Framaconfinement semaine 7 – Framapathique, Framaradeau et Framacamp
C’est à nouveau moi Angie qui reprends le clavier pour vous raconter notre septième semaine de confinement. J’ai de la chance, c’est encore une semaine de 4 jours. Bon, passer après pyg, c’est toujours un peu challengeant (oh le gros mot) parce que c’est sûr que je prends moins de hauteur que lui… encore plus quand il fait un pas de côté ! C’est à se prendre les pieds dans le tapis et moi je tiens à mes deux jambes car bientôt je vais pouvoir renfourcher mon fidèle destrier pour aller respirer le bon air de la campagne ! Mais je vais quand même tenter de vous raconter nos aventures framasoftiennes pour la semaine du 27 avril au 3 mai.
L’accès à l’ensemble de nos articles « framaconfinement » : https://framablog.org/category/framasoft/framaconfinement/
Une pensée en berne
La tentation est grande de mettre sa propre pensée en berne en se disant qu’elle ne vaut plus rien par rapport à ce qui se passe dans le monde. Et une telle attitude est plus que dangereuse.
C’est Jean Morisset, un poète géographe québécois octogénaire qui a écrit cela il y a quelques semaines à l’écrivaine Nancy Huston. C’est à la lecture de cet article de Nancy Huston dans Le Devoir, que je me suis rendu compte en cette septième semaine de confinement que mes réflexions sur ce qui était en train de nous arriver avaient cessé. Que je n’avais plus envie de me questionner, que je n’en pouvais plus de lire et d’entendre les avis des uns et des autres sur comment la situation allait évoluer ou de comment le monde allait changer…
Évidemment que, comme Nancy Huston, je ressens un malaise face à l’écart violent entre l’état du monde et mon quotidien plutôt agréable de confinée. Mais contrairement à certains de mes collègues (coucou la #TeamChauve), après six semaines, je n’arrive plus à penser. Je suis passée en mode « apathique », cet état d’indifférence généralisée qui se manifeste par l’absence d’émotions, de sensations et de désirs, un manque de motivation et d’initiative ainsi que par la perte d’intérêt vis-à-vis d’autrui. Je suis consciente d’avoir mis en place un mécanisme de défense pour me détacher de la situation exceptionnelle que nous vivons toutes et tous. Après avoir été en colère, avoir dû soutenir moralement plusieurs personnes en détresse autour de moi, je ne suis plus en mesure d’éprouver quoi que ce soit. Je me mets en pause. Et donc, ma pensée est en berne…

Ce qui a eu pour incidence que j’ai bien galéré sur l’écriture de l’article Framaconfinement S5… J’ai reporté autant que j’ai pu sa rédaction, trouvant des tas d’autres activités plus nécessaires à faire. Alors que clairement, la rédaction de cet article était bien plus prioritaire que toutes ces petites tâches. Bref, j’ai pas mal procrastiné ! Pour rappel, la procrastination se définit comme la tendance à remettre systématiquement au lendemain. Plusieurs études ont mis en évidence que la procrastination était liée au manque de confiance en soi. Rien d’étonnant : les personnes ayant le moins confiance en elles auraient tendance à se montrer défaitistes, et donc à remettre leurs tâches à plus tard par peur de les rater.
Et en ce qui me concerne, c’est bien de cela qu’il s’agit ! Quand je me lance dans la rédaction d’un article, j’ai toujours des tas de questions : comment avoir l’air de dire des choses pas trop stupides ? Comment ne pas dénaturer ce qu’on fait les collègues ? Comment rendre ce compte-rendu agréable à la lecture ? Et puis, même si on s’est toujours dit qu’on ne se mettait pas la pression 🍺, eh bien c’est plus facile à dire qu’à faire !
Alors, j’ai essayé différents moyens pour me concentrer : faire une petite séance de méditation avant de me relancer dans la rédaction pour ne pas penser à autre chose, me fixer des créneaux dédiés en coupant tous nos outils de communication afin de ne pas me faire polluer par les différentes notifications et même m’autoriser une petite sieste pour décompresser avant de me lancer. Au final, ce qui a le mieux marché, c’est de me fixer une deadline de rendu et de la faire connaître à mes collègues. Je me suis ainsi retrouvée dans la situation de ne plus avoir le choix de reporter cette activité et j’ai donc été obligée de travailler vite et bien pour respecter ce délai. Le stress que génère chez moi cet ultimatum est très positif et me pousse à avoir une meilleure concentration. Enfin, cette méthode a un autre avantage : cela me force à ne plus être aussi perfectionniste, exigeante envers moi-même. Car dans l’urgence (relative, hein !), je suis alors capable de faire la part des choses et de faire du mieux que je peux, même si je ne trouve pas le résultat parfait.

