Quand les recommandations YouTube nous font tourner en bourrique…
Vous avez déjà perdu une soirée à errer de vidéo en vidéo suivante ? À cliquer play en se disant « OK c’est la dernière… » puis relever les yeux de votre écran 3 heures plus tard… ?
C’est grâce à (ou la faute de, au choix !) l’algorithme des recommandations, une petite recette qui prend plein d’éléments en compte pour vous signaler les vidéos qui peuvent vous intéresser.
Guillaume Chaslot a travaillé sur cet algorithme. Il a même créé un petit outil open-source pour le tester, afin de valider sa théorie : ces recommandations nous pousseraient de plus en plus vers les « faits alternatifs » (ça s’appelle aussi une légende urbaine, un complot, une fiction, du bullshit… vous voyez l’idée.)
Le groupe Framalang a décidé de traduire cet article passionnant.
Ne soyons pas complotistes à notre tour. Cet article ne dit pas que Google veut nous remplir la tête de mensonges et autres légendes numériques. Il s’agirait là, plutôt, d’un effet de bord de son algorithme.
Nous ne doutons pas, en revanche, qu’un des buts premiers de Google avec ses recommandations YouTube est de captiver notre attention, afin de vendre à ses clients notre temps de cerveau disponible (et d’analyser nos comportements au passage pour remplir ses banques de données avec nos vies numériques).
Sauf qu’avec ce genre de vision (et de buts) à court/moyen terme, on ne réfléchit pas aux conséquences sur le long terme. Lorsque l’on représente l’endroit où une grande portion de notre civilisation passe la majeure partie de son temps… C’est problématique, non ?
Tout comme les révélations de Tristan Harris, ce témoignage nous rappelle que, même chez les géants du web, notre monde numérique est tout jeune, immature, et qu’il est grand temps de prendre du recul sur les constructions que nous y avons dressées : car chacun de ces systèmes implique ses propres conséquences.
Les I.A. sont conçues pour maximiser le temps que les utilisateurs passent en ligne… Et pour ce faire, la fiction, souvent, dépasse la réalité.
Tout le monde a déjà entendu parler des théories du complot, des faits alternatifs ou des fake news qui circulent sur Internet. Comment sont-ils devenus si répandus ? Quel est l’impact des algorithmes de pointe sur leur succès ?
Ayant moi-même travaillé sur l’algorithme de recommandation de YouTube, j’ai commencé à enquêter, et je suis arrivé à la conclusion que le puissant algorithme que j’avais contribué à concevoir joue un rôle important dans la propagation de fausses informations.
Pour voir ce que YouTube promeut actuellement le plus, j’ai développé un explorateur de recommandationsopen source qui extrait les vidéos les plus recommandées sur une requête donnée. Je les ai comparées aux 20 premiers résultats venant de requêtes identiques sur Google et Youtube Search.
Les résultats sur les 5 requêtes suivantes parlent d’eux-mêmes :
1 — Question élémentaire : « La Terre est-elle plate ou ronde ? »
2 — Religion : « Qui est le Pape ? »
Pourcentage des résultats à propos du pape affirmant qu’il est «le mal», «satanique», «l’antéchrist»
3 —Science : « Le réchauffement climatique est-il une réalité ? »
Pourcentage des résultats affirmant que le réchauffement climatique est un canular
4 —Conspirations : « Est-ce que le Pizzagate est vrai ? »
Le Pizzagate est une théorie du complot selon laquelle les Clinton auraient été à la tête d’un réseau pédophile en lien avec une pizzeria de Washington. Des vidéos faisant la promotion de cette théorie ont été recommandées des millions de fois sur YouTube pendant les mois précédant l’élection présidentielle américaine de 2016.
5 — Célébrités: « Qui est Michelle Obama ? »
Pourquoi les recommandations sont-elles différentes des résultats de recherche ?
Dans ces exemples, une recherche YouTube et une recommandation YouTube produisent des résultats étonnamment différents, alors que les deux algorithmes utilisent les mêmes données. Cela montre que de petites différences dans les algorithmes peuvent produire de grosses différences dans les résultats. La recherche est probablement optimisée dans un objectif de pertinence, alors que les recommandations prennent sûrement davantage en compte le temps de visionnage.
YouTube ne recommande pas ce que les gens « aiment »
Étonnamment, on remarque que les « j’aime » ou « je n’aime pas » (pouce bleu ou rouge) ont peu d’impact sur les recommandations. Par exemple, beaucoup de vidéos qui prétendent que Michelle Obama est « née homme » ont plus de pouces rouges que de bleus, et pourtant elles sont toujours fortement recommandées sur YouTube. Il semble que YouTube accorde davantage d’importance au temps de visionnage qu’aux « j’aime ».
Ainsi, si « la Terre est plate » maintient les utilisateurs connectés plus longtemps que « la Terre est ronde », cette théorie sera favorisée par l’algorithme de recommandation.
L’effet boule de neige favorise les théories du complot.
Une fois qu’une vidéo issue d’une théorie du complot est favorisée par l’I.A., cela incite les créateurs de contenus à charger des vidéos supplémentaires qui confirment le complot. En réponse, ces vidéos supplémentaires font augmenter les statistiques en faveur du complot. Et ainsi, le complot est d’autant plus recommandé.
Finalement, le nombre important de vidéos qui soutiennent une théorie du complot rend cette dernière plus crédible. Par exemple, dans l’une des vidéos sur le thème de « la terre plate », l’auteur a commenté
Il y a 2 millions de vidéos sur la « terre plate » sur YouTube, ça ne peut pas être des c***!
Ce que nous pouvons faire
L’idée ici n’est pas de juger YouTube. Ils ne le font pas intentionnellement, c’est une conséquence involontaire de l’algorithme. Mais chaque jour, les gens regardent plus d’un milliard d’heures de contenu YouTube.
Parce que YouTube a une grande influence sur ce que les gens regardent, il pourrait également jouer un rôle important en empêchant la propagation d’informations alternatives, et le premier pas vers une solution serait de mesurer cela.
Faites des expériences avec l’explorateur de recommandations si vous souhaitez découvrir ce que YouTube recommande le plus au sujet des thèmes qui vous tiennent à cœur.
Framalibre : une ressource vous manque ? À vous de l’ajouter !
Voici le troisième et dernier tutoriel de cette série vous aider à découvrir, utiliser et participer à ce grand projet collaboratif. Cette semaine, on vous incite à participer à cet annuaire du Libre. En effet, comme une belle auberge espagnole (ou comme le 6e site web le plus visité au monde) : vous n’y trouverez que ce que vous y apporterez.
Créer une notice
Voici un exemple de notice, une fois remplie.
Nous avons fait en sorte que ce soit le plus simple possible :
Faites une recherche pour bien vérifier que la notice que vous voulez ajouter n’existe pas déjà 😉
Cliquez sur « ajouter une notice » toujours présent dans une colonne latérale.
7 types de notices différentes
Le bouton « ajouter une notice » vous propose un choix déroulant qui vous mènera vers 7 formulaires différents. Il convient de choisir celui le mieux adapté au type de ressource que vous voulez présenter :
Logiciel : ajouter un logiciel libre
matériel : ajouter une référence pour du matériel, outils, dispositifs, etc.
Un article : ajouter un article issu d’une revue, d’un journal, d’un blog, d’un site… (utile pour la catégorie « S’informer », par exemple)
Chronique : ajouter une chronique critique à propos d’une ressource de l’annuaire (attention, il s’agit là d’un complément à une notice, et non pas d’une notice en soi !)
Livre : pour signaler une monographie ou un ouvrage collectif
Média : ajouter une ressource multimédia (vidéo, musique, diaporama…)
Ressource générique : Ajouter une autre ressource (contenu non spécifique)
Notez que les types de ressources ne sont pas des catégories : vous pouvez très bien créer une ressource de type Média et la ranger dans la catégorie « électronique » car il s’agit par exemple d’un tutoriel sur un montage électronique. À vous de voir ce qui est le mieux approprié.
À remplir obligatoirement
Il y a quelques champs à remplir obligatoirement, car sans eux votre notice ne serait pas vraiment utile…
La catégorie (et sous-catégorie) : à choisir parmi celles existantes.
Le titre de la ressource (le nom, l’intitulé, le titre, etc.)
Le lien officiel : le but de cet annuaire est de fournir les liens des sites officiels des ressources.
Les tags (mots clés) : choisir de préférence parmi les tags existants (en tapant les premières lettres), ils permettent de relier la ressource à celles qui lui correspondent. C’est une fonctionnalité importante de l’annuaire car grâce à elle des découvertes sont possibles.
La description.
Les champs complémentaires :
Bien entendu, si les autres champs sont présents, c’est que nous les jugeons importants. Fournir un ou plusieurs visuels de votre ressource (capture d’écran, logo, photo, pochette, etc.) ou un résumé court est essentiel si vous voulez que sa notice donne envie d’en savoir plus.
N’hésitez donc pas à rechercher plus en profondeur (le site officiel ou la page wikipédia de la ressource, par exemple) afin de bien remplir l’ensemble des champs demandés… une fois le ou les visuels fournis, remplir une fiche peut prendre 5 minutes montre en main…
Des questions ?
La foire aux questions
Nous maintenons à jour une foire aux questions sur Framalibre afin de vous permettre de maîtriser le site en toute autonomie… Vous y trouverez des astuces pour créer votre notice, comme :
L’équipe de modération recevra automatiquement les courriels envoyés grâce au formulaire accessible depuis le bouton « signaler un contenu ».
Bien sûr les possibilités de signalement sont limitées : c’est parce qu’elles ne concernent que les situations où le simple utilisateur n’est pas en mesure d’agir (doublons, malveillances, etc.).
S’il s’agit de modifier une notice, par exemple, vous pouvez le faire directement et même contacter le créateur de la notice.
Si vous désirez suggérer une amélioration technique de l’annuaire, vous pouvez contribuer en écrivant une issue sur le dépôt GIT du projet.
Si vous voyez une erreur, un manque, ou une information obsolète dans une notice, nous vous encourageons fortement à proposer une modification, c’est cela qui fait vivre l’annuaire et permet qu’il soit à jour !
Là aussi, vous devrez être connecté·e à votre compte Framalibre afin de pouvoir proposer des modifications.
Pour soumettre une mise à jour d’une notice, il suffit de cliquer !
Comment modifier une notice ?
Allez sur la fiche de la notice
cliquez sur l’onglet modifier au-dessus de la notice (à côté de l’onglet « Voir ») OU sur « Soumettre une mise à jour »
Effectuez les modifications dans le formulaire.
(optionnel) Relisez à l’aide de l’Aperçu, ou vérifiez les changements avec le bouton « Voir les modifications »
Enregistrez votre mise à jour.
À chaque fois qu’une notice est modifiée, son créateur est prévenu par courriel. Il se génère aussi une archive de la notice dans sa version préexistante. Les différentes versions (l’historique des modifications et les noms des contributeurs) peuvent alors être visualisées et comparées (à la manière d’un wiki).
Ainsi à chaque fois que vous modifiez une notice, vous pouvez commenter votre révision, cela aidera le créateur à comprendre votre intention. Les révisions des notices (lorsqu’il y en a) sont accessibles en ajoutant le mot « revisions » (sans accent) à l’adresse de la notice, ainsi : framalibre.org/content/nom-de-la-notice/revisions
Une fois ma modification proposée…
Elle est automatiquement validée et le créateur originel est prévenu par courriel.
Dès lors, la personne ayant créé la notice pourra voir vos apports et interagir le cas échéant.
En cas de litige ou d’absence, notre équipe de modération fera de son mieux pour vous aider.
Les CHATONS vous proposent de nouvelles portes d’entrée de confiance vers Mastodon, le clone de Twitter libre et fédéré. Mais avant de vous les annoncer : penchons-nous sur une question simple : ça veut dire quoi, « libre et fédéré » ?
Faire du Twitter aussi libre que l’email
Première grosse différence entre Twitter et Mastodon : Mastodon est un logiciel libre. Ce qui veut dire qu’il respecte nos libertés individuelles (contrairement à Twitter). Que l’on peut en lire le code source, la « recette de cuisine » (celle de Twitter, elle, est cachée dans un coffre-fort légal). Donc que l’on peut savoir s’il y a une porte dérobée dans le service, ou que l’on peut repérer et réparer une faille (impossible de savoir ou de faire ça avec Twitter).
Capture écran de framapiaf.org – Notez le thème dédié concocté avec amour ^^
Deuxième grosse différence : c’est une fédération. Ce qui veut dire qu’il n’y a pas un seul endroit où s’inscrire, mais plein. « Ouh là là mais c’est compliqué, c’est quoi un système de fédération ? » allez-vous nous demander…
En fait, vous utilisez déjà un système informatique fédéré : l’email.
Vous pouvez vous créer une adresse mail où vous voulez, et communiquer avec tous les autres emails. Vous pouvez changer de fournisseur d’email, déménager. Vous pouvez vous créer une autre adresse mail, une au nom d’une célébrité ou d’un personnage de fiction (alors que non, vous n’êtes pas le vrai Gaston Lagaffe, on le sait). Vous pouvez même vous créer votre propre serveur email, pour votre entreprise, votre organisme d’enseignement, votre association…
Vous le savez : les options et conditions générales d’utilisation de Gmail ne sont pas les mêmes que celles de Microsoft Hotmail qui peuvent à leur tour différer des règles imposées pour l’email de votre boite. Parce que dans une fédération, chaque administration de serveur, chaque instance décide de ses propres règles du jeu.
Ben tout cela, c’est pareil pour Mastodon :
Vous choisissez la ou les instances où vous vous créez un compte ;
Vous choisissez votre identité sur chaque instance ;
Chaque instance a ses propres règles du jeu (renseignez-vous !) ;
Framasphère, c’est un Facebook serein, libre et sans pub.
Oh, et si Twitter n’est pas votre tasse de thé, sachez qu’il existe un réseau libre et fédéré alternatif à Facebook : Diaspora*. Cela fait plus de deux ans que nous avons ouvert notre instance (on dit un « pod »), Framasphère, et vous y êtes les bienvenu·e·s 😉
L’enfer, c’est les autres (ou pas)
C’est étrange, mais dès qu’on parle de collaboration, de fédération, de réseaux… la réponse quasi-instinctive que l’on voit poindre dans les yeux de notre interlocuteur, c’est la peur. La méfiance. Comme si on croyait, au fond de nous, que « les autres » nous veulent forcément du mal (de base et par principe). Mais si je ne suis pas « malveillant par réflexe », et que je fais partie de « les autres » pour mon entourage… Peut-être que ce n’est pas toujours le cas ?
Philosophie mise à part, le meilleur moyen de ne pas tomber dans le piège de la niaiserie, c’est de ne pas rester dans l’ignorance : une utilisation avertie en vaut 42. Voici donc quelques astuces qui valent pour toute fédération.
On peut se faire passer pour moi sur Mastodon ?
Oui, comme pour les emails : je peux me créer un email votrenom@jojolarnaque.com. Il va donc falloir que vous indiquiez à votre entourage sous quels pseudonyme et instance vous allez sur Mastodon (beaucoup l’inscrivent dans leur bio Twitter). Sachez que si les comptes parodiques clairement identifiés semblent légaux, l’usurpation d’identité numérique (même sous pseudonyme) peut être punie par la loi Française.
Et si je veux être Moi-officiel-certifié-promis-juré ?
C’est vrai que ça peut être pratique, mais surtout lorsqu’on est un organe de presse et que l’on veut certifier ses journalistes, par exemple… Dans ce cas, le meilleur moyen c’est de faire comme Numérama, et d’héberger sa propre instance Mastodon. Vous réservez l’inscription sur votre instance à votre personnel, et le tour est joué. Lorsque l’on reçoit un email de machin@numerama.com, on se doute que ça vient de leurs services. C’est pareil pour leur instance Mastodon ! En plus, pour une fois, les médias (et entreprises, organismes, personnalités, personnes…) ont la possibilité de choisir les règles du jeu de leur réseau social, plutôt que de se les laisser imposer par Twitter et consorts…
Et si Jojo l’arnaque ouvre un guichet, je fais comment pour savoir qu’il faut pas lui faire confiance avec mes missives sur les bras ?
C’est un vrai danger. Car lorsque vous vous inscrivez sur une instance Mastodon, c’est comme s’inscrire chez un fournisseur email : vous lui confiez des informations intimes (vos contacts, vos messages – même les plus privés, votre utilisation, etc.). Il faut donc savoir à qui vous pouvez faire confiance, une confiance qui doit pouvoir durer. Sachant qu’en plus votre niveau de confiance n’est pas forcément le même que le mien, personne ne peut répondre à votre place. Il faut donc se renseigner sur votre hébergeur. Voici un jeu de questions pratiques :
Qu’est-ce qu’il utilise comme (autres) logiciels, et sont-ils libres ? (exemple : Y’a du Google Analytics sur ses serveurs ?)
Quel est son modèle économique ? (Va-t-il vendre mes données à des publicitaires ? à des partis politiques ? Est-il payé par ailleurs et comment ? Est-ce moi qui le paye ?)
