Le Web, tout le monde s’en sert et beaucoup en sont très contents. Mais, même parmi ceux et celles qui sont ravi·es de l’utiliser, il y a souvent des critiques. Elles portent sur de nombreux aspects et je ne vais pas essayer de lister ici toutes ces critiques. Je vais parler d’un problème souvent ressenti : le Web n’est-il pas devenu trop compliqué ?
À noter : cet article bénéficie désormais d’une version audio.
Merci à Sualtam, auteur de lectureaudio.fr pour cette contribution active.
Je ne parle pas de la complexité pour l’utilisateur, par exemple des problèmes qu’il ou elle peut avoir avec telle ou telle application Web, ou tel formulaire incompréhensible ou excluant. Non, je parle de la complexité des nombreuses technologies sous-jacentes. Alors, si vous n’êtes pas technicien·ne, vous avez peut-être envie d’arrêter votre lecture ici en pensant qu’on ne parlera que de technique. Mais ce n’est pas le cas, cet article est pour tous et toutes. (Ceci dit, si vous arrêtez votre lecture pour jouer avec le chat, manger un bon plat, lire un livre passionnant ou faire des câlins à la personne appropriée, cela ne me dérange pas et je vous souhaite un agréable moment.)
Mais revenons à l’objection « OK, les techniques utilisées dans le Web sont compliquées mais cela ne concerne que les développeuses et développeurs, non ? » Eh bien non car cette complication a des conséquences pour tous et toutes. Elle se traduit par des logiciels beaucoup plus complexes, donc elle réduit la concurrence, très peu d’organisations pouvant aujourd’hui développer un navigateur Web. Elle a pour conséquence de rendre l’utilisation du Web plus lente : bien que les machines et les réseaux aient nettement gagné en performance, le temps d’affichage d’une page ne cesse d’augmenter. Passer à la fibre ou à la 5G ne se traduira pas forcément par un gain de temps, puisque ce sont souvent les calculs nécessaires à l’affichage qui ralentissent la navigation. Et enfin cette complication augmente l’empreinte environnementale du Web, en imposant davantage d’opérations aux machines, ce qui pousse au remplacement plus rapide des terminaux.
L’insoutenable lourdeur du Web
Une page Web d’aujourd’hui n’est en effet pas une simple description d’un contenu. Elle inclut la « feuille de style », rédigée dans le langage CSS, qui va indiquer comment présenter la page, du JavaScript, un langage de programmation qui va être exécuté pour faire varier le contenu de la page, des vidéos, et d’autres choses qui souvent distraient du contenu lui-même. Je précise que je ne parle pas ici des applications tournant sur le Web (comme une application d’accès au courrier électronique, ou une application de gestion des évènements ou l’application maison utilisée par les employés d’une organisation pour gérer leur travail), non, je parle des pages Web de contenu, qui ne devraient pas avoir besoin de toute cette artillerie.
Du fait de cette complexité, il n’existe aujourd’hui que quatre ou cinq navigateurs Web réellement distincts. Écrire un navigateur Web aujourd’hui est une tâche colossale, hors de portée de la très grande majorité des organisations. La concurrence a diminué sérieusement. La complexité technique a donc des conséquences stratégiques pour le Web. Et ceci d’autant plus qu’il n’existe derrière ces navigateurs que deux moteurs de rendu, le cœur du navigateur, la partie qui interprète le langage HTML et le CSS et dessine la page. Chrome, Edge et Safari utilisent le même moteur de rendu, WebKit (ou l’une de ses variantes).
Et encore tout ne tourne pas sur votre machine. Derrière votre écran, l’affichage de la moindre page Web va déclencher d’innombrables opérations sur des machines que vous ne voyez pas, comme les calculs des entreprises publicitaires qui vont, en temps réel, déterminer les « meilleures » publicités à vous envoyer dans la figure ou comme l’activité de traçage des utilisateurs, notant en permanence ce qu’ils font, d’où elles viennent et de nombreuses autres informations, dont beaucoup sont envoyées automatiquement par votre navigateur Web, qui travaille au moins autant pour l’industrie publicitaire que pour vous. Pas étonnant que la consommation énergétique du numérique soit si importante. Et ces calculs côté serveur ont une grande influence sur la capacité du serveur à tenir face à une charge élevée, comme on l’a vu pendant les confinements Covid-19. Les sites Web de l’Éducation Nationale ne tenaient pas le coup, même quand il s’agissait uniquement de servir du contenu statique.
La surveillance coûte cher
La complexité du Web cache en effet également cette activité de surveillance, pratiquée aussi bien par les entreprises privées que par les États. Autrefois, acheter un journal à un kiosque et le lire étaient des activités largement privées. Aujourd’hui, toute activité sur le Web est enregistrée et sert à nourrir les bases de données du monde de la publicité, ou les fichiers des États. Comme exemple des informations envoyées par votre navigateur, sans que vous en ayez clairement connaissance, on peut citer bien sûr les fameux cookies. Ce sont des petits fichiers choisis par le site Web et envoyés à votre navigateur. Celui-ci les stockera et, lors d’une visite ultérieure au même site Web, renverra le cookie. C’est donc un outil puissant de suivi de l’utilisateur. Et ne croyez pas que, si vous visitez un site Web, seule l’organisation derrière ce site pourra vous pister. La plupart des pages Web incluent en effet des ressources extérieures (images, vidéos, boutons de partage), pas forcément chargés depuis le site Web que vous visitez et qui ont eux aussi leurs cookies. La loi Informatique et Libertés (et, aujourd’hui, le RGPD) impose depuis longtemps que les utilisateurs soient prévenus de ce pistage et puissent s’y opposer, mais il a fallu très longtemps pour que la CNIL tape sur la table et impose réellement cette information des utilisateurs, le « bandeau cookies ». Notez qu’il n’est pas obligatoire. D’abord, si le site Web ne piste pas les utilisateurs, il n’y a pas d’obligation d’un tel bandeau, ensuite, même en cas de pistage, de nombreuses exceptions sont prévues.
Un bandeau cookies. Notez qu’il n’y a pas de bouton Refuser.
Les bandeaux cookies sont en général délibérément conçus pour qu’il soit difficile de refuser. Le but est que l’utilisateur clique rapidement sur « Accepter » pour en être débarrassé, permettant ainsi à l’entreprise qui gère le site Web de prétendre qu’il y a eu consentement.
Désolé de la longueur de ce préambule, d’autant plus qu’il est très possible que, en tant que lectrice ou lecteur du Framablog, vous soyez déjà au courant. Mais il était nécessaire de revenir sur ces problèmes du Web pour mieux comprendre les projets qui visent à corriger le tir. Notez que les évolutions néfastes du Web ne sont pas qu’un problème technique. Elles sont dues à des raisons économiques et politiques et donc aucune approche purement technique ne va résoudre complètement le problème. Cela ne signifie pas que les techniciens et techniciennes doivent rester les bras croisés. Ils et elles peuvent apporter des solutions partielles au problème.
Bloquer les saletés
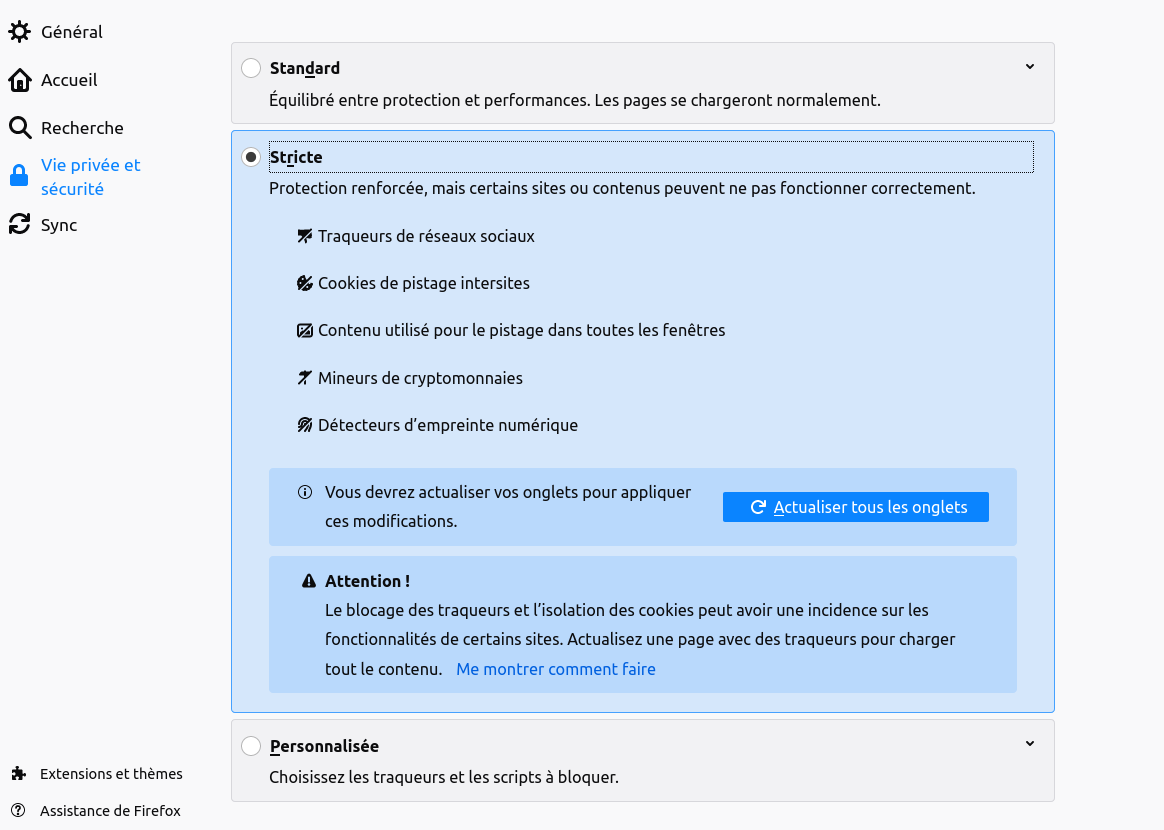
Première approche possible vers un Web plus léger, tenter de bloquer les services néfastes. Tout bon navigateur Web permet ainsi un certain contrôle de l’usage des cookies. C’est par exemple ce que propose Firefox dans une rubrique justement nommée « Vie privée et sécurité ».
