Qual è l’impatto concreto delle azioni della nostra associazione? È questa la domanda a cui ci piace rispondere alla fine dell’anno (vedi dati 2022): prendersi il tempo per quantificare le nostre azioni è essenziale per rendersi conto del servizio che possiamo fornire agli altri. Iniziamo con le Framastatistiche 2023!
Più di 1,8 milioni di persone visitano i nostri siti web ogni mese: è il doppio delle visite che Disneyland Paris riceve ogni mese! Questa cifra è aumentata del 16% rispetto all’anno scorso, quindi è pazzesco (e molto motivante) pensare che ciò che facciamo sia utile a così tante persone. E cosa significa questo, per ogni singolo servizio?
Clicca per sostenerci e aiutare Espéhef e Ahèmvé – Illustrazione CC-By David Revoy
Framadate
Framadate consente di creare dei mini-sondaggi, in particolare per trovare la fascia oraria giusta per gli appuntamenti. E in cifre, Framadate significa:
33.785.780 visite nel 2023
1,2 milioni di sondaggi ospitati nel 2023
80.000 sondaggi creati in più rispetto al 2022
Grafico che mostra il numero di visite a Framadate
Framapad
Framapad consente a più persone di scrivere sullo stesso documento. Framapad è senza dubbio uno dei più grandi servizi Etherpad al mondo, con:
510.900 pad ospitati attualmente
Diversi milioni di pad ospitati dal lancio del servizio
309.000 account su MyPads (+ 60.000 rispetto al 2022)
Oltre 5 milioni di visite nel 2023
Grafico che mostra la distribuzione dei pad in base alle nostre istanze Framapad (pad annuali, bimestrali, settimanali, semestrali, mensili e account Mypads)
Framalistes e Framagroupes
Framalistes e Framagroupes consentono di creare liste di discussione via e-mail. Poiché il server di Framalistes ha raggiunto la sua capacità massima, nel giugno 2023 abbiamo aperto Framagroupes per continuare a offrire questo servizio, che riteniamo indispensabile. Framalistes e Framagroupes sono senza dubbio i più grandi server di liste di discussione (esclusi i giganti del Web) esistenti, con:
Più di 1,1 milioni di utenti
63.900 liste aperte
Circa 280.000 e-mail inviate in media ogni giorno lavorativo
Framaforms
Framaforms semplifica la creazione di questionari online. Framaforms in cifre:
867.000 visite al mese
418.628 moduli attualmente ospitati
172.289 moduli creati quest’anno
Grafico che mostra il numero di visite a Framaforms (in aumento!)
Framacalc
Framacalc consente di creare fogli di calcolo collaborativi. È forse il più grande istanza Ethercalc del mondo, con:
4.235.879 visite nel 2023
218.000 calcoli ospitati
Grafico che mostra il numero di visite a Framacalc
Framateam
Framateam è un servizio di chat che consente di organizzare dei team suddivisi per canale. È probabilmente una delle più grandi istanze pubbliche di Mattermost al mondo, con:
148.870 utenti del servizio (di cui 5.582 si collegano ogni giorno)
29.665 team
168.102 canali di discussione
Più di 43 milioni di messaggi scambiati dal lancio del servizio
Grafico che mostra la distribuzione dei messaggi inviati a Framateam nell’arco di un mese (notare l’utilizzo molto elevato durante la settimana!)
Framagit
Framagit è una fucina di software dove gli sviluppatori possono pubblicare il proprio codice e contribuire a quello degli altri. Framagit è probabilmente uno dei più grandi server Gitlab pubblici in Francia, con:
70 679 progetti ospitati
49 642 utenti
8 966 fork
149 789 issues
91 623 Merge requests
1 764 909 note
Screenshot della home page di Framagit
Framacarte
Framacarte consente di creare mappe online. E in cifre, è:
2 770 510 visite nel 2023
6 690 utenti (+ 1 246 in un anno)
170 845 mappe ospitate (+ 33.476 in un anno)
Grafico del numero di visite a Framacarte
Framatalk
Framatalk consente di creare o di unirsi a una sala di videoconferenza. E in cifre, questo è:
656 765 visite nel 2023 (+ 45 % rispetto all’anno scorso)
Una media di 75 conferenze attive per 200 partecipanti per giorno lavorativo
Grafico che mostra l’evoluzione delle visite a Framatalk (si noti l’enorme picco durante l’anno di confinamento!)
Framindmap
Framindmap consente di creare mappe mentali. In cifre, Framindmap è:
295 379 visite nel 2023
1,13 milioni di mappe mentali ospitate
489 690 utenti
Grafico che mostra il numero di visite a Framindmap
Framavox
Framavox consente a un gruppo di persone di incontrarsi, discutere e prendere decisioni in un unico luogo. Framavox è probabilmente una delle più grandi istanze esistenti dell’eccellente software Loomio, con:
Framadrive, il servizio di archiviazione di documenti, non è più aperto alle iscrizioni, ma funziona ancora! In cifre, si tratta di:
10,8 milioni di file
4 794 utenti
2,6 TB di spazio su disco utilizzato
Framapiaf
Framapiaf, un’istanza del software di micro-blogging Mastodon, non è più aperta a nuove registrazioni ma rimane molto attiva. In cifre, si tratta di:
1 500 utenti che si sono collegati negli ultimi 30 giorni
850 utenti che hanno postato almeno un messaggio negli ultimi 30 giorni
Dorlotons Dégooglisons – Illustrazione di David Revoy
Infrastruttura tecnica
Per quanto ne sappiamo, Framasoft è il più grande fornitore associativo di servizi online al mondo. E a priori, questo modello di funzionamento associativo non esiste da nessun’altra parte! In cifre:
58 server e 60 macchine virtuali che ospitano i nostri servizi online
0,6 tonnellate di CO2 equivalenti per il consumo annuale di elettricità della nostra infrastruttura tecnica (il nostro host, Hetzner, utilizza energia idroelettrica ed eolica rinnovabile)
1 amministratore di sistema a tempo pieno e 2 addetti al supporto tecnico
I servizi online che forniamo al pubblico non sono le uniche cose che ci tengono occupati. Ecco qualche dato su alcune delle altre attività che abbiamo svolto quest’anno.
È grazie alle vostre donazioni che Espéhef e Ahèmvé sono in grado di tenere testa a Hydrooffice! Illustrazione di David Revoy
Attività interna
Framasoft conta 28 membri volontari e 11 dipendenti.
45 presentazioni nel 2023, in presenza e/o online, sulle tecnologie digitali, i beni culturali comuni e le questioni in gioco.
Più di 130 articoli pubblicati sul Framablog nel 2023
Un corso di formazione e un MOOC creato per chi ospita servizi etici
21 operatori in grado di supportare le associazioni nella loro emancipazione digitale elencati sul sito emancipasso.org
5 visite di studio in 5 Paesi europei per il progetto ECHO Network
8 anni di coordinamento del collettivo CHATONS, che attualmente comprende 91 fornitori di hosting alternativi
Abbiamo bisogno del vostro aiuto!
È grazie alle vostre donazioni che possiamo garantire la totale indipendenza finanziaria dell’associazione: la libertà di sperimentare, di continuare, di fallire, di fermarci, di portare avanti i nostri progetti, dai più seri ai più strampalati, sempre in linea con il nostro progetto associativo di educazione popolare ai temi del digitale e dei beni culturali comuni. E in cifre:
Il 93% del nostro bilancio è finanziato dalle donazioni
5 463 donatori finanziano iniziative di cui beneficiano più di 1,8 milioni di persone ogni mese
Il70 % del bilancio è destinato al pagamento degli stipendi.
Ripartizione del bilancio di Framasoft
Framasoft è un’associazione di interesse generale: tutte le donazioni fatte a noi sono deducibili fino al 66% per i contribuenti francesi. Quindi una donazione di 100 euro vi costerà in realtà solo 34 euro dopo gli sgravi fiscali.
Se vogliamo raggiungere il nostro budget per il 2024, abbiamo solo 3 giorni per raccogliere 48 000 € : non possiamo farlo senza il vostro aiuto!
What is the concrete impact of our association’s actions? That’s the question we like to answer at the end of the year: taking the time to quantify our actions is essential if we are to realise the service we can provide to others. Let’s get ready for Framastats 2023!
🦆 VS 😈: Let’s take back some ground from the tech giants!
Click to support us and help push back Hydrooffice – Illustration CC-By David Revoy
As for our online services…
More than 1.8 million people visit our websites every month: that’s twice as many people as visit Disneyland Paris every month! This figure is up 16% on last year, so it’s pretty crazy (and very motivating) to think that what we do is useful to so many people. And what about service by service?
Click here to support us and help Espéhef and Ahèmvé – Illustration CC-By David Revoy
Framadate
Framadate allows you to create mini-surveys, for example to find the right appointment time. And in figures, Framadate is:
33,785,780 visits in 2023
1.2 million hosted surveys in 2023
80,000 more surveys created than in 2022
Graph showing the number of visits (blue) and page views (orange) to Framadate
Framapad
Framapad allows several people to write on the same document. Framapad is undoubtedly one of the largest Etherpad services in the world, with:
510,900 pads currently hosted
Several million pads hosted since the launch of the service
309,000 accounts on MyPads (+ 60,000 compared to 2022)
More than 5 million visits in 2023
Graph showing the distribution of pads according to our Framapad instances (annual, bimonthly, weekly, half-yearly, monthly pads and Mypads accounts).
Framalistes and Framagroupes
Framalistes and Framagroupes allow you to create email discussion lists. As the Framalistes server had reached its maximum capacity, we opened Framagroupes in June 2023 to continue offering this service, which we consider essential. Framalistes and Framagroupes are undoubtedly the largest discussion list servers in existence (excluding the web giants), with:
more than 1.1 million users
63,900 open lists
An average of 280,000 messages sent per working day
Framaforms
Framaforms makes it easy to create online forms. Framaforms in figures:
867,000 visits per month
418,628 forms currently hosted
172.289 forms created this year
Graph showing the evolution of visits (blue) and page views (orange) to Framforms (it’s going up!)
Framacalc
Framacalc allows you to create collaborative spreadsheets. It may also be the largest Ethercalc database in the world, with:
4,235,879 visits in 2023
218,000 hosted spreadsheets
Graph showing the number of visits (blue) and page views (orange) to Framacalc
Framateam
Framateam is a chat service that allows teams to be organised by channel. It is probably one of the largest public Mattermost instances in the world, with:
148,870 users of the service (5,582 of which log on daily)
29,665 teams
168,102 discussion channels
More than 43 million messages exchanged since the launch of the service
Graph showing the distribution of messages sent to Framateam over a month (note the very high usage during the week!).
Framagit
Framagit is a software forge where developers can publish their code and contribute to the code of others. Framagit is probably one of the largest public Gitlab servers in France, with:
70,679 hosted projects
49,642 users
8,966 forks
149,789 issues
91,623 merge requests
1,764,909 commit notes
Screenshot of the Framagit homepage
Framacarte
Framacarte allows you to create maps online. And in figures, it’s:
2,770,510 visits in 2023
6,690 users (+ 1,246 in one year)
170,845 hosted maps (+ 33,476 in one year)
Graph showing the number of visits (blue) and page views (orange) to Framacarte
Framatalk
Framatalk allows you to create or join a video conference room. And in numbers, that’s
656,765 visits in 2023 (+45% compared to last year)
An average of 75 active conferences with 200 participants per working day
Graph showing the number of visits (blue) and page views (orange) to Framatalk (note the huge spike during the year of lockdowns!)
