Frama, c’est aussi des logiciels pour libérer les usages
PeerTube, Mobilizon, Yakforms, Framadate, des nombreuses contributions à Ethercalc, Etherpad, Nextcloud… et dire qu’à une époque nous disions que « Framasoft contribue au logiciel libre, mais sans coder ! »
« Frama, c’est pas que… »
Pour l’automne 2021, chaque semaine, nous voulons vous faire découvrir un nouveau pan des actions menées par Framasoft. Ces actions étant financées par vos dons (défiscalisables à 66 %), vous pouvez en trouver un résumé complet, sous forme de cartes à découvrir et à cliquer, sur le site Soutenir Framasoft.
C’est le cercle vicieux, la pente fatale de la contribution. On commence, presque naïvement, par utiliser un logiciel libre, remercier les devs, et leur suggérer une amélioration qui nous changerait la vie. Puis on se rend compte qu’on peut aider ce logiciel en traduisant, en communiquant, en facilitant, en améliorant son aspect.
Et, sans s’en rendre compte, on se met à contribuer avec un peu de code, une issue par-ci, un bugfix par-là. Jusqu’à ce que l’envie soit trop forte : « y’a personne qui le fait, bon ben OK, on va le faire nous-mêmes ! » Et voilà comment on finit par avoir une activité d’édition de logiciels libres, en plus de tous nos autres projets.
PeerTube
On ne présente plus ce logiciel qui, une fois installé sur un serveur, permet de proposer une alternative libre et fédérée aux plateformes de diffusion vidéo à la YouTube. Mais si vous voulez découvrir pleinement l’écosystème de PeerTube, cela se passe sur notre site officiel JoinPeertube.
Début 2021, nous avons publié la troisième version majeure (v3) de PeerTube, qui ouvre la possibilité de diffuser ses vidéos en direct (live streaming). Depuis, plusieurs versions mineures ont été publiées. Elles font la part belle à la personnalisation (de son site PeerTube, de ses chaînes vidéos), ainsi qu’à la facilité de présenter, trouver et trier des contenus.
Nous avons aussi financé et accompagné deux développements externes, qui enrichissent l’écosystème PeerTube Live. Le premier c’est l’application Android PeerTube Live App, qui permet aux vidéastes de déclencher un direct très facilement depuis un smartphone. L’autre, c’est PeerTube Live Chat, un plugin qui permet aux personnes qui administrent un site PeerTube d’ajouter une fonction de clavardage aux directs diffusés depuis leur serveur.
Cette année de développement de PeerTube a été financée aux deux tiers par les 50 000 € de la bourse octroyée par NLnet, et pour un tiers par les dons que vous faites à notre association. Nous devrions très (très !) prochainement vous annoncer la v4 de PeerTube, avec une version quasi finie (Release Candidate) d’ici début décembre, pour une version finale prévue fin 2021/début 2022.
Comme PeerTube, Mobilizon est un logiciel qui, lorsqu’il est installé sur un serveur, vous permet de créer une plateforme libre et de la fédérer avec d’autres serveurs Mobilizon. Mais ici, on ne diffuse pas de vidéos ! Mobilizon vous permet de créer des événements, de découvrir et vous inscrire à des groupes et surtout de vous y organiser ensemble. Bref, c’est une alternative aux événements, pages et groupes Facebook, mais sans tout le méli-mélo social.
un site pour vous aiguiller dans cette nouvelle fédération
une instance ouverte et maintenue par nous (réservée aux francophones)
un site officiel pour vous présenter le logiciel, ses nouvelles, etc.
Certes, Mobilizon n’a pas encore séduit un public aussi large qu’on l’aimerait. Mais cette nouvelle année de développement nous a permis d’étoffer Mobilizon. En effet, que ce soit dans les résultats de l’enquête des besoins que nous avions menée lors de la conception ou grâce aux retours des personnes l’utilisant, nous savions que Mobilizon gagnerait à intégrer certaines fonctionnalités-clés.
Framaforms est l’un des services les plus utilisés parmi ceux que Framasoft propose. Pourtant, alors que les alternatives à Google Forms sont rares et très demandées, très peu d’autres hébergeurs ont installé la solution que nous proposions. C’est en partie de notre faute.
Comme nous l’expliquions dans cet article, l’histoire de Framaforms fait qu’il était difficile de l’installer sur son serveur, le paramétrer, etc. Mais grâce à plus d’un an de travail d’un membre de Framasoft, ces problèmes appartiennent désormais au passé !
En effet, nous avons donné un sacré coup de jeune au code de ce logiciel, ainsi qu’un nouveau nom : Yakforms ! Notre objectif est de montrer que c’est un outil demandé, facile à installer, pratique à utiliser. Notre espoir est qu’une communauté se rassemble autour de ce logiciel et s’empare du maintien du code et de la direction à lui donner.
En effet, à Framasoft, nous n’aurons pas les épaules ni l’énergie de poursuivre le maintien de ce logiciel. Alors si cela vous intéresse de prendre le lead du développement (ou juste de découvrir le logiciel !), toutes les informations utiles sont sur le site de Yakforms.
Framasoft héberge 16 services en ligne utilisés par plus d’un million de personnes chaque mois. Les logiciels qui font marcher ces services ne sont pas développés par notre petite association, mais par des communautés formidables. Cependant, il nous arrive de contribuer au travail de ces communautés, notamment grâce aux retours des bénéficiaires de nos services.
Ainsi, les membres de notre association qui développent ont par exemple trouvé des astuces pour améliorer les performances d’Etherpad (le logiciel derrière Framapad) qu’ils ont fait remonter à la communauté. De même Mobilizon est un logiciel qui possède de nombreuses dépendances auxquelles nous avons aussi contribué, en particulier dans l’écosystème Elixir !
Nextcloud est le logiciel qui nous permet de proposer Framadrive (stockage et synchronisation de fichiers) et Framagenda (agendas, contacts, todo lists…). Nous avons apporté notre pierre au code du logiciel principal pour améliorer des points mineurs, en particulier sur l’agenda, que nous maîtrisons tout particulièrement.
Framadate (notre alternative à Doodle) est un cas à part. Car même si nous assumons le fait que nous ne maintenons plus le développement de ce logiciel, il a quand même reçu 5 nouvelles versions en 2021. En revanche, nous avons passé beaucoup de temps en réunion avec la DINUM, qui est en train de réécrire le code (lequel commençait à marquer son âge, hein ^^). L’objectif de cette institution de l’État est de contribuer au Libre en offrant un logiciel qui ferait au moins aussi bien que le Framadate actuel, et même mieux (utilisable depuis un mobile, parcours clarifié et simplifié, etc.).
Voilà qui conclut le focus de cette semaine. Vous pourrez retrouver tous les articles de cette série en cliquant sur ce lien.
Sur la page Soutenir Framasoft, vous pourrez découvrir un magnifique jeu de cartes représentant tout ce que Framasoft a fait ces derniers mois. Vous pourrez ainsi donner des couleurs à l’ensemble des activités que vous financez lorsque vous nous faites un don. Nous espérons que ces beaux visuels (merci à David Revoy !) vous donneront envie de partager la page Soutenir Framasoft tout autour de vous !
En effet, le budget de Framasoft est financé quasi-intégralement par vos dons (pour rappel, un don à Framasoft de 100 € ne vous coûtera que 34 € après défiscalisation). Comme chaque année, si ce que nous faisons vous plaît et si vous le pouvez, merci de soutenir Framasoft.
Frama c’est aussi des contributions dans un archipel
L’archipélisation de Framasoft prend de nombreuses formes : participer à des collectifs, travailler en partenariat, s’intégrer à des réseaux… Nous expérimentons, de manière quasi-organique, diverses manières de rencontrer, partager et de contribuer avec d’autres communautés.
« Frama, c’est pas que… »
Pour l’automne 2021, chaque semaine, nous voulons vous faire découvrir un nouveau pan des actions menées par Framasoft. Ces actions étant financées par vos dons (défiscalisables à 66 %), vous pouvez en trouver un résumé complet, sous forme de cartes à découvrir et à cliquer, sur le site Soutenir Framasoft.
Il y a deux ans, nous expliquions ce que nous entendons par le terme d’archipélisation :
Nous concevons aujourd’hui Framasoft comme une île au sein d’un archipel. Tisser des ponts vers d’autres îles où d’autres que nous font d’autres choses, ne signifie pas qu’on y plante notre drapeau (ni qu’on se laisse imposer le leur).
Deux ans plus tard, il est temps d’un bilan sur ces relations et échanges que l’on fait de manière organique, en respectant l’indépendance de chacun·e.
Manifeste
Framasoft a changé. C’était prévu, et même souhaitable. Il est plutôt sain de voir que l’on apprend, et que l’on évolue lorsque l’on va à la rencontre de publics variés, lorsque l’on explore nos relations avec celles et ceux qui font la société de contribution et lorsque l’on constate quotidiennement la toxicité du capitalisme de surveillance.
Le problème quand on change, c’est que tout le monde ne s’en rend pas forcément compte. Nous travaillons donc activement à produire un « manifeste de Framasoft », pour mieux expliquer qui nous sommes, nos valeurs… mais surtout notre rapport au monde et comment nous essayons de le changer (parce que le Libre et les Communs, pour nous, c’est politique !).
« L.A. Coalition – Libertés Associatives » est un collectif d’associations nationales qui s’est donné pour mission de proposer des stratégies de riposte contre les répressions subies par le secteur associatif.
Ce sont des associations qui travaillent sur des sujets parfois très complexes, faisant souvent l’objet de controverses dans la presse, dont nous ne maîtrisons pas le quart de la moitié des enjeux, et avec qui nous serions bien en peine d’être totalement d’accord sur tout. Pourtant, nous partageons ensemble ce besoin de libertés et ce constat du rétrécissement de la capacité d’action de la société civile.
C’est pour cela que Framasoft est membre fondateur de ce collectif, comme nous en parlions dans notre article blog de 2019. Nous participons à différents groupes de travail, et participons à différentes actions et réflexions, comme celles portées par « L’Observatoire des libertés associatives », qui après avoir publié un premier rapport « Une citoyenneté réprimée » en 2020, et organisé un colloque « Démocraties sous pression » publiera bientôt une enquête sur la répression des associations dites « séparatistes ». À cela s’ajoute un rôle d’accompagnement des membres de L.A. Coalition dans leurs usages numériques pour que leurs outils correspondent à leurs valeurs.
Pytition fait partie de ces projets qui ont tourné au ralenti, pour cause d’humain·es fatigué·es, de pandémie, et de vies avec lesquelles il faut jongler avant de concevoir, créer, et donc coder.
Pour autant, cet outil libre pour lancer des pétitions en ligne n’est pas au point mort. Développé par des membres de l’association Résistance à l’Agression Publicitaire, ce logiciel a bénéficié cette année d’un accompagnement en design que nous avons financé afin de concevoir un outil plus proche des besoins de personnes qui veulent se passer d’Avaaz ou de Change.org, ainsi que de nombreuses contributions en traductions, en code, etc.
En effet une petite communauté est en train de se créer autour du code de Pytition, qui a été régulièrement amélioré depuis fin 2019, lorsque nous annoncions que c’est cet outil qui remplacerait Framapétitions. Pytition nous prouve que la route est parfois plus longue, lorsque l’on prend soin des humains… et finalement, c’est probablement mieux ainsi !
