Le groupe Framalang a pour objectif de traduire collaborativement des nouvelles du monde du Libre. La plupart du temps, ces traductions sont destinées à être publiées sur le Framablog, mais elles peuvent aussi servir à des projets amis (LQDN, April, etc.) ou viser à traduire un livre pour une édition Framabook.
Un billet spécial du Framablog a été consacré à ce groupe en guise de présentation et remerciement ainsi qu’une interview croisée de plusieurs de ses membres. Dans la joie et la bonne humeur, traductrices et traducteurs se réunissent sur une liste de discussion (voir plus bas pour l’inscription), exercent une veille du « Libre » anglophone, évaluent les travaux potentiels à traduire, puis s’attellent à la tâche !
Il faut tout d’abord s’inscrire sur la liste de diffusion. Chacun-e peut y répondre et y participer (sans spammer le reste du groupe, bien entendu !)
Ensuite, vous avez les emails et l’outil de suivi des traductions pour retrouver les travaux en cours et leur état d’avancement… donc voir ce que vous pouvez proposer !
Inscription au groupe Framalang
Nous traduisons principalement des articles originellement en Anglais.
Et parce ce qu’il n’y a pas que l’anglais dans la vie, Framalang a récemment créé une nouvelle liste de traducteurs pour la langue espagnole. Il va sans dire que vous y êtes également les bienvenu⋅e⋅s.
Nous vous remercions par avance de votre éventuelle « candidature » 😉
Le chemin d’une traduction
Participer à Framalang, ce n’est pas simplement traduire… En réalité, chaque membre du groupe peut :
Proposer une traduction
Ce travail de veille et de proposition d’article à traduire est très important, et nous sommes toujours avides de nouveaux contenus à traduire ! Nous commençons généralement le sujet de ces email par : [Proposition], avec dans l’email le lien vers la source, l’auteur⋅e et une rapide présentation du propos.
Accepter une proposition
Vous voyez un article sur lequel vous seriez prêt-e à travailler ? Dites-le en répondant à l’email de proposition. En général, à partir de 2, 3 réponses enthousiastes, on lance la traduction.
Contacter l’auteur⋅e d’un article proposé
Si la proposition de traduction n’est pas sous une licence permettant l’adaptation, il faut en contacter l’auteur-e pour demander une autorisation de traduction.
Padifier l’article
Il s’agit simplement de copier l’article original sur un framapad (outil d’écriture collaborative).
soit qu’un administrateur/administratrice le fasse pour vous
soit les droits d’administrations pour vous-même.
Pensez à mentionner le titre, l’auteur, la licence et la source, et à sauter 2 lignes entre chaque paragraphe pour que la traduction se fasse aisément. Une fois le pad prêt, il suffit d’envoyer son adresse au groupe dans un nouvel email marqué [Traduction].
Traduire l’article
C’est la partie où on retrouve le plus de monde, souvent les traductions vont vite ! Il suffit d’aller sur le pad et d’écrire (pensez à mettre votre pseudo et à choisir votre couleur dans l’icône en haut à droite). Toutes les traductions en cours ou passées sont disponibles dans notre outil de suivi des pads.
Proposer chapô et illustration
À l’intérieur du pad, vous pouvez rédiger le chapô : une introduction à cet article qui présente l’auteur-e, le propos, et pourquoi le groupe a trouvé important de le partager auprès du public francophone.
Vous pouvez aussi proposer des illustrations (Libres) à l’aide d’un lien et en mentionnant auteur, titre et licence de l’image (vous pouvez aussi partager ces images via notre outil Framapic !)
Relire la traduction
C’est un travail essentiel. N’hésitez pas à imposer vos choix : la traduction de l’autre n’est pas sacrée, et nous sommes dans une dynamique de confiance. On a souvent plus de recul à la relecture qu’à la traduction, donc une meilleure approche de la bonne tournure à choisir.
Ce n’est que lorsque vous n’êtes pas sûr⋅e de votre proposition que vous la signalez à côté /*en la mettant dans ces signes*/ (attention : vous laisserez alors plus de travail aux personnes qui mettront l’article sur le blog !). Une bonne relecture est une relecture où tous les choix de traductions ont été tranchés ;).
Bloguifier la traduction
Certain⋅e⋅s membres de Framalang ont des accès au Framablog. Leur travail consiste à prendre votre traduction, la vider de l’anglais, trancher dans les derniers choix (il faut qu’il y en ait le moins possible, siouplé), l’illustrer, lui écrire un chapô, la mettre en page… Si vous vous sentez assez à l’aise dans le groupe (pour savoir motiver les troupes) et l’envie de faire ce travail-là, n’hésitez pas à le dire au groupe !
Lancement réussi du premier Traducthon Framalang à l’Ubuntu Party de Paris
Votre mission, si toutefois vous l’acceptez…
Le « Traducthon », mais qu’est-ce donc que ce néologisme barbare que l’on vient d’inventer ?
Cela consiste à traduire collaborativement au même moment et au même endroit un document anglophone sélectionné préalablement. Le challenge étant de commencer et surtout terminer l’ensemble du travail dans le temps imparti[1].
À l’initiative du groupe de traducteurs Framalang, le premier « Traducthon » vient à peine de s’achever. Il a eu lieu ce samedi 29 mai de 11h à 14h lors de l’Ubuntu Party de Paris, dont nous remercions les organisateurs pour leur invitation et leur accueil.
Rencontre et convivialité sans perdre de vue l’objectif. C’est un peu comme un apéro Facebook sans Facebook dont l’apéro viendrait après le boulot 😉
En s’insérant dans cette prestigieuse manifestation, l’idée était également d’inviter spontanément les passants curieux à participer avec nous, ou tout du moins leur expliquer ce que nous faisions là avec tant d’enthousiasme. Parce que « l’esprit du Libre » c’est aussi ça et ça n’est donc pas uniquement réservé aux développeurs chevronnés.
Pour coller à l’actualité, nous avons fait le choix d’un article critique sur l’iPad de Cory Doctorow nous expliquant pourquoi il n’en achètera pas (nous non plus d’ailleurs). Pari tenu puisque la traduction a été mise en ligne dans la foulée sur le Framablog !
Voici un cliché, parmi d’autres[2], où figurent quelques uns des participants :
Nous avons en effet travaillé en temps réel sur un unique fichier issu de l’excellent logiciel d’édition collaborative en ligne Etherpad (dont Google, encore lui, a eu la bonne idée de libérer les sources récemment).
Ceux qui y étaient en témoigneront dans les commentaires, travailler à l’aide de l’application Etherpad est pratique et ludique. À chaque couleur son participant, comme l’illustre l’image ci-contre, que l’on voit éditer en même temps qu’on édite, ce qui n’est d’ailleurs pas sans poser quelques intéressants problèmes d’organisation.
Cliquez (si le serveur tient) sur la frise chronologique de notre fichier à l’instant t=0 et appuyez sur la grosse flèche en haut à droite pour faire défiler le temps… Partagez-vous ma fascination de voir apparaître au fur et à mesure les contibutions, modifications et commentaires de chacun ?
Du coup, ceux qui comme moi n’avaient pu physiquement se rendre sur place à Paris ont eu la possibilité d’apporter néanmoins leur pierre à l’édifice en se connectant à l’instant précis de la date fixée.
Nous n’avions ici que 3 petites heures à notre disposition, ce qui limitait d’autant la taille du document choisi. Mais avec l’expérience de cette première fois plus qu’encourageante, nous vous donnons rendez-vous début juillet à Bordeaux pour la onzième édition des Rencontres Mondiales du Logiciel Libre où nous serons présents durant les 6 jours de la manifestation pour œuvrer cette fois-ci à un projet bien plus ambitieux : la traduction intégrale d’un livre.
Merci à tous les participants et à très bientôt.
Notes
[1] Le Traducthon est un fork non hostile et adapté à un travail de traduction du concept des Book Sprints issu du site FLOSS manuals.
Et si nous faisions plus amplement connaissance avec notre groupe de traduction Framalang ? Tel est l’objet de ce petit questionnaire aux réponses croisées. Remercions Siltaar, Poupoul2, Olivier, Xavier, Yonnel, Don Rico, Goofy, Claude, GaeliX, Burbumpa and last but not least Yostral, de s’y être pliés de plus ou moins bonne grâce.
Ni de vipère, ni de sorcière, et encore moins de bois, ils sont tout sauf mauvaise lang, qu’ils ont bien pendue une fois sortie de leurs poches et donnée au chat[1]. Ce qui donne un article débridé où rien n’a été occulté, pas même le sexe ou l’outrageuse exploitation dont ils font l’objet par le chef présumé de ce gang bang des postiches (surnommé par certains, j’ai les noms, le « dict’aKator »).
L’occasion de leur témoigner une nouvelle fois notre reconnaissance, de ne pas oublier que « my taylor is free », mais aussi et surtout de rappeler que la porte vous est wide open et que toute nouvelle énergie est plus que welcome.
Framalang Quiz
Bonjour à tous, pourriez-vous vous présenter en une phrase ?
Siltaar : Non, je ne peux pas. Il faut être journaliste ou producteur de cinéma pour croire qu’un Homme peut se résumer à moins que la somme de ses actes.
Poupoul2 : Je m’appelle Poupoul2 (enfin presque) et je me drogue aux logiciels et à la culture libres, à l’amour (celui de ma femme et de mes enfants), et un peu aussi à la crème au chocolat et à la blanquette de veau.
Olivier : Olivier, anciennement étudiant, pas tout à faire dans la vie active encore (mais pas inactif pour autant) on appelle ça un doctorant.
Xavier : Xavier, fraichement diplomé d’une école d’ingénieur du fin fond de notre chère région centre et actuellement développeur php5 pour les gens qui fabriquent les gros avions.
Yonnel : Et ta sœur, elle se présente en une phrase ?
Don Rico : Don Rico, parrain de la mafia des traducteurs, je traduis des romans policiers la journée, et à la nuit tombée, quand les cadavres reposent sagement au fond de la Seine, je traduis des articles pour Framalang et écris quelques trop rares billets pour le Framablog.
Goofy : Je suis un vieux crétin de 51 balais.
Claude : I am just a rigolo who likes the show.
GaeliX : François aka GaeliX (j’ai bien écrit aka pas aKa), consultant en Système d’Information Télécom, GNU/Linuxien depuis Yggdrasil avec des périodes forcées de ouindozeries…
Burbumpa : Burbumpa, 86 % d’H2O, quelques connexions neuronales, curiosité, éclectisme et procrastination…
Yostral : Bonjour. Oui je pourrais.
Quels sont vos logiciels libres préférés ?
Siltaar : Ah, ça c’est simple comme question 🙂 Une série de logiciel en mode console, parce qu’ils sont vraiment efficaces : urxvt, screen, irssi (vi, mutt, mocp…). Quelques grand classiques : VideoLAN Client (VLC), Firefox (Iceweasel), Thunderbird (Icedove). Puis une collection de logiciels GNOME : Gedit, Gthumb, Evince, Abiword, Gnumeric. Petit coup de coeur pour Gkrellm2 et Compiz (brut de décoffrage, sans rien autour, tout juste un AWN).
Poupoul2 : Je ne peux plus me passer de Quod libet. Comme je suis un dangereux pirate, je consomme du Transmission en permanence pour télécharger des tas de trucs subversifs comme des images iso de distributions GNU/Linux ou de la musique sous licence Creative Commons. Je suis un fan absolu d’Inkscape et Blender, qui me servent à créer des flyers pour réclamer l’autonomie du Bourkistan Inférieur et la libéralisation des échanges de nouilles aux épinards.
Olivier : Apt-get, on y pense pas forcément, mais ça a été une révélation. Puis Firefox avec ses plug-in et gedit aussi avec ses plug-in. Avec Terminal voilà les logiciels que j’utilises le plus.
Xavier : Mplayer. Etant cinéphile, c’est la référence. C’est un peu ma femme, très long à configurer mais après, c’est que du bonheur. 😀
Yonnel : Microsoft Word 97, Internet Explorer, Photoshop. Excusez-moi, je suis atteint du syndrome Bayrou. Nan, sérieux : un Firefox tuné avec Web Developer, EditCSS, ColorZilla, ScrapBook (entre autres), et Emacs, magnifique, merci à son psy de me tenir compagnie…
Don Rico : GNU/Linux, Ubuntu, Gnome et Xfce pour le système d’exploitation. Pour les programmes : Firefox, OOo,VLC, Miro, Listen. Pour le Web : Identica, WordPress et le protocole BitTorrent. Pour les formats : les formats ouverts ODF et Ogg. Pour terminer, les licences Creative Commons, et les licences libres dans leur ensemble, qui permettent d’adapter à la culture la philosophie du logiciel libre.
Goofy : FrontPage, Tetris, OpenTheDoor.plz (v.4)
Claude : Debian. Je me shoote à Debian tous les jours depuis que j’ai foutu une patate à deux macs qui s’appelaient Jéquatte et Jétrois.
GaeliX : Les plus utilisés… FF évidement, The Gimp, OOo (et encore plus depuis que j’ai appris par notre ministre qu’il y avait un firewall dedans), VLC, Pidgin, Python, Amarok et les « petits » dont je ne peux pas me passer Xpad, Notecase, Xmmp… Et quand je veux faire « light », Links2, mocp, Alpine, Finch, Raggle…
Burbumpa : J’ubuntuse + les classiques Firefox avc un gros tas de plugins, Thunderbird (id), VLC, CDex, OOo, Scribus, Gimp, Compiz.
Yostral : Ceux qui fonctionnent.
Qu’est-ce qui vous a poussé à participer à Framalang ?
Siltaar : La volonté de participer à l’essor des logiciels libres, et aussi un peu celle de soutenir la francophonie.
Poupoul2 : J’ai un principe dans la vie : Je fais ce que je veux. Et ce que je voulais à ce moment là, c’était jouer avec mes petits camarades de Framalang. Sinon, en vrai, c’est une autre manière de contribuer, pour moi qui, en matière de développement, ai 2 mains gauches remplies de pouces carrés achetées d’occasion à un poulpe. Accessoirement (et plus sérieusement), ça m’est très utile dans mon activité professionnelle, pour laquelle j’exerce à 99% en anglais.
Olivier : C’est une somme de petites choses en fait. L’appel à contribution pour traduire le framabook Changer pour OpenOffice.org m’a mis le pied à l’étrier. Ça correspond à peu près au moment où j’ai adopté Linux et je voulais participer à ma manière.
Xavier : Une conférence de notre ami (il nous connait pas mais on l’aime quand même) Eben Moglen qui a changé ma vie. Le patron cherchait quelqu’un qui fasse les sous titres et je me suis proposé.
Yonnel : aKa avait promis des bières gratuites.
Don Rico : Alexis et Pierre-Yves m’ont promis un T-shirt Framasoft. C’était il y a trois ans, et je le porte toujours pour dormir.
Goofy : On m’a obligé.
Claude : La fièvre du samedi libre.
GaeliX : Si mes souvenirs sont bons c’était le démarrage du framabook Changer pour OOo.
Burbumpa : Ouh, c’est loin .. probablement le projet Changer pour OOo, parce que c’est plus facile de convaincre quand on a un outil à disposition dans sa langue : vous je sais pas, mais je connais un nombre ahurissant d’unilingues francophones…
Yostral : aKa.
Qu’est-ce qui vous a poussé à y rester ?
Siltaar : L’ambiance de camaraderie décontractée que j’y ai rencontrée. L’impression de vraiment faire avancer les choses, d’employer efficacement les quelques moments de détente que j’y consacre.
Poupoul2 : Parce que j’ai toujours le même principe de vie : Je fais ce que je veux. Éventuellement aussi parce qu’ils ne m’ont pas encore mis dehors.
Olivier : Je marche par défis, la première question était « suis-je capable de traduire correctement ? » Ensuite je me suis pris au jeu et je m’amuse beaucoup à traduire. Les propositions d’articles plus techniques ou plus longs, de livres complets… ont gardé ma curiosité et mon envie intactes.
Xavier : Une seule raison, j’ai la flemme de me désinscrire de la mailing list 😀 En fait, c’est l’ambiance, la possibilité de lire des textes sur l’opensource d’autres pays, bien moins ignorants et étroits d’esprit que le notre.
Yonnel : L’espoir d’avoir un jour ces fameuses bières gratuites.
Don Rico : La gloire, le pouvoir et la bière gratuite.
Goofy : La crainte des poursuites judiciaires.
Claude : Les médicaments, mais principalement la fribiaire dont la source est libre.
GaeliX : C’est comme Facebook, la fonction « supprimer le compte » est tellement bien planquée qu’on préfère encore se faire spammer par le chef que de la chercher. Bon, depuis une petite année, pour des raisons perso, je ne suis plus très présent, mais avoir des nouvelles du front et voir que la pieuvre bouge toujours, ça donne envie de s’y remettre… Pour l’instant plus de motivation pour les travaux dans la durée (FAIF) que sur les articles. Et puis surement aussi le petit coté « secte » dans la « secte ».
Burbumpa : Ah, on peut se désinscrire ?
Yostral : Pas aKa.
Quels sont les avantages et les inconvénients à traduire ainsi « à plusieurs mains » ?
Siltaar : Le principal avantage, c’est de se donner le droit à l’erreur, les collègues reliront. Tout en essayant de ne pas faire son boulet sur des questions simples. Ensuite, on apprends des remarques et traductions des autres, c’est enrichissant. Enfin, quand un texte est trop long, ou une conférence trop longue à transcrire seul, on est vraiment réconforté de voir que d’autre sont prêt à donner un coup de main.
Poupoul2 : Tout dépend des mains de vos partenaires : Si elles sont douces, c’est un sacré avantage. Sinon, ça permet de confronter des idées, et l’échange d’idées est toujours très intéressant, quel que soit le sujet. Comme inconvénient, je ne vois pas trop : Nos mains se marchent peu sur les pieds.
Olivier : C’est rassurant de savoir que quelqu’un passera derrière pour rectifier le tir si tout n’est pas parfait. Ça permet d’avancer même sans être absolument satisfait du résultat et je pense qu’au final ça nous permet plus de rapidité sans sacrifier la qualité. D’un autre côté les textes doivent passer par plusieurs étapes de validation et sur certaines périodes un peu creuse ça peut être démotivant de voir le travail stagner par manque de temps des volontaires.
Yonnel : Avantages : on se rattrape nos boulettes respectives. Inconvénients : ils me retirent toujours mes merveilleuses formules, toujours très bien trouvées, à chaque fois des exemples qui devraient être enseignés dans toutes les écoles de traduction.
Don Rico : À plusieurs mains, on tape plus vite sur le clavier, c’est pour ça qu’on abat autant de boulot et qu’on déroule de la trad au kilomètre. L’inconvénient, c’est que ça revient cher en savon.
Goofy : Ça chatouille un peu, les autres mains, au début. Après on s’habitue.
Claude : Au départ le chatouillis dérange, surtout quand on touche les zones sensibles, mais vient ensuite un effet laxatif de pur bonheur d’humilité enrichissant.
GaeliX : Avantage & inconvénient : il y a toujours quelqu’un pour corriger la boulette oubliée. Sinon, une certaine émulation, le fait de savoir qu’un travail commencé finira toujours par aboutir. Et pour paraphraser Sam Williams : « If the experience of writing a book has taught me anything, a writer’s weaknesses become much less apparent with the generous assistance of a few hundred collaborators. »
Burbumpa : Partage du temps nécessaire, et puis plus on est de fous…
Yostral : Faire du multithread pour sourds et malentendants, c’est bandant, non ?
Framalang, le « Courrier International » du Libre ?
Siltaar : C’est un bel objectif, et je suis prêt à traduire des textes espagnols, bientôt chinois… Mais traduire ce n’est pas tout. L’implication des traducteurs est presque un loisir à côté du rôle que tient aKa qui, sans cesse, arpente le web à la recherche des perles à traduire, et des articles intéressants à publier dans le Framablog. Après, il n’est pas seul dans ce rôle, et tout le monde peut proposer un article, mais c’est très confortable de ne choisir que parmi que des articles intéressants, lequel on va traduire ce soir.
Poupoul2 : Je vais avoir du mal à répondre : Je ne lis pas Courrier International. Mais ça doit sûrement s’en rapprocher, puisque Courrier Intergalactique n’existe pas. Sinon, Framalang serait clairement dans cette dernière catégorie.
Olivier : À vrai dire le sujet des articles m’intéresse peu, c’est surtout la traduction en elle-même qui compte pour moi, apprendre des nouvelles choses, progresser. Je crois d’ailleurs que souvent l’introduction sur le blog est plus importante que l’article traduit et ça serait dommage de ne résumer le Framablog qu’à une tribune pour articles dans la langue de Shakespeare. On apporte surtout une autre lumière sur de sujets d’actualité en France.
Xavier : Ben oué… bon évidemment, on ne pioche que dans la réserve anglophone mais quelle réserve !!! J’espère que d’autres hispanophiles et germanophiles nous rejoindront pour élargir nos horizons.
Yonnel : J’ose espérer qu’on fera un peu mieux que ce ramassis de presse bas de gamme.
Don Rico : Oui, mais sans pub toutes les deux pages !
Goofy : « Frama, le libre qui embrasse avec la lang »
Claude : Oh oh ! Le Courrier International ! Je fuis la pubkipu.
Burbumpa : Ou Soft Mother Jones.
Yostral : Tant que ce n’est pas l’International du Libre.
