Nous, les geeks, nous bloquons les pubs et nous n’y pensons plus.
Le choc est d’autant plus grand quand nous devons utiliser l’ordinateur de quelqu’un d’autre.
« Mais comment faites-vous pour supporter une telle nuisance ? » avons-nous envie de hurler. Eh bien, c’est simple : quand on ne sait pas s’en protéger, on vit avec le vacarme. Et la majorité des gens que nous côtoyons doivent subir cet incessant bruit de fond publicitaire.
Cet article a pour ambition de recenser les méthodes pour s’éviter l’agression publicitaire sur Internet. Partagez-le, commentez-le, augmentez-le ! C’est libre.
Sur mobile
Un bon conseil au passage : arrêtez d’appeler «téléphone» le parallélépipède que vous promenez partout et qui est plus puissant qu’un PC d’il y a cinq ans. Vous vous rendrez compte que la plupart du temps il vous sert à plein d’autres choses qu’à téléphoner. C’est un ordinateur à part entière, qui sait à tout moment où vous êtes et ce que vous faites. C’est un bon copain très serviable mais c’est aussi un super espion.
L’appeler «ordiphone» ou «smartphone» si vous aimez les anglicismes, c’est déjà prendre conscience de ses capacités.
Sur Android
Fuyez les applications
Utilisez le navigateur et pas les applications (Fennec sur F-droid ou Firefox sur le Play Store/Apple Store).
Pourquoi ?
Le navigateur peut filtrer correctement les cookies, recevoir des réglages de confidentialité plus fins, embarquer des extensions protectrices.
Les applications, elles, sont là pour capter un maximum de données et vous garder en ligne autant que possible. Même si elles ont des réglages de confidentialité, vous ne serez jamais en mesure de vérifier que ces réglages fonctionnent, puisque le code des applications est fermé.
Le navigateur Firefox (ou Fennec, donc) est un logiciel libre dont le code peut être validé par des experts.
Privilégiez les versions web mobiles lorsque c’est possible, et épinglez le site : ça ressemble à une appli mais ça prend moins de place !
Extensions et réglages
Installer uBlock Origindans votre navigateur, c’est le service minimum pour être un peu tranquille.
Choisir «standard» voire « stricte » comme «Protection renforcée» dans les paramètres du navigateur.
Si vous voulez des applis quand même (après tout, c’est ça aussi, la liberté)
Renseignez-vous sur leur propension à vous espionner grâce aux travaux de l’excellente association française Exodus Privacy dont on ne dira jamais assez de bien.
Installez un autre magasin d’application pour y trouver des apps moins invasives.
Attention, toutefois : certaines applis ne sont pas mûres, n’installez pas n’importe quoi.
Youtube sans pub
NewPipe sur F-droid
Twitter sans Twitter
Fritter
Twitch sans Twitch
Twire
Reddit sans…
RedReader
Et pensez aux réseaux sociaux alternatifs comme Mastodon.
S’éviter les appels de télémarketing
L’application Yet Another Call Blocker consulte une liste noire collaborative à chaque appel avant de le laisser passer. C’est un casse-pied qui veut vous parler de votre CPF ? Votre téléphone ne sonne même pas, l’indésirable est détecté et viré sans vous déranger. S’il ne l’est pas vous le signalez et tout le monde est désormais protégé.
Filtrer le trafic Internet
Utilisez des DNS publics qui incluent un filtrage, ou des solutions locales.
C’est quoi un DNS ?
Les «serveurs de noms de domaine» transforment un domaine (une adresse à peu près intelligible pour nous comme framasoft.org) en adresse utilisable par une machine sur Internet («2a01:4f8:141:3421::212»). Partie mise à jour grâce au commentaire de Stéphane Bortzmeyer.
Pourquoi ça marche ?
Si vous donnez une fausse adresse à la machine, la pub n’arrive plus ! Un peu comme si vous mettiez une fausse boite aux lettres reliée directement à votre poubelle à la disposition des personnes qui distribuent des prospectus dans votre quartier.
Vous libérez même de la bande passante sur votre réseau et du temps de calcul à l’affichage des sites puisque votre appareil ne télécharge même pas les contenus publicitaires, qui pèsent généralement lourd dans une page web (images, vidéo).
dns.adguard.com
adblock.doh.mullvad.net
Blocklists locales via intégration VPN
Blokada (à la portée de tout le monde !)
TrackerControl (sur F-droid, assez didactique)
personalDNSFilter
Copie d’écran du réglage «DNS privé» sur Android. Un nom d »hôte personnalisé est saisi (ici dns.adguard.com).
Gérer les permissions aux applications
Les Android récents permettent par exemple d’autoriser une permission ponctuellement.
Si vous avez encore un compte Google
Réglez-le pour limiter la surveillance. Le mieux, c’est encore de ne pas en avoir.
On a l’impression que c’est obligatoire quand on configure un nouvel ordiphone (tout est fait pour vous donner cette impression, c’est ce qu’on appelle une interface déloyale, en anglais dark pattern), mais on peut passer cette étape ! Il suffit de cliquer sur «ignorer».
Vous pouvez parfaitement utiliser un Android sans la surcouche propriétaire de Google ou du fabricant, en installant par exemple Lineage OS ou /e/ OS de Murena.
Attention, «flasher» son engin est une opération délicate, vous risquez de le «briquer», c’est-à-dire de le transformer en presse-papier un peu cher.
Ne le faites pas si vous n’êtes pas à l’aise.
Cerise sur le gâteau : débarrassé de la surcouche Google, votre ordiphone sera plus véloce, moins poussif, et tiendra mieux la batterie ! Une bonne façon de faire durer le matériel (le mien va fêter ses huit ans !).
Autre solution pour un matériel qui dure : l’acheter en reconditionné sur https://murena.com/fr/
Il aura été configuré par des pros. Murena s’engage sur la protection de votre vie privée.
Sur iOS
Apple se targue de protéger vos données. Mais il y a au moins une entreprise qui y accède : Apple !
Et puis la firme a beau… frimer (on ne s’interdit pas les jeux de mots faciles, chez Framasoft), elle est quand même soumises aux lois liberticides américaines.
Gérer qui a accès aux permissions spécifiques
Consulter la section « Confidentialité de l’app » des fiches AppStore
Sur un ordinateur
Utiliser un navigateur bienveillant, la base : Firefox et rien d’autre
Avec Firefox, dans les Préférences, aller à l’onglet « vie privée et sécurité » : plusieurs trucs sont à régler pour se garantir un peu de tranquillité.
Firefox prévoit trois réglages de protection de la vie privée : standard, stricte, ou personnalisée. La protection standard est suffisante pour la plupart des usages, mais vous pouvez pousser la vôtre en mode « strict ». Ne vous ennuyez pas avec le réglage personnalisé si vous n’y comprenez rien.
Vous pouvez paramétrer Firefox pour qu’il envoie un signal « ne pas me pister » (Do Not Track en anglais, vous le verrez abrégé en DNT parfois) et pour supprimer les cookies à intervalle régulier, sachant que vous pouvez instaurer des exceptions sur les sites auxquels vous faites confiance.
Firefox vous demande votre accord pour collecter des données anonymisées sur votre usage du logiciel. Vous pouvez refuser. En revanche sur la partie Sécurité, cochez tout.
Le protocole HTTPS permet de chiffrer les relations entre le navigateur et le serveur, ce qui signifie qu’une personne qui intercepte le flux ne peut pas le lire (c’est le fameux petit cadenas dont vous entendez souvent parler). Mais ce n’est pas parce que la liaison est chiffrée que le site est un site de confiance. En gros ça garantit que l’enveloppe est fermée, pas que l’enveloppe ne contient pas des saloperies.
Les extensions que vous pouvez installer :
uBlock Origin
Privacy Badger
SponsorBlock
Privacy Redirect
Cookie Autodelete
Umatrix
Decentraleyes
Ne le faites pas sans comprendre ! Lisez la documentation.
Youtube sans pub
Invidious
Piped (plus récent, efficace)
FreeTube
Twitter sans Twitter
Nitter
DNS de filtrage, fichier hosts customisé
Comment ça marche ?
Les publicités ne sont généralement pas hébergées sur le serveur du site que vous consultez. Elles sont sur un autre site et téléchargées à la volée. En filtrant via le DNS, on dit à l’ordi d’aller chercher les pubs dans un «trou noir informatique». Le fichier «hosts» de votre système peut lister des adresses de sites et les rediriger vers un espace inexistant de votre ordinateur. En gros on truque l’annuaire ; votre navigateur ne trouve pas les publicités, il ne les affiche pas. Simple et efficace. Ce qui est drôle, c’est que le concepteur du site ne sait pas que vous naviguez sans voir ses pubs. 🙂
pi-hole
À installer sur un nano-ordinateur RaspberryPi dont l’un des spécialistes est français, cocorico, ou un ordinateur recyclé, pi-hole bloque la publicité et les pisteurs sur tout le réseau. Tout ce qui se connecte à votre box est débarrassé de la publicité et des mouchards !
Attention toutefois, en faisant ça vous contrevenez pour votre PC à un des principes d’Internet : la neutralité des tuyaux. Vous ne verrez plus rien en provenance du site tiers dont le trafic est bloqué. En général, ce sont des régies publicitaires, donc on peut choisir de s’en moquer, mais il faut le savoir.
Au pire vous verrez un espace blanc marqué « publicité », au mieux la page se réorganisera et seul le contenu issu du site d’origine apparaîtra.
Mode Expert : changez de système d’exploitation
Une méthode radicale (mais qui n’exclut pas la plupart des autres mentionnées ci-dessus) : passez à un système libre, qui ne trichera pas avec vous pour vous imposer des pubs sous prétexte de vous tenir au courant de l’actualité (oui, Windows, on te voit !).
Les différentes distributions GNU/Linux qui existent sont désormais faciles à installer et à utiliser.
La plupart des geeks installent désormais une Ubuntu ou une Linux Mintsur les ordinateurs familiaux au lieu de réparer le Windows qui plante sans cesse et qui s’encrasse avec le temps. Le changement n’est pas si difficile pour les «clients», qui souvent n’utilisent leur ordinateur que pour aller sur Internet gérer leur courrier et leurs réseaux sociaux (et croyez-nous c’est l’expérience qui parle !). Vérifiez quand même que Papy ou Tantine n’a pas une appli fétiche qui ne tourne que sous Windows et installez un double-démarrage par sécurité.
Au pire si quelqu’un fait une bêtise ça se dépanne à distance dans la majorité des cas (avec par exemple le logiciel AnyDesk qui n’est pas libre mais dont le fonctionnement est compréhensible par le moins dégourdi des cousins).
Mise à jour : on nous signale dans les commentaires une alternative libre et légère à AnyDesk : DWAgent via https://dwservice.net
Si vous ne comprenez pas certains mots du paragraphe ci-dessus, ne vous lancez pas, ou faites-vous aider par une personne compétente.
Difficile de vous conseiller une «distro» plutôt qu’une autre sans déclencher une guerre de chapelles dans les commentaires (on recherche ici la simplicité et l’accessibilité), mais pour détailler les deux citées plus haut :
Ubuntu est de plus en plus gangrenée par des choix discutables, mais elle dispose d’une solide base documentaire en français, est stable et conçue pour plaire au plus grand nombre. Debian, sur laquelle Ubuntu est basée, est plus stricte dans ses choix, pas forcément adaptée aux personnes qui débutent.
Linux Mint est jolie et fonctionne bien.
Si vous le faites pour «libérer» une relation, installez-lui une distribution que vous connaissez bien, pour pouvoir la guider en cas de besoin.
Oui mais la pub
Vous tomberez parfois sur des encarts qui vous culpabiliseront : «notre site ne vit que de la publicité, c’est le prix à payer si vous voulez avoir du contenu de qualité, nos enfants ont faim à cause de vous, vous mettez en danger nos emplois», etc.
Alors, deux-trois trucs à ce sujet :
La dérive (c’en est une) devient proprement insupportable, par exemple dans Youtube. Créateurs, créatrices de contenus, si la pub vous fait vivre, travaillez avec des gens sérieux qui proposent des contenus en lien avec votre site et qui n’espionnent pas les internautes. Bref, c’est pas nous qu’on a commencé, nous ne faisons que nous défendre.
D’autres modèles économiques existent, mais les pratiques des sites depuis des années ont instauré un fonctionnement «apparemment gratuit» des contenus avec des pubs insidieuses et imposées. Un média qui vit de la publicité peut-il sortir un scoop à charge contre son principal annonceur ? Figurez-vous qu’avant Internet les gens achetaient le journal (incroyable), voire avaient des abonnements. Maintenant qu’on se rebiffe ça couine. Fallait peut-être y penser avant ?
Du contenu de qualité, vraiment ? Vous voulez qu’on en parle, mesdames et messieurs les pros du putaclic ? Ce qu’on voit de plus en plus, ce sont des internautes qui doivent choisir entre accepter les cookies ou renoncer à un site, et qui finalement se disent que le contenu ne leur est pas si indispensable que ça.
Source : https://news.ohmymag.com Avouez que ça vous a démangé de cliquer !
Pour aller plus loin
SebSauvage est un gars bien
Seb est un passionné qui compile depuis des années des astuces sur son site. Abonnez-vous ! (y’a pas de pub)
Le potentiel rachat de Twitter par Elon Musk inquiète les membres de ce réseau, qui cherchent des alternatives et se créent en masse des comptes sur Mastodon, dans le fédiverse. Vous n’avez rien compris à tous ces mots ? Tout va bien, on vous explique tout ça dans cet article et en vidéo !
Cette nouvelle qui agite le monde des affaires de la Silicon Valley illustre une certitude qui nous habite depuis des années : derrière le choix des outils numériques, il y a un choix de société.
Twitter, le choix du capitalisme de surveillance
Que ce rachat de Twitter par le milliardaire conservateur se finalise ou non, au final peu importe : le danger a toujours été là.
Elon Musk jouant avec nos attentions (allégorie).
C’est le trop grand pouvoir des géants du web. C’est le danger de l’accumulation des informations et des attentions de centaines de millions d’êtres humains. Lorsqu’on centralise tout le monde sur une plateforme, lorsqu’un outil numérique peut accéder à votre cerveau, alors les personnes qui s’achètent un accès à ces outils s’achètent un accès à nos cerveaux.
Cumulez des accès précis à suffisamment de cerveaux et vous pouvez manipuler une société vers vos intérêts.
Car Twitter, comme Facebook mais aussi comme Framapad, n’est pas neutre. Aucun outil n’est neutre, mais c’est encore plus vrai pour les logiciels, qui sont des outils complexes. Le code fait loi, car il permet de déterminer quelles actions seront possibles ou pas, donc d’influencer l’expérience que vous vivrez en utilisant cet outil.
L’architecture d’un logiciel, c’est (par exemple) faire le choix de fonctionner avec une unique plateforme centralisatrice ou de multiples instances fédérées. Ces choix d’architecture déterminent la politique du logiciel, l’organisation sociale qu’il induit, donc le choix de société qui est porté par l’outil numérique sur lequel vous passez les précieuses minutes de votre vie.
Mastodon, le choix de la fédération des libertés
Si vous désirez tester une alternative indépendante, résiliente et conviviale à Twitter, nous vous recommandons de faire des « pouets » sur un drôle d’éléphant : Mastodon.
Mastodon, ce n’est pas une plateforme qui cumule tous les gens, toute l’attention et donc tout le pouvoir (coucou Twitter 😘) : c’est une fédération de fournisseuses qui se connectent ensemble (un peu comme l’email).
Sur mastodon, on ne tweete pas, on pouette (ou « toot » en anglais)
Ces fournisseuses hébergent une installation du logiciel Mastodon sur leur serveur : si vous vous y créez un compte, vos données se retrouveront sur ce serveur, chez cet hébergeuse. Vous pouvez imaginer que c’est une propriétaire qui vous loue une chambre, ou un stand à la foire : est-ce que vous voulez être chez la méga propriétaire de la foire immensissime et déshumanisée (Twitter) ou chez la petite propriétaire de la petite foire qui s’est connectée avec les foires des villages voisins ? (Mastodon)
Votre mission, c’est de trouver où vous créer un compte. Vous avez donc le choix entre plusieurs fournisseuses de Mastodon, qui ont chacune des motivations, des moyens, des conditions d’utilisations différentes.
L’avantage, c’est que Elon Musk ne peut pas toutes les acheter.
L’inconvénient, c’est de trouver celle qui vous plaît.
C’est important de dire que votre compte Mastodon ne sera pas hébergé par une méga entreprise déshumanisée qui vous considérerait comme une vache-à-données. Les personnes qui fournissent du Mastodon le font par passion, sur leur temps à elles, et c’est du boulot !
Faire la modération, c’est au moins autant de travail que de désherber un jardin. Illustration de David Revoy (CC-By)
Beaucoup de fournisseuses auront des règles (modération, fake news, pornographie…) liées à leurs motivations : vous avez donc tout intérêt à vous demander si leur politique de modération et de publication correspond à vos valeurs. Car liberté ne veut pas dire fête du slip de l’inconséquence : si vous êtes libres d’utiliser Mastodon comme vous voulez (sur votre serveur à vous), les personnes qui vous offrent un compte sur leur hébergement Mastodon n’ont pas pour devoir de vous offrir une plateforme… D’autant plus si elles estiment que vous ne vous arrêtez pas là où commence la liberté des autres.
En fait, on ne s’inscrit pas chez une telle fournisseuse comme on rentre dans un hypermarché, car vous n’êtes ni une cliente ni un produit.
Par ailleurs, il est souvent demandé (ou de bon ton) de se présenter lorsqu’on demande à rentrer sur une instance, ou lorsqu’on vient d’y être acceptée. Ainsi, n’hésitez pas à ce que votre premier pouet inclue le hashtag #introduction pour vous présenter à la communauté.