Initiés par des membres de Framasoft il y a plus de deux ans, les Contribateliers ont bien grandi et ont même quitté le giron de notre association ! Alors bien entendu, une belle partie de nos membres continuent d’y participer, mais c’est tout simplement parce qu’on aime ça !
En effet, ce collectif informel organise régulièrement, et dans de nombreuses communes de France, ces ateliers auto-gérés où l’on vous propose de contribuer au Libre et aux Communs, même (et surtout !) si vous ne savez pas coder.
Découverte et ressenti d’un logiciel libre, traductions et transcriptions, contributions à l’encyclopédie Wikipédia, au projet Common Voice de Mozilla, à l’univers fantastique de Khaganat ou aux cartes libres d’Open Street Map : les programmes des contribateliers sont aussi divers que les personnes qui décident de les animer. Depuis le premier confinement, il existe même une version en ligne : les Confinateliers.
Si le collectif est bien indépendant de Framasoft (ce serait triste que ces ateliers se limitent à notre association !), c’est avec fierté que nous lui fournissons hébergement, nom de domaine, et outils numériques… bref que nous contribuons aux contribateliers !
Le Collectif des Hébergeurs Alternatifs Transparents, Ouverts, Neutres et Solidaires (les CHATONS, quoi !) a été très actif, ces derniers mois ! Ainsi, durant le premier confinement, la Solidarité (le « S » de l’acronyme) a pris tout son sens. Un grand nombre de membres du collectif ont proposés leurs services, que nous avons pu mettre en commun lorsque la demande était gigantesque.
D’ailleurs, c’est ainsi qu’est né le site entraide.chatons.org qui, aujourd’hui encore, propose neuf services libres, sans création de compte et sans pistage, pour vous donner des outils numériques décentralisés sans avoir à y penser.
C’est sur le forum que l’on voit le mieux le dynamisme du collectif. D’ailleurs, si la nouvelle portée (les candidatures à rejoindre le collectif) est validée, la centaine de membres devrait être dépassée avant la fin de l’année.
C’est principalement en termes d’animation que Framasoft contribue à CHATONS : préparer les réunions audio mensuelles, organiser le Camp CHATONS de septembre 2021… Cependant, Framasoft ne reste qu’un membre parmi — bientôt — cent, et notre objectif reste l’autonomisation de ce collectif, qui devrait y travailler dans les prochains mois.
Bénévalibre est un outil permettant aux associations de comptabiliser les heures données par leurs bénévoles, ce qui ensuite peut ouvrir droit à de la formation, etc. Nous l’exprimions dès le départ : nous sommes de plus en plus méfiant·es envers cette société qui veut tout comptabiliser, tout déclarer, tout enregistrer, même le temps donné librement.
C’est justement pour cela qu’il fallait un logiciel libre : on ne va pas confier de telles collectes de données aux logiciels propriétaires de la Startup Nation, non plus ! C’est en tous cas ce qui nous a incités à rejoindre le comité de pilotage du projet aux côtés des ami·es de l’April (et leur groupe Libre Association), avec la Société Coopérative d’Intérêt Collectif CLISS XXI et le Crajep Bourgogne Franche Comté.
Depuis, Bénévalibre a bien grandi : le projet a été présenté dans de nombreux contextes, plus de 1 000 associations se sont créé un compte sur https://app.benevalibre.org/association, et nous avons co-financé (avec le Fond de Développement de la Vie Associative) de nouveaux développements que CLISS XXI est en train de mettre en œuvre.
En 2019, nous avons demandé à La Dérivation de recenser les personnes, structures et organisations réalisant des accompagnements au numérique libre. Ainsi, nous avons pu publier leurs coordonnées dans un annuaire pour celles qui le désirent.
Cet annuaire a mis près d’un an à être réalisé. Alors en effet, c’était un travail nouveau de trouver comment rassembler, organiser et présenter ces informations. Mais il faut surtout dire que la pandémie est passée par là, qu’il était difficile pour chacun·e de tout faire, et que ce n’était pas pertinent de publier un annuaire d’accompagnateur·ices au moment où la France était confinée, ou sous couvre-feu.
Ce genre d’annuaire est forcément incomplet et obsolète à peine publié : les informations changent, les personnes évoluent, d’autres n’ont pas vu passer l’appel à s’y inscrire, etc. Dans l’idéal, c’est le genre de projet qu’il faudrait tenir à jour et étoffer chaque année. À Framasoft, nous n’avons pas les énergies d’assurer le maintien de ce projet.
Cependant, nous espérons que d’autres s’inspireront de ce travail, n’hésiteront pas à contacter la Dérivation et sauront prendre le relais. Car nous constatons régulièrement combien cet annuaire est utile : les demandes d’accompagnement au numérique libre sont toujours aussi nombreuses, et cet outil a été très téléchargé et partagé… or il est libre : n’hésitez donc pas à vous en emparer !
Parmi les bulles de filtres numériques et sociales où Framasoft évolue, notre association a la privilège d’avoir acquis une petite réputation et une certaine visibilité (mais restons modestes, tout est relatif, hein !). C’est donc tout naturellement que nous essayons de soutenir et de contribuer à des initiatives que nous croisons dans notre archipel : pour nous, les ressources ne se cumulent pas, elles se partagent.
Ainsi, nous partageons du temps et de l’expérience avec les ami·es d’Exodus Privacy ou Réseau Infoclimat. Nous relayons et soutenons des collectifs comme Faire École Ensemble ou InterHOP. Nous offrons de hébergement et parfois de l’administration d’outils numériques aux journalistes de DataGueule comme au collectif de Contribulle, l’outil pour trouver où contribuer.
Il nous arrive aussi de faire des dons, comme par exemple à l’équipe de développement de Thunderbird ou à l’événement Entrée Libre. Enfin, nous essayons aussi de mettre en valeur des initiatives culturelles qui libèrent les esprits, par exemple en animant des ciné-débats autour du documentaire La Bataille du Libre, ou autour de certains livres publiés chez C&F éditions qui touchent à des sujets dont nous sommes proches.
Cette petite liste ne pourra jamais être complète, car elle ne cesse d’évoluer, parce que les relations évoluent. Cependant, nous allons essayer de présenter la diversité de nos partenariats sur cette page, en cours de construction, même si elle ne peut être qu’un instantané dont le cadre est trop serré ;).
Voilà qui conclut le focus de cette semaine. Vous pourrez retrouver tous les articles de cette série en cliquant sur ce lien.
Sur la page Soutenir Framasoft, vous pourrez découvrir un magnifique jeu de cartes représentant tout ce que Framasoft a fait ces derniers mois. Vous pourrez ainsi donner des couleurs à l’ensemble des activités que vous financez lorsque vous nous faites un don. Nous espérons que ces beaux visuels (merci à David Revoy !) vous donneront envie de partager la page Soutenir Framasoft tout autour de vous !
En effet, le budget de Framasoft est financé quasi-intégralement par vos dons (pour rappel, un don à Framasoft de 100 € ne vous coûtera que 34 € après défiscalisation). Comme chaque année, si ce que nous faisons vous plaît et si vous le pouvez, merci de soutenir Framasoft.
Nous avons interviewé l’équipe d’Electronic Tales après avoir découvert leur approche accueillant « les développeurs·euses juniors qui n’ont pas suivi un cursus d’ingénieur, ne démontent pas des ordinateurs tous les week-ends et n’ont pas commencé à coder à 5 ans » sur une plateforme « fabriquée avec amour par des devs féministes, queers, inclusifs·ves et autres personnes fucking bienveillant·e·s »
(En plus iels parlent de beurre demi-sel donc forcément, on s’est dit qu’on avait des points communs !)
– Bonjour les histoires électroniques, pouvez-vous vous présenter pour expliquer comment est née votre initiative ?
Bonjour ! À l’origine du projet, on est quatre :
– Officier Azarov (pronoms il/elle) : je suis dev depuis 2017. Dès mes premiers mois dans ce milieu professionnel, j’ai senti deux courants contraires – d’un côté, une vraie soif d’apprendre toujours plus dans le domaine de la programmation, et, de l’autre, la découverte d’un milieu extrêmement dominé par des hommes blancs hétéro cisgenre de 25-35 ans, et une culture beaucoup moins inclusive que ce à quoi je m’attendais. J’ai ensuite travaillé comme formatrice dans un bootcamp, et là encore j’ai été étonnée de voir la vitesse à laquelle des mécanismes d’exclusion se mettaient en place chez les étudiant·e·s. Du coup j’ai eu envie de changer les choses. À terme, le but d’Electronic Tales est d’aider les minorités de la tech (femmes, queers, personnes racisées, personnes handicapées, seniors..), souvent issues de formations courtes ou autodidactes, à combler le gap technique et culturel avec les développeurs·euses ayant suivi des parcours classiques (école d’ingénieur). Au-delà de ce public, beaucoup de juniors en général se reconnaissent dans nos valeurs – et aussi des seniors qui veulent que leur domaine change !
Partenko (pronom il/elle) : je ne viens pas du milieu du dev mais de celui de la tech dite « hardware », et encore avant, j’étais prof des écoles. J’avais un truc en tête au moment de changer de métier : je voulais réparer des trucs et interagir avec des machines. C’est comme ça que je suis tombée dans les entrailles secrètes des ordinateurs et que j’ai commencé à m’intéresser à l’histoire de l’informatique, côté Hardware de la force. Regarder à l’intérieur des ordinateurs me permet de mieux comprendre comment ils fonctionnent. Mon but est de partager ces connaissances avec les personnes qui utilisent ces machines au quotidien afin de les aider à acquérir une culture hardware, ce qui pour nous fait partie intégrante de ce que nous avons appelé la « Computer Culture ». Comme le dit Officier Azarov, le gap technique entre personnes issues d’école d’ingénieur et étudiant·e·s issues de formation courte créé trop souvent des situations de détresse professionnelle pour les juniors qui ne sont pas né·e·s avec un ordinateur dans les mains et/ou un papa ingénieur. Je veux aider les devs juniors à se sentir mieux professionnellement dans un milieu où l’on juge très vite le manque de connaissances comme un manque de compétences.
– Monday Hazard (pronom elle) : Je suis une dev nouvellement arrivée dans le métier suite à une reconversion vaguement improbable entamée un peu avant le confinement (si, si, je vous jure, c’était en 2019). Je suis fascinée par les enjeux socio-culturels qui se nouent dans la tech et convaincue que la question de l’inclusion y est cruciale. C’est toujours la joie de partager avec l’immense communauté de personnes qui vivent les mêmes questionnements et qui les gardent frais dans leur façon d’apprendre, de travailler et de partager les savoirs 🌈
– Le Crampon (pronom il) : Né en 1993 suite à un accident de VTT, je suis un développeur détenteur d’un DUT informatique mais avec un sérieux syndrome de l’imposteur. Actuellement en reconversion en tant que développeur jeux-vidéo en alternance, je tente de combattre ma Nemesis, à savoir la culture des « Petit.e.s Génies du Code qui sont capables de coder un compilateur dès l’âge de 6 ans », qui a tendance à me faire me sentir peu légitime. Et je suis prêt à parier que je ne suis pas le.la seul.e.