Ne craignez-vous pas que le Framablog finisse par donner une couleur trop anglo-saxonne à la culture du logiciel libre ?
Siltaar : Si, et je me suis déjà exprimer dans le groupe à ce sujet. Nous avons pu débattre de manière satisfaisante, et il en est ressorti deux points : tout d’abord le Framablog équilibre au jour d’aujourd’hui la balance du mieux possible, et ensuite, la porte du Framablog est ouverte à d’autres contributeurs que les traducteurs, des « rabatteurs » de perles françaises sont les bienvenus !
Poupoul2 : Aucun risque : Par nature, le logiciel libre est déjà très teinté d’anglo-saxon, puisque mondialement développé avec des échanges facilités par la langue de Shakespeare. C’est très français comme question. Par contre, c’est vrai que si des compétences dans d’autres langues pouvaient nous rejoindre, ce serait sans doute intéressant (et ça me permettrait de dérouiller mon allemand). Et puis, vive les petites anglaises…
Olivier : On ne peut pas tout faire en même temps, et d’ailleurs ça n’est pas à nous de tout faire. Rien n’empêche non plus les lecteurs de faire des propositions d’articles ou de thèmes qui leurs paraissent adaptés… ou d’offrir leur aide 🙂
Yonnel : Je t’en pose, moi, des questions existentielles ?
Don Rico : Je m’en tape complètement. Si certains veulent lire des articles sur le pinard, le calendos et les cuisses de grenouille open-source, qu’ils s’y collent. (Pour de vrais arguments, veuillez vous reporter aux réponses des collègues.)
Goofy : …c’est sûr je crains un peu.
Claude : I don’t care of the franchouillardise. J’ai toujours préféré Tom Waits à Arthur H.
GaeliX : C’est un « risque », mais en même temps le monde anglo-saxon produit à tous les niveaux des analyses plus poussées dans ce domaine. On trouve trop peu de billets français aboutis et étayés. Peu être est-ce qu’à terme cela mettra un petit coup de gégène dans les parties sensibles des blogueurs/journalistes/décideurs français (pas dit francophones) et les sortira de notre chère « exception culturelle ».
Burbumpa : C’est un faux débat. Il se trouve probablement que pas mal des gens qui s’intéressent à la question sont capables d’écrire en anglais (même si ce n’est pas leur langue maternelle), qui reste (oui je déplore, mais la seule chose que je peux y faire est par exemple contribuer à Framalang !) une langue de communication fort répandue. C’est vrai qu’on pourrait fouiner dans les publications en d’autres langues, mais cékiki s’y colle et qui traduit après ?
Yostral : Aucune chance. La langue anglaise est sur le déclin. L’exception culturelle française vaincra ! (ou pas)
Comment doit-on traduire l’expression « Open Source » ?
Siltaar : Ouverte Source ? Logiciel à code source lisible, mais pas forcément modifiable parce que sinon on aurait précisé « Libre »… Je pense qu’il faut traduire les idées dans la tête des anglophones et qu’ils disent « Libre Software » quand il s’agit de logiciel libre, et Open Source pour le reste, quand ça s’applique. Comme ça on s’y retrouverait plus facilement et on parlerait moins de logiciel pas complètement libre mais proposant une ouverture sur leur code source.
Poupoul2 : Ouvrez vos Shakras ?
Olivier : …bizarrement je ne crois pas que la question se soit vraiment posée. C’est entré dans le langage « courant », non ?
Xavier : Libre, tout simplement. C’est un mot qui prend de plus en plus d’importance vu tout ce qu’il passe dans le monde. Je ne suis pas fan de l’associer avec un mot à consonance informatique, c’est trop réducteur pour ce que cela représente.
Yonnel : On ne traduit pas, non, jamais. L’Open Source, c’est le mal incarné, çapucépalibre.
Don Rico : J’ai écrit à maître Capello, qui m’a répondu : « Si l’on estime que le terme est passé dans le vocabulaire et qu’il est pertinent de garder le terme original, il conviendra d’écrire open-source, car c’est ainsi qu’on orthographie les mots composés importés de l’anglais, comme skate-board ou milk-shake. »
Goofy : How should « logiciel libre » be translated ? (j’ai bon, là ?)
Claude : « source d’ennui » ou encore « source de liquide »
GaeliX : Heu… Joker encore, pas envie de me faire lapider par un intégriste de passage pour une inexactitude sémantique.
Burbumpa : Ouvrez les vannes ?
Yostral : On ne doit pas la traduire, non, jamais.
Comment traduiriez-vous la célèbre citation de Linus Torlvalds : « Software is like sex: it’s better when it’s free! » ?
Siltaar : La programmation c’est comme le sexe, c’est meilleur sans limites.
Poupoul2 : Difficile question pour moi qui n’ai jamais essayé le non-free sex : Utilisez des logiciels libres pour décupler votre plaisir ? (Comment ça, c’est capillo-tracté ?)
Xavier : Utiliser un logiciel, c’est comme faire l’amour, c’est mieux quand une société internationale corporatiste capitaliste nous vous oblige pas à utiliser des préservatifs percés et à vous infliger les piqures à la douleur sans nom lorsque vous avez choper une saloperie. 😀
Yonnel : Je ne pourrais pas traduire : c’est beaucoup trop grossier et subversif, cela n’a pas sa place sur le Framablog. Enfin, pas sur le Framablogalbanel.
Don Rico : Quand on est un geek moche, les logiciels payants ou les putes, il faut choisir.
Goofy : Mmmh voyons voir… euh… « Les logiciels qui aiment le sexe sont libres d’être meilleurs » ?
Claude : Le Houaire Doux, c’est comme le vin: meilleur avec de la bouteille.
GaeliX : Linux est à Windows ce qu’une jolie fille est à une prostituée : la jolie fille, il faut la séduire pour obtenir ce que l’on désire, tandis que la prostituée , il suffit de la payer, et surtout bien se protéger.
Burbumpa : Libérons-nous des codes !
Yostral : Vive les pr0ns !
Certaine mauvaises langues qualifient aKa de « Benevolent Dictator For Life » du réseau Framasoft. Qu’en est-il exactement ?
Poupoul2 : C’est indiscutable. Si vous saviez ce qu’on endure. Et en plus, on en re-demande. Du masochisme sans doute.
Olivier : Dictateur je ne sais pas, bienveillant c’est sûr. Je ne sais pas pour les autres mais je m’en accommode très bien. Quand je vois toutes les casquettes qu’il cumule je lui donnerai plutôt le titre de « Benevolent Slave to our cause » 😉
Xavier : Ce n’est pas un dictateur, c’est un être absolument sensationnel et charmant. D’ailleurs, j’ai composé un poème à son honneur.
Ah! Qu’Alexis est un être exquis Un homme que le soleil ne peut éclipser
Surtout ne nous abandonne pas Etourdis par tant de candeur Cassons les barrières qui nous entourent Osons braver les sans foi ni loi Un seul poème suffira t-il ? Reste avec nous, ô notre chef S‘il te plait, dis-nous que tu nous aimes
Yonnel : C’est bien pire que ça. Il nous force à aller sous Windows pour traduire. De la sorte, nous perdons tout sens critique, et devenons des esclaves prêts à tout pour les beaux yeux de sa moustache (!!!)
Don Rico : C’est qui, cet aKa dont tout le monde me parle ?
Goofy : Cki aKa ?
Claude : C’est malheureusement vrai : y’a qu’aKa qui fait.
GaeliX : C’est pas faux, mais comme le geek névrotique qui sommeille en chacun de nous aime ça, tout va pour le mieux dans le meilleurs des mondes. Et la superposition de plusieurs paires de gants de velours rend les choses plus faciles.
Burbumpa : Ça travaille d’habitude les dictateurs ? En tout cas, celui-là fait bien semblant.
Yostral : Exactement.
Une telle quantité de travail abattu, sans la moindre rémunération ! Ce n’est pas abusé tout de même ?
Siltaar : Si, carrément. Faites des dons au Framablog, comme ça aKa aura encore plus de temps pour nous dénicher des trucs à traduire, et il aura peut être même de quoi s’acheter un fouet pour qu’on suive le rythme !
Poupoul2 : Ah bon, ça n’est pas rémunéré ? Zut, j’aurais dû mieux lire les conditions d’entrée lorsque je me suis inscrit. C’est honteux. C’est de l’exploitation, de l’esclavage moderne.
Olivier : Si si, d’ailleurs on va bientôt se mettre en grève si nous n’obtenons pas d’augmentation ! Il y a une bonne ambiance, pas de pression (non non !) et c’est un loisir avant tout.
Xavier : aKa nous a promis 77 dvds vierges lorsqu’on ira au paradis donc pas de soucis de ce côté là.
Yonnel : Ça dépend. Est-ce que les bières promises comptent dans la rémunération ? Ça se place bien dans la colonne « rémunération en liquide », non ? Dans ce cas, et vu le caractère virtuel de ces bières, on peut les considérer comme des « stock-options du libre ».
Don Rico : Framalang est en fait une couverture pour écouler beaucoup de drogue lors des conventions du libre et des install-parties. Tous les membres de Framalang roulent en BM ou en Porsche, possèdent une villa sur la côte et des comptes en Suisse.
Goofy : Je ne sais pas les autres mais moi je suis bien payé.
Claude : Je croyais que Framasoft avait créé sa monnaie virtuelle : La framakro n’était donc qu’une rumeur ! Ô reur ! Ô des espoirs !
GaeliX : Tout à fait ! Même pas un petit sticker Framasoft à coller sur son netbook c’est honteux ! Organiser une journée d’action pour faire valoir nos droits ne serait pas superflue.
Burbumpa : Ne le dites pas à aKa, le FLFEBeC[2] a vu le jour, des actions sont prévues pour bientôt, notamment une rencontre en chair et en os.
Yostral : Si. Mais heureusement on a droit à notre bière annuelle aux ReuMeuLeuLeux.
Que diriez-vous à ceux qui passent devant Framalang, voient de la lumière mais hésitent à entrer ?
Siltaar : Venez donc par centaine nous rejoindre, pour agrandir le banc de corail sur lequel, comme autant de polypes, nous capturons les articles à traduire à notre rythme (au lieu de mouler sur Linuxfr…).
Poupoul2 : La lumière de Framalang, c’est comme le logiciel libre : Ca se partage avec tout le monde, sans déposséder qui que ce soit. Venez, on va partager notre lampe à bronzer. Et puis aussi, devenez un esclave moderne au service exclusif d’aKa et grâce à lui, ouvrez vous de nouveaux horizons sexuels (Ça résume un peu tout le reste)
Olivier : N’hésitez pas à franchir le pas, pour jeter un œil de l’intérieur, ça n’engage à rien et on a des travaux pour tous les goûts 🙂
Xavier : La porte est ouverte, il reste de la nourriture sur le buffet et en plus, cela n’engage à rien.
Yonnel : Viens vers la lumière, tu en seras récompensé ! Une communauté t’attend, qui ne veut que ton bien… N’aie pas peur, ça ne fait mal qu’un peu, au début ; tu sentiras ensuite une onde de bonheur traverser ton corps…
Don Rico : Qu’ils lisent ma réponse à la question précédente !
Goofy : Tous ceux qui ne rentrent pas sont de la Police Nationale.
Claude : Tu veux une bière ?
GaeliX : Viendez, viendez mais réflechissez bien ! « You can check out any time you like, but you can never leave » (Eagles, Hotel California)
Burbumpa : Je crois savoir que certains ont été appâtés grâce à la bière .. moi on m’a dit : « champagne ! ». Il y en a pour tous les goûts.
Yostral : Petits Schtroumpfs attention ! Fuyez cette maison !
[2] FLFEBeC = Front de Libération Framaloguien(ne)s des Exploités Bénévoles en Colère
Framalang ou le prolifique travail de traduction du réseau Framasoft
Suite et bientôt fin des billets anticipant la très prochaine campagne de soutien.
Le réseau Framasoft possède en son sein depuis octobre 2006 une équipe très précieuse dont le nom de code est Framalang, merci à Harrypopof au passage pour le joli logo sous licence Art Libre (cf ci-dessous). Il s’agit d’une trentaine de bénévoles qui participent à des travaux de traduction, principalement de l’anglais vers le français (mais nous avons également créé il y a peu une petite entité s’occupant de l’espagnol)[1].
Cela avait commencé en mars 2005 par la compilation de logiciels libres TheOpenCD réalisée à même notre forum Framagora et qui avait connu à l’époque son petit succès avec de très nombreux téléchargements, un magazine spécialement dédié et des ventes conséquentes chez Ikarios.
Depuis, et suite à un appel sur le blog, nous nous sommes donc regroupés, structurés et organisés sous la bannière Framalang autour d’une liste de discussion et d’un wiki dédié. Les membres exercent une veille sur le libre anglophone, puis l’un propose et d’autres disposent, c’est-à-dire traduisent, relisent et valident.
La richesse de ce groupe tient non seulement à ses compétences, son écoute, sa capacité d’organisation collective et son goût du travail bien fait, mais également à l’atmosphère conviviale qui y règne et que rien ne vient perturber, pas même le trop plein de travail proposé !
En effet, et pour être tout à fait sincères, nous n’arrivons pas forcément à tout mener à bien et certains projets ont un accouchement lent et difficile. Si nous réussissons à nous dôter de la présence d’un ou deux permanents via la campagne de soutien, c’est là encore quelque chose que nous pourrions améliorer.
J’ajoute que sur la trentaine de membres tous ne sont pas actifs et donc les candidatures restent plus que jamais ouvertes (pour cela s’inscrire directement à partir de cette page).
Il n’en demeure pas moins que ce qui a été déjà réalisé par le groupe est impressionnant aussi bien quantitativement que qualitativement. Présentation et exemples.
Les articles
La traduction d’articles qui sont mis en ligne sur ce blog constitue la majeure partie du travail. Avec le temps nous nous retrouvons ainsi avec une belle petite collection (une bonne cinquantaine pour être plus précis). Certains collent à l’actualité mais d’autres sont prétextes à débats et réflexions de fond.
Petit florilège subjectif et non exhaustif (permettant au passage aux nouveaux lecteurs du Framablog de découvrir qui sait quelques articles intéressants dont la plupart n’ont pas pris une ride) :
Un sous-groupe Framalang est spécialement concentré sur le sous-titrage de vidéo. C’est un travail minutieux et de longue haleine car il faut retranscrire en anglais, puis traduire, minuter et intégrer le tout à la vidéo (dont on propose systématiquement le téléchargement dans un format ouvert).
Framalang est également à l’initiative de travaux plus ambitieux, à savoir la traduction de rapports ou de livres entiers. C’est un peu l’épreuve du feu pour nous car il n’est pas toujours facile de gérer et donner une cohérence à des réalisations de cette envergure effectuées collaborativement à plusieurs mains.
Toujours est-il que c’est ainsi que nous avons édité notre framabook numéro 4 Changer pour OpenOffice.org, à l’origine créé par le site OOoAuthors qui avait eu la bonne idée de placer le livre sous licence libre.
Voilà. Je tenais par la présente à mettre un peu en lumière le travail de ce groupe et à lui un rendre hommage mérité car il participe de beaucoup à bonifier non seulement ce blog mais l’ensemble du réseau.
À l’heure où tous les mastodontes du numérique, GAFAM comme instituts de recherche comme nouveaux entrants financés par le capital risque se mettent à publier des modèles en masse (la plateforme Hugging Face a ainsi dépassé le million de modèles déposés le mois dernier), la question du caractère « open-source » de l’IA se pose de plus en plus.
Au milieu de tout cela, OpenAI devient de manière assez prévisible de moins en moins « open », et si Zuckerberg et Meta s’efforcent de jouer la carte de la transparence en devenant des hérauts de l’« IA Open-Source », c’est justement l’OSI qui leur met des bâtons dans les roues en ayant une vision différente de ce que devrait être une IA Open-Source, avec en particulier un pré-requis plus élevé sur la transparence des données d’entraînement.
Néanmoins, la définition de l’OSI, si elle embête un peu certaines entreprises, manque selon la personne ayant écrit ce billet (dont le pseudo est « tante ») d’un élément assez essentiel, au point qu’elle se demande si « l’IA open source existe-t-elle vraiment ? ».
Note : L’article originel a été publié avant la sortie du texte final de l’OSI, mais celui-ci n’a semble t-il pas changé entre la version RC1 et la version finale.
L’Open Source Initiative (OSI) a publié la RC1 (« Release Candidate 1 » signifiant : cet écrit est pratiquement terminé et sera publié en tant que tel à moins que quelque chose de catastrophique ne se produise) de la « Définition de l’IA Open Source ».
D’aucuns pourraient se demander en quoi cela est important. Plein de personnes écrivent sur l’IA, qu’est-ce que cela apporte de plus ? C’est la principale activité sur LinkedIn à l’heure actuelle. Mais l’OSI joue un rôle très particulier dans l’écosystème des logiciels libres. En effet, l’open source n’est pas seulement basé sur le fait que l’on peut voir le code, mais aussi sur la licence sous laquelle le code est distribué : Vous pouvez obtenir du code que vous pouvez voir mais que vous n’êtes pas autorisé à modifier (pensez au débat sur la publication récente de celui de WinAMP). L’OSI s’est essentiellement chargée de définir parmi les différentes licences utilisées partout lesquelles sont réellement « open source » et lesquelles sont assorties de restrictions qui sapent cette idée.
C’est très important : le choix d’une licence est un acte politique lourd de conséquences. Elle peut autoriser ou interdire différents modes d’interaction avec un objet ou imposer certaines conditions d’utilisation. La célèbre GPL, par exemple, vous permet de prendre le code mais vous oblige à publier vos propres modifications. D’autres licences n’imposent pas cette exigence. Le choix d’une licence a des effets tangibles.
Petit aparté : « open source » est déjà un terme un peu problématique, c’est (à mon avis) une façon de dépolitiser l’idée de « Logiciel libre ». Les deux partagent certaines idées, mais là où « open source » encadre les choses d’une manière plus pragmatique « les entreprises veulent savoir quel code elles peuvent utiliser », le logiciel libre a toujours été un mouvement plus politique qui défend les droits et la liberté de l’utilisateur. C’est une idée qui a probablement été le plus abimée par les figures les plus visibles de cet espace et qui devraient aujourd’hui s’effacer.
Qu’est-ce qui fait qu’une chose est « open source » ? L’OSI en dresse une courte liste. Vous pouvez la lire rapidement, mais concentrons-nous sur le point 2 : le code source :
Le programme doit inclure le code source et doit permettre la distribution du code source et de la version compilée. Lorsqu’une quelconque forme d’un produit n’est pas distribuée avec le code source, il doit exister un moyen bien connu d’obtenir le code source pour un coût de reproduction raisonnable, de préférence en le téléchargeant gratuitement sur Internet. Le code source doit être la forme préférée sous laquelle un programmeur modifierait le programme. Le code source délibérément obscurci n’est pas autorisé. Les formes intermédiaires telles que la sortie d’un préprocesseur ou d’un traducteur ne sont pas autorisées. Open Source Initiative
Pour être open source, un logiciel doit donc être accompagné de ses sources. D’accord, ce n’est pas surprenant. Mais les rédacteurs ont vu pas mal de conneries et ont donc ajouté que le code obfusqué (c’est-à-dire le code qui a été manipulé pour être illisible) ou les formes intermédiaires (c’est-à-dire que vous n’obtenez pas les sources réelles mais quelque chose qui a déjà été traité) ne sont pas autorisés. Très bien. C’est logique. Mais pourquoi les gens s’intéressent-ils aux sources ?
Les sources de la vérité
L’open source est un phénomène de masse relativement récent. Nous avions déjà des logiciels, et même certains pour lesquels nous ne devions pas payer. À l’époque, on les appelait des « Freeware », des « logiciels gratuits ». Les freewares sont des logiciels que vous pouvez utiliser gratuitement mais dont vous n’obtenez pas le code source. Vous ne pouvez pas modifier le programme (légalement), vous ne pouvez pas l’auditer, vous ne pouvez pas le compléter. Mais il est gratuit. Et il y avait beaucoup de cela dans ma jeunesse. WinAMP, le lecteur audio dont j’ai parlé plus haut, était un freeware et tout le monde l’utilisait. Alors pourquoi se préoccuper des sources ?
Pour certains, il s’agissait de pouvoir modifier les outils plus facilement, surtout si le responsable du logiciel ne travaillait plus vraiment dessus ou commençait à ajouter toutes sortes de choses avec lesquelles ils n’étaient pas d’accord (pensez à tous ces logiciels propriétaires que vous devez utiliser aujourd’hui pour le travail et qui contiennent de l’IA derrière tous les autres boutons). Mais il n’y a pas que les demandes de fonctionnalités. Il y a aussi la confiance.
Lorsque j’utilise un logiciel, je dois faire confiance aux personnes qui l’ont écrit. Leur faire confiance pour qu’ils fassent du bon travail, pour qu’ils créent des logiciels fiables et robustes. Qu’ils n’ajoutent que les fonctionnalités décrites dans la documentation et rien de caché, de potentiellement nuisible.
Les questions de confiance sont de plus en plus importantes, d’autant plus qu’une grande partie de notre vie réelle repose sur des infrastructures numériques. Nous savons tous que nos infrastructures doivent comporter des algorithmes de chiffrement entièrement ouverts, évalués par des pairs et testés sur le terrain, afin que nos communications soient à l’abri de tout danger.
