Il y a deux ans, nous annoncions notre feuille de route Contributopia. Nous voulions mettre en valeur un imaginaire positif, illustrer un futur que nous voudrions contribuer à construire. David Revoy, connu pour son web-comic libre Pepper & Carrot, a accepté notre demande de prestation et a illustré ces « mondes de Contributopia ».
Cliquez sur les planètes de Contributopia pour aller sur la boutique de David Illustration de David Revoy – Licence : CC-By 4.0
Alors oui, c’est beau. Tellement beau qu’on nous demande, depuis deux ans, où sont les t-shirts, comment avoir les posters, où l’on peut acheter son mug Contributopia… Et jusque-là, la seule réponse que nous avions, c’était : « vous êtes libres de les faire faire vous-mêmes ! ».
Le cercle vertueux de la contribution
Côté coulisses, pendant qu’on travaillait avec David sur l’illustration des Carnets de Voyage de Contributopia, on le tannait gentiment pour qu’il ouvre sa boutique… Aviez-vous remarqué que la carte s’arrange de trois manières différentes suivant la largeur de votre écran ? Imaginez comment ce serait cool d’avoir quatre impressions à arranger comme on veut dans son salon !
Car en plus d’accepter de nous faire de telles prestations et de publier régulièrement de nouveaux épisodes de son webcomic Pepper & Carrot, David contribue à des projets libres ! Par exemple, très récemment, il a offert une mascotte au logiciel PeerTube ! Celle là, on la verrait bien sur des t-shirts, chaussettes et autres sweats à capuche !
On aurait dans l’idée de l’appeler « Sepia », c’est aussi le mot qui a donné « seiche » en latin… Cliquez sur l’image pour la retrouver dans la boutique de David !
Alors comme il est jamais trop tard pour bien faire, on s’est dit qu’on allait en parler maintenant !
Cliquez sur les objets pour aller vers la boutique de David…
David a créé sur sa boutique une section spéciale Contributopia, où on trouve aussi une illustration pour déclarer son amour au collectif C.H.A.T.O.N.S. !
Cliquez sur l’image pour voir les produits disponibles avec cette illustration.
Entre les rencontres geeko-libristes qui approchent et les fêtes de fin d’années où on manque toujours d’idées de cadeaux, on s’est dit que c’était le moment ou jamais de soutenir cet artiste libriste par un achat utile et beau… Alors voilà, si ça vous tente c’est le moment, et si vous êtes pas très objets de consommation, sachez qu’il accepte aussi les dons !
De la difficulté de prendre un selfie de son t-shirt, ou l’empathie du libriste pour les membres d’Instagram. (cliquez sur l’image pour trouver ce T-shirt)
Les carnets de voyage de Contributopia
Voilà deux ans que, grâce à vos dons, nous contribuons à de nombreuses actions qui vont bien au delà de « Dégooglisons Internet ». Nous avons deux ans de découvertes, d’observations et de collaborations à vous raconter.
Voilà deux ans que nous explorons les mondes de Contributopia, alors pour mieux vous rendre compte de ce que représente cette expédition, nous vous invitons à découvrir nos carnets de voyage.
Cet article fait partie des « Carnets de voyage de Contributopia ». D’octobre à décembre 2019, nous y ferons le bilan des nombreuses actions que nous menons, lesquelles sont financées par vos dons (qui peuvent donner lieu à une réduction d’impôts pour les contribuables français). Si vous le pouvez, pensez à nous soutenir.
Pourquoi dégoogliser ne suffit pas
Les membres de Framasoft consacrent beaucoup d’énergie et de ressources à héberger les services web alternatifs à ceux de Google et compagnie, présentés sous la bannière « Dégooglisons Internet ». Pourtant, à l’automne 2017, nous dévoilions notre nouvelle feuille de route nommée Contributopia avec une certitude : Dégoogliser ne suffit pas.
Le mot « dégoogliser » peut être trompeur. Le jour où la tête de Google tombe, il en poussera deux ou trois autres à sa place (les GAFAM, les NATU, les BATX). L’hydre qui se trouve en dessous, c’est le système qui place de telles entreprises dans des positions de domination toxique. C’est une mécanique où les géants du Web analysent nos comportements présents, pour en déduire et influencer nos comportements futurs, et monnayent cette influence aux publicitaires, spéculateurs et spin-doctors.
Comme chez l’ophtalmo : pouvez-vous lire qui sont les entreprises les plus puissantes au monde ? – Extrait d’une diapo utilisée lors de nos conférences.
Face à ce système complexe, aussi appelé capitalisme de surveillance, il serait frustrant que notre réponse se résume à un simple « pareil que Google, mais en libre ». C’est de cette envie, de cette intuition qu’est née la feuille de route Contributopia. Après deux ans à en explorer les sentiers, nous en cernons mieux les objectifs :
Rêver le quotidien des mondes que nous désirons pour mieux passer à l’action ;
Aller vers d’autres communautés, partager ensemble et échanger sur leur raison d’être ;
Prendre soin des communs et des outils numériques qui permettent l’émancipation.
Formulé comme ça, il y a un effet « belles paroles bien abstraites » de ces formules à l’emporte-pièce qui n’engagent à rien. Or voilà deux ans que nous multiplions les partenariats et les actions bien concrètes qui s’inscrivent dans ce triple objectif. Nous avons hâte de vous présenter tout cela !
Contribuons ensemble vers cette Contributopia. Illustration de David Revoy – Licence : CC-By 4.0
Les Carnets de Contributopia
Si Contributopia est notre cheminement dans la découverte de mondes plus ou moins connus… Alors nous voulons vous partager nos carnets de voyage !
Chaque semaine, d’octobre à décembre, nous publierons un à deux articles afin de faire le point sur l’ensemble des actions, des contributions et des réflexions que nous menons depuis deux ans. Ce que vous lirez dans cette série d’articles, nous l’avons mené tout en maintenant les 38 services de Dégooglisons Internet pour plus de 500 000 utilisateurices chaque mois.
Afin que vous puissiez retrouver facilement ces articles, nous avons créé une page spéciale sur le site contributopia.org, qui sera tenue à jour lors de chaque nouvelle publication. Sous la carte des explorations se trouve un sommaire qui vous dévoile :
La première version bêta de Mobilizon, notre alternative aux événements Facebook (présentée dès aujourd’hui sur ce blog) ;
Nos contributions autour d’un outil de pétitions ;
L’importance politique de l’outil Bénévalibre ;
Un exercice en failologie, pour mieux apprendre de nos échecs ;
Ce qu’observent les membres de L.A. Coalition ;
L’évolution de PeerTube, le logiciel pour s’émanciper de YouTube ;
Ce qui se cache derrière l’idée d’un Contri-bouton ;
Mon Parcours Collaboratif, pour faciliter l’usage d’outils libres ;
Le fait que la route reste longue (et nos envies nombreuses) ;
Où en est le MOOC CHATONS, sur les enjeux d’un Internet décentralisé ;
Nos envies d’archipellisation, et les ponts que nous avons déjà construits ;
La mutation des métacartes Dégooglisons ;
La fédération dans Mobilizon, pour ne plus dépendre de Facebook, Meetup… ou Framasoft ;
Notre travail pour une meilleure diffusion de nos actions à l’international ;
Une petite surprise de fin d’année !
Cliquez pour découvrir la page des Carnets de Contributopia, et sa carte qui s’adapte à votre écran… Illustration de David Revoy – Licence : CC-By 4.0
Cette série d’articles se distinguera, dans le Framablog, par une identité visuelle forte (nous remercions d’ailleurs David Revoy pour son travail sur les illustrations). Car ne vous y trompez pas, ces Carnets de Contributopia sont aussi une campagne de dons, un moyen de vous rappeler que Framasoft n’est financée que par votre générosité (et que Framasoft étant reconnue d’intérêt général, nous faire un don ouvre droit à des déductions d’impôts sur le revenu pour les contribuables français·es, ce même avec le prélèvement à la source !).
Cette année encore, nous ne voulons pas utiliser des techniques qui monopolisent votre attention ou manipulent vos émotions. Le principe de cette campagne est simple : cette série d’articles vous exposera ce que nous avons pu faire, grâce à vos dons. Si cela vous plaît, si vous voulez que nous poursuivions sur cette voie, merci de nous soutenir, en faisant un don (pour qui estime en avoir l’envie et les moyens) et en partageant notre appel à la générosité.
Nous avons mis longtemps à définir ces « autres » avec qui nous voulions échanger et partager. Nos services libres sont ouverts à tout le monde. En proposant Framaforms, nous nous attendions à ce qu’il soit plutôt utilisé par de petites structures militantes. Mais quand on voit que ce service est aussi utilisé par JCDecaux, on se dit qu’ils ont les moyens d’installer leurs propres outils libres pour construire leur monde de publicitaires sans nous, sans notre aide. Leur société de (sur-)consommation, ce n’est pas le monde dont nous rêvons.
En revanche, nous voyons bien que nous baignons dans les mêmes eaux que d’autres communautés, qui mouillent la chemise et prennent les choses en main pour changer le monde, à leur échelle. Mais comment nommer ces personnes qui œuvrent dans les milieux associatifs, culturels, de l’ESSE, dans les militances, l’éducation populaire ou la justice sociale ?
C’est pour ces personnes-là que nous prenons le temps de présenter du savoir, des outils, de l’accompagnement… Illustration de David Revoy – Licence : CC-By 4.0
Ce qui nous rapproche de ces communautés si différentes, c’est, à nos yeux, cet effort de contribution. Cette volonté de trouver comment, avec nos différences et nos différends, on peut œuvrer ensemble à concrétiser des idées communes. Ces personnes créent, chacune à leur échelle, une société non pas de consommation, mais de contribution.
Nous pensons que c’est le rôle de Framasoft pour les années à venir. Ne pas se cantonner à proposer des « services alternatifs à ceux des GAFAM », mais aller plus loin dans l’accompagnement de l’émancipation numérique. Nous voulons poursuivre un travail d’éducation populaire sur les enjeux d’Internet. Nous voulons aussi repenser nos outils et leurs usages en fonction des besoins réels des membres de cette société de contribution.
Nous suivrez-vous sur cette voie ?
Rendez-vous sur la page des Carnets de Contributopia pour y découvrir d’autres articles, d’autres actions que nous avons menées grâce à vos dons. Si ce que vous venez de lire vous plaît, pensez à soutenir notre association, qui ne vit que par vos dons. Framasoft étant reconnue d’intérêt général, un don de 100 € d’un contribuable français reviendra, après déduction, à 34 €.
Wait up before you yell at us! but yeah, we are here to announce the gradual closing down, spanning several years, of some services from the De-google-ify Internet campaign. We want to achieve this goal in a spirit of cooperation, so that we can focus on more decentralization and efficiency for people who are aiming to make a positive change in the world, no matter how small .
This article is quite long. Our complex thinking can’t be reduced to a tweetable soundbite. We recommend you read this article from start to finish, but you will find its key points at the end. And the original French blogpost is here.
What’s going on?
We’ve said it time and time again: Framasoft is -and wishes to remain- a human scale organization, a team of enthusiasts DIY-ing their way through changing the world, one byte at a time. Our organization is made of 9 employees and about thirty members and every year, 700 to 800 volunteers help us (whether it be for one hour or throughout the year). Over 4000 patrons fund our projects (thank you <3), and every month, hundreds of thousands people benefit from those.
Yet Framasoft is more than all of this: dozens of blog articles, around a hundred of meetings, conferences & workshops every year, a publishing house for free-libre books, lots of responds to the requests of many media outlets and a collaborative directory of free-libre solutions. We currently develop two important softwares (PeerTube and Mobilizon), and we are working on so many cool partnerships and collaborative projects that we’re going to need three months to introduce you to all of them… (See y’all in October !)
Our pal JCFrog teasing us a bit
One thing is for sure: we, at Framasoft, hold our not-for-profit status close to our hearts. We don’t want to become start-up nor replace Google. We want to preserve our identity without burning ourselves out (we’ll touch on that some more in the following weeks, as we have sometimes overworked ourselves in the past), and keep on experimenting with new things. If we want to achieve all of these goals, we have to reduce our (heavy) workload.
Why are we closing down some services?
From the start, we advertized the De-google-ify Internet project as an experiment, a proof of concept, which was set to stop at the end of 2017. What we had not foreseen was that the discourse about current web centralization (which only nerds like us cared about in 2014) would generate such enthusiasm, and that as a consequence, so many expectations would be placed on us. In plain English: De-google-ify Internet, and all of the services that come with it, was not meant to centralize so many users, nor to lock them up in frama-stuffs that would last to infinity (and beyond).
Apart from our « just for kicks » projects (Framatroll and Framadsense: still love you, fam), there are 38 services on the De-goole-ify Internet servers. That’s a lot. Like, seriously, a lot. This means 35 different softwares (each with its own update pace, active or dormant communities, etc.), written in 11 programming languages (and 5 types of databases), shared on 83 servers and virtual machines, all in need of monitoring, updating, adjusting, backing-up, debugging, promotion and support integration… It’s a lots of care and pampering, in the same vein as keeping hotel rooms visited by thousands of individuals every month.