– Vous êtes en train d’élaborer un cursus de formation pour celleux qui ne sont pas tombés dans la marmite numérique dès le plus jeune âge avec des séquences qui démultiplient les supports d’apprentissage, avec l’idée de rendre la culture geek accessible au plus grand nombre. C’est une super et noble ambition et on vous souhaite de monter en puissance, mais qu’est-ce qui manque aux autres propositions de formation déjà existantes que vous apportez avec E.Tales ?
Les formations courtes qui ont fleuri ces dernières années favorisent l’entrée de nouveaux profils dans la Tech. Certaines ciblent même très bien les groupes sous-représentés dans le dev (Simplon, Ada, DesCodeuses…). Toutes ces initiatives sont formidables, mais elles ne sont que le début de la solution. La question qui nous hante, c’est : une fois que ces minorités ont accédé à un poste de dev, comment les aider à rester dans ce milieu (par exemple, les femmes ont significativement plus de risques d’abandonner leur carrière technique que leurs homologues masculins) et à gravir les échelons jusqu’à des positions de leadership ?
À côté des formations courtes, il existe aussi quelques passerelles vers des diplômes universitaires (licences, master) ou des cursus d’ingénieur. Mais ces formations sont pour la plupart onéreuses, nécessitent d’étudier à temps plein (et donc de quitter son travail) ou manquent cruellement d’attractivité en termes de pédagogie.
L’ambition d’Electronic Tales est de proposer des contenus d’aussi bon niveau que ces formations spécialisées, mais avec en plus un soin particulier apporté à l’expérience d’apprentissage et un plus grand lien avec les technologies modernes.
Pour l’instant, nous sommes en train de constituer une communauté et des contenus participatifs sur notre plateforme, mais nous visons à terme la création d’un cursus d’excellence structuré et reconnu dans le milieu de la Tech.
– Vous souhaitez construire un « safe space » pour les personnes qui participeront. Pouvez-vous expliquer pourquoi cela vous semble nécessaire ?
Le monde du développement, en entreprise mais aussi dans la sphère des « passionné·e·s », peut être très difficile à vivre lorsqu’on débute. Cette difficulté est encore augmentée lorsqu’on est la seule femme et/ou la seule personne queer/racisée/handicapée/de plus de 40 ans/etc. Et souvent, quand on fait partie d’une minorité et qu’on essaie de parler de ses problèmes, on se heurte à une forme d’incompréhension, voire d’hostilité, de la part de ses collègues.
Notre idée, c’est d’annoncer la couleur tout de suite : que ce soit sur la plateforme ou sur le Slack, les gens qui viennent savent qu’ils entrent dans un espace féministe queer inclusif. Si cela ne leur plaît pas, ils peuvent aller dans d’autres communautés 🙂 On aide aussi les membres de la communauté à communiquer entre eux·elles de façon bienveillante et inclusive – ce n’est pas toujours évident, par exemple quand on veut faire des blagues de dev (promis, nous aussi on les adore) ou qu’on a une question très pointue ! Mais on essaie d’inventer une nouvelle « grammaire » de communication technique à inventer pour inclure davantage.
– Vous écrivez : « notre team est en train de concocter une plateforme de learning social. »
euh c’est quoi au juste, le learning social ?
Le learning social, c’est le fait de casser les dynamiques classiques de sachant·e/apprenant·e telles qu’on a pu en vivre à l’école. On veut encourager les juniors à créer des contenus pour expliquer des choses techniques, pour les aider à prendre confiance en leurs capacités et à déconstruire l’idée qu’il faudrait avoir 10 ans d’expérience pour commencer à partager ses connaissances. (Par ailleurs, un.e junior est parfois plus à même d’expliquer une chose technique à d’autres juniors qu’une personne qui a oublié combien les choses ne coulent pas de sens quand on débute) Donc, concrètement, l’équipe d’Electronic Tales crée bien sûr des contenus pour la plateforme, mais tout le monde peut participer.
– Votre proposition s’adresse essentiellement à des devs juniors, est-ce qu’il y a une limite d’âge ?
Non ! Tout le monde est le·la bienvenu·e ! Et il y a même des devs seniors dans notre communauté – des gens formidables et très motivés pour aider les juniors 💪
– Est-ce qu’il y a un prérequis, un niveau minimum de connaissances ou de pratiques pour se joindre à vous, participer et bénéficier de cette initiative ?
Tout dépend du type de contenus. Dans notre section « Modern World », qui parle surtout de programmation, nos contenus s’adressent plutôt à des personnes qui codent déjà un peu – même si on fait attention à toujours s’appuyer sur le minimum de pré-requis possibles.
Pour les contenus des sections « Imaginarium » (qui s’intéresse aux aspects culturels de la Tech, comme les comics, la science fiction, pourquoi les hackers tapent aussi vite sur leurs claviers dans les films, et ainsi de suite) et « Ancient World » (qui parlera plutôt de hardware et de réseau), il n’y a pas de pré-requis à avoir.
– Est-ce qu’il vous arrive d’organiser des moments de rencontre pour les personnes intéressées par le projet ?
On a deux grands événements cet automne :
Les soirées CS50 and chill, où on se retrouve en ligne pour regarder ensemble la célèbre intro à la computer science de Harvard. On communique par chat, pour échapper à la fatigue de la visio. C’est fabuleux et très apprécié par celles·ceux qui nous rejoignent 🙂 Ça a lieu deux fois par mois.
On va commencer un cycle « Hacke les entretiens techniques » en novembre. On va notamment avoir un dev senior d’une GAFA qui fera passer des entretiens fictifs. On va aussi beaucoup déconstruire cet exercice, aussi bien techniquement (pour aider les gens à se préparer) que mentalement (pour aider les gens à relativiser).
– Votre travail pour cette initiative est bénévole ? Comment couvrez-vous les frais de la plateforme ? Envisagez-vous un financement participatif, autre chose ? Les personnes inscrites devront-elles contribuer financièrement ?
Oui, toute l’équipe est bénévole. Pour le moment on finance les frais d’hébergement de notre poche (heureusement, ce n’est pas trop onéreux). Mais comme on espère qu’Electronic Tales va prendre de l’ampleur, notamment grâce à notre projet de cursus d’excellence pour les minorités de la Tech, il est certain qu’il faudra qu’on cherche (et qu’on trouve) des financements – ne serait-ce que pour que l’équipe puisse dégager du temps de travail pour le projet. On a déjà une petite idée pour ça : développer une activité de consulting pour accompagner les entreprises qui souhaiteraient accueillir des juniors dans leurs équipes.
Ce qui est sûr, en tout cas, c’est qu’on tient coûte que coûte à ce que le projet reste open-source et gratuit.
– Fermez les yeux, respirez lentement, et Imaginez que tout se passe hyper bien et que la plateforme rencontre un grand succès (on vous le souhaite !). Selon vous, qu’est-ce qui aura changé à l’issue de cette expérience ? Et envisagez-vous d’autres actions par la suite, pour aller plus loin ?
Concrètement, si on réussit à créer un cursus qui s’adresse plus particulièrement aux groupes sous représentés mais qui est tellement qualitatif qu’il est reconnu sur le marché du travail, alors on aura réussi à changer quelque chose dans le monde de la tech. Nous faisons l’hypothèse que réduire le gap technique et culturel favorisera le sentiment de légitimité des personnes appartenant aux groupes sous-représentés dans la tech. Si tout se passe pour le mieux, celles-ci poursuivront leurs carrières techniques avec plus de succès, devenant in fine les seniors et des décideurs·euses divers·es dont la tech manque cruellement aujourd’hui. Et nous, si on y arrive, on sera épuisé·e·s mais ravi·e·s, comme disait Aznavour (💗).
Des guides, des cartes à jouer, de la documentation et même un MOOC… La médiation au numérique éthique peut passer par de nombreux outils ! Nous réalisons certains d’entre eux et y contribuons, en espérant qu’ils vous servent.
« Frama, c’est pas que… »
Pour l’automne 2021, chaque semaine, nous voulons vous faire découvrir un nouveau pan des actions menées par Framasoft. Ces actions étant financées par vos dons (défiscalisables à 66 %), vous pouvez en trouver un résumé complet, sous forme de cartes à découvrir et à cliquer, sur le site Soutenir Framasoft.
Nous avons eu la chance, à Framasoft, de pouvoir prendre le temps d’apprendre les mécanismes du Web, de documenter le système du capitalisme de surveillance dont les GAFAM sont un des symptômes, et d’expérimenter d’autres manières d’utiliser le numérique dans nos vies.
Partager cette compréhension, ce savoir et cette expérience est important car cela peut aider d’autres personnes à s’émanciper dans leurs usages numériques. Pourtant, transmettre tout cela est une chose complexe. Tout le monde n’a pas les mêmes attentes, les mêmes appétits, les mêmes façons de recevoir ce que nous avons à partager. Voilà pourquoi nous contribuons à et réalisons divers outils de médiation, qui correspondent à divers publics.
MOOC CHATONS
C’est quand même bien dommage de sortir un MOOC un mois avant le premier confinement d’une pandémie qui allait nous submerger ! Pourtant ce cours en ligne massivement ouvert se parcourt en autonomie, sans accompagnement de notre part. Il a déjà séduit 1 050 apprenant⋅es.
Il faut dire que le premier parcours de ce MOOC, « Internet : pourquoi et comment reprendre le contrôle ? », est un condensé de ce que nous avons appris ces dernières années. Riche de nombreuses vidéos, ressources et références, il peut s’adresser à toute personne, sans connaissance technique particulière.
Ce MOOC permet vraiment de comprendre le fonctionnement d’Internet et du Web, d’appréhender la montée en puissance des GAFAM, géants du web, jusqu’à l’avènement du capitalisme de surveillance, pour mieux cerner enfin en quoi le libre, la décentralisation et les communs sont des pistes fiables pour reprendre le contrôle du numérique dans nos vies.
Comment accompagner les organisations de l’Économie Sociale et Solidaire (ESS) qui souhaitent être fidèles à leurs valeurs dans leurs pratiques numériques ? Notre réponse passe forcément par le Libre, la décentralisation et donc l’adoption sereine et réfléchie d’outils pensés avec une forte éthique.
L’avantage de ce guide (déjà traduit en italien !), c’est que ses contenus eux aussi sont libres. Imaginez, il a servi à votre association, votre coopérative, mais il vous manquait une information, un outil essentiel que vous avez trouvé par ailleurs : vous pouvez ajouter cette trouvaille à ce guide et la partager avec les prochaines personnes qui le consulteront. Que vous utilisez le site web, le document pdf ou la version papier, vous aussi, soyez [RÉSOLU] !
Nous vous en parlions il y a plus d’un an dans les Carnets de Contributopia… et après plus d’un an de travail (avec des parenthèses dues à une certaine pandémie, bien entendu), ça y est, les Métacartes Numérique Éthique sont enfin disponibles.
Le concept des Métacartes, c’est d’augmenter la réalité d’un jeu de cartes papier (avec titre, illustration, symboles, texte court). Car chaque carte dispose aussi d’un QR code et d’un lien qui mène vers une page web où on détaille ce qu’illustre la carte. Voilà un outil concret, agréable, convivial pour partager savoirs, questionnements, expériences !
