. Google Analytics et DoubleClick
34. DoubleClick et Google Analytics (GA) sont les produits phares de Google en matière de suivi du comportement des utilisateurs et d’analyse du trafic des pages Web sur les périphériques de bureau et mobiles. GA est utilisé par environ 75 % des 100 000 sites Web les plus visités30. Les cookies DoubleClick sont associés à plus de 1,6 million de sites Web31.
35. GA utilise de petits segments de code de traçage (appelés « balises de page ») intégrés dans le code HTML d’un site Web32. Après le chargement d’une page Web à la demande d’un utilisateur, le code GA appelle un fichier analytics.js qui se trouve sur les serveurs de Google. Ce programme transfère un instantané « par défaut » des données de l’utilisateur à ce moment, qui comprend l’adresse de la page web visitée, le titre de la page, les informations du navigateur, l’emplacement actuel (déduit de l’adresse IP), et les paramètres de langue de l’utilisateur. Les scripts de GA utilisent des cookies pour suivre le comportement des utilisateurs.
36. Le script de GA, la première fois qu’il est exécuté, génère et stocke un cookie spécifique au navigateur sur l’ordinateur de l’utilisateur. Ce cookie a un identificateur de client unique (voir le tableau 1 pour plus de détails)33 Google utilise l’identificateur unique pour lier les cookies précédemment stockés, qui capturent l’activité d’un utilisateur sur un domaine particulier tant que le cookie n’expire pas ou que l’utilisateur n’efface pas les cookies mis en cache dans son navigateur34
37. Alors qu’un cookie GA est spécifique au domaine particulier du site Web que l’utilisateur visite (appelé « cookie de première partie »), un cookie DoubleClick est généralement associé à un domaine tiers commun (tel que doubleclick.net). Google utilise de tels cookies pour suivre l’interaction de l’utilisateur sur plusieurs sites web tiers35 Lorsqu’un utilisateur interagit avec une publicité sur un site web, les outils de suivi de conversion de DoubleClick (par exemple, Floodlight) placent des cookies sur l’ordinateur de l’utilisateur et génèrent un identifiant client unique36 Par la suite, si l’utilisateur visite le site web annoncé, le serveur DoubleClick accède aux informations stockées dans le cookie, enregistrant ainsi la visite comme une conversion valide.
B. AdSense, AdWords et AdMob
38. AdSense et AdWords sont des outils de Google qui diffusent des annonces sur les sites Web et dans les résultats de recherche Google, respectivement. Plus de 15 millions de sites Web ont installé AdSense pour afficher des annonces sponsorisées37 De même, plus de 2 millions de sites web et applications, qui constituent le réseau Google Display Network (GDN) et touchent plus de 90 % des internautes38 affichent des annonces AdWords.
39. AdSense collecte des informations indiquant si une annonce a été affichée ou non sur la page web de l’éditeur. Il recueille également la façon dont l’utilisateur a interagi avec l’annonce, par exemple en cliquant sur l’annonce ou en suivant le mouvement du curseur sur l’annonce39. AdWords permet aux annonceurs de diffuser des annonces de recherche sur Google Search, d’afficher des annonces sur les pages des éditeurs et de superposer des annonces sur des vidéos YouTube. Pour suivre les taux de clics et de conversion des utilisateurs, les publicités AdWords placent un cookie sur les navigateurs des utilisateurs pour identifier l’utilisateur s’il visite par la suite le site web de l’annonceur ou s’il effectue un achat40.
40. Bien qu’AdSense et AdWords recueillent également des données sur les appareils mobiles, leur capacité d’obtenir des renseignements sur les utilisateurs des appareils mobiles est limitée puisque les applications mobiles ne partagent pas de cookies entre elles, une technique d’isolement appelée « bac à sable »41 qui rend difficile pour les annonceurs de suivre le comportement des utilisateurs entre différentes applications mobiles.
41 Pour résoudre ce problème, Google et d’autres entreprises utilisent des « bibliothèques d’annonces » mobiles (comme AdMob) qui sont intégrées dans les applications par leurs développeurs pour diffuser des annonces dans les applications mobiles. Ces bibliothèques compilent et s’exécutent avec les applications et envoient à Google des données spécifiques à l’application à laquelle elles sont intégrées, y compris les emplacements GPS, la marque de l’appareil et le modèle de l’appareil lorsque les applications ont les autorisations appropriées. Comme on peut le voir dans les analyses de trafic de données (Figure 8), et comme on peut trouver confirmation sur les propres pages web des développeurs de Google42, de telles bibliothèques peuvent également envoyer des données personnelles de l’utilisateur, telles que l’âge et le genre, tout cela va vers Google à chaque fois que les développeurs d’applications envoient explicitement leurs valeurs numériques vers la bibliothèque.
