Working Class Heroic Fantasy, le roman-feuilleton qui vous fera l’année
Gee, notre Simon, l’auteur des bandes dessinées GKND et Grise Bouille, que sa plume démange depuis un bon moment comme en témoignent ses nouvelles, se lance dans le roman avec Working Class Heroic Fantasy (notez le jeu de mots, il en est super content, faudrait pas lui gâcher le plaisir).
Gee
Il va publier son ouvrage sous forme de feuilleton (on se demande qui lui a donné des idées pareilles). Pour vous faire découvrir cet univers, les trois premiers chapitres sont disponibles dès aujourd’hui sur son blog, et il devrait poursuive la publication avec un chapitre par semaine.
L’action se passe dans un monde un peu comme le nôtre, avec des open-space, des divorces et des syndicats… Mais aussi avec des elfes, mages, orques et gobelins. Imaginez que nos meilleurs romans de Fantasy soient en fait le chapitre Moyen-Âge de leurs livres d’histoire… Vous y êtes ?
Voilà : c’est la Terre de Grilecques, le monde où vit Barne Mustii, petit employé de bureau chez Boo’Teen Corp, une entreprise qui vend des bottes. Barne est un humain un peu résigné qui subit les brimades de son gobelin de patron, jusqu’au jour où c’est l’insulte de trop. Et si un simple tour à la permanence du syndicat l’entraînait dans une épique lutte des classe contre l’oligarchie orquogobelinesque…?
La couv qui a la classe, et si vous cliquez dessus elle vous mène au premier chapitre.
Ne ratez pas ça, c’est féroce et drôle, et ça rebondit comme une balle magique dans tous les sens : dystopie et gaudriole, anarchie et fantasy, non-binarité et lutte des classes. Ce roman, c’est peu comme si Marx et Tolkien avaient eu un enfant qui aimerait bien se poiler avec Pratchett.
Oui, c’est du copinage, ou alors de la publicité en avance, parce que forcément, il le publiera chez Framabook ensuite. Et tant mieux !
Lorsqu’il s’est penché sur l’actualité des GAFAM, comme il le fait souvent pour préparer ses BD, l’ami Gee n’a pas pu s’empêcher de trouver des similitudes entre certaines informations et une série d’anticipation fort populaire… Il vous livre le résumé d’une saison malheureusement bien réelle.
Quand l’actu singe Black Mirror
Inspiré par la célèbre série dystopique de Netflix, Le Monde Réel™ vous offre une nouvelle série d’épisodes pour la nouvelle année !
ÉPISODE 1 : Hikvision
La société chinoise Hikvision possède un cinquième du marché mondial des caméras de surveillance (avec reconnaissance de visages et de démarches). Elle est détenue à 40 % par l’État chinois qui assied ainsi la surveillance généralisée nécessaire au maintien de la dictature. Ses clients incluent l’armée étatsunienne.
ÉPISODE 2 : Life on Mars
Marseille, France. « L’Observatoire de la tranquillité publique » rassemble, entre autres, les images des caméras de surveillance, les mains courantes déposées à la police, la météo ou les grandes tendances des réseaux sociaux… tout cela pour anticiper les troubles à l’ordre public et optimiser leur gestion. Caroline Pozmentier, adjointe au maire, évoque un « big data de la tranquillité publique, premier pilier de la smart city marseillaise ».
ÉPISODE 3 : Tits or GTFO
Pour lutter contre le « revenge porn », qui consiste à publier des photos érotiques (supposées rester privées) pour humilier son ex-partenaire, Facebook propose à ses utilisateurs d’envoyer leurs photos intimes (susceptibles d’être utilisées) à titre de prévention : seul un « hash », un code permettant d’identifier la photo, sera conservé et permettra, par comparaison, d’empêcher l’ex méprisable de publier la photo en question.
ÉPISODE 4 : Are You Eighteen?
MindGeek, propriétaire d’une grande partie des sites de streaming porno, devient le plus gros fournisseur de solution de vérification d’âge (imposée par le gouvernement britannique pour lutter contre la fréquentation des sites pornos par les mineurs). Ces solutions impliquent de numériser son passeport, d’utiliser le numéro de téléphone ou la carte de crédit pour que le fournisseur certifie l’âge de son client, ou encore de laisser un algorithme d’apprentissage automatique analyser le contenu de ses réseaux sociaux…
ÉPISODE 5 : Six Lines
Le Département d’Immigration étatsunien met en place un algorithme pour détecter les éventuelles menaces posées par des détenteurs de visa aux États-Unis en analysant le contenu de leurs réseaux sociaux.
ÉPISODE 6 : Netflix and (nil)
Dernier épisode un peu plus léger mais bien plus ironique et « méta ». Le téléphone OnePlus 5T n’intègre pas un DRM qui permet de lire Netflix ou encore Google Play Movies en haute définition (le constructeur a annoncé qu’il serait intégré prochainement). Les clients sont donc réduits à visionner des films en basse définition sur un appareil à l’écran d’une définition immensément supérieure. Tout cela à cause d’une limitation purement artificielle provoquée par l’ineptie du système de protection de l’industrie audiovisuelle.
Voilà.
Ça vous plaît ?
De la bonne SF dystopique comme on les aime, pas vrai ?
Le seul problème avec ces épisodes, c’est que leurs synopsis sont tirés de véritables informations (et les dessins sont mes interprétations, bien sûr). La série ne s’arrête pas quand vous éteignez votre écran. Bonne journée.
Les nouveaux Léviathans IV. La surveillance qui vient
Dans ce quatrième numéro de la série Nouveaux Léviathans, nous allons voir dans quelle mesure le modèle économique a développé son besoin vital de la captation des données relatives à la vie privée. De fait, nous vivons dans le même scénario dystopique depuis une cinquantaine d’années. Nous verrons comment les critiques de l’économie de la surveillance sont redondantes depuis tout ce temps et que, au-delà des craintes, le temps est à l’action d’urgence.
Note : voici le quatrième volet de la série des Nouveaux (et anciens) Léviathans, initiée en 2016, par Christophe Masutti, alias Framatophe. Pour retrouver les articles précédents, une liste vous est présentée à la fin de celui-ci.
Aujourd’hui
Avons-nous vraiment besoin des utopies et des dystopies pour anticiper les rêves et les cauchemars des technologies appliquées aux comportements humains ? Sempiternellement rabâchés, le Meilleur de mondes et 1984 sont sans doute les romans les plus vendus parmi les best-sellers des dernières années. Il existe un effet pervers des utopies et des dystopies, lorsqu’on les emploie pour justifier des arguments sur ce que devrait être ou non la société : tout argument qui les emploie afin de prescrire ce qui devrait être se trouve à un moment ou à un autre face au mur du réel sans possibilité de justifier un mécanisme crédible qui causerait le basculement social vers la fiction libératrice ou la fiction contraignante. C’est la raison pour laquelle l’île de Thomas More se trouve partout et nulle part, elle est utopique, en aucun lieu. Utopie et dystopie sont des propositions d’expérience et n’ont en soi aucune vocation à prouver ou prédire quoi que ce soit bien qu’elles partent presque toujours de l’expérience commune et dont tout l’intérêt, en particulier en littérature, figure dans le troublant cheminement des faits, plus ou moins perceptible, du réel vers l’imaginaire.
Pourtant, lorsqu’on se penche sur le phénomène de l’exploitation des données personnelles à grande échelle par des firmes à la puissance financière inégalable, c’est la dystopie qui vient à l’esprit. Bien souvent, au gré des articles journalistiques pointant du doigt les dernières frasques des GAFAM dans le domaine de la protection des données personnelles, les discussions vont bon train : « ils savent tout de nous », « nous ne sommes plus libres », « c’est Georges Orwell », « on nous prépare le meilleur des mondes ». En somme, c’est l’angoisse pendant quelques minutes, juste le temps de vérifier une nouvelle fois si l’application Google de notre smartphone a bien enregistré l’adresse du rendez-vous noté la veille dans l’agenda.
Un petit coup d’angoisse ? allez… que diriez-vous si vos activités sur les réseaux sociaux, les sites d’information et les sites commerciaux étaient surveillées et quantifiées de telle manière qu’un système de notation et de récompense pouvait vous permettre d’accéder à certains droits, à des prêts bancaires, à des autorisations officielles, au logement, à des libertés de circulation, etc. Pas besoin de science-fiction. Ainsi que le rapportait Wired en octobre 20171, la Chine a déjà tout prévu d’ici 2020, c’est-à-dire demain. Il s’agit, dans le contexte d’un Internet déjà ultra-surveillé et non-neutre, d’établir un système de crédit social en utilisant les big data sur des millions de citoyens et effectuer un traitement qui permettra de catégoriser les individus, quels que soient les risques : risques d’erreurs, risques de piratage, crédibilité des indicateurs, atteinte à la liberté d’expression, etc.
Évidemment les géants chinois du numérique comme Alibaba et sa filiale de crédit sont déjà sur le coup. Mais il y a deux choses troublantes dans cette histoire. La première c’est que le crédit social existe déjà et partout : depuis des années on évalue en ligne les restaurants et les hôtels sans se priver de critiquer les tenanciers et il existe toute une économie de la notation dans l’hôtellerie et la restauration, des applications terrifiantes comme Peeple2 existent depuis 2015, les banques tiennent depuis longtemps des listes de créanciers, les fournisseurs d’énergie tiennent à jour les historiques des mauvais payeurs, etc. Ce que va faire la Chine, c’est le rêve des firmes, c’est la possibilité à une gigantesque échelle et dans un cadre maîtrisé (un Internet non-neutre) de centraliser des millions de gigabits de données personnelles et la possibilité de recouper ces informations auparavant éparses pour en tirer des profils sur lesquels baser des décisions.
Le second élément troublant, c’est que le gouvernement chinois n’aurait jamais eu cette idée si la technologie n’était pas déjà à l’œuvre et éprouvée par des grandes firmes. Le fait est que pour traiter autant d’informations par des algorithmes complexes, il faut : de grandes banques de données, beaucoup d’argent pour investir dans des serveurs et dans des compétences, et espérer un retour sur investissement de telle sorte que plus vos secteurs d’activités sont variés plus vous pouvez inférer des profils et plus votre marketing est efficace. Il est important aujourd’hui pour des monopoles mondialisés de savoir combien vous avez de chance d’acheter à trois jours d’intervalle une tondeuse à gazon et un canard en mousse. Le profilage de la clientèle (et des utilisateurs en général) est devenu l’élément central du marché à tel point que notre économie est devenue une économie de la surveillance, repoussant toujours plus loin les limites de l’analyse de nos vies privées.
La dystopie est en marche, et si nous pensons bien souvent au cauchemar orwellien lorsque nous apprenons l’existence de projets comme celui du gouvernement chinois, c’est parce que nous n’avons pas tous les éléments en main pour en comprendre le cheminement. Nous anticipons la dystopie mais trop souvent, nous n’avons pas les moyens de déconstruire ses mécanismes. Pourtant, il devient de plus en plus facile de montrer ces mécanismes sans faire appel à l’imaginaire : toutes les conditions sont remplies pour n’avoir besoin de tracer que quelques scénarios alternatifs et peu différents les uns des autres. Le traitement et l’analyse de nos vies privées provient d’un besoin, celui de maximiser les profits dans une économie qui favorise l’émergence des monopoles et la centralisation de l’information. Cela se retrouve à tous les niveaux de l’économie, à commencer par l’activité principale des géants du Net : le démarchage publicitaire. Comprendre ces modèles économiques revient aussi à comprendre les enjeux de l’économie de la surveillance.
Données personnelles : le commerce en a besoin
Dans le petit monde des études en commerce et marketing, Frederick Reichheld fait figure de référence. Son nom et ses publications dont au moins deux best sellers, ne sont pas vraiment connus du grand public, en revanche la plupart des stratégies marketing des vingt dernières années sont fondées, inspirées et même modélisées à partir de son approche théorique de la relation entre la firme et le client. Sa principale clé de lecture est une notion, celle de la fidélité du client. D’un point de vue opérationnel cette notion est déclinée en un concept, celui de la valeur vie client (customer lifetime value) qui se mesure à l’aune de profits réalisés durant le temps de cette relation entre le client et la firme. Pour Reichheld, la principale activité du marketing consiste à optimiser cette valeur vie client. Cette optimisation s’oppose à une conception rétrograde (et qui n’a jamais vraiment existé, en fait3) de la « simple » relation marchande.
En effet, pour bien mener les affaires, la relation avec le client ne doit pas seulement être une série de transactions marchandes, avec plus ou moins de satisfaction à la clé. Cette manière de concevoir les modèles économiques, qui repose uniquement sur l’idée qu’un client satisfait est un client fidèle, a son propre biais : on se contente de donner de la satisfaction. Dès lors, on se place d’un point de vue concurrentiel sur une conception du capitalisme marchand déjà ancienne. Le modèle de la concurrence « non faussée » est une conception nostalgique (fantasmée) d’une relation entre firme et client qui repose sur la rationalité de ce dernier et la capacité des firmes à produire des biens en réponse à des besoins plus ou moins satisfaits. Dès lors la décision du client, son libre arbitre, serait la variable juste d’une économie auto-régulée (la main invisible) et la croissance économique reposerait sur une dynamique de concurrence et d’innovation, en somme, la promesse du « progrès ».
Évidemment, cela ne fonctionne pas ainsi. Il est bien plus rentable pour une entreprise de fidéliser ses clients que d’en chercher de nouveaux. Prospecter coûte cher alors qu’il est possible de jouer sur des variables à partir de l’existant, tout particulièrement lorsqu’on exerce un monopole (et on comprend ainsi pourquoi les monopoles s’accommodent très bien entre eux en se partageant des secteurs) :
on peut résumer la conception de Reichheld à partir de son premier best seller, The Loyalty Effect (1996) : avoir des clients fidèles, des employés fidèles et des propriétaires loyaux. Il n’y a pas de main invisible : tout repose sur a) le rapport entre hausse de la rétention des clients / hausse des dépenses, b) l’insensibilité aux prix rendue possible par la fidélisation (un client fidèle, ayant dépassé le stade du risque de défection, est capable de dépenser davantage pour des raisons qui n’ont rien à voir avec la valeur marchande), c) la diminution des coûts de maintenance (fidélisation des employés et adhésion au story telling), d) la hausse des rendements et des bénéfices. En la matière la firme Apple rassemble tous ces éléments à la limite de la caricature.
Reichheld est aussi le créateur d’un instrument d’évaluation de la fidélisation : le NPS (Net Promoter Score). Il consiste essentiellement à catégoriser les clients, entre promoteurs, détracteurs ou passifs. Son autre best-seller The Ultimate Question 2.0: How Net Promoter Companies Thrive in a Customer-Driven World déploie les applications possibles du contrôle de la qualité des relations client qui devient dès lors la principale stratégie de la firme d’où découlent toutes les autres stratégies (en particulier les choix d’innovation). Ainsi il cite dans son ouvrage les plus gros scores NPS détenus par des firmes comme Apple, Amazon et Costco.
Il ne faut pas sous-estimer la valeur opérationnelle du NPS. Notamment parce qu’il permet de justifier les choix stratégiques. Dans The Ultimate Question 2.0 Reichheld fait référence à une étude de Bain & Co. qui montre que pour une banque, la valeur vie client d’un promoteur (au sens NPS) est estimée en moyenne à 9 500 dollars. Ce modèle aujourd’hui est une illustration de l’importance de la surveillance et du rôle prépondérant de l’analyse de données. En effet, plus la catégorisation des clients est fine, plus il est possible de déterminer les leviers de fidélisation. Cela passe évidemment par un système de surveillance à de multiples niveaux, à la fois internes et externes :
surveiller des opérations de l’organisation pour les rendre plus agiles et surveiller des employés pour augmenter la qualité des relations client,
rassembler le plus de données possibles sur les comportements des clients et les possibilités de déterminer leurs choix à l’avance.
Savoir si cette approche du marketing est née d’un nouveau contexte économique ou si au contraire ce sont les approches de la valeur vie client qui ont configuré l’économie d’aujourd’hui, c’est se heurter à l’éternel problème de l’œuf et de la poule. Toujours est-il que les stratégies de croissance et de rentabilité de l’économie reposent sur l’acquisition et l’exploitation des données personnelles de manière à manipuler les processus de décision des individus (ou plutôt des groupes d’individus) de manière à orienter les comportements et fixer des prix non en rapport avec la valeur des biens mais en rapport avec ce que les consommateurs (ou même les acheteurs en général car tout ne se réduit pas à la question des seuls biens de consommation et des services) sont à même de pouvoir supporter selon la catégorie à laquelle ils appartiennent.