Faire ses premiers pas chez un hébergeur de confiance
Pour vous aider, on va vous faire une sélection juste après, parmi les amies des CHATONS. Car ce collectif d’hébergeuses alternatives s’engage à appliquer des valeurs de manière concrète (pas de pistage ni de GAFAM, neutralité, transparence) qui inspirent la confiance.
Mais avant de vous créer un compte, souvenez-vous que c’est toujours compliqué de tester un nouveau réseau social : il faut se présenter, se faire de nouvelles amies, comprendre les codes… 🤯 Vous vous doutez bien que Twitter veut garder les gens chez lui, et n’offrira aucune compatibilité, ni moyen de retrouver des personnes. Bref, il faut prendre Mastodon comme un nouveau média social, où on recommence à construire sa communauté de zéro.
Se dire bonjour, c’est un bon début quand on veut communiquer 😉 Illustration CC-By SA LILA
Bonne nouvelle : si vous ne choisissez pas la bonne fournisseuse du premier coup, c’est pas si grave : on peut migrer son compte d’une fournisseuse à l’autre. Peu importe chez qui vous vous inscrivez, vous pourrez communiquer avec tout cet univers fédéré (« federated universe » = fédiverse : on vous explique ça plus bas en vidéo !)
Ne loupez pas la vidéo à la fin de cet article, réalisée par LILA (CC-By SA)
Créer votre compte Mastodon chez une des CHATONS
À Framasoft, nous hébergeons Framapiaf, notre installation de Mastodon. Mais il y a déjà beaucoup trop de monde d’inscrit dessus : nous n’y acceptons plus de nouveaux comptes. Grossir indéfiniment pourrait créer des déséquilibres dans la fédération et surcharger les épaules de notre petite équipe de modération !
Parce que le but, c’est de garder des « instances » Mastodon (c’est le nom qu’on donne au serveur d’une fournisseuse de Mastodon), à taille humaine, dont l’équipe, les choix, les motivations, etc. vous inspirent confiance. Et qu’à cela ne tienne, il en existe beaucoup !
Voici donc notre sélection, mais qui n’est pas exhaustive : il y en a plein d’autres des super bien, et vous pouvez en trouver la plupart sur le site joinmastodon.org.
Vous pouvez aller chez Zaclys, une association franc-comtoise qui, pour professionnaliser ses services, est devenue une SARL, mais avec la même équipe et la même éthique.
Underworld, en revanche, c’est une personne sur Paris qui héberge des services avec amour, pour le plaisir et le savoir, et qui vous aide si vous lui payez l’apéro 🍻
Immaeu, c’est une petite entreprise d’une personne, qui ne cherche pas à faire de profit sur ses services (mais qui accepte les tips ou fait payer les grosses demandes spécifiques).
FACIL est une association québecoise qui œuvre à l’appropriation collective de l’informatique libre. Leur instance Mastodon a le plus beau nom au monde : « Jasette ».
Si vous voulez qu’on vous installe votre propre instance Mastodon en quelques clics (moyennant quelques sous), Ethibox est la micro entreprise là pour vous !
Enfin, Chapril, c’est le chaton de l’APRIL, l’association de défense et de promotion du logiciel libre. Elle vit grâce aux cotisations et dons de ses membres : rejoignez-là !
Les pouets de Mastodon, les vidéos de PeerTube, les événements et groupes de Mobilizon, etc., toutes ces informations se retrouvent dans le « Fédiverse ».
Mais c’est quoi, le fédiverse ? Pour vous répondre, nous avons travaillé avec l’association LILA afin de produire une courte vidéo en anglais (déjà sous-titrée en français : aidez nous à la traduire depuis l’anglais dans d’autres langues sur notre plateforme de traduction).
Nous profitons donc de cet article pour vous dévoiler cette vidéo, que vous pouvez partager massivement autour de vous !
Alliance du Bâtiment : un format de fichier ouvert pour la construction
L’interopérabilité logicielle, c’est à dire la capacité de deux logiciels à parler « la même langue », a souvent été évoquée dans le Framablog.
La plupart du temps, il s’agissait pour nous de traiter de bureautique (« Pourquoi mon fichier LibreOffice est-il mal ouvert par cette saleté de Word ?! ») ou de web (« Pourquoi ce site est-il moins bien affiché avec Firefox qu’avec Chrome ? »).
Comme la langue française a besoin de règles de grammaire et d’orthographe, de dictionnaires, etc, les formats de fichiers ont besoin de spécifications, de normes, et d’être correctement implémentés.
Or, quand un format n’a pas de spécification publique et librement implémentable, cela nous rend dépendant⋅e de l’éditeur du logiciel. Un peu comme si un petit groupe de personnes pouvait décréter que vous ne pouviez pas utiliser le mot « capitalisme » parce que ça ne l’arrangeait pas, ou imposait l’interdiction du mot « autrice » (parce que « auteure » n’aurait été acceptée qu’après 2006). Ce serait assez fou, non ? Oh, wait…
Et bien certains formats de fichiers sont clairement verrouillés. Par exemple les fichiers .DWG du logiciel de dessin Autocad sont dans un format fermé. Alors évidemment, d’autres éditeurs ont essayé de « deviner » comment fonctionnait le format .DWG afin de pouvoir ouvrir et enregistrer des fichiers compatibles AutoCAD avec leur logiciel. C’est ce qu’on appelle de la rétro-ingénierie, mais c’est souvent du bricolage, et l’éditeur original peut régulièrement changer la spécification de son fichier pour embêter ses concurrents, voir aller jusqu’à leur intenter des procès.
Or, s’il existe un domaine où les formats de fichiers devraient bien être ouverts, c’est celui de la construction. Nous interagissons toutes et tous avec des bâtiments au quotidien. Qu’il s’agisse de notre logement, de notre lieu de travail, d’un bâtiment public, etc, nous passons d’un bâtiment à l’autre en permanence.
Or, aussi étonnant que cela puisse paraître, il n’existe pas de format de fichiers de description des données utiles à la construction qui soit à la fois public ET largement utilisé. Le logiciel AutoCAD (et son format .DWG) et le logiciel REVIT (pour le processus BIM et ses formats .rfa, .rvt) de la société Autodesk, dominent largement le marché. Et les conséquences sont loin d’être négligeables. Cela « force la main » des différents corps de métiers (architectes, ingénieurs, constructeurs, artisans, etc) à utiliser ces logiciels et entretient le quasi-monopole d’Autodesk sur le marché. Utiliser d’autres logiciels reste possible, mais imaginez les conséquences si ce logiciel fait une « erreur » en ouvrant le fichier « immeuble-de-12-étages.dwg » à cause d’une erreur dans l’interprétation de la spécification….
Par ailleurs, en dehors des descriptions des murs, des calculs de poids de structures, il faut aussi intégrer des éléments comme les chauffages, les canalisations, les circuits électriques, les fenêtres, etc. Les données générées par un bâtiment (ou autre bâti, tel un pont ou une route) sont donc extrêmement nombreuses. La page wikipédia « Liste des logiciels CAO pour l’architecture, l’ingénierie et la construction » est d’ailleurs plus que conséquente, et sa section logiciels libres est plutôt réduite…
Il existe bien des formats standardisés pour gérer la modélisation du bâti immobilier, appelée « BIM ». Ainsi, l’IFC est un format de fichier standardisé (norme ISO 16739) orienté objet utilisé par l’industrie du bâtiment pour échanger et partager des informations entre logiciels. Mais il est assez peu utilisé et souvent décrit en format natif, ce qui rend l’interopérabilité entre logiciels complexe à réaliser malgré l’existence de l’IFC.
Il apparaît donc essentiel de disposer de formats qui soient ouverts (pour permettre l’interopérabilité), et normalisés (validés et éprouvés par les professionnels du métier) pour nos constructions.
Nous avons rencontré les membres de l’association Alliance Bâtiment qui met à la disposition des maîtres d’ouvrage, maîtres d’œuvre, entreprises, artisans et fabricants PME, TPE, un format ouvert et partagé. Cela permet de normaliser la donnée d’entrée dans les logiciels métiers et rendre les maquettes IFC interopérables. L’accès au processus BIM et l’usage des logiciels BIM est ainsi fortement simplifié !
Bonjour ! Pouvez-vous vous présenter ?
Jean-Paul BRET, Président de l’association : Ma longue carrière professionnelle dans la promotion immobilière à l’OPAC 38, le plus gros bailleur social de l’Isère, et comme Président de la Communauté d’Agglomération du Pays Voironnais (38) durant 12 ans m’incite à penser que le secteur de la construction doit impérativement accélérer sa transition numérique.
Jean-Paul BRET
J’ai pu constater en engageant de nombreuses opérations de construction que les nombreux acteurs autour d’un projet avaient souvent du mal à se coordonner voire se comprendre. C’est une banalité de parler de retard de travaux, de dépassements budgétaires, de malfaçons pouvant conduire à des conflits et de documents descriptifs des ouvrages difficilement exploitables pour la maintenance des ouvrages.
Thierry LEHNEBACH, Administrateur Délégué : Très tôt, j’ai été motivé par la protection de l’environnement, ce qui m’a conduit à m’engager pour l’écologie. Cela m’a amené à avoir un parcours d’élu, conseiller régional, puis maire et vice président de l’intercommunalité. Dans le même temps, mon activité professionnelle s’est organisée autour de la communication orientée vers le numérique et l’informatique en opensource, puis une dernière activité dans une entreprise artisanale.
Thierry LEHNEBACH
Je mets en œuvre ces acquis au service de l’association en tant que cheville ouvrière : communication, animation, gestion.
La transformation numérique de la société ouvre de nouvelles frontières qui donne un avantage disproportionné aux plus puissants qui s’approprient le réel grâce au contrôle de la donnée. Le problème est que la culture de la donnée n’est pas encore développée et qu’il y a une grande naïveté chez tous les décideurs, utilisateurs et simples citoyens.
Didier BALAGUER : Après une première création d’entreprise d’ingénierie spécialisée en acoustique en 1994, j’ai créé datBIM, éditeur de solutions numériques collaboratives pour la construction, en 2000. J’ai identifié dès l’origine qu’une clé de la coopération est l’échange fluide et fiable de données entre les acteurs indépendamment des outils logiciels utilisés, ce qui a amené datBIM à créer le format opendthX.
Didier BALAGUER
Faire en sorte que tout type de données soit exploitable dans tout type d’applications à l’image du secteur des télécommunications où 2 correspondants peuvent communiquer indépendamment de la marque de leur téléphone ou des opérateurs de services auxquels ils souscrivent respectivement leur abonnement. La valeur induite par l’interopérabilité des données avec les applications à l’échelle d’un secteur tel la construction Française est estimée à plusieurs dizaines de milliards d’euros par an.
Qu’est-ce qui vous a incité à vous investir en tant que bénévoles dans cette nouvelle association ALLIANCE DU BATIMENT pour le BIM ?
Didier BALAGUER : Ouvrir le format était une évidence, le concéder à ALLIANCE DU BATIMENT, association loi 1901 gouvernée par les acteurs volontaires de la filière, un moyen d’apporter la confiance pour permettre aux acteurs de maîtriser leur devenir numérique pour répondre collectivement aux enjeux de notre société : transition écologique, liberté d’expression et d’entreprendre tout en renforçant la compétitivité de notre économie.
Jean- Paul BRET : Lorsque Didier BALAGUER m’a proposé de créer l’ALLIANCE DU BATIMENT pour le BIM, avec pour objectif de faciliter la transition numérique de la filière avec les outils mis à disposition en opensource, j’ai tout de suite accepté. Cela a conduit au transfert à l’association de la gestion et la gouvernance du format opendthX initialement développé par la société datBIM pour en faire un bien commun, libre d’usage.
L’absence de langage commun et d’interopérabilité entre les données et les outils pénalise souvent la qualité des projets et l’efficacité de toute la filière constructive. Le BIM qui est la numérisation du processus de construction peut améliorer cette situation. C’est un moyen de le faire depuis la phase de conception d’un projet jusqu’à celle de la déconstruction en passant par la construction et l’exploitation.
Mais il ne doit pas être réservé aux grands acteurs de la filière et conduire à une plateformatisation et une appropriation de la valeur par quelques acteurs dominants ou des plateformes de type GAFAM. Or c’est ce qu’il se passe avec les formats propriétaires des logiciels de CAO adaptés pour le BIM.
Il doit être facilement accessible aux PME, TPE et artisans qui représentent environ 95% des entreprises de la filière constructive.
Pour cela nous allons mettre à leur disposition de nouvelles solutions d’interopérabilité qui faciliteront leur manière d’accéder à la donnée sur les objets. Elles leur permettront de contribuer à la production de la maquette numérique. L’enjeu est important puisqu’en cas de succès l’ALLIANCE DU BATIMENT pourrait avoir valeur d’exemple. Cela pourrait à ce titre, être décliné bien au-delà nos frontières.
Nous sommes d’autant plus motivés que ce projet, qui vise à faciliter la coopération au sein de la filière BTP, est totalement en phase avec les objectifs du plan gouvernemental BIM 2022 qui reposent sur le principe directeur du BIM POUR TOUS. Enfin, pour moi le BIM n’est pas seulement une démarche qui permet d’optimiser l’échange d’information et la collaboration entre acteurs d’un projet constructif. C’est aussi un outil au service de la transition écologique puisqu’il permet une véritable traçabilité environnementale.
Dans les deux cas, les enjeux sont cruciaux tant sur le plan de la compétitivité économique que des aspects sociétaux.
Thierry LEHNEBACH : ALLIANCE DU BATIMENT ouvre un front dans le secteur de la construction qui concerne, en terme d’échange de données relatives à l’objet constructif, 25 % du PIB quand on prend en compte l’ensemble des acteurs (BTP, banques, assurances, etc..) en considérant que la donnée numérique doit être un commun dans cette filière.
Pouvez-vous nous expliquer un peu plus ce qu’est le BIM ?
Maquette numérique
Thierry LEHNEBACH : Le BIM ou Building Information Modeling est la modélisation des informations de la construction. C’est l’utilisation d’une représentation numérique partagée d’un actif bâti. Le BIM facilite les processus de conception, de construction et d’exploitation. Ces actifs bâtis sont des bâtiments, ponts, routes, tunnels, voies de chemin de fer, usines,…
Le processus produit un livrable numérique, le building information model, en français la maquette numérique. C’est le support et en même temps le document numérique du processus qui doit permettre à tous les acteurs de collaborer.
Pouvez-vous nous parler du projet de l’association ?
Thierry LEHNEBACH : ALLIANCE DU BATIMENT pour le BIM met à disposition librement le format opendthX dont elle a acquis les droits exclusifs d’exploitation. Ce format a été développé par la société datBIM pour structurer des bibliothèques d’objets pour le BIM et les diffuser en permettant l’interopérabilité entre tous les logiciels.
La maquette numérique englobe la géométrie de la construction, les relations spatiales, les informations géographiques. Elle englobe également les quantités, ainsi que les propriétés des éléments et sous-éléments de construction. Le format IFC (NF EN ISO 16739) permet de classer ces informations de manière logique selon une arborescence spatiale. Cette arborescence est définie par projet, site, bâtiment, étage, espace, composant.
La maquette numérique standardisée au format international IFC rassemble une bonne partie des informations. Elle rassemble les formes et matériaux, les calculs énergétiques pour le chauffage, la climatisation, la ventilation. Cela comprend également les données sur l’aéraulique, l’hydraulique, l’électricité, radio et télécommunications, levage, emplacement des équipements, alarmes et sécurité, maintenance, etc.
Mais le format IFC n’est pas suffisant pour permettre la réalisation d’un processus BIM abouti. Il y a deux problèmes majeurs :
Le premier est que les objets au sein de la maquette IFC sont généralement structurés par des formats propriétaires et donc non interopérables. Les différents logiciels métiers utilisés sur un même projet utilisent des formats de données natifs. Ces formats concernent les objets avec des données décrites de différentes manières. L’écosystème BIM est un système multi-entrées dans lequel on introduit des données qui sont doublonnées et redondantes. Celles-ci constituent alors obligatoirement une donnée d’entrée de mauvaise qualité. Par conséquent elle amène à produire collectivement un résultat de piètre qualité. Ce phénomène pénalise des échanges fluides avec les logiciels des autres corps de métiers.
Le second problème est que les formats propriétaires permettent aux acteurs les plus puissants de s’approprier le contrôle des données, ce qui créé des barrières et ouvre la voie à des situations de monopole de type GAFAM.
La mise en œuvre du BIM doit être simple pour un déploiement généralisé. L’association met à disposition des acteurs le format opendthX et participe aux développements d’outils pour permettre l’accès au BIM à tous les acteurs.
Comment fonctionnent ces outils ?
Didier Balaguer : Le processus collaboratif proposé par ALLIANCE DU BATIMENT s’appelle le BIM CIQO (Collaboration In – Quality Out). Il est basé sur la normalisation de la donnée d’entrée introduite dans les logiciels métiers de la construction et l’enrichissement des « objets » pour permettre la contribution de tous au processus BIM. C’est la raison d’être du format Open dthX.
Schéma expliquant le BIM facile
Le processus CIQO, ou BIM universel, est le traitement du GIGO (Garbage In Garbage Out), caractéristique du BIM complexe multi-formats natifs.
On peut le mettre en œuvre avec eveBIM, logiciel de visualisation / enrichissement de maquettes IFC développé par le CSTB ou en mode saas en cours de développement (bim-universel.com) pour définir des objets BIM sur la base de modèles génériques de type POBIM (Propriétés des objets BIM ), qui est une bibliothèque de 300 modèles d’objets génériques à partir d’un dictionnaire de 3200 propriétés, définies selon la norme NF XP P 07150 devenue en 2020 NF EN ISO 23386.