Figure 8 : Aperçu des informations renvoyées à Google lorsqu’une application est lancée
C. Association de données recueillies passivement et d’informations à caractère personnel
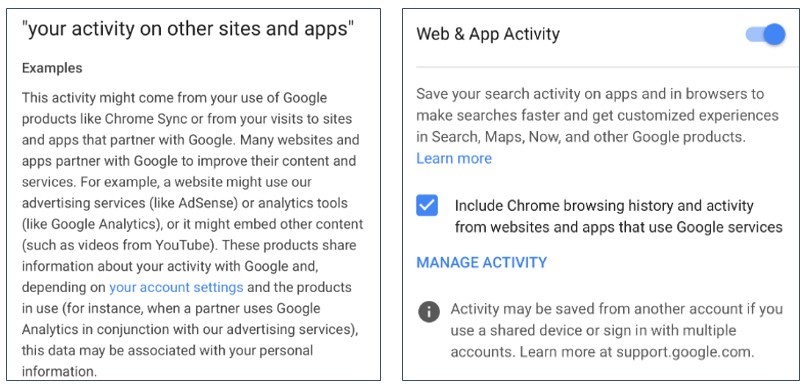
42. Comme nous l’avons vu plus haut, Google recueille des données par l’intermédiaire de produits pour éditeurs et annonceurs, et associe ces données à une variété d’identificateurs semi-permanents et anonymes. Google a toutefois la possibilité d’associer ces identifiants aux informations personnelles d’un utilisateur. C’est ce qu’insinuent les déclarations faites dans la politique de confidentialité de Google, dont des extraits sont présentés à la figure 9. La zone de texte à gauche indique clairement que Google peut associer des données provenant de services publicitaires et d’outils d’analyse aux informations personnelles d’un utilisateur, en fonction des paramètres du compte de l’utilisateur. Cette disposition est activée par défaut, comme indiqué dans la zone de texte à droite.
Figure 9 : Page de confidentialité de Google pour la collecte de sites web tiers et l’association avec des informations personnelles4344.
43. De plus, une analyse du trafic de données échangé avec les serveurs de Google (résumée ci-dessous) a permis d’identifier deux exemples clés (l’un sur Android et l’autre sur Chrome) qui montrent la capacité de Google à corréler les données recueillies de façon anonyme avec les renseignements personnels des utilisateurs.
1) L’identificateur de publicité mobile peut être désanonymé grâce aux données envoyées à Google par Android.
44. Les analyses du trafic de données communiqué entre un téléphone Android et les domaines de serveur Google suggèrent un moyen possible par lequel des identifiants anonymes (GAID dans ce cas) peuvent être associés au compte Google d’un utilisateur. La figure 10 décrit ce processus en une série de trois étapes clés.
45. Dans l’étape 1, une donnée de check-in est envoyée à l’URL android.clients.google.com/checkin. Cette communication particulière fournit une synchronisation de données Android aux serveurs Google et contient des informations du journal Android (par exemple, du journal de récupération), des messages du noyau, des crash dumps, et d’autres identifiants liés au périphérique. Un instantané d’une demande d’enregistrement partiellement décodée envoyée au serveur de Google à partir d’Android est montré en figure 10.
Figure 10 : Les identifiants d’appareil sont envoyés avec les informations de compte dans les requêtes de vérification Android.
46. Comme l’indiquent les zones pointées, Android envoie à Google, au cours du processus d’enregistrement, une variété d’identifiants permanents importants liés à l’appareil, y compris l’adresse MAC de l’appareil, l’IMEI /MEID et le numéro de série du dispositif. En outre, ces demandes contiennent également l’identifiant Gmail de l’utilisateur Android, ce qui permet à Google de relier les informations personnelles d’un utilisateur aux identifiants permanents des appareils Android.
47. À l’étape 2, le serveur de Google répond à la demande d’enregistrement. Ce message contient un identifiant de cadre de services Google (GSF ID)45 qui est similaire à l’« Android ID »46 (voir le tableau 1 pour les descriptions).
48. L’étape 3 implique un autre cas de communication où le même identifiant GSF (de l’étape 2) est envoyé à Google en même temps que le GAID. La figure 10 montre l’une de ces transmissions de données à android.clients.google.com/fdfe/bulkDetails?au=1.