Le fait de catégoriser ainsi les comportements et les influencer, comme nous l’avons vu dans les épisodes précédents de la série Léviathans, est une marque stratégique de ce que Shoshana Zuboff a appelé le capitalisme de surveillance4. Les entreprises ont aujourd’hui un besoin vital de rassembler les données personnelles dans des silos de données toujours plus immenses et d’exploiter ces big data de manière à optimiser leurs modèles économiques. Ainsi, du point de vue des individus, c’est le quotidien qui est scruté et analysé de telle manière que, il y a à peine une dizaine d’années, nous étions à mille lieues de penser l’extrême granularité des données qui cartographient et catégorisent nos comportements. Tel est l’objet du récent rapport publié par Cracked Lab Corporate surveillance in everyday life5 qui montre à quel point tous les aspect du quotidien font l’objet d’une surveillance à une échelle quasi-industrielle (on peut citer les activités de l’entreprise Acxiom), faisant des données personnelles un marché dont la matière première est traitée sans aucun consentement des individus. En effet, tout le savoir-faire repose essentiellement sur le recoupement statistique et la possibilité de catégoriser des milliards d’utilisateurs de manière à produire des représentations sociales dont les caractéristiques ne reflètent pas la réalité mais les comportements futurs. Ainsi par exemple les secteurs bancaires et des assurances sont particulièrement friands des possibilités offertes par le pistage numérique et l’analyse de solvabilité.
Cette surveillance a été caractérisée déjà en 1988 par le chercheur en systèmes d’information Roger Clarke6 :
dans la mesure où il s’agit d’automatiser, par des algorithmes, le traitement des informations personnelles dans un réseau regroupant plusieurs sources, et d’en inférer du sens, on peut la qualifier de « dataveillance », c’est à dire « l’utilisation systématique de systèmes de traitement de données à caractère personnel dans l’enquête ou le suivi des actions ou des communications d’une ou de plusieurs personnes » ;
l’un des attributs fondamentaux de cette dataveillance est que les intentions et les mécanismes sont cachés aux sujets qui font l’objet de la surveillance.
En effet, l’accès des sujets à leurs données personnelles et leurs traitements doit rester quasiment impossible car après un temps très court de captation et de rétention, l’effet de recoupement fait croître de manière exponentielle la somme d’information sur les sujets et les résultats, qu’ils soient erronés ou non, sont imbriqués dans le profilage et la catégorisation de groupes d’individus. Plus le monopole a des secteurs d’activité différents, plus les comportements des mêmes sujets vont pouvoir être quantifiés et analysés à des fins prédictives. C’est pourquoi la dépendance des firmes à ces informations est capitale ; pour citer Clarke en 20177 :
« L’économie de la surveillance numérique est cette combinaison d’institutions, de relations institutionnelles et de processus qui permet aux entreprises d’exploiter les données issues de la surveillance du comportement électronique des personnes et dont les sociétés de marketing deviennent rapidement dépendantes. »
Le principal biais que produit cette économie de la surveillance (pour S. Zuboff, c’est de capitalisme de surveillance qu’il s’agit puisqu’elle intègre une relation d’interdépendance entre centralisation des données et centralisation des capitaux) est qu’elle n’a plus rien d’une démarche descriptive mais devient prédictive par effet de prescription.
Elle n’est plus descriptive (mais l’a-t-elle jamais été ?) parce qu’elle ne cherche pas à comprendre les comportements économiques en fonction d’un contexte, mais elle cherche à anticiper les comportements en maximisant les indices comportementaux. On ne part plus d’un environnement économique pour comprendre comment le consommateur évolue dedans, on part de l’individu pour l’assigner à un environnement économique sur mesure dans l’intérêt de la firme. Ainsi, comme l’a montré une étude de Propublica en 20168, Facebook dispose d’un panel de pas moins de 52 000 indicateurs de profilage individuels pour en établir une classification générale. Cette quantification ne permet plus seulement, comme dans une approche statistique classique, de déterminer par exemple si telle catégorie d’individus est susceptible d’acheter une voiture. Elle permet de déterminer, de la manière la plus intime possible, quelle valeur économique une firme peut accorder à un panel d’individus au détriment des autres, leur valeur vie client.
Tout l’enjeu consiste à savoir comment influencer ces facteurs et c’est en cela que l’exploitation des données passe d’une dimension prédictive à une dimension prescriptive. Pour prendre encore l’exemple de Facebook, cette firme a breveté un système capable de déterminer la solvabilité bancaire des individus en fonction de la solvabilité moyenne de leur réseau de contacts9. L’important ici, n’est pas vraiment d’aider les banques à diminuer les risques d’insolvabilité de leurs clients, car elles savent très bien le faire toutes seules et avec les mêmes procédés d’analyse en big data. En fait, il s’agit d’influencer les stratégies personnelles des individus par le seul effet panoptique10 : si les individus savent qu’ils sont surveillés, toute la stratégie individuelle consistera à choisir ses amis Facebook en fonction de leur capacité à maximiser les chances d’accéder à un prêt bancaire (et cela peut fonctionner pour bien d’autres objectifs). L’intérêt de Facebook n’est pas d’aider les banques, ni de vendre une expertise en statistique (ce n’est pas le métier de Facebook) mais de normaliser les comportements dans l’intérêt économique et augmenter la valeur vie client potentielle de ses utilisateurs : si vous avez des problèmes d’argent, Facebook n’est pas fait pour vous. Dès lors il suffit ensuite de revendre des profils sur-mesure à des banques. On se retrouve typiquement dans un épisode d’anticipation de la série Black Mirror (Chute libre)11.
La fiction, l’anticipation, la dystopie… finalement, c’est-ce pas un biais que de toujours analyser sous cet angle l’économie de la surveillance et le rôle des algorithmes dans notre quotidien ? Tout se passe en quelque sorte comme si nous découvrions un nouveau modèle économique, celui dont nous venons de montrer que les préceptes sont déjà anciens, et comme si nous appréhendions seulement aujourd’hui les enjeux de la captation et l’exploitation des données personnelles. Au risque de décevoir tous ceux qui pensent que questionner la confiance envers les GAFAM est une activité d’avant-garde, la démarche a été initiée dès les prémices de la révolution informatique.
La vie privée à l’époque des pattes d’eph.
Face au constat selon lequel nous vivons dans un environnement où la surveillance fait loi, de nombreux ouvrages, articles de presse et autres témoignages ont sonné l’alarme. En décembre 2017, ce fut le soi-disant repentir de Chamath Palihapitya, ancien vice-président de Facebook, qui affirmait avoir contribué à créer « des outils qui déchirent le tissu social »12. Il ressort de cette lecture qu’après plusieurs décennies de centralisation et d’exploitation des données personnelles par des acteurs économiques ou institutionnels, nous n’avons pas fini d’être surpris par les transformations sociales qu’impliquent les big data. Là où, effectivement, nous pouvons accorder un tant soit peu de de crédit à C. Palihapitya, c’est dans le fait que l’extraction et l’exploitation des données personnelles implique une économie de la surveillance qui modèle la société sur son modèle économique. Et dans ce modèle, l’exercice de certains droits (comme le droit à la vie privée) passe d’un état absolu (un droit de l’homme) à un état relatif (au contexte économique).
Comme cela devient une habitude dans cette série des Léviathans, nous pouvons effectuer un rapide retour dans le temps et dans l’espace. Situons-nous à la veille des années 1970, aux États-Unis, plus exactement dans la période charnière qui vit la production en masse des ordinateurs mainframe (du type IBM 360), à destination non plus des grands laboratoires de recherche et de l’aéronautique, mais vers les entreprises des secteurs de la banque, des assurances et aussi vers les institutions gouvernementales. L’objectif premier de tels investissements (encore bien coûteux à cette époque) était le traitement des données personnelles des citoyens ou des clients.
Comme bien des fois en histoire, il existe des périodes assez courtes où l’on peut comprendre les événements non pas parce qu’ils se produisent suivant un enchaînement logique et linéaire, mais parce qu’ils surviennent de manière quasi-simultanée comme des fruits de l’esprit du temps. Ainsi nous avons d’un côté l’émergence d’une industrie de la donnée personnelle, et, de l’autre l’apparition de nombreuses publications portant sur les enjeux de la vie privée. D’aucuns pourraient penser que, après la publication en 1949 du grand roman de G. Orwell, 1984, la dystopie orwellienne pouvait devenir la clé de lecture privilégiée de l’informationnalisation (pour reprendre le terme de S. Zuboff) de la société américaine dans les années 1960-1970. Ce fut effectivement le cas… plus exactement, si les références à Orwell sont assez courantes dans la littérature de l’époque13, il y avait deux lectures possibles de la vie privée dans une société aussi bouleversée que celle de l’Amérique des années 1960. La première questionnait la hiérarchie entre vie privée et vie publique. La seconde focalisait sur le traitement des données informatiques. Pour mieux comprendre l’état d’esprit de cette période, il faut parcourir quelques références.
Vie privée vs vie publique
Deux best-sellers parus en été 1964 effectuent un travail introspectif sur la société américaine et son rapport à la vie privée. Le premier, écrit par Myron Brenton, s’intitule The privacy invaders14. Brenton est un ancien détective privé qui dresse un inventaire des techniques de surveillance à l’encontre des citoyens et du droit. Le second livre, écrit par Vance Packard, connut un succès international. Il s’intitule The naked Society15, traduit en français un an plus tard sous le titre Une société sans défense. V. Packard est alors universitaire, chercheur en sociologie et économie. Il est connu pour avoir surtout travaillé sur la société de consommation et le marketing et dénoncé, dans un autre ouvrage (La persuasion clandestine16), les abus des publicitaires en matière de manipulation mentale. Dans The naked Society comme dans The privacy invaders les mêmes thèmes sont déployés à propos des dispositifs de surveillance, entre les techniques d’enquêtes des banques sur leurs clients débiteurs, les écoutes téléphoniques, la surveillance audio et vidéo des employés sur les chaînes de montage, en somme toutes les stratégies privées ou publiques d’espionnage des individus et d’abus en tout genre qui sont autant d’atteintes à la vie privée. Il faut dire que la société américaine des années 1960 a vu aussi bien arriver sur le marché des biens de consommation le téléphone et la voiture à crédit mais aussi l’électronique et la miniaturisation croissante des dispositifs utiles dans ce genre d’activité. Or, les questions que soulignent Brenton et Packard, à travers de nombreux exemples, ne sont pas tant celles, plus ou moins spectaculaires, de la mise en œuvre, mais celles liées au droit des individus face à des puissances en recherche de données sur la vie privée extorquées aux sujets mêmes. En somme, ce que découvrent les lecteurs de ces ouvrages, c’est que la vie privée est une notion malléable, dans la réalité comme en droit, et qu’une bonne part de cette malléabilité est relative aux technologies et au médias. Packard ira légèrement plus loin sur l’aspect tragique de la société américaine en focalisant plus explicitement sur le respect de la vie privée dans le contexte des médias et de la presse à sensation et dans les contradictions apparente entre le droit à l’information, le droit à la vie privée et le Sixième Amendement. De là, il tire une sonnette d’alarme en se référant à Georges Orwell, et dénonçant l’effet panoptique obtenu par l’accessibilité des instruments de surveillance, la généralisation de leur emploi dans le quotidien, y compris pour les besoins du marketing, et leur impact culturel.
En réalité, si ces ouvrages connurent un grand succès, c’est parce que leur approche de la vie privée reposait sur un questionnement des pratiques à partir de la morale et du droit, c’est-à-dire sur ce que, dans une société, on est prêt à admettre ou non au sujet de l’intimité vue comme une part structurelle des relations sociales. Qu’est-ce qui relève de ma vie privée et qu’est-ce qui relève de la vie publique ? Que puis-je exposer sans crainte selon mes convictions, ma position sociale, la classe à laquelle j’appartiens, etc. Quelle est la légitimité de la surveillance des employés dans une usine, d’un couple dans une chambre d’hôtel, d’une star du show-biz dans sa villa ?
Il reste que cette approche manqua la grande révolution informatique naissante et son rapport à la vie privée non plus conçue comme l’image et l’estime de soi, mais comme un ensemble d’informations quantifiables à grande échelle et dont l’analyse peut devenir le mobile de décisions qui impactent la société en entier17. La révolution informatique relègue finalement la légitimité de la surveillance au second plan car la surveillance est alors conçue de manière non plus intentionnelle mais comme une série de faits : les données fournies par les sujets, auparavant dans un contexte fermé comme celui de la banque locale, finirent par se retrouver centralisées et croisées au gré des consortiums utilisant l’informatique pour traiter les données des clients. Le même schéma se retrouva pour ce qui concerne les institutions publiques dans le contexte fédéral américain.
Vie privée vs ordinateurs
Une autre approche commença alors à faire son apparition dans la sphère universitaire. Elle intervient dans la seconde moitié des années 1960. Il s’agissait de se pencher sur la gouvernance des rapports entre la vie privée et l’administration des données personnelles. Suivant au plus près les nouvelles pratiques des grands acteurs économiques et gouvernementaux, les universitaires étudièrent les enjeux de la numérisation des données personnelles avec en arrière-plan les préoccupations juridiques, comme celle de V. Packard, qui faisaient l’objet des réflexions de la décennie qui se terminait. Si, avec la société de consommation venait tout un lot de dangers sur la vie privée, cette dernière devrait être protégée, mais il fallait encore savoir sur quels plans agir. Le début des années 1970, en guise de résultat de ce brainstorming général, marquèrent alors une nouvelle ère de la privacy à l’Américaine à l’âge de l’informatisation et du réseautage des données personnelles. Il s’agissait de comprendre qu’un changement majeur était en train de s’effectuer avec les grands ordinateurs en réseau et qu’il fallait formaliser dans le droit les garde-fou les plus pertinents : on passait d’un monde où la vie privée pouvait faire l’objet d’une intrusion par des acteurs séparés, recueillant des informations pour leur propre compte en fonction d’objectifs différents, à un monde où les données éparses étaient désormais centralisées, avec des machines capables de traiter les informations de manière rapide et automatisée, capables d’inférer des informations sans le consentement des sujets à partir d’informations que ces derniers avaient données volontairement dans des contextes très différents.
La liste des publications de ce domaine serait bien longue. Par exemple, la Rand Corporation publia une longue liste bibliographique annotée au sujet des données personnelles informatisées. Cette liste regroupe près de 300 publications entre 1965 et 1967 sur le sujet18.
Des auteurs universitaires firent école. On peut citer :
Alan F. Westin : Privacy and freedom (1967), Civil Liberties and Computerized Data Systems (1971), Databanks in a Free Society: Computers, Record Keeping and Privacy (1972)19 ;
James B. Rule : Private lives and public surveillance: social control in the computer age (1974)20 ;
Arthur R. Miller : The assault on privacy. Computers, Data Banks and Dossier (1971)21 ;
Malcolm Warner et Mike Stone, The Data Bank Society : Organizations, Computers and Social Freedom (1970)22.
Toutes ces publications ont ceci en commun qu’elles procédèrent en deux étapes. La première consistait à dresser un tableau synthétique de la société américaine face à la captation des informations personnelles. Quatre termes peuvent résumer les enjeux du traitement des informations : 1) la légitimité de la captation des informations, 2) la permanence des données et leurs modes de rétention, 3) la transférabilité (entre différentes organisations), 4) la combinaison ou le recoupement de ces données et les informations ainsi inférées23.
La seconde étape consistait à choisir ce qui, dans cette « société du dossier (dossier society) » comme l’appelait Arthur R. Miller, devait faire l’objet de réformes. Deux fronts venaient en effet de s’ouvrir : l’État et les firmes.
Le premier, évident, était celui que la dystopie orwellienne pointait avec empressement : l’État de surveillance. Pour beaucoup de ces analystes, en effet, le fédéralisme américain et la multiplicité des agences gouvernementales pompaient allègrement la privacy des honnêtes citoyens et s’équipaient d’ordinateurs à temps partagé justement pour rendre interopérables les systèmes de traitement d’information à (trop) grande échelle. Un rapide coup d’œil sur les références citées, montre que, effectivement, la plupart des conclusions focalisaient sur le besoin d’adapter le droit aux impératifs constitutionnels américains. Tels sont par exemple les arguments de A. F. Westin pour lequel l’informatisation des données privées dans les différentes autorités administratives devait faire l’objet non d’un recul, mais de nouvelles règles portant sur la sécurité, l’accès des citoyens à leurs propres données et la pertinence des recoupements (comme par exemple l’utilisation restreinte du numéro de sécurité sociale). En guise de synthèse, le rapport de l’U.S. Department of health, Education and Welfare livré en 197324 (et où l’on retrouve Arthur R. Miller parmi les auteurs) repris ces éléments au titre de ses recommandations. Il prépara ainsi le Privacy Act de 1974, qui vise notamment à prévenir l’utilisation abusive de documents fédéraux et garantir l’accès des individus aux données enregistrées les concernant.
Le second front, tout aussi évident mais moins accessible car protégé par le droit de propriété, était celui de la récolte de données par les firmes, et en particulier les banques. L’un des auteurs les plus connus, Arthur R. Miller dans The assault on privacy, fit la synthèse des deux fronts en focalisant sur le fait que l’informatisation des données personnelles, par les agences gouvernementales comme par les firmes, est une forme de surveillance et donc un exercice du pouvoir. Se poser la question de leur légitimité renvoie effectivement à des secteurs différents du droit, mais c’est pour lui le traitement informatique (il utilise le terme « cybernétique ») qui est un instrument de surveillance par essence. Et cet instrument est orwellien :
« Il y a à peine dix ans, on aurait pu considérer avec suffisance Le meilleur des mondes de Huxley ou 1984 de Orwell comme des ouvrages de science-fiction excessifs qui ne nous concerneraient pas et encore moins ce pays. Mais les révélations publiques répandues au cours des dernières années au sujet des nouvelles formes de pratiques d’information ont fait s’envoler ce manteau réconfortant mais illusoire. »
Pourtant, un an avant la publication de Miller fut voté le Fair Credit Reporting Act, portant sur les obligations déclaratives des banques. Elle fut aussi l’une des premières lois sur la protection des données personnelles, permettant de protéger les individus, en particulier dans le secteur bancaire, contre la tenue de bases de données secrètes, la possibilité pour les individus d’accéder aux données et de les contester, et la limitation dans le temps de la rétention des informations.
