Merci de nous avoir donné les moyens de continuer !
Le 21 novembre dernier, à l’occasion de l’annonce du projet Framatube, nous avons lancé un appel aux dons : il nous manquait 90 000 € pour boucler notre budget 2018, sachant que notre principale ressource (90 % de notre budget), ce sont vos dons.
Mer-ci !
Aujourd’hui, nous avons atteint cette somme, alors nous voulons prendre le temps de vous dire, tout simplement : merci.
Soutenir et contribuer à nos actions
Chez Framasoft, nous voyons vraiment notre petite association (qui, rappelons-le, est et reste une bande de potes) comme un lieu d’expérimentation concrète des libertés numériques. Y’a des idées qui nous tentent, alors on se lance, et cela nous permet de nous rendre compte si l’idée parle et si sa réalisation est possible, reproductible, dans quelles limites et avec quels moyens.
Vos dons nous soutiennent en cela : nous vous racontons ce que nous faisons, nous annonçons ce que nous allons faire (par exemple avec notre feuille de route pour les trois années à venir : Contributopia). Si vous voulez nous voir avancer dans cette voie, une des manières (et pas la seule !) de nous soutenir et de contribuer, c’est de nous donner de l’argent. Considérer vos dons comme autant de contributions est quelque chose d’assez inhabituel, en fait.
Merci à Aryeom, du projet Ze Marmott pour cette bien belle illustration !
Aujourd’hui, dans la culture des financements participatifs (crowdfundings) où tout don est soumis à une contrepartie, on essaie de transformer la personne qui donne en une espèce de consommatrice, de « client-roi » qui aurait le droit d’afficher des caprices (« je donne si vous faites ceci ou ne faites plus cela », « je donne donc vous devez répondre oui à ma demande », etc.). Cela crée l’illusion de décider sur des détails, mais aucunement le pouvoir de participer à la production commune, ni de s’en emparer après coup.
Ce fonctionnement-là ne nous parle pas. Vos dons sont parmi les indices qui nous indiquent si nous tenons la barre vers le bon cap. Visiblement, affirmer que Dégoogliser c’est bien mais ça ne suffit pas, aller explorer les outils numériques des mondes de Contributopia, c’est un chemin que vous avez envie de parcourir avec nous. Mine de rien, savoir que nos envies résonnent avec les vôtres, voir votre enthousiasme, cela fait chaud au cœur, alors merci de votre confiance.
À quoi va servir votre argent ?
Alors nous avons déjà détaillé cela dans notre dernière newsletter, donc on peut vous dire que, dans les grandes lignes, nous allons continuer. Pour 2018, cela signifie :
Poursuivre les projets historiques de l’association : l’annuaire Framalibre, la maison d’édition Framabook, la liste est longue… et les projets sont libres ;
Avancer sur les actions permettant de reproduire et adapter cette expérience (les CHATONS, Yunohost, etc.) afin que vous puissiez aisément gagner en autonomie ;
Contribuons ensemble vers cette Contributopia. Illustration de David Revoy – Licence : CC-By 4.0
Ça fait court, dit comme ça, mais mine de rien, nous allons avoir une année bien remplie, et des projets qui vont vous demander, régulièrement, d’intervenir et de vous en emparer si vous désirez que cela avance.
De fait, si nous avons atteint les moyens nécessaires pour accomplir ces actions en 2018, il n’est pas trop tard pour donner : nombreux sont les projets que nous avons budgetés de manière raisonnée, et qui seraient accélérés par des fonds supplémentaires. On pense, notamment, à l’avancement de Framatube après mars 2018 : plus nous dépasserons la barre fixée, mieux nous pourrons accompagner ce projet après ce lancement.
Essaimer c’est aimer
Ce n’est pas pour rien que l’on dit « copier, c’est aimer » : les projets libres sont des communs, et ils ne s’épanouissent que si chacun et chacune d’entre nous les cultivons. Par exemple, grâce à vous, nous avons pu accomplir de bien belles choses en 2017 :
La renaissance de l’annuaire Framalibre, qui fut le tout premier projet Framasoft, et qui est riche aujourd’hui de près de 700 notices ;
Encore une fois, un immense merci à toutes les personnes qui nous ont soutenus cette année (et aussi à celles qui ont soutenu d’autres associations comme, par exemple, La Quadrature du Net, Nos Oignons ou l’April).
Et si ce n’est pas encore le cas : n’hésitez pas ! Rappelons que 100€ de dons en 2017 vous permettront de déduire 66€ de vos impôts en 2018… une belle manière de contribuer à nos actions en utilisant vos… contributions 🙂 ! Soutenez Framasoft
Toute l’équipe de Framasoft vous envoie plein de datalove, et vous souhaite de belles fêtes, dans le partage et la chaleur commune.
Qui veut cadenasser le Web ?
Durant longtemps, des canaris et des pinsons ont travaillé dans les mines de charbon. Ces oiseaux étaient utilisés pour donner l’alarme quand les émanations de monoxyde de carbone se faisaient menaçantes.
Dès qu’ils battaient des ailes ou se hérissaient voire mouraient, les mineurs étaient avertis de la présence du gaz avant qu’eux-mêmes ne la perçoivent. Depuis, les alarmes électroniques ont pris le relais, évitant ainsi le sacrifice de milliers d’oiseaux.
Pour Cory Doctorow (faut-il encore présenter cet écrivain et militant des libertés numériques ?), le canari mort dans la mine, c’est le W3C qui a capitulé devant les exigences de l’industrie du divertissement et des médias numériques.
Il fait le bilan des pressions qui se sont exercées, explique pourquoi l’EFF a quitté le W3C et suggère comment continuer à combattre les verrous numériques inefficaces et dangereux.
Avant de commencer la lecture, vous pourriez avoir besoin d’identifier les acronymes qu’il mentionne fréquemment :
EFF : une organisation non-gouvernementale (Electronic Frontier Foundation) et internationale qui milite activement pour les droits numériques, notamment sur le plan juridique et par des campagnes d’information et de mobilisation. En savoir plus sur la page Wikipédia
W3C : un organisme a but non lucratif (World Wide Web Consortium) qui est censé proposer des standards des technologies du Web pour qu’elles soient compatibles. En savoir plus sur la page Wikipédia
DRM : la gestion des droits numériques (Digital Rights Management). Les DRM visent à contrôler l’utilisation des œuvres numériques. En savoir plus sur la page Wikipédia
EME : des modules complémentaires (Encrypted Media Extensions) créés par le W3C qui permettent aux navigateurs d’accéder aux contenus verrouillés par les DRM. En savoir plus sur la page Wikipédia
Alerte aux DRM : comment nous venons de perdre le Web, ce que nous en avons appris , et ce que nous devons faire désormais
Par CORY DOCTOROW
Cory Doctorow (CC-BY-SA Jonathan Worth)
L’EFF s’est battue contre les DRM et ses lois depuis une quinzaine d’années, notamment dans les affaires du « broadcast flag » américain, du traité de radiodiffusion des Nations Unies, du standard européen DVB CPCM, du standard EME du W3C, et dans de nombreuses autres escarmouches, batailles et même guerres au fil des années. Forts de cette longue expérience, voici deux choses que nous voulons vous dire à propos des DRM :
1. Tout le monde sait dans les milieux bien informés que la technologie DRM n’est pas pertinente, mais que c’est la loi sur les DRM qui est décisive ;
2. La raison pour laquelle les entreprises veulent des DRM n’a rien à voir avec le droit d’auteur.
Ces deux points viennent d’être démontrés dans un combat désordonné et interminable autour de la standardisation des DRM dans les navigateurs, et comme nous avons consacré beaucoup d’argent et d’énergie à ce combat, nous aimerions retirer des enseignements de ces deux points, et fournir une feuille de route pour les combats à venir contre les DRM.
Les DRM : un échec technologique, une arme létale au plan légal
Voici, à peu près, comment fonctionnent les DRM : une entreprise veut fournir à un client (vous) un contenu dématérialisé (un film, un livre, une musique, un jeu vidéo, une application…) mais elle veut contrôler ce que vous faites avec ce contenu une fois que vous l’avez obtenu.
Alors elles chiffrent le fichier. On adore le chiffrement. Parce que ça fonctionne. Avec relativement peu d’efforts, n’importe qui peut chiffrer un fichier de sorte que personne ne pourra jamais le déchiffrer à moins d’obtenir la clef.
Supposons qu’il s’agisse de Netflix. Ils vous envoient un film qui a été chiffré et ils veulent être sûrs que vous ne pouvez pas l’enregistrer ni le regarder plus tard depuis votre disque dur. Mais ils ont aussi besoin de vous donner un moyen de voir le film. Cela signifie qu’il faut à un moment déchiffrer le film. Et il y a un seul moyen de déchiffrer un fichier qui a été entièrement chiffré : vous avez besoin de la clef.
Donc Netflix vous donne aussi la clef de déchiffrement.
Mais si vous avez la clef, vous pouvez déchiffrer les films de Netflix et les enregistrer sur votre disque dur. Comment Netflix peut-il vous donner la clef tout en contrôlant la façon dont vous l’utilisez ?
Netflix doit cacher la clef, quelque part dans votre ordinateur, dans une extension de navigateur ou une application par exemple. C’est là que la technologie atteint ses limites. Bien cacher quelque chose est difficile. Mais bien cacher quelque chose dans un appareil que vous donnez à votre adversaire pour qu’il puisse l’emporter avec lui et en faire ce qu’il veut, c’est impossible.
Peut-être ne pouvez-vous pas trouver les clefs que Netflix a cachées dans votre navigateur. Mais certains le peuvent : un étudiant en fin d’études qui s’ennuie pendant un week-end, un génie autodidacte qui démonte une puce dans son sous-sol, un concurrent avec un laboratoire entier à sa disposition. Une seule minuscule faille dans la fragile enveloppe qui entoure ces clefs et elles sont libérées !
Et une fois que cette faille est découverte, n’importe qui peut écrire une application ou une extension de navigateur avec un bouton « sauvegarder ». C’est l’échec et mat pour la technologie DRM (les clés fuitent assez souvent, au bout d’un temps comparable à celui qu’il faut aux entreprises de gestion des droits numériques pour révoquer la clé).
Il faut des années à des ingénieurs talentueux, au prix de millions de dollars, pour concevoir des DRM. Qui sont brisés au bout de quelques jours, par des adolescents, avec du matériel amateur. Ce n’est pas que les fabricants de DRM soient stupides, c’est parce qu’ils font quelque chose de stupide.
C’est là qu’intervient la loi sur les DRM, qui donne un contrôle légal plus puissant et plus étendu aux détenteurs de droits que les lois qui encadrent n’importe quel autre type de technologie. En 1998, le Congrès a adopté le Digital Milennium Copyright Act, DCMA dont la section 1201 prévoit une responsabilité pénale pour quiconque contourne un système de DRM dans un but lucratif : 5 ans d’emprisonnement et une amende de 500 000 $ pour une première infraction. Même le contournement à des fins non lucratives des DRM peut engager la responsabilité pénale. Elle rend tout aussi dangereux d’un point de vue légal le simple fait de parler des moyens de contourner un système de DRM.
Ainsi, la loi renforce les systèmes de DRM avec une large gamme de menaces. Si les gens de Netflix conçoivent un lecteur vidéo qui n’enregistrera pas la vidéo à moins que vous ne cassiez des DRM, ils ont maintenant le droit de porter plainte – ou faire appel à la police – contre n’importe quel rival qui met en place un meilleur service de lecture vidéo alternatif, ou un enregistreur de vidéo qui fonctionne avec Netflix. De tels outils ne violent pas la loi sur le droit d’auteur, pas plus qu’un magnétoscope ou un Tivo, mais puisque cet enregistreur aurait besoin de casser le DRM de Netflix, la loi sur les DRM peut être utilisée pour le réduire au silence.
La loi sur les DRM va au-delà de l’interdiction du contournement de DRM. Les entreprises utilisent aussi la section 1201 de la DMCA pour menacer des chercheurs en sécurité qui découvrent des failles dans leurs produits. La loi devient une arme qu’ils peuvent pointer sur quiconque voudrait prévenir leurs consommateurs (c’est toujours vous) que les produits auxquels vous faites confiance sont impropres à l’usage. Y compris pour prévenir les gens de failles dans les DRM qui pourraient les exposer au piratage.
Et il ne s’agit pas seulement des États-Unis, ni du seul DCMA. Le représentant du commerce international des États-Unis a « convaincu » des pays dans le monde entier d’adopter une version de cette règle.
Les DRM n’ont rien à voir avec le droit d’auteur
La loi sur les DRM est susceptible de provoquer des dommages incalculables. Dans la mesure où elle fournit aux entreprises le pouvoir de contrôler leurs produits après les avoir vendus, le pouvoir de décider qui peut entrer en compétition avec elles et sous quelles conditions, et même qui peut prévenir les gens concernant des produits défectueux, la loi sur les DRM constitue une forte tentation.
Certaines choses ne relèvent pas de la violation de droits d’auteur : acheter un DVD pendant que vous êtes en vacances et le passer quand vous arrivez chez vous. Ce n’est de toute évidence pas une violation de droits d’auteur d’aller dans un magasin, disons à New Delhi, d’acheter un DVD et de le rapporter chez soi à Topeka. L’ayant droit a fait son film, l’a vendu au détaillant, et vous avez payé au détaillant le prix demandé. C’est le contraire d’une violation de droits d’auteur. C’est l’achat d’une œuvre selon les conditions fixées par l’ayant droit. Mais puisque le DRM vous empêche de lire des disques hors-zone sur votre lecteur, les studios peuvent invoquer le droit d’auteur pour décider où vous pouvez consommer les œuvres sous droit d’auteur que vous avez achetées en toute honnêteté.
D’autres non-violations : réparer votre voiture (General Motors utilise les DRM pour maîtriser qui peut faire un diagnostic moteur, et obliger les mécaniciens à dépenser des dizaines de milliers de dollars pour un diagnostic qu’ils pourraient sinon obtenir par eux-mêmes ou par l’intermédiaire de tierces parties); recharger une cartouche d’encre (HP a publié une fausse mise à jour de sécurité qui a ajouté du DRM à des millions d’imprimantes à jet d’encre afin qu’elles refusent des cartouches reconditionnées ou venant d’un tiers), ou faire griller du pain fait maison (même si ça ne s’est pas encore produit, rien ne pourrait empêcher une entreprise de mettre des DRM dans ses grille-pains afin de contrôler la provenance du pain que vous utilisez).
Ce n’est pas non plus une violation du droit d’auteur de regarder Netflix dans un navigateur non-approuvé par Netflix. Ce n’est pas une violation du droit d’auteur d’enregistrer une vidéo Netflix pour la regarder plus tard. Ce n’est pas une violation du droit d’auteur de donner une vidéo Netflix à un algorithme qui pourra vous prévenir des effets stroboscopiques à venir qui peuvent provoquer des convulsions potentiellement mortelles chez les personnes atteintes d’épilepsie photosensible.
Ce qui nous amène au W3C
Le W3C est le principal organisme de normalisation du Web, un consortium dont les membres (entreprises, universités, agences gouvernementales, associations de la société civile entre autres) s’impliquent dans des batailles sans fin concernant le meilleur moyen pour tout le monde de fournir du contenu en ligne. Ils créent des « recommandations » (la façon pour le W3C de dire « standards »), ce sont un peu comme des étais invisibles qui soutiennent le Web. Ces recommandations, fruits de négociations patientes et de compromis, aboutissent à un consensus des principaux acteurs sur les meilleures (ou les moins pires) façons de résoudre certains problèmes technologiques épineux.
En 2013, Netflix et quelques autres entreprises du secteur des médias ont convaincu le W3C de commencer à travailler sur un système de DRM pour le Web. Ce système de DRM, Encrypted Media Extensions, constitue un virage à 180 degrés par rapport aux habitudes du W3C. Tout d’abord, les EME ne seraient pas un standard à part entière : l’organisation spécifierait une API au travers de laquelle les éditeurs et les vendeurs de navigateurs pourraient faire fonctionner les DRM, mais le « module de déchiffrement du contenu » (content decryption module, CDM) ne serait pas défini par la norme. Ce qui signifie que les EME n’ont de norme que le nom : si vous lanciez une entreprise de navigateurs en suivant toutes les recommandations du W3C, vous seriez toujours incapables de jouer une vidéo Netflix. Pour cela, vous auriez besoin de la permission de Netflix.
Je n’exagère pas en disant que c’est vraiment bizarre. Les standards du Web existent pour assurer « une interopérabilité sans permission ». Les standards de formatage de texte sont tels que n’importe qui peut créer un outil qui peut afficher les pages du site web du New York Times, les images de Getty ou les diagrammes interactifs sur Bloomberg. Les entreprises peuvent toujours décider de qui peut voir quelles pages de leur site web (en décidant qui possède un mot de passe et quelles parties du site sont accessibles par chaque mot de passe), mais elles ne décident pas de qui peut créer le programme de navigateur web dans lequel vous entrez le mot de passe pour accéder au site.
Un Web où chaque éditeur peut choisir avec quels navigateurs vous pouvez visiter son site est vraiment différent du Web historique. Historiquement, chacun pouvait concevoir un nouveau navigateur en s’assurant qu’il respecte les recommandations du W3C, puis rivaliser avec les navigateurs déjà présents. Et bien que le Web ait toujours été dominé par quelques navigateurs, le navigateur dominant a changé toutes les décennies, de sorte que de nouvelles entreprises ou même des organisations à but non lucratif comme Mozilla (qui a développé Firefox) ont pu renverser l’ordre établi. Les technologies qui se trouvaient en travers de cette interopérabilité sans permission préalable – comme les technologies vidéos brevetées – ont été perçues comme des entraves à l’idée d’un Web ouvert et non comme des opportunités de standardisation.
Quand les gens du W3C ont commencé à créer des technologies qui marchent uniquement quand elles ont reçu la bénédiction d’une poignée d’entreprises de divertissement, ils ont mis leurs doigts – et même leurs mains – dans l’engrenage qui assurera aux géants de la navigation un règne perpétuel.
Mais ce n’est pas le pire. Jusqu’aux EME, les standards du W3C étaient conçus pour donner aux utilisateurs du Web (i.e. vous) plus de contrôle sur ce que votre ordinateur fait quand vous visitez les sites web d’autres personnes. Avec les EME, et pour la toute première fois, le W3C est en train de concevoir une technologie qui va vous enlever ce contrôle. Les EME sont conçus pour autoriser Netflix et d’autres grosses entreprises à décider de ce que fait votre navigateur, même (et surtout) quand vous êtes en désaccord avec ce qui devrait se passer.
Il y a un débat persistant depuis les débuts de l’informatique pour savoir si les ordinateurs existent pour contrôler leurs utilisateurs, ou vice versa (comme le disait l’informaticien visionnaire et spécialiste de l’éducation Seymour Papert « les enfants devraient programmer les ordinateurs plutôt que d’être programmés par eux » – et ça s’applique aussi bien aux adultes). Tous les standards du W3C jusqu’en 2017 ont été en faveur du contrôle des ordinateurs par les utilisateurs. Les EME rompent avec cette tradition. C’est un changement subtil mais crucial.
…et pourquoi le W3C devrait faire ça ?
Aïe aïe aïe. C’est la question à trois milliards d’utilisateurs.
La version de cette histoire racontée par le W3C ressemble un peu à ce qui suit. L’apparition massive des applications a affaibli le Web. À l’époque « pré-applis», le Web était le seul joueur dans la partie, donc les sociétés devaient jouer en suivant ses règles : standards libres, Web libre. Mais maintenant que les applications existent et que presque tout le monde les utilise, les grandes sociétés peuvent boycotter le Web, obligeant leurs utilisateurs à s’orienter vers les applications. Ce qui ne fait qu’accélérer la multiplication des applis, et affaiblit d’autant plus le Web. Les applications ont l’habitude d’implémenter les DRM, alors les sociétés utilisant ces DRM se sont tournées vers les applis. Afin d’empêcher les entreprises du divertissement de tuer le Web, celui-ci doit avoir des DRM également.
Toujours selon cette même théorie, même si ces sociétés n’abandonnent pas entièrement le Web, il est toujours préférable de les forcer à faire leurs DRM en suivant le W3C que de les laisser faire avec les moyens ad hoc. Laissées à elles-mêmes, elles pourraient créer des DRM ne prenant pas en compte les besoins des personnes à handicap, et sans l’influence modératrice du W3C, ces sociétés créeraient des DRM ne respectant pas la vie privée numérique des utilisateurs.
On ne peut pas espérer d’une organisation qu’elle dépense des fortunes pour créer des films ou en acquérir des licences puis distribue ces films de telle sorte que n’importe qui puisse les copier et les partager.
Nous pensons que ces arguments sont sans réel fondement. Il est vrai que le Web a perdu une partie de sa force liée à son exclusivité du début, mais la vérité c’est que les entreprises gagnent de l’argent en allant là où se trouvent leurs clients. Or tous les clients potentiels ont un navigateur, tandis que seul les clients déjà existants ont les applications des entreprises. Plus il y aura d’obstacles à franchir entre vous et vos clients, moins vous aurez de clients. Netflix est sur un marché hyper-compétitif avec des tonnes de nouveaux concurrents (p.ex. Disney), et être considéré comme « ce service de streaming inaccessible via le Web » est un sérieux désavantage.
Nous pensons aussi que les médias et les entreprises IT auraient du mal à se mettre d’accord sur un standard pour les DRM hors W3C, même un très mauvais standard. Nous avons passé beaucoup de temps dans les salles remplies de fumée où se déroulait la standardisation des systèmes de DRM ; la dynamique principale était celles des médias demandant le verrouillage complet de chaque image de chaque vidéo, et des entreprises IT répondant que le mieux que quiconque puisse espérer était un ralentissement peu efficace qu’elles espéraient suffisant pour les médias. La plupart du temps, ces négociations s’effondrent sans arriver nulle part.
Il y a aussi la question des brevets : les entreprises qui pensent que les DRM sont une bonne idée adorent les brevets logiciels, et le résultat est un fouillis sans nom de brevets qui empêchent de parvenir à faire quoi que ce soit. Le mécanisme de regroupement de brevets du W3C (qui se démarque par sa complétude dans le monde des standards et constitue un exemple de la meilleure façon d’accomplir ce genre de choses) a joué un rôle indispensable dans le processus de standardisation des DRM. De plus, dans le monde des DRM, il existe des acteurs-clefs – comme Adobe – qui détiennent d’importants portfolios de brevets mais jouent un rôle de plus en plus réduit dans le monde des DRM (l’objectif avoué du système EME est de « tuer Flash »).
Si les entreprises impliquées devaient s’asseoir à la table des négociations pour trouver un nouvel accord sur les brevets sans le framework du W3C, n’importe laquelle de ces entreprises pourrait virer troll et décider que les autres doivent dépenser beaucoup d’argent pour obtenir une licence sur leurs brevets – elle n’aurait rien à perdre à menacer le processus de négociations et tout à gagner même sur des droits par utilisateur, même minuscules, pour quelque chose qui sera installé dans trois milliards de navigateurs.
En somme, il n’y a pas de raison de penser que les EME ont pour objectif de protéger des intérêts commerciaux légitimes. Les services de streaming vidéo comme Netflix reposent sur l’inscription de leurs clients à toute une collection, constamment enrichie avec de nouveaux contenus et un système de recommandations pour aider ses utilisateurs à s’y retrouver.
Les DRM pour les vidéos en streaming sont ni plus ni moins un moyen d’éviter la concurrence, pas de protéger le droit d’auteur. L’objectif des DRM est de munir les entreprises d’un outil légal pour empêcher des activités qui seraient autorisées sinon. Les DRM n’ont pas vocation à « fonctionner » (au sens de prévenir les atteintes au droit d’auteur) tant qu’ils permettent d’invoquer le DMCA.
Pour vous en convaincre, prenez simplement l’exemple de Widevine, la version des EME de Google. Ce mastodonte a racheté la boîte qui développait Widevine en 2010, mais il a fallu attendre 2016, pour qu’un chercheur indépendant se penche réellement sur la façon dont elle empêchait la fuite de ses vidéos. Ce chercheur, David Livshits a remarqué que Widevine était particulièrement facile à contourner, et ce dès sa création, et que les erreurs qui rendaient Widevine aussi inefficace étaient évidentes, même avec un examen superficiel. Si les millions de dollars et le personnel hautement qualifié affectés aux EME avaient pour but de créer une technologie qui lutterait efficacement contre les atteintes au droit d’auteur, alors vous pourriez croire que Netflix ou une des autres entreprises de médias numériques impliquées dans les négociations auraient utilisé une partie de toutes ces ressources à un rapide audit, pour s’assurer que leur produit fonctionne réellement comme annoncé.
(Détail amusant : Livshits est un Israélien qui travaille à l’université Ben Gourion, et il se trouve que l’Israël est un des rares pays qui ne condamnent pas les violations de DRM, ce qui signifie que les Israéliens font partie des seules personnes qui peuvent faire ce type de recherche, sans craintes de représailles juridiques)
Mais la plus belle preuve que les EME étaient tout simplement un moyen d’éliminer les concurrents légitimes, et non une tentative de protection du droit d’auteur, la voici.
Une expérience sous contrôle
Lorsque l’EFF a rejoint le W3C, notre principale condition était « ne faites pas de DRM ».
Nous avons porté l’affaire devant l’organisation, en décrivant la façon dont les DRM interférent avec les exceptions aux droits auteurs essentielles (comme celles qui permettent à chaque individu d’enregistrer et modifier un travail protégé par droits d’auteur, dans le cadre d’une critique, ou d’une adaptation) ainsi que la myriade de problèmes posés par le DMCA et par d’autres lois semblables à travers le monde.
L’équipe de direction de la W3C a tout simplement réfuté tous les arguments à propos des usages raisonnables et des droits d’utilisateurs prévus par le droit d’auteur, comme étant, en quelque sorte, des conséquences malheureuses de la nécessité d’éviter que Netflix n’abandonne le Web, au profit des applications. Quant au DMCA, ils ont répondu qu’ils ne pouvaient faire quoi que ce soit à propos de cette loi irrationnelle, mais qu’ils avaient la certitude que les membres du W3C n’avaient aucunement l’intention de violer le DMCA, ils voulaient seulement éviter que leurs films de grande valeur ne soient partagés sur Internet.
Nous avons donc changé de stratégie, et proposé une sorte d’expérience témoin afin de savoir ce que les fans de DRM du W3C avaient comme projets.
Le W3C est un organisme basé sur le consensus : il crée des standards, en réunissant des gens dans une salle pour faire des compromis, et aboutir à une solution acceptable pour chacun. Comme notre position de principe était « pas de DRM au W3C » et que les DRM sont une si mauvaise idée, il était difficile d’imaginer qu’un quelconque compromis pouvait en sortir.