Le menu de Firefox pour contrôler notamment les cookies
On peut ainsi bloquer une partie du système de surveillance. Cette approche est très recommandée mais notez que Firefox vous avertit que cela risque d’ « empêcher certains sites de fonctionner ». Cet avertissement peut faire hésiter certains utilisateurs, d’autant plus qu’avec les sites en question, il n’y aura aucun message clair, uniquement des dysfonctionnements bizarres. La plupart des sites Web commerciaux sont en effet développés sans tenir compte de la possibilité que le visiteur ait activé ces options. Si le site de votre banque ne marche plus après avoir changé ces réglages, ne comptez pas sur le support technique de la banque pour vous aider à analyser le problème, on vous dira probablement uniquement d’utiliser Google Chrome et de ne pas toucher aux réglages. D’un côté, les responsables du Web de surveillance disent qu’on a le choix, qu’on peut changer les réglages, d’un autre côté ils exercent une pression sociale intense pour qu’on ne le fasse pas. Et puis, autant on peut renoncer à regarder le site Web d’un journal lorsqu’il ne marche pas sans cookies, autant on ne peut guère en faire autant lorsqu’il s’agit de sa banque.
De même qu’on peut contrôler, voire débrayer les cookies, on peut supprimer le code Javascript. À ma connaissance, Firefox ne permet pas en standard de le faire, mais il existe une extension nommée NoScript pour le faire. Comme avec les cookies, cela posera des problèmes avec certains sites Web et, pire, ces problèmes ne se traduiront pas par des messages clairs mais par des dysfonctionnements. Là encore, peu de chance que le logiciel que l’entreprise en question a chargé de répondre aux questions sur Twitter vous aide.
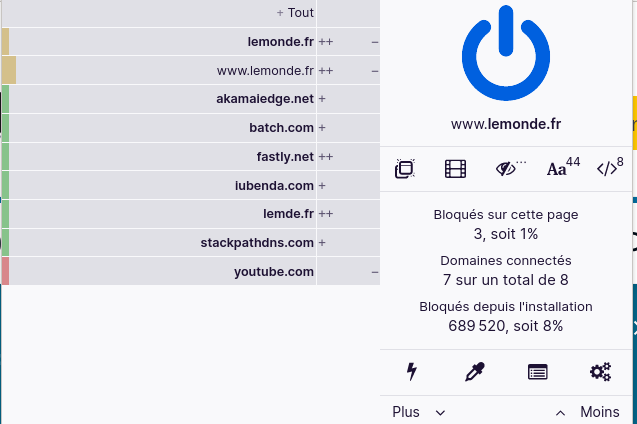
Enfin, un troisième outil pour limiter les divers risques du Web est le bloqueur de publicité. (Personnellement, j’utilise uBlock Origin.)
uBlock Origin sur le site du Monde, où il a bloqué trois pisteurs et publicités. On voit aussi à gauche la liste des sites chargés automatiquement par votre navigateur quand vous regardez Le Monde.
Absolument indispensable à la fois pour éviter de consacrer du temps de cerveau à regarder les publicités, pour la sécurité (les réseaux de distribution de la publicité sont l’endroit idéal pour diffuser du logiciel malveillant) et aussi pour l’empreinte environnementale, le bloqueur empêchant le chargement de contenus qui feront travailler votre ordinateur pour le profit des agences de publicité et des annonceurs.
Un navigateur Web léger ?
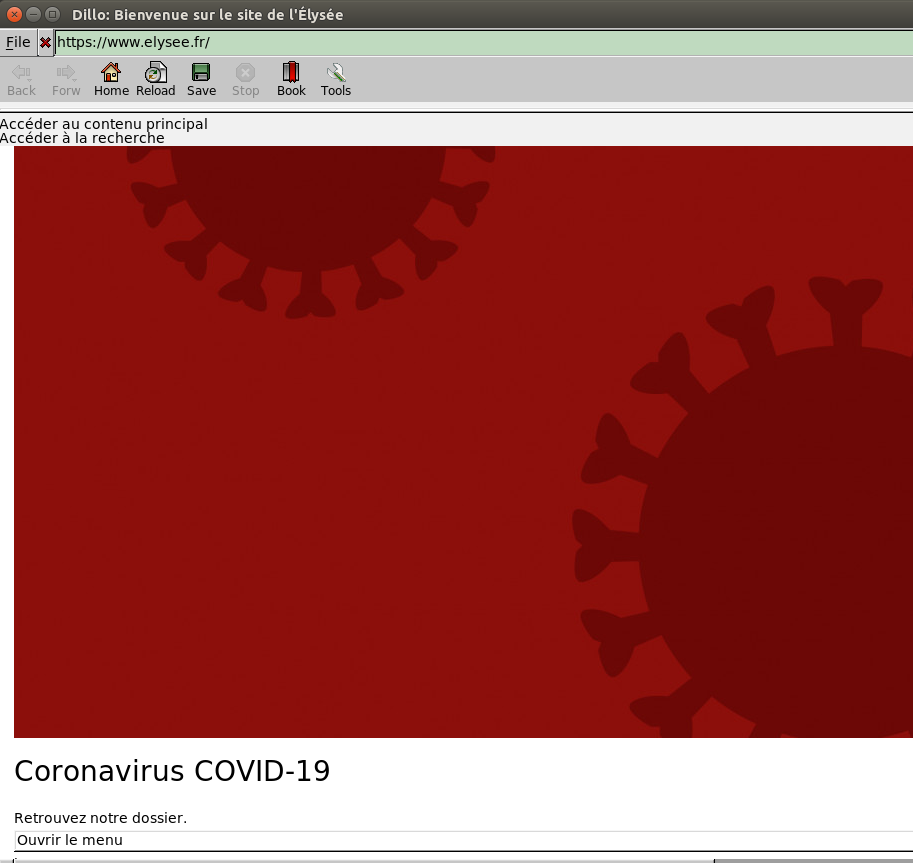
Une solution plus radicale est de changer de navigateur Web. On peut ainsi préférer le logiciel Dillo, explicitement conçu pour la légèreté, les performances et la vie privée. Dillo marche parfaitement avec des sites Web bien conçus, mais ceux-ci ne sont qu’une infime minorité. La plupart du temps, le site sera affiché de manière bizarre. Et on ne peut pas le savoir à l’avance ; naviguer sur le Web avec Dillo, c’est avoir beaucoup de mauvaises surprises et seulement quelques bonnes (le Framablog, que vous lisez en ce moment, marche très bien avec Dillo).
Le site de l’Élysée vu par Dillo. Inutilisable (et pas par la faute de Dillo mais par le choix de l’Élysée d’un site spectaculaire plutôt qu’informatif).
Autre navigateur « alternatif », le Tor Browser. C’est un Firefox modifié, avec NoScript inclus et qui, surtout, ne se connecte pas directement au site Web visité mais passe par plusieurs relais du réseau Tor, supprimant ainsi un moyen de pistage fréquent, l’adresse IP de votre ordinateur. Outre que certains sites ne réagissent pas bien aux réglages du Tor Browser, le passage par le réseau Tor se traduit par des performances décrues.
Toutes ces solutions techniques, du bloqueur de publicités au navigateur léger et protecteur de la vie privée, ont un problème commun : elles sont perçues par les sites Web comme « alternatives » voire « anormales ». Non seulement le site Web risque de ne pas fonctionner normalement mais surtout, on n’est pas prévenu à l’avance, et même après on n’a pas de diagnostic clair. Le Web, pourtant devenu un écosystème très complexe, n’a pas de mécanismes permettant d’exprimer des préférences et d’être sûr qu’elles sont suivies. Certes, il existe des techniques comme l’en-tête « Do Not Track » où votre navigateur annonce qu’il ne souhaite pas être pisté mais il est impossible de garantir qu’il sera respecté et, vu le manque d’éthique de la grande majorité des sites Web, il vaut mieux ne pas compter dessus.