L’open source est – en particulier pour les systèmes et infrastructures critiques – un élément clé de l’établissement de cette confiance : Parce que vous voulez que (quelqu’un) soit en mesure de vérifier ce qui se passe. On assiste depuis longtemps à une poussée en faveur d’une plus grande reproductibilité des processus de construction. Ces processus de compilation garantissent essentiellement qu’avec le même code d’entrée, on obtient le même résultat compilé. Cela signifie que si vous voulez savoir si quelqu’un vous a vraiment livré exactement ce qu’il a dit, vous pouvez le vérifier. Parce que votre processus de construction créerait un artefact identique.
Le projet Reproducible builds cherche à promouvoir la reproductibilité des systèmes libres, pour plus de transparence. Le projet est notamment financé par le Sovereign Tech Fund.
Bien entendu, tout le monde n’effectue pas ce niveau d’analyse. Et encore moins de personnes n’utilisent que des logiciels issus de processus de construction reproductibles – surtout si l’on considère que de nombreux logiciels ne sont pas compilés aujourd’hui. Mais les relations sont plus nuancées que le code et la confiance est une relation : si vous me parlez ouvertement de votre code et de la manière dont la version binaire a été construite, il me sera beaucoup plus facile de vous faire confiance. Savoir ce que contient le logiciel que j’exécute sur la machine qui contient également mes relevés bancaires ou mes clés de chiffrement.
Mais quel est le rapport avec l’IA ?
Les systèmes d’IA et les 4 libertés
Les systèmes d’IA sont un peu particuliers. En effet, les systèmes d’IA – en particulier les grands systèmes qui fascinent tout le monde – ne contiennent pas beaucoup de code par rapport à leur taille. La mise en œuvre d’un réseau neuronal se résume à quelques centaines de lignes de Python, par exemple. Un « système d’IA » ne consiste pas seulement en du code, mais en un grand nombre de paramètres et de données.
Un LLM moderne (ou un générateur d’images) se compose d’un peu de code. Vous avez également besoin d’une architecture de réseau, c’est-à-dire de la configuration des neurones numériques utilisés et de la manière dont ils sont connectés. Cette architecture est ensuite paramétrée avec ce que l’on appelle les « poids » (weights), qui sont les milliards de chiffres dont vous avez besoin pour que le système fasse quelque chose. Mais ce n’est pas tout.
Pour traduire des syllabes ou des mots en nombres qu’une « IA » peut consommer, vous avez besoin d’une intégration, une sorte de table de recherche qui vous indique à quel « jeton » (token) correspond le nombre « 227 ». Si vous prenez le même réseau neuronal mais que vous lui appliquez une intégration différente de celle avec laquelle il a été formé, tout tomberait à l’eau. Les structures ne correspondraient pas.
Ensuite, il y a le processus de formation, c’est-à-dire le processus qui a créé tous les « poids ». Pour entraîner une « IA », vous lui fournissez toutes les données que vous pouvez trouver et, après des millions et des milliards d’itérations, les poids commencent à émerger et à se cristalliser. Le processus de formation, les données utilisées et la manière dont elles le sont sont essentiels pour comprendre les capacités et les problèmes d’un système d’apprentissage automatique : si vous voulez réduire les dommages dans un réseau, vous devez savoir s’il a été formé sur Valeurs Actuelles ou non, pour donner un exemple.
Utiliser le système à n’importe quelle fin et sans avoir à demander la permission.
Étudier le fonctionnement du système et inspecter ses composants.
Modifier le système dans n’importe quel but, y compris pour changer ses résultats.
Partager le système pour que d’autres puissent l’utiliser, avec ou sans modifications, dans n’importe quel but.
Jusqu’ici tout va bien. Cela semble raisonnable, n’est-ce pas ? Vous pouvez inspecter, modifier, utiliser et tout ça. Génial. Tout est couvert dans les moindre détails, n’est-ce pas ? Voyons rapidement ce qu’un système d’IA doit offrir. Le code : Check. Les paramètres du modèle (poids, configurations) : Check ! Nous sommes sur la bonne voie. Qu’en est-il des données ?
Informations sur les données : Informations suffisamment détaillées sur les données utilisées pour entraîner le système, de manière à ce qu’une personne compétente puisse construire un système substantiellement équivalent. Les informations sur les données sont mises à disposition dans des conditions approuvées par l’OSI.
En particulier, cela doit inclure (1) une description détaillée de toutes les données utilisées pour la formation, y compris (le cas échéant) des données non partageables, indiquant la provenance des données, leur portée et leurs caractéristiques, la manière dont les données ont été obtenues et sélectionnées, les procédures d’étiquetage et les méthodes de nettoyage des données ; (2) une liste de toutes les données de formation accessibles au public et l’endroit où les obtenir ; et (3) une liste de toutes les données de formation pouvant être obtenues auprès de tiers et l’endroit où les obtenir, y compris à titre onéreux. Open Source Initiative
Que signifie « informations suffisamment détaillées » ? La définition de l’open source ne parle jamais de « code source suffisamment détaillé ». Vous devez obtenir le code source. Tout le code source. Et pas sous une forme obscurcie ou déformée. Le vrai code. Sinon, cela ne veut pas dire grand-chose et ne permet pas d’instaurer la confiance.
La définition de l’« IA Open Source » donnée par l’OSI porte un grand coup à l’idée d’open source : en rendant une partie essentielle du modèle (les données d’entraînement) particulière de cette manière étrange et bancale, ils qualifient d’« open source » toutes sortes de choses qui ne le sont pas vraiment, sur la base de leur propre définition de ce qu’est l’open source et de ce à quoi elle sert.
Les données d’apprentissage d’un système d’IA font à toutes fins utiles partie de son « code ». Elles sont aussi pertinentes pour le fonctionnement du modèle que le code littéral. Pour les systèmes d’IA, elles le sont probablement encore plus, car le code n’est qu’une opération matricielle générique avec des illusions de grandeur.
L’OSI met une autre cerise sur le gâteau : les utilisateurs méritent une description des « données non partageables » qui ont été utilisées pour entraîner un modèle. Qu’est-ce que c’est ? Appliquons cela au code à nouveau : si un produit logiciel nous donne une partie essentielle de ses fonctionnalités simplement sous la forme d’un artefact compilé et nous jure ensuite que tout est totalement franc et honnête, mais que le code n’est pas « partageable », nous n’appellerions pas ce logiciel « open source ». Parce qu’il n’ouvre pas toutes les sources.
Une « description » de données partiellement « non partageables » vous aide-t-elle à reproduire le modèle ? Non. Vous pouvez essayer de reconstruire le modèle et il peut sembler un peu similaire, mais il est significativement différent. Cela vous aide-t-il d’« étudier le système et d’inspecter ses composants » ? Seulement à un niveau superficiel. Mais si vous voulez vraiment analyser ce qu’il y a dans la boîte de statistiques magiques, vous devez savoir ce qu’il y a dedans. Qu’est-ce qui a été filtré exactement, qu’est-ce qui est entré ?
Cette définition semble très étrange venant de l’OSI, n’est-ce pas ? De toute évidence, cela va à l’encontre des idées fondamentales de ce que les gens pensent que l’open source est et devrait être. Alors pourquoi le faire ?
L’IA (non) open source
Voici le truc. À l’échelle où nous parlons aujourd’hui de ces systèmes statistiques en tant qu’« IA », l’IA open source ne peut pas exister.
De nombreux modèles plus petits ont été entraînés sur des ensembles de données publics explicitement sélectionnés et organisés. Ceux-ci peuvent fournir toutes les données, tout le code, tous les processus et peuvent être appelés IA open-source. Mais ce ne sont pas ces systèmes qui font s’envoler l’action de NVIDIA.
Ces grands systèmes que l’on appelle « IA » – qu’ils soient destinés à la génération d’images, de texte ou multimodaux – sont tous basés sur du matériel acquis et utilisé illégalement. Parce que les ensembles de données sont trop volumineux pour effectuer un filtrage réel et garantir leur légalité. C’est tout simplement trop.
Maintenant, les plus naïfs d’entre vous pourraient se demander : « D’accord, mais si vous ne pouvez pas le faire légalement, comment pouvez-vous prétendre qu’il s’agit d’une entreprise légitime ? » et vous auriez raison, mais nous vivons aussi dans un monde étrange où l’espoir qu’une innovation magique et / ou de l’argent viendront de la reproduction de messages Reddit, sauvant notre économie et notre progrès.
L’« IA open source » est une tentative de « blanchir » les systèmes propriétaires. Dans leur article « Repenser l’IA générative open source : l’openwashing et le règlement sur l’IA de l’UE », Andreas Liesenfeld et Mark Dingemanse ont montré que de nombreux modèles d’IA « Open-Source » n’offrent guère plus que des poids de modèles ouverts. Signification : Vous pouvez faire fonctionner la chose mais vous ne savez pas vraiment ce que c’est.
Cela ressemble à quelque chose que nous avons déjà eu : c’est un freeware. Les modèles open source que nous voyons aujourd’hui sont des blobs freeware propriétaires. Ce qui est potentiellement un peu mieux que l’approche totalement fermée d’OpenAI, mais seulement un peu.
Certains modèles proposent des fiches de présentation du modèle ou d’autres documents, mais la plupart vous laissent dans l’ignorance. Cela s’explique par le fait que la plupart de ces modèles sont développés par des entreprises financées par le capital-risque qui ont besoin d’une voie théorique vers la monétisation.
L’« open source » est devenu un autocollant comme le « Commerce équitable », quelque chose qui donne l’impression que votre produit est bon et digne de confiance. Pour le positionner en dehors du diabolique espace commercial, en lui donnant un sentiment de proximité. « Nous sommes dans le même bateau » et tout le reste. Mais ce n’est pas le cas. Nous ne sommes pas dans le même bateau que Mark fucking Zuckerberg, même s’il distribue gratuitement des poids de LLM parce que cela nuit à ses concurrents. Nous, en tant que personnes normales vivant sur cette planète qui ne cesse de se réchauffer, ne sommes avec aucune de ces personnes.
Mais il y a un autre aspect à cette question, en dehors de redorer l’image des grands noms de la technologie et de leurs entreprises. Il s’agit de la légalité. Au moins en Allemagne, il existe des exceptions à certaines lois qui concernent normalement les auteurs de LLM : si vous le faites à des fins de recherche, vous êtes autorisé à récupérer pratiquement n’importe quoi. Vous pouvez ensuite entraîner des modèles et publier ces poids, et même s’il y a des contenus de Disney là-dedans, vous n’avez rien à craindre. C’est là que l’idée de l’IA open source joue un rôle important : il s’agit d’un moyen de légitimer un comportement probablement illégal par le biais de l’openwashing : en tant qu’entreprise, vous prenez de l’« IA open source » qui est basée sur tous les éléments que vous ne seriez pas légalement autorisé à toucher et vous l’utilisez pour construire votre produit. Faites de l’entraînement supplémentaire avec des données sous licence, par exemple.
L’Open Source Initiative a attrapé le syndrome FOMO (N.d.T : Fear of Missing Out) – tout comme le jury du prix Nobel. Elle souhaite également participer à l’engouement pour l’« IA ».
Mais pour les systèmes que nous appelons aujourd’hui « IA », l’IA open source n’est pas possible dans la pratique. En effet, nous ne pourrons jamais télécharger toutes les données d’entraînement réelles.
« Mais tante, nous n’aurons jamais d’IA open source ». C’est tout à fait exact. C’est ainsi que fonctionne la réalité. Si vous ne pouvez pas remplir les critères d’une catégorie, vous n’appartenez pas à cette catégorie. La solution n’est pas de changer les critères. C’est comme jouer aux échecs avec les pigeons.
Dégooglisons Internet fête ses 10 ans : mises à jour et nouveaux services
Pétitions, Tableau blanc, Tricount-like, etc… De nouveaux services Framasoft sont en préparation, et des services existants sont en rénovation. On vous dit tout, et notamment pourquoi nous avons besoin de vous.
Cet article étant particulièrement long, on vous en propose ici un court résumé.
Il y a dix ans, nous annoncions notre campagne Dégooglisons Internet, qui fut un succès relativement retentissant : en couplant le plaidoyer (c’est à dire le fait de dénoncer la « triple domination » des GAFAM et leur toxicité) avec la mise en place de solutions concrètes, cette campagne de Framasoft a marqué les esprits, et nous pensons même en toute humilité qu’elle a été parfois un socle pour apporter une réponse structurée à l’envahissement des Big Tech dans nos vies.
Dans la foulée (en 2016), nous impulsions le collectif CHATONS, qui compte aujourd’hui plus de 80 structures.
Puis, quelques années plus tard, nous fermions une partie des services Dégooglisons. Les raisons étaient nombreuses (au moins 10 !) mais il y avait l’envie d’arrêter la course à l’échalote de la sortie de services, puisque nous en avions publié quasiment un par mois pendant trois ans. Notre épuisement (surtout post COVID) était alors à la hauteur de la pression du public.
Des CHATONS autonomisés pour des GAFAM atomisés ?
En parallèle le collectif CHATONS continuait sa montée en puissance. Coordonné par Framasoft, qui finançait son animation, nous estimons que fin 2023, l’association Framasoft a investi environ 100 000€ (essentiellement en temps de travail salarié) dans la mise en place de ce collectif.
Alors, certes, comme tout projet collectif, celui-ci comporte des faiblesses et des failles. Mais cette association de fait est réellement un succès à de nombreux points de vue :
la marque « CHATONS » est connue et reconnue par de très nombreux utilisateur⋅ices, qui peinaient à retenir les identités de nombreuses structures locales ;
le fait d’avoir un projet structurant a encouragé de nombreuses personnes à créer leur propre organisation. Ces personnes se sont senties légitimes à créer ou rejoindre des associations locales. Avoir réussi à faciliter ce « faire ensemble » est une véritable fierté pour nous ;
Le collectif est maintenant autonome et auto-géré depuis plusieurs mois, Framasoft étant depuis redevenu un « simple membre ».
Ne pas regarder le train du numérique passer
Cependant, en 10 ans, le numérique a bien évolué, et les GAFAM, les NATU, et autres BATX ne sont pas gentiment restées à attendre de se faire démanteler par des CHATONS ou la commission européenne.
Le cloud s’est généralisé, l’usage du mobile s’est imposé que ce soit pour payer son parcmètre ou ses impôts, l’intelligence artificielle participe certes d’une certaine hype, mais elle bouscule et percute aujourd’hui déjà de nombreux usages (et ce n’est qu’un début).
Dépenses des utilisateur⋅ices dans le cloud public entre 2017 et 2024
Estimation de dépenses liées à l’IA par secteur d’activité
Bref, le numérique est toujours plus présent, et pour le dire clairement, nous, militant⋅es du libre, des communs culturels et d’un numérique émancipateur n’avons gagné quasiment aucune bataille dans la lutte contre un adversaire gigantesque et tentaculaire. Cependant, le simple fait de critiquer, de se réunir, de manifester, de s’opposer, de proposer… est déjà une victoire en soi !
Il convient donc, aujourd’hui de « mettre à jour notre logiciel ». L’expression peut évidemment être entendue dans les deux sens. Mettre à jour notre façon d’agir, mettre à jour l’objet de nos luttes, relever la tête du guidon numérique libriste pour regarder comment le TGV du numérique capitaliste a évolué cette dernière décennie.
Cela s’est traduit par des prises de conscience pour Framasoft ces dernières années :
le libre est un moyen nécessaire (mais non suffisant) pour aller vers une société libre, mais il n’est pas une fin en soi. Savoir que du logiciel libre équipe des drones larguant des bombes en Palestine ou en Ukraine ne nous réjouit pas (litote) ;
la centralisation est une source de puissance pour les BigTech, la décentralisation est donc l’équivalent d’un caillou dans leur chaussure. Et dans ce cadre, la fédération (par exemple via ActivityPub) est une réponse pertinente, a minima pour explorer les interstices dans lesquels ces entreprises n’arrivent pas encore à se glisser ;
il y a une forme de « paradoxe de la tolérance » dans le libre : d’un côté une espèce de « pureté militante » à vouloir du 100% libre sans reconnaître que le libre est un chemin sur lequel chaque individu ou communauté se situe à une étape qui lui est propre ; et à l’inverse, une réelle difficulté du monde libre à reconnaître que l’autorisation explicite de réutiliser le travail produit par les communautés profite aussi largement aux géants du numériques qui, eux, n’ont ensuite aucun scrupule à mettre des bâtons dans les roues des projets de ces mêmes communautés ;
nous comprenons et adhérons à l’adage « Tout seul on va plus vite, ensemble on va plus loin. ». Nous croyons fortement dans l’intérêt des processus collectifs. Mais… en vingt ans d’existence, force nous a été de constater que « Ensemble, on va moins vite. » (sauf à être très bien organisé, ce qui n’est que rarement le cas des communautés libristes). Il y a souvent une énergie folle dépensée dans la structuration de nos luttes, souvent due à un impensé : l’animation/coordination est un métier, qui réclame des compétences souvent ignorées ou peu valorisées. Or comme on l’a vu, le numérique « avance » vite. ChatGPT 4 est sorti depuis ~18 mois, et quelle a été, à quelques exceptions près, la réaction du monde libriste ? Un silence plutôt assourdissant au mieux, des moqueries en mode « ça ne marchera jamais » au pire.
Ce sont ces raisons qui nous ont poussé⋅es ces dernières années à développer avec nos petits bras associatifs un logiciel comme PeerTube, ou à proposer des projets comme Emancip’Asso ou Framaspace, qui nous permettent de mettre nos compétences aux services de communautés la plupart du temps non-libristes, mais qui partagent nos valeurs.
Ainsi, dans le contexte social et politique actuel, il nous paraît essentiel de renforcer notre offre de services en ligne à dispositions des collectifs et militant⋅es.
Mais « mettre à jour notre logiciel » peut aussi être entendu d’un point de vue beaucoup plus littéral : il s’agit en effet de mettre à jour les logiciels qui motorisent notre campagne « Dégooglisons Internet », voire d’en proposer de nouveaux au public.
Mettre à jour son logiciel (intellectuel) ou mettre à jour son logiciel (sur son serveur) ?
Framasoft ouvre et va rouvrir de nouveaux services
« Hein ? Quoi ? Mais vous n’aviez pas dit que vous vouliez « déframasoftiser internet » ? »
Mais 4 à 5 ans ont passé depuis. Et il faut bien se rendre à l’évidence, la situation est moins propice au libre aujourd’hui qu’à l’époque. Pour les raisons évoquées ci-dessus, et bien d’autres encore.
L’année précédente, c’était l’ouverture de Framaspace, espace cloud destiné aux petites associations et collectifs militants. Nous hébergeons à ce jour plus de 1 130 Framaspaces, soit autant d’instances du logiciel Nextcloud, le tout gratuitement.
Cette année encore, Framasoft souhaite proposer de nouveaux services. Toujours gratuitement (enfin, pas tout à fait, puisque ce sont vos dons qui financent), toujours respectueux de votre vie privée, toujours sur la base de logiciels libres, toujours sans aucune exploitation commerciale de vos données. Car les usages numériques évoluent, et nous devons évoluer avec eux. Ou plutôt nous devons évoluer avec vous, car ce sont avant tout le cheminement de vos pratiques qui guide nos actions.
Nous sommes bien conscient⋅es que ça peut donner cette impression.
En conséquence, cette seconde campagne « Dorlotons Dégooglisons » nous permet de faire le point sur ce que nous avons fait depuis un an, mais aussi ce sur quoi nous travaillons en ce moment, ainsi que ce que nous envisageons pour les mois à venir.
Passez à l’action ! Framasoft souhaite ouvrir de nouveaux services libres, éthiques, décentralisés et solidaires. Pour cela, nous nous sommes fixés un objectif de collecte de 60 000€ pour nous permettre de financer les machines, mais surtout le temps de travail pour leur mise en place. Si vous le pouvez : soutenez-nous !
Nous avons publié le service Framagroupes. Pour information, aujourd’hui, ce service expédie plus de 50 000 mails par jour (!) et accueille déjà 7 900 listes de discussions, ce qui, avec les 59 000 listes de Framalistes, fait probablement de Framasoft l’organisation à but non lucratif hébergeant le plus gros serveurs de listes au… monde (si on compare par exemple à RiseUp (15,225 listes 389,871 utilisateur⋅ices) ou Renater/Universalistes (1 600 listes).
À cause d’utilisations (très) malveillantes de Framatalk, nous avons développé un logiciel (libre, bien entendu) qui permet d’imposer l’authentification des personnes qui souhaitent ouvrir un salon de visioconférence. Si on peut entendre que cela représente une contrainte pour vous, au vu des usages (on le répète, très) malveillants qui étaient faits de ce service, nous n’avions tout simplement pas le choix.
Nous avons migré plus de 1 000 instances Framaspace en version 28. Nous avons fait développer un logiciel de supervision spécifique, Argos Panoptès, pour gérer autant d’instances.
Notre infrastructure email, malgré plus de 8 millions de mails envoyés par mois (oui oui, 271 000 mails en moyenne par jour !) continue d’être régulièrement boudée par certains acteurs (oui, c’est vous qu’on regarde Orange, La Poste et SFR !). À tel point qu’après une lutte de plusieurs mois qui nous aura demandé autant d’énergie que de paracétamol, nous avons dû nous résoudre, à contrecœur, à utiliser les services d’un prestataire externe, pour les envois de nos newsletters (431 129 abonné⋅es en double opt-in).