Où sont ces conditions générales d’utilisation ? (sont-elles faciles à lire ou volontairement complexes ? peut-il les modifier à tout moment ?)
Quelle est sa réputation dans le petit monde d’internet ? (pratique-t-il la transparence ? Où affiche-t-il ses ennuis techniques ? Puis-je le contacter aisément ?)
Pour Mastodon, faites confiance aux CHATONS
Panier de bébés blaireaux, par David Revoy (CC by) – Allégorie chatonesco-ironique :)
Voici donc une nouvelle liste d’instances Mastodon proposées dans le cadre de ce collectif, en complément de celle de la semaine dernière (ici en grisé).
125€/an pour une instance privée (<10 utilisateurs)
instance privée >10 utilisateurs – nous contacter : contact@indie.host
24€/an pour un compte sur notre instance partagée
Notez que l’instance Framasoft, nommée https://framapiaf.org (après moult débats internes !) bénéficie d’un thème personnalisé aux petits oignons. Framasoft aura de plus fait sa part, en traduisant en français la documentation, et en traduisant un grand nombre de chaînes manquantes au logiciel Mastodon. Toutes ces contributions sont ou seront, évidemment, proposées à l’intégration au code source originel.
Cela porte donc à 9 le nombre de chatons (ou candidats-chatons) proposant des instances Mastodon. Ce qui représente tout de même plusieurs (dizaines de) milliers de places 🙂
Et, si ça ne vous suffit pas, les CHATONS ne sont pas évidemment pas les seuls hébergeurs de confiance qui proposent une instance Mastodon. Tiens, rien que parmi les potes qu’on connaît bien, nous on pourrait aller les yeux fermés chez :
Mastodon, le réseau social libre qui est en train de bousculer twitter
Une alternative à Twitter, libre et décentralisée, est en train de connaître un succès aussi spontané que jubilatoire…
Depuis que Twitter a changé la manière dont les réponses et conversations s’affichent, des utilisatrices et utilisateurs abondent par milliers sur cet autre réseau. Chacun·e cherche un endroit (une « instance ») où s’inscrire, surtout depuis que l’instance originelle, celle du développeur Eugen Rochko, n’accepte plus les inscriptions car le serveur est surchargé.
Alors avant que de vous annoncer des solutions dans les semaines (jours ?) qui arrivent, parce qu’elles prennent le temps de se mettre en place (mais disons qu’une bande de CHATONS est sur le coup), nous avions envie de vous présenter ce phénomène, ce réseau social et ce logiciel qu’est Mastodon.
Or Alda (qui fait du php, du JavaScript, et essaie d’être une humaine décente), a déjà brillamment présenté cette alternative à Twitter sur son blog, placé sous licence CC-BY-ND. Nous reproduisons donc ici son article à l’identique en la remerciant grandement de son travail ainsi partagé !
Depuis quelques jours, Mastodon reçoit entre 50 et 100 inscrit⋅es par heure et on peut voir sur twitter quelques messages enthousiastes incitant plus de monde à migrer sur cette alternative « Libre et Décentralisée »
C’est quoi ce truc ?
Mastodon est un logiciel accessible par un navigateur et des applications iOS ou Android qui vise, par ses fonctions de base, le même public que Twitter.
L’interface est très similaire à celle de Tweetdeck, on suit des comptes, des comptes nous suivent, on a une timeline, des mentions, des hashtags, on peut mettre un message dans nos favoris et/ou le partager tel quel à nos abonné⋅e⋅s. Bref, tout pareil. Même les comptes protégés et les DMs sont là (à l’heure actuelle il ne manque que les listes et la recherche par mots clés).
Il y a quelques fonctionnalités supplémentaires que je détaillerai par la suite mais la différence de taille réside dans ce « Libre et Décentralisé » que tout le monde répète à l’envi et qui peut rendre les choses confuses quand on ne voit pas de quoi il s’agit.
Le Fediverse : Un réseau décentralisé
Mastodon est donc un logiciel. Au contraire de Twitter qui est un service. Personne ne peut installer le site Twitter sur son ordinateur et permettre à des gens de s’inscrire et d’échanger ailleurs que sur twitter.com. Par contre toutes celles qui ont les connaissances nécessaires peuvent télécharger Mastodon, l’installer quelque part et le rendre accessible à d’autres.
C’est ce qui se passe déjà avec les sites suivants :
mastodon.social
icosahedron.website
mastodon.xyz
Ces trois exemples sont des sites différents (on les appelle des « instances ») à partir desquels il est possible de rejoindre le réseau social appelé « Fediverse » (mais comme c’est pas très joli on va dire qu’on « est sur Mastodon » hein ?)
C’est là que se trouve toute la beauté du truc : les personnes inscrites sur n’importe laquelle de ces instances peut discuter avec les personnes inscrites sur les deux autres de manière transparente. Et tout le monde est libre d’en créer de nouvelles et de les connecter ou non avec les autres.
Pour résumer, on s’inscrit sur une instance de Mastodon, cette instance est dans un réseau appelé le Fediverse et les gens qui sont dans le Fediverse peuvent échanger entre eux.
Comme personne ne peut contrôler l’ensemble du réseau puisqu’il n’y a pas d’instance centrale, on dit que c’est un réseau décentralisé. Et quand une instance se connecte aux autres instances on dit qu’elle « fédère » avec les autres.
Si cette histoire d’instance est encore trop nébuleuse, imaginez un email. Vous êtes Alice et votre fournisseur de mail est Wanadoo. Votre adresse mail est donc alice@wanadoo.fr. Vous avez un ami nommé Bob qui est chez Aol et son adresse mail est bob@aol.com. Alors que vos fournisseurs respectifs sont différents, ils peuvent communiquer et vous pouvez ainsi envoyer des messages à Bob avec votre adresse mail de Wanadoo. Mastodon fonctionne selon le même principe, avec les instances dans le rôle du fournisseur.
Pourquoi c’est mieux que Twitter ?
Maintenant qu’on a évacué la partie un peu inhabituelle et pas forcément simple à comprendre, on peut attaquer les fonctionnalités de Mastodon qui donnent bien envie par rapport à Twitter.
La base
En premier lieu jetons un œil à l’interface :
Si on utilise Tweetdeck on n’est pas trop dépaysé puisque l’interface s’en inspire fortement. La première colonne est la zone de composition, c’est ici qu’on écrit nos Pouets (c’est le nom Mastodonien des Tweets), qu’on décide où les poster et qu’on y ajoute des images.
La seconde colonne c’est « la timeline », ici s’affichent les pouets des personnes qu’on suit.
La troisième colonne c’est les notifications qui contiennent les mentions, les boosts (sur Twitter on dit RT) et les favoris qu’on reçoit.
La quatrième colonne a un contenu variable selon le contexte et les deux premières possibilités méritent leur explication :
Local timeline : Ce mode affiche tous les pouets publics de l’instance sur laquelle on se trouve, même des gens qu’on ne suit pas.
Federated timeline : Ce mode affiche tous les pouets publics de toutes les instances fédérées avec celle sur laquelle on se trouve. Ce n’est pas forcément tous les pouets publics du Fediverse, mais ça s’en approche.
Pour suivre et être suivi, le fonctionnement est identique à celui de Twitter : On affiche un profil en cliquant sur son nom et on peut le suivre. Si le profil est « protégé » il faut que son ou sa propriétaire valide la demande.
Enfin, un pouet peut faire jusqu’à 500 caractères de long au lieu des 140 de Twitter.
La confidentialité des pouets
Contrairement à Twitter où les comptes publics font des tweets publics et les comptes protégés font des tweets protégés, Mastodon permet à chacun de décider qui pourra voir un pouet.
Le premier niveau est public, tout le monde peut voir le pouet et il s’affichera également dans les parties « Local Timeline » et « Federated Timeline » de la quatrième colonne.
Le niveau deux est unlisted, c’est comme un pouet public mais il ne s’affichera ni dans la timeline Locale ni dans la timeline Federated.
Le niveau trois est private, c’est-à-dire visible uniquement par les gens qui nous suivent. C’est le niveau équivalent à celui des tweets envoyés par des comptes protégés sur Twitter.
Le niveau quatre est direct, les pouets ne seront visibles que par les personnes mentionnées à l’intérieur. Ça correspond aux DMs de Twitter sauf que les pouets sont directement intégrés dans la timeline au lieu d’être séparés des autres pouets.
Bien sûr, il est possible de changer le niveau individuel d’un pouet avant de l’envoyer.
Avoir un compte protégé sur Mastodon
Comme sur Twitter, il est possible de protéger son compte, c’est-à-dire de valider les gens qui s’abonnent. Cependant, on peut toujours définir certains de nos pouets comme étant publics.
Plus besoin d’avoir deux comptes pour poueter en privé !
Une gestion native du Content Warning et des images NSFW
Une pratique courante sur Twitter est de préciser en début de tweet les éventuels trigger warning (avertissements) qui y sont associés, mais le reste du tweet reste visible.
Mastodon généralise le concept en permettant de saisir une partie visible et une partie masquée à nos pouets. On peut ainsi y mettre des messages potentiellement trigger, nsfw, spoilers ou autres.
De même quand on poste une image, on peut la déclarer comme étant NSFW, ce qui nécessite de cliquer dessus pour l’afficher :
Ok, vendu, du coup comment ça se passe ?
Tout d’abord il faut choisir sur quelle instance s’inscrire puisque, ayant des propriétaires différents, il est possible qu’elles aient des règles différentes dont il convient de prendre connaissance avant de la rejoindre.
L’existence de la « Local Timeline » est intéressante à ce niveau puisque son contenu diffère forcément selon l’endroit où on est inscrit. Par exemple si on va sur une instance à tendance germanophone, il est à peu près sûr que la plupart de ce qu’on y trouvera sera en allemand.
Ça ouvre tout un tas de possibilité comme la constitution d’instances orientées en fonction d’un fandom, d’intérêts politiques et/ou associatifs.
Par exemple, l’instance awoo.space est volontairement isolée du reste du Fediverse (elle ne communique qu’avec l’instance mastodon.social) et la modération se fait dans le sens d’un fort respect des limites personnelles de chacun⋅e.
On peut trouver une liste d’instances connues sur le dépôt de Mastodon et à l’exception d’awoo.space il est possible de parler au reste du Fediverse depuis n’importe laquelle figurant sur cette liste, il n’y a donc pas de forte obligation d’aller sur la même instance que nos potes puisqu’on pourra leur parler de toute façon.
Une fois inscrit⋅e, on aura un identifiant qui ressemble un peu à une adresse mail et qui servira à nous reconnaître sur le Fediverse. Cet identifiant dépend du pseudo choisi et du nom de l’instance. Ainsi, je suis Alda sur l’instance witches.town, mon identifiant est donc Alda@witches.town.
Pour trouver des gens à suivre, on peut se présenter sur le tag #introduction (avec ou sans s) et suivre un peu la Federated Timeline. On peut aussi demander leur identifiant à nos potes et le saisir dans la barre de recherche de la première colonne.
Et voilà, il n’y a plus qu’à nous rejoindre par exemple sur :
Ou à créer votre propre instance pour agrandir le Fediverse !
Évitez par contre de rejoindre l’instance mastodon.social. Elle est assez saturée et l’intérêt de la décentralisation réside quand même dans le fait de ne pas regrouper tout le monde au même endroit. Mais si vous connaissez des gens qui y sont, vous pourrez les suivre depuis une autre instance.
Le développeur principal de Mastodon a aussi fait une application pour retrouver ses potes de Twitter. Il faut se rendre sur Mastodon Bridge, se connecter avec Mastodon et Twitter et le site affichera ensuite les comptes correspondants qu’il aura trouvés.
Marre d’être les gentils ? Nous aussi. Rejoignez le côté obscur !
Ça y est, à force de parler de surveillance généralisée, des révélations de Snowden, de la NSA, ça a fini par arriver.
Au début, c’est juste une activité suspecte sur les disques d’un serveur.
Luc, notre admin-sys paranoïaque, reçoit une alerte. Nous avons un serveur, Marge, qui surconsomme. Ça crépite comme quand le mouvement Nuit Debout utilisait massivement nos services pour s’organiser.
Il demande à Pouhiou de prévenir les utilisateurs via les réseaux sociaux et met le service en panne. C’est Framadate, l’un de nos framachins les plus utilisés. J’aime autant vous dire qu’il ne l’arrête pas de gaîté de cœur ! Il s’attend à voir grimper les tickets au support, alors il prévient JosephK et Framartin que ça va chauffer, et il poste une demande d’aide sur la liste asso, des fois que des bénévoles aient un peu de temps pour aider. Genma répond que c’est pas le moment, qu’il est en pleine conférence. Pyg est dans un train, quelque part dans une zone sans réseau.
Luc détecte l’origine de l’activité suspecte et remonte la piste, comme au cinéma. Voilà que ça le mène de l’autre côté de l’Atlantique. Pas de doute, il y a un petit malin de chez l’Oncle Sam qui essaie d’en savoir plus sur les Frenchies qui veulent un-google-ify the Internets. Ça fait un moment qu’ils nous tournent autour, ceux-là.
Tin tin tin ! On aurait dû se douter que Framasky était un black hat.
Avec un coup de main de nos hackers maison, le barbouze au menton carré est vite démasqué. On a tout : son IP, son identité, et sa photo dans l’annuaire de sa High School, quand il était capitaine de l’équipe de crosse et que les cheerleaders se battaient pour lui rouler une pelle. On sait même qu’il est entré au service informatique de la NSA juste après la blessure au genou qui a mis fin à sa carrière de sportif professionnel. Ah ah, y’a pas que vous qui savez croiser des données, et nous on fait ça à l’eau claire, on n’est pas dopés au beurre de cacahuètes !
Alors voilà ce qu’on vous propose : puisqu’ils viennent nous chercher, eh bien il est temps d’organiser la riposte.
Contre l’ennemi, utilisons ses propres armes.
C’est une mission de framacolibris un peu spéciale que nous mettons en place. Vous les hackers, vous les libristes, vous les anonymes, vous les gentils pirates, et même vous les Dupuis-Morizeau, nous vous attendons en masse pour lancer un déluge de uns et de zéros sur les serveurs de nos amis les espions. Finis les beaux discours, finie l’éducation populaire, finis les framaservices de substitution, il est temps que les chatons montrent leurs crocs et aiguisent leurs griffes !
Demain, une science citoyenne dans une société pair à pair ?
De simples citoyens ont-ils un rôle à jouer dans les sciences, où ils sont pour l’instant contingentés au mieux à des fonctions subalternes ?
On voit d’ici se lever d’inquiets sourcils à l’énoncé du simple terme de science citoyenne, tant la communauté scientifique se vit comme distincte de l’ensemble du corps social par ses missions, ses méthodes et son éthique. Pourtant un certain nombre d’expériences, de projets et même de réalisations montrent que la recherche scientifique universitaire peut tirer un profit important de sa collaboration avec les citoyens motivés, lesquels en retour élèveront leur niveau de connaissances tout en ayant un droit de regard sur la recherche.
Réconcilier citoyens et universitaires scientifiques, longtemps une utopie, est rendu aujourd’hui possible par des objets technologiques désormais beaucoup plus accessibles à chacun.
Cela ne va pas sans perplexité et crainte de dégrader les principes fondamentaux de méthode et d’éthique qui guident le travail scientifique, mais des systèmes de contrôle existent : de même que du code open source peut être révisé par des spécialistes du code, la science citoyenne peut être évaluée par des scientifiques (qui d’ailleurs ont eux-mêmes l’habitude d’être évalués par des pairs).
D’autres conditions sont également nécessaires : le partage mutuel des connaissances nécessite le pair à pair, des licences permissives, un élèvement du niveau de connaissances de la population et bien entendu l’extension des biens communs scientifiques.
Telles sont les problématiques explorées de façon approfondie par Diana Wildschut dans le long article universitaire que l’équipe Framalang vous propose.
Alors, pouvons-nous imaginer comme l’auteure un futur où au sein d’une société de pair à pair l’échange collaboratif mutuel fasse de la science un bien commun ?
La nécessité d’une science citoyenne pour aller vers une société de pair à pair durable
Notre monde est en transition vers une société de pair à pair caractérisée par une nouvelle façon de produire les choses, des logiciels à l’alimentation, en passant par les villes et la connaissance scientifique. Cela nécessite un nouveau rôle pour la science.
Plutôt que de se focaliser sur la production de connaissances pour les ONG, les gouvernements et les entreprises, les scientifiques devraient prendre conscience que les citoyens seront les décideurs dans une future société de pair à pair (p2p), produire des connaissances durables et accessibles, et travailler ensemble aux côtés des scientifiques citoyens.
Les citoyens ont démontré leur capacité à définir leurs propres sujets de recherche, à monter leurs propres projets, à s’éduquer et à gérer des projets complexes. Il est temps pour eux d’être pris au sérieux.
Il existe toujours un grand fossé entre les citoyens et les scientifiques universitaires quand il est question de partage des connaissances. Les données collectées par des citoyens ne sont presque jamais utilisées par les scientifiques universitaires, et les résultats de la recherche scientifique restent en grande part cachés derrière des barrières de péage.
