Glyn Moody sur l’article 13 – Une aberration judiciaire
Glyn Moody est infatigable dans son combat contre les dispositions néfastes de la directive européenne sur le droit d’auteur dont le vote est maintenant imminent. Il y consacre une série d’articles dont nous avons déjà proposé deux traductions.
Voici un troisième volet où l’auteur expose notamment le danger de plaintes injustifiées et automatisées de la part de cyberdélinquants.
Traduction Framalang : jums , Khrys, goofy, Barbara
L’article 13 est criminel et irresponsable
par Glyn Moody
Dans un éditorial précédent, j’ai souligné qu’il existe un gros mensonge au cœur de l’Article 13 de la proposition de directive européenne au sujet du droit d’auteur : il est possible de vérifier les téléversements de matériels non-autorisés sans pouvoir inspecter chaque fichier. L’UE s’est retrouvée dans cette position absurde car elle sait que de nombreux parlementaires européens rejetteraient l’idée d’imposer une obligation de suivi général sur les services en ligne, ne serait-ce que parce que la directive sur le commerce en ligne l’interdit de manière explicite. Au lieu de cela, le texte de l’article 13 prétend simplement que des alternatives techniques peuvent être trouvées, sans les préciser. La session parue récemment de « Q & R sur la proposition de directive au sujet du Copyright numérique » par le Parlement Européen explique encore que si les services ne sont pas assez intelligents pour trouver des solutions et utiliser des filtres sur les téléversements de contenu, c’est forcément de leur faute.
Image par Sheila Sund.
Imposer des obligations légales qu’il est impossible de remplir, c’est avoir une conception totalement irresponsable de la chose judiciaire. Mais il existe un autre aspect de l’article 13 qui est pire encore : c’est qu’il va encourager une nouvelle vague de criminalité. On a du mal à imaginer un plus grand échec qu’une loi qui augmente l’absence de loi.
Une fois encore, le problème vient de l’idée erronée qu’il faut contraindre les entreprises à installer des filtres d’upload (c’est-à-dire de mise en ligne par téléversement). De même que les législateurs européens semblent incapables de comprendre l’idée que les services en ligne seront obligés de mener une surveillance généralisée pour se conformer à l’article 13, de même leur manque de connaissances techniques les rend incapables de comprendre les immenses défis pratiques que représente l’implémentation de cette forme de surveillance généralisée.
Au moins le gouvernement français est bien plus cohérent et honnête sur ce point. Il veut aller encore plus loin que l’accord conclu avec le gouvernement allemand, qui a fini par donner la base de l’article 13 sous le nouveau mandat de la présidence roumaine du Conseil, adopté le vendredi 8 février. La France veut supprimer les références à l’article 15 de la directive sur le e-commerce, qui interdit aux États membres d’imposer des obligations de contrôle généralisé, de manière à rendre plus « clair » que ces catégories d’obligations sont parfaitement justifiées quand il s’agit de protéger des contenus sous droits d’auteur.
Un autre éditorial soulignait certains des défis pratiques que pose la mise en œuvre de cette forme de surveillance généralisée. L’article 13 s’appliquera à tous les supports imaginables. Cela signifie que les services en ligne auront besoin de filtres pour le texte, la musique, l’audio, les images, les cartes, les diagrammes, les photos, les vidéos, les films, les logiciels, les modèles 3D, etc. L’article ne peut être filtré que s’il existe une liste de choses qui doivent être bloquées. Ainsi, dans la pratique, l’article 13 signifie que tout site important acceptant les téléversements d’utilisateurs doit avoir des listes de blocage pour chaque type de matériel. Même lorsqu’elles existent, ces listes sont incomplètes. Pour de nombreux domaines – photos, cartes, logiciels, etc. – elles n’existent tout simplement pas. En outre, pour une grande partie du contenu qui devrait être surveillé, les filtres n’existent pas non plus. En un nouvel exemple de législation irresponsable et paresseuse, l’article 13 demande l’impossible.
Que feront les services en ligne dans une telle situation ? La directive sur le droit d’auteur n’est d’aucune aide, elle dit seulement ce qui doit être fait, pas comment le faire. Cela incitera les entreprises à mettre en place des systèmes susceptibles d’offrir la meilleure protection lorsqu’elles seront confrontées à d’inévitables poursuites judiciaires. La principale préoccupation sera de bloquer avec un matériel d’une efficacité maximale ce qui est censé être bloqué, plutôt que de choisir les approches les moins intrusives possible qui maximisent la liberté d’expression pour les utilisateurs. L’absence de systèmes pour se protéger de cette responsabilité pourrait également signifier que certaines plateformes utiliseront le géoblocage, disparaîtront ou s’éloigneront de l’UE, et que d’autres ne seront, en premier lieu, jamais créées en Europe.
Cette injonction va encourager la mise en place de systèmes permettant à quiconque de soumettre des réclamations sur du contenu, qui sera ensuite bloqué. En adoptant ce système, les entreprises seront en mesure de traiter du contenu pour lequel il n’existe pas de listes de blocage générales et pourront ainsi éviter toute responsabilité en cas de téléchargement non autorisé. En plus d’être le seul moyen pratique de relever l’énorme défi que représente le filtrage de tous les types de contenus protégés par le droit d’auteur, cette approche a l’avantage d’avoir déjà été utilisée ailleurs, bien qu’à une plus petite échelle.
Par exemple, YouTube permet à quiconque de prétendre qu’il est le détenteur des droits d’auteur du contenu qui a été posté sur le service Google, et de le faire supprimer automatiquement. Les conséquences négatives de cette fonctionnalité ont été discutées précédemment ; il suffit de dire ici que le matériel légitime est souvent retiré par erreur, et que faire appel contre ces décisions est difficile et prend du temps, et les résultats sont très imprévisibles. La même chose se produira inévitablement avec les filtres de téléchargement de l’article 13, avec ce détail supplémentaire que le contenu sera bloqué avant même qu’il ne soit affiché, alors que le système automatisé de retrait créé par la Digital Millennium Copyright Act (DMCA) des États-Unis ne fonctionne qu’après que le contenu soit affiché en ligne. Cependant, un article récent sur TorrentFreak révèle une autre possibilité troublante :
Par un horrible abus du système de copyright de YouTube, un YouTubeur rapporte que des arnaqueurs utilisent le système des « 3 coups »1 de la plate-forme pour extorquer de l’argent. Après avoir déposé deux fausses plaintes contre ObbyRaidz, les escrocs l’ont contacté et exigé de l’argent comptant pour éviter un troisième – et la résiliation de son canal.
Avec l’article 13, trois avertissements ne sont même pas nécessaires : si votre téléchargement est repéré par le filtre, votre contenu sera bloqué à jamais. On semble penser qu’il importe peu que des erreurs soient commises, parce que les gens peuvent tout bonnement faire appel. Mais comme nous l’avons déjà mentionné, les processus d’appel sont lents, ne fonctionnent pas et ne sont pas utilisés par les gens ordinaires, qui sont intimidés par le processus dans son ensemble. Ainsi, même la menace de revendiquer du contenu sera beaucoup plus forte avec l’article 13 qu’avec YouTube.
Ce qui veut dire que personne ne peut garantir que son contenu pourra seulement paraître en ligne, sauf pour les grosses sociétés de droits de diffusion (américaines) qui forceront les principales plateformes américaines à passer des accords de licence. Même si votre contenu arrive à passer le filtre sur les téléversements, vous allez encore courir le risque d’être racketté par les arnaqueurs au droit d’auteur qui abusent du système. Les obligations de suspension de l’article 13, qui impliquent que le matériel protégé par le droit d’auteur qui a été signalé par les titulaires de droits (ou les arnaqueurs) ne puisse plus être re-téléchargé, rendent les tentatives de réclamer du contenu ou de remettre quelque chose en ligne avec l’article 13 plus difficiles qu’elles ne le sont actuellement sur YouTube.