49. Grâce aux trois échanges de données susmentionnés, Google reçoit les informations nécessaires pour connecter un GAID avec des identifiants d’appareil permanents ainsi que les identifiants de compte Google des utilisateurs.
50. Ces échanges de données interceptés avec les serveurs de Google à partir d’un téléphone Android montrent comment Google peut connecter les informations anonymisées collectées sur un appareil mobile Android via les outils DoubleClick, Analytics ou AdMob avec l’identité personnelle de l’utilisateur. Au cours de la collecte de données sur 24 heures à partir d’un téléphone Android sans mouvement ni activité, deux cas de communications d’enregistrement avec des serveurs Google ont été observés. Une analyse supplémentaire est toutefois nécessaire pour déterminer si un tel échange d’informations a lieu avec une certaine périodicité ou s’il est déclenché par des activités spécifiques sur les téléphones.
2) L’ID du cookie DoubleClick est relié aux informations personnelles de l’utilisateur sur le compte Google.
51. La section précédente expliquait comment Google peut désanonymiser l’identité de l’utilisateur via les données passives et anonymisées qu’il collecte à partir d’un appareil mobile Android. Cette section montre comment une telle désanonymisation peut également se produire sur un ordinateur de bureau/ordinateur portable.
52. Les données anonymisées sur les ordinateurs de bureau et portables sont collectées par l’intermédiaire d’identifiants basés sur des cookies (par ex. Cookie ID), qui sont typiquement générés par les produits de publicité et d’édition de Google (par ex. DoubleClick) et stockés sur le disque dur local de l’utilisateur. L’expérience présentée ci-dessous a permis d’évaluer si Google peut établir un lien entre ces identificateurs (et donc les renseignements qui y sont associés) et les informations personnelles d’un utilisateur.
Cette expérience comportait les étapes ordonnées suivantes :
Ouverture d’une nouvelle session de navigation (Chrome ou autre) (pas de cookies enregistrés, par exemple navigation privée ou incognito) ;
Visite d’un site Web tiers qui utilisait le réseau publicitaire DoubleClick de Google ;
Visite du site Web d’un service Google largement utilisé (Gmail dans ce cas) ;
Connexion à Gmail.
53. Au terme des étapes 1 et 2, dans le cadre du processus de chargement des pages, le serveur DoubleClick a reçu une demande lorsque l’utilisateur a visité pour la première fois le site Web tiers. Cette demande faisait partie d’une série de reqêtes comprenant le processus d’initialisation DoubleClick lancé par le site Web de l’éditeur, qui a conduit le navigateur Chrome à installer un cookie pour le domaine DoubleClick. Ce cookie est resté sur l’ordinateur de l’utilisateur jusqu’à son expiration ou jusqu’à ce que l’utilisateur efface manuellement les cookies via les paramètres du navigateur.
54. Ensuite, à l’étape 3, lorsque l’utilisateur visite Gmail, il est invité à se connecter avec ses identifiants Google. Google gère l’identité à l’aide d’une architecture single sign on (SSO) [NdT : authentification unique], dans laquelle les identifiants sont fournis à un service de compte (ici accounts.google.com) en échange d’un « jeton d’authentification », qui peut ensuite être présenté à d’autres services Google pour identifier les utilisateurs. À l’étape 4, lorsqu’un utilisateur accède à son compte Gmail, il se connecte effectivement à son compte Google, qui fournit alors à Gmail un jeton d’autorisation pour vérifier l’identité de l’utilisateur.47 Ce processus est décrit à la figure 24 de la section IX.E de l’annexe.