Actually, even we can’t keep up with the list of the services we offer -_-‘…
Well, some services barely work anymore (Tonton Roger). Other started as experiments that we couldn’t carry on with (Framastory, Framaslides). Some services have such a large technical debt that even when we spent several days of development in them, we are only delaying their inevitable collapse (Framacalc). Other services could, left to their own devices, grow forever, limitless, which is unsustainable (Framasite, Framabag, Framabin, etc.). When you are as known as Framasoft in the French-speaking community (Framalink, Framapic), some service are extremely work-intensive in order to prevent and fight misuse. And don’t get us started on federated social medias (Framapiaf, Framasphere): they require a lot of moderation, and would operate much more fluidly had we not welcomed so many users.
And to top it all off… this is no healthy functioning! We all know how handy it is to be able to say « if you want alternative solutions, just look at Framastuffs! ». It is very reassuring to find everything in the same place, under the same name… We are aware of this phenomenon, and that’s why we decided to use « frama », in a way not dissimilar to a brand -though that is frankly not our cup of tea. Except internet centralization is unhealthy.
Internet centralization is risky, too. Not only was it not meant to become so centralized, but also putting all of our data in the same basket is just how you centralize power in the hands of hosts system administrators. Besides, this is precisely the slippery slope from which Google and Facebook emerged.
On the contrary, free softwares allow anyone to take the reigns. For example, Framapic doesn’t belong to Framasoft: everyone is legally entitled to install the Lutim software somewhere on their server and let anyone they see fit benefit from it… Actually, this spirit of decentralization is the reason why we have worked with self hosting-easing tools (like Yunohost), as well as with CHATONS (collective of independant, transparent, open, neutral and ethical hosters).
Our goal with this early announcements (concerning, for example, Framapic) is twofold.
Firstly, we hope this will incentivize many hosts to open their Lutim instances, aka the same service (looking at you, fellow CHATONS). Secondly, this gives us time to pick hosting offers and to display them on the Framapic landing page, redirecting you in one click to the same service, except with a different host. All of this will be implemented as soon as we announce Framapic’s close down (one year before it actually happens).
So, what happens next?
Smoothly, and over two years! at the very least. (Might take longer if we stumble on our keyboards and sprain our phalanxes! You never know until you know).
Now that we can all catch our breath, reassured that free and ethical services are SWAG, it is (high) time we start transitionning from the « everything Framasoft » instinct. Less frama services means all of you can explore elsewhere. It’s kinda as if we said:
Our digital CSA is at full capacity, but we are not leaving you with an empty basket: our network of CSAs and other network members will be delighted to welcome you.
We are laying the groundwork for y’all. In a spirit of transparency, you can dowload this spreadsheet [FR] that shows in detail our estimated closing down schedule. And if you prefer to have a general look, here is our we plan this closing down:
If we take a closer look, there’s a similar pattern for each service involved:
0. First things first, we announce today our plan to close down some of our services, allowing everyone to see clearly what’s happening, and to self-manage so as to fill in for this or that service. During all the following months we will attempt, as much as can be, to make the job of migrating towards other service providers easier.
Then, we announce on each concerned service that it will be first restricted, then closed down (1rst column). We will display on the landing page a link to hand-picked alternative hosts (same software or similar one).
Afterwards, we limit the service use (2nd column). The goal here is to close the door to newcomers (they won’t be able to create a new account, a new calc, or to upload a new file). We will advise them on alternatives solutions, all the while giving existing users time to migrate their account and personal data if they still up on our services.
At last, we close down the service whenever possible (last column on the board) or we make it invisible when maintaining a certain amount of continuity is necessary (e.g. existing frama.link will still redirect to the right web address).
We are not closing down everything, and certainly not now (save for one)
Framastory and Framanews pose a lot of technical issues, forcing us to act quickly. They will be the first services impacted. They will be restricted at the start of 2020, and closed down a semester later. For all of the other services we talked about earlier, restrictions will only start during summer 2020 (even summer 2021 for some), and the first closing downs will not happen before 2021 – in some cases, not before 2022!
Simply put, the only exceptions to this rule will be the service we won’t close down, (Framadate, Framapads and MyPads, Framavox, Framagenda, Framatalk, the collaborative Framindmap, Framacarte), as well as those we are just moving to our « free-libre culture » project (Framagames and Framinetest). This includes Framadrive, which now has been on limited access for a while because of how popular it became, with 5000 accounts created. This is the limit we had set from the start, and we intend on keeping things that way.
And then, there’s Framabee, aka good old Tonton Roger, our meta search engine that no longer quite works. Some might say we should just finish it off, other would prefer for the landing page to state « killed by Google » . Indeed, no matter how much we hacked, Google & Co received too many queries from us and started refusing them en masse… which proves further that centralizing uses, even here at Framasoft, just won’t cut it! We’ll let Tonton Roger retire early: next month, we’ll wave him goodbye and gift him a pair of slippers.
That night when we came up with the brilliant idea of picking 3 different domain names for the same search engine
Spring cleaning so we can more forwards together
We have learnt a lot. The “de-google-ify” campaign showed us that users don’t have to follow the « the client is king » model, or to behave like Karen « I wanna speak to the manager » Von Soccer Mom. Yall have gracefully dealt with week-end server crashes (our system administrators don’t have to work on week-ends), slightly less fancy-looking tools, and limitations on service use so as to give space for other users… In short: there is room in our lives for hand-crafted digital tech, aka small techs, in the most noble sense of the term.
Everything we have learnt since 2014 leads us to think we need a change. Clearly, we don’t want to let people (i.e. y’all!) high and dry, or give you the impression that free culture and softwares is an unkept promise. Quite the opposite: we were happy to introduce you to FLOSS solutions and to help you take them on (thanks for your efforts!). Your trust in and craving for for ethical digital tools are precious: we don’t want to make anyone lose their mojo, only to take you all one step further.
And by the way, we are taking the time to do something GAFAMs & Co have never cared to do: announcing way ahead of time our closing down plans and helping our users in the road towards de-google-ifying. We are getting rid of what no longer sparks joy, putting some order in the tools and experiment we have accumulated over the years in our backpacks. This will give space and availability for what’s next.
PeerTube and Mobilizon are proof of our desire to move away from the « just-like-Google-but-with-ethics » software model. Starting this October and spanning three months, we will be reviewing our « Contributopia » roadmap, and y’all will see that there is a lot to talk about. You’ll discover many more projects we hadn’t seen at the bottom of our digital backpack.
We are very excited for the next steps, as we have many announcements and contribution stories to share… see you in mid-October, we can’t wait!
One year to offer you a new proposition
Drawing on what we learnt from De-google-ify Internet, we sense that it’s possible to build a new, simpler, and handier offer for a range of services, both for users and hosts.
Through observing your uses of those services and listening to your expectations, we (along with many other people!) believe that Nextcloud, rich in many applications, is one way to go. We believe this software could fulfill most of the needs of people trying to change the world.
You can do a lot with Nextcloud
We’re giving ourselves a year to contribute (once again) to this software, stir in it, experiment with buddies and offer you a new proposition, which hopefully will make de-google-ifiying even easier… just like de-frama-tifying!
Key points:
We refuse to become the « default » solution and to monopolize your uses and attention (that’s how we empowered GAFAM & Co)
38 services, it’s way too complex for you to adopt and for us to host
We wish to stay an organization of a human scale, and retain our human warmth… a sort of digital CSA;
We propose to take the next step towards data decentralization:
By gradually closing-down some frama-services so their landing-pages can become gateways to other hosters
By taking the time to offer a new simpler range of services for users (through a single sign-on account for example)
Déframasoftisons Internet !
Ne hurlez pas tout de suite, mais nous annonçons ici la fermeture progressive, sur plusieurs années, de certains services de « Dégooglisons Internet ». Nous voulons le faire en bonne intelligence, afin de concentrer nos énergies vers plus de décentralisation et d’efficacité pour les actrices et les acteurs de la contribution.
Cet article est long. Notre réflexion, complexe, ne peut pas se réduire à un tweet. Nous vous recommandons de lire cet article dans son intégralité, mais nous avons essayé d’en extraire les points principaux, que vous retrouverez en bas de cette page.
Mise à jour (janvier 2021) :
Nous avons complètement remis à jour notre plan de « déframasoftisation ». Nous avons pris en compte de nombreux paramètres (vos usages, l’évolution de certains logiciels, la disponibilité d’alternatives, les conséquences des événements de 2020…) et décidé de poursuivre en 2021 le maintien de certains services, le temps d’y voir plus clair.
Si les raisons exposées ici restent valables, merci de ne pas tenir compte des annonces dans les textes et images de cet article.
On le répète à l’envi : Framasoft est, et souhaite rester, une association à taille humaine, un groupe de passionné·es qui expérimentent pour tenter de changer le monde (un octet à la fois). Il y a 9 salarié⋅es, dans une association qui compte une trentaine de membres depuis plusieurs années. Des membres qui, chaque année, maintiennent des actions auxquelles contribuent 700 à 800 bénévoles (pour une heure ou tout au long de l’année), des actions financées par plus de 4 000 donatrices et donateurs (merci <3), et qui bénéficient à des centaines de milliers de personnes chaque mois…
Une chose est sûre, à Framasoft : nous tenons à notre modèle associatif, nous ne voulons pas croître en mode « la start up qui veut se faire plus grosse que Google ». Si nous voulons garder notre identité sans nous épuiser à la tâche (et là aussi, on en reparlera dans les semaines qui viennent, mais on s’est parfois surmené·es), et si nous voulons continuer d’expérimenter de nouvelles choses, il faut que nous réduisions la charge qui pèse sur nos épaules.
Pourquoi fermer certains services ?
Dès le départ, Dégooglisons Internet a été annoncé comme une expérimentation, une démonstration, qui devait s’achever fin 2017. Nous n’avions pas prévu que parler de la centralisation du web (qui n’intéressait que les passionné·es, en 2014) susciterait une telle adhésion, et donc autant d’attentes. En clair : Dégooglisons Internet, et l’ensemble des services qui y sont proposés, n’a pas été pensé pour centraliser autant d’utilisateurs et d’utilisatrices, ni pour les enfermer dans des framachins qui dureraient à l’infini (et au delà).
Si on exclut les services « pour la vanne » (mais on vous aime, Framatroll et Framadsense !), il y a 38 services sur les serveurs de Dégooglisons Internet. C’est beaucoup. Vraiment beaucoup. Cela signifie 35 logiciels différents (chacun avec son rythme de mise à jour, ses communautés qui s’activent ou s’épuisent, etc.), écrits dans 11 langages (et 5 types de bases de données), répartis sur 83 serveurs et machines virtuelles, qu’il faut surveiller, mettre à jour, régler, sauvegarder, déboguer, promouvoir, intégrer à notre support… bref qu’il faut bichonner, comme on nettoie et prépare les chambres d’un hôtel disparate visité par des centaines de milliers de personnes chaque mois.
Même nous nous n’arrivons pas à tenir à jour la liste de tous les services que nous proposons -_-‘…
Or il y a des services qui ne marchent quasiment plus (Tonton Roger). Des services qui étaient des expérimentations que nous n’avons pas pu poursuivre (Framastory, Framaslides). Des services dont la dette technique est si lourde que même en y investissant plusieurs jours de développement dessus, on ne fait que retarder leur inévitable effondrement (Framacalc). Il y a aussi des services qui, si on les laisse faire, peuvent croître de manière illimitée et infinie, ce qui n’est pas tenable (Framasite, Framabag, Framabin, etc.). Il y a des services qui demandent beaucoup, beaucoup d’efforts si on veut éviter les utilisations frauduleuses, quand on est aussi visible que Framasoft (Framalink, Framapic). Ne parlons pas du cas des médias sociaux fédérés (Framapiaf, Framasphere), qui demandent un lourd travail de modération et fonctionneraient de façon bien plus fluide si nous n’avions pas accueilli autant d’inscriptions.
Sans compter que… ce n’est pas sain ! On le sait, c’est hyper pratique de pouvoir dire « tu veux une alternative, va voir les Framachins ! ». C’est rassurant d’avoir tout dans un même endroit, sous un même nom… On le sait, et c’est même pour cela qu’on a utilisé cette technique de la marque « frama », qui pourtant, n’est vraiment pas notre tasse de thé.
Mais centraliser des trucs sur Internet, ce n’est pas une bonne idée : non seulement ce réseau n’a pas été pensé pour créer des points de centralisation, mais surtout c’est en mettant toutes nos données dans le même panier que l’on concentre les pouvoirs entre les mains des personnes qui gèrent les serveurs, et c’est sur cette pente glissante que se sont créés des géants du web tels que Google ou Facebook.
cliquez sur l’image pour découvrir le collectif CHATONS
Le logiciel libre, au contraire, permet à d’autres de prendre le relais. Par exemple, Framapic n’est pas exclusif à Framasoft : n’importe qui a le droit d’installer le logiciel Lutim sur un coin de serveur et d’en faire profiter qui bon lui semble… C’est d’ailleurs dans cette optique de décentralisation que nous avons travaillé sur des outils facilitant l’auto-hébergement (tel que Yunohost), ainsi qu’avec le collectif d’hébergeurs alternatifs qu’est CHATONS.