C’est vraiment une mauvaise nouvelle pour les nouveaux artistes, qui ont absolument besoin de visibilité et qui n’ont pas les poches pleines pour payer des avocats qui règlent ce genre de problèmes, ou pas assez de temps pour s’en occuper eux-mêmes. Les artistes plus établis perdront des revenus à chaque fois que leur contenu sera bloqué, donc ils décideront peut-être aussi de payer des arnaqueurs qui déposeront des fausses plaintes d’infraction au droit d’auteur. Avec cette nouvelle menace, les militants qui utilisent des sites permettant le téléversement public seront aussi sérieusement touchés : beaucoup de campagnes en ligne sont liées à des événements ou des journées particulières. Elles perdent la majeure partie de leur efficacité si leurs actions sont retardées de plusieurs semaines ou même de plusieurs jours, ce que les procédures d’appel ne manqueront pas de faire valoir. C’est plus simple de payer celui qui vous fait chanter.
Ce problème révèle une autre faille de l’Article 13 : il n’y a aucune pénalité pour avoir injustement prétendu être le détenteur des droits sur un contenu, ce qui empêche la mise en ligne de contenus légitimes bloqués par les filtres. Cela veut dire qu’il n’existe presque aucun obstacle si l’on veut envoyer des milliers, voire des millions, de menaces contre des artistes, des militants et autres. Il est clair que c’est de l’extorsion, évidemment illégale. Mais comme les forces de police sont dépassées aujourd’hui, il est à parier qu’elles ne dédieront que des ressources réduites à chasser les fantômes sur Internet. Il est facile pour les gens de se cacher derrière de faux noms, des comptes temporaires et d’utiliser des systèmes de paiement anonymisés tels que le Bitcoin. Avec assez de temps, il est possible d’établir qui se trouve derrière ces comptes, mais si la somme demandée est trop faible, les autorités ne s’en occuperont pas.
En d’autres termes, la nature trop peu réfléchie de l’Article 13 sur les filtres à l’upload crée une nouvelle catégorie de « crime parfait » en ligne. D’une part, tout le monde peut déposer plainte, pourvu d’avoir une connexion Internet, et ce depuis n’importe où dans le monde, et de l’autre cette plainte est prise sans aucun risque pratiquement. Une combinaison particulièrement séduisante et mortelle. Loin d’aider les artistes, la Directive Copyright pourrait créer un obstacle majeur sur la route de leurs succès.
[MISE À JOUR 13/02 22:50]
Dernières nouvelles de l’article 13 : Julia Reda (Parti Pirate européen) explique ici juliareda.eu/2019/02/eu-copyri où on en est et termine en expliquant ce qu’on peut faire (=intervenir auprès des parlementaires européens)
Voir aussi ce que propose saveyourinternet.eu/fr/
Glyn Moody sur l’article 13 – Les utilisateurs oubliés
Pour faire suite à l’article de Glyn Moody traduit dans le Framablog voici un autre billet du même auteur, publié ce vendredi 8 février, qui évoque des possibilités d’aménagement de l’article 13, mais surtout la nécessité de faire entrer dans la loi de larges exceptions pour ne pas oublier tous ceux et celles qui utilisent Internet…
Un vaste oubli au cœur de l’article 13 : les droits des utilisateurs
par Glyn Moody
Le feuilleton à suspense de l’article 13 se poursuit. Les désaccords entre la France et l’Allemagne sur les exemptions à l’obligation d’utiliser des filtres de téléchargement ont stoppé la progression vers la mise au point de la nouvelle législation et permis d’espérer que les graves dommages causés par l’article 13 à Internet pourraient être évités à la dernière minute.
Mais les deux pays semblent être parvenus à un compromis qui est sans doute pire que le texte original. Cela implique qu’en pratique, même les plus petits sites seront obligés de demander des licences et d’accepter les conditions qui leur sont offertes. Il s’agit là d’une recette qui risque d’entraîner encore plus d’abus de la part de l’industrie du droit d’auteur et d’éloigner les jeunes entreprises numériques de l’UE.
Mais à côté de cette proposition incroyablement stupide de la France et de l’Allemagne, il y a un commentaire intéressant de Luigi Di Maio, le vice-premier ministre et ministre italien du Développement économique (original en italien), qui a été largement négligé :
La priorité est de modifier les articles 11 et 13, qui traitent de la taxe sur les liens et du filtrage du contenu. La directive sur le droit d’auteur connaît actuellement une période mouvementée. Les signes qui nous parviennent de Bruxelles ne sont pas encourageants, mais je suis convaincu que l’on peut trouver une solution qui protège les droits des internautes tout en garantissant en même temps les droits des auteurs.
Ce qui est important ici, c’est la mention des droits des utilisateurs. Les discussions à leur sujet ont été marquées par leur absence la plupart du temps où la directive de l’UE sur le droit d’auteur a été en cours d’élaboration. C’est vraiment scandaleux et cela montre à quel point le projet de loi est partial. Il s’agit de donner encore plus de droits à l’industrie du droit d’auteur, sans tenir compte de l’impact négatif sur les autres. Cette considération primordiale est si extrême que les conséquences désastreuses que l’article 13 aura sur l’Internet dans l’UE ont d’abord été niées, puis ignorées.
L’une des manifestations les plus évidentes de cette indifférence à l’égard des faits et du mépris des citoyens de l’UE concerne les mèmes. Comme nous l’avons expliqué il y a quelques mois, il n’est pas vrai que les mèmes ne seront pas affectés par l’article 13, et de nombreux politiciens l’ont souligné. Il n’y a pas d’exception au droit d’auteur à l’échelle de l’UE pour les mèmes : dans certains pays, les mèmes seraient couverts par certaines des exceptions existantes, dans d’autres non.
Actuellement, l’article 5 de la directive de 2001 sur le droit d’auteur stipule que « les États membres peuvent prévoir des exceptions ou des limitations », y compris « à des fins de caricature, de parodie ou de pastiche », qui pourraient couvrir les mèmes, selon l’interprétation que le juge en fait lorsqu’il est saisi d’une affaire judiciaire. Si les politiciens de l’UE se souciaient le moins du monde des utilisateurs ordinaires d’Internet, ils pourraient au minimum rendre ces exceptions obligatoires afin de fournir un espace juridique bien défini pour les mèmes. C’est précisément ce que l’eurodéputée Julia Reda a proposé dans son rapport de 2015 au Parlement européen évaluant l’actuelle directive de 2001 sur le droit d’auteur. Elle a écrit :
L’exception relative à la parodie, à la caricature et au pastiche devrait s’appliquer quel que soit le but de l’œuvre dérivée. Il ne devrait pas être limité par le droit d’auteur d’un titulaire de droit, mais seulement par les droits moraux de l’auteur.
Elle a également proposé une reconnaissance beaucoup plus large des droits des utilisateurs, leur permettant d’exploiter la technologie numérique, en particulier les téléphones mobiles, pour créer de nouvelles œuvres basées sur des éléments de leur vie quotidienne – photos, vidéos et audio – ainsi que du matériel qu’ils rencontrent sur Internet :
La législation sur le droit d’auteur ne devrait pas faire obstacle à cette vague sans précédent d’expression créative émergente et devrait reconnaître les nouveaux créateurs comme des acteurs culturels et des parties prenantes valables.
Une loi sur le droit d’auteur vraiment moderne comprendrait cette nouvelle dimension passionnante. Par exemple, l’article 29.21 de la Loi sur le droit d’auteur du Canada prévoit une vaste exception pour le contenu généré par les utilisateurs. Son existence démontre que l’inclusion d’une disposition similaire dans le droit communautaire n’est pas une demande déraisonnable et qu’elle est compatible avec les traités internationaux régissant le droit d’auteur. Pourtant, la proposition de directive sur le droit d’auteur ignore complètement cet aspect et avec lui, les besoins et les aspirations de centaines de millions de citoyens européens dont la vie s’est enrichie grâce à leur expression personnelle en ligne. Au lieu de cela, les préoccupations de ce groupe d’intervenants clés n’ont fait l’objet que d’un vœu pieux. Ici, par exemple, dans un récent « non-papier » – le nom même trahit sa nature marginale – la Commission européenne propose une petite concession pour les utilisateurs :
les co-législateurs pourraient prévoir que les utilisations mineures de contenu par des téléchargeurs amateurs ne devraient pas être automatiquement bloquées… ni engager la responsabilité de l’auteur du téléchargement.