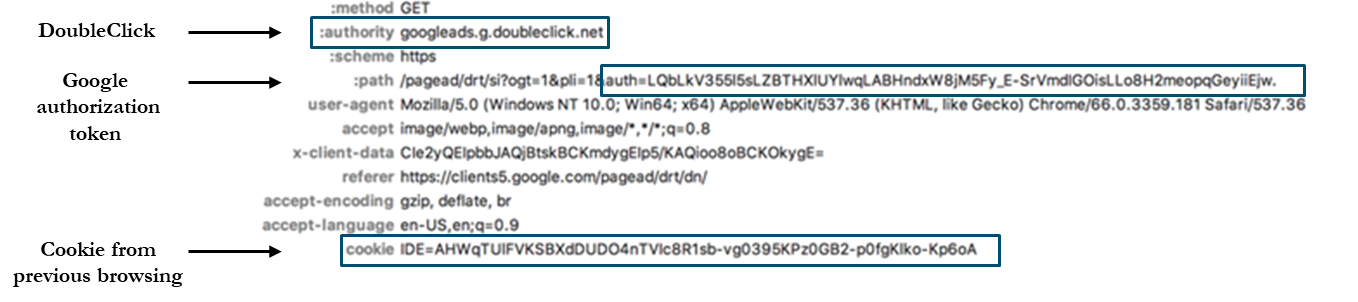
55. Dans la dernière étape de ce processus de connexion, une requête est envoyée au domaine DoubleClick. Cette requête contient à la fois le jeton d’authentification fourni par Google et le cookie de suivi défini lorsque l’utilisateur a visité le site web tiers à l’étape 2 (cette communication est indiquée à la figure 11). Cela permet à Google de relier les informations d’identification Google de l’utilisateur à un cookie DoubleClick. Par conséquent, si les utilisateurs n’effacent pas régulièrement les cookies de leur navigateur, leurs informations de navigation sur les pages Web de tiers qui utilisent les services DoubleClick pourraient être associées à leurs informations personnelles sur Google Account.
Figure 11 : La requête à DoubleClick.net inclut le jeton d’authentification Google et les cookies passés.
56. Il est donc établi à présent que Google recueille une grande variété de données sur les utilisateurs par l’intermédiaire de ses outils d’éditeur et d’annonceur, sans que l’utilisateur en ait une connaissance directe. Bien que ces données soient collectées à l’aide d’identifiants anonymes, Google a la possibilité de relier ces informations collectées aux identifiants personnels de l’utilisateur stockés sur son compte Google.
57. Il convient de souligner que la collecte passive de données d’utilisateurs de Google à partir de pages web tierces ne peut être empêchée à l’aide d’outils populaires de blocage de publicité48, car ces outils sont conçus principalement pour empêcher la présence de publicités pendant que les utilisateurs naviguent sur des pages web tierces49. La section suivante examine de plus près l’ampleur de cette collecte de données.
Ce que peut faire votre Fournisseur d’Accès à l’Internet
Nous sommes ravis et honorés d’accueillir Stéphane Bortzmeyer qui allie une compétence de haut niveau sur des questions assez techniques et une intéressante capacité à rendre assez claires des choses complexes. Nous le remercions de nous expliquer dans cet article quelles pratiques douteuses tentent certains fournisseurs d’accès à l’Internet, quelles menaces cela représente pour la confidentialité comme pour la neutralité du Net, et pourquoi la parade du chiffrement fait l’objet d’attaques répétées de leur part.
Pour vous connecter à l’Internet, vous avez besoin d’un FAI (Fournisseur d’Accès à l’Internet), une entreprise ou une association dont le métier est de relier des individus ou des organisations aux autres FAI. En effet, l’Internet est une coalition de réseaux, chaque FAI a le sien, et ce qui constitue l’Internet global, c’est la connexion de tous ces FAI entre eux. À part devenir soi-même FAI, la seule façon de se connecter à l’Internet est donc de passer par un de ces FAI. La question de la confiance est donc cruciale : qu’est-ce que mon FAI fait sans me le dire ?
Outre son travail visible (vous permettre de regarder Wikipédia, et des vidéos avec des chats mignons), le FAI peut se livrer à des pratiques plus contestables, que cet article va essayer d’expliquer. L’article est prévu pour un vaste public et va donc simplifier une réalité parfois assez compliquée.
Notons déjà tout de suite que je ne prétends pas que tous les FAI mettent en œuvre les mauvaises pratiques décrites ici. Il y a heureusement des FAI honnêtes. Mais toutes ces pratiques sont réellement utilisées aujourd’hui, au moins par certains FAI.
La langue française a un seul verbe, « pouvoir », pour désigner à la fois une possibilité technique (« ma voiture peut atteindre 140 km/h ») et un droit (« sur une route ordinaire, je peux aller jusqu’à 80 km/h »). Cette confusion des deux possibilités est très fréquente dans les discussions au sujet de l’Internet. Ici, je parlerais surtout des possibilités techniques. Les règles juridiques et morales encadrant les pratiques décrites ici varient selon les pays et sont parfois complexes (et je ne suis ni juriste ni moraliste) donc elles seront peu citées dans cet article.