Cependant, pour Miller, le Fair Credit Reporting Act est bien la preuve que la bureaucratie informatisée et le réseautage des données personnelles impliquent deux pertes de contrôle de la part de l’individu et pour lesquelles la régulation par le droit n’est qu’un pis-aller (pp. 25-38). On peut de même, en s’autorisant quelque anachronisme, s’apercevoir à quel point les deux types de perte de contrôles qu’il pointe nous sont éminemment contemporains.
The individual loss of control over personal information : dans un contexte où les données sont mises en réseau et recoupées, dès lors qu’une information est traitée par informatique, le sujet et l’opérateur n’ont plus le contrôle sur les usages qui pourront en être faits. Sont en jeu la sécurité et l’intégrité des données (que faire en cas d’espionnage ? que faire en cas de fuite non maîtrisée des données vers d’autres opérateurs : doit-on exiger que les opérateurs en informent les individus ?).
The individual loss of control over the accuracy of his informational profil : la centralisation des données permet de regrouper de multiples aspects de la vie administrative et sociale de la personne, et de recouper toutes ces données pour en inférer des profils. Dans la mesure où nous assistons à une concentration des firmes par rachats successifs et l’émergence de monopoles (Miller prend toujours l’exemple des banques), qu’arrive-t-il si certaines données sont erronées ou si certains recoupements mettent en danger le droit à la vie privée : par exemple le rapport entre les données de santé, l’identité des individus et les crédits bancaires.
Et Miller de conclure (p. 79) :
« Ainsi, l’informatisation, le réseautage et la réduction de la concurrence ne manqueront pas de pousser l’industrie de l’information sur le crédit encore plus profondément dans le marasme du problème de la protection de la vie privée. »
Les échos du passé
La lutte pour la préservation de la vie privée dans une société numérisée passe par une identification des stratégies intentionnelles de la surveillance et par l’analyse des procédés d’extraction, rétention et traitement des données. La loi est-elle une réponse ? Oui, mais elle est loin de suffire. La littérature nord-américaine dont nous venons de discuter montre que l’économie de la surveillance dans le contexte du traitement informatisé des données personnelles est née il y a plus de 50 ans. Et dès le début il fut démontré, dans un pays où les droits individuels sont culturellement associés à l’organisation de l’État fédéral (la Déclaration des Droits), non seulement que la privacy changeait de nature (elle s’étend au traitement informatique des informations fournies et aux données inférées) mais aussi qu’un équilibre s’établissait entre le degré de sanctuarisation de la vie privée et les impératifs régaliens et économiques qui réclament une industrialisation de la surveillance.
Puisque l’intimité numérique n’est pas absolue mais le résultat d’un juste équilibre entre le droit et les pratiques, tout les jeux post-révolution informatique après les années 1960 consistèrent en une lutte perpétuelle entre défense et atteinte à la vie privée. C’est ce que montre Daniel J. Solove dans « A Brief History of Information Privacy Law »25 en dressant un inventaire chronologique des différentes réponses de la loi américaine face aux changements technologiques et leurs répercussions sur la vie privée.
Il reste néanmoins que la dimension industrielle de l’économie de la surveillance a atteint en 2001 un point de basculement à l’échelle mondiale avec le Patriot Act26 dans le contexte de la lutte contre le terrorisme. À partir de là, les principaux acteurs de cette économie ont vu une demande croissante de la part des États pour récolter des données au-delà des limites strictes de la loi sous couvert des dispositions propres à la sûreté nationale et au secret défense. Pour rester sur l’exemple américain, Thomas Rabino écrit à ce sujet27 :
« Alors que le Privacy Act de 1974 interdit aux agences fédérales de constituer des banques de données sur les citoyens américains, ces mêmes agences fédérales en font désormais l’acquisition auprès de sociétés qui, à l’instar de ChoicePoint, se sont spécialisées dans le stockage d’informations diverses. Depuis 2001, le FBI et d’autres agences fédérales ont conclu, dans la plus totale discrétion, de fructueux contrats avec ChoicePoint pour l’achat des renseignements amassés par cette entreprise d’un nouveau genre. En 2005, le budget des États-Unis consacrait plus de 30 millions de dollars à ce type d’activité. »
Dans un contexte plus récent, on peut affirmer que même si le risque terroriste est toujours agité comme un épouvantail pour justifier des atteintes toujours plus fortes à l’encontre de la vie privée, les intérêts économiques et la pression des lobbies ne peuvent plus se cacher derrière la Raison d’État. Si bien que plusieurs pays se mettent maintenant au diapason de l’avancement technologique et des impératifs de croissance économique justifiant par eux-mêmes des pratiques iniques. Ce fut le cas par exemple du gouvernement de Donald Trump qui, en mars 2017 et à la plus grande joie du lobby des fournisseurs d’accès, abroge une loi héritée du gouvernement précédent et qui exigeait que les FAI obtiennent sous conditions la permission de partager des renseignements personnels – y compris les données de localisation28.
Encore en mars 2017, c’est la secrétaire d’État à l’Intérieur Britannique Amber Rudd qui juge publiquement « inacceptable » le chiffrement des communications de bout en bout et demande aux fournisseurs de messagerie de créer discrètement des backdoors, c’est à dire renoncer au chiffrement de bout en bout sans le dire aux utilisateurs29. Indépendamment du caractère moralement discutable de cette injonction, on peut mesurer l’impact du message sur les entreprises comme Google, Facebook et consors : il existe des décideurs politiques capables de demander à ce qu’un fournisseur de services propose à ses utilisateurs un faux chiffrement, c’est-à-dire que le droit à la vie privée soit non seulement bafoué mais, de surcroît, que le mensonge exercé par les acteurs privés soit couvert par les acteurs publics, et donc par la loi.
Comme le montre Shoshana Zuboff, le capitalisme de surveillance est aussi une idéologie, celle qui instaure une hiérarchie entre les intérêts économiques et le droit. Le droit peut donc être une arme de lutte pour la sauvegarde de la vie privée dans l’économie de la surveillance, mais il ne saurait suffire dans la mesure où il n’y pas de loyauté entre les acteurs économiques et les sujets et parfois même encore moins entre les décideurs publics et les citoyens.
Dans ce contexte où la confiance n’est pas de mise, les portes sont restées ouvertes depuis les années 1970 pour créer l’industrie des big data dont le carburant principal est notre intimité, notre quotidienneté. C’est parce qu’il est désormais possible de repousser toujours un peu plus loin les limites de la captation des données personnelles que des théories économique prônent la fidélisation des clients et la prédiction de leurs comportements comme seuls points d’appui des investissements et de l’innovation. C’est vrai dans le marketing, c’est vrai dans les services et l’innovation numériques. Et tout naturellement c’est vrai dans la vie politique, comme le montre par exemple l’affaire des dark posts durant la campagne présidentielle de D. Trump : la possibilité de contrôler l’audience et d’influencer une campagne présidentielle via les réseaux sociaux comme Facebook est désormais démontrée.
Tant que ce modèle économique existera, aucune confiance ne sera possible. La confiance est même absente des pratiques elles-mêmes, en particulier dans le domaine du traitement algorithmique des informations. En septembre 2017, la chercheuse Zeynep Tufekci, lors d’une conférence TED30, reprenait exactement les questions d’Arthur R. Miller dans The assault on privacy, soit 46 ans après. Miller prenait comme étude de cas le stockage d’information bancaire sur les clients débiteurs, et Tufekci prend les cas des réservation de vols aériens en ligne et du streaming vidéo. Dans les deux réflexions, le constat est le même : le traitement informatique de nos données personnelles implique que nous (les sujets et les opérateurs eux-mêmes) perdions le contrôle sur ces données :
« Le problème, c’est que nous ne comprenons plus vraiment comment fonctionnent ces algorithmes complexes. Nous ne comprenons pas comment ils font cette catégorisation. Ce sont d’énormes matrices, des milliers de lignes et colonnes, peut-être même des millions, et ni les programmeurs, ni quiconque les regardant, même avec toutes les données, ne comprend plus comment ça opère exactement, pas plus que vous ne sauriez ce que je pense en ce moment si l’on vous montrait une coupe transversale de mon cerveau. C’est comme si nous ne programmions plus, nous élevons une intelligence que nous ne comprenons pas vraiment. »
Z. Tufekci montre même que les algorithmes de traitement sont en mesure de fournir des conclusions (qui permettent par exemple d’inciter les utilisateurs à visualiser des vidéos sélectionnées d’après leur profil et leur historique) mais que ces conclusions ont ceci de particulier qu’elle modélisent le comportement humain de manière à l’influencer dans l’intérêt du fournisseur. D’après Z. Tufekci : « L’algorithme a déterminé que si vous pouvez pousser les gens à penser que vous pouvez leur montrer quelque chose de plus extrême (nda : des vidéos racistes dans l’exemple cité), ils ont plus de chances de rester sur le site à regarder vidéo sur vidéo, descendant dans le terrier du lapin pendant que Google leur sert des pubs. »
Ajoutons de même que les technologies de deep learning, financées par millions par les GAFAM, se prêtent particulièrement bien au jeu du traitement automatisé en cela qu’elle permettent, grâce à l’extrême croissance du nombre de données, de procéder par apprentissage. Cela permet à Facebook de structurer la grande majorité des données des utilisateurs qui, auparavant, n’était pas complètement exploitable31. Par exemple, sur les milliers de photos de chatons partagées par les utilisateurs, on peut soit se contenter de constater une redondance et ne pas les analyser davantage, soit apprendre à y reconnaître d’autres informations, comme par exemple l’apparition, en arrière-plan, d’un texte, d’une marque de produit, etc. Il en est de même pour la reconnaissance faciale, qui a surtout pour objectif de faire concorder les identités des personnes avec toutes les informations que l’on peut inférer à partir de l’image et du texte.
Si les techniques statistiques ont le plus souvent comme objectif de contrôler les comportements à l’échelle du groupe, c’est parce que le seul fait de catégoriser automatiquement les individus consiste à considérer que leurs données personnelles en constituent l’essence. L’économie de la surveillance démontre ainsi qu’il n’y a nul besoin de connaître une personne pour en prédire le comportement, et qu’il n’y a pas besoin de connaître chaque individu d’un groupe en particulier pour le catégoriser et prédire le comportement du groupe, il suffit de laisser faire les algorithmes : le tout est d’être en mesure de classer les sujets dans les bonnes catégories et même faire en sorte qu’ils y entrent tout à fait. Cela a pour effet de coincer littéralement les utilisateurs des services « capteurs de données » dans des bulles de filtres où les informations auxquelles ils ont accès leur sont personnalisées selon des profils calculés32. Si vous partagez une photo de votre chat devant votre cafetière, et que dernièrement vous avez visité des sites marchands, vous aurez de grandes chance pour vos futures annonces vous proposent la marque que vous possédez déjà et exercent, par effet de répétition, une pression si forte que c’est cette marque que vous finirez par acheter. Ce qui fonctionne pour le marketing peut très bien fonctionner pour d’autres objectifs, même politiques.
En somme tous les déterminants d’une société soumise au capitalisme de surveillance, apparus dès les années 1970, structurent le monde numérique d’aujourd’hui sans que les lois ne puissent jouer de rôle pleinement régulateur. L’usage caché et déloyal des big data, le trafic de données entre organisations, la dégradation des droits individuels (à commencer par la liberté d’expression et le droit à la vie privée), tous ces éléments ont permis à des monopoles d’imposer un modèle d’affaire et affaiblir l’État-nation. Combien de temps continuerons-nous à l’accepter ?
Sortir du marasme
En 2016, à la fin de son article synthétique sur le capitalisme de surveillance33, Shoshana Zuboff exprime personnellement un point de vue selon lequel la réponse ne peut pas être uniquement technologique :
« (…) les faits bruts du capitalisme de surveillance suscitent nécessairement mon indignation parce qu’ils rabaissent la dignité humaine. L’avenir de cette question dépendra des savants et journalistes indignés attirés par ce projet de frontière, des élus et des décideurs indignés qui comprennent que leur autorité provient des valeurs fondamentales des communautés démocratiques, et des citoyens indignés qui agissent en sachant que l’efficacité sans l’autonomie n’est pas efficace, la conformité induite par la dépendance n’est pas un contrat social et être libéré de l’incertitude n’est pas la liberté. »
L’incertitude au sujet des dérives du capitalisme de surveillance n’existe pas. Personne ne peut affirmer aujourd’hui qu’avec l’avènement des big data dans les stratégies économiques, on pouvait ignorer que leur usage déloyal était non seulement possible mais aussi que c’est bien cette direction qui fut choisie d’emblée dans l’intérêt des monopoles et en vertu de la centralisation des informations et des capitaux. Depuis les années 1970, plusieurs concepts ont cherché à exprimer la même chose. Pour n’en citer que quelques-uns : computocracie (M. Warner et M. Stone, 1970), société du dossier (Arthur R. Miller, 1971), surveillance de masse (J. Rule, 1973), dataveillance (R. Clarke, 1988), capitalisme de surveillance (Zuboff, 2015)… tous cherchent à démontrer que la surveillance des comportements par l’usage des données personnelles implique en retour la recherche collective de points de rupture avec le modèle économique et de gouvernance qui s’impose de manière déloyale. Cette recherche peut s’exprimer par le besoin d’une régulation démocratiquement décidée et avec des outils juridiques. Elle peut s’exprimer aussi autrement, de manière violente ou pacifiste, militante et/ou contre-culturelle.
Plusieurs individus, groupes et organisation se sont déjà manifestés dans l’histoire à ce propos. Les formes d’expression et d’action ont été diverses :
institutionnelles : les premières formes d’action pour garantir le droit à la vie privée ont consisté à établir des rapports collectifs préparatoires à des grandes lois, comme le rapport Records, computers and the rights of citizens, de 1973, cité plus haut ;
individualistes, antisociales et violentes : bien que s’inscrivant dans un contexte plus large de refus technologique, l’affaire Theodore Kaczynski (alias Unabomber) de 1978 à 1995 est un bon exemple d’orientation malheureuse que pourraient prendre quelques individus isolés trouvant des justifications dans un contexte paranoïaque ;
collectives – activistes – légitimistes : c’est le temps des manifestes cypherpunk des années 199034, ou plus récemment le mouvement Anonymous, auxquels on peut ajouter des collectifs « événementiels », comme le Jam Echelon Day ;
Les limites de l’attente démocratique sont néanmoins déjà connues. La société ne peut réagir de manière légale, par revendication interposée, qu’à partir du moment où l’exigence de transparence est remplie. Lorsqu’elle ne l’est pas, au pire les citoyens les plus actifs sont taxés de complotistes, au mieux apparaissent de manière épisodique des alertes, à l’image des révélations d’Edward Snowden, mais dont la fréquence est si rare malgré un impact psychologique certain, que la situation a tendance à s’enraciner dans un statu quo d’où sortent généralement vainqueurs ceux dont la capacité de lobbying est la plus forte.
À cela s’ajoute une difficulté technique due à l’extrême complexité des systèmes de surveillance à l’œuvre aujourd’hui, avec des algorithmes dont nous maîtrisons de moins en moins les processus de calcul (cf. Z. Tufekci). À ce propos on peut citer Roger Clarke35 :
« Dans une large mesure, la transparence a déjà été perdue, en partie du fait de la numérisation, et en partie à cause de l’application non pas des approches procédurales et d’outils de développement des logiciels algorithmiques du XXe siècle, mais à cause de logiciels de dernière génération dont la raison d’être est obscure ou à laquelle la notion de raison d’être n’est même pas applicable. »
Une autre option pourrait consister à mettre en œuvre un modèle alternatif qui permette de sortir du marasme économique dans lequel nous sommes visiblement coincés. Sans en faire l’article, le projet Contributopia de Framasoft cherche à participer, à sa mesure, à un processus collectif de réappropriation d’Internet et, partant:
montrer que le code est un bien public et que la transparence, grâce aux principes du logiciel libre (l’ouverture du code), permet de proposer aux individus un choix éclairé, à l’encontre de l’obscurantisme de la dataveillance ;
promouvoir des apprentissages à contre-courant des pratiques de captation des vies privées et vers des usages basés sur le partage (du code, de la connaissance) entre les utilisateurs ;
rendre les utilisateurs autonomes et en même temps contributeurs à un réseau collectif qui les amènera naturellement, par l’attention croissante portée aux pratiques des monopoles, à refuser ces pratiques, y compris de manière active en utilisant des solutions de chiffrement, par exemple.