Cette bibliothèque à été réalisée dans le cadre des travaux du plan de transition numérique du Bâtiment (PTNB) accessible depuis kroqi.MydatBIM.com, plateforme d’objets labellisée par l’AMI (appel à manifestation d’intérêt) kroqi, plateforme de gestion de projets BIM de référence du Plan gouvernemental BIM 2022. Il existe également d’autres bibliothèques :
Jean-Paul BRET : L’association est structurée par 6 collèges, dont les deux principaux piliers sont les organisations professionnelles telles que des CAPEB et des syndicats qui représentent des acteurs petits et moyens de la filière, et de maîtres d’ouvrage publics et privés. Il y a également des collèges association, organismes de formation, entreprises et citoyens.
Acteurs impliqués dans Alliance du Bâtiment
Le modèle économique repose sur des adhésions, des financements sur projets et sur le produit de la formation par le biais de modules destinés à être mis en œuvre par des organismes de formation que l’association labellise.
C’est une structure légère qui a vocation à le rester tout en se professionnalisant pour s’inscrire dans la durée.
Selon vous, quels sont les enjeux d’un « BIM libre » ?
Le BIM libre permet à tous les acteurs de la filière des garder leur autonomie sans être rendus dépendants par des outils qu’ils ont eux même développés avec leur compétence mais dans un format qu’ils ne maîtrisent pas. L’interopérabilité complète permet aussi d’envisager le développement de savoir-faire partagés par l’ensemble de la filière pour faire monter celle-ci en efficacité. Il est possible par exemple d’imaginer de mettre en œuvre l’intelligence artificielle pour extraire de plusieurs projets des règles pour optimiser l’efficacité énergétique d’un type de construction.
L’accès à ce processus pour tous les acteurs est aussi un élément important pour les maîtres d’ouvrage qui veulent garder un écosystème d’entreprises de proximité. C’est une garantie pour la résilience des territoires et une sécurité contre la concentration qui conduit aux monopoles de fait.
Quelles sont les particularités de ce format Open dthx ?
Le format Open dthX a été développé par la société datBIM à partir de 2011 dans le cadre d’une collaboration avec l’école Centrale de Lyon et des experts en modélisation de la connaissance et ingénierie des systèmes. Les travaux ont bénéficié du soutien de la région Rhône-Alpes et l’Ademe (Innov’R) ainsi que de l’Europe (GreenConserve pour l’innovation de services à valeur ajoutée pour la construction durable et Eurostars).
L’enjeu de départ est de permettre aux acteurs du bâtiment (fournisseurs de matériaux, architectes, ingénieurs, …) de s’échanger – dès les premières phases du projet – les caractéristiques techniques des produits mis en œuvre dans la construction.
Logo du format Open dthX
Un Dictionnaire Technique Harmonisé (DTH) a été mis en place à cette fin de nature dynamique afin que la sémantique puisse s’enrichir en fonction des besoins sans perturber les usages du format. Il maintient une liste de propriétés dans différents domaines (géométrique, acoustique, thermique, incendie, environnement, administratif…) en définissant pour chaque propriété un identifiant unique et une unité de mesure standard.
En 2015, la documentation du format est rendue publique, en faisant un format ouvert. Il est proposé à la normalisation entraînant la création d’un groupe d’experts sur les formats d’échange à la commission de normalisation, Afnor PPBIM. En 2019, il permet la distribution de la première bibliothèque d’objets génériques POBIM (propriétés des objets pour le BIM) décrit à partir d’un dictionnaire national de 3200 propriétés issues des travaux réalisés dans le cadre du plan gouvernemental de transition numérique du bâtiment (PTNB). En 2021, le plan gouvernemental BIM 2022 l’expérimente pour la réalisation d’un référentiel d’objets pour produire une maquette numérique contenant les informations nécessaires à l’instruction des autorisations d’urbanisme.
Normaliser la donnée d’entrée dans les logiciels métiers pour produire collectivement un livrable numérique de qualité (au sens interopérabilité du terme : exploiter le livrable qui est une base de données dans une application autre que celle qui l’a produite) et assurer l’enrichissement des objets à l’avancement du projet pour permettre la contribution de tous au processus BIM indépendamment des logiciels utilisés.
Quelle est la licence retenue pour la spécification de ce format ?
L’usage du format Open dthX est soumis à l’acceptation des termes de la licence « Creative Commons Attribution Pas de Modification 3.0 France ».
Sa principale valeur c’est justement qu’il soit unique afin d’assurer l’interopérabilité d’où le choix de ce type de licence. Des variantes porteraient préjudices à l’interopérabilité.
Qui utilise ce format de fichier Open dthx aujourd’hui ? Avec quels logiciels ?
Les utilisateurs du format Open dthX sont les acteurs de la construction : architectes, ingénieurs, entreprises, fabricants, maîtres d’ouvrage qui utilisent des logiciels de CAO tels Revit, ArchiCAD et de visualisation tels eveBIM, ciqo.eu…
De quoi avez-vous besoin aujourd’hui ? Et à plus long terme ?
Le premier enjeux est de faire connaître le projet de l’association. C’est assez difficile car la conscience de l’enjeu est très peu développé chez les décideurs et la communication des leaders du BIM qui vantent la puissance de leurs outils impose l’idée que leurs solutions sont le BIM alors que ces solutions n’en sont qu’une partie et que celle-ci est inadaptée à une approche data performante généralisable.
Nous cherchons aussi des partenaires qui mettent en œuvre ces outils. Nous sommes convaincus que les bénéfices de ces réalisations se diffuseront très rapidement auprès des décideurs vigilants sur les questions de maîtrise des données.
Enfin, nous voulons mettre en place un modèle qui nous permette de nouer des partenariats avec des développeurs qui peuvent proposer des développements qui utilisent le format pour des solutions correspondantes à des besoins métier liés à la construction.
Un mot ou une question à ajouter ?
Nous proposons à tous les décideurs en matière de construction de les accompagner pour mettre en œuvre le BIM universel de façon à avoir le plus grand nombre de références et de cas d’usage à diffuser pour propager la démarche.
L’équipe de traduction des bénévoles de Framalang vous propose aujourd’hui le bref témoignage de Silvia, une designeuse indépendante1, qui avait atteint comme beaucoup un degré d’addiction élevé aux réseaux sociaux. Comme d’autres aussi, elle a renoncé progressivement à ces réseaux, et fait le bilan après six mois du nouvel état d’esprit dont elle a bénéficié, une sorte de sentiment de soulagement, celui d’avoir retrouvé un peu de liberté… Bien sûr chacun a une trajectoire différente et la démarche peut n’être pas aussi facile, mais pourquoi ne pas tenter ?
Article original sur le blog de l’autrice : Life off social media, six months in
Traduction Framalang : Bromind, Diane, Florence, goofy, Marius, ngfchristian, Penguin
Six mois hors réseaux sociaux, six mois dans ma vie
par Silvia Maggi
J’étais vraiment partout. Citez-moi un réseau social, et sans doute, j’y avais un compte… Internet a toujours été important pour moi, et un certain degré de présence en ligne était bon pour mon travail, mes hobbies et mes relations sociales.
Mes préférés étaient Twitter, Flickr et LinkedIn. J’ai été une utilisatrice plutôt précoce. Puis sont arrivés Facebook et Instagram, qui sont ensuite devenus les principales raisons pour lesquelles j’ai fermé la plupart de mes comptes. Dès l’origine, j’ai eu une relation d’amour-haine avec Facebook. La première fois que je m’y suis connectée, j’ai détesté l’interface, les couleurs, et j’avais du mal à voir l’intérêt. D’ailleurs, j’ai aussitôt fermé le compte que je venais d’ouvrir, et je n’y suis revenue que plus tard, poussée par des amis qui me disaient « on y est tous et c’est marrant ».
Avec Instagram, le ressentiment est monté progressivement. Mon amour pour la photographie aurait pu être satisfait par l’application mais c’était également une période où les filtres étaient utilisés à outrance – à l’époque, l’autre application en vogue pour la prise de photos était Hipstamatic – et je préférais de toute façon prendre des clichés plutôt avec un appareil photo.
À mesure que la popularité d’Instagram augmentait, associée à la qualité du contenu, je suis devenue accro. Je n’ai jamais effacé mon compte Flickr, mais je ne visitais que rarement la plateforme : à un moment, on a eu l’impression que tout le monde avait migré vers l’application aux photos carrées. Cependant, quand Facebook a acheté Instagram pour 1 milliard de dollars en 2012, son avenir est devenu malheureusement évident. Avance rapide jusqu’à janvier 2021 : j’ai désactivé ce que je considérais à une époque comme mon précieux compte Instagram, et j’ai également fermé mon compte WhatsApp. Avant cela, j’avais fermé mes comptes Twitter, Facebook et Pinterest. Six mois plus tard, je peux dire comment les choses se sont passées.
Le bruit de fond s’est tu
Au début, c’était une sensation étrange : quelque chose manquait. Dans ma vie, je m’étais habituée à un certain niveau de bruit, au point de ne plus m’en rendre compte. Une fois qu’il a disparu, cela est devenu si évident que je m’en suis sentie soulagée. J’ai désormais moins d’opportunités de distractions et ainsi, il m’est devenu progressivement, plus facile de rester concentrée plus longtemps. En conséquence, cela a considérablement amélioré ma productivité et désormais, je suis à même de commencer et terminer la lecture de livres.
Le monde a continué de tourner
Je ne prête plus l’oreille aux mèmes, scandales ni à tout ce qui devient viral ou tendance sur les réseaux sociaux. Au lieu d’avoir peur de rater quelque chose, j’y suis indifférente. Le temps que je passais à suivre ce qui arrivait en ligne, je le passe ailleurs. Et le mieux dans tout ça, c’est que je ne me sens pas obligée de donner mon avis. J’ai des opinions précises sur les choses qui me tiennent à cœur, mais je doute que le monde entier ait besoin de les connaître.
En ce moment historique, tout peut être source de division, et les réseaux sociaux sont un endroit où la plupart des gens choisissent un camp. C’est un triste spectacle à voir car les arguments clivants sont amplifiés mais jamais réellement apaisés.
Ma santé mentale s’est améliorée
Il y a quelques années, je pensais qu’avoir du succès sur Instagram pourrait devenir mon boulot d’appoint. C’est arrivé à beaucoup de gens, alors pourquoi pas moi ? J’avais acheté un cours en ligne, proposé par un influenceur célèbre, pour comprendre comment rendre mon compte Instagram digne d’intérêt, et faire monter mes photos tout en haut grâce à l’algorithme.
À partir de ce moment, je me suis retrouvée enfermée dans une boucle. Je sortais et prenais avec frénésie plein de photos, les publiais puis je vérifiais les statistiques pour voir comment elles évoluaient. J’ai eu de bons moments, rencontré des personnes géniales, mais ce n’était jamais assez. En tant que photographe, je n’en faisais jamais assez. Les statistiques sont devenues un problème : j’en étais obsédée. Je les vérifiais tout le temps, me demandant ce que je faisais mal. Quand tout cela est devenu trop, je suis passée à un compte personnel, espérant résoudre mon problème en cliquant sur un simple bouton. Ça ne s’est pas passé ainsi : les chiffres n’étaient pas le vrai problème.
À chaque fois que j’éprouvais comme une démangeaison de photographier, et que je ne pouvais pas prendre de photos, je me sentais coupable parce que je n’avais rien à poster. Ma passion pour la photographie est passée d’une activité qui ne m’a jamais déçue, à une source d’anxiété et de sentiment d’infériorité. Depuis que j’ai désactivé mon compte Instagram, je prends des photos quand j’en ai envie. Je les poste sur Flickr, ou bien je les garde pour moi. Ça ne compte plus vraiment, tant que c’est un exutoire créatif.
Chaque fois que j’avais quelque chose à dire ou à montrer, je postais presque immédiatement sur un réseau social. C’était la chose normale à faire. Même si cela a diminué pendant les dernières années, je vois cela comme une attitude étrange de ma part. C’est peut-être une réflexion due au fait que je me connais un peu mieux désormais, mais il m’a toujours fallu du temps pour assimiler des concepts et me forger des opinions. C’est pour cela que je préfère écrire sur mon blog et que j’ai réduit récemment ma fréquence de publication : je donne davantage de détails sur mes apprentissages et mes réalisations récentes.
Conclusion
Quitter les réseaux sociaux a été une bonne décision pour moi. Je suis plus concentrée, moins anxieuse et j’ai à présent plus de temps libre. Cela, en plus des divers confinements, m’a permis de mieux me concentrer et réfléchir davantage à ce qui compte vraiment. Prendre cette décision ne conviendrait certainement pas à tout le monde, mais il est important de réaliser à quel point les réseaux sociaux influencent nos vies, et à quel point ils peuvent changer nos habitudes ainsi que notre manière de penser. Et ainsi, prendre des décisions à notre place.
Des très nombreux témoignages en français qui mettent souvent l’accent sur la difficulté à se « sevrer »…
Mise à jour
22 Novembre 2021. Il y a deux mois, je me suis connectée à Instagram et n’ai rien ressenti. J’ai vu une vidéo d’un ami, mais je n’ai nullement éprouvé le besoin de regarder plus loin.
Il n’y avait aucun intérêt à maintenir ce compte en mode inactif, alors j’ai demandé sa suppression.
Maintenant c’est fini.
Publicité ciblée en ligne : rien ne changera tant que…
AdContrarian (en français, à peu près « Poil à gratter de la pub ») est le titre du blog de Bob Hoffman et ce choix dit assez combien ce journaliste notoire aux U.S.A s’évertue à « mettre mal à l’aise les marketeux » qu’il connaît bien et ne se lasse pas de les fustiger sans prendre de gants…
Dans sa newsletter de février que les bénévoles de Framalang ont traduit pour vous, il fait preuve d’un certain pessimisme par rapport au RGPD et à sa transposition dans les réglements étatsuniens, tant les acteurs de la publicité ciblée, Google et autres, ont peu de difficultés à contourner les lois ou à payer, même si le ciblage publicitaire est déclaré illégal…
L’intégralité de la publicité en ligne en Europe repose sur un pistage illégal.
Tel a été le verdict, en février dernier, du bras armé chargé du respect du RGPD (Règlement Général sur la Protection des Données).
Mardi 2 février 2022, les autorités chargées de la protection des données de l’Union européenne ont statué sur l’illégalité des « fenêtres popup qui sollicitent le consentement », ces affreuses notifications qui vous demandent dans un charabia incompréhensible d’accepter des cookies à chaque fois que vous arrivez sur un site web. Déroulons toute l’histoire depuis le début.
Il y a presque cinq ans, l’Union européenne a voté pour l’application du RGPD dont l’objectif était de protéger la vie privée des citoyens contre les abus de l’industrie de la collecte de données en ligne. Ce RGPD fixe certaines normes pour la collecte et l’utilisation des données, y compris pour les activités des agences publicitaires en ligne.
Pour se conformer au RGPD, les publicitaires ont demandé à leur regroupement industriel, la malhonnête et peu recommandable Interactive Advertising Bureau (ou IAB) Europe, d’imaginer un classique du genre, le « Cadre de transparence et de consentement » (TCF), qui selon eux permettait aux annonceurs de ne pas se conformer au RGPD. Le TCF est une justification bidon de ces stupides fenêtres de consentement.
Cette semaine, l’autorité de protection des données a jugé que le TCF c’est des grosses conneries et que c’est illégal. Ils ont jugé que le TCF :
• ne conserve pas les données personnelles de façon sécurisée, comme l’exige le RGPD ;
• ne recueille pas correctement le consentement des personnes ;
• n’a pas défini un « intérêt légitime » légalement valide pour la collecte de ces informations ;
• échoue à être transparent sur ce qui est fait de ces données personnelles ;
• échoue à veiller à ce que ces données soient traitées en accord avec les lignes directrices du RGPD ;
• échoue à respecter les critères du RGPD de « protection des données dès la conception ».
À part ça, c’est absolument super.
Chapeau à l’ICCL (Conseil irlandais pour les libertés civiles) pour avoir porté cette grosse affaire devant les instances européennes. Et un prix Nobel de quelque chose pour Johnny Ryan qui veille sans relâche sur les droits à la vie privée au nom de nous tous. On peut voir Johnny Ryan parler aux infos de ce jugement.
Question suivante : qu’est-ce que ça va changer pour le secteur de la publicité ciblée ? Comme nous le savons, ce secteur fait régulièrement un doigt d’honneur aux régulateurs et fait absolument tout ce qui lui chante. Les régulateurs pensent qu’ils gèrent les choses, mais leur incompétence pathétique et leur couardise ont permis au secteur de la publicité ciblée d’en faire voir de toutes les couleurs aux régulateurs et au public, depuis l’instauration du RGPD. Une conséquence de ce jugement est que Google et tous les autres acteurs du secteur de la publicité ciblée en ligne sont sommés de brûler toutes les données qu’ils ont collectées illégalement. Google se conformera à ça quand les réfrigérateurs auront des ailes.
L’IAB Europe a maintenant six mois pour corriger l’illégalité flagrante de leur TCF absurde. Que vont-ils faire ? À mon avis, ils vont pondre une autre magnifique bouse qui va prendre des années à contester, pendant que les publicitaires continueront d’entuber joyeusement le public. Comme d’habitude, j’espère avoir tort.
Le secteur de la publicité ciblée, en particulier Google et Amazon, amasse beaucoup trop d’argent pour en avoir quoi que ce soit à faire des amendes de pacotille que les régulateurs leur distribuent pour leurs activités criminelles. Pour eux, ce sont juste des frais de fonctionnement. Facebook n’essaie même pas de se soumettre au TCF, ils n’ont de comptes à rendre à personne.
Rien ne changera tant que personne n’aura été envoyé en prison.
