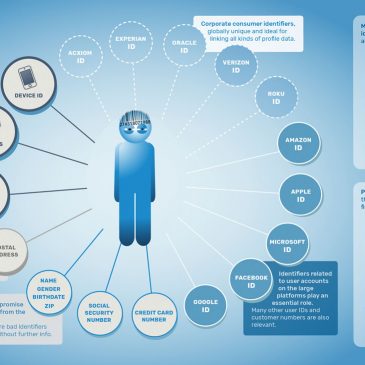
Échirolles libérée ! La dégooglisation (3)
Voici déjà le troisième volet du processus de dégooglisation de la ville d’Échirolles (si vous avez manqué le début) tel que Nicolas Vivant nous en rend compte. Nous le re-publions volontiers, en souhaitant bien sûr que cet exemple suscite d’autres … Lire la suite