Mais après avoir entendu les partisans du DRM nier leurs abus du DCMA, nous avons pensé que nous pouvions trouver quelque chose qui permettrait d’avancer par rapport à l’actuel statu quo et pourrait satisfaire le point de vue qu’ils avaient évoqué.
Nous avons proposé un genre de pacte de non-agression par DRM, par lequel les membres du W3C promettraient qu’ils ne poursuivraient jamais quelqu’un en justice en s’appuyant sur des lois telles que la DMCA 1201, sauf si d’autres lois venaient à être enfreintes. Ainsi, si quelqu’un porte atteinte à vos droits d’auteur, ou incite quelqu’un à le faire, ou empiète sur vos contrats avec vos utilisateurs, ou s’approprie vos secrets de fabrication, ou copie votre marque, ou fait quoique ce soit d’autre, portant atteinte à vos droits légaux, vous pouvez les attaquer en justice.
Mais si quelqu’un s’aventure dans vos DRM sans enfreindre aucune autre loi, le pacte de non-agression stipule que vous ne pouvez pas utiliser le standard DRM du W3C comme un moyen de les en empêcher. Cela protégerait les chercheurs en sécurité, cela protégerait les personnes qui analysent les vidéos pour ajouter des sous-titres et d’autres outils d’aide, cela protégerait les archivistes, qui ont légalement le droit de faire des copies, et cela protégerait ceux qui créent de nouveaux navigateurs.
Si tout ce qui vous intéresse c’est de créer une technologie efficace contre les infractions à la loi, ce pacte ne devrait poser aucun problème. Tout d’abord, si vous pensez que les DRM sont une technologie efficace, le fait qu’il soit illégal de les critiquer ne devrait pas avoir d’importance.
Et étant donné que le pacte de non-agression permet de conserver tous les autres droits juridiques, il n’y avait aucun risque que son adoption permette à quelqu’un d’enfreindre la loi en toute impunité. Toute personne qui porterait atteinte à des droits d’auteur (ou à tout autre droit) serait dans la ligne de mire du DMCA, et les entreprises auraient le doigt sur la détente.
Pas surprenant, mais très décevant
Bien entendu, ils ont détesté cette idée.
Les studios, les marchands de DRM et les grosses entreprises membres du W3C ont participé à une « négociation » brève et décousue avant de voter la fin des discussions et de continuer. Le représentant du W3C les a aidés à éviter les discussions, continuant le travail sur la charte de EME sans prévoir de travail en parallèle sur la protection du Web ouvert, même quand l’opposition à l’intérieur du W3C grandissait.
Le temps que la poussière retombe, les EME ont été publiés après le vote le plus controversé que le W3C ait jamais vu, avec le représentant du W3C qui a déclaré unilatéralement que les problèmes concernant la sûreté des recherches, l’accessibilité, l’archivage et l’innovation ont été traités au mieux (malgré le fait que littéralement rien de contraignant n’a été décidé à propos de ces sujets). La recherche de consensus du W3C a été tellement détournée de son cours habituel que la publication de EME a été approuvée par seulement 58% des membres qui ont participé au vote final, et nombre de ces membres ont regretté d’avoir été acculés à voter pour ce à quoi ils avaient émis des objections.
Quand le représentant du W3C a déclaré que n’importe quelle protection pour un Web ouvert était incompatible avec les souhaits des partisans des DRM, cela ressemblait à une justification ironique. Après tout, c’est comme ça que l’on a commencé avec l’EFF insistant sur le fait que les DRM n’étaient pas compatibles avec les révélations de faille de sécurité, avec l’accessibilité, avec l’archivage ou encore l’innovation. Maintenant, il semble que nous soyons tous d’accord.
De plus, ils se sont tous implicitement mis d’accord pour considérer que les DRM ne concernent pas la protection du droit d’auteur. Mais concerne l’utilisation du droit d’auteur pour s’emparer d’autres droits, comme celui de décider qui peut critiquer ou non votre produit – ou qui peut le concurrencer.
Le simulacre de cryptographie des DRM implique que ça marche seulement si vous n’êtes pas autorisé à comprendre ses défauts. Cette hypothèse s’est confirmée lorsqu’un membre du W3C a déclaré au consortium qu’il devrait protéger les publications concernant les « environnements de tests de confidentialité » des EME permettant l’espionnage intrusif des utilisateurs, et dans la minute, un représentant de Netflix a dit que cette option n’était même pas envisageable.
D’une certaine façon, Netflix avait raison. Les DRM sont tellement fragiles, tellement incohérents, qu’ils sont simplement incompatibles avec les normes du marché et du monde scientifique, où tout le monde est libre de décrire ses véritables découvertes, même si elles frustrent les aspirations commerciales d’une multinationale.
Le W3C l’a implicitement admis, car il a tenté de réunir un groupe de discussion pour élaborer une ligne de conduite à destination des entreprises utilisant l’EME : dans quelle mesure utiliser la puissance légale des DRM pour punir les détracteurs, à quel moment autoriser une critique.
« Divulgation responsable selon nos règles,
ou bien c’est la prison »
Ils ont appelé ça la divulgation responsable, mais elle est loin de celle qu’on voit aujourd’hui. En pratique, les entreprises font les yeux doux aux chercheurs en sécurité pour qu’ils communiquent leurs découvertes à des firmes commerciales avant de les rendre publiques. Leurs incitations vont de la récompense financière (bug bounty), à un système de classement qui leur assure la gloire, ou encore l’engagement de donner suite aux divulgations en temps opportun, plutôt que de croiser les doigts, de s’asseoir sur les défauts fraîchement découverts et d’espérer que personne d’autre ne les redécouvrira dans le but de les exploiter.
La tension qui existe entre les chercheurs indépendants en sécurité et les grandes entreprises est aussi vieille que l’informatique. Il est difficile de protéger un ordinateur du fait de sa complexité. La perfection est inatteignable. Garantir la sécurité des utilisateurs d’ordinateurs en réseau nécessite une évaluation constante et la divulgation des conclusions, afin que les fabricants puissent réparer leurs bugs et que les utilisateurs puissent décider de façon éclairée quels systèmes sont suffisamment sûrs pour être utilisés.
Mais les entreprises ne réservent pas toujours le meilleur accueil aux mauvaises nouvelles lorsqu’il s’agit de leurs produits. Comme des chercheurs ont pu en faire l’expérience — à leurs frais — mettre une entreprise face à ses erreurs peut être une question de savoir-vivre, mais c’est un comportement risqué, susceptible de faire de vous la cible de représailles si vous vous avisez de rendre les choses publiques. Nombreux sont les chercheurs ayant rapporté un bogue à une entreprise, pour constater l’intolérable durée de l’inaction de celle-ci, laissant ses utilisateurs exposés au risque. Bien souvent, ces bogues ne font surface qu’après avoir été découverts par ailleurs par des acteurs mal intentionnés ayant vite fait de trouver comment les exploiter, les transformant ainsi en attaques touchant des millions d’utilisateurs. Bien trop nombreux pour que l’existence de bogues puisse plus longtemps être passée sous silence.
Comme le monde de la recherche renâclait de plus en plus à leur parler, les entreprises ont été obligées de s’engager concrètement à ce que les découvertes des chercheurs soient suivies de mesures rapides, dans un délai défini, à ce que les chercheurs faisant part de leurs découvertes ne soient pas menacés et même à offrir des primes en espèces pour gagner la confiance des chercheurs. La situation s’est améliorée au fil des ans, la plupart des grandes entreprises proposant une espèce de programme relatif aux divulgations.
Mais la raison pour laquelle les entreprises donnent des assurances et offrent des primes, c’est qu’elles n’ont pas le choix. Révéler que des produits sont défectueux n’est pas illégal, et donc les chercheurs qui mettent le doigt sur ces problèmes n’ont aucune obligation de se conformer aux règles des entreprises. Ce qui contraint ces dernières à faire preuve de leur bonne volonté par leur bonne conduite, des promesses contraignantes et des récompenses.
Les entreprises veulent absolument être capables de déterminer qui a le droit de dire la vérité sur leurs produits et quand. On le sait parce que, quand elles ont une occasion d’agir en ce sens, elles la saisissent. On le sait parce qu’elles l’ont dit au W3C. On le sait parce qu’elles ont exigé ce droit comme partie intégrante du paquet DRM dans le cadre EME.
De tous les flops du processus DRM au sein du W3C, le plus choquant a été le moment où les avocats historiques du Web ouvert ont tenté de convertir un effort de protection des droits des chercheurs à avertir des milliards de gens des vulnérabilités de leurs navigateurs web en un effort visant à conseiller les entreprises quant au moment où renoncer à exercer ce droit. Un droit qu’elles n’ont que grâce à la mise au point des DRM pour le Web par le W3C.
Les DRM sont le contraire de la sécurité
Depuis le début de la lutte contre les DRM au W3C, on a compris que les fabricants de DRM et les entreprises de médias qu’elles fournissent n’étaient pas là pour protéger le droit d’auteur, mais pour avoir une base légale sur laquelle asseoir des privilèges sans rapport avec le droit d’auteur. On savait aussi que les DRM étaient incompatibles avec la recherche en sûreté : puisque les DRM dépendent de l’obfuscation (NdT: rendre illisible pour un humain un code informatique), quiconque documente comment les DRM marchent les empêche aussi de fonctionner.
C’est particulièrement clair à travers ce qui n’a pas été dit au W3C : quand on a proposé que les utilisateurs puissent contourner les DRM pour générer des sous-titres ou mener des audits de sécurité, les intervenants se demandaient toujours si c’était acceptable, mais jamais si c’était possible.
Il faut se souvenir que EME est supposé être un système qui aide les entreprises à s’assurer que leurs films ne sont pas sauvegardés sur les disques durs de leurs utilisateurs et partagés sur Internet. Pour que ça marche, cela doit être, vous savez, compliqué.
Mais dans chaque discussion pour déterminer quand une personne peut être autorisée à casser EME, il était toujours acquis que quiconque voulait le faire le pouvait. Après tout, si vous cachez des secrets dans le logiciel que vous donnez aux mêmes personnes dont vous voulez cacher les secrets, vous allez probablement être déçu.
Dès le premier jour, nous avons compris que nous arriverions à un point où les défenseurs des DRM au W3C seraient obligés d’admettre que le bon déroulement de leur plan repose sur la capacité à réduire au silence les personnes qui examineront leurs produits.
Cependant, nous avons continué à espérer : une fois que cela sera clair pour tout le monde, ils comprendront que les DRM ne peuvent coexister pacifiquement avec le Web ouvert.
Le succès des DRM au W3C est une parabole de la concentration des marchés et de la fragilité du Web ouvert. Des centaines de chercheurs en sécurité ont fait du lobbying au W3C pour protéger leur travail, l’UNESCO a condamné publiquement l’extension des DRM au Web, et les nombreuses crypto-monnaies membres du W3C ont prévenu que l’utilisation de navigateurs pour des applications critiques et sûres, par exemple pour déplacer les avoirs financiers des gens, ne peut se faire que si les navigateurs sont soumis aux mêmes normes de sécurité que les autres technologies utilisées dans nos vies (excepté les technologies DRM).
Il ne manque pas de domaines d’activités qui veulent pouvoir contrôler ce que leurs clients et concurrents font avec leurs produits. Quand les membres du Copyright Office des États-Unis ont entendu parler des DRM en 2015, il s’agissait pour eux des DRM dans des implants médicaux et des voitures, de l’équipement agricole et des machines de votes. Des entreprises ont découvert qu’ajouter des DRM à leurs produits est la manière la plus sûre de contrôler le marché, une façon simple et fiable de transformer en droits exclusifs les choix commerciaux pour déterminer qui peut réparer, améliorer et fournir leurs produits .
Les conséquences néfastes sur le marché économique de ce comportement anticoncurrentiel sont faciles à voir. Par exemple, l’utilisation intempestive des DRM pour empêcher des magasins indépendants de réparer du matériel électronique provoque la mise à la poubelle de tonnes de composants électroniques, aux frais des économies locales et de la possibilité des clients d’avoir l’entière propriété de leurs objets. Un téléphone que vous recyclez au lieu de le réparer est un téléphone que vous avez à payer pour le remplacer – et réparer crée beaucoup plus d’emplois que de recycler (recycler une tonne de déchets électroniques crée 15 emplois, la réparer crée 150 emplois). Les emplois de réparateurs sont locaux et incitent à l’entrepreneuriat, car vous n’avez pas besoin de beaucoup de capital pour ouvrir un magasin de réparations, et vos clients voudront amener leurs objets à une entreprise locale (personne ne veut envoyer un téléphone en Chine pour être réparé – encore moins une voiture !).
Mais ces dégâts économiques sont seulement la partie émergée de l’iceberg. Des lois comme le DMCA 1201 incitent à l’utilisation de DRM en promettant de pouvoir contrôler la concurrence, mais les pires dommages des DRM sont dans le domaine de la sécurité. Quand le W3C a publié EME, il a légué au Web une surface d’attaque qu’on ne peut auditer dans des navigateurs utilisés par des milliards de personnes pour leurs applications les plus risquées et importantes. Ces navigateurs sont aussi l’interface de commande utilisée pour l’Internet des objets : ces objets, garnis de capteurs, qui peuvent nous voir, nous entendre, et agir sur le monde réel avec le pouvoir de nous bouillir, geler, électrifier, blesser ou trahir de mille façons différentes.
Ces objets ont eux-mêmes des DRM, conçus pour verrouiller nos biens, ce qui veut dire que tout ce qui va de votre grille-pain à votre voiture devient hors de portée de l’examen de chercheurs indépendants qui peuvent vous fournir des évaluations impartiales et sans fard sur la sécurité et de la fiabilité de ces appareils.
Dans un marché concurrentiel, on pourrait s’attendre à ce que des options sans DRM prolifèrent en réaction à ce mauvais comportement. Après tout, aucun client ne veut des DRM : aucun concessionnaire automobile n’a jamais vendu une nouvelle voiture en vantant le fait que c’était un crime pour votre mécanicien préféré de la réparer.
Mais nous ne vivons pas dans un marché concurrentiel. Les lois telles que DMCA 1201 minent toute concurrence qui pourrait contrebalancer leurs pires effets.
Les entreprises qui se sont battues pour les DRM au W3C – vendeurs de navigateurs, Netflix, géants de la haute technologie, l’industrie de la télévision par câble – trouvent toutes l’origine de leur succès dans des stratégies commerciales qui ont, au moment de leur émergence, choqué et indigné les acteurs du secteur déjà établis. La télévision par câble était à ses débuts une activité qui retransmettait des émissions et facturait ce service sans avoir de licence. L’hégémonie d’Apple a commencé par l’extraction de cédéroms, en ignorant les hurlements de l’industrie musicale (exactement comme Firefox a réussi en bloquant les publicités pénibles et en ignorant les éditeurs du web qui ont perdu des millions en conséquence). Bien sûr, les enveloppes rouges révolutionnaires de Netflix ont été traitées comme une forme de vol.
Ces boîtes ont démarré comme pirates et sont devenus des amiraux, elles traitent leurs origines comme des légendes de courageux entrepreneurs à l’assaut d’une structure préhistorique et fossilisée. Mais elles traitent toute perturbation à leur encontre comme un affront à l’ordre naturel des choses. Pour paraphraser Douglas Adams, toute technologie inventée pendant votre adolescence est incroyable et va changer le monde ; tout ce qui est inventé après vos 30 ans est immoral et doit être détruit.
Leçons tirées du W3C
La majorité des personnes ne comprennent pas le danger des DRM. Le sujet est bizarre, technique, ésotérique et prend trop de temps à expliquer. Les partisans des DRM veulent faire tourner le débat autour du piratage et de la contrefaçon, qui sont des histoires simples à raconter.
Mais les promoteurs des DRM ne se préoccupent pas de ces aspects et on peut le prouver : il suffit de leur demander s’ils seraient partants pour promettre de ne pas avoir recours au DMCA tant que personne ne viole de droit d’auteur. On pourrait alors observer leurs contorsions pour ne pas évoquer la raison pour laquelle faire appliquer le droit d’auteur devrait empêcher des activités connexes qui ne violent pas le droit d’auteur. À noter : ils n’ont jamais demandé si quelqu’un pourrait contourner leurs DRM, bien entendu. Les DRM sont d’une telle incohérence technique qu’ils ne sont efficaces que s’il est interdit par la loi de comprendre leur fonctionnement. Il suffit d’ailleurs de les étudier un peu attentivement pour les mettre en échec.
Demandez-leur de promettre de ne pas invoquer le DMCA contre les gens qui ont découvert des défauts à leurs produits et écoutez-les argumenter que les entreprises devraient obtenir un droit de veto contre la publication de faits avérés sur leurs erreurs et manquements.
Ce tissu de problèmes montre au moins ce pour quoi nous nous battons : il faut laisser tomber les discussions hypocrites relatives au droit d’auteur et nous concentrer sur les vrais enjeux : la concurrence, l’accessibilité et la sécurité.
Ça ne se réglera pas tout seul. Ces idées sont toujours tordues et nébuleuses.
Voici une leçon que nous avons apprise après plus de 15 ans à combattre les DRM : il est plus facile d’inciter les personnes à prêter attention à des problèmes de procédure qu’à des problèmes de fond. Nous avons travaillé vainement à alerter le grand public sur le Broadcasting Treaty, un traité d’une complexité déconcertante et terriblement complexe de l’OMPI, une institution spécialisée des Nations Unies. Tout le monde s’en moquait jusqu’à ce que quelqu’un dérobe des piles de nos tracts et les dissimule dans les toilettes pour empêcher tout le monde de les lire. Et c’est cela qui a fait la Une : il est très difficile de se faire une idée précise d’un truc comme le Broadcast Treaty, mais il est très facile de crier au scandale quand quelqu’un essaie de planquer vos documents dans les toilettes pour que les délégués ne puissent pas accéder à un point de vue contradictoire.
C’est ainsi qu’après quatre années de lutte inefficace au sujet des DRM au sein du W3C, nous avons démissionné ; c’est alors que tout le monde s’est senti concerné, demandant comment résoudre le problème. La réponse courte est « Trop tard : nous avons démissionné, car il n’y a plus rien à faire ».
Mais la réponse longue laisse un peu plus d’espoir. EFF est en train d’attaquer le gouvernement des États-Unis pour casser la Section 1201 du DMCA. Comme on l’a montré au W3C, il n’y a pas de demande pour des DRM à moins qu’il y ait une loi comme le DMCA 1201. Les DRM en soi ne font rien d’autre que de permettre aux compétiteurs de bloquer des offres innovantes qui coûtent moins et font plus.
Le Copyright Office va bientôt entendre des nouveaux échos à propos du DMCA 1201.
Le combat du W3C a montré que nous pouvions ramener le débat aux vrais problèmes. Les conditions qui ont amené le W3C à être envahi par les DRM sont toujours d’actualité et d’autres organisations vont devoir faire face à cette menace dans les années à venir. Nous allons continuer à affiner notre tactique et à nous battre, et nous allons aussi continuer à rendre compte des avancées afin que vous puissiez nous aider. Tout ce que nous demandons est que vous continuiez à être vigilant. Comme on l’a appris au W3C, on ne peut pas le faire sans vous.
Framatube : nos réponses à vos questions pratiques !
Avant de vous partager ces échanges, voici un petit résumé de la situation 😉
Expliquer Framatube en 3mn
Si vous n’avez pas encore entendu parler de Framatube et de PeerTube (ou si vous voulez en parler autour de vous), on a une astuce ! Hélène Chevallier, journaliste à France Inter, nous a interviewé et a résumé les enjeux et notre démarche dans sa chronique « C’est déjà demain » du 28 novembre dernier, que voici :
Pour rappel, n’hésitez pas à nous soutenir dans le financement de PeerTube et dans l’ensemble de nos actions, en faisant un don.
Mais revenons-en au propos de cet article : vos questions ! Nous avons regroupé les réponses à des questions plus techniques dans un autre article sur ce blog ^^. Sauf mention contraire, toutes les réponses sont de Chocobozzz, le développeur que nous avons accueilli dans notre équipe salariée afin qu’il puisse finaliser le code de PeerTube. De même, la plupart des questions ont été raccourcies ou reformulées pour plus de lisibilité, mais l’intégralité des échanges se trouve sur notre forum !
Olivier Massain a profité de notre foire aux questions pour proposer son aide sur le design de PeerTube : ça va péter la classe !
Quels contenus, quelles vidéos…?
TeemoT
— Je voudrais en savoir plus sur le type de contenus qui y seraient hébergés, n’importe quelle vidéo pourrait y être ? Ou y a-t-il des règles à respecter ?
Pouhiou souhaite répondre ici :
À vrai dire, cela dépendra de chaque hébergement PeerTube.
Car, et c’est important de le souligner : a priori, Framasoft n’hébergera pas vos vidéos sur Framatube.
En effet, notre but est que se monte une fédération d’instances PeerTube à la fois indépendantes et dans une entraide commune. Or, si nous ouvrons notre instance de PeerTube (qui sera donc Framatube) aux vidéos de tout le monde, la facilité fera que les vidéos seront postées chez nous et de ne pas chercher à créer sa propre instance ou a se regrouper par communauté d’intérêts.
Du coup, nous serons là pour aider et accompagner les personnes, associations, collectifs de vidéastes, lieux de formation, médias, etc. qui veulent monter leur instance et se fédérer. Mais ce sera à chacune de ces instances de choisir quelle porte d’entrée vers PeerTube elle veut être, donc par exemple de déterminer leurs conditions générales d’utilisation.
Du coup, le type de contenus vidéos dépendra forcément des personnes qui se regrouperont pour héberger des vidéos sur leurs instances et des vidéos qu’elles y accepteront ;).
arthurrambo
— Qu’en est-il des vidéos prônant l’homophobie, l’antisémitisme et le racisme ? Seront-elles supprimées comme sur YouTube ? Quelles conséquences pourra-t-il y avoir sur le créateur ?
Une vidéo peut-être signalée par un utilisateur. Le signalement va à l’administrateur/modérateurs du serveur sur lequel est enregistré l’utilisateur, plus à l’administrateur/modérateurs du serveur qui possède la vidéo.
C’est donc à eux d’évaluer s’ils veulent ou non supprimer la vidéo (puis potentiellement l’utilisateur) :
Si le serveur détient la vidéo elle est supprimée en local puis sur l’ensemble du réseau (par fédération) ;
Si le serveur ne détient pas la vidéo elle est simplement supprimée en local.
Pyg se permet d’ajouter :
À la réponse de Chocobozzz concernant l’outil, j’ajoute celle de la loi.
En effet, trop peu de contenus contenant des discours de haine sont signalés. Certes, les procédures sont longues, mais trop peu de gens les utilisent, ce qui a pour conséquence de laisser croire que la plateforme (Twitter, Facebook, ou ici une instance PeerTube) est « le » interlocuteur pour signaler les contenus.
Sur Mastodon, on a bien vu que beaucoup s’étaient crus, au départ, dans un nouveau Far West (« c’est mon instance, je fais ce que je veux »). Il faut rappeler la loi, encore et encore, et la faire vivre, car c’est elle qui est l’un des principaux supports du « vivre ensemble ».
Il va de soi, mais ça va mieux en le disant, que sur notre future instance PeerTube, aucun propos contraire à ces lois ne saura être toléré.
JonathanMM
— Est ce qu’à l’ouverture du service, il est prévu des vidéos de gens connus (style gros youtubeurs), histoire qu’il y ait déjà un peu de contenu grand public et que ça ne part pas de presque rien ?
Pouhiou a un début de réponse :
Pour l’instant, peu de choses sont prévues : on vient tout juste d’annoncer le projet !
L’idée est justement de commencer à entrer en contact avec divers collectifs pour voir s’ils ont envie d’avoir une instance PeerTube, de s’approprier leurs moyens de diffusion. Nous discutons actuellement avec des associations, des fédérations, et avec quelques vidéastes pour voir si et comment nous pourrions les accompagner. Mais ne mettons pas la charrue avant les bœufs : il faut d’abord avoir un code fonctionnel, une interface accueillante, bref un outil qui soit facile à installer et utiliser.
Du coup, ce travail d’accompagnement se fera entre janvier et février, et nous enjoignons tout groupe souhaitant devenir son propre hébergeur de vidéos (même si c’est en parallèle d’une chaîne YouTube, au moins au début) à nous contacter pour qu’on puisse les aider ;).
Mais soyons francs : en mars 2018, ce sera le début d’un nouveau réseau d’hébergement de vidéos, et non un bouquet final !
acryline
— J’aimerais savoir si un jour Peertube pourra permettre le live streaming ?
Ça risque d’être compliqué, car le torrent fonctionne sur des fichiers finis immuables.
Certains ont essayé en générant en boucle un fichier torrent toutes les x secondes, puis en l’envoyant aux autres clients. Je n’ai pas testé mais c’est plutôt ingénieux. Après est-ce que ça marche bien et efficacement, je ne sais pas parce que c’est un peu de la bidouille.
Au lieu d’utiliser BitTorrent on pourrait imaginer utiliser que la fédération de serveurs, on partagerait la bande passante entre les serveurs. Après ça ne reste qu’une idée. Mais c’est loin d’être pour tout de suite. 🙂
Oui, il y a possibilité d’incruster la vidéo dans n’importe quelle page web.
— Comment se comporte PeerTube quand il y a des accès simultanés depuis un même réseau intranet ?
Que ce soit via intranet ou internet il y utilisation de WebRTC, qui regardera s’il y a un moyen pour ces différents utilisateurs de s’échanger de la donnée. S’il y a possibilité (pare-feu/routeur sympa) ça sera fait automatiquement. Sinon ça passera simplement par HTTP sans notion de pair-à-pair.
buyaman
— Comment procéder pour une transition en douceur entre les plateformes actuelles et la vôtre ? Ex: je suis un vidéaste au contenu prolifique (1000 vidéos) en combien de temps je fais le transfert ?
Tout dépend de votre plate-forme actuelle, mais on aimerait ajouter une interface d’import (depuis YouTube notamment).
— Et serait-ce une transition abrupte ou en douceur (les deux plateformes utilisées le temps de la transition) ?
C’est à vous de décider 😉
Aitua;
— J’imagine que si le filtrage automatique est inscrit dans la loi européenne, les serveurs dans l’UE seraient obligés d’imposer un tel filtrage ?
Pouhiou a été invité à répondre :
Question très très intéressante, car elle montre que ce projet de loi n’est pensé que pour des plateformes centralisatrices de gros hébergeurs (qui ont les moyens de mettre en place de tels filtres) et pénalise de fait l’auto-hébergement ou l’hébergement mutualisé, tout en déconsidérant d’emblée les systèmes décentralisés ou distribués.
Déjà, il faut se dire qu’entre le fait que cela entre dans une loi/directive européenne, le fait d’avoir des décrets d’application, le fait que cela ne soit pas démonté par le conseil constitutionnel (j’avais lu quelque part que cette proposition avait toutes les chances d’être écartée à ce niveau)… Bref : on a le temps de voir venir !