Perspective locale
L’ironie dans tout ça, c’est que juste au moment où l’IAB étatsunienne est sur le point de spammer le monde entier avec sa version du TCF, les régulateurs de l’UE l’ont détruite.
Un peu de contexte…
Ici, aux États-Unis, il n’y a pas de loi contre quoi que ce soit. L’entité la plus proche que nous possédons pour réguler ce secteur corrompu de la publicité ciblée en ligne est appelée Loi de protection du consommateur en Californie (ou CCPA en anglais, California Consumer Protection Act). Elle est largement inspirée par le RGPD et aussi loin que remontent les mémoires, elle n’a jamais protégé qui que ce soit de quoi que ce soit (elle sera remplacée l’année prochaine par une autre bouillie de lettres appelée CPRA).
L’IAB étatsunienne a repris la formule illégale du TCF de leur branche Europe et l’a maladroitement transposée à la CCPA. Ils ont aussi convaincu les clowns, les escrocs et les collaborateurs de l’ANA, de la 4As (respectivement « Association of National Advertisers » et « American Association of Advertising Agencies » [des associations américaines de publicitaires, NdT]) et de grandes marques d’implémenter le TCF maintenant discrédité sous un nouveau nom foireux, « Global Privacy Platform » (Plateforme globale de la vie privée). Ouais, c’est ça.
Vue d’ensemble : L’arrogance des secteurs de la tech et du marketing aux États-Unis est tellement énorme que les actions des régulateurs n’ont quasi aucun poids. Quel sera l’effet le plus probable du jugement de cette semaine sur l’abus des données aux États-Unis ? En comptant à rebours, qu’est-ce qui vient après zéro ?
Ai-je déjà mentionné que rien ne changera tant que personne ne sera envoyé en prison ?
Comédie-ballet
La danse des régulateurs et du secteur de la publicité ciblée n’est rien d’autre qu’une performance artistique : les régulateurs portent plainte, les escrocs paient une petite amende, et tout le monde retourne à ses petites affaires.
Tout individu doté d’un cerveau fonctionnel peut comprendre qu’un secteur de la publicité ciblée basé sur du pistage est un racket criminel aux proportions gigantesques. C’est une vaste escroquerie planétaire, un crime organisé à l’échelle mondiale auquel participent quasi toutes les grandes entreprises, les organisations commerciales les plus réputées et l’ensemble des secteurs de la publicité, du marketing et des médias en ligne. Même l’IAB a reconnu avoir indiqué à la Commission européenne que les achats automatiques basés sur des enchères en temps réel sont « incompatibles avec le consentement prévu par le RGPD ».
Mais trop de personnes se font trop d’argent.
Rien ne changera tant que personne… ooooh, laissez tomber.
Infoclimat : un commun météorologique et climatologique à préserver !
Infoclimat est une association de passionné·es de météo, qui agit pour favoriser et vulgariser l’échange de données et de connaissances autour de la météo et du climat. Nous baignons dans les mêmes eaux et partageons les mêmes valeurs : les communs culturels doivent être ouverts à toutes et tous pour l’intérêt général !
L’association va fêter ses 20 ans et se lancer dans un nouveau projet : le recrutement de son·sa premier·ère salarié·e. C’est l’occasion de donner la parole à Frédéric Ameye et Sébastien Brana, tous deux bénévoles.
Bonjour Frédéric et Sébastien, pouvez-vous vous présenter ?
Frédéric Ameye (FA), 27 ans, je suis ingénieur dans les systèmes embarqués pendant les heures ouvrables… et en-dehors de ça, je suis depuis longtemps « Linuxien » et (modeste) défenseur du logiciel libre, mais aussi de l’égalité des chances à l’école — issu d’une famille ouvrière très modeste, c’est quelque chose qui me tient beaucoup à cœur. Le reste du temps (quand il en reste), vous me trouverez principalement en rando au fin fond de la montagne…
J’ai intégré l’aventure Infoclimat en 2009 (j’avais alors 15 ans), période à laquelle j’ai « refondu » le site web de l’asso à partir de l’ordinateur familial à écran cathodique, que je monopolisais des dizaines d’heures par semaine, jusqu’à très tard dans la nuit. J’ai continué ce rôle jusqu’à aujourd’hui (avec un écran plat, et moins d’heures dans la nuit car la trentaine arrive vite). Entre-temps, j’ai rejoint le Conseil d’Administration, et je suis ensuite devenu Vice-Président en 2015.
Sébastien Brana (SB), 42 ans. Dans la vie « hors Infoclimat », je suis chef de projet informatique à la Direction générale des finances publiques… et comme Frédéric, en dehors de « ça », j’occupe une grande partie de mon temps libre (soirées, week-end et congés) au profit du site et de l’association que j’ai rejoint en 2005 et dont je suis également Vice-Président depuis 12 ans. Au-delà des phénomènes météo (orages et chutes de neige notamment) qui m’ont toujours fasciné depuis aussi loin que je me souvienne, je suis également passionné par la communauté que nous avons formée depuis une vingtaines d’années, rassemblant des personnes de tous âges (des gamins de 10 ans aux retraités) et de tous milieux, amateurs ou professionnels, scientifiques ou littéraires, ou simplement amoureux de beaux paysages et de photographies. La météo touche tout le monde, les questions liées au climat interrogent tout le monde – bref, ces sujets intéressent voire passionnent bien au-delà des barrières sociales habituelles !
Vous êtes membres bénévoles de Infoclimat, pouvez-vous nous parler du projet de l’association ?
SB : Initialement, Infoclimat était un petit groupe de passionnés de météo et de climat, qui partageaient leurs relevés entre-eux à la fin des années 90, sur un site web appelé « OrageNet ». Tout cela a progressivement grossi, jusqu’à l’année 2003, où l’association a été créée principalement pour subvenir aux besoins d’hébergement du site web. A l’époque, nous étions déjà (et sans le savoir!) en « Web 2.0 » et pratiquions les sciences participatives puisque l’essentiel du contenu était apporté par les passionnés ; nous étions alors bien loin d’imaginer que les problématiques liées au climat deviendraient un enjeu mondial avec une telle résonance médiatique.
Infoclimat a beaucoup évoluée, entre les débuts sur un internet confidentiel des années 90 dédié au partage, au web d’aujourd’hui.
FA : Depuis, l’objet social s’est considérablement diversifié, avec la montée en puissance de notre asso. Aujourd’hui, nous visons trois thématiques particulières :
L’engagement citoyen au service de la météo et du climat : partager ses relevés, ses observations météo, installer des stations météorologiques,… au service de tous ! Cela permet de comprendre comment le climat change, mais aussi de déceler des particularités locales que les modèles de prévision ne savent pas bien prendre en compte, ou qui ne peuvent pas être mesurées facilement.
Valoriser la donnée météo et climato, qu’elle soit issue de services officiels ou diffusée en « OpenData » par nous ou nos passionnés, et en particulier en faire des outils utiles autant aux « pros » et chercheurs, qu’au service de la vulgarisation des sujets climatiques pour le grand public. Les utilisations sont très nombreuses : agriculture, viabilité hivernale, thermique dans l’habitat, recherches sur le changement climatique, production électrique, journalistes…
Former et transmettre les connaissances, par la production de contenus de vulgarisation scientifique, l’organisation de « rencontres météo », ou encore des interventions auprès des écoles, dans des événements sur le terrain ou sur les réseaux sociaux. Bref, contrer la désinformation et le buzz !
Quand Infoclimat débarque quelque part, c’est rarement pour pique-niquer… Mais plutôt pour installer du matériel météo !
Vous faites donc des prévisions météo ?
SB : Même si le forum est largement animé par des prévisionnistes amateurs, nous parlons finalement assez peu de prévisions météo : le cœur du site, c’est l’observation météo en temps réel et la climatologie qui résulte des données collectées, qui sont des sujets bien différents ! Il y aurait tant à dire sur le monde de la prévision météo, mais cela mériterait un article à lui seul, car il y a un gros sujet là aussi sur l’ouverture des données et la paternité des algorithmes… Souvent négligée, l’observation météorologique est pourtant fondamentale pour produire une bonne prévision. Pour faire court, la donnée météo « observée » est la nourriture qu’il faut pour entraîner les modèles climatiques, et faire tourner les modèles numériques qui vous diront s’il faut un parapluie demain sur votre pixel de 1km².
Quantité d’observations météo intégrées dans le modèle de prévisions français « AROME », source principale de toutes les prévisions en France métropolitaine. La performance des modèles météorologiques est fortement corrélée à la quantité, la fréquence, et à la qualité de leurs données d’entrées (observations radar, satellite, avions, stations météo au sol,…). La quantité d’observations des stations Météo-France est à peu près équivalente à la quantité de données produites par les passionnés d’Infoclimat. Graphique simplifié, hors données radar. Avec l’aimable autorisation de Météo-France et du CNRM.
FA : Ce qu’il faut savoir, c’est que l’immense majorité des sites internet ou appli que vous consultez ne font pas de prévisions météo, mais utilisent des algorithmes automatisés qui traitent des données fournies (gratuitement ou avec redevance) par les organismes publics (Météo-France, la NOAA, le Met-Office, l’organisme européen ECMWF,…). La qualité des prévisions est en gros corrélée à l’argent que les créateurs des sites et des applis peuvent injecter pour récolter des données brutes de ces modèles numériques. Par exemple, pour avoir les données du modèle de Météo-France « AROME », c’est à peu près gratuit car les données sont sous licence Etalab, mais si vous voulez des données plus complètes, permettant d’affiner vos algorithmes et de proposer « mieux », c’est sur devis.
Dès lors, Infoclimat ne souhaite pas se lancer dans cette surenchère, et propose uniquement des prévisions automatisées issues de données ouvertes de Météo-France et de la NOAA, et indique très clairement la différence entre prévisions automatisées et bulletins rédigés par des passionnés.
La Terre est découpée en petits cubes dans lesquels les modèles météo estiment les paramètres de l’atmosphère à venir. Les cubes sont généralement bien plus gros lorsque les échéances sont lointaines (J+4, J+5…), ce qui empêche les modèles météorologiques de discerner les phénomènes météo de petite échelle (averses, orages, neige, effets des reliefs et des côtes). Pourtant, de nombreuses appli météo se contentent de vous fournir grossièrement ces données sans l’explication qui va avec. Chez Infoclimat, on laisse volontairement la résolution native, pour ne pas induire le lecteur en erreur sur la résolution réelle des données.
Cela me fait toujours rire (jaune) quand j’entends « [site ou appli] a de meilleures prévisions à chaque fois, et en plus, on les a à 15 jours ! » : lorsqu’il s’agit de prévisions « automatiques », par ville, il est probable qu’il utilise les mêmes données que tous les autres, présentées légèrement différemment, et qu’il s’agisse juste d’un biais de confirmation. Il existe bien sûr quelques exceptions, certaines entreprises faisant un vrai travail de fusion de données, d’analyse, de suppression des biais, pour proposer des informations de très grande qualité, généralement plutôt payantes ou pour les pros. Mais même chez ceux qui vous vendent du service d’aide à la décision, de protection des biens et des personnes, des données expertisées ou à vocation assurantielles, vous seriez très surpris de la piètre qualité de l’exploitation qui est faite de ces données brutes.
Les modélisateurs météo ont plein de techniques pour prendre en compte les incertitudes dans les observations et les modèles, notamment ce que l’on appelle la « prévision ensembliste ». Mais ces incertitudes sont rarement présentées ou expliquées au public. Ici par exemple, le graphique présente la quantité de pluie prédite par un modèle météo le 6 janvier, pour la période entre le 6 janvier et le 16 janvier 2022, sur un point de la France. Le modèle considère plusieurs scénarios d’évolution possible des futurs météorologiques. Source : ECMWF, CC BY 4.0.
Malheureusement, cette situation rend très délicate la perception des prévisions météo par le grand public (« ils se trompent tout le temps ») : la majorité des applis prend des données gratuites, de faible qualité, sur le monde entier, qui donnent une prévision différente 4 fois par jour au fil des calculs. Cela ne met vraiment pas en valeur le travail des modélisateurs, qui font pourtant un travail formidable, les modèles numériques s’améliorant considérablement, et décrédibilisent aussi les conclusions des organismes de recherche pour le climat (« ils ne savent pas prévoir à 3 jours, pourquoi ils sauraient dans 50 ans ?! »), alors qu’il s’agit surtout d’une exploitation maladroite de données brutes, sans accompagnement dans leur lecture.
Ce graphique présente, grosso-modo, l’amélioration de la qualité des prévisions de l’état de l’atmosphère au fil des années, à diverses échéances de temps (jaune = J+10, vert = J+7, rouge = J+5, bleu = J+3) et selon les hémisphères terrestres. Plus c’est proche de 100%, meilleures sont les prévisions ! Source : ECMWF, CC BY 4.0.
Du coup, quelles actions menez-vous ?
FA : Notre action principale, c’est la fourniture d’une plateforme sur le web, qu’on assimile souvent au « Wikipédia de la météo », ou à un « hub de données » : nous récoltons toutes sortes de données climatiques et météorologiques de par le monde, pour les décoder, les rendre digestes pour différents publics, et la mettre en valeur pour l’analyse du changement climatique. Ce sont par exemple des cartographies, ou des indices d’évolution du climat. C’est notre rôle initial, qui aujourd’hui compile plus de 6 milliards de données météo, à la qualité souvent rigoureusement contrôlée par des passionnés ! Il faut savoir que nous n’intégrons pas toutes les stations météo : nous respectons des normes de qualité du matériel et de l’environnement, pour que les données soient exploitables et comparables entre-elles, comparables avec des séries climatiques historiques, et assimilables dans des modèles numériques de prévision.
Infoclimat propose l’accès à toutes les informations météo et climatiques dans des interfaces qui se veulent simples d’accès, mais suffisamment complètes pour les plus experts. Dur équilibre !
SB : Avec l’accroissement de notre budget, nous avons pu passer à l’étape supérieure : installer nos propres stations météo, et soutenir les associations locales et les passionnés qui en installent et qui souhaitent mettre leurs données au service d’une base de données commune et libre.
Les passionnés ne reculent devant rien pour l’intérêt général. Aller installer une station météo à Casterino, village des Alpes Maritimes qui s’est retrouvé isolé de tout après la tempête Alex ? C’est fait, et avec le sourire malgré les kilomètres avec le matériel sur le dos ! Retrouvez l’article ici
Il faut savoir que la donnée météo se « monnaye », et chèrement: Météo-France, par exemple, ne met à disposition du grand public que quelques pourcents de ses données, le reste étant soumis à des redevances de plusieurs centaines de milliers d’euros par an (on y reviendra). Ce n’est d’ailleurs pas le cas dans tous les pays du monde, les États-Unis (NOAA) ont été précurseurs, beaucoup de pays Européens s’y mettent, mais la France est un peu en retard… Nous sommes partenaires de Météo-France, participons à des travaux communs dans le cadre du « Conseil Supérieur de la Météorologie », mais c’est très long, trop long, et cela prive Météo-France d’une source de revenus importante dans un contexte de stricte restriction budgétaire. L’établissement public administratif se retrouve en effet pris dans une injonction contradictoire par son autorité de tutelle (le Ministère de la Transition écologique et solidaire) : d’un côté il doit « libérer » les données publiques et mettre en place les infrastructures nécessaires, de l’autre, on lui intime l’ordre de trouver de nouvelles sources de financement par sa branche commerciale, et on lui réduit ses effectifs !
Redevances demandées par Météo-France pour accéder aux données météo de son réseau « RADOME » (90% des stations françaises). Hors de portée de notre association ! Source
Le réseau de stations en France, avec les données ouvertes de Météo-France (à gauche), et avec les données Infoclimat et partenaires en plus (à droite). Remarquez le contraste avec certains autres pays Européens !
Aujourd’hui, Infoclimat c’est donc un bon millier de stations météo (les nôtres, celles des passionnés, et de nos associations partenaires), qui complètent les réseaux nationaux dans des zones non couvertes, et qui permettront à l’avenir d’améliorer la fiabilité des modèles météo de Météo-France, dans des travaux que nous menons avec eux sur l’assimilation des réseaux de données partenaires. Parfois d’ailleurs, nous réinstallons des stations météo là où Météo-France est parti ou n’a pas souhaité améliorer ou maintenir des installations, comme au Mont-Ventoux (84), ou à Castérino (06). Et ces données intéressent une multitude d’acteurs, que nous découvrons souvent au hasard des installations : au-delà de l’intérêt pour la météo des particuliers (« combien fait-il au soleil? » « quelle quantité de pluie est tombée la nuit dernière? »), les activités professionnelles météo-sensibles allant de l’agriculture à l’expertise en assurance, en passant par les études de risques et/ou d’impacts jusqu’aux recherches sur les « ICU » (ilots de chaleurs urbains observés dans les milieux urbanisés) se montrent très demandeuses et n’hésitent pas à se tourner vers nous pour leur fournir de la « bonne data-météo ».
Enfin, le troisième pilier, c’est la pédagogie. Nous avons repris en 2018, à nos frais et sans aucune subvention, l’initiative « Météo à l’École », qui avait été lancée en 2008 par le Ministère de l’Éducation Nationale avec Météo-France et l’Observatoire de Paris, mais qui a failli disparaître faute de budget à la fin du « Grand Emprunt ». L’objectif : sensibiliser de manière ludique les publics du primaire et du secondaire aux enjeux de la météo et du climat. Installer une station météo dans un collège permet de faire un peu de techno, traiter les données en faisant des maths, des stats et de l’informatique, et enfin les analyser pour parler climat et Système Terre.
Aujourd’hui, nous hébergeons les données des quelques 60 stations, ainsi que les contenus pédagogiques de Météo À l’École, permettant aux profs d’échanger entre eux.