Au final, j’ai donc fini par y arriver, mais ça n’a pas été une partie de plaisir. Et en même temps, j’ai accepté cette même semaine de prendre en charge la rédaction de notre journal de confinement pour les semaines 7 et 8. Ça peut paraître bizarre de s’imposer une tâche qu’il nous est difficile de réaliser, mais j’aime bien les challenges. Et d’ailleurs, la rédaction de l’article que vous lisez actuellement a été beaucoup plus aisée. Peut-être parce que j’ai eu énormément de retours positifs sur l’article Framaconfinement S5 et que ça m’a permis d’avoir davantage confiance en moi, en ma capacité à dire des choses pas trop débiles. Et c’est aussi sûrement parce que je me suis immédiatement fixé une deadline pour sa rédaction.
Et pourtant, tout continue !
Ce n’est pas parce que moi je suis en mode apathique qui galère sur la rédaction d’un article que mes collègues s’arrêtent pour autant. Bien au contraire…
La semaine a commencé en beauté puisqu’au sein d’un de nos canaux de discussion, est apparue l’idée de développer une contre application StopCovid qu’on appellerait FramaRadeau (©️ Lise) et dont le pitch serait : « cette appli ne fait absolument rien, mais si ça vous fait aller mieux quelques secondes, voici un bouton pour aller mieux » (©️ Tcit). Il vaut mieux en rire qu’en pleurer ! Et de toute façon, comme l’a indiqué pyg dans son compte-rendu de notre sixième semaine de confinement, on a fait notre part sur cette question et on n’ira pas plus loin !

Luc râle au sein de notre Framateam car certain⋅es d’entre nous postent des images en direct au lieu d’utiliser le service Framapic ou que nous n’utilisons pas la fonctionnalité des fils de discussion. Et quand c’est le brol, Luc, il n’aime pas ça ! Et puis toutes ces images, c’est que ça prend de la place sur le serveur ! Alors, on essaie de systématiquement utiliser Framapic et de bien répondre aux publications pour maintenir de jolis fils de discussion. Mais c’est plus facile à dire qu’à faire ! Ce qui est certain, c’est que rappeler ces bonnes pratiques est essentiel pour que l’outil soit efficace, car quand au sein d’un même canal, plus de 5 discussions ont lieu en parallèle, il est impossible de tout suivre si cette rigueur n’est pas respectée.

Nos stagiaires sont toujours à fond eux aussi ! Arthur continue à produire les sous-titres de la vidéo The Age of Surveillance Capitalism, une interview de Shoshana Zuboff, et a découvert cette semaine que le logiciel Omega T qu’il utilise pour ses traductions est bien plus simple à utiliser qu’il ne le pensait ! Il s’est senti un peu bête sur le moment. Mais comme il apprécie l’autodérision, il en a fait un joli article de journal !

Lise a préparé le texte d’un communiqué de presse présentant l’initiative entraide.chatons.org avant de l’envoyer à différents médias. Elle a aussi créé une nouvelle fiche sur le wiki pour présenter le logiciel Shaarli, que nous utilisons pour vous fournir le service MyFrama. Cet outil de conservation et de partage de liens est vraiment hyper pratique quand on veut se créer des dossiers documentaires ou bien tout simplement conserver un contenu pour y revenir plus tard.