Notre objectif, en annonçant longtemps à l’avance des fermetures de services comme Framapic, par exemple, est double. Premièrement, nous espérons que cela motivera de nombreux hébergeurs à ouvrir leur instance du logiciel Lutim, donc du même service (nous pensons aux camarades du collectif CHATONS). Et ensuite, cela nous donne le temps de repérer des offres d’hébergement et de les afficher sur la page d’accueil de Framapic. Ainsi, cette page d’accueil vous emmènera, d’un clic, vers le même service, chez un autre hébergeur… et ce, dès l’annonce de la fermeture de Framapic (un an avant qu’il ne ferme).
Comment ça va se passer ?
En douceur, et sur deux ans ! Enfin deux ans… au moins. (Non parce que si on trébuche sur nos claviers et qu’on se foule une phalange, ça peut prendre plus longtemps !)
Maintenant que nous nous sommes rassuré·es ensemble, et assuré·es du fait que les services libres et éthiques, c’est chouette… Il est temps de lancer un mouvement de transition pour sortir du réflexe « tout Framasoft ». Mettre les frama-services en retrait pour que vos usages rebondissent ailleurs, c’est un peu comme si nous vous disions :
Notre AMAP du numérique est au maximum de sa capacité, mais on ne va pas vous laisser comme ça avec votre cabas : nous faisons partie d’un réseau d’AMAPs et d’autres membres du réseau seront ravis de vous accueillir.
On va vous préparer le terrain. Afin d’agir en toute transparence, nous vous proposons de télécharger un tableur détaillé du calendrier prévisionnel des fermetures. Et pour les personnes qui veulent juste avoir un regard global, voici un tableau résumant la manière dont nous envisageons ce plan de fermetures.
Si on regarde de plus près, le schéma est le même pour tous les services concernés :
Étape 0. D’abord, nous annonçons notre plan de fermeture d’une partie des services (ça, c’est aujourd’hui). Cela permet à chacun·e d’y voir clair, de prendre les devants et de s’auto-gérer pour prendre le relais sur tel ou tel service. Tout au long des mois à venir, nous essaierons, tant que faire se peut, de faciliter la migration vers d’autres hébergeurs de services ;
Ensuite, on annonce sur chaque service concerné qu’il va bientôt être restreint, puis fermé (1ère colonne du tableau). On affiche alors sur la page d’accueil un lien vers des hébergements alternatifs (d’un même logiciel ou équivalent) que nous aurons repérés et sélectionnés ;
Après, on restreint l’usage du service (2e colonne). L’idée est de fermer la porte aux nouveaux venus (ne plus pouvoir créer un nouveau compte, un nouveau calc, ou uploader un nouveau fichier) en les redirigeant vers des alternatives disponibles… tout en donnant le temps de pouvoir migrer son compte et ses données aux personnes qui sont encore inscrites sur nos services ;
Enfin, on ferme le service lorsque c’est possible (dernière colonne du tableau) ou alors on l’invisibilise lorsqu’il est nécessaire d’assurer la continuité de ce qui y a été fait (par exemple, les frama.link existants continueront de rediriger vers la bonne adresse web).
On ne ferme pas tout, et certainement pas tout de suite (sauf un)
Framastory et Framanews, dont les lourdes contraintes techniques nous forcent à agir rapidement, seront les premiers à suivre cette route avec une restriction début 2020 et une fermeture un semestre plus tard. Pour tous les autres services concernés, les restrictions ne débuteront qu’à l’été 2020 (voire l’été 2021 pour certains), et les premières fermetures n’interviendront pas avant 2021 ; voire, pour certains services, pas avant 2022 !
Les seules exceptions à cette façon de faire sont, tout simplement, les services que nous ne fermerons pas (Framadate, les Framapads et MyPads, Framavox, Framagenda, Framatalk, le Framindmap collaboratif, Framacarte), auxquels s’ajoutent ceux que nous déplaçons juste dans notre axe « Culture Libre » (Framagames et Framinetest), ainsi que Framadrive (qui, lui, a très vite atteint la restriction des 5000 comptes que nous nous étions imposés… ce qui va rester ainsi).
Ah, oui…. et puis il y a Framabee, aussi connu sous le nom de Tonton Roger, le méta-moteur de recherche qui ne marche vraiment plus. D’aucuns disent qu’il faut l’achever, d’autres pensent qu’il faut lui faire dire que « Google m’a tuer », car malgré nos bidouillages, Google (et ses collègues) recevait trop de requêtes de notre part et s’est mis à les refuser en masse… comme quoi centraliser les usages, même chez Framasoft, ça ne marche vraiment pas ! Nous, on pense lui offrir une retraite anticipée : dès le mois prochain on dit bye bye à Framabee et on offre des charentaises à Tonton Roger !
Cliquez pour lire le document historique retraçant la soirée où nous avons eu la brillante idée d’avoir 3 noms de domaines pour un moteur de recherche.
Ranger le sac à dos, pour mieux avancer ensemble
Nous avons beaucoup appris. L’expérience de « Dégooglisons Internet » a démontré que lorsqu’on ne vous traite pas de consommatrices-ménagères et de clients-rois, vous savez accepter avec grâce qu’un serveur reste planté durant le week-end (parce qu’on n’impose pas d’astreintes à nos admin-sys), qu’un outil soit parfois un poil moins joli ou qu’il faille limiter son utilisation du service afin de partager l’espace avec d’autres… bref : qu’il y a une place, dans vos vies, pour du numérique artisanal, au sens noble du terme.
Toutes ces leçons, que nous récoltons depuis 2014, nous mènent à penser qu’il faut entamer une transition. Nous ne voulons certainement pas laisser les gens (vous !) le bec dans l’eau, et donner l’impression que le Libre est une promesse non-tenue. Au contraire, nous avons eu la joie d’attirer votre attention vers des solutions libres et de vous avoir aidé à les adopter (merci pour ces efforts !). Cette confiance, cette appétence pour des outils numériques pensés de manière éthique est précieuse : nous ne voulons pas la décevoir, juste l’accompagner un pas de plus sur le chemin.
Vous noterez au passage que nous prenons le soin de faire ce que les géants du web n’ont jamais fait : annoncer longtemps à l’avance un plan de fermetures et travailler pour vous accompagner encore plus loin dans votre dégooglisation. Ce grand remue-ménage nous permet aussi de ranger l’ensemble des outils et expériences que nous avons accumulé dans nos sac-à-dos ces dernières années… car cela fera plus de place, plus de disponibilité à ce qui arrive.
PeerTube et Mobilizon montrent combien nous souhaitons nous éloigner du modèle de logiciels « pareils-que-google-mais-en-libre ». A partir d’octobre, nous allons prendre trois mois pour faire le point sur nos explorations de la feuille de route « Contributopia », et vous verrez qu’il y a de nombreuses choses à dire, de nombreux projets qu’on n’avait pas vus, là, tout au fond du sac à dos…
C’est un moment très excitant qui s’approche, car nous avons de nombreuses annonces et histoires de contribution à vous partager… rendez-vous mi-octobre, nous, on a hâte !
Un an pour construire une nouvelle proposition
Fort·es de ce que ces années à Dégoogliser Internet nous ont enseigné, nous avons l’intuition qu’il est possible de construire une nouvelle proposition de service moins complexe, et plus pratique, pour les usager⋅es comme pour les hébergeur⋅ses. À force d’observer vos usages et d’écouter vos attentes, nous pensons que Nextcloud, riche de ses nombreuses applications, est une piste (et onn’estpaslesseul·es !). Nous croyons que ce logiciel peut répondre à a majorité des besoins des gens qui contribuent à changer le monde.
Une illustration des nombreuses utilisations possibles du logiciel Nextcloud
Nous nous donnons un an pour y contribuer (à nouveau), touiller dedans, expérimenter avec les copines et les copains afin de vous faire une autre proposition qui, nous l’espérons, facilitera encore mieux les dégooglisations…. comme les « déframasoftisations » !
Pour résumer :
Nous ne voulons pas devenir la « solution par défaut », et centraliser vos usages et vos attentions (c’est comme ça qu’on a créé des géants du web) ;
38 services c’est une trop grande diversité et complexité de logiciels à aborder (pour vous) ainsi qu’à maintenir et promouvoir (pour nous) ;
Nous voulons rester une association à taille humaine, à chaleur humaine… une espèce d’AMAP du numérique ;
Nous proposons donc une nouvelle étape dans la décentralisation des données :
Fermer progressivement des frama-services pour en faire des portes qui vous renvoient vers d’autres hébergeurs ;
Prendre le temps de mettre en place une autre proposition simplifiée pour les usager·es (qui offrira par exemple un compte unique).
Un manifeste des données utilisateurs, aujourd’hui ?
Le User Data Manifesto a été initié par Frank Karlitschek un militant du logiciel libre qui a fondé Nextcloud et Owncloud et participé à d’autres projets open source.
La source de cette traduction française figure sur ce dépôt Github, la dernière traduction que je reprends ici avec quelques modifications mineures date de 2015 et semble essentiellement due à Hugo Roy. Le dernier contributeur en date est Philippe Batailler.
[EDIT] Hugo Roy nous apporte cette précision : hello – la traduction est bien de moi, mais le texte en anglais aussi 😉 la version actuelle du manifeste est une œuvre collaborative avec Frank et @jancborchardt
À la lecture on est frappé de la pertinence des propositions, cependant malgré quelques avancées du côté des directives de l’Union européenne, certains droits revendiqués ici sont encore à conquérir ! Et après 4 ans il faudrait peut-être ajouter d’autres éléments à ce manifeste : le droit d’échapper au pistage publicitaire, le droit d’anonymiser vraiment sa navigation, le droit de ne pas fournir ses données biométriques etc.
Mais c’est plutôt à vous de dire ce qui manque ou est à modifier dans ce manifeste pour qu’il soit solidement inscrit dans les lois et les usages. Comme toujours, le commentaires sont ouverts et modérés.
Manifeste des données utilisateur
Ce manifeste a pour but de définir les droits fondamentaux des utilisateurs sur leurs données à l’ère d’Internet. Chacun devrait être libre sans avoir à faire allégeance aux fournisseurs de service.
Par données utilisateur, on entend les données envoyées par un utilisateur ou une utilisatrice pour son propre usage.
Par exemple, les données utilisateur comprennent :
les fichiers qu’un utilisateur ou qu’une utilisatrice synchronise entre plusieurs appareils ou qu’il ou elle partage avec un⋅e proche
une bibliothèque d’albums photos, de livres ou d’autres fichiers qu’un utilisateur envoie depuis son appareil afin de pouvoir lire, voir, et modifier tout cela en ligne
les données générées par un appareil de l’utilisateur (comme un thermostat ou une montre connectée) et envoyées vers un serveur
les requêtes d’un utilisateur à un moteur de recherche, si de telles requêtes sont enregistrées comme telles
Ainsi, les utilisateurs devraient pouvoir…
1. Maîtriser leur accès à leurs données
Les données explicitement et volontairement envoyées par une utilisatrice devraient être sous la pleine maîtrise de l’utilisatrice. Les utilisateurs devraient être capables de décider à qui accorder un accès direct à leurs données et avec quelles permissions et licences cet accès devrait être accordé.
Lorsque les utilisateurs maîtrisent l’accès aux données qu’ils envoient, les données censées restées privées ou partagées à un cercle restreint ne devraient pas être rendues accessibles au fournisseur du service, ni divulguées aux États.
Cela implique que le droit d’utiliser le chiffrement ne devrait jamais être bafoué.
Cela implique également que lorsque des utilisateurs n’ont pas la pleine maîtrise sur l’envoi de leurs données (par exemple s’ils n’utilisent pas le chiffrement avant l’envoi) un fournisseur de service ne doit pas :
forcer les utilisateurs à divulguer des données privées (ce qui inclut la correspondance privée) pour eux, ni
imposer des conditions de licence (ex. : de droit d’auteur ou d’exploitation des données personnelles) qui vont au-delà de ce qui est nécessaire pour l’objectif du service.
Lorsque les utilisateurs rendent des données accessibles à d’autres, qu’il s’agisse d’un groupe de gens restreint ou d’un groupe plus large, ils devraient pouvoir décider sous quelles permissions l’accès à leurs données est autorisé. Cependant, ce droit n’est pas absolu et ne devrait pas empiéter sur le droit des tierces personnes à utiliser et exploiter ces données une fois qu’elles leur ont été rendues accessibles. Qui plus est, cela ne signifie pas que les utilisateurs devraient avoir le droit d’imposer des restrictions injustes à d’autres personnes. Dans tous les cas, les systèmes techniques ne doivent pas être conçus pour faire appliquer de telles restrictions (par exemple avec des DRM).