Framindmap
Framindmap allows you to create mind maps. In numbers, Framindmap is:
295,379 visits in 2023
1.13 million hosted mind maps
489,690 users
Graph showing the number of visits (blue) and page views (orange) to Framindmap
Framavox
Framavox allows a group of people to meet, discuss and make decisions in one place. Framavox is probably one of the largest existing instances of the excellent Loomio software, with:
Framadrive, the document storage service, is no longer open for registration, but it’s still working! And in numbers, that’s:
10.8 million files
4,794 users
2.6 TB of storage used
Framapiaf
Framapiaf, an installation of the microblogging software Mastodon, is no longer open to new registrations, but remains very active. In figures, there are:
1,500 users who have registered in the last 30 days
850 users who have posted at least one message in the last 30 days
The care given to our online services – Illustration by David Revoy
Technical infrastructure
To the best of our knowledge, Framasoft is the world’s largest web host for online services. And a priori, this associative operating model doesn’t exist anywhere else! In figures:
58 servers and 60 virtual machines hosting our online services
0.6 tonnes of CO2 equivalent for the annual electricity consumption of our technical infrastructure (our host, Hetzner, uses renewable hydro and wind energy)
1 full-time sysadmin and 2 technical support staff
The online services we provide to the public are not the only things that keep us busy. Here are some figures on some of the other things we’ve been up to this year.
It’s thanks to your donations that Espéhef and Ahèmvé are facing Hydrooffice. Illustration de David Revoy
Internally
Framasoft has 28 volunteers and 11 paid employees
45 presentations in 2023, face-to-face and/or online, on digital technology, the cultural commons and related issues
over 130 articles published on the Framablog in 2023
It’s thanks to your donations that we can guarantee the total financial independence of the association: the freedom to experiment, to continue, to fail, to stop, to continue our projects, from the most serious to the most mad, always in line with our associative project of popular education on digital issues and the cultural commons. And in figures:
93% of our budget comes from donations
5,463 donors finance initiatives that benefit more than 1.8 million people every month
70% of the budget is spent on salaries
Breakdown of Framasoft’s budget (in order: Human resources, Servers and domains, Operating costs, Interventions, Communication, Project services, Bank charges and tax)
Once again this year, we need you, your support, your sharing to help us regain ground on the toxic GAFAM web and multiply the number of ethical digital spaces.
If we want to balance our budget for 2024, we only have 3 days left to raise €48 000: we can’t do it without your help!
Quel est l’impact concret des actions de notre association ? C’est la question à laquelle nous aimons répondre en fin d’année (cf. chiffres 2022) : prendre le temps de chiffrer nos actions est essentiel pour réaliser le service que l’on peut rendre aux autres. En route pour les Framastats 2023 !
Cliquez pour nous soutenir et aider à repousser Hydrooffice – Illustration CC-By David Revoy
Du côté de nos services en ligne…
Plus de 1,8 million de personnes naviguent sur nos sites internet chaque mois : c’est deux fois plus de visites que n’en reçoit Disneyland Paris par mois ! Ce chiffre a augmenté de 16 % par rapport à l’année dernière, c’est assez fou (et très motivant) d’imaginer que ce que nous faisons est utile à tant de monde. Et service par service, ça donne quoi ?
Cliquez pour nous soutenir et aider Espéhef et Ahèmvé – Illustration CC-By David Revoy
Framadate
Framadate permet de créer des mini-sondages, notamment pour trouver le bon créneau de rendez-vous. Et en chiffres, Framadate c’est :
33 785 780 visites en 2023
1,2 million de sondages hébergés en 2023
80 000 sondages créés de plus par rapport à l’année 2022
Graphique présentant l’évolution des visites sur Framadate
Framapad
Framapad permet de rédiger à plusieurs sur un même document. Framapad est sans doute l’un des plus gros services Etherpad au monde avec :
510 900 pads hébergés actuellement
Plusieurs millions de pads hébergés depuis le lancement du service
309 000 comptes sur MyPads (+ 60 000 par rapport à 2022)
Plus de 5 millions de visites en 2023
Graphique présentant la répartition des pads selon nos instances Framapad (pads annuels, bimestriels, hebdomadaires, semestriels, mensuels et comptes Mypads)
Framalistes et Framagroupes
Framalistes et Framagroupes permettent de créer des listes de discussion par email. Le serveur de Framalistes étant arrivé au maximum de ses capacités, nous avons ouvert Framagroupes en juin 2023, pour continuer à proposer ce service que nous trouvons indispensable. Framalistes et Framagroupes sont certainement les plus gros serveurs de listes de discussion (hors géants du Web) qui existent, avec :
Plus d’1,1 million d’utilisateurs et utilisatrices
63 900 listes ouvertes
Environ 280 000 mails envoyés en moyenne par jour ouvré
Framaforms
Framaforms permet de créer simplement des questionnaires en ligne. Framaforms en chiffres c’est :
867 000 visites par mois
418 628 formulaires actuellement hébergés
172 289 formulaires créés cette année
Graphique présentant l’évolution des visites sur Framforms (ça grimpe !)
Framacalc
Framacalc permet de créer des tableurs collaboratifs. C’est peut-être là encore la plus grosse base Ethercalc au monde avec :
4 235 879 visites en 2023
218 000 calcs hébergés
Graphique présentant l’évolution des visites sur Framacalc
Framateam
Framateam est un service de tchat, et permet une organisation d’équipe par canaux. C’est probablement l’une des plus grosses instances Mattermost publique au monde avec :
148 870 utilisateurs et utilisatrices sur le service (dont 5 582 se connectent tous les jours)
29 665 équipes qui s’organisent
168 102 canaux de discussions
Plus de 43 millions de messages échangés depuis le lancement du service
Graphique présentant la répartition des messages envoyés sur Framateam sur un mois (on remarque une très forte utilisation en semaine !)
Framagit
Framagit est une forge logicielle, où développeurs et développeuses peuvent publier leur code et contribuer à celui des autres. Framagit est probablement un des plus gros serveurs Gitlab publics de France avec :
70 679 projets hébergés
49 642 utilisateurs et utilisatrices
8 966 forks
149 789 issues
91 623 Merge requests
1 764 909 notes
Capture écran du tableau d’accueil de Framagit
Framacarte
Framacarte permet de créer des cartes géographiques en ligne. Et en chiffres, c’est :
2 770 510 visites en 2023
6 690 utilisateurs et utilisatrices (+ 1 246 en un an)
170 845 cartes hébergées (+ 33 476 en un an)
Graphique présentant l’évolution des visites sur Framacarte
Framatalk
Framatalk permet de créer ou rejoindre un salon de vidéoconférence. Et en chiffres, c’est :
656 765 visites en 2023 (+ 45 % par rapport à l’an passé)
En moyenne 75 conférences actives pour 200 participant⋅es par jour ouvré
Graphique présentant l’évolution des visites sur Framatalk (remarquez cet énorme pic pendant l’année des confinements !)
Framindmap
Framindmap permet de créer des cartes mentales. En chiffres, Framindmap c’est :
295 379 visites en 2023
1,13 million de cartes mentales hébergées
489 690 utilisateurs et utilisatrices
Graphique présentant l’évolution des visites sur Framindmap
Framavox
Framavox permet à un collectif de se réunir, débattre et prendre des décisions, dans un seul endroit. Framavox est probablement une des plus grosses instances existantes de l’excellent logiciel Loomio, avec :
Framadrive, service de stockage de documents, n’est plus ouvert aux inscriptions, mais fonctionne toujours ! Et en chiffres, c’est :
10,8 millions de fichiers
4 794 utilisateurs et utilisatrices
2,6 To d’espace disque utilisé
Framapiaf
Framapiaf, installation du logiciel de micro-bloging Mastodon, n’est plus ouvert aux nouvelles inscriptions mais reste bien actif. En chiffres, c’est :
1 500 utilisateurs et utilisatrices s’étant connecté·es dans les 30 derniers jours
850 utilisateurs et utilisatrices ayant posté au moins un message dans les 30 derniers jours
Dorlotons Dégooglisons – Illustration de David Revoy
Infrastructure technique
Framasoft est, à notre connaissance, le plus gros hébergeur associatif de services en ligne au monde. Et a priori, ce modèle de fonctionnement associatif n’existe nulle part ailleurs ! En chiffres :
58 serveurs et 60 machines virtuelles qui hébergent nos services en ligne
0,6 tonne équivalent CO2 pour la consommation électrique annuelle de notre infrastructure technique (notre hébergeur Hetzner utilisant des énergies renouvelables hydroélectriques et éoliennes)
1 admin sys à temps plein et 2 personnes tech en soutien
Les services en ligne que nous mettons à disposition du public ne sont pas les seuls à occuper nos journées. Voilà quelques chiffres concernant d’autres actions que nous avons menées à bien cette année.
C’est grâce à vos dons que Espéhef et Ahèmvé font face à Hydrooffice ! Illustration de David Revoy
En interne
Framasoft c’est 28 membres bénévoles et 11 salarié⋅es
45 interventions en 2023, en présentiel et/ou en ligne sur le numérique, les communs culturels et leurs enjeux
Plus de 130 articles publiés sur le Framablog en 2023
C’est grâce à vos dons que nous pouvons garantir une totale indépendance financière de l’association : liberté d’expérimenter, de poursuivre, de rater, d’arrêter, de continuer nos projets, des plus sérieux aux plus loufoques, toujours en gardant le cap de notre projet associatif d’éducation populaire aux enjeux du numérique et des communs culturels. Et en chiffres :
93 % de notre budget est financé par des dons
5 463 donateur⋅ices financent des actions utiles à plus de 1,8 million de personnes chaque mois
70 % du budget est consacré à la masse salariale
Répartition du budget de Framasoft
Framasoft est une association d’intérêt général : tous les dons qui nous sont faits sont défiscalisables à hauteur de 66 % pour les contribuables français⋅es. Ainsi un don de 100 € ne vous coûtera en réalité que 34 € après défiscalisation.
Si nous voulons boucler notre budget pour 2024, il ne nous reste que 3 jours pour récolter 48 000 € : nous n’y arriverons pas sans votre aide !
There was one more present left at the foot of the Christmas tree… The French free software directory and founding project of Framasoft is evolving once again, into a site that’s nicer, simpler, more ergonomic… and a lot more practical for recommending your favourite free software!
🦆 VS 😈: Let’s take back some ground from the tech giants!
There was one more present left at the foot of the Christmas tree… The free software directory and founding project of Framasoft is evolving once again, into a site that’s nicer, simpler, more ergonomic… and a lot more practical for recommending your favourite free software!
So, for people who were used to the previous version of Framalibre, we warn you: it’s going to leave a gap… You have every right to exclaim “but where’s all my junk?” … But for many newcomers to the world of free software, that was the problem!
Maiwann has done a lot of usability testing for us, especially at conferences and at the stands where we meet. These tests helped her to realise, for example, that putting a simple ‘mail’ label on the home page wasn’t helping people who were ‘looking for an alternative to Gmail’.
So for this new version, we’ve made a radical choice: simplicity. So we’ve gone to great lengths to simplify menus, sub-menus, drop-down menus, labels, boxes, notes, buttons, and so on.
This radical choice for simplicity came at a price: we had to refocus the Framalibre directory on digital tools. The previous version wanted to open up to free culture, objects and structures. But the problem with doing a bit of everything is that it’s hard to do everything well: presenting all open source resources meant multiplying menus and categories, while increasing the complexity of creating a listing.
The new Framalibre site is deliberately bare bones. It welcomes you with a page displaying tags (the most frequently used search terms) and a search bar. Goodbye the meta-categories, categories, sub-categories and sub-category filters… In short, the tree structure inherited from the 2001 directory!
Our aim is to respond as quickly as possible to your need to find free software to do what you need to do, or to find an alternative to the service provided by the web giants that you want to free yourself from: you search, you find.