Et la question finale : qu’est-ce qu’un filtre automatique ? S’il suffit d’analyser le texte donné en titre à la vidéo ou d’ajouter une case à cocher lors de l’upload « promis je respecte le copyright« , ça peut facilement être implémenté…
Bref, c’est une des raisons pour laquelle moi aussi je veux passer à PeerTube et ne plus avoir à subir ces filtrages !
Nous n’avons clairement pas les mêmes moyens que Google ! Illustration : CC-By-SA Emma Lidbury
Parlons sous…
choosebzh
— Je vais peut-être poser la question qui fâche, mais qu’en est-il des annonceurs? Certains vidéastes prolifiques pourront-ils en retirer une source de revenus? Même faible, bien sûr. Car être libriste, oui, mais faut vivre aussi. 🙂
Techniquement il n’est pas prévu d’ajouter de la pub.
Rien n’empêche pour le vidéaste d’incorporer une annonce dans sa vidéo (ça commence à se faire sur les autres plate-formes) même si ça a ses limites.
Il est probable qu’on ajoute la possibilité d’afficher des boutons Liberapay, Tipeee, Patreon, etc., en dessous de la vidéo. Mais ce n’est pas notre priorité pour l’instant.
Pouhiou se permet d’ajouter :
Sur la question des annonceurs, et en tant qu’ancien « youtubeur » qui connaît encore beaucoup de monde dans le milieu, j’ajoute une précision.
L’annonce publicitaire est un modèle de rémunération qui paye très très mal les vidéastes. Avec l’explosion des créations vidéos, les annonces sont payées de moins en moins, et on est bien loin du « 1€ pour 1000 vues » de 2013… C’est un modèle qui marche encore pour les très très très gros succès (des millions de vues sur plusieurs vidéos), ce qui représente une infime partie des vidéastes.
Actuellement, si un·e vidéaste veut se faire de l’argent avec de la pub, le meilleur moyen reste les partenariats et placements de produits.
Le modèle économique le plus efficace pour les « petit·e·s vidéastes » semble encore être le modèle du don (Tipee, Patreon, Liberapay) qui, s’il n’est pas intégré à PeerTube dès sa bêta, sera relativement facile à implémenter (parce que PeerTube est un logiciel libre).
Framasoft
Et tant que nous parlons sous, faisons un petit point sur le financement…
(oui, nous avons rajouté cette question nous-mêmes, c’est triché… mais cela nous permet de faire le point avec vous, en toute transparence)
Et Framasoft de s’auto-répondre :
Comme nous l’affichons sur le site présentant le projet Framatube, nous finançons le développement de PeerTube sur le budget de l’association, dont 90 % des revenus proviennent de vos dons.
En effet, sur les 90 000 € qu’il nous manque pour boucler notre budget 2018 :
instantané des dons 9 jours après le lancement de la campagne PeerTube.
À la rédaction de cet article, nous avons déjà récolté pas loin de 20 000 € en une semaine, ce qui est formidable, parce que vous êtes des personnes formidables (n’en doutez jamais) ! Néanmoins, rien n’est gagné et si nous ne voulons pas revoir nos ambitions à la baisse, il faudrait que nous atteignions cette barre des 90 000 € d’ici le 31 décembre.
Pour rappel, notre association étant reconnue d’intérêt général, tout don de contribuables français·es peut être déduit de leurs impôts sur les revenus. Ainsi, un don de 100 € vous reviendra, après déduction fiscale, à 34 €.
Sachez que, si nous dépassons cet objectif des 90 000 €, notre priorité sera de permettre à Chocobozzz de poursuivre le développement de PeerTube, et donc d’ajouter à cette solution des fonctionnalités très attendues (ce ne sont pas les idées qui manquent, juste les moyens ^^).
Depuis les années 1950 et l’apparition des premiers hackers, l’informatique est porteuse d’un message d’émancipation. Sans ces pionniers, notre dépendance aux grandes firmes technologiques aurait déjà été scellée.
Aujourd’hui, l’avènement de l’Internet des objets remet en question l’autonomisation des utilisateurs en les empêchant de « bidouiller » à leur gré. Pire encore, les modèles économiques apparus ces dernières années remettent même en question la notion de propriété. Les GAFAM et compagnie sont-ils devenus nos nouveaux seigneurs féodaux ?
Une traduction de Framalang : Relec’, Redmood, FranBAG, Ostrogoths, simon, Moutmout, Edgar Lori, Luc, jums, goofy, Piup et trois anonymes
Est-ce vraiment ainsi que se définissent maintenant nos rapports avec les entreprises de technologie numérique ? Queen Mary Master
Les appareils connectés à Internet sont si courants et si vulnérables que des pirates informatiques ont récemment pénétré dans un casino via… son aquarium ! Le réservoir était équipé de capteurs connectés à Internet qui mesuraient sa température et sa propreté. Les pirates sont entrés dans les capteurs de l’aquarium puis dans l’ordinateur utilisé pour les contrôler, et de là vers d’autres parties du réseau du casino. Les intrus ont ainsi pu envoyer 10 gigaoctets de données quelque part en Finlande.
En observant plus attentivement cet aquarium, on découvre le problème des appareils de « l’Internet des objets » : on ne les contrôle pas vraiment. Et il n’est pas toujours évident de savoir qui tire les ficelles, bien que les concepteurs de logiciels et les annonceurs soient souvent impliqués.
Dans mon livre récent intitulé Owned : Property, Privacy, and the New Digital Serfdom (Se faire avoir : propriété, protection de la vie privée et la nouvelle servitude numérique), je définis les enjeux liés au fait que notre environnement n’a jamais été truffé d’autant de capteurs. Nos aquariums, téléviseurs intelligents, thermostats d’intérieur reliés à Internet, Fitbits (coachs électroniques) et autres téléphones intelligents recueillent constamment des informations sur nous et notre environnement. Ces informations sont précieuses non seulement pour nous, mais aussi pour les gens qui veulent nous vendre des choses. Ils veillent à ce que les appareils connectés soient programmés de manière à ce qu’ils partagent volontiers de l’information…
Les atteintes à la sécurité et à la vie privée sont intégrées
Comme le Roomba, d’autres appareils intelligents peuvent être programmés pour partager nos informations privées avec les annonceurs publicitaires par le biais de canaux dissimulés. Dans un cas bien plus intime que le Roomba, un appareil de massage érotique contrôlable par smartphone, appelé WeVibe, recueillait des informations sur la fréquence, les paramètres et les heures d’utilisation. L’application WeVibe renvoyait ces données à son fabricant, qui a accepté de payer plusieurs millions de dollars dans le cadre d’un litige juridique lorsque des clients s’en sont aperçus et ont contesté cette atteinte à la vie privée.
Ces canaux dissimulés constituent également une grave faille de sécurité. Il fut un temps, le fabricant d’ordinateurs Lenovo, par exemple, vendait ses ordinateurs avec un programme préinstallé appelé Superfish. Le programme avait pour but de permettre à Lenovo — ou aux entreprises ayant payé — d’insérer secrètement des publicités ciblées dans les résultats de recherches web des utilisateurs. La façon dont Lenovo a procédé était carrément dangereuse : l’entreprise a modifié le trafic des navigateurs à l’insu de l’utilisateur, y compris les communications que les utilisateurs croyaient chiffrées, telles que des transactions financières via des connexions sécurisées à des banques ou des boutiques en ligne.
Le problème sous-jacent est celui de la propriété
L’une des principales raisons pour lesquelles nous ne contrôlons pas nos appareils est que les entreprises qui les fabriquent semblent penser que ces appareils leur appartiennent toujours et agissent clairement comme si c’était le cas, même après que nous les avons achetés. Une personne peut acheter une jolie boîte pleine d’électronique qui peut fonctionner comme un smartphone, selon les dires de l’entreprise, mais elle achète une licence limitée à l’utilisation du logiciel installé. Les entreprises déclarent qu’elles sont toujours propriétaires du logiciel et que, comme elles en sont propriétaires, elles peuvent le contrôler. C’est comme si un concessionnaire automobile vendait une voiture, mais revendiquait la propriété du moteur.
Ce genre de disposition anéantit le fondement du concept de propriété matérielle. John Deere a déjà annoncé aux agriculteurs qu’ils ne possèdent pas vraiment leurs tracteurs, mais qu’ils ont, en fait, uniquement le droit d’en utiliser le logiciel — ils ne peuvent donc pas réparer leur propre matériel agricole ni même le confier à un atelier de réparation indépendant. Les agriculteurs s’y opposent, mais il y a peut-être des personnes prêtes à l’accepter, lorsqu’il s’agit de smartphones, souvent achetés avec un plan de paiement échelonné et échangés à la première occasion.
Combien de temps faudra-t-il avant que nous nous rendions compte que ces entreprises essaient d’appliquer les mêmes règles à nos maisons intelligentes, aux téléviseurs intelligents dans nos salons et nos chambres à coucher, à nos toilettes intelligentes et à nos voitures connectées à Internet ?
Un retour à la féodalité ?
La question de savoir qui contrôle la propriété a une longue histoire. Dans le système féodal de l’Europe médiévale, le roi possédait presque tout, et l’accès à la propriété des autres dépendait de leurs relations avec le roi. Les paysans vivaient sur des terres concédées par le roi à un seigneur local, et les ouvriers ne possédaient même pas toujours les outils qu’ils utilisaient pour l’agriculture ou d’autres métiers comme la menuiserie et la forge.
Au fil des siècles, les économies occidentales et les systèmes juridiques ont évolué jusqu’à notre système commercial moderne : les individus et les entreprises privées achètent et vendent souvent eux-mêmes des biens de plein droit, possèdent des terres, des outils et autres objets. Mis à part quelques règles gouvernementales fondamentales comme la protection de l’environnement et la santé publique, la propriété n’est soumise à aucune condition.
Ce système signifie qu’une société automobile ne peut pas m’empêcher de peindre ma voiture d’une teinte rose pétard ou de faire changer l’huile dans le garage automobile de mon choix. Je peux même essayer de modifier ou réparer ma voiture moi-même. Il en va de même pour ma télévision, mon matériel agricole et mon réfrigérateur.
Pourtant, l’expansion de l’Internet des objets semble nous ramener à cet ancien modèle féodal où les gens ne possédaient pas les objets qu’ils utilisaient tous les jours. Dans cette version du XXIe siècle, les entreprises utilisent le droit de la propriété intellectuelle — destiné à protéger les idées — pour contrôler les objets physiques dont les utilisateurs croient être propriétaires.
Mainmise sur la propriété intellectuelle
Mon téléphone est un Samsung Galaxy. Google contrôle le système d’exploitation ainsi que les applications Google Apps qui permettent à un smartphone Android de fonctionner correctement. Google en octroie une licence à Samsung, qui fait sa propre modification de l’interface Android et me concède le droit d’utiliser mon propre téléphone — ou du moins c’est l’argument que Google et Samsung font valoir. Samsung conclut des accords avec de nombreux fournisseurs de logiciels qui veulent prendre mes données pour leur propre usage.
Mais ce modèle est déficient, à mon avis. C’est notre droit de pouvoir réparer nos propres biens. C’est notre droit de pouvoir chasser les annonceurs qui envahissent nos appareils. Nous devons pouvoir fermer les canaux d’information détournés pour les profits des annonceurs, pas simplement parce que nous n’aimons pas être espionnés, mais aussi parce que ces portes dérobées constituent des failles de sécurité, comme le montrent les histoires de Superfish et de l’aquarium piraté. Si nous n’avons pas le droit de contrôler nos propres biens, nous ne les possédons pas vraiment. Nous ne sommes que des paysans numériques, utilisant les objets que nous avons achetés et payés au gré des caprices de notre seigneur numérique.
Même si les choses ont l’air sombres en ce moment, il y a de l’espoir. Ces problèmes deviennent rapidement des cauchemars en matière de relations publiques pour les entreprises concernées. Et il y a un appui bipartite important en faveur de projets de loi sur le droit à la réparation qui restaurent certains droits de propriété pour les consommateurs.
Ces dernières années, des progrès ont été réalisés dans la reconquête de la propriété des mains de magnats en puissance du numérique. Ce qui importe, c’est que nous identifiions et refusions ce que ces entreprises essaient de faire, que nous achetions en conséquence, que nous exercions vigoureusement notre droit d’utiliser, de réparer et de modifier nos objets intelligents et que nous appuyions les efforts visant à renforcer ces droits. L’idée de propriété est encore puissante dans notre imaginaire culturel, et elle ne mourra pas facilement. Cela nous fournit une opportunité. J’espère que nous saurons la saisir.
Le chemin vers une informatique éthique
Le logiciel « open source » a gagné, tant mieux, c’est un préalable pour une informatique éthique, explique Daniel Pascot, qui a tout au long d’une carrière bien remplie associé enseignement et pratique de l’informatique, y compris en créant une entreprise.
Du côté de nos cousins d’Outre-Atlantique, on lui doit notamment d’avoir présidé aux destinées de l’association libriste FACIL (c’est un peu l’April du Québec) et milité activement pour la promotion de solutions libres jusqu’aux instances gouvernementales.
On peut se réjouir de l’ubiquité du logiciel libre mais les fameuses quatre libertés du logiciel libre (merci Mr Stallman) ne semblent en réalité concerner que les créateurs de logiciels. Les utilisateurs, peu réceptifs au potentiel ouvert par les licences libres, sont intéressés essentiellement par l’usage libre des logiciels et les services proposés par des entreprises intermédiaires. Hic jacet lupus… Quand ces services échappent à la portée des licences libres, comment garantir qu’ils sont éthiques ? La réflexion qu’entame Daniel Pascot à la lumière d’exemples concrets porte de façon très intéressante sur les conditions d’un contrat équilibré entre utilisateurs et fournisseurs de services. Les propositions de charte qu’il élabore ressemblent d’ailleurs plutôt à une liste des droits des utilisateurs et utilisatrices 😉
Chez Framasoft, nous trouvons que ce sont là des réflexions et propositions fort bien venues pour le mouvement de CHATONS qui justement vous proposent des services divers en s’engageant par une charte.
Comme toujours sur le Framablog, les commentaires sont ouverts…
Le logiciel « open source » a gagné, oui mais…
Photo Yann Doublet
Les « libristes »1 se rendent progressivement compte que bien des combats qu’ils ont livrés étaient une cause perdue d’avance car ils sous-estimaient les conséquences de la complexité des logiciels. Quels que soient les bienfaits des logiciels libres, les utiliser exige une compétence et un entretien continu qui ne sont pas envisageables pour la grande majorité des individus ou organisations2.
Richard Stallman a fait prendre conscience de la nécessité de contrôler les programmes pour garantir notre liberté. La dimension éthique était importante : il parlait du bon et du mauvais logiciel. L’importance de ce contrôle a été mise en évidence par Lawrence Lessig avec son « Code is law »3. La nature immatérielle et non rivale du logiciel faisait que les libristes le considéraient naturellement comme un bien commun. Il leur semblait évident qu’il devait être partagé. Comme on vivait alors dans un monde où les ordinateurs étaient autonomes, la licence GPL avec ses libertés offrait un socle satisfaisant sur lequel les libristes s’appuyaient.
J’ai depuis plus de 20 ans enseigné et milité pour le logiciel libre que j’utilise quotidiennement. Comme tout bon libriste convaincu, j’ai présenté les quatre libertés de la GPL, et je reconnais que je n’ai pas convaincu grand monde avec ce discours. Qu’il faille garder contrôle sur le logiciel, parfait ! Les gens comprennent, mais la solution GPL ne les concerne pas parce que ce n’est absolument pas dans leur intention d’installer, étudier, modifier ou distribuer du logiciel. Relisez les licences et vous conviendrez qu’elles sont rédigées du point de vue des producteurs de logiciels plus que des utilisateurs qui n’envisagent pas d’en produire eux-mêmes.
Mais un objet technique et complexe, c’est naturellement l’affaire des professionnels et de l’industrie. Pour eux, la morale ou l’éthique n’est pas une préoccupation première, ce sont des techniciens et des marchands qui font marcher l’économie dans leur intérêt. Par contre, la liberté du partage du code pour des raisons d’efficacité (qualité et coût) les concerne. Ils se sont alors débarrassés de la dimension éthique en créant le modèle open source4. Et ça a marché rondement au point que ce modèle a gagné la bataille du logiciel. Les cinq plus grandes entreprises au monde selon leurs capitalisations boursières, les GAFAM, reposent sur ce modèle. Microsoft n’est plus le démon privatif à abattre, mais est devenu un acteur du libre. Enlevez le code libre et plus de Web, plus de courrier électronique, plus de réseaux sociaux comme Facebook, plus de service Google ou Amazon, ou de téléphone Apple ou Android. Conclusion : le logiciel libre a gagné face au logiciel propriétaire, c’est une question de temps pour que la question ne se pose plus.
Oui, mais voilà, c’est du logiciel libre débarrassé de toute évidence de sa dimension éthique, ce qui fait que du point de vue de l’utilisateur qui dépend d’un prestataire, le logiciel libre n’apporte rien. En effet, les prestataires de services, comme les réseaux sociaux ou les plates-formes de diffusion, ne distribuent pas de logiciel, ils en utilisent et donc échappent tout à fait légalement aux contraintes éthiques associées aux licences libres. Ce qui importe aux utilisateurs ce ne sont pas les logiciels en tant qu’objets, mais le service qu’ils rendent qui, lui, n’est pas couvert par les licences de logiciel libre. Circonstance aggravante, la gratuité apparente de bien des services de logiciel anesthésie leurs utilisateurs face aux conséquences de leur perte de liberté et de l’appropriation de leurs données et comportements (méta données) souvent à leur insu5.
Pourtant, aujourd’hui, nous ne pouvons plus nous passer de logiciel, tout comme nous ne pouvons pas nous passer de manger. Le logiciel libre c’est un peu comme le « bio » : de plus en plus de personnes veulent manger bio, tout simplement parce que c’est bon pour soi (ne pas s’empoisonner), bon pour la planète (la préserver de certaines pollutions) ou aussi parce que cela permet d’évoluer vers une économie plus humaine à laquelle on aspire (économie de proximité). Le « bio » est récent, mais en pleine expansion, il y a de plus en plus de producteurs, de marchands, et nos gouvernements s’en préoccupent par des lois, des règlements, des certifications ou la fiscalité. Ainsi le « bio » ce n’est pas seulement un produit, mais un écosystème complexe qui repose sur des valeurs : si le bio s’était limité à des « écolos » pour auto-consommation, on n’en parlerait pas. Eh bien le logiciel c’est comme le bio, ce n’est pas seulement un produit mais aussi un écosystème complexe qui concerne chacun de nous et la société avec tous ses acteurs.
Dans l’écosystème logiciel, les éditeurs et les prestataires de service qui produisent et opèrent le logiciel, ont compris que le logiciel libre (au sens open source) est bon pour eux et s’en servent, car ils le contrôlent. Par contre il n’en va pas de même pour ceux qui ne contrôlent pas directement le logiciel. La licence du logiciel ne suffit pas à leur donner contrôle. Mais alors que faire pour s’assurer que le service rendu par le logiciel via un prestataire soit bon pour nous, les divers utilisateurs dans cet écosystème numérique complexe ?
Je vais ici commenter la dimension éthique de deux projets de nature informatique qui s’appuient sur du logiciel libre sur lesquels je travaille actuellement en tentant d’intégrer ma réflexion de militant, d’universitaire et de praticien. PIAFS concerne les individus et donc le respect de nos vies privées pour des données sensibles, celles de notre santé dans un contexte de partage limité, la famille. REA vise à garantir à une organisation le contrôle de son informatisation dans le cadre d’une relation contractuelle de nature coopérative.
Deux cas qui ont alimenté ma réflexion
PIAFS : Partage des Informations Avec la Famille en Santé
PIAFS est projet qui répond à un besoin non satisfait : un serveur privé pour partager des données de santé au sein d’une unité familiale à des fins d’entr’aide (http://piafs.org/). Cette idée, dans un premier temps, a débouché sur un projet de recherche universitaire pour en valider et préciser la nature. Pour cela il nous fallait un prototype.
Au-delà de la satisfaction d’un besoin réel, je cherchais en tant que libriste comment promouvoir le logiciel libre. Je constatais que mes proches n’étaient pas prêts à renoncer à leurs réseaux sociaux même si je leur en montrais les conséquences. Il fallait éviter une première grande difficulté : changer leurs habitudes. J’avais là une opportunité : mes proches, comme beaucoup de monde, n’avaient pas encore osé organiser leurs données de santé dans leur réseau social.
Si ce projet avait dès le départ une dimension éthique, il n’était pas question de confier ces données sensibles à un réseau social. J’étais dès le départ confronté à une dimension pratique au-delà de la disponibilité du logiciel. De plus, pour les utilisateurs de PIAFS, l’auto-hébergement n’est pas une solution envisageable. Il fallait recourir à un fournisseur car un tel service doit être assuré d’une manière responsable et pérenne. Même si l’on s’appuyait sur des coopératives de santé pour explorer le concept, il est rapidement apparu qu’il fallait recourir à un service professionnel classique dont il faut alors assumer les coûts6. Il fallait transposer les garanties apportées par le logiciel libre au fournisseur de service : l’idée de charte que l’on voyait émerger depuis quelques années semblait la bonne approche pour garantir une informatique éthique, et en même temps leur faire comprendre qu’ils devaient eux-mêmes assurer les coûts du service.
REA : Pour donner au client le contrôle de son informatisation
J’ai enseigné la conception des systèmes d’information dans l’université pendant près de 40 ans (à Aix-en-Provence puis à Québec), et eu l’occasion de travailler dans des dizaines de projets. J’ai eu connaissance de nombreux dérapages de coût ou de calendrier et j’ai étudié la plupart des méthodologies qui tentent d’y remédier. J’ai aussi appris qu’une des stratégies commerciales de l’industrie informatique (ils ne sont pas les seuls !) est la création de situations de rente pas toujours à l’avantage du client. Dans tout cela je n’ai pas rencontré grande préoccupation éthique.
J’ai eu, dès le début de ma carrière de professeur en systèmes d’information (1971), la chance d’assister, sinon participer, à la formalisation de la vision de Jean-Louis Le Moigne7 : un système d’information consiste à capturer, organiser et conserver puis distribuer et parfois traiter les informations créées par l’organisation. Cette vision s’opposait aux méthodologies naissantes de l’analyse structurée issues de la programmation structurée. Elle établissait que l’activité de programmation devait être précédée par une compréhension du fonctionnement de l’organisation à partir de ses processus. L’approche qui consiste à choisir une « solution informatique » sans vraiment repenser le problème est encore largement dominante. J’ai ainsi été conduit à développer, enseigner et pratiquer une approche dite à partir des données qui s’appuie sur la réalisation précoce de prototypes fonctionnels afin de limiter les dérapages coûteux (je l’appelle maintenant REA pour Référentiel d’Entreprise Actif, le code de REA est bien sûr libre).
Mon but est, dans ma perspective libriste, de redonner le contrôle au client dans la relation client-fournisseur de services d’intégration. Si ce contrôle leur échappe trop souvent du fait de leur incompétence technique, il n’en reste pas moins que ce sont eux qui subissent les conséquences des systèmes informatiques « mal foutus ». Là encore le logiciel libre ne suffit pas à garantir le respect du client et le besoin d’une charte pour une informatique éthique s’impose8 .
Vers une charte de l’informatique libre, c’est-à-dire bonne pour l’écosystème numérique
Dans les deux cas, si l’on a les ressources et la compétence pour se débrouiller seul, les licences libres comme la GPL ou une licence Creative Commons pour la méthodologie garantissent une informatique éthique (respect de l’utilisateur, contribution à un bien commun). S’il faut recourir à un hébergeur ou un intégrateur, les garanties dépendent de l’entente contractuelle entre le client-utilisateur et le fournisseur.
Il y a une différence fondamentale entre le logiciel et le service. Le logiciel est non rival, il ne s’épuise pas à l’usage, car il peut être reproduit sans perte pour l’original, alors que le service rendu est à consommation unique. Le logiciel relève de l’abondance alors que le service relève de la rareté qui est le fondement de l’économie qui nous domine, c’est la rareté qui fait le prix. Le logiciel peut être mis en commun et partagé alors que le service ne le peut pas. L’économie d’échelle n’enlève pas le caractère rival du service. Et c’est là que la réalité nous rattrape : la mise en commun du logiciel est bonne pour nous tous, mais cela n’a pas de sens pour le service car aucun fournisseur ne rendra ce service gratuitement hormis le pur bénévolat.
Des propositions balisant un comportement éthique existent, en voici quelques exemples:
dans Le Manifeste pour le développement Agile de logiciels, des informaticiens ont proposé une démarche dite agile qui repose sur 4 valeurs et 12 principes. Sans être explicitement une charte éthique, la démarche est clairement définie dans l’optique du respect du client. Ce manifeste est utile dans le cas REA ;
la charte du collectif du mouvement CHATONS concerne les individus, elle est pensée dans un contexte d’économie sociale et solidaire, elle est inspirante pour le cas PIAFS ;
la charte de Framasoft définit un internet éthique, elle est inspirante pour le cas PIAFS mais aussi pour la définition d’un cadre global;
dernièrement sous forme de lettre ouverte, un collectif issu du Techfestival de Copenhague propose une pratique éthique, utile pour les deux cas et qui permet de réfléchir au cadre global.
Les libristes, mais dieu merci ils ne sont pas les seuls, ont une bonne idée des valeurs qui président à une informatique éthique, bonne pour eux, à laquelle ils aspirent lorsqu’ils utilisent les services d’un fournisseur. Les exigences éthiques ne sont cependant pas les mêmes dans les deux cas car l’un concerne un service qui n’inclut pas de développement informatique spécifique et l’autre implique une activité de développement significative (dans le tableau ci-dessous seuls des critères concernant l’éthique sont proposés):
Critères pour le client
Dans le cas de PIAFS
Dans le cas d’un projet REA
Respect de leur propriété
Les données qu’ils produisent leur appartiennent, ce n’est pas négociable
Tout document produit (analyse, …) est propriété du client
Respect de leur identité
Essentiel
Le client doit contrôler la feuille de route, ce sont ses besoins que l’on doit satisfaire par ceux du fournisseur
Respect de leur indépendance vis à vis du fournisseur
Important, préside au choix des logiciels et des formats
Critique : mais difficile à satisfaire.