Gemini, une solution de rupture
Cela a mené à une approche plus radicale, sur laquelle je souhaitais terminer cet article, le projet Gemini. Gemini est un système complet d’accès à l’information, alternatif au Web, même s’il en reprend quelques techniques. Gemini est délibérément très simple : le protocole, le langage parlé entre le navigateur et le serveur, est très limité, afin d’éviter de transmettre des informations pouvant servir au pistage (comme l’en-tête User-Agent du Web) et il n’est pas extensible. Contrairement au Web, aucun mécanisme n’est prévu pour ajouter des fonctions, l’expérience du Web ayant montré que ces fonctions ne sont pas forcément dans l’intérêt de l’utilisateur. Évidemment, il n’y a pas l’équivalent des cookies. Et le format des pages est également très limité, à la fois pour permettre des navigateurs simples (pas de CSS, pas de Javascript), pour éviter de charger des ressources depuis un site tiers et pour diminuer la consommation de ressources informatiques par le navigateur. Il n’y a même pas d’images. Voici deux exemples de navigateurs Gemini :
Le client Gemini LagrangeLe même site Gemini, vu par un client différent, Elpher
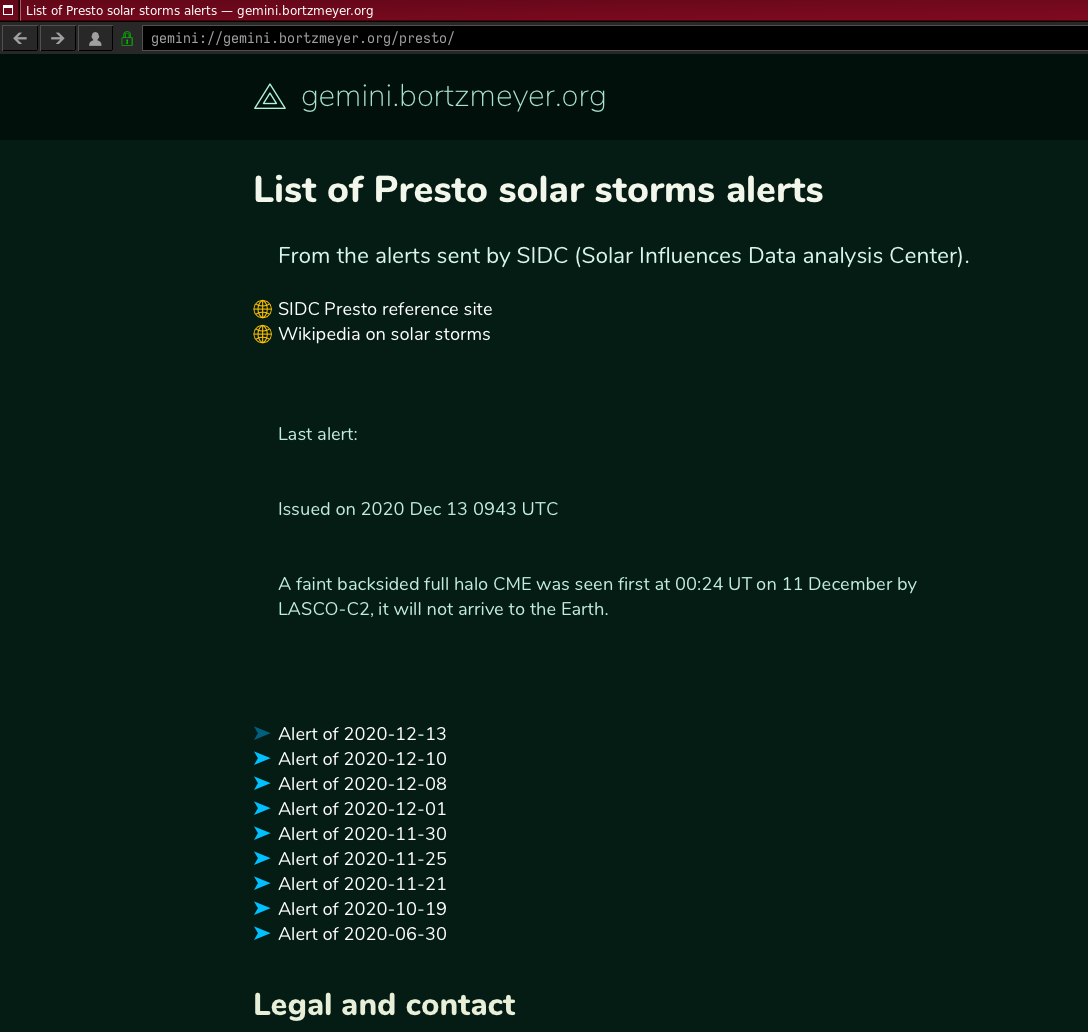
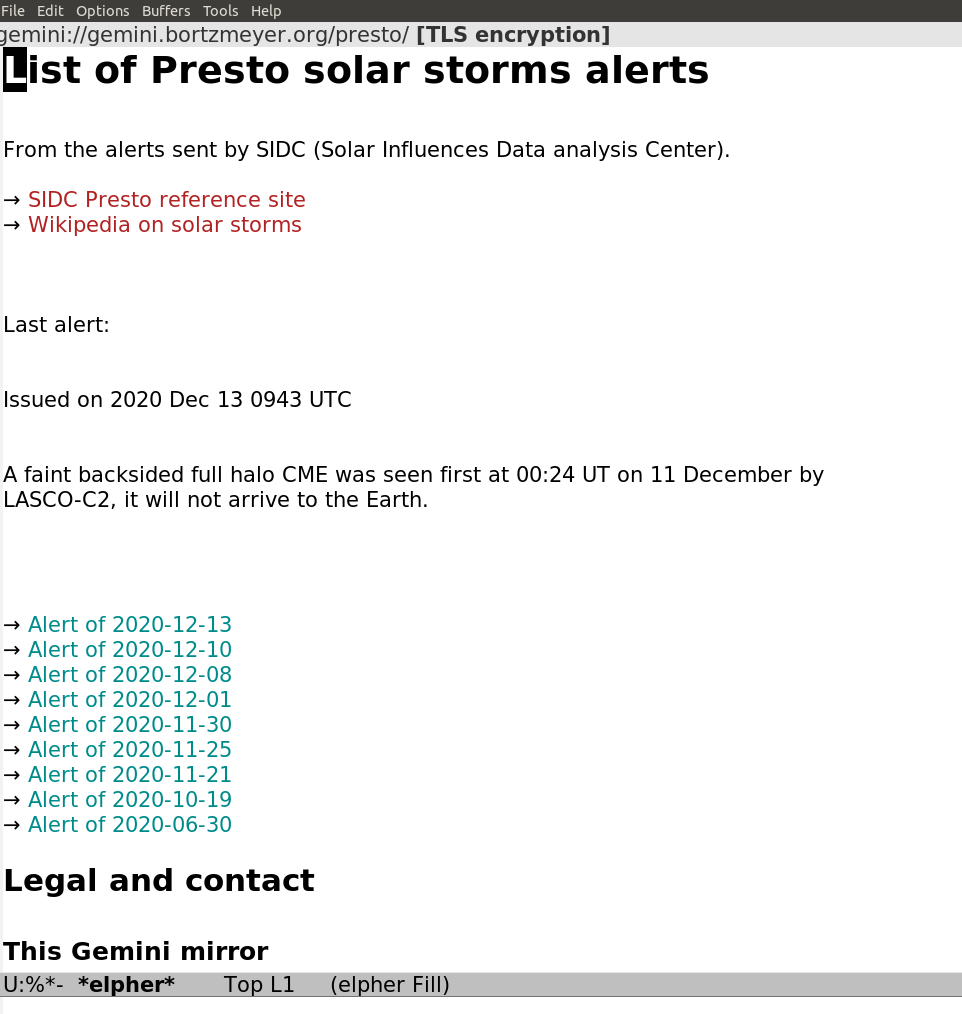
Gemini est un système récent, s’inspirant à la fois de systèmes anciens (comme le Web des débuts) et de choses plus récentes (ainsi, contrairement au Web, le chiffrement du trafic, pour compliquer la surveillance, est systématique). Il reprend notamment le concept d’URL donc par exemple le site d’informations sur les alertes de tempêtes solaires utilisé plus haut à titre d’exemple est gemini://gemini.bortzmeyer.org/presto/. Gemini est actuellement en cours de développement, de manière très ouverte, notamment sur la liste de diffusion publique du projet. Tout le monde peut participer à sa définition. (Mais, si vous voulez le faire, merci de lire la FAQ d’abord, pour ne pas recommencer une question déjà discutée.) Conformément aux buts du projet, écrire un client ou un serveur Gemini est facile et des dizaines de logiciels existent déjà. Le nom étant une allusion aux missions spatiales étatsuniennes Gemini, mais signifiant également « jumeaux » en latin, beaucoup de ces logiciels ont un nom qui évoque le spatial ou la gémellité. Pour la même raison spatiale, les sites Gemini se nomment des capsules, et il y en a actuellement quelques centaines opérationnelles. (Mais, en général, avec peu de contenu original. Gemini ressemble pour l’instant au Web des débuts, avec du contenu importé automatiquement d’autres services, et du contenu portant sur Gemini lui-même.)
