Formation Emancip’Asso : donner les clés aux hébergeurs de services éthiques pour accompagner les assos
Première étape du projet Emancip’Asso, laformation « Développer une offre de services pour accompagner les associations dans leur transition numérique éthique » se déroulera à Paris du 16 au 20 janvier 2023. Les inscriptions sont désormais possibles !
Pour atteindre cet objectif, le projet que nous coordonnons avec nos partenaires et ami⋅es d’Animafac s’est doté d’un comité de pilotage constitué d’acteurs impliqués dans le secteur de l’éducation populaire, de l’associatif et du numérique.
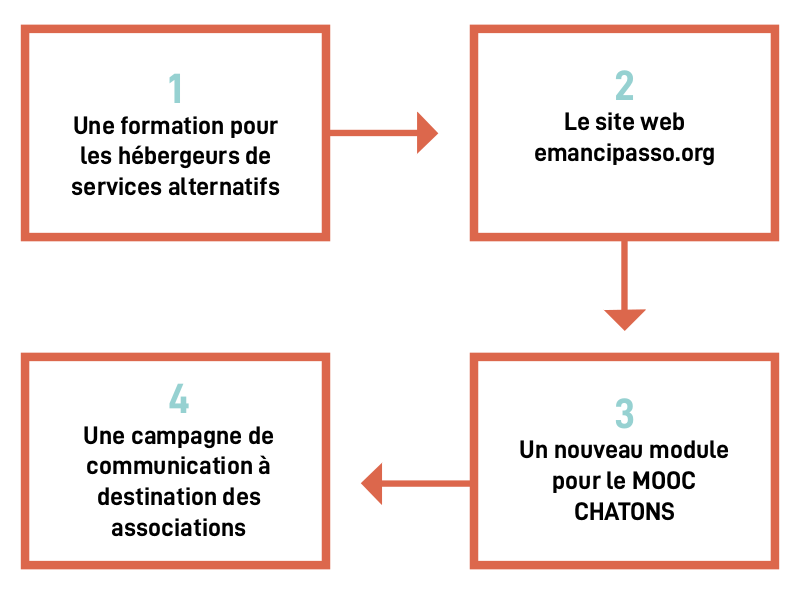
Ensemble, nous avons établi que pour atteindre son objectif, le projet devait se répartir en 4 actions :
une formation pour les hébergeurs de services alternatifs
un site web emancipasso.org qui permettra aux associations d’identifier des hébergeurs proposant des offres d’accompagnement des associations
un nouveau module pour le MOOC CHATONS (adaptation numérique de la formation) afin que de nombreux hébergeurs fassent émerger des offres
une campagne de communication de grande ampleur pour inciter les associations à prendre conscience de l’incohérence qu’il y a à vouloir changer le monde en utilisant les outils du capitalisme.
Une formation pour les hébergeurs de services alternatifs
Constatant que les hébergeurs éthiques sont peu nombreux à proposer des solutions prenant en compte les besoins des associations, et notamment l’accompagnement nécessaire pour mener à bien une démarche de transition vers des outils numériques libres, le projet Emancip’Asso souhaite accompagner la montée en compétence des hébergeurs de services alternatifs en leur proposant une formation.
Destinée en priorité aux hébergeurs alternatifs membres du Collectif des Hébergeurs Alternatifs Transparents Ouverts Neutres et Solidaires (CHATONS), cette formation intitulée « Développer une offre de services pour accompagner les associations dans leur transition numérique éthique » se déroulera à Paris du 16 au 20 janvier 2023. Son objectif principal est de permettre à ces hébergeurs d’acquérir les compétences nécessaires pour ensuite proposer des offres appropriées au milieu associatif.
Demandez le programme !
Élaborée par les membres du comité de pilotage, cette formation sera animée par des professionnel·les de la formation et intégrera de nombreux retours d’expériences et mises en pratique.
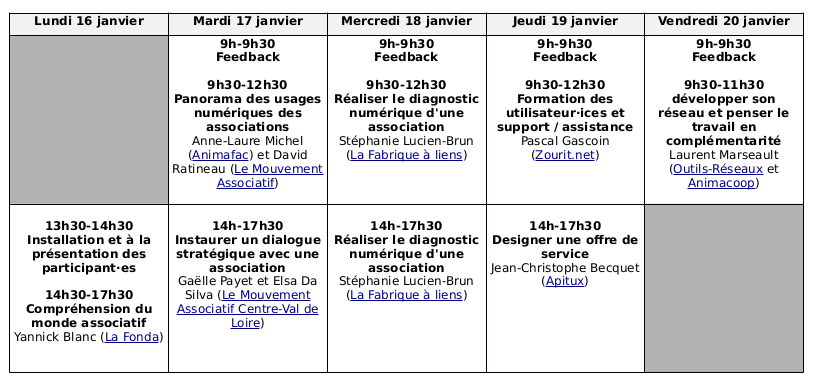
Lundi 16 janvier 2023
La formation débutera à 13h30, pour permettre aux participant⋅es de rejoindre facilement le lieu de formation pendant la matinée. La première heure sera dédiée à l’installation et à la présentation des participant⋅es.
A partir de 14h30, Yannick Blanc (La Fonda) interviendra pour apporter des éléments de compréhension du monde associatif. A travers une présentation de l’écosystème associatif, nous pourrons mieux appréhender la diversité du monde associatif, ce qui définit une association, quels sont ses modes de fonctionnement, ses modèles économiques, ses types de gouvernance et ses modalités de financement.
L’objectif de cette première séquence est d’apporter aux participant⋅es une meilleure connaissance des organisations auxquelles iels vont s’adresser.
Mardi 17 janvier 2023
Après un petit temps collectif de retours sur les apprentissages de la journée précédente (de 9h à 9h30), Anne-Laure Michel (Animafac) et David Ratineau (Le Mouvement Associatif) viendront, au nom du dispositif PANA (Points d’appui au numérique associatif) nous présenter un panorama des usages numériques des associations.
S’appuyant sur les études sur le numérique et les associations réalisées par les équipes de Recherche & Solidarité et Solidatech, ce panorama permettra de mieux saisir la position des associations par rapport au numérique et leur réalité budgétaire. Ce sera l’occasion de mieux comprendre pourquoi elles rencontrent souvent des difficultés à adopter des outils libres et de se questionner sur comment dépasser ces freins à l’adoption. Cette réflexion sera alimentée par plusieurs retours de démarches de transition numérique qui ont abouti ou n’ont pas abouti (et pourquoi). La fin de la matinée sera dédiée à des échanges sur les différentes manières de soutenir une structure associative engagée dans une démarche de transition numérique à trouver les financements pour se faire accompagner.
Après une pause déjeuner bien méritée, Gaëlle Payet et Elsa Da Silva (Le Mouvement Associatif Centre-Val de Loire) nous expliqueront comment instaurer un dialogue stratégique avec une association. Comment faire comprendre que la question est politique et qu’elle doit donc être discutée dans les instances ad hoc ? Comment faire comprendre que la démarche doit être co-construite avec l’ensemble des utilisateur⋅ices ?
Nous découvrirons alors, via une méthodologie pratique, quelles sont les pistes pour mettre en capacité les associations, quelles sont les étapes nécessaires à la mise en place d’une stratégie libre réussie, quelles sont les principales clés qui fluidifient la démarche et quelles sont les erreurs à éviter. Nous parlerons aussi de démarche partenariale et d’accompagnement au changement.
Mercredi 18 janvier 2023
Après un petit temps collectif de retours sur les apprentissages de la journée précédente (de 9h à 9h30), nous passerons toute la journée avec Stéphanie Lucien-Brun (La Fabrique à liens) sur comment réaliser le diagnostic numérique d’une association.
Nous découvrirons ce qu’est un diagnostic numérique, ses étapes, et les différentes méthodes de diagnostic existantes (auto-diagnostic, entretiens dirigés, design thinking, etc.) en analysant plusieurs diagnostics. Nous réaliserons des mises en situation en groupes afin de mettre en œuvre les connaissances acquises et mieux comprendre ce qui se joue dans cette étape essentielle du processus d’accompagnement.
Nous verrons ensuite comment on passe d’un diagnostic à des préconisations et sous quelles formes celles-ci peuvent être communiquées. Un moment sera dédié à la co-production d’un cahier des charges type. La journée se terminera par un temps spécifique pour construire une réflexion commune sur la posture de l’accompagnant.
Jeudi 19 janvier 2023
Après un petit temps collectif de retours sur les apprentissages de la journée précédente (de 9h à 9h30), Pascal Gascoin (Zourit.net) nous parlera formation des utilisateur⋅ices et support / assistance. On le sait, la formation initiale et continue est un élément clé pour une adoption facilitée des outils. Nous découvrirons donc que se doter de techniques pédagogiques (vulgarisation scientifique et médiation numérique) est nécessaire pour accompagner dans la durée.
Un focus sera proposé sur la co-construction de ressources (documentation, FAQ) permettant d’établir une base de référence à disposition des utilisateur⋅ices et limiter le recours à la fonction support. Et nous terminerons la matinée sur la notion de communautés d’utilisateur⋅ices : comment la mettre en place ? quels outils utiliser pour cela ? comment animer ces espaces d’échanges ?
Après une pause déjeuner pour mieux recharger les batteries, Jean-Christophe Becquet (Apitux) nous expliquera comment designer une offre de service. Il définira ce qu’est une offre de service claire (au sens de facile à comprendre), cadrée (ce que l’on propose et ce qu’on ne propose pas) et complète (intégrant l’accompagnement, la maintenance et le support) à destination des associations. Nous découvrirons comment construire les conditions de confiance nécessaires (pérennité de service, place du financement des services, clarté sur les modalités de rupture) à un échange sain avec les associations.
À travers la découverte de plusieurs techniques de design d’offre de services, nous traiterons la question de comment fixer un tarif juste dans un contexte concurrentiel. La fin de la journée sera dédiée à la découverte de techniques de marketing et de communication pour rendre lisible et visible une offre auprès des clients associatifs potentiels. Nous travaillerons au packaging d’offres spécifiques (à destination de grosses associations, pour celles dont les membres sont à distance, etc.), à comment les adapter et les décliner.
Vendredi 20 janvier 2023
Après un petit temps collectif de retours sur les apprentissages de la journée précédente (de 9h à 9h30), nous terminerons cette semaine de formation avec Laurent Marseault (co-fondateur d’Outils-Réseaux et d’Animacoop) qui nous expliquera pendant 2 heures comment développer son réseau et penser le travail en complémentarité.
Comment développer son réseau en tant qu’hébergeur ? Comment ne pas rester, forcément, en solo ? Comment développer des partenariats entre hébergeurs pour mettre en commun des compétences ? Comment identifier et travailler avec des partenaires spécialisés dans l’accompagnement associatif et/ou dans la formation ? Comment proposer des offres communes ? Après avoir réfléchi à ces questions, nous aborderons la question des modèles économiques des réseaux et spécifiquement la question de l’économie non-marchande. Et nous conclurons sur la distinction entre l’Économie Cynique et Suicidaire et l’Économie Sociale et Solidaire.
La fin de la matinée sera dédiée à la réalisation d’un bilan collectif à chaud. Nous nous interrogerons sur le format de la formation et l’articulation entre les différentes séquences pour imaginer une version encore plus pertinente de la formation. Nous questionnerons les participant⋅es sur leur capacité / envie / besoin de mettre en œuvre les connaissances acquises et nous identifierons les freins pressentis à cette mise en œuvre.
Modalités d’inscription
Cette formation s’adresse à toutes les personnes actives au sein d’une structure (association, micro-entreprise / entreprise ou coopérative) proposant l’hébergement de services en ligne alternatifs. La formation est gratuite, mais les frais de déplacement (transport + hébergement + restauration) sont à la charge des participant⋅es.
Si le programme de cette formation vous intéresse, nous vous invitons à vous inscrire en complétant ce formulaire d’inscription. En vous inscrivant à cette formation, vous vous engagez à en suivre l’intégralité : il n’est pas possible de participer uniquement à certaines séquences. Cette formation étant limitée à 20 participant⋅es, nous serons sûrement amenés à devoir sélectionner parmi vos candidatures. C’est la raison pour laquelle, nous vous incitons à bien expliciter les raisons qui vous poussent à vous y inscrire.
Première partie du formulaire d’inscription
Nous rappelons aussi que les membres du Collectif des Hébergeurs Alternatifs Transparents Ouverts Neutres et Solidaires (CHATONS) seront prioritaires. Cependant, si votre organisation n’est pas encore membre du collectif, nous vous recommandons de tout de même compléter le formulaire.
Et si vous n’êtes pas sélectionné pour cette session de formation, vous aurez toujours la possibilité de découvrir en détail les contenus qui y seront traités puisque nous publierons dans l’année un MOOC qui en sera la transposition. Et qui sait, si cette formation est un succès, peut-être pourrons-nous trouver de nouveaux financements pour organiser une seconde session ?
Voyage en Contributopia : ça nous a fait mûrir !
« Dégoogliser ne suffit pas ! », et c’est avec cette affirmation dans la tête que nous sommes parti⋅es explorer les mondes de Contributopia. Cette aventure de 5 ans (déjà ?!) se termine, et c’est maintenant le moment de confronter nos attentes du voyage et ce qu’on y a vraiment fait. Cap sur ces mondes numériques où l’humain⋅e et ses libertés fondamentales sont respectées !
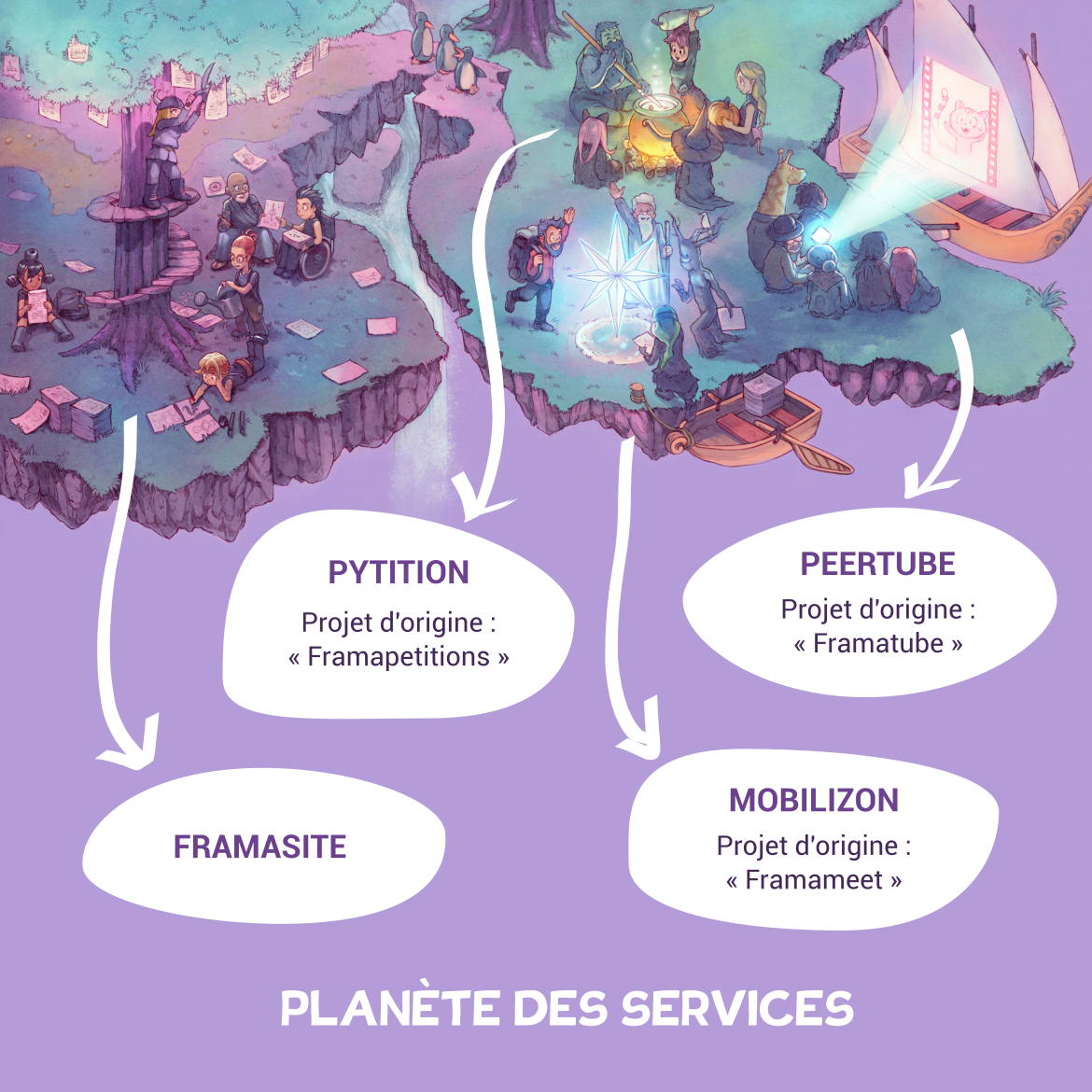
Planète des services : créer et proposer des outils
En commençant ce voyage, l’association avait vraiment envie de s’impliquer davantage dans la conception de services et d’outils conçus pour favoriser des échanges apaisés. L’envie, c’est bien, mais la réalité peut aussi être autre chose. On vous raconte point par point les différents éléments qui étaient sur notre feuille de route initiale (et aussi comment on a fait bifurquer la barque !)
PeerTube libère la vidéo
Alors là, on va se lancer quelques fleurs : PeerTube, c’est un succès !
Notre alternative aux grandes plateformes vidéos (YouTube pour n’en citer qu’une) est un logiciel libre et fédéré qui permet non seulement de visionner, publier et interagir avec des vidéos mais aussi de créer sa plateforme de vidéos. Un salarié de l’association (un seul !) est en charge de son développement, assisté en interne par d’autres salarié·es sur des aspects moins techniques.
La version 1.0 du logiciel, parue en octobre 2018, a remporté rapidement un vif succès. En quelques mois, on comptait déjà environ 14 000 comptes utilisateurs, et près de 100 000 vidéos réparties sur 350 installations recensées publiquement. Depuis, une nouvelle version majeure sort chaque année (la v5 est prévue pour la fin d’année 2022), et PeerTube va bientôt atteindre le million de vidéos hébergées.
On ne va pas refaire ici toute l’histoire de PeerTube (vous pouvez tout retrouver ici), mais dans les temps forts à mentionner : la possibilité de faire des vidéos en direct, le moteur de recherche Sépia Search permettant de chercher toutes les vidéos des instances publiques, la personnalisation de l’interface et de nombreuses améliorations réalisées aussi grâce à vos retours (merci !).
Sépia, mascotte de PeerTube
Mobilizon, pour faciliter rencontres et mobilisations
Pendant ce voyage en Contributopia, Mobilizon fut le deuxième logiciel libre et fédéré développé par l’association (par un seul salarié, là encore). Mobilizon est une alternative aux événements et groupes Facebook qui permet de facilement organiser ses événements et rencontres, sans passer par une entreprise qui raffole de surveillance.
La version 1.0 de Mobilizon, sortie pendant le confinement d’octobre 2020, n’a pour ainsi dire pas bénéficié de l’entrain espéré (Quoi ? Organiser des événements pendant un confinement, c’est pas une bonne idée ?). L’accueil du logiciel a toutefois été très positif. Comme PeerTube, une nouvelle version majeure sort chaque année, et la v3 est prévue pour fin 2022 (vous trouverez toutes les actualités par ici).
Quelques temps forts à mentionner : l’amélioration de l’accessibilité (un travail avec Koena), l’export de liste des participant·es (pratique !), la prise en compte des fuseaux horaires ou encore l’ajout possible de métadonnées pour mettre en avant certaines informations essentielles. Nous avons aussi rapidement décidé de mettre en place une instance dédiée et ouverte au public francophone : mobilizon.fr (essayez donc pour organiser votre prochaine fête d’anniversaire, rencontre-tricot ou manif-climat !).
Rȯse, mascotte de Mobilizon
Pytition : faire entendre les opinions
Après une rencontre bienvenue avec l’équipe de Résistance à l’Agression Publicitaire en 2017, nous avons décidé de ne pas entamer le travail de développement prévu sur un outil de pétitions en ligne. En effet, un de leurs administrateurs avait déjà avancé sur le développement d’un tel outil : Pytition.
L’enjeu restant pour nous particulièrement important, nous avons décidé de soutenir leur travail, plutôt que de créer un n-ième « Framatruc » (et ainsi ne pas tout centraliser chez nous). Framasoft a donc affecté un budget à Pytition. Cela a permis de financer une prestation de design, une partie du travail de développement (faire du temps bénévole investi de véritables journées de travail rémunérées) et la mise à disposition d’une machine virtuelle pour héberger le proto site web.
Cependant les emplois du temps de chacun (y compris du côté de Framasoft) n’ont pas concordé, et « l’usure » due à la pandémie s’est fortement ressentie. Le développement prend donc du temps, et, même si le Pytition actuel est « fonctionnel », il reste trop « frais » pour être proposé à tous les publics.
Nous qui pensions que gérer des projets de développements « extérieurs » nous prendrait moins de temps que des développements en interne, on a appris : l’accompagnement prend du temps, et il est indispensable. Cela nous a ainsi questionné⋅es : quelle énergie sommes-nous capables d’investir dans de tels projets ?
On se sentirait presque comme ces petits poissons dans l’eau, non ?
Framasite ou comment créer simplement son site (spoiler : ça n’existe plus !)
Permettre aux gens de créer leur propre site internet sans passer par une plateforme privée, ça donne envie non ?
Nous avons ouvert Framasite, service d’hébergement et de création de sites web, en 2018 et ainsi proposé un lieu d’expression libre en ligne, sans nécessité de connaissances techniques préalables.
