Mobilizon v2 : la version de la maturité ?
Mobilizon, c’est notre réponse à la question : « Comment faire pour que les Marches pour le Climat ne s’organisent pas sur Facebook ? ». Cet outil permet de créer des groupes, des pages et des événements, sans devoir offrir ses données, mettre à jour son statut, taguer ses ami·es, partager ses photos…
« Frama, c’est pas que… »
Pour l’automne 2021, chaque semaine, nous voulons vous faire découvrir un nouveau pan des actions menées par Framasoft. Ces actions étant financées par vos dons (défiscalisables à 66 %), vous pouvez en trouver un résumé complet, sous forme de cartes à découvrir et à cliquer, sur le site Soutenir Framasoft.
➡️ Lire cette série d’articles (oct. – déc. 2021)
Alors vous pouvez tout à fait utiliser Mobilizon en vous inscrivant sur Mobilizon.fr que nous hébergeons, mais vous pouvez aussi vous inscrire sur d’autres hébergements de Mobilizon (nous proposons une sélection sur Mobilizon.org).
Mais c’est quoi, déjà, Mobilizon ?
Car Mobilizon est avant tout un logiciel, que des hébergeurs installent sur un serveur, afin de créer une plateforme, un site web Mobilizon, qui peut se fédérer et donc synchroniser ses données avec d’autres sites web Mobilizon.
Imaginez : si Facebook était un réseau, mais avec plusieurs portes d’entrée, comme pour les emails. Vous auriez le choix de vous inscrire chez tel ou telle fournisseuse Facebook (comme vous avez le choix de votre fournisseur d’email), parce que vous lui feriez confiance pour traiter vos données ou pour appliquer une modération rassurante. Cependant, votre fournisseuse Facebook vous donnerait accès à un maximum d’événements et de groupes du réseau, parce qu’elle se fédérerait avec les autres hébergements (comme vous pouvez recevoir des emails de tout le monde, peu importe leur fournisseur).
Voilà ce qu’est Mobilizon : un outil fédéré pour publier vos événements, vos pages, vos informations… et pour organiser votre groupe en toute quiétude.

illustration : David Revoy (CC-By)
Un an de mises à jour à votre écoute
Voilà un peu plus d’un an que nous avons publié la première version (la « v1 ») de Mobilizon. Avouons que proposer un outil pour s’organiser et rassembler son groupe en pleine période de confinements et couvre-feux n’était pas franchement idéal !
Pourtant Mobilizon est un logiciel prometteur, avec plus de 75 hébergements (on parle d’instances) publics et une portée déjà internationale. Il faut dire que depuis un an, nous avons enchaîné les mises à jour pour vous fournir des fonctionnalités très demandées.
En mars dernier sortait la version 1.1. Elle a enrichi Mobilizon d’un historique des activités, de la possibilité d’afficher les événements par proximité géographique et de pouvoir accéder à des flux RSS (pour s’abonner aux flux d’information et ne rien louper).
C’est fin juin que nous avons publié la version 1.2. Elle apporte notamment un système de notifications (pratique pour informer les participant·es à son événement), et une nette amélioration des interfaces (plus agréables sur mobile).
À la mi-août, nous avons publié la version 1.3 de Mobilizon. Elle permet une meilleure gestion des groupes, dont les administratrices ou modérateurs peuvent éditer les événements ou les billets de blog. Par ailleurs, on peut désormais ajouter de nombreuses métadonnées aux événements : niveau d’accessibilité, compte Twitter, adresse d’un live stream…
Enfin, nous avons travaillé en partenariat avec Koena à améliorer l’accessibilité de Mobilizon, en proposant un canal de retours directs aux personnes concernées, que notre logiciel pourrait mettre en situation de handicap.