Mais Contributopia de Framasoft ne concerne que quelques aspects des stratégies de sortie du capitalisme de surveillance. Par exemple, pour pouvoir œuvrer dans cet esprit, une politique rigide en faveur de la neutralité du réseau Internet doit être menée. Les entreprises et les institutions publiques doivent être aussi parmi les premières concernées, car il en va de leur autonomie numérique, que cela soit pour de simples questions économiques (ne pas dépendre de la bonne volonté d’un monopole et de la logique des brevets) mais aussi pour des questions de sécurité. Enfin, le passage du risque pour la vie privée au risque de manipulation sociale étant avéré, toutes les structures militantes en faveur de la démocratie et les droits de l’homme doivent urgemment porter leur attention sur le traitement des données personnelles. Le cas de la britannique Amber Rudd est loin d’être isolé : la plupart des gouvernements collaborent aujourd’hui avec les principaux monopoles de l’économie numérique et, donc, contribuent activement à l’émergence d’une société de la surveillance. Aujourd’hui, le droit à la vie privée, au chiffrement des communications, au secret des correspondances sont des droits à protéger coûte que coûte sans avoir à choisir entre la liberté et les épouvantails (ou les sirènes) agités par les communicants.
Comme beaucoup d’associations, Graines de troc est née un peu par hasard, de rencontres et d’envies. Cinq ans après, Sébastien Wittevert a toujours les mains dans la terre quand elles ne sont pas sur un clavier.
Tripou l’a interviewé pour nous en vue de savoir ce qu’il devenait depuis l’article que l’ami Calimaq lui a consacré. Tiens, tiens, mais alors ce serait encore une histoire de biens communs ?
Comment s’est faite ta transition entre informatique et maraîchage, pour transformer les lignes de code en lignes de carottes ?
J’ai mis le pied par gourmandise dans une AMAP (association pour le maintien d’une agriculture paysanne / de proximité), et j’ai pris l’habitude de venir y chercher mes légumes facilement. A l’heure ou je sortais du boulot, il n’y avait plus grand-chose d’ouvert, et difficile pour moi de me lever pour aller au marché le dimanche. Du coup, j’ai pu avoir accès à un autre monde alternatif, convivial, militant, engagé qui m’a ouvert les yeux, et y rencontrer ma compagne. Après avoir rendu plusieurs fois service aux maraîchers, nous avons voulu voir d’autres formes de maraîchage, et nous avons atterri à la ferme du Bec-Hellouin pour un stage découverte de la traction animale. Séduit par la ferme et les techniques de permaculture, nous avons décidé de nous y former.
En novembre 2011, alors que je remplissais déjà mes poches de graines, suite à de nouvelles lois liberticides sur les échanges de semences, nouvelle atteinte au bien commun des semences. Je me demandais, jeune colibri, que pouvais-je donc faire ?
En alliant mes compétences informatiques, ma passion des graines, et une dose de monnaie complémentaire, j’ai imaginé et codé la plateforme qui a vu le jour en mai 2012.
Après avoir réfléchi le projet agricole, nous avons déménagé à La Rochelle pour y semer les premières lignes de carottes et y faire vivre les balbutiements de l’association.
Graines de troc, c’est une association pour échanger des graines, comment ça marche concrètement ?
Le logo de Graines de troc
La plateforme est aujourd’hui un projet de l’association comme un autre, chacun pouvant y échanger des graines et son savoir-faire.
Le site recense par exemple les trocs locaux qui peuvent avoir lieu en France.
Nous avons également lancé le concept des grainothèques, afin de promouvoir la biodiversité locale, et les échanges, dans un tiers lieu, comme les médiathèques.
Adhérer et agir avec graines de troc, c’est donc un peu tout ça. Faire sa part, pour défendre, promouvoir, échanger et sauvegarder notre héritage commun.
Y a t-il des différences par rapport à semeur.fr ?
Je ne sais pas si Semeur est constitué en association. Mais pour le projet de la plateforme en lui-même, les différences sont le jeton, la gestion/suivi des échanges, la non-mise à disposition du contact des troqueurs.
En fait, il n’y a pas besoin d’obtenir l’accord ou négocier avec un troqueur pour échanger. On peut suivre les échanges. Si l’échange n’aboutit pas, on récupère nos jetons. Et tout le monde est au même niveau, ce qui fait qu’on ne s’adressera pas juste à quelqu’un parce qu’il a une liste longue comme le bras.
Alors comme pour les logiciels, y’a des graines libres et des graines propriétaires, comment les reconnaît-on ?
Les graines commerciales ont effectivement parfois un COV, Certificat d’Obtention Végétale. Pour ce qui est des hybrides F1, inutile de les reproduire et les échanger, ils sont dégénérescents. On les reconnaît car l’inscription est obligatoire sur les sachets de graines HF1 ou F1. Sinon, la législation concerne essentiellement les usages commerciaux. Nous n’encourageons que les échanges de variétés anciennes et reproductibles, et les pratiques naturelles, qui permettent seules une autonomie semencière et alimentaire. Aller utiliser des semences dopées aux engrais de synthèses n’est donc pas notre objectif.
L’érosion variétale, baisse de la diversité des végétaux cultivés
Après la graine, sont arrivées les grainothèques, puis les greniers (lieux pour relier les initiatives locales, s’entraider, se réapproprier, échanger ensemble graines et savoir-faire…) puis drôles de jardiniers (animations avec les enfants, conservation variétale,etc.). Quels sont les retours que vous avez de ces différentes initiatives ?
Graines de troc a 5 ans, et nous vivons la jeunesse de chacun de ces projets.
La plateforme attire de nombreux jardiniers, et souffre de son succès, nous nous lançons actuellement dans un projet de refonte. Les grainothèques sont encore en plein essor, les citoyens y voient un moyen de faire leur part et mettre en place un outil de reliance locale, une belle manière de médiatiser la graine. Nous aurons la deuxième réunion des grainothécaires en mai/juin 2018, afin de discuter des retours d’expérience, des ateliers, et différentes évolutions possibles. Les greniers sont en effet, la deuxième marche après la grainothèque, c’est la constitution d’un groupe local, un outil pour fédérer les initiatives locales, les mettre en avant et les relier aux utilisateurs de la plateforme. Il y a de formidables initiatives à soutenir. Nous les soutenons en les mettant en avant, localement.
Pour drôles de jardiniers, c’est une formidable expérience de faire passer aux enfants nos passions pour la graine, la terre. En leur amenant des fondamentaux qu’ils sont rares à connaître chez eux. Cette mission nous sollicite beaucoup sur La Rochelle, mais le projet semble vouloir essaimer un peu partout tant il semble important.
Quelle est la prochaine étape de votre conquête du monde ?
C’est que graine par graine, j’ai bien le sentiment, qu’ensemble, avec un grand nombre d’acteurs, on arrive à nourrir les consciences. On ne se sent plus du tout seul ! Les graines s’échangent, elles poussent, et gagnent du terrain.
Plus pragmatiquement, nous concernant, nous souhaitons vraiment limiter le frein que nous imposent les problèmes techniques pour améliorer les échanges, avec le projet de refonte de la plateforme. Cela pourra nous permettre de mieux nous concentrer sur les graines, les savoirs-faire, et réussir à aider la myriade de petits colibris semeurs qui œuvrent partout, mettre la lumière sur cette biodiversité si belle et gourmande, celle qui nous nourrit et nous soigne. Plus d’autonomie et de conscience, plus de mains dans la terre plutôt que sur un clavier…
La prochaine étape est locale, et entre les mains de chacun, sur chaque territoire, dans chaque école, dans chaque jardin, dans chaque champ, et que cette biodiversité regagne sa place, avec tout ce que cela implique pour notre alimentation, autonomie, santé, et notre regard sur la terre et l’environnement.
Comment ça se passe si je souhaite participer à un de vos projets ?
Ça va dépendre des projets.
Pour la plateforme, et sa refonte : nous sommes en train de former le groupe de travail et les équipes qui vont y travailler. Nous aurons besoin d’informaticiens, mais aussi de testeurs, de conseils.
Pour la partie échanges : il suffit de participer en ligne, mais il y a aussi les trocs locaux bien réels, que la plateforme met en avant. N’hésitez pas à inscrire ces événements dans l’agenda des graines afin de les faire mieux connaître.
Pour le projet grainothèque, c’est une initiative citoyenne libre. Il est possible de proposer le dispositif dans les lieux qui vous sembleront utiles. Il faut ensuite idéalement faire vivre cette initiative, mais il est possible qu’il en existe déjà, vers lesquelles il suffit de se rapprocher. Apportez le surplus de graines de vos jardins !
Pour le projet, « j’adopte une graine », nous le lançons tout juste, et il s’agit de cultiver une variété particulière, de la graine à la graine, et de nous renvoyer une part de votre production afin de contribuer à son essaimage. Le projet est également pédagogique, car si vous participez, récupérez des graines, vous apprenez aussi son itinéraire cultural et semencier !
Pour aider localement, depuis chez vous, ou sur un projet de l’association en France, nous avons établi un questionnaire afin de proposer à chacun de nous aider selon son lieu, ses envies et sa disponibilité : http://grainesdetroc.fr/article.php?id=396. Par exemple : ensacher des graines, reproduire des semences, rejoindre un projet de jardinage local, proposer vos compétences …
Quelles seront les fonctionnalités du nouveau site Internet ?
Nous souhaitons effectivement refondre notre plateforme afin de moderniser un site initialement très amateur, apporter les nombreuses améliorations que nous avons imaginées en 5 ans, et construire les outils dont l’association a besoin avec sa dimension actuelle. Nous prévoyons des outils pour faciliter les échanges, des outils de communication et de reliance pour les groupes locaux de l’association, et nous permettre de mieux communiquer sur la vie de l’association, sur les histoires de graines … et des projets qui germent un peu partout…
Nous faisons cette interview au mois de novembre, il y a des choses à semer actuellement, quelles graines à récolter ?
Dans notre région, on peut se permettre de semer pas mal de choses : mâches, épinards, fèves, pois, et on tente aussi des semis plus risqués, car à la vue des changements qui nous attendent, ça vaut le coup d’essayer. Des laitues, des engrais verts, des carottes…
En novembre la récolte de graines est sur la fin. Normalement il pleut trop, c’est trop humide de manière générale, mais comme un peu partout il ne pleut pas assez, on en profite pour récolter sur les derniers portes graines. Maintenant, on extrait plutôt à l’intérieur les graines de courges par exemple ou les portes-graines qui sèchent…
Un dernier mot à ajouter ?
Chapeau à l’équipe Framasoft pour son engagement, et à l’exemple qu’elle concrétise en défendant nos biens communs. Merci pour mettre en œuvre la reliance nécessaire à nos causes communes, et pour le plaisir à l’idée que se croisent nos causes à l’occasion d’un projet concret…
Merci de nous avoir donné les moyens de continuer !
Le 21 novembre dernier, à l’occasion de l’annonce du projet Framatube, nous avons lancé un appel aux dons : il nous manquait 90 000 € pour boucler notre budget 2018, sachant que notre principale ressource (90 % de notre budget), ce sont vos dons.
Mer-ci !
Aujourd’hui, nous avons atteint cette somme, alors nous voulons prendre le temps de vous dire, tout simplement : merci.
Soutenir et contribuer à nos actions
Chez Framasoft, nous voyons vraiment notre petite association (qui, rappelons-le, est et reste une bande de potes) comme un lieu d’expérimentation concrète des libertés numériques. Y’a des idées qui nous tentent, alors on se lance, et cela nous permet de nous rendre compte si l’idée parle et si sa réalisation est possible, reproductible, dans quelles limites et avec quels moyens.
Vos dons nous soutiennent en cela : nous vous racontons ce que nous faisons, nous annonçons ce que nous allons faire (par exemple avec notre feuille de route pour les trois années à venir : Contributopia). Si vous voulez nous voir avancer dans cette voie, une des manières (et pas la seule !) de nous soutenir et de contribuer, c’est de nous donner de l’argent. Considérer vos dons comme autant de contributions est quelque chose d’assez inhabituel, en fait.
Merci à Aryeom, du projet Ze Marmott pour cette bien belle illustration !
Aujourd’hui, dans la culture des financements participatifs (crowdfundings) où tout don est soumis à une contrepartie, on essaie de transformer la personne qui donne en une espèce de consommatrice, de « client-roi » qui aurait le droit d’afficher des caprices (« je donne si vous faites ceci ou ne faites plus cela », « je donne donc vous devez répondre oui à ma demande », etc.). Cela crée l’illusion de décider sur des détails, mais aucunement le pouvoir de participer à la production commune, ni de s’en emparer après coup.
Ce fonctionnement-là ne nous parle pas. Vos dons sont parmi les indices qui nous indiquent si nous tenons la barre vers le bon cap. Visiblement, affirmer que Dégoogliser c’est bien mais ça ne suffit pas, aller explorer les outils numériques des mondes de Contributopia, c’est un chemin que vous avez envie de parcourir avec nous. Mine de rien, savoir que nos envies résonnent avec les vôtres, voir votre enthousiasme, cela fait chaud au cœur, alors merci de votre confiance.
À quoi va servir votre argent ?
Alors nous avons déjà détaillé cela dans notre dernière newsletter, donc on peut vous dire que, dans les grandes lignes, nous allons continuer. Pour 2018, cela signifie :
Poursuivre les projets historiques de l’association : l’annuaire Framalibre, la maison d’édition Framabook, la liste est longue… et les projets sont libres ;
Avancer sur les actions permettant de reproduire et adapter cette expérience (les CHATONS, Yunohost, etc.) afin que vous puissiez aisément gagner en autonomie ;
Contribuons ensemble vers cette Contributopia. Illustration de David Revoy – Licence : CC-By 4.0
Ça fait court, dit comme ça, mais mine de rien, nous allons avoir une année bien remplie, et des projets qui vont vous demander, régulièrement, d’intervenir et de vous en emparer si vous désirez que cela avance.
De fait, si nous avons atteint les moyens nécessaires pour accomplir ces actions en 2018, il n’est pas trop tard pour donner : nombreux sont les projets que nous avons budgetés de manière raisonnée, et qui seraient accélérés par des fonds supplémentaires. On pense, notamment, à l’avancement de Framatube après mars 2018 : plus nous dépasserons la barre fixée, mieux nous pourrons accompagner ce projet après ce lancement.
Essaimer c’est aimer
Ce n’est pas pour rien que l’on dit « copier, c’est aimer » : les projets libres sont des communs, et ils ne s’épanouissent que si chacun et chacune d’entre nous les cultivons. Par exemple, grâce à vous, nous avons pu accomplir de bien belles choses en 2017 :
La renaissance de l’annuaire Framalibre, qui fut le tout premier projet Framasoft, et qui est riche aujourd’hui de près de 700 notices ;
Encore une fois, un immense merci à toutes les personnes qui nous ont soutenus cette année (et aussi à celles qui ont soutenu d’autres associations comme, par exemple, La Quadrature du Net, Nos Oignons ou l’April).
Et si ce n’est pas encore le cas : n’hésitez pas ! Rappelons que 100€ de dons en 2017 vous permettront de déduire 66€ de vos impôts en 2018… une belle manière de contribuer à nos actions en utilisant vos… contributions 🙂 ! Soutenez Framasoft
Toute l’équipe de Framasoft vous envoie plein de datalove, et vous souhaite de belles fêtes, dans le partage et la chaleur commune.
Framatube : fédération et design de PeerTube
Cela fait quelques semaines déjà que Chocobozzz a rejoint notre équipe pour se consacrer au développement de PeerTube, le logiciel que l’on vous présente sur Framatube.org.
L’occasion de faire un premier point d’étape, avec quelques belles nouvelles à vous annoncer !
Fédérer c’est bien, bien fédérer c’est mieux.
Pour rappel, Framatube ne sera qu’une des portes d’entrée des fédérations PeerTube. Et Framatube n’hébergera pas vos vidéos : nous préférerons vous accompagner pour créer votre propre hébergement PeerTube (ou rejoindre un existant), afin que se multiplient ces portes d’entrées, ces instances de PeerTube.
Car c’est un des gros intérêts de PeerTube, pouvoir faire en sorte que chacune de ces instances, que chacun de ces sites d’hébergement de vidéos puisse se relier aux autres, se fédérer. Le tout est de savoir comment fédérer !
Pour cela, PeerTube vient d’implémenter une première version du protocole ActivityPub [EN]. Pour ceux qui ne le connaîtraient pas, il s’agit d’un protocole de fédération développé par le W3C. C’est-à-dire qu’on standardise la manière dont différentes instances communiquent. Si deux plateformes différentes savent parler la même langue, alors elles peuvent s’échanger des données. Ça n’a l’air de rien comme ça mais ça ouvre des possibilités immenses aux logiciels décentralisés.
Imaginez que demain MediaGoblin implémente le protocole ActivityPub (et ce sera normalement le cas !) et soit compatible avec PeerTube, alors votre ami qui avait installé ce logiciel sur son serveur pourra envoyer l’index de ses vidéos à votre serveur PeerTube et vice versa. Vous pourrez chercher n’importe quelle vidéo stockée sur son serveur (ou encore d’autres serveurs !) en restant tranquillement sur votre interface web PeerTube. Au lieu d’avoir des plateformes concurrentes, nous avons un réseau fédéré encore plus puissant à l’aide de la collaboration. Et c’est une valeur qui nous est chère, dans le libre.