Au sujet du numérique
Pour résumer les possibilités du FAI (Fournisseur d’Accès à l’Internet), il faut se rappeler de quelques propriétés essentielles du monde numérique :
Modifier des données numériques ne laisse aucune trace. Contrairement à un message physique, dont l’altération, même faite avec soin, laisse toujours une trace, les messages envoyés sur l’Internet peuvent être changés sans que ce changement ne se voit.
Copier des données numériques, par exemple à des fins de surveillance des communications, ne change pas ces données, et est indécelable. Elle est très lointaine, l’époque où (en tout cas dans les films policiers), on détectait une écoute à un « clic » entendu dans la communication ! Les promesses du genre « nous n’enregistrons pas vos données » sont donc impossibles à vérifier.
Modifier les données ou bien les copier est très bon marché, avec les matériels et logiciels modernes. Le FAI qui voudrait le faire n’a même pas besoin de compétences pointues : les fournisseurs de matériel et de logiciel pour FAI ont travaillé pour lui et leur catalogue est rempli de solutions permettant modification et écoute des données, solutions qui ne sont jamais accompagnées d’avertissements légaux ou éthiques.
Une publicité pour un logiciel d’interception des communications, même chiffrées. Aucun avertissement légal ou éthique dans la page.
Modifier le trafic réseau
Commençons avec la possibilité technique de modification des données numériques. On a vu qu’elle était non seulement faisable, mais en outre facile. Citons quelques exemples où l’internaute ne recevait pas les données qui avaient été réellement envoyées, mais une version modifiée :
de 2011 à 2013 (et peut-être davantage), en France, le FAI SFR modifiait les images envoyées via son réseau, pour en diminuer la taille. Une image perdait donc ainsi en qualité. Si la motivation (diminuer le débit) était compréhensible, le fait que les utilisateurs n’étaient pas informés indique bien que SFR était conscient du caractère répréhensible de cette pratique.
en 2018 (et peut-être avant), Orange Tunisie modifiait les pages Web pour y insérer des publicités. La modification avait un intérêt financier évident pour le FAI, et aucun intérêt pour l’utilisateur. On lit parfois que la publicité sur les pages Web est une conséquence inévitable de la gratuité de l’accès à cette page mais, ici, bien qu’il soit client payant, l’utilisateur voit des publicités qui ne rapportent qu’au FAI. Comme d’habitude, l’utilisateur n’avait pas été notifié, et le responsable du compte Twitter d’Orange, sans aller jusqu’à nier la modification (qui est interdite par la loi tunisienne), la présentait comme un simple problème technique.
en 2015 (et peut-être avant), Verizon Afrique du Sud modifiait les échanges effectués entre le téléphone et un site Web pour ajouter aux demandes du téléphone des informations comme l’IMEI (un identificateur unique du téléphone) ou bien le numéro de téléphone de l’utilisateur. Cela donnait aux gérants des sites Web des informations que l’utilisateur n’aurait pas donné volontairement. On peut supposer que le FAI se faisait payer par ces gérants de sites en échange de ce service.
Il s’agit uniquement des cas connus, c’est-à-dire de ceux où des experts ont décortiqué ce qui se passait et l’ont documenté. Il y a certainement de nombreux autres cas qui passent inaperçus. Ce n’est pas par hasard si la majorité de ces manipulations se déroulent dans les pays du Sud, où il y a moins d’experts disponibles pour l’analyse, et où l’absence de démocratie politique n’encourage pas les citoyens à regarder de près ce qui se passe. Il n’est pas étonnant que ces modifications du trafic qui passe dans le réseau soient la règle en Chine. Ces changements du trafic en cours de route sont plus fréquents sur les réseaux de mobiles (téléphone mobile) car c’est depuis longtemps un monde plus fermé et davantage contrôlé, où les FAI ont pris de mauvaises habitudes.
Quelles sont les motivations des FAI pour ces modifications ? Elles sont variées, souvent commerciales (insertion de publicités) mais peuvent être également légales (obligation de censure passant techniquement par une modification des données).
Mais ces modifications sont une violation directe du principe de neutralité de l’intermédiaire (le FAI). La « neutralité de l’Internet » est parfois présentée à tort comme une affaire financière (répartition des bénéfices entre différents acteurs de l’Internet) alors qu’elle est avant tout une protection des utilisateurs : imaginez si la Poste modifiait le contenu de vos lettres avant de les distribuer !
Les FAI qui osent faire cela le savent très bien et, dans tous les cas cités, aucune information des utilisateurs n’avait été faite. Évidemment, « nous changerons vos données au passage, pour améliorer nos bénéfices » est plus difficile à vendre aux clients que « super génial haut débit, vos vidéos et vos jeux plus rapides ! » Parfois, même une fois les interférences avec le trafic analysées et publiées, elles sont niées, mais la plupart du temps, le FAI arrête ces pratiques temporairement, sans explications ni excuses.