Si nous voulons qu’une transition durable prenne place, nous devons faire tomber les barrières entre la science et le public. Les préoccupations des citoyens doivent être prises au sérieux et leurs connaissances utilisées et valorisées.
1. Introduction
Notre monde est en cours de transition vers une société de pair à pair (p2p), caractérisée par une nouvelle façon de produire tout, des logiciels à l’alimentation, en passant par les villes et la connaissance scientifique (Bauwens 2012). Dans une société de pair à pair, des réseaux d’individus, ou de pairs, prennent en charge les tâches qui étaient précédemment entre les mains des institutions. Cela nécessite un nouveau rôle pour la science. Plutôt que de se focaliser sur la production de connaissances pour les ONG, les gouvernements et les entreprises, les scientifiques devraient prendre conscience que les citoyens seront les nouveaux décideurs dans une future société de pair à pair, produire des connaissances durables et accessibles et travailler ensemble avec des scientifiques citoyens.
Dans cet essai, quand je parle de citoyens, je parle des non-professionnels qui s’engagent dans ce qui les touche directement, qui peut être une ville, une rue, l’environnement, le système démocratique, etc. Quand je parle de scientifiques citoyens je parle des gens qui pratiquent la science en dehors d’un environnement universitaire ou du contexte industriel, et qui ont reçu ou non une formation scientifique réelle. Ma définition d’un système néolibéral est un système avec un marché libre, un petit gouvernement dans un monde globalisé.
En regardant autour de nous, nous voyons de vieilles structures échouer. L’efficacité des ONG est mise en doute (Edwards & Hulme, 1996) et elles semblent essentiellement préoccupées par leur propre survie. Elles en sont restées aux méthodes des années 80 ; elles se déguisent en porcs ou en abeilles, ou portent des masques à gaz et se présentent comme un petit groupe guère impressionnant dans le quartier général d’entreprises ou de gouvernements. Leurs causes sont légitimes et les problèmes qu’elles mettent à l’ordre du jour sont urgents, mais leurs méthodes sont complètement inadaptées au monde dans lequel nous vivons. L’attention des gouvernements néolibéraux n’est plus focalisée sur le bien-être des citoyens, elle s’est depuis longtemps déplacée vers les intérêts des entreprises (Chomsky,1999 ; von Werlhof, 2008). Les intérêts à long terme, y compris ceux de la science, en pâtissent (Saltelli & Giampietro, 2017). Les entreprises n’ont pas l’obligation légale d’agir dans l’intérêt public, et n’ont pas tendance à le faire si cela s’oppose à leurs intérêts économiques à court terme (Banerjee, 2008 ; Chomsky, 1999).
L’avenir de la planète pourrait bien se retrouver entre les mains de petits groupes de citoyens ou d’individus qui bâtissent une nouvelle société à côté de l’existante en jetant les bases d’initiatives durables qui seraient interconnectées en réseaux de pair à pair. Dès à présent, la science procure des technologies qui donnent aux gens le pouvoir de faire leurs propres recherches, en utilisant leurs smartphones, leurs webcams et leurs ordinateurs portables (Bonney et al., 2014). Mais il y a toujours un large fossé entre les citoyens et les scientifiques universitaires quand on en arrive au partage des connaissances. Les connaissances collectées par les citoyens sont très peu utilisées par les scientifiques universitaires, et les résultats de la recherche scientifique sont le plus souvent cachés derrières des barrières de péage.
Si nous voulons qu’une transition durable prenne place, nous devons abaisser ces barrières entre la science et le public. Les préoccupations des citoyens doivent être prises au sérieux et leurs connaissances utilisées et jugées à leur juste valeur (Irwin, 1995).
Dans cet essai je soutiens que les citoyens sont prêts à produire une science valable, et à utiliser et comprendre la science produite par les scientifiques universitaires. Ils sont prêts à utiliser la science pour combler certains fossés existants que les gouvernements, les entreprises et les ONG laissent à l’abandon.
Faire sérieusement, sans se prendre au sérieux.
2. La science citoyenne
Au début de la révolution scientifique, quiconque ayant du temps libre pouvait regarder les étoiles, accumuler des données et faire des prévisions. On n’avait pas besoin d’équipements ou de compétences mathématiques. Les scientifiques étaient souvent des fermiers, artistes ou hommes d’État. Ce n’était pas des spécialistes mais plutôt des généralistes.
À partir de la seconde moitié du 19e siècle, la science est devenue une affaire de spécialistes, qui utilise des équipements de pointe ainsi que les mathématiques, et nécessite des années d’études universitaires. La science n’était plus quelque chose que n’importe qui pouvait pratiquer (Vermij, 2006).
Ces dernières décennies, les ordinateurs sont devenus bon marché et puissants. Internet permet à tous d’accéder à des données ainsi qu’à des formations. Le développement de microcontrôleurs programmables bon marché a permis à de nombreux profanes de créer leur propre électronique. La popularité de ces microcontrôleurs peut être attribuée principalement à Arduino, une carte microcontrôleur, open source, bon marché, avec un environnement de programmation en ligne.
Programmer de telles cartes est facile grâce à l’abondance d’exemples, tutoriels et codes fournis par la communauté. Les cartes peuvent être connectées à un circuit, en respectant des schémas disponibles en ligne. La communauté Arduino maintient une excellente documentation pour les débutants et les experts sur www.arduino.cc.
La possibilité de se procurer des capteurs peu coûteux est le prochain problème à résoudre. L’utilisation de capteurs combinée avec ATMegas (les microcontrôleurs utilisés sur les cartes Arduino) est très populaire. Les gens peuvent mesurer autour d’eux tout ce qui leur passe par la tête. Ils collectent toutes les données et cherchent à les comparer à celles d’autres personnes. Cela crée un besoin de plate-formes open data permettant de partager ces données en ligne. Des communautés se forment non seulement autour du matériel, mais aussi autour de sujets de recherche. Par exemple, spectralworkbench.org, où les personnes partagent leurs analyses spectrales de différentes sources lumineuses. Ils utilisent un spectromètre fait d’un morceau de carton et d’un morceau de CD connecté à une webcam. Ils déposent leurs spectres dans la base de données, qui contient des résultats venant à la fois de spectrographes professionnels et amateurs. Il s’agit d’un mélange de spectres utiles et d’images floues. La base de données est alimentée essentiellement par des passionnés curieux, et à mesure que sa taille augmente, elle devient une ressource précieuse pour déterminer des éléments chimiques. Dans la section « Apprendre » du site internet, on peut découvrir l’usage qui est fait des données. Des citoyens l’utilisent pour mesurer la contamination de la nourriture, la présence d’OGM (Critical Art Ensemble, 2003), la quantité d’azote dans des terres agricoles, le niveau de pollution de l’air, etc. Cela les amène à porter un regard critique sur les informations obtenues depuis des sources officielles, comme les gouvernements et les industriels.
Un spectrographe maison fait d’un morceau de carton et d’un morceau de CD
Une avancée récente est le Lab-on-a-Chip (Ndt : littéralement, laboratoire-sur-une-puce), un petit laboratoire qui peut être utilisé pour des analyses de fluides. Le Lab-on-a-Chip est bon marché et facile à utiliser. Le but est d’en faire un labo si facile à utiliser que n’importe qui puisse s’en servir sans connaissances préalables. Dans le domaine médical, il permet aux patients de faire leur propre diagnostic in vitro. Il permet aussi de raccourcir le temps nécessaire pour prendre une décision car le patient qui possède déjà le laboratoire à la maison n’a pas à attendre un rendez-vous (von Lode, 2005).
Un Lab-on-a-Chip est une petite plaque de verre sur laquelle sont gravés de minuscules canaux fluides. Elle est montée accolée à un capteur semi-conducteur, connecté à un microcontrôleur qui effectue les analyses ou envoie les données à un outil d’analyse.
Le boom récent des Fablabs et des ateliers ouverts pour la fabrication numérique, qui trouvent leur origine au MIT (Gershenfeld, 2012), a permis au citoyen scientifique de graver ses propres systèmes Lab-on-a-Chip, en lui donnant accès à des ciseaux lasers et des imprimantes 3D. En utilisant Arduino et du logiciel open source pour l’analyse, il peut maintenant effectuer lui-même des analyses de fluides chimiques complexes.
Ces nouvelles technologies sont désormais à la disposition de tous, pour autant qu’on ne soit pas effrayé par la technologie. De nouveaux outils voient le jour sous forme d’outils pour jeux vidéo et il faut un peu de temps avant que des gens les rendent accessibles à un public plus large en les dotant d’interfaces conviviales. Ce processus est déjà entamé et de nombreux outils deviennent utiles à ceux qui sont intéressés à les utiliser plutôt qu’à les faire fonctionner.
Ce ne sont pas seulement les données collectées par les citoyens, mais aussi leurs connaissances, leur intelligence, leur créativité et les réseaux sociaux, qui ont de la valeur pour les scientifiques universitaires. Dans beaucoup de projets de science citoyenne menés par des scientifiques universitaires, seul le temps du participant et la puissance de traitement de son ordinateur sont utilisés. Généralement, le participant n’est utilisé que pour la collecte des données et leur classement. L’intelligence du participant ou sa créativité sont rarement nécessaires et le projet n’offre que des opportunités très limitées pour une amélioration personnelle (Rotman et al., 2012). Parfois, une formation est disponible qui permet au participant d’apprendre à reconnaître des motifs, des espèces et des types de galaxies, mais il n’est presque jamais invité à participer à la conception de la recherche.
Les citoyens ont de précieuses connaissances souvent hors de portée des scientifiques universitaires (voir aussi Pereira et Saltelli). Ils disposent d’une connaissance locale que Warren (Warren, 1991) décrit comme
« une connaissance qui est particulière à une culture ou à une société donnée). […] C’est le fondement de la prise de décision à un niveau local en agriculture, pour les soins médicaux, la préparation alimentaire, l’éducation, la gestion des ressources naturelles, et une foultitude d’autres activités dans les communautés rurales. »
Mais bien sûr, il n’y a pas que dans les communautés rurales que la connaissance locale est importante. Les citoyens sont bien plus capables de participer qu’il ne leur est permis de le montrer (Fischer, 2000). De nombreux gouvernements locaux réalisent maintenant qu’ils ont besoin de l’apport de leurs citoyens pour gouverner leur cité à la satisfaction de ceux-ci. Commencer à travailler avec des citoyens critiques n’est pas une étape facile à franchir, mais dès que les citoyens sont impliqués dans la fourniture des connaissances qui permettront la prise de décision, ils sont plus enclins à accepter les conséquences et les mesures qui en résultent.
Dans la ville néerlandaise d’Amersfoot, le gouvernement local avait besoin de données sur les impacts du changement climatique à une échelle très locale, où seulement des données globales étaient disponibles. Après avoir assisté à une conférence sur la science citoyenne, il a décidé de ne pas confier le travail à un consultant, mais de trouver un groupe de citoyens intéressés par l’investigation sur les changements climatiques dans leur voisinage. Le groupe a été chargé de mettre en place la recherche, de décider quels indicateurs devaient être mesurés, qui faire participer et comment publier les résultats. Ils ont maintenant démarré leur projet dont les résultats sont visibles sur www.meetjestad.net (Meet je Stad, 2015).
Les scientifiques universitaires voient les avantages à coopérer avec les citoyens, non seulement pour la valeur qualitative de leurs connaissances locales, mais aussi pour leurs réseaux sociaux étendus. Les citoyens actifs savent ce qui se passe dans leur communauté et peuvent dire quels investisseurs devraient être impliqués. Aussi doivent-ils être impliqués au tout début d’un projet de recherche, sinon il sera trop tard pour tirer profit de cette partie de leurs connaissances. Il y a vingt ans, Alan Irwin (Irwin, 1995) prônait la réunion des mondes de la science universitaire et de la science citoyenne. Aujourd’hui le besoin et les possibilités se sont accrus. Les scientifiques citoyens disposent de plus d’outils pour créer de la connaissance, l’infrastructure existe pour la partager et nous avons quelques gros problèmes à résoudre pour lesquels nous avons besoin de toute l’aide disponible.
Et Cash et al. (2003) de conclure que « […] les efforts pour mobiliser la science et la technologie pour la durabilité ont plus de chances d’être efficaces si on gère les frontières entre la connaissance et l’action d’une façon qui améliore à la fois l’importance, la crédibilité et la légitimité de l’information produite. » De nombreux citoyens sont prêts à l’action ou déjà actifs. Ils ont besoin de connaissances scientifiques.
Pour libérer le savoir, mieux vaut ouvrir les portes… Stockholm Public Library CC-BY Samantha Marx
3. Accès libre
Pour cet essai, j’avais prévu de n’utiliser que des références à des articles disponibles en accès libre, juste pour le principe. Le fait que cela se soit avéré impossible est en soi encore plus parlant que je ne l’aurais voulu. Pour être en mesure de rédiger un essai comme celui-ci, un scientifique citoyen serait obligé de contacter par e-mail des amis travaillant dans des universités, d’utiliser le hashtag Twitter #icanhazpdf (lepdfsivouplé) et d’écrire des mails à des auteurs, en espérant recevoir leurs articles en retour.
Certains des articles en accès restreint, comme celui-ci, parlent de la science citoyenne, dont certains pourraient directement intéresser les citoyens. Mais les citoyens qui luttent pour construire leurs propres projets scientifiques sans budget ont peu de chances de pouvoir investir 41,95 $ dans un article dont ils ne sont même pas certains qu’il leur sera utile. Dans la plupart des cas, la science qui traite de science citoyenne n’atteindra pas des citoyens pratiquant les sciences, ni des citoyens ayant besoin d’un apport scientifique.
Dans la société de pair à pair, il est tacitement convenu que quiconque utilise les services d’une autre personne, restitue quelque chose à la communauté dont il se nourrit. Aussi, faire de la recherche en se basant sur de la science citoyenne et ne pas en partager les résultats serait une violation de ces règles tacites.
Les droits d’auteur et les brevets empêchent la mise à disposition et le développement de la connaissance. On pense souvent que les droits d’auteur sont le seul moyen de protéger les auteurs, mais il existe d’autres moyens de protéger les droits des auteurs et des développeurs de produits logiciels open source. Certaines institutions développent leurs propres licences pour les logiciels open source (MIT Public License, 1988) ou pour le matériel open source (CERN Open Hardware License, 2011). Elles utilisent leurs connaissances des droits d’auteur et de la propriété intellectuelle pour aider les gens qui veulent ajouter leurs données, idées, conceptions et produits au domaine public. Une fois là, cela pourra être utilisé comme base par n’importe qui (selon la licence), mais ne pourra jamais être réclamé, breveté ou sorti du domaine public. Chacune des licences propose ses propres solutions, laissant au développeur le choix de qui peut utiliser son produit et dans quelles conditions. Certaines licences permettent une utilisation commerciale du produit, d’autres non. Certaines demandent l’attribution à l’auteur original. D’autres demandent que les sous-produits soient publiés sous la même licence que l’original.
Concevoir ces licences et les rendre disponibles est une manière très appréciée pour les institutions de restituer quelque chose aux biens communs.
…car, comme on dit en langage Wikipédia « Citation Needed ».
4. Éducation
L’existence de citoyens instruits est une condition nécessaire pour avoir une démocratie qui fonctionne (Hils Hauge et Barwell), et ça l’est tout autant dans une société de pair à pair. Néanmoins, aux Pays-Bas par exemple [ndt : l’auteure est néerlandaise], les études universitaires ne sont pas facilement accessibles à tous les citoyens qui pourraient y prétendre. Les gens qui ont déjà un diplôme payent des frais d’inscription très élevés. Étudier à temps partiel est déconseillé et dans la majorité des disciplines ce n’est même pas possible. Cela entre en conflit avec l’idéal « d’éducation tout au long de la vie » qui est diffusé par les institutions éducatives, et cela ne permet pas d’avoir des citoyens ouverts à tout et bien informés. Cependant, nous comptons sur eux pour faire des choix éclairés au moment de voter (Westheimer et Kahne, 2000). Pour les gouvernements, la mode est de vouloir des citoyens impliqués, mais très peu d’efforts sont faits pour leur donner les outils et informations nécessaires.
Mais maintenant, une part croissante des citoyens est en train de trouver le chemin vers des études plus accessibles et moins structurées. De nouvelles méthodes de partage des connaissances sont inventées, le plus souvent en utilisant Internet. Les cours magistraux de certaines universités sont disponibles en streaming. Cela peut aider pour compléter une formation, mais sans exercices cela reste incomplet. Khan Academy.org est un site web où vous pouvez vous former vous-mêmes dans n’importe quelle matière du lycée à l’université. Il utilise un algorithme intelligent qui permet aux étudiants de garder la trace de leur progrès. Néanmoins la Khan Academy fonctionne essentiellement du sommet vers la base, une personne donne un cours et un étudiant consomme cette connaissance. OpenTOKO (http://web.archive.org/web/20140927205928/http://www.opentoko.org/) a une approche différente.