Seulement, Framasite, c’était un service complexe qui reposait sur 3 logiciels libres et une surcouche maison, ce qui le rendait particulièrement difficile à maintenir sur la durée. Ainsi, malgré l’enthousiasme et l’utilité du service, nous nous sommes vite rendu compte qu’en laissant faire, le service pouvait croître de manière illimitée et infinie. Et le problème c’est que plusieurs de nos services en ligne nous ont amenés à cette même conclusion : la situation devenait ni tenable, ni gérable pour notre petite association.
Après de nombreux questionnements et réflexions, Framasoft a pris position en décidant de fermer progressivement certains de ces services, de manière planifiée (on vous en parle plus en détail en dernière partie de cet article). Framasite a donc fermé en juillet 2021.
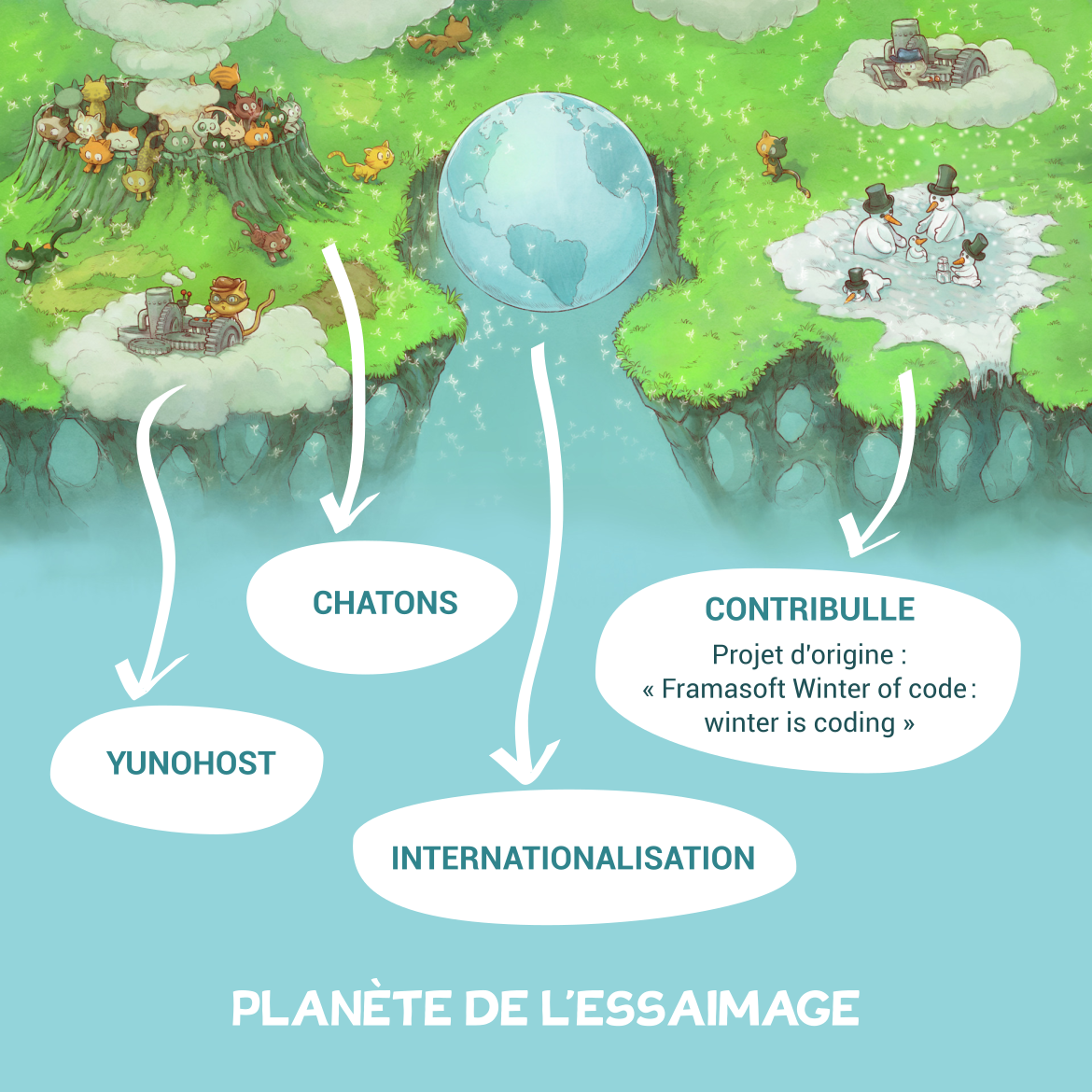
Planète de l’essaimage : transmettre les savoir-faire
Un monde où chacun et chacune peut acquérir et approfondir son indépendance numérique, nous ça nous fait rêver. Nous avons souhaité favoriser des actions qui encouragent l’autonomie numérique, pour mettre à la portée du plus grand nombre un hébergement de confiance solidaire de nos vies numériques. Une belle vision, même si pas toujours facile à mettre en œuvre.
Des CHATONS pour favoriser les petits hébergeurs locaux
C’est suite à l’embauche d’Angie en 2019 que la dynamique du collectif aura réellement pris : un tiers de son temps de travail est consacré à animer les échanges entre les membres et à donner davantage de visibilité au collectif et aux structures qui le composent.
Le collectif CHATONS, maintenant reconnu comme solution de confiance pour trouver un hébergeur éthique et des services libres, nous a permis d’essaimer notre projet « Dégooglisons Internet » et d’ainsi explorer d’autres horizons.
Le temps d’animation restant important pour Framasoft, la prochaine étape est la reprise en main progressive de l’animation du collectif… par le collectif lui-même ! Et il se trouve que le sujet est justement en pleine discussion parmi ses membres. Affaire à suivre…!
Trois chatons en pleine exploration
YunoHost ou l’auto-hébergement facile
YunoHost, c’est génial ! C’est un système d’exploitation pour serveur permettant d’installer des services (et leurs mises à jour) en auto-hébergement, facilement, par un clic. Le but de ce projet libre ? Permettre à quiconque d’auto-héberger ses services avec un minimum de connaissances techniques.
Pour soutenir ce projet bénévole, Framasoft, dès janvier 2017, a consacré du temps salarié au développement de YunoHost pour qu’un maximum de services libres de notre campagne « Dégooglisons Internet » puisse être disponible dans cette solution. En 2019 la majorité de ces services y sont présents (mission accomplie !).
Sauf que, si YunoHost a réussi à faciliter grandement l’auto-hébergement, le choix de gérer son propre serveur reste encore difficilement accessible à la majorité des personnes. Nous n’avons donc pas contribué davantage à ce projet pour consacrer nos énergies à explorer d’autres possibles. Et ça aussi, ça fait partie du voyage !
Quand la technique est poétique
Partager notre expérience hors des frontières
« Dégooglisons Internet » est un projet que nous avons volontairement ouvert exclusivement à un public francophone : une petite association française comme la nôtre n’avait pas les épaules pour prendre en charge les données du monde entier, et encore moins l’envie. Seulement, au vu de l’engouement qu’a généré « Dégooglisons Internet » et les questionnements particulièrement riches qu’il a amenés, nous nous sommes mis à rêver. Et si un projet comme « Dégooglisons Internet » pouvait essaimer dans d’autres pays, s’adapter à d’autres cultures, dans d’autres langues et inspirer d’autres collectifs ? Et si « Dégooglisons Internet » devenait un commun international ? (Rien que ça ?!)
Traduction. Le premier pas à franchir est la barrière de la langue : traduire certains contenus a donc été indispensable. Nous avons mené un gros chantier pour rendre différents supports multilangues : articles de blog, pages d’accueil de nos services, site du collectif CHATONS.
Conception d’outils comme des communs internationaux. Nous avons décidé de développer PeerTube et Mobilizon en anglais, puis de les traduire en français. Tout contenu en rapport avec ces logiciels (utilisation du logiciel, actualités, etc.) peut ainsi toucher un public non francophone. Nous avons aussi coordonné la vidéo « What is the Fediverse » en anglais (qui a rapidement été traduite par de nombreuses contributions – merci !). Nos tentatives d’animations sur le réseau social Reddit sont une autre initiative allant dans ce sens.
Interventions en anglais. Nous sommes intervenus en anglais à différentes reprises pour partager notre expérience assez unique : réussir à informer sur les enjeux actuels du numérique tout en proposant des alternatives à une si large échelle tout en restant une structure indépendante du monde capitaliste (sans se la péter, hein !). Nous continuons ces interventions en anglais (tout en assumant notre bel accent), que vous pourrez en partie retrouver sur notre Framatube.
On partait de (vraiment) loin, mais savoir vers où on avait envie d’aller, ça nous a aidées. Le but de tous ces efforts ? Fournir un compost riche, pour que les expérimentations de Framasoft puissent faire germer d’autres initiatives, un peu partout !
Le partage d’expérience, c’est toujours riche !
Contribulle : contribuer au libre
Alors même si on avait trouvé le super slogan « winter is coding », nous n’avons jamais réalisé le projet « Framasoft Winter of Code », un contrepied (de nez) au programme de formation « Google Summer of Code ». À la place, nous avons contribué à Contribulle, un projet qui a pour objectif d’informer sur les nombreuses manières de contribuer au Libre (sans forcément savoir coder) et de mettre en relation les talents et les besoins.
Derrière Contribulle, il y a le groupe de travail « Design et Libre » dont fait partie l’une des membres de Framasoft. Le groupe de travail a exprimé sa volonté de garder une certaine indépendance sur le niveau d’implication de Framasoft dans ce projet (et nous, on trouve ça super !). Nous fournissons ainsi l’infrastructure technique nécessaire à la bonne réalisation du projet (nom de domaine et machine virtuelle pour l’hébergement du site web).
Planète de l’éducation populaire : inspirer les possibles
Pour nous, l’éducation populaire, c’est la liberté de chacune et chacun de partager les connaissances et d’y accéder : la base d’un monde meilleur, quoi !
Actions de médiation pour faciliter l’accès à un web éthique
Notre constat de départ : trouver un service web libre et éthique qui corresponde à ses usages demande de nombreuses connaissances et reste difficile d’accès aux personnes les moins à l’aise avec l’outil numérique.
Nous avons donc continué et renforcé nos interventions et ateliers sur le sujet (en présentiel ou en ligne) pour garder un contact humain avec les personnes (c’est toujours bien plus impactant). Vous trouverez quelques-unes de ces interventions sur notre chaîne Framatube.
Nous avons aussi rédigé, soutenu ou participé à de nombreux contenus de sensibilisation et/ou pédagogiques autour du numérique. En voici quelques exemples :
[RÉSOLU] : fiches théoriques permettant d’illustrer les enjeux d’un changement des usages numériques dans le contexte de l’ESS
entraide.chatons.org : 9 services en ligne alternatifs sans inscription en accès libre proposés par le collectif CHATONS
Au fil du temps, nous avons pris conscience que soutenir, participer et réaliser de tels contenus est un levier essentiel pour une émancipation du plus grand nombre, même si un accompagnement humain reste probablement le moyen le plus efficace…
Annuaire « médiation numérique », pratique !
Contribateliers : contribuer au libre
Les Contrib’ateliers sont des rendez-vous de découverte de la contribution au logiciel libre, selon ses compétences et ses envies, et pas seulement sur du code (oui, c’est possible !). Ces ateliers ont commencé sans attente particulière, mais vraiment en se disant « on verra bien si ça prend » – et ça a pris !
Comment ça se passe ? Les co-organisateur·rices réfléchissent à des propositions (des pôles d’activités). Les participant·es choisissent à quel projet libre contribuer parmi ces pôles. Quelques exemples de Contrib’ateliers : participer à la cartographie libre OpenStreetMap, au projet de reconnaissance audio libre Common Voice, à la traduction de logiciels, mais aussi à des discussions autour de la vie privée en général…il y en a pour tous les goûts !
La pandémie passant par là, cette belle dynamique a été un peu chamboulée, mais, continuant sur sa lancée, l’équipe d’organisation a proposé des Confin’ateliers, la version en ligne des Contrib’ateliers.
L’expérimentation a été réellement intéressante, même si le rythme s’est, aujourd’hui, un peu essoufflé. Si l’envie vous prend de rejoindre l’aventure des Contrib’ateliers, sachez que toute l’équipe vous accueillera à bras ouverts !
Un Contrib’atelier pas si commun
MOOC CHATONS : saisir les enjeux des géants du web sur nos vies
Ce fut particulièrement stressant pour nous de faire en sorte de respecter nos engagements avec notre partenaire (la Ligue de l’Enseignement) et le financeur (la fondation Afnic), tout en faisant face à de nombreux obstacles. Nous avons à différents moments pris de mauvaises décisions (sur la manière d’ordonner nos idées et de nous organiser à plusieurs) et nos équipes (Framasoft et la Ligue) se sont retrouvées en effectif réduit : des conditions non optimales qui nous ont fait prendre un an dans la vue. La sortie du MOOC a donc eu lieu quelques semaines avant l’annonce du tout premier confinement : les équipes de Framasoft ont très rapidement eu beaucoup d’urgences à traiter, prenant la priorité sur la promotion et l’animation du MOOC. Nous n’avons donc pas pu prendre soin du projet ou de sa communauté autant que nous l’aurions voulu.
Toutefois, nous sommes fier⋅ères du travail réalisé et du contenu créé qui correspondent tout à fait au discours porté par l’association autour des enjeux du numérique, et notamment celui de la toxicité des GAFAM.
L’objectif ? Contribuer (à notre échelle) à rendre la société plus juste et notre monde plus vivable, en misant sur la formation des citoyen⋅nes par les citoyen⋅nes. Les sujets traités sont vastes, on inclut ainsi « tous les sujets qui intéressent la société », mais pour le moment surtout en lien avec le numérique (parce que c’est la génétique de Framasoft) et l’écologie (parce que c’est inévitable).
Les principaux projets que l’on trouve dans UPLOAD :
UPLOAD est ainsi un projet expérimental, où, pour le moment, la production de ressources et le tissage de liens prennent volontairement le pas sur la structuration formelle du projet.
Un voyage riche en apprentissages
Comme tout voyage, l’exploration des planètes de Contributopia nous a beaucoup appris. On a expérimenté, essayé, changé d’avis. On s’est formé, on s’est entraidé, on a partagé. Et on a aussi profité de tous ces moments, parce que c’est ça aussi le voyage !
État des lieux de Framasoft en 2022
« Déframasoftisons Internet » : une étape nécessaire et maintenant terminée !
Au fur et à mesure de notre exploration, nous nous sommes rendu compte que rester une petite association à taille humaine (moins de 40 membres dont 10 salarié⋅es) et continuer à un rythme si intense (près de 40 services en ligne à maintenir), ce n’est pas compatible. Nous tenons à notre petite taille, à la qualité des liens que nous avons entre membres et avec le public de l’association. Nous tenons surtout au soin que l’on peut s’apporter les un⋅es aux autres. Grossir n’étant pas une option, nous avons choisi une toute autre stratégie.
Nous avons ainsi, en 2019, annoncé une nouvelle étape : «Déframasoftisons Internet ». Une fermeture planifiée (jusqu’en 2022) de certains services, pour progressivement réduire la charge qui pesait sur nos épaules (tout en proposant des alternatives !). Nous avons pris le temps de détailler nos raisons (en ayant conscience qu’elles pouvaient paraître parfois contre-intuitives).
Maintenant, « Déframasoftisons Internet », c’est fini ! Les différentes fermetures ou restrictions de services sont bel et bien terminées. Nous avons ainsi mis à jour le site degooglisons-internet.org pour laisser une vitrine à l’ensemble de nos services libres et gratuits, à disposition de toutes et tous. Vous trouverez également les alternatives aux services expérimentaux dorénavant fermés sur la page alt.framasoft.org.
Quand Framasoft renvoie vers d’autres hébergeurs éthiques
Nos intentions ont évolué
En expérimentant généreusement sur la planète de l’éducation populaire, nous nous sommes rendu compte que l’association était en pleine mutation, et qu’il était temps de l’officialiser.
Ainsi, notre objet social a évolué pour passer « d’association de promotion de la culture libre en général et du logiciel libre en particulier » en « association d’éducation populaire aux enjeux du numérique et des communs culturels ».
Selon nous, le logiciel et la culture libre restent au cœur des actions de l’association, mais deviennent un moyen, et non une fin. L’objectif devient alors de réfléchir et mettre en place des actions diverses qui facilitent l’émancipation des internautes.
L’association réalisant qu’il est temps de changer l’objet social
Framasoft n’est pas bonne partout…
…et on l’assume !
On ne sait pas accueillir la contribution. Le comble ! Dans l’association, beaucoup de projets avancent en parallèle, menés par des membres qui sont déjà sur différents fronts. Nous sommes peu nombreux et nombreuses, nos énergies sont limitées, et quand on nous dit « J’aimerais vous aider », on ne sait jamais quoi répondre. Et c’est en partie parce que l’on sait qu’un accompagnement de qualité demande du temps, et on a plutôt tendance à en manquer !
On ne fait pas émerger une communauté comme par magie. On a voulu laisser Yakforms à la communauté, mais sans l’animer, ça ne fonctionne pas ! En 2020, nous avons fait le choix de séparer clairement Yakforms (le logiciel) et framaforms.org (l’instance de Yakforms gérée par Framasoft), pour faire émerger une communauté pouvant le maintenir quand nous n’en aurions plus les moyens. Seulement, à une période où l’équipe était déjà épuisée, nous n’avons pas eu l’énergie de « pousser » Yakforms pour justement faire émerger cette communauté. Raté !
On a du mal à avancer au rythme des autres. À Framasoft, on aime expérimenter, et en expérimentant souvent on va vite, on essaye, on se plante, on réessaye, on y arrive (ou pas !). En tout cas, les expériences de travail avec d’autres collectifs ou partenaires nous ont appris que souvent nous n’avons ni le même rythme, ni la même façon de travailler, et que ça peut être très frustrant (parce que nous on aime avancer plutôt vite, quitte à se planter…).
Oups !
Archipélisation : les liens avec les autres sont essentiels
Chacun⋅e son identité, sa culture, sa raison d’être, ses objectifs, ses moyens.
Mais on se retrouve sur des valeurs ou des stratégies communes.
On fait le choix de coopérer, même ponctuellement.
Le problème général de notre société étant le système (capitalisme de surveillance), contribuer à un autre système (qui favorise les communs) nous semble une voie d’espoir. Alors, l’idée d’accompagner celles et ceux qui veulent changer le monde vers des usages numériques cohérents avec leurs valeurs, ça nous plaît !
Nous avons ainsi beaucoup expérimenté et tissé de liens avec d’autres acteurs et actrices dont l’objet social n’est pas nécessairement le numérique. Interconnecter différentes militances apporte énormément au savoir commun, et par ricochet au bénéfice commun.
La contribution aux communs, ça génère une sacrée énergie !
L’énergie humaine est la plus précieuse
On a beau s’investir et travailler sur des sujets en rapport avec le numérique, on se rend très bien compte que l’énergie des femmes et des hommes est indispensable.
Dans la force de notre collectif. Framasoft ne souhaite pas grossir pour bien des raisons, et prendre soin de ses membres est une des plus importantes. Garder des relations privilégiées où on peut échanger, débattre, ne pas être d’accord, s’écouter, prendre le temps de se comprendre, et avancer, c’est pour nous essentiel.
Dans l’animation de collectif et de communautés. Pour qu’une dynamique commune prenne, il faut y mettre de l’énergie et de l’énergie humaine ! CHATONS est un collectif qui a pris une fois qu’une personne y a consacré une partie de son temps. La communauté Yakforms n’a pas émergé, car pour le moment personne n’a pris les devants. Comme toute relation qui s’entretient, la vie d’un collectif doit être prise avec soin, où chacun⋅e y met de soi.
Dans l’accompagnement au changement d’outils. Un changement d’outil numérique, c’est un changement d’habitudes, et changer son quotidien c’est difficile. Nous nous rendons compte qu’un accompagnement humain est souvent plus « efficace », moins déstabilisant et plus facile à appréhender. Mais comment trouver un bon équilibre entre accompagner les bénéficiaires et les autonomiser ? Sans trop vous en dire, on va travailler sur la question prochainement.
Petits humain⋅es chatons très investis
Besoin d’affirmer à l’extérieur du pourquoi on fait tout ça
Ce long voyage nous a permis, en tant que collectif, de nous affirmer, d’évoluer et de donner du sens à notre projet associatif. Nous faisons des choix qui ne plaisent pas à tout le monde mais qui sont en accord avec le monde que l’on désire (eh oui, on va continuer à assumer l’écriture inclusive !), une dose de déconne ça nous motive à avancer (framaprout c’est la concrétisation d’une bonne blague), et notre positionnement politique se clarifie (on a de plus en plus envie de s’adresser à celles et ceux qui œuvrent pour plus de progrès social et de justice sociale).
Seulement, ces convictions internes ne sont pas toujours connues par nos bénéficiaires, et parfois en total décalage (non, nous ne sommes pas neutres : nous ne « devons » ni ne voulons cette place !). C’est pour clarifier tout ça au monde (rien que ça ?) que nous avons travaillé dernièrement à l’élaboration d’un manifeste qui exprimera clairement et sincèrement nos intentions aux yeux de toutes et tous. Et on nous glisse dans l’oreillette que très bientôt vous en verrez le bout du nez…
Framasoft, auto-portrait (presque) réaliste
Et maintenant ?
Ce passionnant voyage nous a permis d’expérimenter, d’essayer, de nous tromper, de réessayer, d’être plus à l’écoute de ce que nous voulons, ce à quoi nous aspirons, et ce vers quoi nous voulons aller.
On a maintenant envie d’embarquer toute la basse-cour sur notre radeau, parcourir les ruisseaux, les mares, les rivières. Prendre aussi le temps de barboter, de se prendre le bec ou de profiter. Aller plus loin avec celles et ceux qui partagent nos valeurs. Inviter les contributopistes à notre table, préparer ensemble le repas et confronter nos points de vue.