Proximité du service : favoriser l’économie locale et protection contre les monopoles
Important
Important
Pérennité du service
Important, mais peut être tempéré par la facilité du changement
Essentiel : le changement est difficile et coûteux, mais la « prise en otage » est pire
Payer le juste prix
Important
Important
Partage équitable des risques
Risque faible
Essentiel car le risque est élevé
Mise en réseau
Essentiel : la connexion « sociale » est impérative mais dans le respect des autres valeurs
Plus aucune organisation vit en autarcie
Contribution (concerne le fournisseur)
Non discutable, obligatoire
Important mais aménageable
Entente sur le logiciel
Le client, individu ou organisation, doit avoir l’assurance que les logiciels utilisés par le fournisseur de services font bien et seulement ce qu’ils doivent faire. Comme il n’a pas la connaissance requise pour cette expertise, il doit faire confiance au fournisseur. Or, parce que celui-ci n’offre pas toute la garantie requise (volonté et capacité de sa part), il faut, dans cette situation, recourir à un tiers de confiance. Cette expertise externe par un tiers de confiance est très problématique. Il faut d’une part que le fournisseur donne accès aux logiciels et d’autre part trouver un expert externe qui accepte d’étudier les logiciels, autrement dit résoudre la quadrature du cercle !
Le logiciel libre permet de la résoudre. Il est accessible puisqu’il est public, il est produit par une communauté qui a les qualités requises pour jouer ce rôle de tiers de confiance. Ainsi, pour une informatique éthique :
tout logiciel utilisé par le fournisseur doit être public, couvert par une licence libre, ce qui le conduit à ne pas redévelopper un code existant ou le moins possible,
s’il est amené à produire du nouveau code,
le fournisseur doit le rendre libre. C’est à l’avantage de la société mais aussi du client dans un contexte de partage et de protection contre les situations de rente qui le tiennent en otage,
ou du moins le rendre accessible au client,
garantir que seul le code montré est utilisé,
utiliser des formats de données et documents libres.
L’éthique est complexe, il est difficile sinon impossible d’anticiper tous les cas. L’exigence de logiciel libre peut être adaptée à des situations particulières, par exemple si le prestataire est engagé pour un logiciel que le client ne désire pas partager il en prend alors la responsabilité, ou si la nécessité de poursuivre l’utilisation de logiciels non libres est non contournable temporairement.
Entente sur le bien ou service
Le critère du coût est propre au service. Dans une approche éthique le juste coût n’est pas la résultante du jeu de l’offre et de la demande, ni d’un jeu de négociation basé sur des secrets, et encore moins le résultat d’une rente de situation. Il s’agit pour le fournisseur de couvrir ses coûts et de rentabiliser son investissement (matériel, formation…). Une approche éthique impose de la transparence, le client :
doit savoir ce qu’il paye,
doit avoir la garantie que le contrat couvre tous les frais pour l’ensemble du service (pas de surprise à venir),
doit être capable d’estimer la valeur de ce qu’il paye,
doit connaître les coûts de retrait du service et en estimer les conséquences.
Le partage équitable du risque concerne essentiellement les projets d’informatisation avec un intégrateur. Il est rare que l’on puisse estimer correctement l’ampleur d’un projet avant de l’avoir au moins partiellement réalisé. Une part du risque provient de l’organisation et de son environnement, une autre part du risque provient des capacités du fournisseur et de ses outils. Ceci a un impact sur le découpage du projet, chaque étape permet d’estimer les suivantes :
tout travail réalisé par le fournisseur contributif au projet :
doit être payé,
appartient au client,
doit pouvoir être utilisé indépendamment du fournisseur.
le travail dont le volume est dépendant du client est facturé au temps,
le travail sous le contrôle du fournisseur doit si possible être facturé sur une base forfaitaire,
le client est maître de la feuille de route,
tout travail entamé par le fournisseur doit être compris et accepté par le client,
la relation entre le client et le fournisseur est de nature collaborative, le client participe au projet qui évolue au cours de la réalisation à la différence d’une relation contractuelle dans laquelle le client commande puis le fournisseur livre ce qui est commandé.
Conclusion : l’informatique éthique est possible
Pour tous les utilisateurs de l’informatique, c’est à dire pratiquement tout le monde et toutes les organisations de notre société numérique, il est aussi difficile de nier l’intérêt d’une informatique éthique que de rejeter le « bio », mais encore faut-il en être conscient. Le débat au sein des producteurs de logiciels reste difficile à comprendre. Ce qui est bon pour un libriste c’est un logiciel qui avant tout le respecte, alors que pour les autres informaticiens, c’est à dire la grande majorité, c’est un logiciel qui ne bogue pas. Fait aggravant : la vérité des coûts nous est cachée. Cependant au-delà de cette différence philosophique, l’intérêt du logiciel partagé est tel qu’un immense patrimoine de logiciel libre ou open source est disponible. Ce patrimoine est le socle sur lequel une informatique éthique est possible. Les deux cas présentés nous montent que les conditions existent dès maintenant.
Une informatique éthique est possible, mais elle ne sera que si nous l’exigeons. Les géants du Net sont de véritables états souverains devant lesquels même nos états baissent pavillon. La route est longue, chaotique et pleine de surprises, comme elle l’a été depuis la naissance de l’ordinateur, mais un fait est acquis, elle doit reposer sur le logiciel libre.
Le chemin se fait en marchant, comme l’écrivait le poète Antonio Machado, et c’est à nous libristes de nous donner la main et de la tendre aux autres. Ce ne sera pas facile car il faudra mettre la main à la poche et la bataille est politique. Il nous faut exiger, inspirés par le mouvement « bio », un label informatique éthique et pourquoi pas un forum mondial de l’écosystème numérique. La piste est tracée (à l’instar de la Quadrature du Net), à nous de l’emprunter.
Notes
J’ai utilisé ce mot de libriste pour rendre compte de la dimension militante et à certains égards repliée sur elle-même, qu’on leur reproche souvent à raison.↩
Dans un article paru en 2000, Lawrence Lessig -auquel on doit les licences Creative Commons- a clairement mis en lumière que l’usage d’internet (et donc des logiciels) nous contraint, tout comme nous sommes contraint par les lois. Il nous y a alerté sur les conséquences relatives à notre vie privée. Voir la traduction française sur Framablog « Le code fait loi – De la liberté dans le cyberespace » (publié le 22/05/2010),↩
Dans l’optique open source, un bon logiciel est un logiciel qui n’a pas de bogue. Dans l’optique logiciel libre, un bon logiciel est un logiciel éthique qui respecte son utilisateur et contribue au patrimoine commun. Dans les deux cas il est question d’accès au code source mais pour des raisons différentes, ce qui au plan des licences peut sembler des nuances : « Né en 1998 d’une scission de la communauté du logiciel libre (communauté d’utilisateurs et de développeurs) afin de conduire une politique jugée plus adaptée aux réalités économiques et techniques, le mouvement open source défend la liberté d’accéder aux sources des programmes qu’ils utilisent, afin d’aboutir à une économie du logiciel dépendant de la seule vente de prestations et non plus de celle de licences d’utilisation ». Voir la page Wikipédia, « Open Source Initiative ».↩
La question de recourir à une organisation de l’économie sociale et solidaire s’est posée et ce n’est pas exclu.Cela n’a pas été retenu pour des raisons pratiques et aussi parce que la démarche visait à promouvoir une informatique éthique de la part des fournisseurs traditionnels locaux.↩
Avant d’être connu comme un constructiviste Jean-Louis Le Moigne, alors professeur à l’IAE d’Aix-en-Provence, créait un enseignement de systèmes d’information organisationnels et lançait avec Huber Tardieu la recherche qui a conduit à la méthode Merise à laquelle j’ai participé car j’étais alors assistant dans sa petite équipe universitaire et il a été mon directeur de doctorat.↩
Caliopen, la messagerie libre sur la rampe de lancement
Le projet Caliopen, lancé il y a trois ans, est un projet ambitieux. Alors qu’il est déjà complexe de créer un nouveau logiciel de messagerie, il s’agit de proposer un agrégateur de correspondance qui permette à chacun d’ajuster son niveau de confidentialité.
Ce logiciel libre mûrement réfléchi est tout à fait en phase avec ce que Framasoft s’efforce de promouvoir à chaque fois que des libristes donnent aux utilisateurs et utilisatrices plus d’autonomie et de maîtrise, plus de sécurité et de confidentialité.
Après une nécessaire période d’élaboration, le projet Caliopen invite tout le monde à tester la version alpha et à faire remonter les observations et suggestions. La première version grand public ce sera pour dans un an environ.
Vous êtes curieux de savoir ce que ça donne ? Nous l’étions aussi, et nous avons demandé à Laurent Chemla, qui bidouillait déjà dans l’Internet alors que vous n’étiez même pas né⋅e, de nous expliquer tout ça, puisqu’il est le père tutélaire du projet Caliopen, un projet que nous devons tous soutenir et auquel nous pouvons contribuer.
Bonjour, pourrais-tu te présenter brièvement ?
J’ai 53 ans, dont 35 passés dans les mondes de l’informatique et des réseaux. Presque une éternité dans ce milieu – en tous cas le temps d’y vivre plusieurs vies (« pirate », programmeur, hacktiviste, entrepreneur…). Mais ces temps-ci je suis surtout le porteur du projet Caliopen, même si je conserve une petite activité au sein du CA de la Quadrature du Net. Et je fais des macarons.
Le projet Caliopen arrive ce mois-ci au stade de la version alpha, mais comment ça a commencé ?
Jérémie Zimmermann est venu me sortir de ma retraite nîmoise en me poussant à relancer un très ancien projet de messagerie après les révélations de Snowden. Ça faisait déjà un petit moment que je me demandais si je pouvais encore être utile à la communauté autrement qu’en publiant quelques billets de temps en temps, alors j’ai lancé l’idée en public, pour voir, et il y a eu un tel retour que je n’ai pas pu faire autrement que d’y aller, malgré ma flemme congénitale.
Quand tu as lancé le projet publiquement (sur une liste de diffusion il me semble) quelle était la feuille de route, ou plutôt la « bible » des spécifications que tu souhaitais voir apparaître dans Caliopen ?
Très vite on a vu deux orientations se dessiner : la première, très technique, allait vers une vision maximaliste de la sécurité (réinventer SMTP pour protéger les métadonnées, garantir l’anonymat, passer par du P2P, ce genre de choses), tandis que la seconde visait à améliorer la confidentialité des échanges sans tout réinventer. Ça me semblait plus réaliste – parce que compatible avec les besoins du grand public – et c’est la direction que j’ai choisi de suivre au risque de fâcher certains contributeurs.
J’ai alors essayé de lister toutes les fonctionnalités (aujourd’hui on dirait les « User Stories ») qui sont apparues dans les échanges sur cette liste, puis de les synthétiser, et c’est avec ça que je suis allé voir Stephan Ramoin, chez Gandi, pour lui demander une aide qu’il a aussitôt accepté de donner. Le projet a ensuite évolué au rythme des échanges que j’ai pu avoir avec les techos de Gandi, puis de façon plus approfondie avec Thomas Laurent pendant la longue étape durant laquelle nous avons imaginé le design de Caliopen. C’est seulement là, après avoir défini le « pourquoi » et le « quoi » qu’on a pu vraiment commencer à réfléchir au « comment » et à chercher du monde pour le réaliser.
La question qui fâche : quand on lit articles et interviews sur Caliopen, on a l’impression que le concept est encore super flou. C’est quoi l’elevator pitch pour vendre le MVP de la start-up aux business angels des internets digitaux ? (en français : tu dis quoi pour convaincre de nouveaux partenaires financiers ?)
Ça fait bien 3 ans que le concept de base n’a pas bougé : un agrégateur de correspondances qui réunit tous nos échanges privés (emails, message Twitter ou Facebook, messageries instantanées…), sous forme de conversations, définies par ceux avec qui on discute plutôt que par le protocole utilisé pour le faire. Voilà pour ton pitch.
Ce qui est vrai c’est qu’en fonction du public auquel on s’adresse on ne présente pas forcément le même angle. Le document qui a été soumis à BPI France pour obtenir le financement actuel fait 23 pages, très denses. Il aborde les aspects techniques, financiers, l’état du marché, la raison d’être de Caliopen, ses objectifs sociétaux, ses innovations, son design, les différents modèles économiques qui peuvent lui être appliqués… ce n’est pas quelque chose qu’on peut développer en un article ou une interview unique.
Si j’aborde Caliopen sous l’angle de la vie privée, alors j’explique par exemple le rôle des indices de confidentialité, la façon dont le simple fait d’afficher le niveau de confidentialité d’un message va influencer l’utilisateur dans ses pratiques: on n’écrit pas la même chose sur une carte postale que dans une lettre sous enveloppe. Rien que sur ce sujet, on vient de faire une conférence entière (à Paris Web et à BlendWebMix) sans aborder aucun des autres aspects du projet.
Si je l’aborde sous l’angle technique, alors je vais peut-être parler d’intégration « verticale ». Du fait qu’on ne peut pas se contenter d’un nouveau Webmail, ou d’un nouveau protocole, si on veut tenir compte de tous les aspects qui font qu’un échange est plus ou moins secret. Ce qui fait de Caliopen un ensemble de différentes briques plutôt qu’une unique porte ou fenêtre. Ou alors je vais parler de la question du chiffrement, de la diffusion des clés publiques, de TOFU et du RFC 7929…
Mais on peut aussi débattre du public visé, de design, d’économie du Web, de décentralisation… tous ces angles sont pertinents, et chacun peut permettre de présenter Caliopen avec plus ou moins de détails.
Caliopen est un projet complexe, fondé sur un objectif (la lutte contre la surveillance de masse) et basé sur un moyen (proposer un service utile à tous), qui souhaite changer les habitudes des gens en les amenant à prendre réellement conscience du niveau d’exposition de leur vie privée. Il faut plus de talent que je n’en ai pour le décrire en quelques mots.
Il reste un intérêt pour les mails ? On a l’impression que tout passe par les webmails ou encore dans des applis de communication sur mobile, non ?
Même si je ne crois pas à la disparition de l’email, c’est justement parce qu’on a fait le constat qu’aujourd’hui la correspondance numérique passe par de très nombreux services qu’on a imaginé Caliopen comme un agrégateur de tous ces échanges.
C’est un outil qui te permet de lire et d’écrire à tes contacts sans avoir à te préoccuper du service, ou de l’application, où la conversation a commencé. Tu peux commencer un dialogue avec quelqu’un par message privé sur Twitter, la poursuivre par email, puis par messagerie instantanée… ça reste une conversation: un échange privé entre deux humains, qui peuvent aborder différents sujets, partager différents contenus. Et quand tu vas vouloir chercher l’information que l’autre t’a donné l’année passée, tu vas faire comment ?
C’est à ça que Caliopen veut répondre. Pour parler moderne, c’est l’User Story centrale du projet.
C’est quoi exactement cette histoire de niveaux de confidentialité ? Quel est son but ?
Il faut revenir à l’objectif principal du projet : lutter contre la surveillance de masse que les révélations d’Edward Snowden ont démontrée.
Pour participer à cette lutte, Caliopen vise à convaincre un maximum d’utilisateurs de la valeur de leur vie privée. Et pour ça, il faut d’abord leur montrer, de manière évidente, que leurs conversations sont très majoritairement espionnables, sinon espionnées. Notre pari, c’est que quand on voit le risque d’interception, on réagit autrement que lorsqu’on est seulement informé de son existence. C’est humain : regarde l’exemple de la carte postale que je te donne plus haut.
D’où l’idée d’associer aux messages (mais aussi aux contacts, aux terminaux, et même à l’utilisateur lui-même) un niveau de confidentialité. Représenté par une icône, des couleurs, des chiffres, c’est une question de design, mais ce qui est important c’est qu’en voyant le niveau de risque, l’utilisateur ne va plus pouvoir faire semblant de l’ignorer et qu’il va accepter de changer – au moins un peu – ses pratiques et ses habitudes pour voir ce niveau augmenter.
Bien sûr, il faudra l’accompagner. Lui proposer des solutions (techniques, comportementales, contextuelles) pour améliorer son « score ». Sans le culpabiliser (ce n’est pas la bonne manière de faire) mais en le récompensant – par une meilleure note, de nouvelles fonctionnalités, des options gratuites si le service est payant… bref par une ludification de l’expérience utilisateur. C’est notre piste en tous cas.
Et c’est en augmentant le niveau global de confidentialité des échanges qu’on veut rendre plus difficile (donc plus chère) la surveillance de tous, au point de pousser les états – et pourquoi pas les GAFAM – à changer de pratiques, eux aussi.
Financièrement, comment vit le projet Caliopen ? C’était une difficulté qui a retardé l’avancement ?
Sans doute un peu, mais je voudrais quand même dire que, même si je suis bien conscient de l’impression de lenteur que peut donner le projet, il faut se rendre compte qu’on parle d’un outil complexe, qui a démarré de zéro, avec aucun moyen, et qui s’attaque à un problème dont les racines datent de plusieurs dizaines d’années. Si c’était facile et rapide à résoudre, ça se saurait.
Dès l’instant où nous avons pris conscience qu’on n’allait pas pouvoir continuer sur le modèle du bénévolat, habituel au milieu du logiciel libre, nous avons réagi assez vite : Gandi a décidé d’embaucher à plein temps un développeur front end, sur ses fonds propres. Puis nous avons répondu à un appel à projet de BPI France qui tombait à pic et auquel Caliopen était bien adapté. Nous avons défendu notre dossier, devant un comité de sélection puis devant un panel d’experts, et nous avons obtenu de quoi financer deux ans de développement, avec une équipe dédiée et des partenaires qui nous assurent de disposer de compétences techniques rares. Et tout ça est documenté sur notre blog, depuis le début (tout est public depuis le début, d’ailleurs, même si tous les documents ne sont pas toujours faciles à retrouver, même pour nous).
Et finalement c’est qui les partenaires ?
Gandi reste le partenaire principal, auquel se sont joints Qwant et l’UPMC (avec des rôles moins larges mais tout aussi fondamentaux).
Quel est le modèle économique ? Les développeurs (ou développeuses, y’en a au fait dans l’équipe ?) sont rémunérés autrement qu’en macarons ? Combien faudra-t-il payer pour ouvrir un compte ?
Je ne suis pas sûr qu’on puisse parler de « modèle économique » pour un logiciel libre : après tout chacun pourra en faire ce qu’il voudra et lui imaginer tel ou tel modèle (économique ou non d’ailleurs).
Une fois qu’on a dit ça, on peut quand même dire qu’il ne serait pas cohérent de baser des services Caliopen sur l’exploitation des données personnelles des utilisateurs, et donc que le modèle « gratuité contre données » n’est pas adapté. Nous imaginons plutôt des services ouverts au public de type freemium, d’autres fournis par des entreprises pour leurs salariés, ou par des associations pour leurs membres. On peut aussi supposer que se créeront des services pour adapter Caliopen à des situations particulières, ou encore qu’il deviendra un outil fourni en Saas, ou vendu sous forme de package associé, par exemple, à la vente d’un nom de domaine.
Bref : les modèles économiques ce n’est pas ce qui manque le plus.
L’équipe actuelle est salariée, elle comporte des développeuses, et tu peux voir nos trombinettes sur https://www.caliopen.org
L’équipe de Caliopen
Trouver des développeurs ou développeuses n’est jamais une mince affaire dans le petit monde de l’open source, comment ça s’est passé pour Caliopen ?
Il faut bien comprendre que – pour le moment – Caliopen n’a pas d’existence juridique propre. Les gens qui bossent sur le projet sont des employés de Gandi (et bientôt de Qwant et de l’UPMC) qui ont soit choisi de consacrer une partie de leur temps de travail à Caliopen (ce que Gandi a rendu possible) soit été embauchés spécifiquement pour le projet. Et parfois nous avons des bénévoles qui nous rejoignent pour un bout de chemin 🙂
Le projet est encore franco-français. Tu t’en félicites (cocorico) ou ça t’angoisse ?
J’ai bien des sujets d’angoisse, mais pas celui-là. C’est un problème, c’est vrai, et nous essayons de le résoudre en allant, par exemple, faire des conférences à l’étranger (l’an dernier au FOSDEM, et cette année au 34C3 si notre soumission est acceptée). Et le site est totalement trilingue (français, anglais et italien) grâce au travail (bénévole) de Daniele Pitrolo.
D’un autre côté il faut quand même reconnaître que bosser au quotidien dans sa langue maternelle est un vrai confort dont il n’est pas facile de se passer. Même si on est tous conscients, je crois, qu’il faudra bien passer à l’anglais quand l’audience du projet deviendra un peu plus internationale, et nous comptons un peu sur les premières versions publiques pour que ça se produise.
Et au fait, c’est codé en quoi, Caliopen ? Du JavaScript surtout, d’après ce qu’on voit sur GitHub, mais nous supposons qu’il y a pas mal de technos assez pointues pour un tel projet ?
Sur GitHub, le code de Caliopen est dans un mono-repository, il n’y a donc pas de paquet (ou dépôt) spécifique au front ou au back. Le client est développé en JavaScript avec la librarie ReactJS. Le backend (l’API ReST, les workers …) sont développés en python et en Go. On n’a pas le détail mais ce doit être autour de 50% JS+css, 25% python, 25% Go. L’architecture est basée sur Cassandra et ElasticSearch.
Ce n’est pas que l’on utilise des technos pointues, mais plutôt qu’ on évite autant que possible la dette technique en intégrant le plus rapidement possible les évolutions des langages et des librairies que l’on utilise.
Donc il faut vraiment un haut niveau de compétences pour contribuer ?
Difficile à dire. Si on s’arrête sur l’aspect développement pur, les technos employées sont assez grand public, et si on a suivi un cursus standard on va facilement retrouver ses habitudes (cf. https://github.com/kamranahmedse/developer-roadmap).
Effectivement quelqu’un qui n’a pas l’habitude de développer sur ces outils (docker, Go, webpack, ES6+ …) risque d’être un peu perdu au début. Mais on est très souvent disponibles sur IRC pour répondre directement aux questions.
Néanmoins nous avons de « simples » contributions qui ne nécessitent pas de connaître les patrons de conception par cœur ou de devoir monter un cluster; par exemple proposer des corrections orthographiques, de nouvelles traductions, décrire des erreurs JavaScript dans des issues sur github, modifier un bout de css…
Qu’est-ce qui différencie le projet Caliopen d’un projet comme Protonmail ?
Protonmail est un Gmail-like orienté vers la sécurité. Caliopen est un agrégateur de correspondance privée (ce qui n’est rien-like) orienté vers l’amélioration des pratiques du grand public via l’expérience utilisateur. Protonmail est centralisé, Caliopen a prévu tout un (futur) écosystème exclusivement destiné à garantir la décentralisation des échanges. Et puis Caliopen est un logiciel libre, pas Protonmail.
Mais au-delà de ces différences techniques et philosophiques, ce sont surtout deux visions différentes, et peut-être complémentaires, de la lutte contre la surveillance de masse: Protonmail s’attaque à la protection de ceux qui sont prêts à changer leurs habitudes (et leur adresse email) parce qu’ils sont déjà convaincus qu’il faut faire certains efforts pour leur vie privée. Caliopen veut changer les habitudes de tous les autres, en leur proposant un service différent (mais utile) qui va les sensibiliser à la question. Parce qu’il faut bien se rendre compte que, malgré son succès formidable, aujourd’hui le nombre d’utilisateurs de Protonmail ne représente qu’à peine un millième du nombre d’utilisateurs de Gmail, et que quand les premiers échangent avec les seconds ils ne sont pas mieux protégés que M. Michu.
Maintenant, si tu veux bien imaginer que Caliopen est aussi un succès (on a le droit de rêver) et qu’il se crée un jour disons une dizaine de milliers de services basés sur noooootre proooojet, chacun ne gérant qu’un petit dixième du nombre d’utilisateurs de Protonmail… Eh ben sauf erreur on équilibre le nombre d’utilisateurs de Gmail et – si on a raison de croire que l’affichage des indices de confidentialité va produire un effet – on a significativement augmenté le niveau global de confidentialité.
Et peut-être même assez pour que la surveillance de masse devienne hors de prix.
Est-ce que dans la future version de Caliopen les messages seront chiffrés de bout en bout ?
À chaque fois qu’un utilisateur de Caliopen va vouloir écrire à un de ses contacts, c’est le protocole le plus sécurisé qui sera choisi par défaut pour transporter son message. Prenons un exemple et imaginons que tu m’ajoutes à tes contacts dans Caliopen : tu vas renseigner mon adresse email, mon compte Twitter, mon compte Mastodon, mon Keybase… plus tu ajouteras de moyens de contact plus Caliopen aura de choix pour m’envoyer ton message. Et il choisira le plus sécurisé par défaut (mais tu pourras décider de ne pas suivre son choix).
Plus tes messages auront pu être sécurisés, plus hauts seront leurs indices de confidentialité affichés. Et plus les indices de confidentialité de tes échanges seront hauts, plus haut sera ton propre indice global (ce qui devrait te motiver à mieux renseigner ma fiche contact afin d’y ajouter l’adresse de mon email hébergé sur un service Caliopen, parce qu’alors le protocole choisi sera le protocole intra-caliopen qui aura un très fort indice de confidentialité).
Mais l’utilisateur moyen n’aura sans doute même pas conscience de tout ça. Simplement le système fera en sorte de ne pas envoyer un message en clair s’il dispose d’un moyen plus sûr de le faire pour tel ou tel contact.
Est-ce qu’on pourra (avec un minimum de compétences, par exemple pour des CHATONS) installer Caliopen sur un serveur et proposer à des utilisateurs et utilisatrices une messagerie à la fois sécurisée et respectueuse ?
C’est fondamental, et c’est un des enjeux de Caliopen. Souvent quand je parle devant un public technique je pose la question : « combien de temps mettez-vous à installer un site Web en partant de zéro, et combien de temps pour une messagerie complète ? ». Et les réponses aujourd’hui sont bien sûr diamétralement opposées à ce qu’elle auraient été 15 ans plus tôt, parce qu’on a énormément travaillé sur la facilité d’installation d’un site, depuis des années, alors qu’on a totalement négligé la messagerie.
Si on veut que Caliopen soit massivement adopté, et c’est notre objectif, alors il faudra qu’il soit – relativement – facile à installer. Au moins assez facile pour qu’une entreprise, une administration, une association… fasse le choix de l’installer plutôt que de déléguer à Google la gestion du courrier de ses membres. Il faudra aussi qu’il soit facilement administrable, et facile à mettre à jour. Et tout ceci a été anticipé, et analysé, durant tout ce temps où tu crois qu’on n’a pas été assez vite !
On te laisse le dernier mot comme il est de coutume dans nos interviews pour le blog…
À lire tes questions j’ai conscience qu’on a encore beaucoup d’efforts à faire en termes de communication. Heureusement pour nous, Julien Dubedout nous a rejoints récemment, et je suis sûr qu’il va beaucoup améliorer tout ça. 🙂
Depuis un an, l’actualité a régulièrement mis en lumière les premiers effets déstructurants pour le travail salarié de l’ubérisation de la société : hier les taxis, aujourd’hui les livreurs à vélo…
Et demain sans doute d’autres pans de l’économie réelle vont être confrontés au tech-libéralisme, nouvel avatar du capitalisme prédateur (pardon du pléonasme).
Confrontés de plein fouet à cette problématique, les membres de l’association CoopCycle ont élaboré une réponse originale et peut-être prometteuse : une structure coopérative et un outil crucial en cours de développement, une plateforme numérique.