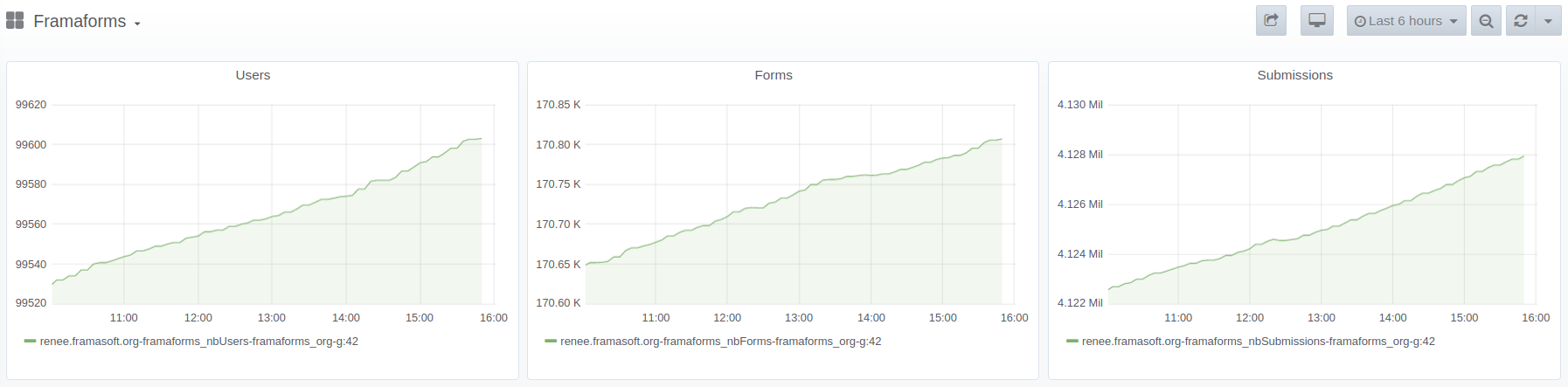
Théo a travaillé cette semaine à la mise en place d’un système permettant aux internautes de contacter directement l’administrateur⋅ice d’un formulaire Framaforms. C’est une fonctionnalité qui va nous être très utile car nous recevons via notre formulaire de contact de plus en plus de messages de personnes qui souhaitent contacter le créateur⋅ice d’un formulaire. N’étant pas nous même créateur⋅ice de ces formulaires, nous sommes dans l’incapacité de pouvoir donner cette information aux personnes qui nous sollicitent. Cependant, mettre en place cette nouvelle fonctionnalité nous a demandé de bien y réfléchir en amont. En effet, nous n’avons pas souhaité que ce mail de contact soit visible directement sur le formulaire car les robots spammeurs s’en seraient donnés à cœur joie ! Il nous fallait donc mettre en place un formulaire de contact directement dans Framaforms. Et puis, nous ne voulions pas non plus obliger les créateur⋅ices à être contacté⋅es. Théo est donc parti sur plusieurs pistes avant de trouver celle qui permettait de prendre en compte tous ces aspects. Cette fonctionnalité n’est pas encore implémentée dans Framaforms, mais Théo m’indique que c’est imminent !
Pouhiou, en plus d’animer nos comptes sur les médias sociaux au quotidien, a passé une partie de la semaine à préparer la lettre d’informations Framasoft dans laquelle il récapitule tout ce que nous avons fait ces derniers mois. Je l’admire car regarder dans le rétroviseur pour identifier tout ce que nous avons fait depuis janvier, c’est un boulot de dingue !
Tcit continue à travailler au développement de Mobilizon. J’ai pas tout bien suivi mais il continue à développer les fonctionnalités pour les groupes et fait des tests. J’imagine que ça veut dire qu’il voit si les fonctionnalités qu’il a développées fonctionnent correctement. Notre designeuse associée au projet Mobilizon, Marie-Cécile Godwin Paccard a lancé sur les médias sociaux un formulaire permettant de demander des précisions aux futur⋅es utilisateur⋅ices de Mobilizon sur le vocabulaire utilisé sur les pages événements.
Chocobozzz est lui aussi le nez dans le développement de nouvelles fonctionnalités pour PeerTube. Apparemment, il s’agirait de pouvoir ajouter des plugins d’authentification. Je ne suis pas certaine d’avoir bien compris de quoi il s’agissait, et puis comme ce n’est pas fini, mieux vaut que vous patientiez avant d’en savoir plus.