Bref, quelque chose de plus collectif, de plus convivial. Et on vous en parle très vite.
Dans les débats politiques au sujet du Web et du numérique en général, on parle souvent d’« algorithmes ». Il n’est peut-être pas inutile de revenir sur ce qu’est un algorithme et sur ce qu’il n’est pas. Si vous êtes informaticien·ne, vous savez déjà tout cela, mais, si ce n’est pas le cas, vous apprendrez peut-être ici une chose ou deux.
Par exemple, dans le numéro 3790 du magazine Télérama, en date du 3 septembre 2022, la directrice générale de YouTube, Susan Wojcicki, déclarait « Nous ne faisons pas d’éditorial au sens propre puisque tous nos contenus sont recommandés par des algorithmes ». Cette phrase est un condensé de mensonges, bien sûr. Wojcicki est bien placée pour savoir ce qu’est un algorithme mais elle essaie de faire croire qu’il s’agirait d’une sorte de processus magique et éthéré, flottant loin au-dessus des passions humaines, et n’agissant que pour notre bien.
Au contraire, un algorithme est une suite de décisions. Un algorithme, c’est un ensemble d’étapes qu’on va suivre pour un certain but. Choisir le but est déjà une décision. (Quel est le but des algorithmes de recommandation de YouTube ? Probablement de vous faire rester le plus longtemps possible, pour que vous avaliez davantage de publicité.) Mais choisir les étapes est aussi une décision. Rien dans le monde numérique ne se fait tout seul : des personnes ont décidé de l’algorithme. Que les recommandations de YouTube soient issues d’un humain qui vous observerait et déciderait, ou d’un programme automatique, dans les deux cas, c’est la décision de YouTube. Et il y a donc bien « éditorialisation ». YouTube n’est pas neutre. Même chose évidemment pour le moteur de recherche de la même entreprise, Google. Il classe les résultats en fonction de ce que Google a décidé, lors de l’écriture du programme. (Notez que c’est bien ce qu’on demande à un moteur de recherche : s’il trouvait 10 000 résultats et ne les classait pas, on serait bien ennuyé·e.)
On explique parfois l’algorithme en citant l’exemple d’une recette de cuisine : faites ceci, puis faites cela, ajouter ça, mettez le four à telle température. Mais les algorithmes ne sont pas juste une suite d’étapes, à effectuer quoiqu’il arrive. Ils incluent notamment ce qu’on nomme des tests, par exemple « si telle condition, alors faire ceci, sinon faire cela ». Un recette de cuisine qui contiendrait « si vous avez de la moutarde, ajoutez-en une cuillère » donne une meilleure idée de ce qu’est un algorithme.
Le mot d’algorithme vient d’Al-Khwârizmî (محمد بن موسى الخوارزمي), un mathématicien d’origine persane du 8e-9e siècle, qui travaillait à Bagdad (la Silicon Valley de l’époque, là où il fallait être pour travailler au plus haut niveau). Mais le concept d’algorithme existait bien avant lui. Vous avez peut-être appris à l’école l’algorithme d’Euclide pour trouver le PGCD (plus grand commun diviseur), algorithme conçu plus de dix siècles avant Al-Khwârizmî. Mais ce dernier a été le premier à décrire en détail l’idée d’algorithme et à proposer une classification des algorithmes.
Statue d’Al-Khwârizmî à Khiva, Ouzbékistan (portrait imaginaire, car on ne connait pas de portrait réel de l’époque).
Le principe de l’algorithme est donc très antérieur à l’ordinateur. Par exemple, une personne qui répond au téléphone pour une « hotline » a en général reçu des instructions extrêmement précises sur ce qu’il faut dire et pas dire, avec interdiction de s’en éloigner. Dans le monde des « hotlines », cela se nomme un script, mais c’est aussi un algorithme ; si le client dit ceci, répondre cela, etc. Remplacer les algorithmes par des humains pour les décisions, comme le préconisent certains, n’a donc pas de sens si ces humains appliquent strictement un script : ce sera toujours un algorithme.
Euclide, vu par le peintre Justin de Gand. (Là encore, c’est une œuvre d’imagination, on ne sait pas à quoi ressemblait Euclide)
Et à propos d’humains qui suivent un algorithme, comment se faisaient les calculs longs et complexes avant l’invention de l’ordinateur ? Il y avait des aides mécaniques (boulier, règle à calcul…) mais le gros du travail était fait par des humains. En français, autrefois, une « calculatrice » n’était pas un ordinateur mais une humaine qui passait sa journée à mouliner des chiffres. On pouvait avoir comme métier « calculatrice dans une compagnie d’assurances ». Même chose pour « computer » en anglais ; désignant aujourd’hui un ordinateur, il désignait autrefois un·e humain·e. Ce travail est bien montré dans le film « Les figures de l’ombre », de Theodore Melfi, qui se passe au moment où ces calculateurs humains sont peu à peu remplacés par des ordinateurs. (Le titre français du film fait perdre le double sens du mot « figures » en anglais, qui désigne un visage mais aussi un chiffre.)
Les programmes, eux, sont bien plus récents que les algorithmes. Ils sont également apparus avant l’invention de l’ordinateur, mais n’ont réellement décollé qu’une fois qu’on disposait d’une machine pour les exécuter automatiquement, et fidèlement. Un programme, c’est la forme concrète d’un algorithme. Écrit dans un langage de programmation, comme PHP, Java, Python ou Rust, le programme est plus précis que l’algorithme et ne laisse place à aucune ambiguïté : les ordinateurs ne prennent pas d’initiatives, tout doit être spécifié. La maternité de la programmation est souvent attribuée à Ada Lovelace au 19e siècle. Comme toujours dans l’histoire des sciences et des techniques, il n’y a évidement pas un·e inventeu·r·se unique, mais une longue chaîne de personnes qui ont petit à petit développé l’idée.
Un programme écrit dans le langage Python, et mettant en œuvre l’algorithme d’Euclide de calcul du PGCD.
Le premier point important de cet article était qu’un algorithme, c’est une série de décisions (et la déclaration de Wojcicki au début, lorsqu’elle essaie de diminuer la responsabilité de YouTube, est donc ridicule). Un algorithme n’est pas un phénomène naturel mais la formalisation de décisions prises par des humains. Le fait qu’il soit programmé, puis exécuté par un ordinateur, n’exonère donc pas ces humains de leurs choix. (Et, je me répète, demander que les décisions soient prises « par des humains et pas par des algorithmes » n’a guère de sens : ce sont toujours des humains qui ont décidé, même quand leur décision passe via un algorithme.)
Le deuxième point qui me semble important est que tout système informatique (et je rappelle que l’engin plat qu’on met dans sa poche, et que le marketing nomme « smartphone », est un ordinateur) fonctionne avec des algorithmes. Le ministre de l’Intérieur Gérald Darmanin avait déclaré, à propos de la surveillance automatisée des citoyens, « De plus, alors que toutes les sociétés commerciales peuvent utiliser les données fournies par des algorithmes, seul l’État n’aurait pas le droit de le faire […] ? » et avait appelé à « pérenniser l’utilisation des algorithmes ». Par delà la question politique de fond, ces déclarations sont bien sûr absurdes. L’État utilise des algorithmes depuis longtemps, depuis qu’il utilise des ordinateurs. Mais il ne s’agit pas seulement de l’ignorance (et du mépris pour la technique) d’un ministre. L’utilisation du terme « algorithme » vise à faire croire qu’il s’agit de quelque chose de nouveau, afin de brouiller le débat sur les usages de l’informatique, et d’empêcher les citoyen·nes d’y participer utilement. La réalité, je le redis, est que cela fait longtemps qu’il existe des algorithmes et qu’ils sont utilisés.
Il y a par contre une nouveauté qui a pris de l’importance ces dernières années, ce sont les systèmes à apprentissage (parfois désignés par l’acronyme marketing IA – Intelligence Artificielle, qui ne veut rien dire) ou machine learning en anglais. Il existe de nombreux systèmes de ce genre, très variés. Mais le point commun est l’utilisation d’algorithmes qui évoluent sous l’influence des données qu’on leur donne. Pour prendre un exemple simpliste, on donne au programme des photos de chiens et de chats, lui indiquant à chaque fois s’il s’agit d’un chien ou d’un chat, et, après un grand nombre de photos, le programme aura « appris » et pourra classer correctement une nouvelle photo. Il y a beaucoup à dire sur ces systèmes à apprentissage mais, ici, je vais me contenter de faire remarquer qu’ils ne remettent pas en cause le pouvoir de décision. Au lieu de règles explicites dans un algorithme (« s’il a des griffes rétractiles, c’est un chat »), le système de décision est composé de l’algorithme qui apprend et des données qu’on lui soumet.
Il n’y a donc pas de changement fondamental : le système informatique qui prend la décision a toujours été conçu et entraîné par des humains, et ce sont leurs choix qui se refléteront dans les décisions. Ainsi, si on utilise un tel système pour traiter les CV dans un service de ressources humaines, si l’entreprise avait l’habitude de recruter préférentiellement des hommes, et si on entraîne l’algorithme avec les choix passés, il se mettra à privilégier les CV des hommes, pas parce qu’il serait « sexiste » (les algorithmes n’ont pas d’opinion ou de préjugés) mais parce que c’est ce que ses maîtres humains lui ont demandé, via les données qu’ils ont choisies.
Bref, chaque fois que vous entendrez quelqu’un éluder sa responsabilité en se cachant derrière « c’est l’algorithme », rappelez-lui qu’un algorithme, c’est un ensemble de décisions prises par des humains, et que ces humains sont responsables de ces décisions.
Enquête « Ce que vous pensez de Framasoft » : les résultats
« Framasoft ne piste personne. Pour savoir ce que vous pensez de ce que nous sommes et ce que nous faisons, nous avons bien quelques indices… Mais le mieux reste de vous poser la question ! »
Ainsi débutait l’enquête que nous avions lancée le 23 mai 2022 et qui aura duré jusqu’au 26 juin dernier.
L’objectif était donc de mieux connaître les utilisateur⋅ices de nos services (tranche d’âge, vos engagements, votre rapport au numérique, etc.), et d’essayer de comprendre comment vous, vous nous perceviez. Rappelons aussi que l’enquête était parfaitement anonyme (on ne vous demandait ni votre nom/pseudo, ni adresse mail, et les adresse IP étaient anonymisées).
Capture écran du formulaire, cliquez pour l’agrandir.
Le premier fait marquant de cette enquête, c’est d’abord le nombre de réponses collectées : 12 664 !
Honnêtement, nous n’en espérions pas autant. Votre large implication nous permet d’avoir un échantillon que nous pensons être suffisamment représentatif. En effet, même si le réseau Framasoft accueille plus d’un million de visiteur⋅euses par mois, la plupart de ces personnes ne savent pas du tout qu’elles utilisent un service associatif, financé par les dons (merci !).
Le second fait marquant, c’est que les réponses libres sont, dans leur immense majorité, très élogieuses ! Alors évidemment, on ne s’emballe pas : nous nous doutons bien que les personnes qui ont pris cinq minutes de leur vie pour répondre au formulaire d’enquête d’une association sont plutôt « bien disposées » vis-à-vis de cette association.
Vous avez en effet apporté 10 482 commentaires à la question « Vous pouvez commenter vos cinq choix dans le champ libre suivant, si vous le souhaitez », et 7 092 messages à la question « Si vous voulez nous adresser un petit mot ». L’inconvénient, c’est que, par conséquent, nous ne pouvons pas en faire une synthèse complète ici 😅 (mais on les a tous lus, promis !!)
Donc, faisons une rapide analyse concernant la perception de Framasoft pour les répondant⋅es 🙂
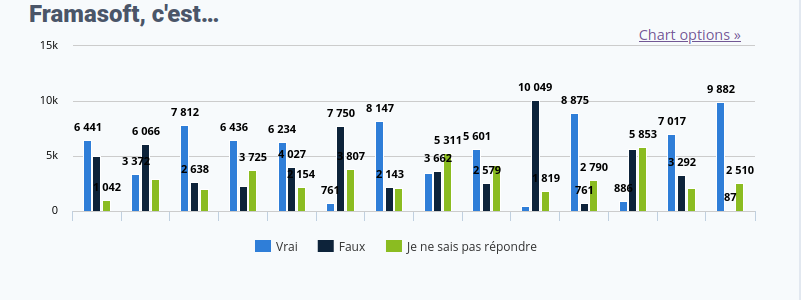
Framasoft, c’est…
Nous commencions par essayer de comprendre ce que Framasoft représentait pour vous
Cliquez pour agrandir l’image
Vrai
Faux
Je ne sais pas répondre
…une entreprise de développement de logiciels libres
6 441
4 983
1 042
…des gauchistes du web
3 372
6 066
2 905
…apolitique (et ça doit le rester)
7 812
2 638
1 992
…une structure qui doit grandir pour accueillir la demande
6 436
2 230
3 725
…uniquement pour la défense et promotion du logiciel libre
6 234
4 027
2 154
…trop neutre, politiquement
761
7 750
3 807
…pour tout le monde, même les grosses entreprises
8 147
2 143
2 134
…une association qui ne veut pas grossir
3 417
3 662
5 311
…anticapitaliste
5 601
2 579
4 194
…bien sympa, mais j’aimerais un peu plus de sérieux
500
10 049
1 819
…contre la centralisation
8 875
761
2 790
…trop peu engagé dans l’écologie
886
5 617
5 853
…fait pour des personnes qui partagent les mêmes valeurs
7 017
3 292
2 091
…un collectif qui tient à son statut associatif
9 882
87
2 510
Les trois réponses récoltant le plus de « Vrai » sont
…un collectif qui tient à son statut associatif
…contre la centralisation
…pour tout le monde, même les grosses entreprises
Les trois réponses qui récoltent le plus de « Faux » sont
…bien sympa, mais j’aimerais un peu plus de sérieux
…trop neutre, politiquement
…des gauchistes du web
Quant aux trois réponses ayant le plus de « Je ne sais pas » (et donc intéressant pour nous à clarifier)
…trop peu engagé dans l’écologie
…une association qui ne veut pas grossir
…anticapitaliste
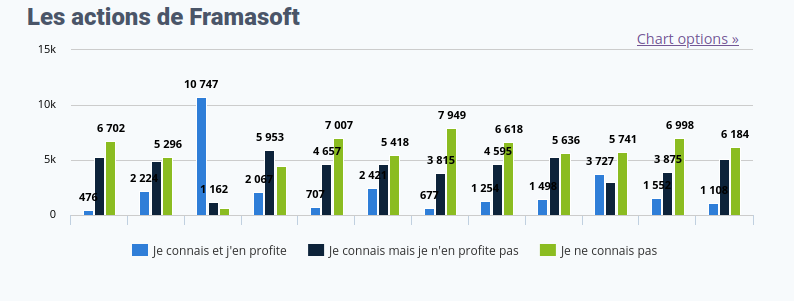
Ce que Frama fait
Cette question nous permettait de savoir si vous connaissiez (ou pas) nos actions phares, et si vous en avez bénéficié au moins une fois en 2021 ou 2022.
Cliquez pour agrandir l’image
Je connais et j’en profite
Je connais mais je n’en profite pas
Je ne connais pas
Conférences, ateliers et rencontres (en 2021-2022)
Bon, sans surprise, plus de 9 personnes sur 10 ayant répondu nous connaissent avant tout pour nos services. Par contre, nous étions un peu surpris⋅e de nous rendre compte qu’autant de personnes ne connaissent pas Mobilizon, Framabook, ou nous imagine uniquement derrière des écrans, et non devant le public.
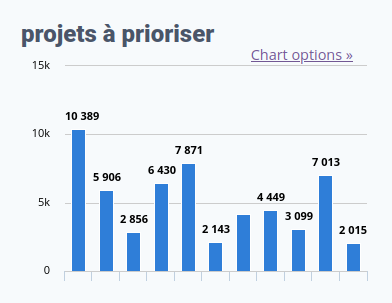
Si vous étiez aux manettes…
D’après vos messages, il a été particulièrement difficile pour vous de répondre à cette question, qui vous proposait de vous mettre à la place de « pilote dans l’avion Framasoft » et de choisir cinq (et uniquement cinq) actions à prioriser.
Cliquez pour agrandir l’image
Services en ligne (Framapad, Framadate, Framaforms, Framalistes, etc.)
10 389
Conseils aux associations et collectifs
5 906
Animation du collectif CHATONS
2 856
Développements de logiciels fédérés (PeerTube, Mobilizon)
6 430
Travail de fond sur des logiciels vieillissants (par ex. ceux derrière Framaforms, Framadate, Framacalc…)
Guides et outils d’émancipation numérique (Résolu, MOOC CHATONS)
7 013
Contributions à des projets externes (Pytitions, bénévalibre, etc.)
2 015
Les trois actions les plus plébiscitées, si vous étiez aux manettes, sont donc :
Les services en ligne (ça ne nous surprend pas)
Améliorer les logiciels vieillissants
La production de guides et outils d’émancipation numérique
Et les trois que vous laisseriez de côté :
Contributions à des projets externes
Support et modération des services en ligne (facile à dire, moins facile à faire)
Animation du collectif CHATONS
Framasoft et … vous !
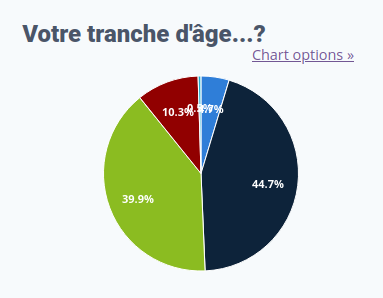
Les tranches d’âge des répondant⋅es
Cliquez pour agrandir l’image
moins de 25 ans
589
26-45 ans
5 645
46-65 ans
5 037
plus de 66 ans
1 304
je préfère ne pas répondre
60
Sans surprise, l’énorme majorité des répondant⋅es ont entre 26 et 65 ans.
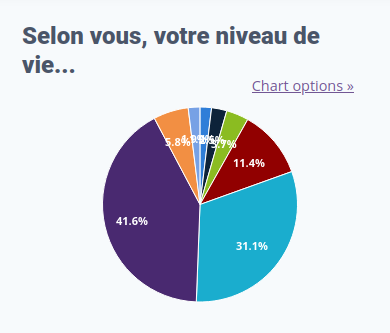
Le niveau de vie des répondant⋅es
Cliquez pour agrandir l’image
Je dépends de ma famille (collège, lycée, etc.)
240
Je suis en mode survie : minima sociaux, etc.
320
Fin du mois difficiles, je croise les doigts
469
Ça va, mais je vis sans filet
1 438
Je suis « OK », sans plus
3 926
Je suis à l’aise
5 261
J’ai bien plus qu’il ne m’en faut
734
je préfère ne pas répondre
244
Ici, une répartition sensiblement équivalente est observée entre les personnes qui se déclarent « à l’aise » ou plus, et celle qui se déclarent dans une certaine précarité, voir une précarité certaine.
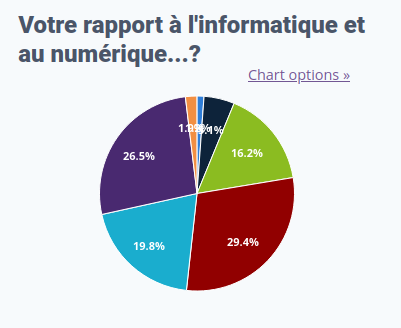
Le rapport au numérique des répondant⋅es
Cliquez pour agrandir l’image
Conflictuel : je déteste tout ça
145
Neutre : je fais comme on me dit sans chercher à comprendre
638
Méfiant·e : je m’y intéresse mais avec méfiance
2 036
Enthousiaste : je m’y intéresse avec enthousiasme
3 696
Geek : je suis considéré comme le / la geek de mon entourage
2 494
Expert·e : j’ai une expertise dans ce domaine
3 343
Je préfère ne pas répondre
240
Dans quel(s) domaine(s) les répondant⋅es se déclarent engagé⋅e ou militant⋅e
Cliquez pour agrandir l’image
l’associatif
7 074
la création d’entreprise(s)
1 122
l’éducation populaire
3 384
le logiciel libre
4 583
la lutte contre les discriminations (sexisme, racisme, validisme, LGBT-phobies, etc.)
3 288
la justice sociale
3 706
la politique
2 269
la communication
753
la culture et les arts
2 195
l’écologie
5 783
les crypto monnaies
254
l’éducation
3 455
l’humanitaire
1 148
le marketing
139
l’entraide sociale
2 833
la vie privée
2 810
je ne suis ni militante, ni engagé
1 543
autre
546
Les trois domaines dans lesquels les répondant⋅es se déclarent le plus engagé⋅es sont donc :
l’associatif
l’écologie
le logiciel libre
La communication, le marketing et les crypto-monnaies fermant le ban (on s’y attendait un peu 🙂 )
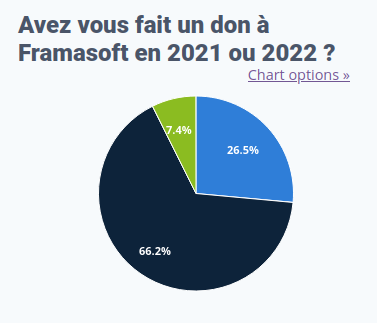
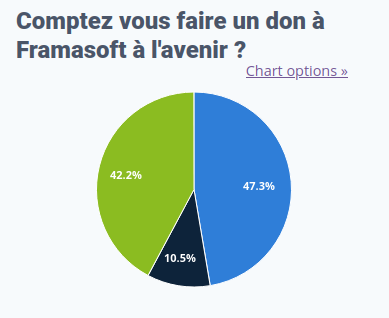
Le nombre de répondant⋅es ayant fait un don à Framasoft en 2021/2022
Cliquez pour agrandir l’image
Oui
3 351
Non
8 382
Je ne sais pas
931
Le nombre de répondant⋅es souhaitant faire un don à Framasoft à l’avenir
Cliquez pour agrandir l’image
Oui
5 956
Non
1 318
Je ne sais pas
5 306
Une indication plutôt positive pour nous : si 3 351 répondant⋅es ont indiqué avoir fait un don récemment (cf. question précédente), ce sont quasiment 6 000 répondant⋅es qui nous apprennent qu’ils ou elles comptent nous faire un don à l’avenir.