Du côté de Framaforms, nous avons amélioré la gestion du spam, cette chienlit qui n’en finit pas de revenir dégrader un service pourtant parmi les plus utilisés de Framasoft.
C’est vrai, ça, hein : et personne ne le prendrait au sérieux !
Pour faciliter les recherches de vidéos sur l’ensemble du réseau PeerTube (notre alternative à YouTube), nous avons changé le logiciel qui motorise Sepiasearch, notre moteur de recherche du « vidiverse». Ce dernier utilise maintenant la brique logicielle Meilisearch, et non plus Elasticsearch, dont la licence a pris un chemin bien moins libre.
Framacarte a aussi fait l’objet d’une mise à jour majeure, qui fait suite au travail de la communauté uMap, avec laquelle nous restons très en lien.
Concernant MyPads, le plugin qui permet de gérer et d’organiser vos Framapad, les changements ont été subtils, mais nombreux. Ainsi, grâce au travail de Pierre, stagiaire à Framasoft pour (seulement) 6 semaines, de nombreuses petites améliorations ont été faites.
Parmi les améliorations d’ores et déjà disponibles :
ajout d’un logo pour revenir à l’accueil (oui, c’est bête, mais il n’y en avait pas et beaucoup d’utilisateur⋅ices peinaient à retourner sur la page d’accueil)
meilleure identification des dossiers restreints ou publics
les dossiers archivés sont maintenant repliés par défaut pour une meilleure lisibilité
les propriétés du dossiers sont maintenant repliées par défaut pour une meilleure lisibilité
la recherche, en page d’accueil, permet maintenant de rechercher sur les noms de pads (en plus des dossiers)
possibilité de trier les dossiers ou les pads par noms ou par dates de création
Quelques améliorations de MyPads apportées par Pierre, stagiaire Framasoft
Quelques améliorations de MyPads apportées par Pierre, stagiaire Framasoft
Enfin, Mobilizon, notre logiciel libre et fédéré alternatif aux groupes et pages Facebook, a été transmis à la communauté (aujourd’hui coordonnée par la communauté Kaihuri/Keskonfai). Nous annoncions en effet il y a quelques mois que nous estimions notre engagement initial concernant Mobilizon rempli. Nous souhaitions pouvoir rediriger une partie de notre capacité de développement logiciel vers les projets les plus prioritaires (contrairement à ce que beaucoup de personnes pensent, en dehors de PeerTube, nous ne disposons « que » d’un mi-temps de développeur salarié).
Passez à l’action ! Framasoft accueille plus de 2 millions de personnes par mois, et améliore et maintient de très nombreux services tout au long de l’année. Cela implique énormément de travail humain (développement, support, administration système, etc), ainsi qu’une infrastructure technique conséquente. Si vous le pouvez : soutenez-nous !
Il existe de nombreuses plateformes de pétitions, mais ces dernières ne sont que rarement basées sur du code libre. Par ailleurs, ces plateformes sont aussi largement soupçonnées d’utiliser vos données personnelles (nom, email, cause soutenue) à d’autres fins que d’ajouter votre signature à une pétition.
Framapétitions est donc un service en test (on répète : il n’est PAS finalisé) qui permet de créer ou signer des pétitions citoyennes. Le service peut d’ores et déjà être utilisé, mais reconnaissons-le, il mérite encore d’être amélioré. Ça tombe bien, nous allons travailler dessus dans les mois qui viennent.
Dans les coulisses
Un projet de plateforme de pétitions qui n’exploiterait pas vos données était donc dans nos cartons depuis plus de 10 ans. Mais… faute de temps et d’énergies, nous repoussions sans cesse le sujet. Une autre raison était plus politique : à quoi servent vraiment les pétitions ? Parfois uniquement à se donner bonne conscience en se disant « J’ai agi », nous dédouanant alors d’un passage à l’action plus directe. Cependant, vos demandes régulières à ce que nous avancions sur le sujet nous ont motivés à remettre ce projet au goût du jour.
Voilà plusieurs années que nous soutenons un projet libre nommé « Pytition« . Fonctionnel, mais nécessitant encore pas mal de travail sur les aspects visuels. Nous soutenir financièrement, c’est nous permettre d’allouer du temps de travail pour améliorer Pytition, en lien avec le développeur originel et permettre, à moyen terme, d’ouvrir une plateforme de pétitions réellement libre, ouverte, et avec une garantie de non-exploitation commerciale de vos données.
Framalab, pour expérimenter des logiciels avant qu’ils ne deviennent (potentiellement) des services
Mettre en place un logiciel utilisable en ligne est assez simple, surtout quand, comme nous, vous disposez d’un administrateur système très compétent. Cependant, entre installer un service en ligne et être capable d’y accueillir plusieurs centaines de milliers de personnes par mois, il y a tout un monde. Il faut tester les fonctionnalités du logiciel, évaluer sa maintenance, savoir jauger le temps et l’énergie qu’il nous prendra en support et en modération, créer une page d’accueil, parfois corriger quelques bugs gênants, constituer une Foire Aux Questions, communiquer dessus, etc.
Afin de faciliter ce processus, nous avons décidé de rendre public le site Framalab. Sur ce site vous trouverez quelques unes de nos applications en test.
Notez bien que les applications qui suivent sont en test. Elles peuvent disparaître à tout moment, ce qui signifie que vous pouvez perdre vos données du jour au lendemain. Par ailleurs, elles ne feront l’objet d’aucun support de notre équipe salariée : si vous avez des questions ou rencontrez des difficultés, vous pouvez les remonter sur notre forum, où l’entraide sera communautaire (comprendre : peut-être que quelqu’un vous répondra, peut-être pas).
Tricount est une application (non libre) de gestion des dépenses de groupes (familles, ami⋅es, colocataires, etc).
Elle compte plus de 5 millions d’utilisateur⋅ices dans le monde.
L’application fonctionnait auparavant très bien sur le web, qui s’affichait dans une version mobile tout à fait correcte. Mais depuis peu la version web n’est plus disponible, et vous êtes obligé⋅es de télécharger et installer une application web sur votre smartphone. Nos ami⋅es d’ Exodus Privacy détectent, sur cette application, pas moins de 12 pisteurs et 16 permissions. D’où l’idée de vous proposer des alternatives libres, garanties sans pisteurs.
I Hate Money
Un « petit » projet libre comme on les aime : il fait une chose, mais la fait bien, et sans fioriture. Par exemple pour un voyage entre ami⋅es, une première personne créée un projet (pas besoin de créer un compte : il suffit de choisir un nom, de définir un code d’accès, et de laisser un email). Les autres personnes pourront alors s’y connecter, et ajouter chacune leurs dépenses. Au final, un clic sur « remboursement » permettra de savoir très facilement « Qui doit combien à qui ? ». Simple, rapide, efficace, on vous dit !
Cette application, née en 2011, n’a peut-être pas le « look and feel » le plus moderne. Cependant, nous l’avons testé en conditions réelles, et… elle fonctionne très très bien et nous l’avons trouvée simple et efficace sur mobile. Elle a principalement été développée par Alexis Métaireau (oui, le même qui a développé pour nous Argos Panoptes, que nous évoquions plus haut dans la partie « Framaspace »).
Encore une fois, un petit projet très simple, mais avec un look résolument moderne : pas besoin de s’authentifier, quelqu’un créé un groupe, puis ensuite ajoute des participant·es, et enfin leur partage l’URL. Tout le monde peut rentrer des dépenses simplement, et l’application calcule ensuite automatiquement qui doit quoi à qui. Il est possible d’utiliser des modes de partage plus avancés : par nombre de portions ou encore par pourcentage. Seul hic, le projet est à l’heure actuelle uniquement anglophone, donc il vous faudra comprendre a minima la langue de Shakespeare pour pouvoir l’utiliser. Sans pour autant le garantir, si cela devait devenir un service Framasoft, peut-être que notre communauté pourrait aider à le rendre traductible puis à le traduire pour un public francophone !
Vous connaissez peut-être Cospend, l’application Nextcloud qui propose des fonctionnalités similaires. Nous avons choisi de ne pas expérimenter avec cette dernière, pour plusieurs raisons. La première, c’est qu’elle nécessite une instance de Nextcloud (bravo Sherlock !), et que cela signifierait de mettre en place une instance de Nextcloud uniquement dédiée à ce service. La deuxième, c’est qu’il faudrait également rajouter des modifications au logiciel, pour que les utilisateur·ices de l’instance ne puissent pas ajouter n’importe qui d’autre utilisant le service à un groupe de dépense. La troisième, c’est que la version Web mobile nous a semblé peu utilisable (avec des écrans qui se recouvrent les uns les autres), et bien qu’une application mobile Android MoneyBuster propose en théorie de se lier à un Cospend, en pratique il n’est plus possible de rejoindre un groupe de dépense Cospend avec cette dernière, et ce depuis quelques mois, sans visiblement de résolution apparente de ce bug critique). Alors on sait ce que c’est qu’être bénévole sur un logiciel libre, donc on ne jettera la pierre à personne, et au contraire on encouragera le développement, depuis les gradins. Mais en l’état actuel, cela nous semble plutôt une alternative dont l’évolution est à surveiller, ou viable à utiliser sur des instances Nextcloud (coucou les Framaspaces !), plutôt qu’un service que nous voudrions proposer à grande échelle. Affaire à suivre…
Draw.io permet de créer des diagrammes professionnels. Ce service est plutôt adapté si vous souhaitez réaliser un organigramme ou un diagramme UML.
Interface de Draw.io
Dans les coulisses
La version de Draw.io que nous proposons actuellement est une version offline dans le sens où elle ne permet que l’enregistrement local, et ne permet pas la modification collaborative.
Il faut donc considérer notre version de draw.io comme un logiciel « à l’ancienne » où vous allez créer votre diagramme (dans votre navigateur), puis l’enregistrer. Il est cependant possible de partager votre diagramme publiquement (en lecture seule) en utilisant la commande « Fichier → Publier → Lien ».
Nous avons tout de même ajouté la possibilité d’enregistrer vos données sur Framagit (il faudra vous y créer un compte).
Les fonctions collaboratives en temps réel imposent, elles, de passer par les serveurs de la société Jgraph qui édite le logiciel, elles ne sont donc pour le moment pas supportées.
Nous choisissons cependant de tester draw.io car nous le trouvons très intéressant de par ses fonctionnalités avancées. Peut-être le proposerons nous, à terme, comme plugin au sein de Framaspace.
Là où Draw.io permet d’organiser des diagrammes, voyez plutôt Excalidraw comme un outil de « tableau blanc » (qui permet, aussi, de réaliser des diagrammes simples).
Cette simplicité rend Excalidraw, selon nous, plus accessible au grand public.
Dans les coulisses
Contrairement à Draw.io, notre version d’Excalidraw permet de travailler de façon collaborative. Nous expérimentons cette fonctionnalité, mais nous pourrions la retirer si nous ne la trouvons pas suffisamment stable et sécurisée. Cependant, Excalidraw utilisant à ce jour la plateforme Firebase de Google pour enregistrer les images en ligne, nous avons pour l’instant désactivé la possibilité d’ajouter des images dans notre version d’Excalidraw.
Notez que nous avons aussi évalué le logiciel tldraw, qui nous a paru une initiative intéressante, mais sa licence n’est pas libre car interdisant les usages commerciaux (ce qui n’aurait pas été le cas de Framasoft, mais ne répond pas pour autant aux exigences d’une licence libre).
Excalidraw, un tableau blanc pour mettre en forme vos idées collaborativement
Ahhhh, les PDF ! Un format ouvert certes, pratique pour l’impression, mais clairement pas adapté à la modification. Si vous devez réorganiser des pages, en supprimer, en ajouter, les faire pivoter, ou les signer, c’est assez rapidement la croix et la bannière. Par ailleurs, il faut parfois pouvoir réduire leur poids avant de l’envoyer par email. Ça tombe bien, les deux outils que nous proposons sont là pour ça !
Signature PDF
Créé par la société coopérative « La 24eme », ce logiciel permet, au travers de quelques entrées simples, de manipuler vos PDF :
« Signer » : permet de signer, parapher, tamponner un pdf, mais aussi de partager le PDF signé, pour qu’il puisse être signé par d’autres personnes ;
« Organiser » : permet de tourner les pages d’un PDF (rotation), de déplacer des pages, d’en supprimer, d’en ajouter (depuis un autre PDF, par exemple pour faire un seul PDF à partir de plusieurs fichiers), etc.
« Métadonnées » : permet d’afficher les métadonnées d’un fichier PDF (par exemple la date de création ou le logiciel utilisé pour sa création), mais aussi d’éditer ces métadonnées ou d’en supprimer ;
« Compresser » : pour réduire la taille d’un PDF. Si le PDF original a déjà été compressé, cela n’aura aucun effet évidemment. Mais nos tests ont démontré qu’un PDF constitué de pages scannées de 38Mo au départ n’en faisait plus que 6 au final, ce qui est un gain conséquent.
Là, on sort la grosse artillerie. Stirling PDF propose pas moins de 71 outils différents !
Depuis des outils « simples » (fusion, rotation, etc) à ceux bien plus complexes (extraire les tableaux d’un PDF pour un faire un fichier .csv exploitable par un tableur, ajuster les couleurs, transformer une URL de page web en PDF, etc), en passant par des fonctions bien utiles (protéger par mot de passe, numéroter automatiquement les pages, etc.). Il existe même un outil « pipeline » qui permet d’enchaîner différentes actions (par exemple : rotation 90°, puis suppression des pages 1 et 14, puis ajout de numéros de pages, puis compression).
Framaforms est basé sur le logiciel Yakforms, logiciel qui arrive en fin de vie. Pour différentes raisons (cf. « coulisses »), nous avons dû faire le choix de lui trouver un successeur, qui permettra de continuer à fournir un service proche de celui que vous utilisez actuellement.
Après moult essais-recherches (et quelques déceptions), notre choix s’est arrêté sur Liberaforms, un logiciel libre de formulaires créé et développé par une petite équipe espagnole.
Le « périmètre fonctionnel », c’est à dire l’ensemble de ce que vous pouvez faire avec ce logiciel, est sensiblement le même que celui que propose Yakforms, en dehors de certaines fonctions avancées (gestion de conditions, ou emails de validation, par exemple). Nous vous proposons de le tester sur notre plateforme https://beta.framaforms.org pendant plusieurs mois. Au terme de cette phase de tests, pendant laquelle nous pensons (si vous nous en donnez les moyens) améliorer quelque peu l’interface, nous pourrons alors commencer une bascule entre Yakforms et Liberaforms qui, rassurez-vous, s’étalera elle aussi sur plusieurs mois (vous ne perdrez donc pas vos formulaires en cours).
L’histoire de Framaforms/Yakforms s’étale sur près de 10 ans et est racontée sur le Framablog. Yakforms est donc basé sur Drupal 7, publié en 2011, qui aura donc eu une durée de vie de 14 ans, ce qui en fait une longévité relativement exceptionnelle pour une application web. La « fin de vie » de Drupal 7, plusieurs fois repoussée, s’achève finalement le 5 janvier 2025. À compter de cette date, il n’y aura donc plus de mise à jour de sécurité : si une faille était découverte, elle ne serait plus couverte (annoncée, réparée, suivie, etc) par la communauté, et donc Yakforms serait touché par ricochet.
Notre première idée a donc été, évidemment, de migrer Yakforms vers Drupal 8, 9, ou même maintenant Drupal 10. Cependant, c’était plus facile à dire qu’à faire, car Yakforms est composé de nombreux modules compatibles avec Drupal 7 mais pas avec les versions suivantes. C’est notamment le cas du module « form_builder » qui n’a jamais été porté dans les versions suivantes.
Il y a eu différentes tentatives de migration de Yakforms, la dernière en date par le Centre d’Expressions Musicales, au Havre, qui utilise massivement Framaforms (et bien d’autres logiciels libres, d’ailleurs). Mais le sujet étant complexe, le projet n’a pas abouti.
Début 2024, nous nous sommes donc lancés à la recherche de logiciels libres de formulaires alternatifs. Bonne nouvelle : le paysage avait bien évolué depuis la sortie de Framaforms en 2016, et de nombreuses alternatives existent aujourd’hui. Voici quelques unes des solutions testées :
https://www.limesurvey.org/fr : la référence en matière de logiciel libre d’enquête. Cependant, « enquête » ≠ « formulaire » ! LimeSurvey est un logiciel idéal si vous voulez réaliser une enquête de plusieurs dizaines ou centaines de questions, avec des embranchements, etc. Mais notre objectif avec Framaforms est de proposer une alternative à Google Forms, à savoir un logiciel simple à prendre en main, qui permet de publier son premier formulaire en 5mn chrono. Ce qui est très, très loin d’être le cas de LimeSurvey ;
https://apps.nextcloud.com/apps/forms : une app pour Nextcloud (logiciel que l’on connaît bien à Framasoft) pour créer des formulaires. Ce choix est arrivé en second dans notre évaluation. D’autant que nos ami⋅es du chaton La Contre-Voie ont apporté un développement spécifique permettant un accès simplifié. Mais nous avons estimé que le code de Nextcloud Forms n’était pas encore suffisamment stable pour nos besoins, ni capable d’accueillir des dizaines de milliers de visiteurs quotidien ;
https://cryptpad.fr/form/ : issu de l’excellente suite bureautique chiffrée Cryptpad. L’interface n’est pas très jolie, mais plutôt fonctionnelle. Cependant, le côté 100% chiffré du logiciel était, paradoxalement, rédhibitoire pour nous : nous gérons plusieurs centaines de milliers de formulaires par an, et un chiffrement de bout en bout aurait largement limité notre capacité de support, et donc multiplié les personnes qui se seraient plaintes auprès de nous ;
https://formbricks.com/ : ce logiciel nous a semblé tout à fait correct. Par contre, il est pensé pour faire de « l’enquête pas à pas » et non des formulaires. Par ailleurs, il nous aurait fallu adapter de nombreuses fonctionnalités (souvent marquées comme « pro » ;
https://getinput.co : comme SurveyJS, il s’agit plus d’une alternative à Typeform qu’à GoogleForms, avec « une question = un écran ». Le travail de traduction aurait été conséquent, mais nous l’avons éliminé aussi parce que bien que le code soit libre, l’entreprise qui édite ce logiciel semble avoir une politique commerciale relativement agressive et n’aurait probablement pas bien accepté de voir Framasoft proposer son logiciel gratuitement, devenant un concurrent de poids qui aurait « récupéré » leur travail ;
https://ec.europa.eu/eusurvey/ : Développé par l’Union Européenne depuis 2016. Le rythme de développement est relativement lent. Ça aurait pu être un candidat intéressant, mais le code nous a semblé une véritable usine à gaz, puisque conçu pour gérer des formulaires au sein d’institutions publiques de grandes tailles, avec l’obligation de gérer plusieurs langues, etc ;
https://ohmyform.com/ : là encore, plutôt une alternative à Typeform qu’à Google Forms. Notez qu’en l’absence de plateforme pour tester ce logiciel, il vous faudra donc l’installer. Par ailleurs, le développement, bien que toujours en cours, semble relativement ralenti ;
https://tripetto.app/ a clairement le concepteur de formulaire le plus avancé. Malheureusement le logiciel est uniquement en anglais (et non facilement traduisible). Mais surtout, si le « builder » (l’interface de création de formulaire) est libre, d’autres parties essentielles du logiciel ne le sont pas, ce qui était évidemment rédhibitoire pour nous ;
Nous avons aussi évalué plusieurs outils « no-code » (comme NocoDB ou Baserow) qui sont aussi très pertinents pour créer des formulaires. Cependant, nous avons estimé que nous n’étions pas sur des outils simples à prendre en main alors que c’était un critère essentiel pour nous. Nous n’excluons pas de proposer ces outils à termes, mais cela nous paraissait prématuré pour le moment.
https://gitlab.com/liberaforms/liberaforms – ce n’est ni la plus belle, ni la plus moderne des alternatives testées. Cependant, elle fait correctement le travail, et semble bien pouvoir passer à l’échelle en gérant plusieurs dizaines ou centaines de milliers de formulaires. Par conséquent, nous avons contacté les développeurs de Liberaforms, qui semblaient enchantés que Framasoft propose leur logiciel à l’évaluation (merci à eux !).
Le logiciel n’était pas traduit en français, alors… nous l’avons fait ! Un grand merci à Framalang, spf et Booteille pour leur aide !
Dans les mois qui viennent, grâce à vos dons, nous nous appliquerons donc à finaliser la traduction, à améliorer l’interface (notre code sera bien évidemment reversé auprès de la communauté Liberaforms), et évaluerons vos retours pour déterminer si, oui ou non, Liberaforms remplacera à terme Yakforms comme moteur de Framaforms.
Framaspace, de l’accompagnement pour une plus grande autonomisation
Framaspace accueille plus de 1 100 associations et collectifs. Nous envisageons de doubler ce chiffre, au moins, d’ici la fin de l’année. Ce qui positionne Framasoft comme un des plus gros hébergeurs Nextcloud (le logiciel qui motorise Framaspace) de France, hors opérateurs type OVH.