Les données reçues, générées ou collectées à partir de l’activité des utilisateurs dans l’utilisation du service (ex. : les métadonnées ou les données du graphe social) devraient leur être rendues accessibles et être également sous leur maîtrise. Si cette maîtrise n’est pas possible, alors ce type de données devrait être anonyme ou bien ne pas être stockée pour une période plus longue que nécessaire.
Certains services permettent aux utilisateurs de soumettre des données avec l’intention de les rendre publiquement accessibles à toutes et à tous. Y compris dans ces cas de figure, quelques données utilisateur restent privées (ex. : les métadonnées ou les données du graphe social). L’utilisatrice et l’utilisateur devraient pouvoir contrôler aussi ces données.
2. Savoir comment les données sont stockées
Quand les données sont envoyées à un fournisseur de service particulier, les utilisateurs et utilisatrices devraient être informé⋅e⋅s du lieu de stockage des données du fournisseur de service, de la durée, de la juridiction dans laquelle le fournisseur de service particulier opère et des lois qui s’y appliquent.
Lorsque les utilisateurs utilisent des services centralisés pour envoyer leurs données à un fournisseur de stockage particulier plutôt que de reposer sur des systèmes pair à pair, il est important de savoir où les fournisseurs pourraient stocker ces données car ils pourraient être obligés par les États à divulguer ces données qu’ils ont en leur possession.
Ce point est sans objet si les utilisateurs sont capables de stocker leurs propres données sur leurs appareils (ex. : des serveurs) dans leur environnement personnel et sous leur contrôle direct ou bien s’ils font confiance à des systèmes sans contrôle centralisé (ex. : le pair à pair).
Les utilisateurs ne devraient pas reposer sur des services centralisés. Les systèmes pair à pair et les applications unhosted sont un moyen d’y arriver. À long terme, tous les utilisateurs devraient être capables d’avoir leur propre serveur avec des logiciels libres.
3. Être libres de choisir une plateforme
Les utilisatrices devraient toujours être en mesure d’extraire leurs données d’un service à tout moment sans subir l’enfermement propriétaire.
Les utilisateurs ne devraient pas être bloqués par une solution technique particulière. C’est pourquoi ils devraient toujours être capables de quitter une plateforme et de s’installer ailleurs.
Les formats ouverts sont nécessaires pour garantir cela. Évidemment, sans le code source des programmes utilisés pour les données utilisateurs, cela n’est pas pratique. C’est pourquoi des programmes devraient être distribués sous une licence libre.
Si les utilisateurs ont ces droits, ils ont la maîtrise de leurs données plutôt que d’être sous la coupe des fournisseurs de service.
De nombreux services qui gèrent les données utilisateur à ce jour sont gratuits, mais cela ne signifie pas qu’ils soient libres. Plutôt que de payer avec de l’argent, les utilisateurs font allégeance aux fournisseurs de services pour que ceux-ci puissent exploiter les données utilisateurs (par ex. en les vendant, en offrant des licences ou en construisant des profils pour les annonceurs publicitaires).
Abandonner ainsi la maîtrise de sa vie privée et d’autres droits semble être un acte trivial pour de nombreuses personnes, un faible prix à payer en échange du confort que ces services Internet apportent.
Les fournisseurs de service ont ainsi été obligés de transformer leurs précieux services Internet en systèmes massifs et centralisés de surveillance. Il est crucial que chacun réalise et comprenne cela, puisqu’il s’agit d’une menace importante pour les libertés de l’humanité et le respect de la vie privée de chacun.
Enfin, pour assurer que les données utilisateurs soient sous la maîtrise des utilisateurs, les meilleurs conceptions techniques incluent les systèmes distribués ou pair-à-pair, ainsi que les applications unhosted. Juridiquement, cela signifie que les conditions générales d’utilisation devraient respecter les droits des utilisateurs et leur donner la possibilité d’exercer leurs droits aux données définis dans ce manifeste.
Illustration réalisée avec https://framalab.org/gknd-creator/
C’est Qwant qu’on va où ?
L’actualité récente de Qwant était mouvementée, mais il nous a semblé qu’au-delà des polémiques c’était le bon moment pour faire le point avec Qwant, ses projets et ses valeurs.
Si comme moi vous étiez un peu distrait⋅e et en étiez resté⋅e à Qwant-le-moteur-de-recherche, vous allez peut-être partager ma surprise : en fouinant un peu, on trouve tout un archipel de services, certains déjà en place et disponibles, d’autres en phase expérimentale, d’autres encore en couveuse dans le labo.
Voyons un peu avec Tristan Nitot, Vice-président Advocacy de Qwant, de quoi il retourne et si le principe affiché de respecter la vie privée des utilisateurs et utilisatrices demeure une ligne directrice pour les applications qui arrivent.
Tristan Nitot, autoportrait (licence CC-BY)
Bonjour Tristan, tu es toujours content de travailler pour Qwant malgré les périodes de turbulence ?
Oui, bien sûr ! Je reviens un peu en arrière : début 2018, j’ai déjeuné avec un ancien collègue de chez Mozilla, David Scravaglieri, qui travaillait chez Qwant. Il m’a parlé de tous les projets en logiciel libre qu’il lançait chez Qwant en tant que directeur de la recherche. C’est ce qui m’a convaincu de postuler chez Qwant.
J’étais déjà fan de l’approche liée au respect de la vie privée et à la volonté de faire un moteur de recherche européen, mais là, en plus, Qwant se préparait à faire du logiciel libre, j’étais conquis. À peine arrivé au dessert, j’envoie un texto au président, Eric Léandri pour savoir quand il m’embauchait. Sa réponse fut immédiate : « Quand tu veux ! ». J’étais aux anges de pouvoir travailler sur des projets qui rassemblent mes deux casquettes, à savoir vie privée et logiciel libre.
Depuis, 18 mois ont passé, les équipes n’ont pas chômé et les premiers produits arrivent en version Alpha puis Bêta. C’est un moment très excitant !
Récemment, Qwant a proposé Maps en version Bêta… Vous comptez vraiment rivaliser avec Google Maps ? Parce que moi j’aime bien Street View par exemple, est-ce que c’est une fonctionnalité qui viendra un jour pour Qwant Maps ?
Rivaliser avec les géants américains du capitalisme de surveillance n’est pas facile, justement parce qu’on cherche un autre modèle, respectueux de la vie privée. En plus, ils ont des budgets incroyables, parce que le capitalisme de surveillance est extrêmement lucratif. Plutôt que d’essayer de trouver des financements comparables, on change les règles du jeu et on se rapproche de l’écosystème libre OpenStreetMap, qu’on pourrait décrire comme le Wikipédia de la donnée géographique. C’est une base de données géographiques contenant des données et des logiciels sous licence libre, créée par des bénévoles autour desquels viennent aussi des entreprises pour former ensemble un écosystème. Qwant fait partie de cet écosystème.
En ce qui concerne les fonctionnalités futures, c’est difficile d’être précis, mais il y a plein de choses que nous pouvons mettre en place grâce à l’écosystème OSM. On a déjà ajouté le calcul d’itinéraires il y a quelques mois, et on pourrait se reposer sur Mapillary pour avoir des images façon StreetView, mais libres !
Dis donc, en comparant 2 cartes du même endroit, on voit que Qwant Maps a encore des progrès à faire en précision ! Pourquoi est-ce que Qwant Maps ne reprend pas l’intégralité d’Open Street Maps ?
vue du centre de la ville de La Riche avec la requête « médiathèque la Riche » par OpenStreetMap
vue du centre de la ville de La Riche avec la requête « médiathèque la Riche » par QwantMaps
En fait, OSM montre énormément de détails et on a choisi d’en avoir un peu moins mais plus utilisables. On a deux sources de données pour les points d’intérêt (POI) : Pages Jaunes, avec qui on a un contrat commercial et OSM. On n’affiche qu’un seul jeu de POI à un instant t, en fonction de ce que tu as recherché.
Quand tu choisis par exemple « Restaurants » ou « Banques », sans le savoir tu fais une recherche sur les POI Pages Jaunes. Donc tu as un fond de carte OSM avec des POI Pages Jaunes, qui sont moins riches que ceux d’OSM mais plus directement lisibles.
Bon d’accord, Qwant Maps utilise les données d’OSM, c’est tant mieux, mais alors vous vampirisez du travail bénévole et libre ? Quelle est la nature du deal avec OSM ?
Non, bien sûr, Qwant n’a pas vocation à vampiriser l’écosystème OSM : nous voulons au contraire être un citoyen modèle d’OSM. Nous utilisons les données et logiciels d’OSM conformément à leur licence. Il n’y a donc pas vraiment de deal, juste un respect des licences dans la forme et dans l’esprit. Par exemple, on met un lien qui propose aux utilisateurs de Qwant Maps d’apprendre à utiliser et contribuer à OSM. En ce qui concerne les logiciels libres nécessaires au fonctionnement d’OSM, on les utilise et on y contribue, par exemple avec les projets Mimirsbrunn, Kartotherian et Idunn. Mes collègues ont écrit un billet de blog à ce sujet.
Nous avons aussi participé à la réunion annuelle d’OSM, State Of the Map (SOTM) à Montpellier le 14 juin dernier, où j’étais invité à parler justement des relations entre les entreprises comme Qwant et les projets libres de communs numériques comme OSM. Les mauvais exemples ne manquent pas, avec Apple qui, avec Safari et Webkit, a sabordé le projet Konqueror de navigateur libre, ou Google qui reprend de la data de Wikipédia mais ne met pas de lien sur comment y contribuer (alors que Qwant le fait). Chez Qwant, on vise à être en symbiose avec les projets libres qu’on utilise et auxquels on contribue.
Google Maps a commencé à monétiser les emplois de sa cartographie, est-ce qu’un jour Qwant Maps va être payant ?
En réalité, Google Maps est toujours gratuit pour les particuliers (approche B2C Business to consumer). Pour les organisations ou entreprises qui veulent mettre une carte sur leur site web (modèle B2B Business to business), Google Maps a longtemps été gratuit avant de devenir brutalement payant, une fois qu’il a éliminé tous ses concurrents commerciaux. Il apparaît assez clairement que Google a fait preuve de dumping.
Pour le moment, chez Qwant, il n’y a pas d’offre B2B. Le jour où il y en aura une, j’espère que le un coût associé sera beaucoup plus raisonnable que chez Google, qui prend vraiment ses clients pour des vaches à lait. Je comprends qu’il faille financer le service qui a un coût, mais là, c’est exagéré !
Quand j’utilise Qwant Maps, est-ce que je suis pisté par des traqueurs ? J’imagine et j’espère que non, mais qu’est-ce que Qwant Maps « récolte » et « garde » de moi et de ma connexion si je lui demande où se trouve Bure avec ses opposants à l’enfouissement de déchets nucléaires ? Quelles garanties m’offre Qwant Maps de la confidentialité de mes recherches en cartographie ?
C’est un principe fort chez Qwant : on ne veut pas collecter de données personnelles. Bien sûr, à un instant donné, le serveur doit disposer à la fois de la requête (quelle zone de la carte est demandée, à quelle échelle) et l’adresse IP qui la demande. L’adresse IP pourrait permettre de retrouver qui fait quelle recherche, et Qwant veut empêcher cela. C’est pourquoi l’adresse IP est salée et hachée aussitôt que possible et c’est le résultat qui est stocké. Ainsi, il est impossible de faire machine arrière et de retrouver quelle adresse IP a fait quelle recherche sur la carte. C’est cette méthode qui est utilisée dans Qwant Search pour empêcher de savoir qui a recherché quoi dans le moteur de recherche.
Est-ce que ça veut dire qu’on perd aussi le relatif confort d’avoir un historique utile de ses recherches cartographiques ou générales ? Si je veux gagner en confidentialité, j’accepte de perdre en confort ?
Effectivement, Qwant ne veut rien savoir sur la personne qui recherche, ce qui implique qu’on ne peut pas personnaliser les résultats, ni au niveau des recherches Web ni au niveau cartographique : pour une recherche donnée, chaque utilisateur reçoit les mêmes résultats que tout le monde.
Ça peut être un problème pour certaines personnes, qui aimeraient bien disposer de personnalisation. Mais Qwant n’a pas dit son dernier mot : c’est exactement pour ça que nous avons fait « Masq by Qwant ». Masq, c’est une application Web en logiciel libre qui permet de stocker localement dans le navigateur (en LocalStorage)1 et de façon chiffrée des données pour la personnalisation de l’expérience utilisateur. Masq est encore en Alpha et il ne permet pour l’instant que de stocker (localement !) ses favoris cartographiques. À terme, nous voulons que les différents services de Qwant utilisent Masq pour faire de la personnalisation respectueuse de la vie privée.
Ouverture d’un compte Masq.
Ah bon alors c’est fini le cloud, on met tout sur sa machine locale ? Et si on vient fouiner dans mon appareil alors ? N’importe quel intrus peut voir mes données personnelles stockées ?