Les militants de cette opération sont engagés dans une lutte pour un autre rapport à leur propre travail : il s’agit de « rééquilibrer les forces » dans un contexte où jusqu’alors, une poignée d’entreprises imposaient leurs conditions léonines.
Ils inscrivent également leur combat dans une continuité entre les coopératives éthiques-équitables et les biens communs où ils veulent verser leur code.
Bien sûr les libristes seront surpris et probablement critiques sur la licence particulière choisie pour des raisons qui laissent perplexe. Mais c’est l’occasion aussi pour nos lecteurs de suggérer avec bienveillance et bien sûr de contribuer au code, pour qu’aboutisse et se développe cette courageuse et fort intéressante démarche.
Aider cette association à affiner les outils numériques qui rendent plus libres et modifient les rapports sociaux, c’est tout à fait dans la logique de Contributopia.
La techno ça sert à rien si ça change pas la vie des gens.
Voici les prénoms des CoopCycle qui nous ont répondu : Alexandre, Aurélien, Aloïs, Antoine, Basile, Jérôme, Kevin, Laury-Anne, Liova, Lison, Paul, Pauline, Vincent.
Logo de CoopCycle
D’habitude on demande à nos interviewés de se présenter mais je vois bien que vous avez depuis quelques mois une sacrée visibilité médiatique et c’est tant mieux…
Coopcycle – L’explosion médiatique est détaillée sur notre blog Médiapart en toute transparence. Effectivement, ça a explosé au mois d’août en parallèle des rassemblements de livreurs suite au changement de tarification de Deliveroo. Non seulement les journaux ont beaucoup parlé de ces « cyber-grèves » (des travailleurs numériques qui appellent à la déconnexion, ou qui vont empêcher l’utilisation d’un iPad dans un restaurant, c’est original), mais en plus tous étaient unanimes pour condamner le modèle des plateformes.
Tout le monde a entendu parler de votre initiative et s’y intéresse, pourquoi à votre avis ?
– L’intérêt pour notre initiative vient à notre avis de l’attente qui existait face à un manque d’alternatives permettant de lutter contre une ubérisation de la société parfois perçue comme une fatalité. Le modèle qui se généralise, c’est l’individu auto-entrepreneur dans la « gig economy », l’économie des petits boulots. Face à des plateformes dotées de très gros moyens, tout le monde est un peu les bras ballants, les pouvoirs publics en tête, qui ont même tendance à encourager, « sécuriser » le modèle des plateformes : en penchant pour une jurisprudence qui empêche la requalification des contrats précaires en contrats salariés, en encourageant la délégation de service public, ou en réduisant les normes sur les activités classiques pour leur permettre de faire face à la concurrence à moindre coût des plateformes…
En somme, les pouvoirs publics semblent accompagner l’ubérisation (comme le développe le Conseil d’État au sein de ce document), et accepter le dumping et la casse sociale que ces modèles impliquent, tandis que les livreurs, les restaurateurs et les clients se débrouillent avec une évolution qui semble être un fait accompli.
De plus en plus de monde prend conscience que c’est l’ensemble des régimes de protection sociale qui sont menacés, et personne ne savait comment faire pour répondre à ces problématiques.
Notre initiative cristallise donc beaucoup d’espoirs car c’est une proposition positive, mais qui soulève des problématiques structurelles et interroge la possibilité d’une économie des Communs. En tout cas, ce n’est pas une énième réaction de critique passive à une logique que l’on ne serait pas en position de ralentir ou contrecarrer aujourd’hui. Nous pensons qu’une alternative est possible, et nous allons plus loin en concrétisant nos idées. Dans le débat tel qu’il existe aujourd’hui, c’est déjà une perspective séduisante.
À cause de Nuit Debout ? C’est là que tout a commencé ? À cause des conflits sociaux autour de Deliveroo et autres starteupes qui font tourner les jambes des livreurs pour des rémunérations de misère ?
– Ce n’est pas « à cause de Nuit Debout », c’est plutôt « grâce à Nuit Debout » !
Selon nous, c’est plus la possibilité d’une alternative qui intéresse les gens. Le fait que le projet « vienne de » Nuit Debout, la plupart des gens ne le savent pas.
Mais effectivement ce projet n’existerait pas sans Nuit Debout. C’est un des rares événements politiques qui a eu lieu ces dernières années en France, et même si tout ça paraît déjà lointain, il a suscité une vague d’espoir.
Ce qui nous a réunis sur la place de la République, c’est la lutte contre la loi El Khomri et la précarisation de nos conditions de travail. À partir de là, on se retrouve à participer aux manifestations, on rencontre le Collectif des Livreurs Autonomes de Paris alors que l’idée n’était encore qu’une idée… C’est ce qui a permis l’émergence de groupes de personnes engagées, militantes ou non, qui cherchent des solutions, mènent des campagnes, montent des projets ensemble. Et un de ces projets, c’est CoopCycle.
Elle est destinée à qui cette plateforme en cours de réalisation ? Aux livreurs à vélo, aux restaurateurs, aux consommateurs qui se font livrer ?
– La plateforme est destinée avant tout aux livreurs et aux commerçants, c’est un outil d’émancipation. Les collectivités territoriales ont également une place dans ce genre dispositif car cela leur permet de reprendre le contrôle sur l’espace public ainsi que sur les modes de vivre ensemble.
Mais au final, la plateforme en version « communs » est là pour servir à tout le monde, et pour outiller tout le monde. Quant aux clients finaux, nous sommes persuadés que beaucoup de consommateurs seraient prêts à payer un peu plus cher pour que les livreurs aient de bonnes conditions de travail.
Regardez l’engouement pour les Biocoop, regardez aussi la réussite d’Enercoop, qui fournit de l’énergie durable. À leurs débuts, ces derniers étaient 50 % plus chers que l’opérateur historique et pourtant, ils ont réussi à séduire des clients conscients, qui veulent consommer autrement.
Pour la livraison de repas à domicile, qu’on soit client ou restaurateur, on peut très bien vouloir consommer et commercer de façon éthique et équitable, mais si les seuls outils disponibles sont ceux des capitalistes, on se retrouve à consommer et travailler au profit du capitalisme, qu’on le veuille ou non.
CoopCycle est donc une initiative de reprise en main de la logique des plateformes afin de permettre un rééquilibrage du rapport de force en faveur des livreurs et des restaurateurs dans le secteur de la livraison.
C’est quoi cette licence bizarre que vous avez exhumée des tréfonds du web ? pourquoi celle-là plutôt que d’autres parmi les nombreuses licences libres ?
— La licence qui encadre l’application que nous développons restreint l’utilisation à des groupes de livreurs qui se lancent en coopérative ou respectent des critères de réciprocité. Le fait que dans ce cadre son utilisation serait gratuite fait que la marge qu’ils peuvent proposer aux restaurateurs peut être largement moindre que celle des plateformes capitalistes. Si les livreurs ne veulent pas adhérer à la SCIC nationale sur laquelle nous travaillons ils pourront également y avoir accès.
Néanmoins, cette licence n’est pas parfaite ! Premièrement car nous ne savons pas concrètement comment elle est reconnue et s’inscrit à l’échelle de la France ou plus largement à l’échelle européenne. Plus largement, le respect et la défense des licences est difficile à réellement mettre en œuvre dans le cadre de l’économie numérique. Comment pourrions-nous réellement prouver qu’une entité lucrative privée, fermée par nature, utilise des bouts d’un code développé par le travail Commun ? La problématique est la même dans le cadre d’une utilisation propriétaire du code source. Car une fois la captation identifiée, comment pourrions-nous financer les frais judiciaires qu’un procès impliquerait et qui resteraient à notre charge ?
Enfin ce type de licence ne permet pas l’élaboration d’une cotisation qui permettrait de rémunérer le travail à l’origine de ce Commun. Dès lors, aucun retour de la valeur économique produite ne pourrait être assuré aux contributeurs d’un commun dans la mesure ou ce dernier n’a ni périmètre juridique clairement établi, ni force d’opposition face à un grand groupe. Le cadre légal doit être repensé et c’est toutes ces questions que nous souhaitons traiter au cours des conférences suivantes du cycle que nous avons lancé le 20 septembre.
Et au fait pourquoi open source et pas « libre » ?
Le code n’est pas libre car s’il l’était, n’importe qui pourrait se le réapproprier et l’utiliser pour faire du profit. Aujourd’hui dans le libre, c’est souvent la loi du plus fort qui l’emporte, avec toutes les conséquences que l’on connaît. Il faut donc une licence qui permet de protéger l’utilisation de ce code pour la réserver aux coopératives qui ne veulent pas exploiter les gens. Nous savons qu’il faut travailler sur cette histoire de licence et nous sommes en contact avec des avocats spécialisés sur le sujet. D’ailleurs, si vous en connaissez, on les accueille avec plaisir !
Dans ce monde, on est malheureusement toujours ramené au célèbre « there is no alternative » prononcé par Margaret Thatcher. Il faut être « pragmatique», à savoir accepter les règles du jeu capitaliste, pour que rien ne change.
Aujourd’hui, on voit des gens qui «travaillent » sur des alternatives à Uber, par exemple. Pour certains, le premier réflexe, c’est de vérifier que leur modèle peut avoir des retombées commerciales, qu’ils peuvent financer leur développement avant même d’avoir produit une seule ligne de code…
Ça n’est certainement pas notre approche. You don’t need to know how to do it, you just need to start comme dirait l’autre sur un article Medium.
À l’heure où les plateformes représentent une source non négligeable d’emplois (précaires), l’open source offre une vraie possibilité d’implémenter enfin la copropriété d’usage de l’outil de travail.
Mais il faut des règles pour garantir que l’essentiel de la valeur créée aille aux travailleurs, afin de poursuivre sur le chemin de l’émancipation. Sinon, ce seront forcément ceux qui auront les capitaux qui pourront enclencher les effets de réseau, tout ça en utilisant du « travail gratuit ».
Il est temps d’en finir avec le solutionnisme technologique, il faut ajouter une dimension sociale, sans quoi on retombe dans l’aliénation.
Votre projet n’est donc pas simplement de développer une plateforme informatique, aussi open source soit-elle, c’est aussi un tout autre modèle social, celui de la coopérative. C’est possible de nous expliquer ça simplement ?
Nous n’avons pas envie de créer une startup de l’économie sociale et solidaire. Ce qui nous intéresse, c’est justement le projet politique. Il existe aujourd’hui tout un archipel de sites et d’initiatives qui espèrent « changer le monde » et pourtant, rien de bouge vraiment au niveau macro-économique. Les structures qui permettent l’exploitation des travailleurs sont toujours bien en place. Nous aimerions « secouer le cocotier », et faire du lobbying citoyen pour essayer de modifier ces structures. Certes, nous n’avons pas encore une loi anti-ubérisation dans nos cartons, mais réunir des gens de différents milieux permet de faire réfléchir, de rassembler et à terme d’influencer le jeu politique.
Sur le choix de la coopérative, il s’est assez simplement imposé à nous. Nous sommes en passe d’avoir ce bel outil numérique mais sommes conscients que face aux géants de la foodtech et malgré la surmédiatisation ponctuelle, il ne suffira pas de dire « voici le moyen de vous réapproprier votre outil de travail, à vous de jouer ».
La question qui se pose à nous est celle de l’articulation entre une ressource que l’on gère comme un commun et un circuit économique composé de coopératives qui permettent une rémunération et des conditions de travail correctes pour ceux qui y travaillent. La forme coopérative nous semble la plus adaptée puisqu’elle permet des règles économiques et démocratiques plus équitables (statut salarié, intégration de l’ensemble des acquis sociaux y afférant, mutualisation des moyens comme des risques, une personne une voix, etc.).
Mais nous ne sommes pas dupes évidemment, le développement de ces modèles « sociaux et solidaires » est un mouvement positif, témoignant d’une certaine prise de conscience nécessaire mais non suffisante. La création de structures privées socialisées dans un marché libéral combat le capitalisme sur ses terres mais n’emporte pas de sortie réelle de ce système. Pire encore, on peut également considérer que ce développement parallèle organise le désengagement de l’état in fine, puisque la mutualisation se réorganise à plus petite échelle.
C’est pour cela que nous tenons à agir sur les 3 plans :
développer un outil open source et libre d’accès sous condition, pour créer l’outil de travail ;
construire une structure coopérative nationale et des structures locales pour organiser les moyens du travail ;
questionner les problématiques macro-économiques et structurelles qui se posent aux différentes étapes de notre construction à travers des cycles de conférences thématiques.
Si l’initiative de Coopcycle faisait tache d’huile ? Ici, solidarité avec les livreurs espagnols.
Bon alors où en est-il ce code open source de plateforme ? Vous êtes combien là-derrière ? Vous auriez peut-être besoin d’un coup de main, de patches, de bêta-testeurs, de pintes de bières, enfin tous les trucs qu’on s’échange dans le petit monde du logiciel libre. C’est le moment de lancer un appel à contributions hein…
Pour l’instant il y a 3 personnes qui ont contribué. Notre but est de construire une communauté autour du code, pour assurer la pérennité du projet notamment. On a posé les premiers jalons avec des règles de contribution et une installation en local facile (crash testée !). Nous avons reçu plusieurs propositions spontanées d’aide, mais cherchons encore à voir comment intégrer chacun suivant son temps disponible et ses langages de prédilection. De même nous devons établir une roadmap claire pour le projet. Tout cela explique que nous n’ayons pas encore fait d’appel à contribution.
En tout cas tous les repos ont des issues ouvertes, et n’attendent que vous !
Le feedback sur la démo (UI/UX ou bugs) est plus que bienvenu. Vous pouvez contacter l’équipe dev à dev@coopcycle.org.
Toutefois il ne faut pas résumer notre approche au groupe de développeurs, nous sommes une bonne quinzaine à travailler sur ce projet ; journalisme, portage politique, propagande, représentation, construction du modèle économique, lien avec les livreurs et les restaurateurs. Tous ces travaux sont complémentaires et nous essayons justement de ne pas tomber dans le solutionnisme de l’outil en assumant toutes ces tâches collectivement.
On vous laisse le mot de la fin, comme de coutume sur le Framablog !
Merci pour tous vos outils, c’est un plaisir de pouvoir bâtir son projet avec des logiciels libres ! En attente de Framameet pour nos apéros devs 🙂
Comment les entreprises surveillent notre quotidien
Vous croyez tout savoir déjà sur l’exploitation de nos données personnelles ? Parcourez plutôt quelques paragraphes de ce très vaste dossier…
Il s’agit du remarquable travail d’enquête procuré par Craked Labs, une organisation sans but lucratif qui se caractérise ainsi :
… un institut de recherche indépendant et un laboratoire de création basé à Vienne, en Autriche. Il étudie les impacts socioculturels des technologies de l’information et développe des innovations sociales dans le domaine de la culture numérique.
… Il a été créé en 2012 pour développer l’utilisation participative des technologies de l’information et de la communication, ainsi que le libre accès au savoir et à l’information – indépendamment des intérêts commerciaux ou gouvernementaux. Cracked Labs se compose d’un réseau interdisciplinaire et international d’experts dans les domaines de la science, de la théorie, de l’activisme, de la technologie, de l’art, du design et de l’éducation et coopère avec des parties publiques et privées.
Bien sûr, vous connaissez les GAFAM omniprésents aux avant-postes pour nous engluer au point que s’en déprendre complètement est difficile… Mais connaissez-vous Acxiom et LiveRamp, Equifax, Oracle, Experian et TransUnion ? Non ? Pourtant il y a des chances qu’ils nous connaissent bien…
Il existe une industrie très rentable et très performante des données « client ».
Dans ce long article documenté et qui déploie une vaste gamme d’exemples dans tous les domaines, vous ferez connaissance avec les coulisses de cette industrie intrusive pour laquelle il semble presque impossible de « passer inaperçu », où notre personnalité devient un profil anonyme mais tellement riche de renseignements que nos nom et prénom n’ont aucun intérêt particulier.
L’article est long, vous pouvez préférer le lire à votre rythme en format .PDF (2,3 Mo)
avec les contributions de : Katharina Kopp, Patrick Urs Riechert / Illustrations de Pascale Osterwalder.
Comment des milliers d’entreprises surveillent, analysent et influencent la vie de milliards de personnes. Quels sont les principaux acteurs du pistage numérique aujourd’hui ? Que peuvent-ils déduire de nos achats, de nos appels téléphoniques, de nos recherches sur le Web, de nos Like sur Facebook ? Comment les plateformes en ligne, les entreprises technologiques et les courtiers en données font-ils pour collecter, commercialiser et exploiter nos données personnelles ?
Ces dernières années, des entreprises dans de nombreux secteurs se sont mises à surveiller, pister et suivre les gens dans pratiquement tous les aspects de leur vie. les comportements, les déplacements, les relations sociales, les centres d’intérêt, les faiblesses et les moments les plus intimes de milliards de personnes sont désormais continuellement enregistrés, évalués et analysés en temps réel. L’exploitation des données personnelles est devenue une industrie pesant plusieurs milliards de dollars. Pourtant, de ce pistage numérique omniprésent, on ne voit que la partie émergée de l’iceberg ; la majeure partie du processus se déroule dans les coulisses et reste opaque pour la plupart d’entre nous.
Ce rapport de Cracked Labs examine le fonctionnement interne et les pratiques en vigueur dans cette industrie des données personnelles. S’appuyant sur des années de recherche et sur un précédent rapport de 2016, l’enquête donne à voir la circulation cachée des données entre les entreprises. Elle cartographie la structure et l’étendue de l’écosystème numérique de pistage et de profilage et explore tout ce qui s’y rapporte : les technologies, les plateformes, les matériels ainsi que les dernières évolutions marquantes.
Le rapport complet (93 pages, en anglais) est disponible en téléchargement au format PDF, et cette publication web en présente un résumé en dix parties.
En 2007, Apple a lancé le smartphone, Facebook a atteint les 30 millions d’utilisateurs, et des entreprises de publicité en ligne ont commencé à cibler les internautes en se basant sur des données relatives à leurs préférences individuelles et leurs centres d’intérêt. Dix ans plus tard, un large ensemble d’entreprises dont le cœur de métier est les données (les data-companies ou entreprises de données en français) a émergé, on y trouve de très gros acteurs comme Facebook ou Google mais aussi des milliers d’autres entreprises, qui sans cesse, se partagent et se vendent les unes aux autres des profils numériques. Certaines entreprises ont commencé à combiner et à relier des données du web et des smartphones avec les données clients et les informations hors-ligne qu’elles avaient accumulées pendant des décennies.
La machine omniprésente de surveillance en temps réel qui a été développée pour la publicité en ligne s’étend rapidement à d’autres domaines, de la tarification à la communication politique en passant par le calcul de solvabilité et la gestion des risques. Des plateformes en ligne énormes, des entreprises de publicité numérique, des courtiers en données et des entreprises de divers secteurs peuvent maintenant identifier, trier, catégoriser, analyser, évaluer et classer les utilisateurs via les plateformes et les matériels. Chaque clic sur un site web et chaque mouvement du doigt sur un smartphone peut activer un large éventail de mécanismes de partage de données distribuées entre plusieurs entreprises, ce qui, en définitive, affecte directement les choix offerts aux gens. Le pistage numérique et le profilage, en plus de la personnalisation ne sont pas seulement utilisés pour surveiller, mais aussi pour influencer les comportements des personnes.
Vous devez vous battre pour votre vie privée, sinon vous la perdrez.
Eric Schmidt, Google/Alphabet, 2013
Analyser les individus
Des études scientifiques démontrent que de nombreux aspects de la personnalité des individus peuvent être déduits des données générées par des recherches sur Internet, des historiques de navigation, des comportements lors du visionnage d’une vidéo, des activités sur les médias sociaux ou des achats. Par exemple, des données personnelles sensibles telles que l’origine ethnique, les convictions religieuses ou politiques, la situation amoureuse, l’orientation sexuelle, ou l’usage d’alcool, de cigarettes ou de drogues peuvent être assez précisément déduites des Like sur Facebook d’une personne. L’analyse des profils de réseaux sociaux peut aussi prédire des traits de personnalité comme la stabilité émotionnelle, la satisfaction individuelle, l’impulsivité, la dépression et l’intérêt pour le sensationnel.
Analyser les like Facebook, les données des téléphones, et les styles de frappe au clavier
Pour plus de détails, se référer à Christl and Spiekermann 2016 (p. 14-20). Sources : Kosinski et al 2013, Chittaranjan et al 2011, Epp at al 2011.
De la même façon, il est possible de déduire certains traits de caractères d’une personne à partir de données sur les sites Web qu’elle a visités, sur les appels téléphoniques qu’elle a passés, et sur les applis qu’elle a utilisées. L’historique de navigation peut donner des informations sur la profession et le niveau d’étude. Des chercheurs canadiens ont même réussi à évaluer des états émotionnels comme la confiance, la nervosité, la tristesse ou la fatigue en analysant la façon dont on tape sur le clavier de l’ordinateur.
Analyser les individus dans la finance, les assurances et la santé
Les résultats des méthodes actuelles d’extraction et d’analyse des données reposent sur des corrélations statistiques avec un certain niveau de probabilité. Bien qu’ils soient significativement plus fiables que le hasard dans la prédiction des caractéristiques ou des traits de caractère d’un individu, ils ne sont évidemment pas toujours exacts. Néanmoins, ces méthodes sont déjà mises en œuvre pour trier, catégoriser, étiqueter, évaluer, noter et classer les personnes, non seulement dans une approche marketing mais aussi pour prendre des décisions dans des domaines riches en conséquence comme la finance, l’assurance, la santé, pour ne citer qu’eux.
L’évaluation de crédit basée sur les données de comportement numérique
Des startups comme Lenddo, Kreditech, Cignifi et ZestFinance utilisent déjà les données récoltées sur les réseaux sociaux, lors de recherches sur le web ou sur les téléphones portables pour calculer la solvabilité d’une personne sans même utiliser de données financières. D’autres se basent sur la façon dont quelqu’un va remplir un formulaire en ligne ou naviguer sur un site web, sur la grammaire et la ponctuation de ses textos, ou sur l’état de la batterie de son téléphone. Certaines entreprises incluent même des données sur les amis avec lesquels une personne est connectée sur un réseau social pour évaluer sa solvabilité.
Cignifi, qui calcule la solvabilité des clients en fonction des horaires et de la fréquence des appels téléphoniques, se présente comme « la plateforme ultime de monétisation des données pour les opérateurs de réseaux mobiles ». De grandes entreprises, notamment MasterCard, le fournisseur d’accès mobile Telefonica, les agences d’évaluation de solvabilité Experian et Equifax, ainsi que le géant chinois de la recherche web Baidu, ont commencé à nouer des partenariats avec des startups de ce genre. L’application à plus grande échelle de services de cette nature est particulièrement en croissance dans les pays du Sud, ainsi qu’auprès de groupes de population vulnérables dans d’autres régions.
Réciproquement, les données de crédit nourrissent le marketing en ligne. Sur Twitter, par exemple, les annonceurs peuvent cibler leurs publicités en fonction de la solvabilité supposée des utilisateurs de Twitter sur la base des données client fournies par le courtier en données Oracle. Allant encore plus loin dans cette logique, Facebook a déposé un brevet pour une évaluation de crédit basée sur la cote de solvabilité de vos amis sur un réseau social. Personne ne sait s’ils ont l’intention de réellement mettre en application cette intégration totale des réseaux sociaux, du marketing et de l’évaluation des risques.
On peut dire que toutes les données sont des données sur le crédit, mais il manque encore la façon de les utiliser.
Douglas Merrill, fondateur de ZestFinance et ancien directeur des systèmes d’informations chez Google, 2012
Prédire l’état de santé à partir des données client
Les entreprises de données et les assureurs travaillent sur des programmes qui utilisent les informations sur la vie quotidienne des consommateurs pour prédire leurs risques de santé. Par exemple, l’assureur Aviva, en coopération avec la société de conseil Deloitte, a utilisé des données clients achetées à un courtier en données et habituellement utilisées pour le marketing, pour prédire les risques de santé individuels (comme le diabète, le cancer, l’hypertension et la dépression) de 60 000 personnes souhaitant souscrire une assurance.
La société de conseil McKinsey a aidé à prédire les coûts hospitaliers de patients en se basant sur les données clients d’une « grande compagnie d’assurance » santé américaine. En utilisant les informations concernant la démographie, la structure familiale, les achats, la possession d’une voiture et d’autres données, McKinsey a déclaré que ces « renseignements peuvent aider à identifier des sous-groupes stratégiques de patients avant que des périodes de coûts élevés ne surviennent ».
L’entreprise d’analyse santé GNS Healthcare a aussi calculé les risques individuels de santé de patients à partir d’un large champ de données tel que la génétique, les dossiers médicaux, les analyses de laboratoire, les appareils de santé mobiles et le comportement du consommateur. Les sociétés partenaires des assureurs tels que Aetna donnent une note qui identifie « les personnes susceptibles de subir une opération » et proposent de prédire l’évolution de la maladie et les résultats des interventions. D’après un rapport sectoriel, l’entreprise « classe les patients suivant le retour sur investissement » que l’assureur peut espérer s’il les cible pour des interventions particulières.
LexisNexis Risk Solutions, à la fois, un important courtier en données et une société d’analyse de risque, fournit un produit d’évaluation de santé qui calcule les risques médicaux ainsi que les frais de santé attendus individuellement, en se basant sur une importante quantité de données consommateurs, incluant les achats.
Collecte et utilisation massives de données client
Les plus importantes plates-formes connectées d’aujourd’hui, Google et Facebook en premier lieu, ont des informations détaillées sur la vie quotidienne de milliards de personnes dans le monde. Ils sont les plus visibles, les plus envahissants et, hormis les entreprises de renseignement, les publicitaires en ligne et les services de détection des fraudes numériques, peut-être les acteurs les plus avancés de l’industrie de l’analyse et des données personnelles. Beaucoup d’autres agissent en coulisse et hors de vue du public.
Le cœur de métier de la publicité en ligne consiste en un écosystème de milliers d’entreprises concentrées sur la traque constante et le profilage de milliards de personnes. À chaque fois qu’une publicité est affichée sur un site web ou une application mobile, un profil d’utilisateur vient juste d’être vendu au plus gros enchérisseur dans les millisecondes précédentes. Contrairement à ces nouvelles pratiques, les agences d’analyse de solvabilité et les courtiers en données clients exploitent des données personnelles depuis des décennies. Ces dernières années, ils ont commencé à combiner les très nombreuses données dont ils disposent sur la vie hors-ligne des personnes avec les bases de données utilisateurs et clients utilisées par de grandes plateformes, par des entreprises de publicité et par une multitude d’autres entreprises dans de nombreuses secteurs.