Results for Photoshop search on Framalibre 2024
📃 Under the hood, the pages 📃
Click on GNU and Tux to support Framalibre! – illustration David Revoy – License : CC-By 4.0
For the more technical among you (the rest of you can skip straight to the next part ^^), this simplicity can also be found under the hood.
Framalibre 2017’s Drupal 7 needed a good upgrade, which takes time and energy. The entries database was difficult to access: while we’d done a good job of tinkering with something so that it could be used by others, we would have had to spend more time and energy developing a practical, documented API…
Instead, we decided to devote this energy to applying this choice of simplicity to the software itself, by making the new Framalibre a static site, which we hope will be lighter and faster. The code for this tool, based on Jekyll software, was developed by the talents of l’Échappée Belle (thanks to Fanny and David <3), and of course it’s free and available online.
This choice of static allowed us to modify the structure of the entries and the database. Now written in markdown, these records can be read by both humans and scripts (as long as your robots remain well-behaved, of course :p). As the Framalibre records are CC-By SA, we hope that making them more accessible and readable will lead to some interesting re-uses!
We’ve also taken the opportunity to simplify the manuals as much as possible: you won’t find any screenshots of the software, for example. After a few years, these images are often outdated and misleading. From now on, the information presented in a manual will be simple and concise, and if you like this first look at a particular free software product, we invite you to find out more on the official website.
Entry for Krita on Framalibre 2024
🎁 “Here, this is what I use to free myself…” 🎁.
Click to support us and help to push back MS Blue Scream – Illustration CC-By David Revoy
Because our goal is not for you to stay on Framalibre as long as possible (yes, in the game of attention economy, Framasoft is frankly – and deliberately – bad 😉 ). On the contrary, Framalibre aims to be a mediator, a ramp to take you to the official site of the free tool that meets your needs.
In addition to being a search tool, we have designed this new Framalibre as a tool for recommending free and ethical alternatives. Whether it’s during the preliminary surveys and tests for this redesign of Framalibre, during the regular meetings we attend, or even when we look at how we operate ourselves… we observe the same constant:
It’s much easier to adopt a free tool when it comes highly recommended by people we trust.
This is how we came up with the idea of adding a “used by Framasoft members” box at the top of certain search pages. This doesn’t mean that other software isn’t as good, or that it won’t meet your specific needs: it just shows the free software and services that we use regularly.
[capture mini-site]
💝 Framalibre mini-sites: offer your choices! 💝
With this new version of Framalibre, we wanted to go even further to encourage peer-to-peer recommendations. We know from experience that a person who uses free software today is a person who will help those around him or her to liberate their digital use tomorrow.
On the new Framalibre, you can make your own selection of free tools and get a link to a page that you can share with your friends and family!
Just for fun, here are a few examples we’ve put together for you:
We look forward to hearing your choice of free tools!
GNU and Tux against MB Blue Scream – Illustration David Revoy – License : CC-By 4.0
🤝 Collaboration is about sharing! 🤝
Of course, Framalibre is and will remain a collaborative directory. Whether you want to add a record to the directory or correct an existing record, contributions are just a click away!
What’s more, we’ve made the whole process a lot easier (you can see there’s a theme here!). The downside is that your submissions will be reviewed by our team of moderators before they are published (rather than being moderated after submission, as was previously the case).
The upside is that there are already almost 1,019 entries to discover, like so many of the solutions that open source communities offer each of us to make our digital practices better.
And if you can’t find the entry for that great free software or application that freed you from the web giants… feel free to add it: you’ll see, it’s (unsurprisingly) easy!
So now it’s up to you!
It’s up to you to use Framalibre to find, share and, above all, recommend the free tools that make your digital life easier… and life in general!
Because, yes, at the end of the year, we need you, your support and your sharing to help us regain ground on the toxic GAFAM web and create more ethical digital spaces.
So we’ve asked David Revoy to help us present this on our ‘Support Framasoft’ page, which we invite you to visit (because it’s beautiful) and above all to share as widely as possible:
If we are to balance our budget for 2024, we have just 5 days left to raise € 71 398 : we can’t do it without your help !
Offrez le cadeau du logiciel libre, avec Framalibre !
Il restait un cadeau au pied du sapin… L’annuaire du logiciel libre et projet fondateur de Framasoft évolue à nouveau, en un site plus beau, plus simple, plus ergonomique… et beaucoup plus pratique pour recommander ses logiciels libres préférés !
C’est donc riches de tous ces enseignements que nous avons concocté cette nouvelle version « 2024 » de Framalibre que nous vous présentons aujourd’hui, avec fierté, sur Framalibre.org
Alors pour les personnes qui étaient habituées à la version précédente de Framalibre, on vous prévient : ça va faire un vide… Vous êtes tout à fait en droit de vous écrier « mais il est où, tout mon bazar ? » … Or, pour beaucoup de nouvelles et de nouveaux dans le monde du libre, c’était bien ça le problème !
Maiwann a réalisé pour nous des tests d’utilisation, notamment lors de conférences, ou sur des stands où l’on se rencontre. Ces tests lui ont, par exemple, permis de réaliser qu’afficher une simple étiquette « mail » sur la page d’accueil n’aidait pas pour autant les personnes dont le besoin serait « trouver une alternative à Gmail ».
Pour cette nouvelle mouture, nous avons donc fait un choix radical : celui de la simplicité. Nous avons donc réalisé un grand travail pour simplifier les menus, sous-menus, menus secondaires, étiquettes, encadrés, affichages de notices, boutons…
Ce choix radical de la simplicité a un coût : nous avons dû recentrer l’annuaire Framalibre sur les outils numériques. La version précédente avait voulu s’ouvrir à la culture, aux objets et aux structures du libre. Mais le problème quand on fait un peu de tout, c’est que c’est dur de faire tout bien : présenter tout le Libre induisait de multiplier les menus et les catégories tout en augmentant la complexité pour créer une notice.
Le nouveau site Framalibre est volontairement dépouillé. Il vous accueille par une page affichant des étiquettes (les recherches les plus utilisées) et une barre de recherche. Finies les méta-catégories, catégories, sous catégories, et filtres de sous-catégories… Bref, l’arborescence héritée de l’annuaire de 2001 !
Notre d’objectif est de répondre au plus vite à votre besoin de trouver un logiciel libre pour faire ce que vous avez à faire, ou de trouver une alternative pour remplacer ce service des géants du web dont vous voulez vous libérer : vous cherchez, vous trouvez.
résultats d’une recherche photoshop sur Framalibre 2024
📃 Sous le capot, les pages 📃
Cliquez sur GNU et Tux pour soutenir Framalibre ! – illustration David Revoy – Licence : CC-By 4.0
Pour les plus techniques d’entre vous (les autres, vous pouvez passer directement à la partie suivante ^^), cette simplicité se retrouve aussi sous le capot.
Le Drupal 7 de Framalibre 2017 avait besoin d’une bonne mise à niveau, ce qui demande du temps et de l’énergie. La base de données des notices était difficile d’accès : si nous avions bien bricolé quelque chose pour que cela puisse être utilisé par d’autres, il nous aurait fallu mettre plus de temps et d’énergie à développer une API pratique et documentée…
Nous avons préféré consacrer cette énergie à appliquer ce choix de la simplicité dans le logiciel même, en faisant du nouveau Framalibre un site statique, que l’on espère plus léger et rapide. Le code de cet outil, basé sur le logiciel Jekyll, a été développé par les talents de l’Échappée Belle (merci à Fanny et David <3), et bien entendu il est libre et disponible en ligne.
Ce choix du statique nous a permis de modifier la structure des notices et de la base de données. Désormais écrites en markdown, ces notices sont lisibles aussi bien par des humaines que par des scripts (tant que vos robots restent bien élevés, ça va de soi :p). Les notices de Framalibre étant sous CC-By SA, nous espérons que faciliter leur accès et leur lisibilité permettra des réutilisations intéressantes !
Nous en avons d’ailleurs profité pour simplifier au maximum les notices : vous n’y trouverez plus, par exemple, de capture d’écran du logiciel. En effet, au bout de quelques années, ces images sont souvent périmées et trompeuses. Désormais, les informations présentées dans une notice sont simples, succinctes, et si ce premier regard sur tel ou tel logiciel libre vous plaît, on vous invite à trouver plus d’informations sur le site officiel.
Notice de Krita sur Framalibre 2024
🎁 « Tiens, voici ce que j’utilise pour me libérer… » 🎁
Cliquez pour nous soutenir et aider à repousser MS Blue Scream – Illustration CC-By David Revoy
Car notre objectif n’est pas que vous restiez sur Framalibre le plus longtemps possible (oui, au jeu de l’économie de l’attention, Framasoft est franchement -et volontairement- mauvaise 😉 ). Au contraire, Framalibre se veut un intermédiaire, une rampe pour vous élancer vers le site officiel de l’outil libre qui répond à votre besoin.
Au-delà d’être un outil de recherche, nous avons pensé ce nouveau Framalibre comme un outil de recommandation d’alternatives libres et éthiques. Que ce soit lors des enquêtes et tests préliminaires à cette refonte de Framalibre, durant les rencontres régulières auxquelles nous participons ou même lorsque l’on regarde nos fonctionnements à nous.… nous observons la même constante :
Il est beaucoup plus facile d’adopter un outil libre lorsqu’il nous est chaudement recommandé par des personnes en qui nous avons confiance.
C’est comme cela que nous avons eu l’idée d’ajouter un encadré « utilisé par les membres de Framasoft » en haut de certaines pages de recherche. Cela ne veut pas dire que les autres logiciels soient moins bien, ni qu’ils ne répondent pas à votre attente spécifique : cela permet juste de montrer les logiciels et services libres que nous utilisons régulièrement.
Un mini-site de recommandations Framalibre
💝 Les mini-sites Framalibre : offrez vos sélections ! 💝
Avec cette nouvelle version de Framalibre, nous avions envie d’aller encore plus loin pour favoriser la recommandation de pair à pair. Nous savons, d’expérience, qu’une personne qui utilise du libre aujourd’hui est une personne qui, demain, aidera ses proches à libérer leurs usages numériques.
Sur le nouveau Framalibre, vous pouvez faire votre sélection d’outils libres, et obtenir le lien d’une page à partager avec vos proches !
Rien que pour le plaisir, voici quelques exemples que nous vous avons concoctés :
Nous avons hâte de vous voir partager vos sélections d’outils libres !
GNU & Tux contre MB Blue Scream – Illustration David Revoy – Licence : CC-By 4.0
🤝 Le collaboratif, ça se partage ! 🤝
Bien entendu, Framalibre est et reste un annuaire collaboratif. Que vous vouliez ajouter une notice à l’annuaire ou corriger une notice existante, la contribution est à portée de clic !
Nous avons d’ailleurs rendu tout le processus plus… simple (vous sentiez qu’il y a comme un thème, là !). La contrepartie, c’est que vos contributions seront vérifiées avant publication par notre équipe de modératrices et modérateurs (et non plus modérées a posteriori comme avant).
L’avantage, c’est qu’il y a déjà près de 1 019 notices à aller découvrir, comme autant de solutions que les communautés du Libre offrent à chacune et chacun d’entre nous pour mieux émanciper ses pratiques numériques.
Et si vous n’y trouvez pas la fiche de ce super logiciel libre ou de cette app formidable qui vous a émancipé des géants du web… Libre à vous de l’ajouter : vous allez voir, c’est (sans trop de surprise) simple !
Alors désormais, c’est à vous de jouer !
À vous de vous emparer de Framalibre pour trouver, partager mais surtout pour recommander les outils libres qui vous facilitent la vie numérique… et la vie tout court !
Car oui : cette fin d’année encore, nous avons besoin de vous, de votre soutien, de vos partages, pour nous aider à reprendre du terrain sur le web toxique des GAFAM, et multiplier les espaces de numérique éthique.