Effectivement, tes données étant chiffrées, et comme tu es le seul à disposer du mot de passe, c’est ta responsabilité de conserver précieusement ledit mot de passe. Quant à la sauvegarde des données, tu as bien pensé à faire une sauvegarde, non ? 😉
Ah mais vous avez aussi un projet de reconnaissance d’images ? Comment ça marche ? Et à quoi ça peut être utile ?
C’est le résultat du travail de chercheurs de Qwant Research, une intelligence artificielle (plus concrètement un réseau de neurones) qu’on a entraînée avec Pytorch sur des serveurs spécialisés DGX-1 en vue de proposer des images similaires à celles que tu décris ou que tu téléverses.
On peut chercher une image ou bien « déposer une image » pour en trouver de similaires.
Ah tiens j’ai essayé un peu, ça donne effectivement des résultats rigolos : si on cherche des saucisses, on a aussi des carottes, des crevettes et des dents…
C’est encore imparfait comme tu le soulignes, et c’est bien pour ça que ça n’est pas encore un produit en production ! On compte utiliser cette technologie de pointe pour la future version de notre moteur de recherche d’images.
Comment je fais pour signaler à l’IA qu’elle s’est plantée sur telle ou telle image ? C’est prévu de faire collaborer les bêta-testeurs ? Est-ce que Qwant accueille les contributions bénévoles ou militantes ?
Il est prévu d’ajouter un bouton pour que les utilisateurs puissent valider ou invalider une image par rapport à une description. Pour des projets de plus en plus nombreux, Qwant produit du logiciel libre et donc publie le code. Par exemple pour la recherche d’image, c’est sur https://github.com/QwantResearch/text-image-similarity. Les autres projets sont hébergés sur les dépôts https://github.com/QwantResearch : les contributions au code (Pull requests) et les descriptions de bugs (issues) sont les bienvenus !
Bon je vois que Qwant a l’ambition de couvrir autant de domaines que Google ? C’est pas un peu hégémonique tout ça ? On se croirait dans Dégooglisons Internet !
Effectivement, nos utilisateurs attendent de Qwant tout un univers de services. La recherche est pour nous une tête de pont, mais on travaille à de nouveaux services. Certains sont des moteurs de recherche spécialisés comme Qwant Junior, pour les enfants de 6 à 12 ans (pas de pornographie, de drogues, d’incitation à la haine ou à la violence).
Comment c’est calculé, les épineuses questions de résultats de recherche ou non avec Qwant Junior ? Ça doit être compliqué de filtrer…
Qwant Junior ne montre pas d’images de sexe masculin, tant mieux/tant pis ?
Nous avons des équipes qui gèrent cela et s’assurent que les sujets sont abordables par les enfants de 6 à 12 ans, qui sont notre cible pour Junior.
Ça n’est pas facile effectivement, mais nous pensons que c’est important. C’est une idée qui nous est venue au lendemain des attentats du Bataclan où trop d’images choquantes étaient publiées par les moteurs de recherche. C’était insupportable pour les enfants. Et puis Junior, comme je le disais, n’a pas vocation à afficher de publicité ni à capturer de données personnelles. C’est aussi pour cela que Qwant Junior est très utilisé dans les écoles, où il donne visiblement satisfaction aux enseignants et enseignantes.
Mais euh… « filtrer » les résultats, c’est le job d’un moteur de recherche ?
Il y a deux questions en fait. Pour un moteur de recherche pour enfants, ça me parait légitime de proposer aux parents un moteur qui ne propose pas de contenus choquants. Qwant Junior n’a pas vocation à être neutre : c’est un service éditorialisé qui fait remonter des contenus à valeur pédagogique pour les enfants. C’est aux parents de décider s’ils l’utilisent ou pas.
Pour un moteur de recherche généraliste revanche, la question est plutôt d’être neutre dans l’affichage des résultats, dans les limites de la loi.
Tiens vous avez même des trucs comme Causes qui propose de reverser l’argent des clics publicitaires à de bonnes causes ? Pour cela il faut désactiver les bloqueurs de pub auxquels nous sommes si attachés, ça va pas plaire aux antipubs…
En ce qui concerne Qwant Causes, c’est le moteur de recherche Qwant mais avec un peu plus de publicité. Et quand tu cliques dessus, cela rapporte de l’argent qui est donné à des associations que tu choisis. C’est une façon de donner à ces associations en faisant des recherches. Bien sûr si tu veux utiliser un bloqueur de pub, c’est autorisé chez Qwant, mais ça n’a pas de sens pour Qwant Causes, c’est pour ça qu’un message d’explication est affiché.
Est-ce que tous ces services sont là pour durer ou bien seront-ils fermés au bout d’un moment s’ils sont trop peu employés, pas rentables, etc. ?
Tous les services n’ont pas vocation à être rentables. Par exemple, il n’y a pas de pub sur Qwant Junior, parce que les enfants y sont déjà trop exposés. Mais Qwant reste une entreprise qui a vocation à générer de l’argent et à rémunérer ses actionnaires, donc la rentabilité est pour elle une chose importante. Et il y a encore de la marge pour concurrencer les dizaines de services proposés par Framasoft et les CHATONS 😉
Est-ce que Qwant est capable de dire combien de personnes utilisent ses services ? Qwant publie-t-elle des statistiques de fréquentation ?
Non. D’abord, on n’identifie pas nos utilisateurs, donc c’est impossible de les compter : on peut compter le nombre de recherches qui sont faites, mais pas par combien de personnes. Et c’est très bien comme ça ! Tout ce que je peux dire, c’est que le nombre de requêtes évolue très rapidement : on fait le point en comité de direction chaque semaine, et nous battons presque à chaque fois un nouveau record !
Bon venons-en aux questions que se posent souvent nos lecteurs et lectrices : Qwant et ses multiples services, c’est libre, open source, ça dépend ?
Non, tout n’est pas en logiciel libre chez Qwant, mais si tu vas sur les dépôts de Qwant et Qwant Research tu verras qu’il y a déjà plein de choses qui sont sous licence libre, y compris des choses stratégiques comme Graphee (calcul de graphe du Web) ou Mermoz (robot d’indexation du moteur). Et puis les nouveaux projets comme Qwant Maps et Masq y sont aussi.
La publicité est une source de revenus dans votre modèle économique, ou bien vous vendez des services à des entreprises ou institutions ? Qwant renonce à un modèle économique lucratif qui a fait les choux gras de Google, mais alors comment gagner de l’argent ?
Oui, Qwant facture aussi des services à des institutions dans le domaine de l’open data par exemple, mais l’essentiel du revenu vient de la publicité contextuelle, à ne pas confondre avec la publicité ciblée telle que faite par les géants américains du Web. C’est très différent.
La publicité ciblée, c’est quand tu sais tout de la personne (ses goûts, ses habitudes, ses déplacements, ses amis, son niveau de revenu, ses recherches web, son historique de navigation, et d’autres choses bien plus indiscrètes telles que ses opinions politiques, son orientation sexuelle ou religieuse, etc.). Alors tu vends à des annonceurs le droit de toucher avec de la pub des personnes qui sont ciblées. C’est le modèle des géants américains.
Qwant, pour sa part, ne veut pas collecter de données personnelles venant de ses utilisateurs. Tu as sûrement remarqué que quand tu vas sur Qwant.com la première fois, il n’y a pas de bannière « acceptez nos cookies ». C’est normal, nous ne déposons pas de cookies quand tu fais une recherche Qwant !
L’équipe Qwant’Comm en plein brainstorming…
Quand tu fais une recherche, Qwant te donne une réponse qui est la même pour tout le monde. Tu fais une recherche sur « Soupe à la tomate » ? On te donne les résultats et en même temps on voit avec les annonceurs qui est intéressé par ces mots-clés. On ignore tout de toi, ton identité ou ton niveau de revenu. Tout ce qu’on sait, c’est que tu as cherché « soupe à la tomate ». Et c’est ainsi que tu te retrouves avec de la pub pour du Gaspacho ou des ustensiles de cuisine. La publicité vaut un peu moins cher que chez nos concurrents, mais les gens cliquent dessus plus souvent. Au final, ça permet de financer les services et d’en inventer de nouveaux tout en respectant la vie privée des utilisateurs et de proposer une alternative aux services américains gourmands en données personnelles. On pourrait croire que ça ne rapporte pas assez, pourtant c’était le modèle commercial de Google jusqu’en 2006, où il a basculé dans la collecte massive de données personnelles…
Dans quelle mesure Qwant s’inscrit-il dans la reconquête de la souveraineté européenne contre la domination des géants US du Web ?
Effectivement, parmi les deux choses qui différencient Qwant de ses concurrents, il y a la non-collecte de données personnelles et le fait qu’il est français et à vocation européenne. Il y a un truc qui me dérange terriblement dans le numérique actuel, c’est que l’Europe est en train de devenir une colonie numérique des USA et peut-être à terme de la Chine. Or, le numérique est essentiel dans nos vies. Il les transforme ! Ces outils ne sont pas neutres, ils sont le reflet des valeurs de ceux qui les produisent.
Aux USA, les gens sont considérés comme des consommateurs : tout est à vendre à ou à acheter. En Europe, c’est différent. Ça n’est pas un hasard si la CNIL est née en France, si le RGPD est européen : on a conscience de l’enjeu des données personnelles sur la citoyenneté, sur la liberté des gens. Pour moi, que Qwant soit européen, c’est très important.
Merci d’avoir accepté de répondre à nos questions. Comme c’est la tradition de nos interviews, on te laisse le mot de la fin…
Je soutiens Framasoft depuis toujours ou presque, parce que je sais que ce qui y est fait est vraiment important : plus de libre, moins d’hégémonie des suspects habituels, plus de logiciel libre, plus de valeur dans les services proposés.
J’ai l’impression d’avoir avec Qwant une organisation différente par nature (c’est une société, avec des actionnaires), mais avec des objectifs finalement assez proches : fournir des services éthiques, respectueux de la vie pivée, plus proches des gens et de leurs valeurs, tout en contribuant au logiciel libre. C’est ce que j’ai tenté de faire chez Mozilla pendant 17 ans, et maintenant chez Qwant. Alors, je sais que toutes les organisations ne sont pas parfaites, et Qwant ne fait pas exception à la règle. En tout cas, chez Qwant on fait du mieux qu’on peut !
Vive l’Internet libre et ceux qui œuvrent à le mettre en place et à le défendre !
Nous sommes déjà des cyborgs mais nous pouvons reprendre le contrôle
Avec un certain sens de la formule, Aral Balkan allie la sévérité des critiques et l’audace des propositions. Selon lui nos corps « augmentés » depuis longtemps font de nous des sujets de la surveillance généralisée maintenant que nos vies sont sous l’emprise démultipliée du numérique.
Selon lui, il nous reste cependant des perspectives et des pistes pour retrouver la maîtrise de notre « soi », mais elles impliquent, comme on le devine bien, une remise en cause politique de nos rapports aux GAFAM, une tout autre stratégie d’incitation aux entreprises du numérique de la part de la Communauté européenne, le financement d’alternatives éthiques, etc.
Ce qui suit est la version française d’un article qu’a écrit Aral pour le numéro 32 du magazine de la Kulturstiftung des Bundes (Fondation pour la culture de la République fédérale d’Allemagne). Vous pouvez également lire la version allemande.
Traduction Framalang : goofy, jums, Fifi, MO, FranBAG, Radical Mass
L’esclavage 2.0 et comment y échapper : guide pratique pour les cyborgs.
par Aral Balkan
Il est très probable que vous soyez un cyborg et que vous ne le sachiez même pas.
Vous avez un smartphone ?
Vous êtes un cyborg.
Vous utilisez un ordinateur ? Ou le Web ?
Cyborg !
En règle générale, si vous utilisez une technologie numérique et connectée aujourd’hui, vous êtes un cyborg. Pas besoin de vous faire greffer des microprocesseurs, ni de ressembler à Robocop. Vous êtes un cyborg parce qu’en utilisant des technologies vous augmentez vos capacités biologiques.
À la lecture de cette définition, vous pourriez marquer un temps d’arrêt : « Mais attendez, les êtres humains font ça depuis bien avant l’arrivée des technologies numériques ». Et vous auriez raison.
Nous étions des cyborgs bien avant que le premier bug ne vienne se glisser dans le premier tube électronique à vide du premier ordinateur central.
L’homme des cavernes qui brandissait une lance et allumait un feu était le cyborg originel. Galilée contemplant les cieux avec son télescope était à la fois un homme de la Renaissance et un cyborg. Lorsque vous mettez vos lentilles de contact le matin, vous êtes un cyborg.
Tout au long de notre histoire en tant qu’espèce, la technologie a amélioré nos sens. Elle nous a permis une meilleure maîtrise et un meilleur contrôle sur nos propres vies et sur le monde qui nous entoure. Mais la technologie a tout autant été utilisée pour nous opprimer et nous exploiter, comme peut en témoigner quiconque a vu un jour de près le canon du fusil de l’oppresseur.