Installer des stations météo dans les écoles, expliquer les concepts de la météo et du climat, « jouer » avec des données, et discuter entre profs : c’est ce que permet le programme Météo à l’École
Depuis de nombreuses années, nous complétons cela avec des interventions auprès des jeunes et moins jeunes, sous forme d’ateliers ou de journées à thème (« Rencontres Météo et Espace », « Nuit des Chercheurs », « Fête du Vent »,…), un peu partout en France selon la disponibilité de nos bénévoles !
Lors des Rencontres Météo et Espace organisées par le CNES, Infoclimat et Météo-France, les enfants apprennent par exemple comment on mesure les paramètres en altitude dans l’atmosphère, grâce aux ballons sondes.
Nous aimons autant apprendre des choses aux très jeunes (à gauche), qu’aux moins jeunes (à droite), lors d’événements tout-publics.
Quelles valeurs défendez-vous ?
FA : La première de nos valeurs, c’est l’intérêt général ! Ce que nous avons conçu au cours de ces vingt dernières années n’appartient à personne, c’est un commun au service de tous, et pour certaines informations, c’est même le point de départ d’un cercle vertueux de réutilisation, par la libération des données en Open-Data.
La page OpenData d’Infoclimat, qui permet de s’abstraire des complexités des formats météo, des différents fournisseurs, et tente de résoudre au mieux la problématique des licences des données.
Comme on l’a dit plus haut, le monde de la météo est un juteux business. Vous trouverez pléthore de sites et applis météo, et leur composante commune, c’est que ce sont des sociétés à but lucratif qui en font un business, sous couvert d’engagement citoyen et de « communauté ». Vous y postez vos données et vos photos, et ils en tirent en retour des revenus publicitaires, quand ils ne revendent pas les données météo à d’autres sociétés (qui les mâchouillent et en font de l’analyse pour d’autres secteurs d’activité).
Parmi les initiatives similaires, on peut citer parmi les plus connues « Weather Underground » (appartenant à IBM et destinée à alimenter Watson) ou encore « Awekas » (Gmbh allemande), « Windy » (société tchèque), « Météociel » (SAS française), qui sont des sociétés privées à plusieurs centaines de milliers ou quelques millions d’euros de CA. On notera d’ailleurs que toutes ces initiatives ont des sites souvent moins complets que le notre !
On se retrouve dans une situation parfois ubuesque : ces types de sociétés peuvent acheter des données payantes à l’établissement public Météo-France (pour quelques centaines de milliers d’euros par an), et les proposent ensuite à tous sur leur site web, rémunéré par la publicité ou par abonnement à des fonctionnalités « premium ». Alors qu’elles pourraient bénéficier à tous dans une base de données librement gérée comme celle d’Infoclimat, et aussi servir nos outils d’analyse du changement climatique ; il faut passer obligatoirement par les sites de ces sociétés privées pour bénéficier des données produites par l’établissement public… et donc en partie avec l’argent public. D’autres acteurs de notre communauté en faisant déjà echo il y a bien des années, et la situation n’a pas changé : https://blog.bacpluszero.com/2014/06/comment-jai-failli-faire-doubler-le.html.
Nos adhérents et administrateurs lors d’une visite chez Météo-France, en 2016. Malgré un partenariat depuis 2009, l’établissement public éprouve toujours des difficultés à partager ses données avec la communauté, mais s’engage à ses côtés dans la formation et le support technique. En mémoire de nos bénévoles disparus Pouic, Mich’, Enzo.
SB : Notre force, c’est de pouvoir bénéficier d’une totale indépendance, grâce à nos adhérents, mécènes et donateurs. On a réalisé le site dont on a toujours rêvé, pas celui qui générera le plus de trafic possible pour en tirer un revenu. Les données des stations météo que nous finançons sont toutes placées sous licences ouvertes, et nos communications sont rigoureuses et factuelles plutôt que « putaclic » (ce qui nous vaut d’ailleurs une notoriété encore assez limitée chez le grand public, en dehors des photos de nos contributeurs reprises dans les bulletins météo de France TV notamment).
Trouvez-vous aussi votre indépendance vis-à-vis des GAFAM ?
FA : Cela reste encore perfectible : si nous croyons à notre indépendance et au respect des utilisateurs, il y aurait encore des reproches à nous faire. Nous mettons vraiment beaucoup en place pour respecter les données (qu’elles soient météo, personnelles, ou les droits des photographes), nous auto-hébergeons l’immense majorité des contenus (sur 12 serveurs dédiés OVH, du cloud Scaleway, et des machines gracieusement prêtées par Gandi, et même un NAS chez un administrateur fibré !), et essayons d’éviter les services tiers, et les fuyons au possible lorsqu’ils sont hébergés ou contrôlés à l’étranger. Mais tout n’est pas toujours si simple.
Par exemple, nous utilisions jusqu’à très récemment encore Google Analytics, par « simplicité » : tout notre historique depuis 2008 y est stocké, et une instance Matomo assez dimensionnée pour 150M de pages vues par an, ça veut dire gérer une nouvelle machine, et des coûts supplémentaires… pour une utilisation assez marginale, notre exploitation des statistiques étant très basique, puisque pas de publicités et pas de « conversions » ou « cibles d’audience »… Mais tout de même appréciée des bénévoles pour analyser la fréquentation et l’usage des rubriques du site. Il doit aussi traîner quelques polices de caractères hébergées par Google, mais tout le reste est 100% auto-hébergé et/ou « fait maison ».
Nos cartes sont complexes et nécessitent des données géospatiales de bonne qualité, et à jour. Maintenir à jour une telle base, seuls, et à l’échelle mondiale, est… un projet à lui tout seul.
Nous sommes aussi de gros consommateurs de contenus cartographiques, et proposons des interfaces de visualisation mondiales plutôt jolies (basées sur OpenLayers plutôt que GoogleMaps), mais qui nécessitent des extractions de données particulières (juste les villes, un modèle de terrain haute résolution, ou bien juste les rivières ou limites administratives). C’est un sujet qui peut aussi être vite difficile à gérer.
À une époque, on stockait donc une copie partielle de la base de données OpenStreetMap sur l’Europe, et je générais moi-même des carto avec Tilemill / Mapserver / Geowebcache et des styles personnalisés. Les ressources nécessaires pour faire ça étaient immenses (disque et CPU), la complexité technique était grande, et que dire quand il faut tenir toutes ces bases à jour. C’est un projet à lui tout seul, et on ne peut pas toujours réinventer la roue. Bref, pour le moment, nous utilisons les coûteux services de Mapbox.
Vous nous avez parlé de certaines limites dans votre travail bénévole, qu’est-ce qui vous pose problème ?
FA : Le problème majeur, c’est le développement web du site. La majorité de nos outils sont basés sur le site web : cartes, graphiques, statistiques climatiques, espaces d’échange, contenus pédagogiques, tout est numérique. Aujourd’hui, et depuis 13 ans, le développement et la maintenance du site et de ses serveurs repose sur un seul bénévole (moi !). Déjà, ce n’est pas soutenable humainement, mais c’est aussi assez dangereux.
La raison est simple : un logiciel avec 400.000 lignes de code, 12 serveurs, des technologies « compliquées » (formats de fichiers spécifiques à la météo, cartes interactives, milliards d’enregistrements, bases de données de plusieurs téraoctets,…), ce n’est pas à la portée du premier bénévole qui se pointe ! Et il faut aussi beaucoup d’accompagnement, ce qui est difficile à combiner avec la charge de travail existante.
Pour les plus geeks d’entre-vous, concrètement, voici les technos sur lesquelles sont basées nos plateformes : PHP (sans framework ni ORM !), Javascript/jQuery, OpenLayers, Leaflet, Highcharts, Materialize (CSS), pas mal de Python pour le traitement de données météo (Scipy/Numpy) du NGINX, et pour les spécifiques à notre monde, énormément de GDAL et mapserver, geowebcache, des outils loufoques comme NCL, des librairies pour lire et écrire des formats de fichiers dans tous les sens (BUFR, SYNOP, METAR, GRIB2, NetCDF).
Et bien sûr surtout MariaDB, en mode réplication (et bientôt on aura besoin d’un mode « cluster » pour scaler), des protocoles de passage de message (RabbitMQ, WebSockets), de l’ElasticSearch et SphinxSearch pour la recherche fulltext, et du Redis + Memcached pour les caches applicatifs.
Au niveau infra, évidemment de la gestion de firewall, de bannissement automatique des IP, un peu de répartition de charge, de l’IP-failover, un réseau dédié entre machines (« vRack » chez OVH), beaucoup de partages NFS ou de systèmes de fichiers distribués (GlusterFS, mais c’est compliqué à maintenir donc on essaie de migrer vers de l’Object-Storage type S3).
Et on a aussi une appli mobile Android en Java, et iOS en Swift, mais elles sont vieillissantes, fautes de moyens (leur développement a été sous-traité), et la majorité des fonctionnalités est de toutes façons destinée à être intégrée sur le site en mode « responsive design ».
Je passe sur la nécessité de s’interfacer avec des API externes (envois de mails, récupération de données météo sur des serveurs OpenData, parsing de données météo, API de la banque pour les paiements d’adhésions), des outils de gestion interne (Google Workspace, qui est « gratuit » pour les assos, hé oui !), des serveurs FTP et VPN pour connecter nos stations météo, un Gitlab auto-hébergé pour le ticketing et le code source …
SB : On a aussi des difficultés à dégager du temps pour d’autres actions : installer des stations météo par exemple, ce n’est pas négligeable. Il faut démarcher des propriétaires, obtenir des autorisations, parfois signer des conventions compliquées avec des collectivités locales, gérer des problématiques « Natura 2000 » ou « Bâtiments de France », aller sur site,… c’est assez complexe. Nous essayons de nous reposer au maximum sur notre communauté de bénévoles et adhérents pour nous y assister.
Quels sont vos besoins actuels ?
SB : Dans l’idéal, et pour venir en renfort de Frédéric, nous aurions besoin d’un développeur « full-stack » PHP à plein temps, et d’un DevOps pour pouvoir améliorer l’architecture de tout ça (qui n’est plus au goût des stacks technologiques modernes, et sent un peu trop l’année 2010 plutôt que 2022, ce qui rend la maintenance compliquée alors que le trafic web généré suppose de la perf’ et des optimisations à tous les niveaux).
Ce n’était pas immédiatement possible au vu des revenus de l’association, qui atteignaient environ 60.000€ en 2021, dont 15.000€ sont dépensés en frais de serveurs dédiés chez OVH (passer au tout-cloud coûte trop cher, en temps comme en argent,… mais gérer des serveurs aussi !).
FA : On développe aussi deux applis Android et iOS, qui reprennent les contenus du site dans un format simplifié, et surtout permettent de recevoir des alertes « push » selon les conditions météo, et d’afficher des widgets. Elles sont dans le même esprit que le site (pas de pubs, le moins de contenus tiers possibles), cependant ce sont des applis que l’on a sous-traité à un freelance, ce qui finit par coûter très cher. Nous réfléchissons à quelle direction donner à celles-ci, surtout au vu de l’essor de la version « responsive » de notre site.
Nous aimerions commencer à donner une direction européenne à notre plateforme, et la mettre à disposition des communautés d’autres pays. Il y a un gros travail de traduction, mais surtout de travaux techniques pour rendre les pages de notre site « traduisibles » dans différentes langues.
Vous ouvrez cette année un premier poste salarié, quelle a été votre démarche ?
SB : Dès lors, nous avions surtout un besoin intermédiaire, qui vise à faire progresser nos revenus. Pour cela, notre première marche sur l’escalier de la réussite, c’est de recruter un·e chargé·e de développement associatif, chargé d’épauler les bénévoles du Conseil d’Administration à trouver des fonds : mécènes et subventionneurs publics. Les sujets climat sont au cœur du débat public aujourd’hui, l’engagement citoyen aussi (on l’a vu avec CovidTracker !), nous y participons depuis 20 ans, mais sans savoir nous « vendre ».
FA : Cette première marche, nous l’avons franchie grâce à Gandi, dans le cadre de son programme « Gandi Soutient », qui nous a mis en relation avec vous, Framasoft. Vous êtes gentiment intervenus auprès de nos membres de Conseil d’Administration, et vous nous avez rassurés sur la capacité d’une petite association à se confronter aux monopoles commerciaux, en gardant ses valeurs fondatrices. Sans votre intervention, nous n’aurions probablement pas franchi le pas, du moins pas aussi vite !
Intervention de Framasoft pendant une réunion du CA de Infoclimat
SB : Cela va nous permettre de faire souffler une partie de nos bénévoles. Même si cela nous fait peur, car c’est une étape que nous n’osions pas franchir pour préserver nos valeurs, c’est avec une certaine fierté que nous pouvons aujourd’hui dire : « nous sommes une asso d’intérêt général, nous proposons un emploi au bénéfice de tous, et qui prend sa part dans la mobilisation contre le changement climatique, en en donnant des clés de compréhension aux citoyens ».
FA : La seconde étape, c’est recruter un⋅e dév’ web full-stack PHP/JS, quelqu’un qui n’aurait pas été impressionné par ma liste de technos évoquée précédemment ! Comme nous avons eu un soutien particulièrement fort de notre communauté en ce début d’année, et que notre trésorerie le permet, nous avons accéléré le mouvement, et la fiche de poste est d’ores-et-déjà disponible, pour un recrutement envisagé à l’été 2022.
Comment pouvons-nous soutenir Infoclimat, même sans s’y connaître en stations météo ?
FA : Pour celles et ceux qui en ont les moyens, ils peuvent nous soutenir financièrement : c’est le nerf de la guerre. Quelques euros sont déjà un beau geste ; et pour les entreprises qui utilisent quotidiennement nos données (on vous voit !), un soutien plus important permet à nos outils de continuer à exister. C’est par exemple le cas d’un de nos mécènes, la Compagnie Nationale du Rhône, qui produit de l’électricité hydroélectrique et éolienne, et est donc légitimement intéressée de soutenir une asso qui contribue au développement des données météo !
Pour cela, nous avons un dossier tout prêt pour expliquer le détail de nos actions auprès des décideurs. Pour aller plus loin, une seule adresse : association@infoclimat.fr
Et pour ceux qui veulent aussi s’investir, nous avons une page spécifique qui détaille le type de tâches bénévoles réalisables : https://www.infoclimat.fr/contribuer.
Ce n’est pas exhaustif, il y a bien d’autres moyens de nous épauler bénévolement, pour celles et ceux qui sont prêts à mettre les mains dans le cambouis : des webdesigners, développeurs aguerris, experts du traitement de données géographique, « datavizualisateurs », ou même des gens qui veulent faire de l’IA sur des séries de données pour en trouver les erreurs et biais : il y a d’infinies possibilités ! Je ne vous cacherai pas que le ticket d’entrée est assez élevé du point de vue de la technique, cela dit…
SB : Pour les autres, il reste l’énorme possibilité de participer au site en reportant des observations via le web ou l’appli mobile (une paire d’yeux suffit!) ainsi que des photos, ou… simplement nous faire connaître ! Une fois comprise la différence entre Infoclimat et tous les sites météo, dans le mode de fonctionnement et l’exploitation commerciale ou non des données, on comprend vite que notre association produit vraiment de la valeur au service des citoyens, sans simplement profiter des données des autres, sans apporter sa pierre à l’édifice, comme le font nonchalamment d’autres initiatives. Par ailleurs, nous avions pour projet d’avoir une page sur Wikipédia, refusée par manque de notoriété 🙁 . Idem pour la demande de certification du compte Twitter de l’Association, qui pourtant relaie de l’information vérifiée et montre son utilité lors des événements météo dangereux ou inhabituels, comme lors de l’éruption tout récente du volcan Hunga Tonga-Hunga Ha’apai sur les Iles Tonga qui a été détectée 15h plus tard et 17.000 km plus loin par nos stations météo lors du passage de l’onde de choc sur la métropole!
FA : Infoclimat, c’est un peu l’OpenFoodFacts du Yuka, l’OpenStreetMap du GoogleMaps, le PeerTube du YouTube, le Wikipédia de l’Encarta (pour les plus vieux)… et surtout une formidable communauté, que l’on en profite pour remercier ici !
On vous laisse maintenant le mot de la fin !
SB : Bien sûr, on aimerait remercier tous ceux qui ont permis à cette aventure de progresser : tous les bénévoles qui ont œuvré depuis 20 ans, tous les adhérent⋅e⋅s qui ont apporté leur pierre, nos mécènes et donateurs, ainsi que les passionnés qui alimentent le site et nous soutiennent depuis toutes ces années!
FA : Le soutien de Gandi et Framasoft a aussi été un déclencheur, et j’espère que cela pourra continuer à être fructueux, au service d’un monde meilleur et désintéressé. Des initiatives comme la notre montrent qu’être une asso, ça permet de produire autant voire plus de valeur que bien des start-up ou qu’un gros groupe qu’on voit passer dans le paysage météo. Et pourtant, nous sommes souvent bien moins soutenus, ou compris.
Mais où sont les livres universitaires open-source ?
Où sont les livres universitaires libres, ceux qu’on pourrait télécharger gratuitement à la façon d’un logiciel open-source ? Les lecteurs et lectrices du Framablog qui étudient ou travaillent à l’université se sont probablement posé la question.
Olivier Cleynen vous soumet ici quelques réponses auxquelles nous ouvrons bien volontiers nos colonnes.
Les manuels universitaires libres, j’en ai fabriqué un : Thermodynamique de l’ingénieur, publié en 2015 au sein du projet Framabook. Cette année, alors que Framabook se métamorphose en Des livres en commun et abandonne le format papier, je reprends le livre à mon nom et j’expérimente avec différentes formes de commercialisation pour sa troisième édition. C’est pour moi l’occasion de me poser un peu et de partager avec vous ce que j’ai appris sur ce monde au cours des sept dernières années.