Mais ça, ce n’est que la partie émergée de l’iceberg. Là où ça devient vraiment très excitant, c’est lorsque deux plateformes n’ayant pas la même fonction communiquent entre elles. Imaginez une instance Mastodon, qui est une alternative décentralisée à Twitter avec plus d’un million de comptes et qui implémente déjà le protocole ActivityPub. Imaginez maintenant une instance PeerTube avec un vidéaste que vous appréciez et qui poste régulièrement des vidéos. Est-ce que ce ne serait pas génial de pouvoir le suivre via votre interface Mastodon, et de voir des statuts dans votre fil d’actualité contenant directement la vidéo à chaque fois qu’il en publie une ? Eh bien ce sera possible.
Mais là ou ça deviendra vraiment très, très excitant, c’est que lorsque vous répondrez au statut de la vidéo sur Mastodon, le message sera envoyé ensuite à l’instance PeerTube. Votre réponse sera donc visible en dessous de la vidéo, dans l’espace commentaire. Bien sûr si une autre personne à l’autre bout du monde répond à votre commentaire via son instance PeerTube ou Mastodon, vous le verrez comme une réponse à votre statut dans Mastodon. Si demain Diaspora (l’alternative à Facebook derrière Framasphere) implémente ActivityPub, ce sera la même chose. Nous aurons une multitude de plateformes capables de fédérer les commentaires.
Il a l’air balourd, mais ce vieux mastodonte pourrait bien écrabouiller Twitter, si nous nous laissions aller à le choisir…
On reproche souvent à raison aux alternatives libres de ne pas avoir de valeur ajoutée par rapport aux plateformes centralisées. Avec ActivityPub, voilà notre premier gros avantage. Car avec les plateformes centralisées, vous aurez du mal à avoir sous votre vidéo YouTube les réactions des personnes qui auront commenté sur Facebook, Twitter, DailyMotion, etc. 😉
Bien sûr, nous n’y sommes pas encore.
Il reste un peu de travail dans PeerTube pour améliorer l’implémentation d’ActivityPub, puis tester la communication avec les autres plateformes. Mais les premiers retours sont très encourageants :). En revanche, il nous semble important de dire que les implémentations d’ActivityPub dans PeerTube et Mastodon ne vous permettront pas de vous créer un compte sur une instance PeerTube depuis votre compte Mastodon, ou vice versa.
Le design, c’est un métier !
Au milieu des questions que vous nous avez posées sur le forum FramaColibri, Olivier Massain s’est proposé de nous donner un coup de main pour améliorer le design de PeerTube (et y’en avait besoin !). Les maquettes créées sont magnifiques. Nous avons donc décidé de partager avec vous en avant-première l’intégration de son fantastique travail, avec un petit « avant/après » ! Un énorme merci à lui.
Utiliser le protocole ActivityPub revenait très souvent dans les questions les plus techniques que vous nous avez posées sur PeerTube. D’ailleurs, l’ensemble de vos questions nous ont permis d’améliorer la présentation de PeerTube, en proposant de découvrir Framatube en 10 réponses.
C’est, encore une fois, dans ce même espace d’échanges et de discussion qu’Olivier Massain s’est proposé de contribuer au design de PeerTube. Voici donc la preuve, s’il en fallait une de plus, que la contribution est la clé de la réussite des projets Libres. Ce n’est pas pour rien si nous avons placé Framatube dans le paysage du premier monde de Contributopia : c’est parce que nous savons que nous ne pourrons y arriver que si nous le faisons ensemble.
Une autre manière de contribuer est de participer au financement des activités de Framasoft, et, là aussi, nous devons vous dire combien nous sommes émerveillé·e·s du soutien que vous nous accordez. Le 21 novembre dernier, nous avons associé l’annonce de Framatube avec notre appel aux dons, car il nous manquait alors 90 000 € pour boucler le budget 2018 de l’association. Nous avons découpé cette somme en trois paliers :
À l’heure où nous écrivons ces lignes, le deuxième palier est presque atteint ! Alors oui, il reste un effort à faire et rien n’est gagné, mais d’ores et déjà, nous tenons à vous remercier de cette confiance que vous nous portez et nous souhaitons tout faire pour nous en montrer dignes. Petit rappel aux personnes qui paient des impôts sur le revenu en France : il vous reste jusqu’au 31 décembre pour faire un don à Framasoft qui puisse être déduit de vos revenus 2017 (sachant qu’un don de 100 € revient, après déduction, à 34 €).
Si vous le voulez et le pouvez, pensez à soutenir Framasoft , et/ou à faire passer cette information autour de vous !
Durant longtemps, des canaris et des pinsons ont travaillé dans les mines de charbon. Ces oiseaux étaient utilisés pour donner l’alarme quand les émanations de monoxyde de carbone se faisaient menaçantes.
Dès qu’ils battaient des ailes ou se hérissaient voire mouraient, les mineurs étaient avertis de la présence du gaz avant qu’eux-mêmes ne la perçoivent. Depuis, les alarmes électroniques ont pris le relais, évitant ainsi le sacrifice de milliers d’oiseaux.
Pour Cory Doctorow (faut-il encore présenter cet écrivain et militant des libertés numériques ?), le canari mort dans la mine, c’est le W3C qui a capitulé devant les exigences de l’industrie du divertissement et des médias numériques.
Il fait le bilan des pressions qui se sont exercées, explique pourquoi l’EFF a quitté le W3C et suggère comment continuer à combattre les verrous numériques inefficaces et dangereux.
Avant de commencer la lecture, vous pourriez avoir besoin d’identifier les acronymes qu’il mentionne fréquemment :
EFF : une organisation non-gouvernementale (Electronic Frontier Foundation) et internationale qui milite activement pour les droits numériques, notamment sur le plan juridique et par des campagnes d’information et de mobilisation. En savoir plus sur la page Wikipédia
W3C : un organisme a but non lucratif (World Wide Web Consortium) qui est censé proposer des standards des technologies du Web pour qu’elles soient compatibles. En savoir plus sur la page Wikipédia
DRM : la gestion des droits numériques (Digital Rights Management). Les DRM visent à contrôler l’utilisation des œuvres numériques. En savoir plus sur la page Wikipédia
EME : des modules complémentaires (Encrypted Media Extensions) créés par le W3C qui permettent aux navigateurs d’accéder aux contenus verrouillés par les DRM. En savoir plus sur la page Wikipédia
Alerte aux DRM : comment nous venons de perdre le Web, ce que nous en avons appris , et ce que nous devons faire désormais
Par CORY DOCTOROW
Cory Doctorow (CC-BY-SA Jonathan Worth)
L’EFF s’est battue contre les DRM et ses lois depuis une quinzaine d’années, notamment dans les affaires du « broadcast flag » américain, du traité de radiodiffusion des Nations Unies, du standard européen DVB CPCM, du standard EME du W3C, et dans de nombreuses autres escarmouches, batailles et même guerres au fil des années. Forts de cette longue expérience, voici deux choses que nous voulons vous dire à propos des DRM :
1. Tout le monde sait dans les milieux bien informés que la technologie DRM n’est pas pertinente, mais que c’est la loi sur les DRM qui est décisive ;
2. La raison pour laquelle les entreprises veulent des DRM n’a rien à voir avec le droit d’auteur.
Ces deux points viennent d’être démontrés dans un combat désordonné et interminable autour de la standardisation des DRM dans les navigateurs, et comme nous avons consacré beaucoup d’argent et d’énergie à ce combat, nous aimerions retirer des enseignements de ces deux points, et fournir une feuille de route pour les combats à venir contre les DRM.
Les DRM : un échec technologique, une arme létale au plan légal
Voici, à peu près, comment fonctionnent les DRM : une entreprise veut fournir à un client (vous) un contenu dématérialisé (un film, un livre, une musique, un jeu vidéo, une application…) mais elle veut contrôler ce que vous faites avec ce contenu une fois que vous l’avez obtenu.
Alors elles chiffrent le fichier. On adore le chiffrement. Parce que ça fonctionne. Avec relativement peu d’efforts, n’importe qui peut chiffrer un fichier de sorte que personne ne pourra jamais le déchiffrer à moins d’obtenir la clef.
Supposons qu’il s’agisse de Netflix. Ils vous envoient un film qui a été chiffré et ils veulent être sûrs que vous ne pouvez pas l’enregistrer ni le regarder plus tard depuis votre disque dur. Mais ils ont aussi besoin de vous donner un moyen de voir le film. Cela signifie qu’il faut à un moment déchiffrer le film. Et il y a un seul moyen de déchiffrer un fichier qui a été entièrement chiffré : vous avez besoin de la clef.
Donc Netflix vous donne aussi la clef de déchiffrement.
Mais si vous avez la clef, vous pouvez déchiffrer les films de Netflix et les enregistrer sur votre disque dur. Comment Netflix peut-il vous donner la clef tout en contrôlant la façon dont vous l’utilisez ?
Netflix doit cacher la clef, quelque part dans votre ordinateur, dans une extension de navigateur ou une application par exemple. C’est là que la technologie atteint ses limites. Bien cacher quelque chose est difficile. Mais bien cacher quelque chose dans un appareil que vous donnez à votre adversaire pour qu’il puisse l’emporter avec lui et en faire ce qu’il veut, c’est impossible.
Peut-être ne pouvez-vous pas trouver les clefs que Netflix a cachées dans votre navigateur. Mais certains le peuvent : un étudiant en fin d’études qui s’ennuie pendant un week-end, un génie autodidacte qui démonte une puce dans son sous-sol, un concurrent avec un laboratoire entier à sa disposition. Une seule minuscule faille dans la fragile enveloppe qui entoure ces clefs et elles sont libérées !
Et une fois que cette faille est découverte, n’importe qui peut écrire une application ou une extension de navigateur avec un bouton « sauvegarder ». C’est l’échec et mat pour la technologie DRM (les clés fuitent assez souvent, au bout d’un temps comparable à celui qu’il faut aux entreprises de gestion des droits numériques pour révoquer la clé).
Il faut des années à des ingénieurs talentueux, au prix de millions de dollars, pour concevoir des DRM. Qui sont brisés au bout de quelques jours, par des adolescents, avec du matériel amateur. Ce n’est pas que les fabricants de DRM soient stupides, c’est parce qu’ils font quelque chose de stupide.
C’est là qu’intervient la loi sur les DRM, qui donne un contrôle légal plus puissant et plus étendu aux détenteurs de droits que les lois qui encadrent n’importe quel autre type de technologie. En 1998, le Congrès a adopté le Digital Milennium Copyright Act, DCMA dont la section 1201 prévoit une responsabilité pénale pour quiconque contourne un système de DRM dans un but lucratif : 5 ans d’emprisonnement et une amende de 500 000 $ pour une première infraction. Même le contournement à des fins non lucratives des DRM peut engager la responsabilité pénale. Elle rend tout aussi dangereux d’un point de vue légal le simple fait de parler des moyens de contourner un système de DRM.
Ainsi, la loi renforce les systèmes de DRM avec une large gamme de menaces. Si les gens de Netflix conçoivent un lecteur vidéo qui n’enregistrera pas la vidéo à moins que vous ne cassiez des DRM, ils ont maintenant le droit de porter plainte – ou faire appel à la police – contre n’importe quel rival qui met en place un meilleur service de lecture vidéo alternatif, ou un enregistreur de vidéo qui fonctionne avec Netflix. De tels outils ne violent pas la loi sur le droit d’auteur, pas plus qu’un magnétoscope ou un Tivo, mais puisque cet enregistreur aurait besoin de casser le DRM de Netflix, la loi sur les DRM peut être utilisée pour le réduire au silence.
La loi sur les DRM va au-delà de l’interdiction du contournement de DRM. Les entreprises utilisent aussi la section 1201 de la DMCA pour menacer des chercheurs en sécurité qui découvrent des failles dans leurs produits. La loi devient une arme qu’ils peuvent pointer sur quiconque voudrait prévenir leurs consommateurs (c’est toujours vous) que les produits auxquels vous faites confiance sont impropres à l’usage. Y compris pour prévenir les gens de failles dans les DRM qui pourraient les exposer au piratage.
Et il ne s’agit pas seulement des États-Unis, ni du seul DCMA. Le représentant du commerce international des États-Unis a « convaincu » des pays dans le monde entier d’adopter une version de cette règle.
Les DRM n’ont rien à voir avec le droit d’auteur
La loi sur les DRM est susceptible de provoquer des dommages incalculables. Dans la mesure où elle fournit aux entreprises le pouvoir de contrôler leurs produits après les avoir vendus, le pouvoir de décider qui peut entrer en compétition avec elles et sous quelles conditions, et même qui peut prévenir les gens concernant des produits défectueux, la loi sur les DRM constitue une forte tentation.
Certaines choses ne relèvent pas de la violation de droits d’auteur : acheter un DVD pendant que vous êtes en vacances et le passer quand vous arrivez chez vous. Ce n’est de toute évidence pas une violation de droits d’auteur d’aller dans un magasin, disons à New Delhi, d’acheter un DVD et de le rapporter chez soi à Topeka. L’ayant droit a fait son film, l’a vendu au détaillant, et vous avez payé au détaillant le prix demandé. C’est le contraire d’une violation de droits d’auteur. C’est l’achat d’une œuvre selon les conditions fixées par l’ayant droit. Mais puisque le DRM vous empêche de lire des disques hors-zone sur votre lecteur, les studios peuvent invoquer le droit d’auteur pour décider où vous pouvez consommer les œuvres sous droit d’auteur que vous avez achetées en toute honnêteté.
D’autres non-violations : réparer votre voiture (General Motors utilise les DRM pour maîtriser qui peut faire un diagnostic moteur, et obliger les mécaniciens à dépenser des dizaines de milliers de dollars pour un diagnostic qu’ils pourraient sinon obtenir par eux-mêmes ou par l’intermédiaire de tierces parties); recharger une cartouche d’encre (HP a publié une fausse mise à jour de sécurité qui a ajouté du DRM à des millions d’imprimantes à jet d’encre afin qu’elles refusent des cartouches reconditionnées ou venant d’un tiers), ou faire griller du pain fait maison (même si ça ne s’est pas encore produit, rien ne pourrait empêcher une entreprise de mettre des DRM dans ses grille-pains afin de contrôler la provenance du pain que vous utilisez).
Ce n’est pas non plus une violation du droit d’auteur de regarder Netflix dans un navigateur non-approuvé par Netflix. Ce n’est pas une violation du droit d’auteur d’enregistrer une vidéo Netflix pour la regarder plus tard. Ce n’est pas une violation du droit d’auteur de donner une vidéo Netflix à un algorithme qui pourra vous prévenir des effets stroboscopiques à venir qui peuvent provoquer des convulsions potentiellement mortelles chez les personnes atteintes d’épilepsie photosensible.
Ce qui nous amène au W3C
Le W3C est le principal organisme de normalisation du Web, un consortium dont les membres (entreprises, universités, agences gouvernementales, associations de la société civile entre autres) s’impliquent dans des batailles sans fin concernant le meilleur moyen pour tout le monde de fournir du contenu en ligne. Ils créent des « recommandations » (la façon pour le W3C de dire « standards »), ce sont un peu comme des étais invisibles qui soutiennent le Web. Ces recommandations, fruits de négociations patientes et de compromis, aboutissent à un consensus des principaux acteurs sur les meilleures (ou les moins pires) façons de résoudre certains problèmes technologiques épineux.
En 2013, Netflix et quelques autres entreprises du secteur des médias ont convaincu le W3C de commencer à travailler sur un système de DRM pour le Web. Ce système de DRM, Encrypted Media Extensions, constitue un virage à 180 degrés par rapport aux habitudes du W3C. Tout d’abord, les EME ne seraient pas un standard à part entière : l’organisation spécifierait une API au travers de laquelle les éditeurs et les vendeurs de navigateurs pourraient faire fonctionner les DRM, mais le « module de déchiffrement du contenu » (content decryption module, CDM) ne serait pas défini par la norme. Ce qui signifie que les EME n’ont de norme que le nom : si vous lanciez une entreprise de navigateurs en suivant toutes les recommandations du W3C, vous seriez toujours incapables de jouer une vidéo Netflix. Pour cela, vous auriez besoin de la permission de Netflix.
Je n’exagère pas en disant que c’est vraiment bizarre. Les standards du Web existent pour assurer « une interopérabilité sans permission ». Les standards de formatage de texte sont tels que n’importe qui peut créer un outil qui peut afficher les pages du site web du New York Times, les images de Getty ou les diagrammes interactifs sur Bloomberg. Les entreprises peuvent toujours décider de qui peut voir quelles pages de leur site web (en décidant qui possède un mot de passe et quelles parties du site sont accessibles par chaque mot de passe), mais elles ne décident pas de qui peut créer le programme de navigateur web dans lequel vous entrez le mot de passe pour accéder au site.