Mélanie et Lilian ont réalisé un jeu nommé « Numérique Éthique », qui aidera grandement les médiateurs, formatrices et bénévoles du monde du Libre. Ce jeu est composé de trois familles de cartes :
Les #critères permettent de questionner les attentes en éthique et le niveau de confiance que l’on a dans un outil numérique.
Les #usages permettent de découvrir les possibles que le numérique nous offre en termes de collaboration, d’échanges et d’émancipation.
Et les cartes MÉTHODES vous permettront de faire le point sur vos usages, découvrir des alternatives et passer à l’action.
C’est un trait d’humour amer assez révélateur, prononcé par les personnes qui, chez nous, conçoivent et rédigent la documentation :
#LesGens ne lisent pas la doc.
Pourtant, si vous saviez les ressources que l’on met à votre disposition ! Chez Framasoft, nous maintenons :
Une Foire aux Questions sur tout ce que nous proposons et nous sommes, conçue à partir des questions que vous nous posez le plus souvent ;
La documentation générale de nos services, avec des guides pratiques, des exemples simples à comprendre, et des captures d’écrans à foison pour vous aider à mieux utiliser les Frama-services ;
La documentation de PeerTube, très riche en ce qui concerne l’administration d’une instance, mais dans laquelle on veut encore améliorer la partie utilisation ;
La documentation de Mobilizon, pour mieux comprendre comment installer, administrer ou utiliser cette alternative aux événements, pages et groupes Facebook ;
La documentation de Yakforms, le logiciel qui propulse le service de formulaires libres Framaforms, parce que nous espérons que la communauté va s’emparer du code et que des organisations vont l’installer sur leurs serveurs.
Loin de nous l’idée de rejeter les demandes d’aide et de support d’un méprisant « RTFM » (« Read The Fucking Manual », une expression bien peu glorieuse, quand on sait qu’elle se traduit par « lis le foutu mode d’emploi ! »). Cependant, nous avons l’impression de travailler à rédiger et tenir à jour un véritable trésor de connaissances, d’astuces… À vous de voir comment ce trésor peut vous enrichir.
Voilà qui conclut le focus de cette semaine. Vous pourrez retrouver tous les articles de cette série en cliquant sur ce lien.
Sur la page Soutenir Framasoft, vous pourrez découvrir un magnifique jeu de cartes représentant tout ce que Framasoft a fait ces derniers mois. Vous pourrez ainsi donner des couleurs à l’ensemble des activités que vous financez lorsque vous nous faites un don. Nous espérons que ces beaux visuels (merci à David Revoy !) vous donneront envie de partager la page Soutenir Framasoft tout autour de vous !
En effet, le budget de Framasoft est financé quasi-intégralement par vos dons (pour rappel, un don à Framasoft de 100 € ne vous coûtera que 34 € après défiscalisation). Comme chaque année, si ce que nous faisons vous plaît et si vous le pouvez, merci de soutenir Framasoft.
Il est forcément complexe d’évaluer la date anniversaire d’un projet aussi divers que Framasoft. Doit-on retenir la date où le projet a été pensé ? Celle d’une première réunion ? Celle de la première communication publique ?
Comme il nous semblait difficile de choisir, nous avons décidé de ne pas nous limiter, et de fêter plusieurs événements, comme autant d’occasions de célébrer les expériences et les événements qui ont jalonné l’histoire de l’association.
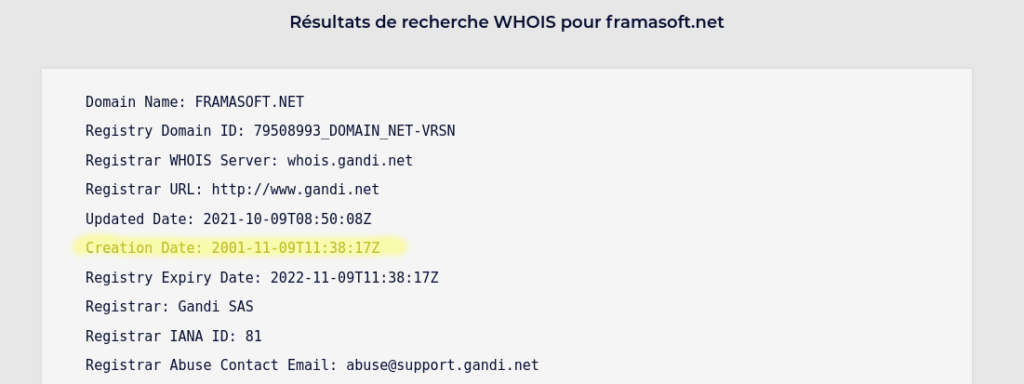
Aujourd’hui, nous fêtons un de ces événements marquants : le dépôt du nom de domaine « Framasoft.net » chez nos partenaires et amis de toujours, Gandi. C’était le 9 novembre 2001. Il y a tout juste 20 ans.
Ce « .net » a précédé l’usage du « .org » déposé – toujours chez Gandi – deux ans plus tard.
Cet épisode de notre histoire est l’occasion de donner la parole à différentes personnes, témoins des évolutions d’un projet toujours très actif.
WHOIS du domaine Framasoft.net, réservé chez Gandi le 09 novembre 2001.
C’est l’histoire d’un nom de domaine
Alexis Kauffmann est la personne à l’origine de Framasoft (en 2001), et l’un des cofondateurs de l’association (fin 2003, début 2004) avec Paul Lunetta et Georges Silva. Après avoir été président de l’association de 2004 à 2011, il fut salarié de Framasoft de septembre 2012 à septembre 2014.
Alexis a arrêté de contribuer à Framasoft en 2014, avant le lancement de la campagne « Dégooglisons Internet ». Mais cela ne l’a pas empêché de poursuivre ses actions en faveur de la promotion du logiciel libre et des communs.
Cet article est donc l’occasion de lui donner la parole.
Bonjour Alexis ! Ta dernière participation à Framasoft, et au Framablog, remonte à il y a maintenant plus de 7 ans. Nous imaginons que cela doit te procurer une certaine émotion, et sans doute même plusieurs. Souhaites-tu les partager ?
Alexis : La peinture a été refaite mais il me semble quand même reconnaitre les lieux.
Framasoft c’est une partie de ma vie et j’en aurai passé du temps dessus avec vous (sûrement trop d’ailleurs). Aujourd’hui est une date anniversaire symbolique qui me fait regarder subrepticement dans le rétroviseur mais ce que je souhaite surtout partager c’est mon admiration et ma reconnaissance pour ce qu’est devenu Framasoft depuis que j’ai passé la main. Le chemin tracé par le collectif des CHATONS en est un exemple emblématique, source de liens et signe d’espoir ce dont on a fortement besoin actuellement. Et plus généralement, il y a cette évolution qui fait sens : un autre ordi est possible, un autre internet est possible, un autre monde est possible.
Et dire que j’ai été à l’origine de tout ça. J’en éprouve une certaine ivresse rien que d’y penser 😉
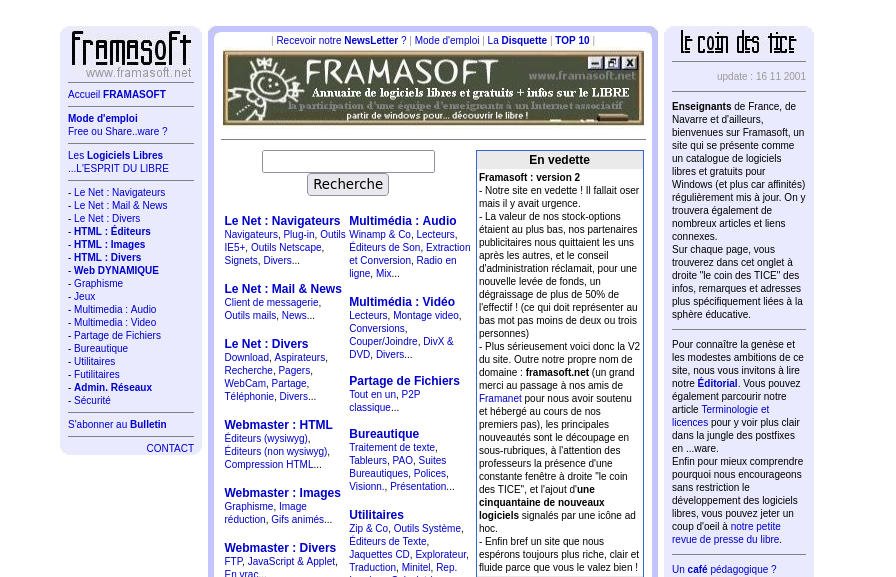
Capture écran de la page d’accueil de Framasoft.net en novembre 2001, telle que présentée sur archive.org
Revenons au dépôt du nom de domaine framasoft.net. Te souviens-tu de l’état d’esprit dans lequel tu étais à ce moment là ? Tu as cliqué sur le bouton « Réserver » sans trop y penser entre deux cafés serrés, ou étais-tu conscient d’être en train d’impulser une aventure qui durerait plusieurs décennies ?
Alexis : C’est surtout qu’il s’en est fallu de peu que Framasoft n’existât pas.
Jeune prof de maths, je travaillais en étroite collaboration avec ma collègue de français Caroline d’Atabekian dans un collège de Seine-Saint-Denis. C’était notre premier poste à tous les deux et ça n’était pas forcément l’endroit le plus facile pour débuter. Il y avait une salle informatique flambant neuve au fond du couloir. Alors nous sommes partis en exploration numérique pédagogique…
Et à chaque fois qu’un logiciel nous semblait utile, je le notais pour ne pas l’oublier sur une discrète page web du site de notre établissement scolaire consacré à notre projet interdisciplinaire « Framanet » (pour FRAnçais et MAthématiques en IntraNET). Et puisqu’il fallait bien lui donner un titre, je l’ai appelée « Framasoft ». Voilà, c’est tout, ça a débuté comme ça comme dirait l’autre.
La page devenant de plus en plus longue, Caroline a commencé à me suggérer, en y revenant à intervalle régulier, que ça méritait peut-être d’en faire un site dédié et que cette distinction libre/pas libre était assez convaincante, a fortiori dans le secteur éducatif.
Un site à part entière ? J’étais dubitatif et en plein syndrome de l’imposteur à vouloir parler du libre sans jamais avoir écrit une seule ligne de code, et à en parler depuis Windows et non GNU/Linux qui plus est !
L’histoire retiendra que plusieurs mois plus tard j’ai fini par céder, le 9 novembre 2001 nous dit le whois de Gandi. Avec le recul, l’initiative n’a pas été si mal accueillie et l’intuition de départ était plutôt bonne : le logiciel libre est plus important que la communauté de celles et ceux qui le créent.
Dans ces années Framasoft de 2001 à 2014, quels ont été les événements les plus marquants dont tu souhaiterais partager le souvenir ?
Alexis : Je suis d’accord avec toi sur la difficulté à dater précisément les débuts de Framasoft.
En amont de la naissance de framasoft.net, il y a eu la lecture, décisive pour moi, de cet article de Jean-Claude Guédon adressé à sa ministre de l’éducation québécoise. Et en aval, je crois que la création du forum a aussi été fondamentale, puisque c’est là que le projet a commencé à prendre son envol collectif. Un total de 268 687 messages mine de rien, à l’époque on s’ennuyait ferme sans les réseaux sociaux. Il y en avait de l’énergie, portée par ces valeurs du libre qui nous réunissaient. De ces nombreux échanges ont émergé de beaux projets collaboratifs mais surtout de belles rencontres. C’est avant tout cela que je retiens.