Les entreprises de données ont des informations détaillées sur des milliards de personnes
Plateformes en ligne grand public
Facebook dispose
des profils de
1,9 milliards d’utilisateurs de Facebook
1,2 milliards d’utilisateurs de Whatsapp
600 millions d’utilisateurs d’Instagram
Google dispose
des profils de
2 milliards d’utilisateurs d’Android
+ d’un milliard d’utilisateurs de Gmail
+ d’un milliard d’utilisateurs de Youtube
Apple dispose
des profils de
1 milliard d’utilisateurs d’iOS
Sociétés d’analyse de la solvabilité
Experian
dispose des données de solvabilité de 918 millions de personnes
dispose des données marketing de 700 millions de personnes
a un “aperçu” sur 2,3 milliards de personnes
Equifax
dispose des données de 820 millions de personnes
et d’1 milliard d’appareils
TransUnion
dispose des données d’1 milliard de personnes
Courtiers en données clients
Acxiom
dispose des données de
700 millions de personnes
1 milliard de cookies et d’appareils mobiles
3,7 milliards de profils clients
Oracle
dispose des données de
1 milliard d’utilisateurs d’appareils mobiles
1,7 milliards d’internautes
donne accès à
5 milliards d’identifiants uniques client
Facebook utilise au moins 52 000 caractéristiques personnelles pour trier et classer ses 1,9 milliard d’utilisateurs suivant, par exemple, leur orientation politique, leur origine ethnique et leurs revenus. Pour ce faire, la plateforme analyse leurs messages, leurs Likes, leurs partages, leurs amis, leurs photos, leurs mouvements et beaucoup d’autres comportements. De plus, Facebook acquiert à d’autres entreprises des données sur ses utilisateurs. En 2013, la plateforme démarre son partenariat avec les quatre courtiers en données Acxiom, Epsilon, Datalogix et BlueKai, les deux derniers ont ensuite été rachetés par le géant de l’informatique Oracle. Ces sociétés aident Facebook à pister et profiler ses utilisateurs bien mieux qu’il le faisait déjà en lui fournissant des données collectées en dehors de sa plateforme.
Les courtiers en données et le marché des données personnelles
Les courtiers en données client ont un rôle clé dans le marché des données personnelles actuel. Ils agrègent, combinent et échangent des quantités astronomiques d’informations sur des populations entières, collectées depuis des sources en ligne et hors-ligne. Les courtiers en données collectent de l’information disponible publiquement et achètent le droit d’utiliser les données clients d’autres entreprises. Leurs données proviennent en général de sources qui ne sont pas les individus eux-mêmes, et sont collectées en grande partie sans que le consommateur soit au courant. Ils analysent les données, en font des déductions, construisent des catégories de personnes et fournissent à leurs clients des informations sur des milliers de caractéristiques par individu.
Dans les profils individuels créés par les courtiers en données, on trouve non seulement des informations à propos de l’éducation, de l’emploi, des enfants, de la religion, de l’origine ethnique, de la position politique, des loisirs, des centres d’intérêts et de l’usage des médias, mais aussi à propos du comportement en ligne, par exemple les recherches sur Internet. Sont également collectées les données sur les achats, l’usage de carte bancaire, le revenu et l’endettement, la gestion bancaire et les polices d’assurance, la propriété immobilière et automobile, et tout un tas d’autres types d’information. Les courtiers en données calculent et attribuent aussi des notes aux individus afin de prédire leur comportement futur, par exemple en termes de stabilité économique, de projet de grossesse ou de changement d’emploi.
Quelques exemples de données clients fournies par Acxiom et Oracle
exemples de données clients fournies par Axciom et Oracle (en avril/mai 2017) – sources : voir le rapport
Acxiom, un important courtier en données
Fondée en 1969, Acxiom gère l’une des plus grandes bases de données client commerciales au monde. Disposant de milliers de sources, l’entreprise fournit jusqu’à 3000 types de données sur 700 millions de personnes réparties dans de nombreux pays, dont les États-Unis, le Royaume-Uni et l’Allemagne. Née sous la forme d’une entreprise de marketing direct, Acxiom a développé ses bases de données client centralisées à la fin des années 1990.
À l’aide de son système Abilitek Link, l’entreprise tient à jour une sorte de registre de la population dans lequel chaque personne, chaque foyer et chaque bâtiment reçoit un identifiant unique. En permanence, l’entreprise met à jour ses bases de données sur la base d’informations concernant les naissances et les décès, les mariages et les divorces, les changements de nom ou d’adresse et aussi bien sûr de nombreuses autres données de profil. Quand on lui demande des renseignements sur une personne, Acxiom peut par exemple donner une appartenance religieuse parmi l’une des 13 retenues comme « catholique », « juif », ou « musulman » et une appartenance ethnique sur quasiment 200 possibles.
Acxiom commercialise l’accès aux profils détaillés des consommateurs et aide ses clients à trouver, cibler, identifier, analyser, trier, noter et classer les gens. L’entreprise gère aussi directement pour ses propres clients 15 000 bases de données clients représentant des milliards de profils consommateurs. Les clients d’Acxiom sont des grandes banques, des assureurs, des services de santé et des organismes gouvernementaux. En plus de son activité de commercialisation de données, Acxiom fournit également des services de vérification d’identité, de gestion du risque et de détection de fraude.
Acxiom et ses fournisseurs de données, ses partenaires et ses services
Axciom et ses fournisseurs de données, ses partenaires et ses clients (en avril/mai 2017) – sources : voir le rapport
Depuis l’acquisition en 2014 de la société de données en ligne LiveRamp, Acxiom a déployé d’importants efforts pour connecter son dépôt de données – couvrant une dizaine d’années – au monde numérique. Par exemple, Acxiom était parmi les premiers courtiers en données à fournir de l’information additionnelle à Facebook, Google et Twitter afin d’aider ces plateformes à mieux pister ou catégoriser les utilisateurs en fonction de leurs achats mais aussi en fonction d’autres comportements qu’ils ne savaient pas encore eux-mêmes pister.
LiveRamp de Acxiom connecte et combine les profils numériques issus de centaines d’entreprises de données et de publicité. Au centre se trouve son système IdentityLink, qui aide à reconnaître les individus et à relier les informations les concernant, dans les bases de données, les plateformes et les appareils en se basant sur leur adresse de courriel, leur numéro de téléphone, l’identifiant de leur téléphone, ou d’autres identifiants. Bien que l’entreprise assure que les correspondances et les associations se fassent de manière « anonyme » et « dé-identifiée », elle dit aussi pouvoir « connecter des données hors-ligne et en ligne sur un seul identifiant ».
Parmi les entreprises qui ont récemment été reconnues comme étant des fournisseurs de données par LiveRamp, on trouve les géants de l’analyse de solvabilité Equifax, Experian et TransUnion. De plus, de nombreux services de pistage numérique collectant des données par Internet, par les applications mobiles, et même par des capteurs placés dans le monde réel, fournissent des données à LiveRamp. Certains d’entre eux utilisent les base de données de LiveRamp, qui permettent aux entreprises « d’acheter et de vendre des données client précieuses ». D’autres fournissent des données afin que Acxiom et LiveRamp puissent reconnaître des individus et relier les informations enregistrées avec les profils numériques d’autres provenances. Mais le plus préoccupant, c’est sans doute le partenariat entre Acxiom et Crossix, une entreprise avec des données détaillées sur la santé de 250 millions de consommateurs américains. Crossix figure parmi les fournisseurs de données de LiveRamp.
Quiconque enregistrant des données sur les consommateurs peut potentiellement être un fournisseur de données. »
Travis May, Directeur général de Acxiom-LiveRamp
Oracle, un géant des technologies de l’information pénètre le marché des données client
En faisant l’acquisition de plusieurs entreprises de données telles que Datalogix, BlueKai, AddThis et CrossWise, Oracle, un des premiers fournisseurs de logiciels d’entreprises et de bases de données dans le monde, est également récemment devenu un des premiers courtiers en données clients. Dans son « cloud », Oracle rassemble 3 milliards de profils utilisateurs issus de 15 millions de sites différents, les données d’un milliard d’utilisateurs mobiles, des milliards d’historiques d’achats dans des chaînes de supermarchés et 1500 détaillants, ainsi que 700 millions de messages par jour issus des réseaux sociaux, des blogs et des sites d’avis de consommateurs.
Oracle rassemble des données sur des milliards de consommateurs
Oracle et ses fournisseurs de données, ses partenaires et ses clients (en avril/mai 2017) – sources : voir le rapport
Oracle catalogue près de 100 fournisseurs de données dans son répertoire de données, parmi lesquels figurent Acxiom et des agences d’analyse de solvabilité telles que Experian et TransUnion, ainsi que des entreprises qui tracent les visites de sites Internet, l’utilisation d’applications mobiles et les déplacements, ou qui collectent des données à partir de questionnaires en ligne. Visa et MasterCard sont également référencés comme fournisseurs de données. En coopération avec ses partenaires, Oracle fournit plus de 30 000 catégories de données différentes qui peuvent être attribuées aux consommateurs. Réciproquement, l’entreprise partage des données avec Facebook et aide Twitter à calculer la solvabilité de ses utilisateurs.
Le Graphe d’Identifiants Oracle détermine et combine des profils utilisateur provenant de différentes entreprises. Il est le « trait d’union entre les interactions » à travers les différentes bases de données, services et appareils afin de « créer un profil client adressable » et « d’identifier partout les clients et les prospects ». D’autres entreprises peuvent envoyer à Oracle, des clés de correspondance construites à partir d’adresses courriel, de numéros de téléphone, d’adresse postale ou d’autres identifiants, Oracle les synchronisera ensuite à son « réseau d’identifiants utilisateurs et statistiques, connectés ensemble dans le Graphe d’Identifiants Oracle ». Bien que l’entreprise promette de n’utiliser que des identifiants utilisateurs anonymisés et des profils d’utilisateurs anonymisés, ceux-ci font tout de même référence à certains individus et peuvent être utilisés pour les reconnaître et les cibler dans de nombreux contextes de la vie.
Le plus souvent, les clients d’Oracle peuvent télécharger dans le « cloud » d’Oracle leurs propres données concernant : leurs clients, les visites sur leur site ou les utilisateurs d’une application ; ils peuvent les combiner avec des données issues de nombreuses autres entreprises, puis les transférer et les utiliser en temps réel sur des centaines d’autres plateformes de commerce et de publicité. Ils peuvent par exemple les utiliser pour trouver et cibler des personnes sur tous les appareils et plateformes, personnaliser leurs interactions, et le cas échéant mesurer la réaction des clients qui ont été personnellement ciblés.
La surveillance en temps réel des comportements quotidiens
Les plateformes en ligne, les fournisseurs de technologies publicitaires, les courtiers en données, et les négociants de toutes sortes d’industries peuvent maintenant surveiller, reconnaître et analyser des individus dans de nombreuses situations. Ils peuvent étudier ce qui intéresse les gens, ce qu’ils ont fait aujourd’hui, ce qu’ils vont sûrement faire demain, et leur valeur en tant que client.
Les données concernant les vies en ligne et hors ligne des personnes
Une large spectre d’entreprises collecte des informations sur les personnes depuis des décennies. Avant l’existence d’Internet, les agences de crédit et les agences de marketing direct servaient de point d’intégration principal entre les données provenant de différentes sources. Une première étape importante dans la surveillance systématique des consommateurs s’est produite dans les années 1990, par la commercialisation de bases de données, les programmes de fidélité et l’analyse poussée de solvabilité. Après l’essor d’Internet et de la publicité en ligne au début des années 2000, et la montée des réseaux sociaux, des smartphones et de la publicité en ligne à la fin des années 2000, on voit maintenant dans les années 2010 l’industrie des données clients s’intégrer avec le nouvel écosystème de pistage et de profilage numérique.
Cartographie de la collecte de données clients
Différents niveaux, domaines et sources de collecte de données clients par les entreprises
De longue date, les courtiers en données clients et d’autres entreprises acquièrent des informations sur les abonnés à des journaux et à des magazines, sur les membres de clubs de lecture et de ciné-clubs, sur les acheteurs de catalogues de vente par correspondance, sur les personnes réservant dans les agences de voyage, sur les participants à des séminaires et à des conférences, et sur les consommateurs qui remplissent les cartes de garantie pour leurs achats. La collecte de données d’achats grâce à des programmes de fidélité est, de ce point de vue, une pratique établie depuis longtemps.
En complément des données provenant directement des individus, sont utilisées, par exemple les informations concernant le type quartiers et d’immeubles où résident les personnes afin de décrire, étiqueter, trier et catégoriser ces personnes. De même, les entreprises utilisent maintenant des profils de consommateurs s’appuyant sur les métadonnées concernant le type de sites Internet fréquentés, les vidéos regardées, les applications utilisées et les zones géographiques visitées. Au cours de ces dernières années, l’échelle et le niveau de détail des flux de données comportementales générées par toutes sortes d’activités du quotidien, telles que l’utilisation d’Internet, des réseaux sociaux et des équipements, ont rapidement augmenté.
Ce n’est pas un téléphone, c’est mon mouchard /pisteur/. New York Times, 2012
Un pistage et un profilage omniprésents
Une des principales raisons pour lesquelles le pistage et le profilage commerciaux sont devenus si généralisés c’est que quasiment tous les sites Internet, les fournisseurs d’applications mobiles, ainsi que de nombreux vendeurs d’équipements, partagent activement des données comportementales avec d’autres entreprises.
Il y a quelques années, la plupart des sites Internet ont commencé à inclure dans leur propre site des services de pistage qui transmettent des données à des tiers. Certains de ces services fournissent des fonctions visibles aux utilisateurs. Par exemple, lorsqu’un site Internet montre un bouton Facebook « j’aime » ou une vidéo YouTube encapsulée, des données utilisateur sont transmises à Facebook ou à Google. En revanche, de nombreux autres services ayant trait à la publicité en ligne demeurent cachés et, pour la plupart, ont pour seul objectif de collecter des données utilisateur. Le type précis de données utilisateur partagées par les éditeurs numériques et la façon dont les tierces parties utilisent ces données reste largement méconnus. Une partie de ces activités de pistage peut être analysée par n’importe qui ; par exemple en installant l’extension pour navigateur Lightbeam, il est possible de visualiser le réseau invisible des trackers des parties tierces.
Une étude récente a examiné un million de sites Internet différents et a trouvé plus de 80 000 services tiers recevant des données concernant les visiteurs de ces sites. Environ 120 de ces services de pistage ont été trouvés sur plus de 10 000 sites, et six entreprises surveillent les utilisateurs sur plus de 100 000 sites, dont Google, Facebook, Twitter et BlueKai d’Oracle. Une étude sur 200 000 utilisateurs allemands visitant 21 millions de pages Internet a montré que les trackers tiers étaient présents sur 95 % des pages visitées. De même, la plupart des applications mobiles partagent des informations sur leurs utilisateurs avec d’autres entreprises. Une étude menée en 2015 sur les applications à la mode en Australie, en Allemagne et aux États-Unis a trouvé qu’entre 85 et 95 % des applications gratuites, et même 60 % des applications payantes se connectaient à des tierces parties recueillant des données personnelles.
Une carte interactive des services cachés de pistage tiers sur les applications Android créée par des chercheurs européens et américains peut être explorée à l’adresse suivante : haystack.mobi/panopticon
En matière d’appareils, ce sont peut-être les smartphones qui actuellement contribuent le plus au recueil omniprésent données. L’information enregistrée par les téléphones portables fournit un aperçu détaillé de la personnalité et de la vie quotidienne d’un utilisateur. Puisque les consommateurs ont en général besoin d’un compte Google, Apple ou Microsoft pour les utiliser, une grande partie de l’information est déjà reliée à l’identifiant d’une des principales plateformes.
La vente de données utilisateurs ne se limite pas aux éditeurs de sites Internet et d’applications mobiles. Par exemple, l’entreprise d’intelligence commerciale SimilarWeb reçoit des données issues non seulement de centaines de milliers de sources de mesures directes depuis les sites et les applications, mais aussi des logiciels de bureau et des extensions de navigateur. Au cours des dernières années, de nombreux autres appareils avec des capteurs et des connexions réseau ont intégré la vie de tous les jours, cela va des liseuses électroniques et autres accessoires connectés aux télés intelligentes, compteurs, thermostats, détecteurs de fumée, imprimantes, réfrigérateurs, brosses à dents, jouets et voitures. À l’instar des smartphones, ces appareils donnent aux entreprises un accès sans précédent au comportement des consommateurs dans divers contextes de leur vie.
Publicité programmatique et technologie marketing
La plus grande partie de la publicité numérique prend aujourd’hui la forme d’enchères en temps réel hautement automatisées entre les éditeurs et les publicitaires ; on appelle cela la publicité programmatique. Lorsqu’une personne se rend sur un site Internet, les données utilisateur sont envoyées à une kyrielle de services tiers, qui cherchent ensuite à reconnaître la personne et extraire l’information disponible sur le profil. Les publicitaires souhaitant livrer une publicité à cet individu, en particulier du fait de certains attributs ou comportements, placent une enchère. En quelques millisecondes, le publicitaire le plus offrant gagne et place la pub. Les publicitaires peuvent de la même façon enchérir sur les profils utilisateurs et le placement de publicités au sein des applications mobiles.
Néanmoins, ce processus ne se déroule pas, la plupart du temps, entre les éditeurs et les publicitaires. L’écosystème est constitué d’une pléthore de toutes sortes de données différentes et de fournisseurs de technologies en interaction les uns avec les autres, parmi lesquels des réseaux publicitaires, des marchés publicitaires, des plateformes côté vente et des plateformes côté achat. Certains se spécialisent dans le pistage et la publicité suivant les résultats de recherche, dans la publicité généraliste sur Internet, dans la pub sur mobile, dans les pubs vidéos, dans les pubs sur les réseaux sociaux, ou dans les pubs au sein des jeux. D’autres se concentrent sur l’approvisionnement en données, en analyse ou en services de personnalisation.
Pour tracer le portrait des utilisateurs d’Internet et d’applications mobiles, toutes les parties impliquées ont développé des méthodes sophistiquées pour accumuler, regrouper et relier les informations provenant de différentes entreprises afin de suivre les individus dans tous les aspects de leur vie. Nombre d’entre elles recueillent et utilisent des profils numériques sur des centaines de millions de consommateurs, leurs navigateurs Internet et leurs appareils.
De nombreux secteurs rejoignent l’économie de pistage
Au cours de ces dernières années, des entreprises dans plusieurs secteurs ont commencé à partager et à utiliser à très grande échelle des données concernant leurs utilisateurs et clients.
La plupart des détaillants vendent des formes agrégées de données sur les habitudes d’achat auprès des entreprises d’études de marchés et des courtiers en données. Par exemple, l’entreprise de données IRI accède aux données de plus de 85 000 magasins (‘alimentation, grande distribution, médicaments, d’alcool et d’animaux de compagnie, magasin à prix unique et magasin de proximité). Nielsen déclare recueillir les informations concernant les ventes de 900 000 magasins dans le monde dans plus de 100 pays. L’enseigne de grande distribution britannique Tesco sous-traite son programme de fidélité et ses activités en matière de données auprès d’une filiale, Dunnhumby, dont le slogan est « transformer les données consommateur en régal pour le consommateur ». Lorsque Dunnhumby a fait l’acquisition de l’entreprise technologique de publicité allemande Sociomantic, il a été annoncé que Dunnhumby « conjuguerait ses connaissances étendues au sujet sur les préférences d’achat de 400 millions de consommateurs » avec les « données en temps réel de plus de 700 millions de consommateurs en ligne » de Sociomantic afin personnaliser et d’évaluer les publicités.
Cartographie de l’écosystème du pistage et du profilage commercial
Aujourd’hui de nombreux industriels dans divers secteurs ont rejoint l’écosystème de pistage et de profilage numérique, aux cotés des grandes plateformes en ligne et des professionnels de l’analyse des données clients.
De grands groupes médiatiques sont aussi fortement intégrés dans l’écosystème de pistage et de profilage numérique actuel. Par exemple, Time Inc. a fait l’acquisition d’Adelphic, une importante société de pistage et de technologies publicitaires multi-support, mais aussi de Viant, une entreprise qui déclare avoir accès à plus de 1,2 milliard d’utilisateurs enregistrés. La plateforme de streaming Spotify est un exemple célèbre d’éditeur numérique qui vend les données de ses utilisateurs. Depuis 2016, la société partage avec le département données du géant du marketing WPP des informations à propos de ce que les utilisateurs écoutent, sur leur humeur ainsi que sur leur comportement et leur activité en termes de playlist. WPP a maintenant accès « aux préférences et comportements musicaux des 100 millions d’utilisateurs de Spotify ».
De nombreuses grandes entreprises de télécom et de fournisseurs d’accès Internet ont fait l’acquisition d’entreprises de technologies publicitaires et de données. Par exemple, Millennial Media, une filiale d’AOL-Verizon, est une plateforme de publicité mobile qui collecte les données de plus de 65 000 applications de différents développeurs, et prétend avoir accès à environ 1 milliard d’utilisateurs actifs distincts dans le monde. Singtel, l’entreprise de télécoms basée à Singapour, a acheté Turn, une plateforme de technologies publicitaires qui donne accès aux distributeurs à 4,3 milliards d’appareils pouvant être ciblés et d’identifiants de navigateurs et à 90 000 attributs démographiques, comportementaux et psychologiques.
Comme les compagnies aériennes, les hôtels, les commerces de détail et les entreprises de beaucoup d’autres secteur, le secteur des services financiers a commencé à agréger et utiliser des données clients supplémentaires grâce à des programmes de fidélité dans les années 80 et 90. Les entreprises dont la clientèle cible est proche et complémentaires partagent depuis longtemps certaines de leurs données clients entre elles, un processus souvent géré par des intermédiaires. Aujourd’hui, l’un de ces intermédiaires est Cardlytics, une entreprise qui gère des programmes de fidélité pour plus de 1 500 institutions financières, telles que Bank of America et MasterCard. Cardlytics s’engage auprès des institutions financières à « générer des nouvelles sources de revenus en exploitant le pouvoir de [leurs] historiques d’achat ». L’entreprise travaille aussi en partenariat avec LiveRamp, la filiale d’Acxiom qui combine les données en ligne et hors ligne des consommateurs.
Pour MasterCard, la vente de produits et de services issus de l’analyse de données pourrait même devenir son cœur de métier, sachant que la production d’informations, dont la vente de données, représentent une part considérable et croissante de ses revenus. Google a récemment déclaré qu’il capture environ 70 % des transactions par carte de crédit aux États-Unis via « partenariats tiers » afin de tracer les achats, mais n’a pas révélé ses sources.
Ce sont vos données. Vous avez le droit de les contrôler, de les partager et de les utiliser comme bon vous semble.
C’est ainsi que le courtier en données Lotame s’adresse sur son site Internet à ses entreprises clientes en 2016.
Relier, faire correspondre et combiner des profils numériques
Jusqu’à récemment, les publicitaires, sur Facebook, Google ou d’autres réseaux de publicité en ligne, ne pouvaient cibler les individus qu’en analysant leur comportement en ligne. Mais depuis quelques années, grâce aux moyens offerts par les entreprises de données, les profils numériques issus de différentes plateformes, de différentes bases de données clients et du monde de la publicité en ligne peuvent désormais être associés et combinés entre eux.
Connecter les identités en ligne et hors ligne
Cela a commencé en 2012, quand Facebook a permis aux entreprises de télécharger leurs propres listes d’adresses de courriel et de numéros de téléphone sur la plateforme. Bien que les adresses et numéros de téléphone soient convertis en pseudonyme, Facebook est en mesure de relier directement ces données client provenant d’entreprises tierces avec ses propres comptes utilisateur. Cela permet par exemple aux entreprises de trouver et de cibler très précisément sur Facebook les personnes dont elles possèdent les adresses de courriel ou les numéros de téléphone. De la même façon, il leur est éventuellement possible d’exclure certaines personnes du ciblage de façon sélective, ou de déléguer à la plateforme le repérage des personnes qui ont des caractéristiques, centre d’intérêts, et comportements communs.
C’est une fonctionnalité puissante, peut-être plus qu’il n’y paraît au premier abord. Elle permet en effet aux entreprises d’associer systématiquement leurs données client avec les données Facebook. Mieux encore, d’autres publicitaires et marchands de données peuvent également synchroniser leurs bases avec celles de la plateforme et en exploiter les ressources, ce qui équivaut à fournir une sorte de télécommande en temps réel pour manipuler l’univers des données Facebook. Les entreprises peuvent maintenant capturer en temps réel des données comportementales extrêmement précises comme un clic de souris sur un site, le glissement d’un doigt sur une application mobile ou un achat en magasin, et demander à Facebook de trouver et de cibler aussitôt les personnes qui viennent de se livrer à ces activités. Google et Twitter ont mis en place des fonctionnalités similaires en 2015.
Les plateformes de gestion de données
De nos jours, la plupart des entreprises de technologie publicitaire croisent en continu plusieurs sources de codage relatives aux individus. Les plateformes de gestion de données permettent aux entreprises de tous les domaines d’associer et de relier leurs propres données clients, comprenant des informations en temps réel sur les achats, les sites web consultés, les applications utilisées et les réponses aux courriels, avec des profils numériques fournis par une multitude de fournisseurs tiers de données. Les données associées peuvent alors être analysées, triées et classées, puis utilisées pour envoyer un message donné à des personnes précises via des réseaux ou des appareils particuliers. Une entreprise peut, par exemple, cibler un groupe de clients existants ayant visité une page particulière sur son site ; ils sont alors perçus comme pouvant devenir de bons clients, bénéficiant alors de contenus personnalisés ou d’une réduction, que ce soit sur Facebook, sur une appli mobile ou sur le site même de l’entreprise.
L’émergence des plateformes de gestion de données marque un tournant dans le développement d’un envahissant pistage des comportements d’achat. Avec leur aide, les entreprises dans tous les domaines et partout dans le monde peuvent très facilement associer et relier les données qu’elles ont collectées depuis des années sur leurs clients et leurs prospects avec les milliards de profils collectés dans le monde numérique. Les principales entreprises faisant tourner ces plateformes sont : Oracle, Adobe, Salesforce (Krux), Wunderman (KBM Group/Zipline), Neustar, Lotame et Cxense.
Nous vous afficherons des publicités basées sur votre identité, mais cela ne veut pas dire que vous serez identifiable.
Erin Egan, Directeur de la protection de la vie privée chez Facebook, 2012
Identifier les gens et relier les profils numériques
Pour surveiller et suivre les gens dans les différentes situations de leur vie, pour leur associer des profils et toujours les reconnaître comme un seul et même individu, les entreprises amassent une grande variété de types de données qui, en quelque sorte, les identifient.
Parce qu’il est ambigu, le nom d’une personne a toujours été un mauvais identifiant pour un recueil de données. L’adresse postale, par contre, a longtemps été et est encore, une indication clé qui permet d’associer et de relier des données de différentes origines sur les consommateurs et leur famille. Dans le monde numérique, les identifiants les plus pertinents pour relier les profils et les comportements sur les différentes bases de données, plateformes et appareils sont : l’adresse de courriel, le numéro de téléphone, et le code propre à chaque smartphone ou autre appareil.