On a vu que Gemini est une solution très disruptive et qui ne sera pas facilement adoptée, tant le marketing a réussi à convaincre que, sans vidéos incluses dans la page, on ne peut pas être vraiment heureux. Gemini ne prétend pas à remplacer le Web pour tous ses usages. Par exemple, un CMS, logiciel de gestion de contenu, comme le WordPress utilisé pour cet article, ne peut pas être fait avec Gemini, et ce n’est pas son but. Son principal intérêt est de nous faire réfléchir sur l’accès à l’information : de quoi avons-nous besoin pour nous informer ?
Sur Android, il y a aussi Duckduckgo brower ou Firefox focus : ça accepte tout et efface toute trace de navigation à la demande.
Sur F-droid, il y a un dépôt avec le navigateur Bromite qui repose sur le moteur de Chromium, mais accès sécurité vie privée.
Toujours sur F-droid (ne pas prendre la version sur le store Google), il existe Blokada, dont le but est de bloquer les régies publicitaires.
Mon but n’était pas de lister la totalité des navigateurs « alternatifs », d’autant plus que, contrairement à Dillo, ceux-ci ont l’inconvénient de ne pas être trop différents puisqu’ils reposent sur un des « gros » navigateurs existants (par exemple Firefox Focus envoie le User-Agent, et d’autres techniques de « fingerprinting »). Et, surtout, l’article explique pourquoi juste utiliser un navigateur « vertueux » n’est pas une solution parfaite.
Reno
|
Blokada, PiHole et sans doute d’autres solutions.
Tom
|
La dernière version de dyllo date de 2015. Si utiliser un navigateur web léger, c’est utiliser un navigateur web obsolète qui ne fonctionnera pas sur la plupart des sites, c’est pas génial comme conseil. Autant conseiller de ne plus naviguer sur Internet.
Votre commentaire est intéressant par les pré-supposés qu’il révèle. D’abord, le caractère obsolète de Dillo. C’est justement un des problèmes du Web qu’un logiciel datant de 2015 ne fonctionne plus. Il n’y a aucune raison que ce soit le cas. HTML, CSS et Javascript sont bien plus anciens que cela. Que le logiciel de 2015 ne puisse pas profiter des nouveautés, c’est normal, qu’il ne puisse pas afficher les sites Web, cela ne l’est pas. Quelle technique ultra-moderne utilise le site Web de l’Élysée pour ne pas être affichable par Dillo ? Qu’on considère comme « obsolète » un outil de 2015 est un problème. Cette course permanente à l’armement, à la toute dernière nouveauté, est justement un des problèmes du numérique. Le choix de Gemini de faire un protocole qui n’évoluera pas (ou, plus exactement, qui a été conçu pour être difficile à faire évoluer) est un choix délibéré, justement pour éviter cette obsolescence programmée.
Ensuite, je me demande quelle erreur ai-je fait dans mon article pour que vous n’ayez pas vu que, justement, j’estime que Dillo n’est pas une solution satisfaisante, précisément parce que le navigateur léger ne sait pas à l’avance si le site Web sera visible ou pas. C’est ce qui motive les solutions radicales comme Gemini.
Enfin, le raisonnement « si on utilise Dillo, autant ne plus naviguer sur Internet [sic, puisqu’il s’agit de toute façon du Web, pas de l’Internet] » est du même niveau que de répondre à toute critique de la politique énergétique « ah, vous voulez retourner à la bougie ». On peut critiquer le système existant sans vouloir revenir des dizaines d’années en arrière.
Reno
|
Sinon : links, lynx, w3m, elinks…
Mais ce n’est pas « user friendly ».
Le but n’est-il pas aussi de rendre le tout accessible au plus grand nombre ?
Si. Cela implique donc des navigateurs légers, pouvant tourner sur de vieilles machines, rapides, et ne faisant pas de la lecture un parcours du combattant (vidéos qui se lancent seules, fenêtres-polichinelles à fermer, pubs à ignorer, etc).
Zatalyz
|
J’ai commencé à utiliser links, puis elinks, pour vérifier certains aspects de l’accessibilité de mes sites web (est-ce que ça reste « lisible » même sans les zigougouis ? ). Finalement, j’ai trouvé ça vraiment sympa. Évidement on ne navigue pas sur tout le web avec ça, mais les sites que j’utilise au quotidien fonctionnent sous ces navigateurs vraiment bizarres, et ça fait moins de distraction. C’est devenu pour moi un critère de qualité : si je peux naviguer sur un site avec elinks, alors c’est un « bon » site !
Je crois que c’est un enjeu à chercher quand on développe un site web : faire que le html seul suffise à avoir un site utilisable et confortable. Une fois cette base en place, on peut toujours s’amuser avec le css et le javascript, tant que ça ne casse pas la base. Ainsi on peut avoir des sites flamboyants si on aime les glitters, pardon les vidéos ! mais on reste avec quelque chose d’utilisable par tout le monde.
Car on a une vraie responsabilité du côté des développeurs de site web. C’est un peu de notre faute que le web devienne un endroit malsain, chaque fois qu’on choisit de faire le fainéant en suivant les chemins bien tracés : utiliser des CDN, de la pub, des frameworks énormes pour afficher trois pauvres informations, etc… J’ai encore du boulot, certains des CMS que j’utilise ont du progrès à faire, mais je travaille peu à peu dans ce sens : comprendre mieux mon coin de web, plutôt que de cliquer et ne pas poser de question…
« …très peu d’organisation pouvant aujourd’hui développer un navigateur Web. »
C’est quelque chose comme ça que j’ai dit (en anglais) ici. Je l’appelle « standards bloat ».
pimou
|
Bien d’accord avec vous. Il faudrait prôner un web light et vertueux, des technologies simples, légères et efficaces. J’ignorais l’existence du protocole gemini, une bonne nouvelle !
nojhan
|
Je trouve l’idée sympa, mais je crois qu’on pourrait dire que c’est un essai transformé quand on pourra avoir accès à Wikipédia avec.
Cependant, le refus des hyperliens dans le texte me semble être une limitation difficile à surmonter. Mais peut-être qu’en étant créatif ?
De la même façon, serait-il possibile d’éditer un article ? (après tout, ça n’est que du wikicode, derrière)
Pour Wikipédia, c’est possible, mais pas sans travail. Première possibilité, servir le text/html sur Gemini. Avantage : moins de travail, on ne convertit pas les articles. Inconvénient : peu de navigateurs Gemini savent afficher le HTML (ce qui est logique). Deuxième possibilité, convertir le Wikicode en gemtext. C’est faisable légalement et techniquement mais le wikicode utilise pas mal de choses qui n’ont pas d’équivalent en gemtext donc ce sera « moins bien » que sur le Web.
Pour l’édition de code, le gemtext étant très simple, une édition en local suivie d’un rsync suffit. Encore plus que pour HTML, un éditeur spécialisé n’est pas nécessaire.
Richard
|
Merci Stéphane pour la pertinence des informations apportées et les pistes pratiques fournies.
Pipou
|
Merci pour cet article de qualité, avec amha, juste ce qu’il faut de détail pour comprendre pour un quidam comme moi.
Je pense comprendre le but de tout cela, mais j’ai un doute sur la méthode :
* Il faut pouvoir mettre à disposition un web simple et frugal.
* ceci ne peut concerner qu’une part limité du web (pas les sites commerciaux)
* ça peut être fait aujourd’hui avec un site HTML simple, sans javascript, sans cookies et visible dans un navigateur actuel ou « frugal »
Qu’est-ce qu’un nouveau protocole peut apporter ? Si demain il existe et est bien implanté, vais-je utiliser deux outils pour accéder au web ? Les navigateurs leaders ne vont-il pas développer un moteur de rendu Gemini ?
Ceux qui veulent mettre a disposition un site d’information simple sur Gemini ne vont-ils pas créer son pendant html ?
Yaacov
|
Commentaires intéressants je suis également preneurs des réponses !
Merci Stéphane pour cet article très bien ficelé ;)
Ce que le nouveau système (protocole + format) Gemini apporte, c’est un espace où on est sûr que tout est visible avec son navigateur simple, et qu’il y aura le moins de surveillance possible. Sur le Web, on ne sait jamais à l’avance ce sur quoi on va tomber (un site Web bien fichu, ou une catastrophe).
Il n’y aura pas besoin de « deux outils » pour naviguer sur le Web car Gemini, ce n’est pas le Web, c’est un autre espace.
Les navigateurs Web peuvent évidemment intégrer Gemini, ils sont déjà tellement obèses que cela n’aggraverait pas grand’chose. Mais je n’ai pas vu de plan en ce sens.
Pour le contenu, en effet, si on a le contenu dans un langage structuré, on peut produire une version HTML *et* une version gemtext. C’est un peu de travail, quand même et, par exemple, je ne l’ai pas (encore) fait pour mon propre blog.