Nos ressources reposant quasi-exclusivement sur vos dons, et le contexte économique, social, sanitaire, politique et géopolitique étant pour le moins… tendu, cela nous donne un signal d’espoir dans l’avenir et de la motivation et de l’énergie non seulement pour poursuivre nos actions, mais aussi pour en développer de nouvelles.
Merci encore infiniment à toutes les personnes ayant répondu ! 🙏
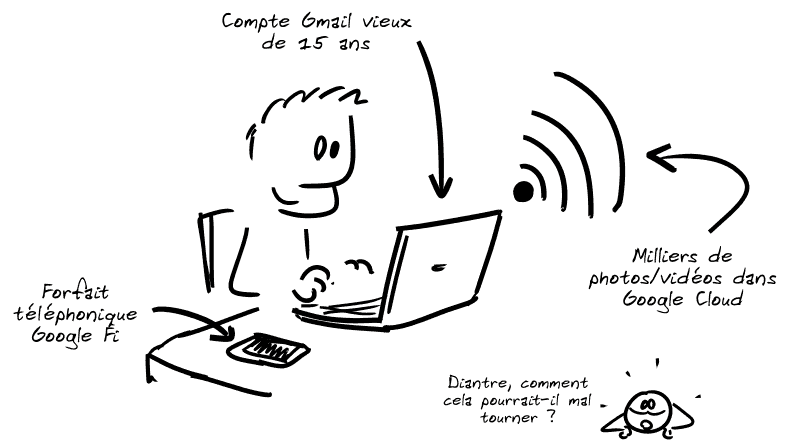
Google, l’espion le plus con du monde
On le sait bien : Google se permet de tranquillement lire tous les mails qui passent sur ses serveurs, ceux des boîtes Gmail ainsi que ceux adressés à des boîtes Gmail…
En général, le but est de refourguer de la publicité ciblée. Mais pas seulement. Une petite histoire (vraie) qui montre que les conséquences peuvent être autrement plus dramatiques…
Google, l’espion le plus con du monde
Aujourd’hui, je vais vous raconter une drôle d’histoire au pays des GAFAM. C’est l’histoire de Mark, Californien père au foyer d’un très jeune garçon. Mark est ultra-connecté, notamment aux services de Google.
En février 2021, Mark remarque que le sexe de son fils est gonflé et douloureux.
Comme c’est un vendredi soir en pleine pandémie, un rendez-vous d’urgence en téléconsultation est pris avec l’hôpital.
Le mal est identifié, des antibiotiques sont prescrits, la santé du bambin s’améliore ensuite rapidement, bref tout va bien.
Sauf que bien sûr, l’histoire ne s’arrête pas là.
Deux jours plus tard…
Eh oui, car Google (tout comme Apple, Microsoft et les autres) est très engagé dans la lutte contre la pédocriminalité. Jusqu’à se permettre de lire et analyser vos conversations mail, qui, rappelons-le, sont des conversations PRIVÉES.
Le pire étant donc que non contents d’espionner tranquillou tous les mails qui passent sur leurs serveurs, les empafés de chez Google sont infoutus de faire la différence entre une image pédopornographique et une photo d’ordre médical.
La police est bien entendu prévenue par Google et arrive rapidement à la conclusion évidente qu’il s’agit de photos médicales et qu’il n’y a aucune raison de poursuivre Mark. Elle tente de le joindre mais…
Bien sûr, Mark, ingénieur logiciel de formation, est confiant : la police l’ayant déjà lavé de tous soupçons, il va faire une réclamation à Google, expliquer la situation qui est somme toute très claire et toute bête, et tout va rentrer dans l’ordre.
Le compte finit par être définitivement supprimé, et comme Mark y a attaché à peu près toute sa vie numérique (comptes liés, forfait de téléphone, sauvegardes, etc.)…
L’identité numérique de Mark ne vécut pas heureuse et n’eut pas beaucoup d’avatars.
Fin.
L’histoire de Mark est une histoire vraie, et elle n’est pas un cas isolé.
Heureusement, il n’y a aucune fatalité à ce que cela nous arrive à nous aussi.
Pour cela, commençons évidemment par ne pas utiliser Gmail, Outlook et compagnie pour nos mails.
Si, parfois, nous n’avons pas d’autre choix que d’avoir un compte Gmail, ne l’utilisons pas pour des mails sensibles, et n’utilisons pas nos comptes Google/Facebook/autre pour nous identifier sur d’autres sites, même si c’est pratique.
Enfin, et surtout, même s’il peut nous arriver d’utiliser ces outils… n’obligeons pas les autres à le faire.
(De manière générale : faisons au mieux. L’hygiène numérique, c’est pas simple, c’est pas à la portée de tout le monde. Faisons ce que nous pouvons.)
Contra Chrome : une BD décapante maintenant en version française
Il y a loin de la promotion du navigateur Chrome à ses débuts, un outil cool au service des internautes, au constat de ce qu’il est devenu, une plateforme de prédation de Google, c’est ce que permet de mesurer la bande dessinée de Leah,
Contra Chrome est un véritable remix de la BD promotionnelle originale (lien vers le document sur google.com) que Leah Elliott s’est évertuée à détourner pour exposer la véritable nature de ce navigateur qui a conquis une hégémonie au point d’imposer ses règles au Web.
Nous avons trouvé malicieux et assez efficace son travail qui a consisté à conserver les images en leur donnant par de nouveaux textes un sens satirique et pédagogique pour démontrer la toxicité de Google Chrome.
La traduction qui est aujourd’hui disponible a été effectuée par les bénévoles de Framalang et par Calimero (qui a multiplié sans relâche les ultimes révisions). Voici en même temps que l’ouvrage, les réponses que Leah a aimablement accepté de faire à nos questions.
Bonjour, peux-tu te présenter brièvement pour nos lecteurs et lectrices… Je m’appelle Leah et je suis autrice de bandes dessinées et artiste. J’ai une formation en art et en communication, et je n’ai jamais travaillé dans l’industrie technologique.
Est-ce que tu te considères comme une militante pour la préservation de la vie privée ?
Eh bien, le militantisme en matière de vie privée peut prendre de nombreuses formes. Parfois, c’est être lanceur d’alerte en fuitant des révélations, parfois c’est une bande dessinée, ou la simple installation d’une extension de navigateur comme Snowflake, avec laquelle vous pouvez donner aux dissidents des États totalitaires un accès anonyme à un internet non censuré.
Dans ce dernier sens, j’espère avoir été une militante avant de créer Contra Chrome, et j’espère l’être encore à l’avenir.
Comment t’es venue l’idée initiale de réaliser Contra Chrome ?
Ça s’est fait progressivement.
Lorsque la bande dessinée Chrome de Scott McCloud est sortie en 2008, je n’avais qu’une très vague idée du fonctionnement d’Internet et de la façon dont les entreprises récoltent et vendent mes données. Je me figurais essentiellement que je pouvais me cacher dans ce vaste chaos. Je pensais qu’ils récoltaient tellement de données aléatoires dans le monde entier qu’ils ne pouvaient pas espérer me trouver, moi petite aiguille dans cette botte de foin planétaire.
Et puis les révélations de Snowden ont éclaté, et il a dit : « Ne vous y trompez pas », en dévoilant tous les ignobles programmes de surveillance de masse. C’est alors que j’ai compris qu’ils ne se contenteraient pas de moissonner le foin, mais aussi des aiguilles.
Depuis, j’ai essayé de m’éduquer et d’adopter de meilleurs outils, découvrant au passage des logiciels libres et open source respectueux de la vie privée, dont certains des excellents services proposés par Framasoft.
Lorsque j’ai retrouvé la bande dessinée de McCloud quelque temps après les révélations de Snowden, j’ai soudain réalisé qu’il s’agissait d’un véritable trésor, il ne manquait que quelques pages…
Qu’est-ce qui t’a motivée, à partir de ce moment ?
L’indignation, principalement, et le besoin de faire quelque chose contre un statu quo scandaleux. Il y a un décalage tellement affreux entre la société que nous nous efforçons d’être, fondée sur des valeurs et les droits de l’homme, et les énormes structures d’entreprises barbares comme Google, qui récoltent agressivement des masses gigantesques de données personnelles sans jamais se soucier d’obtenir le consentement éclairé de l’utilisateur, sans aucune conscience de leurs responsabilités sur les retombées individuelles ou sociétales, et sans aucun égard pour les conséquences que cela a sur le processus démocratique lui-même.
En lisant Shoshana Zuboff, j’ai vu comment ce viol massif de données touche à la racine de la liberté personnelle de chacun de se forger sa propre opinion politique, et comment il renforce ainsi les régimes et les modes de pensée autoritaires.
Trop de gens n’ont aucune idée de ce qui est activé en continu 24 heures sur 24 au sein de leur propre maisons intelligente et sur les téléphones de leurs enfants, et je voulais contribuer à changer ça.
Certains aspects de la surveillance via le navigateur Chrome sont faciles à deviner, cependant ta BD va plus en profondeur et révèle la chronologie qui va des promesses rassurantes du lancement à la situation actuelle qui les trahit. Est-ce que tu as bénéficié d’aide de la part de la communauté des défenseurs de la vie privée sur certains aspects ou bien as-tu mené seule ton enquête ?
Comme on peut le voir dans les nombreuses annotations à la fin de la bande dessinée, il s’agit d’un énorme effort collectif. En fin de compte, je n’ai fait que rassembler et organiser les conclusions de tous ces militants, chercheurs et journalistes. J’ai également rencontré certains d’entre eux en personne, notamment des experts reconnus qui ont mené des recherches universitaires sur Google pendant de nombreuses années. Je leur suis très reconnaissante du temps qu’ils ont consacré à ma bande dessinée, qui n’aurait jamais existé sans cette communauté dynamique.
Pourquoi avoir choisi un « remix » ou plutôt un détournement de la BD promotionnelle, plutôt que de créer une bande dessinée personnelle avec les mêmes objectifs ?
En relisant la BD pro-Google de McCloud, j’ai constaté que, comme dans toute bonne bande dessinée, les images et le texte ne racontaient pas exactement la même histoire. Alors que le texte vantait les fonctionnalités du navigateur comme un bonimenteur sur le marché, certaines images me murmuraient à l’oreille qu’il existait un monde derrière la fenêtre du navigateur, où le contenu du cerveau des utilisateurs était transféré dans d’immenses nuages, leur comportement analysé par des rouages inquiétants tandis que des étrangers les observaient à travers un miroir sans tain.
Pour rendre ces murmures plus audibles, il me suffisait de réarranger certaines cases et bulles, un peu comme un puzzle à pièces mobiles. Lorsque les éléments se sont finalement mis en place un jour, ils se sont mis à parler d’une voix très claire et concise, et ont révélé beaucoup plus de choses sur Chrome que l’original.
Lawrence Lessig a expliqué un jour que, tout comme les essais critiques commentent les textes qu’ils citent, les œuvres de remixage commentent le matériel qu’elles utilisent. Dans mon cas, la BD originale de Chrome expliquait prétendument le fonctionnement de Chrome, et j’ai transformé ce matériel en une BD qui rend compte de son véritable fonctionnement.
Est-ce que tu as enregistré des réactions du côté de l’équipe de développement de Chrome ? Ou du côté de Scott Mc Cloud, l’auteur de la BD originale ?
Non, c’est le silence radio. Du côté de l’entreprise, il semble qu’il y ait eu quelques opérations de nettoyage à la Voldemort : Des employés de Google sur Reddit et Twitter, se sont conseillé mutuellement de ne pas créer de liens vers le site, de ne pas y réagir dans les fils de discussion publics, exigeant même parfois que les tweets contenant des images soient retirés.
Quant à Scott, rien non plus jusqu’à présent, et j’ai la même curiosité que vous.
Ton travail a suscité beaucoup d’intérêt dans diverses communautés, de sorte que les traductions plusieurs langues sont maintenant disponibles (anglais, allemand, français et d’autres à venir…). Tu t’attendais à un tel succès ?
Absolument pas. Le jour où je l’ai mis en ligne, il n’y a eu aucune réaction de qui que ce soit, et je me souviens avoir pensé : « bah, tu t’attendais à quoi d’autre, de toutes façons ? ». Je n’aurais jamais imaginé le raz-de-marée qui a suivi. Tant de personnes proposant des traductions, qui s’organisaient, tissaient des liens. Et tous ces messages de remerciement et de soutien, certaines personnes discutent de ma BD dans les écoles et les universités, d’autres l’impriment et la placent dans des espaces publics. Ça fait vraiment plaisir de voir tout ça.
Il y a une sorte de réconfort étrange dans le fait que tant d’êtres humains différents, de tous horizons et de tous les coins de la planète, partagent ma tristesse et mon horreur face au système du capitalisme de surveillance. Cette tristesse collective ne devrait pas me rendre heureuse, et pourtant elle me donne le courage de penser à un avenir très différent.
Quel navigateur utilises-tu au lieu de Chrome ? Lequel recommanderais-tu aux webnautes soucieux de préserver leur vie privée ?
Je suis peut-être allée un peu loin désormais, mais je pratique ce que je prêche dans la BD : pour 95 % de ma navigation, j’utilise simplement le navigateur Tor. Et lorsque Tor est bloqué ou lorsqu’une page ne fonctionne pas correctement, j’utilise Firefox avec quelques modifications et extensions pour améliorer la confidentialité.
Donc généralement, que je cherche des recettes de muffins, que je vérifie la météo ou que je lise les nouvelles, c’est toujours avec Tor. Parce que j’ai l’impression que le navigateur Tor ne peut prendre toute sa valeur que si suffisamment de personnes l’utilisent en même temps, pour qu’un brouillard suffisamment grand de non-sens triviaux entoure et protège les personnes vulnérables dont la sécurité dépend actuellement de son utilisation.
Pour moi, c’est donc une sorte de devoir civique en tant que citoyenne de la Terre. De plus, je peux parcourir mes recettes de muffins en ayant la certitude qu’il ne s’agit que d’un navigateur et non d’un miroir sans tain.
Merci Leah et à bientôt peut-être !
Cliquez sur l’image ci-dessous pour accéder à la version française de Contra chrome
De la bureau-cratie à la tout-doux-cratie : refonder la gouvernance associative
Une asso qui se lance, comment ça marche ? Ou plutôt quels écueils ça rencontre, comment on peut les contourner, quel mode de gouvernance installer… ? Ces questions et bien d’autres qui agitent ses membres jusqu’à les rendre perplexes, Quentin et ses complices les ont affrontées au sein de l’association Picasoft…
Faut-il préciser que chez Framasoft, asso déjà plus ancienne, ces questions et leurs réponses nous ont tout de suite « parlé », car d’une saison à l’autre ce sont bien les mêmes perplexités que nous avons rencontrés et retrouvons encore périodiquement sans avoir beaucoup plus de certitudes malgré les années…
C’est donc avec beaucoup de plaisir et d’intérêt que nous avons lu l’analyse très fine et teintée d’humour que propose Quentin et que nous vous partageons, tant il nous semble que beaucoup de membres d’associations diverses (et pas seulement les CHATONS) pourraient en tirer profit, du moins une saine réflexion.
Ce billet raconte une histoire : l’histoire d’un hébergeur associatif étudiant et universitaire face à ses dilemmes internes. Un chaton au bord de la crise de nerfs. Mieux sécuriser les données des utilisateur·ices au prix d’un flicage des bénévoles ? Militer pour des thèmes qui ne parlent pas à tout le monde ou rester consensuel ?
En fait, c’est l’histoire de dilemmes qui se transforment en crise. Je vous propose de me suivre dans cette enquête pour comprendre ce qui n’a pas fonctionné, et comment on a réagi. On y réalisera notamment que cette histoire est terriblement banale et que le ver était dans le fruit depuis le début. Toute organisation, tôt ou tard, doit regarder ses tensions dans les yeux sous peine d’imploser, et il y a fort à parier que certains machins résonneront avec vos propres histoires.
Rappelons d’abord qu’il n’y a pas de méthode optimale pour résoudre des conflits, ou plus généralement, pour décider de la bonne chose à faire – en premier lieu parce que tout le monde a ses propres besoins et ses propres valeurs et qu’il est rare de pouvoir les satisfaire simultanément et pleinement. Tout processus de décision porte en lui-même des arbitrages. Il peut favoriser la fluidité au détriment du consensus. Il peut préférer la lenteur à l’urgence. Il peut chercher à maximiser la satisfaction globale quitte à autoriser une insatisfaction marginale très forte. En bref, un processus de décision n’est jamais neutre.
Et pourtant, on verra qu’il est indispensable de choisir explicitement un processus de décision, sous peine de laisser les rapports de domination se reproduire subrepticement. Le nôtre, c’est la tout-doux-cratie, qui occupera la suite de ce billet. Nous l’avons écrit avec l’espoir qu’il essaimera et fera fleurir des idées fécondes, pour nos ami·es CHATONS mais pas seulement ; vers toutes les structures qui, un jour, se retrouveront face à des dilemmes explosifs. Bonne lecture! ☺️
J’oubliais… évidemment, ce système n’est pas parfait, alors après la théorie, il sera utile de regarder la pratique. Deux ans de tout-doux-cratie plus tard, je vous proposerai un retour d’expérience, quelques cas pratiques et un essai d’auto-critique. Mais ça… ce sera pour un autre billet. 😉
Qui sont-ils ? Quel est leur projet ?
Nous, je, on, c’est Picasoft. Je vous propose un peu de contexte pour se mettre dans le bain. Picasoft est une association étudiante créée en 2016 à l’Université de Technologie de Compiègne (UTC). Elle est membre du collectif CHATONS.
Le logo de Picasoft fait référence au collectif CHATONS et à la décentralisation du web, deux thèmes largement repris des campagnes de Framasoft.
Le nombre de membres est plutôt stable dans le temps : entre cinq et dix membres actifs, entre vingt et trente enthousiastes prêt·es à donner un coup de main. Ses bénévoles sont étudiant·es ou enseignant·es chercheur·ses.
Quant à notre projet…
L’Association Picasoft a pour objet de promouvoir et défendre une approche libriste inclusive, respectueuse de la vie privée, respectueuse de la liberté d’expression, respectueuse de la solidarité entre les humains et respectueuse de l’environnement, notamment dans le domaine de l’informatique.
C’est un extrait de nos statuts. Vous l’aurez compris, la voie est libre. Plus concrètement, Picasoft s’est engagée dans trois voies :
Héberger des services web libres et respectueux de la vie privée ;
Sensibiliser les citoyenn·es aux enjeux autour du numérique ;
Former les étudiant·es ingénieur·es à des façons de faire (auto-hébergement, hébergement à petite échelle…) peu ou pas traitées en cours.
Un chamboule-tout avec des services propriétaires à renverser, et des gâteaux sous licence libre. Voyez comme chez Picasoft, on sait s’amuser. N’hésitez pas à nous inviter pour mettre l’ambiance à tous vos événements.
Par ailleurs, Picasoft s’inscrit dans un écosystème particulier, qui est important pour la suite ; je vous prie donc de me pardonner ces précisions administratives. L’UTC compte plus d’une centaine d’associations étudiantes, fédérées de manière très verticale jusqu’au Bureau Des Étudiants (BDE), un organe essentiellement administratif.
Lors de sa création, Picasoft fait le choix de se constituer en association loi 1901, pour s’assurer une relative indépendance par rapport au BDE. En effet, les autres associations, des genres de « projets » du BDE, n’ont pas d’existence légale propre ni de compte en banque. Pour autant, le couplage entre Picasoft et l’UTC reste très fort, notamment à travers le soutien fort du laboratoire de sciences humaines et sociales, Costech.
Et qui dit association loi 1901 dit statuts.
Les statuts sont l’acte fondateur d’une association [qui comporte] les informations décrivant l’objet (ou le but) de l’association et ses règles de fonctionnement.1
Ça ne rigole pas, des règles de fonctionnement. Finie l’insouciance, fini de se rouler dans l’herbe pieds nus en jouant du djembé : il faut rédiger des statuts et les envoyer à la préfecture (bruit de tonnerre).
Alors l’équipe de l’époque s’attelle à la tâche. L’idée est moins de contrôler ses membres que de faciliter les roulements dans l’association en lui donnant un cadre. En effet, l’UTC fonctionne sur un rythme semestriel. Tous les semestres, des étudiant·es partent en stage ou à l’étranger : il faut sans cesse renouveler les membres, transmettre les savoir-faire technique, financier et administratif, s’assurer d’un service minimum… En bref, faire de Picasoft un chaton étudiant durable et compostable.
Alors, on signe où et quoi ?
Vieux pots et (dé)confiture
Les premiers statuts de Picasoft sont calqués sur ceux de Rhizome, le Fournisseur d’Accès à Internet étudiant de l’UTC. Et pour cause, c’est Kyâne, un ancien membre de Rhizome, qui a aidé à lancer l’aventure Picasoft.
Expérimenté plusieurs années chez Rhizome, c’est un modèle très classique qui a « fait ses preuves ». Examinons-en quelques concepts-clés. D’abord, les décisions sont prises par un sous-ensemble des membres.
L’Association est dirigée par un Bureau d’au moins trois membres. […] Toute prise de décision relevant du Bureau est soumise au vote. Ce vote a lieu lors d’une réunion où doivent être présents au minimum deux-tiers des membres du Bureau. La décision est adoptée à la majorité absolue des membres du Bureau.
Les membres doivent adhérer à l’association (chez Rhizome, c’est 1€ symbolique).
Est membre de l’Association toute personne à jour de la cotisation fixée dans le Règlement Intérieur.