Les identifiants de compte utilisateur sur les immenses plateformes comme Google, Facebook, Apple et Microsoft jouent aussi un rôle important dans le suivi des gens sur Internet. Google, Apple, Microsoft et Roku attribuent un « identifiant publicitaire » aux individus, qui est maintenant largement utilisé pour faire correspondre et relier les données d’appareils tels que les smartphones avec les autres informations issues du monde numérique. Verizon utilise son propre identifiant pour pister les utilisateurs sur les sites web et les appareils. Certaines grandes entreprises de données comme Acxiom, Experian et Oracle disposent, au niveau mondial, d’un identifiant unique par personne qu’elles utilisent pour relier des dizaines d’années de données clients avec le monde numérique. Ces identifiants d’entreprise sont constitués le plus souvent de deux identifiants ou plus qui sont attachés à différents aspects de la vie en ligne et hors ligne d’une personne et qui peuvent être d’une certaine façon reliés l’un à l’autre.
Des Identifiants utilisés pour pister les gens sur les sites web, les appareils et les lieux de vie
Comment les entreprises identifient les consommateurs et les relient à des informations de profils – sources : voir le rapport
Les entreprises de pistage utilisent également des identifiants plus ou moins temporaires, comme les cookies qui sont attachés aux utilisateurs surfant sur le web. Depuis que les utilisateurs peuvent ne pas autoriser ou supprimer les cookies dans leur navigateur, elles ont développé des méthodes sophistiquées permettant de calculer une empreinte numérique unique basée sur diverses caractéristiques du navigateur et de l’ordinateur d’une personne. De la même manière, les entreprises amassent les empreintes sur les appareils tels que les smartphones. Les cookies et les empreintes numériques sont continuellement synchronisés entre les différents services de pistage et ensuite reliés à des identifiants plus permanents.
D’autres entreprises fournissent des services de pistage multi-appareils qui utilisent le machine learning (voir Wikipédia) pour analyser de grandes quantités de données. Par exemple, Tapad, qui a été acheté par le géant des télécoms norvégiens Telenor, analyse les données de deux milliards d’appareils dans le monde et utilise des modèles basés sur les comportements et les relations pour trouver la probabilité qu’un ordinateur, une tablette, un téléphone ou un autre appareil appartienne à la même personne.
Un profilage « anonyme » ?
Les entreprises de données suppriment les noms dans leurs profils détaillés et utilisent des fonctions de hachage (voir Wikipedia) pour convertir les adresses de courriel et les numéros de téléphone en code alphanumérique comme “e907c95ef289”. Cela leur permet de déclarer sur leur site web et dans leur politique de confidentialité qu’elles recueillent, partagent et utilisent uniquement des données clients « anonymisées » ou « dé-identifiées ».
Néanmoins, comme la plupart des entreprises utilisent les mêmes process déterministes pour calculer ces codes alphanumériques, on devrait les considérer comme des pseudonymes qui sont en fait bien plus pratiques que les noms réels pour identifier les clients dans le monde numérique. Même si une entreprise partage des profils contenant uniquement des adresses de courriels ou des numéros de téléphones chiffrés, une personne peut toujours être reconnue dès qu’elle utilise un autre service lié avec la même adresse de courriel ou le même numéro de téléphone. De cette façon, bien que chaque service de pistage impliqué ne connaissent qu’une partie des informations du profil d’une personne, les entreprises peuvent suivre et interagir avec les gens au niveau individuel via les services, les plateformes et les appareils.
Si une entreprise peut vous suivre et interagir avec vous dans le monde numérique – et cela inclut potentiellement votre téléphone mobile ou votre télé – alors son affirmation que vous êtes anonyme n’a aucun sens, en particulier quand des entreprises ajoutent de temps à autre des informations hors-ligne aux données en ligne et masquent simplement le nom et l’adresse pour rendre le tout « anonyme ».
Joseph Turow, spécialiste du marketing et de la vie privée dans son livre « The Daily You », 2011
Gérer les clients et les comportements : personnalisation et évaluation
S’appuyant sur les méthodes sophistiquées d’interconnexion et de combinaison de données entre différents services, les entreprises de tous les secteurs d’activité peuvent utiliser les flux de données comportementales actuellement omniprésents afin de surveiller et d’analyser une large gamme d’activités et de comportements de consommateurs pouvant être pertinents vis-à-vis de leurs intérêts commerciaux.
Avec l’aide des vendeurs de données, les entreprises tentent d’entrer en contact avec les clients tout au long de leurs parcours autant de fois que possible, à travers les achats en ligne ou en boutique, le publipostage, les pubs télé et les appels des centres d’appels. Elles tentent d’enregistrer et de mesurer chaque interaction avec un consommateur, y compris sur les sites Internet, plateformes et appareils qu’ils ne contrôlent pas eux-mêmes. Elles peuvent recueillir en continu une abondance de données concernant leurs clients et d’autres personnes, les améliorer avec des informations provenant de tiers, et utiliser les profils améliorés au sein de l’écosystème de commercialisation et de technologie publicitaire. À l’heure actuelle, les plateformes de gestion des données clients permettent la définition de jeux complexes de règles qui régissent la façon de réagir automatiquement à certains critères tels que des activités ou des personnes données ou une combinaison des deux.
Par conséquent, les individus ne savent jamais si leur comportement a déclenché une réaction de l’un de ces réseaux de pistage et de profilage constamment mis à jour, interconnectés et opaques, ni, le cas échéant, comment cela influence les options qui leur sont proposées à travers les canaux de communication et dans les situations de vie.
Tracer, profiler et influencer les individus en temps réel
Chaque interaction enclenche un large éventail de flux de données entre de nombreuses entreprises.
Personnalisation en série
Les flux de données échangés entre les publicitaires en ligne, les courtiers en données, et les autres entreprises ne sont pas seulement utilisés pour diffuser de la publicité ciblée sur les sites web ou les applis mobiles. Ils sont de plus en plus utilisés pour personnaliser les contenus, les options et les choix offerts aux consommateurs sur le site d’une entreprise par exemple. Les entreprises de technologie des données, comme par exemple Optimizely, peuvent aider à personnaliser un site web spécialement pour les personnes qui le visitent pour la première fois, en s’appuyant sur les profils numériques de ces visiteurs fournis par Oracle.
Les boutiques en ligne, par exemple, personnalisent l’accueil des visiteurs : quels produits seront mis en évidence, quelles promotions seront proposées, et même le prix et des produits ou des services peuvent être différents selon la personne qui visite le site. Les services de détection de la fraude évaluent les utilisateurs en temps réel et décident quels moyens de paiement et de transport peuvent être proposés.
Les entreprises développent des technologies pour calculer et évaluer en continu le potentiel de valeur à long terme d’un client en s’appuyant sur son historique de navigation, de recherche et de localisation, mais aussi sur son usage des applis, sur les produits achetés et sur ses amis sur les réseaux sociaux. Chaque clic, chaque glissement de doigt, chaque Like, chaque partage est susceptible d’influencer la manière dont une personne est traitée en tant que client, combien de temps elle va attendre avant que la hotline ne lui réponde, ou si elle sera complètement exclue des relances et des services marketing.
L’Internet des riches n’est pas le même que celui des pauvres.
Michael Fertik, fondateur de reputation.com, 2013
Trois types de plateformes technologiques jouent un rôle important dans cette sorte de personnalisation instantanée. Premièrement, les entreprises utilisent des systèmes de gestion de la relation client pour gérer leurs données sur les clients et les prospects. Deuxièmement, elles utilisent des plateformes de gestion de données pour connecter leurs propres données à l’écosystème de publicité numérique et obtiennent ainsi des informations supplémentaires sur le profil de leurs clients. Troisièmement, elles peuvent utiliser des plateformes de marketing prédictif qui les aident à produire le bon message pour la bonne personne au bon moment, calculant comment convaincre quelqu’un en exploitant ses faiblesses et ses préjugés.
Par exemple, l’entreprise de données RocketFuel promet à ses clients de « leur apporter des milliers de milliards de signaux numériques ou non pour créer des profils individuels et pour fournir aux consommateurs une expérience personnalisée, toujours actualisée et toujours pertinente » s’appuyant sur les 2,7 milliards de profils uniques de son dépôt de données. Selon RocketFuel, il s’agit « de noter chaque signal selon sa propension à influencer le consommateur ».
La plateforme de marketing prédictif TellApart, qui appartient à Twitter, associe une valeur à chaque couple client/produit acheté, une « synthèse entre la probabilité d’achat, l’importance de la commande et la valeur à long terme », s’appuyant sur « des centaines de signaux en ligne et en magasin sur un consommateur anonyme unique ». En conséquence, TellApart regroupe automatiquement du contenu tel que « l’image du produit, les logos, les offres et toute autre métadonnée » pour construire des publicités, des courriels, des sites web et des offres personnalisées.
Tarifs personnalisés et campagnes électorales
Des méthodes identiques peuvent être utilisées pour personnaliser les tarifs dans les boutiques en ligne, par exemple, en prédisant le niveau d’achat d’un client à long terme ou le montant qu’il sera probablement prêt à payer un peu plus tard. Des preuves sérieuses suggèrent que les boutiques en ligne affichent déjà des tarifs différents selon les consommateurs, ou même des prix différents pour le même produit, en s’appuyant sur leur comportement et leurs caractéristiques. Un champ d’action similaire est la personnalisation lors des campagnes électorales. Le ciblage des électeurs avec des messages personnalisés, adaptés à leur personnalité, et à leurs opinions politiques sur des problèmes donnés a fait monter les débats sur une possible manipulation politique.
Utiliser les données, les analyser et les personnaliser pour gérer les consommateurs
Actuellement, dans tous les domaines, les entreprises peuvent mobiliser les réseaux de suivi et de profilage pour trouver, évaluer, contacter, trier et gérer les consommateurs
Tests et expériences sur les personnes
La personnalisation s’appuyant sur de riches informations de profil et sur du suivi invasif en temps réel est devenue un outil puissant pour influencer le comportement du consommateur quand il visite une page web, clique sur une pub, s’inscrit à un service, s’abonne à une newsletter, télécharge une application ou achète un produit.
Pour améliorer encore cela, les entreprises ont commencé à faire des expériences en continu sur les individus. Elles procèdent à des tests en faisant varier les fonctionnalités, le design des sites web, l’interface utilisateur, les titres, les boutons, les images ou mêmes les tarifs et les remises, surveillent et mesurent avec soin comment les différents groupes d’utilisateurs interagissent avec ces modifications. De cette façon, les entreprises optimisent sans arrêt leur capacité à encourager les personnes à agir comme elles veulent qu’elles agissent.
Les organes de presse, y compris à grand tirage comme le Washington Post, utilisent différentes versions des titres de leurs articles pour voir laquelle est la plus performante. Optimizely, un des principaux fournisseurs de technologies pour ce genre de tests, propose à ses clients la capacité de « faire des tests sur l’ensemble de l’expérience client sur n’importe quel canal, n’importe quel appareil, et n’importe quelle application ». Expérimenter sur des usagers qui l’ignorent est devenu la nouvelle norme.
En 2014, Facebook a déclaré faire tourner « plus d’un millier d’expérimentations chaque jour » afin « d’optimiser des résultats précis » ou pour « affiner des décisions de design sur le long terme ». En 2010 et 2012, la plateforme a mené des expérimentations sur des millions d’utilisateurs et montré qu’en manipulant l’interface utilisateur, les fonctionnalités et le contenu affiché, Facebook pouvait augmenter significativement le taux de participation électorale d’un groupe de personnes. Leur célèbre expérimentation sur l’humeur des internautes, portant sur 700 000 individus, consistait à manipuler secrètement la quantité de messages émotionnellement positifs ou négatifs présents dans les fils d’actualité des utilisateurs : il s’avéra que cela avait un impact sur le nombre de messages positifs ou négatifs que les utilisateurs postaient ensuite eux-mêmes.
Suite à la critique massive de Facebook par le public concernant cette expérience, la plateforme de rendez-vous OkCupid a publié un article de blog provocateur défendant de telles pratiques, déclarant que « nous faisons des expériences sur les êtres humains » et « c’est ce que font tous les autres ». OkCupid a décrit une expérimentation dans laquelle a été manipulé le pourcentage de « compatibilité » montré à des paires d’utilisateurs. Quand on affichait un taux de 90 % entre deux utilisateurs qui en fait étaient peu compatibles, les utilisateurs échangeaient nettement plus de messages entre eux. OkCupid a déclaré que quand elle « dit aux gens » qu’ils « vont bien ensemble », alors ils « agissent comme si c’était le cas ».
Toutes ces expériences qui posent de vraies questions éthiques montrent le pouvoir de la personnalisation basée sur les données pour influer sur les comportements.
Dans les mailles du filet : vie quotidienne, données commerciales et analyse du risque
Les données concernant les comportements des personnes, les liens sociaux, et les moments les plus intimes sont de plus en plus utilisées dans des contextes ou à des fins complètement différents de ceux dans lesquels elles ont été enregistrées. Notamment, elles sont de plus en plus utilisées pour prendre des décisions automatisées au sujet d’individus dans des domaines clés de la vie tels que la finance, l’assurance et les soins médicaux.
Données relatives aux risques pour le marketing et la gestion client
Les agences d’évaluation de la solvabilité, ainsi que d’autres acteurs clés de l’évaluation du risque, principalement dans des domaines tels que la vérification des identités, la prévention des fraudes, les soins médicaux et l’assurance fournissent également des solutions commerciales. De plus, la plupart des courtiers en données s’échangent divers types d’informations sensibles, par exemple des informations concernant la situation financière d’un individu, et ce à des fins commerciales. L’utilisation de l’évaluation de solvabilité à des fins de marketing afin soit de cibler soit d’exclure des ensembles vulnérables de la population a évolué pour devenir des produits qui associent le marketing et la gestion du risque.
L’agence d’évaluation de la solvabilité TransUnion fournit, par exemple, un produit d’aide à la décision piloté par les données à destination des commerces de détail et des services financiers qui leur permet « de mettre en œuvre des stratégies de marketing et de gestion du risque sur mesure pour atteindre les objectifs en termes de clients, canaux de vente et résultats commerciaux », il inclut des données de crédit et promet « un aperçu inédit du comportement, des préférences et des risques du consommateur. » Les entreprises peuvent alors laisser leurs clients « choisir parmi une gamme complète d’offres sur mesure, répondant à leurs besoins, leurs préférences et leurs profils de risque » et « évaluer leurs clients sur divers produits et canaux de vente et leur présenter uniquement la ou les offres les plus pertinente pour eux et les plus rentables » pour l’entreprise. De même, Experian fournit un produit qui associe « crédit à la consommation et informations commerciales, fourni avec plaisir par Experian. »
En matière de surveillance, il n’est pas question de connaître vos secrets, mais de gérer des populations, de gérer des personnes.
Katarzyna Szymielewicz, Vice-Présidente EDRi, 2015
Vérification des identités en ligne et détection de la fraude
Outre la machine de surveillance en temps réel qui a été développée au travers de la publicité en ligne, d’autres formes de pistage et de profilage généralisées ont émergé dans les domaines de l’analyse de risque, de la détection de fraudes et de la cybersécurité.
De nos jours, les services de détection de fraude en ligne utilisent des technologies hautement intrusives afin d’évaluer des milliards de transactions numériques. Ils recueillent d’énormes quantités d’informations concernant les appareils, les individus et les comportements. Les fournisseurs habituels dans l’évaluation de solvabilité, la vérification d’identité, et la prévention des fraudes ont commencé à surveiller et à évaluer la façon dont les personnes surfent sur le web et utilisent leurs appareils mobiles. En outre, ils ont entrepris de relier les données comportementales en ligne avec l’énorme quantité d’information hors-connexion qu’ils recueillent depuis des dizaines d’années.
Avec l’émergence de services passant par l’intermédiaire d’objets technologiques, la vérification de l’identité des consommateurs et la prévention de la fraude sont devenues de plus en plus importantes et de plus en plus contraignantes, notamment au vu de la cybercriminalité et de la fraude automatisée. Dans un même temps, les systèmes actuels d’analyse du risque ont agrégé des bases de données gigantesques contenant des informations sensibles sur des pans entiers de population. Nombre de ces systèmes répondent à un grand nombre de cas d’utilisation, parmi lesquels la preuve d’identité pour les services financiers, l’évaluation des réclamations aux compagnies d’assurance et des demandes d’indemnités, de l’analyse des transactions financières et l’évaluation de milliards de transactions en ligne.
De tels systèmes d’analyse du risque peuvent décider si une requête ou une transaction est acceptée ou rejetée ou décider des options de livraison disponibles pour une personne lors d’une transaction en ligne. Des services marchands de vérification d’identité et d’analyse de la fraude sont également employés dans des domaines tels que les forces de l’ordre et la sécurité nationale. La frontière entre les applications commerciales de l’analyse de l’identité et de la fraude et celles utilisées par les agences gouvernementales de renseignement est de plus en plus floue.
Lorsque des individus sont ciblés par des systèmes aussi opaques, ils peuvent être signalés comme étant suspects et nécessitant un traitement particulier ou une enquête, ou bien ils peuvent être rejetés sans plus d’explication. Ils peuvent recevoir un courriel, un appel téléphonique, une notification, un message d’erreur, ou bien le système peut tout simplement ne pas indiquer une option, sans que l’utilisateur ne connaisse son existence pour d’autres. Des évaluations erronées peuvent se propager d’un système à l’autre. Il est souvent difficile, voire impossible de faire recours contre ces évaluations négatives qui excluent ou rejettent, notamment à cause de la difficulté de s’opposer à quelque chose dont on ne connaît pas l’existence.
Exemples de détection de fraude en ligne et de service d’analyse des risques
L’entreprise de cybersécurité ThreatMetrix traite les données concernant 1,4 milliard de « comptes utilisateur uniques » sur des « milliers de sites dans le monde. » Son Digital Identity Network (Réseau d’Identité Numérique) enregistre des « millions d’opérations faites par des consommateurs chaque jour, notamment des connexions, des paiements et des créations de nouveaux comptes », et cartographie les « associations en constante évolution entre les individus et leurs appareils, leurs positions, leurs identifiants et leurs comportements » à des fins de vérification des identités et de prévention des fraudes. L’entreprise collabore avec Equifax et TransUnion. Parmi ses clients se trouvent Netflix, Visa et des entreprises dans des secteurs tels que le jeu vidéo, les services gouvernementaux et la santé.
De façon analogue, l’entreprise de données ID Analytics, qui a récemment été achetée par Symantec, exploite un Réseau d’Identifiants fait de « 100 millions de nouveaux éléments d’identité quotidiens issus des principales organisations interprofessionnelles. ». L’entreprise agrège des données concernant 300 millions de consommateurs, sur les prêts à haut risque, les achats en ligne et les demandes de carte de crédit ou de téléphone portable. Son Indice d’Identité, ID Score, prend en compte les appareils numériques ainsi que les noms, les numéros de sécurité sociale et les adresses postales et courriel.
Trustev, une entreprise en ligne de détection de la fraude dont le siège se situe en Irlande et qui a été rachetée par l’agence d’évaluation de la solvabilité TransUnion en 2015, juge des transactions en ligne pour des clients dans les secteurs des services financiers, du gouvernement, de la santé et de l’assurance en s’appuyant sur l’analyse des comportements numériques, les identités et les appareils tels que les téléphones, les tablettes, les ordinateurs portables, les consoles de jeux, les télés et même les réfrigérateurs. L’entreprise propose aux entreprises clientes la possibilité d’analyser la façon dont les visiteurs cliquent et interagissent avec les sites Internets et les applications. Elle utilise une large gamme de données pour évaluer les utilisateurs, y compris les numéros de téléphone, les adresses courriel et postale, les empreintes de navigateur et d’appareil, les vérifications de la solvabilité, les historiques d’achats sur l’ensemble des vendeurs, les adresses IP, les opérateurs mobiles et la géolocalisation des téléphones. Afin d’aider à « accepter les transactions futures », chaque appareil se voit attribuer une empreinte digitale d’appareil unique. Trustev propose aussi une technologie de marquage d’empreinte digitale sociale qui analyse le contenu des réseaux sociaux, notamment une « analyse de la liste d’amis » et « l’identification des schémas ». TransUnion a intégré la technologie Trustev dans ses propres solutions identifiantes et anti-fraude.
Selon son site Internet, Trustev utilise une large gamme de données pour évaluer les personnes
Capture d’écran du site Internet de Trustev, 2 juin 2016
De façon similaire, l’agence d’évaluation de la solvabilité Equifax affirme qu’elle possède des données concernant près de 1 milliard d’appareils et peut affirmer « l’endroit où se situe en fait un appareil et s’il est associé à d’autres appareils utilisés dans des fraudes connues ». En associant ces données avec « des milliards d’identités et d’événements de crédit pour trouver les activités douteuses » dans tous les secteurs, et en utilisant des informations concernant la situation d’emploi et les liens entre les ménages, les familles et les partenaires, Equifax prétend être capable « de distinguer les appareils ainsi que les individus ».
Je ne suis pas un robot
Le produit reCaptcha de Google fournit en fait un service similaire, du moins en partie. Il est incorporé dans des millions de sites Internets et aide les fournisseurs de sites Internets à décider si un visiteur est un être humain ou non. Jusqu’à récemment, les utilisateurs devaient résoudre diverses sortes de défis rapides tels que le déchiffrage de lettres dans une image, la sélection d’images dans une grille, ou simplement en cochant la case « Je ne suis pas un robot ». En 2017, Google a présenté une version invisible de reCaptcha, en expliquant qu’à partir de maintenant, les utilisateurs humains pourront passer « sans aucune interaction utilisateur, contrairement aux utilisateurs douteux et aux robots ». L’entreprise ne révèle pas le type de données et de comportements utilisateurs utilisés pour reconnaître les humains. Des analyses laissent penser que Google, outre les adresses IP, les empreintes de navigateur, la façon dont l’utilisateur frappe au clavier, déplace la souris ou utilise l’écran tactile « avant, pendant et après » une interaction reCaptcha, utilise plusieurs témoins Google. On ne sait pas exactement si les individus sans compte utilisateur sont désavantagés, si Google est capable d’identifier des individus particuliers plutôt que des « humains » génériques, ou si Google utilise les données enregistrées par reCaptcha à d’autres fins que la détection de robots.
Le pistage numérique à des fins publicitaires et de détection de la fraude ?
Les flux omniprésents de données comportementales enregistrées pour la publicité en ligne s’écoulent vers les systèmes de détection de la fraude. Par exemple, la plateforme de données commerciales Segment propose à ses clients des moyens faciles d’envoyer des données concernant leurs clients, leur site Internet et les utilisateurs mobiles à une kyrielle de services de technologies commerciales, ainsi qu’à des entreprises de détection de fraude. Castle est l’une d’entre-elles et utilise « les données comportementales des consommateurs pour prédire les utilisateurs qui présentent vraisemblablement un risque en matière de sécurité ou de fraude ». Une autre entreprise, Smyte, aide à « prévenir les arnaques, les messages indésirables, le harcèlement et les fraudes par carte de crédit ».
La grande agence d’analyse de la solvabilité Experian propose un service de pistage multi-appareils qui fournit de la reconnaissance universelle d’appareils, sur mobile, Internet et les applications pour le marketing numérique. L’entreprise s’engage à concilier et à associer les « identifiants numériques existants » de leurs clients, y compris des « témoins, identifiants d’appareil, adresses IP et d’autres encore », fournissant ainsi aux commerciaux un « lien omniprésent, cohérent et permanent sur tous les canaux ».
La technologie d’identification d’appareils provient de 41st parameter (le 41e paramètre), une entreprise de détection de la fraude rachetée par Experian en 2013. En s’appuyant sur la technologie développée par 41st parameter, Experian propose aussi une solution d’intelligence d’appareil pour la détection de la fraude au cours des paiements en ligne. Cette solution qui « créé un identifiant fiable pour l’appareil et recueille des données appareil abondantes » « identifie en quelques millisecondes chaque appareil à chaque visite » et « fournit une visibilité jamais atteinte de l’individu réalisant le paiement ». On ne sait pas exactement si Experian utilise les mêmes données pour ses services d’identification d’appareils pour détecter la fraude que pour le marketing.
Cartographie de l’écosystème du pistage et du profilage commercial
Au cours des dernières années, les pratiques déjà existantes de surveillance commerciale ont rapidement muté en un large éventail d’acteurs du secteur privé qui surveillent en permanence des populations entières. Certains des acteurs de l’écosystème actuel de pistage et de profilage, tels que les grandes plateformes et d’autres entreprises avec un grand nombre de clients, tiennent une position unique en matière d’étendue et de niveau de détail de leurs profils de consommateurs. Néanmoins, les données utilisées pour prendre des décisions concernant les individus sur de nombreux sujets ne sont généralement pas centralisées en un lieu, mais plutôt assemblées en temps réel à partir de plusieurs sources selon les besoins.
Un large éventail d’entreprises de données et de services d’analyse en marketing, en gestion client et en analyse du risque recueillent, analysent, partagent et échangent de façon uniforme des données client et les associent avec des informations supplémentaires issues de milliers d’autres entreprises. Tandis que l’industrie des données et des services d’analyse fournissent les moyens pour déployer ces puissantes technologies, les entreprises dans de nombreuses industries contribuent à augmenter la quantité et le niveau de détail des données collectées ainsi que la capacité à les utiliser.
Cartographie de l’écosystème du pistage et du profilage commercial numérique
En plus des grandes plateformes en ligne et de l’industrie des données et des services d’analyse des consommateurs, des entreprises dans de nombreux secteurs ont rejoint les écosystèmes de pistage et de profilage numérique généralisé.
Google et Facebook, ainsi que d’autres grandes plateformes telles que Apple, Microsoft, Amazon et Alibaba ont un accès sans précédent à des données concernant les vies de milliards de personnes. Bien qu’ils aient des modèles commerciaux différents et jouent par conséquent des rôles différents dans l’industrie des données personnelles, ils ont le pouvoir de dicter dans une large mesure les paramètres de base des marchés numériques globaux. Les grandes plateformes limitent principalement la façon dont les autres entreprises peuvent obtenir leurs données. Ainsi, ils les obligent à utiliser les données utilisateur de la plateforme dans leur propre écosystème et recueillent des données au-delà de la portée de la plateforme.
Bien que les grandes multinationales de différents secteurs ayant des interactions fréquentes avec des centaines de millions de consommateurs soient en quelque sorte dans une situation semblable, elles ne font pas qu’acheter des données clients recueillies par d’autres, elles en fournissent aussi. Bien que certaines parties des secteurs des services financiers et des télécoms ainsi que des domaines sociétaux critiques tels que la santé, l’éducation et l’emploi soient soumis à une réglementation plus stricte dans la plupart des juridictions, un large éventail d’entreprises a commencé à utiliser ou fournissent des données aux réseaux actuels de surveillance commerciale.