Mobilizon v2, un outil pensé pour vous servir
Depuis cet été, nous travaillons dur (avec notre équipe de UN développeur salarié qui consacre 75 % de son temps sur le projet) à implémenter des fonctionnalités inspirées de vos remarques et demandes.
Désormais, il est possible pour un de vos profils Mobilizon de suivre les activités publiques d’un groupe sans avoir à vous y inscrire. Vous aurez donc ces événements dans votre page « Mes Événements » (augmentée d’un nouveau système pour filtrer ce qui s’y affiche. Ils seront aussi visibles sur votre page d’accueil et notifiés dans vos emails (si vous le souhaitez), dès que ce groupe publiera un événement.
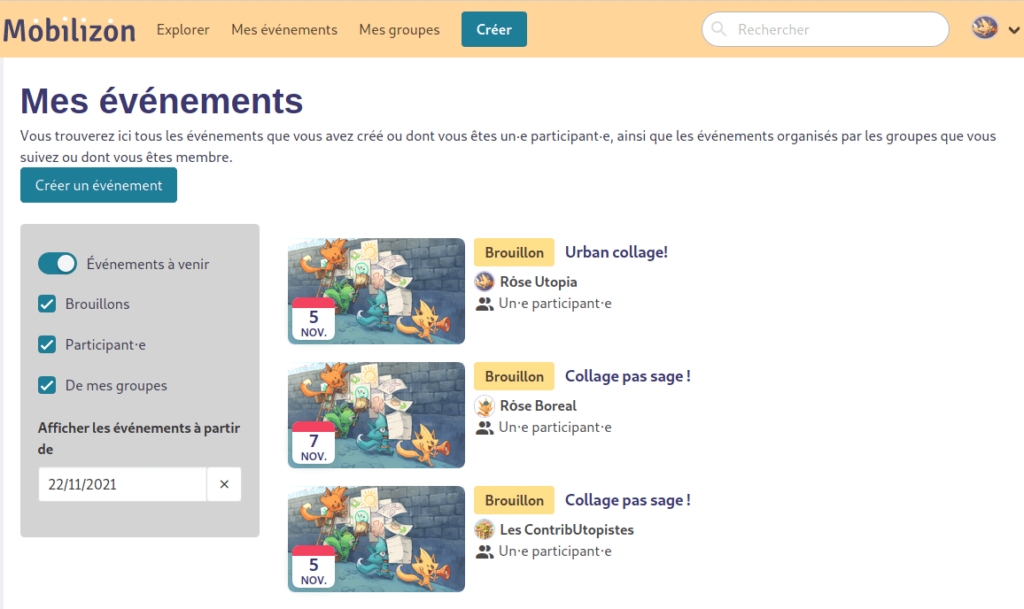
Les personnes qui organisent des événements peuvent désormais exporter une liste des participant·es, par exemple pour pointer qui s’est inscrit à l’avance. Cette liste est proposée sous les formats les plus pratiqués (csv, odf, pdf), et ne contient pour l’instant que les noms des profils ayant cliqué « Je Participe » (et les messages des comptes anonymes). Mais c’est là le début d’un travail qui pourrait s’étoffer, en fonction de vos attentes.
Mobilizon v2 permet de résoudre un vrai casse-tête (et ça en fut un à développer :p !) : la prise en compte des fuseaux horaires. Désormais si vous organisez un événement à Londres, l’heure de votre événement sera, par défaut, associée au fuseau horaire britannique.


Ainsi, Mobilizon fera la conversion horaire pour les personnes qui voudraient s’y inscrire depuis la France, en affichant l’horaire de l’événement selon l’heure de Paris, par exemple. Pour cela, Mobilizon regarde le fuseau horaire déclaré par votre navigateur web (et vous pouvez maîtriser ce paramètre dans votre compte). Cela permet aussi à Mobilizon de vous envoyer des emails de rappel « l’événement démarre dans une heure » à la bonne heure, c’est à dire : la vôtre (quel bonheur !).
Un gros travail a été fait pour afficher correctement les langues qui s’écrivent de droite à gauche, dont une adaptation de l’interface même du logiciel. Car il faut aussi s’adapter aux cas « bidirectionnels », où deux langues au sens de lecture différents sont mélangés, par exemple une interface en arabe et un événement décrit en français.
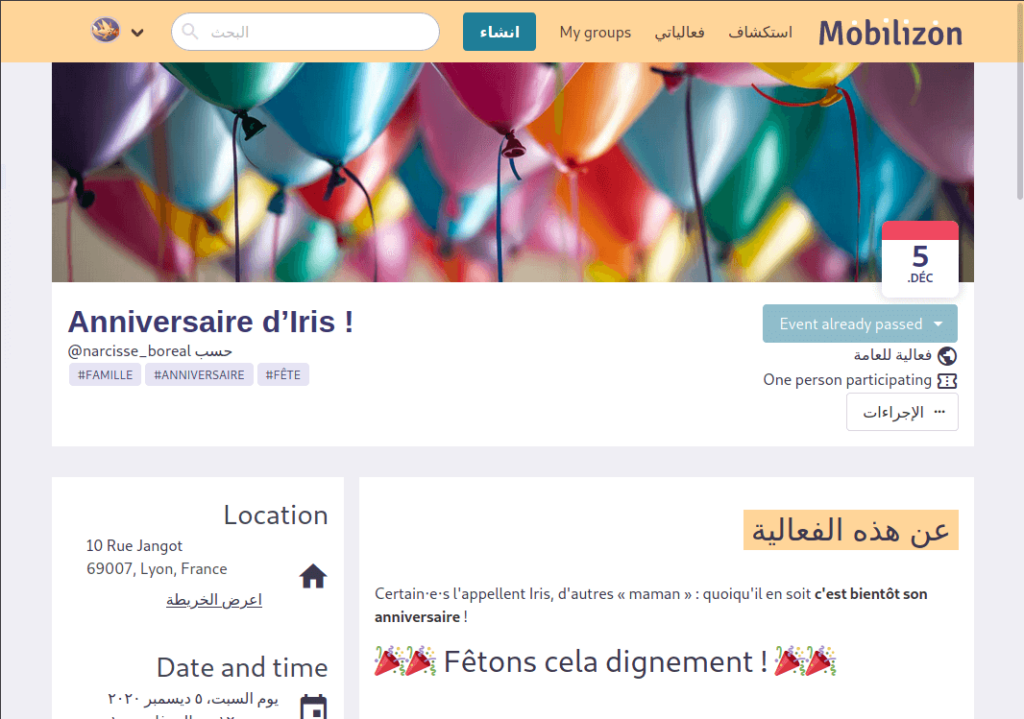
Vous l’avez (beaucoup) demandé, et c’est d’autant plus pertinent en temps de pandémie, vous avez désormais la possibilité de définir un événement comme en ligne, donc sans lieu géographique. Nous avons aussi ajouté un nouveau filtre dans la recherche de Mobilizon, pour que vous puissiez directement voir les événements « en ligne » parmi vos résultats.
D’ailleurs, toujours en parlant du moteur de recherche, il est désormais possible de chercher parmi les événements passés, histoire de retrouver ceux qui vous ont intéressé⋅e.
Nous avons implémenté une détection automatique de la langue des événements. Lorsque vous écrivez votre titre et la description de votre événement, Mobilizon lui attribuera une langue. Cela permet une meilleure accessibilité pour les personnes qui utilisent un lecteur d’écran, mais améliore aussi l’aperçu de la date de vos événements dans les médias sociaux.