Mais il n’y a pas d’explication sur la façon dont cela va se produire – par magie, peut-être ? Au lieu de ces mots vagues, nous avons besoin d’une exception concrète qui reconnaisse la réalité de la façon dont la plupart des gens utilisent l’Internet de nos jours – pour partager des éléments du matériel protégé par le droit d’auteur à des fins non commerciales, pour le divertissement et l’édification de la famille et des amis.
S’il est trop difficile d’espérer une exception complète et appropriée pour le contenu généré par les utilisateurs que des pays avant-gardistes comme le Canada ont introduit, il existe une alternative que même les législateurs timorés devraient pouvoir accepter. L’article 10.2 de la Convention de Berne , cadre général des lois sur le droit d’auteur dans le monde, se lit comme suit :
Est réservé l’effet de la législation des pays de l’Union et des arrangements particuliers existants ou à conclure entre eux, en ce qui concerne la faculté d’utiliser licitement, dans la mesure justifiée par le but à atteindre, des œuvres littéraires ou artistiques à titre d’illustration de l’enseignement par le moyen de publications, d’émissions de radiodiffusion ou d’enregistrements sonores ou visuels, sous réserve qu’une telle utilisation soit conforme aux bons usages.
Pourquoi ne pas créer une exception générale au droit d’auteur au sein de l’UE pour de telles « illustrations », qui s’appliqueraient au-delà des établissements d’enseignement, au grand public réutilisant du matériel dans le but limité « d’illustrer » une pensée ou un commentaire ? Après tout, on pourrait faire valoir qu’une telle utilisation est, en effet, un nouveau type d’enseignement, en ce sens qu’elle transmet des connaissances et des opinions sur le monde, en s’appuyant sur les possibilités offertes par les technologies modernes. Ce n’est pas la meilleure solution, mais c’est mieux que rien. Cela montrerait au moins que la Commission européenne, les États membres et les députés européens sont conscients de l’existence du public et sont prêts à jeter une petite miette dans sa direction.
En fait, il y a peu de temps, le texte proposé pour la directive sur le droit d’auteur a inclus une telle formulation dans une section sur le contenu généré par l’utilisateur. Celle-ci a été initialement proposée sous la présidence autrichienne en décembre 2018, demandée par les Allemands dans leur document officieux de janvier 2019, et reprise initialement par la présidence roumaine. Cependant, la présidence roumaine l’a ensuite supprimée à la suite de plaintes émanant de certains pays de l’UE (très probablement les Français). Peut-être que l’Italie devrait la faire remettre à sa place.
Glyn Moody sur l’article 13 – Mensonges et mauvaise foi
Glyn Moody est un journaliste, blogueur et écrivain spécialisé dans les questions de copyright et droits numériques. Ses combats militants le placent en première ligne dans la lutte contre l’article 13 de la directive européenne sur le droit d’auteur, dont le vote final est prévu ce mois-ci. Cet article a été combattu par des associations en France telles que La Quadrature du Net, dénoncé pour ses effet délétères par de nombreuses personnalités (cette lettre ouverte par exemple, signée de Vinton Cerf, Tim Berners-lee, Bruce Schneier, Jimmy Wales…) et a fait l’objet de pétitions multiples.
Dans une suite d’articles en cours (en anglais) ou dans diverses autres interventions (celle-ci traduite en français) que l’on parcourra avec intérêt, Glyn Moody démonte un à un les éléments de langage des lobbyistes des ayants droit. Le texte que Framalang a traduit pour vous met l’accent sur la mauvaise foi des défenseurs de l’article 13 qui préparent des réponses biaisées aux objections qui leur viennent de toutes parts, et notamment de 4 millions d’Européens qui ont manifesté leur opposition.
Pour Glyn Moody, manifestement l’article 13 est conçu pour donner des pouvoirs exorbitants (qui vont jusqu’à une forme de censure automatisée) aux ayants droit au détriment des utilisateurs et utilisatrices « ordinaires »
L’article 13 n’est pas seulement un travail législatif dangereux, mais aussi foncièrement malhonnête
par Glyn Moody
La directive sur Copyright de l’Union Européenne est maintenant en phase d’achèvement au sein du système législatif européen. Étant donné la nature avancée des discussions, il est déjà très surprenant que le comité des affaires juridiques (JURI), responsable de son pilotage à travers le Parlement Européen, ait récemment publié une session de « Questions et Réponses » sur la proposition de « Directive au sujet du Copyright numérique ». Mais il n’est pas difficile de deviner pourquoi ce document a été publié maintenant. De plus en plus de personnes prennent conscience que la directive sur le Copyright en général, et l’Article 13 en particulier, vont faire beaucoup de tort à l’Internet en Europe. Cette session de Q & R tente de contrer les objections relevées et d’étouffer le nombre grandissant d’appels à l’abandon de l’Article 13.
La première question de cette session de Q & R, « En quoi consiste la directive sur le Copyright ? », souligne le cœur du problème de la loi proposée.
La réponse est la suivante : « La proposition de directive sur le Copyright dans le marché unique numérique » cherche à s’assurer que les artistes (en particulier les petits artistes, par exemple les musiciens), les éditeurs de contenu ainsi que les journalistes, bénéficient autant du monde connecté et d’Internet que du monde déconnecté. »
Il n’est fait mention nulle part des citoyens européens qui utilisent l’Internet, ou de leurs priorités. Donc, il n’est pas surprenant qu’on ne règle jamais le problème du préjudice que va causer la directive sur le Copyright à des centaines de millions d’utilisateurs d’Internet, car les défenseurs de la directive sur le Copyright ne s’en préoccupent pas. La session de Q & R déclare : « Ce qu’il est actuellement légal et permis de partager, restera légal et permis de partager. » Bien que cela soit sans doute correct au sens littéral, l’exigence de l’Article 13 concernant la mise en place de filtres sur la mise en ligne de contenus signifie en pratique que c’est loin d’être le cas. Une information parfaitement légale à partager sera bloquée par les filtres, qui seront forcément imparfaits, et parce que les entreprises devant faire face à des conséquences juridiques, feront toujours preuve d’excès de prudence et préféreront trop bloquer.
La question suivante est : « Quel impact aura la directive sur les utilisateurs ordinaires ? ».
Là encore, la réponse est correcte mais trompeuse : « Le projet de directive ne cible pas les utilisateurs ordinaires. »
Personne ne dit qu’elle cible les utilisateurs ordinaires, en fait, ils sont complètement ignorés par la législation. Mais le principal, c’est que les filtres sur les chargements de contenu vont affecter les utilisateurs ordinaires, et de plein fouet. Que ce soit ou non l’intention n’est pas la question.
« Est-ce que la directive affecte la liberté sur Internet ou mène à une censure d’Internet ? » demande la session de Q & R.
La réponse ici est « Un utilisateur pourra continuer d’envoyer du contenu sur les plateformes d’Internet et (…) ces plateformes / agrégateurs d’informations pourront continuer à héberger de tels chargements, tant que ces plateformes respectent les droits des créateurs à une rémunération décente. »
Oui, les utilisateurs pourront continuer à envoyer du contenu, mais une partie sera bloquée de manière injustifiable parce que les plateformes ne prendront pas le risque de diffuser du contenu qui ne sera peut-être couvert par l’une des licences qu’elles ont signées.
La question suivante concerne le mensonge qui est au cœur de la directive sur le Copyright, à savoir qu’il n’y a pas besoin de filtre sur les chargements. C’est une idée que les partisans ont mise en avant pendant un temps, et il est honteux de voir le Parlement Européen lui-même répéter cette contre-vérité. Voici l’élément de la réponse :
« La proposition de directive fixe un but à atteindre : une plateforme numérique ou un agrégateur de presse ne doit pas gagner d’argent grâce aux productions de tierces personnes sans les indemniser. Par conséquent, une plateforme ou un agrégateur a une responsabilité juridique si son site diffuse du contenu pour lequel il n’aurait pas correctement rémunéré le créateur. Cela signifie que ceux dont le travail est illégalement utilisé peuvent poursuivre en justice la plateforme ou l’agrégateur. Toutefois, le projet de directive ne spécifie pas ni ne répertorie quels outils, moyens humains ou infrastructures peuvent être nécessaires afin d’empêcher l’apparition d’une production non rémunérée sur leur site. Il n’y a donc pas d’obligation de filtrer les chargements.