Nous avons donc demandé à David Revoy de nous aider à montrer cela sur notre site Soutenir Framasoft, que nous vous invitons à visiter (parce que c’est beau) et surtout à partager le plus largement possible :
Si nous voulons boucler notre budget pour 2024, il ne nous reste plus que 5 jours pour récolter 71 398 € : nous n’y arriverons pas sans votre aide !
Until 2022, the time spent on Emancip’Asso was mainly used to find funding for the project, set up and run a steering committee and organise training for ethical service providers, but it was in 2023 that the project really took off. We’re well on the way to enabling associations that want to free themselves from the digital tools of the web giants to find structures that can support them in this transition.
🦆 VS 😈: Let’s take back some ground from the tech giants!
Click to support us and push back Toxicloud – Illustration CC-By David Revoy
Emancip’Asso, a 4-part project
Conceived in 2021 in partnership with Animafac, co-piloted by a large number of organisations from the popular education, voluntary and digital sectors, and integrated into our roadmap “Collectivese Internet / Convivialise Internet”, the main objective of the Emancip’Asso project is to bring together ethical digital service providers and voluntary organisations in need of support in their emancipatory digital transition.
In order to achieve its objective, the project will include 4 actions:
Training for providers of ethical online services;
An online course, a digital version of the training;
A website listing service providers who specialise in helping associations make the digital transition and providing a place for associations to help each other and share their needs;
A major communications campaign to encourage associations to recognise the contradiction of trying to change the world using the tools of capitalism.
It’s been a busy year: the first 3 actions detailed above have now been completed! We’ll tell you all about them in the rest of this article.
Training suppliers of ethical digital services to support associations
We’ve come to the conclusion that there are very few ethical digital service providers offering solutions that really take into account the needs of voluntary organisations, and in particular the support required to make a successful transition to open source digital tools. The first stage of the Emancip’Asso project therefore aims to support the development of the skills of these actors through two mechanisms: training and an online course (MOOC).
A much-appreciated training course in January 2023
20 people met in Paris from 16 to 20 January at the premises of the FPH (Charles Léopold Mayer Foundation for the Progress of Humanity) to take part in the training course “Developing a range of services to support associations in their ethical digital transition” (in French). Although the original training programme (in French) had to be slightly modified as Thursday 19 January was a day of action against the pension reform, all presentations were able to take place during the week.
Once again, we would like to thank the 9 people who agreed to take part in this training session to share their expertise and exchange views with the participants. Their contributions were much appreciated (see below) and proved invaluable in providing a solid base of knowledge and resources for the production of the MOOC.
We would also like to thank the 20 people who attended the 7 training sessions and took part in the many informal discussions that took place. Our objective of giving priority to alternative hosts who are members of the Collectif des Hébergeurs Alternatifs Transparents Ouverts Neutres et Solidaires (CHATONS) was achieved, as 70% of the participants are active within an organisation that is a member of the CHATONS collective (14 people), representing a total of 11 structures that are members of the CHATONS collective (Alolise, Assodev-Marsnet, le Cloud Girofle, la Contre-Voie, Deuxfleurs, Immae. eu, Libretic, Nebulae, Pâquerette, Picasoft and Sleto). Of the 6 other participants, one has seen his organisation (FuturEtic) join the CHATONS collective in June 2023 and another (Krashboyz Bordel Klub) is currently applying to join.
The satisfaction questionnaire we sent out to participants highlights the fact that, overall, the week was beneficial for everyone. For example, 35% of participants found the training very satisfactory, 60% fairly satisfactory and only one participant found the training fairly unsatisfactory.
The most popular teaching sequences were:
Carry out a digital diagnosis of an association
Developing your network and thinking about complementary work
Communicating and designing a service offer
User training and support/assistance
An overview of the digital uses of associations
Understand the non-profit sector
Establish a strategic dialogue with the association
(Satisfaction rate calculated on the basis of 5 criteria: quality of theoretical content, quality of practical content, quality of teaching approach, quality of facilitation tools and listening ability/availability).
We also asked participants how satisfied they were with other aspects of the training. And as the graph below shows, overall satisfaction was high, with a few rare exceptions.
However, we recognise that certain aspects could be improved:
encourage less top-down methods of knowledge transfer,
providing more practical work and exchange of practice
improving the coherence between the different interventions
using more appropriate premises.
And we’ll do our best if we decide to run the course again in the future. But at the moment we don’t have the funding to do so.
A full MOOC in December 2023
It took us almost a year to turn the training into a MOOC, but that’s it: the online course “Developing a range of services to support voluntary organisations in their ethical digital transition” is now available on the CHATONS MOOC platform (only in French, sorry!). Mind you, the paint is still fresh and there are bound to be a few typos, but this online course, which is primarily aimed at organisations and individuals who already provide online services or who want to offer them to associations, will enable you to acquire a methodology and support techniques that go far beyond simply providing services.
The CHATONS #2 MOOC is broadly based on the educational sequence of the training course and allows you to navigate as you wish within 8 major themes, each of which offers several lessons and an MCQ (for self-assessment of acquired knowledge). Each lesson is structured around illustrated textual content and sometimes includes activities for you to complete. While we do not aim to be exhaustive, we have tried to summarise the state of knowledge on each topic and systematically include a ‘further reading’ section so that anyone wishing to delve deeper into the subject can consult additional resources.
The course is now open and anyone can join whenever they like: there’s no registration period to keep to. In fact, you don’t even need to register to view the lessons. However, we recommend that you create an account to take advantage of advanced features:
Access to self-assessment exercises in the form of multiple choice questions;
Access to the self-help forum
Track your progress through the course (so you can pick up a lesson where you left off, or keep track of your assessment results).
The key word here is autonomy. We want to give learners as much freedom as possible in their learning path: everyone can follow the lessons at their own pace and manage the time they devote to this MOOC.
As usual with Framasoft, all content created for this MOOC is released under a free CC-By-SA licence (some images and videos from third party sites are marked as such). We hope that it will evolve, especially thanks to the contributions and feedback on the support forum. This MOOC should therefore be seen as an organic, living community: it will grow if we take care of it. If there are missing resources, if an activity is off the mark, if a lesson is too long, we invite you to share your opinion and suggest improvements on the support forum.
A website to help associations get in touch with service providers, but that’s not all…
The first objective of the Emancip’Asso project was to enable ethical online service providers to develop their skills in supporting associations, but the second was to create an online space where associations could identify them. That’s why, right from the start of the project, we planned to create a website to bring people together. But before we could start creating the site, we had to create a graphic identity for Emancip’Asso.
A graphic identity and design 👌
In September 2022, we asked a group of students to work on the creation of the graphic charter and visual identity for the Emancip’Asso project, as part of the supervised projects within the Colibre pro degree. After an initial phase in which the project was presented and our brief explained, 4 students⋅es carried out a comparison of the graphic charters/visual identities of ‘neighbouring’ projects before drawing up a set of specifications presenting their analysis of the needs, from which they each developed a proposal for the graphic charter. One of these proposals met our expectations and served as the inspiration for our service provider, Thomas Nicolas (thanks to him), to create the logo.
At the same time, we responded to a call for projects from the Latitudes association, which each year offers to help organisations with a committed digital project to bring it to fruition through a tutoring programme with students from their partner schools. Between October 2022 and January 2023, three second-year students from the CentraleSupélec engineering school worked on a prototype of the future website. After learning about the project, they thought about the tree structure of the future website and the functionalities to be offered on each page, before creating mock-ups using the Penpot tool. These mock-ups were then used by our service provider, the Coopérative des Internets, to build the site.
The graphic identity and design of emancipasso.org is the result of the work of many people, and we’re pretty damn proud of it.
A directory of service providers, a community and resources
The emancipasso.org website, created by La Coopérative des Internets (thanks to them!), is divided into 3 sections.
The first is a directory of service providers able to support associations wishing to make the transition to open source digital tools.
By “support”, we mean accompanying the association through all the stages necessary for its transition (co-development of a digital strategy, diagnosis and recommendations, implementation of these recommendations and assistance in getting to grips with the solutions deployed). We found that associations often had difficulty finding professionals who could provide this type of tailored support. Like many organisations, not-for-profits think in terms of ‘tools’ first, before thinking about a digital strategy to ensure a smooth transition (without having to return to the services of the web giants after a few months because they haven’t thought through all the aspects of this transition). For this reason, associations will not find in this directory providers who only offer technical solutions. In fact, we have systematically asked service providers who have volunteered to be included in this directory to prove that they have already carried out several projects to support associations.
Click to support us and help Shane, Émancip’Asso mascot – Illustration CC-By David Revoy
So far, 20 service providers are listed in this directory. That’s a start. Over the past month, we have been actively communicating with support professionals about the existence of this site. What’s more, we’re expecting service providers who have taken the training or the MOOC to register in the next few months. So it’s still a work in progress and you can access it. If you know of people or organisations that could be listed, please let us know.
The emancipasso.org website is also intended to be a gateway to a community where associations and other players in the emancipatory digital ecosystem can help and advise each other, share best practices and communicate their needs in terms of tools and/or functionalities so that development costs can be shared between several organisations. Based on the observation that associations, and in particular the people in charge of the digital aspects within them, currently have very few forums in which to discuss their practices in relation to the digital transition (thanks, incidentally, to the Mouvement Associatif and its regional delegations, which regularly address this issue), we felt it was essential to offer a space where they could feel less isolated on these issues.
Finally, the Resources section offers a selection of content aimed at voluntary organisations, so that they can familiarise themselves with ethical digital technology, but also at service providers, so that they can improve their knowledge of the voluntary sector and their methods of support. Our aim here is to list as much educational content as possible to promote the emancipation of the voluntary sector. If you have resources that we have not identified, please let us know (by sending a message to contact(at)emancipasso(dot)org) so that we can add them.
We will also continue to invite service providers to join the Emancip’Asso directory and to process applications. It’s a long-term task to identify all the existing structures and ensure that they really offer services to associations that include a support dimension. Throughout the year, we will try to be present at the main gatherings of ethical and responsible digital professionals to inform them about the scheme and encourage them to join.
Thanks to your donations, Shane is not afraid to fight Toxicloud. – Illustration CC-By David Revoy
But the biggest task will be to carry out the fourth stage of the project: to make associations aware of the incoherence of trying to change the world using the tools of capitalism and to encourage them to go to emancipasso.org to find resources, peer support and service providers to help them in their transition. To do this, we plan to launch a targeted communications campaign throughout March 2024. We are currently working on this and hope you will help us by sharing our communication materials with your favourite associations! And throughout the year, we will be presenting the project at the main events that bring together the voluntary sector (Forum national de l’ESS, Universités d’été du Mouvement Associatif, Forum national des associations, etc.) to raise awareness.
Finally, once the associations are aware of the project and have joined the Emancip’Asso community, we will put more energy into animating this community in order to facilitate exchanges between participants. Our goal is for the Emancip’Asso community to become an essential space for all associations in transition or that have completed their digital transition, and for frequent visits to this community to become an integral part of associative practices.
Thank you for supporting Emancip’Asso and Framasoft
Although the costs of the Emancip’Asso project have so far been covered by the Fondation Charles Léopold Mayer pour le Progrès de l’Homme (FPH), the Fondation Crédit Coopératif and the Fondation Un monde par tous, we no longer have any external sources of funding for the rest of the project.
So if you like this project and if it’s possible for you, we encourage you to support Framasoft. A part of your donations will help us to finance the costs (communication campaign and project coordination) of the Emancip’Asso project in 2024.
Once again this year, we need you, your support, your sharing to help us regain ground on the toxic GAFAM web and multiply the number of ethical digital spaces.