« La technologie », d’après la première loi de la technologie de Melvin Kranzberg, « n’est ni bonne ni mauvaise, mais elle n’est pas neutre non plus. »
Qu’est-ce qui détermine alors si la technologie améliore notre bien-être, les droits humains et la démocratie ou bien les dégrade ? Qu’est-ce qui distingue les bonnes technologies des mauvaises ? Et, tant qu’on y est, qu’est-ce qui différencie la lunette de Galilée et vos lentilles de contact Google et Facebook ? Et en quoi est-ce important de se considérer ou non comme des cyborgs ?
Nous devons tous essayer de bien appréhender les réponses à ces questions. Sinon, le prix à payer pourrait être très élevé. Il ne s’agit pas de simples questions technologiques. Il s’agit de questions cruciales sur ce que signifie être une personne à l’ère du numérique et des réseaux. La façon dont nous choisirons d’y répondre aura un impact fondamental sur notre bien-être, tant individuellement que collectivement. Les réponses que nous choisirons détermineront la nature de nos sociétés, et à long terme pourraient influencer la survie de notre espèce.
Propriété et maîtrise du « soi » à l’ère numérique et connectée
Imaginez : vous êtes dans un monde où on vous attribue dès la naissance un appareil qui vous observe, vous écoute et vous suit dès cet instant. Et qui peut aussi lire vos pensées.
Au fil des ans, cet appareil enregistre la moindre de vos réflexions, chaque mot, chaque mouvement et chaque échange. Il envoie toutes ces informations vous concernant à un puissant ordinateur central appartenant à une multinationale. À partir de là, les multiples facettes de votre personnalité sont collectionnées par des algorithmes pour créer un avatar numérique de votre personne. La multinationale utilise votre avatar comme substitut numérique pour manipuler votre comportement.
Votre avatar numérique a une valeur inestimable. C’est tout ce qui fait de vous qui vous êtes (à l’exception de votre corps de chair et d’os). La multinationale se rend compte qu’elle n’a pas besoin de disposer de votre corps pour vous posséder. Les esprits critiques appellent ce système l’Esclavage 2.0.
À longueur de journée, la multinationale fait subir des tests à votre avatar. Qu’est-ce que vous aimez ? Qu’est-ce qui vous rend heureux ? Ou triste ? Qu’est-ce qui vous fait peur ? Qui aimez-vous ? Qu’allez-vous faire cet après-midi ? Elle utilise les déductions de ces tests pour vous amener à faire ce qu’elle veut. Par exemple, acheter cette nouvelle robe ou alors voter pour telle personnalité politique.
La multinationale a une politique. Elle doit continuer à survivre, croître et prospérer. Elle ne peut pas être gênée par des lois. Elle doit influencer le débat politique. Heureusement, chacun des politiciens actuels a reçu le même appareil que vous à la naissance. Ainsi, la multinationale dispose aussi de leur avatar numérique, ce qui l’aide beaucoup à parvenir à ses fins.
Ceci étant dit, la multinationale n’est pas infaillible. Elle peut toujours faire des erreurs. Elle pourrait de façon erronée déduire, d’après vos pensées, paroles et actions, que vous êtes un terroriste alors que ce n’est pas le cas. Quand la multinationale tombe juste, votre avatar numérique est un outil d’une valeur incalculable pour influencer votre comportement. Et quand elle se plante, ça peut vous valoir la prison.
Dans les deux cas, c’est vous qui perdez !
Ça ressemble à de la science-fiction cyberpunk dystopique, non ?
Remplacez « multinationale » par « Silicon Valley ». Remplacez « puissant ordinateur central » par « cloud ». Remplacez « appareil » par « votre smartphone, l’assistant de votre smart home, votre smart city et votre smart ceci-cela, etc. ».
Bienvenue sur Terre, de nos jours ou à peu près.
Le capitalisme de surveillance
Nous vivons dans un monde où une poignée de multinationales ont un accès illimité et continu aux détails les plus intimes de nos vies. Leurs appareils, qui nous observent, nous écoutent et nous pistent, que nous portons sur nous, dans nos maisons, sur le Web et (de plus en plus) sur nos trottoirs et dans nos rues. Ce ne sont pas des outils dont nous sommes maîtres. Ce sont les yeux et les oreilles d’un système socio-techno-économique que Shoshana Zuboff appelle « le capitalisme de surveillance ».
Tout comme dans notre fiction cyberpunk dystopique, les barons voleurs de la Silicon Valley ne se contentent pas de regarder et d’écouter. Par exemple, Facebook a annoncé à sa conférence de développeurs en 2017 qu’ils avaient attelé 60 ingénieurs à littéralement lire dans votre esprit2.
J’ai demandé plus haut ce qui sépare la lunette de Galilée de vos lentilles de contact produites par Facebook, Google ou d’autres capitalistes de surveillance. Comprendre la réponse à cette question est crucial pour saisir à quel point le concept même de personnalité est menacé par le capitalisme de surveillance.
Lorsque Galilée utilisait son télescope, lui seul voyait ce qu’il voyait et lui seul savait ce qu’il regardait. Il en va de même lorsque vous portez vos lentilles de contact. Si Galilée avait acheté son télescope chez Facebook, Facebook Inc. aurait enregistré tout ce qu’il voyait. De manière analogue, si vous allez achetez vos lentilles de contact chez Google, des caméras y seront intégrées et Alphabet Inc. verra tout ce que vous voyez. (Google ne fabrique pas encore de telles lentilles, mais a déposé un brevet3 pour les protéger. En attendant, si vous êtes impatient, Snapchat fait des lunettes à caméras intégrées.)
Lorsque vous rédigez votre journal intime au crayon, ni le crayon ni votre journal ne savent ce que vous avez écrit. Lorsque vous écrivez vos réflexions dans des Google Docs, Google en connaît chaque mot.
Quand vous envoyez une lettre à un ami par courrier postal, la Poste ne sait pas ce que vous avez écrit. C’est un délit pour un tiers d’ouvrir votre enveloppe. Quand vous postez un message instantané sur Facebook Messenger, Facebook en connaît chaque mot.
Si vous vous identifiez sur Google Play avec votre smartphone Android, chacun de vos mouvements et de vos échanges sera méticuleusement répertorié, envoyé à Google, enregistré pour toujours, analysé et utilisé contre vous au tribunal du capitalisme de surveillance.
On avait l’habitude de lire les journaux. Aujourd’hui, ce sont eux qui nous lisent. Quand vous regardez YouTube, YouTube vous regarde aussi.
Vous voyez l’idée.
À moins que nous (en tant qu’individus) n’ayons notre technologie sous contrôle, alors « smart » n’est qu’un euphémisme pour « surveillance ». Un smartphone est un mouchard, une maison intelligente est une salle d’interrogatoire et une ville intelligente est un dispositif panoptique.
Google, Facebook et les autres capitalistes de surveillance sont des fermes industrielles pour êtres humains. Ils gagnent des milliards en vous mettant en batterie pour vous faire pondre des données et exploitent cette connaissance de votre intimité pour vous manipuler votre comportement.
Ce sont des scanners d’être humains. Ils ont pour vocation de vous numériser, de conserver cette copie numérique et de l’utiliser comme avatar pour gagner encore plus en taille et en puissance.
Nous devons comprendre que ces multinationales ne sont pas des anomalies. Elles sont la norme. Elles sont le courant dominant. Le courant dominant de la technologie aujourd’hui est un débordement toxique du capitalisme américain de connivence qui menace d’engloutir toute la planète. Nous ne sommes pas vraiment à l’abri de ses retombées ici en Europe.
Nos politiciens se laissent facilement envoûter par les millions dépensés par ces multinationales pour abreuver les lobbies de Bruxelles. Ils sont charmés par la sagesse de la Singularity University (qui n’est pas une université). Et pendant ce temps-là, nos écoles entassent des Chromebooks pour nos enfants. On baisse nos taxes, pour ne pas handicaper indûment les capitalistes de surveillance, au cas où ils voudraient se commander une autre Guinness. Et les penseurs de nos politiques, institutionnellement corrompus, sont trop occupés à organiser des conférences sur la protection des données – dont les allocutions sont rédigées par Google et Facebook – pour protéger nos intérêts. Je le sais car j’ai participé à l’une d’elles l’an passé. L’orateur de Facebook quittait tout juste son boulot à la CNIL, la commission française chargée de la protection des données, réputée pour la beauté et l’efficacité de ses chaises musicales.
Il faut que ça change.
Je suis de plus en plus convaincu que si un changement doit venir, il viendra de l’Europe.
La Silicon Valley ne va pas résoudre le problème qu’elle a créé. Principalement parce que des entreprises comme Google ou Facebook ne voient pas leurs milliards de bénéfices comme un problème. Le capitalisme de surveillance n’est pas déstabilisé par ses propres critères de succès. Ça va comme sur des roulettes pour les entreprises comme Google et Facebook. Elles se marrent bien en allant à la banque, riant au visage des législateurs, dont les amendes cocasses excèdent à peine un jour ou deux de leur revenu. D’aucuns diraient que « passible d’amende » signifie « légal pour les riches ». C’est peu de le dire lorsqu’il s’agit de réglementer des multinationales qui brassent des milliers de milliards de dollars.
De manière analogue, le capital-risque ne va pas investir dans des solutions qui mettraient à mal le business immensément lucratif qu’il a contribué à financer.
Alors quand vous voyez passer des projets comme le soi-disant Center for Humane Technology, avec des investisseurs-risques et des ex-employés de Google aux commandes, posez-vous quelques questions. Et gardez-en quelques-unes pour les organisations qui prétendent créer des alternatives éthiques alors qu’elles sont financées par les acteurs du capitalisme de surveillance. Mozilla, par exemple, accepte chaque année des centaines de millions de dollars de Google4. Au total, elle les a délestés de plus d’un milliard de dollars. Vous êtes content de lui confier la réalisation d’alternatives éthiques ?
Si nous voulons tracer une autre voie en Europe, il faut financer et bâtir notre technologie autrement. Ayons le courage de nous éloigner de nos amis d’outre-Atlantique. Ayons l’aplomb de dire à la Silicon Valley et à ses lobbyistes que nous n’achetons pas ce qu’ils vendent.
Et nous devons asseoir tout ceci sur de solides fondations légales en matière de droits de l’homme. J’ai dit « droits de l’homme » ? Je voulais dire droits des cyborgs.
Les droits des cyborgs sont des droits de l’homme
La crise juridique des droits de l’homme que nous rencontrons nous ramène au fond à ce que nous appelons « humain ».
Traditionnellement, on trace les limites de la personne humaine à nos frontières biologiques. En outre, notre système légal et judiciaire tend à protéger l’intégrité de ces frontières et, par là, la dignité de la personne. Nous appelons ce système le droit international des droits de l’Homme.
Malheureusement, la définition de la personne n’est plus adaptée pour nous protéger complètement à l’ère du numérique et des réseaux.
Dans cette nouvelle ère, nous étendons nos capacités biologiques par des technologies numériques et en réseau. Nous prolongeons nos intellects et nos personnes par la technologie moderne. C’est pour ça que nous devons étendre notre concept des limites de la personne jusqu’à inclure les technologies qui nous prolongent. En étendant la définition de la personne, on s’assure que les droits de l’homme couvrent et donc protègent la personne dans son ensemble à l’ère du numérique et des réseaux.
En tant que cyborgs, nous sommes des êtres fragmentaires. Des parties de nous vivent dans nos téléphones, d’autres quelque part sur un serveur, d’autres dans un PC portable. C’est la somme totale de tous ces fragments qui compose l’intégralité de la personne à l’ère du numérique et des réseaux.
Les droits des cyborgs sont donc les droits de l’homme tels qu’appliqués à la personne cybernétique. Ce dont nous n’avons pas besoin, c’est d’un ensemble de « droits numériques » – probablement revus à la baisse. C’est pourquoi, la Déclaration universelle des droits cybernétiques n’est pas un document autonome, mais un addendum à la Déclaration universelle des droits de l’Homme.
La protection constitutionnelle des droits cybernétiques étant un but à long terme, il ne faut pas attendre un changement constitutionnel pour agir. Nous pouvons et devons commencer à nous protéger en créant des alternatives éthiques aux technologies grand public.
Pour des technologies éthiques
Une technologie éthique est un outil que vous possédez et que vous contrôlez. C’est un outil conçu pour vous rendre la vie plus facile et plus clémente. C’est un outil qui renforce vos capacités et améliore votre vie. C’est un outil qui agit dans votre intérêt – et jamais à votre détriment.
Une technologie non éthique est au contraire un outil aux mains de multinationales et de gouvernements. Elle sert leurs intérêts aux dépens des vôtres. C’est un miroir aux alouettes conçu pour capter votre attention, vous rendre dépendant, pister chacun de vos mouvements et vous profiler. C’est une ferme industrielle déguisée en parc récréatif.
La technologie non éthique est nuisible pour les êtres humains, le bien-être et la démocratie.
Semer de meilleures graines
La technologie éthique ne pousse pas sur des arbres, il faut la financer. La façon de la financer a de l’importance.