Sidonie
|
Je suis 100 % d’accord avec cet article. Il m’a fallut voir ma mère (84 ans) se débattre avec les sollicitations constantes, les fenêtres contextuelles qui viennent en permanence ajouter une proposition, une demande, qui nécessitent de trouver cachée en haut à droite la croix ou en bas à gauche le bouton qui permettra de s’en débarrasser pour enfin arriver à l’endroit qu’on souhaitait.
Oui, le web est devenu très compliqué et ressemble de plus en plus à une course d’obstacles qui laisse de plus en plus de personnes sur le bord de la route.
Je vous recommande également cette génialissime extension : « I don’t care about cookies » qui refuse à ma place tous les cookies sans que j’ai besoin à chaque fois de cliquer sur 3 fenêtres. Depuis que je l’ai installée, le web a pris une nouvelle figure, et moi aussi :-)
Baloo
|
En fait ‘I don’t care about coockies’ ne refuse pas les coockies mais auc contraire les accepte tous par défaut.
L’extension qui refuse les coockies par défaut c’est ‘ninja coockie’.
cayenne
|
Merci pour le partage. Il y a quelques mois, j’ai cherché une extension et effectivement la plus par des extensions accept tous et ce n’est pas ce que l’on veux. je viens de l’installer pour tester. j’ai désactivé le filtre EasyList Cookie sur ublock origin. je vais tester pour voir.
Par contre, dommage qu’elle n’est pas opensource. Elle devrait l’être bientôt.
LoverDose
|
Intéressé par de tels articles et « en même temps » incapable de mettre en pratique. J’adhère à 100 % sur les principes de précautions, Framasoft, LaQuadratureduNet, etc… Seulement voilà, en tant que Boomer, peu anglophone, mon intellect sature. VPN*, Ublock Origin, Doubles Identifications foireuses (Discord*), NoScript*, Firefox(au pluriel), linux*, Clouds, et même l’impossibilité d’utiliser avec une box mon tel fixe, des F.A.I. sourds, des Gestionnaires de mots de passe, les Réseaux dits Sociaux, FB*, Twitter, Pinterest*, Linkdin*, et même des émojis qui ne s’affichent pas correctement sur mon ordi à cause d’un OS ?(obsolète ou plus précisément non mis à jour), Des sites où l’on peut se procurer de bons ebook si l’on dispose d’un OS particulier à l’exclusion de tout autre (config box ?), les spams qu’on ne peut guère éviter… Tout ça (me) rend dingue et nous prend un temps incroyable ! sans parler de Twitch et autres plateformes.
Seul sentiment de victoire c’est d’avoir réussi sans vraiment savoir comment à ôter les pubs sur YT et pendant quelques temps utiliser les framapads (ce qui n’a pas été si facile que ça).
(*)= Non utilisé, ou abandonné (sauf Linkdin qui refuse le droit à l’oubli)
Désolé pour le hors sujet. Prenez soin de vous. Amitiés.
C’est très loin d’être hors sujet ! Qu’on galère avec Internet « en général », ou avec la technologie en tout cas, c’est une chose, mais le web est supposément utilisable par tout le monde, surtout qu’on nous pousse à faire nos démarches administratives et commerciales par ce biais.
baloo
|
Le site de la CAF a été mis hors service pour implémenter le nouveau calcul de l’APL du 1 au 3 janvier inclus. Les gens qui font la maintenance de ce site doivent le mettre hors réseau pour pouvoir travailler dessus ? ! ! ! !
Comme à partir du 1er les allocataires se connectent à leur compte CAF pour savoir si leur(s) allocation(s) vont être versées et sinon pourquoi et dans ce cas comment y remédier – ce qui n’est pas une mince affaire depuis la crise du Covid -, le 4 au matin, le site affichait une belle page erreur 503 car incapable de supporter la charge des connexions des usagers.
Votre expérience est celle de beaucoup d’utilisateurs et trices. Y compris ceux et celles qui sont des professionnels de l’informatique, car ce n’est pas uniquement une question de compétence, mais aussi de temps libre (et de charge mentale, pour prendre un terme à la mode).
C’est justement pour cela que je pense que la réponse souvent entendue « les gens n’ont qu’à installer [logiciel X] et [logiciel Y], s’ils ne le font pas tant pis pour eux » n’est pas satisfaisante.
gvdmoort
|
Pour étoffer le sujet, je vous suggère un article où l’on offrirait un florilège des sites pratiquant un usage malveillant de la proposition de paramétrer les cookies. La situation est atterrante, y compris pour des sites relevant du secteur public. Je prends en exemple celui de la RTBF, radio et télévision publique francophone de Belgique. Jusqu’il y a peu, le bandeau affichant la proposition d’effectuer ce choix occupait les 15 % inférieurs de l’écran. On pouvait se contenter de le faire disparaître en augmentant la taille de la fenêtre et l’ignorer. Il est passé à 80 % de la hauteur ( !), rendant impossible de lire la page. Pire, il s’affiche à chaque fois qu’on ouvre un lien dans un nouvel onglet, imposant à chaque fois trois actions supplémentaires : « configurer »,« tout refuser »,« enregistrer ».
Ce qui me sidère, c’est d’imaginer le contenu des réunions de travail entre les développeurs et les business-managers : « Dites, le site permet un peu trop facilement de ne pas être espionné. vous pourriez compliquer la tâche des utilisateurs ? ». Triste monde…
Internet est compliqué. Le Web se limitant pour une grande partie d’utilisateurs à Google ou à FB ne leur semble pas plus compliqué. Ce qui n’est pas simple c’est quand on se pose des questions. Les cookies n’ont posé de problèmes qu’à l’apparition des bannières suite au RGPD. Avant madame et monsieur toutlmonde n’en avaient jamais entendu parler. Les pubs les gênent surtout lorsqu’elles apparaissent en pop-up… Peu de personnes ont reçu les bonnes informations pour naviguer sans embarquer une flopée de pages sur le site ou elles vont.Puis si elles grognent de trop, on va leur proposer un bloqueur de pub qui a passé un marché avec des régies publicitaires. Et pourtant la naissance du Web a été l’occasion pour les non informaticiens l’occasion de pouvoir utiliser et de démocratiser internet. C’est donc bien dommage qu’il s’alourdisse.
Quand à gemini ! J’ai installé le navigateur Lagrange avec l’aide d’un copain de mastodon, en suivant des consignes à distance. pour celleux qui sont sous Linux et qui veulent savoir comment faire, j’ai recopié les étapes sur Framacolibri https://framacolibri.org/t/gemini/10492
En tout cas je suis charmée par cette découverte.
grz
|
Bonjour
Article intéressant et la techno Gemini semble répondre à un cas d’usage du Web. Mais qui, selon moi, se limite à la publication de données techniques qui nécessitent effectivement un affichage épuré.
Je comprends l’intérêt et les problèmes soulevés, Gemini est délibérément ultra-light pour tenter d’y répondre en apportant une alternative, mais au point qu’on ne peut afficher une image sur sa page.
Sans vouloir faire le rabat-joie, les images sont une forme d’art et d’expression tout comme l’écriture. Ne pas permettre d’afficher des images sur une techno alternative à un navigateur Web c’est censurer une forme d’art et d’expression. Je pense juste aux talentueux dessinateurs dont j’ai l’occasion de contempler les œuvres qui n’auraient absolument aucun intérêt à adopter une telle technologie.
Certains me répondront : « Mais si, il suffit qu’ils mettent un lien de téléchargement vers l’image ! »
Ce à quoi je répondrais : « Lorsque je visite un site galerie, une exposition virtuelle, je n’ai pas des liens à cliquer dans tous les sens pour télécharger une image, mais une galerie d’images qui s’affichent de manière intuitive. »
Sinon on parle des photos/musiques/vidéos ? (ou c’est encore trop lourd comme forme d’expression ?) :)
Ce n’est que mon avis : au lieu de vouloir refaire le Web ou d’en créer encore une alternative, pourquoi ne pas s’attaquer directement à la source du problème ? Sensibiliser les développeurs, intégrateurs, webmaster, directeurs de publication aux problèmes soulevés dans cet article ?
« pourquoi ne pas s’attaquer directement à la source du problème ? Sensibiliser les développeurs, intégrateurs, webmaster, directeurs de publication aux problèmes soulevés dans cet article » Ah mais allez-y. Beaucoup d’articles publiés sur le Framablog sont d’ailleurs en ce sens. Ainsi que l’excellente série « 24 jours de Web » https://www.24joursdeweb.fr/
Mais, personnellement, je suis un peu fatigué de me battre contre les moulins. Beaucoup de gens très bien (par exemple les participants de Paris Web) le font depuis des années, avec des résultats limités.
Surtout, imaginons que 50 % du Web supprime les cookies, le pistage, les images inutiles et tout ça, cela ne suffirait pas : l’utilisateur ne pourrait pas savoir à l’avance s’il ne va pas tomber sur les autres 50 %.
Loz
|
À moitié pour la blague : quelle différence avec le WAP ?
Merci beaucoup pour cette découverte ! Gemini semble à la fois répondre au problème des sites web de plus en plus gourmands en ressources et consommateurs en énergie, ainsi qu’à la surveillance généralisée et son modèle mortifère. Chouette !