Toutefois, si de grandes plateformes ou agrégateurs de presse ne proposent pas de solutions innovantes, ils pourraient finalement opter pour le filtrage. »
La session Q & R essaye d’affirmer qu’il n’est pas nécessaire de filtrer les chargements et que l’apport de « solutions innovantes » est à la charge des entreprises du web. Elle dit clairement que si une entreprise utilise des filtres sur les chargements, on doit lui reprocher de ne pas être suffisamment « innovante ». C’est une absurdité. D’innombrables experts ont signalé qu’il est impossible « d’empêcher la diffusion de contenu non-rémunéré sur un site » à moins de vérifier, un à un, chacun les fichiers et de les bloquer si nécessaire : il s’agit d’un filtrage des chargements. Aucune “innovation” ne permettra de contourner l’impossibilité logique de se conformer à la directive sur le Copyright, sans avoir recours au filtrage des chargements.
En plus de donner naissance à une législation irréfléchie, cette approche montre aussi la profonde inculture technique de nombreux politiciens européens. Ils pensent encore manifestement que la technologie est une sorte de poudre de perlimpinpin qui peut être saupoudrée sur les problèmes afin de les faire disparaître. Ils ont une compréhension médiocre du domaine numérique et sont cependant assez arrogants pour ignorer les meilleurs experts mondiaux en la matière lorsque ceux-ci disent que ce que demande la Directive sur le Copyright est impossible.
Pour couronner le tout, la réponse à la question : « Pourquoi y a-t-il eu de nombreuses contestations à l’encontre de cette directive ? » constitue un terrible affront pour le public européen. La réponse reconnaît que : « Certaines statistiques au sein du Parlement Européen montrent que les parlementaires ont rarement, voire jamais, été soumis à un tel niveau de lobbying (appels téléphoniques, courriels, etc.). » Mais elle écarte ce niveau inégalé de contestation de la façon suivante :
« De nombreuses campagnes antérieures de lobbying ont prédit des conséquences désastreuses qui ne se sont jamais réalisées.
Par exemple, des entreprises de télécommunication ont affirmé que les factures téléphoniques exploseraient en raison du plafonnement des frais d’itinérance ; les lobbies du tabac et de la restauration ont prétendu que les personnes allaient arrêter d’aller dans les restaurants et dans les bars suite à l’interdiction d’y fumer à l’intérieur ; des banques ont dit qu’elles allaient arrêter de prêter aux entreprises et aux particuliers si les lois devenaient plus strictes sur leur gestion, et le lobby de la détaxe a même argué que les aéroports allaient fermer, suite à la fin des produits détaxés dans le marché intérieur. Rien de tout ceci ne s’est produit. »
Il convient de remarquer que chaque « contre-exemple » concerne des entreprises qui se plaignent de lois bénéficiant au public. Mais ce n’est pas le cas de la vague de protestation contre la directive sur le Copyright, qui vient du public et qui est dirigée contre les exigences égoïstes de l’industrie du copyright. La session de Q & R tente de monter un parallèle biaisé entre les pleurnichements intéressés des industries paresseuses et les attentes d’experts techniques inquiets, ainsi que de millions de citoyens préoccupés par la préservation des extraordinaires pouvoirs et libertés de l’Internet ouvert.
Voici finalement la raison pour laquelle la directive sur le Copyright est si pernicieuse : elle ignore totalement les droits des usagers d’Internet. Le fait que la nouvelle session de Q & R soit incapable de répondre à aucune des critiques sérieuses sur la loi autrement qu’en jouant sur les mots, dans une argumentation pitoyable, est la confirmation que tout ceci n’est pas seulement un travail législatif dangereux, mais aussi profondément malhonnête. Si l’Article 13 est adopté, il fragilisera l’Internet dans les pays de l’UE, entraînera la zone dans un marasme numérique et, par le refus réitéré de l’Union Européenne d’écouter les citoyens qu’elle est censée servir, salira le système démocratique tout entier.
Aujourd’hui Framasoft (parmi d’autres) montre son soutien à l’association RAP (Résistance à l’Agression Publicitaire) ainsi qu’à la Quadrature du Net qui lancent une campagne de sensibilisation et d’action pour lutter contre les nuisances publicitaires non-consenties sur Internet.
#BloquelapubNet : un site pour expliquer comment se protéger
Cliquez sur l’image pour aller directement sur bloquelapub.net
Si vous, vous savez comment vous prémunir de cette pollution informationnelle… avez-vous déjà songé à aider vos proches, collègues et connaissances ? C’est compliqué de tout bien expliquer avec des mots simples, hein ? C’est justement à ça que sert le site bloquelapub.net : un tutoriel à suivre qui permet, en quelques clics, d’apprendre quelques gestes essentiels pour notre hygiène numérique. Voilà un site utile, à partager et communiquer autour de soi avec enthousiasme, sans modération et accompagné du mot clé #bloquelapubnet !
Pourquoi bloquer ? – Le communiqué
Nous reproduisons ci dessous le communiqué de presse des associations Résistance à l’Agression Publicitaire et La Quadrature du Net.
Internet est devenu un espace prioritaire pour les investissements des publicitaires. En France, pour la première fois en 2016, le marché de la publicité numérique devient le « premier média investi sur l’ensemble de l’année », avec une part de marché de 29,6%, devant la télévision. En 2017, c’est aussi le cas au niveau mondial. Ce jeune « marché » est principalement capté par deux géants de la publicité numérique. Google et Facebook. Ces deux géants concentrent à eux seuls autour de 50% du marché et bénéficient de la quasi-totalité des nouveaux investissements sur ce marché. « Pêché originel d’Internet », où, pour de nombreuses personnes et sociétés, il demeure difficile d’obtenir un paiement monétaire direct pour des contenus et services commerciaux et la publicité continue de s’imposer comme un paiement indirect.
Les services vivant de la publicité exploitent le « temps de cerveau disponible » des internautes qui les visitent, et qui n’en sont donc pas les clients, mais bien les produits. Cette influence est achetée par les annonceurs qui font payer le cout publicitaire dans les produits finalement achetés.
La publicité en ligne a plusieurs conséquences : en termes de dépendance vis-à-vis des annonceurs et des revenus publicitaires, et donc des limites sur la production de contenus et d’information, en termes de liberté de réception et de possibilité de limiter les manipulations publicitaires, sur la santé, l’écologie…
En ligne, ces problématiques qui concernent toutes les publicités ont de plus été complétées par un autre enjeu fondamental. Comme l’exprime parfaitement Zeynep Tufekci, une chercheuse turque, « on a créé une infrastructure de surveillance dystopique juste pour que des gens cliquent sur la pub ». De grandes entreprises telles que Google, Facebook et d’autres « courtiers en données » comme Criteo ont développés des outils visant à toujours mieux nous « traquer » dans nos navigations en ligne pour nous profiler publicitairement. Ces pratiques sont extrêmement intrusives et dangereuses pour les libertés fondamentales.
Il est plus temps que cette législation soit totalement respectée et que les publicitaires cessent de nous espionner en permanence en ligne.
Un sondage BVA-La Dépêche de 2018, révélait que 77% des Français·es se disent inquiet·es de l’utilisation que pouvaient faire des grandes entreprises commerciales de leurs données numériques personnelles. 83% des Français·es sont irrité·es par la publicité en ligne selon un sondage de l’institut CSA en mars 2016 et « seulement » 24% des personnes interrogées avaient alors installé un bloqueur de publicité.
Le blocage de la publicité en ligne apparait comme un bon outil de résistance pour se prémunir de la surveillance publicitaire sur Internet. Pour l’aider à se développer, nos associations lancent le site Internet :
Plusieurs opérations collectives ou individuelles de sensibilisation et blocages de la publicité auront lieu sur plusieurs villes du territoire français et sur Internet peu de temps avant et le jour du 28 janvier 2019, journée européenne de la « protection des données personnelles ». Le jour rêvé pour s’opposer à la publicité en ligne qui exploite ces données !