Un Web où chaque éditeur peut choisir avec quels navigateurs vous pouvez visiter son site est vraiment différent du Web historique. Historiquement, chacun pouvait concevoir un nouveau navigateur en s’assurant qu’il respecte les recommandations du W3C, puis rivaliser avec les navigateurs déjà présents. Et bien que le Web ait toujours été dominé par quelques navigateurs, le navigateur dominant a changé toutes les décennies, de sorte que de nouvelles entreprises ou même des organisations à but non lucratif comme Mozilla (qui a développé Firefox) ont pu renverser l’ordre établi. Les technologies qui se trouvaient en travers de cette interopérabilité sans permission préalable – comme les technologies vidéos brevetées – ont été perçues comme des entraves à l’idée d’un Web ouvert et non comme des opportunités de standardisation.
Quand les gens du W3C ont commencé à créer des technologies qui marchent uniquement quand elles ont reçu la bénédiction d’une poignée d’entreprises de divertissement, ils ont mis leurs doigts – et même leurs mains – dans l’engrenage qui assurera aux géants de la navigation un règne perpétuel.
Mais ce n’est pas le pire. Jusqu’aux EME, les standards du W3C étaient conçus pour donner aux utilisateurs du Web (i.e. vous) plus de contrôle sur ce que votre ordinateur fait quand vous visitez les sites web d’autres personnes. Avec les EME, et pour la toute première fois, le W3C est en train de concevoir une technologie qui va vous enlever ce contrôle. Les EME sont conçus pour autoriser Netflix et d’autres grosses entreprises à décider de ce que fait votre navigateur, même (et surtout) quand vous êtes en désaccord avec ce qui devrait se passer.
Il y a un débat persistant depuis les débuts de l’informatique pour savoir si les ordinateurs existent pour contrôler leurs utilisateurs, ou vice versa (comme le disait l’informaticien visionnaire et spécialiste de l’éducation Seymour Papert « les enfants devraient programmer les ordinateurs plutôt que d’être programmés par eux » – et ça s’applique aussi bien aux adultes). Tous les standards du W3C jusqu’en 2017 ont été en faveur du contrôle des ordinateurs par les utilisateurs. Les EME rompent avec cette tradition. C’est un changement subtil mais crucial.
…et pourquoi le W3C devrait faire ça ?
Aïe aïe aïe. C’est la question à trois milliards d’utilisateurs.
La version de cette histoire racontée par le W3C ressemble un peu à ce qui suit. L’apparition massive des applications a affaibli le Web. À l’époque « pré-applis», le Web était le seul joueur dans la partie, donc les sociétés devaient jouer en suivant ses règles : standards libres, Web libre. Mais maintenant que les applications existent et que presque tout le monde les utilise, les grandes sociétés peuvent boycotter le Web, obligeant leurs utilisateurs à s’orienter vers les applications. Ce qui ne fait qu’accélérer la multiplication des applis, et affaiblit d’autant plus le Web. Les applications ont l’habitude d’implémenter les DRM, alors les sociétés utilisant ces DRM se sont tournées vers les applis. Afin d’empêcher les entreprises du divertissement de tuer le Web, celui-ci doit avoir des DRM également.
Toujours selon cette même théorie, même si ces sociétés n’abandonnent pas entièrement le Web, il est toujours préférable de les forcer à faire leurs DRM en suivant le W3C que de les laisser faire avec les moyens ad hoc. Laissées à elles-mêmes, elles pourraient créer des DRM ne prenant pas en compte les besoins des personnes à handicap, et sans l’influence modératrice du W3C, ces sociétés créeraient des DRM ne respectant pas la vie privée numérique des utilisateurs.
On ne peut pas espérer d’une organisation qu’elle dépense des fortunes pour créer des films ou en acquérir des licences puis distribue ces films de telle sorte que n’importe qui puisse les copier et les partager.
Nous pensons que ces arguments sont sans réel fondement. Il est vrai que le Web a perdu une partie de sa force liée à son exclusivité du début, mais la vérité c’est que les entreprises gagnent de l’argent en allant là où se trouvent leurs clients. Or tous les clients potentiels ont un navigateur, tandis que seul les clients déjà existants ont les applications des entreprises. Plus il y aura d’obstacles à franchir entre vous et vos clients, moins vous aurez de clients. Netflix est sur un marché hyper-compétitif avec des tonnes de nouveaux concurrents (p.ex. Disney), et être considéré comme « ce service de streaming inaccessible via le Web » est un sérieux désavantage.
Nous pensons aussi que les médias et les entreprises IT auraient du mal à se mettre d’accord sur un standard pour les DRM hors W3C, même un très mauvais standard. Nous avons passé beaucoup de temps dans les salles remplies de fumée où se déroulait la standardisation des systèmes de DRM ; la dynamique principale était celles des médias demandant le verrouillage complet de chaque image de chaque vidéo, et des entreprises IT répondant que le mieux que quiconque puisse espérer était un ralentissement peu efficace qu’elles espéraient suffisant pour les médias. La plupart du temps, ces négociations s’effondrent sans arriver nulle part.
Il y a aussi la question des brevets : les entreprises qui pensent que les DRM sont une bonne idée adorent les brevets logiciels, et le résultat est un fouillis sans nom de brevets qui empêchent de parvenir à faire quoi que ce soit. Le mécanisme de regroupement de brevets du W3C (qui se démarque par sa complétude dans le monde des standards et constitue un exemple de la meilleure façon d’accomplir ce genre de choses) a joué un rôle indispensable dans le processus de standardisation des DRM. De plus, dans le monde des DRM, il existe des acteurs-clefs – comme Adobe – qui détiennent d’importants portfolios de brevets mais jouent un rôle de plus en plus réduit dans le monde des DRM (l’objectif avoué du système EME est de « tuer Flash »).
Si les entreprises impliquées devaient s’asseoir à la table des négociations pour trouver un nouvel accord sur les brevets sans le framework du W3C, n’importe laquelle de ces entreprises pourrait virer troll et décider que les autres doivent dépenser beaucoup d’argent pour obtenir une licence sur leurs brevets – elle n’aurait rien à perdre à menacer le processus de négociations et tout à gagner même sur des droits par utilisateur, même minuscules, pour quelque chose qui sera installé dans trois milliards de navigateurs.
En somme, il n’y a pas de raison de penser que les EME ont pour objectif de protéger des intérêts commerciaux légitimes. Les services de streaming vidéo comme Netflix reposent sur l’inscription de leurs clients à toute une collection, constamment enrichie avec de nouveaux contenus et un système de recommandations pour aider ses utilisateurs à s’y retrouver.
Les DRM pour les vidéos en streaming sont ni plus ni moins un moyen d’éviter la concurrence, pas de protéger le droit d’auteur. L’objectif des DRM est de munir les entreprises d’un outil légal pour empêcher des activités qui seraient autorisées sinon. Les DRM n’ont pas vocation à « fonctionner » (au sens de prévenir les atteintes au droit d’auteur) tant qu’ils permettent d’invoquer le DMCA.
Pour vous en convaincre, prenez simplement l’exemple de Widevine, la version des EME de Google. Ce mastodonte a racheté la boîte qui développait Widevine en 2010, mais il a fallu attendre 2016, pour qu’un chercheur indépendant se penche réellement sur la façon dont elle empêchait la fuite de ses vidéos. Ce chercheur, David Livshits a remarqué que Widevine était particulièrement facile à contourner, et ce dès sa création, et que les erreurs qui rendaient Widevine aussi inefficace étaient évidentes, même avec un examen superficiel. Si les millions de dollars et le personnel hautement qualifié affectés aux EME avaient pour but de créer une technologie qui lutterait efficacement contre les atteintes au droit d’auteur, alors vous pourriez croire que Netflix ou une des autres entreprises de médias numériques impliquées dans les négociations auraient utilisé une partie de toutes ces ressources à un rapide audit, pour s’assurer que leur produit fonctionne réellement comme annoncé.
(Détail amusant : Livshits est un Israélien qui travaille à l’université Ben Gourion, et il se trouve que l’Israël est un des rares pays qui ne condamnent pas les violations de DRM, ce qui signifie que les Israéliens font partie des seules personnes qui peuvent faire ce type de recherche, sans craintes de représailles juridiques)
Mais la plus belle preuve que les EME étaient tout simplement un moyen d’éliminer les concurrents légitimes, et non une tentative de protection du droit d’auteur, la voici.
Une expérience sous contrôle
Lorsque l’EFF a rejoint le W3C, notre principale condition était « ne faites pas de DRM ».
Nous avons porté l’affaire devant l’organisation, en décrivant la façon dont les DRM interférent avec les exceptions aux droits auteurs essentielles (comme celles qui permettent à chaque individu d’enregistrer et modifier un travail protégé par droits d’auteur, dans le cadre d’une critique, ou d’une adaptation) ainsi que la myriade de problèmes posés par le DMCA et par d’autres lois semblables à travers le monde.
L’équipe de direction de la W3C a tout simplement réfuté tous les arguments à propos des usages raisonnables et des droits d’utilisateurs prévus par le droit d’auteur, comme étant, en quelque sorte, des conséquences malheureuses de la nécessité d’éviter que Netflix n’abandonne le Web, au profit des applications. Quant au DMCA, ils ont répondu qu’ils ne pouvaient faire quoi que ce soit à propos de cette loi irrationnelle, mais qu’ils avaient la certitude que les membres du W3C n’avaient aucunement l’intention de violer le DMCA, ils voulaient seulement éviter que leurs films de grande valeur ne soient partagés sur Internet.
Nous avons donc changé de stratégie, et proposé une sorte d’expérience témoin afin de savoir ce que les fans de DRM du W3C avaient comme projets.
Le W3C est un organisme basé sur le consensus : il crée des standards, en réunissant des gens dans une salle pour faire des compromis, et aboutir à une solution acceptable pour chacun. Comme notre position de principe était « pas de DRM au W3C » et que les DRM sont une si mauvaise idée, il était difficile d’imaginer qu’un quelconque compromis pouvait en sortir.
Mais après avoir entendu les partisans du DRM nier leurs abus du DCMA, nous avons pensé que nous pouvions trouver quelque chose qui permettrait d’avancer par rapport à l’actuel statu quo et pourrait satisfaire le point de vue qu’ils avaient évoqué.
Nous avons proposé un genre de pacte de non-agression par DRM, par lequel les membres du W3C promettraient qu’ils ne poursuivraient jamais quelqu’un en justice en s’appuyant sur des lois telles que la DMCA 1201, sauf si d’autres lois venaient à être enfreintes. Ainsi, si quelqu’un porte atteinte à vos droits d’auteur, ou incite quelqu’un à le faire, ou empiète sur vos contrats avec vos utilisateurs, ou s’approprie vos secrets de fabrication, ou copie votre marque, ou fait quoique ce soit d’autre, portant atteinte à vos droits légaux, vous pouvez les attaquer en justice.
Mais si quelqu’un s’aventure dans vos DRM sans enfreindre aucune autre loi, le pacte de non-agression stipule que vous ne pouvez pas utiliser le standard DRM du W3C comme un moyen de les en empêcher. Cela protégerait les chercheurs en sécurité, cela protégerait les personnes qui analysent les vidéos pour ajouter des sous-titres et d’autres outils d’aide, cela protégerait les archivistes, qui ont légalement le droit de faire des copies, et cela protégerait ceux qui créent de nouveaux navigateurs.
Si tout ce qui vous intéresse c’est de créer une technologie efficace contre les infractions à la loi, ce pacte ne devrait poser aucun problème. Tout d’abord, si vous pensez que les DRM sont une technologie efficace, le fait qu’il soit illégal de les critiquer ne devrait pas avoir d’importance.
Et étant donné que le pacte de non-agression permet de conserver tous les autres droits juridiques, il n’y avait aucun risque que son adoption permette à quelqu’un d’enfreindre la loi en toute impunité. Toute personne qui porterait atteinte à des droits d’auteur (ou à tout autre droit) serait dans la ligne de mire du DMCA, et les entreprises auraient le doigt sur la détente.
Pas surprenant, mais très décevant
Bien entendu, ils ont détesté cette idée.
Les studios, les marchands de DRM et les grosses entreprises membres du W3C ont participé à une « négociation » brève et décousue avant de voter la fin des discussions et de continuer. Le représentant du W3C les a aidés à éviter les discussions, continuant le travail sur la charte de EME sans prévoir de travail en parallèle sur la protection du Web ouvert, même quand l’opposition à l’intérieur du W3C grandissait.
Le temps que la poussière retombe, les EME ont été publiés après le vote le plus controversé que le W3C ait jamais vu, avec le représentant du W3C qui a déclaré unilatéralement que les problèmes concernant la sûreté des recherches, l’accessibilité, l’archivage et l’innovation ont été traités au mieux (malgré le fait que littéralement rien de contraignant n’a été décidé à propos de ces sujets). La recherche de consensus du W3C a été tellement détournée de son cours habituel que la publication de EME a été approuvée par seulement 58% des membres qui ont participé au vote final, et nombre de ces membres ont regretté d’avoir été acculés à voter pour ce à quoi ils avaient émis des objections.
Quand le représentant du W3C a déclaré que n’importe quelle protection pour un Web ouvert était incompatible avec les souhaits des partisans des DRM, cela ressemblait à une justification ironique. Après tout, c’est comme ça que l’on a commencé avec l’EFF insistant sur le fait que les DRM n’étaient pas compatibles avec les révélations de faille de sécurité, avec l’accessibilité, avec l’archivage ou encore l’innovation. Maintenant, il semble que nous soyons tous d’accord.
De plus, ils se sont tous implicitement mis d’accord pour considérer que les DRM ne concernent pas la protection du droit d’auteur. Mais concerne l’utilisation du droit d’auteur pour s’emparer d’autres droits, comme celui de décider qui peut critiquer ou non votre produit – ou qui peut le concurrencer.
Le simulacre de cryptographie des DRM implique que ça marche seulement si vous n’êtes pas autorisé à comprendre ses défauts. Cette hypothèse s’est confirmée lorsqu’un membre du W3C a déclaré au consortium qu’il devrait protéger les publications concernant les « environnements de tests de confidentialité » des EME permettant l’espionnage intrusif des utilisateurs, et dans la minute, un représentant de Netflix a dit que cette option n’était même pas envisageable.
D’une certaine façon, Netflix avait raison. Les DRM sont tellement fragiles, tellement incohérents, qu’ils sont simplement incompatibles avec les normes du marché et du monde scientifique, où tout le monde est libre de décrire ses véritables découvertes, même si elles frustrent les aspirations commerciales d’une multinationale.
Le W3C l’a implicitement admis, car il a tenté de réunir un groupe de discussion pour élaborer une ligne de conduite à destination des entreprises utilisant l’EME : dans quelle mesure utiliser la puissance légale des DRM pour punir les détracteurs, à quel moment autoriser une critique.
« Divulgation responsable selon nos règles,
ou bien c’est la prison »
Ils ont appelé ça la divulgation responsable, mais elle est loin de celle qu’on voit aujourd’hui. En pratique, les entreprises font les yeux doux aux chercheurs en sécurité pour qu’ils communiquent leurs découvertes à des firmes commerciales avant de les rendre publiques. Leurs incitations vont de la récompense financière (bug bounty), à un système de classement qui leur assure la gloire, ou encore l’engagement de donner suite aux divulgations en temps opportun, plutôt que de croiser les doigts, de s’asseoir sur les défauts fraîchement découverts et d’espérer que personne d’autre ne les redécouvrira dans le but de les exploiter.
La tension qui existe entre les chercheurs indépendants en sécurité et les grandes entreprises est aussi vieille que l’informatique. Il est difficile de protéger un ordinateur du fait de sa complexité. La perfection est inatteignable. Garantir la sécurité des utilisateurs d’ordinateurs en réseau nécessite une évaluation constante et la divulgation des conclusions, afin que les fabricants puissent réparer leurs bugs et que les utilisateurs puissent décider de façon éclairée quels systèmes sont suffisamment sûrs pour être utilisés.
Mais les entreprises ne réservent pas toujours le meilleur accueil aux mauvaises nouvelles lorsqu’il s’agit de leurs produits. Comme des chercheurs ont pu en faire l’expérience — à leurs frais — mettre une entreprise face à ses erreurs peut être une question de savoir-vivre, mais c’est un comportement risqué, susceptible de faire de vous la cible de représailles si vous vous avisez de rendre les choses publiques. Nombreux sont les chercheurs ayant rapporté un bogue à une entreprise, pour constater l’intolérable durée de l’inaction de celle-ci, laissant ses utilisateurs exposés au risque. Bien souvent, ces bogues ne font surface qu’après avoir été découverts par ailleurs par des acteurs mal intentionnés ayant vite fait de trouver comment les exploiter, les transformant ainsi en attaques touchant des millions d’utilisateurs. Bien trop nombreux pour que l’existence de bogues puisse plus longtemps être passée sous silence.
Comme le monde de la recherche renâclait de plus en plus à leur parler, les entreprises ont été obligées de s’engager concrètement à ce que les découvertes des chercheurs soient suivies de mesures rapides, dans un délai défini, à ce que les chercheurs faisant part de leurs découvertes ne soient pas menacés et même à offrir des primes en espèces pour gagner la confiance des chercheurs. La situation s’est améliorée au fil des ans, la plupart des grandes entreprises proposant une espèce de programme relatif aux divulgations.
Mais la raison pour laquelle les entreprises donnent des assurances et offrent des primes, c’est qu’elles n’ont pas le choix. Révéler que des produits sont défectueux n’est pas illégal, et donc les chercheurs qui mettent le doigt sur ces problèmes n’ont aucune obligation de se conformer aux règles des entreprises. Ce qui contraint ces dernières à faire preuve de leur bonne volonté par leur bonne conduite, des promesses contraignantes et des récompenses.
