
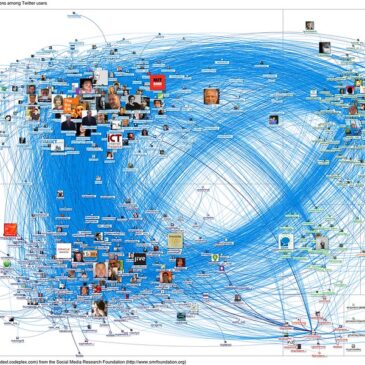
Ouvrir le code des algorithmes ? — oui, mais… (2/2)
Voici le deuxième volet (si vous avez raté le premier) de l’enquête approfondie d’Hubert Guillaud sur l’exploration des algorithmes, et de son analyse des enjeux qui en découlent. Dans le code source de l’amplification algorithmique : que voulons-nous vraiment savoir ? par … Lire la suite