RAP et La Quadrature du Net demandent :
Le respect de la liberté de réception dans l’espace public et ailleurs, le droit et la possibilité de refuser d’être influencé par la publicité,
Le strict respect du règlement général pour la protection des données et l’interdiction de la collecte de données personnelles à des fins publicitaires sans le recueil d’un consentement libre (non-conditionnant pour l’accès au service), explicite et éclairé où les paramètres les plus protecteurs sont configurés par défaut. Les sites Internet et services en ligne ne doivent par défaut collecter aucune information à des fins publicitaires sans que l’internaute ne les y ait expressément autorisés.
Rendez-vous sur bloquelapub.net et sur Internet toute la journée du 28 janvier 2019
Les associations soutiens de cette mobilisation : Framasoft, Le CECIL, Globenet, Le Creis-Terminal
Pour un Web frugal ?
Sites lourds, sites lents, pages web obèses qui exigent pour être consultées dans un délai raisonnable une carte graphique performante, un processeur rapide et autant que possible une connexion par fibre optique… tel est le quotidien de l’internaute ordinaire.
Nul besoin de remonter aux débuts du Web pour comparer : c’est d’une année sur l’autre que la taille moyenne des pages web s’accroît désormais de façon significative.
Quant à la consommation en énergie de notre vie en ligne, elle prend des proportions qui inquiètent à juste titre : des lointains datacenters aux hochets numériques dont nous aimons nous entourer, il y a de quoi se poser des questions sur la nocivité environnementale de nos usages collectifs et individuels.
Bien sûr, les solutions économes à l’échelle de chacun sont peut-être dérisoires au regard des gigantesques gaspillages d’un système consumériste insatiable et énergivore.
Cependant nous vous invitons à prendre en considération l’expérience de l’équipe barcelonaise de Low-Tech Magazine dont nous avons traduit pour vous un article. Un peu comme l’association Framasoft l’avait fait en ouverture de la campagne dégooglisons… en se dégooglisant elle-même, les personnes de Low-tech Magazine ont fait de leur mieux pour appliquer à leur propre site les principes de frugalité qu’elles défendent : ce ne sont plus seulement les logiciels mais aussi les matériels qui ont fait l’objet d’une cure d’amaigrissement au régime solaire.
En espérant que ça donnera des idées à tous les bidouilleurs…
article original : How to build a Low-tech website Traduction Framalang : Khrys, Mika, Bidouille, Penguin, Eclipse, Barbara, Mannik, jums, Mary, Cyrilus, goofy, simon, xi, Lumi, Suzy + 2 auteurs anonymes
Comment créer un site web basse technologie
Low-tech Magazine a été créé en 2007 et n’a que peu changé depuis. Comme une refonte du site commençait à être vraiment nécessaire, et comme nous essayons de mettre en œuvre ce que nous prônons, nous avons décidé de mettre en place une version de Low Tech Magazine en basse technologie, auto-hébergée et alimentée par de l’énergie solaire. Le nouveau blog est conçu pour réduire radicalement la consommation d’énergie associée à l’accès à notre contenu.
Premier prototype du serveur alimenté à l’énergie solaire sur lequel tourne le nouveau site.
Pour éviter les conséquences négatives d’une consommation énergivore, les énergies renouvelables seraient un moyen de diminuer les émissions des centres de données. Par exemple, le rapport annuel ClickClean de Greenpeace classe les grandes entreprises liées à Internet en fonction de leur consommation d’énergies renouvelables.
Cependant, faire fonctionner des centres de données avec des sources d’énergie renouvelables ne suffit pas à compenser la consommation d’énergie croissante d’Internet. Pour commencer, Internet utilise déjà plus d’énergie que l’ensemble des énergies solaire et éolienne mondiales. De plus, la réalisation et le remplacement de ces centrales électriques d’énergies renouvelables nécessitent également de l’énergie, donc si le flux de données continue d’augmenter, alors la consommation d’énergies fossiles aussi.
Cependant, faire fonctionner les centres de données avec des sources d’énergie renouvelables ne suffit pas à combler la consommation d’énergie croissante d’Internet.
Enfin, les énergies solaire et éolienne ne sont pas toujours disponibles, ce qui veut dire qu’un Internet fonctionnant à l’aide d’énergies renouvelables nécessiterait une infrastructure pour le stockage de l’énergie et/ou pour son transport, ce qui dépend aussi des énergies fossiles pour sa production et son remplacement. Alimenter les sites web avec de l’énergie renouvelable n’est pas une mauvaise idée, mais la tendance vers l’augmentation de la consommation d’énergie doit aussi être traitée.
Des sites web qui enflent toujours davantage
Tout d’abord, le contenu consomme de plus en plus de ressources. Cela a beaucoup à voir avec l’importance croissante de la vidéo, mais une tendance similaire peut s’observer sur les sites web.
La taille moyenne d’une page web (établie selon les pages des 500 000 domaines les plus populaires) est passée de 0,45 mégaoctets en 2010 à 1,7 mégaoctets en juin 2018. Pour les sites mobiles, le poids moyen d’une page a décuplé, passant de 0,15 Mo en 2011 à 1,6 Mo en 2018. En utilisant une méthode différente, d’autres sources évoquent une moyenne autour de 2,9 Mo en 2018.
La croissance du transport de données surpasse les avancées en matière d’efficacité énergétique (l’énergie requise pour transférer 1 mégaoctet de données sur Internet), ce qui engendre toujours plus de consommation d’énergie. Des sites plus « lourds » ou plus « gros » ne font pas qu’augmenter la consommation d’énergie sur l’infrastructure du réseau, ils raccourcissent aussi la durée de vie des ordinateurs, car des sites plus lourds nécessitent des ordinateurs plus puissants pour y accéder. Ce qui veut dire que davantage d’ordinateurs ont besoin d’être fabriqués, une production très coûteuse en énergie.
Être toujours en ligne ne fait pas bon ménage avec des sources d’énergies renouvelables telles que l’éolien ou le solaire, qui ne sont pas toujours disponibles.
La deuxième raison de l’augmentation de la consommation énergétique d’Internet est que nous passons de plus en plus de temps en ligne. Avant l’arrivée des ordinateurs portables et du Wi-Fi, nous n’étions connectés au réseau que lorsque nous avions accès à un ordinateur fixe au bureau, à la maison ou à la bibliothèque. Nous vivons maintenant dans un monde où quel que soit l’endroit où nous nous trouvons, nous sommes toujours en ligne, y compris, parfois, sur plusieurs appareils à la fois.
Un accès Internet en mode « toujours en ligne » va de pair avec un modèle d’informatique en nuage, permettant des appareils plus économes en énergie pour les utilisateurs au prix d’une dépense plus importante d’énergie dans des centres de données. De plus en plus d’activités qui peuvent très bien se dérouler hors-ligne nécessitent désormais un accès Internet en continu, comme écrire un document, remplir une feuille de calcul ou stocker des données. Tout ceci ne fait pas bon ménage avec des sources d’énergies renouvelables telles que l’éolien ou le solaire, qui ne sont pas disponibles en permanence.
Conception d’un site internet basse technologie
La nouvelle mouture de notre site répond à ces deux problématiques. Grâce à une conception simplifiée de notre site internet, nous avons réussi à diviser par cinq la taille moyenne des pages du blog par rapport à l’ancienne version, tout en rendant le site internet plus agréable visuellement (et plus adapté aux mobiles). Deuxièmement, notre nouveau site est alimenté à 100 % par l’énergie solaire, non pas en théorie, mais en pratique : il a son propre stockage d’énergie et sera hors-ligne lorsque le temps sera couvert de manière prolongée.
Internet n’est pas une entité autonome. Sa consommation grandissante d’énergie est la résultante de décisions prises par des développeurs logiciels, des concepteurs de site internet, des départements marketing, des annonceurs et des utilisateurs d’internet. Avec un site internet poids plume alimenté par l’énergie solaire et déconnecté du réseau, nous voulons démontrer que d’autres décisions peuvent être prises.