Le bureau est renouvelé régulièrement…
L’Assemblée Générale Ordinaire se réunit obligatoirement au moins une fois par semestre. […] Il est aussi procédé à l’élection des membres du Bureau.
…et doit rendre des comptes.
Lors de cette réunion dite « semestrielle », le Président soumet à l’Assemblée Générale un rapport sur l’activité de l’Association. Le Trésorier soumet le rapport financier comportant les comptes de l’exercice écoulé.
L’intention de ces statuts est de déléguer aux membres de l’association à un bureau élu lors des Assemblées Générales (AG). En pratique, le bureau assure la gestion quotidienne, sous mandat de l’AG. Notamment, s’il est en rupture avec les autres membres, il peut être dissous par les membres.
Alors, à parler de bureau, d’AG et de préfecture, le suspense monte inévitablement. Je vous devine derrière l’écran, les yeux pétillants, à vous demander : mais quand est-ce-qu’on arrive ? qu’est-ce-qui a mal tourné alors que tout semblait si bien parti ?
Eh bien pour le savoir, il faut examiner dans le détail les cruels dilemmes qui ont déchiré l’association (le lecteur découvrira plus tard que j’en fais trop, mais j’espère pour l’heure avoir retenu son attention).
Picasoft, « respectueux de la vie privée » ?
À la fin de l’année 2017, nos services connaissent leur première hausse de fréquentation. 1000 utilisateur·ices sur Mattermost, 500 pads créés… C’est modeste, mais c’est aussi l’occasion de se poser une question : quelles sont les garanties que les utilisateur·ices sont en droit d’attendre ? Il y a en effet une tension entre la présentation de nos services et nos Conditions Générales d’Utilisation.
D’un côté, on pourrait tendre l’oreille sur un stand Picasoft et glaner un bout de conversation :
L’idée, c’est de proposer une alternative locale, pour les services collaboratifs mais pas que. Tes données restent à toi, on ne les regarde pas, on ne les vend pas, elles restent sur nos serveurs et personne n’y touche! 😙 — un·e sympathisant·e de Picasoft
De l’autre, nos CGU sont plus prudentes :
Picasoft fera tout son possible pour que vos données personnelles ne puissent être consultées par personne d’autre que vous et votre destinataire le cas échéant. […] On n’est pas obligé de réparer. Picasoft propose ce service gratuitement et librement. Si vous perdez des données, par votre faute ou par la nôtre, désolé, mais ça arrive. — nos sympathiques CGU
Cette prudence est naturelle : personne n’a envie d’engager la responsabilité juridique de Picasoft parce que quelqu’un a perdu son pad. Le message est clair : on fait de notre mieux. Mais est-ce vraiment cette version que les utilisateur·ices ont en tête ? Car mécaniquement, plus le public s’agrandit, plus le lien humain avec l’association est ténu. Et, aux convaincu·es du début, s’ajoutent deux types de personnes : les convaincu·es par un·e convaincu·e et les obligé·es par un·e convaincu·e. Avec un public encore élargi, on peut y ajouter les personnes qui découvrent les services par hasard.
Le public de Picasoft s’élargit petit à petit… vers des publics différents.
Dans tous les cas, ces personnes n’ont généralement pas lu nos CGU ni échangé avec nous. Les convaincu·es attendent a minima que leur vie privée soit effectivement respectée tandis que les autres attendent que leurs données soient accessibles et intègres. Cette pseudo-catégorisation est bien entendu très réductrice ; on y oublie par exemple les personnes qui ont conscience de l’aspect artisanal des petites structures comme Picasoft. Ces dernières savent que la disponibilité permanente nécessite un fort investissement et se fait parfois au prix d’une infrastructure technique complexe, coûteuse et énergivore. Par ce prisme, il semble raisonnable que les services soient parfois indisponibles. Mais l’image marketing du Cloud, partout-tout-le-temps-pour-toujours, invisibilise la difficulté et les moyens à déployer pour obtenir ces garanties.
Alors, pour beaucoup, un service Picasoft c’est au pire un énième service, au mieux un service qui lui, respecte la confidentialité. La confidentialité est un des éléments du triptyque de la sécurité informatique : confidentialité (ma vie privée est respectée), intégrité (mes données ne sont pas perdues) et disponibilité (mes données sont accessibles). Ces attributs sont généralement pris comme des présupposés. Alors, quelle posture adopter ? Il est délicat de se cacher derrière nos CGU, car nous ne voulons pas ternir l’image du libre et des CHATONS, mais nous ne voulons pas non plus jouer le jeu des « Cloud » commerciaux2.
Nous souhaitons véritablement faire de notre mieux pour la sécurité. Et en matière de sécurité, les déclarations d’intention ne suffisent pas. Les risques sont nombreux et concrets : clés d’accès aux machines perdues dans la nature, failles de sécurité non corrigées et exploitées par un·e attaquant·e, curiosité mal placée d’un·e membre… Au boulot : un des processus de base pour améliorer la sécurité d’une infrastructure est de réduire la surface d’attaque, c’est-à-dire la réunion des points d’entrée par lesquels une attaque est susceptible de se produire. Intuitivement, plus il y a de logiciels installés sur les serveurs et plus il y a de personnes qui y ont accès, plus la surface d’attaque augmente.
Cette question cruciale est débattue pendant l’AG extraordinaire de l’été 2018, a fortiori car à cette époque, personne n’est véritablement en maîtrise des accès à l’infrastructure. Ils sont donnés de la main à la main, sans trace nette, et ne sont jamais révoqués, même pas après que le départ des membres. L’idée que cette situation est problématique fait consensus. Parmi les options pour y remédier, la désignation d’une personne qui centralise la gestion des accès à l’infrastructure. C’est la solution retenue et de nouveaux statuts sont rédigés dans ce sens.
Le Responsable technique est responsable de la gestion de l’équipe technique et des accès à l’infrastructure de Picasoft. C’est la personne qui est apte à donner ou retirer les accès aux différents bénévoles de l’équipe technique. De plus le Responsable technique s’assure que l’infrastructure de Picasoft est correctement maintenue dans le temps.
C’est à ce moment de l’histoire que la péripétie principale entre en piste (bruits de roulement de tambour).
Une mayonnaise qui ne prend pas
On a testé pour vous : mélanger bureaucratie sécuritaire et fluidité artisanale, puis secouer très fort. Eh bien, ne refaites pas ça chez vous : ça explose. Prenons un peu de recul et mettons-nous en quête du ver dans la pomme.
État de Picasoft après un semestre de nouveaux statuts : allégorie. Crédit photo : SDIS du Bas-Rhin
D’un côté, le rôle de responsable technique est très inconfortable. Mettez-vous en condition : vous êtes seul·e responsable de la distribution des accès. Grand pouvoir, grandes responsabilités, tout ça. Une seule erreur de votre part et l’image publique de Picasoft part en lambeaux, la confiance avec. Une mise à jour de sécurité oubliée, un compte de bénévole piraté, une machine et ses données inondées : vous êtes techniquement responsable. Votre obsession devient dès lors la réduction systématique de la surface d’attaque de l’infrastructure. Pour autant, trancher entre « avoir accès » et « ne pas avoir accès » est trop binaire ; un membre pourrait avoir des droits d’édition sur la documentation sans pouvoir supprimer la base de données de Mattermost. Vous appliquez naturellement le très classique principe de moindre privilège (principle of least privilege en anglais). Chacun·e ne doit pouvoir faire que ce dont iel a strictement besoin, et pas plus. Autrement dit, la compromission des accès d’un·e membre ou ses maladresses ont un impact limité à ses privilèges — un compte de wiki ne pourra jamais supprimer les données de Mattermost. La question épineuse, en tant que responsable technique, est de définir les contours du besoin de chaque membre. Bien entendu, vous pourriez faire confiance et considérer que chacun·e demande les accès dont il a besoin. Mais c’est vous qui portez cette lourde responsabilité ; c’est vous qui connaissez les risques. Alors à défaut de sombrer dans la folie, vous préparez des procédures standardisées et un examen minutieux des demandes d’accès. Pas de sécurité sans ordre.
Maintenant, changement de costume. Vous êtes membre de Picasoft, enthousiaste et plein·e de vie. Vous aimez son fonctionnement artisanal et les projets spontanés qui en émergent. Pour vous, pas de doute : on se forme en faisant, et surtout en faisant des erreurs. C’est d’ailleurs aussi pour vous former que vous avez rejoint le navire. Alors, vous faites de votre mieux. Parfois vous cassez quelque chose, vous pleurez en vous demandant pourquoi vous n’avez pas choisi le maraîchage, puis, après vous être fait une raison, vous réparez du mieux que vous pouvez. Vous en sortez grandi. D’ailleurs, ces temps-ci, personne ne s’occupe de la maintenance des services — il faut dire que c’est un peu rébarbatif. Pas facile de se motiver. Mais aujourd’hui, après votre meilleur chocolat chaud, vous vous sentez en pleine forme. Time to upgrade. Vous enfilez votre plus beau hoodie, et quand vient minuit, vous vous lancez. Sur l’écran, les commandes se succèdent au rythme effréné de vos frappes. Les tests sont impeccables, la conclusion implacable : plus qu’à mettre en production et aller vous coucher. Mais au moment de lancer la dernière commande, un message s’affiche : permission denied. Accès refusé. Incrédule, vous essayez à nouveau, comme on tente d’ouvrir une porte qu’on sait fermement verrouillée. Il faut vous rendre à l’évidence, impossible de faire quoi que ce soit : on ne négocie pas plus avec les ordinateurs qu’avec les portes. Frustré·e, votre motivation tombe à plat. Vous rallumez la lumière et vous partagez votre malheureuse aventure au reste de l’équipe technique, avant d’aller vous rouler en boule sous votre couette.
Le lendemain matin, la réponse manque de vous faire tomber de votre chaise : ce refus n’est pas une erreur, bien au contraire : vous n’aviez pas besoin a priori de ces accès. Question de surface d’attaque. Si vous avez pour projet de faire la maintenance des services, pas de soucis : prévenez un peu avant et on vous donnera les accès nécessaires. Question de sécurité. Vous ne voudriez pas mettre à mal la confiance des gens, n’est-ce-pas ? Et puis c’est quand même pas grand-chose, de demander des accès. On ne vous interdit rien, on fait juste de la prévention. Pas de quoi en faire un plat.
Dernier tour de veste : vous êtes franchement arrivé·e dans l’équipe technique, et motivé·e comme jamais pour monter un nouveau service. On s’y met ? Eh ien, j’espère que vous avez du temps devant vous. Car avec le raisonnement qui précède, chaque étape (test, partage, déploiement, gestion des sauvegardes, communication…) nécessite des accès différents, et autant de potentielles discussions et argumentations sur votre légitimité à briguer ces accès. Légitimité dont l’appréciation revient en dernière instance au/à la responsable technique.
J’espère que cette mise en situation, quoique caricaturale, donne une bonne intuition des tensions qui macèrent pendant cette année. D’un côté, une responsabilité forte et mal définie qui repose sur une seule personne ; de l’autre, des membres de bonne volonté qui perdent leur autonomie et dont les actions sont sous contrôle.
Libre ou open source ?
À l’été 2019, le semestre se clôt par une assemblée générale électrique. Les tensions accumulées appellent un changement radical, c’est-à-dire un changement qui prend le problème à la racine. Or ces tensions ne sont que des manifestations d’un problème plus fondamental. La boîte de Pandore est ouverte.
Le procès verbal de l’AG donne quelques exemples de dissensus qui agitent les membres :
— Picasoft peut-elle être militante ou politique ?
— Picasoft doit-elle se positionner sur des questions éthiques, par exemple pour le choix d’une banque ?
— Qui doit décider de l’attribution des accès à l’infrastructure ? Faut-il privilégier la sécurité ou l’ouverture ?
— La monnaie libre rentre-t-elle dans les prérogatives de l’association ?
Passer à une banque plus dosée en éthique et payer plus cher, donc avoir moins d’argent pour agir, ou rester clients d’une banque bon marché, mais qui finance des projets écocides ? Organiser des événements autour de la monnaie libre, dont l’écosystème est très libriste-compatible, mais qui assume une critique radicale du système économique ?
En sous-texte de toutes ces questions, on retrouve en réalité la question à cent balles : une association d’informatique libre a-t-elle vocation à se positionner politiquement et idéologiquement ? Cette question fera peut-être tiquer certain·es d’entre vous, car elle est mal posée : elle suppose qu’il soit possible d’agir apolitiquement. Or, dans les exemples précédents, ne pas se positionner signifie en réalité adhérer au système dominant. Ne pas choisir une banque qui refuse de soutenir des projets écocides quand on en a les moyens, c’est adhérer, même mollement, à la ruine écologique. Par cette affirmation, je ne cherche à culpabiliser personne. Mais surtout en tant qu’association, c’est-à-dire en tant que personne morale, il est important de réaliser ce que veut vraiment dire rester apolitique. Ce qui ne veut pas dire que c’est une posture indéfendable.
À gauche, on lit « Proposition : je suis apolitique. » À droite, on lit : « Traduction : je suis privilégié et ne suis pas affecté par les politiques actuelles, j’en suis même peut-être bénéficiaire ».
Dans notre milieu, cette question prend la forme de la vieille dispute open source versus libre. Ce débat est resté relativement confidentiel, bien que la mainmise d’Amazon, Google ou Microsoft sur des outils open-source contribue à amplifier les voix qui s’élèvent contre l’open source. Je vous en propose un résumé à la hache. Open source et libre partagent les mêmes libertés fondamentales, exprimées par des licences qui ont valeur de contrat. Ces quatre libertés ne sont plus à présenter : droit d’utiliser, d’étudier, de modifier et de redistribuer.
Les tenants de l’open source s’intéressent particulièrement à la sécurité et à la performance : par exemple, l’ouverture du code d’un logiciel au plus grand nombre permet de détecter les failles plus rapidement. Aussi, les efforts des développeur·ses pourront se concentrer en un seul point plutôt que d’être gaspillés pour développer dix fois le même logiciel (competitive waste). Dans l’open source, l’accent est mis sur la liberté absolue : on ne vous donne que des droits mais aucun devoir. L’exemple typique est la licence MIT, qui dit en substance : faites ce que vous voulez. Vous pouvez donc faire de l’open source tout en créant un écosystème qui utilise tous les leviers pour rendre vos utilisateurs captifs d’outils qui, par ailleurs, ne sont pas libres3.
En miroir, le mouvement du libre a pour vocation de créer des communs. Un commun ne peut pas être approprié par une personne qui en tirerait du profit sans contrepartie. Cette vision des communs prône l’absolue liberté. L’exemple typique serait alors la licence GPL, qui est contagieuse : si vous utilisez un programme sous licence GPL comme base d’un autre programme, celui-ci devra également être sous licence GPL ou équivalent. De la sorte, vous rendez à la communauté ce qu’elle vous a donné. Cette contrainte ne contredit pas les 4 libertés fondamentales, mais porte en elle une vision marquée de l’intérêt général : il ne saurait être optimisé par une liberté totale, bien au contraire. Pour le dire en peu de mots, le libre est anti-libéral.
Pour clarifier cette affirmation un peu provocatrice, il est intéressant de s’attarder sur Eric S. Raymond, un défenseur emblématique de l’open source. Il est notamment l’auteur de la Cathédrale et le Bazar, un essai populaire qui théorise différents modes de développement de logiciels open source. Dans une réponse à une critique, il clarifie son positionnement idéologique :
In fact, I find the imputation of Marxism deeply and personally offensive as well as untrue. While I have made a point of not gratuitously waving my politics around in my papers, it is no secret in the open-source world that I am a libertarian, a friend of the free market, and implacably hostile to all forms of Marxism and socialism (which I regard as coequal in evil with Nazism).
Ce qui, traduit relativement fidèlement, donne ceci (tenez-vous bien) :
En fait, je trouve l’imputation de marxisme [à cet essai] profondément et personnellement offensante et inexacte. Même si j’ai toujours mis un point d’honneur à ne pas étaler mes convictions politiques dans mes articles [de recherche], ce n’est un secret pour personne dans le monde de l’open source que je suis libertarien favorable au libre marché et implacablement hostile à toutes formes de marxisme et de socialisme (que je considère comme aussi dangereux que le nazisme).
Là encore, l’exemple est caricatural, mais donne une intuition correcte du conflit. La parenthèse étant fermée, il était évident qu’une remise en cause de l’identité profonde de l’association ne pouvait pas être résolue en quelques heures.
L’AG vote alors pour le compromis suivant : le bureau proposé est élu, mais à la condition qu’il organise une journée de réflexion qui devra aboutir à des propositions concrètes pour trancher ces questions. Le bureau signe le mandat, l’AG est close. Les vacances peuvent enfin aérer les esprits.
Haïssez le jeu, pas les joueurs
À l’automne 2019, le premier Picacamp est organisé. Pas du tout inspiré du Framacamp (comme rien n’est inspiré de Framasoft d’ailleurs), une équipe de choc de — tenez-vous bien — quatre bénévoles se réunit à cette occasion.
Quatre, c’est peu. Trop peu pour décider de l’orientation idéologique de Picasoft. Sautons directement à la conclusion de cette journée : le problème n’est pas là. Il est encore plus profond. Décider d’une posture politique ne changera rien, car c’est le mode de gouvernance même de Picasoft qui est en cause.
En d’autres termes, ce qui s’est passé n’est pas un problème de personnes : certes, l’asso aurait pu continuer à rouler quelques semestres avec une bande de potes très complices, mais ses règles de fonctionnement étaient propices à faire émerger ce genre de tensions. Comme le rappelle le mathématicien et vulgarisateur Lê Nguyên Hoang dans son excellente série de vidéos sur la démocratie, il faut haïr le jeu, pas les joueurs.
En d’autres termes, les règles du jeu — ici les statuts — déterminent très majoritairement les comportements des joueurs, sur le long terme et à l’échelle globale. Une intuition de cette idée est que toutes les personnes qui jouent au Monopoly ne sont pas d’affreux·ses capitalistes ; de même, tout·es les responsables techniques ne sont pas d’affreux·ses autoritaires. Pourtant, les règles du jeu les incitent à se comporter comme tel·les.
Mais alors, si mon analyse se tient, pourquoi est-ce-que ce genre de conflits n’est pas arrivé à Rhizome, puisque les statuts de Picasoft sont peu ou prou les mêmes ? J’ai posé cette question à Kyâne — qui a adapté les statuts de Rhizome pour Picasoft. L’explication tient en ce que chez Rhizome, les modalités d’implication sont très différentes. D’un côté, il y a les abonné·es, celleux qui louent un accès à Internet, et qui votent en AG. De l’autre côté, il y a celleux qui font, qui mettent les mains dans le cambouis. Il y a peu de bras : les personnes motivées sont plus que bienvenues. Le format « pouvoir à l’AG et petit bureau qui mène les affaires », dixit Kyâne, fonctionne bien.
Mais chez Picasoft, les utilisateur·ices ne sont pas membres. Les membres, c’est un groupe hétéroclite fait de sympathisant·es, de bonnes volontés qui donnent parfois un coup de main, de motivé·es qui passent leurs nuits à déboguer, de personnes qui aiment aller en conventions, de curieux·ses timides qu’on ne voit jamais. Ce spectre de participation ne peut pas être correctement représenté par un bureau qui fait autorité.
À bien y réfléchir, l’entité même de bureau n’a plus de sens quand on lui ôte la fonction qu’elle avait chez Rhizome. C’est un archétype, un cliché, un spectre qui hante le monde associatif. C’est le modèle auquel nous sommes le plus exposés, des associations aux entreprises cotées en bourse en passant par notre démocratie représentative. Aussi, une recherche de modèle de statuts sur Internet a peu de chances de donner idée d’un autre système. C’est ainsi que la bureau-cratie et ses pièges se reproduisent en infrabasses.
La conclusion est sans appel : la gouvernance de l’association doit être intégralement repensée pour permettre l’inclusion de chaque membre et la répartition des responsabilités.
Les pièges de l’horizontalité
J’espère vous avoir convaincu⋅e, à ce stade, qu’un mode de gouvernance plus horizontal est nécessaire. Mais avec horizontal, on a tout et rien dit. On comprend bien qu’on l’oppose à une gouvernance verticale, hiérarchique, et on y perçoit des velléités d’inclusion et de participation. Mais l’horizontalité est du même genre que la bienveillance, l’inclusion ou l’agilité, à savoir un vernis qui part bien vite sans actes concrets.
Une première approche serait prendre l’idée de bureau à contre-pied et de soumettre l’ensemble des décisions au vote. De la sorte, chaque décision représente l’association dans sa majorité. Le problème évident de cette approche est que toute initiative est bloquante jusqu’à participation des membres. Or tout le monde est toujours occupé ; se tenir au courant des tenants et aboutissants de l’ensemble de la vie d’une association est coûteux ; donner son avis sur tout est encore plus difficile4. De plus, ce système charge les personnes motivées : elles doivent convaincre tou·tes les membres et aller quémander des voix. Ce système produit facilement du découragement et il est hostile aux initiatives originales. Il pousse à un fonctionnement plutôt conservateur.
Une approche orthogonale serait d’instaurer une do-ocratie : en gros, les personnes qui font ont le pouvoir. La do-ocratie est séduisante car les personnes motivées ne sont pas empêchées de faire, mais ne sont pas non plus statutairement tributaires de l’autorité. Il suffit de s’impliquer activement pour avoir son mot à dire. C’est d’ailleurs le mode informel qu’adoptent de nombreuses structures, où « déjà qu’il y a pas beaucoup personne pour faire les trucs chiants, si en plus on les emmerde, y’aura vraiment plus personne ».
Cependant, ce système est problématique à deux égards. D’abord, à y regarder de plus près, c’est virtuellement le même système que celui des premiers statuts. En effet, chez Rhizome, ce sont ceux qui font qui se présentent pour constituer un bureau, à qui l’AG confie la gestion quotidienne. À Picasoft, donc, ce sont généralement les personnes qui s’investissaient le plus à un moment donné qui se retrouvent membres du bureau, et confisquent involontairement le pouvoir aux autres membres.