Bon, je vais commencer par prendre le problème à l’envers. Un manuel universitaire, c’est d’abord un livre et comme tout autre livre il faut qu’il parte d’un désir fort de la part de l’auteur/e, car c’est une création culturelle au même titre qu’une composition musicale par exemple. Et d’autre part c’est un outil de travail, il faut qu’il soit très cohérent, structuré, qu’il justifie constamment l’effort qu’il demande au lecteur ou à la lectrice, en l’aidant à accomplir quelque chose de précis. Ces deux facettes font qu’il doit être le produit du travail d’un nombre faible de personnes très impliquées. On le voit bien avec les projets Wikibooks et Wikiversity par exemple, qui à mes yeux ne peuvent pas décoller, par contraste avec Wikipédia où le fait que certains articles soient plus touffus que d’autres et utilisent des conventions de notation différentes ne pose aucun problème.
Leonardo da Vinci (1452-1519), Codex Leicester, un manuel italien écrit en miroir, ayant un peu vieilli, mais heureusement déjà dans le domaine public.
Pour écrire un livre comme Thermodynamique de l’ingénieur j’estime (à la louche) qu’il faut un an de travail à quelqu’un de niveau ingénieur. En plus de ça il faut au moins deux personne-mois de travail pour mettre le tout en page et avoir un livre prêt à l’impression.
Je n’aime pas beaucoup ce genre de calculs qui ont tendance à tout réduire à des échanges mercantiles, mais dans un monde où l’équipe d’en face loue l’accès à un PDF en ligne à 100 euros par semestre, on peut se permettre d’écrire quelques nombres au dos d’une enveloppe, pour se faire une idée. Un an de travail pour une ingénieur médiane coûte 58 k€ brut en France. Pour deux personnes-mois de mise en page, on peut certainement compter 5 k€ de rémunération brute, soit au total: 63 000 euros.
Maintenant en partant sur la base de 1000 livres vendus on voit qu’il faudrait récolter 63 euros par livre pour financer au “prix du marché”, si je peux me permettre, le travail purement créatif. C’est une mesure (très approximative…) de ce que les créateurs choisissent de ne pas gagner ailleurs, lorsqu’ils/elles font un livre en accès gratuit ou en vente à prix coûtant, comme l’a été le Framabook de thermodynamique.
Thermodynamique de l’ingénieur – troisième édition
Bien sûr, si l’on reprend le problème à l’endroit, le prix d’un livre acheté par un étudiant ou une universitaire n’est pas du tout calculé sur cette base, car il faut aussi et surtout rémunérer les autres acteurs entre l’auteure et la lectrice.
La part du lion est assurément réservée aux distributeurs, et parmi eux Amazon, qui sont passés progressivement de purs agents logistiques à de véritables plateformes éditoriales. Les distributeurs ont ainsi dépassé leur rôle initial (être une réponse à la question : « où vais-je me procurer ce livre qui m’intéresse ? ») et saturé le niveau d’au-dessus, en proposant de facto toutes les réponses les plus pertinentes à la question : « quel est le meilleur livre sur ce sujet ? ».
Au milieu de tout ça, il y a les éditeurs. Un peu comme les producteurs dans le monde de la musique, leur rôle est de résoudre l’équation qui va lier et satisfaire tous les acteurs impliqués dans l’arrivée du livre entre les mains de la lectrice. Ils sont ceux qui devraient le mieux connaître les particularités de ce produit pas tout à fait comme les autres, et pourtant…
Dans notre exploration du monde des manuels universitaires, je vais choisir de diviser les éditeurs en trois groupes.
tout un patrimoine est rendu légalement inaccessible.
Au centre, nous avons les petits. Ils sont écrasés par tous les autres, mais je peux dire d’emblée qu’ils n’ont que ce qu’ils méritent. Leurs outils et méthodes de travail sont désuets voire archaïques, et ils saisissent très mal les mécanismes du succès éditorial. Donc, ils se contentent de sortir beaucoup de livres pour espérer en réussir quelques-uns. Contactez-les avec votre projet, et ils vous proposeront un contrat dans lequel vous renoncez ad vitam à tout contrôle, et à 93% des revenus de la vente. Faites le calcul : même avec un prix de vente élevé, disons 40€, ce qu’ils vous présenteront sans sourciller comme un succès (mille livres vendus) ne vous rapportera même pas 3000 euros bruts, étalés sur dix ans.
Vous me direz que ce n’est pas bien grave, qu’avoir une haute rentabilité, une haute efficacité, n’est pas un but en soi : tout le monde ne veut pas être Jeff Bezos, et le monde a bien besoin de petits acteurs, de diversité éditoriale, de tentatives risquées, tout comme le secteur de la musique. Certes ! Mais voyons les conséquences en aval. Lorsque le contrat est signé, le copyright sur l’œuvre passe irréversiblement dans les mains de l’éditeur, qui ne l’exploitera vraisemblablement que dix ans. Que se passe-t-il après ? Le livre n’est plus imprimé, il sort de la sphère commerciale, et… il est envoyé en prison. Il rejoint la montagne de livres abandonnés, qui attendent, sous l’œil du gendarme copyright, le premier janvier de la 71ème année après la mort de leur auteur, que l’on puisse les réutiliser. Un siècle de punition ! Quelle bibliothèque en aura encore un exemplaire en rayon lorsqu’ils en sortiront ?
Et voilà comment nous entretenons cette situation absurde, dans laquelle une masse de travail faramineuse, sans plus aucune valeur commerciale, est mise hors d’accès de ceux qui en ont besoin. Il y a des manuels universitaires par centaines, parfaitement fonctionnels, dont le contenu aurait juste besoin d’un petit dépoussiérage pour servir dans les amphis après une mise à jour. Ils pourraient aussi être traduits en d’autres langues, ou bien dépecés pour servir à construire de nouvelles choses. Au lieu de ça, en thermodynamique les petits éditeurs sortent chaque année de nouveaux manuels dans lesquels les auteurs décrivent une nouvelle fois l’expérience de Joule et Gay-Lussac de 1807, condamnés à refaire eux-mêmes le même schéma, les mêmes diagrammes pression-volume, donner les mêmes explications sans pouvoir utiliser ce qui a déjà été fait par leurs prédécesseurs. Certes, d’autres disciplines évoluent plus vite que la mienne, mais partout il y a des fondamentaux qu’il n’est pas nécessaire de revisiter très souvent, et pour lesquels tout un patrimoine est rendu légalement inaccessible. Quel gâchis !
des pratiques difficiles à accepter pour ceux pour qui un livre doit aussi être un outil d’émancipation.
Grimpons maintenant d’un étage. Au dessus des petits éditeurs, les gros ; eux résolvent l’équation autrement, en partant du point de vue qu’un manuel universitaire est un outil de travail professionnel : un produit pointu, hyper-spécialisé et qui coûte cher. Aux États-Unis, ce sont eux qui mènent la course. Pour pouvoir suivre un cours de thermodynamique ou de chimie organique, l’étudiant/e lambda est forcée d’utiliser un manuel qui coûte entre 100 et 300 euros par le/la prof, qui va baser tous ses cours, diapositives, sessions d’exercices et examens dessus. Nous parlons de pavés de 400 pages, écrits par plusieurs auteur/es et illustrés par des professionnels, des outils magnifiques qui non seulement attisent votre curiosité, mais aussi vous rassasient d’applications concrètes et récentes, en vous permettant de progresser à votre rythme. On est loin des petits aides-mémoire français avec leurs résumés de cours abscons !
Ces manuels sont de véritables navires, conduits avec soin pour maximiser leur potentiel commercial, avec des pratiques pas toujours très éthiques. Par exemple, les nouvelles éditions s’enchaînent à un rythme rapide, et les données et la numérotation des exercices sont souvent modifiés, pour rendre plus difficile l’utilisation des éditions antérieures. Pour pouvoir capter de nouveaux marchés, en Asie notamment, les éditeurs impriment pour eux des versions beaucoup moins chères, dont ils tentent après par tous les moyens d’interdire la vente dans les autres pays.
Le prix de vente des livres est en fait tel que pour les étudiants, la location devient le moyen d’accès principal. Les distributeurs (comme Amazon US ou Chegg) vous envoient l’enveloppe de retour affranchie directement avec le livre. Vous pouvez tout de même surligner et annoter l’intérieur du livre : il ne sera probablement pas reloué plus d’une fois. Après tout, le coût de fabrication est faible au regard des autres sommes en jeu : il s’agit surtout de pouvoir contrôler le nombre de livres en circulation (lire : empêcher la revente de livres récents et bon marché).
Les éditeurs tentent aussi de ne pas louper le virage (très lent…) de la dématérialisation, en louant l’accès au contenu du livre via leur site Internet ou leur appli. Pensiez-vous que l’on vous donnerait un PDF à télécharger ? Que nenni. Nos amis francophones au Canada ont déjà testé pour vous : « Les étudiants sont pris en otage avec une plateforme difficile d’utilisation à un prix très élevé. Difficile de faire des recherches, difficile de naviguer, difficile de zoomer, difficile d’imprimer. Difficile de toute. En plus, on perd l’accès au livre après un certain temps, alors qu’on paie presque la totalité du prix d’un livre physique. Il y a un problème. »
En bref, cet étage combine le meilleur et le pire : des outils pédagogiques de très bon niveau, empaquetés dans des pratiques difficiles à accepter pour ceux pour qui un livre doit aussi être un outil d’émancipation.
l’émergence de créateurs et créatrices de biens culturels plus indépendants et plus justement rétribués
En dessous de ces deux groupes, il y a tout un ensemble désordonné d’entreprises qui proposent aux auteurs potentiels de court-circuiter les voies d’édition traditionnelles (j’expérimente en ce moment avec plusieurs de ces acteurs pour mon livre). On peut mentionner Lulu, qui fournit un service d’impression à la demande (Framabook l’a longtemps utilisé), mais aussi Amazon qui accepte de plus en plus facilement dans son catalogue physique et immatériel (Kindle) des livres auto-édités. En marge, il y a un grand nombre d’acteurs qui facilitent la rémunération des créateurs et créatrices en tout genre, par exemple en permettant la vente de fichiers informatiques, de services en ligne, et le financement ponctuel ou régulier de leur travail par leur audience. Ces choses étaient très difficiles à mettre en pratique il y a quinze ans ; maintenant ces entreprises érodent par le bas les piliers financiers de l’édition traditionnelle. Elles permettent, d’une part, l’émergence de créateurs et créatrices de biens culturels plus indépendants et plus justement rétribués, qui ne se feront pas manger tout/es cru/es par les machines de l’édition traditionnelle. Elles permettent aussi, et c’est plus regrettable, la monétisation d’échanges qui auraient dû rester non-commerciaux ; par exemple on ne peut que grincer des dents en voyant des enseignants fonctionnaires de l’éducation nationale, sur une plateforme quelconque, se vendre les uns aux autres l’accès à leurs fiches de travaux pratiques de collège. Dans l’ensemble toutefois, je pense que la balance penche franchement dans le bon sens, et je me réjouis de savoir que de plus en plus de personnes se voient offrir la possibilité de se demander : « tiens, et si j’en faisais un livre ? ».
Alors toi, petit/e prof de l’enseignement supérieur, qui voudrais bien faire un livre de ce que tu as déjà construit avec tes cours, et qui regardes ce paysage, tu te demandes si tu ne devrais pas faire un manuel universitaire open-source, un truc que les étudiants et les autres profs pourraient télécharger et réadapter sans rien devoir demander. Qu’est-ce que je peux te recommander ?
Pour commencer, le plus important — fonce ! Tu ne le regretteras pas. Je partage volontiers avec toi quelques chiffres et quelques retours, sept ans après m’être lancé (mais sans avoir jamais travaillé sur la communication ou la diffusion). Une trentaine de personnes télécharge le PDF de mon livre depuis mon site Internet chaque jour, la moitié depuis les pays d’Afrique francophone, et une sur cinq-cent met la main à sa poche pour acheter un exemplaire imprimé. Après six ans, ça représente 250 livres vendus (250 kilos de papier !). Je retrouve des traces de mon livre un peu partout sur Internet, pour le meilleur et pour le pire. Il y a eu un gros lot de mauvaises surprises, parce qu’il y a beaucoup de dilution : le PDF du livre est repris, en entier ou en petits morceaux, par de nombreux acteurs plus ou moins bien intentionnés. Le plus souvent ce sont simplement des banques de PDFs et miroirs informes qui s’efforcent de bien se positionner dans les résultats des moteurs de recherche, puis génèrent un revenu en apposant de la publicité à côté du contenu qu’ils reproduisent. Il y a aussi des plateformes (par exemple Academia.edu pour ne pas les nommer) qui encouragent leurs utilisateurs à republier comme les leurs les travaux des autres, et mon livre fait partie de milliers d’autres qui sont partagés sous une nouvelle licence et en étant mal attribués. Le plus désagréable est certainement de voir mon travail occasionnellement plagié par des universitaires qui ont voulu croire que le livre était simplement déposé dans le domaine public et qu’il n’était pas nécessaire d’en mentionner l’auteur. Mais je pense que ces problèmes sont propres à tous les livres et pas seulement ceux que l’on diffuse sous licence Creative Commons.
Il y a aussi de bonnes surprises ! Recevoir un paquet de correctifs par quelqu’un qui a pris le temps de refaire tes exercices. Recevoir un compliment et un remerciement d’une consœur que tu n’as jamais pu rencontrer. Voir ton PDF téléchargé depuis des adresses IP associées à une ville au milieu du désert algérien, ou bien d’endroits où personne ne n’a jamais vu une librairie universitaire ou une camionnette Amazon. Ces moments à eux seuls font du projet un succès à mes yeux, et ils te porteront toi aussi dans tes efforts.
Dans tout cela, il faut bien voir que les quantités d’argent mises en jeu dans la circulation du livre sont dérisoires, à des années-lumières de la valeur que vont créer les étudiants ingénieurs avec ce qu’ils ont appris à l’aide du manuel. Et surtout, après avoir de bon cœur mis son livre en libre téléchargement et la version papier en vente à prix coûtant, l’auteur/e réalise un matin, comme certainement beaucoup de programmeurs libristes avant lui/elle, que des œuvres concurrentes objectivement bien moins bonnes et beaucoup plus chères se vendent bien mieux.
Où trouver notre place alors dans ce paysage compliqué ? Un livre sous licence Creative Commons peut-il être une bonne réponse au problème ?
Cette treizième édition du livre, préférez-vous l’acheter neuve pour 190 euros, ou d’occasion pour 100 euros ? Sinon, je vous propose de la louer pour 37 euros…
Je pense qu’une bonne recette de fabrication pour livre universitaire doit en tout premier satisfaire trois groupes : les auteur/es, les enseignant/es et les étudiant/es. De quoi ont-ils/elles besoin ? Je propose ici mes réponses (évidemment toutes biaisées par mon expérience), en listant les points les plus importants en premier.
Ce que veulent les auteur/es :
Fabriquer une œuvre qui n’est pas cloisonnée, qui peut servir à d’autres si je disparais ou si le projet ne m’intéresse plus (donc quelque chose de ré-éditable, qu’on peut corriger, remettre à jour, traduisible en japonais et tout ça sans devoir obtenir de permission).
Une reconnaissance de mon travail, quelque chose que je peux valoriser dans un CV académique (donc quelque chose qui va être cité par ceux qui s’en servent).
De l’argent, mais pas cent-douze euros par an. Soit le livre contribue significativement à mes revenus, soit je préfère renoncer à gagner de l’argent avec (pour maximiser sa diffusion et m’éviter les misères administratives, la contribution à la sécu des artistes-auteurs ou à l’Urssaf etc).
Ce que veulent les enseignant/es :
Un contenu fiable (un livre bien ancré dans la littérature scientifique existante et dans lequel l’auteur/e n’essaie pas de glisser un point de vue « alternatif » ou personnel).
Un livre remixable, dont on peut reprendre le contenu dans ses diapos ou son polycopié, de façon flexible (ne pas devoir scanner les pages du livre ou bien tout redessiner).
Un livre dont le prix est supportable pour les étudiant/es.
Et enfin, ce que veulent les étudiant/es :
Un livre qui les aide à s’en sortir dans leur cours. C’est d’abord un outil, et il faut survivre aux examens ! Si le livre rend le sujet intéressant, c’est un plus.
Un livre très bon marché, ou encore mieux, gratuit.
Un livre déjà désigné pour elles et eux, et qui correspond bien au programme : personne n’a envie d’arpenter les rayons de bibliothèque ou le catalogue d’Amazon en espérant trouver de l’aide.
On le voit, finalement nous ne sommes pas loin du compte avec des livres sous licence Creative Commons ! Tous les outils importants sont déjà à portée de main, pour créer le livre (avec des logiciels libres en tout genre), l’encadrer (avec des contrats de licence solides) et le distribuer (avec l’Internet pour sa forme numérique et, si nécessaire d’autres plateformes pour sa forme physique). C’est peut-être un évidence, mais il est bon de se rappeler parfois qu’on vit une époque formidable.