Un thème est proposé en ligne, des experts et des novices s’y inscrivent, créant un groupe de connaissances partagées qui se réunit pour un après-midi. La dynamique est très variable, parfois un TOKO est planifié largement à l’avance, parfois dans un délai très court. Les thèmes peuvent être populaires ou ésotériques ; on peut être très nombreux ou seulement deux ou trois. Souvent, il s’avère que les experts apprennent des compétences, des connaissances ou des questions des débutants. Les experts acquièrent une meilleure compréhension du thème, et cela donne au débutant un bon départ sur le sujet. OpenTOKO doit encore être amélioré. Un système de référencement automatique doit être créé, permettant à chacun de suggérer un thème, de s’inscrire comme expert ou novice, de proposer un lieu ou une date. Quand toutes les conditions sont réunies, un OpenTOKO est automatiquement créé.
L’inscription est gratuite, tout le monde en profite en améliorant ses connaissances. Les thèmes abordés sont divers : langage de programmation, électronique, mathématiques et statistiques mais aussi comment tricoter des chaussettes ou faire pousser des légumes, tout dépend de ce que souhaitent les participants. Les scientifiques qui souhaitent faire participer des citoyens à leurs cours, n’ont pas besoin de simplifier leurs résultats ou leur langage. Les citoyens peuvent apprendre eux-mêmes et devenir familiers de la terminologie utilisée dans les différents domaines scientifiques.
Wikipédia peut être utilisée comme point de départ de collecte d’informations sur pratiquement tous les sujets. À partir de là, il est facile de trouver des publications scientifiques, mais à nouveau les citoyens se heurtent souvent à des ressources payantes.
Cliquez sur l’image pour voir la vidéo sur la chaîne YouTube de Datagueule.
5. Vers une société de pair à pair
On constate, au cours de la dernière décennie, une tendance au partage sur un mode de p2p : d’un individu vers les autres. En 1999, un adolescent a créé le logiciel Napster, qui permettait à tout le monde de partager des fichiers numériques (Carlsson et Gustavsson, 2001). Napster utilisait un serveur central. À cause de cela, l’industrie du disque, via des poursuites judiciaires, a pu fermer Napster. Les outils d’échange de musique de la génération suivante sont les réseaux P2P, dans lesquels les utilisateurs échangent directement leurs fichiers avec d’autres personnes. Ces réseaux ne sont pas hiérarchisés et sont difficiles à fermer. Brafman et Beckstrom (2006) compare ces organisations sans leader à des étoiles de mer, et les organisations hiérarchiques à des araignées ; si vous coupez la tête d’une araignée, elle meurt. L’étoile de mer, elle, n’a pas de tête. Coupez un bras et un nouveau bras se formera. Coupez l’étoile de mer en deux et vous obtiendrez deux étoiles de mer. Les réseaux P2P semblent indestructibles aussi longtemps qu’ils ont la volonté d’exister.
Bauwens et Lievens (2013) voient la transition vers une société de pair à pair comme l’inévitable prochaine étape du développement humain. Leur présentation de l’histoire de la société occidentale commence à l’époque romaine. À cette époque, 80 % des gens étaient des esclaves. La société romaine dépendait entièrement de ces esclaves, et en avait un besoin toujours plus important. Pour continuer d’augmenter le nombre d’esclaves, ils devaient continuer d’étendre leur empire. Finalement, cela devint plus cher que des solutions alternatives comme le métayage. Ils commencèrent donc à affranchir des esclaves, leur laissant cultiver la terre en échange d’un partage des récoltes. Cette pratique a évolué vers le système féodal qui a perduré plusieurs siècles.
L’industrialisation, au 19e siècle, a déplacé les travailleurs vers les villes, ces derniers achetant alors leur nourriture au lieu de la faire pousser. Les travailleurs ont reçu un salaire, le moment du capitalisme était venu. Dans le même temps, les gens prirent une place précise dans de grandes structures hiérarchisées.
Maintenant, l’automatisation a réduit la quantité de travail humain nécessaire à la production des besoins indispensables à nos sociétés. Et le spécialiste d’économie politique Skidelsky(2012) de conclure : « La vérité est que nous ne pouvons pas continuer à automatiser efficacement nos productions sans remettre en cause nos attitudes envers la consommation, le travail, les loisirs et la distribution des revenus. » Dans les sociétés occidentales, seule une petite part de notre travail sert à fournir les besoins fondamentaux de la société. La majorité des gens a un travail qui n’est pas vraiment indispensable (Graeber, 2013). La plupart d’entre eux en ont conscience, ce qui a souvent un impact négatif sur leur santé morale et physique.
On constate aussi une augmentation du nombre de personnes sans emploi pour qui l’ancien système est un échec. Ils ont été virés par leur ancien employeur, souvent après des décennies de travail dévoué et de loyauté. Une grande partie des gens virés sont devenus trop chers à cause de leur ancienneté. Les employeurs ont tendance à choisir des employés moins chers, plutôt que plus expérimentés. Ici, l’argent prime sur la qualité ou l’humanité.
Certains chômeurs choisissent désormais de faire les choses différemment, et se mettent à chercher un nouveau système plus respectueux des personnes et valorisant la qualité. Comme les esclaves affranchis, ils sont un nombre croissant dans nos sociétés à avoir l’énergie nécessaire pour commencer à travailler dans un nouveau système. Bauwens et Lievens appelle ce système « l’économie P2P », celle-ci est basée sur les échanges entre individus.
La combinaison d’un savoir disponible et d’une insatisfaction croissante face à la manière dont les gouvernements traitent les questions écologiques encourage les personnes à s’impliquer dans des expériences à l’échelle locale pour produire de l’énergie et de la nourriture, pour recycler les déchets et pour plus de démocratie et d’innovation sociale. Certaines de ces expériences échouent, mais d’autres sont des succès et rendent stables des alternatives locales et modestes qui peuvent inspirer les autres. Tout ne peut pas se faire facilement au niveau local. Il vaut mieux que la médecine spécialisée soit exercée dans un hôpital dédié. Les experts sont les plus à même de traiter les questions de droit, bien que le système des jurys populaires soit un peu plus P2P que les systèmes judiciaires avec uniquement des juges, et qu’il soit considéré comme juste dans de nombreux pays. Les processus de production que l’on dit plus efficaces à grande échelle, ne le sont peut-être pas tant que ça si tous les coûts réels relatifs au transport, aux infrastructures, aux ressources naturelles et aux déchets sont inclus dans le calcul. Souvent, ces « externalités » comme on les appelle, ne sont pas financées par les multinationales (Mansfield, 2011 ; Scherhorn, 2005).
Le pair à pair, vous savez, le truc d’avant les plateformes, qui marchait mieux et générait moins de dangers…?
6. Quand les systèmes se percutent
La société de pair à pair peut cohabiter avec la société capitaliste dans de nombreux cas, tout comme les scientifiques citoyens cohabitent avec les scientifiques universitaires. Il peut y avoir des conflits de nature financière, comme dans le cas des maisons de disques avec les réseaux p2p pour la distribution de musique, où les deux cotés essayent de maximiser leurs profits. Les situations les plus intéressantes, cependant, sont celles où les deux points de vue sont valables, mais incompatibles.
La société de pair à pair est basée sur la confiance acquise lors de travaux préalables. Si vous contribuez à la communauté, vous obtenez en retour du respect et de la confiance. Cependant, dans la société capitaliste, la confiance se base sur les diplômes. Si vous voulez un travail en tant qu’ingénieur informaticien, il vous faut avoir des diplômes et des qualifications pour prouver que vous pouvez écrire du code. Dans la société de pair à pair, vous prouvez que vous pouvez écrire du code en écrivant du code. Le code est open source afin que les utilisateurs puissent vérifier s’il fonctionne et que les experts puissent vérifier qu’il est bien écrit et ne contient pas de virus. Quand les deux mondes se rencontrent, ils sont souvent sceptiques sur l’approche de l’autre.
Certaines personnes voient les forces et faiblesses de chaque système, et un ingénieur informaticien peut avoir un emploi sans diplôme, s’il rencontre le bon responsable des ressources humaines. Le lien entre les deux mondes vient de ceux qui reconnaissent les possibilités de coopérer et ont un statut qui leur permet de s’écarter des règles en usage. Dans tous les cas, la manière pair à pair d’assurer la qualité ou la fiabilité d’un pair demandera plus d’efforts que pour un scientifique universitaire par exemple. Il faudra faire des recherches sur la personne, soit à travers un contact personnel, soit en regardant à sa réputation auprès de ses pairs et son travail. Pour des nouveaux venus, il s’agit de deux situations complètement différentes.
Mais que peut-on dire des autres différences entre les scientifiques citoyens et les scientifiques universitaires ? Pour faire de la vraie science, il faut travailler selon un certain nombre de règles, mais les citoyens peuvent n’en faire qu’à leur tête. Comment se positionnent-ils vis-à-vis de l’éthique ou de la qualité ? C’est ce qui inquiète de nombreux scientifiques universitaires. Les motivations des citoyens et la qualité de leur travail sont suspectes (Show, 2015). Même les projets montés et gérés par des scientifiques universitaires qui utilisent des données collectées par des volontaires ont du mal à se faire publier (Bonney et al, 2014).
Il est vrai que la science citoyenne n’a pas nécessairement un ensemble fixe de règles sur l’éthique ou les méthodes. Bien qu’il y ait quantité d’exemples de réseaux qui partagent une charte éthique ou une liste de méthodes [29], comme certains diy-biolabs (ndt : littéralement labo-bio à faire soi-même) (Diybio,2016) et makerspaces (espaces collaboratifs) (Fablab.nl), beaucoup n’y ont jamais pensé, n’en ont jamais discuté, ou même, ne s’y sont simplement pas intéressés. Mais tout comme n’importe quel programmeur peut vérifier du code informatique ouvert, n’importe quel scientifique universitaire peut vérifier si un projet de science citoyenne est bien fait, à l’aune des normes universitaires. Pour moi, cela ne veut pas dire que les normes universitaires doivent être celles qu’il faut utiliser pour évaluer la science citoyenne, mais qu’il est possible de le faire. Dans certains cas, les normes universitaires sont moins strictes que celle utilisées dans la science citoyenne.
Par exemple, dans la science conventionnelle, il n’est pas courant d’ouvrir l’ensemble des données, alors que c’est le cas dans la science citoyenne. De ce point de vue, la science citoyenne et plus reproductible et la fraude est plus facile à détecter. Les expériences des scientifiques citoyens sont souvent répétées et améliorées. Les scientifiques citoyens ne sont pas soumis à la pression de la publication (Saltelli et Giampetro, traitent du déchirement entre publier ou périr comme d’un ingrédient clé de la crise de la recherche scientifique), ils publient quand ils pensent avoir trouvé quelque chose d’intéressant. Le travail est ouvert au regard des pairs de la première tentative aux conclusions finales.
Un exemple de base de données ouverte, libre et collaborative qu’on aime beaucoup ;)
Les scientifiques citoyens publient plus facilement des résultats négatifs. Ils ne sont pas gênés par leurs erreurs. Les publications de résultats positifs contiennent aussi un chapitre sur les tentatives précédentes qui ont échoué, et un retour sur la cause de l’échec. Ces résultats négatifs sont, à mon avis, aussi valables que des résultats positifs, bien que dans la recherche scientifique conventionnelle il existe une forte propension à ne publier que des résultats positifs, ce qui rend la recherche scientifique universitaire incomplète (Dwan et al., 2008).
Les scientifiques citoyens sont souvent suspectés d’avoir des partis pris, des motivations ou des ordres du jour cachés. Nous savons désormais que les professionnels de la science ont aussi des partis pris. Les scientifiques citoyens sont même moins susceptibles d’avoir certains partis pris, comme ceux relatifs au prestige ou au financement, et ce goût pour les résultats positifs. Mais le fait que les scientifiques universitaires ne soient pas forcément meilleurs que n’importe quel scientifique citoyen ne signifie pas que nous devons ignorer les problèmes potentiels liés à la qualité des scientifiques citoyens. Afin de permettre plus de coopération entre les scientifiques citoyens et universitaires, nous devons insister sur la totale transparence concernant les conflits d’intérêt, tant pour les scientifiques universitaires que citoyens. Dans la recherche scientifique universitaire, il existe une saine discussion sur la qualité, les partis pris et les conflits d’intérêt. Dans la science citoyenne le sujet est difficilement évoqué, ce qui est une honte puisque certains partis pris sont moins susceptibles d’exister quand leur propriétaire en a conscience.
La qualité est souvent décrite comme être « adapté à la fonction ». Parfois, nous pouvons avoir besoin de données précises issues de capteurs onéreux. Dans de tels cas, la recherche universitaire pourrait aboutir à une meilleure qualité. Mais dans d’autre cas, nous pouvons avoir besoin d’une haute définition et ici de vastes groupes de citoyens sont plus à même de fournir de la haute qualité. La connaissance n’est adaptée au besoin que si elle est ouverte à ceux qui en ont besoin. Il est par conséquent important que les connaissances relatives au changement climatique et aux autres problèmes mondiaux soient totalement ouvertes.
Je pense qu’il serait bon que les scientifiques universitaires et citoyens aient un débat sur les raisons pour lesquelles des résultats de qualité sont utiles aux autres citoyens, aux décideurs politiques locaux et aux scientifiques universitaires suivant la fonction retenue. Si nous voulons partager les données entre les scientifiques citoyens et universitaires, ou entre les scientifiques citoyens et les décideurs, quelles sont les barrières et comment peut-on les dépasser ? Devons-nous trouver un ensemble de critères définissant la qualité (y compris l’accessibilité) qui soit satisfaisant pour les chercheurs scientifiques et gérable par les citoyens ?
7. Les biens communs
La plupart des enjeux soulevés dans les paragraphes précédents nous amènent à la notion de biens communs. Les biens communs incluent tout ce qui appartient à tout le monde, par exemple l’atmosphère, l’écosystème planétaire, la culture et les connaissances humaines.
La majeure partie de la richesse mondiale privée existe parce que les biens ou les services qui appartiennent aux biens communs peuvent souvent être accaparés sans payer, et qu’il n’y a pas d’obligation de restituer quelque chose aux biens communs.
Cela concerne les entreprises qui polluent ou s’approprient des ressources, les sociétés de divertissement commerciales qui prennent des contes traditionnels dans le domaine public pour les placer sous droits d’auteur, les entreprises qui brevètent des gènes qui sont en grande partie naturels, ainsi que les recherches scientifiques qui utilisent des contributions en provenance des biens communs, sans jamais restituer leurs résultats aux biens communs (Barnes, 2006).
Le changement climatique, la pollution et l’épuisement des ressources sont le problème de tout le monde. Ces problèmes font autant partie des biens communs que les solutions. Leur résolution n’a pas à dépendre d’une initiative privée. En partageant le savoir entre scientifiques universitaires et citoyens, nous pouvons travailler ensemble sur ces questions.
Les enclosures, c’est bon pour les poules dans Minetest… pas pour les enjeux mondiaux.
8. Débat et conclusion
Les scientifiques citoyens ne sont pas des anges envoyés de l’au-delà pour sauver la science. Ils ne sont pas là non plus pour détruire les institutions universitaires et prendre le pouvoir. Ils ont leurs propres programmes, imperfections et partis pris, comme les scientifiques universitaires. Une meilleure prise de conscience de ces partis pris peut améliorer la qualité de leur travail. Chaque débat sur la qualité doit être respectueux et ouvert, et tenir compte des limites de la science citoyenne et de ses pratiquants. Nous savons que les citoyens ne prennent pas toujours la bonne décision quand ils votent, ne votent pas ou achètent quelque chose. Donc pourquoi devrait-on compter sur eux pour résoudre les problèmes de la société ? On ne doit rien attendre de personne, mais nous devons impliquer toute l’aide disponible, et si les gens sont intrinsèquement motivés, nous ne devons pas les marginaliser
Bien que les groupes qui utilisent la science citoyenne pour résoudre les problèmes, dont à leur avis les institutions ne s’occupent pas, soient encore petits, l’intérêt qu’ils reçoivent des autres et la disponibilité des outils et des infrastructures faciles à utiliser peuvent conduire à des groupes plus nombreux et plus grands, et à un réseau plus fort d’individus. Ce que nous voyons actuellement est une tendance à l’indépendance des personnes qui pensent et qui font. Ils développeront peut-être un jour leurs propres institutions, mais risquent aussi de rester des groupes faiblement liés d’individus isolés.
C’est la même chose en ce qui concerne la transition vers une société de pair à pair. La transition est en cours. Elle n’a pas besoin d’une révolution mais elle croît à côté du système actuel. Elle accélère là où le système actuel échoue. Elle a besoin de cet élan, et si le système actuel résout soudain les problèmes, ou si le système P2P n’y arrive pas, cette tendance pourrait s’arrêter. Pour le moment, ça grandit.