Mais il nous reste un problème majeur auquel il faut répondre : comment accompagner les personnes qui découvrent Nextcloud ? En effet, comme nos enquêtes le démontraient, et comme nous l’indiquions dans notre conférence de lancement, Nextcloud reste relativement peu connu, et pas aussi simple à prendre en main qu’un Google Drive, par exemple. Il nous faut donc trouver des façons qui permettent à une personne qui n’a jamais utilisé le logiciel de s’y retrouver : qu’elle puisse importer ses fichiers ou calendriers, qu’elle sache comment partager publiquement un fichier, qu’elle comprenne comment utiliser le tableur ou le traitement de texte intégré, etc.
Nos actions en cours sont nombreuses sur le sujets : nous soutenons par exemple l’initiative d’ateliers Nextcloud (en juin 2024) organisé par L‘Établi Numérique et La Dérivation. Nous avons aussi un stagiaire, Val, qui travaille sur deux sujets : faciliter la migration depuis un espace cloud externe (Google Drive, Dropbox, ou même un autre Nextcloud) vers Framaspace ; proposer un tutoriel aux nouvelles et nouveaux arrivants sur Framaspace, en utilisant la bibliothèque IntroJS.
Vidéo de démonstration de l’application IntroJs, développée par Val, pour faciliter la prise en main de Framaspace.
Là encore, vos dons nous permettent de faire, et surtout de faire sans trop attendre.
Passez à l’action ! Pour pouvoir répondre à vos besoins et vos envies en termes de services libres émancipateurs, nous nous sommes fixés un objectif de collecte de 60 000€ qui nous permettront de mettre l’énergie nécessaire à la mise en place de ces services. Si vous le pouvez : soutenez-nous !
D’autres projets sont en cours, mais sont, eux, plus incertains.
Leur mise en place dépendra évidemment du succès de cette collecte (oui, on manque peut-être un peu de subtilité 😉), mais aussi des résultats des études de faisabilité technique qui sont en cours.
Nous pouvons cependant les évoquer ici, en insistant sur le fait qu’en parler maintenant n’est pas pour autant un engagement de mise en place de notre part.
Aktivisda : décliner des visuels rapidement
Un des besoins récurrents repérés parmi les associations que Framasoft côtoie est celui de pouvoir rapidement créer ou décliner des visuels. Par exemple, pour une chorale qui ferait 5 représentations en fin d’année, il s’agit surtout, sur la base d’un affiche commune, de changer les dates, les heures, et les lieux. C’est un besoin simple, qui doit prendre quelques minutes maximum, afin de consacrer l’essentiel du temps et de l’énergie à imprimer et diffuser les affiches.
C’est aussi le même besoin qui revient avec les réseaux sociaux, où le besoin est d’avoir un visuel commun identifiable (par exemple avec le logo de l’association), puis de pouvoir ajouter un texte dessus pour inviter à une action ou un événement.
Par ailleurs, mettre à disposition ce type d’outil permettant en quelques clics de partager un visuel (une affiche, par exemple), de l’imprimer, ou de créer un code QR personnalisé, nous semble utile dans le contexte social et politique actuel.
Ce sont justement à ces besoins que répond le logiciel Aktivisda.
Éditer un visuel dans Aktivisda (un message subliminal s’est glissé dans cette capture, saurez-vous le retrouver ?)
Pour l’instant, aucune version « diffusée par Framasoft » n’est disponible, mais nous travaillons avec le développeur originel, ainsi que la société qui l’emploie (Telescoop) afin de faciliter son déploiement pour de multiples organisations, ainsi que l’ajout de nouveaux visuels (il faut actuellement passer par Framagit, ce qui peut être fastidieux).
Nous espérons donc, d’ici la fin de l’année, revenir avec de bonnes nouvelles du côté de Aktivisda 🙂
C’est un peu par hasard, lors des JDLL 2023 que nous avons découvert Aktivisda. En décembre 2023, nous rencontrions alors son développeur, Marc-Antoine, avec qui nous avons discuté de ses projets pour Aktivida, mais aussi de nos envies et de nos besoins d’un logiciel plus simple à déployer. Les échanges se sont poursuivis ponctuellement, mais régulièrement, avec l’objectif de rendre le logiciel multi-tenant, c’est à dire facilement utilisable par de multiples individus ou organisations. Marc-Antoine et ses collègues sont actuellement en train d’explorer le sujet (de façon bénévole, précisons-le), et nous y verrons donc plus clair d’ici quelques semaines.
Framaspace : gestion des adhérent⋅es, de la comptabilité, nouvelles applications
Comme évoqué plus haut, l’année 2024 sera largement dédiée à améliorer la prise en main et l’accompagnement des utilisateur⋅ices qui découvrent Framaspace.
Cependant, cela ne signifie pas que nous n’allons pas avoir de missions plus techniques. Ainsi, nous comptons passer tous les espaces en version 29 (vous pouvez en lire une description en français chez nos ami⋅es d’Arawa. En parallèle, nous allons évaluer l’ajout de quelques applications, comme par exemple Tables qui permet de construire et partager une petite base de données, ou Impersonate pour permettre à l’admin d’un espace de dépanner un utilisateur. Suivant vos retours sur Excalidraw (évoqué plus haut), nous pourrons aussi le proposer comme application complémentaire.
Tables dans Framaspace : créer des tableaux pour différents usages
Tables dans Framaspace : des formulaires pour que vos utilisateur⋅ices puissent saisir leurs données
Tables dans Framaspace : visualisez et manipulez vos données
Cependant, le plus gros du travail, qui commencera au second semestre 2024, sera de voir jusqu’où nous pouvons aller dans l’intégration de Paheko dans Framaspace. Paheko est un logiciel libre de gestion d’associations complet et qui bénéficie aujourd’hui d’une belle réputation. De plus son développeur est français, et impliqué dans différentes communautés libristes depuis longtemps. Lors du dernier camp CHATONS, nous avons commencé à discuter de la possibilité d’intégrer des parties de Paheko à Framaspace. Notamment, nous savons que pouvoir gérer les adhérent⋅es (dates d’entrée et sortie de l’association, gestion des cotisations, etc.), mais aussi la comptabilité (suivant le Plan Comptable Associatif) seraient de gros avantages pour Framaspace. Pour l’instant, nous sommes toujours dans une démarche exploratoire, mais l’idée nous paraît suffisamment importante pour que nous y consacrions du temps et de l’énergie.
Nous ne sommes pas climato-sceptiques. Nous considérons que le réchauffement climatique est la mère de toutes les batailles. Nous pensons que la réponse au dérèglement climatique est avant tout politique, et nous sommes irrité⋅es de voir à quel point les politiques publiques sont avant tout orientées, parfois de façon très culpabilisantes, sur les gestes individuels. Cependant, pour pouvoir correctement faire face à un problème et y répondre de façon pertinente, il peut être utile de bien comprendre les enjeux, mais aussi les leviers sur lesquels agir. C’est dans cette optique que Framasoft, en partenariat avec le groupement de recherche Labos 1point5 souhaite proposer, à moyen terme, une application en ligne permettant d’évaluer l’empreinte carbone de son association (ainsi qu’un simulateur permettant de voir l’impact de chaque levier activable).
Possibilité de jouer sur des leviers impactant l’empreinte carbone
Évaluation de l’empreinte carbone
Saisie de données dans l’application 1point5
Dans les coulisses
Il n’y a pas, et il n’y aura jamais de numérique « vert ». Le numérique est intrinsèquement écocidaire. Cependant, nous vivons dans un monde où le numérique existe, et a aussi des apports (pour calculer, pour communiquer, pour être en lien, pour faire ensemble, etc.). Et ni vous, ni nous, ni personne, ne peut faire disparaître le numérique d’un claquement de doigts. C’est ce qu’on appelle une problématique complexe, face à laquelle aucune solution n’est triviale. Les solutions aux problèmes complexes reposent souvent sur des décisions politiques à grande échelle. Et le plus souvent, ces décisions font face à une grande réactance au début, ce qui est assez naturel.
Concernant le réchauffement climatique, nous ne croyons pas aux « petits pas », et nous condamnons les politiques publiques qui pointent beaucoup plus facilement les gestes individuels (le fameux « pipi sous la douche ») plutôt que les actions à grande échelle.
Cependant, pour bien comprendre un problème complexe, il faut pouvoir prendre conscience des « sous-problèmes » qui le composent. Et là, ça tombe bien, Framasoft peut avoir un (petit) rôle à jouer.
Ainsi, nous avons été contacté·es il y a quelques mois par le Groupement de Recherche Labos 1point5 qui propose, pour les labos de recherche (Universités, CNRS, etc.) des outils pour évaluer et comprendre l’empreinte carbone liée au laboratoire. Ils et elles nous ont annoncé travailler sur un outil équivalent, mais destiné aux associations et nous ont demandé si nous serions d’accord pour « porter » ces outils auprès du monde associatif.
Pour être franc⋅hes, nous avons d’abord hésité, car ce genre d’outils fait souvent l’objet de gros biais de calcul, et « oublie » le scope 3 (et même parfois le scope 1). Mais nous avons testé l’outil, et l’avons trouvé très complet. Par ailleurs, le fait que ces outils soient produits par des chercheuses et chercheurs pointu⋅es sur ce sujet permet de sortir des nombreuses démarches marketing de « greenwashing » que l’on peut observer ces derniers temps.
Nous avons donc entamé un dialogue qui nous semble fort constructif. Pour l’instant, nous laissons l’équipe de recherche avancer sur le sujet, et nous vous tiendrons informé⋅es des avancées d’ici quelques mois.
D’ici là, si votre association est intéressée à tester lesdites avancées ou à participer aux échanges avec les chercheuses et chercheurs, vous pouvez vous inscrire au panel d’associations testeuses.
Ah… Framadate sur mobile… Si on avait touché 1€ à chaque fois que l’on avait reçu une plainte concernant l’usage de Framadate sur smartphone, nous n’aurions probablement pas besoin de faire de collecte 😅.
Cependant, le code de Framadate est tellement daté (certaines parties du code datent de 2008) qu’il paraît aujourd’hui bien plus simple de repartir de zéro.
Bref, ça ne sera pas pour tout de suite, et surtout, on ne sait pas encore quelle sera la voie (longue, mais libre) suivie par Framasoft, mais les choses avancent 🙂
Nous étudions aussi de près la possibilité de mettre à votre disposition des outils « No Code » comme Baserow ou NoCoDB, car ils nous semblent répondre à des besoins courants. Cependant d’un point de vue technique, ce n’est pas simple (ces logiciels sont gourmands et coûtent donc cher à héberger), et il s’agit de logiciels un peu complexes à prendre en main, donc il faudrait aussi travailler à leur accompagnement.
Pour tout cela, nous avons (encore) besoin de votre aide
Félicitations si vous nous avez lu jusqu’ici, car nous avions beaucoup à dire !
Vous l’aurez compris, de nombreux chantiers sont en cours, et il nous faudra des semaines, voire des mois, pour les faire avancer.
Cependant, comme toujours, nous ne pourrons nous atteler à ces projets que si vous nous donnez les moyens de le faire.
Nous pensons sincèrement que nous avons la possibilité de faire bouger les lignes, comme nous l’avons fait avec Framadate, Framalistes, Framapad, ou maintenant Framaspace. Le contexte politique et social actuel nous presse à « outiller la société de contribution », c’est à dire à équiper numériquement celles et ceux qui souhaitent changer le monde vers plus de collectif, plus de diversité, plus de communs. Notre boussole reste notre volonté de vous proposer des outils libres et éthiques, un peu comme si nous fournissions des planches, des marteaux et des clous numériques pour que vous puissiez concrétiser les projets qui vous ressemblent, et non ceux qui sont téléguidés par les géants du numérique.
Nous pensons avoir prouvé lors de ces dix dernières années de « dégooglisation » que votre confiance n’était pas mal placée, et que chaque euro perçu avait été bien dépensé.
Aujourd’hui, au regard de nos ambitions à vous proposer de nouveaux services (mais aussi à maintenir ceux qui sont en place !), nous faisons donc de nouveau appel à votre générosité, en vous rappelant que l’association Framasoft ne vit que de vos dons, et en vous invitant donc, si vous en avez l’envie et les moyens, à nous soutenir pour cette nouvelle campagne. Merci 🙏
Un créateur passe de DC (Comics) à DP (Domaine Public)
Bill Willingham, fort mécontent de son éditeur DC Comics, décide de porter toutes ses Fables dans le Domaine Public. Il s’en explique dans un communiqué de presse du 14 septembre.
En édition, le modèle auquel nous sommes conformé·es, c’est qu’une personne qui souhaite avoir un revenu de sa plume confie le fruit de son labeur à un tiers, l’éditeur, qui se chargera de le faire fructifier et qui reversera en échange de cet accord encadré par contrat une partie des revenus générés à l’artiste. C’est ce que le droit d’auteur standard défend comme modèle.
Sauf que la réalité est bien loin de cette jolie fiction et les relations conflictuelles qui naissent au sein de l’industrie ne sont pas rares. Auteurs et autrices sont fréquemment confronté·es à des soucis avec leur « partenaire » : retards de paiements, mensonges sur les tirages, obfuscation des résultats de vente, obligation de participation gratuite au marketing, non-respect des souhaits initiaux, abus au sein des clauses contractuelles.
Bref, il arrive que le capitalisme basé sur la propriété intellectuelle ne puisse s’empêcher de traiter auteurs et autrices comme tous ses fournisseurs : comme des quantités négligeables dont il faut extraire le plus de valeur possible tout en minimisant au maximum les contreparties, quitte à profiter d’un rapport de force favorable pour ne pas honorer ses accords ou en le faisant de façon abusive. Et, comme le prouve l’histoire ci-dessous, la réaction des artistes tend parfois à la radicalité.
Nous ne pouvons déterminer exactement quelles seront les conséquences juridiques (et pratiques quant à l’usage de son univers) des décisions de Bill Willingham, surtout qu’elles prennent place en milieu anglo-saxon où la propriété intellectuelle ne relève pas des mêmes cadres juridiques qu’en France (soumise à la convention de Berne), mais il nous semblait intéressant de traduire le billet où il exprime son ras-le-bol et sa décision d’autant plus surprenante qu’il s’est toujours considéré comme un conservateur, politiquement parlant.
Vous trouverez au bas de cet article des liens qui exposent la situation des auteurs en France (spoiler alert : c’est pas brillant…).
Bill Willingham élève Fables dans le domaine public
À compter du 15 septembre 2023, la propriété de la BD Fables, ce qui inclut tous les personnages et les séries dérivées, entre dans le domaine public. Ce qui appartenait intégralement au seul Bill Willingham est désormais la propriété de tout le monde et pour toujours. C’est chose faite et comme vous le diront la plupart des spécialistes, une fois que c’est fait, pas de retour en arrière possible. Ce n’est ni possible ni envisageable.
— Pourquoi avoir fait ça ?
Pour plusieurs de raisons. Voilà un certain temps que j’y réfléchis. Donc, sans ordre particulier :
1. Sous l’angle pratique : quand j’ai signé mon premier contrat d’édition en tant qu’auteur-créateur avec DC Comics, l’entreprise était dirigée par des hommes et des femmes honnêtes et intègres. La plupart interprétaient les détails du contrat de façon équitable et transparente. Il arrivait immanquablement que des problèmes apparaissent et nous réglions ça comme des femmes et des hommes raisonnables. Depuis lors, au cours d’une vingtaine d’années à peu près, ces personnes sont parties ou ont été virées pour être remplacées par un ballet renouvelé d’inconnus sans intégrité mesurable, qui dorénavant choisissent d’interpréter chaque détail du contrat dans le seul intérêt de DC Comics et ses filiales. À une époque la propriété des Fables était entre de bonnes mains, mais maintenant, avec l’usure et le remplacement des personnels, la propriété des Fables est tombée entre de mauvaises mains.
Comme je n’ai pas les moyens d’intenter un procès à DC Comics pour les contraindre à respecter la lettre et l’esprit de nos accords de longue date, et puisque même si je gagnais un procès ça me coûterait des sommes d’argent pharamineuses et des années de ma vie (j’ai 67 ans donc pas d’années à perdre), j’ai décidé de suivre une autre voie et de combattre sur un autre front, inspiré par les principes de la guerre asymétrique.
J’ai choisi de l’offrir à tout le monde. Si je n’ai pas pu empêcher Fables de tomber entre de mauvaises mains, c’est au moins une façon de faire en sorte qu’elles tombent également entre de nombreuses bonnes mains. Puisque je crois sincèrement qu’il y a encore davantage de bonnes personnes que de mauvaises dans le monde, je considère cela comme une forme de victoire.
2. Sous l’angle philosophique : au cours de la dernière décennie, mes réflexions sur la manière de réformer les lois sur les marques et le droit d’auteur dans ce pays (et dans d’autres, je suppose) ont subi une transformation radicale. Les lois actuelles sont un méli-mélo d’accords sous la table et contraires à l’éthique visant à maintenir les marques et les droits d’auteur entre les mains de grandes entreprises, qui peuvent largement se permettre d’acheter les résultats qu’elles souhaitent.
Dans mon modèle idéal de réforme radicale de ces lois, j’aimerais qu’une propriété intellectuelle soit la propriété de son créateur d’origine pendant une période pouvant aller jusqu’à vingt ans à compter de la première publication, puis qu’elle tombe dans le domaine public pour que tous puissent l’utiliser. Cependant, à tout moment avant l’expiration de cette période de vingt ans, vous, le propriétaire de la propriété intellectuelle, pouvez la vendre à une autre personne physique ou morale, qui peut en avoir l’usage exclusif pendant une durée maximale de dix ans. C’est ainsi maintenant et il ne peut alors pas être revendu. Cela entre dans le domaine public. Toute propriété intellectuelle peut-elle être conservée à usage exclusif au maximum pendant une trentaine d’années au maximum, et pas plus, sans exception.
Bien sûr, si je dois croire à des idées aussi radicales, quel genre d’hypocrite serais-je si je ne les mettais pas en pratique ? Fables est mon bébé depuis une vingtaine d’années maintenant. Il est temps de laisser tomber. C’est mon premier test de ce processus. Si cela fonctionne, et je ne vois aucune raison légale pour laquelle cela ne fonctionnerait pas, d’autres propriétés viendront à l’avenir. Étant donné que DC, ou tout autre personne morale, n’est pas réellement propriétaire de l’œuvre, ils n’ont pas leur mot à dire dans cette décision.
— Qu’est-ce que DC Comics vous a fait au juste pour provoquer ça ?
Trop de choses pour les lister de manière exhaustive, mais voici les points essentiels. Pendant toutes ces années où j’ai été en affaires avec DC Comics, que ce soit avec Fables ou d’autres propriétés intellectuelles, DC a toujours violé ses accords avec moi. En général sur des points mineurs, comme d’oublier de me demander mon avis sur les artistes pour de nouvelles histoires, ou pour les images de couverture, les formats des nouvelles collections, etc.
À cette époque, quand on les appelait pour ça, ils répondaient à chaque fois : « Désolé, on vous a encore oublié, c’est passé entre les mailles du filet. Ils ont utilisé si souvent cette expression « passer entre les mailles » comme un automatisme que j’ai fini par leur interdire de l’employer encore. Ils sont souvent en retard pour la déclaration des royalties et les sous-estiment souvent, ce qui me force à les poursuivre pour qu’ils paient le reste de ce qu’ils me doivent.
Dernièrement, leurs pratiques sont devenues plus que pénibles, débouchant sur une espèce de confrontation. Pour commencer, ils ont essayé de m’extorquer la propriété de Fables. Lorsque Mark Doyle et Dan Didio (tout deux bons professionnels et licenciés par DC depuis) m’avaient approché avec le projet de republier Fables pour son 20e anniversaire, pendant les négociations contractuelles pour ces nouvelles parutions, leurs négociateurs juridiques ont tenté d’imposer comme condition que le travail soit réalisé comme prestataire1, transférant de fait, et irrévocablement, la propriété à DC.
Lorsque ça n’a pas fonctionné, leur excuse a été : « Désolé, nous n’avons pas lu votre contrat avant ces négociations, nous pensions que nous en étions propriétaires ».
Plus récemment, lors de discussions pour tenter de résoudre ces différends, les personnes de DC ont admis que leur interprétation de notre accord de publication et de l’accord subséquent sur les droits des médias, étaient qu’ils pouvaient faire ce que bon leur semble avec cette propriété intellectuelle. Ils pourraient changer les histoires ou les personnages à leur convenance. Ils n’auraient aucune obligation de protéger l’intégrité et la valeur de la propriété intellectuelle, d’eux-mêmes ou de parties tierces (Telltale Games par exemple) et qu’ils pourraient radicalement modifier les personnages, le cadre, le prologue de l’histoire (je suis tombé sur le script (texte) qu’ils avaient essayé de me cacher il y a quelques années). Comme une telle licence d’utilisation n’avait pas été négociée dans notre accord de publication initial, ils ne me devraient pas non plus d’argent s’ils fournissaient des droits d’usages de Fables à de tierces parties.
Puis, après avoir capitulé sur certains points lors de réunions téléphoniques suivantes, promettant de me payer l’argent qu’ils me devaient pour avoir fourni une licence de Fables à Telltale Games, dans le cadre de notre nouvel accord, ils sont revenus sur leur parole et m’ont proposé de me payer le montant comme « honoraires de consultant », ce qui leur évitait d’admettre qu’ils me devaient cet argent, tout en incluant un accord de confidentialité m’empêchant de dire quoi que ce soit de négatif à propos de Telltale ou de la licence.