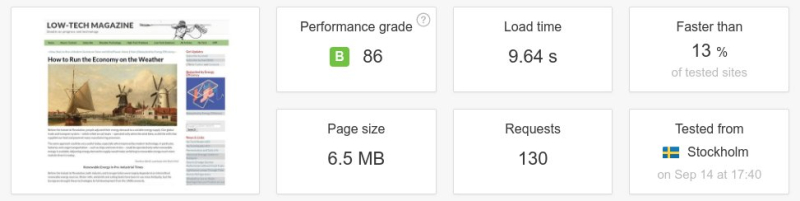
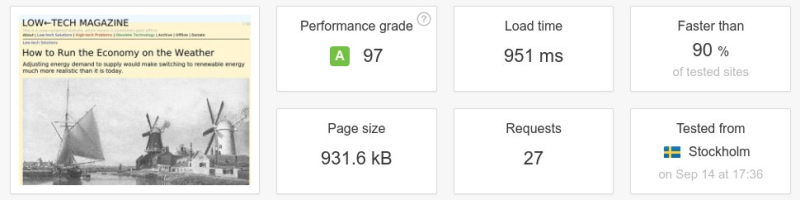
Avec 36 articles en ligne sur environ une centaine, le poids moyen d’une page sur le site internet alimenté par énergie solaire est environ cinq fois inférieur à celui de la version précédente.
Pour commencer, la nouvelle conception du site va à rebours de la tendance à des pages plus grosses. Sur 36 articles actuellement en ligne sur environ une centaine, le poids moyen d’une page sur le site internet alimenté par énergie solaire est 0,77 Mo – environ cinq fois inférieur à celui de la version précédente, et moins de la moitié du poids moyen d’une page établi sur les 500 000 blogs les plus populaires en juin 2018.
Ci-dessous : un test de vitesse d’une page web entre l’ancienne et la nouvelle version du magazine Low-Tech. La taille de la page a été divisée par plus de six, le nombre de requêtes par cinq, et la vitesse de téléchargement a été multipliée par dix. Il faut noter que l’on n’a pas conçu le site internet pour être rapide, mais pour une basse consommation d’énergie. La vitesse aurait été supérieure si le serveur avait été placé dans un centre de données et/ou à une position plus centrale de l’infrastructure d’Internet.
Ci-dessous sont détaillées plusieurs des décisions de conception que nous avons faites pour réduire la consommation d’énergie. Des informations plus techniques sont données sur une page distincte. Nous avons aussi libéré le code source pour la conception de notre site internet.
Site statique
Un des choix fondamentaux que nous avons faits a été d’élaborer un site internet statique. La majorité des sites actuels utilisent des langages de programmation côté serveur qui génèrent la page désirée à la volée par requête à une base de données. Ça veut dire qu’à chaque fois que quelqu’un visite une page web, elle est générée sur demande.
Au contraire, un site statique est généré une fois pour toutes et existe comme un simple ensemble de documents sur le disque dur du serveur. Il est toujours là, et pas seulement quand quelqu’un visite la page. Les sites internet statiques sont donc basés sur le stockage de fichiers quand les sites dynamiques dépendent de calculs récurrents. En conséquence, un site statique nécessite moins de puissance de calcul, donc moins d’énergie.
Le choix d’un site statique nous permet d’opérer la gestion de notre site de manière économique depuis notre bureau de Barcelone. Faire la même chose avec un site web généré depuis une base de données serait quasiment impossible, car cela demanderait trop d’énergie. Cela présenterait aussi des risques importants de sécurité. Bien qu’un serveur avec un site statique puisse toujours être piraté, il y a significativement moins d’attaques possibles et les dommages peuvent être plus facilement réparés.
Images optimisées pour en réduire le « poids »
Le principal défi a été de réduire la taille de la page sans réduire l’attractivité du site. Comme les images consomment l’essentiel de la bande passante il serait facile d’obtenir des pages très légères et de diminuer l’énergie nécessaire en supprimant les images, en réduisant leur nombre ou en réduisant considérablement leur taille. Néanmoins, les images sont une part importante de l’attractivité de Low-tech Magazine et le site ne serait pas le même sans elles.
Par optimisation, on peut rendre les images dix fois moins gourmandes en ressources, tout en les affichant bien plus largement que sur l’ancien site.
Nous avons plutôt choisi d’appliquer une ancienne technique de compression d’image appelée « diffusion d’erreur ». Le nombre de couleurs d’une image, combiné avec son format de fichier et sa résolution, détermine la taille de cette image. Ainsi, plutôt que d’utiliser des images en couleurs à haute résolution, nous avons choisi de convertir toutes les images en noir et blanc, avec quatre niveaux de gris intermédiaires.
Ces images en noir et blanc sont ensuite colorées en fonction de la catégorie de leur contenu via les capacités de manipulation d’image natives du navigateur. Compressées par ce module appelé dithering, les images présentées dans ces articles ajoutent beaucoup moins de poids au contenu ; par rapport à l’ancien site web, elles sont environ dix fois moins consommatrices de ressources.
Police de caractère par défaut / Pas de logo
Toutes les ressources chargées, y compris les polices de caractères et les logos, le sont par une requête supplémentaire au serveur, nécessitant de l’espace de stockage et de l’énergie. Pour cette raison, notre nouveau site web ne charge pas de police personnalisée et enlève toute déclaration de liste de polices de caractères, ce qui signifie que les visiteurs verront la police par défaut de leur navigateur.
Une page du magazine en version basse consommation
Nous utilisons une approche similaire pour le logo. En fait, Low-tech Magazine n’a jamais eu de véritable logo, simplement une bannière représentant une lance, considérée comme une arme low-tech (technologie sobre) contre la supériorité prétendue des « high-tech » (hautes technologies).
Au lieu d’un logo dessiné, qui nécessiterait la production et la distribution d’image et de polices personnalisées, la nouvelle identité de Low-Tech Magazine consiste en une unique astuce typographique : utiliser une flèche vers la gauche à la place du trait d’union dans le nom du blog : LOW←TECH MAGAZINE.
Pas de pistage par un tiers, pas de services de publicité, pas de cookies
Les logiciels d’analyse de sites tels que Google Analytics enregistrent ce qui se passe sur un site web, quelles sont les pages les plus vues, d’où viennent les visiteurs, etc. Ces services sont populaires car peu de personnes hébergent leur propre site. Cependant l’échange de ces données entre le serveur et l’ordinateur du webmaster génère du trafic de données supplémentaire et donc de la consommation d’énergie.
Avec un serveur auto-hébergé, nous pouvons obtenir et visualiser ces mesures de données avec la même machine : tout serveur génère un journal de ce qui se passe sur l’ordinateur. Ces rapports (anonymes) ne sont vus que par nous et ne sont pas utilisés pour profiler les visiteurs.
Avec un serveur auto-hébergé, pas besoin de pistage par un tiers ni de cookies.
Low-tech Magazine a utilisé des publicités Google Adsense depuis ses débuts en 2007. Bien qu’il s’agisse d’une ressource financière importante pour maintenir le blog, elles ont deux inconvénients importants. Le premier est la consommation d’énergie : les services de publicité augmentent la circulation des données, ce qui consomme de l’énergie.
Deuxièmement, Google collecte des informations sur les visiteurs du blog, ce qui nous contraint à développer davantage les déclarations de confidentialité et les avertissements relatifs aux cookies, qui consomment aussi des données et agacent les visiteurs. Nous avons donc remplacé Adsense par d’autres sources de financement (voir ci-dessous pour en savoir plus). Nous n’utilisons absolument aucun cookie.
À quelle fréquence le site web sera-t-il hors-ligne ?
Bon nombre d’entreprises d’hébergement web prétendent que leurs serveurs fonctionnent avec de l’énergie renouvelable. Cependant, même lorsqu’elles produisent de l’énergie solaire sur place et qu’elles ne se contentent pas de « compenser » leur consommation d’énergie fossile en plantant des arbres ou autres, leurs sites Web sont toujours en ligne.
Cela signifie soit qu’elles disposent d’un système géant de stockage sur place (ce qui rend leur système d’alimentation non durable), soit qu’elles dépendent de l’énergie du réseau lorsqu’il y a une pénurie d’énergie solaire (ce qui signifie qu’elles ne fonctionnent pas vraiment à 100 % à l’énergie solaire).
Le panneau photo-voltaïque solaire de 50 W. Au-dessus, un panneau de 10 W qui alimente un système d’éclairage.