Après avoir installé Lagrange et navigué sur gemini, j’ai vraiment apprécié ce nouvel espace du net. D’où ma question : on fait comment pour créer un serveur gemini ou, plus simplement, une ou des capsules ? Des ressources à nous conseiller svp ? en version « pour les nuls » ?
Il n’y a pas encore de documentation orientée « large public » pour la création d’une capsule. Distinguons deux cas, l’écriture du contenu et l’installation/gestion du serveur.
Pour l’écriture de contenu, le format gemtext est trivial et on peut facilement écrire ses textes à la main. Pour assurer une certaine homogénéité des pages (présence d’un texte identique à la fin de toute les pages, par exemple), il existe déjà des outils qui assurent cette homogénéité à partir d’un gabarit mais je n’en ai testé aucun.
Pour l’installation et la gestion du serveur, les différences avec le Web ne sont pas énormes : il faut une machine allumée en permanence, un nom de domaine, etc. Globalement, cela prend moins de ressources que le Web (sauf si on fait des pages dynamiques) donc le plus petit des Raspberry Pi suffit. J’ai utilisé les serveurs Agate et Gemserv et tous les deux sont triviaux à installer (mais pas forcément à maintenir à jour car ils ne sont typiquement pas paquagés pour votre systsème d’exploitation). Si on ne veut pas faire d’administration système du tout, il existe des services d’hébergement comme gemini://flounder.online/.
Voilà, désolé, ce n’est pas vraiment une documentation pour les débutants mais cela donne une idée des points à regarder avant de se lancer.
Bob Lafrite
|
Plus riche, ça veut forcément dire plus compliqué, plus dépendant. C’est un problème d’entropie.
Les navigateurs et le web est plus compliqué parce qu’ils « font » plus de choses, c’est tout. Les normes (HTML, etc.) évoluent très vite. On ne peut pas utiliser un navigateur d’il y a 10 ans sur la plupart des sites actuels. C’est pas parce que les GAFAM sont des méchants, c’est que ces technologies sont très loin d’avoir atteint un point de stabilité (contrairement à d’autres par exemple le four à micro ondes, je sais pas) et qu’il sont améliorables.
C’est comme quand les utilisateurs comparaient leur télephone ou leur voiture avec un ordinateur en disant qu’ils avaient moins de problème, de bugs, etc. Bien sûr, car ce sont des sytèmes infiniment moins complexes qu’un ordinateur. Depuis que les téléphones sont devenus smart et que les voitures sont éléctroniques, ils ont les même problèmes. Mais tout le monde ne veut pas rouler en 4L de 1970 qui se réparait avec un chewing gum et 3 boulons, mais n’avait pas de chauffage, de vitre électrique, d’auto radio, de caméra de recul, etc.
Votre proposition c’est un peu comme retourner 200 ans en arrière, plus d’électricité, plus de voiture, plus d’internet :-) Alors oui, tout serait beaucoup plus simple.

 Je ne parle pas de la complexité pour l’utilisateur, par exemple des problèmes qu’il ou elle peut avoir avec telle ou telle application Web, ou tel formulaire incompréhensible ou excluant. Non, je parle de la complexité des nombreuses technologies sous-jacentes. Alors, si vous n’êtes pas technicien·ne, vous avez peut-être envie d’arrêter votre lecture ici en pensant qu’on ne parlera que de technique. Mais ce n’est pas le cas, cet article est pour tous et toutes. (Ceci dit, si vous arrêtez votre lecture pour jouer avec le chat, manger un bon plat, lire un livre passionnant ou faire des câlins à la personne appropriée, cela ne me dérange pas et je vous souhaite un agréable moment.)
Mais revenons à l’objection « OK, les techniques utilisées dans le Web sont compliquées mais cela ne concerne que les développeuses et développeurs, non ? » Eh bien non car cette complication a des conséquences pour tous et toutes. Elle se traduit par des logiciels beaucoup plus complexes, donc elle réduit la concurrence, très peu d’organisations pouvant aujourd’hui développer un navigateur Web. Elle a pour conséquence de rendre l’utilisation du Web plus lente : bien que les machines et les réseaux aient nettement gagné en performance, le temps d’affichage d’une page ne cesse d’augmenter. Passer à la fibre ou à la 5G ne se traduira pas forcément par un gain de temps, puisque ce sont souvent les calculs nécessaires à l’affichage qui ralentissent la navigation. Et enfin cette complication augmente l’empreinte environnementale du Web, en imposant davantage d’opérations aux machines, ce qui pousse au remplacement plus rapide des terminaux.
Je ne parle pas de la complexité pour l’utilisateur, par exemple des problèmes qu’il ou elle peut avoir avec telle ou telle application Web, ou tel formulaire incompréhensible ou excluant. Non, je parle de la complexité des nombreuses technologies sous-jacentes. Alors, si vous n’êtes pas technicien·ne, vous avez peut-être envie d’arrêter votre lecture ici en pensant qu’on ne parlera que de technique. Mais ce n’est pas le cas, cet article est pour tous et toutes. (Ceci dit, si vous arrêtez votre lecture pour jouer avec le chat, manger un bon plat, lire un livre passionnant ou faire des câlins à la personne appropriée, cela ne me dérange pas et je vous souhaite un agréable moment.)
Mais revenons à l’objection « OK, les techniques utilisées dans le Web sont compliquées mais cela ne concerne que les développeuses et développeurs, non ? » Eh bien non car cette complication a des conséquences pour tous et toutes. Elle se traduit par des logiciels beaucoup plus complexes, donc elle réduit la concurrence, très peu d’organisations pouvant aujourd’hui développer un navigateur Web. Elle a pour conséquence de rendre l’utilisation du Web plus lente : bien que les machines et les réseaux aient nettement gagné en performance, le temps d’affichage d’une page ne cesse d’augmenter. Passer à la fibre ou à la 5G ne se traduira pas forcément par un gain de temps, puisque ce sont souvent les calculs nécessaires à l’affichage qui ralentissent la navigation. Et enfin cette complication augmente l’empreinte environnementale du Web, en imposant davantage d’opérations aux machines, ce qui pousse au remplacement plus rapide des terminaux.


Reno
Sur Android, il y a aussi Duckduckgo brower ou Firefox focus : ça accepte tout et efface toute trace de navigation à la demande.
Sur F-droid, il y a un dépôt avec le navigateur Bromite qui repose sur le moteur de Chromium, mais accès sécurité vie privée.
Toujours sur F-droid (ne pas prendre la version sur le store Google), il existe Blokada, dont le but est de bloquer les régies publicitaires.
Stéphane Bortzmeyer
Mon but n’était pas de lister la totalité des navigateurs « alternatifs », d’autant plus que, contrairement à Dillo, ceux-ci ont l’inconvénient de ne pas être trop différents puisqu’ils reposent sur un des « gros » navigateurs existants (par exemple Firefox Focus envoie le User-Agent, et d’autres techniques de « fingerprinting »). Et, surtout, l’article explique pourquoi juste utiliser un navigateur « vertueux » n’est pas une solution parfaite.
Reno
Blokada, PiHole et sans doute d’autres solutions.
Tom
La dernière version de dyllo date de 2015. Si utiliser un navigateur web léger, c’est utiliser un navigateur web obsolète qui ne fonctionnera pas sur la plupart des sites, c’est pas génial comme conseil. Autant conseiller de ne plus naviguer sur Internet.
Stéphane Bortzmeyer
Votre commentaire est intéressant par les pré-supposés qu’il révèle. D’abord, le caractère obsolète de Dillo. C’est justement un des problèmes du Web qu’un logiciel datant de 2015 ne fonctionne plus. Il n’y a aucune raison que ce soit le cas. HTML, CSS et Javascript sont bien plus anciens que cela. Que le logiciel de 2015 ne puisse pas profiter des nouveautés, c’est normal, qu’il ne puisse pas afficher les sites Web, cela ne l’est pas. Quelle technique ultra-moderne utilise le site Web de l’Élysée pour ne pas être affichable par Dillo ? Qu’on considère comme « obsolète » un outil de 2015 est un problème. Cette course permanente à l’armement, à la toute dernière nouveauté, est justement un des problèmes du numérique. Le choix de Gemini de faire un protocole qui n’évoluera pas (ou, plus exactement, qui a été conçu pour être difficile à faire évoluer) est un choix délibéré, justement pour éviter cette obsolescence programmée.
Ensuite, je me demande quelle erreur ai-je fait dans mon article pour que vous n’ayez pas vu que, justement, j’estime que Dillo n’est pas une solution satisfaisante, précisément parce que le navigateur léger ne sait pas à l’avance si le site Web sera visible ou pas. C’est ce qui motive les solutions radicales comme Gemini.
Enfin, le raisonnement « si on utilise Dillo, autant ne plus naviguer sur Internet [sic, puisqu’il s’agit de toute façon du Web, pas de l’Internet] » est du même niveau que de répondre à toute critique de la politique énergétique « ah, vous voulez retourner à la bougie ». On peut critiquer le système existant sans vouloir revenir des dizaines d’années en arrière.
