
Temps de lecture 6 min
Vous cherchez des images utilisables pour vos sites ou publications ? Savez-vous qu’il est facile d’en trouver avec divers niveaux de permissions via le moteur de recherche des Creative Commons ?
Ces petits logos, familiers des libristes, sont souvent combinés et permettent de savoir précisément à quelles conditions vous pouvez utiliser les images :
![]() Attribution : vous devez mentionner l’identité de l’auteur initial (obligatoire en droit français) (sigle : BY)
Attribution : vous devez mentionner l’identité de l’auteur initial (obligatoire en droit français) (sigle : BY)
![]() Non Commercial : vous ne pouvez pas tirer un profit commercial de l’œuvre sans autorisation de l’auteur (sigle : NC)
Non Commercial : vous ne pouvez pas tirer un profit commercial de l’œuvre sans autorisation de l’auteur (sigle : NC)
![]() No derivative works : vous ne pouvez pas intégrer tout ou partie dans une œuvre composite (sigle : ND)
No derivative works : vous ne pouvez pas intégrer tout ou partie dans une œuvre composite (sigle : ND)
![]() Share alike : partage de l’œuvre, vous pouvez rediffuser mais selon la même licence ou une licence similaire (sigle : SA)
Share alike : partage de l’œuvre, vous pouvez rediffuser mais selon la même licence ou une licence similaire (sigle : SA)
Si vous êtes dans le monde de l’éducation, pensez à faire adopter les bonnes pratiques aux élèves et étudiants qui ont besoin d’illustrer un document et qui ont tendance à piller Google images sans trop se poser de questions…
… mais il arrive souvent que de grands médias donnent aussi de bien mauvais exemples !
Si vous êtes embarrassé⋅e pour ajouter les crédits nécessaires sous l’image que vous utilisez, le nouveau moteur de recherche de Creative Commons vous facilite la tâche. C’est une des nouveautés qui en font une ressource pratique et précieuse, comme Jane Park l’explique dans l’article ci-dessous.
Article original : CC Search is out of beta with 300M images and easier attribution
Traduction Framalang : Goofy
Le moteur de recherche de Creative Commons propose maintenant 300 millions d’images plus faciles à attribuer
par Jane Park
Désormais la recherche Creative Commons n’est plus en version bêta, elle propose plus de 300 millions d’images indexées venant de multiples collections, une interface entièrement redessinée ainsi qu’une recherche plus pertinente et plus rapide. Tel est le résultat de l’énorme travail de l’équipe d’ingénieurs de Creative Commons avec l’appui de notre communauté de développeurs bénévoles.
CC Search parcourt les images de 19 collections grâce à des API ouvertes et le jeu de données Common Crawl, ce qui inclut les œuvres artistiques et culturelles des musées (le Metropolitan Museum of Art, le Cleveland Museum of Art), les arts graphiques (Behance, DeviantArt), les photos de Flickr, et un premier jeu de créations en 3D sous CC0 issus de Thingiverse.
Au plan esthétique et visuel, vous allez découvrir des changements importants : une page d’accueil plus sobre, une navigation meilleure avec des filtres, un design en harmonie avec le portail creativecommons.org, des options d’attribution faciles à utiliser et des canaux de communication efficaces pour faire remonter vos questions, réactions et désirs, tant sur les fonctionnalités du site que sur les banques d’images. Vous trouverez également un lien direct vers la page d’accueil des Creative Commons (le site de l’ancienne recherche est toujours disponible si vous préférez).
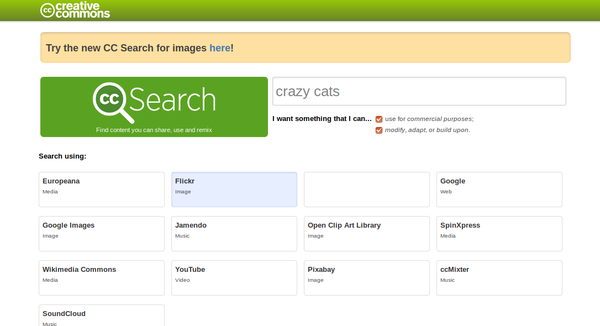

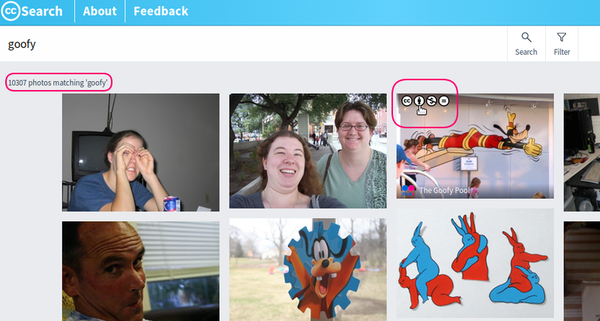
Si vous jetez un œil sous le capot, vous verrez que nous avons réussi à diminuer le temps de recherche et nous avons amélioré la pertinence de la recherche par phrase. Nous avons aussi implémenté des métriques pour mieux comprendre quand et comment les fonctionnalités sont utilisées. Enfin, nous avons bien sûr corrigé beaucoup de bugs que la communauté nous a aidé à identifier.