So we’ve asked David Revoy to help us present this on our « Support Framasoft » page, which we invite you to visit (because it’s beautiful) and above all to share as widely as possible :
If we are to balance our budget for 2024, we have just 12 days left to raise € 109000: we can’t do it without your help !
Emancip’Asso – L’éthique, jusqu’au bout du numérique !
Si en 2022, le temps passé sur Emancip’Asso avait surtout permis de trouver de quoi financer le projet, de constituer et d’animer un comité de pilotage et d’organiser une formation pour les hébergeurs de services éthiques, c’est en 2023 que le projet a vraiment décollé. Nous voilà en bonne voie pour permettre aux associations qui souhaitent s’émanciper des outils numériques des géants du web de trouver des structures pouvant les accompagner dans cette transition.
Cliquez pour nous soutenir et aider à repousser Toxicloud – Illustration CC-By David Revoy
Emancip’Asso, un projet en 4 actions
Conçu en 2021 en partenariat avec Animafac, copiloté par un grand nombre d’organisations impliquées dans les secteurs de l’éducation populaire, de l’associatif et du numérique et intégré dans notre feuille de route « Collectivisons Internet / Convivialisons Internet », le projet Emancip’Asso a pour objectif principal de mettre en lien fournisseurs de services numériques éthiques et associations ayant besoin d’être accompagnées dans leur démarche de transition numérique émancipatrice.
Pour atteindre son objectif, le projet prévoit de se décliner en 4 actions :
une formation pour les fournisseurs de services en ligne éthiques ;
un cours en ligne, déclinaison en numérique de la formation ;
un site web recensant des prestataires spécialistes de l’accompagnement à la transition numérique des associations et proposant un espace d’entraide et de mutualisation des besoins entre associations ;
une campagne de communication de grande ampleur pour inciter les associations à prendre conscience de l’incohérence qu’il y a à vouloir changer le monde en utilisant les outils du capitalisme.
Cette année aura été bien remplie : les 3 premières actions détaillées ci-dessus sont désormais réalisées ! On vous détaille tout ça dans la suite de cet article.
Former les fournisseurs de services numériques éthiques à l’accompagnement des associations
Nous faisons un constat : les fournisseurs de services numériques éthiques sont peu nombreux à proposer des solutions prenant réellement en compte les besoins des associations, notamment l’accompagnement nécessaire pour mener à bien une démarche de transition vers des outils numériques libres. La première étape du projet Emancip’Asso se donne ainsi pour objectif d’accompagner la montée en compétences de ces acteurices à travers deux dispositifs : une formation et un cours en ligne (MOOC).
Remercions encore une fois les 9 personnes qui ont accepté d’intervenir pendant cette session de formation pour partager leurs domaines d’expertise et échanger avec les participant⋅es. Leurs interventions ont été très appréciées (voir ci-dessous) et se sont révélées précieuses, constituant une base solide de savoirs et de ressources pour la production du MOOC.
Remercions aussi les 20 personnes qui ont suivi avec assiduité les 7 séquences de cette formation et ont pris part aux nombreux échanges informels qui s’y sont tenus. Notre objectif de former en priorité les hébergeurs alternatifs membres du Collectif des Hébergeurs Alternatifs Transparents Ouverts Neutres et Solidaires (CHATONS) est atteint puisque 70% des participant⋅es sont actif⋅ves au sein d’une organisation membre du collectif CHATONS (14 personnes), représentant au total 11 structures membres du collectif CHATONS (Alolise, Assodev-Marsnet, le Cloud Girofle, la Contre-Voie, Deuxfleurs, Immae.eu, Libretic, Nebulae, Pâquerette, Picasoft et Sleto). Sur les 6 autres participant⋅es, l’un a vu son organisation (FuturEtic) intégrer le collectif CHATONS en juin 2023 et un autre (Krashboyz Bordel Klub) est actuellement candidat pour le rejoindre.
Le questionnaire de satisfaction que nous avons transmis aux participant⋅es met en évidence le fait que dans sa globalité, cette semaine a été bénéfique pour toustes. Ainsi, 35% des apprenant⋅es ont trouvé la formation très satisfaisante, 60% plutôt satisfaisante et un⋅e seul⋅e participant⋅e a considéré que cette formation était plutôt insatisfaisante.
Les séquences pédagogiques qui ont le plus été appréciées sont les suivantes :
réaliser le diagnostic numérique d’une association
développer son réseau et penser le travail en complémentarité
communication et design d’une offre de service
formation des utilisateur⋅ices et support / assistance
panorama des usages numériques des associations
compréhension du monde associatif
instaurer un dialogue stratégique avec l’association
(taux de satisfaction calculé sur la base de 5 critères : qualité du contenu théorique, qualité du contenu pratique, qualité de l’approche pédagogique, qualité des outils d’animation et capacité d’écoute/disponibilité)
Nous avons aussi demandé aux participant⋅es leur degré de satisfaction sur les autres aspects de la formation. Et comme nous l’indique le schéma ci-dessous, la satisfaction est globale, sauf quelques rares exceptions.
Nous gardons cependant en tête que certains aspects pourraient être améliorés :
favoriser des modalités de transmission des savoirs moins descendantes,
prévoir davantage de travaux pratiques et d’échanges de pratiques,
améliorer la cohérence entre les interventions,
utiliser des locaux plus adaptés.
Et nous ferons de notre mieux si nous venions à envisager de reconduire cette formation à l’avenir. Mais pour le moment, nous n’avons pas les financements pour cela.
Un MOOC très complet en décembre 2023
Il nous a fallu quasiment une année pour transformer la session de formation en MOOC, mais ça y est, le cours en ligne « Développer une offre de services pour accompagner les associations dans leur transition numérique éthique » est désormais accessible sur la plateforme MOOC CHATONS. Attention, la peinture est encore fraîche et il doit encore rester quelques coquilles, mais ce cours en ligne, principalement destiné aux organisations et personnes qui fournissent déjà des services en ligne ou qui souhaitent en proposer à destination des associations, permet d’acquérir en autonomie une méthodologie et des techniques d’accompagnement qui vont bien au delà de la simple fourniture de services.
Les chapitres du MOOC
Reprenant dans les grandes lignes le séquençage pédagogique de la formation, le MOOC CHATONS #2 vous propose de naviguer à votre convenance au sein de 8 grandes thématiques, chacune d’entre elles proposant plusieurs leçons et un QCM (pour auto-évaluer les connaissances acquises). Chaque leçon s’articule autour de contenus textuels illustrés et propose parfois des activités à réaliser. Même si nous ne cherchons pas l’exhaustivité, nous avons essayé de synthétiser l’état des connaissances à disposition sur chaque sujet traité, et proposons systématiquement une rubrique « Pour aller plus loin » permettant à celles et ceux qui voudraient approfondir la question de consulter des ressources complémentaires.
Exemple sur la séquence 4 de l’articulation entre leçons, activités et QCM.
Le cours est dorénavant ouvert, et chacun·e peut y participer quand bon lui semble : il n’y a pas de période d’inscription à respecter. D’ailleurs, il n’est même pas nécessaire de s’inscrire pour consulter les leçons. Nous vous conseillons cependant de créer un compte pour bénéficier de fonctionnalités avancées :
accès aux exercices d’autoévaluation sous forme de QCM ;
accès au forum d’entraide ;
suivi de l’avancement de son parcours de formation (pour reprendre une leçon là où on s’est arrêté ou pour suivre les résultats aux évaluations).
Le maître-mot, ici, c’est l’autonomie. Nous voulons laisser aux apprenant·es un maximum de libertés dans leur parcours pédagogique : chacun⋅e peut suivre les leçons à son rythme et gérer son temps consacré à ce MOOC.
Comme d’habitude avec Framasoft, tous les contenus créés pour ce MOOC sont placés sous licence libre CC-By-SA (certaines images et vidéos issues de sites tiers sont signalées comme telles). Car nous espérons bien qu’il va évoluer, notamment grâce aux contributions et retours sur le forum d’entraide. Il faut donc voir ce MOOC comme un commun, organique, vivant : il grandit si l’on en prend soin. S’il manque des ressources, si une activité est à côté de la plaque, si une leçon est trop longue, nous vous invitons à partager votre avis sur le forum d’entraide et à proposer des améliorations.
Un site web pour faciliter la mise en relation des associations avec des prestataires, mais pas que…
Si permettre à des fournisseurs de services en ligne éthiques de monter en compétences en matière d’accompagnement des associations était le premier objectif du projet Emancip’Asso, le second était de créer un espace en ligne où les associations pourraient les identifier. C’est pourquoi dès l’origine du projet, nous avons prévu la création d’un site web permettant cette mise en relation. Mais avant de nous lancer dans la création du site, il nous fallait d’abord nous lancer dans la réalisation d’une identité graphique pour Emancip’Asso.
Une identité graphique et un design 👌
En septembre 2022, nous avons candidaté pour bénéficier de l’intervention d’un groupe d’étudiant⋅es sur la réalisation de la charte graphique et de l’identité visuelle du projet Emancip’Asso dans le cadre des projets tuteurés au sein de la licence pro Colibre. Après une première phase de présentation du projet et d’explicitation de notre commande, 4 étudiant⋅es ont réalisé un comparatif de chartes graphiques / identités visuelles de projets « voisins » avant de rédiger un cahier des charges présentant leur analyse du besoin, à partir duquel iels ont chacun⋅e élaboré une proposition de charte graphique. L’une de ces propositions correspondait à nos attentes et a servi d’inspiration à notre prestataire, Thomas Nicolas (merci à lui), pour la réalisation du logo.
En parallèle, nous avons postulé à un appel à projet de l’association Latitudes qui propose chaque année d’accompagner les organisations ayant un projet numérique engagé à le concrétiser via un dispositif de tutorat avec des élèves de leurs écoles partenaires. Entre octobre 2022 et janvier 2023, 3 étudiant⋅es de 2ème année de l’école d’ingénieurs CentraleSupélec ont travaillé à la réalisation d’un prototype pour le futur site web. Après un temps de découverte du projet, iels ont réfléchi à l’arborescence du futur site web et aux fonctionnalités à proposer sur chaque page avant de réaliser des maquettes via l’outil Penpot. Ces mock-up ont ensuite servi de base à notre prestataire, la Coopérative des Internets, pour créer le site web.
L’identité graphique et le design du site emancipasso.org résulte donc du travail de nombreuses personnes et nous sommes sacrément fier⋅es du résultat.
Un répertoire de prestataires, une communauté et des ressources
Le site emancipasso.org réalisé par La Coopérative des Internets (merci à elleux !) s’articule autour de 3 rubriques.
La première consiste en un répertoire de prestataires en mesure d’accompagner les associations souhaitant se lancer dans une démarche de transition vers des outils numériques libres.
On entend ici par « accompagnement », le fait d’accompagner l’association dans l’ensemble des étapes nécessaires à sa transition (co-élaboration d’une stratégie numérique, d’un diagnostic et de préconisations, mise en œuvre de celles-ci et accompagnement à la prise en main des solutions déployées). Nous avons en effet constaté que les associations peinaient souvent à trouver des professionnel⋅les réalisant ce type d’accompagnements sur mesure. Comme beaucoup d’organisations, les associations pensent d’abord « outils » avant de réfléchir à une stratégie numérique permettant que leur transition se déroule dans de bonnes conditions (sans retour aux services des géants du web au bout de quelques mois faute d’avoir pensé tous les aspects de cette transition). C’est pour cette raison que les associations ne trouveront pas dans ce répertoire des prestataires ne réalisant que le déploiement de solutions techniques. Nous avons d’ailleurs systématiquement demandé aux prestataires s’étant montré volontaires pour intégrer ce répertoire de nous fournir la preuve qu’ils avaient déjà mené plusieurs projets d’accompagnements auprès d’associations.