On pourrait encore continuer longtemps ainsi. Il y a tant d’autres, mais comme je l’ai dit, il s’agit là de quelques points saillants. À ce moment-là, comme je n’étais pas d’accord avec toutes leurs nouvelles interprétations de nos accords de longue date, nous étions en conflit. Ils m’ont pratiquement mis au défi de les poursuivre en justice pour faire valoir mes droits, sachant que ce serait une procédure longue, débilitante et coûteuse. Au lieu de cela, j’ai commencé à envisager d’autres solutions.
— Êtes-vous inquiet de savoir ce que DC va faire maintenant ?
Non. Je leur ai donné des années pour faire ce qu’il fallait. J’ai essayé de les raisonner, mais on ne peut pas raisonner ceux qui ne sont pas raisonnables. Ils ont utilisé ces années pour faire des promesses lénifiantes, mentir sur leur volonté de résoudre le problème et faire traîner les choses le plus longtemps possible. Je leur ai donné l’occasion de renégocier les contrats de fond en comble, en formulant les choses sans ambiguïté, et ils ont ignoré cette offre. Je leur ai donné l’occasion, à deux reprises, de simplement déchirer nos contrats et de nous séparer, mais ils ont ignoré ces offres. J’ai essayé de passer par-dessus leur tête, de traiter directement avec leurs nouveaux maîtres et peut-être de trouver quelqu’un disposé à traiter de bonne foi, mais ils ont bloqué toute tentative en ce sens. (Je vous mets au défi d’essayer de demander à n’importe quel responsable de DC Comics d’indiquer à qui il rend compte dans la hiérarchie de l’entreprise). Quoi qu’il en soit, sans leur donner de détails, je les ai prévenus des mois à l’avance que ce moment allait arriver. Je leur ai dit que ce que j’allais faire serait « à la fois légal et éthique ». Et maintenant, c’est arrivé.
Notez que mes contrats avec DC Comics sont toujours en vigueur. Je n’ai rien fait pour les rompre et je ne peux pas y mettre fin unilatéralement. Je ne peux toujours pas publier les bandes dessinées Fables par l’intermédiaire de quelqu’un d’autre que DC Comics. Je ne peux toujours pas autoriser un film Fables par l’intermédiaire de quelqu’un d’autre que DC Comics. Je ne peux pas non plus concéder de licence pour des jouets, des boîtes à lunch ou quoi que ce soit d’autre. Ils doivent toujours me payer pour les livres qu’ils publient. Et je n’abandonne pas les autres sommes qu’ils me doivent. D’une manière ou d’une autre, j’ai l’intention d’obtenir mes 50 % de l’argent qu’ils me doivent depuis des années pour le jeu Telltale et d’autres projets.
De toutes façons, les nouveaux propriétaires à 100 % de Fables n’ont jamais signé de tels contrats.
Pour le meilleur et pour le pire, DC et moi sommes enchaînés par un mariage malheureux, peut-être pour toujours. Mais pas vous.
Si ma compréhension de la loi est correcte (et je préfère vous dire que la loi sur le copyright est un bazar, intentionnellement vague et trouble et qu’il n’y a pas deux avocats, même ceux spécialisés sur les lois des marques et du copyright, qui tomberaient d’accord sur ces sujets), vous avez le droit de créer vos propres films, dessins animés Fables, de publier vos libres Fables, de fabriquer vos jouets Fables, de faire ce que bon vous semble avec cette propriété, car c’est de la vôtre dont il s’agit.
Mark Buckingham est libre d’écrire sa propre version de Fables (et j’espère de tout mon cœur qu’il le fera). Steve Leialoha est libre d’écrire sa version de Fables (que j’aimerais beaucoup voir), etc. Vous n’avez pas besoin de ma permission (mais vous pouvez avoir mon aval ma bénédiction, selon votre projet). Vous n’avez pas besoin de la permission de DC ou de qui que ce soit d’autres. Vous n’avez jamais signé les accords que j’ai signés avec DC Comics.
Je possède toujours 100% de Fables. Mais maintenant, chaque homme, chaque femme et chaque enfant du monde, ainsi que tous ceux qui naîtront jusqu’à la fin des temps, possèdent également 100 % de Fables. Ce n’est pas une propriété divisée entre nous tous, c’est une propriété multipliée à l’infini entre nous tous. Plutôt cool, non ? Chaque personne possède Fables en totalité et peut décider elle-même de ce qu’elle veut en faire, le cas échéant. C’est un peu comme le miracle de la multiplication des pains et des poissons, métaphoriquement parlant, bien sûr. Quel que soit le nombre de participants, il y en a assez pour tout le monde.
J’ai eu l’immense joie et le plaisir de vous proposer les récits de Fables pendant les vingt dernières années. J’ai hâte de voir ce que vous allez en faire.
« Le comics Fables et ses différents romans graphiques publiés chez DC Comics, de même que les personnages, les histoires et les éléments qui les composent, sont la propriété de DC Comics et restent protégés par la loi des États-Unis sur le copyright et à travers le monde, en accord avec les lois appliquées sur chaque territoire, et ne font pas partie des œuvres tombées dans le domaine public.
DC conserve l’intégralité des droits et prendra les décisions nécessaires pour protéger ses droits à la propriété intellectuelle. »
Liens utiles sur la situation des auteurs en France :
Voilà ce qui arrive quand on se met à lire vraiment les politiques de confidentialité
Une récente polémique sur la capacité de Zoom à entraîner des intelligences artificielles avec les conversations des utilisateurs montre l’importance de lire les petits caractères
Bonjour, je m’appelle Aaron Sankin, je suis journaliste d’investigation à The Markup. J’écris ici pour vous expliquer que si vous faites quelque chose de très pénible (lire les documents dans lesquels les entreprises expliquent ce qu’elles peuvent faire avec vos données), vous pourrez ensuite faire quelque chose d’un peu drôle (piquer votre crise en ligne).
Au cours du dernier quart de siècle, les politiques de protection de la vie privée – ce langage juridique long et dense que l’on parcourt rapidement avant de cliquer sans réfléchir sur « J’accepte » – sont devenues à la fois plus longues et plus touffues. Une étude publiée l’année dernière a montré que non seulement la longueur moyenne des politiques de confidentialité a quadruplé entre 1996 et 2021, mais qu’elles sont également devenues beaucoup plus difficiles à comprendre.
Voici ce qu’a écrit Isabel Wagner, professeur associé à l’université De Montfort, qui a utilisé l’apprentissage automatique afin d’analyser environ 50 000 politiques de confidentialité de sites web pour mener son étude :
« En analysant le contenu des politiques de confidentialité, nous identifions plusieurs tendances préoccupantes, notamment l’utilisation croissante de données de localisation, l’exploitation croissante de données collectées implicitement, l’absence de choix véritablement éclairé, l’absence de notification efficace des modifications de la politique de confidentialité, l’augmentation du partage des données avec des parties tierces opaques et le manque d’informations spécifiques sur les mesures de sécurité et de confidentialité »
Si l’apprentissage automatique peut être un outil efficace pour comprendre l’univers des politiques de confidentialité, sa présence à l’intérieur d’une politique de confidentialité peut déclencher un ouragan. Un cas concret : Zoom.
En début de semaine dernière, Zoom, le service populaire de visioconférence devenu omniprésent lorsque les confinements ont transformé de nombreuses réunions en présentiel en réunions dans de mini-fenêtres sur des mini-écrans d’ordinateurs portables, a récemment fait l’objet de vives critiques de la part des utilisateurs et des défenseurs de la vie privée, lorsqu’un article du site d’actualités technologiques Stack Diary a mis en évidence une section des conditions de service de l’entreprise indiquant qu’elle pouvait utiliser les données collectées auprès de ses utilisateurs pour entraîner l’intelligence artificielle.
version anglaise début août, capturée par la Wayback Machine d’Internet Archive
version française fin juillet, capturée par la Wayback Machine d’Internet Archive
Le contrat d’utilisation stipulait que les utilisateurs de Zoom donnaient à l’entreprise « une licence perpétuelle, non exclusive, libre de redevances, susceptible d’être cédée en sous-licence et transférable » pour utiliser le « Contenu client » à des fins diverses, notamment « de marketing, d’analyse des données, d’assurance qualité, d’apprentissage automatique, d’intelligence artificielle, etc.». Cette section ne précisait pas que les utilisateurs devaient d’abord donner leur consentement explicite pour que l’entreprise puisse le faire.
Une entreprise qui utilise secrètement les données d’une personne pour entraîner un modèle d’intelligence artificielle est particulièrement controversée par les temps qui courent. L’utilisation de l’IA pour remplacer les acteurs et les scénaristes en chair et en os est l’un des principaux points d’achoppement des grèves en cours qui ont paralysé Hollywood. OpenAI, la société à l’origine de ChatGPT, a fait l’objet d’une vague de poursuites judiciaires l’accusant d’avoir entraîné ses systèmes sur le travail d’écrivains sans leur consentement. Des entreprises comme Stack Overflow, Reddit et X (le nom qu’Elon Musk a décidé de donner à Twitter) ont également pris des mesures énergiques pour empêcher les entreprises d’IA d’utiliser leurs contenus pour entraîner des modèles sans obtenir elles-mêmes une part de l’activité.
La réaction en ligne contre Zoom a été féroce et immédiate, certaines organisations, comme le média Bellingcat, proclamant leur intention de ne plus utiliser Zoom pour les vidéoconférences. Meredith Whittaker, présidente de l’application de messagerie Signal spécialisée dans la protection de la vie privée, a profité de l’occasion pour faire de la publicité :
« HUM : Les appels vidéo de @signalapp fonctionnent très bien, même avec une faible bande passante, et ne collectent AUCUNE DONNÉE SUR VOUS NI SUR LA PERSONNE À QUI VOUS PARLEZ ! Une autre façon tangible et importante pour Signal de s’engager réellement en faveur de la vie privée est d’interrompre le pipeline vorace de surveillance des IA. »
Zoom, sans surprise, a éprouvé le besoin de réagir.
Dans les heures qui ont suivi la diffusion de l’histoire, le lundi même, Smita Hashim, responsable des produits chez Zoom, a publié un billet de blog visant à apaiser des personnes qui craignent de voir leurs propos et comportements être intégrés dans des modèles d’entraînement d’IA, alors qu’elles souhaitent virtuellement un joyeux anniversaire à leur grand-mère, à des milliers de kilomètres de distance.
« Dans le cadre de notre engagement en faveur de la transparence et du contrôle par l’utilisateur, nous clarifions notre approche de deux aspects essentiels de nos services : les fonctions d’intelligence artificielle de Zoom et le partage de contenu avec les clients à des fins d’amélioration du produit », a écrit Mme Hashim. « Notre objectif est de permettre aux propriétaires de comptes Zoom et aux administrateurs de contrôler ces fonctions et leurs décisions, et nous sommes là pour faire la lumière sur la façon dont nous le faisons et comment cela affecte certains groupes de clients ».
Mme Hashim écrit que Zoom a mis à jour ses conditions d’utilisation pour donner plus de contexte sur les politiques d’utilisation des données par l’entreprise. Alors que le paragraphe sur Zoom ayant « une licence perpétuelle, non exclusive, libre de redevances, pouvant faire l’objet d’une sous-licence et transférable » pour utiliser les données des clients pour « l’apprentissage automatique, l’intelligence artificielle, la formation, les tests » est resté intact [N de T. cependant cette mention semble avoir disparu dans la version du 11 août 2023], une nouvelle phrase a été ajoutée juste en dessous :
« Zoom n’utilise aucun Contenu client audio, vidéo, chat, partage d’écran, pièces jointes ou autres communications comme le Contenu client (tels que les résultats des sondages, les tableaux blancs et les réactions) pour entraîner les modèles d’intelligence artificielle de Zoom ou de tiers. »
Dans son billet de blog, Mme Hashim insiste sur le fait que Zoom n’utilise le contenu des utilisateurs que pour former l’IA à des produits spécifiques, comme un outil qui génère automatiquement des résumés de réunions, et seulement après que les utilisateurs auront explicitement choisi d’utiliser ces produits. « Un exemple de service d’apprentissage automatique pour lequel nous avons besoin d’une licence et de droits d’utilisation est notre analyse automatisée des invitations et des rappels de webinaires pour s’assurer que nous ne sommes pas utilisés involontairement pour spammer ou frauder les participants », écrit-elle. « Le client est propriétaire de l’invitation au webinaire et nous sommes autorisés à fournir le service à partir de ce contenu. En ce qui concerne l’IA, nous n’utilisons pas de contenus audios, de vidéos ou de chats pour entraîner nos modèles sans le consentement du client. »
La politique de confidentialité de Zoom – document distinct de ses conditions de service – ne mentionne l’intelligence artificielle ou l’apprentissage automatique que dans le contexte de la fourniture de « fonctions et produits intelligents (sic), tels que Zoom IQ ou d’autres outils pour recommander le chat, le courrier électronique ou d’autres contenus ».
Pour avoir une idée de ce que tout cela signifie, j’ai échangé avec Jesse Woo, un ingénieur spécialisé en données de The Markup qui, en tant qu’avocat spécialisé dans la protection de la vie privée, a participé à la rédaction de politiques institutionnelles d’utilisation des données.
M. Woo explique que, bien qu’il comprenne pourquoi la formulation des conditions d’utilisation de Zoom touche un point sensible, la mention suivant laquelle les utilisateurs autorisent l’entreprise à copier et à utiliser leur contenu est en fait assez standard dans ce type d’accord d’utilisation. Le problème est que la politique de Zoom a été rédigée de manière à ce que chacun des droits cédés à l’entreprise soit spécifiquement énuméré, ce qui peut sembler beaucoup. Mais c’est aussi ce qui se passe lorsque vous utilisez des produits ou des services en 2023, désolé, bienvenue dans le futur !
Pour illustrer la différence, M. Woo prend l’exemple de la politique de confidentialité du service de vidéoconférence concurrent Webex, qui stipule ce qui suit : « Nous ne surveillerons pas le contenu, sauf : (i) si cela est nécessaire pour fournir, soutenir ou améliorer la fourniture des services, (ii) pour enquêter sur des fraudes potentielles ou présumées, (iii) si vous nous l’avez demandé ou autorisé, ou (iv) si la loi l’exige ou pour exercer ou protéger nos droits légaux ».
Cette formulation semble beaucoup moins effrayante, même si, comme l’a noté M. Woo, l’entraînement de modèles d’IA pourrait probablement être mentionné par une entreprise sous couvert de mesures pour « soutenir ou améliorer la fourniture de services ».
L’idée que les gens puissent paniquer si les données qu’ils fournissent à une entreprise dans un but évident et simple (comme opérer un appel de vidéoconférence) sont ensuite utilisées à d’autres fins (comme entraîner un algorithme) n’est pas nouvelle. Un rapport publié par le Forum sur le futur de la vie privée (Future of Privacy Forum), en 2018, avertissait que « le besoin de grandes quantités de données pendant le développement en tant que « données d’entraînement » crée des problèmes de consentement pour les personnes qui pourraient avoir accepté de fournir des données personnelles dans un contexte commercial ou de recherche particulier, sans comprendre ou s’attendre à ce qu’elles soient ensuite utilisées pour la conception et le développement de nouveaux algorithmes. »
Pour Woo, l’essentiel est que, selon les termes des conditions de service initiales, Zoom aurait pu utiliser toutes les données des utilisateurs qu’elle souhaitait pour entraîner l’IA sans demander leur consentement et sans courir de risque juridique dans ce processus.
Ils sont actuellement liés par les restrictions qu’ils viennent d’inclure dans leurs conditions d’utilisation, mais rien ne les empêche de les modifier ultérieurement. Jesse Woo, ingénieur en données chez The Markup
« Tout le risque qu’ils ont pris dans ce fiasco est en termes de réputation, et le seul recours des utilisateurs est de choisir un autre service de vidéoconférence », explique M. Woo. « S’ils avaient été intelligents, ils auraient utilisé un langage plus circonspect, mais toujours précis, tout en proposant l’option du refus, ce qui est une sorte d’illusion de choix pour la plupart des gens qui n’exercent pas leur droit de refus. »
Changements futurs mis à part, il y a quelque chose de remarquable dans le fait qu’un tollé public réussisse à obtenir d’une entreprise qu’elle déclare officiellement qu’elle ne fera pas quelque chose d’effrayant. L’ensemble de ces informations sert d’avertissement à d’autres sur le fait que l’entraînement de systèmes d’IA sur des données clients sans leur consentement pourrait susciter la colère de bon nombre de ces clients.
Les conditions d’utilisation de Zoom mentionnent la politique de l’entreprise en matière d’intelligence artificielle depuis le mois de mars, mais cette politique n’a attiré l’attention du grand public que la semaine dernière. Ce décalage suggère que les gens ne lisent peut-être pas les données juridiques, de plus en plus longues et de plus en plus denses, dans lesquelles les entreprises expliquent en détail ce qu’elles font avec vos données.
Heureusement, Woo et Jon Keegan, journalistes d’investigation sur les données pour The Markup, ont récemment publié un guide pratique (en anglais) indiquant comment lire une politique de confidentialité et en identifier rapidement les parties importantes, effrayantes ou révoltantes.
l’installation « I Agree » de l’artiste Dima Yarovinsky qui en 2018 a imprimé les conditions d’utilisation de WhatsApp, Google, Tinder, Twitter, Facebook, Snapchat et Instagram et les a ensuite accrochées dans une galerie en précisant le nombre de mots de chaque document et son temps de lecture.




 Ceux qui y étaient en témoigneront dans les commentaires, travailler à l’aide de l’application Etherpad est pratique et ludique. À chaque couleur son participant, comme l’illustre l’image ci-contre, que l’on voit éditer en même temps qu’on édite, ce qui n’est d’ailleurs pas sans poser quelques intéressants problèmes d’organisation.
Ceux qui y étaient en témoigneront dans les commentaires, travailler à l’aide de l’application Etherpad est pratique et ludique. À chaque couleur son participant, comme l’illustre l’image ci-contre, que l’on voit éditer en même temps qu’on édite, ce qui n’est d’ailleurs pas sans poser quelques intéressants problèmes d’organisation. Et si nous faisions plus amplement connaissance avec notre groupe de traduction
Et si nous faisions plus amplement connaissance avec notre groupe de traduction  Suite et bientôt fin des billets anticipant la très prochaine campagne de soutien.
Suite et bientôt fin des billets anticipant la très prochaine campagne de soutien.