En revanche, ce site web fonctionne sur un système d’énergie solaire hors réseau avec son propre stockage d’énergie et hors-ligne pendant les périodes de temps nuageux prolongées. Une fiabilité inférieure à 100 % est essentielle pour la durabilité d’un système solaire hors réseau, car au-delà d’un certain seuil, l’énergie fossile utilisée pour produire et remplacer les batteries est supérieure à l’énergie fossile économisée par les panneaux solaires.
Reste à savoir à quelle fréquence le site sera hors ligne. Le serveur web est maintenant alimenté par un nouveau panneau solaire de 50 Wc et une batterie plomb-acide (12V 7Ah) qui a déjà deux ans. Comme le panneau solaire est à l’ombre le matin, il ne reçoit la lumière directe du soleil que 4 à 6 heures par jour. Dans des conditions optimales, le panneau solaire produit ainsi 6 heures x 50 watts = 300 Wh d’électricité.
Le serveur web consomme entre 1 et 2,5 watts d’énergie (selon le nombre de visiteurs), ce qui signifie qu’il consomme entre 24 et 60 Wh d’électricité par jour. Dans des conditions optimales, nous devrions donc disposer de suffisamment d’énergie pour faire fonctionner le serveur web 24 heures sur 24. La production excédentaire d’énergie peut être utilisée pour des applications domestiques.
Nous prévoyons de maintenir le site web en ligne pendant un ou deux jours de mauvais temps, après quoi il sera mis hors ligne.
Cependant, par temps nuageux, surtout en hiver, la production quotidienne d’énergie pourrait descendre à 4 heures x 10 watts = 40 watts-heures par jour, alors que le serveur nécessite entre 24 et 60 Wh par jour. La capacité de stockage de la batterie est d’environ 40 Wh, en tenant compte de 30 % des pertes de charge et de décharge et de 33 % de la profondeur ou de la décharge (le régulateur de charge solaire arrête le système lorsque la tension de la batterie tombe à 12 V).
Par conséquent, le serveur solaire restera en ligne pendant un ou deux jours de mauvais temps, mais pas plus longtemps. Cependant, il s’agit d’estimations et nous pouvons ajouter une deuxième batterie de 7 Ah en automne si cela s’avère nécessaire. Nous visons un uptime, c’est-à-dire un fonctionnement sans interruption, de 90 %, ce qui signifie que le site sera hors ligne pendant une moyenne de 35 jours par an.
Premier prototype avec batterie plomb-acide (12 V 7 Ah) à gauche et batterie Li-Po UPS (3,7V 6600 mA) à droite. La batterie au plomb-acide fournit l’essentiel du stockage de l’énergie, tandis que la batterie Li-Po permet au serveur de s’arrêter sans endommager le matériel (elle sera remplacée par une batterie Li-Po beaucoup plus petite).
Quel est la période optimale pour parcourir le site ?
L’accessibilité à ce site internet dépend de la météo à Barcelone en Espagne, endroit où est localisé le serveur. Pour aider les visiteurs à « planifier » leurs visites à Low-tech Magazine, nous leur fournissons différentes indications.
Un indicateur de batterie donne une information cruciale parce qu’il peut indiquer au visiteur que le site internet va bientôt être en panne d’énergie – ou qu’on peut le parcourir en toute tranquillité. La conception du site internet inclut une couleur d’arrière-plan qui indique la charge de la batterie qui alimente le site Internet grâce au soleil. Une diminution du niveau de charge indique que la nuit est tombée ou que la météo est mauvaise.
Outre le niveau de batterie, d’autres informations concernant le serveur du site web sont affichées grâce à un tableau de bord des statistiques. Celui-ci inclut des informations contextuelles sur la localisation du serveur : heure, situation du ciel, prévisions météorologiques, et le temps écoulé depuis la dernière fois où le serveur s’est éteint à cause d’un manque d’électricité.
SERVEUR : Ce site web fonctionne sur un ordinateur Olimex A20. Il est doté de 2 GHz de vitesse de processeur, 1 Go de RAM et 16 Go d’espace de stockage. Le serveur consomme 1 à 2,5 watts de puissance.
SOFTWARE DU SERVEUR : le serveur web tourne sur Armbian Stretch, un système d’exploitation Debian construit sur un noyau SUNXI. Nous avons rédigé une documentation technique sur la configuration du serveur web.
LOGICIEL DE DESIGN : le site est construit avec Pelican, un générateur de sites web statiques. Nous avons publié le code source de « solar », le thème que nous avons développé.
CONNEXION INTERNET. Le serveur est connecté via une connexion Internet fibre 100 MBps. Voici comment nous avons configuré le routeur. Pour l’instant, le routeur est alimenté par le réseau électrique et nécessite 10 watts de puissance. Nous étudions comment remplacer ce routeur gourmand en énergie par un routeur plus efficace qui pourrait également être alimenté à l’énergie solaire.
SYSTÈME SOLAIRE PHOTOVOLTAÏQUE. Le serveur fonctionne avec un panneau solaire de 50 Wc et une batterie plomb-acide 12 V 7 Ah. Cependant, nous continuons de réduire la taille du système et nous expérimentons différentes configurations. L’installation photovoltaïque est gérée par un régulateur de charge solaire 20A.
Qu’est-il arrivé à l’ancien site ?
Le site Low-tech Magazine alimenté par énergie solaire est encore en chantier. Pour le moment, la version alimentée par réseau classique reste en ligne. Nous encourageons les lecteurs à consulter le site alimenté par énergie solaire, s’il est disponible. Nous ne savons pas trop ce qui va se passer ensuite. Plusieurs options se présentent à nous, mais la plupart dépendront de l’expérience avec le serveur alimenté par énergie solaire.
Tant que nous n’avons pas déterminé la manière d’intégrer l’ancien et le nouveau site, il ne sera possible d’écrire et lire des commentaires que sur notre site internet alimenté par réseau, qui est toujours hébergé chez TypePad. Si vous voulez envoyer un commentaire sur le serveur web alimenté en énergie solaire, vous pouvez en commentant cette page ou en envoyant un courriel à solar (at) lowtechmagazine (dot) com.
Est-ce que je peux aider ?
Bien sûr, votre aide est la bienvenue.
D’une part, nous recherchons des idées et des retours d’expérience pour améliorer encore plus le site web et réduire sa consommation d’énergie. Nous documenterons ce projet de manière détaillée pour que d’autres personnes puissent aussi faire des sites web basse technologie.
D’autre part, nous espérons recevoir des contributions financières pour soutenir ce projet. Les services publicitaires qui ont maintenu Low-tech Magazine depuis ses débuts en 2007 sont incompatibles avec le design de notre site web poids plume. C’est pourquoi nous cherchons d’autres moyens de financer ce site :
1. Nous proposerons bientôt un service de copies du blog imprimées à la demande. Grâce à ces publications, vous pourrez lire le Low-tech Magazine sur papier, à la plage, au soleil, où vous voulez, quand vous voulez.
2. Vous pouvez nous soutenir en envoyant un don sur PayPal, Patreon ou LiberaPay.
3. Nous restons ouverts à la publicité, mais nous ne pouvons l’accepter que sous forme d’une bannière statique qui renvoie au site de l’annonceur. Nous ne travaillons pas avec les annonceurs qui ne sont pas en phase avec notre mission.
La bataille du libre, un documentaire contributopique !
Nous avons eu la chance de voir le nouveau documentaire de Philippe Borrel. Un conseil : ne le loupez pas, et surtout emmenez-y vos proches qui ne comprennent pas pourquoi vous les bassinez avec « vos trucs de libristes, là »…
Ce n’est pas de la publicité, c’est de la réclame
Avertissement : cet article de blog est enthousiaste sans être sponsorisé (et oui : nous vivons à une époque où ce genre de précision est devenue obligatoire -_-‘…), car en fait, il est simplement sincère.
Et c’est pas parce qu’on y voit apparaître tonton Richard (the Stallman himself), l’ami Calimaq, les potes de Mozilla ou notre Pyg à nous, hein… C’est parce que ce documentaire montre que la palette du Libre s’étend très largement au-delà du logiciel : agriculture, outils, santé, autogestion… Il montre combien le Libre concrétise dès aujourd’hui les utopies contributives de demain, et ça, bizarrement, ça nous parle.