Cliquez pour nous soutenir et aider Shane, la mascotte d’Émancip’Asso – Illustration CC-By David Revoy
A ce jour, 20 prestataires sont recensés dans ce répertoire. C’est un début. Cela fait un petit mois que nous communiquons de manière active auprès des professionnel⋅les de l’accompagnement sur l’existence de ce site. De plus, nous comptons sur le fait que des hébergeurs de services ayant suivi la formation ou le MOOC se lancent à leur tour d’ici quelques mois. C’est donc encore actuellement un répertoire en devenir auquel vous avez accès. Si d’ailleurs vous connaissez des personnes ou organisations susceptibles d’y être référencées, n’hésitez pas à leur transmettre l’information.
Le site emancipasso.org est aussi pensé comme entrée pour rejoindre une communauté où les associations et les acteurices de l’écosystème du numérique émancipateur s’entraident, se conseillent, échangent des bonnes pratiques et font connaître leurs besoins en matière d’outils et/ou de fonctionnalités afin de mutualiser entre plusieurs organisations des coûts de développement. Partant du constat que les associations, et particulièrement les personnes en charge des aspects numériques au sein de celles-ci, n’ont à ce jour que très peu d’espaces pour échanger sur leurs pratiques en matière de transition numérique (merci d’ailleurs au Mouvement Associatif et ses délégations régionales qui s’emparent régulièrement de cette question), il nous a semblé essentiel de proposer un espace pour qu’elles se sentent moins isolées sur ces questions.
La page d’accueil de la communauté Emancip’Asso
Enfin, la rubrique Ressources propose une sélection de contenus à destination des associations afin qu’elles puissent s’acculturer en autonomie à cette thématique du numérique éthique mais aussi à destination des prestataires afin qu’iels puissent perfectionner leur connaissance du monde associatif et leurs méthodes d’accompagnement. Notre objectif est de recenser ici un maximum de contenus pédagogiques pour favoriser l’émancipation du monde associatif. Si vous avez en stock des ressources que nous n’avons pas identifiées, n’hésitez pas à nous les faire connaître (en nous envoyant un petit mot sur contact (chez)emancipasso(point)org) afin qu’on les ajoute.
Nous allons aussi continuer à solliciter des prestataires susceptibles de rejoindre le répertoire Emancip’Asso et traiter les candidatures. C’est un travail au long cours d’identifier toutes les structures existantes et de s’assurer qu’elles proposent réellement des offres à destination des associations intégrant une dimension d’accompagnement. Tout au long de l’année, nous essaierons d’être présent⋅es lors des principaux rassemblements des professionnel⋅les du numérique éthique et responsable afin de leur faire connaître ce dispositif et les inciter à le rejoindre.
C’est grâce à vos dons que Shane n’a pas peur de lutter contre Toxicloud – Illustration de David Revoy – Licence : CC-By 4.0
Mais le plus gros du travail va être de réaliser la quatrième étape du projet : faire prendre conscience aux associations de l’incohérence qu’il y a à vouloir changer le monde en utilisant les outils du capitalisme et les inciter à se rendre sur le site emancipasso.org pour trouver ressources, entraide entre pairs et prestataires pour les accompagner dans leur transition. Pour cela, nous prévoyons de lancer une campagne de communication ciblée durant tout le mois de mars 2024. Nous y travaillons actuellement et espérons que vous nous aiderez à relayer nos supports de communication auprès de vos associations préférées ! Et toute l’année, nous présenterons le projet lors des principaux événements fédérateurs du monde associatif (Forum national de l’ESS, Universités d’été du Mouvement Associatif, Forum national des associations, etc.) afin de le faire connaître.
Enfin, à partir du moment où les associations auront connaissance du projet et qu’elles auront rejoins la communauté Emancip’Asso, nous mettrons davantage d’énergie sur l’animation de cette communauté afin de faciliter au mieux les échanges entre les participant⋅es. Notre objectif est que la communauté Emancip’Asso devienne un espace incontournable pour toutes les associations en cours de transition ou ayant réalisé leur transition numérique et que fréquenter cette communauté s’inscrive de manière permanente dans les pratiques associatives.
Merci de soutenir Emancip’Asso et Framasoft
Si jusqu’à maintenant les coûts liés au projet Emancip’Asso ont été pris en charge par la Fondation Charles Léopold Mayer pour le progrès de l’Homme (FPH), la Fondation Crédit Coopératif et la Fondation Un monde par tous, nous n’avons plus de sources de financement externe pour la suite du projet.
Donc si ce projet vous plaît, et que c’est possible pour vous, nous vous encourageons à soutenir Framasoft. Une partie de vos dons nous aideront à financer les coûts (campagne de communication et coordination du projet) du projet Emancip’Asso en 2024.
Cette année encore, nous avons besoin de vous, de votre soutien, de vos partages, pour nous aider à reprendre du terrain sur le web toxique des GAFAM, et multiplier les espaces de numérique éthique.
Nous avons donc demandé à David Revoy de nous aider à montrer cela sur notre site « Soutenir Framasoft », qu’on vous invite à visiter (parce que c’est beau) et surtout à partager le plus largement possible :
Si nous voulons boucler notre budget pour 2024, il nous reste tout juste 12 jours pour récolter 109 000 € : nous n’y arriverons pas sans votre aide !
Mobile App, redesign, new dev, promotion… let’s build a bright future for PeerTube !
Developing an ethical and emancipating alternative to YouTube, Twitch or Vimeo without Surveillance Capitalism’s means is a huge undertaking. Especially for a small French not-for-profit that already manages several projects to promote digital commons.
🦆 VS 😈: Let’s take back some ground from the tech giants!
We (Bonjour ! We are Framasoft !) have been developing PeerTube for six years. Two weeks after releasing the sixth version of the software, let’s take a step back on six years of work, examine the huge opportunity that the present times hold for PeerTube, and look towards what we plan to do next year to prepare for its success… if you give us the means to get there!
Click to support Framasoft and push back against the Yetube – Illustration CC-By David Revoy
Not a rival, just an alternative
The realization that led us to develop PeerTube is that no one can rival YouTube or Twitch. You would need Google’s money, Amazon servers’ farms… Above all, you would need the greed to exploit millions of creators and videomakers, groom them into formatting their content to your needs, and feed them the crumbs of the wealth you gain by farming their audience into data livestock.
Monopolistic centralized video platforms can only be sustained by surveillance capitalism.
We wanted small groups such as institutions, educators, communities, artists, citizens, etc. to be able to afford to emancipate themselves from Big Tech’s platforms, without getting lost in the world wide web. We needed to develop a tool to democratize videohosting, so it had to be designed with radically different values in mind.
And that is what we did. We build PeerTube to empower people, not databases or shareholders.
Today, PeerTube is:
a Free-Libre software (transparency, protection against monopoly)
you can host on your server (self-hosting, autonomy, empowerment)
to create your video and livestream platform, with your own rules (community building, self-management)
that lets you federate (or not!) to other PeerTube platforms through ActivityPub protocol (federation, network, outreach)
that adds (optional) peer-to-peer streaming to classic streaming so it can withstand affluence (resilience, sharing, decentralization)
where more powerful servers can help less fortunate ones with redundancy (solidarity, resilience)
that can store videos externally with S3 storage (adaptability, cost-efficiency)
that can deport CPU-hungry tasks such as video or live transcoding to a dedicated server (efficiency, resilience, sustainability)
So no: PeerTube is not, and will not be a rival to YouTube or Twitch. PeerTube is powered by other values that those coded into Google’s and Amazon’s ecosystems. PeerTube is an alternative, and that’s exactly why this is so exciting.
In the last six years, with more than 275 000 lines of code, we got:
From a POC to a fully operative federated video platform with p2p broadcasting, complete with subtitles, redundancy, video import, search tools and localization (PeerTube v1, oct. 2018)
Notifications, playlists, a plugin system, moderation tools, federation tools, a better video player, a presentation website and an instances index (PeerTube v2, nov. 2019)
Federated research tool (and a search engine https://sepiasearch.org), more moderation tools, lots of code improvement, UX revamping, and last but not least: p2p livestream (PeerTube v3, Jan. 2021)
Improved transcoding, channels and instances homepage customization, improved search, an even better video player, filtering videos on pages, advanced administration and moderation tools, new video management tool, and a big code cleaning session (PeerTube v4, Dec. 2021)
A video editing tool, improved video statistics and metrics display, replay feature for permanent livestreams, latency settings for lives, an improved video player (for mobile displays), a more powerful plugin system, more customization options, more video filtering options, a new and user friendly feedback tool and a renewed presentation website (PeerTube v5, Dec. 2022)
Account request moderation, « back to live » button, remote transcoding (to deport CPU hungry task on a dedicated server). storyboard (previews in the progress bar), video chapters, improved accessibility, upload a new version of a video, and password-protected videos. (PeerTube v6, Nov. 2023)
And that is just when you only consider the software development part of PeerTube. In order to support and promote this software, we had to build a whole ecosystem.
PeerTube is also an ecosystem
PeerTube, nowadays, is also a coding community. On the project forge (online space to contribute on developments), we’ve had more than 400 contributors, 4,300 issues (features and support requests) closed over 6 years and 500 still open, and 12,400 contributions integrated upstream.
As not anyone can familiarize themselves with more than 275 000 lines of code, an easy way to contribute to PeerTube is by developing plugins : there are hundreds of them! Among them, there are the live chat (to get a chat during livestreams), plugins to authenticate against external authentication platforms, annotations to add in the video player, a transcription plugin to automatically create subtitles for your videos or plugins to add monetization to PeerTube videos.
There are now more than a thousand PeerTube platforms all over the world (that we know of ^^), hosting almost a million videos. We have created an instances index that feeds content to SepiaSearch, our search engine for PeerTube videos, channels and playlists. We moderate it according to our terms and conditions, but anyone is free to use the code we develop to create their own index and search engine.
We promote PeerTube with an official website Joinpeertube.org, where the latest news are shared on the blog and the newsletter. There is also a mastodon account (and an -almost abandoned- account on Twitter). We also spend lots of hours talking to medias, researchers, innovators, communities, contributors, etc.
Fighting dragons with toothpicks
So, how can we estimate the cost of those 6 years of work? Should we just consider development time and the management of the development community (issues, code review, support)?
Should we also count the work done on blogposts, illustrations and promotion material, establishing roadmaps, working with designers, exchanging experience with researchers, videomakers, and amazing projects, some of which we have supported with funds? What about the time for moderating our search engine or cleaning after spammers on our feedback tool?
Even though we cannot pinpoint the exact budget Framasoft spent on PeerTube since 2017, our conservative estimate would be around 500 000 €. Over six years. As we got two grants from the European commission (through the NGI0 Search & Discovery and Entrust programs) totaling 132 000 €, it means that 73,6 % of PeerTube budget came from donations.
Now let’s overestimate the cost of PeerTube to 600 000 € over 6 years, to make sure we have covered every expense.
Even then, PeerTube total cost would represent 22 millionth (0.0022 %) of YouTube’s ad revenues last year. Yes, we did the math.
We are – figuratively – fighting dragons with toothpicks. That’s why we think that PeerTube cannot and will not rival YouTube nor Twitch (and even less TikTok that presents a whole other experience).
But, as an alternative, PeerTube is already successful.
Click to support Sepia against the Videoraptor – illustration David Revoy – Licence : CC-By 4.0
A success in our eyes
Today, we know of more than 1000 instances (servers on which PeerTube is installed and running), sharing almost a million videos.