La technologie non éthique est financée par le capital risque. Le capital risque n’investit pas dans une entreprise, il investit dans la vente de l’entreprise. Il investit aussi dans des affaires très risquées. Un investisseur risque de la Silicon Valley va investir, disons, 5 millions de dollars dans 10 start-ups différentes, en sachant que 9 d’entre elles vont capoter. Alors il (c’est habituellement un « lui/il ») a besoin que la 10e soit une licorne à un milliard de dollars pour que ça lui rapporte 5 à 10 fois l’argent investi (Ce n’est même pas son argent, mais celui de ses clients.). Le seul modèle d’affaires que nous connaissions dans les nouvelles technologies qui atteigne une croissance pareille est la mise en batterie des gens. L’esclavage a bien payé.
L’esclavage 2.0 paie bien aussi.
Pas étonnant qu’un système qui attache autant de valeur à un mode de croissance de type prolifération cancéreuse ait engendré des tumeurs telles que Google et Facebook. Ce qui est stupéfiant, c’est que nous semblions célébrer ces tumeurs au lieu de soigner le patient. Et plus déconcertant encore, nous nous montrons obstinément déterminés à nous inoculer la même maladie ici en Europe.
Changeons de direction.
Finançons des alternatives éthiques
À partir des biens communs
Pour le bien commun.
Oui, cela signifie avec nos impôts. C’est en quelque sorte ce pour quoi ils existent (pour mettre en place des infrastructures partagées et destinées au bien commun qui font progresser le bien-être de nos populations et nos sociétés). Si le mot « impôt » vous effraie ou sonne trop vieux jeu, remplacez-le simplement par « financement participatif obligatoire » ou « philanthropie démocratisée ».
Financer une technologie éthique à partir des biens communs ne signifie pas que nous laissions aux gouvernements le pouvoir de concevoir, posséder ou contrôler nos technologies. Pas plus que de nationaliser des entreprises comme Google et Facebook. Démantelons-les ! Bien sûr. Régulons-les ! Évidemment. Mettons en œuvre absolument tout ce qui est susceptible de limiter autant que possible leurs abus.
Ne remplaçons pas un Big Brother par un autre.
À l’inverse, investissons dans de nombreuses et petites organisations, indépendantes et sans but lucratif, et chargeons-les de concevoir les alternatives éthiques. Dans le même temps, mettons-les en compétition les unes avec les autres. Prenons ce que nous savons qui fonctionne dans la Silicon Valley (de petites organisations travaillant de manière itérative, entrant en compétition, et qui échouent rapidement) et retirons ce qui y est toxique : le capital risque, la croissance exponentielle, et les sorties de capitaux.
À la place des startups, lançons des entreprises durables, des stayups en Europe.
À la place de sociétés qui n’ont comme possibilités que d’échouer vite ou devenir des tumeurs malignes, finançons des organisations qui ne pourront qu’échouer vite ou devenir des fournisseurs durables de bien social.
Lorsque j’ai fait part de ce projet au Parlement européen, il y a plusieurs années, celui-ci a fait la sourde oreille. Il n’est pas encore trop tard pour s’y mettre. Mais à chaque fois que nous repoussons l’échéance, le capitalisme de surveillance s’enchevêtre plus profondément encore dans le tissu de nos vies.
Nous devons surmonter ce manque d’imagination et fonder notre infrastructure technologique sur les meilleurs principes que l’humanité ait établis : les droits de l’homme, la justice sociale et la démocratie.
Aujourd’hui, l’UE se comporte comme un département de recherche et développement bénévole pour la Silicon Valley. Nous finançons des startups qui, si elles sont performantes, seront vendues à des sociétés de la Silicon Valley. Si elles échouent, le contribuable européen réglera la note. C’est de la folie.
La Communauté Européenne doit mettre fin au financement des startups et au contraire investir dans les stayups. Qu’elle investisse 5 millions d’euros dans dix entreprises durables pour chaque secteur où nous voulons des alternatives éthiques. À la différence des startups, lorsque les entreprises durables sont performantes, elles ne nous échappent pas. Elles ne peuvent être achetées par Google ou Facebook. Elles restent des entités non lucratives, soutenables, européennes, œuvrant à produire de la technologie en tant que bien social.
En outre, le financement d’une entreprise durable doit être soumis à une spécification stricte sur la nature de la technologie qu’elle va concevoir. Les biens produits grâce aux financements publics doivent être des biens publics. La Free Software Foundation Europe sensibilise actuellement l’opinion sur ces problématiques à travers sa campagne « argent public, code public ». Cependant, nous devons aller au-delà de l’open source pour stipuler que la technologie créée par des entreprises durables doit être non seulement dans le domaine public, mais également qu’elle ne peut en être retirée. Dans le cas des logiciels et du matériel, cela signifie l’utilisation de licences copyleft. Une licence copyleft implique que si vous créez à partir d’une technologie publique, vous avez l’obligation de la partager à l’identique. Les licences share-alike, de partage à l’identique, sont essentielles pour que nos efforts ne soient pas récupérés pour enjoliver la privatisation et pour éviter une tragédie des communs. Des corporations aux poches sans fond ne devraient jamais avoir la possibilité de prendre ce que nous créons avec des deniers publics, habiller tout ça de quelques millions d’investissement et ne plus partager le résultat amélioré.
En fin de compte, il faut préciser que les technologies produites par des entreprises stayups sont des technologies pair-à-pair. Vos données doivent rester sur des appareils que vous possédez et contrôlez. Et lorsque vous communiquez, vous devez le faire en direct (sans intervention d’un « homme du milieu », comme Google ou Facebook). Là où ce n’est techniquement pas possible, toute donnée privée sous le contrôle d’une tierce partie (par exemple un hébergeur web) doit être chiffrée de bout à bout et vous seul devriez en détenir la clé d’accès.
Même sans le moindre investissement significatif dans la technologie éthique, de petits groupes travaillent déjà à des alternatives. Mastodon, une alternative à Twitter fédérée et éthique, a été créée par une seule personne d’à peine vingt ans. Quelques personnes ont collaboré pour créer un projet du nom de Dat qui pourrait être la base d’un web décentralisé. Depuis plus de dix ans, des bénévoles font tourner un système de nom de domaine alternatif non commercial appelé OpenNIC5 qui pourrait permettre à chacun d’avoir sa propre place sur le Web…
Si ces graines germent sans la moindre assistance, imaginez ce qui serait à notre portée si on commençait réellement à les arroser et à en planter de nouvelles. En investissant dans des stayups, nous pouvons entamer un virage fondamental vers la technologie éthique en Europe.
Nous pouvons construire un pont de là où nous sommes vers là où nous voulons aller.
D’un monde où les multinationales nous possèdent par procuration à un monde où nous n’appartenons qu’à nous-mêmes.
D’un monde où nous finissons toujours par être la propriété d’autrui à un monde où nous demeurons des personnes en tant que telles.
Du capitalisme de surveillance à la pairocratie.
DIFFUser bientôt vos articles dans le Fediverse ?
Chaque mois le Fediverse s’enrichit de nouveaux projets, probablement parce nous désirons toujours plus de maîtrise de notre vie numérique.
Décentralisé et fédéré, ce réseau en archipel s’articule autour de briques technologiques qui permettent à ses composantes diverses de communiquer. Au point qu’à chaque rumeur de projet nouveau dans le monde du Libre la question est vite posée de savoir s’il sera « fédéré » et donc relié à d’autres projets.
Si vous désirez approfondir vos connaissances au plan technique et au plan de la réflexion sur la fédération, vous trouverez matière à vous enrichir dans les deux mémoires de Nathalie, stagiaire chez Framasoft l’année dernière.
Aujourd’hui, alors que l’idée de publier sur un blog semble en perte de vitesse, apparaît un nouvel intérêt pour la publication d’articles sur des plateformes libres et fédérées, comme Plume et WriteFreely. Maîtriser ses publications sans traqueurs ni publicités parasites, sans avoir à se plier aux injonctions des GAFAM pour se connecter et publier, sans avoir à brader ses données personnelles pour avoir un espace numérique d’expression, tout en étant diffusé dans un réseau de confiance et pouvoir interagir avec lui, voilà dans quelle mouvance se situe le projet DIFFU auquel nous vous invitons à contribuer et que vous présente l’interviewé du jour…
Bonjour, peux-tu te présenter, ainsi que tes activités ?
Jean-Pierre et une partie de l’équipe de développement en arrière-plan
Bonjour Framasoft. Je m’appelle Jean-Pierre Morfin, on me connaît aussi sur les réseaux sociaux et dans le monde du libre sous le pseudo jpfox. J’ai 46 ans, je vis avec ma tribu familiale recomposée dans un village ardéchois où je pratique un peu (pas assez) le vélo. Informaticien depuis mon enfance, je suis membre du GULL G3L basé à Valence, où je gère avec d’autres l’activité C.H.A.T.O.N.S qui propose plusieurs services comme Mastodon, Diaspora, TT-Rss, boite mail, owncloud…
Passionnés par le libre, Michaël, un ami de longue date et moi-même avons créé en 2010 ce qui s’appelle désormais une Entreprise du Numérique Libre nommée Befox qui propose ses services aux TPE/PME dans la Drôme et l’Ardèche principalement : réalisation de sites à base de solutions libres comme Prestashop, Drupal ou autres, installation Dolibarr et interconnexion entre différents logiciels ou plateformes, hébergement applicatif, évolutions chez nos fidèles clients constituent l’essentiel de notre activité.
Et donc, vous voulez vous lancer dans le développement d’un nouveau logiciel fédéré, « Diffu ». Pourquoi ?
Tout d’abord nous avons ressenti tous les deux le besoin de retourner aux fondamentaux du Libre, et quoi de plus fondamental que le développement d’un logiciel ? Lors de nos divagations sur le Fédiverse, les remarques récurrentes qu’on y trouve icioulà contre l’utilisation de Medium, nous ont fait penser qu’une alternative pouvait être intéressante. De plus, l’ouverture d’un compte Medium se fait nécessairement avec un compte Facebook ou Google, c’est leur façon d’authentifier un utilisateur ; en bons adeptes de la dégafamisation, c’est une raison de plus de créer une alternative à cette plateforme.
Voyant le succès et tout le potentiel de la Fédération, il fallait que cette nouvelle solution entre de ce cadre-là, car recréer une plateforme unique de publication ou un nouveau moteur de blog avec une gestion interne des commentaires ne présente aucun intérêt. Avec Diffu, la publication d’un article sur une des instances du réseau sera poussée sur le Fédiverse et les commentaires et réactions faits sur Mastodon, Pleroma, Hubzilla ou autre… seront agrégés pour être restitués directement sur la page de l’article. J’invite les lecteurs à jeter un œil à la maquette que nous avons réalisée pour se faire une idée, elle n’est pas fonctionnelle car cela reste encore un projet.
Quant au nom Diffu, on lui trouve deux sens : abréviation de Diffusion, ce qui reste l’objectif d’une plateforme de publication d’articles. Et dans sa prononciation à l’anglaise Diff You qui peut se comprendre Differentiate yourself – Différenciez vous ! C’est un peu ce que l’on fait lorsqu’on livre son avis, son expertise, ses opinions ou ses pensées dans un article.
Il existe déjà des logiciels fédérés de publication, tels que Plume ou WriteFreely. Quelles différences entre Diffu et ces projets ?
Absolument, ces deux applications libres, elles aussi, proposent de nombreux points de similitude avec Diffu notamment dans l’interconnexion avec le Fediverse et la possibilité de réagir aux articles avec un simple compte compatible avec ActivityPub.
La première différence est que pour Plume et WriteFreely, il est nécessaire de créer un compte sur l’instance que l’on souhaite utiliser. Avec Diffu, suivant les restrictions définies par l’administrateur⋅e de l’instance, il sera possible de créer un article juste en donnant son identifiant Mastodon par exemple (pas le mot de passe, hein, juste le pseudo et le nom de l’instance). L’auteur recevra un lien secret par message direct sur son compte Mastodon lui permettant d’accéder à son environnement de publication et de rédiger un nouvel article. Ce dernier sera associé à son auteur ou autrice, son profil Mastodon s’affichant en signature de l’article. Lors de la publication de l’article sur le Fediverse, l’autrice ou l’auteur sera mentionné⋅e dans le pouet qu’il n’aura plus qu’à repartager. L’adresse de la page de l’article sera utilisable sur les autres réseaux sociaux bien évidemment.
Nous voyons plus les instances Diffu comme des services proposés aux possesseurs de comptes ActivityPub. Comme on crée un Framadate ou un Framapad en deux clics, on pourra créer un article.
Les modes de modération et de workflow proposés par Diffu, la thématique choisie, les langues acceptées, la définition des règles de gestion permettront aux administrateurs de définir le public pouvant poster sur leur instance. Il sera par exemple possible de n’autoriser que les auteurs ayant un compte sur telle instance Mastodon, Diffu devenant un service complémentaire que pourrait proposer un CHATONS à ses utilisateurs Mastodon.