Sans compter que sa bande annonce a le bon goût d’être présente et présentée sur PeerTube :
Ce qui est brillant, c’est que ce documentaire peut toucher les cœurs et les pensées de nos proches dont le regard divague au loin dès qu’on leur parle de « logiciels », « services », « clients » et autre « code-source »… et qui ne comprennent pas pourquoi certaines variétés de tomates anciennes ont circulé clandestinement dans leur AMAP, ou qui s’indignent de la montée du prix de l’insuline et des prothèses médicales.
Des avant-premières à Fontaine, Nantes et Paris… et sur Arte
Une version « condensée » du documentaire (55 minutes sur les 87 de la version cinéma) sera diffusée le mardi 19 février à 23h45 sur Arte, sous le titre « Internet ou la révolution du partage »… et disponible en accès libre et gratuit sur la plateforme VOD d’Arte jusqu’au 12 avril prochain.
Mais pour les plus chanceuxses d’entre nous, pour celles et ceux qui aiment les grandes toiles et les ciné-débats, il y a déjà quelques avant-premières :
Nous continuerons d’en parler sur nos médias sociaux, car nous considérons que ce documentaire est un bien bel outil dont on peut s’emparer pour se relier à ces communautés qui partagent les valeurs du Libre dans des domaines autre que le numérique… Et il n’est pas impossible que vous rencontriez certain·e·s de nos membres lors d’une projection 😉
Un navigateur pour diffuser votre site web en pair à pair
Les technologies qui permettent la décentralisation du Web suscitent beaucoup d’intérêt et c’est tant mieux. Elles nous permettent d’échapper aux silos propriétaires qui collectent et monétisent les données que nous y laissons.
Vous connaissez probablement Mastodon, peerTube, Pleroma et autres ressources qui reposent sur le protocole activityPub. Mais connaissez-vous les projets Aragon, IPFS, ou ScuttleButt ?
Aujourd’hui nous vous proposons la traduction d’un bref article introducteur à une technologie qui permet de produire et héberger son site web sur son ordinateur et de le diffuser sans le moindre serveur depuis un navigateur.
Nous sommes Blue Link Labs, une équipe de trois personnes qui travaillent à améliorer le Web avec le protocole Dat et un navigateur expérimental pair à pair qui s’appelle Beaker.
L’équipe Blue Link Labs
Nous travaillons sur Beaker car publier et partager est l’essence même du Web. Cependant pour publier votre propre site web ou seulement diffuser un document, vous avez besoin de savoir faire tourner un serveur ou de pouvoir payer quelqu’un pour le faire à votre place.
Nous nous sommes donc demandé « Pourquoi ne pas partager un site Internet directement depuis votre navigateur ? »
Un protocole pair-à-pair comme dat:// permet aux appareils des utilisateurs ordinaires d’héberger du contenu, donc nous utilisons dat:// dans Beaker pour pouvoir publier depuis le navigateur et donc au lieu d’utiliser un serveur, le site web d’un auteur et ses visiteurs l’aident à héberger ses fichiers. C’est un peu comme BitTorrent, mais pour les sites web !
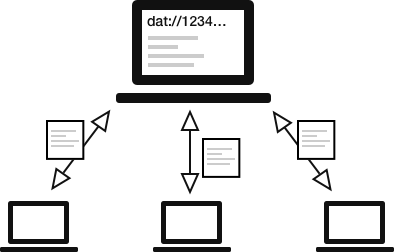
Architecture
Beaker utilise un réseau pair-à-pair distribué pour publier des sites web et des jeux de données (parfois nous appelons ça des « dats »).
Les sites web dat:// sont joignables avec une clé publique faisant office d’URL, et chaque donnée ajoutée à un site web dat:// est attachée à un log signé.
Les visiteurs d’un site web dat:// peuvent se retrouver grâce à une table de hachage distribuée2, puis ils synchronisent les données entre eux, agissant à la fois comme téléchargeurs et téléverseurs, et vérifiant que les données n’ont pas été altérées pendant le transit.
Une illustration basique du réseau dat://
Techniquement, un site Web dat:// n’est pas tellement différent d’un site web https:// . C’est une collection de fichiers et de dossiers qu’un navigateur Internet va interpréter suivant les standards du Web. Mais les sites web dat:// sont spéciaux avec Beaker parce que nous avons ajouté une API (interface de programmation) qui permet aux développeurs de faire des choses comme lire, écrire, regarder des fichiers dat:// et construire des applications web pair-à-pair.
Créer un site Web pair-à-pair
Beaker rend facile pour quiconque de créer un nouveau site web dat:// en un clic (faire le tour des fonctionnalités). Si vous êtes familier avec le HTML, les CSS ou le JavaScript (même juste un peu !) alors vous êtes prêt⋅e à publier votre premier site Web dat://.
L’exemple ci-dessous montre comment fabriquer le site Web lui-même via la création et la sauvegarde d’un fichier JSON. Cet exemple est fictif mais fournit un modèle commun pour stocker des données, des profils utilisateurs, etc. pour un site Web dat:// : au lieu d’envoyer les données de l’application sur un serveur, elles peuvent être stockées sur le site web lui-même !
// index.js // first get an instance of the website's files var files = new DatArchive(window.location) document.getElementById('create-json-button').addEventListener('click', saveMessage) async function saveMessage () { var timestamp = Date.now() var filename = timestamp + '.json' var content = { timestamp, message: document.getElementById('message').value }
// write the message to a JSON file // this file can be read later using the DatArchive.readFile API await files.writeFile(filename, JSON.stringify(content)) }
Pour aller plus loin
Nous avons hâte de voir ce que les gens peuvent faire de dat:// et de Beaker. Nous apprécions tout spécialement quand quelqu’un crée un site web personnel ou un blog, ou encore quand on expérimente l’interface de programmation pour créer une application.
Beaucoup de choses sont à explorer avec le Web pair-à-pair !
Cela peut faire sourire car le meilleur moyen de ne pas être espionné par ce genre d’objet, c’est encore de s’en passer. La question qui se pose alors, c’est : doit-on accepter d’aller chez des gens qui ont ce genre d’objet chez eux ?
Allergie au Google Home
Se passer des GAFAM est un défi technique (surtout pour les néophytes), même si ça l’est de moins en moins.
Mais c’est souvent aussi un défi social.
On prend toujours les réseaux du genre Facebook comme exemple de site qui n’a aucun intérêt si vous êtes tout seul dessus…
Seulement, même les outils pour lesquels on peut se déGAFAMiser gentiment dans son coin deviennent problématiques si un tiers utilise du GAFAM.
Non contents de permettre la surveillance généralisée de nos vies numériques, les GAFAM se proposent maintenant de surveiller directement nos maisons par le biais d’enceintes connectées (objets qui colleraient des crises de priapisme à tout cadre de la Stasi).
Pour contrer ces dispositifs de surveillance (qui fileraient des crampes au poignet à tout agent de la DINA), un moyen simple existe :
NE PAS EN ACHETER.
Mais ça, vous le saviez déjà, et c’est relativement simple à appliquer.
Le problème se situe encore une fois dans nos relations sociales avec des gens moins prévenants : que faire si une de vos connaissances possédant un tel objet vous invite chez elle ? Doit-on se soumettre à la surveillance par pression sociale ?
Vous voyez, moi qui suis allergique aux poils de chats…
Bon.
Quand je dis allergique, c’est ALLERGIQUE.
Pour vous donner une idée, petit, je faisais des crises d’asthme quand j’étais assis à côté d’un camarade de classe qui avait un chat chez lui…
À ce niveau d’allergie, les antihistaminiques limitent la casse, mais faut pas rêver.
Donc.
Moi qui suis allergique aux poils de chats, je ne vais pas chez les possesseurs de chats. Tout simplement.
Ça fait rarement plaisir mais c’est une question de survie.
Eh bien, je me demande si je n’vais pas tout simplement me considérer comme allergique aux enceintes connectées. Ça simplifiera les choses.
Alors je sais ce que vous allez me dire : c’est un coup à se retrouver assez vite isolé.
Bah pas forcément.
Mettons qu’on ait tous une grosse poussée d’allergie anti-Google-Home, anti-Amazon-Echo, etc.
Moralité : sauvons nos potes. Devenons allergiques aux enceintes connectées.