Alors, que manque-t-il ? Pourquoi les livres libres n’ont-ils toujours pas envahi les amphis ? Quels sont les points faibles qui rendent l’équation si difficile à résoudre ? Je pense qu’une partie de la réponse vient de nous-mêmes, nous dans les communautés impliquées autour des concepts de culture libre, de partage des connaissances et de logiciels open-source. Voici quelques éléments de critique, que je propose avec beaucoup de respect et en grimaçant un peu car je m’identifie avec ces communautés et m’inclus parmi les responsables.
la monnaie de cette reconnaissance est la citation académique
Je voudrais d’abord me tourner vers les enseignant/es du supérieur. Confrères, consœurs, nous devons citer nos sources dans nos documents de cours, et les publier ! Je sais que construire un cours est un travail très chronophage, souvent fait seul/e et à la volée — comment pourrait-il en être autrement, puisque souvent seul le travail de recherche est valorisé à l’université. Mais trop de nos documents (résumés de cours, exercices, diapositives) ne citent aucune source, et restent en plus coincés dans un intranet universitaire, cachés dans un serveur Moodle, invisibles depuis l’extérieur. Sous nos casquettes de chercheurs, nous sommes déjà les premiers responsables d’une crise sans fin dans l’édition des publications scientifiques. Nous devons faire mieux avec nos chapeaux d’enseignants. Nous le devons à nos étudiants, à qui nous reprochons souvent de faire la même chose que nous. Et nous le devons à ceux et celles dont nous reprenons le travail (les plans de cours, les schémas, les exercices…), qui ont besoin de reconnaissance pour leur partage ; la monnaie de cette reconnaissance est la citation académique. Il faut surmonter le syndrome de l’imposteur : mentionner un livre dans la bibliographie officielle de la fiche descriptive du cours ne suffit pas. Il faut aussi le citer dans ses documents de travail, et les laisser en libre accès ensuite.
Quant aux institutions de l’enseignement supérieur (écoles, instituts, universités en tous genres), je souhaite qu’elles acceptent l’idée que la création de supports de cours universitaires est un processus qui demande de l’argent au même titre que la création de savoir par l’activité de recherche. Il faut y consacrer du temps, et il y a des frais de fonctionnement. Sans cela, on laisse les enseignants perpétuellement réinventer la roue, coincés entre des livres trop courts ou trop chers pour leurs étudiants. Il manque plus généralement une prise de conscience que l’enseignement supérieur a tout d’un processus industriel (il se fait à grande échelle, il a de très nombreux aspects qui sont mesurables directement etc.): nous devons arrêter d’enseigner avec des méthodes de travail qui relèvent de l’artisanat, chacun avec ses petits outils, ses méthodes et son expérience.
Un peu plus loin, au cœur-même des communautés libristes, il y a aussi beaucoup d’obstacles à franchir pour l’auteur/e universitaire : ainsi les défauts de la bibliothèque multimédia communautaire Wikimedia Commons, et du projet Creative Commons en général, pourraient faire chacun l’objet d’un article entier.
Ce que j’ai appris avec ce projet de livre, c’est que travailler à l’intersection de tous ces groupes consomme une certaine quantité d’énergie, parce que mon espoir n’est pas que le fruit de tout ce travail reste à l’intérieur. J’ai envie d’envoyer mon livre de l’autre côté de la colline, où il se retrouve en concurrence avec des manuels de gros éditeurs, parce que c’est ce public que je veux rencontrer — l’espoir n’est pas de faire un livre pour geeks libristes, mais plutôt d’arriver dans les mains d’étudiants qui n’ont pas l’habitude de copier légalement des trucs. Créer ce pont entre deux mondes est un travail en soi. En le réalisant, j’ai appris deux choses.
un travail de communication et de présence en amont.
La première, c’est que nous dépendons toujours d’une plate-forme ou d’une autre. Comme beaucoup d’autres avant moi, je me suis hissé sur les épaules de géants depuis une chambre d’étudiant, en montant une pile de logiciels libres sur mon ordinateur et en me connectant à un réseau informatique global décentralisé. L’euphorie perdure encore jusqu’à ce jour, mais elle ne doit pas m’empêcher d’accepter qu’on ne peut pas toujours tout faire soi-même, et qu’une activité qui implique des transactions financières se fait toujours à l’intérieur d’un ou plusieurs systèmes. Quel que soit son métier, avocate, auteure, chauffagiste, restaurantiste, une personne qui veut s’adresser à un public doit passer par une plate-forme : il faut une boutique avec vitrine sur rue, ou un emplacement dans une galerie commerciale, ou une fiche dans un annuaire professionnel, ou bien un emplacement publicitaire physique ou numérique, ou encore être présent dans un salon professionnel. Chaque public a des attentes particulières. Pour que quelqu’un pense à vous même sans se tourner activement vers une plateforme (simplement en pensant silencieusement « bon il me faut un livre de thermodynamique » ou « bon il faut que quelqu’un répare cette chaudière ») il faut que vous ayez fait un travail de communication et de présence en amont. Toutes les plateformes ne sont pas équivalentes, loin de là ! Le web est certainement une des toutes meilleures, mais là aussi nous voulons trop souvent oublier qu’elle est de facto mécaniquement couplée à une autre, celle du moteur de recherche duquel émanent 92% des requêtes mondiales : c’est ce moteur qu’il faut satisfaire pour y grandir.
Autre plateforme, Amazon: l’utiliser pour distribuer ses livres, c’est participer à beaucoup de choses difficiles à accepter sociétalement. Framasoft a fait le choix de ne plus l’utiliser, et c’est tout à leur honneur, d’autant plus lorsqu’on voit le travail qu’ils abattent pour en construire de meilleures, des plateformes ! Personnellement, j’ai choisi de continuer à y vendre mon livre, car il y a des publics pour lesquels un livre qui n’est pas sur Amazon n’existe pas. Idem pour Facebook, sur lequel je viens bon gré mal gré de me connecter pour la première fois, parce que mon livre s’y partage que je le veuille ou non et que je voudrais bien voir ça de plus près. Ainsi, au cours des dernières années j’ai appris à observer les flux au delà de la connexion entre mon petit serveur et mon petit ordinateur.
La seconde chose que j’ai apprise, c’est que nous avons, nous au sein des communautés du logiciel et de la culture libres, une relation assez dysfonctionnelle à l’argent. Il nous manque globalement de l’argent, ça je le savais déjà (j’ai fondé et travaillé à plein temps pour une association sont les objectifs ressemblaient un peu à ceux de Framasoft il y a 15 ans), mais j’avais toujours attribué cela à de vagues circonstances extérieures. Maintenant, je suis convaincu qu’une grande part de responsabilité nous revient : il nous manque de la culture et de la sensibilité autour de l’argent et du commerce. Dès que l’on professionnalise son activité, on vient à bout du credo « il est seulement interdit d’interdire » que nous avons adopté pour encadrer le partage des biens communs culturels. Nos licences et nos organisations sont en décalage avec la réalité et nous faisons collectivement un amalgame entre « amateur », « non-commercial » et « à but non-lucratif ». — j’y reviendrai dans un autre article.
Voilà tout ce que j’ai en tête lors que je me demande où sont les livres universitaires libres. Qui sera là pour faire un pont entre tous ces mondes ? Il y a quelques années, le terme “Open Educationnal Resource” (OER ou en français REL) a pris de l’essor un peu comme le mot-clé “MOOC”, une idée intéressante pas toujours suivie d’applications concrètes. Plusieurs projets ont été lancés pour éditer des livres et cours universitaires libres. Aujourd’hui beaucoup on jeté l’éponge : Lyryx, Boundless, Flatworld, Tufts OpenCourseWare, Bookboon se sont arrêtés ou tournés vers d’autres modèles. Il reste, à ma connaissance, un seul éditeur avec un catalogue substantiel et à jour (je ne vous cache pas que je rêve d’y contribuer un jour) : c’est OpenStax, une organisation américaine à but non-lucratif, avec une quarantaine de manuels en anglais. Et dans la sphère francophone ? Un groupe de geeks de culture libre arrivera-t-il jamais à faire peur à tout le monde en mettant dans les mains des étudiants des outils qu’ils peuvent utiliser comme ils le veulent ?
Le Petit Crypto-Prince
À l’heure où l’on en vient à vendre ses propres pets en NFT, notre dessinateur Gee nous offre une parodie du Petit Prince pour le moins… cryptique.
Notez que la BD a été réalisée en direct sur PeerTube ! Vous pouvez regarder la rediffusion ici :
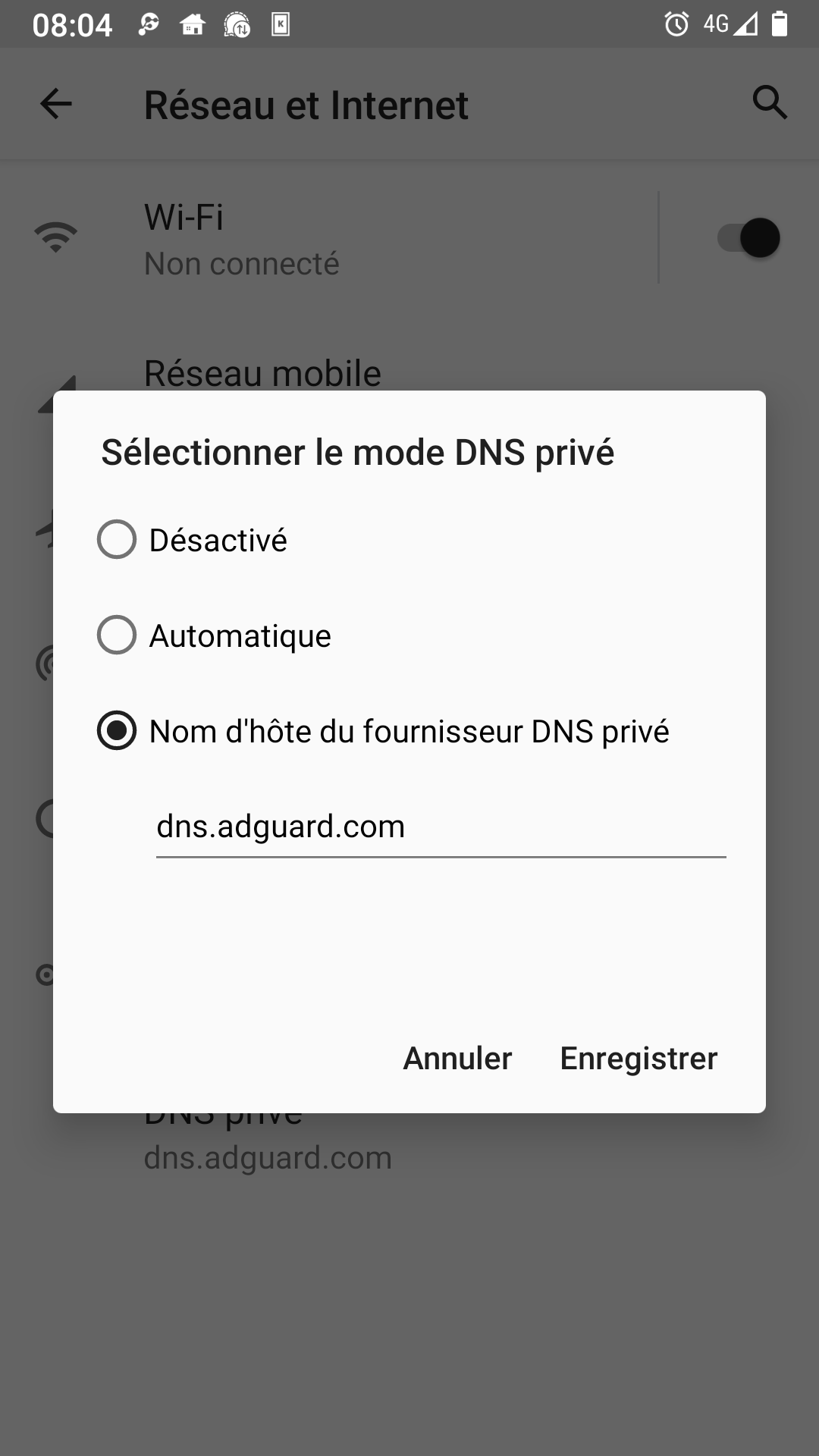
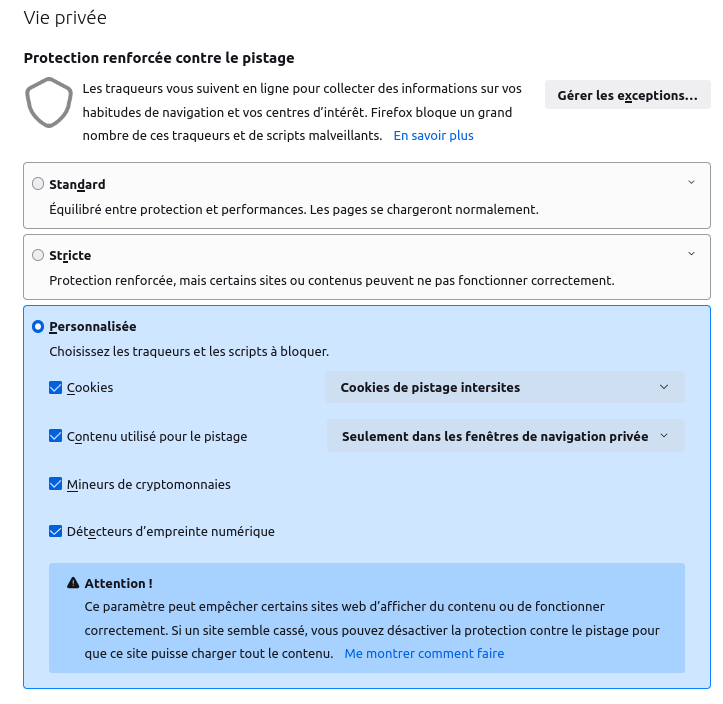















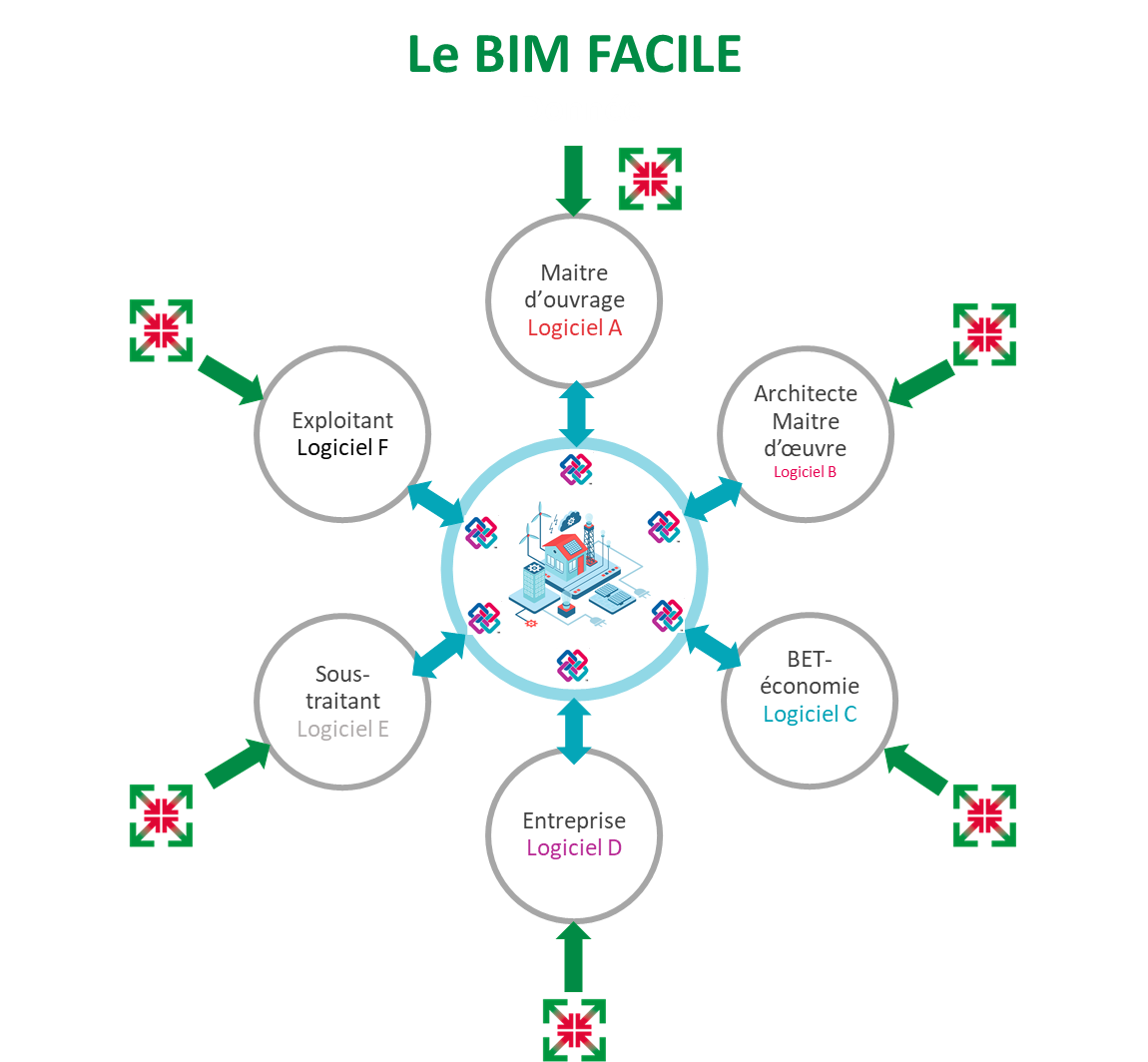




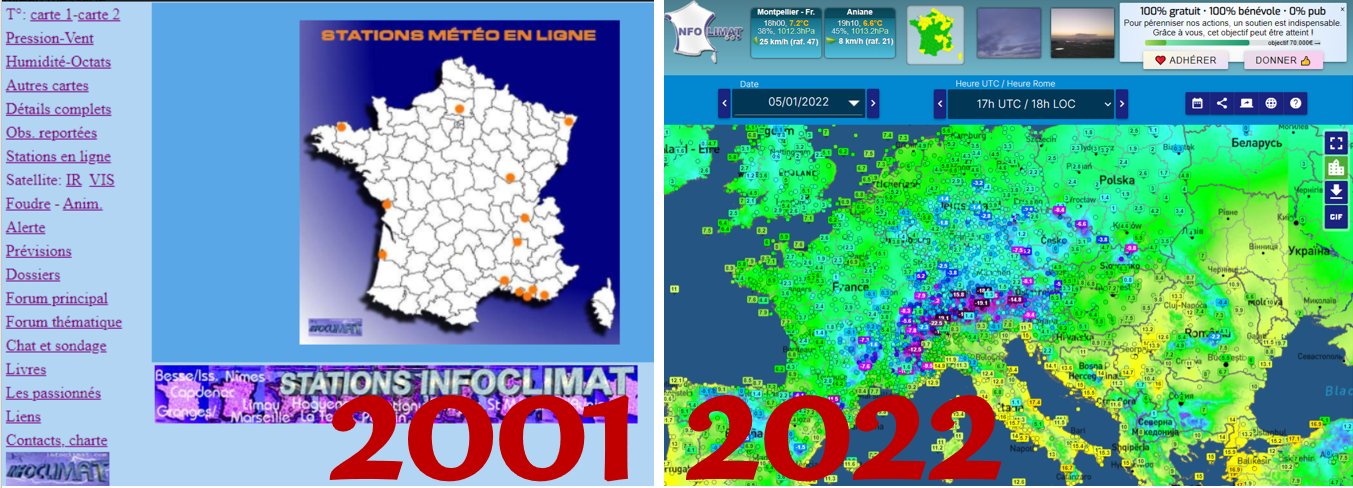

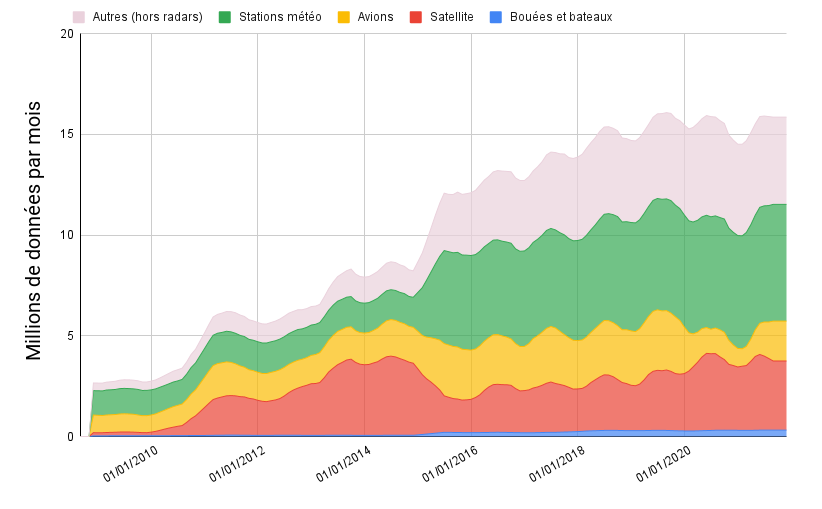
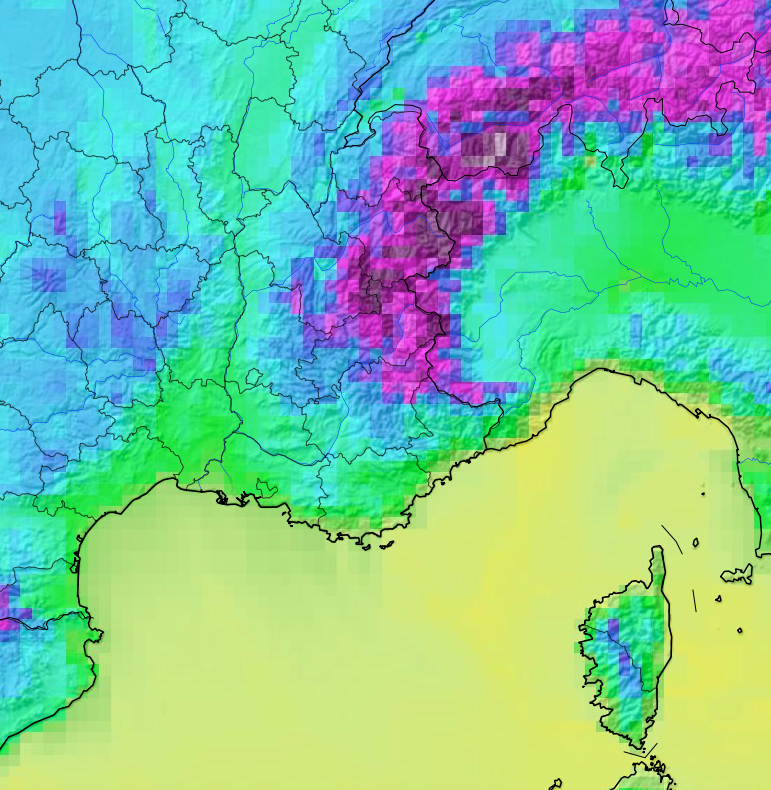
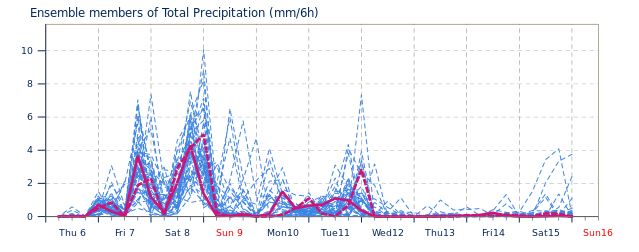
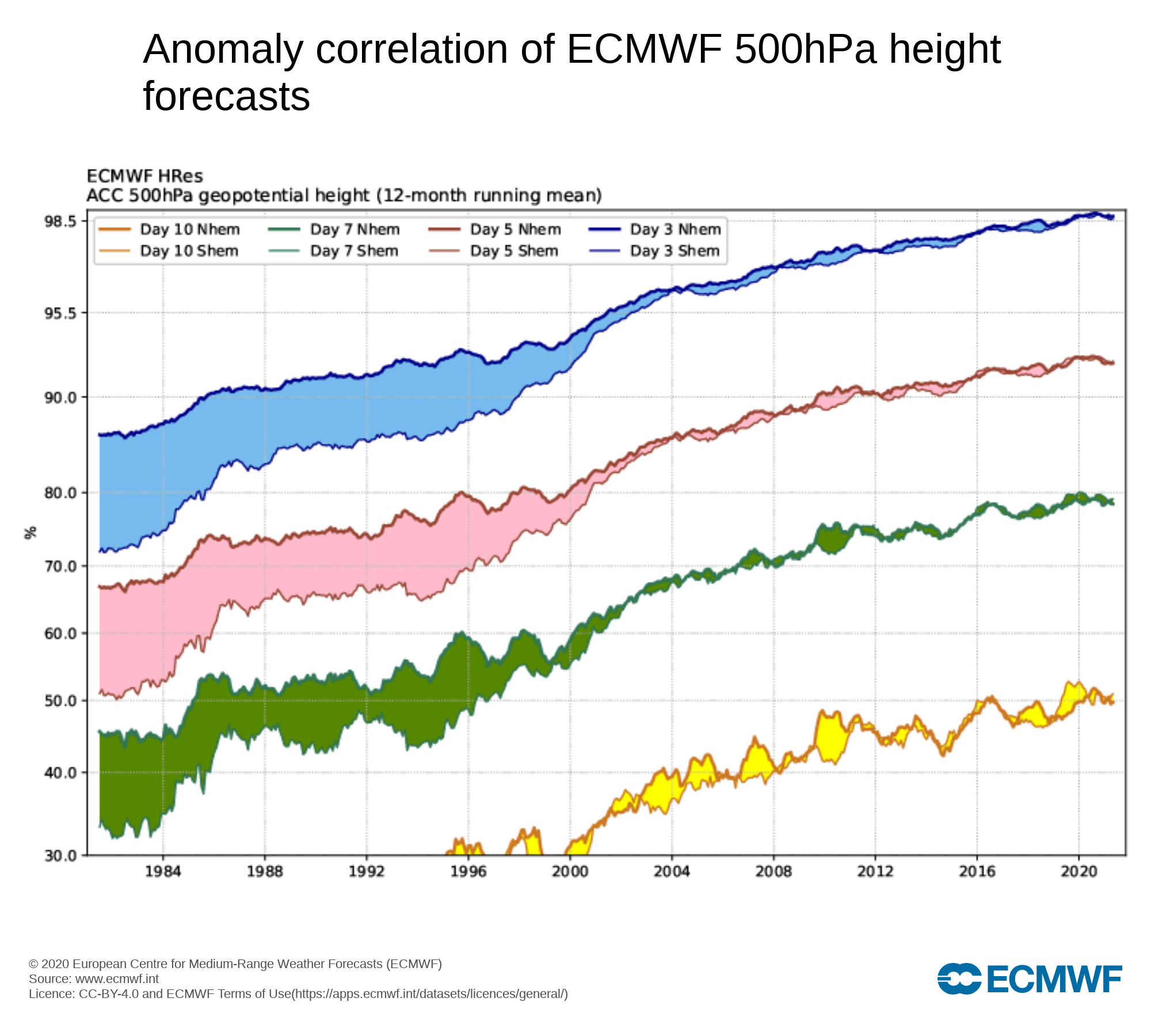
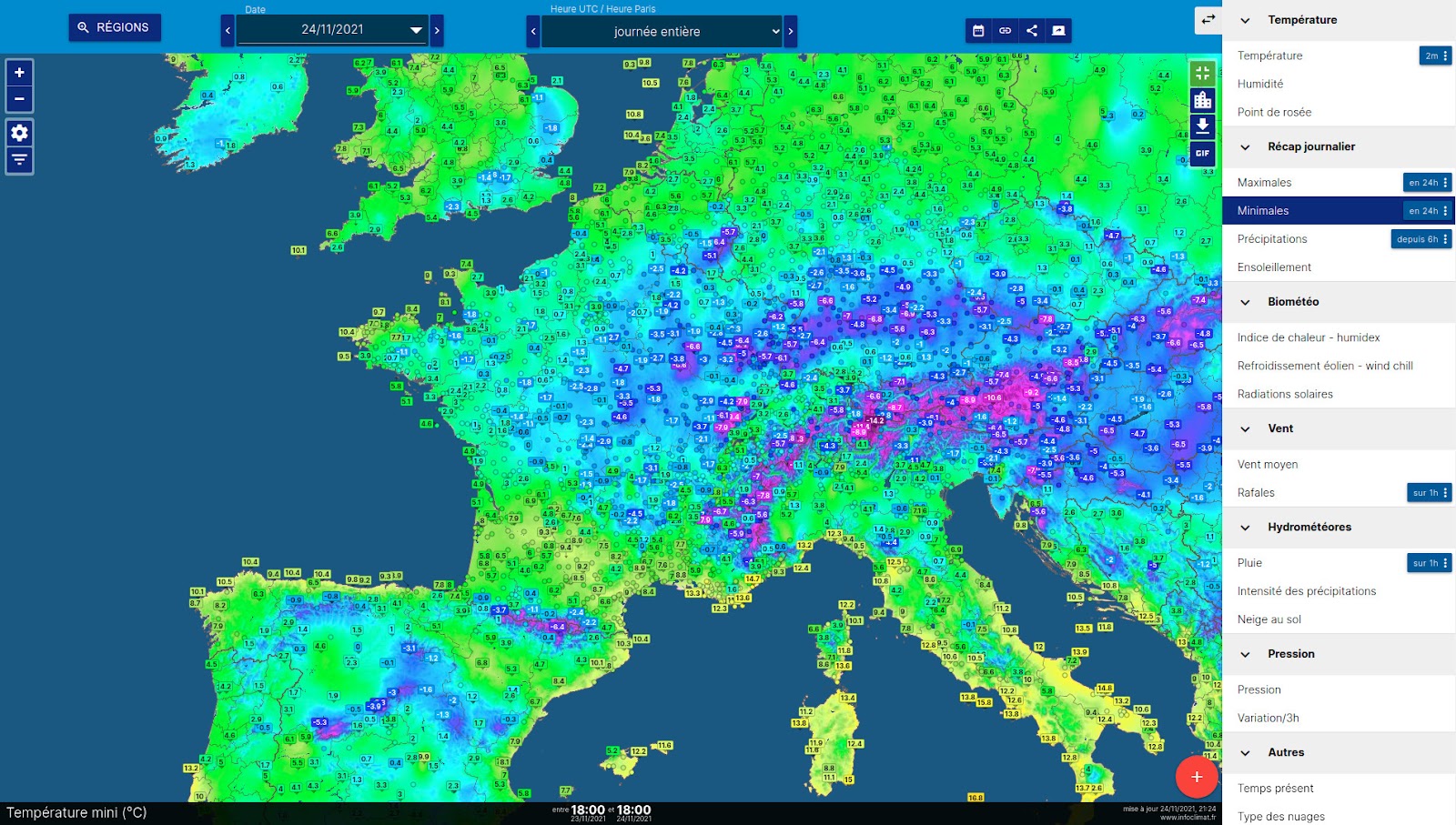

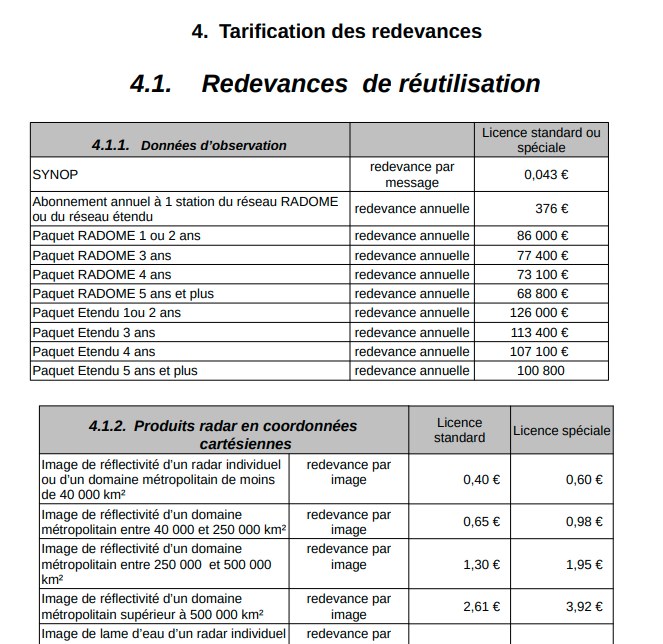





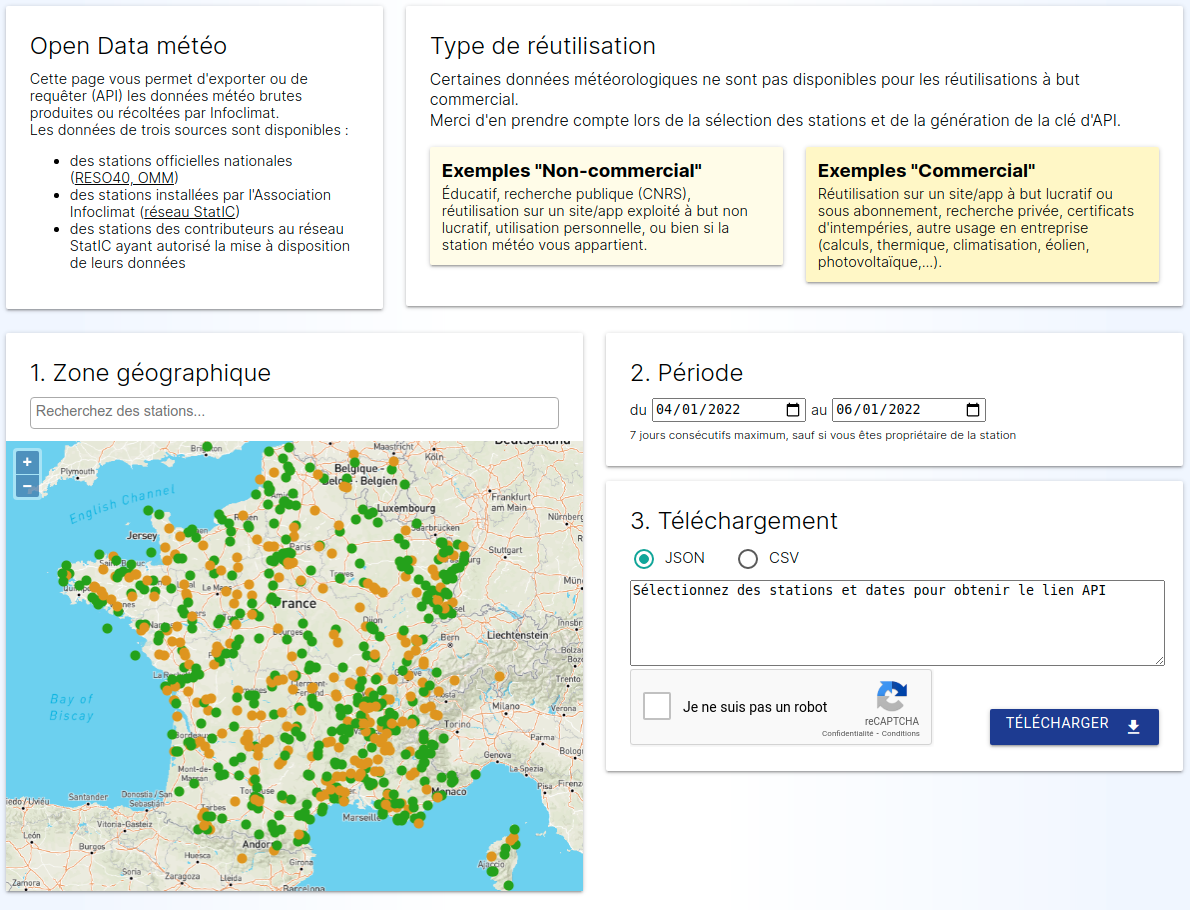











{kind=link}