Mais ce système fait pire encore : il déstructure le mode de gouvernance. Il ne donne aucun moyen de résoudre les conflits entre les doers, i.e. celles et ceux qui s’impliquent. Mais qui fait, et qui ne fait pas ? Où est la limite ? Qui est légitime et aux yeux de qui ? Comment s’assurer que ce n’est pas à celui qui gueule le plus fort ? À bien y regarder, ce système simpliste s’identifie à la caricature classique de l’anarchisme, qui voudrait que la loi du plus fort soit le seul principe qui tienne. C’est au fond l’idée nauséabonde du darwinisme social : briser tout cadre qui pourrait gêner la compétition, dont sortiront vainqueur·es les plus aptes. Si l’on s’en fie à cette idée, toute association sans structure devrait un jour arriver à son fonctionnement optimal. Ça vous rappelle quelque chose ?
Sans transition, l’article de blog du chaton deuxfleurs au sujet de l’autogestion est particulièrement éclairant. Je vais en paraphraser une partie (peut-être mal, alors foncez le lire!). Il s’attarde sur un texte de Jo Freeman, une avocate, politologue et militante féministe américaine. Intitulé « La tyrannie de l’absence de structure », elle le prononce en 1970 devant des militant·es féministes. On peut en trouver une traduction en français sur Infokiosques.
Ce texte s’adresse aux « groupes sans leader ni structure » du Mouvement de Libération des Femmes étatsunien. Jo Freeman remarque que l’absence de structure est « passée du stade de saine contre-tendance à celui d’idée allant de soi ».
Lors de la gestation du mouvement, le caractère détendu et informel qui régissait [le groupe de conscientisation] était propice à la participation aux discussions, et le climat de soutien mutuel qui se créait en général permettait une meilleure expression des visions personnelles. [Des problèmes surgirent lorsque] les petits groupes d’action épuisèrent les vertus de la conscientisation et décidèrent qu’ils voulaient faire quelque chose de plus concret.
Assez de contexte : pourquoi est-ce-que l’absence de structure ne fonctionne pas ? Jo Freeman est claire : parce que l’absence de structure n’existe pas. Nos différences interpersonnelles, nos intentions, la distribution des tâches — qu’elle soit équitable ou injuste — est de fait une structure, au même titre que ne pas se positionner est un positionnement et l’apolitisme n’existe pas. Il est seulement possible de choisir la nature de la structure : formelle ou informelle.
Lorsque la structure est intégralement informelle, deux phénomènes peuvent se produire : la formation d’élites et de stars.
Une élite est un petit groupe de gens qui domine un autre groupe plus grand […], et qui agit fréquemment sans son consentement ou sa connaissance.
Une élite, ce n’est pas une conspiration de méchants de film. Ce peut être ce groupe de bons potes au sein d’un mouvement, qui boit des coups au bar et y discute du mouvement. L’élite échange en son sein plus d’information que n’en reçoit le reste du groupe. Elle peut faire bloc pour pousser telle ou telle orientation, dans des discussions déséquilibrées d’avance. C’est moins par malveillance que par contingence que les élites se forment : leur activité politique et leur amitié coïncident. C’est aussi ce qui rend difficile leur dissolution, car l’élite ne commet pas de faute fondamentale. Elle s’entretient par affinité, et comme gagner la confiance de l’élite existante est difficile et nécessite d’intégrer ses codes, elle est sujette à une certaine homogamie.
Quant aux stars, ce sont des personnes qui sont mises en avant au sein du groupe, voire qui le représente dans l’inconscient collectif. Mais au sens de Freeman, elle n’ont pas été désignées explicitement. Une personne charismatique qui s’exprime bien prendra souvent plus de place. En plus de favoriser les normes dominantes, le « statut » de star n’est pas révocable dans la mesure où il n’a été attribué par personne. La star, comme l’élite, est rarement consciente de son statut. Les critiques légitimes qu’elle reçoit peuvent être vécues violemment et la conduire à quitter le groupe, et par là même, le fragiliser.
Pour lutter contre l’émergence d’élites et de stars, Jo Freeman propose 7 principes pour formaliser la structure d’un mouvement de sorte à faire émerger une horizontalité inclusive et politiquement efficace :
Assigner démocratiquement des tâches précises à des personnes concrètes, qui ont préférablement manifesté leur intérêt.
Assurer que toute personne qui exerce une autorité le fasse sous le contrôle du groupe.
Distribuer l’autorité au plus grand nombre de personnes raisonnablement possible.
Faire tourner les postes ; pas trop souvent (pour avoir le temps d’apprendre), pas trop peu (pour ne pas créer d’élite).
Rationaliser les critères d’assignation des tâches, par compétence plutôt que par sympathie.
Diffuser l’information au plus grand nombre, le plus possible. L’information, c’est le pouvoir.
Rendre accessibles les ressources de manière équitable (un local, du matériel, des identifiants…)
Ce billet tirant déjà en longueur, je vous laisse vous convaincre de la pertinence des propositions, et à la lumière de cette analyse, je vous propose de passer à l’examen de la tout-doux-cratie. 😙
Bienvenue en tout-doux-cratie
La tout-doux-cratie est le mode de gouvernance qui émerge pendant le Picacamp. Il est forgé selon trois principes :
Faire et laisser faire (permettre à Picasoft d’être un lieu où chacun·e peut agir) ;
Se préoccuper des opinions des autres membres (partager l’information, s’informer)
Rechercher le consensus (accepter les compromis, être amical·e et favoriser la vie ensemble).
Tout système de gouvernance s’ancre sur des partis pris adaptés au contexte dans lequel il se déploie. Pour Picasoft, on l’a vu, il y a un véritable enjeu à faciliter l’action des personnes motivées sans écraser les autres ; c’est pourquoi le nom dénote la fluidité (to-do) et le soin (tout-doux). L’intention du système de règles lui-même est d’être suffisamment simple pour être intégré rapidement (fluidité) mais suffisamment robuste pour être mis à l’épreuve dans les cas difficiles (soin).
Voyons très concrètement comment ça se passe5. Tout membre peut engager des actions, séparées en deux catégories.
Une action ordinaire ressemble aux actions habituelles menées dans le cadre de l’Association. Le règlement intérieur contient une tout-doux-liste qui aide à déterminer si une action est ordinaire.
Une action extraordinaire n’est pas habituelle dans le cadre et l’historique de l’Association, en particulier lorsqu’elle n’est pas réversible.
Certaines actions (modification du règlement intérieur, exclusion d’un membre, dissolution de l’association…) sont statutairement extraordinaires. En cas de doute ou de cas limite, l’action extraordinaire est préférée. Le mode de décision collectif diffère en fonction de l’action.
Une action ordinaire peut être lancée sans accord préalable, à partir du moment où la personne informe les membres de l’association de son action. Tout membre a la possibilité de suspendre l’action en posant un verrou non-bloquant : il lui faut alors convaincre une majorité des membres que l’action doit être annulée. S’il n’y parvient pas, l’action est maintenue.
Une action extraordinaire est associée à un verrou bloquant par défaut : l’action peut être réalisée uniquement si une majorité de membres y sont favorables, ou si dix jours se sont écoulés sans qu’une majorité des membres n’y soient défavorables.
Voici un petit résumé graphique pour tenter de rendre le processus plus tangible.
Action extraordinaire : peut se mener en cas de consensus **ou** d’absence de dissensus fort à l’issue d’un délai.
Action ordinaire : laisser faire a priori, pouvoir revenir dessus a posteriori.
Si ce fonctionnement peut paraître alambiqué, il provient du raisonnement suivant :
L’horizontalité par consensus à majorité absolue ne fonctionne pas ;
Le « laisser-faire sauf en cas de véto » donne un pouvoir disproportionné à chaque membre, en tant qu’il peut empêcher l’action d’un autre membre seul et pour de mauvaises raisons (détruire est plus facile que construire) ;
La charge doit alors peser sur la personne qui est contre ; elle devra prouver que l’action doit être annulée en sollicitant un rejet collectif. Si elle n’y parvient pas, alors l’action est légitime à être menée.
Ce raisonnement a des accents conflictuels qui semblent bien loin du tout-doux. C’est pourquoi la tout-doux-cratie n’utilise pas ce mécanisme en fonctionnement nominal. En première instance, la recherche du consensus et la discussion sont les modes d’interaction privilégiés. Le vote agit généralement comme une chambre d’enregistrement. En d’autres termes, un membre qui a connaissance d’un dissensus devrait d’abord informer et, le cas échéant, chercher le compromis avant de lancer une action ordinaire ou extraordinaire. Si le dissensus persiste, le vote permettra de rendre compte de l’opinion générale des membres, tout en préservant la personne agissante d’une trop grande charge mentale.
De ce fonctionnement découle naturellement l’abolition du bureau. L’association ayant toujours besoin de personnes pour la représenter (juridiquement, économiquement…), trois personnes sont élues chaque semestre pour constituer un genre de spectre de bureau :
Un·e représentant·e administratif, qui doit lever la main quand quelqu’un demande le·la président·e et qui signe tous les documents administratifs concernant Picasoft ;
Un·e représentant·e financie·re, qui effectue les opérations bancaires ;
Un·e représentant·e technique, qui distribue les accès aux machines.
Chaque représentant·e est la seule personne en capacité de réaliser ces actions ou de les déléguer. En revanche, la différence majeure avec l’ancien bureau est que les représentant·es n’ont aucun pouvoir décisionnaire ; iels exécutent simplement les décisions de l’association.
Dans la mesure où leurs actions peuvent engager leur responsabilité, iels disposent d’un droit de retrait, c’est-à-dire de la possibilité de démissionner sans aucune justification en cas de refus d’exécuter une action. Là aussi, ce droit de retrait correspond à la dernière alternative et n’a en pratique jamais été utilisé.
Enfin, la tout-doux-cratie a été conçue pour fonctionner correctement même en système ouvert, c’est-à-dire que devient membre toute personne qui en fait la demande. Si la plupart des associations fonctionnent par cooptation, Picasoft est une association dont les membres tournent beaucoup et qui a besoin de maintenir ses effectifs. Rendre l’adhésion peu coûteuse en temps et gratuite incite plus facilement à tenter l’expérience. C’est sans danger, car l’arrivée d’un·e nouveau·elle ne peut pas bouleverser l’association du fait du mode de décision : si cette nouvelle personne se trouve en opposition avec le reste des membres, elle ne sera pas en mesure de bloquer les décisions, quel que soit son poste. Enfin, si sa présence est réellement problématique, son exclusion peut être décidée par action extraordinaire.
Être membre implique cependant un nombre minimal d’obligations définies dans les statuts.
Agir conformément à l’objet de l’Association ;
Aider les autres à agir ;
Participer au processus de tout-doux-cratie, c’est-à-dire donner son avis lorsqu’il est demandé, voter, rester informé·e et participer aux AG.
En pratique, seul la dernière obligation est cruciale, capitale, essentielle, indispensable, vitale, critique ; bref, vous l’aurez compris, faut pas passer à côté. Car pour bien fonctionner, la tout-doux-cratie a besoin de l’opinion de ses membres : sans prendre le temps de s’informer, on peut se lancer dans des actions conflictuelles. Sans voter, on allonge le délai de réalisation des actions extraordinaires et on démotive ses auteur·ices. Sans participer aux discussions, on perd le lien et la dynamique qui animent Picasoft.
En définitive, ce sont la circulation horizontale de l’information et la participation active aux décisions qui forment les clés de voûte d’une tout-doux-cratie saine.
Gardez de la place pour le dessert
Nous arrivons tranquillement à la fin du premier chapitre de cette enquête. Vous l’aurez compris, Picasoft fonctionne depuis plus de deux ans en tout-doux-cratie. Ce mode de gouvernance n’a rien de révolutionnaire. Au contraire, il s’appuie sur des idées théorisées depuis plusieurs décennies et qui structurent nombre de collectifs militants, plus ou moins informellement. On lui a donné un nom car on aime bien les jeux de mots mignons, et qu’on peut en parler plus facilement, voilà tout. ✨
Pour autant, si la critique de la bureau-cratie est facile et que j’ai présenté la tout-doux-cratie sous son meilleur jour, à ce stade, il vous manque cruellement de passage à la pratique à vous mettre sous la dent. Et l’occasion, inévitable, de relever les failles de ce système. Mais ça… ce sera pour la seconde et dernière partie de ce billet, par ici : https://framablog.org/2022/10/24/deux-ans-en-tout-doux-cratie-bilan-et-perspectives/ 😄
Un grand merci à Antoine, Audrey, Gaëtan, Jérôme, Stph, R01, Tobias, et tout·es les membres de Picasoft et de Framasoft pour leurs contributions, relecture, corrections et leur accueil bienveillants!
En effet, l’idée qu’il est normal que les services et contenus soit disponibles partout et tout le temps est largement et sciemment véhiculée par l’imaginaire du « Cloud », des nuages. La très haute disponibilité est par ailleurs un sujet de recherche actif. L’idée de diminuer la disponibilité d’un service rencontre des résistances similaires à l’idée de « décroissance », parfois vécue comme une régression. Pourtant, il y a de quoi s’interroger sur la disponibilité totale, mais c’est un autre sujet. Ne pas jouer le jeu du Cloud, c’est donc ne pas se fixer un objectif de disponibilité, mais en restant prudent pour ne pas se marginaliser. ↩︎
Les mécanismes par lesquels l’open-source devient un puissant outil de domination politique et économique sont passionnants, même si largement au-delà du sujet principal de ce billet. Néanmoins, pour les anglophones, cet article récemment paru sur l’éditeur de code open-source Visual Studio Code, développé par Microsoft, est édifiant : https://ghuntley.com/fracture. ↩︎
D’ailleurs, il est vraisemblable qu’avoir un avis sur tout n’est pas souhaitable. Un système qui oblige à prendre chaque décision à la majorité sera soit démesurément inefficace (car lent), soit irréfléchi (car la plupart des votes seront au doigt mouillé). C’est un raccourci que je me permets de faire dans cet espace plus confidentiel des notes de bas de page. On peut légitimement objecter que la lenteur n’est pas un problème en soi, et que des modes de gouvernance l’assument, et même plus, la revendiquent. Voir le cas fascinant des zapatistes : https://hal.archives-ouvertes.fr/hal-02567515/document ↩︎
Bifurquer avant l’impact : l’impasse du capitalisme de surveillance
La chaleur de l’été ne nous fait pas oublier que nous traversons une crise dont les racines sont bien profondes. Pendant que nos forêts crament, que des oligarques jouent aux petits soldats à nos portes, et vu que je n’avais que cela à faire, je lisais quelques auteurs, ceux dont on ne parle que rarement mais qui sont Ô combien indispensables. Tout cela raisonnait si bien que, le temps de digérer un peu à l’ombre, j’ai tissé quelques liens avec mon sujet de prédilection, la surveillance et les ordinateurs. Et puis voilà, paf, le déclic. Dans mes archives, ces mots de Sébastien Broca en 2019 : « inscrire le capitalisme de surveillance dans une histoire plus large ». Mais oui, c’est là dessus qu’il faut insister, bien sûr. On s’y remet.
Je vous livre donc ici quelques réflexions qui, si elles sont encore loin d’être pleinement abouties, permettront peut-être à certains lecteurs d’appréhender les luttes sociales qui nous attendent ces prochains mois. Alimentons, alimentons, on n’est plus à une étincelle près.
— Christophe Masutti
Le capitalisme de surveillance est un mode d’être du capitalisme aujourd’hui dominant l’ensemble des institutions économiques et politiques. Il mobilise toutes les technologies de monitoring social et d’analyse de données dans le but de consolider les intérêts capitalistes à l’encontre des individus qui se voient spoliés de leur vie privée, de leurs droits et du sens de leur travail. L’exemple des entreprises-plateformes comme Uber est une illustration de cette triple spoliation des travailleurs comme des consommateurs. L’hégémonie d’Uber dans ce secteur d’activité s’est imposée, comme tout capitalisme hégémonique, avec la complicité des décideurs politiques. Cette complicité s’explique par la dénégation des contradictions du capitalisme et la contraction des politiques sur des catégories anciennes largement dépassées. Que les décideurs y adhèrent ou non, le discours public reste campé sur une idée de la production de valeur qui n’a plus grand-chose de commun avec la réalité de l’économie sur-financiarisée.
Il est donc important d’analyser le capitalisme de surveillance à travers les critiques du capitalisme et des technologies afin de comprendre, d’une part pourquoi les stratégies hégémoniques des multinationales de l’économie numérique ne sont pas une perversion du capitalisme mais une conséquence logique de la jonction historique entre technologie et finance, et d’autre part que toute régulation cherchant à maintenir le statu quo d’un soi-disant « bon » capitalisme est vouée à l’échec. Reste à explorer comment nous pouvons produire de nouveaux imaginaires économiques et retrouver un rapport aux technologies qui soit émancipateur et générateur de libertés.
Une critique du capitalisme qui s’est déjà bien étoffée au cours de l’histoire.
Situer le capitalisme de surveillance dans une histoire critique du capitalisme
Dans la Monthly Review en 2014, ceux qui forgèrent l’expression capitalisme de surveillance inscrivaient cette dernière dans une critique du capitalisme monopoliste américain depuis la fin de la Seconde Guerre Mondiale. En effet, lorsqu’on le ramène à l’histoire longue, qui ne se réduit pas aux vingt dernières années de développement des plus grandes plateformes numériques mondiales, on constate que le capitalisme de surveillance est issu des trois grands axes de la dynamique capitaliste de la seconde moitié du XXᵉ siècle. Pour John B. Foster et Robert W. McChesney, la surveillance cristallise les intérêts de marché de l’économie qui soutient le complexe militaro-industriel sur le plan géopolitique, la finance, et le marketing de consommation, c’est-à-dire un impérialisme sur le marché extérieur (guerre et actionnariat), ce qui favorise en retour la dynamique du marché intérieur reposant sur le crédit et la consommation. Ce système impérialiste fonctionne sur une logique de connivence avec les entreprises depuis plus de soixante ans et a instauré la surveillance (de l’espionnage de la Guerre Froide à l’apparition de l’activité de courtage de données) comme le nouveau gros bâton du capitalisme.
Plus récemment, dans une interview pour LVSL, E. Morozov ne dit pas autre chose lorsqu’il affirme qu’aujourd’hui l’enjeu des Big Tech aux États-Unis se résume à la concurrence entre les secteurs d’activités technologiques sur le marché intérieur et « la volonté de maintenir le statut hégémonique des États-Unis dans le système financier international ».
Avancées technologiques et choix sociaux
Une autre manière encore de situer le capitalisme de surveillance sur une histoire longue consiste à partir du rôle de l’émergence de la microélectronique (ou ce que j’appelle l’informatisation des organisations) à travers une critique radicale du capitalisme. C’est sur les écrits de Robert Kurz (et les autres membres du groupe Krisis) qu’il faut cette fois se pencher, notamment son travail sur les catégories du capitalisme.
Ici on s’intéresse à la microélectronique en tant que troisième révolution industrielle. Sur ce point, comme je le fais dans mon livre, je préfère maintenir mon approche en parlant de l’informatisation des organisations, car il s’agit surtout de la transformation des processus de production et pas tellement des innovations techniques en tant que telles. Si en effet on se concentre sur ce dernier aspect de la microélectronique, on risque d’induire un rapport mécanique entre l’avancement technique et la transformation capitaliste, alors que ce rapport est d’abord le résultat de choix sociaux plus ou moins imposés par des jeux de pouvoirs (politique, financier, managérial, etc.). Nous y reviendrons : il est important de garder cela en tête car l’objet de la lutte sociale consiste à prendre la main sur ces choix pour toutes les meilleures raisons du monde, à commencer par notre rapport à l’environnement et aux techniques.
Pour expliquer, je vais devoir simplifier à l’extrême la pensée de R. Kurz et faire des raccourcis. Je m’en excuse par avance. R. Kurz s’oppose à l’idée de la cyclicité des crises du capitalisme. Au contraire ce dernier relève d’une dynamique historique, qui va toujours de l’avant, jusqu’à son effondrement. On peut alors considérer que la succession des crises ont été surmontées par le capitalisme en changeant le rapport structurel de la production. Il en va ainsi pour l’industrialisation du XIXᵉ siècle, le fordisme (industrialisation moderne), la sur-industrialisation des années 1930, le marché de consommation des années 1950, ou de la financiarisation de l’économie à partir des années 1970. Pour R. Kurz, ces transformations successives sont en réalité une course en avant vers la contradiction interne du capitalisme, son impossibilité à renouveler indéfiniment ses processus d’accumulation sans compter sur les compensations des pertes de capital, qu’elles soient assurées par les banques centrales qui produisent des liquidités (keynésianisme) ou par le marché financier lui-même remplaçant les banques centrales (le néolibéralisme qui crée toujours plus de dettes). Cette course en avant connaît une limite indépassable, une « borne interne » qui a fini par être franchie, celle du travail abstrait (le travail socialement nécessaire à la production, créant de la valeur d’échange) qui perd peu à peu son sens de critère de valeur marchande.
Cette critique de la valeur peut être vue de deux manières qui se rejoignent. La première est amenée par Roswitha Scholz et repose sur l’idée que la valeur comme rapport social déterminant la logique marchande n’a jamais été critiquée à l’aune tout à fait pratique de la reproduction de la force de travail, à savoir les activités qu’on détermine comme exclusivement féminines (faire le ménage, faire à manger, élever les enfants, etc.) et sont dissociées de la valeur. Or, cette tendance phallocrate du capitalisme (comme de la critique marxiste/socialiste qui n’a jamais voulu l’intégrer) rend cette conception autonome de la valeur complètement illusoire. La seconde approche situe dans l’histoire la fragilité du travail abstrait qui dépend finalement des processus de production. Or, au tournant des années 1970 et 1980, la révolution informatique (la microélectronique) est à l’origine d’une rationalisation pour ainsi dire fulgurante de l’ensemble des processus de production en très peu de temps et de manière mondialisée. Il devient alors plus rentable de rationaliser le travail que de conquérir de nouveaux espaces pour l’accumulation de capital. Le régime d’accumulation atteint sa limite et tout se rabat sur les marchés financiers et le capital fictif. Comme le dit R. Kurz dans Vies et mort du capitalisme1 :
C’est le plus souvent, et non sans raison, la troisième révolution industrielle (la microélectronique) qui est désignée comme la cause profonde de la nouvelle crise mondiale. Pour la première fois dans l’histoire du capitalisme, en effet, les potentiels de rationalisation dépassent les possibilités d’une expansion des marchés.