Ou, à l’opposé, un défenseur de la liberté d’expression peut laisser son instance Diffu open bar, au risque de voir son instance bloquée par d’autres acteurs du Fediverse, la régulation se faisant à plusieurs niveaux. Nous travaillons encore sur la définition des options de modération possibles, le but étant de laisser à l’administrateur⋅e toute la maîtrise des règles du jeu.
Les options retenues seront clairement explicites sur son instance pour que chacun⋅e puisse choisir la bonne plateforme qui lui convient le mieux. On imagine déjà faire un annuaire reprenant les règles de chaque instance pour aider les auteurs et autrices à trouver la plus appropriée à leur publication. Quitte à écrire sur plusieurs instances en fonction du sujet de l’article : « J’ai testé un nouveau vélo à assistance électrique » sur diffu.velo-zone.fr et « Comment installer LineageOS sur un Moto G4 » sur diffu.g3l.org.
L’autre différence avec Plume et WriteFreely est le langage retenu pour le développement de Diffu. Nous avons choisi PHP car il reste à nos yeux le plus simple à installer dans un environnement web et nous allons tout faire pour que ce soit vraiment le cas. Le locataire d’un simple hébergement mutualisé pourra installer Diffu : on dézippe le fichier de la dernière version, on envoie le tout par ftp sur le site, on accède à la page de configuration pour définir les options de son instance et ça fonctionne. Idem pour les mises à jour.
Nous avons déjà des contacts avec les dev de Plume qui sont tout aussi motivés que nous pour connecter nos plateformes et permettre une interaction entre les utilisateurs. C’est la magie du Fediverse !
Vous êtes en phase de crowdfunding pour le projet Diffu. À quoi va servir cet argent ?
Tout simplement à nous libérer du temps pour développer ce logiciel. On ne peut malheureusement pas se permettre de laisser en plan l’activité de Befox pendant des semaines car cela correspondrait à une absence complète de revenu pour nous deux. C’est donc notre société Befox qui va récolter le fruit de cette campagne et le transformer en rémunération. Nous avons visé au plus juste l’objectif de cette campagne de financement même si on sait que l’on va passer pas mal de temps en plus sur ce projet mais quand on aime…
Il faut aussi mentionner les 8 % de la campagne destinés à rétribuer la plateforme de financement Ulule.
Comment envisages-tu l’avenir de Diffu ?
Comme tout projet libre, après la publication des premières versions, la mise en ligne du code source, nous allons être à l’écoute des utilisateurs pour ajouter les fonctionnalités les plus attendues, garder la compatibilité avec le maximum d’acteurs du Fediverse. On sait que le protocole ActivityPub et ceux qui s’y rattachent peuvent avoir des interprétations différentes. On le voit pour les plateformes déjà en places comme Pleroma, Mastodon, Hubzilla, GNUSocial, PeerTube, PixelFed, WriteFreely et Plume… c’est une nécessité de collaborer avec les autres équipes de développement pour une meilleure expérience des utilisateurs.
Comme souvent ici, on te laisse le mot de la fin, pour poser LA question que tu aurais aimé qu’on te pose, et à laquelle tu aimerais répondre…
La question que l’on peut poser à tous les développeurs du Libre : quel éditeur de sources, Vim ou Emacs ?
Image : https://framalab.org/gknd-creator/
La réponse en ce qui me concerne, c’est Vim bien sûr.
Plus sérieusement, cela me permet d’évoquer ce que je trouve génial avec les Logiciels Libres, le fait qu’il y en a pour tous les goûts, que si un outil ne te convient pas, tu peux en utiliser un autre ou modifier/faire modifier celui qui existe pour l’adapter à tes attentes.
Alors même si Plume et WriteFreely existent et font très bien certaines choses, ils sont tous les deux différents et je suis convaincu que Diffu a sa place et viendra en complément de ceux-ci. J’ai hâte de pouvoir m’investir à fond dans ce projet.
Merci pour cette interview, à bientôt sur le Fediverse !














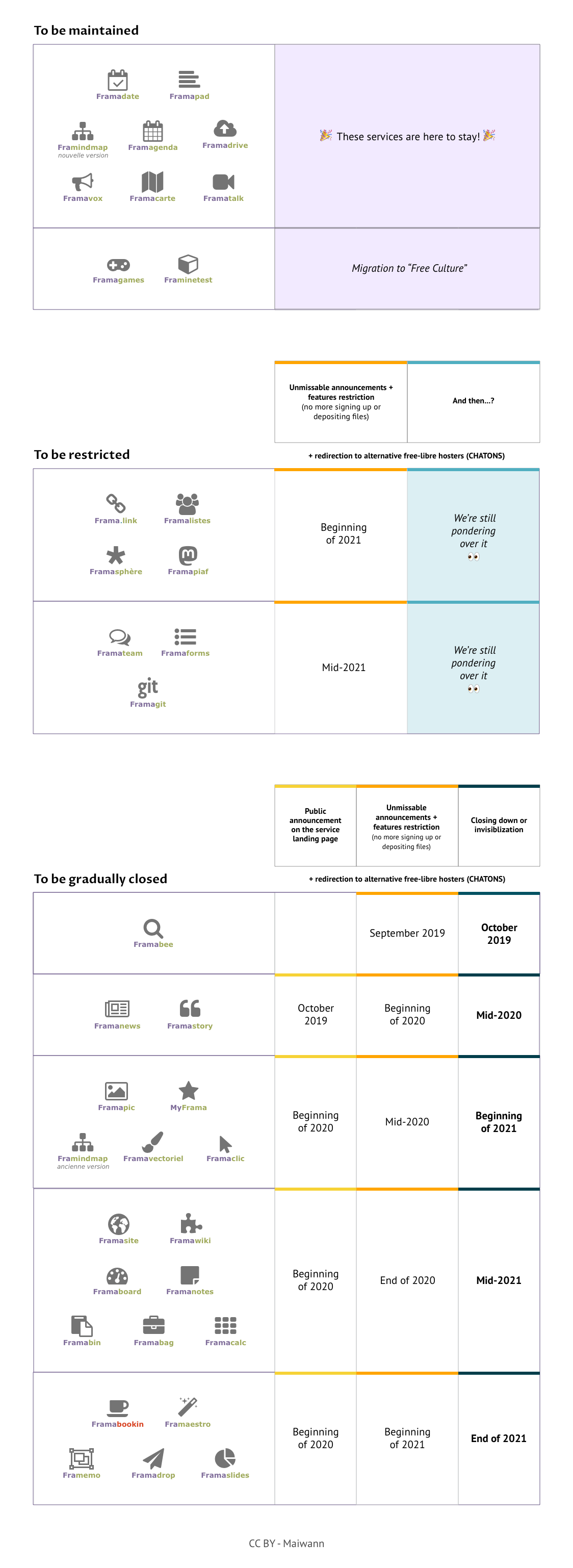


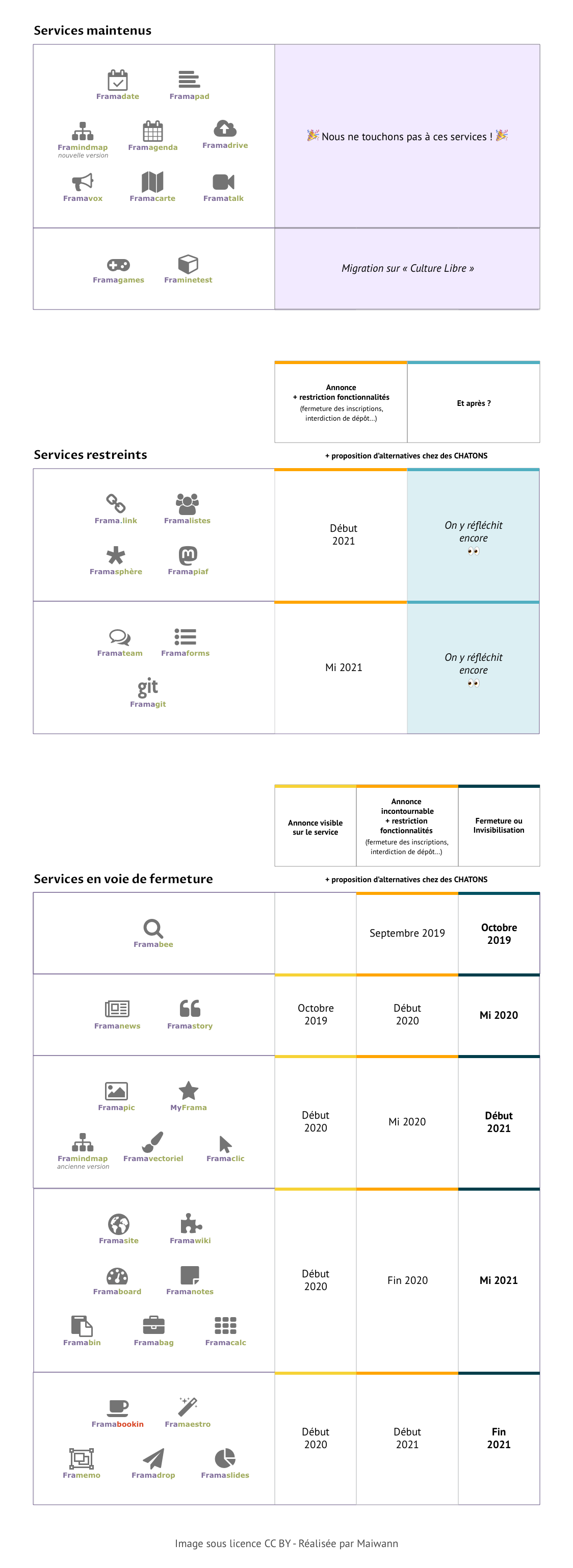





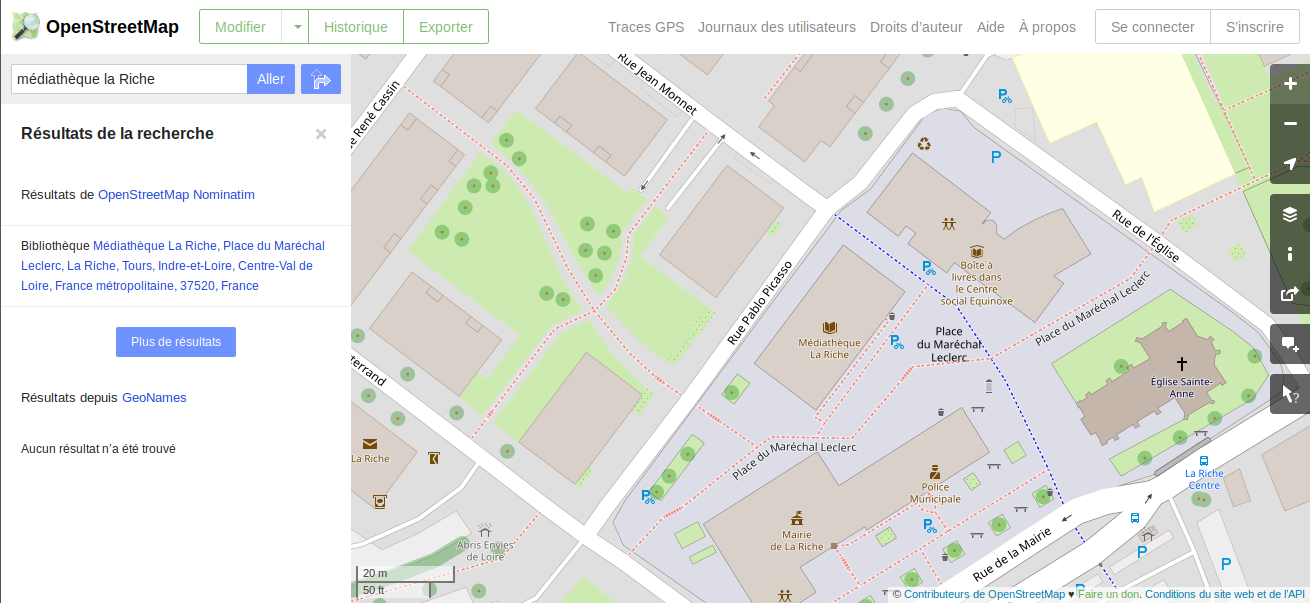

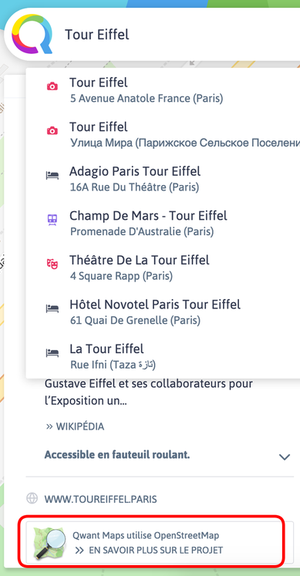










#/media/Fichier:H96566k.jpg){kind=link}
{kind=link}