Du côté du support, spf ne chôme pas car les sollicitations sont toujours aussi nombreuses. D’ailleurs parfois, il s’énerve un peu de recevoir des messages de certain⋅es de nos utilisateur⋅ices qui ne prennent même pas la peine d’appliquer les règles de base de la politesse. On a beau être conscient que très souvent lorsque vous nous contactez, c’est que vous rencontrez un problème, mais commencer un mail par un « bonjour », c’est tout de même pas la mer à boire ! Heureusement qu’on reçoit des tickets qui nous donnent l’opportunité de nous marrer un peu ! Par exemple, on s’est amusé de recevoir une demande d’aide comprenant un fichier .odt dans lequel étaient copiées des captures d’écran… Je vous le dis, on s’amuse comme on peut du côté du support !

Pyg continue à jongler entre les interviews, les réunions avec certains partenaires et les interventions à distance, tout en rédigeant l’article Framaconfinement de la semaine 6. Et comme il a toujours des tas de choses à nous dire, eh bien ça prend du temps (mais pour vous ça ne vous prendra que 30 minutes à lire !). Il a aussi trouvé le temps de publier le Memorandum Covid-19 pour du libre et de l’open en conscience : enseignements et impulsions futures le mercredi 29 avril.
On se réadapte pour les mois à venir
Pyg a annoncé cette semaine à l’association l’annulation de notre Framacamp annuel, du moins sous sa forme habituelle. Le Framacamp, c’est le second rendez-vous annuel des membres de l’association (l’autre étant notre AG). Pendant une dizaine de jours, les membres qui le peuvent se retrouvent physiquement dans un lieu agréable pour faire le point sur les projets en cours, discuter des grandes orientations de l’association et avancer sur certains projets.
Étant arrivée chez Framasoft en février 2019, je n’ai vécu qu’un seul Framacamp, celui de juin 2019, mais ça a été pour moi une expérience incroyable. Déjà, parce que c’est un boulot de fou de tout organiser. Et ça on le doit à AnMarie qui gère avec brio tous les aspects logistiques (réservation d’un gîte, déplacements, alimentation). Et comme nos membres ne sont pas tous hyper-organisé⋅es, entre celleux qui veulent changer de jour d’arrivée ou de départ, celleux qui ne peuvent finalement pas venir et celleux qui ont des régimes alimentaires spéciaux, c’est un sacré exercice d’agilité (en mode à l’arrache donc !). Ensuite, parce que se revoir, discuter, échanger, réflexionner, boire des coups pendant plusieurs jours d’affilée, c’est un super moyen de consolider le groupe. Je n’avais jamais vécu ce type d’expérience (je n’arrive déjà pas à partir en vacances avec plus de 2 personnes sans que ça soit angoissant pour moi !) et même si j’ai trouvé que c’était sacrément épuisant, j’étais hyper enthousiaste à l’idée de recommencer ! Parce que ce Framacamp a complètement du sens pour moi et que finalement, être entourée de personnes bienveillantes et brillantes, qui savent exposer leurs pensées et les confronter à celles des autres sans animosité, m’a permis de revoir mon point de vue sur le collectif et de croire encore plus à la nécessité de faire ensemble.
Pour revenir au sujet, pyg a donc proposé à l’association une nouvelle forme pour le Framacamp prévu en juin prochain. Les raisons :
- cet événement réunit des personnes de toute la France et nous ne savons pas si nous pourrons nous déplacer aisément ;
- les membres représentent une mixité d’âge forte (vingtaine d’années à soixantaine d’années) et certains sont identifiés comme ayant des facteurs de risque ;
- les mesures de distanciation physique ne paraissent pas applicables dans un tel événement (dortoir, douches partagées, salon commun, besoin de proximité pour échanger, nourriture préparée en commun) ;
- il est probable qu’une partie des membres sera dans des situations difficilement prévisibles (ceux qui auront perdu des congés, celles qui n’auront pas d’autre choix que de bosser, celles qui veulent limiter leurs déplacements, ceux qui veulent rester auprès de leur famille, etc.).
Il est donc proposé que ce Framacamp prenne une nouvelle forme : 3 journées de temps cadrés et non-cadrés en ligne. L’événement serait évidemment sur la base du volontariat (participe qui veut et qui peut, quand iel peut). Pour cela, nous utiliserons le logiciel Big Blue Button, un outil de visioconférence adapté à la formation en ligne. Testé lors du Confin’atelier du 25 avril dernier (compte-rendu), Big Blue Button semble être l’outil le plus approprié pour ce temps de travail collectif puisqu’on pourra y créer plusieurs salons de discussion. Au sein de ces salons, il est possible de partager des présentations (avec ou sans tableau blanc), de discuter via un tchat, et même de créer des documents en mode collaboratif puisqu’y est disponible l’outil Etherpad.