Parmi ces messages, il y eut un dialogue live en 2006 entre deux députés et les membres du forum autour de la loi DADVSI. On nous avait laissé jouer relativement tranquilles avec notre Internet jusque-là mais le politique avait décidé qu’il était temps de siffler la fin de la récréation, sans forcément tout bien comprendre puisqu’on envisageait par exemple la coupure d’accès au réseau si l’on avait le malheur de confondre partage et piratage. Je me souviens qu’on leur disait que l’offre était rare, dispersée et que s’acquitter d’une sorte de licence globale pour accéder à la culture pouvait être une bonne idée. Aujourd’hui on écoute sa musique sur Spotify et on regarde ses films sur Netflix…
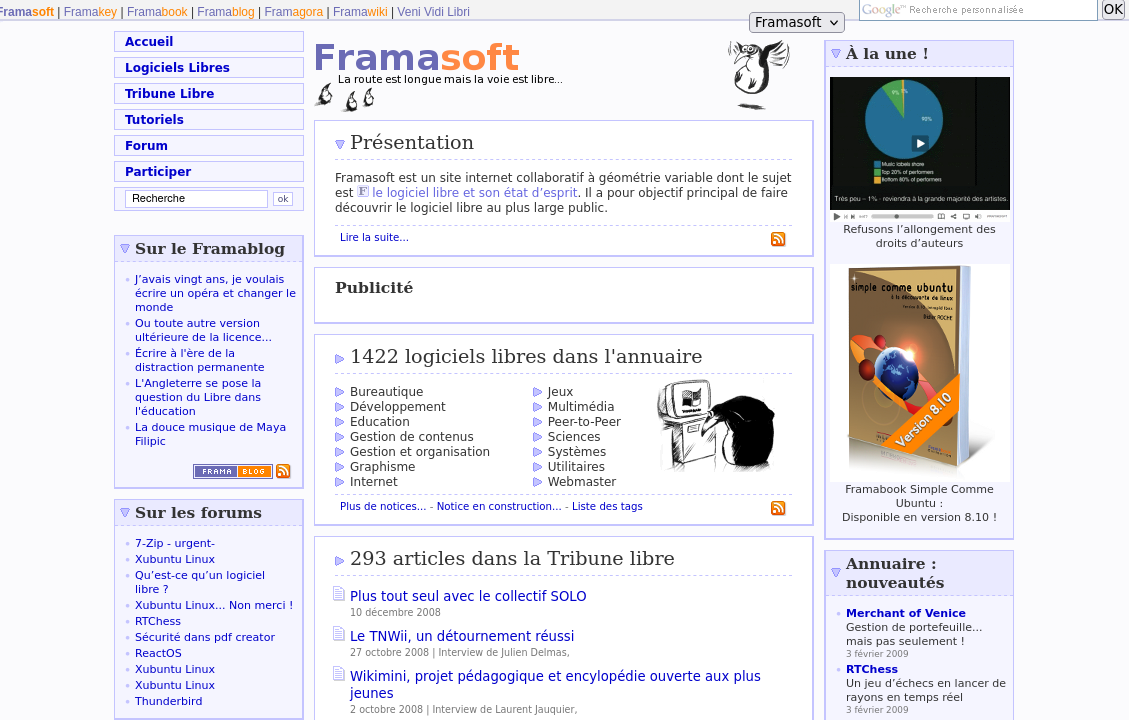
Capture écran de la page d’accueil de Framasoft.net en novembre 2009, telle que présentée sur archive.org
Nous ne sommes pas sans savoir que tu as mis entre parenthèses ta carrière de professeur de mathématiques pour occuper un nouveau poste. Souhaites-tu nous en dire plus sur tes missions et tes ambitions quant à celui-ci ?
Alexis : On a organisé l’année dernière des États généraux du numérique pour l’éducation à l’issue desquels de nombreuses personnes ont émis le souhait de donner une plus large place au libre et aux communs. Non pas le libre pour le libre mais pour ce qu’il est susceptible d’apporter à l’éducation en général et aux élèves en particulier.
On a pensé que je pouvais y participer. Et me voici au ministère depuis la rentrée en tant que chef de projet logiciels et ressources éducatives libres et mixité dans les filières du numérique. Ce poste est déjà une belle avancée en soi mais on va essayer de ne pas s’en contenter 😉
Merci Alexis !
C’est l’histoire d’une évolution du numérique
Donnons maintenant la parole à Pouhiou et Pierre-Yves, codirecteurs de Framasoft.
Pierre-Yves Gosset (« pyg »), membre de l’association depuis 2005, en fut le délégué général puis directeur pendant 12 ans (2008 à 2020). Pouhiou, lui, est membre de Framasoft depuis 2011, puis fut embauché en tant que responsable de la communication de 2015 à 2020. Ils forment aujourd’hui un tandem de choc à la codirection de l’association.
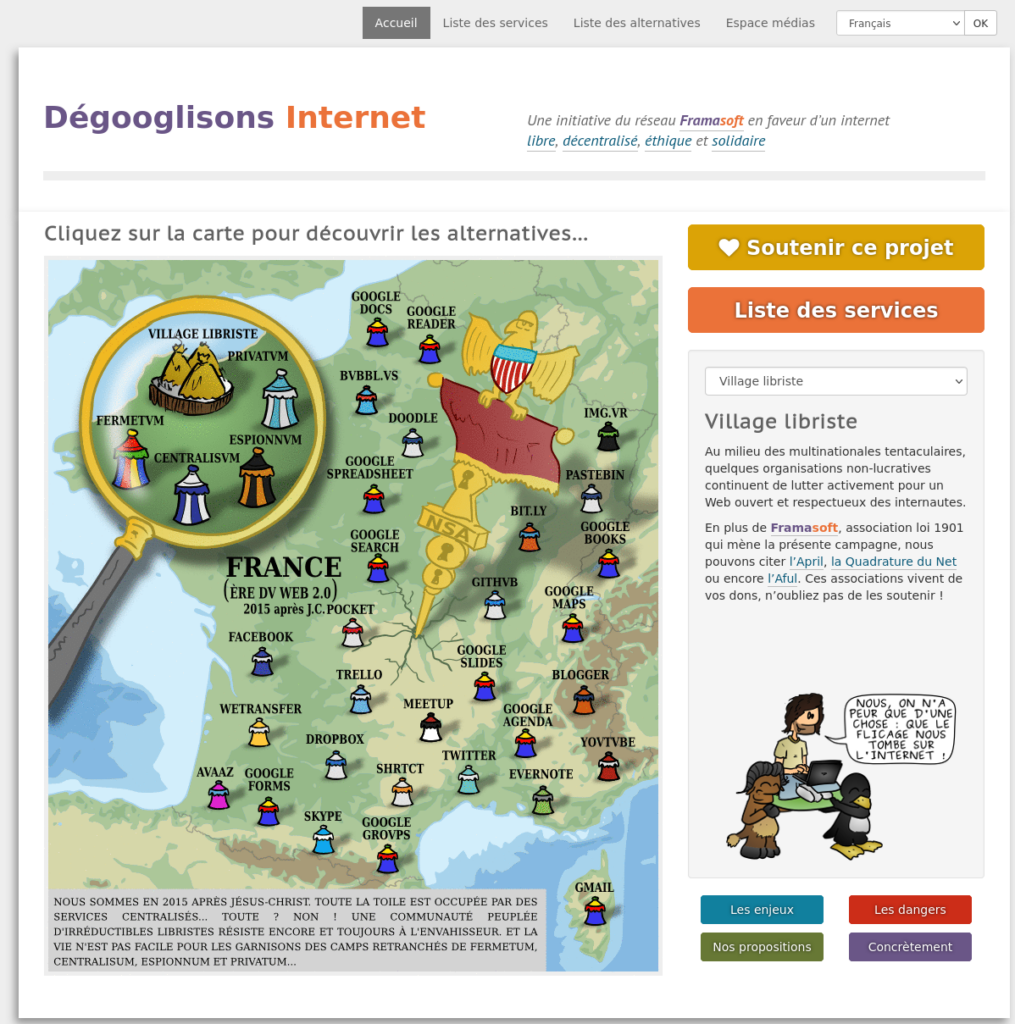
Capture écran de la page d’accueil de la campagne « Dégooglisons Internet » en 2015, telle que présentée sur archive.org
Pouvez-vous nous parler de la campagne « Dégooglisons Internet » et de son impact pour l’association ?
Pierre-Yves : Cette campagne initiée en 2014 a clairement été le virage le plus marquant pris par l’association.
D’abord parce qu’elle a été un succès vis-à-vis de ses objectifs : elle a participé activement à la sensibilisation de la toxicité des GAFAM (via nos conférences, nos interviews, nos analyses, etc) ; elle a démontré que le logiciel libre était une alternative réelle, concrète, disponible aux services des géants du web, et elle nous a permis d’amorcer la constitution du collectif CHATONS.
Ensuite parce qu’elle a accompagné un certain virage politique : nous restons convaincus qu’il ne peut y avoir de société libre sans logiciel libre. Mais la question de la licence logicielle n’a que peu de sens dans un monde où les enjeux sociaux, politiques, économiques, techniques du numérique restent incompris. Ce fut l’occasion pour nous d’affirmer notre volonté d’accompagner, par l’éducation populaire, les acteurs et actrices du changement vers une plus grande autonomie sur ces questions.
Enfin, la visibilité de cette campagne nous a permis (grâce à vos dons !) de construire une équipe salariée solide et efficace, capable d’accueillir plusieurs millions de visiteur⋅euses par an.
La campagne « Contributopia » a pris le relai de « Dégooglisons Internet » à partir de fin 2017. Pourquoi n’avoir pas « tout simplement » poursuivi l’expérience « Dégooglisons » ? Formulé autrement : qu’attendiez-vous de « Contributopia » ?
Pouhiou : Le succès (relatif, hein) de « Dégooglisons Internet » a été aussi intense et riche d’enseignements sur nos limites, nos impensés, nos imprécisions. Dit moins poliment, ça nous a mis le nez dans notre caca !
D’une part, il était urgent de ralentir. En trois ans, nous avons ouvert trente services. Je me souviens de pyg raillant son embonpoint « Ben oui : 30 services, 30 kilos ! ». La vanne est drôle, mais pour les avoir pris aussi, ces kilos de stress et d’excitation, c’est quand même hyper violent que cela marque ainsi des corps ! Il nous fallait se sortir de cette vision guerrière, de (re-)conquête, de se battre sur le terrain de Google & co.
C’est une des leçons importantes qu’on a appliquées à Contributopia. Non seulement on ne peut pas s’adresser à tout le monde, mais on ne le veut même pas ! Ouvrir des services pour « les gens », ça ne marche pas, parce que #LesGens n’existe pas.
À force d’expliquer la toxicité des géants du web de mille manières différentes, nous avons réalisé que le problème ce n’est pas le logiciel propriétaire, ni la propriété intellectuelle, ni les GAFAM, ni l’Ubérisation. Le problème est systémique, et le système qui engendre ces acteurs et que ces entreprises perpétuent dans nos sociétés s’appelle le Capitalisme de Surveillance.