Surveiller le trafic réseau
De même que le numérique permet de modifier les données en cours de route, il rend possible leur écoute, à des fins de surveillance, politique ou commerciale. Récolter des quantités massives de données, et les analyser, est désormais relativement simple. Ne croyez pas que vos données à vous sont perdues dans la masse : extraire l’aiguille de la botte de foin est justement ce que les ordinateurs savent faire le mieux.
Grâce au courage du lanceur d’alerte Edward Snowden, la surveillance exercée par les États, en exploitant ces possibilités du numérique, est bien connue. Mais il n’y a pas que les États. Les grands intermédiaires que beaucoup de gens utilisent comme médiateurs de leurs communications (tels que Google ou Facebook) surveillent également massivement leurs utilisateurs, en profitant de leur position d’intermédiaire. Le FAI est également un intermédiaire, mais d’un type différent. Il a davantage de mal à analyser l’information reçue, car elle n’est pas structurée pour lui. Mais par contre, il voit passer tout le trafic réseau, alors que même le plus gros des GAFA (Google, Apple, Facebook, Amazon) n’en voit qu’une partie.
L’existence de cette surveillance par les FAI ne fait aucun doute, mais est beaucoup plus difficile à prouver que la modification des données. Comme pour la modification des données, c’est parfois une obligation légale, où l’État demande aux FAI leur assistance dans la surveillance. Et c’est parfois une décision d’un FAI.
Les données ainsi récoltées sont parfois agrégées (regroupées en catégories assez vastes pour que l’utilisateur individuel puisse espérer qu’on ne trouve pas trace de ses activités), par exemple quand elles sont utilisées à des fins statistiques. Elles sont dans ce cas moins dangereuses que des données individuelles. Mais attention : le diable est dans les détails. Il faut être sûr que l’agrégation a bien noyé les détails individuels. Quand un intermédiaire de communication proclame bien fort que les données sont « anonymisées », méfiez-vous. Le terme est utilisé à tort et à travers, et désigne souvent des simples remplacements d’un identificateur personnel par un autre, tout aussi personnel.
La solution du chiffrement
Ces pratiques de modification ou de surveillance des données sont parfois légales et parfois pas. Même quand elles sont illégales, on a vu qu’elles étaient néanmoins pratiquées, et jamais réprimées par la justice. Il est donc nécessaire de ne pas compter uniquement sur les protections juridiques mais également de déployer des protections techniques contre la modification et l’écoute. Deux catégories importantes de protections existent : minimiser les données envoyées, et les chiffrer. La minimisation consiste à envoyer moins de données, et elle fait partie des protections imposées par le RGPD (Règlement [européen] Général sur la Protection des Données). Combinée au chiffrement, elle protège contre la surveillance. Le chiffrement, lui, est la seule protection contre la modification des données.
Mais c’est quoi, le chiffrement ? Le terme désigne un ensemble de techniques, issues de la mathématique, et qui permet d’empêcher la lecture ou la modification d’un message. Plus exactement, la lecture est toujours possible, mais elle ne permet plus de comprendre le message, transformé en une série de caractères incompréhensibles si on ne connait pas la clé de déchiffrement. Et la modification reste possible mais elle est détectable : au déchiffrement, on voit que les données ont été modifiées. On ne pourra pas les lire mais, au moins, on ne recevra pas des données qui ne sont pas les données authentiques.
Dans le contexte du Web, la technique de chiffrement la plus fréquente se nomme HTTPS (HyperText Transfer Protocol Secure). C’est celle qui est utilisée quand une adresse Web commence par https:// , ou quand vous voyez un cadenas vert dans votre navigateur, à gauche de l’adresse. HTTPS sert à assurer que les pages Web que vous recevez sont exactement celles envoyées par le serveur Web, et il sert également à empêcher des indiscrets de lire au passage vos demandes et les réponses. Ainsi, dans le cas de la manipulation faite par Orange Tunisie citée plus haut, HTTPS aurait empêché cet ajout de publicités.
Pour toutes ces raisons, HTTPS est aujourd’hui massivement déployé. Vous le voyez de plus en plus souvent par exemple sur ce blog que vous êtes en train de lire.