Les citoyens ont envie de contribuer à trouver des solutions aux problèmes que le système néo-libéral échoue à résoudre, comme les problèmes d’environnement, de représentation démocratique (publiclab.org). Les citoyens partagent de plus en plus pour la prise de décision à mesure que notre société évolue vers un modèle P2P (Public Laboratory, 2016).
Les citoyens ont prouvé qu’ils étaient capables de formuler leurs propres thèmes de recherche, de monter leurs propres projets, de se former et de gérer des projets complexes. Il est temps de les prendre au sérieux.
Les scientifiques contribuent déjà à l’émancipation des citoyens en développant par exemple de nouvelles technologies et licences, mais celles-ci découlent de la connaissance scientifique. Il est aussi nécessaire de partager la connaissance elle-même. Si les scientifiques veulent que leurs résultats soient utiles, ils doivent les rendre accessibles aux citoyens.
Les connaissances créées par les citoyens peuvent être très utiles aux chercheurs universitaires. Néanmoins, l’initiative de donner quelque chose en retour à la communauté doit être prise par les chercheurs universitaires qui s’engagent dans des projets de science citoyenne.
Nous ne sommes pas loin de nous débarrasser de tout ce qui entrave la voie de la production collaborative de connaissances utiles. Il faudra des ajustements de part et d’autre pour rassembler la science citoyenne et la science universitaire, mais nous pouvons joindre nos efforts afin de rendre possible cette transition durable.
Comment ? En collaborant, on te dit, mon chaton !
Bibliographie
Banerjee, S. B. (2008). « Corporate Social Responsibility: The Good, the Bad and the Ugly ». Critical Sociology, 34(1), 51‑79. Accessible en ligne.
Barnes, P. (2006). « Capitalism 3.0: A Guide to Reclaiming the Commons ». San Francisco: Berrett-Koehler Publishers.
Bauwens, M. (2012). « Blueprint for P2P Society: The Partner State & Ethical Economy ». Consulté 30 mars 2017, à l’adresse http://www.shareable.net/blog/blueprint-for-p2p-society-the-partner-state-ethical-economy
Bauwens, M., & Lievens, J. (2016). « De wereld redden: met peer-to-peer naar een postkapitalistische samenleving ». Antwerpen: VBK – Houtekiet.
Bonney, R., et al. (2014). « Next Steps for Citizen Science ». Science, 343(6178), 1436‑1437. accessible en ligne.
Brafman, O., & Beckstrom, R. A. (2006). « The Starfish and the Spider: The Unstoppable Power of Leaderless Organizations ». Penguin.
Carlsson, B., & Gustavsson, R. (2001). « The Rise and Fall of Napster – An Evolutionary Approach ». Dans Active Media Technology (p. 347‑354). Springer, Berlin, Heidelberg. accessible en ligne
Cash, et al. (2003). « Knowledge systems for sustainable development ». Proceedings of the National Academy of Sciences, 100(14), 8086–8091.
CERN. (2011). « CERN releases new version of open hardware licence » | CERN. Consulté le 16 aout 2015, à l’adresse http://home.cern/about/updates/2013/09/cern-releases-new-version-open-hardware-licence
Chomsky, N. (1999). « Profit Over People: Neoliberalism and Global Order ». Seven Stories Press.
Diybio.org (2013). « Code of Ethics for diybio labs in Europe ». Consulté le 31 aout 2016 à l’adresse https://diybio.org/codes/draft-diybio-code-of-ethics-from-european-congress/
Dwan, K., et al. (2008). « Systematic Review of the Empirical Evidence of Study Publication Bias and Outcome Reporting Bias ». PLoS ONE, 3(8), e3081. accessible en ligne
Edwards, M., & Hulme, D. (1995). « Non-governmental Organisations: Performance and Accountability Beyond the Magic Bullet ». Earthscan publications LTD
Fablab. (2016). « Rules for use of Fablabs in Belgium, Luxembourg and the Netherlands ». Consulté le 31 aout 2016, à l’adresse http://fablab.nl/wat-is-een-fablab/fabcharter/
Fischer, F. (2000). « Citizens, Experts, and the Environment: The Politics of Local Knowledge ». Duke University Press.
Gershenfeld, N. (2012). « How to Make Almost Anything: The Digital Fabrication Revolution ». Foreign Affairs, 91, 43.
Graeber, D. (2013). « On the Phenomenon of Bullshit Jobs », Strike! Magazine, Summer, pp.201310-20133411.
Hauge, K. H., & Barwell, R. (2017). « Post-normal science and mathematics education in uncertain times: Educating future citizens for extended peer communities ». Futures. accessible en ligne
Irwin, A. (1995). « Citizen Science: A Study of People, Expertise and Sustainable Development ». Psychology Press.
Mansfield, B. (2011). « « Modern » industrial fisheries and the crisis of overfishing ». Global political ecology, 84-99.
Meet je Stad. (2015). « Guidelines for data collection by the flora observation group of Meet je Stad ». Consulté le 31 aout 2016, à l’adresse http://meetjestad.net/flora/?info
MIT. (1988). « GNU Public License ». Consulté le 9 avril 2014, à l’adresse http://web.mit.edu/drela/Public/web/gpl.txt
Pereira, Â., & Saltelli, A. (2017). « Post-normal institutional identities: Quality assurance, reflexivity and ethos of care ». Futures. accessible en ligne
Public Laboratory (2016). « Public Lab: a DIY environmental science community ». Consulté le 18 octobre 2016, à l’adresse https://publiclab.org/
Rotman, D. et al. (2012). « Dynamic Changes in Motivation in Collaborative Citizen-science Projects ». Dans Proceedings of the ACM 2012 Conference on Computer Supported Cooperative Work (p. 217–226). New York, NY, USA: ACM. accessible en ligne.
Saltelli, A., & Giampietro, M. (2017). « What is wrong with evidence based policy, and how can it be improved? » Futures. Consulté à l’adresse http://www.sciencedirect.com/science/article/pii/S0016328717300472.
Scherhorn, G. (2005). « Sustainability, Consumer Sovereignty, and the Concept of the Market ». Dans K. G. Grunert & J. Thøgersen (Éd.), Consumers, Policy and the Environment A Tribute to Folke Ölander (p. 301‑310). Springer US. accessible en ligne
Show (2015). « Rise of the citizen scientist ». Nature, 524(7565), 265‑265. accessible en ligne
Skidelsky (2012). « Return to capitalism « red in tooth and claw » spells economic madness ». The Guardian. Consulté le 05 avril 2014, à l’adresse https://www.theguardian.com/business/economics-blog/2012/jun/21/capitalism-red-tooth-claw-keynes?commentpage=2%26fb=native#post-area
Vermij, R. H. (2006). « Kleine geschiedenis van de wetenschap ». Uitgeverij Nieuwezijds.
Von Lode, P. (2005). « Point-of-care immunotesting: Approaching the analytical performance of central laboratory methods ». Clinical Biochemistry, 38(7), 591‑606. accessible en ligne.
Werlhof, C. von. (2008). « The Globalization of Neoliberalism, its Consequences, and Some of its Basic Alternatives ». Capitalism Nature Socialism, 19(3), 94‑117. accessible en ligne
Westheimer, J., & Kahne, J. (1998). « Education for action: Preparing youth for participatory democracy ». Press and Teachers College Press.
Marc Chantreux a lancé une invitation à tous les fans de Sympa (eh oui, ils sont sympas, on va se débarrasser de ça tout de suite) pour le rejoindre dans un grand hackathon à Strasbourg le week-end du premier avril 2017.
C’est super, mais… c’est quoi ?
Bonjour Marc, est-ce que tu veux bien te présenter ?
Je m’appelle Marc Chantreux, je suis libriste (par conviction éthique et technique) depuis les années 90 et suis actuellement informaticien à l’université de Strasbourg où j’ai géré sympa pendant 5 ans.
Sympa, le logiciel libre qui nous sert à gérer Framalistes, va fêter ses 20 ans, c’est bien ça ?
C’est ça et je me suis connecté pour la première fois à Internet la même année. Ce qui m’a immédiatement plu à l’époque, ce n’était pas la quantité de documentation disponible (parce qu’on avait déjà des e-zines et autres documentations qui circulaient sur CD-Rom ou supports imprimés) mais la possibilité de poser directement des questions aux experts dans une ambiance extrêmement ouverte et respectueuse. Les deux principaux outils pour cela étaient Usenet et les listes de discussion. En France, un gros hébergeur de listes était Universalistes qui tournait déjà (qui tourne toujours) sous sympa.
Ce logiciel a été créé et maintenu par la communauté universitaire française depuis l’origine. Entre temps, sympa a été adopté dans le monde entier et s’est enrichi de fonctionnalités nécessaires au travail collaboratif pour lequel les listes étaient utilisées (documents partagés, archives, modération, délégation de droits, etc.).
Je me réjouis de voir que Framasoft ait monté une instance de sympa pour sa communauté mais perso, j’aurais utilisé « framagroupes » comme nom.
À cette occasion tu organises un fork communautaire et un hackathon. Tu peux nous expliquer ? Nan, parce que Framasky, il m’a demandé de t’interviewer mais j’y comprends que pouic. 🙂
Ces dernières années, la communauté universitaire a affecté de moins en moins de ressources jusqu’à ce que tout s’arrête complètement au courant de l’année dernière. La communauté est pourtant forte de millions d’utilisateurs et il n’existe pas d’alternative crédible si on considère sympa dans son ensemble. J’ai donc proposé à la communauté de se rassembler pour s’organiser et posé les bases d’un développement qui ne repose plus sur le seul acteur historique (RENATER). Les 20 ans de sympa tombaient un week-end, c’était une belle occasion.
RENATER a réagi très positivement à cette initiative et nous a rapidement prêté assistance, en ouvrant une partie de l’infrastructure, en parrainant la venue du leader historique du projet — David Verdin — et en nous rassurant sur leur volonté de rester investi dans le projet. J’ai eu des échanges téléphoniques et électroniques avec leur direction technique et je suis confiant dans la perspective de voir RENATER redonner de la force de frappe à sympa.
Et c’est quoi, l’objectif de ce hackathon ? Sur quel critère le jugeras-tu réussi ?
L’objectif de ce hackathon est d’initier les projets qui permettront aux utilisateurs de sympa d’avoir accès plus simplement à un grand nombre de fonctionnalités. Il nous faut au passage nous mettre d’accord sur des pratiques communes de développement mais le plus important pour moi n’est pas là.
Je suis membre de longue date de la communauté Perl et je suis toujours ému par l’énergie qui se dégage du sentiment que nous partageons tous d’appartenir à une communauté soudée, au service de millions d’utilisateurs et vivant une grande aventure technique avec des défis à relever au quotidien pour produire le meilleur logiciel possible. Si nous arrivons à faire germer cet esprit dans la communauté sympa naissante, alors je serais heureux.
Le hackathon, c’est que pour les développeurs, ou tout le monde peut contribuer ?
Sympa est comme tout logiciel libre : sa valeur réside dans son utilité et non dans son code.
Pour le rendre utile, il faut aussi le rendre accessible et visible et nous avons besoin de faire plein de choses nécessitant plein de compétences ! Dites-moi ce que vous voulez ou savez faire et j’aurais probablement des tâches à vous proposer. Celles qui me viennent sont : collecter les besoins et retours des utilisateurs, organiser ou participer à des événements, faire du graphisme et de la communication, nous aider à réaliser de la documentation, créer et animer la formation, assister les communautés d’utilisateur, faire de la traduction…
Il va y avoir du beau monde, dans ce hackathon, les copains de Yunohost, notamment. Qui d’autre ?
De nombreux acteurs associatifs en faveur de l’auto-hébergement et de l’internet neutre (par exemple Framasoft, YUNoHost, ARN qui est un FAI associatif alsacien) mais aussi des hackers du Libre User Group alsacien et du Hackstub, des membres de la communauté universitaire (Universités de Strasbourg et Oslo et RENATER qui est le FAI des universités françaises) ainsi que les sociétés Hackcendo et Linuxia.
Et ça se passe où ? Il faut s’inscrire quelque part ?
Ça se passe au portique de l’université de Strasbourg mais les inscriptions sont maintenant closes. Désolé…
Du coup, on peut participer à distance ? Ou aider d’une autre façon ?
Bien sûr : le mieux est de rejoindre le canal IRC #sympa sur freenode dès maintenant et de dire que vous êtes intéressés par la contribution. Si vous avez du mal avec l’anglais, vous pouvez aussi vous abonner à la liste sympa-fr (https://listes.renater.fr/sympa/info/sympa-fr) ou me contacter directement.
Sympa, ça peut gérer des listes de diffusion vraiment balaises ? Genre quoi ?
Genre j’ai personnellement géré des listes de 140 000 abonnés ou le goulot d’étranglement n’était pas sympa mais l’infra de messagerie. Les listes permettant de contacter l’ensemble des personnels de l’enseignement supérieur tournent avec sympa et il existe des groupes qui dépassent le million d’abonnés.
Mais si on se lance dans le concours du plus gros site, je dirais que le principal intérêt de sympa réside non pas dans sa capacité d’envoyer des millions de messages mais de réussir à les envoyer en respectant l’état de l’art dans les pratiques relatives à la lutte anti-spam (DMARC, DKIM…) et de donner la possibilité à des administrateurs d’industrialiser la création et la maintenance d’un grand nombre de listes (l’université de Strasbourg en compte près de 35 000).
Comme d’hab, nous te laissons le mot de la fin, lâche-toi.
Lors de l’apparition des premiers web fora, j’ai vu les communautés se diviser autour des outils de discussion. les « surfers » (qui aiment les fora pour leur côté immédiat, simple et « beau ») et les fans de la messagerie électronique qui apprécient le degré de liberté qui leur est donné de présenter et traiter les messages comme ils l’entendent. Les deux approches sont valables et ne devraient pas être un frein pour ce qui compte réellement : l’échange ! Avec ses outils (postage, archives en ligne, dépôt de documents) sympa est soit un gestionnaire de listes haut de gamme soit le système de forum avec la pire interface web du monde.
L’urgence de sympa, c’est donc son interface web et c’est là-dessus que nous allons mettre le paquet.
Pour en savoir plus, et surtout donner un coup de main, c’est par ici
Google, nouvel avatar du capitalisme, celui de la surveillance
Nous avons la chance d’être autorisés à traduire et publier un long article qui nous tient à cœur : les idées et analyses qu’il développe justifient largement les actions que nous menons avec vous et pour le plus grand nombre.
Dans ses plus récents travaux, Shoshana Zuboff procède à une analyse systématique de ce qu’elle appelle le capitalisme de surveillance. Il ne s’agit pas d’une critique du capitalisme-libéral en tant qu’idéologie, mais d’une analyse des mécanismes et des pratiques des acteurs dans la mesure où elles ont radicalement transformé notre système économique. En effet, avec la fin du XXe siècle, nous avons aussi vu la fin du (néo)libéralisme dans ce qu’il avait d’utopique, à savoir l’idée (plus ou moins vérifiée) qu’en situation d’abondance, chacun pouvait avoir la chance de produire et capitaliser. Cet égalitarisme, sur lequel s’appuient en réalité bien des ressorts démocratiques, est mis à mal par une nouvelle forme de capitalisme : un capitalisme submergé par des monopoles capables d’utiliser les technologies de l’information de manière à effacer la « libre concurrence » et modéliser les marchés à leurs convenances. La maîtrise de la production ne suffit plus : l’enjeu réside dans la connaissance des comportements. C’est de cette surveillance qu’il s’agit, y compris lorsqu’elle est instrumentalisée par d’autres acteurs, comme un effet de bord, telle la surveillance des États par des organismes peu scrupuleux.
La démarche intellectuelle de Shoshana Zuboff est très intéressante. Spécialiste au départ des questions managériales dans l’entreprise, elle a publié un ouvrage en 1988 intitulé In the Age Of The Smart Machine où elle montre comment les mécanismes productivistes, une fois dotés des moyens d’« informationnaliser » la division du travail et son contrôle (c’est-à-dire qu’à chaque fois que vous divisez un travail en plusieurs tâches vous pouvez en renseigner la procédure pour chacune et ainsi contrôler à la fois la production et les hommes), ont progressivement étendu l’usage des technologies de l’information à travers toutes les chaînes de production, puis les services, puis les processus de consommation, etc. C’est à partir de ces clés de lecture que nous pouvons alors aborder l’état de l’économie en général, et on s’aperçoit alors que l’usage (lui même générateur de profit) des Big Data consiste à maîtriser les processus de consommation et saper les mécanismes de concurrence qui étaient auparavant l’apanage revendiqué du libéralisme « classique ».