Les entreprises veulent absolument être capables de déterminer qui a le droit de dire la vérité sur leurs produits et quand. On le sait parce que, quand elles ont une occasion d’agir en ce sens, elles la saisissent. On le sait parce qu’elles l’ont dit au W3C. On le sait parce qu’elles ont exigé ce droit comme partie intégrante du paquet DRM dans le cadre EME.
De tous les flops du processus DRM au sein du W3C, le plus choquant a été le moment où les avocats historiques du Web ouvert ont tenté de convertir un effort de protection des droits des chercheurs à avertir des milliards de gens des vulnérabilités de leurs navigateurs web en un effort visant à conseiller les entreprises quant au moment où renoncer à exercer ce droit. Un droit qu’elles n’ont que grâce à la mise au point des DRM pour le Web par le W3C.
Les DRM sont le contraire de la sécurité
Depuis le début de la lutte contre les DRM au W3C, on a compris que les fabricants de DRM et les entreprises de médias qu’elles fournissent n’étaient pas là pour protéger le droit d’auteur, mais pour avoir une base légale sur laquelle asseoir des privilèges sans rapport avec le droit d’auteur. On savait aussi que les DRM étaient incompatibles avec la recherche en sûreté : puisque les DRM dépendent de l’obfuscation (NdT: rendre illisible pour un humain un code informatique), quiconque documente comment les DRM marchent les empêche aussi de fonctionner.
C’est particulièrement clair à travers ce qui n’a pas été dit au W3C : quand on a proposé que les utilisateurs puissent contourner les DRM pour générer des sous-titres ou mener des audits de sécurité, les intervenants se demandaient toujours si c’était acceptable, mais jamais si c’était possible.
Il faut se souvenir que EME est supposé être un système qui aide les entreprises à s’assurer que leurs films ne sont pas sauvegardés sur les disques durs de leurs utilisateurs et partagés sur Internet. Pour que ça marche, cela doit être, vous savez, compliqué.
Mais dans chaque discussion pour déterminer quand une personne peut être autorisée à casser EME, il était toujours acquis que quiconque voulait le faire le pouvait. Après tout, si vous cachez des secrets dans le logiciel que vous donnez aux mêmes personnes dont vous voulez cacher les secrets, vous allez probablement être déçu.
Dès le premier jour, nous avons compris que nous arriverions à un point où les défenseurs des DRM au W3C seraient obligés d’admettre que le bon déroulement de leur plan repose sur la capacité à réduire au silence les personnes qui examineront leurs produits.
Cependant, nous avons continué à espérer : une fois que cela sera clair pour tout le monde, ils comprendront que les DRM ne peuvent coexister pacifiquement avec le Web ouvert.
Le succès des DRM au W3C est une parabole de la concentration des marchés et de la fragilité du Web ouvert. Des centaines de chercheurs en sécurité ont fait du lobbying au W3C pour protéger leur travail, l’UNESCO a condamné publiquement l’extension des DRM au Web, et les nombreuses crypto-monnaies membres du W3C ont prévenu que l’utilisation de navigateurs pour des applications critiques et sûres, par exemple pour déplacer les avoirs financiers des gens, ne peut se faire que si les navigateurs sont soumis aux mêmes normes de sécurité que les autres technologies utilisées dans nos vies (excepté les technologies DRM).
Il ne manque pas de domaines d’activités qui veulent pouvoir contrôler ce que leurs clients et concurrents font avec leurs produits. Quand les membres du Copyright Office des États-Unis ont entendu parler des DRM en 2015, il s’agissait pour eux des DRM dans des implants médicaux et des voitures, de l’équipement agricole et des machines de votes. Des entreprises ont découvert qu’ajouter des DRM à leurs produits est la manière la plus sûre de contrôler le marché, une façon simple et fiable de transformer en droits exclusifs les choix commerciaux pour déterminer qui peut réparer, améliorer et fournir leurs produits .
Les conséquences néfastes sur le marché économique de ce comportement anticoncurrentiel sont faciles à voir. Par exemple, l’utilisation intempestive des DRM pour empêcher des magasins indépendants de réparer du matériel électronique provoque la mise à la poubelle de tonnes de composants électroniques, aux frais des économies locales et de la possibilité des clients d’avoir l’entière propriété de leurs objets. Un téléphone que vous recyclez au lieu de le réparer est un téléphone que vous avez à payer pour le remplacer – et réparer crée beaucoup plus d’emplois que de recycler (recycler une tonne de déchets électroniques crée 15 emplois, la réparer crée 150 emplois). Les emplois de réparateurs sont locaux et incitent à l’entrepreneuriat, car vous n’avez pas besoin de beaucoup de capital pour ouvrir un magasin de réparations, et vos clients voudront amener leurs objets à une entreprise locale (personne ne veut envoyer un téléphone en Chine pour être réparé – encore moins une voiture !).
Mais ces dégâts économiques sont seulement la partie émergée de l’iceberg. Des lois comme le DMCA 1201 incitent à l’utilisation de DRM en promettant de pouvoir contrôler la concurrence, mais les pires dommages des DRM sont dans le domaine de la sécurité. Quand le W3C a publié EME, il a légué au Web une surface d’attaque qu’on ne peut auditer dans des navigateurs utilisés par des milliards de personnes pour leurs applications les plus risquées et importantes. Ces navigateurs sont aussi l’interface de commande utilisée pour l’Internet des objets : ces objets, garnis de capteurs, qui peuvent nous voir, nous entendre, et agir sur le monde réel avec le pouvoir de nous bouillir, geler, électrifier, blesser ou trahir de mille façons différentes.
Ces objets ont eux-mêmes des DRM, conçus pour verrouiller nos biens, ce qui veut dire que tout ce qui va de votre grille-pain à votre voiture devient hors de portée de l’examen de chercheurs indépendants qui peuvent vous fournir des évaluations impartiales et sans fard sur la sécurité et de la fiabilité de ces appareils.
Dans un marché concurrentiel, on pourrait s’attendre à ce que des options sans DRM prolifèrent en réaction à ce mauvais comportement. Après tout, aucun client ne veut des DRM : aucun concessionnaire automobile n’a jamais vendu une nouvelle voiture en vantant le fait que c’était un crime pour votre mécanicien préféré de la réparer.
Mais nous ne vivons pas dans un marché concurrentiel. Les lois telles que DMCA 1201 minent toute concurrence qui pourrait contrebalancer leurs pires effets.
Les entreprises qui se sont battues pour les DRM au W3C – vendeurs de navigateurs, Netflix, géants de la haute technologie, l’industrie de la télévision par câble – trouvent toutes l’origine de leur succès dans des stratégies commerciales qui ont, au moment de leur émergence, choqué et indigné les acteurs du secteur déjà établis. La télévision par câble était à ses débuts une activité qui retransmettait des émissions et facturait ce service sans avoir de licence. L’hégémonie d’Apple a commencé par l’extraction de cédéroms, en ignorant les hurlements de l’industrie musicale (exactement comme Firefox a réussi en bloquant les publicités pénibles et en ignorant les éditeurs du web qui ont perdu des millions en conséquence). Bien sûr, les enveloppes rouges révolutionnaires de Netflix ont été traitées comme une forme de vol.
Ces boîtes ont démarré comme pirates et sont devenus des amiraux, elles traitent leurs origines comme des légendes de courageux entrepreneurs à l’assaut d’une structure préhistorique et fossilisée. Mais elles traitent toute perturbation à leur encontre comme un affront à l’ordre naturel des choses. Pour paraphraser Douglas Adams, toute technologie inventée pendant votre adolescence est incroyable et va changer le monde ; tout ce qui est inventé après vos 30 ans est immoral et doit être détruit.
Leçons tirées du W3C
La majorité des personnes ne comprennent pas le danger des DRM. Le sujet est bizarre, technique, ésotérique et prend trop de temps à expliquer. Les partisans des DRM veulent faire tourner le débat autour du piratage et de la contrefaçon, qui sont des histoires simples à raconter.
Mais les promoteurs des DRM ne se préoccupent pas de ces aspects et on peut le prouver : il suffit de leur demander s’ils seraient partants pour promettre de ne pas avoir recours au DMCA tant que personne ne viole de droit d’auteur. On pourrait alors observer leurs contorsions pour ne pas évoquer la raison pour laquelle faire appliquer le droit d’auteur devrait empêcher des activités connexes qui ne violent pas le droit d’auteur. À noter : ils n’ont jamais demandé si quelqu’un pourrait contourner leurs DRM, bien entendu. Les DRM sont d’une telle incohérence technique qu’ils ne sont efficaces que s’il est interdit par la loi de comprendre leur fonctionnement. Il suffit d’ailleurs de les étudier un peu attentivement pour les mettre en échec.
Demandez-leur de promettre de ne pas invoquer le DMCA contre les gens qui ont découvert des défauts à leurs produits et écoutez-les argumenter que les entreprises devraient obtenir un droit de veto contre la publication de faits avérés sur leurs erreurs et manquements.
Ce tissu de problèmes montre au moins ce pour quoi nous nous battons : il faut laisser tomber les discussions hypocrites relatives au droit d’auteur et nous concentrer sur les vrais enjeux : la concurrence, l’accessibilité et la sécurité.
Ça ne se réglera pas tout seul. Ces idées sont toujours tordues et nébuleuses.
Voici une leçon que nous avons apprise après plus de 15 ans à combattre les DRM : il est plus facile d’inciter les personnes à prêter attention à des problèmes de procédure qu’à des problèmes de fond. Nous avons travaillé vainement à alerter le grand public sur le Broadcasting Treaty, un traité d’une complexité déconcertante et terriblement complexe de l’OMPI, une institution spécialisée des Nations Unies. Tout le monde s’en moquait jusqu’à ce que quelqu’un dérobe des piles de nos tracts et les dissimule dans les toilettes pour empêcher tout le monde de les lire. Et c’est cela qui a fait la Une : il est très difficile de se faire une idée précise d’un truc comme le Broadcast Treaty, mais il est très facile de crier au scandale quand quelqu’un essaie de planquer vos documents dans les toilettes pour que les délégués ne puissent pas accéder à un point de vue contradictoire.
C’est ainsi qu’après quatre années de lutte inefficace au sujet des DRM au sein du W3C, nous avons démissionné ; c’est alors que tout le monde s’est senti concerné, demandant comment résoudre le problème. La réponse courte est « Trop tard : nous avons démissionné, car il n’y a plus rien à faire ».
Mais la réponse longue laisse un peu plus d’espoir. EFF est en train d’attaquer le gouvernement des États-Unis pour casser la Section 1201 du DMCA. Comme on l’a montré au W3C, il n’y a pas de demande pour des DRM à moins qu’il y ait une loi comme le DMCA 1201. Les DRM en soi ne font rien d’autre que de permettre aux compétiteurs de bloquer des offres innovantes qui coûtent moins et font plus.
Le Copyright Office va bientôt entendre des nouveaux échos à propos du DMCA 1201.
Le combat du W3C a montré que nous pouvions ramener le débat aux vrais problèmes. Les conditions qui ont amené le W3C à être envahi par les DRM sont toujours d’actualité et d’autres organisations vont devoir faire face à cette menace dans les années à venir. Nous allons continuer à affiner notre tactique et à nous battre, et nous allons aussi continuer à rendre compte des avancées afin que vous puissiez nous aider. Tout ce que nous demandons est que vous continuiez à être vigilant. Comme on l’a appris au W3C, on ne peut pas le faire sans vous.
Avancer ensemble vers la contribution…
Contribuer, oui, mais comment ? Comment susciter des contributions, les accueillir, les dynamiser, lever les obstacles et les blocages de tous ordres ?
Tel a été le questionnement à l’origine du Fabulous Contribution Camp qui s’est déroulé à Lyon, du 24 au 26 novembre dernier, à l’initiative de La Quadrature et de Framasoft. Toutes les personnes qui ont participé ont eu à cœur d’identifier les difficultés honnêtement mais aussi de proposer des pistes et des pratiques pour les surmonter…
Pour en témoigner, nous donnons la parole aujourd’hui à Maiwann qui est UX designer et que nous avions invitée. L’article ci-dessous est la simple republication de son compte-rendu sur son blog. Ses observations, ses réactions et ses chouettes sketchnotes font véritablement plaisir (bientôt peut-être d’autres billets des participants?) et nous indiquent des voies qui sont déjà celles de Contributopia.. C’est un début prometteur, parions que beaucoup d’associations pourront en tirer profit et continuer l’exploration de la contribution positive.
Fabulous Contribution Camp
Pour finir ce mois de novembre en beauté, j’ai été invitée par Framasoft à participer au Fabulous Contribution Camp qu’ils co-organisaient avec La Quadrature du Net. Je suis donc partie à Lyon pour rencontrer des contributeur·ice·s de tous horizons (et pas seulement de la technique !) pour parler des outils et de comment aider celleux qui le souhaitent à contribuer plus simplement.
Un petit état des lieux
Pyg le disait lors du Capitole du Libre (dans la conférence Contributopia que vous pouvez retrouver ici), la majorité des projets de logiciel libre sont soutenus par très peu (voire pas) de contributeur·ice·s. L’exemple le plus marquant est celui des pads (une alternative à GoogleDocs permettant d’écrire collaborativement en ligne): Sur l’année dernière, il n’y a pas une seule personne ayant réalisé plus de 50 contributions, alors que le logiciel est très populaire !
C’est assez inquiétant, et en même temps pour avoir déjà échoué personnellement, parfois On a l’envie de contribuer et on y arrive pas. Ce qui est quand même assez comique lorsqu’on voit à quel point le logiciel libre a besoin encore et toujours de personnes volontaires !
J’avais donc hâte de me joindre à des groupes de réflexion sur le sujet afin d’identifier les problématiques et envisager des pistes de solution tout au long du FCC. Autant vous dire que tout le monde s’est transformé·e·s en designer pour concevoir une meilleure expérience contributeur·ice (Peut-on envisager de dire des CX Designer qui au lieu de signifier Customer eXperience sera notre Contributor eXperience Designer ? ^.^ )
FCC c’est parti !
Le FCC avait lieu à Grrrnd Zero, un lieu au caractère très affirmé, où les murs sont recouverts d’illustrations, près d’un immense chantier participatif destiné à devenir à la fois salle de concert, d’enregistrement et atelier de bricolage/dessin… Nous nous sommes fait accueillir avec un petit déjeuner fabuleux, cette première journée démarrait vraiment bien !
Après un icebreaker rigolo nous demandant de nous regrouper d’abord par provenance géographique (mais comment font les nomades ?), ensuite par coiffure, ensuite par système d’exploitation préféré (oui on était un peu chez les geeks quand même) et enfin par notre engagement associatif principal, nous nous sommes lancés sur des ateliers collaboratifs, animés par les enthousiastes Meli et lunar !
Failosophy : Identifier les problèmes
Pour démarrer, nous nous sommes regroupés par 4 et avons raconté chacun une expérience marquante où notre envie de contribuer s’est soldée par un fail. Nous notions les différentes problématiques rencontrées sur des post-its avant de toutes les regrouper sur un grand mur pour avoir une vue d’ensemble des cas les plus fréquents. Ensuite, nous avons collaborativement trié les post-it ce qui prend “étrangement toujours 8 minutes peu importe le nombre de post-its ou de personne” d’après Lunar… Il faut dire qu’il avait raison 😉
De grandes catégories regroupent les post-its et font apparaître des motifs récurrents. Ceux que je retiens (car ils me font écho) :
La difficulté d’identifier un interlocuteur référent pour s’intégrer au projet
La peur de demander « Comment faire »
La peur de ne pas être assez doué·e / de dire des « choses bêtes »
Ne pas savoir par où commencer
La peur de ne pas s’intégrer à la communauté
Le manque de temps
La difficulté de déléguer à d’autres un projet qu’on a toujours porté
Le fait de ne pas avoir réussi à créer une communauté autour d’un projet
Ne pas connaître la ligne de route d’un projet
Ne pas savoir comment exprimer les besoins de contribution pour que les intéressé·e·s les comprennent
J’ai la sensation qu’un grand nombre de ces problèmes peuvent être résolus en:
Listant clairement les besoins de contributions, avec les compétences nécessaires, via une interface plus facile d’accès qu’un github (qui est réellement anxiogène pour les non-développeur·euse·s)
Désignant une personne accueillante comme point d’entrée pour les nouveaux·lles arrivant·e·s, à laquelle il sera facile de s’adresser, et qui saura aiguiller chacun·e vers des tâches simples pour découvrir le projet.
Cela se recoupe avec les discussions du Capitole du Libre, ce qui donne la sensation que nous sommes sur la bonne voie et que les hypothèses que j’ai entendues la semaine dernière sont des solutions à des problèmes récurrents pour les contributeur·ice·s !
Étude de cas : 6 projets appelant à la contribution
Dans la phase suivante, pour s’imprégner un peu de ce qui se fait parmi les projets nécessitant contribution, nous avons eu le droit à la présentation de:
Exodus, une plateforme qui analyse les applications Android et liste les logiciels traquant notre activité qu’elle y trouve.