Reno
Sinon : links, lynx, w3m, elinks…
Mais ce n’est pas « user friendly ».
Le but n’est-il pas aussi de rendre le tout accessible au plus grand nombre ?
Stéphane Bortzmeyer
Si. Cela implique donc des navigateurs légers, pouvant tourner sur de vieilles machines, rapides, et ne faisant pas de la lecture un parcours du combattant (vidéos qui se lancent seules, fenêtres-polichinelles à fermer, pubs à ignorer, etc).
Zatalyz
J’ai commencé à utiliser links, puis elinks, pour vérifier certains aspects de l’accessibilité de mes sites web (est-ce que ça reste « lisible » même sans les zigougouis ? ). Finalement, j’ai trouvé ça vraiment sympa. Évidement on ne navigue pas sur tout le web avec ça, mais les sites que j’utilise au quotidien fonctionnent sous ces navigateurs vraiment bizarres, et ça fait moins de distraction. C’est devenu pour moi un critère de qualité : si je peux naviguer sur un site avec elinks, alors c’est un « bon » site !
Je crois que c’est un enjeu à chercher quand on développe un site web : faire que le html seul suffise à avoir un site utilisable et confortable. Une fois cette base en place, on peut toujours s’amuser avec le css et le javascript, tant que ça ne casse pas la base. Ainsi on peut avoir des sites flamboyants si on aime les glitters, pardon les vidéos ! mais on reste avec quelque chose d’utilisable par tout le monde.
Car on a une vraie responsabilité du côté des développeurs de site web. C’est un peu de notre faute que le web devienne un endroit malsain, chaque fois qu’on choisit de faire le fainéant en suivant les chemins bien tracés : utiliser des CDN, de la pub, des frameworks énormes pour afficher trois pauvres informations, etc… J’ai encore du boulot, certains des CMS que j’utilise ont du progrès à faire, mais je travaille peu à peu dans ce sens : comprendre mieux mon coin de web, plutôt que de cliquer et ne pas poser de question…
Stéphane Bortzmeyer
Bien d’accord sur le « test lynx ». Si un site Web d’information n’est pas visible avec lynx, c’est sans doute qu’il ne vaut pas la peine.
Tom
Merci pour votre réponse intéressante.
tarix
Merci Stephane pour cet article tres éclairant.
Lori
« …très peu d’organisation pouvant aujourd’hui développer un navigateur Web. »
C’est quelque chose comme ça que j’ai dit (en anglais) ici. Je l’appelle « standards bloat ».
pimou
Bien d’accord avec vous. Il faudrait prôner un web light et vertueux, des technologies simples, légères et efficaces. J’ignorais l’existence du protocole gemini, une bonne nouvelle !
nojhan
Je trouve l’idée sympa, mais je crois qu’on pourrait dire que c’est un essai transformé quand on pourra avoir accès à Wikipédia avec.
Cependant, le refus des hyperliens dans le texte me semble être une limitation difficile à surmonter. Mais peut-être qu’en étant créatif ?
De la même façon, serait-il possibile d’éditer un article ? (après tout, ça n’est que du wikicode, derrière)
Stéphane Bortzmeyer
Pour Wikipédia, c’est possible, mais pas sans travail. Première possibilité, servir le text/html sur Gemini. Avantage : moins de travail, on ne convertit pas les articles. Inconvénient : peu de navigateurs Gemini savent afficher le HTML (ce qui est logique). Deuxième possibilité, convertir le Wikicode en gemtext. C’est faisable légalement et techniquement mais le wikicode utilise pas mal de choses qui n’ont pas d’équivalent en gemtext donc ce sera « moins bien » que sur le Web.
Pour l’édition de code, le gemtext étant très simple, une édition en local suivie d’un rsync suffit. Encore plus que pour HTML, un éditeur spécialisé n’est pas nécessaire.
Richard
Merci Stéphane pour la pertinence des informations apportées et les pistes pratiques fournies.
Pipou
Merci pour cet article de qualité, avec amha, juste ce qu’il faut de détail pour comprendre pour un quidam comme moi.
Je pense comprendre le but de tout cela, mais j’ai un doute sur la méthode :
* Il faut pouvoir mettre à disposition un web simple et frugal.
* ceci ne peut concerner qu’une part limité du web (pas les sites commerciaux)
* ça peut être fait aujourd’hui avec un site HTML simple, sans javascript, sans cookies et visible dans un navigateur actuel ou « frugal »
Qu’est-ce qu’un nouveau protocole peut apporter ? Si demain il existe et est bien implanté, vais-je utiliser deux outils pour accéder au web ? Les navigateurs leaders ne vont-il pas développer un moteur de rendu Gemini ?
Ceux qui veulent mettre a disposition un site d’information simple sur Gemini ne vont-ils pas créer son pendant html ?
Yaacov
Commentaires intéressants je suis également preneurs des réponses !
Merci Stéphane pour cet article très bien ficelé ;)
Stéphane Bortzmeyer
Ce que le nouveau système (protocole + format) Gemini apporte, c’est un espace où on est sûr que tout est visible avec son navigateur simple, et qu’il y aura le moins de surveillance possible. Sur le Web, on ne sait jamais à l’avance ce sur quoi on va tomber (un site Web bien fichu, ou une catastrophe).
Il n’y aura pas besoin de « deux outils » pour naviguer sur le Web car Gemini, ce n’est pas le Web, c’est un autre espace.
Les navigateurs Web peuvent évidemment intégrer Gemini, ils sont déjà tellement obèses que cela n’aggraverait pas grand’chose. Mais je n’ai pas vu de plan en ce sens.
Pour le contenu, en effet, si on a le contenu dans un langage structuré, on peut produire une version HTML *et* une version gemtext. C’est un peu de travail, quand même et, par exemple, je ne l’ai pas (encore) fait pour mon propre blog.
Sidonie
Je suis 100 % d’accord avec cet article. Il m’a fallut voir ma mère (84 ans) se débattre avec les sollicitations constantes, les fenêtres contextuelles qui viennent en permanence ajouter une proposition, une demande, qui nécessitent de trouver cachée en haut à droite la croix ou en bas à gauche le bouton qui permettra de s’en débarrasser pour enfin arriver à l’endroit qu’on souhaitait.
Oui, le web est devenu très compliqué et ressemble de plus en plus à une course d’obstacles qui laisse de plus en plus de personnes sur le bord de la route.
Je vous recommande également cette génialissime extension : « I don’t care about cookies » qui refuse à ma place tous les cookies sans que j’ai besoin à chaque fois de cliquer sur 3 fenêtres. Depuis que je l’ai installée, le web a pris une nouvelle figure, et moi aussi :-)
Baloo
En fait ‘I don’t care about coockies’ ne refuse pas les coockies mais auc contraire les accepte tous par défaut.
L’extension qui refuse les coockies par défaut c’est ‘ninja coockie’.
cayenne
Merci pour le partage. Il y a quelques mois, j’ai cherché une extension et effectivement la plus par des extensions accept tous et ce n’est pas ce que l’on veux. je viens de l’installer pour tester. j’ai désactivé le filtre EasyList Cookie sur ublock origin. je vais tester pour voir.
Par contre, dommage qu’elle n’est pas opensource. Elle devrait l’être bientôt.
LoverDose
Intéressé par de tels articles et « en même temps » incapable de mettre en pratique. J’adhère à 100 % sur les principes de précautions, Framasoft, LaQuadratureduNet, etc… Seulement voilà, en tant que Boomer, peu anglophone, mon intellect sature. VPN*, Ublock Origin, Doubles Identifications foireuses (Discord*), NoScript*, Firefox(au pluriel), linux*, Clouds, et même l’impossibilité d’utiliser avec une box mon tel fixe, des F.A.I. sourds, des Gestionnaires de mots de passe, les Réseaux dits Sociaux, FB*, Twitter, Pinterest*, Linkdin*, et même des émojis qui ne s’affichent pas correctement sur mon ordi à cause d’un OS ?(obsolète ou plus précisément non mis à jour), Des sites où l’on peut se procurer de bons ebook si l’on dispose d’un OS particulier à l’exclusion de tout autre (config box ?), les spams qu’on ne peut guère éviter… Tout ça (me) rend dingue et nous prend un temps incroyable ! sans parler de Twitch et autres plateformes.
Seul sentiment de victoire c’est d’avoir réussi sans vraiment savoir comment à ôter les pubs sur YT et pendant quelques temps utiliser les framapads (ce qui n’a pas été si facile que ça).
(*)= Non utilisé, ou abandonné (sauf Linkdin qui refuse le droit à l’oubli)
Désolé pour le hors sujet. Prenez soin de vous. Amitiés.
Frédéric Urbain
C’est très loin d’être hors sujet ! Qu’on galère avec Internet « en général », ou avec la technologie en tout cas, c’est une chose, mais le web est supposément utilisable par tout le monde, surtout qu’on nous pousse à faire nos démarches administratives et commerciales par ce biais.
baloo
Le site de la CAF a été mis hors service pour implémenter le nouveau calcul de l’APL du 1 au 3 janvier inclus. Les gens qui font la maintenance de ce site doivent le mettre hors réseau pour pouvoir travailler dessus ? ! ! ! !