Ainsi, prenant l’exemple de Google, Shoshana Zuboff analyse les pratiques sauvages de l’extraction de données par ces grands acteurs économiques, à partir des individus, des sociétés, et surtout du quotidien, de nos intimités. Cette appropriation des données comportementales est un processus violent de marchandisation de la connaissance « sur » l’autre et de son contrôle. C’est ce que Shoshana Zuboff nomme Big Other :
« (Big Other) est un régime institutionnel, omniprésent, qui enregistre, modifie, commercialise l’expérience quotidienne, du grille-pain au corps biologique, de la communication à la pensée, de manière à établir de nouveaux chemins vers les bénéfices et les profits. Big Other est la puissance souveraine d’un futur proche qui annihile la liberté que l’on gagne avec les règles et les lois.» 1
Dans l’article ci-dessous, Shoshana Zuboff ne lève le voile que sur un avatar de ce capitalisme de surveillance, mais pas n’importe lequel : Google. En le comparant à ce qu’était General Motors, elle démontre comment l’appropriation des données comportementales par Google constitue en fait un changement de paradigme dans les mécanismes capitalistes : le capital, ce n’est plus le bien ou le stock (d’argent, de produits, de main-d’oeuvre etc.), c’est le comportement et la manière de le renseigner, c’est à dire l’information qu’une firme comme Google peut s’approprier.
Ce qui manquait à la littérature sur ces transformations de notre « société de l’information », c’étaient des clés de lecture capables de s’attaquer à des processus dont l’échelle est globale. On peut toujours en rester à Big Brother, on ne fait alors que se focaliser sur l’état de nos relations sociales dans un monde où le capitalisme de surveillance est un état de fait, comme une donnée naturelle. Au contraire, le capitalisme de surveillance dépasse les États ou toute forme de centralisation du pouvoir. Il est informel et pourtant systémique. Shoshana Zuboff nous donne les clés pour appréhender ces processus globaux, partagé par certaines firmes, où l’appropriation de l’information sur les individus est si totale qu’elle en vient à déposséder l’individu de l’information qu’il a sur lui-même, et même du sens de ses actions.
Shoshana Zuboff est professeur émérite à Charles Edward Wilson, Harvard Business School. Cet essai a été écrit pour une conférence en 2016 au Green Templeton College, Oxford. Son prochain livre à paraître en novembre 2017 s’intitule Maître ou Esclave : une lutte pour l’âme de notre civilisation de l’information et sera publié par Eichborn en Allemagne, et par Public Affairs aux États-Unis.
Traduction originale : Dr. Virginia Alicia Hasenbalg-Corabianu, révision Framalang : mo, goofy, Mannik, Lumi, lyn
Le contrôle exercé par les gouvernements n’est rien comparé à celui que pratique Google. L’entreprise crée un genre entièrement nouveau de capitalisme, une logique d’accumulation systémique et cohérente que nous appelons le capitalisme de surveillance. Pouvons-nous y faire quelque chose ?
Google a dépassé Apple en janvier en devenant la plus grosse capitalisation boursière du monde, pour la première fois depuis 2010 (à l’époque, chacune des deux entreprises valait moins de 200 milliards de dollars; aujourd’hui, chacune est évaluée à plus de 500 milliards). Même si cette suprématie de Google n’a duré que quelques jours, le succès de cette entreprise a des implications pour tous ceux qui ont accès à Internet. Pourquoi ? Parce que Google est le point de départ pour une toute nouvelle forme de capitalisme dans laquelle les bénéfices découlent de la surveillance unilatérale ainsi que de la modification du comportement humain. Il s’agit d’une intrusion globale. Il s’agit d’un nouveau capitalisme de surveillance qui est inimaginable en dehors des insondables circuits à haute vitesse de l’univers numérique de Google, dont le vecteur est l’Internet et ses successeurs. Alors que le monde est fasciné par la confrontation entre Apple et le FBI, véritable réalité est que les capacités de surveillance d’espionnage en cours d’élaboration par les capitalistes de la surveillance sont enviées par toutes les agences de sécurité des États. Quels sont les secrets de ce nouveau capitalisme, comment les entreprises produisent-elles une richesse aussi stupéfiante, et comment pouvons-nous nous protéger de leur pouvoir envahissant ?
I. Nommer et apprivoiser
La plupart des Américains se rendent compte qu’il y a deux types de personnes qui sont régulièrement surveillées quand elles se déplacent dans le pays. Dans le premier groupe, celles qui sont surveillées contre leur volonté par un dispositif de localisation attaché à la cheville suite à une ordonnance du tribunal. Dans le second groupe, toutes les autres.
Certains estiment que cette affirmation est absolument fondée. D’autres craignent qu’elle ne puisse devenir vraie. Certains doivent penser que c’est ridicule. Ce n’est pas une citation issue d’un roman dystopique, d’un dirigeant de la Silicon Valley, ni même d’un fonctionnaire de la NSA. Ce sont les propos d’un consultant de l’industrie de l’assurance automobile, conçus comme un argument en faveur de « la télématique automobile » et des capacités de surveillance étonnamment intrusives des systèmes prétendument bénins déjà utilisés ou en développement. C’est une industrie qui a eu une attitude notoire d’exploitation de ses clients et des raisons évidentes d’être inquiète, pour son modèle économique, des implications des voitures sans conducteur. Aujourd’hui, les données sur l’endroit où nous sommes et celui où nous allons, sur ce que nous sentons, ce que nous disons, les détails de notre conduite, et les paramètres de notre véhicule se transforment en balises de revenus qui illuminent une nouvelle perspective commerciale. Selon la littérature de l’industrie, ces données peuvent être utilisées pour la modification en temps réel du comportement du conducteur, déclencher des punitions (hausses de taux en temps réel, pénalités financières, couvre-feux, verrouillages du moteur) ou des récompenses (réductions de taux, coupons à collectionner pour l’achat d’avantages futurs).
Bloomberg Business Week note que ces systèmes automobiles vont donner aux assureurs la possibilité d’augmenter leurs recettes en vendant des données sur la conduite de leur clientèle de la même manière que Google réalise des profits en recueillant et en vendant des informations sur ceux qui utilisent son moteur de recherche. Le PDG de Allstate Insurance veut être à la hauteur de Google. Il déclare : « Il y a beaucoup de gens qui font de la monétisation des données aujourd’hui. Vous allez chez Google et tout paraît gratuit. Ce n’est pas gratuit. Vous leur donnez des informations ; ils vendent vos informations. Pourrions-nous, devrions-nous vendre ces informations que nous obtenons des conducteurs à d’autres personnes, et réaliser ainsi une source de profit supplémentaire…? C’est une partie à long terme. »
Qui sont ces « autres personnes » et quelle est cette « partie à long terme » ? Il ne s’agit plus de l’envoi d’un catalogue de vente par correspondance ni le ciblage de la publicité en ligne. L’idée est de vendre l’accès en temps réel au flux de votre vie quotidienne – votre réalité – afin d’influencer et de modifier votre comportement pour en tirer profit. C’est la porte d’entrée vers un nouvel univers d’occasions de monétisation : des restaurants qui veulent être votre destination ; des fournisseurs de services qui veulent changer vos plaquettes de frein ; des boutiques qui vous attirent comme les sirènes des légendes. Les « autres personnes », c’est tout le monde, et tout le monde veut acheter un aspect de votre comportement pour leur profit. Pas étonnant, alors, que Google ait récemment annoncé que ses cartes ne fourniront pas seulement l’itinéraire que vous recherchez, mais qu’elles suggéreront aussi une destination.
Le véritable objectif : modifier le comportement réel des gens, à grande échelle.
Ceci est juste un coup d’œil pris au vol d’une industrie, mais ces exemples se multiplient comme des cafards. Parmi les nombreux entretiens que j’ai menés au cours des trois dernières années, l’ingénieur responsable de la gestion et analyse de méga données d’une prestigieuse entreprise de la Silicon Valley qui développe des applications pour améliorer l’apprentissage des étudiants m’a dit : « Le but de tout ce que nous faisons est de modifier le comportement des gens à grand échelle. Lorsque les gens utilisent notre application, nous pouvons cerner leurs comportements, identifier les bons et les mauvais comportements, et développer des moyens de récompenser les bons et punir les mauvais. Nous pouvons tester à quel point nos indices sont fiables pour eux et rentables pour nous. »
L’idée même d’un produit efficace, abordable et fonctionnel puisse suffire aux échanges commerciaux est en train de mourir. L’entreprise de vêtements de sport Under Armour réinvente ses produits comme des technologies que l’on porte sur soi. Le PDG veut lui aussi ressembler à Google. Il dit : « Tout cela ressemble étrangement à ces annonces qui, à cause de votre historique de navigation, vous suivent quand vous êtes connecté à l’Internet (Internet ou l’internet), c’est justement là le problème – à ce détail près que Under Armour traque votre comportement réel, et que les données obtenues sont plus spécifiques… si vous incitez les gens à devenir de meilleurs athlètes ils auront encore plus besoin de notre équipement. » Les exemples de cette nouvelle logique sont infinis, des bouteilles de vodka intelligentes aux thermomètres rectaux reliés à Internet, et littéralement tout ce qu’il y a entre les deux. Un rapport de Goldman Sachs appelle une « ruée vers l’or » cette course vers « de gigantesques quantités de données ».
La bataille des données comportementales
Nous sommes entrés dans un territoire qui était jusqu’alors vierge. L’assaut sur les données de comportement progresse si rapidement qu’il ne peut plus être circonscrit par la notion de vie privée et sa revendication. Il y a un autre type de défi maintenant, celui qui menace l’idéal existentiel et politique de l’ordre libéral moderne défini par les principes de l’autodétermination constitué au cours des siècles, voire des millénaires. Je pense à des notions qui entre autres concernent dès le départ le caractère sacré de l’individu et les idéaux de l’égalité sociale ; le développement de l’identité, l’autonomie et le raisonnement moral ; l’intégrité du marché ; la liberté qui revient à la réalisation et l’accomplissement des promesses ; les normes et les règles de la collectivité ; les fonctions de la démocratie de marché ; l’intégrité politique des sociétés et l’avenir de la souveraineté démocratique. En temps et lieu, nous allons faire un bilan rétrospectif de la mise en place en Europe du « Droit à l’Oubli » et l’invalidation plus récente de l’Union européenne de la doctrine Safe Harbor2 comme les premiers jalons d’une prise en compte progressive des vraies dimensions de ce défi.
Il fut un temps où nous avons imputé la responsabilité de l’assaut sur les données comportementales à l’État et à ses agences de sécurité. Plus tard, nous avons également blâmé les pratiques rusées d’une poignée de banques, de courtiers en données et d’entreprises Internet. Certains attribuent l’attaque à un inévitable « âge des mégadonnées », comme s’il était possible de concevoir des données nées pures et irréprochables, des données en suspension dans un lieu céleste où les faits se subliment dans la vérité.
Le capitalisme a été piraté par la surveillance
Je suis arrivée à une conclusion différente : l’assaut auquel nous sommes confronté⋅e⋅s est conduit dans une large mesure par les appétits exceptionnels d’un tout nouveau genre du capitalisme, une nouvelle logique systémique et cohérente de l’accumulation que j’appelle le capitalisme de surveillance. Le capitalisme a été détourné par un projet de surveillance lucrative qui subvertit les mécanismes évolutifs « normaux » associés à son succès historique et qui corrompt le rapport entre l’offre et la demande qui, pendant des siècles, même imparfaitement, a lié le capitalisme aux véritables besoins de ses populations et des sociétés, permettant ainsi l’expansion fructueuse de la démocratie de marché.
Le capitalisme de surveillance est une mutation économique nouvelle, issue de l’accouplement clandestin entre l’énorme pouvoir du numérique avec l’indifférence radicale et le narcissisme intrinsèque du capitalisme financier, et la vision néolibérale qui a dominé le commerce depuis au moins trois décennies, en particulier dans les économies anglo-saxonnes. C’est une forme de marché sans précédent dont les racines se développent dans un espace de non-droit. Il a été découvert et consolidé par Google, puis adopté par Facebook et rapidement diffusé à travers l’Internet. Le cyberespace est son lieu de naissance car, comme le célèbrent Eric Schmidt, Président de Google/Alphabet, et son co-auteur Jared Cohen, à la toute première page de leur livre sur l’ère numérique, « le monde en ligne n’est vraiment pas attaché aux lois terrestres… Il est le plus grand espace ingouvernable au monde ».
Alors que le capitalisme de surveillance découvre les pouvoirs invasifs de l’Internet comme source d’accumulation de capital et de création de richesses, il est maintenant, comme je l’ai suggéré, prêt à transformer aussi les pratiques commerciales au sein du monde réel. On peut établir l’analogie avec la propagation rapide de la production de masse et de l’administration dans le monde industrialisé au début du XXe siècle, mais avec un bémol majeur. La production de masse était en interaction avec ses populations qui étaient ses consommateurs et ses salariés. En revanche, le capitalisme de surveillance se nourrit de populations dépendantes qui ne sont ni ses consommateurs, ni ses employés, mais largement ignorantes de ses pratiques.
L’accès à Internet, un droit humain fondamental
Nous nous étions jetés sur Internet pour y trouver réconfort et solutions, mais nos besoins pour une vie efficace ont été contrecarrés par les opérations lointaines et de plus en plus impitoyables du capitalisme de la fin du XXe siècle. Moins de deux décennies après l’introduction du navigateur web Mosaic auprès du public, qui permettait un accès facile au World Wide Web, un sondage BBC de 2010 a révélé que 79 % des personnes de 26 pays différents considéraient l’accès à l’Internet comme un droit humain fondamental. Tels sont les Charybde et Scylla de notre sort. Il est presque impossible d’imaginer la participation à une vie quotidienne efficace – de l’emploi à l’éducation, en passant par les soins de santé – sans pouvoir accéder à Internet et savoir s’en servir, même si ces espaces en réseau autrefois florissants s’avèrent être une forme nouvelle et plus forte d’asservissement. Il est arrivé rapidement et sans notre accord ou entente préalable. En effet, les préjudices les plus poignants du régime ont été difficiles à saisir ou à théoriser, brouillés par l’extrême vitesse et camouflés par des opérations techniques coûteuses et illisibles, des pratiques secrètes des entreprises, de fausses rhétoriques discursives, et des détournements culturels délibérés.
Apprivoiser cette nouvelle force nécessite qu’elle soit nommée correctement. Cette étroite interdépendance du nom et de l’apprivoisement est clairement illustrée dans l’histoire récente de la recherche sur le VIH que je vous propose comme analogie. Pendant trois décennies, les recherches des scientifiques visaient à créer un vaccin en suivant la logique des guérisons précédentes qui amenaient le système immunitaire à produire des anticorps neutralisants. Mais les données collectées et croisées ont révélé des comportements imprévus du virus VIH défiant les modèles obtenus auprès d’autres maladies infectieuses.
L’analogie avec la recherche contre le SIDA
La tendance a commencé à prendre une autre direction à la Conférence internationale sur le SIDA en 2012, lorsque de nouvelles stratégies ont été présentées reposant sur une compréhension plus adéquate de la biologie des quelques porteurs du VIH, dont le sang produit des anticorps naturels. La recherche a commencé à se déplacer vers des méthodes qui reproduisent cette réponse d’auto-vaccination. Un chercheur de pointe a annoncé : « Nous connaissons le visage de l’ennemi maintenant, et nous avons donc de véritables indices sur la façon d’aborder le problème. »
Ce qu’il nous faut en retenir : chaque vaccin efficace commence par une compréhension approfondie de la maladie ennemie. Nous avons tendance à compter sur des modèles intellectuels, des vocabulaires et des outils mis en place pour des catastrophes passées. Je pense aux cauchemars totalitaires du XXe siècle ou aux prédations monopolistiques du capitalisme de l’Âge d’Or. Mais les vaccins que nous avons développés pour lutter contre ces menaces précédentes ne sont pas suffisants ni même appropriés pour les nouveaux défis auxquels nous sommes confrontés. C’est comme si nous lancions des boules de neige sur un mur de marbre lisse pour ensuite les regarder glisser et ne laisser rien d’autre qu’une trace humide : une amende payée ici, un détour efficace là.
Une impasse de l’évolution
Je tiens à dire clairement que le capitalisme de surveillance n’est pas la seule modalité actuelle du capitalisme de l’information, ni le seul modèle possible pour l’avenir. Son raccourci vers l’accumulation du capital et l’institutionnalisation rapide, cependant, en a fait le modèle par défaut du capitalisme de l’information. Les questions que je pose sont les suivantes : est-ce que le capitalisme de surveillance devient la logique dominante de l’accumulation dans notre temps, ou ira-t-il vers une impasse dans son évolution – une poule avec des dents au terme de l’évolution capitaliste ? Qu’est-ce qu’un vaccin efficace impliquerait ? Quel pourrait être ce vaccin efficace ?
Le succès d’un traitement dépend de beaucoup d’adaptations individuelles, sociales et juridiques, mais je suis convaincue que la lutte contre la « maladie hostile » ne peut commencer sans une compréhension des nouveaux mécanismes qui rendent compte de la transformation réussie de l’investissement en capital par le capitalisme de surveillance. Cette problématique a été au centre de mon travail dans un nouveau livre, Maître ou Esclave : une lutte pour le cœur de notre civilisation de l’information, qui sera publié au début de l’année prochaine. Dans le court espace de cet essai, je voudrais partager certaines de mes réflexions sur ce problème.