As it is not limited by the captology mechanics of an ad-and-attention-based model, PeerTube offers features not available from tech giants:
compatibility with other social tools via ActivityPub (Imagine you could tweet a comment to a YouTube video: with Mastodon and PeerTube, you can.)
share a video from a start timecode to a stop timecode (YouTube has caught up with us, since)
untempered chronological access to your suscriptions feed (no need to « click the bell » in addition to subscribing)
password-protected videos (unavailable in YouTube, paid in Vimeo)
replace a video by an updated version
We intended to make PeerTube specifically for people that need (and want) to share their videos outside of the surveillance capitalism model. Obviously we all know (and like) some YouTubers and Twitch-streamers, but they are the visible part of the iceberg of online video sharing.
Institutions, Educators, Independent medias, Citizens, and even creators should have the freedom to share videos online without contributing to a company’s monopoly, having to accept forced advertisement, or sacrificing on their audience’s data and privacy. The great news is, some of them have already found such freedom, and it makes us proud :
Skeptikon (French collective, videos about critical thinking and scepticism)
TILvids (Til = Today I Learned, edutainment videos in English, with authorized and official YouTube mirroring)
Bunseed (French initiative, FOSS-based alternative to Patreon, by and for creators, built upon PeerTube)
We want to build on the recognition PeerTube is getting, that’s why we have planned a lot of work for 2024!
PeerTube’s roadmap for v7, in 2024
The features we have planned for the next year of development on PeerTube all have the same goal: facilite adoption by improving ease-of-use in several ways. As for version 6, most of those features has been chosen from the ideas you shared and voted for on our feedback tool.
We plan to:
Add a data export/import system (with or without video files), so users can easily change their instance.
Get a full accessibility audit, to facilitate use for people with specific needs, and complete the work done this year (see version 6 release). If we have time left on integrating the report’s recommandations, we will see if and how we could add speech-to-text transcription
Add a comment moderation tool usable for both instance administrators and video uploaders.
Create a new moderation tool to sort content according to preset keywords lists ( « far-right dogwhistling words in German », « queerphobic idioms in English », etc). This tool will present corresponding content to instance administrators and moderators, that will then determine if it fits their moderation policy.
(Technical) separation of audio and video streams. Such improvement will unlock the possibility, in the future, to develop and get multi-audio track videos (e.g. multiple langages), or multi-videos track with the same audio stream (e.g. multiple angles)
Add a new « audio-only » resolution (in the « 720p », « 1080p », etc. menu) for our HLS player. It will enable users to only get the audio track streamed to them, improving sustainability when they only want to listen to a video and look at other tabs.
Rethink the sensitive content characterization. At the moment, you can only tag videos as « Safe For Work » / « Not Safe For Work ». But « sensitive content » can imply lots of cases: violence, nudity, strong langage, etc. We will work with designers to think about the appropriate way to characterize and treat such cases.
Revamp the video management space. We have added lots of new features along the years (live and replay, studio editor, etc.)… it’s great, but tabs and menus accumulated. We will work with designers to rethink it from the ground up and make it easy-to-use.
Get a complete review and implement a redesign of the experience and interface of PeerTube. Even though we’ve had lots of help along the way, PeerTube has not benefited of guidance in design from the get-go. We want to think this work as a reboot, where everything (even the orange?) is on the table, if it helps with adoption and ease of use.
Hep us push back against the Videoraptor- Illustration CC-By David Revoy
Doubling the dev team for resilience…
OK, when you go from one to two developers, « doubling » is easier… but it was still a big deal to us.
First, because Framasoft is a not-for-profit funded mainly by donations. So far, we’ve had the honor and privilege to get enough support to fund our expenses, the main being our 10 employees. But donation-based economics models are, by definition, highly unpredictable. That is especially true in an economy where inflation, energy costs, etc. make most of our supporters rethink their budget.
Another reason lies within our core values: we believe in decentralization and networks of small actors (over growing into giants and monopolies). We also believe that prioritizing humans and care implies to stay in a small team configuration, where we truly know each other.
And we think that the way we have applied those values into our not-for-profit is key to the efficiency, the creativity and the talents expressed by our members (both volunteers and employees). That’s why we have worked on limiting Framasoft’s growth, and have set the symbolic limit of « ten employees tops ».
During 2022 and 2023, there were lots of discussions on this topic within Framasoft. On one hand, we can’t keep on developing PeerTube with only one developer (even though someone as talented as Chocobozzz), who could win the lottery, leave, or just change careers. On the other hand, if we hired a new developer, what would be their profile? How can we make sure they would fit in? Can we secure a long lasting job for them?
In late 2022, Chocobozzz asked us to post an internship offer. It was both to test if, after 5 years coding solo on PeerTube, teamwork came back easily (it did) ; but also to train someone on PeerTube’s code core, see how it can be apprehended by newcomers, and how to improve its documentation.
Wicklow joined us for an internship between February and August 2023, and produced the « password protected video features » released in version 6 of PeerTube. We hadn’t plan to hire him: we had, then, other profiles in mind, and thought we wouldn’t be able to start a hiring process before 2024. We specifically told him so, as not to give him false hope… But as we benefited from a grant extension from NGI0 program, we also realized that he was a perfect fit in the project, for the team and in our not-for-profit.
Long story short: we hired Wicklow in September 2023, just as he graduated, on a one-year contract (that we hope to secure with your help!).
…and to create an iOS/Android mobile app!
This new hire has two goals. First and foremost, we want another developer to become familiar with PeerTube’s core code, and lessen the « bus factor« . Wicklow should also become gradually able to help Chocobozzz in managing the code community.
As the community grows (and we are very thankful), so does the managing workload: answering to issues and support requests on our forum, reviewing code contributions, etc. Even though being present for the community is important, it’s taking up to half of Chocobozzz’s time, and that means even less time to develop new features.
The second and main goal for Wicklow in 2024 would be, with the help of designers, to create and publish an official PeerTube mobile app. Mobile viewing has become the main way to watch videos. Even though there are already mobile apps that can play videos on PeerTube, we feel that an official app could help with PeerTube’s adoption and attractiveness.
For 2024, the app would be limited to finding and watching videos. We want users to be able to use a federated search engine, watch videos and livestreams, log in to their account on their PeerTube instance, access their notifications, subscriptions, playlists, etc. If successful, this first version of the app could be extended to other use-cases and features in the future.
Our plan is to publish this app both on iOS (pending Apple’s review, that can be tricky) and Android… and, as an extended goal (so « if all goes well »), on Android TV as well.
Sepia, PeerTube’s mascot, strong from your support – illustration David Revoy – Licence : CC-By 4.0
Promoting the PeerTube Ecosystem
PeerTube is more than code, and we want to shed a light on the incredible community that is thriving around this project.
We often see amazing plugins, interesting instances and channels, new initiatives and experiments… that we would like to share. But we seldom have and take time to do so.
In the meantime, we also witness many people wondering if PeerTube allows livestream (it does!) if there is a chat for lives (yes: it’s a great plugin!), or if there are websites to find content on PeerTube (yes again!)
To kick off this work, we will go live and answer all your questions about PeerTube during a livestream hosted by Laurens from the Fediverse Report blog and newsletter, on our Peer.Tube channel! You can already go on Mastodon and ask your questions with the #PeerTubeAMA hashtag.
This AMA (« Ask Me Anything ») will take place tomorrow, Dec 13th, from 6 to 8pm (CET), on this link.
As we stated sooner in this (long) blogpost, we were fortunate enough to get grants from the European Commission program NGI, through the NLnet foundation (many thanks to them!). The previous grants helped us fund a quarter of our six years of work on PeerTube. We are glad to announce that we got another grant for 2024, that will cover planned development costs.
It means that, as it was for 75 % of the work until now, funding the rest of our plans relies on donations. Communicating about PeerTube and its ecosystem, sharing experience with diverse actors, design costs, community support and management, etc. All those costs will be, as usual, funded by… some of you!
Our current donation campaign will determine Framasoft budget for 2024, and from its success we will know if we can secure a stable job for our second developer, while keep on all the other projects and actions that we take on.
Once again this year we need you, your support, your sharing, to help us regain ground on the toxic GAFAM web and multiply ethical digital spaces.
So we’ve asked David Revoy to help us present this on our « Support Framasoft » page, which we invite you to visit (because it’s beautiful) and above all to share as widely as possible:
If we are to balance our budget for 2024, we have three weeks to raise €138,659 : we can’t do it without your help !