Tous les sites Web sérieux ont aujourd’hui HTTPS
Le chiffrement n’est pas utilisé que par HTTPS. Si vous utilisez un VPN (Virtual Private Network, « réseau privé virtuel »), celui-ci chiffre en général les données, et la motivation des utilisateurs de VPN est en effet en général d’échapper à la surveillance et à la modification des données par les FAI. C’est particulièrement important pour les accès publics (hôtels, aéroports, Wifi du TGV) où les manipulations et filtrages sont quasi-systématiques.
Comme toute technique de sécurité, le chiffrement n’est pas parfait, et il a ses limites. Notamment, la communication expose des métadonnées (qui communique, quand, même si on n’a pas le contenu de la communication) et ces métadonnées peuvent être aussi révélatrices que la communication elle-même. Le système « Tor », qui peut être vu comme un type de VPN particulièrement perfectionné, réduit considérablement ces métadonnées.
Le chiffrement est donc une technique indispensable aujourd’hui. Mais il ne plait pas à tout le monde. Lors du FIC (Forum International de la Cybersécurité) en 2015, le représentant d’un gros FAI français déplorait en public qu’en raison du chiffrement, le FAI ne pouvait plus voir ce que faisaient ses clients. Et ce raisonnement est apparu dans un document d’une organisation de normalisation, l’IETF (Internet Engineering Task Force). Ce document, nommé « RFC 8404 »50 décrit toutes les pratiques des FAI qui peuvent être rendues difficiles ou impossibles par le chiffrement. Avant le déploiement massif du chiffrement, beaucoup de FAI avaient pris l’habitude de regarder trop en détail le trafic qui circulait sur leur réseau. C’était parfois pour des motivations honorables, par exemple pour mieux comprendre ce qui passait sur le réseau afin de l’améliorer. Mais, aujourd’hui, compte-tenu de ce qu’on sait sur l’ampleur massive de la surveillance, il est urgent de changer ses pratiques, au lieu de simplement regretter que ce qui était largement admis autrefois soit maintenant rejeté.
Cette liste de pratiques de certains FAI est une information intéressante mais il est dommage que ce document de l’IETF les présente comme si elles étaient toutes légitimes, alors que beaucoup sont scandaleuses et ne devraient pas être tolérées. Si le chiffrement les empêche, tant mieux !
Conclusion
Le déploiement massif du chiffrement est en partie le résultat des pratiques déplorables de certains FAI. Il est donc anormal que ceux-ci se plaignent des difficultés que leur pose le chiffrement. Ils sont les premiers responsables de la méfiance des utilisateurs !
La guerre contre les pratiques douteuses, déjà au XIe siècle… – Image retrouvée sur ce site.
J’ai surtout parlé ici des risques que le FAI écoute les messages, ou les modifie. Mais la place cruciale du FAI dans la communication fait qu’il existe d’autres risques, comme celui de censure de certaines activités ou certains services, ou de coupure d’accès. À l’heure où la connexion à l’Internet est indispensable pour tant d’activités, une telle coupure serait très dommageable.
Quelles sont les solutions, alors ? Se passer de FAI n’est pas réaliste. Certes, des bricoleurs peuvent connecter quelques maisons proches en utilisant des techniques fondées sur les ondes radio, mais cela ne s’étend pas à tout l’Internet. Par contre, il ne faut pas croire qu’un FAI est forcément une grosse entreprise commerciale. Ce peut être une collectivité locale, une association, un regroupement de citoyens. Dans certains pays, des règles très strictes imposées par l’État limitent cette activité de FAI, afin de permettre le maintien du contrôle des citoyens. Heureusement, ce n’est pas (encore ?) le cas en France. Par exemple, la FFDN (Fédération des Fournisseurs d’Accès Internet Associatifs) regroupe de nombreux FAI associatifs en France. Ceux-ci se sont engagés à ne pas recourir aux pratiques décrites plus haut, et notamment à respecter le principe de neutralité.
Bien sûr, monter son propre FAI ne se fait pas en cinq minutes dans son garage. Mais c’est possible en regroupant un collectif de bonnes volontés.
Et, si on n’a pas la possibilité de participer à l’aventure de la création d’un FAI, et pas de FAI associatif proche, quelles sont les possibilités ? Peut-on choisir un bon FAI commercial, en tout cas un qui ne viole pas trop les droits des utilisateurs ? Il est difficile de répondre à cette question. En effet, aucun FAI commercial ne donne des informations détaillées sur ce qui est possible et ne l’est pas. Les manœuvres comme la modification des images dans les réseaux de mobiles sont toujours faites en douce, sans information des clients. Même si M. Toutlemonde était prêt à passer son week-end à comparer les offres de FAI, il ne trouverait pas l’information essentielle « est-ce que ce FAI s’engage à rester strictement neutre ? » En outre, contrairement à ce qui existe dans certains secteurs économiques, comme l’agro-alimentaire, il n’existe pas de terminologie standardisée sur les offres des FAI, ce qui rend toute comparaison difficile.
