IA : les machines du doute
Il va nous falloir apprendre à travailler avec l’instabilité des machines.

... mais ce serait peut-être l'une des plus grandes opportunités manquées de notre époque si le logiciel libre ne libérait rien d'autre que du code

Il va nous falloir apprendre à travailler avec l’instabilité des machines.

Comment distinguer le bon grain de l’ivraie de l’Intelligence artificielle ? C’est la promesse que font les chercheurs Arvind Narayanan et Sayash Kapoor dans leur nouveau livre, AI Snake Oil. S’ils n’y arrivent pas toujours, les deux spécialistes nous aident à comprendre les défaillances de l’IA dans un livre qui mobilise la science pour qu’elle nous aide à éclairer le chemin critique qu’il reste à accomplir.

Chaque second mercredi du mois, découvrez l’actualité de l’IA mise en perspective par Framasoft !
Cette semaine, on vous invite à saisir les limites de l’IA dite « open source » en regardant comment ces jeux de données sont utilisés et comment ils agissent.
Le sujet de l’intelligence artificielle est omniprésent dans les discours médiatiques et politiques. Et il serait difficile de nier que ses impacts sur nos vies n’ont, eux, rien d’artificiels. Qu’il s’agisse d’écologie, de surveillance, d’économie, de santé, d’éducation, de médias, … Lire la suite

Qu’est-ce que le technocolonialisme et comment faire advenir les luttes pour l’indépendance dont nous avons besoin ?
Grazie alle vostre donazioni, Framasoft aiuta più di 2 milioni di persone a diventare digitalmente indipendenti. Dopo un ventesimo anno difficile, la nostra associazione vi chiede i mezzi per continuare il suo lavoro… e per affrontare le sfide del futuro.
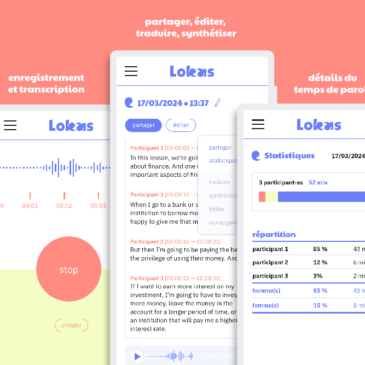
Framasoft vous propose d’essayer le prototype de Lokas, une nouvelle application de transcription « speech to text » qui respecte votre vie privée. Cette démo fonctionnelle est aussi une expérimentation de Framasoft dans le domaine de l’IA, accompagnée du site Framamia, que … Lire la suite