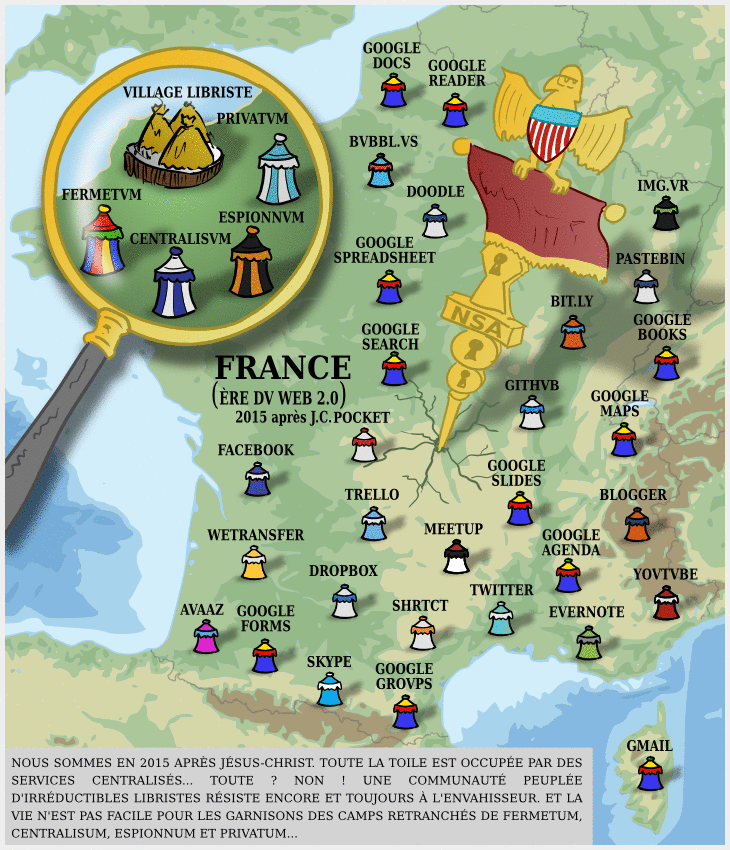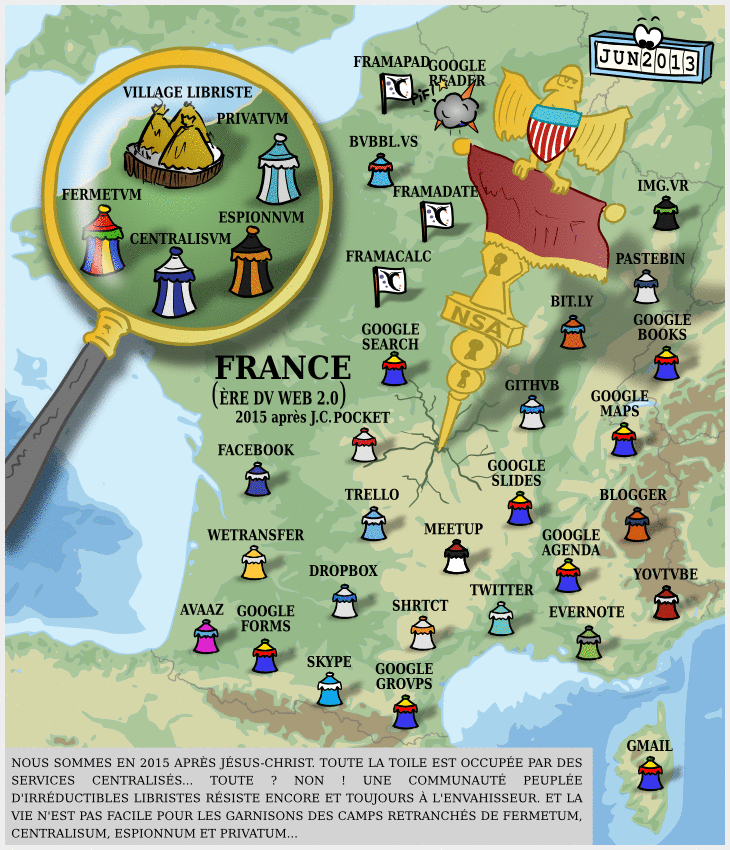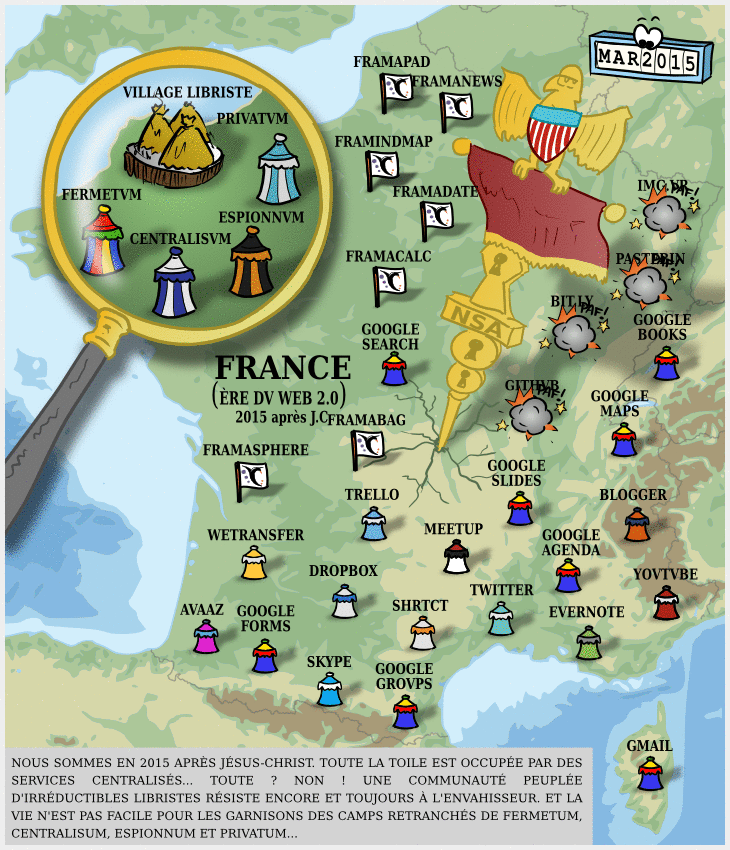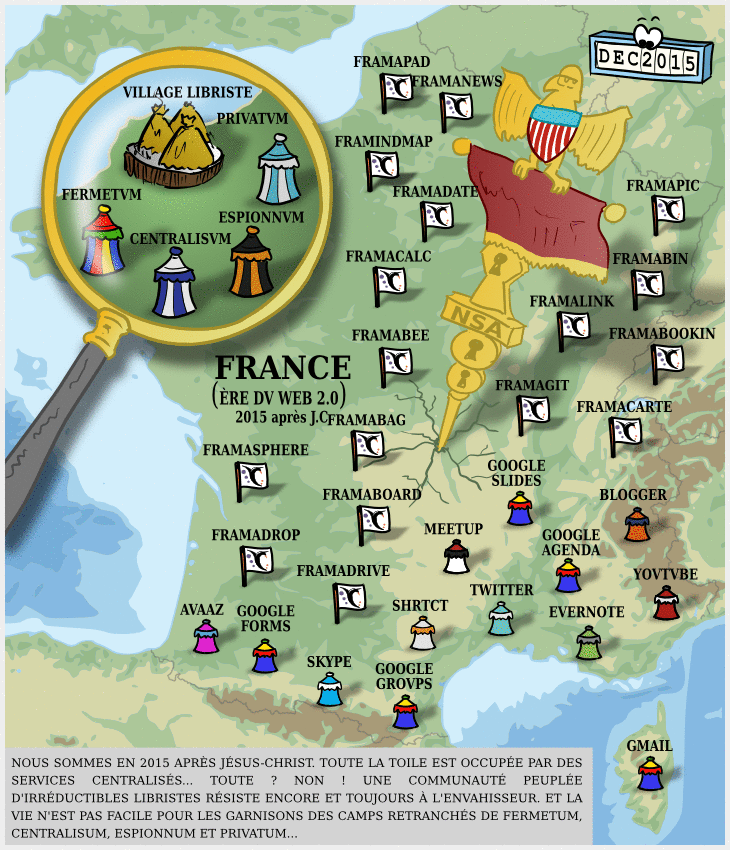
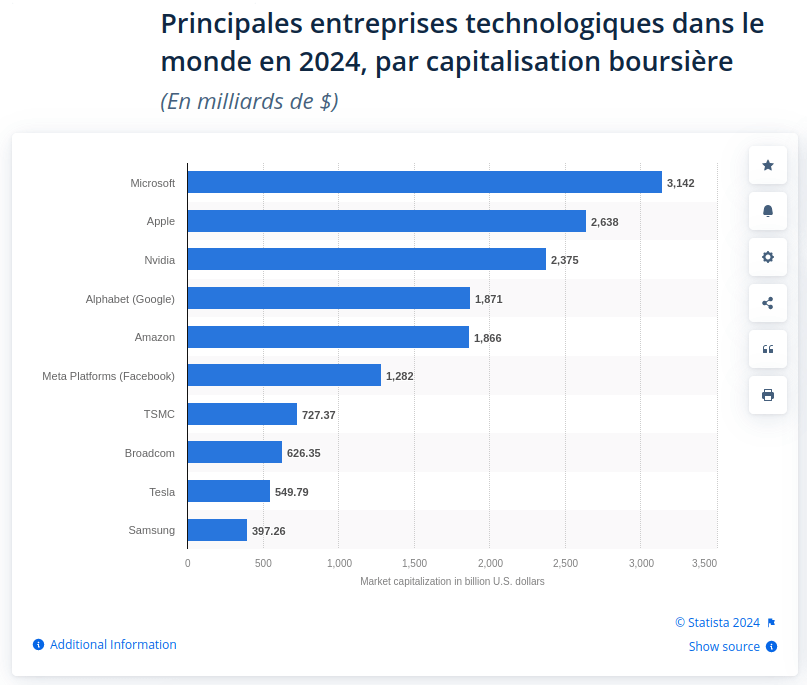
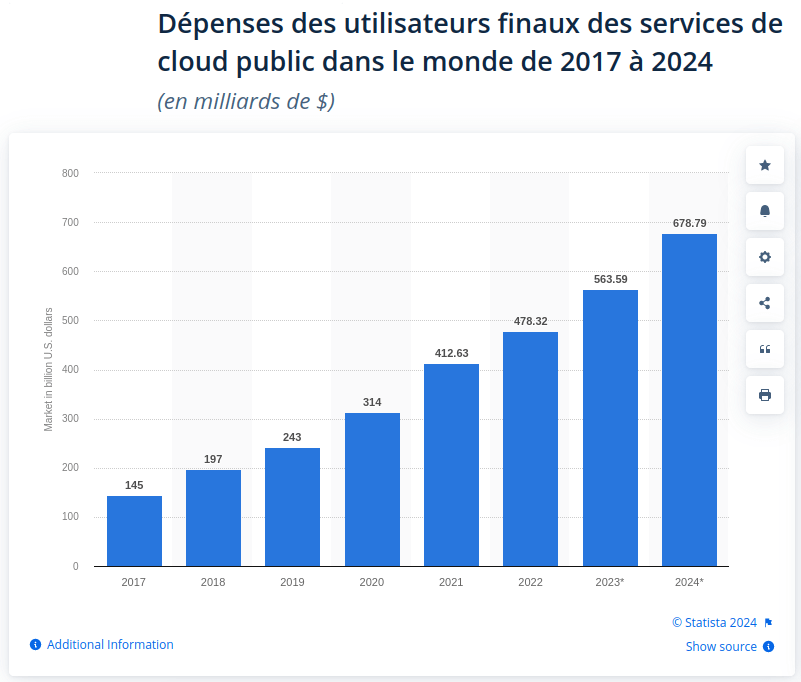
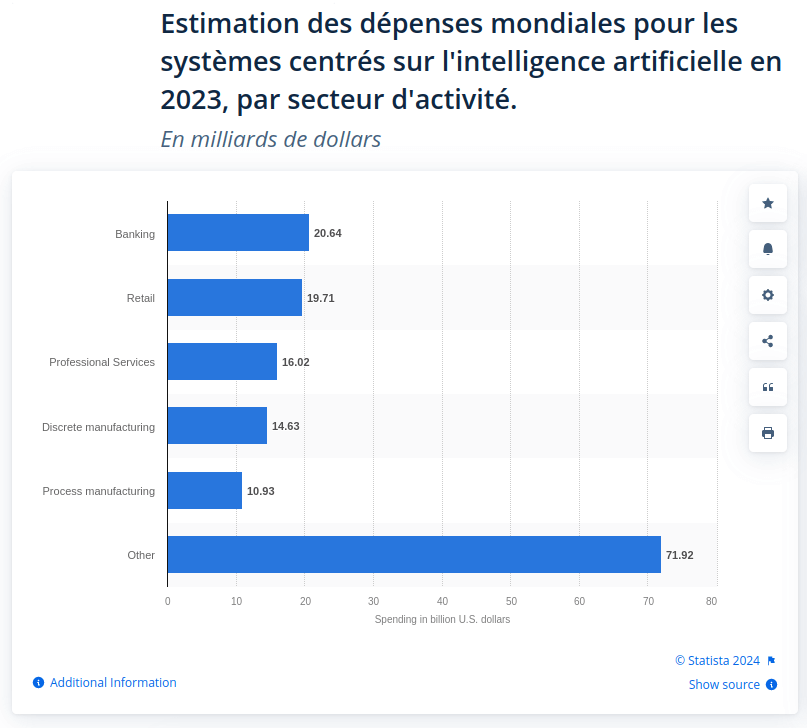



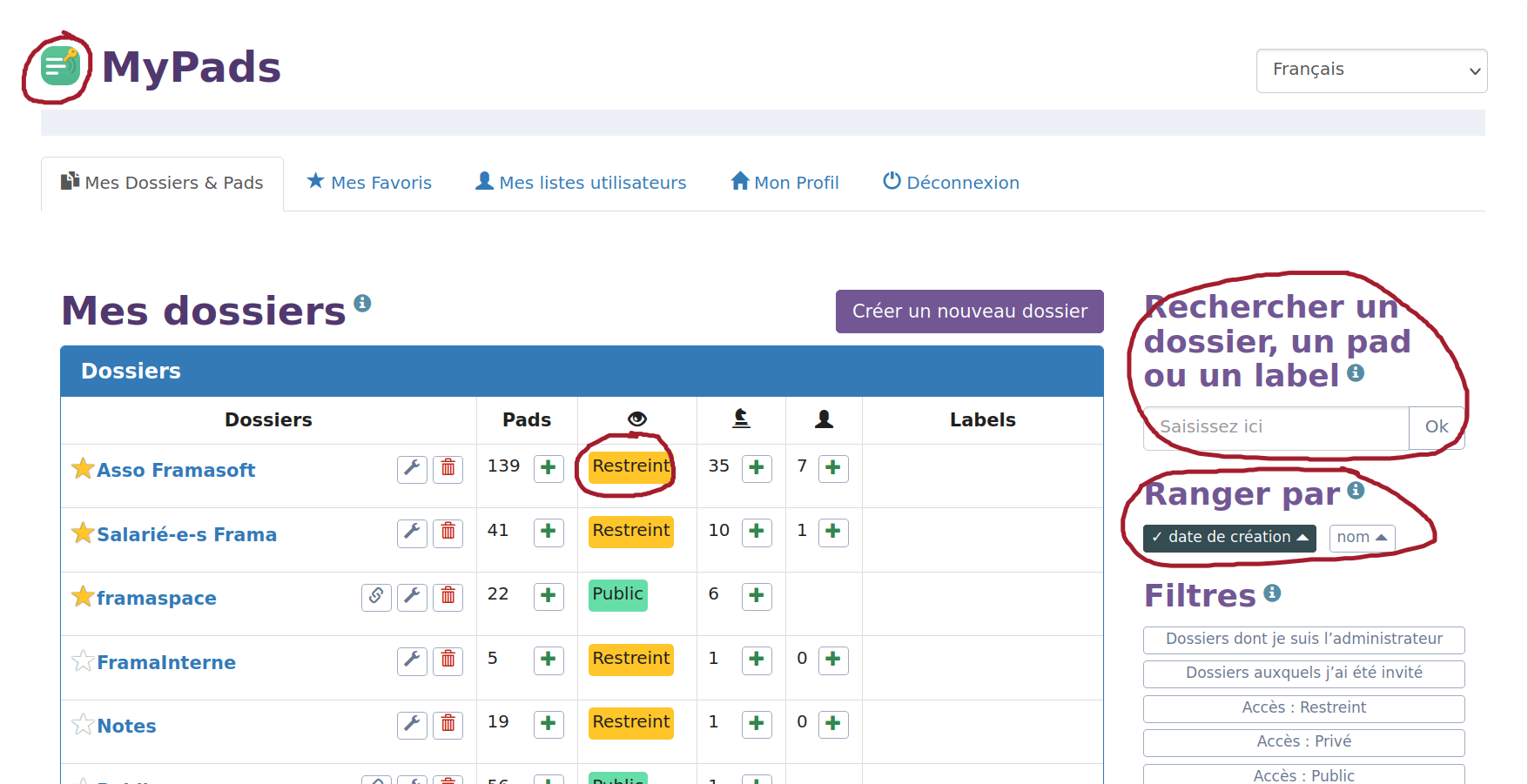
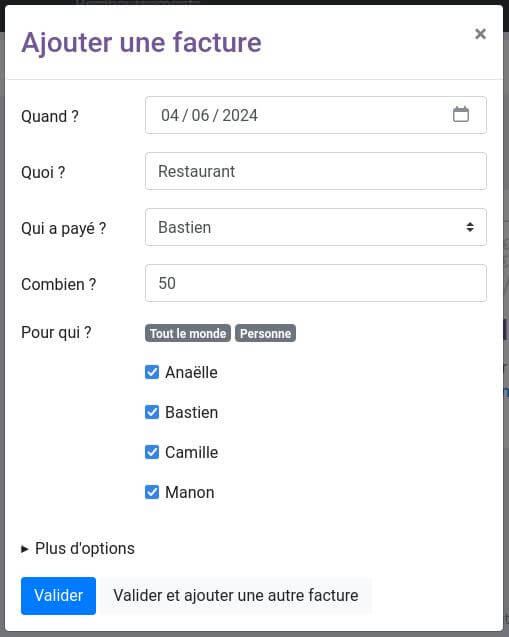
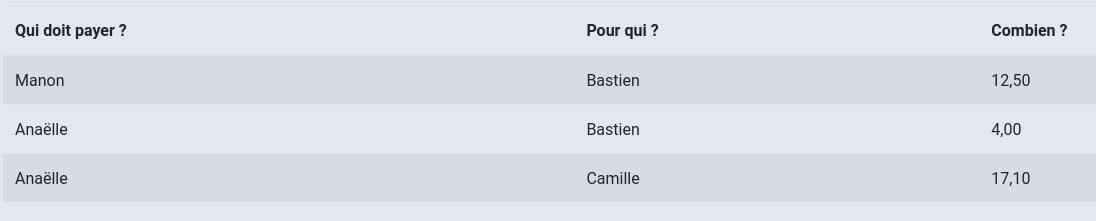

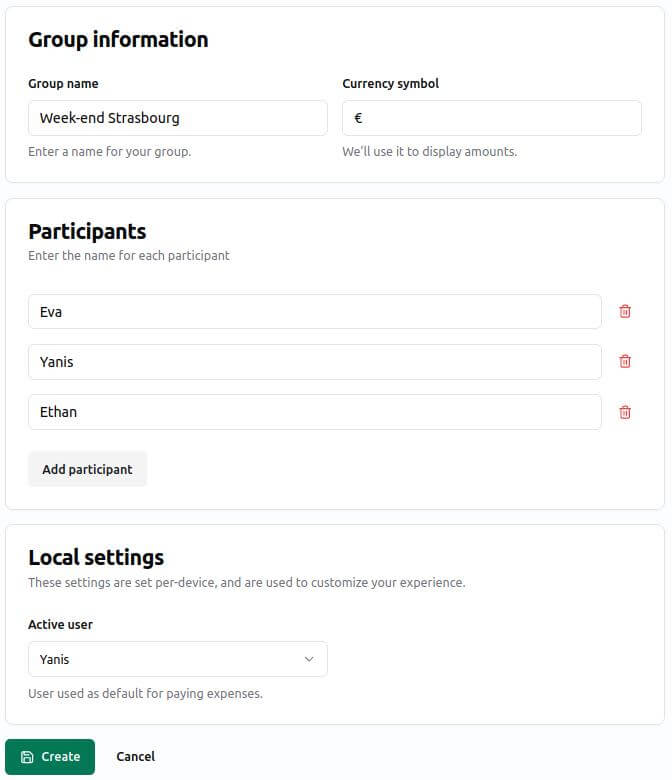