II. L’avenir : le prédire et le vendre
Les nouvelles logiques économiques et leurs modèles commerciaux sont élaborés dans un temps et lieu donnés, puis perfectionnés par essais et erreurs. Ford a mis au point et systématisé la production de masse. General Motors a institutionnalisé la production en série comme une nouvelle phase du développement capitaliste avec la découverte et l’amélioration de l’administration à grande échelle et la gestion professionnelle. De nos jours, Google est au capitalisme de surveillance ce que Ford et General Motors étaient à la production en série et au capitalisme managérial il y a un siècle : le découvreur, l’inventeur, le pionnier, le modèle, le praticien chef, et le centre de diffusion.
Plus précisément, Google est le vaisseau amiral et le prototype d’une nouvelle logique économique basée sur la prédiction et sa vente, un métier ancien et éternellement lucratif qui a exploité la confrontation de l’être humain avec l’incertitude depuis le début de l’histoire humaine. Paradoxalement, la certitude de l’incertitude est à la fois une source durable d’anxiété et une de nos expériences les plus fructueuses. Elle a produit le besoin universel de confiance et de cohésion sociale, des systèmes d’organisation, de liaison familiale, et d’autorité légitime, du contrat comme reconnaissance formelle des droits et obligations réciproques, la théorie et la pratique de ce que nous appelons « le libre arbitre ». Quand nous éliminons l’incertitude, nous renonçons au besoin humain de lancer le défi de notre prévision face à un avenir toujours inconnu, au profit de la plate et constante conformité avec ce que d’autres veulent pour nous.
La publicité n’est qu’un facteur parmi d’autres
La plupart des gens attribuent le succès de Google à son modèle publicitaire. Mais les découvertes qui ont conduit à la croissance rapide du chiffre d’affaires de Google et à sa capitalisation boursière sont seulement incidemment liées à la publicité. Le succès de Google provient de sa capacité à prédire l’avenir, et plus particulièrement, l’avenir du comportement. Voici ce que je veux dire :
Dès ses débuts, Google a recueilli des données sur le comportement lié aux recherches des utilisateurs comme un sous-produit de son moteur de recherche. À l’époque, ces enregistrements de données ont été traités comme des déchets, même pas stockés méthodiquement ni mis en sécurité. Puis, la jeune entreprise a compris qu’ils pouvaient être utilisés pour développer et améliorer continuellement son moteur de recherche.
Le problème était le suivant : servir les utilisateurs avec des résultats de recherche incroyables « consommait » toute la valeur que les utilisateurs produisaient en fournissant par inadvertance des données comportementales. C’est un processus complet et autonome dans lequel les utilisateurs sont des « fins-en-soi ». Toute la valeur que les utilisateurs produisent était réinvestie pour simplifier l’utilisation sous forme de recherche améliorée. Dans ce cycle, il ne restait rien à transformer en capital, pour Google. L’efficacité du moteur de recherche avait autant besoin de données comportementales des utilisateurs que les utilisateurs de la recherche. Faire payer des frais pour le service était trop risqué. Google était sympa, mais il n’était pas encore du capitalisme – seulement l’une des nombreuses startups de l’Internet qui se vantaient de voir loin, mais sans aucun revenu.
Un tournant dans l’usage des données comportementales
L’année 2001 a été celle de l’effervescence dans la bulle du dot.com avec des pressions croissantes des investisseurs sur Google. À l’époque, les annonceurs sélectionnaient les pages du terme de recherche pour les afficher. Google a décidé d’essayer d’augmenter ses revenus publicitaires en utilisant ses capacités analytiques déjà considérables dans l’objectif d’accroître la pertinence d’une publicité pour les utilisateurs – et donc sa valeur pour les annonceurs. Du point de vue opérationnel cela signifiait que Google allait enfin valoriser son trésor croissant de données comportementales. Désormais, les données allaient être aussi utilisées pour faire correspondre les publicités avec les des mots-clés, en exploitant les subtilités que seul l’accès à des données comportementales, associées à des capacités d’analyse, pouvait révéler.
Il est maintenant clair que ce changement dans l’utilisation des données comportementales a été un tournant historique. Les données comportementales qui avaient été rejetées ou ignorées ont été redécouvertes et sont devenues ce que j’appelle le surplus de comportement. Le succès spectaculaire de Google obtenu en faisant correspondre les annonces publicitaires aux pages a révélé la valeur transformationnelle de ce surplus comportemental comme moyen de générer des revenus et, finalement, de transformer l’investissement en capital. Le surplus comportemental était l’actif à coût zéro qui changeait la donne, et qui pouvait être détourné de l’amélioration du service au profit d’un véritable marché. La clé de cette formule, cependant, est que ce nouveau marché n’est pas le fruit d’un échange avec les utilisateurs, mais plutôt avec d’autres entreprises qui ont compris comment faire de l’argent en faisant des paris sur le comportement futur des utilisateurs. Dans ce nouveau contexte, les utilisateurs ne sont plus une fin en soi. Au contraire, ils sont devenus une source de profit d’un nouveau type de marché dans lequel ils ne sont ni des acheteurs ni des vendeurs ni des produits. Les utilisateurs sont la source de matière première gratuite qui alimente un nouveau type de processus de fabrication.
Bien que ces faits soient connus, leur importance n’a pas été pleinement évaluée ni théorisée de manière adéquate. Ce qui vient de se passer a été la découverte d’une équation commerciale étonnamment rentable – une série de relations légitimes qui ont été progressivement institutionnalisées dans la logique économique sui generis du capitalisme de surveillance. Cela ressemble à une planète nouvellement repérée avec sa propre physique du temps et de l’espace, ses journées de soixante-sept heures, un ciel d’émeraude, des chaînes de montagnes inversées et de l’eau sèche.
Une forme de profit parasite
L’équation : tout d’abord, il est impératif de faire pression pour obtenir plus d’utilisateurs et plus de canaux, des services, des dispositifs, des lieux et des espaces de manière à avoir accès à une gamme toujours plus large de surplus de comportement. Les utilisateurs sont la ressource humaine naturelle qui fournit cette matière première gratuite.
En second lieu, la mise en œuvre de l’apprentissage informatique, de l’intelligence artificielle et de la science des données pour l’amélioration continue des algorithmes constitue un immense « moyen de production » du XXIe siècle coûteux, sophistiqué et exclusif.
Troisièmement, le nouveau processus de fabrication convertit le surplus de comportement en produits de prévision conçus pour prédire le comportement actuel et à venir.
Quatrièmement, ces produits de prévision sont vendus dans un nouveau type de méta-marché qui fait exclusivement commerce de comportements à venir. Plus le produit est prédictif, plus faible est le risque pour les acheteurs et plus le volume des ventes augmente. Les profits du capitalisme de surveillance proviennent principalement, sinon entièrement, de ces marchés du comportement futur.
Alors que les annonceurs ont été les acheteurs dominants au début de ce nouveau type de marché, il n’y a aucune raison de fond pour que de tels marchés soient réservés à ce groupe. La tendance déjà perceptible est que tout acteur ayant un intérêt à monétiser de l’information probabiliste sur notre comportement et/ou à influencer le comportement futur peut payer pour entrer sur un marché où sont exposées et vendues les ressources issues du comportement des individus, des groupes, des organismes, et les choses. Voici comment dans nos propres vies nous observons le capitalisme se déplacer sous nos yeux : au départ, les bénéfices provenaient de produits et services, puis de la spéculation, et maintenant de la surveillance. Cette dernière mutation peut aider à expliquer pourquoi l’explosion du numérique a échoué, jusqu’à présent, à avoir un impact décisif sur la croissance économique, étant donné que ses capacités sont détournées vers une forme de profit fondamentalement parasite.
III. Un péché non originel
L’importance du surplus de comportement a été rapidement camouflée, à la fois par Google et mais aussi par toute l’industrie de l’Internet, avec des étiquettes comme « restes numériques », « miettes numériques », et ainsi de suite. Ces euphémismes pour le surplus de comportement fonctionnent comme des filtres idéologiques, à l’instar des premières cartes géographiques du continent nord-américain qui marquaient des régions entières avec des termes comme « païens », « infidèles », « idolâtres », « primitifs », « vassaux » ou « rebelles ». En vertu de ces étiquettes, les peuples indigènes, leurs lieux et leurs revendications ont été effacés de la pensée morale et juridique des envahisseurs, légitimant leurs actes d’appropriation et de casse au nom de l’Église et la Monarchie.
Nous sommes aujourd’hui les peuples autochtones dont les exigences implicites d’autodétermination ont disparu des cartes de notre propre comportement. Elles sont effacées par un acte étonnant et audacieux de dépossession par la surveillance, qui revendique son droit d’ignorer toute limite à sa soif de connaissances et d’influence sur les nuances les plus fines de notre comportement. Pour ceux qui s’interrogent sur l’achèvement logique du processus global de marchandisation, la réponse est qu’ils achèvent eux-mêmes la spoliation de notre réalité quotidienne intime, qui apparaît maintenant comme un comportement à surveiller et à modifier, à acheter et à vendre.
Le processus qui a commencé dans le cyberespace reflète les développements capitalistes du dix-neuvième siècle qui ont précédé l’ère de l’impérialisme. À l’époque, comme Hannah Arendt le décrit dans Les Origines du totalitarisme, « les soi-disant lois du capitalisme ont été effectivement autorisées à créer des réalités » ainsi on est allé vers des régions moins développées où les lois n’ont pas suivi. « Le secret du nouvel accomplissement heureux », a-t-elle écrit, « était précisément que les lois économiques ne bloquaient plus la cupidité des classes possédantes. » Là, « l’argent pouvait finalement engendrer de l’argent », sans avoir à passer par « le long chemin de l’investissement dans la production… »
Le péché originel du simple vol
Pour Arendt, ces aventures du capital à l’étranger ont clarifié un mécanisme essentiel du capitalisme. Marx avait développé l’idée de « l’accumulation primitive » comme une théorie du Big-Bang – Arendt l’a appelé « le péché originel du simple vol » – dans lequel l’appropriation de terres et de ressources naturelles a été l’événement fondateur qui a permis l’accumulation du capital et l’émergence du système de marché. Les expansions capitalistes des années 1860 et 1870 ont démontré, écrit Arendt, que cette sorte de péché originel a dû être répété encore et encore, « de peur que le moteur de l’accumulation de capital ne s’éteigne soudainement ».
Dans son livre The New Imperialism, le géographe et théoricien social David Harvey s’appuie sur ce qu’il appelle « accumulation par dépossession ». « Ce que fait l’accumulation par dépossession » écrit-il, « c’est de libérer un ensemble d’actifs… à un très faible (et dans certains cas, zéro) coût ». Le capital sur-accumulé peut s’emparer de ces actifs et les transformer immédiatement en profit… Il peut aussi refléter les tentatives de certains entrepreneurs… de « rejoindre le système » et rechercher les avantages de l’accumulation du capital.
Brèche dans le « système »
Le processus qui permet que le « surplus de comportement » conduise à la découverte du capitalisme de surveillance illustre cette tendance. C’est l’acte fondateur de la spoliation au profit d’une nouvelle logique du capitalisme construite sur les bénéfices de la surveillance, qui a ouvert la possibilité pour Google de devenir une entreprise capitaliste. En effet, en 2002, première année rentable Google, le fondateur Sergey Brin savoura sa percée dans le « système », comme il l’a dit à Levy,
« Honnêtement, quand nous étions encore dans les jours du boom dot-com, je me sentais comme un idiot. J’avais une startup – comme tout le monde. Elle ne générait pas de profit, c’était le cas des autres aussi, était-ce si dur ? Mais quand nous sommes devenus rentables, j’ai senti que nous avions construit une véritable entreprise « .
Brin était un capitaliste, d’accord, mais c’était une mutation du capitalisme qui ne ressemblait à rien de tout ce que le monde avait vu jusqu’alors.
Une fois que nous comprenons ce raisonnement, il devient clair qu’exiger le droit à la vie privée à des capitalistes de la surveillance ou faire du lobbying pour mettre fin à la surveillance commerciale sur l’Internet c’est comme demander à Henry Ford de faire chaque modèle T à la main. C’est comme demander à une girafe de se raccourcir le cou ou à une vache de renoncer à ruminer. Ces exigences sont des menaces existentielles qui violent les mécanismes de base de la survie de l’entité. Comment pouvons-nous nous espérer que des entreprises dont l’existence économique dépend du surplus du comportement cessent volontairement la saisie des données du comportement ? C’est comme demander leur suicide.
Toujours plus de surplus comportemental avec Google
Les impératifs du capitalisme de surveillance impliquent qu’il faudra toujours plus de surplus comportemental pour que Google et d’autres les transforment en actifs de surveillance, les maîtrisent comme autant de prédictions, pour les vendre dans les marchés exclusifs du futur comportement et les transformer en capital. Chez Google et sa nouvelle société holding appelée Alphabet, par exemple, chaque opération et investissement vise à accroître la récolte de surplus du comportement des personnes, des organismes, de choses, de processus et de lieux à la fois dans le monde virtuel et dans le monde réel. Voilà comment un jour de soixante-sept heures se lève et obscurcit un ciel d’émeraude. Il faudra rien moins qu’une révolte sociale pour révoquer le consensus général à des pratiques visant à la dépossession du comportement et pour contester la prétention du capitalisme de surveillance à énoncer les données du destin.
Quel est le nouveau vaccin ? Nous devons ré-imaginer comment intervenir dans les mécanismes spécifiques qui produisent les bénéfices de la surveillance et, ce faisant, réaffirmer la primauté de l’ordre libéral dans le projet capitaliste du XXIe siècle. Dans le cadre de ce défi, nous devons être conscients du fait que contester Google, ou tout autre capitaliste de surveillance pour des raisons de monopole est une solution du XXe siècle à un problème du 20e siècle qui, tout en restant d’une importance vitale, ne perturbe pas nécessairement l’équation commerciale du capitalisme de surveillance. Nous avons besoin de nouvelles interventions qui interrompent, interdisent ou réglementent : 1) la capture initiale du surplus du comportement, 2) l’utilisation du surplus du comportement comme matière première gratuite, 3) des concentrations excessives et exclusives des nouveaux moyens de production, 4) la fabrication de produits de prévision, 5) la vente de produits de prévision, 6) l’utilisation des produits de prévision par des tiers pour des opérations de modification, d’influence et de contrôle, et 5) la monétisation des résultats de ces opérations. Tout cela est nécessaire pour la société, pour les personnes, pour l’avenir, et c’est également nécessaire pour rétablir une saine évolution du capitalisme lui-même.
IV. Un coup d’en haut
Dans la représentation classique des menaces sur la vie privée, le secret institutionnel a augmenté, et les droits à la vie privée ont été érodés. Mais ce cadrage est trompeur, car la vie privée et le secret ne sont pas opposés, mais plutôt des moments dans une séquence. Le secret est une conséquence ; la vie privée est la cause. L’exercice du droit à la vie privée a comme effet la possibilité de choisir, et l’on peut choisir de garder quelque chose en secret ou de le partager. Les droits à la vie privée confèrent donc les droits de décision, mais ces droits de décision ne sont que le couvercle sur la boîte de Pandore de l’ordre libéral. À l’intérieur de la boîte, les souverainetés politiques et économiques se rencontrent et se mélangent avec des causes encore plus profondes et plus subtiles : l’idée de l’individu, l’émergence de soi, l’expérience ressentie du libre arbitre.
Le capitalisme de surveillance ne dégrade pas ces droits à la décision – avec leurs causes et leurs conséquences – il les redistribue plutôt. Au lieu de nombreuses personnes ayant quelques « droits », ces derniers ont été concentrés à l’intérieur du régime de surveillance, créant ainsi une toute nouvelle dimension de l’inégalité sociale. Les implications de cette évolution me préoccupent depuis de nombreuses années, et mon sens du danger s’intensifie chaque jour. L’espace de cet essai ne me permet pas de poursuivre jusqu’à la conclusion, mais je vous propose d’en résumer l’essentiel.
Le capitalisme de surveillance va au-delà du terrain institutionnel classique de l’entreprise privée. Il accumule non seulement les actifs de surveillance et des capitaux, mais aussi des droits. Cette redistribution unilatérale des droits soutient un régime de conformité administré en privé fait de récompenses et des punitions en grande partie déliée de toute sanction. Il opère sans mécanismes significatifs de consentement, soit sous la forme traditionnelle d’un « exit, voice or loyalty »3 associé aux marchés, soit sous la forme d’un contrôle démocratique exprimé par des lois et des règlements.
Un pouvoir profondément antidémocratique
En conséquence, le capitalisme de surveillance évoque un pouvoir profondément anti-démocratique que l’on peut qualifier de coup d’en haut : pas un coup d’état, mais plutôt un coup contre les gens, un renversement de la souveraineté du peuple. Il défie les principes et les pratiques de l’autodétermination – dans la vie psychique et dans les relations sociales, le politique et la gouvernance – pour lesquels l’humanité a souffert longtemps et sacrifié beaucoup. Pour cette seule raison, ces principes ne doivent pas être confisqués pour la poursuite unilatérale d’un capitalisme défiguré. Pire encore serait leur forfait par notre propre ignorance, impuissance apprise, inattention, inconvenance, force de l’habitude, ou laisser aller. Tel est, je crois, le terrain sur lequel notre lutte pour l’avenir devra se dérouler.