Enfin, il y a de très nombreuses retouches qui peuvent sembler minimes mais qui changent la vie. C’est le cas des évolutions de l’apparence des emails, de celle des cartes présentant les événements ou les groupes, de la vue publique des groupes (l’alternative aux « pages » Facebook).
Mais ce sont aussi des progrès en accessibilité numérique grâce à nos échanges avec Koena, ou encore le fait que Mobilizon puisse désormais s’exécuter aisément sur des machines sous ARM, ce qui facilitera l’auto-hébergement sur des nano-ordinateurs (type Raspberry Pi) ou avec Yunohost, par exemple.

Entrez dans la communauté Mobilizon
Le logiciel Mobilizon est encore au début de sa vie, avec une communauté très motivée. Les discussions sur notre salon Matrix sont animées, et les personnes qui contribuent aux traductions sont d’une redoutable efficacité (merci et plein de datalove à elles !).
Nous ne savons pas encore exactement ce que nous allons faire sur Mobilizon en 2022. Nos intuitions nous soufflent qu’il va falloir travailler à faire connaître cette solution auprès des personnes qu’elle pourrait séduire.
Pour cela, un des axes de travail serait d’améliorer la découverte des contenus (les événements, les groupes, leur page publique, les articles publics de ces groupes), notamment en travaillant sur les outils de recherche, filtres, etc.
Mais rien n’est encore décidé et nous sommes impatient·es d’entendre vos retours (sur notre forum ou notre salon Matrix, par exemple) pour savoir quelle direction donner à Mobilizon.

Dès que nous aurons une proposition plus claire de feuille de route, nous ne manquerons pas de vous en informer sur la lettre d’information Mobilizon (alors pensez à vous y inscrire ici).
Hasard du calendrier, c’est aujourd’hui que le documentaire Disparaître – Sous les radars des algorithmes est publié par ArteTV. Réalisé par Marc Meillassoux, ce documentaire met en scène un performer voulant s’extraire des griffes de Facebook, et Mobilizon semble y jouer un rôle… important !
Mobilizon est financé grâce à vos dons
Nous vous rappelons que cette v2 de Mobilizon a été financée sur notre budget 2021, donc directement grâce aux dons des personnes qui soutiennent Framasoft. En effet, Framasoft est une association loi 1901 financée à 93 % par vos dons.
Parce que Framasoft est reconnue d’intérêt général, les dons à notre association sont déductibles des impôts pour les contribuables Français. Ainsi, un don de 100 € à Framasoft revient, après déduction des impôts sur le revenu, à 34 €
Nous avons expliqué dans cette série d’articles sur le Framablog, l’ensemble des actions qui sont financées par un don à Framasoft. Elles sont résumées en un jeu de cartes à cliquer, retourner et colorer sur le site Soutenir Framasoft.
Merci d’avance de visiter et partager ce site, et pour celles et ceux d’entre vous qui le peuvent, de donner des couleurs à nos actions en faisant un don à Framasoft.

Cliquez sur l’image pour lire un roman photo qui vous présente comment utiliser Mobilizon.
illustration : David Revoy (CC-By)
Liens utiles
- Site officiel de Mobilizon
- Tester notre instance francophone Mobilizon.fr
- Découvrez la fédération sur Mobilizon.org
- Voir le code source de Mobilizon
- Soutenir Framasoft
































![Carte "[RÉSOLU]" [RÉSOLU] est un guide composé de fiches pratiques pour aider les structures de l’économie sociale et solidaire à adopter des solutions numériques libres et éthiques. Co-construit avec le mouvement des CÉMÉA, ce guide peut être modifié, amélioré et distribué librement.](https://framablog.org/wp-content/uploads/2021/11/E2_Resolu.jpg)