Non seulement il y a la perte de sens du travail (la rationalisation à des échelles inédites) mais aussi une rupture radicale avec les catégories du capitalisme qui jusque-là reposaient surtout sur la valeur marchande substantiellement liée au travail abstrait (qui lui-même n’intégrait pas de toute façon ses propres conditions de reproduction).
Très voisins, les travaux d’Ernst Lohoff et de Norbert Trenkle questionnent la surfinanciarisation de l’économie dans La grande dévalorisation2. Pour eux, c’est la forme même de la richesse capitaliste qui est en question. Ils en viennent aux mêmes considérations concernant l’informatisation de la société. La troisième révolution industrielle a créé un rétrécissement de la production de valeur. La microélectronique (entendue cette fois en tant que description de dispositifs techniques) a permis l’avancée de beaucoup de produits innovants mais l’innovation dans les processus de production qu’elle a induits a été beaucoup plus forte et attractive, c’est-à-dire beaucoup plus rentable : on a préféré produire avec toujours moins de temps de travail, et ce temps de travail a fini par devenir une variable de rentabilité au lieu d’être une production de valeur.
Si bien qu’on est arrivé à ce qui, selon Marx, est une incompatibilité avec le capitalisme : l’homme finit par se situer en dehors du processus de production. Du moins, il tend à l’être dans nos économies occidentales. Et ce fut pourtant une sorte d’utopie formulée par les capitalistes eux-mêmes dans les années 1960. Alors que les industries commençaient à s’informatiser, le rêve cybernéticien d’une production sans travailleurs était en plein essor. Chez les plus techno-optimistes on s’interrogeait davantage à propos des répercussions de la transformation des processus de production sur l’homme qu’à propos de leur impact sur la dynamique capitaliste. La transformation « cybernétique » des processus de production ne faisait pas vraiment l’objet de discussion tant la technologie était à l’évidence une marche continue vers une nouvelle société. Par exemple, pour un sociologue comme George Simpson3, au « stade 3 » de l’automatisation (lorsque les machines n’ont plus besoin d’intervention humaine directe pour fonctionner et produire), l’homme perd le sens de son travail, bien que libéré de la charge physique, et « le système industriel devient un système à boutons-poussoirs ». Que l’automatisation des processus de production (et aussi des systèmes décisionnels) fasse l’objet d’une critique ou non, ce qui a toujours été questionné, ce sont les répercussions sur l’organisation sociale et le constat que le travail n’a jamais été aussi peu émancipateur alors qu’on en attendait l’inverse4.
La surveillance comme catégorie du capitalisme
Revenons maintenant au capitalisme de surveillance. D’une part, son appellation de capitalisme devient quelque peu discutable puisqu’en effet il n’est pas possible de le désincarner de la dynamique capitaliste elle-même. C’est pour cela qu’il faut préciser qu’il s’agit surtout d’une expression initialement forgée pour les besoins méthodiques de son approche. Par contre, ce que j’ai essayé de souligner sans jamais le dire de cette manière, c’est que la surveillance est devenue une catégorie du capitalisme en tant qu’elle est une tentative de pallier la perte de substance du travail abstrait pour chercher de la valeur marchande dans deux directions :
la rationalisation à l’extrême des processus productifs qu’on voit émerger dans l’économie de plateformes, de l’esclavagisme moderne des travailleurs du clic à l’ubérisation de beaucoup de secteurs productifs de services, voire aussi industriels (on pense à Tesla). Une involution du travail qui en retour se paie sur l’actionnariat tout aussi extrême de ces mêmes plateformes dont les capacités d’investissement réel sont quasi-nulles.
L’autre direction est née du processus même de l’informatisation des organisations dès le début, comme je l’ai montré à propos de l’histoire d’Axciom, à savoir l’extraction et le courtage de données qui pillent littéralement nos vies privées et dissocient cette fois la force de travail elle-même du rapport social qu’elle implique puisque c’est dans nos intimités que la plus-value est recherchée. La financiarisation de ces entreprises est d’autant plus évidente que leurs besoins d’investissement sont quasiment nuls. Quant à leurs innovations (le travail des bases de données) elles sont depuis longtemps éprouvées et reposent aussi sur le modèle de plateforme mentionné ci-dessus.
Mais alors, dans cette configuration, on a plutôt l’impression qu’on ne fait que placer l’homme au centre de la production et non en dehors ou presque en dehors. Il en va ainsi des livreurs d’Uber, du travail à la tâche, des contrats de chantiers adaptés à la Recherche et à l’Enseignement, et surtout, surtout, nous sommes nous-mêmes producteurs des données dont se nourrit abondamment l’industrie numérique.
On comprend que, par exemple, certains ont cru intelligent de tenter de remettre l’homme dans le circuit de production en basant leur raisonnement sur l’idée de la propriété des données personnelles et de la « liberté d’entreprendre ». En réalité la configuration du travail à l’ère des plateformes est le degré zéro de la production de valeur : les données n’ont de valeur qu’une fois travaillées, concaténées, inférées, calculées, recoupées, stockées (dans une base), etc. En soi, même si elles sont échangeables sur un marché, il faut encore les rendre rentables et pour cela il y a de l’Intelligence Artificielle et des travailleurs du clic. Les seconds ne sont que du temps de travail volatile (il produit de la valeur en tant que travail salarié, mais si peu qu’il en devient négligeable au profit de la rationalisation structurelle), tandis que l’IA a pour objectif de démontrer la rentabilité de l’achat d’un jeu de données sur le marché (une sorte de travail mort-vivant5 qu’on incorporerait directement à la marchandisation). Et la boucle est bouclée : cette rentabilité se mesure à l’aune de la rationalisation des processus de production, ce qui génère de l’actionnariat et une tendance au renforcement des monopoles. Pour le reste, afin d’assurer les conditions de permanence du capitalisme (il faut bien des travailleurs pour assurer un minimum de salubrité de la structure, c’est-à-dire maintenir un minimum de production de valeur), deux choses :
on maintient en place quelques industries dont tout le jeu mondialisé consiste à être de plus en plus rationalisées pour coûter moins cher et rapporter plus, ce qui accroît les inégalités et la pauvreté (et plus on est pauvre, plus on est exploité),
on vend du rêve en faisant croire que le marché de produits innovants (concrets) est en soi producteur de valeur (alors que s’accroît la pauvreté) : des voitures Tesla, des services par abonnement, de l’école à distance, un métavers… du vent.
Réguler le capitalisme ne suffit pas
Pour l’individu comme pour les entreprises sous perfusion technologique, l’attrait matériel du capitalisme est tel qu’il est extrêmement difficile de s’en détacher. G. Orwell avait (comme on peut s’y attendre de la part d’un esprit si brillant) déjà remarqué cette indécrottable attraction dans Le Quai de Wigan : l’adoration de la technique et le conformisme polluent toute critique entendable du capitalisme. Tant que le capitalisme maintiendra la double illusion d’une production concrète et d’un travail émancipateur, sans remettre en cause le fait que ce sont bien les produits financiers qui représentent l’essentiel du PIB mondial6, les catégories trop anciennes avec lesquelles nous pensons le capitalisme ne nous permettront pas de franchir le pas d’une critique radicale de ses effets écocides et destructeurs de libertés.
Faudrait-il donc s’en accommoder ? La plus importante mise en perspective critique des mécanismes du capitalisme de surveillance, celle qui a placé son auteure Shoshana Zuboff au-devant de la scène ces trois dernières années, n’a jamais convaincu personne par les solutions qu’elle propose.
Premièrement parce qu’elle circonscrit le capitalisme de surveillance à la mise en œuvre par les GAFAM de solutions de rentabilité actionnariale en allant extraire le minerai de données personnelles afin d’en tirer de la valeur marchande. Le fait est qu’en réalité ce modèle économique de valorisation des données n’est absolument pas nouveau, il est né avec les ordinateurs dont c’est la principale raison d’être (vendables). Par conséquent ces firmes n’ont créé de valeur qu’à la marge de leurs activités principales (le courtage de données), par exemple en fournissant des services dont le Web aurait très bien pu se passer. Sauf peut-être la fonction de moteur de recherche, nonobstant la situation de monopole qu’elle a engendrée au détriment de la concurrence, ce qui n’est que le reflet de l’effet pervers du monopole et de la financiarisation de ces firmes, à savoir tuer la concurrence, s’approprier (financièrement) des entreprises innovantes, et tuer toute dynamique diversifiée d’innovation.
Deuxièmement, les solutions proposées reposent exclusivement sur la régulation des ces monstres capitalistes. On renoue alors avec d’anciennes visions, celles d’un libéralisme garant des équilibres capitalistes, mais cette fois presque exclusivement du côté du droit : c’est mal de priver les individus de leur vie privée, donc il faut plus de régulation dans les pratiques. On n’est pas loin de renouer avec la vieille idée de l’ethos protestant à l’origine du capitalisme moderne selon Max Weber : la recherche de profit est un bien, il s’accomplit par le travail et le don de soi à l’entreprise. La paix de nos âmes ne peut donc avoir lieu sans le capitalisme. C’est ce que cristallise Milton Friedman dans une de ses célèbres affirmations : « la responsabilité sociale des entreprises est de maximiser leurs profits »7. Si le capitalisme est un dispositif géant générateur de profit, il n’est ni moral ni immoral, c’est son usage, sa destination qui l’est. Par conséquent, ce serait à l’État d’agir en assumant les conséquences d’un mauvais usage qu’en feraient les capitalistes.
Contradiction : le capitalisme n’est pas un simple dispositif, il est à la fois marché, organisation, choix collectifs, et choix individuels. Son extension dans nos vies privées est le résultat du choix de la rationalisation toujours plus drastique des conditions de rentabilité. Dans les années 1980, les économistes néoclassiques croyaient fortement au triptyque gagnant investissement – accroissement de main d’œuvre – progrès technique. Sauf que même l’un des plus connus des économistes américains, Robert Solow, a dû se rendre à une évidence, un « paradoxe » qu’il soulevait après avoir admis que « la révolution technologique [de l’informatique] s’est accompagnée partout d’un ralentissement de la croissance de la productivité, et non d’une augmentation ». Il conclut : « Vous pouvez voir l’ère informatique partout, sauf dans les statistiques de la productivité »8. Pour Solow, croyant encore au vieux monde de la croissance « productrice », ce n’était qu’une question de temps, mais pour l’économie capitaliste, c’était surtout l’urgence de se tourner vers des solutions beaucoup plus rapides : l’actionnariat (et la rationalisation rentable des process) et la valorisation quasi-immédiate de tout ce qui pouvait être valorisable sur le marché le plus facile possible, celui des services, celui qui nécessite le moins d’investissements.
La volonté d’aller dans le mur
Le capitalisme à l’ère numérique n’a pas créé de stagnation, il est structurellement destructeur. Il n’a pas créé de défaut d’investissement, il est avant tout un choix réfléchi, la volonté d’aller droit dans le mur en espérant faire partie des élus qui pourront changer de voiture avant l’impact. Dans cette hyper-concurrence qui est devenue essentiellement financière, la seule manière d’envisager la victoire est de fabriquer des monopoles. C’est là que la fatuité de la régulation se remarque le plus. Un récent article de Michael Kwet9 résume très bien la situation. On peut le citer longuement :
Les défenseurs de la législation antitrust affirment que les monopoles faussent un système capitaliste idéal et que ce qu’il faut, c’est un terrain de jeu égal pour que tout le monde puisse se faire concurrence. Pourtant, la concurrence n’est bonne que pour ceux qui ont des ressources à mettre en concurrence. Plus de la moitié de la population mondiale vit avec moins de 7,40 dollars [7,16 euros] par jour, et personne ne s’arrête pour demander comment ils seront “compétitifs” sur le “marché concurrentiel” envisagé par les défenseurs occidentaux de l’antitrust. C’est d’autant plus décourageant pour les pays à revenu faible ou intermédiaire que l’internet est largement sans frontières.
À un niveau plus large […] les défenseurs de l’antitrust ignorent la division globalement inégale du travail et de l’échange de biens et de services qui a été approfondie par la numérisation de l’économie mondiale. Des entreprises comme Google, Amazon, Meta, Apple, Microsoft, Netflix, Nvidia, Intel, AMD et bien d’autres sont parvenues à leur taille hégémonique parce qu’elles possèdent la propriété intellectuelle et les moyens de calcul utilisés dans le monde entier. Les penseurs antitrust, en particulier ceux des États-Unis, finissent par occulter systématiquement la réalité de l’impérialisme américain dans le secteur des technologies numériques, et donc leur impact non seulement aux États-Unis, mais aussi en Europe et dans les pays du Sud.
Les initiatives antitrust européennes ne sont pas meilleures. Là-bas, les décideurs politiques qui s’insurgent contre les maux des grandes entreprises technologiques tentent discrètement de créer leurs propres géants technologiques.
Dans la critique mainstream du capitalisme de surveillance, une autre erreur s’est révélée, en plus de celle qui consiste à persister dans la défense d’un imaginaire capitaliste. C’est celle de voir dans l’État et son pouvoir de régulation un défenseur de la démocratie. C’est d’abord une erreur de principe : dans un régime capitaliste monopoliste, l’État assure l’hégémonie des entreprises de son cru et fait passer sous l’expression démocratie libérale (ou libertés) ce qui favorise l’émergence de situations de domination. Pour lutter contre, il y a une urgence dans notre actualité économique : la logique des start-up tout autant que celle de la « propriété intellectuelle » doivent laisser place à l’expérimentation collective de gouvernance de biens communs de la connaissance et des techniques (nous en parlerons plus loin). Ensuite, c’est une erreur pratique comme l’illustrent les affaires de lobbying et de pantouflage dans le petit monde des décideurs politiques. Une illustration parmi des centaines : les récents Uber Files démontrant, entre autres, les accords passés entre le président Emmanuel Macron et les dirigeants d’Uber (voir sur le site Le Monde).
Situer ces enjeux dans un contexte historique aussi général suppose de longs développements, rarement simples à exposer. Oui, il s’agit d’une critique du capitalisme, et oui cette critique peut être plus ou moins radicale selon que l’on se place dans un héritage marxiste, marxien ou de la critique de la valeur, ou que l’on demeure persuadé qu’un capitalisme plus respectueux, moins « féodal » pourrait advenir. Sans doute qu’un mirage subsiste, celui de croire qu’autant de bienfaits issus du capitalisme suffisent à le dédouaner de l’usage dévoyé des technologies. « Sans le capitalisme nous en serions encore à nous éclairer à la bougie…» En d’autres termes, il y aurait un progrès indiscutable à l’aune duquel les technologies de surveillance pourraient être jugées. Vraiment ?
« Il y a une application pour ça », le slogan d’Apple qui illustre bien le solutionnisme technologique.
Situer le capitalisme de surveillance dans notre rapport à la technique
C’est un poncif : les technologies de surveillance ont été développées dans une logique de profit. Il s’agit des technologies dont l’objectif est de créer des données exploitables à partir de nos vies privées, à des fins de contrôle ou purement mercantiles (ce qui revient au même puisque les technologies de contrôle sont possédées par des firmes qui achètent des données).
Or, il est temps de mettre fin à l’erreur répandue qui consiste à considérer que les technologies de surveillance sont un mal qui pervertit le capitalisme censé être le moteur de la démocratie libérale. Ceci conduit à penser que seule une régulation bien menée par l’État dans le but de restaurer les vertus du « bon » capitalisme serait salutaire tant nos vies privées sont sur-exploitées et nos libertés érodées. Tel est le credo de Shoshana Zuboff et avec elle bon nombre de décideurs politiques.
Croire qu’il y a de bons et de mauvais usages
L’erreur est exactement celle que dénonçait en son temps Jacques Ellul. C’est celle qui consiste à vouloir absolument attribuer une valeur à l’usage de la technique. Le bon usage serait celui qui pousse à respecter la vie privée, et le mauvais usage celui qui tend à l’inverse. Or, il n’y a d’usage technique que technique. Il n’y a qu’un usage de la bombe atomique, celui de faire boum (ou pas si elle est mal utilisée). Le choix de développer la bombe est, lui, par contre, un choix qui fait intervenir des enjeux de pouvoir et de valeurs.
Au tout début des années 1970, à l’époque où se développaient les techniques d’exploitation des bases de données et le courtage de données, c’est ce qu’ont montré James Martin et Adrian Norman pour ce qui concerne les systèmes informatiques10 : à partir du moment où un système est informatisé, la quantification est la seule manière de décrire le monde. Ceci est valable y compris pour les systèmes décisionnels. Le paradoxe que pointaient ces auteurs montrait que le traitement de l’information dans un système décisionnel – par exemple dans n’importe quelle organisation économique, comme une entreprise – devait avoir pour objectif de rationaliser les procédures et les décisions en utilisant une quantité finie de données pour en produire une quantité réduite aux éléments les plus stratégiques, or, l’informatisation suppose un choix optimum parmi une grande variété d’arbres décisionnels et donc un besoin croissant de données, une quantité tendant vers l’infini.
Martin et Norman illustraient ce qu’avait affirmé Jacques Ellul vingt ans auparavant : la technique et sa logique de développement seraient autonomes. Bien que discutable, cette hypothèse montre au moins une chose : dans un monde capitaliste, tout l’enjeu consisterait comme au rugby à transformer l’essai, c’est-à-dire voir dans le développement des techniques autant d’opportunités de profit et non pas d’investissements productifs. Les choix se posent alors en termes d’anti-productivité concrète. Dans le monde des bases de données et leur exploitation la double question qui s’est posée de 1970 à aujourd’hui est de savoir si nous sommes capables d’engranger plus ou moins de données et comment leur attribuer une valeur marchande.
Le reste n’est que sophismes : l’usine entièrement automatisée des rêves cybernéticiens les plus fous, les boules de cristal des statistiques électorales, les données de recouvrement bancaires et le crédit à la consommation, les analyses marketing et la consommation de masse, jusqu’à la smart city de la Silicon Valley et ses voitures autonomes (et ses aspirateurs espions)… la justification de la surveillance et de l’extraction de données repose sur l’idée d’un progrès social, d’un bon usage des technologies, et d’une neutralité des choix technologiques. Et il y a un paralogisme. Si l’on ne pense l’économie qu’en termes capitalistes et libéraux, cette neutralité est un postulat qui ne peut être remis en cause qu’à l’aune d’un jugement de valeur : il y aurait des bons et des mauvais usages des technologies, et c’est à l’État d’assurer le rôle minimal de les arbitrer au regard de la loi. Nul ne remet alors en question les choix eux-mêmes, nul ne remet en question l’hégémonie des entreprises qui nous couvrent de leurs « bienfaits » au prix de quelques « négligeables » écarts de conduite, nul ne remet en question l’exploitation de nos vies privées (un mal devenu nécessaire) et l’on préfère nous demander notre consentement plus ou moins éclairé, plus ou moins obligé.
La technologie n’est pas autonome
Cependant, comme nous le verrons vers la fin de ce texte, les études en sociologie des sciences montrent en fait qu’il n’y a pas d’autonomie de la technique. Sciences, technologies et société s’abreuvent mutuellement entre les usages, les expérimentations et tous ces interstices épistémiques d’appropriation des techniques, de désapprentissage, de renouvellement, de détournements, et d’expression des besoins pour de nouvelles innovations qui seront à leur tour appropriées, modifiées, transformées, etc. En réalité l’hypothèse de l’autonomie de la technique a surtout servi au capitalisme pour suivre une course à l’innovation qui ne saurait être remise en question, comme une loi naturelle qui justifie en soi la mise sur le marché de nouvelles technologies et au besoin faire croire en leur utilité. Tel est le fond de commerce du transhumanisme et son « économie des promesses ».
L’erreur consiste à prêter le flanc au solutionnisme technologique (le même qui nous fait croire que des caméras de surveillance sont un remède à la délinquance, ou qu’il faut construire des grosses berlines sur batteries pour ne plus polluer) et à se laisser abreuver des discours néolibéraux qui, parce qu’il faut bien rentabiliser ces promesses par de la marchandisation des données – qui est elle-même une promesse pour l’actionnariat –, nous habituent petit à petit à être surveillés. Pour se dépêtrer de cela, la critique du capitalisme de surveillance doit être une critique radicale du capitalisme et du néolibéralisme car la lutte contre la surveillance ne peut être décorrélée de la prise en compte des injustices sociales et économiques dont ils sont les causes pratiques et idéologiques.
Je vois venir les lecteurs inquiets. Oui, j’ai placé ce terme de néolibéralisme sans prévenir. C’est mettre la charrue avant les bœufs mais c’est parfois nécessaire. Pour mieux comprendre, il suffit de définir ce qu’est le néolibéralisme. C’est l’idéologie appelée en Allemagne ordolibéralisme, si l’on veut, c’est-à-dire l’idée que le laissez-faire a démontré son erreur historique (les crises successives de 1929, 1972, 2008, ou la crise permanente), et que par conséquent l’État a fait son grand retour dans le marché au service du capital, comme le principal organisateur de l’espace de compétition capitaliste et le dépositaire du droit qui érige la propriété et le profit au titre de seules valeurs acceptables. Que des contrats, plus de discussion, there is no alternative, comme disait la Margaret. Donc partant de cette définition, à tous les niveaux organisationnels, celui des institutions de l’État comme celui des organisations du capital, la surveillance est à la fois outil de contrôle et de génération de profit (dans les limites démontrées par R. Kurz, à savoir : pas sans compter presque exclusivement sur l’actionnariat et les produits financiers, cf. plus haut).