Car ces entreprises ont un idéal : celui d’un monde où tous les comportements sont captés, et où les consommations sont prédictibles, influençables et pléthoriques. Face à cela, quel est notre monde idéal à nous, qui le partage, et comment on se rencontre pour bidouiller tout ça ?
C’est pour cela que nous avons eu l’envie d’explorer nos utopies. Avec une conviction, une leçon que nous avons tirée des rencontres autour de Dégooglisons, c’est que d’autres partagent nos valeurs, et que ces personnes font partie des milieux associatifs, éducatifs, militants… Bref, des personnes de la « société de contribution » qui partagent les valeurs du Libre mais dans des domaines parfois pas du tout liés au numérique.
Aller à la rencontre de personnes hors de notre sphère libriste, c’est un exercice d’humilité. On n’y va pas pour enseigner, en imposant son savoir de manière verticale. Mais plus pour partager, échanger, et accepter de se voir changer en retour.
De même, nous avons essayé de travailler le logiciel libre autrement. Par exemple en sortant des sentiers battus par Google, et en concevant un PeerTube qui permet de diffuser de la vidéo sans capter les attentions, sans les monétiser, sans chercher à imposer du contenu à coups d’algorithmes.
Nous avons aussi travaillé avec des designers et graphistes dès la conception de Mobilizon. Cela nous a permis de façonner cette alternative aux événements, pages et groupes Facebook directement selon les besoins des groupes militants qui n’avaient pas d’autres endroits pour organiser leurs marches pour le climat ou permanences associatives.
Bref, Contributopia, c’était notre manière à nous de dire que si on se lance dans un Dégooglisons², le retour de la vengeance à la puissance du carré, on va droit dans le mur de la startup nation. Alors, même si on ne sait pas exactement où on va, allons explorer des utopies qui nous permettent de voir comment on peut concrétiser nos valeurs dans des outils numériques.
Quels bilans tirez-vous de cette période ?
Pyghiou : Nous avons beaucoup appris. Sur nous-mêmes, en tant que personnes et en tant que collectif associatif. Mais aussi sur le monde qui nous entoure et les règles qui le régissent, et dont beaucoup ne nous conviennent pas ou plus.
Nous avons aussi pu explorer ce qui constitue aujourd’hui un certain nombre de caractéristiques de Framasoft : la transparence, le désir de « prendre soin des humain⋅es», la dimension d’expérimentation et de prototypage de nos actions, l’acceptation des échecs qui en découlent, un certain « refus de parvenir », la volonté d’archipéliser nos relations et de travailler notre propre compostabilité.
Les routes furent multiples, certaines furent longues, mais nous avons su rester libres.
C’est une histoire qu’il nous reste encore à écrire
Pour envisager l’exercice (difficile) de la projection à 10 ans, nous avons sollicité l’avis des membres de l’association. Hommes ou femmes, jeunes ou moins jeunes, ces personnes partagent un intérêt pour le collectif, les communs, les expérimentations sociales et techniques, le « faire » et le « prendre soin ». Leurs espoirs et leurs convictions militantes portent chaque projet, chaque acte posé par Framasoft.
Bonjour, membres de Framasoft ! L’exercice de l’auto-interview en mode « boule de cristal » n’est pas simple, mais pour celles et ceux qui souhaiteraient s’exprimer sur le sujet : comment imaginez-vous l’avenir de Framasoft pour les 10 prochaines années ?
kinou : le nouveau projet est la framamaison où des amis viennent pour parler, manger et se retrouver. Une île loin de la fureur extérieure, mais pas déconnectée. Juste un endroit où reprendre des forces pour essayer de construire ensemble.
Marien : Framasoft n’est plus, vive Framasoft ! L’association s’est mise d’accord : nous venons de voter sa dissolution. Rassurez-vous, tout va bien : le vote a été unanime — une fois de plus ! Elle sera bientôt remplacée par une myriade d’autres structures, avec des idées et des projets toujours plus utopiques et farfelus. Tout ce petit monde bénéficiera des connaissances et des ressources que Framasoft aura pris le soin de rédiger et de partager au fil des années : la nouvelle mode est de faire du Frama dans son garage ! C’est quoi « faire du Frama » ? Tout simplement penser un monde plus social, plus solidaire et émancipateur, tout en agissant concrètement pour le voir advenir… sans trop se prendre au sérieux, évidemment. Finalement, ce qu’il reste de Framasoft, c’est un groupe de potes ; et c’est franchement pas mal, non ?
Goofy : Novembre 2031. Framas0ft est depuis 5 ans dans la clandestinité et diffuse des samizdats électroniques sur le libRezo pour maintenir la flamme de la rébellion techno-luddiste. Dans son dernier communiqué passé en boucle 3D sur les PolComm du Triumvirat grâce à un hack illégal, Framas0ft annonce avoir repris le contrôle de la ZEL (Zone Électronique Libre) de Lyon4, rendue silencieuse pendant plusieurs mois après la « neutralisation » policière de sa co-direction. Grâce à l’alliance avec l’Anarchipel se construit, je cite, « une zone étendue de libération qui ambitionne de faire échec à la tyrannie numérocratique »
stph : Framasoft a initié le réseau d’universités populaires UPLOAD. Ce sont des lieux bricolés un peu partout. Des granges, des garages, des sous-sols, quelques bâtiments prêtés par des communes ou des boîtes privées. On y apporte et y trouve un peu de tout, mais globalement ça tourne autour de savoir-faire simples et accessibles qui permettent de comprendre comment les machines, les humains et les réseaux qu’ils forment fonctionnent. Un peu de philo, un peu de tech, et du jardinage et du bricolage. C’est pas grand-chose, mais tout de même, c’est quelques milliers de personnes par an qui partagent une autre vision de ce qu’on peut faire quand on est grand.
Cyrille :
Vision négative : Framasoft, comme toutes les structures d’éducation populaire, est devenue hors-la-loi depuis l’élection du nouveau président qui veut contrôler strictement l’éducation. MJC et autres structures associatives ont été dissoutes. Tous les membres de Frama ont été fichés. Pouhiou tricote des pulls pour Pyg qui est emprisonné. Nos techs essaient de hacker le système de sécurité pour le faire sortir de là. L’asso continue la lutte illégalement.
Vision positive : Le combat est gagné. Avec les différents chatons et autres structures d’éducation populaire, nous avons réussi à essaimer suffisamment. La très grande majorité des associations ont repris le contrôle de leurs données et les GAFAM n’ont plus le droit de leur proposer leurs produits. Framasoft n’a plus de raison d’être et les membres votent avec joie la fin de cette belle aventure.
Merci à toustes pour votre participation et ce récit à plusieurs voix !
On se donne rendez-vous dans 10 ans (Place des AMAP numériques ?) pour fêter une nouvelle décennie ? À moins que nous n’ayons tellement bien travaillé notre « compostabilité » que finalement, notre présence ne soit devenue superflue ? 😉
Quoi qu’il en soit, merci aussi à toustes les anonymes, celles et ceux qui ont contribué, par leurs codes, leurs écrits, leurs encouragements, leurs dons (on vous a dit que Framasoft ne vivait que grâce à vos dons ? Ça tombe bien, on est en campagne !). C’est grâce à vous que nous pouvons continuer, ensemble, à écrire de nouvelles pages, et de nouveaux chapitres !
Frama, c’est aussi des personnes au service des services
Installer 16 services en ligne sur des serveurs, c’est une chose. Assurer leur sécurité, leurs mises à jour, leur sauvegarde, en est une autre. Si on ajoute à cela un travail sur l’accueil, les réponses aux questions de chacun·e et l’accompagnement vers d’autres hébergeurs de confiance… Alors cela représente un effort quotidien de multiples personnes.
« Frama, c’est pas que… »
Pour l’automne 2021, chaque semaine, nous voulons vous faire découvrir un nouveau pan des actions menées par Framasoft. Ces actions étant financées par vos dons (défiscalisables à 66 %), vous pouvez en trouver un résumé complet, sous forme de cartes à découvrir et à cliquer, sur le site Soutenir Framasoft.
Héberger un service en ligne, ce n’est pas juste appuyer sur un bouton. C’est plusieurs personnes qui appuient sur de nombreux boutons, toute la journée. Car si on veut proposer des services en lesquels vous pouvez avoir confiance, il faut forcément mettre des humain·es derrière les machines.
Accueil des services
Nous entreprenons actuellement une campagne de mise à jour des pages d’accueil des services que nous proposons. La page d’accueil, c’est LA page de référence qui doit vous donner les bons accès et les explications que vous recherchez au premier coup d’œil.
Pour cette nouvelle version, nous avons conçu une page d’accueil qui vous permet une découverte progressive du service, au fur et à mesure de votre défilement sur la page. Le premier bandeau vous accueille avec le nom, la description, et une magnifique illustration du service… mais surtout avec de gros boutons pour l’utiliser directement. Puis des onglets vous exposent ses fonctionnalités principales, avant que l’on précise les limitations et les règles qui régissent son utilisation.
Ensuite la page d’accueil détaille comment et pourquoi nous hébergeons ce service. C’est avant tout un acte politique qui nous motive à poursuivre ce travail, et nos intentions n’étaient souvent pas bien comprises ni même connues des bénéficiaires de nos services. Désormais, nos motivations sont clairement affichées.
Ces pages d’accueil se concluent par une présentation de Framasoft et notre formulaire de don, car c’est bel et bien grâce aux dons des personnes qui soutiennent Framasoft que ces services sont utilisés gratuitement par plus d’un million de personnes chaque mois. L’objectif n’est ni de culpabiliser ni de pousser au don, mais bien de montrer concrètement que le « gratuit » est toujours financé, d’une manière ou d’une autre.
On vous le confirme : le cloud, c’est loin d’être vaporeux ! Il s’agit d’ordinateurs très concrets, toujours allumés et toujours connectés (des serveurs), qu’il faut bichonner constamment.
Parce que Framasoft, c’est 43 serveurs physiques et 4 serveurs de stockage, avec des sauvegardes réparties sur 2 sites géographiques, pour éviter que les données ne soient perdues en cas d’un problème physique (incendie, inondation, séisme, etc.).
Sur 11 de ces serveurs sont installées 48 machines virtuelles, alors que les 32 autres serveurs sont utilisés directement. Virtuelles ou physiques, cela fait donc 91 machines, chacune avec son système d’exploitation, qu’il faut tenir à jour, mettre à niveau, etc.
Ces serveurs abritent les logiciels qui font tourner les services (et vous envoient vos emails de notification, etc.). Ces logiciels sont monitorés (on surveille si l’activité est normale, pour savoir quand ça rame ou quand ça surchauffe, par exemple), régulièrement mis à jour, et migrés sur une autre machine lorsqu’il y en a besoin.
Derrière ces logiciels, ces machines virtuelles, ces serveurs et cette infrastructure, il y a une petite équipe de 3 personnes (dont une à temps plein) qui se relaient et se décarcassent pour que tout fonctionne au mieux. Car si l’informatique a facilité l’automatisation, l’humain reste indispensable pour servir les serveurs.
