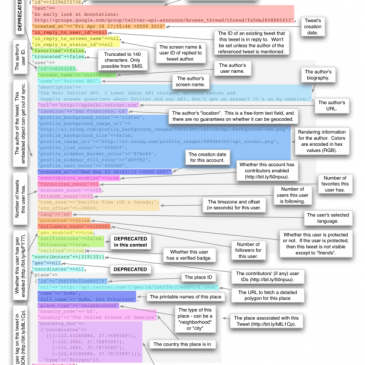
Laurent Chemla propose : exigeons des GAFAM l’interopérabilité
« Il est évidemment plus qu’urgent de réguler les GAFAM pour leur imposer l’interopérabilité. » écrit Laurent Chemla. Diable, il n’y va pas de main morte, le « précurseur dans le domaine d’Internet » selon sa page Wikipédia.