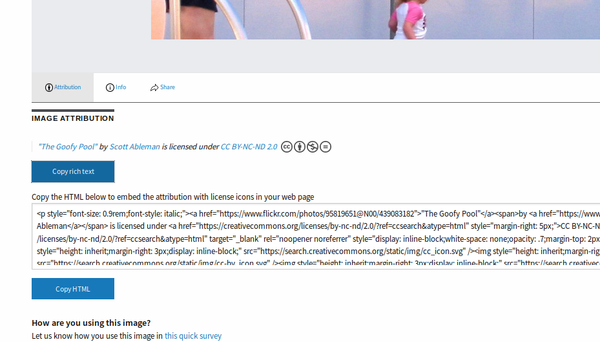
Et bientôt…
Nous allons continuer à augmenter la quantité d’images de notre catalogue, en visant en priorité les collections d’images comme celles de Europeana et Wikimedia Commons. Nous projetons aussi d’indexer davantage de types d’œuvres sous licences CC, tels que les manuels et les livres audio, vers la fin de l’année. Notre but final demeure inchangé : donner l’accès à 1,4 milliard d’œuvres qui appartiennent aux Communs), mais nous sommes avant tout concentrés sur les images que les créateurs et créatrices désirent utiliser de diverses façons, comment ils peuvent apprendre à partir de ces images, les utiliser avec de larges permissions, et restituer leur exp)érience à tous pour nourrir la recherche Creative Commons.
Du point de vue des fonctionnalités, des avancées spécifiques figurent dans notre feuille de route pour ce trimestre : des filtres pour une utilisation avancée sur la page d’accueil, la possibilité de parcourir les collections sans entrer de termes de recherche, et une meilleure accessibilité et UX sur mobile. De plus, nous nous attendons à ce que certains travaux liés à la recherche CC soient effectués par nos étudiants du Google Summer of Code à partir du mois de mai.
Le mois prochain à Lisbonne, au Portugal, nous présenterons l’état de la recherche (“State of CC Search”) à notre sommet mondial (CC Global Summit) où sera réunie toute une communauté internationale pour discuter des développements souhaités et des collections pour CC Search.
Participez !
Vos observations sont précieuses, nous vous invitons à nous communiquer ce que vous souhaiteriez voir s’améliorer. Vous pouvez également rejoindre le canal #cc-usability sur le Slack de CC pour vous tenir au courant des dernières avancées.
Tout notre code, y compris celui qui est utilisé pour la recherche CC, est open source (CC Search, CC Catalog API, CC
Catalog) et nous faisons toujours bon accueil aux contributions de la communauté. Si vous savez coder, nous vous
invitons à nous rejoindre pour renforcer la communauté grandissante de développeurs de CC.
Remerciements
CC Search est possible grâce à un certain nombre d’institutions et d’individus qui la soutiennent par des dons. Nous aimerions remercier en particulier Arcadia, la fondation de Lisbet Rausing et Peter Baldwin, Mozilla, et la fondation Brin Wojcicki pour leur précieux soutien.

antistress
Pour info chez moi Decentraleyes est configuré pour bloquer les scripts manquants ce qui casse https://search.creativecommons.org/
J’ai dû créer une exception pour ce site
libre fan
C’est génial ça fait plaisir, mais pourquoi creativecommons.org est chez CloudFlare (c’est vraiment un problème, pas une phobie de crétin·e·s) — et, de la même façon, pourquoi plein de sites (ou domaines) de Mozilla sont chez Amazon (son cloud), notamment la plateforme des Add-ons dont on a parlé récemment. Pour Amazon en général (pas son cloud), Framablog nous en parle là : https://framablog.org/2019/05/03/amazon-des-robots-avec-des-etres-humains/
Ces assoc’/entreprises ont de l’argent ou la possibilité de demander des dons et ont les compétences pour installer des serveurs indépendants des GAFAM. Il faudrait qu’elles prennent conseil chez Framasoft, eh !
Sur Torbrower : https://search.creativecommons.org/, si on met le curseur de sécurité tout en haut (Safest), on a une page blanche. Il faut mettre le curseur au niveau intermédiaire (Safer), ce qui est raisonnable pour un site web en HTTPS (connexion sécurisée), noté A par SSL Labs, ce qui est parfait. Les requêtes sont évidemment moins satisfaisantes, grr.
En plus, Cloudflare bloque très souvent TorBrowser avec ses capchas Google ou autres, même si en l’occurence, CreativeCommons n’est pas bloqué.
Adrien
J’ajouterai que leur formulaire de contact est un Google Forms. Voilà voilà …
Mais sinon c’est une super initiative !
Gustave
Merci pour ces précisions. C’est bon à savoir quand on possède un blog. Il existe aussi des site comme Pexels ou les images peuvent être utilisées librement.