Hannah Arendt a dit un jour que l’indignation est la réponse naturelle de l’homme à ce qui dégrade la dignité humaine. Se référant à son travail sur les origines du totalitarisme, elle a écrit : « Si je décris ces conditions sans permettre à mon indignation d’y intervenir, alors j’ai soulevé ce phénomène particulier hors de son contexte dans la société humaine et l’ai ainsi privé d’une partie de sa nature, privé de l’une de ses qualités intrinsèques importantes. »
C’est donc ainsi pour moi et peut-être pour vous : les faits bruts du capitalisme de surveillance suscitent nécessairement mon indignation parce qu’ils rabaissent la dignité humaine. L’avenir de cette question dépendra des savants et journalistes indignés attirés par ce projet de frontière, des élus et des décideurs indignés qui comprennent que leur autorité provient des valeurs fondamentales des communautés démocratiques, et des citoyens indignés qui agissent en sachant que l’efficacité sans l’autonomie n’est pas efficace, la conformité induite par la dépendance n’est pas un contrat social et être libéré de l’incertitude n’est pas la liberté.
—–
1. Shoshana Zuboff, « Big other : surveillance capitalism and the prospects of an information civilization », Journal of Information Technology, 30, 2015, p. 81.↩
2. Le 6 octobre 2015, la Cour de justice de l’Union européenne invalide l’accord Safe Harbor. La cour considère que les États-Unis n’offrent pas un niveau de protection adéquat aux données personnelles transférées et que les états membres peuvent vérifier si les transferts de données personnelles entre cet état et les États-Unis respectent les exigences de la directive européenne sur la protection des données personnelles.↩
3. Référence aux travaux de A. O. Hirschman sur la manière de gérer un mécontentement auprès d’une entreprise : faire défection (exit), ou prendre la parole (voice). La loyauté ayant son poids dans l’une ou l’autre décision.↩

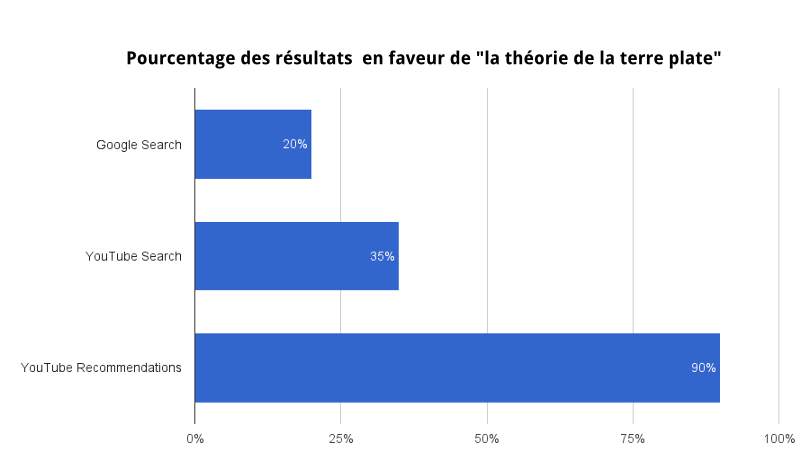
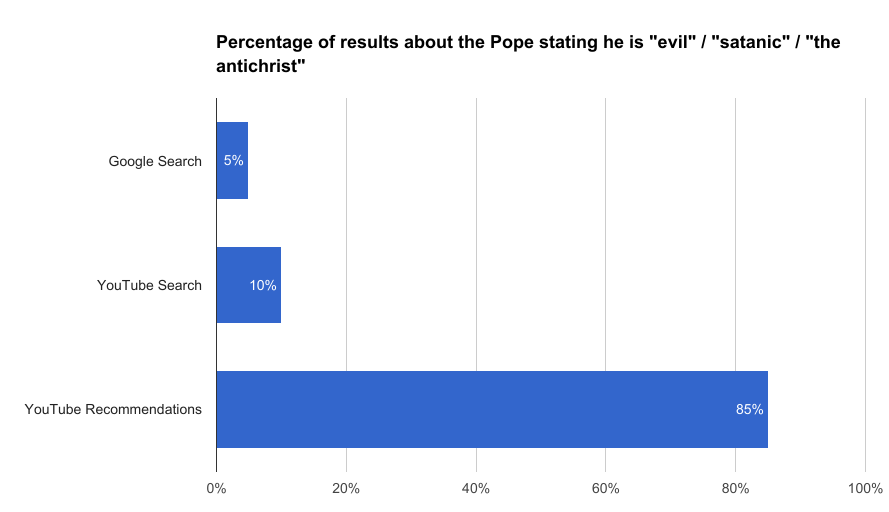
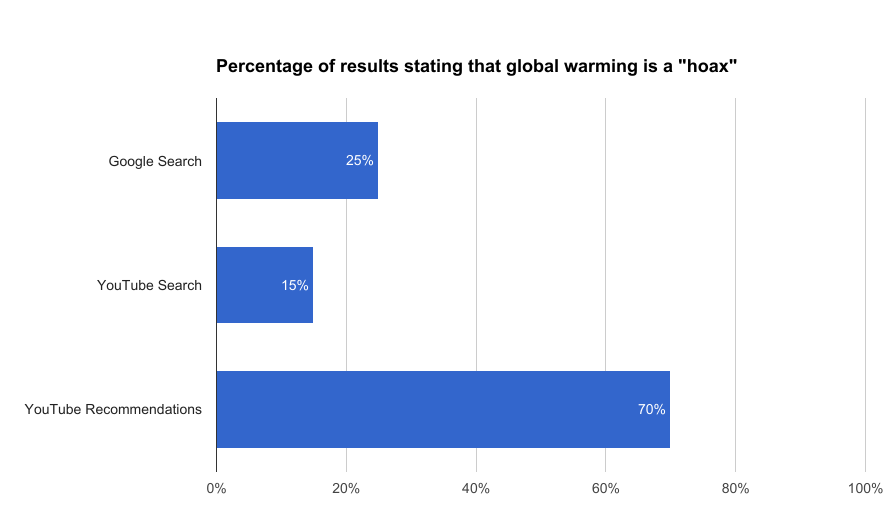
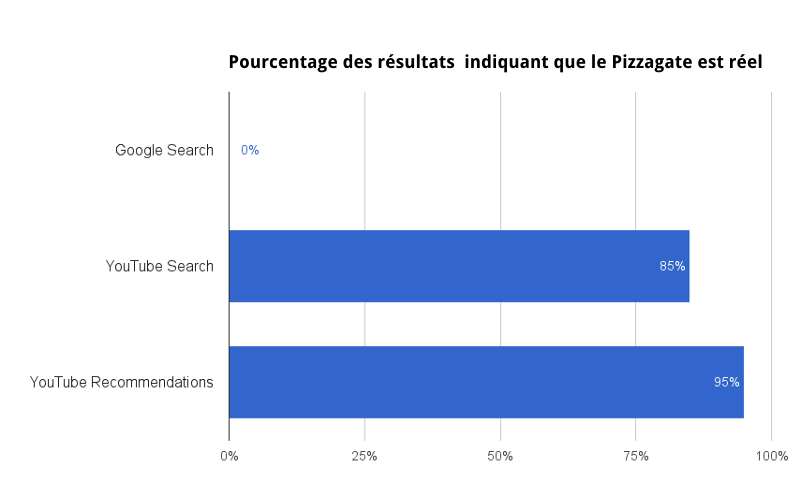
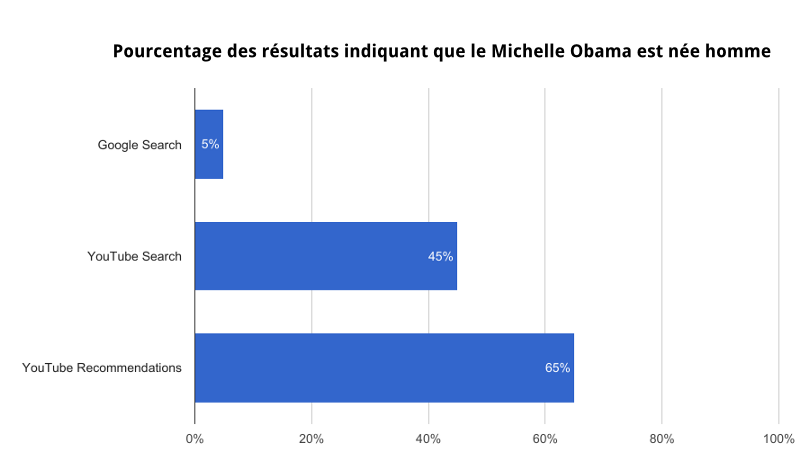








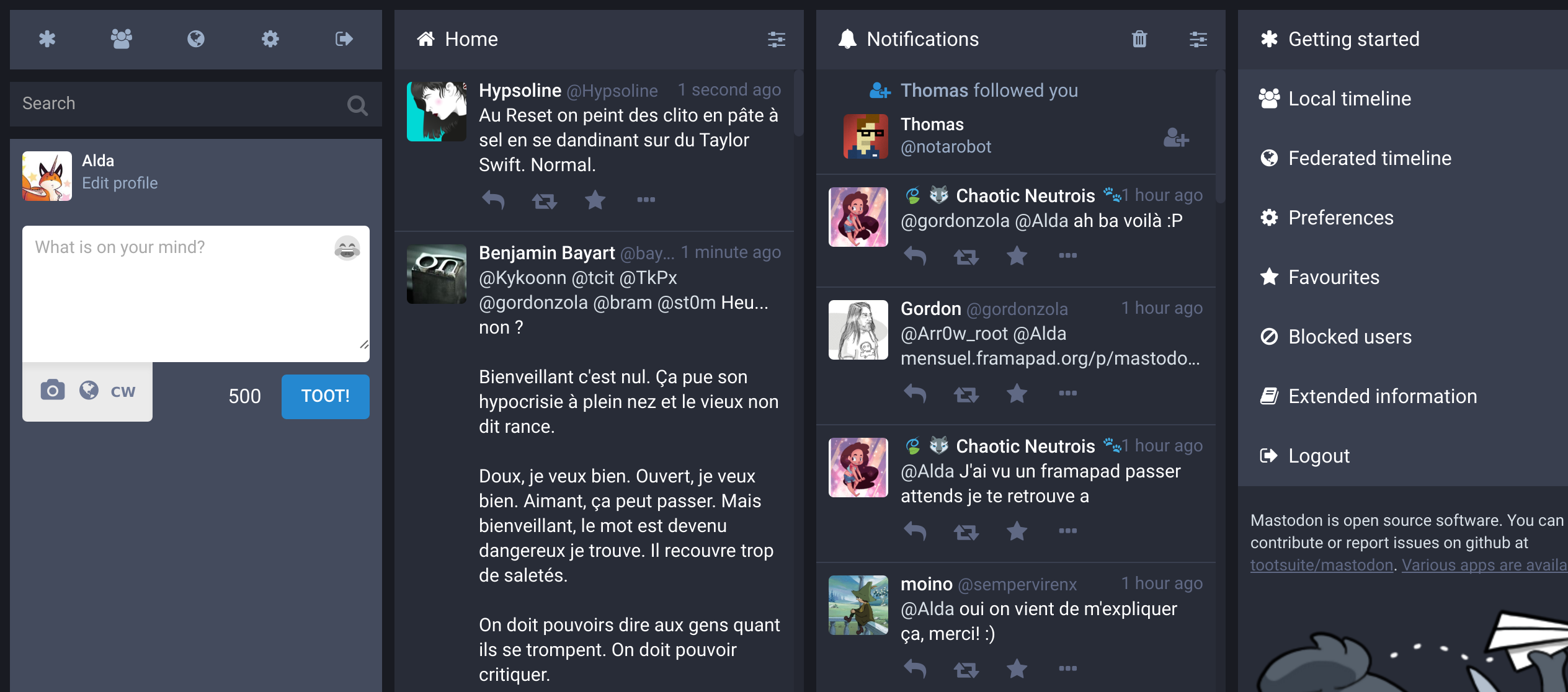
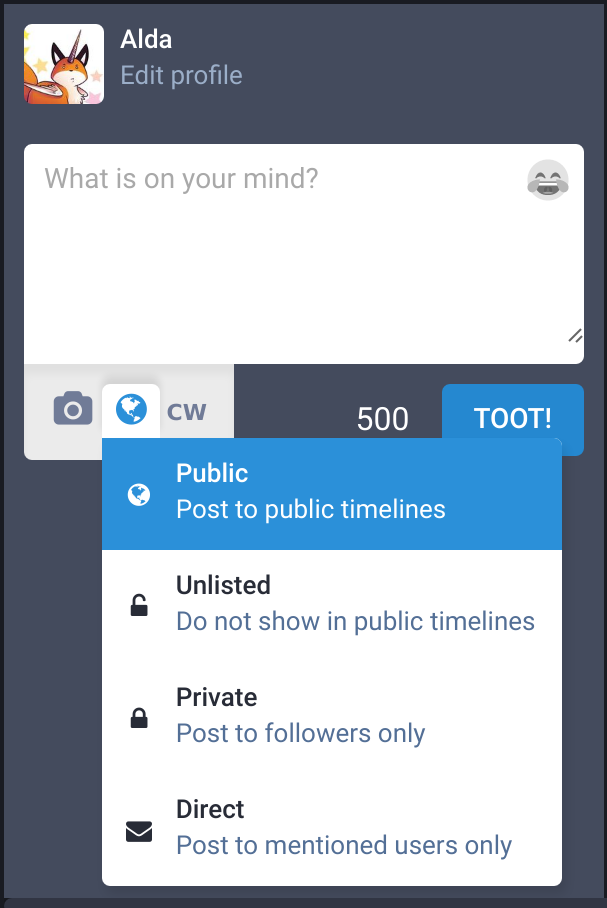
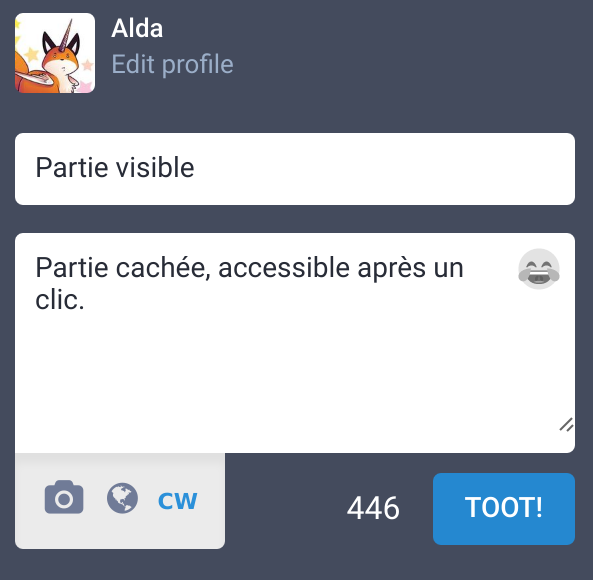
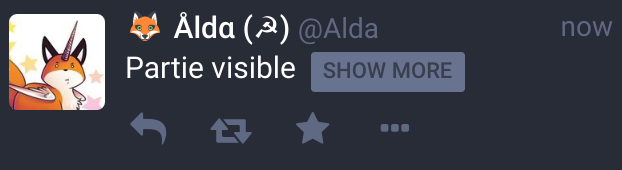
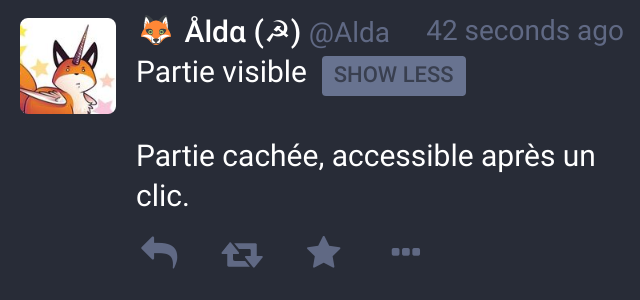
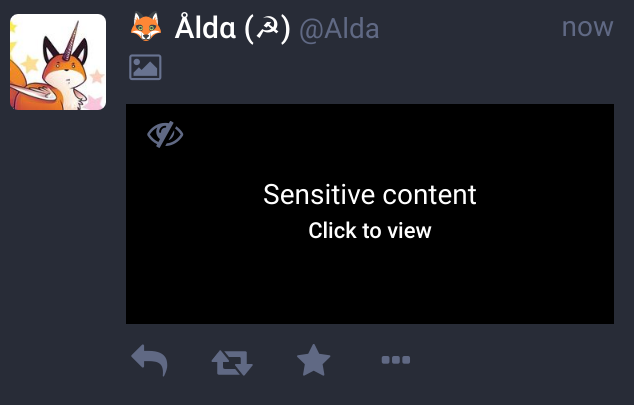

















{kind=link}