Dans ces conditions, il est difficile de compter sur le marché pour réguler les pratiques des FAI. Une régulation par l’État n’est pas forcément non plus souhaitable (on a vu que c’est parfois l’État qui oblige les FAI à surveiller les communications, ainsi qu’à modifier les données transmises). À l’heure actuelle, la régulation la plus efficace reste la dénonciation publique des mauvaises pratiques : les FAI reculent souvent, lorsque des modifications des données des utilisateurs sont analysées et citées en public. Cela nécessite du temps et des efforts de la part de ceux et celles qui font cette analyse, et il faut donc saluer leur rôle.
Impôts et dons à Framasoft : le prélèvement à la source en 2019
De nombreux donateurs s’inquiètent de savoir comment cela va se passer l’année prochaine pour les dons effectués à Framasoft en 2018 et le prélèvement à la source à partir de 2019. Pour une fois les choses sont très simples : rien ne change pour votre réduction d’impôt.
En 2019, les impôts seront prélevés à la source. Pour autant, la réduction fiscale demeure inchangée si vous faites un don à Framasoft : un don de 100 € en 2018 peut vous donner droit à 66 € de réduction fiscale, qui vous seront remboursés en août 2019.
Illustration du processus de don
Le déroulement en détail
Jusqu’à présent, vous faisiez votre déclaration au printemps en indiquant votre don ouvrant droit à une réduction d’impôt de 66%, dans la limite de 20 % du revenu imposable. En fin d’année, les services fiscaux vous indiquaient le montant à régler en tenant compte d’une éventuelle mensualisation demandée de votre part.
À partir de 2019, vous allez faire des règlements mensuels dès le mois de janvier en fonction d’un taux déterminé par l’administration fiscale et des paramètres que vous leur aurez fournis. Ceux qui ont fait un don en 2017 recevront, dès le 15 janvier 2019, un acompte de 60% de la réduction d’impôt dont ils ont bénéficié en 2018 au titre des dons effectués en 2017.
Vous ferez, comme chaque année, votre déclaration au printemps, vers mai-juin. Vous indiquerez alors le montant des dons faits à Framasoft en 2018 et pourrez, si demandé, joindre le justificatif que nous vous aurons fait parvenir vers mars-avril. C’est vers la fin de l’été que les impôts vous enverront votre avis, en tenant compte de ce don et d’un éventuel acompte versé de leur part en janvier. C’est alors que l’administration procédera à un recalcul de vos mensualités ou un remboursement, selon le cas et les montants. Les prélèvements mensuels se poursuivront ensuite pour ajuster vos paiements au montant de l’impôt dont vous devrez vous acquitter.
Et c’est tout. En gros, rien ne change pour votre réduction d’impôt pour les dons faits à Framasoft.
En mars 2018, Framasoft lui a envoyé un reçu fiscal pour ce don de 100€.
En mai 2018, Camille a déclaré ses revenus 2017, en précisant qu’elle avait fait un don de 100€ à Framasoft dans la case 7UF «Dons versés à d’autres organismes d’intérêt général».
En août 2018, Camille a reçu son avis d’imposition, qui indiquait prendre en compte une déduction de 66€ (100€ x 66%).
En mars 2019, Framasoft lui envoie son reçu fiscal pour un don de 100€.
En mai 2019, Camille reçoit des impôts sa déclaration de revenus 2018. Elle déclare alors (sur papier ou en ligne) ses revenus 2018, et indique (toujours dans la case « Dons versés à d’autres organismes d’intérêt général ») un montant de 100€.
En août/septembre 2019 (environ), les impôts envoient à Camille son avis d’imposition indiquant prendre en compte sa déduction de 66€ (100 € x 66%).
Son don de 100€ à Framasoft, après déduction, ne lui aura coûté que 34€ (100€ de don – 66€ de déduction).
Son don de 100€ à Framasoft, après déduction, ne lui aura coûté que 34€ (100€ de don – 66€ de déduction).
Maintenant que vous voilà rassurés, nous ne pouvons que vous encourager à faire un don pour soutenir nos actions 🙂