21 degrés de liberté – 04
Hier notre position dans l’espace géographique était notre affaire et nous pouvions être invisibles aux yeux du monde si nous l’avions décidé. C’est devenu presque impossible aujourd’hui dans l’espace numérique.

... mais ce serait peut-être l'une des plus grandes opportunités manquées de notre époque si le logiciel libre ne libérait rien d'autre que du code

Hier notre position dans l’espace géographique était notre affaire et nous pouvions être invisibles aux yeux du monde si nous l’avions décidé. C’est devenu presque impossible aujourd’hui dans l’espace numérique.
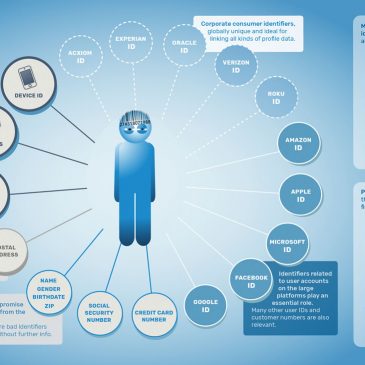
Vous croyez tout savoir déjà sur l’exploitation de nos données personnelles ? Parcourez plutôt quelques paragraphes de ce très vaste dossier…
Depuis un an ou deux une conscience floue de l’ubiquité du pistage est perceptible dans les conversations sous la forme de brèves remarques fatalistes : — De toutes façons on est espionnés, alors… — Ils peuvent savoir tout ce qu’on fait … Lire la suite