S’il y a bien un travail dont on n’imagine pas l’ampleur avant d’ouvrir un service en ligne au grand public, c’est le nombre de demandes d’aide auxquelles il faut répondre. Enfin, quand nous disons qu’ « il faut », c’est plutôt un choix : notez que les géants du Web font tout pour être injoignables et ne pas répondre à vos demandes (sauf si vous payez cher un service de support).
Or nous avons les ressources d’une petite association pour affronter des problèmes de géants. Avec un million de personnes qui utilisent nos services chaque mois, et 37 membres dans notre association (dont un salarié à plein temps sur les réponses à vos demandes), l’astuce est de trouver comment vous autonomiser au maximum.
Depuis près d’un an, nous avons remodelé notre seule et unique page de contact (vraiment, si vous voulez une réponse fiable par la personne concernée, ne nous interpellez pas sur les médias sociaux, mais bien sur contact.framasoft.org !).
Cette page a été conçue pour vous rendre indépendant·e :
avec un accès direct aux réponses les plus courantes sur le sujet qui vous concerne (dans 90 % des cas, votre réponse se trouve déjà là) ;
avec un lien vers le forum d’entraide où toute une communauté est présente pour vous répondre ;
avec le formulaire de contact si votre demande ne peut pas être publique (données personnelles, invitation, etc.).
Grâce à ces outils d’autonomisation, nous sommes passé·es de 450 à 200 demandes à traiter par mois (sans compter les spams, sinon il faut doubler). Cela permet de ne pas perdre d’énergies à vous copier-coller les réponses de notre Foire aux Questions, pour mieux se consacrer aux échanges, éclaircissements, investigations, tests, etc. qui permettent de répondre à vos besoins parfois très spécifiques.
Dès le lancement de la campagne Dégooglisons Internet, nous savions que Framasoft ne pourrait pas répondre à elle seule à tous les besoins qui existent pour s’émanciper dans ses usages numériques. C’est pourquoi, sur le site degooglisons-internet.org, il y a une page qui recense des alternatives dans et hors Framasoft : des alternatives à Google Chrome, à BlablaCar ou à Gmail par exemple.
On parle souvent du travail que c’est de construire un projet, par exemple lorsqu’on ouvre un nouveau service. Mais déconstruire demande aussi un effort non négligeable, surtout lorsqu’on essaie de le faire proprement. Ainsi, pour chaque service que nous avons fermé, nous avons créé une page permettant de recenser des alternatives, souvent le même outil, proposé par des hébergeurs de confiance.
Lister, recenser et mettre en valeur des alternatives, c’est un travail régulier, car il faut se tenir à jour, répondre à ceux qui signalent leur nouvelle alternative, voir si celles qui sont présentées sont toujours pertinentes.
C’est cependant un effort logique : si l’on veut promouvoir la décentralisation, si l’on ne veut pas que tout le monde aille chez le même hébergeur et crée un nouveau géant du Web, alors il faut présenter la diversité des propositions.
C’est d’ailleurs en cela que le site entraide.chatons.org, qui avait été ouvert en urgence pour répondre aux besoins nés de la pandémie, reste une ressource très utile : 9 services en ligne, 0 compte à créer, le choix d’hébergeurs qui tourne automatiquement, pour décentraliser sans y penser.
Voilà qui conclut le focus de cette semaine. Vous pourrez retrouver tous les articles de cette série en cliquant sur ce lien.
Sur la page Soutenir Framasoft, vous pourrez découvrir un magnifique jeu de cartes représentant tout ce que Framasoft a fait ces derniers mois. Vous pourrez ainsi donner des couleurs à l’ensemble des activités que vous financez lorsque vous nous faites un don. Nous espérons que ces beaux visuels (merci à David Revoy !) vous donneront envie de partager la page Soutenir Framasoft tout autour de vous !
En effet, le budget de Framasoft est financé quasi-intégralement par vos dons (pour rappel, un don à Framasoft de 100 € ne vous coûtera que 34 € après défiscalisation). Comme chaque année, si ce que nous faisons vous plaît et si vous le pouvez, merci de soutenir Framasoft.
Frama, c’est aussi de la médiation aux communs numériques
De l’édition de livres aux ateliers et conférences, des interviews aux traductions sur le blog et jusqu’au podcast… À Framasoft, nous explorons de nombreuses manières de partager ce que nous savons et d’apporter notre pierre à l’édifice des communs culturels.
« Frama, c’est pas que… »
Pour l’automne 2021, chaque semaine, nous voulons vous faire découvrir un nouveau pan des actions menées par Framasoft. Ces actions étant financées par vos dons (défiscalisables à 66 %), vous pouvez en trouver un résumé complet, sous forme de cartes à découvrir et à cliquer, sur le site Soutenir Framasoft.
Nous avons la chance, à Framasoft, d’avoir du temps libéré pour observer et tenter de comprendre le monde numérique actuel, ses règles, ses mécanismes. Cette connaissance nous sert à imaginer et explorer des pistes pour faire autrement, s’extraire du capitalisme de surveillance et de l’économie de l’attention. Mais ce serait bien triste si les savoirs et expériences que nous accumulons n’étaient pas partagés !
Rencontres et conférences
Les 37 membres de l’association Framasoft vivent dans une trentaine de villes différentes. C’est une chance, cela nous permet de pouvoir régulièrement répondre à des invitations de participer à des ateliers, tables-rondes, conférences, échanges, etc. Et si les agendas ne s’alignent pas, nous savons refuser poliment aussi.
Certes, la pandémie qui continue de façonner nos vies a réduit le nombre de rencontres auxquelles nous participons actuellement. Mais elle a aussi normalisé les webinaires et autres interventions à distance auprès du grand public et des personnes qui organisent ces événements (ce qui nous a par exemple permis de participer à L’Özgürkon, la convention des libristes en Turquie).
Voilà qui tombe bien, causer à distance, c’est une chose que nous savons faire !
Soyons clair·es : Framasoft n’a aucune stratégie médias. Nos timidités, nos syndromes de l’imposteur, notre refus de se poser en expertes, notre vigilance à éviter d’avoir des têtes d’affiche, font que nous ne sommes pas de « bons clients ». L’association est de toute façon peu représentée à Paris, où une majeure partie de la sphère médiatique cherche ses intervenant·es.
Cependant, nous nous efforçons de répondre aux médias qui viennent nous interroger sur les enjeux du numérique (là où nous avons une expérience et une expertise à partager). Il nous arrive donc de nous frotter à l’interview « face cam » pour un documentaire, à la courte citation pour un quotidien, à des questions de la presse spécialisée indépendante, à celles d’un podcast pas du tout porté sur la « tech »…
Répondre aux entrevues n’est pas un exercice que nous recherchons, ni que nous affectionnons particulièrement (sauf lorsqu’il s’agit de contribuer aux recherches des universitaires). Cela reste cependant une manière intéressante d’accueillir la remise en question, de sortir de notre zone de confort et de semer des graines d’émancipation numérique aux quatre vents des internets.
Le Framablog est le principal organe de communication et de publication de Framasoft : dès que nous avons une action à annoncer, une déclaration qui nous démange, c’est sur le blog que ça se passe. Cependant, nous voulons que le Framablog soit plus que cela.
Régulièrement, le comité communication s’applique à faire découvrir une démarche libre intéressante, amusante, bouleversante, au travers d’interviews variées.
Par ailleurs, nous nous évertuons à inviter d’autres voix sur le Framablog. Il s’agit de personnes du monde du libre et des communs qui partagent leur expertise et leur expérience, dont nous reprenons (avec leur accord) des textes publiés sur leur propre blog.
Depuis l’été 2021, nous expérimentons autre chose : « commander » (c’est-à-dire solliciter et non pas diriger) des textes auprès de plumes qui nous inspirent et dont nous aimerions qu’elles consacrent un peu de leur verve à détailler un sujet qui nous importe. C’est ainsi qu’est né le dossier publié en feuilleton sur le Militantisme Déconnant de Viciss (du blog Hacking Social).
Cette collaboration est la première d’une série que nous espérons longue et fructueuse.
Framalang est né de cette envie de partager des nouvelles du monde du Libre avec les non-anglophones. Ce groupe cherche des articles (voire livres, sites web, etc.) en anglais (et parfois en italien, en espagnol) que les membres ont envie de traduire pour les partager avec le monde francophone (souvent sur le Framablog).
Le groupe Framalang est, à nos yeux, un très bel exemple de la relation qu’il peut y avoir entre une association (Framasoft) et un groupe de contributeurices auto-géré·es (Framalang). Le rôle de Framasoft se borne à donner à Framalang les moyens d’œuvrer : un espace, des outils, une audience, du temps et du soin dans l’animation du groupe…
Le collectif Framalang prend ses propres décisions, que ce soit dans le choix des textes à traduire, dans les méthodes et outils (qui ont évolué au fil des ans), ou les choix linguistiques et de mise en page. Framalang illustre une règle importante chez Framasoft : dans le respect du collectif, c’est kikifé kidécide.
Ah ! si vous saviez comme nous sommes impatient·es de vous montrer cette nouvelle évolution de notre maison d’édition ! Depuis plus d’un an, les membres du projet Framabook ont décidé de revoir intégralement le fonctionnement actuel qui reposait sur « le pari du livre libre ». En effet, jusqu’à présent, ce pari consistait à distribuer librement et gratuitement les ebooks tout en rémunérant honnêtement les auteurs et autrices sur les ventes papier.
Seulement, nous n’avons jamais su intégrer Framabook aux chaînes de distribution et de diffusion du livre en France, qui sont verrouillées et dirigées par les industries culturelles. Leur fonctionnement repose sur la propriété, la vente, l’exploitation.
Des Livres en Communs (ce sera le nouveau nom de Framabook) a pour intention de changer de paradigme, en se concentrant sur la création et la production de communs culturels.
Nous comptons attribuer à des auteurices une bourse d’écriture pour reconnaître et rémunérer plus équitablement leur travail de création. Nous donnerons davantage de détails ultérieurement, notamment sur la façon dont nous choisirons les bénéficiaires de ces bourses. L’objectif est d’accompagner ces auteurices dans leur processus, pour qu’iels mènent à bien leur création qui deviendra un Commun.
En attendant, ces derniers mois, il nous a fallu faire l’inventaire des contrats et projets existants chez Framabook, et imaginer comment accompagner la transition de ce beau projet dans un nouveau paradigme.
Les projets évoluent mais les envies restent. Annoncée en 2017 comme une université populaire du libre, UPLOAD représente désormais pour nous une Université Populaire Libre, Ouverte, Autonome et Décentralisée. Ici le libre n’est plus une fin en soi (ce que l’on apprend) mais bien une manière de partager les connaissances.
Ces derniers mois, les membres de Framasoft ont exploré différentes manières d’envisager UPLOAD. Parce que trouver un nom qui claque, c’est bien, mettre quelque chose derrière, c’est mieux ! Est-ce que c’est une plateforme où l’on peut partager des connaissances ? Une série d’outils pour aider des groupes locaux à organiser des temps d’éducation populaire ? Une série de parcours pédagogiques où l’on accompagne les personnes qui s’y engagent…?
La question n’est pas tranchée, et la réponse dépendra beaucoup des personnes, collectifs et initiatives que nous rencontrerons dans nos explorations, des besoins que nous percevrons et de l’utilité que Framasoft pourrait avoir ici ou là (sans forcément réinventer la roue, car des personnes ont déjà montré la voie et construit des ressources).