Le choix du « monitoring »
La course en avant des technologies de surveillance est donc le résultat d’un choix. Il n’y a pas de bon ou de mauvais usage de la surveillance électronique : elle est faite pour récolter des données. Le choix en question c’est celui de n’avoir vu dans ces données qu’un objet marchand. Peu importe les bienfaits que cela a pu produire pour l’individu, ils ne sont visibles que sur un court terme. Par exemple les nombreuses applications de suivi social que nous utilisons nous divertissent et rendent parfois quelque service, mais comme le dit David Lyon dans The Culture of Surveillance, elle ne font que nous faire accepter passivement les règles du monitoring et du tri social que les États comme les multinationales mettent en œuvre.
Il n’y a pas de différence de nature entre la surveillance des multinationales et la surveillance par l’État : ce sont les multinationales qui déterminent les règles du jeu de la surveillance et l’État entérine ces règles et absorbe les conditions de l’exercice de la surveillance au détriment de sa souveraineté. C’est une constante bien comprise, qu’il s’agisse des aspects techniques de la surveillance sur lesquels les Big Tech exercent une hégémonie qui en retour sert les intérêts d’un ou plusieurs États (surtout les États-Unis aujourd’hui), ou qu’il s’agisse du droit que les Big Tech tendent à modifier en leur faveur soit par le jeu des lobbies soit par le jeu des accords internationaux (tout comme récemment le nouvel accord entre l’Europe et les États-Unis sur les transferts transatlantiques de données, qui vient contrecarrer les effets d’annonce de la Commission Européenne).
Trouver et cultiver nos espaces de libertés. Illustration CC-By David Revoy (sources)
Quels espaces de liberté dans ce monde technologique ?
Avec l’apparition des ordinateurs et des réseaux, de nombreuses propositions ont vu le jour. Depuis les années 1970, si l’on suit le développement des différents mouvements de contestation sociale à travers le monde, l’informatique et les réseaux ont souvent été plébiscités comme des solutions techniques aux défauts des démocraties. De nombreux exemples d’initiatives structurantes pour les réseaux informatiques et les usages des ordinateurs se sont alors vus détournés de leurs fonctions premières. On peut citer le World Wide Web tel que conçu par Tim Berners Lee, lui même suivant les traces du monde hypertextuel de Ted Nelson et son projet Xanadu. Pourquoi ce design de l’internet des services s’est-il trouvé à ce point sclérosé par la surveillance ? Pour deux raisons : 1) on n’échappe pas (jamais) au développement technique de la surveillance (les ordinateurs ont été faits et vendus pour cela et le sont toujours11) et 2) parce qu’il y a des intérêts de pouvoir en jeu, policiers et économiques, celui de contrôler les communications. Un autre exemple : le partage des programmes informatiques. Comme chacun le sait, il fut un temps où la création d’un programme et sa distribution n’étaient pas assujettis aux contraintes de la marchandisation et de la propriété intellectuelle. Cela permettait aux utilisateurs de machines de partager non seulement des programmes mais des connaissances et des nouveaux usages, faisant du code un bien commun. Sous l’impulsion de personnages comme Bill Gates, tout cela a changé au milieu des années 1970 et l’industrie du logiciel est née. Cela eut deux conséquences, négative et positive. Négative parce que les utilisateurs perdaient absolument toute maîtrise de la machine informatique, et toute possibilité d’innovation solidaire, au profit des intérêts d’entreprises qui devinrent très vite des multinationales. Positive néanmoins, car, grâce à l’initiative de quelques hackers, dont Richard Stallman, une alternative fut trouvée grâce au logiciel libre et la licence publique générale et ses variantes copyleft qui sanctuarisent le partage du code. Ce partage relève d’un paradigme qui ne concerne plus seulement le code, mais toute activité intellectuelle dont le produit peut être partagé, assurant leur liberté de partage aux utilisateurs finaux et la possibilité de créer des communs de la connaissance.
Alors que nous vivons dans un monde submergé de technologies, nous aurions en quelque sorte gagné quelques espaces de liberté d’usage technique. Mais il y a alors comme un paradoxe.
À l’instar de Jacques Ellul, pour qui l’autonomie de la technique implique une aliénation de l’homme à celle-ci, beaucoup d’auteurs se sont inquiétés du fait que les artefacts techniques configurent par eux-mêmes les actions humaines. Qu’on postule ou pas une autonomie de la technique, son caractère aliénant reste un fait. Mais il ne s’agit pas de n’importe quels artefacts. Nous ne parlons pas d’un tournevis ou d’un marteau, ou encore d’un silex taillé. Il s’agit des systèmes techniques, c’est-à-dire des dispositifs qu’on peut qualifier de socio-techniques qui font intervenir l’homme comme opérateur d’un ensemble d’actions techniques par la technique. En quelque sorte, nous perdons l’initiative et les actions envisagées tendent à la conformité avec le dispositif technique et non plus uniquement à notre volonté. Typiquement, les ordinateurs dans les entreprises à la fin des années 1960 ont été utilisés pour créer des systèmes d’information, et c’est à travers ces systèmes techniques que l’action de l’homme se voit configurée, modelée, déterminée, entre ce qui est possible et ce qui ne l’est pas. Dans son article « Do artefacts have politics ? », Langdon Winner s’en inquiétait à juste titre : nos objectifs et le sens de nos actions sont conditionnés par la technique. Cette dernière n’est jamais neutre, elle peut même provoquer une perte de sens de l’action, par exemple chez le travailleur à la chaîne ou le cadre qui non seulement peuvent être noyés dans une organisation du travail trop grande, mais aussi parce que l’automatisation de la production et de la décision les prive de toute initiative (et de responsabilité).
La tentation du luddisme
Pour lutter contre cette perte de sens, des choix sont envisageables. Le premier consiste à lutter contre la technique. En évacuant la complexité qu’il y a à penser qu’un mouvement réfractaire au développement technique puisse aboutir à une société plus libre, on peut certes imaginer des fronts luddites en certains secteurs choisis. Par exemple, tel fut le choix du CLODO dans la France des années 1980, prétendant lutter contre l’envahissement informatique dans la société. Concernant la surveillance, on peut dire qu’au terme d’un processus de plus de 50 ans, elle a gagné toutes les sphères socio-économiques grâce au développement technologique. Un front (néo-)luddite peut sembler justifié tant cette surveillance remet en cause très largement nos libertés et toutes les valeurs positives que l’on oppose généralement au capitalisme : solidarité et partage, notamment.
Pour autant, est-ce que la lutte contre le capitalisme de surveillance doit passer par la négation de la technique ? Il est assez évident que toute forme d’action directe qui s’oppose en bloc à la technique perd sa crédibilité en ce qu’elle ne fait que proposer un fantasme passéiste ou provoquer des réactions de retrait qui n’ont souvent rien de constructif. C’est une critique souvent faite à l’anarcho-primitivisme qui, lorsqu’il ne se contente pas d’opposer une critique éclairée de la technique (et des processus qui ont conduit à la création de l’État) en vient parfois à verser dans la technophobie. C’est une réaction aussi compréhensible que contrainte tant l’envahissement technologique et ses discours ont quelque chose de suffoquant. En oubliant cette question de l’autonomie de la technique, je suis personnellement tout à fait convaincu par l’analyse de J. Ellul selon laquelle nous sommes à la fois accolés et dépendants d’un système technique. En tant que système il est devenu structurellement nécessaire aux organisations (qu’elles soient anarchistes ou non) au moins pour communiquer, alors que le système capitaliste, lui, ne nous est pas nécessaire mais imposé par des jeux de pouvoirs. Une réaction plus constructive consiste donc à orienter les choix technologiques, là où l’action directe peut prendre un sens tout à fait pertinent.
Prenons un exemple qui pourrait paraître trivial mais qui s’est révélé particulièrement crucial lors des périodes de confinement que nous avons subies en raison de l’épidémie Covid. Qu’il s’agisse des entreprises ou des institutions publiques, toutes ont entamé dans l’urgence une course en avant vers les solutions de visio-conférence dans l’optique de tâcher de reproduire une forme présentielle du travail de bureau. La visio-conférence suscite un flux de données bien plus important que la voix seule, et par ailleurs la transmission vocale est un ensemble de techniques déjà fort éprouvées depuis plus d’un siècle. Que s’est-il produit ? Les multinationales se sont empressées de vendre leurs produits et pomper toujours plus de données personnelles, tandis que les limites pratiques de la visio-conférence se sont révélées : dans la plupart des cas, réaliser une réunion « filmée » n’apporte strictement rien de plus à l’efficacité d’une conférence vocale. Dans la plupart des cas, d’ailleurs, afin d’économiser de la bande passante (croit-on), la pratique courante consiste à éteindre sa caméra pendant la réunion. Où sont les gains de productivité tant annoncés par les GAFAM ? Au lieu de cela, il y a en réalité un détournement des usages, et même des actes de résistance du quotidien (surtout lorsqu’il s’agit de surveiller les salariés à distance).
Les choix technologiques doivent être collectifs
Une critique des techniques pourrait donc consister à d’abord faire le point sur nos besoins et en prenant en compte l’urgence climatique et environnementale dans laquelle nous sommes (depuis des décennies). Elle pourrait aussi consister à prendre le contrepoint des discours solutionnistes qui tendent à justifier le développement de techniques le plus souvent inutiles en pratique mais toujours plus contraignantes quant au limites éthiques vers lesquelles elles nous poussent. Les choix technologiques doivent donc d’abord être des choix collectifs, dont l’assentiment se mesure en fonction de l’économie énergétique et de l’acceptabilité éthique de la trajectoire choisie. On peut revenir à une technologie ancienne et éprouvée et s’en contenter parce qu’elle est efficace et on peut refuser une technologie parce qu’elle n’est pas un bon choix dans l’intérêt collectif. Et par collectif, j’entends l’ensemble des relations inter-humaines et des relations environnementales dont dépendent les premières.
Les attitudes de retraits par rapports aux technologies, le refus systématique des usages, sont rarement bénéfiques et ne constituent que rarement une démarche critique. Ils sont une réaction tout à fait compréhensible du fait que la politique a petit à petit déserté les lieux de production (pour ce qu’il en reste). On le constate dans le désistement progressif du syndicalisme ces 30 ou 40 dernières années et par le fait que la critique socialiste (ou « de gauche ») a été incapable d’intégrer la crise du capitalisme de la fin du XXᵉ siècle. Pire, en se transformant en un centre réactionnaire, cette gauche a créé une technocratie de la gestion aux ordres du néolibéralisme : autoritarisme et pansements sociaux pour calmer la révolte qui gronde. Dès lors, de désillusions en désillusions, dans la grande cage concurrentielle de la rareté du travail rémunéré (rentable) quelle place peut-il y avoir pour une critique des techniques et de la surveillance ? Peut-on demander sérieusement de réfléchir à son usage de Whatsapp à une infirmière qui a déjà toutes les difficultés du monde à concilier la garde de ses enfants, les heures supplémentaires (parfois non payées) à l’hôpital, le rythme harassant du cycle des gardes, les heures de transports en commun et par dessus le marché, le travail domestique censé assurer les conditions de reproduction du travail abstrait ? Alors oui, dans ces conditions où le management du travail n’est devenu qu’une affaire de rationalisation rentable, les dispositifs techniques ne font pas l’objet d’usages réfléchis ou raisonnés, il font toujours l’objet d’un usage opportuniste : je n’utilise pas Whatsapp parce que j’aime Facebook ou que je me fiche de savoir ce que deviennent mes données personnelles, j’utilise Whatsapp parce que c’est le moyen que j’ai trouvé pour converser avec mes enfants et m’assurer qu’ils sont bien rentrés à la maison après l’école.
Low tech et action directe
En revanche, un retrait que je pourrais qualifier de technophobe et donc un minimum réfléchi, laisse entier le problème pour les autres. La solidarité nous oblige à créer des espaces politiques où justement technologie et capitalisme peuvent faire l’objet d’une critique et surtout d’une mise en pratique. Le mouvement Low Tech me semble être l’un des meilleurs choix. C’est en substance la thèse que défend Uri Gordon (« L’anarchisme et les politiques techniques ») en voyant dans les possibilités de coopérations solidaires et de choix collectivement réfléchis, une forme d’éthique de l’action directe.
Je le suivrai sur ce point et en étendant davantage le spectre de l’action directe. Premièrement parce que si le techno-capitalisme aujourd’hui procède par privation de libertés et de politique, il n’implique pas forcément l’idée que nous ne soyons que des sujets soumis à ce jeu de manière inconditionnelle. C’est une tendance qu’on peut constater dans la plupart des critiques du pouvoir : ne voir l’individu que comme une entité dont la substance n’est pas discutée, simplement soumis ou non soumis, contraint ou non contraint, privé de liberté ou disposant de liberté, etc. Or il y a tout un ensemble d’espaces de résistance conscients ou non conscients chez tout individu, ce que Michel de Certeau appelait des tactiques du quotidien12. Il ne s’agit pas de stratégies où volonté et pouvoir se conjuguent, mais des mouvements « sur le fait », des alternatives multiples mises en œuvre sans chercher à organiser cet espace de résistance. Ce sont des espaces féconds, faits d’expérimentations et d’innovations, et parfois même configurent les techniques elles-mêmes dans la différence entre la conception initiale et l’usage final à grande échelle. Par exemple, les ordinateurs et leurs systèmes d’exploitations peuvent ainsi être tantôt les instruments de la surveillance et tantôt des instruments de résistance, en particulier lorsqu’ils utilisent des logiciels libres. Des apprentissages ont lieu et cette fois ils dépassent l’individu, ils sont collectifs et ils intègrent des connaissances en commun.
En d’autres termes, chaque artefact et chaque système technique est socialement digéré, ce qui en retour produit des interactions et détermine des motivations et des objectifs qui peuvent s’avérer très différents de ceux en fonction desquels les dispositifs ont été créés. Ce processus est ce que Sheila Jasanoff appelle un processus de coproduction épistémique et normatif13 : sciences et techniques influencent la société en offrant un cadre tantôt limitatif, tantôt créatif, ce qui en retour favorise des usages et des besoins qui conditionnent les trajectoires scientifiques et technologiques. Il est par conséquent primordial de situer l’action directe sur ce créneau de la coproduction en favorisant les expériences tactiques individuelles et collectives qui permettent de déterminer des choix stratégiques dans l’orientation technologique de la société. Dit en des mots plus simples : si la décision politique n’est plus suffisante pour garantir un cadre normatif qui reflète les choix collectifs, alors ce sont les collectifs qui doivent pouvoir créer des stratégies et au besoin les imposer par un rapport de force.
Créer des espaces d’expérimentations utopiques
Les hackers ne produisent pas des logiciels libres par pur amour d’autrui et par pure solidarité : même si ces intentions peuvent être présentes (et je ne connais pas de libristes qui ne soient pas animés de tels sentiments), la production de logiciel libre (ou open source) est d’abord faite pour créer de la valeur. On crée du logiciel libre parce que collectivement on est capable d’administrer et valoriser le bien commun qu’est le code libre, à commencer par tout un appareillage juridique comme les licences libres. Il en va de même pour toutes les productions libres qui emportent avec elles un idéal technologique : l’émancipation, l’activité libre que représente le travail du code libre (qui n’est la propriété de personne). Même si cela n’exempte pas de se placer dans un rapport entre patron (propriétaire des moyens de production) et salarié, car il y a des entreprises spécialisées dans le Libre, il reste que le Libre crée des espaces d’équilibres économiques qui se situent en dehors de l’impasse capitaliste. La rentabilité et l’utilité se situent presque exclusivement sur un plan social, ce qui explique l’aspect très bigarré des modèles d’organisations économiques du Libre, entre associations, fondations, coopératives…
L’effet collatéral du Libre est aussi de créer toujours davantage d’espaces de libertés numériques, cette fois en dehors du capitalisme de surveillance et ses pratiques d’extraction. Cela va des pratiques de chiffrement des correspondances à l’utilisation de logiciels dédiés explicitement aux luttes démocratiques à travers le monde. Cela a le mérite de créer des communautés plus ou moins fédérées ou archipélisées, qui mettent en pratique ou du moins sous expérimentation l’alliance entre les technologies de communication et l’action directe, au service de l’émancipation sociale.
Il ne s’agit pas de promettre un grand soir et ce n’est certes pas avec des expériences qui se complaisent dans la marginalité que l’on peut bouleverser le capitalisme. Il ne s’agit plus de proposer des alternatives (qui fait un détour lorsqu’on peut se contenter du droit chemin?) mais des raisons d’agir. Le capitalisme est désuet. Dans ses soubresauts (qui pourraient bien nous mener à la guerre et la ruine), on ressort l’argument du bon sens, on cherche le consentement de tous malgré l’expérience que chacun fait de l’exploitation et de la domination. Au besoin, les capitalistes se montrent autoritaires et frappent. Mais que montrent les expériences d’émancipation sociales ? Que nous pouvons créer un ordre fait de partage et d’altruisme, de participation et de coopération, et que cela est parfaitement viable, sans eux, sur d’autres modèles plus cohérents14. En d’autres termes, lutter contre la domination capitaliste, c’est d’abord démontrer par les actes que d’autres solutions existent et sans chercher à les inclure au forceps dans ce système dominant. Au contraire, il y a une forme d’héroïsme à ne pas chercher à tordre le droit si ce dernier ne permet pas une émancipation franche et durable du capitalisme. Si le droit ne convient pas, il faut prendre le gauche.
La lutte pour les libertés numériques et l’application des principes du Libre permettent de proposer une sortie positive du capitalisme destructeur. Néanmoins on n’échappera pas à la dure réalité des faits. Par exemple que l’essentiel des « tuyaux » des transmissions numériques (comme les câbles sous-marins) appartiennent aux multinationales du numérique et assurent ainsi l’un des plus écrasants rapports de domination de l’histoire. Pourtant, on peut imaginer des expériences utopiques, comme celle du Chaos Computer Club, en 2012, consistant à créer un Internet hors censure via un réseau de satellite amateur.
L’important est de créer des espaces d’expérimentation utopiques, parce qu’ils démontrent tôt ou tard la possibilité d’une solution, il sont préfiguratifs15. Devant la décision politique au service du capital, la lutte pour un réseau d’échanges libres ne pourra certes pas se passer d’un rapport de force mais encore moins de nouveaux imaginaires. Car, finalement, ce que crée la crise du capitalisme, c’est la conscience de son écocide, de son injustice, de son esclavagisme technologique. Reste l’espoir, première motivation de l’action.
Notes
R. Kurz, Vies et mort du capitalisme, Nouvelles Éditions Ligne, 2011, p. 37↩︎
Ernst Lohoff et Norbert Trenkle, La grande dévalorisation. Pourquoi la spéculation et la dette de l’État ne sont pas les causes de la crise, Paris, Post-éditions, 2014.↩︎
Georges Simpson, « Western Man under Automation », International Journal of Comparative Sociology, num. 5, 1964, pp. 199-207.↩︎
Comme le dit Moishe Postone dans son article « Repenser Le Capital à la lumière des Grundrisse » : « La transformation radicale du processus de production mentionnée plus haut n’est pas le résultat quasi-automatique du développement rapide des savoirs techniques et scientifique et de leurs applications. C’est plutôt une possibilité qui naît d’une contradiction sociale intrinsèque croissante. Bien que la course du développement capitaliste génère la possibilité d’une structure nouvelle et émancipatrice du travail social, sa réalisation générale est impossible dans le capitalisme. »↩︎
Là je reprends une catégorie marxiste. Marx appelle le (résultat du -) travail mort ce qui a besoin de travail productif. Par exemple, une matière comme le blé récolté est le résultat d’un travail déjà passé, il lui faut un travail vivant (celui du meunier) pour devenir matière productive. Pour ce qui concerne l’extraction de données, il faut comprendre que l’automatisation de cette extraction, le stockage, le travail de la donnée et la marchandisation sont un seul et même mouvement (on ne marchande pas des jeux de données « en l’air », ils correspondent à des commandes sur une marché tendu). Les données ne sont pas vraiment une matière première, elles ne sont pas non plus un investissement, mais une forme insaisissable du travail à la fois matière première et système technique.↩︎
On peut distinguer entre économie réelle et économie financière. Voir cette étude de François Morin, juste avant le crack de 2008. François Morin, « Le nouveau mur de l’argent », Nouvelles Fondations, num. 3-4, 2007, p. 30-35.↩︎
James Martin et Adrian R. D. Norman, The Computerized Society. An Appraisal of the Impact of Computers on Society over the next 15 Years, Englewood Cliffs, Prentice-Hall, 1970, p. 522.↩︎
c’est ce que je tâche de montrer dans une partie de mon livre Affaires privées. Aux sources du capitalisme de surveillance : pourquoi fabriquer et acheter des ordinateurs ? Si les entreprises sont passées à l’informatique c’est pour améliorer la production et c’est aussi pourquoi le courtage de données s’est développé.↩︎
Sheila Jasanoff, « Ordering Knowledge, Ordering Society », dans S. Jasanoff (éd.), States of knowledge. The co-production of science and social order, Londres, Routledge, 2004, pp. 13-45.↩︎
Voir David Graeber, et Alexie Doucet, Comme si nous étions déjà libres, Montréal, Lux éditeur, 2014. La préfiguration est l’« idée selon laquelle la forme organisationnelle qu’adopte un groupe doit incarner le type de société qu’il veut créer ». Voir aussi Marianne Maeckelbergh, « Doing is Believing: Prefiguration as Strategic Practice in the Alterglobalization Movement », Social Movement Studies, vol. 10, num. 1, 2011, pp. 1‑20.↩︎