Comme à partir du 1er les allocataires se connectent à leur compte CAF pour savoir si leur(s) allocation(s) vont être versées et sinon pourquoi et dans ce cas comment y remédier – ce qui n’est pas une mince affaire depuis la crise du Covid -, le 4 au matin, le site affichait une belle page erreur 503 car incapable de supporter la charge des connexions des usagers.
Stéphane Bortzmeyer
Votre expérience est celle de beaucoup d’utilisateurs et trices. Y compris ceux et celles qui sont des professionnels de l’informatique, car ce n’est pas uniquement une question de compétence, mais aussi de temps libre (et de charge mentale, pour prendre un terme à la mode).
C’est justement pour cela que je pense que la réponse souvent entendue « les gens n’ont qu’à installer [logiciel X] et [logiciel Y], s’ils ne le font pas tant pis pour eux » n’est pas satisfaisante.
gvdmoort
Pour étoffer le sujet, je vous suggère un article où l’on offrirait un florilège des sites pratiquant un usage malveillant de la proposition de paramétrer les cookies. La situation est atterrante, y compris pour des sites relevant du secteur public. Je prends en exemple celui de la RTBF, radio et télévision publique francophone de Belgique. Jusqu’il y a peu, le bandeau affichant la proposition d’effectuer ce choix occupait les 15 % inférieurs de l’écran. On pouvait se contenter de le faire disparaître en augmentant la taille de la fenêtre et l’ignorer. Il est passé à 80 % de la hauteur ( !), rendant impossible de lire la page. Pire, il s’affiche à chaque fois qu’on ouvre un lien dans un nouvel onglet, imposant à chaque fois trois actions supplémentaires : « configurer »,« tout refuser »,« enregistrer ».
Ce qui me sidère, c’est d’imaginer le contenu des réunions de travail entre les développeurs et les business-managers : « Dites, le site permet un peu trop facilement de ne pas être espionné. vous pourriez compliquer la tâche des utilisateurs ? ». Triste monde…
lareinedeselfes
Internet est compliqué. Le Web se limitant pour une grande partie d’utilisateurs à Google ou à FB ne leur semble pas plus compliqué. Ce qui n’est pas simple c’est quand on se pose des questions. Les cookies n’ont posé de problèmes qu’à l’apparition des bannières suite au RGPD. Avant madame et monsieur toutlmonde n’en avaient jamais entendu parler. Les pubs les gênent surtout lorsqu’elles apparaissent en pop-up… Peu de personnes ont reçu les bonnes informations pour naviguer sans embarquer une flopée de pages sur le site ou elles vont.Puis si elles grognent de trop, on va leur proposer un bloqueur de pub qui a passé un marché avec des régies publicitaires. Et pourtant la naissance du Web a été l’occasion pour les non informaticiens l’occasion de pouvoir utiliser et de démocratiser internet. C’est donc bien dommage qu’il s’alourdisse.
Quand à gemini ! J’ai installé le navigateur Lagrange avec l’aide d’un copain de mastodon, en suivant des consignes à distance. pour celleux qui sont sous Linux et qui veulent savoir comment faire, j’ai recopié les étapes sur Framacolibri https://framacolibri.org/t/gemini/10492
En tout cas je suis charmée par cette découverte.
grz
Bonjour
Article intéressant et la techno Gemini semble répondre à un cas d’usage du Web. Mais qui, selon moi, se limite à la publication de données techniques qui nécessitent effectivement un affichage épuré.
Je comprends l’intérêt et les problèmes soulevés, Gemini est délibérément ultra-light pour tenter d’y répondre en apportant une alternative, mais au point qu’on ne peut afficher une image sur sa page.
Sans vouloir faire le rabat-joie, les images sont une forme d’art et d’expression tout comme l’écriture. Ne pas permettre d’afficher des images sur une techno alternative à un navigateur Web c’est censurer une forme d’art et d’expression. Je pense juste aux talentueux dessinateurs dont j’ai l’occasion de contempler les œuvres qui n’auraient absolument aucun intérêt à adopter une telle technologie.
Certains me répondront : « Mais si, il suffit qu’ils mettent un lien de téléchargement vers l’image ! »
Ce à quoi je répondrais : « Lorsque je visite un site galerie, une exposition virtuelle, je n’ai pas des liens à cliquer dans tous les sens pour télécharger une image, mais une galerie d’images qui s’affichent de manière intuitive. »
Sinon on parle des photos/musiques/vidéos ? (ou c’est encore trop lourd comme forme d’expression ?) :)
Ce n’est que mon avis : au lieu de vouloir refaire le Web ou d’en créer encore une alternative, pourquoi ne pas s’attaquer directement à la source du problème ? Sensibiliser les développeurs, intégrateurs, webmaster, directeurs de publication aux problèmes soulevés dans cet article ?
Mon grain de sel
Stéphane Bortzmeyer
« pourquoi ne pas s’attaquer directement à la source du problème ? Sensibiliser les développeurs, intégrateurs, webmaster, directeurs de publication aux problèmes soulevés dans cet article » Ah mais allez-y. Beaucoup d’articles publiés sur le Framablog sont d’ailleurs en ce sens. Ainsi que l’excellente série « 24 jours de Web » https://www.24joursdeweb.fr/
Mais, personnellement, je suis un peu fatigué de me battre contre les moulins. Beaucoup de gens très bien (par exemple les participants de Paris Web) le font depuis des années, avec des résultats limités.
Surtout, imaginons que 50 % du Web supprime les cookies, le pistage, les images inutiles et tout ça, cela ne suffirait pas : l’utilisateur ne pourrait pas savoir à l’avance s’il ne va pas tomber sur les autres 50 %.
Loz
À moitié pour la blague : quelle différence avec le WAP ?
Stéphane Bortzmeyer
WAP était du pur vaporware, il n’a connu aucun déploiement, juste des PowerPoint. Gemini fonctionne déjà. https://www.bortzmeyer.org/statistics-gemini.html
EricL
Merci beaucoup pour cette découverte ! Gemini semble à la fois répondre au problème des sites web de plus en plus gourmands en ressources et consommateurs en énergie, ainsi qu’à la surveillance généralisée et son modèle mortifère. Chouette !
Après avoir installé Lagrange et navigué sur gemini, j’ai vraiment apprécié ce nouvel espace du net. D’où ma question : on fait comment pour créer un serveur gemini ou, plus simplement, une ou des capsules ? Des ressources à nous conseiller svp ? en version « pour les nuls » ?
Stéphane Bortzmeyer
Il n’y a pas encore de documentation orientée « large public » pour la création d’une capsule. Distinguons deux cas, l’écriture du contenu et l’installation/gestion du serveur.
Pour l’écriture de contenu, le format gemtext est trivial et on peut facilement écrire ses textes à la main. Pour assurer une certaine homogénéité des pages (présence d’un texte identique à la fin de toute les pages, par exemple), il existe déjà des outils qui assurent cette homogénéité à partir d’un gabarit mais je n’en ai testé aucun.
Pour l’installation et la gestion du serveur, les différences avec le Web ne sont pas énormes : il faut une machine allumée en permanence, un nom de domaine, etc. Globalement, cela prend moins de ressources que le Web (sauf si on fait des pages dynamiques) donc le plus petit des Raspberry Pi suffit. J’ai utilisé les serveurs Agate et Gemserv et tous les deux sont triviaux à installer (mais pas forcément à maintenir à jour car ils ne sont typiquement pas paquagés pour votre systsème d’exploitation). Si on ne veut pas faire d’administration système du tout, il existe des services d’hébergement comme gemini://flounder.online/.
Voilà, désolé, ce n’est pas vraiment une documentation pour les débutants mais cela donne une idée des points à regarder avant de se lancer.
Bob Lafrite
Plus riche, ça veut forcément dire plus compliqué, plus dépendant. C’est un problème d’entropie.
Les navigateurs et le web est plus compliqué parce qu’ils « font » plus de choses, c’est tout. Les normes (HTML, etc.) évoluent très vite. On ne peut pas utiliser un navigateur d’il y a 10 ans sur la plupart des sites actuels. C’est pas parce que les GAFAM sont des méchants, c’est que ces technologies sont très loin d’avoir atteint un point de stabilité (contrairement à d’autres par exemple le four à micro ondes, je sais pas) et qu’il sont améliorables.
C’est comme quand les utilisateurs comparaient leur télephone ou leur voiture avec un ordinateur en disant qu’ils avaient moins de problème, de bugs, etc. Bien sûr, car ce sont des sytèmes infiniment moins complexes qu’un ordinateur. Depuis que les téléphones sont devenus smart et que les voitures sont éléctroniques, ils ont les même problèmes. Mais tout le monde ne veut pas rouler en 4L de 1970 qui se réparait avec un chewing gum et 3 boulons, mais n’avait pas de chauffage, de vitre électrique, d’auto radio, de caméra de recul, etc.
Votre proposition c’est un peu comme retourner 200 ans en arrière, plus d’électricité, plus de voiture, plus d’internet :-) Alors oui, tout serait beaucoup plus simple.