La Revue de Presse de la Quadrature du Net, permettant de soumettre des articles à la revue de presse de façon collaborative.
Diaspora, un réseau social décentralisé assez proche de la configuration initiale de facebook.
FAI Maison, un fournisseur d’accès associatif et nantais, qui propose le prix libre (ou contribution consciente)
Le PiPhone, une plateforme de La Quadrature du Net permettant d’avoir accès à des numéros de députés afin de les appeler pour les encourager à soutenir (ou non) une loi, en proposant un set d’arguments et un retour d’expérience après l’appel.
FramaForm, une des alternatives de Dégooglisons Internet lancée par Framasoft, que Pyg a développée seul (!) en 15 jours (!!!). Avec le souci notamment que le logiciel permet plein de choses différentes mais que les options sont difficiles à trouver.
Le tour d’horizon permet de voir que si chaque projet recherche à fédérer une communauté de contribution, ils sont tous très différents et n’intéressent sans doute pas du tout les même personnes. Les présentations étaient elles aussi très variées selon la personne, de celui qui démarre par l’aspect technique à celui qui met tout de suite en avant les problématiques d’ergonomie. Bien sur, la présentation varie énormément selon les affinités et les problématiques rencontrées par chacun·e. Peut-être qu’avoir une description homogène (qui ne parte dans l’aspect technique que face à des personnes orientées technique) puis des pistes selon les compétences / envies de la personne en face serait à envisager ? (c’est un point que je laisse en suspens, mais il faut avouer qu’à force je suis rebutée par ceux qui m’expliquent immédiatement en quelle technologie est leur application alors que je suis très interessée par celleux qui ont des problématiques de conception 😉 )
Icebreaker rigolo
Petite recette: Prenez une feuille et écrivez en gros au marqueur ce dont vous avez envie de parler / un truc à apprendre à quelqu’un, montrez la feuille à tout le monde et formez un binôme avec une personne qui est intéressé·e par votre thème et a un thème qui vous intéresse (ou pas) !
Grodébat I
Après déjeuner (des lasagnes végétariennes à tomber <3) nous avons repris certaines catégories de problématiques listées le matin et nous sommes séparés en petits groupes pour déterminer:
C’est quoi le problème ?
Dans l’idéal, avec une baguette magique, qu’est-ce qu’on fait ?
Quelles solutions concrètes pour y arriver ?
Nous sommes arrivés à tout un tas de solutions pour nous mettre le pied à l’étrier:
Vision :
Créer un manifeste et créer des rencontres mêlant communauté de contributeur·ice·s et utilisateur·ice·s
Accès au savoir & Appropriation :
Formuler des avantages concurrentiels pour les marchés publics et rendre transparents les logiciels utilisés dans le service public
Sortir de l’entre-soi :
Trouver des métaphores pour expliquer sans être technique, lister les communautés avec des objectifs similaires mais des besoins différents.
Répartition des tâches :
Lister l’ensemble des tâches à faire et leur avancement.
Expression des besoins :
Lister & Publier les besoins de contribution en petites tâches, Créer un bouton “J’ai un problème” qui s’adresse à un humain (facilitateur ou UX designer)
Rapports de pouvoir :
Mettre et afficher un système de résolution des conflits.
Gestion du temps (et de l’argent) :
Mesurer le temps mis pour une tâche pour le prioriser dans le futur et compléter le financement par le don.
Accueil :
Avoir un·e référent·e du projet, co-rédiger une charte d’accueil “Comment accueillir les personnes”.
Toutes ces solutions qui sont autant de petits pas à mettre en œuvre m’ont beaucoup enthousiasmée : j’ai l’impression que le chemin est tout tracé pour réaliser de belles choses ensemble ! Nous avons d’ailleurs enchaîné avec de petits groupes de travail concrets permettant de débuter la rédaction d’une charte, designer un bouton “J’ai un problème” ou encore réfléchir à une plateforme listant les besoins de contribution.
Tout ça en une seule journée autant vous dire que nous étions lessivé·e·s à la fin, mais après un bon repas (préparé par les cuistots de Grrrnd Zero) il était temps de se coucher pour être fraî·che·s le lendemain !
C’est reparti pour un tour !
C’est avec une fraîcheur toute relative que nous avons entamé la seconde journée du FCC. La fatigue est là, mais la bonne humeur et l’enthousiasme général donnent vraiment envie de finir le week-end en beauté. Nous entamons un tour de météo avec pas mal de personnes dans le brouillard du matin, mais très vite nous faisons chauffer les méninges collectivement.
Contributeur·ice·s, où êtes-vous ?
Nous démarrons par une séance de « boule de neige » où nous sommes invité·e·s à lister les endroits où, demain, nous pourrions aller pour parler du logiciel libre et trouver de nouvelles personnes pour contribuer ! Sur un autre tas, nous écrivons plutôt ce qui nous empêche de le faire actuellement.
Je liste personnellement mes précédentes écoles de design qui sont, à mon avis, des nids à designers motivé·e·s mais pour qui le monde du libre est inexistant (on a tendance à nous parler principalement de droit d’auteur et nous n’entendons jamais parler de licences libres). Pour y aller cependant, il me faut plus de connaissances sur les licences et une liste de projet dont ils pourraient s’emparer afin de commencer à contribuer rapidement.
À la fin nous collons tout nos post-it sur les murs et, comme a dit lunar: “Si chacun ramène 3 personnes, la prochaine fois on est 300.”. Il n’y a plus qu’à !
Gros Débat II : Le retour
Nous enchaînons sur des groupes de travail thématiques. Je rejoins celui qui aborde le sujet du financement, et y apprends sans surprise que les subventions demandent un investissement énorme (environ 1/3 du temps total de travail passé pour les demander) et que, si le fonctionnement grâce aux dons permet beaucoup plus de liberté, il est soumis à des règles strictes, notamment au fait qu’on ne peut pas donner de contrepartie en échange d’un don, qui doit être fait uniquement pour soutenir le travail passé et à venir de l’association (dans les grandes lignes).
Le monde des financements a l’air très nébuleux, ce qui nous fait envisager de rechercher des contributeur·ice·s s’y connaissant en financement comme l’on en rechercherait en design ou en admin sys !
Les autres groupes ont pour leur part envisagé :
Accueil :
Montrer de l’intérêt aux personnes qui arrivent, lister les besoins afin qu’iels puissent s’en emparer.
Discutons ensemble :
Diversifier les compétences en listant les besoins (les solutions se regroupent, chouette !), ne pas imposer des outils libres aux futurs utilisateur·ice·s mais partir de leurs problèmes plutôt (on dirait bien une démarche de conception centrée utilisateur·ice \o/ )
Rencontrer les utilisateur·ice·s :
Avoir des relais au sein de l’association ou se greffer à une rencontre existante afin de faciliter les échanges, demander à des UX Designers de se joindre aux rencontres et motiver certains devs à venir voir les tests utilisateurs.
Comment on garde le lien post-FCC :
Avoir une plateforme ou l’on puisse mettre des photos, un article de blog (collaboratif ?) récapitulant le week-end, et au-delà, une plateforme listant les besoins de contribution (oui, encore, chouette !)
La machine infernale !
Après le repas composé de pizzas maison (c’est vraiment sympa Grrrnd Zero), nous nous lançons dans la machine infernale : une première personne se place et commence à enchaîner un son et un geste, de façon répétitive. Une seconde personne la rejoint et va elle aussi réaliser son geste, et chacun va à son tour rejoindre la machine infernale, en répétant indéfiniment son geste et son son jusqu’à ce que… la machine s’emballe ! C’était un petit jeu très chouette et revigorant après la phase digestive !
Gros Débat III
Pour ce troisième groupe de réflexion, je rejoins pyg qui a envie de réunir des associations afin de les informer sur le logiciel libre, qui leur plaît pour des raisons évidentes de prix, mais aussi de valeurs ! Cependant le numérique est un domaine assez vaste et pour des assos qui ne s’y connaissent pas, il y a besoin de faire de l’éducation aux usages et à ce que cela engendre d’utiliser tel ou telle logiciel ou application.
Le groupe fourmille d’idées, je retiens pêle-mêle:
Il y a un besoin de sensibilisation, de démonstration des possibilités des logiciels libres, et d’accompagnement à la transition,
Les associations ont besoin d’indépendance, de communiquer et de collaborer
Les mettre en relation vis à vis de leurs besoins peut permettre une mise en commun de financement pour développer des logiciels ouverts et adaptés
Il faut aller voir les assos pour savoir ce dont elles ont besoin et ce qu’elles recherchent
Selon les retours, décider du format, plutôt conférence organisée ou Summer Camp très ouvert ?
Moi qui recherche à participer à des choses qui ont du sens, me voilà pile au bon endroit et j’en suis très heureuse ^.^
Ça sent la fin !
Enfin, pour finaliser le FCC, nous avons 4 catégories de post-it, à remplir puis à afficher au mur:
❤️ Ce que nous avons fait ce week-end et qui nous a plu !
🌟 Ce que j’ai envie de faire dès demain pour contribuer.
➡ Ce que je fais dans les prochains mois.
😊 Ce que j’ai envie que quelqu’un d’autre ici fasse (et chacun pouvait récupérer un post-it de ce type pour s’y engager)
Voici les miens :
Merci le FCC !
Ce Fabulous Contribution Camp a été une très bonne expérience : J’ai pu parler UX en long, en large et en travers, à des personnes qui se sont montrées à l’écoute de ce que j’avais à leur raconter (et ça ça fait plaisir !). Les différentes solutions énoncées, avec des pistes concrètes de réalisation pour se lancer rapidement me donnent des ailes, et j’espère que cette motivation ne va pas retomber de sitôt !
Je vous tiendrai au courant de mes avancées dans le monde du libre et de la contribution, en tout cas je remercie Framasoft de m’avoir permis de venir partager un week-end à Lyon avec eux à parler et rêver du futur du numérique !
Pour finir, voici les sketchnotes de ce week-end collaboratif. Prenez soin de vous 🙂

























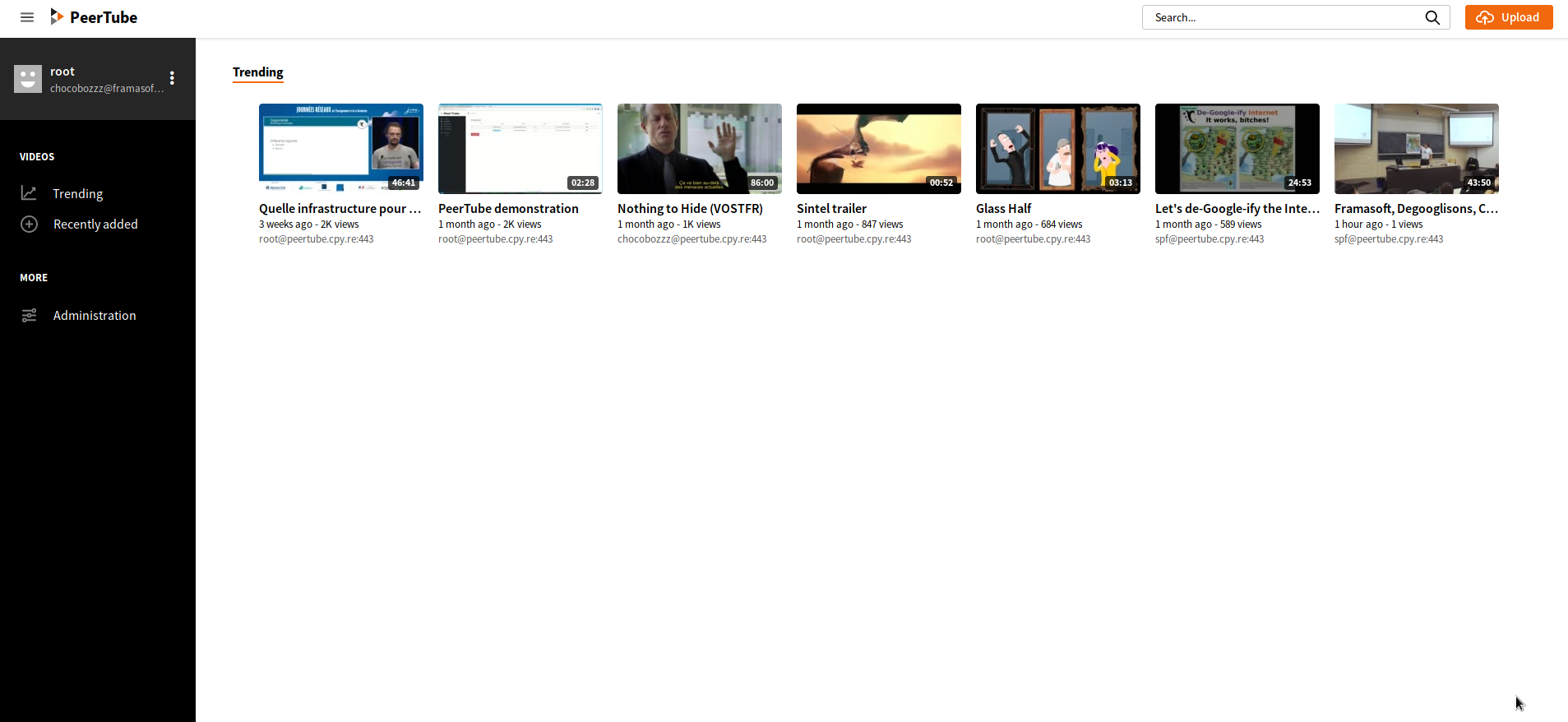
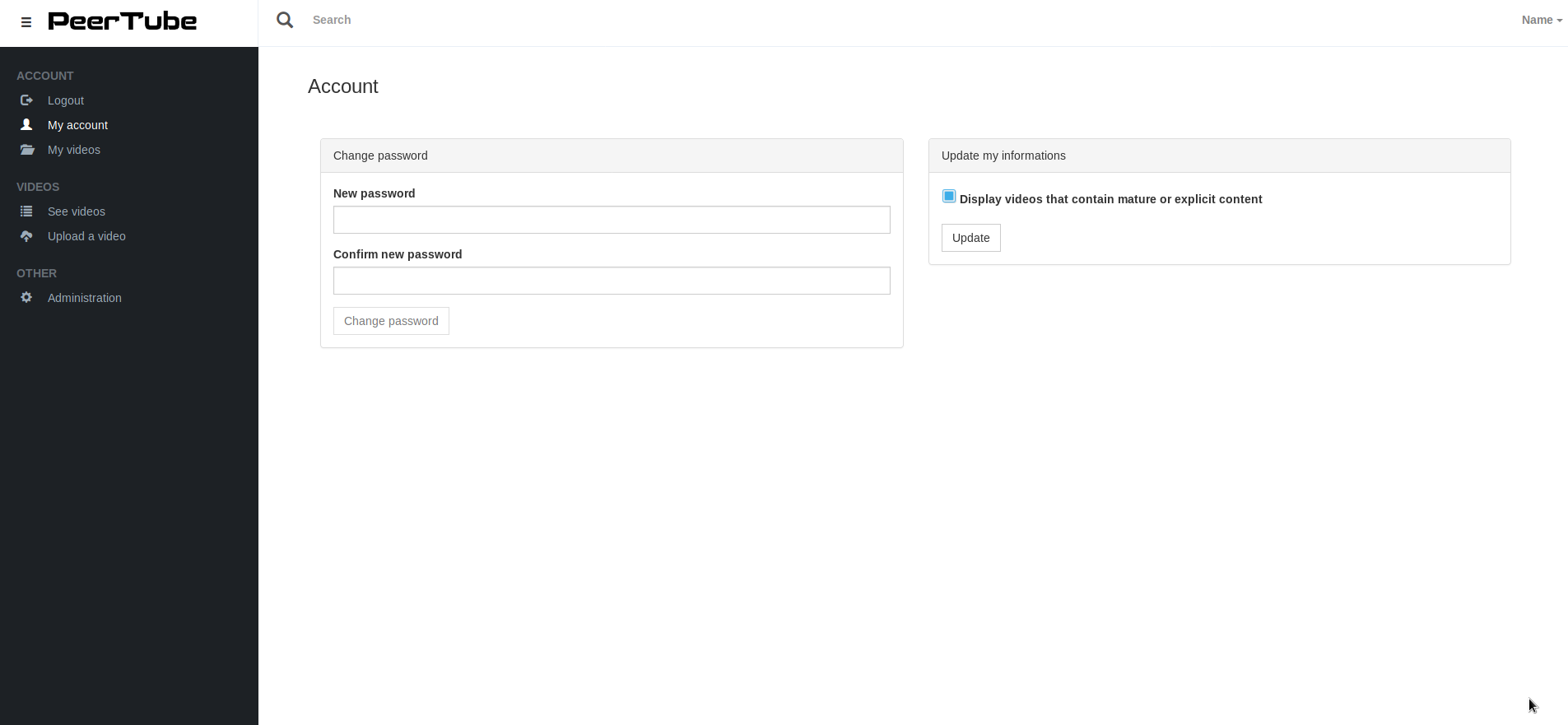












{kind=link}