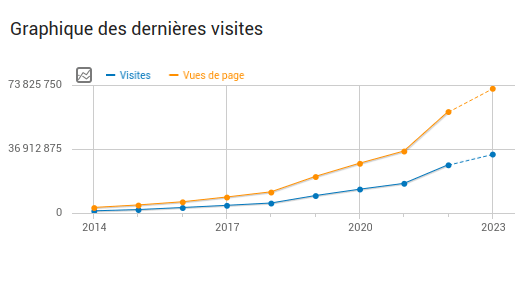
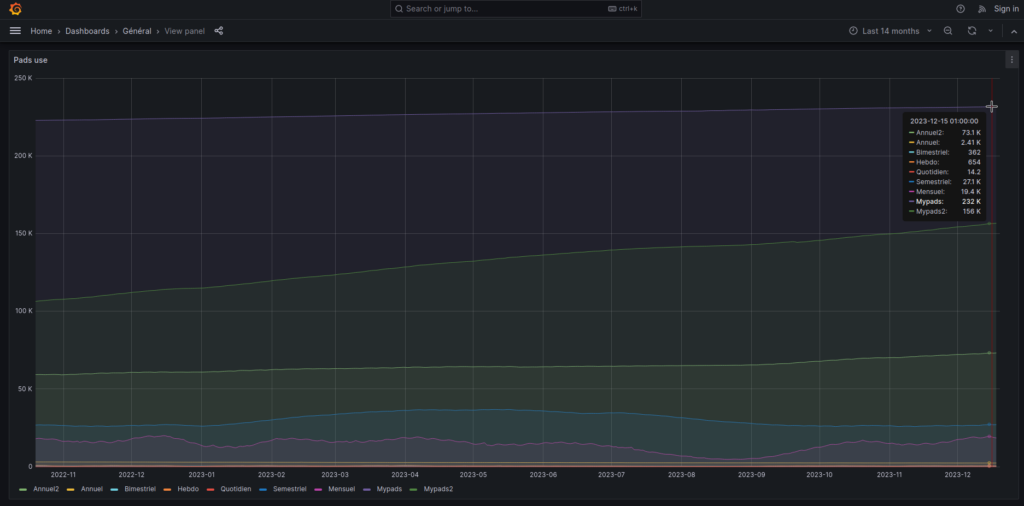
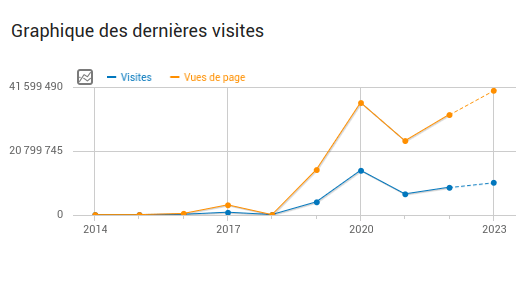
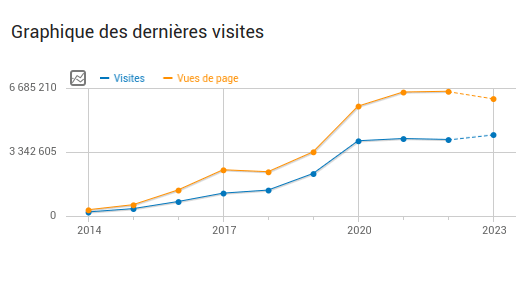
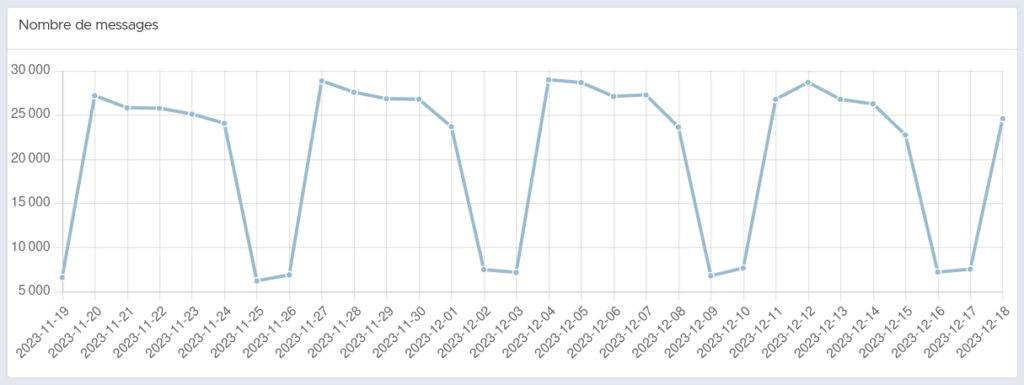
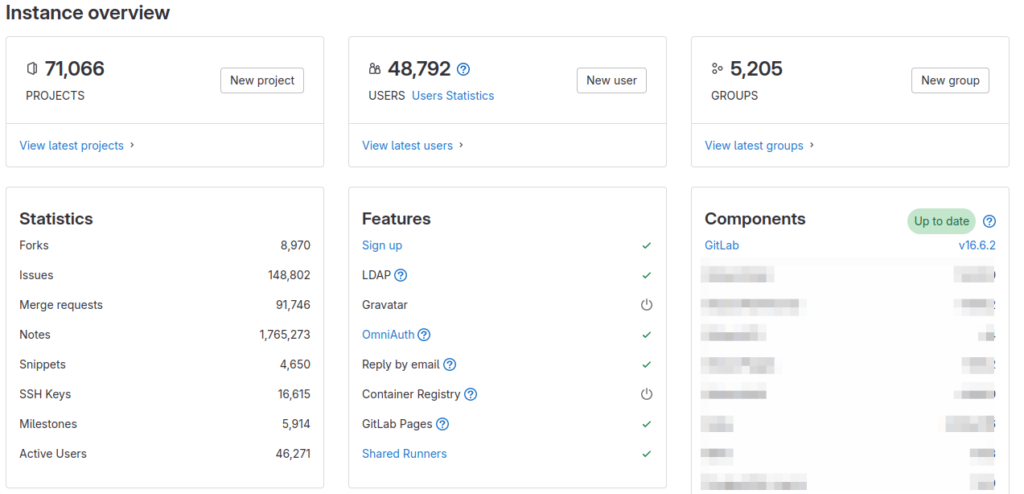
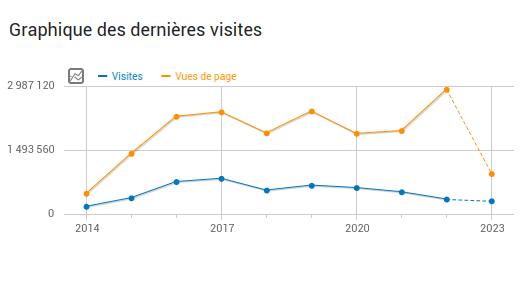





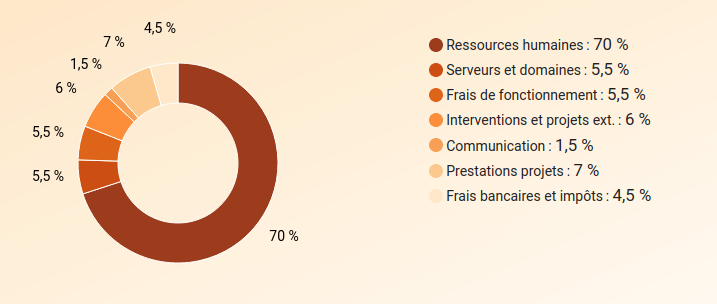

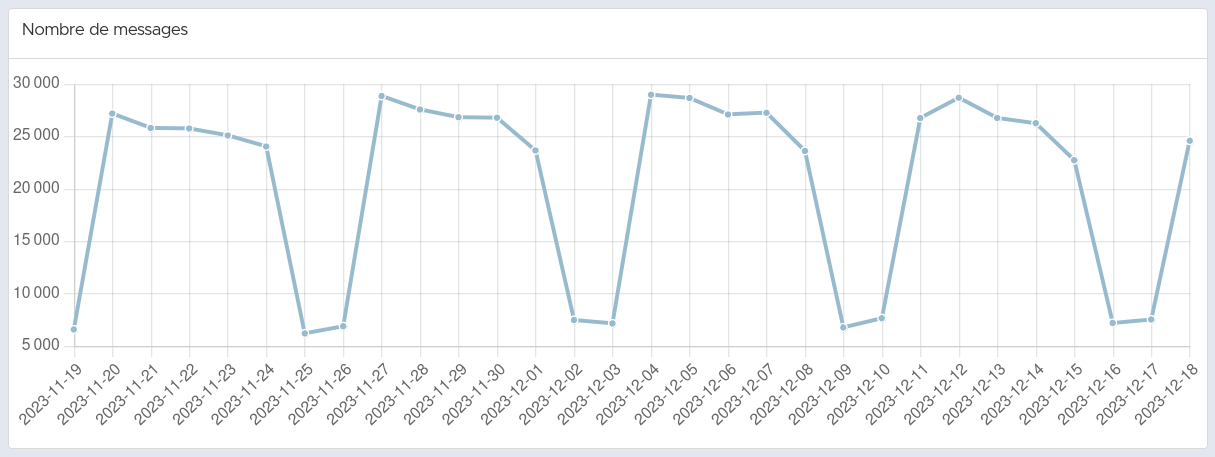

















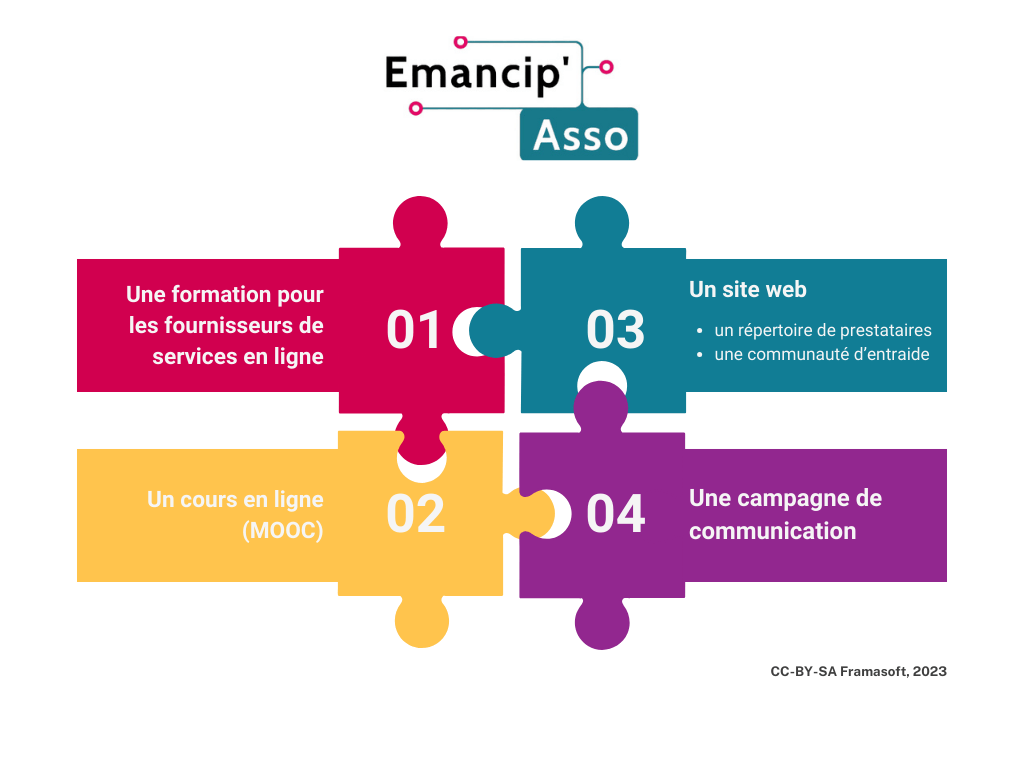
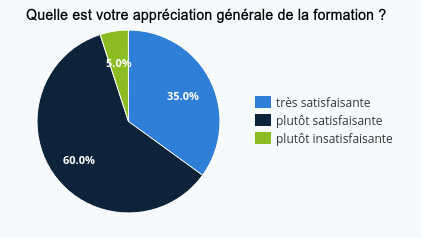
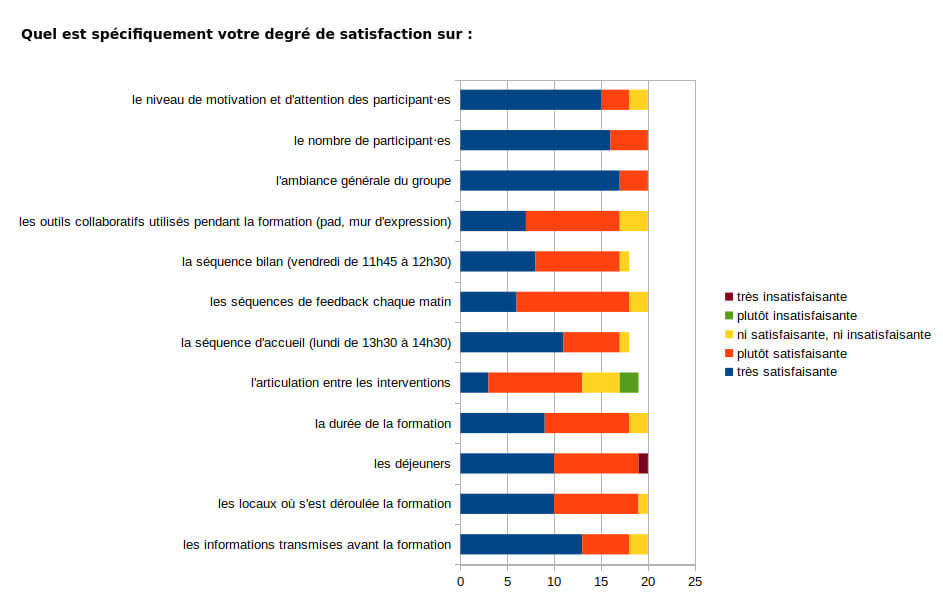







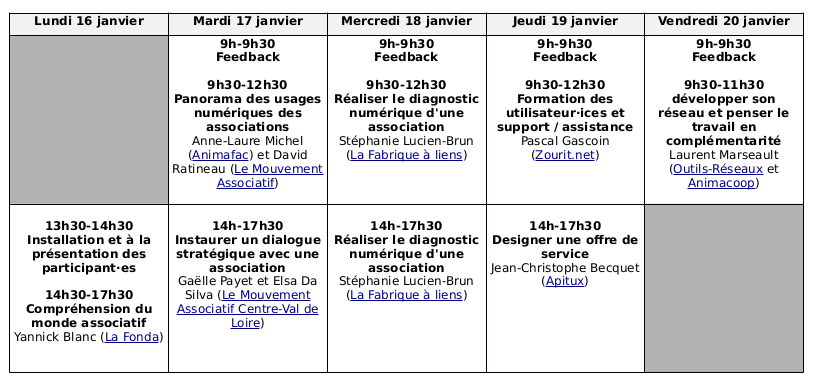{kind=link}