Le détail des différentes sessions est encore en cours de préparation au sein de l’association, mais on sait déjà qu’une de ces sessions sera dédiée à la restitution des travaux menés par l’équipe du laboratoire CEPN UMR de l’Université Paris XIII dans le cadre du projet TAPAS (There Are Platforms as AlternativeS). Ce projet de recherche vise à approfondir et affiner la distinction entre « plateformes collaboratives » et « entreprises plateformes » et apprécier sa portée sur le plan des évolutions du travail, de l’emploi et in fine de la protection sociale dans le champ du numérique. Dans ce cadre, Framasoft a été sujet d’étude en 2019 et une partie des enseignants-chercheurs associés sont même venus assister au Framacamp de l’année dernière afin de comprendre nos modes de gouvernance en interne et en lien avec nos communautés. L’association est donc très enthousiaste à l’idée de découvrir ce qu’iels auront compris de nous !
Toujours dans l’idée de s’adapter, Pouhiou a passé une grande partie de la semaine à travailler à la rédaction d’un article dont l’objectif est de vous expliquer que nous revoyons notre feuille de route 2020. Car comme pyg vous l’a déjà expliqué dans Framaconfinement S6, il ne nous semble pas décent de nous lancer dans un crowdfunding selon les mêmes modalités que nos précédentes campagnes pour financer la V3 de PeerTube. Et nous allons avoir du retard pour la sortie de la V1 de Mobilizon. Mais je ne doute pas de ses capacités de nous expliquer tout cela de la manière la plus claire possible.
EDIT : l’article a été publié le 6 mai : https://framablog.org/2020/05/06/ce-que-framasoft-va-faire-en-2020-post-confinement/.
Nos membres bénévoles sont formidables
Une très bonne interview de Framatophe a été publiée dans Politis cette semaine. Il y revient sur le concept de capitalisme de surveillance qui prend encore plus de sens en cette période.
Enfin, Fred et Numahell ont passé une bonne partie de leur week-end à réaliser une vidéo de présentation de l’association pour la Fête des Possibles qui aura lieu du 12 au 27 septembre prochain. Portée par Le Collectif pour une Transition Citoyenne, la Fête des Possibles recense de nombreux évènements (plus de 1100 en 2019) qui souhaitent rendre visibles toutes les initiatives citoyennes qui construisent une société plus juste, plus écolo et plus humaine et qui permettent à chacun⋅e d’agir immédiatement. Toutes les formes sont plébiscitées : des ateliers d’expérimentation, des circuits de découverte, des portes ouvertes, des rassemblements publics, etc. au-delà de temps d’échanges ou de transmissions de savoirs. Cette Fête des Possibles sera celle des interdépendances, des interconnexions, des coopérations, des solidarités et bien plus encore !
Toutes les associations partenaires de cet évènement ont été sollicitées pour produire et partager une courte vidéo dans le cadre du lancement de la première campagne de communication et de mobilisation des réseaux des possibles sortie le 4 mai ! Cette vidéo d’environ 1min30 doit raconter comment elles agissent déjà pour le monde de demain, afin d’inciter leur public à témoigner ou s’engager lui aussi. Fred et Numahell se sont emparé⋅es de cette mission et se sont lancé⋅e⋅s dans le grand bain de la réalisation vidéo. Armé⋅e⋅s d’un pad, iels ont rédigé les éléments de langage nécessaire et une trame pour le contenu. Pas simple de résumer l’action de Framasoft en quelques minutes ! C’est Fred qui s’est essayé au jeu d’acteur seul face à sa caméra et là aussi chapeau car c’est un exercice pas du tout évident ! Numahell en a profité pour découvrir 2 logiciels libres de montage vidéo : Openshot et pitivi. Et selon Fred, c’était rigolo de faire une framaconférence en 4 minutes.
Et comme toujours la #TeamMèmes est au taquet : cet article ne serait rien sans leurs chouettes contributions ! Merci !