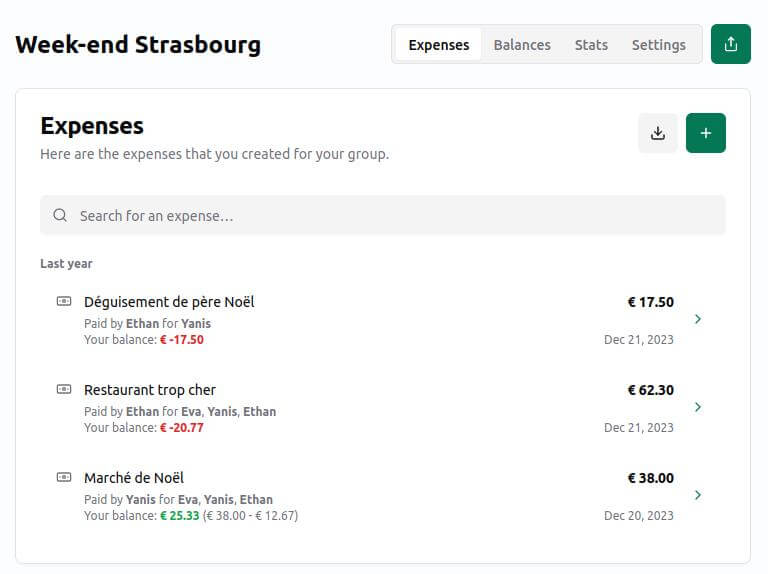
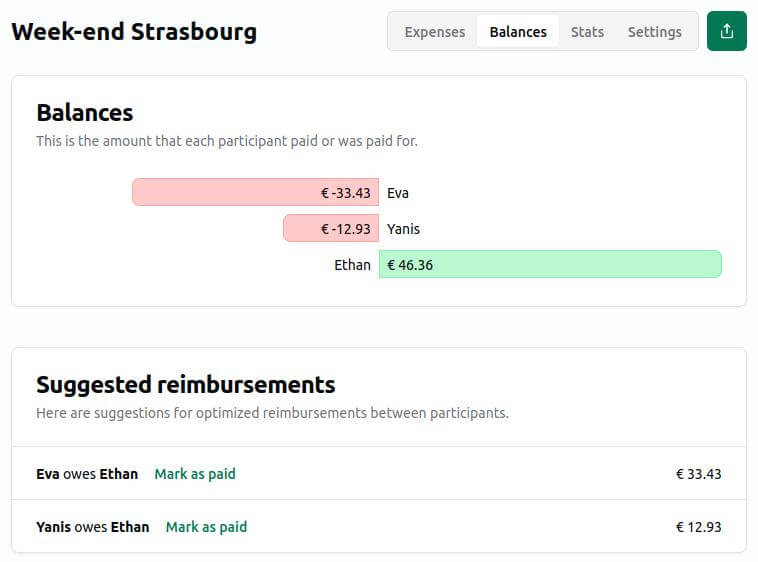
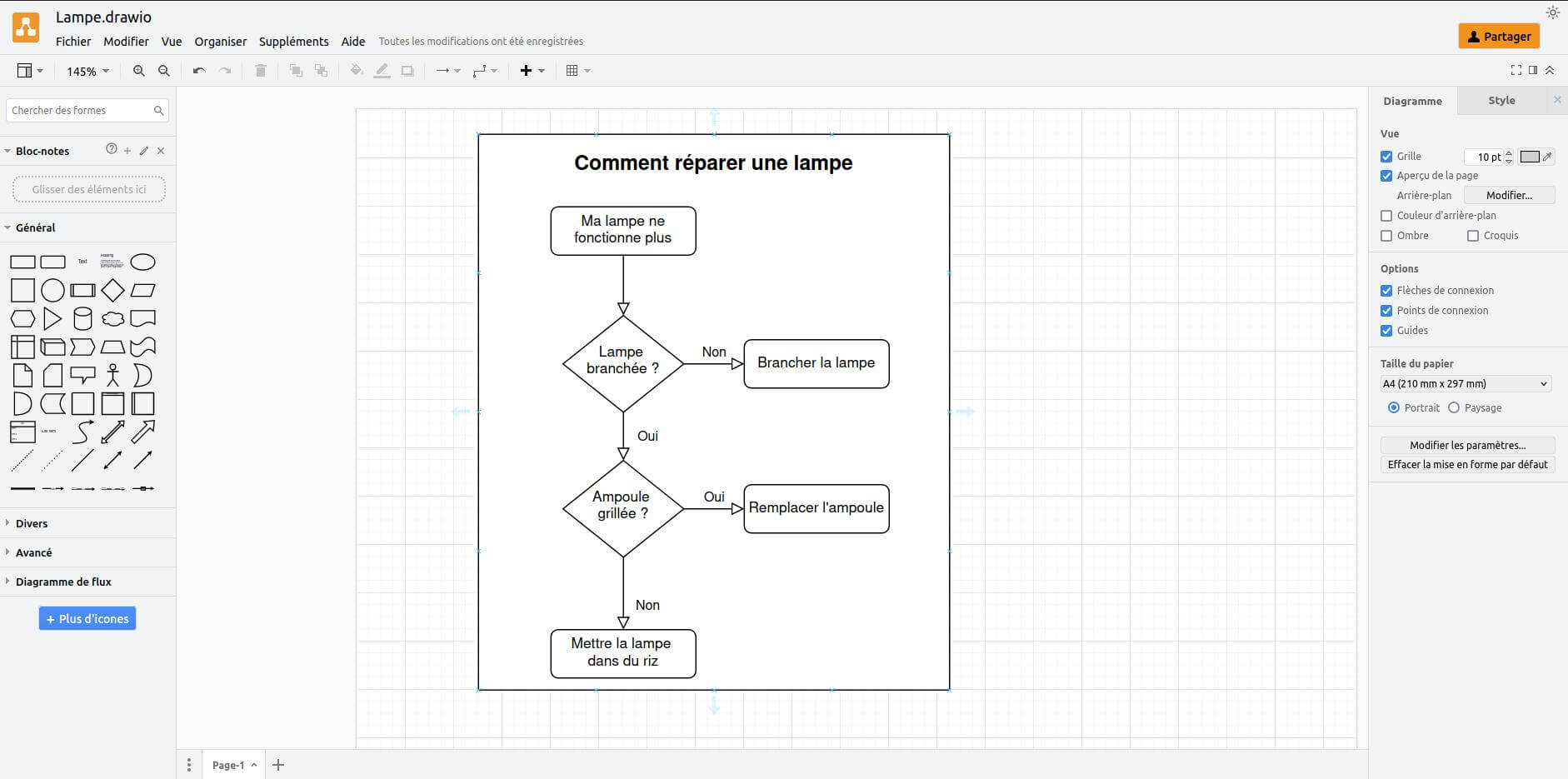
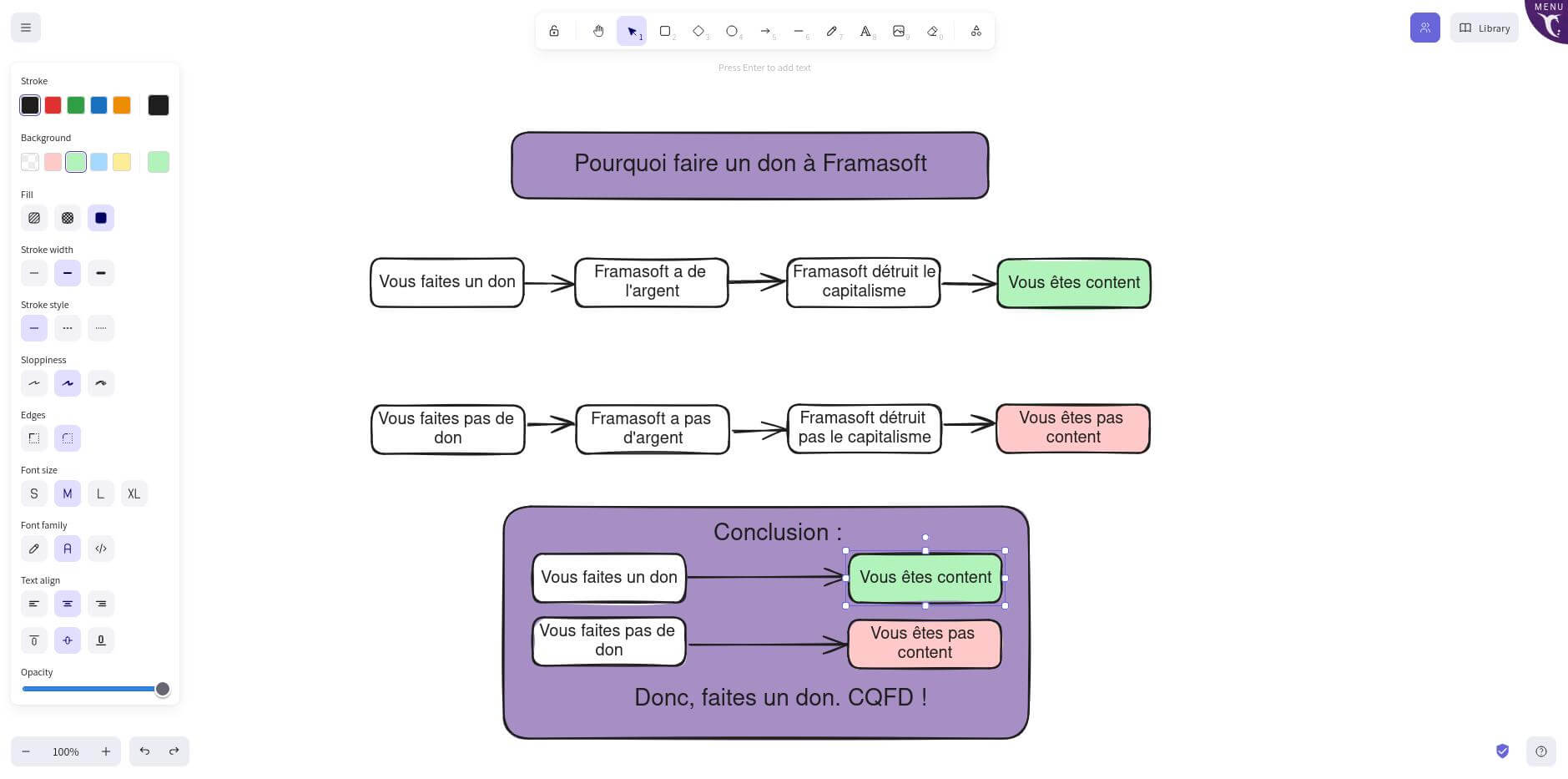


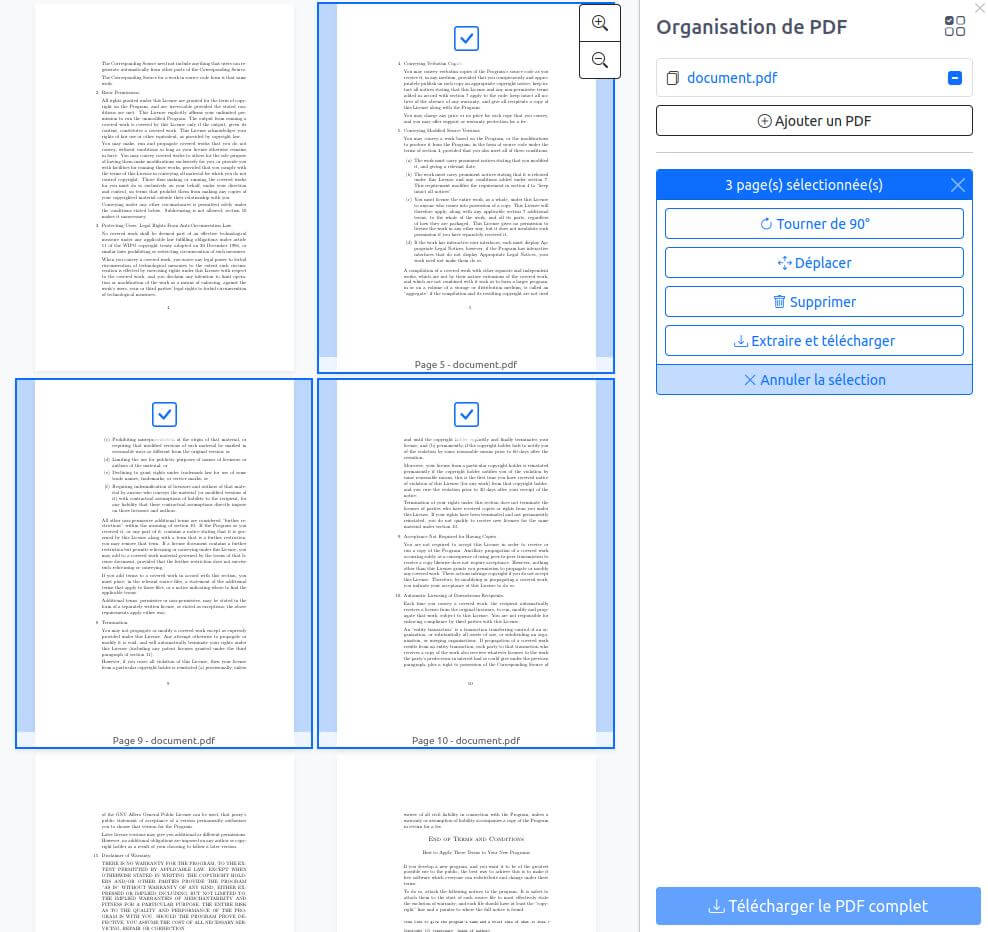
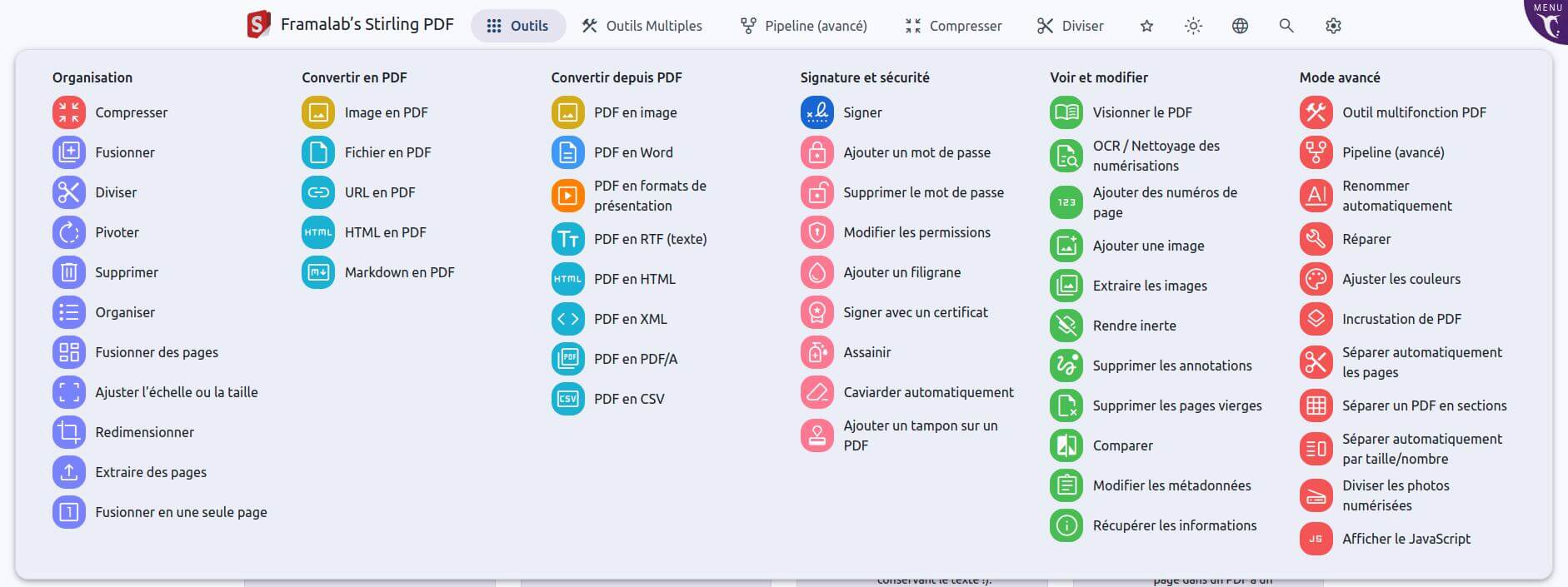
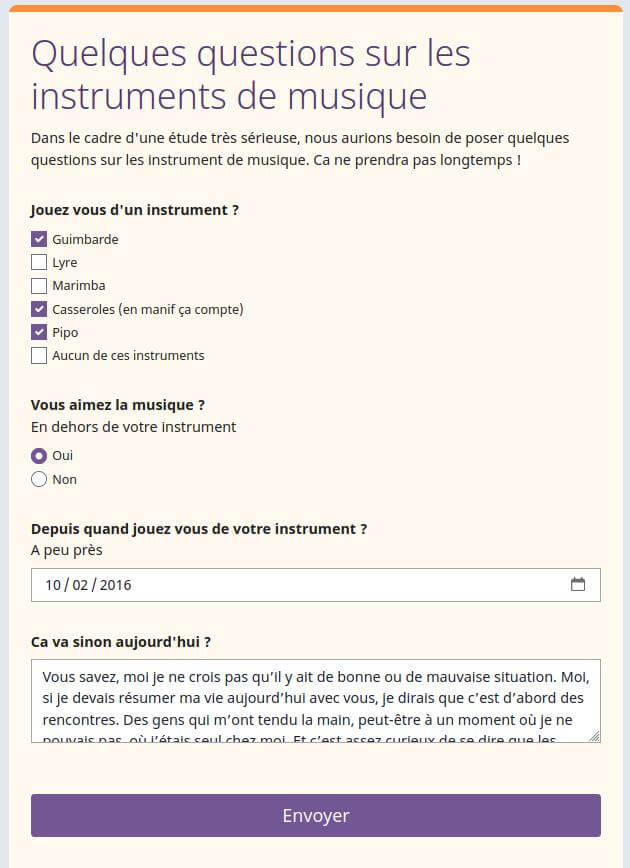
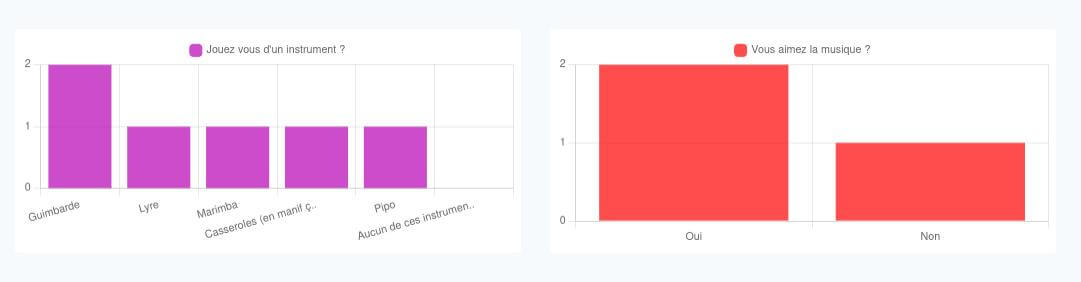
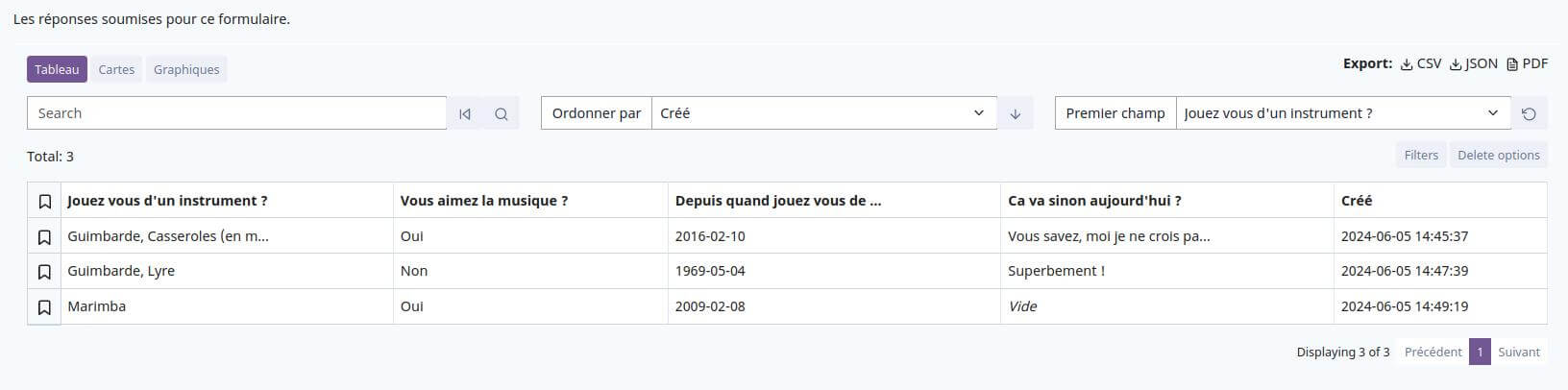

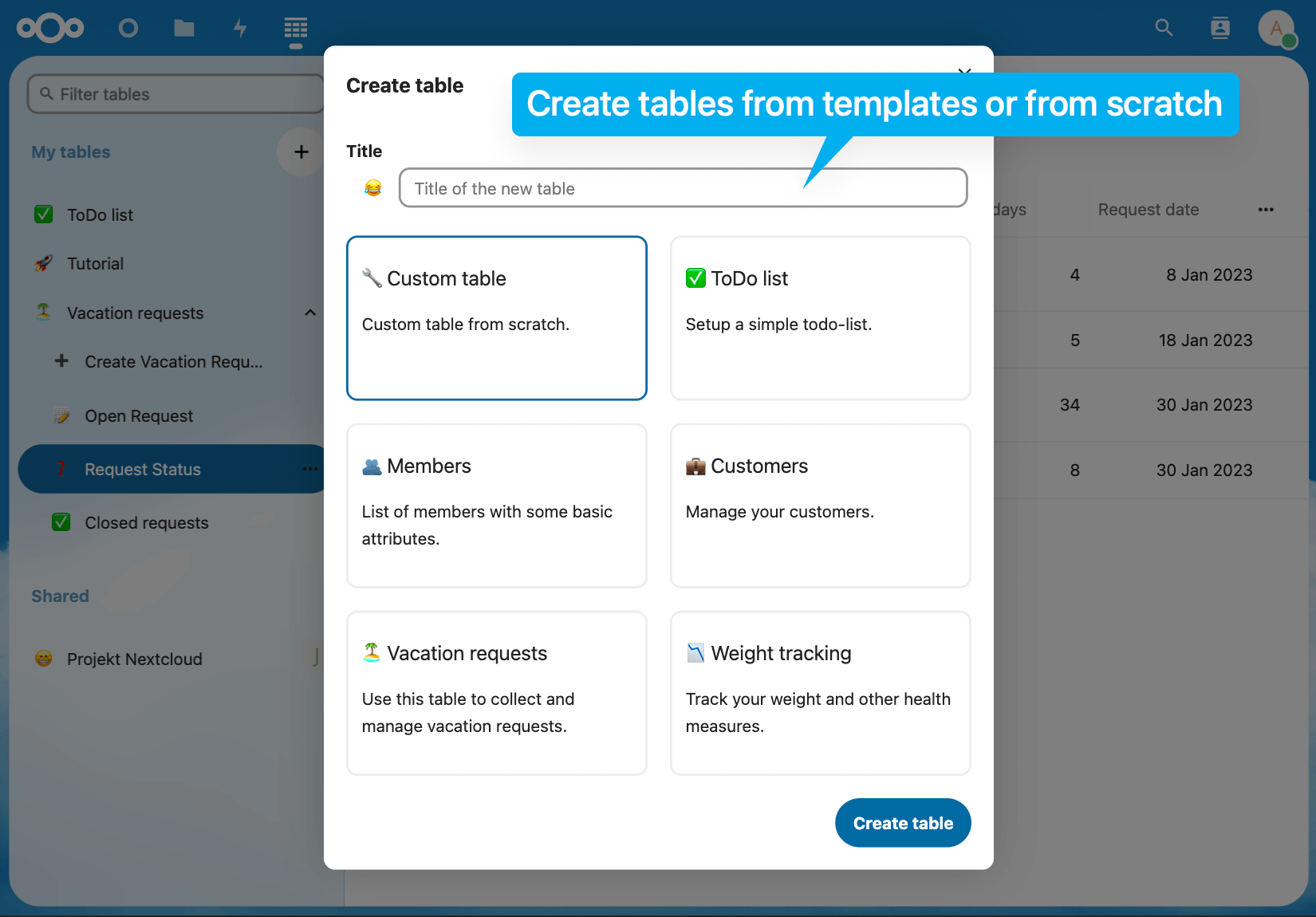









{kind=link}