En attendant, quelques-unes de nos expérimentations préfigurent cette université populaire : qu’il s’agisse du MOOC CHATONS, des Librecours ou du podcast UPLOAD, toutes illustrent notre envie de partager le savoir, et la capacitation qui va avec l’acquisition de connaissances.
Voilà qui conclut le focus de cette semaine. Vous pourrez retrouver tous les articles de cette série en cliquant sur ce lien.
Sur la page Soutenir Framasoft, vous pourrez découvrir un magnifique jeu de cartes représentant tout ce que Framasoft a fait ces derniers mois. Vous pourrez ainsi donner des couleurs à l’ensemble des activités que vous financez lorsque vous nous faites un don. Nous espérons que ces beaux visuels (merci à David Revoy !) vous donneront envie de partager la page Soutenir Framasoft tout autour de vous !
En effet, le budget de Framasoft est financé quasi-intégralement par vos dons (pour rappel, un don à Framasoft de 100 € ne vous coûtera que 34 € après défiscalisation). Comme chaque année, si ce que nous faisons vous plaît et si vous le pouvez, merci de soutenir Framasoft.
Un commun numérique fête ses 25 ans : Internet Archive
Par curiosité ou nécessité, vous avez sûrement essayé de savoir à quoi ressemblait une ancienne page web, et vous avez utilisé la Wayback Machine pour remonter le temps. Eh bien ce génial service, qui permet d’accéder à des clichés instantanés de pages web archivées, est une des nombreuses ressources d’Internet Archive, qui fête cette année ses 25 ans.
On pourrait le célébrer avec une cascade de chiffres impressionnants : déjà plus de 70 pétaoctets de données stockées, 475 milliards de pages web, 28 millions de livres, 14 millions de fichiers audio, etc. Un succès considérable.
Mais le plus important c’est que Internet Archive est un commun numérique. Si vous savez déjà ce que ça signifie, passez au-delà du paragraphe explicatif suivant :
Comment se caractérise un commun numérique ?
Un commun désigne une ressource produite et/ou entretenue collectivement par une communauté d’acteurs hétérogènes, et gouvernée par des règles qui lui assurent son caractère collectif et partagé.
Il est dit numérique lorsque la ressource est numérique : logiciel, base de données, contenu numérique (texte, image, vidéo et/ou son), etc.
Les communs numériques ont des caractéristiques nouvelles : l’usage de la ressource par les uns ne limite pas les possibilités d’usage par les autres (la ressource est non rivale) et il n’est pas nécessaire d’en réserver le droit d’usage à une communauté restreinte afin de préserver la ressource (la ressource est non-exclusive).
Ainsi, les communs numériques gagnent à être partagés, car ce partage augmente directement la valeur de la ressource et permet par ailleurs d’étendre la communauté qui la préservera. Le numérique est donc à l’origine du développement de communs d’un nouveau genre, ouverts et partagés, accroissant d’autant plus leur potentiel.
Eh oui, Internet Archive coche toutes les cases et c’est une ressource partagée de laquelle on peut bénéficier et à laquelle on peut contribuer par un don, par un document mis en ligne (plus de 17 000 par jour…).
Voyez ce qu’en dit son fondateur, Brewster Kahle, 25 ans après les débuts :
Il y a 25 ans, je pensais que la construction de cette nouvelle bibliothèque serait surtout un processus technologique, mais je me trompais. Il s’avère que c’est surtout un processus humain. Internet Archive a été soutenu par des centaines d’organisations. Environ 800 bibliothèques ont participé à la création des collections web qui se trouvent dans la Wayback Machine. Plus de 1 000 bibliothèques ont fourni des livres à numériser dans les collections, qui comptent désormais 5 millions de volumes. En outre, des personnes spécialisées dans, par exemple, les horaires de chemin de fer, les radios anciennes ou les disques 78 tours, ont fait don de supports physiques et téléchargé des fichiers numériques sur nos serveurs […] L’année dernière, plus de 100 millions de personnes ont utilisé les ressources d’Internet Archive, et plus de 100 000 personnes ont fait un don pour nous soutenir financièrement. Il s’agit véritablement d’un projet mondial, la bibliothèque du peuple.
Jeune homme, je voulais participer à la création d’un nouveau média qui constituerait une avancée par rapport à l’invention de Gutenberg, quelques centaines d’années auparavant.
En construisant une bibliothèque pour tout à l’ère du numérique, je me suis dit qu’il y avait là une chance pour la rendre non seulement disponible à tout le monde mais également plus performante et intelligente que son équivalent papier. En utilisant des ordinateurs, cette bibliothèque ne serait pas seulement un outil de recherche mais également d’organisation : de sorte que l’on puisse naviguer au sein de millions, voire de milliards, de pages web.
La première étape a été de créer des ordinateurs capables de traiter d’énormes collections de riches contenus. Il a fallu ensuite créer un réseau qui puisse capter des ordinateurs du monde entier : l’Arpanet, qui allait devenir l’Internet. Plus tard, est arrivée l’intelligence augmentée qu’on a ensuite appelée les moteurs de recherche. J’ai alors contribué au WAIS (Wide Area Information Server) qui a aidé les éditeurs à rejoindre en ligne ce nouveau système ouvert, lequel a fini par être englobé dans le World Wide Web.
En 1996 est venu le moment de lancer la construction de la bibliothèque.
Cette bibliothèque contiendrait tous les ouvrages publiés de l’humanité. Cette bibliothèque ne serait pas uniquement accessible à ceux qui peuvent payer le dollar par minute que LexisNexis demandait, ou à l’élite des universités. Ce serait une bibliothèque accessible à n’importe qui, n’importe où dans le monde. Pourrions-nous pousser le rôle d’une bibliothèque plus loin, de sorte que les écrits de tous y soient inclus, pas seulement celles et ceux qui ont signé un contrat avec un éditeur new-yorkais ? Pourrions-nous construire une archive multimédia qui contiendrait non seulement des écrits, mais aussi des chansons, des recettes, des jeux et des vidéos ? Pourrions-nous permettre à tous de trouver des informations sur leur grand-mère dans cent ans ?
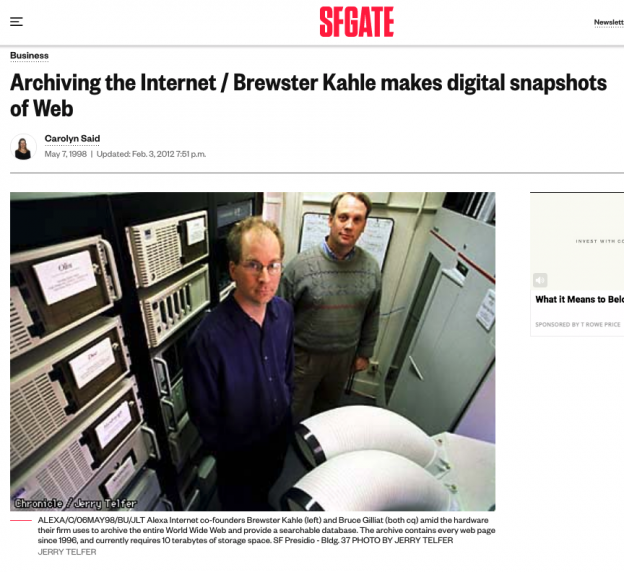
Un article du San Francisco Chronicle, Business Section, 7 mai 1988. Photo parJerry Telfer. Brewster Kahle est ici en compagnie de Bruce Gilliat, avec qui il a fondé Alexa Internet.
Depuis le début, l’Internet Archive devait être à but non lucratif parce qu’elle contient les œuvres de tout le monde. Ses motivations devaient être transparentes. Elle devait durer longtemps.
Dans la Silicon Valley, le but est de trouver une sortie de projet rentable, par un rachat ou par une introduction en bourse, et de passer au projet suivant. Cela n’a jamais été mon but. Le but de l’Internet Archive est de créer une mémoire permanente du Web qui puisse être utilisée pour fabriquer un nouveau cerveau global. Pour trouver au fil du temps des chemins dans les données qui nous offriront de nouvelles perspectives, bien au-delà de ce qu’un moteur de recherche peut faire. Pour être non seulement une référence historique, mais aussi une part vivante du cœur battant de l’Internet.
Ce que j’ai préféré des premiers temps de l’ère du Web, ce sont les personnes qui rêvaient.
Dans les débuts du Web, on a vu les gens essayer de faire marcher un système plus démocratique. Les gens ont essayé de rendre la publication plus inclusive.
On a aussi vu les autres facettes de l’humanité : les pornographes, les arnaqueurs, les harceleurs et les trolls. Eux aussi ont vu l’occasion de réaliser leurs rêves dans ce nouveau monde. Finalement, l’Internet et le World Wide Web sont simplement à notre image. C’est juste une histoire de l’humanité. Et ça a été une expérience de partage et d’ouverture d’esprit.
Le World Wide Web sous son meilleur jour est un outil qui permet à chaque personne de partager ses connaissances, presque toujours gratuitement, et de trouver sa communauté, peu importe où l’on se trouve dans le monde.
Brewster Kahle au cours d’une conférence à la Bibliothèque de Charleston en 2019. Photo de Corey Seeman– CC by 4.0
Regardons vers l’avenir
Nous n’avons peut-être pas encore atteint l’accès universel à toutes connaissances, mais nous pouvons encore le faire. Dans 25 ans, nous pouvons collecter les écrits non pas de cent millions de personnes, mais d’un milliard de personnes, et les préserver à jamais. Nous pouvons avoir des systèmes de rémunération qui ne soient pas basés sur des modèles publicitaires qui profitent seulement à certains.
Nous pouvons avoir un monde avec de nombreux gagnants, avec des personnes qui participent, qui trouvent des communautés qui partagent leur façon de penser, et dont elles peuvent apprendre, partout dans le monde. Nous pouvons créer un Internet où nous nous sentons aux commandes.
Je crois que nous pouvons construire ce futur ensemble. Vous avez déjà aidé Internet Archive à construire ce futur. Durant les 25 dernières années, nous avons rassemblé des milliards de pages, 70 pétaoctets de données à offrir aux générations futures. Offrons-leur cela de manière innovante et passionnante. Construisons et rêvons ensemble pour les 25 prochaines années.
— — — — —
Dans cette courte vidéo le jeune Brewster Kahle (en 1996) expose les principes du projet. Le document retrace ensuite l’évolution du projet Internet Archive jusqu’à aujourd’hui. Source de la vidéo (sous-titrages en français par nos soins)
Et encore…
Un article récent dans lequel Brewster Kahle proteste contre les poursuites judiciaires dont Internet Archive a été l’objet pendant la pandémie de la part des éditeurs qui voulaient lui interdire le prêt des ouvrages électroniques.

































![Carte "[RÉSOLU]" [RÉSOLU] est un guide composé de fiches pratiques pour aider les structures de l’économie sociale et solidaire à adopter des solutions numériques libres et éthiques. Co-construit avec le mouvement des CÉMÉA, ce guide peut être modifié, amélioré et distribué librement.](https://framablog.org/wp-content/uploads/2021/11/E2_Resolu.jpg)