Les détaillants et d’autres entreprises qui vendent des produits et services aux consommateurs vendent pour la plupart les données concernant les achats de leurs clients. Les conglomérats médiatiques et les éditeurs numériques vendent des données au sujet de leur public qui sont ensuite utilisées par des entreprises dans la plupart des autres secteurs. Les fournisseurs de télécoms et d’accès haut débit ont entrepris de suivre leurs clients sur Internet. Les grandes groupes de distribution, de médias et de télécoms ont acheté ou achètent des entreprises de données, de pistage et de technologie publicitaire. Avec le rachat de NBC Universal par Comcast et le rachat probable de Time Warner par AT&T, les grands groupes de télécoms aux États-Unis sont aussi en train de devenir des éditeurs gigantesques, créant par là même des portefeuilles puissants de contenu, de données et de capacité de pistage. Avec l’acquisition de AOL et de Yahoo, Verizon aussi est devenu une « plateforme ».
Les institutions financières ont longtemps utilisé des données sur les consommateurs pour la gestion du risque, notamment dans l’évaluation de la solvabilité et la détection de fraude, ainsi que pour le marketing, l’acquisition et la rétention de clientèle. Elles complètent leurs propres données avec des données externes issues d’agences d’évaluation de la solvabilité, de courtiers en données et d’entreprises de données commerciales. PayPal, l’entreprise de paiements en ligne la plus connue, partage des informations personnelles avec plus de 600 tiers, parmi lesquels d’autres fournisseurs de paiements, des agences d’évaluation de la solvabilité, des entreprises de vérification de l’identité et de détection de la fraude, ainsi qu’avec les acteurs les plus développés au sein de l’écosystème de pistage numérique. Tandis que les réseaux de cartes de crédit et les banques ont partagé des informations financières sur leurs clients avec les fournisseurs de données de risque depuis des dizaines d’années, ils ont maintenant commencé à vendre des données sur les transactions à des fins publicitaires.
Une myriade d’entreprises, grandes ou petites, fournissant des sites Internets, des applications mobiles, des jeux et d’autres solutions sont étroitement liées à l’écosystème de données commerciales. Elles utilisent des services qui leur permettent de facilement transmettre à des services tiers des données concernant leurs utilisateurs. Pour nombre d’entre elles, la vente de flux de données comportementales concernant leurs utilisateurs constitue un élément clé de leur business model. De façon encore plus inquiétante, les entreprises qui fournissent des services tels que les enregistreurs d’activité physique intègrent des services qui transmettent les données utilisateurs à des tierces parties.
L’envahissante machine de surveillance en temps réel qui a été développée pour la publicité en ligne est en train de s’étendre vers d’autres domaines dont la politique, la tarification, la notation des crédits et la gestion des risques. Partout dans le monde, les assureurs commencent à proposer à leurs clients des offres incluant du suivi en temps réel de leur comportement : comment ils conduisent, quelles sont leurs activités santé ou leurs achats alimentaires et quand ils se rendent au club de gym. Des nouveaux venus dans l’analyse assurantielle et les technologies financières prévoient les risques de santé d’un individu en s’appuyant sur les données de consommation, mais évaluent aussi la solvabilité à partir de données de comportement via les appels téléphoniques ou les recherches sur Internet.
Les courtiers en données sur les consommateurs, les entreprises de gestion de clientèle et les agences de publicité comme Acxiom, Epsilon, Merkle ou Wunderman/WPP jouent un rôle prépondérant en assemblant et reliant les données entre les plateformes, les multinationales et le monde de la technologie publicitaire. Les agences d’évaluation de crédit comme Experian qui fournissent de nombreux services dans des domaines très sensibles comme l’évaluation de crédit, la vérification d’identité et la détection de la fraude jouent également un rôle prépondérant dans l’actuel envahissant écosystème de la commercialisation des données.
Des entreprises particulièrement importantes qui fournissent des données, des analyses et des solutions logicielles sont également appelées « plateforme ». Oracle, un fournisseur important de logiciel de base de données est, ces dernières années, devenu un courtier en données de consommation. Salesforce, le leader sur le marché de la gestion de la relation client qui gère les bases de données commerciales de millions de clients qui ont chacun de nombreux clients, a récemment acquis Krux, une grande entreprise de données, connectant et combinant des données venant de l’ensemble du monde numérique. L’entreprise de logiciels Adobe joue également un rôle important dans le domaine des technologies de profilage et de publicité.
En plus, les principales grandes entreprises du conseil, de l’analyse et du logiciel commercial, comme IBM, Informatica, SAS, FICO, Accenture, Capgemini, Deloitte et McKinsey et même des entreprises spécialisées dans le renseignement et la défense comme Palantir, jouent également un rôle significatif dans la gestion et l’analyse des données personnelles, de la gestion de la relation client à celle de l’identité, du marketing à l’analyse de risque pour les assureurs, les banques et les gouvernements.
Vers une société du contrôle social numérique généralisé ?
Ce rapport montre qu’aujourd’hui, les réseaux entre plateformes en ligne, fournisseurs de technologies publicitaires, courtiers en données, et autres peuvent suivre, reconnaître et analyser des individus dans de nombreuses situations de la vie courante. Les informations relatives aux comportements et aux caractéristiques d’un individu sont reliées entre elles, assemblées, et utilisées en temps réel par des entreprises, des bases de données, des plateformes, des appareils et des services. Des acteurs uniquement motivés par des buts économiques ont fait naître un environnement de données dans lequel les individus sont constamment sondés et évalués, catégorisés et regroupés, notés et classés, numérotés et comptés, inclus ou exclus, et finalement traités de façon différente.
Ces dernières années, plusieurs évolutions importantes ont donné de nouvelles capacités sans précédent à la surveillance omniprésente par les entreprises. Cela comprend l’augmentation des médias sociaux et des appareils en réseau, le pistage et la mise en relation en temps réel de flux de données comportementales, le rapprochement des données en ligne et hors ligne, et la consolidation des données commerciales et de gestion des risques. L’envahissant pistage et profilage numériques, mélangé à la personnalisation et aux tests, ne sont pas seulement utilisés pour surveiller, mais aussi pour influencer systématiquement le comportement des gens. Quand les entreprises utilisent les données sur les situations du quotidien pour prendre des décisions parfois triviales, parfois conséquente sur les gens, cela peut conduire à des discriminations, et renforcer voire aggraver des inégalités existantes.
Malgré leur omniprésence, seul le haut de l’iceberg des données et des activités de profilage est visible pour les particuliers. La plupart d’entre elles restent opaques et à peine compréhensible par la majorité des gens. Dans le même temps, les gens ont de moins en moins de solutions pour résister au pouvoir de cet ecosystème de données ; quitter le pistage et le profilage envahissant, est devenu synonyme de quitter la vie moderne. Bien que les responsables des entreprises affirment que la vie privée est morte (tout en prenant soin de préserver leur propre vie privée), Mark Andrejevic suggère que les gens perçoivent en fait l’asymétrie du pouvoir dans le monde numérique actuel, mais se sentent « frustrés par un sentiment d’impuissance face à une collecte et à une exploitation de données de plus en plus sophistiquées et exhaustives. »
Au regard de cela, ce rapport se concentre sur le fonctionnement interne et les pratiques en vigueur dans l’actuelle industrie des données personnelles. Bien que l’image soit devenue plus nette, de larges portions du système restent encore dans le noir. Renforcer la transparence sur le traitement des données par les entreprises reste un prérequis indispensable pour résoudre le problème de l’asymétrie entre les entreprises de données et les individus. Avec un peu de chance, les résultats de ce rapport encourageront des travaux ultérieurs de la part de journalistes, d’universitaires, et d’autres personnes concernés par les libertés civiles, la protection des données et celle des consommateurs ; et dans l’idéal des travaux des législateurs et des entreprises elles-mêmes.
En 1999, Lawrence Lessig, avait bien prédit que, laissé à lui-même, le cyberespace, deviendrait un parfait outil de contrôle façonné principalement par la « main invisible » du marché. Il avait dit qu’il était possible de « construire, concevoir, ou programmer le cyberespace pour protéger les valeurs que nous croyons fondamentales, ou alors de construire, concevoir, ou programmer le cyberespace pour permettre à toutes ces valeurs de disparaître. » De nos jours, la deuxième option est presque devenue réalité au vu des milliards de dollars investis dans le capital-risque pour financer des modèles économiques s’appuyant sur une exploitation massive et sans scrupule des données. L’insuffisance de régulation sur la vie privée aux USA et l’absence de son application en Europe ont réellement gêné l’émergence d’autres modèles d’innovation numérique, qui seraient fait de pratiques, de technologies, de modèles économiques qui protègent la liberté, la démocratie, la justice sociale et la dignité humaine.
À un niveau plus global, la législation sur la protection des données ne pourra pas, à elle seule, atténuer les conséquences qu’un monde « conduit par les données » a sur les individus et la société que ce soit aux USA ou en Europe. Bien que le consentement et le choix soient des principes cruciaux pour résoudre les problèmes les plus urgents liés à la collecte massive de données, ils peuvent également mener à une illusion de volontarisme. En plus d’instruments de régulation supplémentaires sur la non-discrimination, la protection du consommateur, les règles de concurrence, il faudra en général un effort collectif important pour donner une vision positive d’une future société de l’information. Sans quoi, on pourrait se retrouver bientôt dans une société avec un envahissant contrôle social numérique, dans la laquelle la vie privée deviendrait, si elle existe encore, un luxe pour les riches. Tous les éléments en sont déjà en place.
La production de ce rapport, matériaux web et illustrations a été soutenue par Open Society Foundations.
Bibliographie
Christl, W. (2017, juin). Corporate surveillance in everyday life. Cracked Labs.
Christl, W., & Spiekermann, S. (2016). Networks of Control, a Report on Corporate Surveillance, Digital Tracking, Big Data & Privacy (p. 14‑20). Consulté à l’adresse https://www.privacylab.at/wp-content/uploads/2016/09/Christl-Networks__K_o.pdf
Epp, C., Lippold, M., & Mandryk, R. L. (2011). Identifying emotional states using keystroke dynamics (p. 715). ACM Press. https://doi.org/10.1145/1978942.1979046
Kosinski, M., Stillwell, D., & Graepel, T. (2013). Private traits and attributes are predictable from digital records of human behavior. Proceedings of the National Academy of Sciences, 110(15), 5802‑5805. https://doi.org/10.1073/pnas.1218772110
Turow, J. (s. d.). Daily You | Yale University Press. Consulté 25 septembre 2017, à l’adresse https://yalebooks.yale.edu/book/9780300188011/daily-you






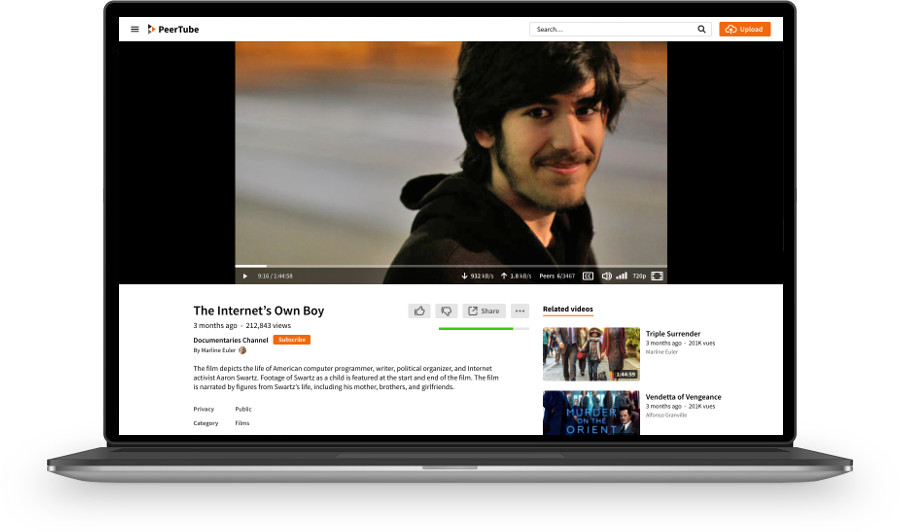













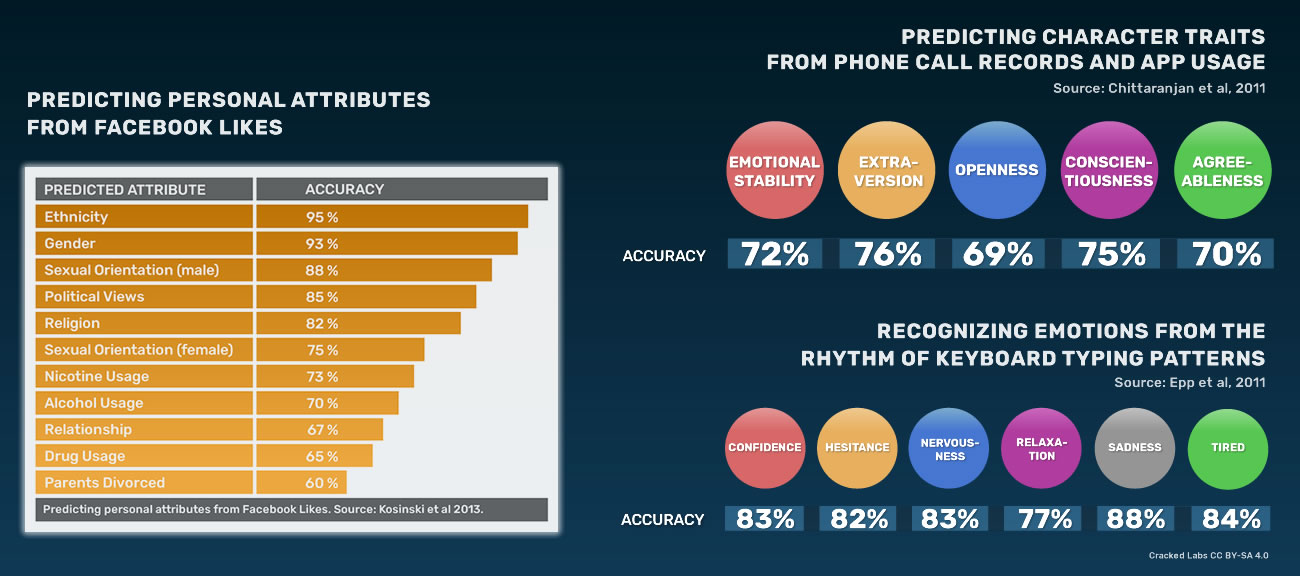
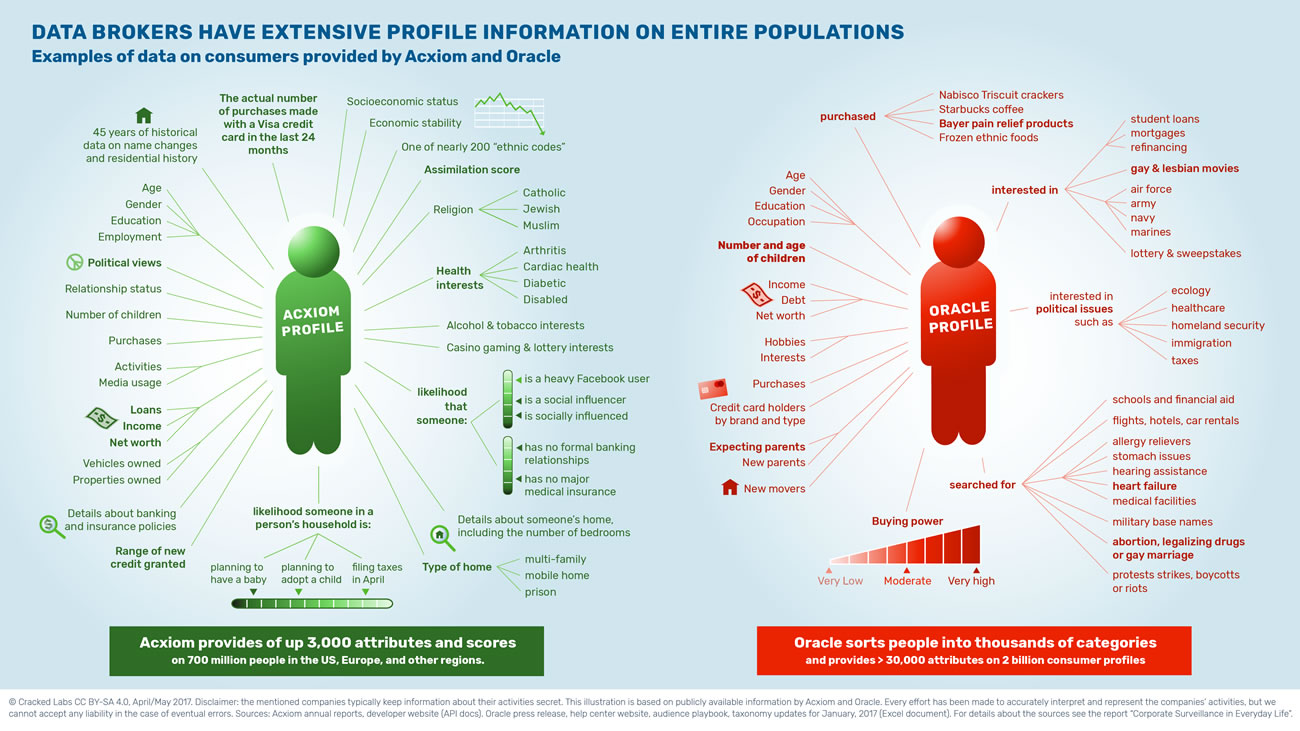
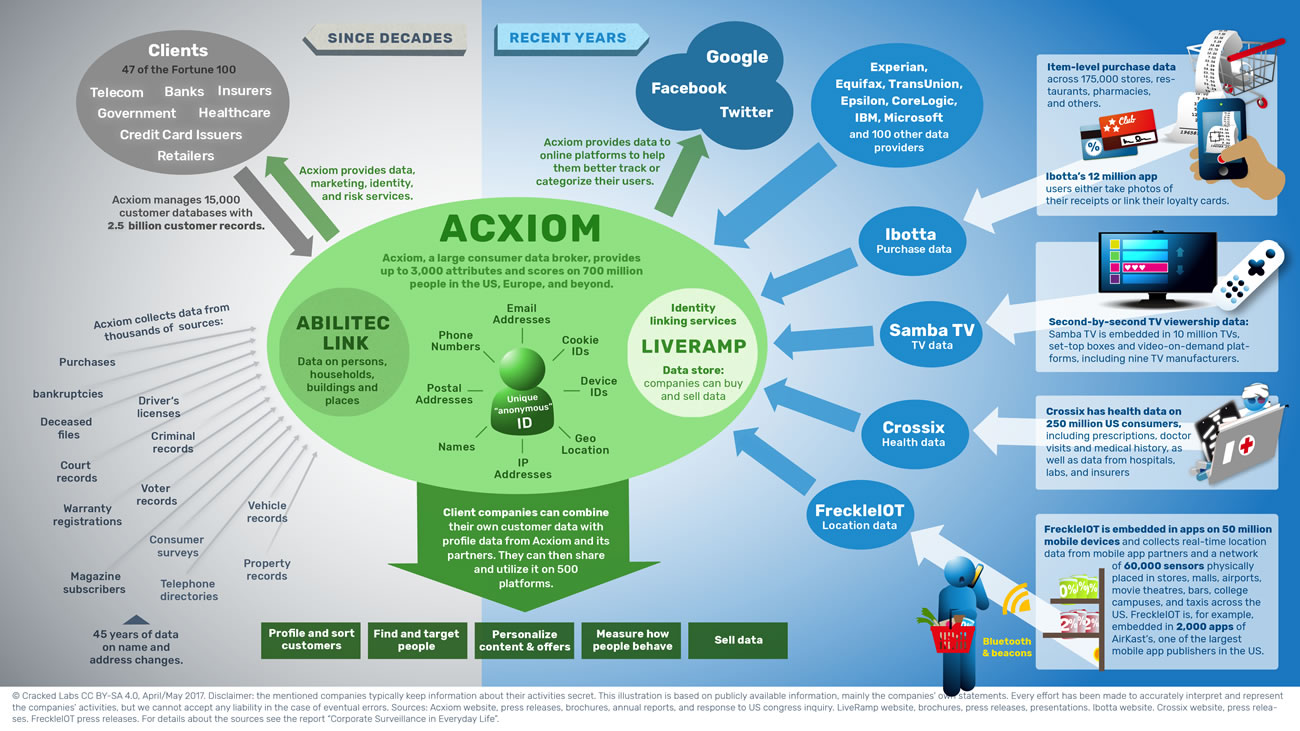
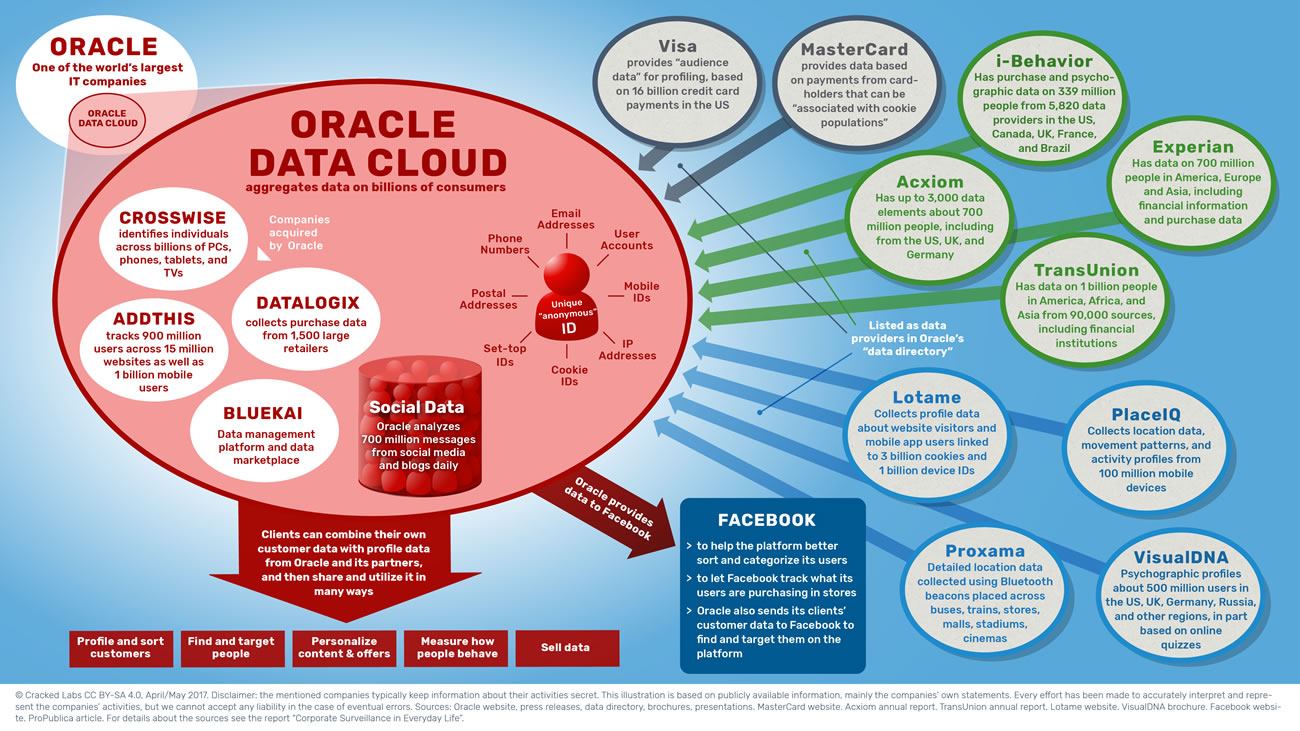
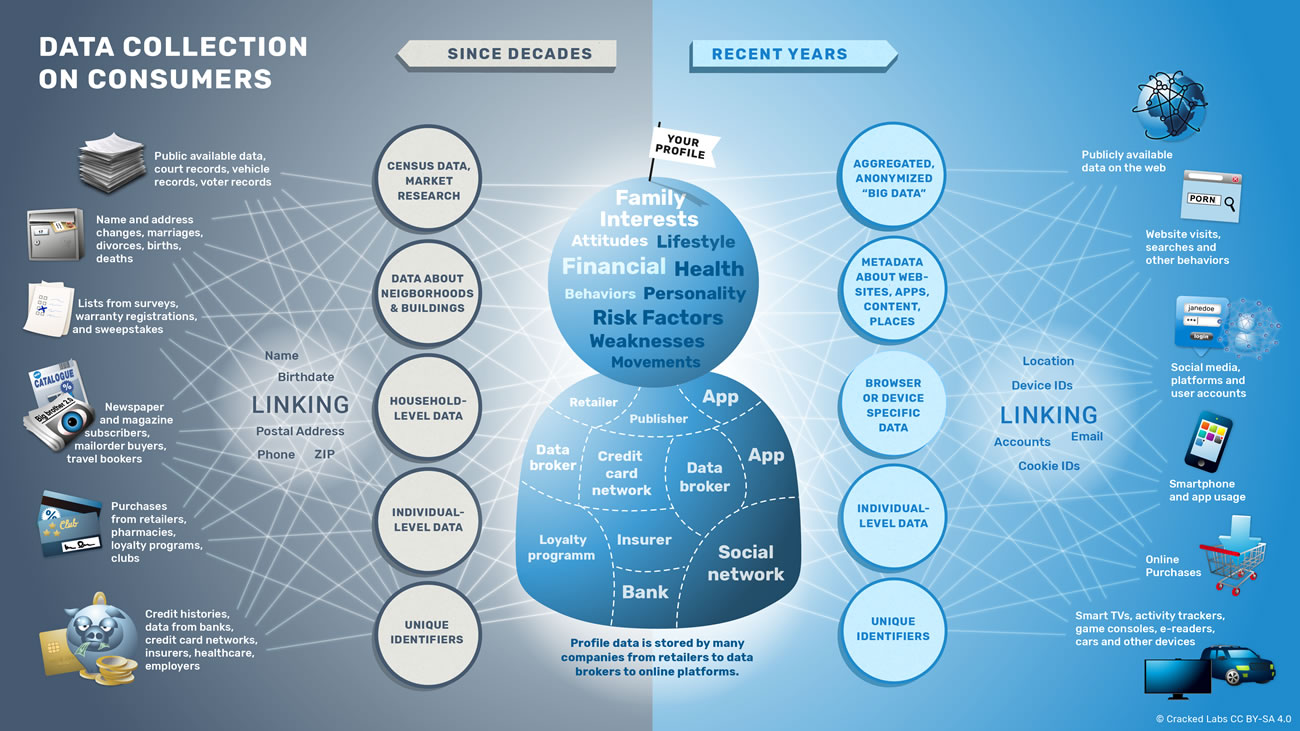

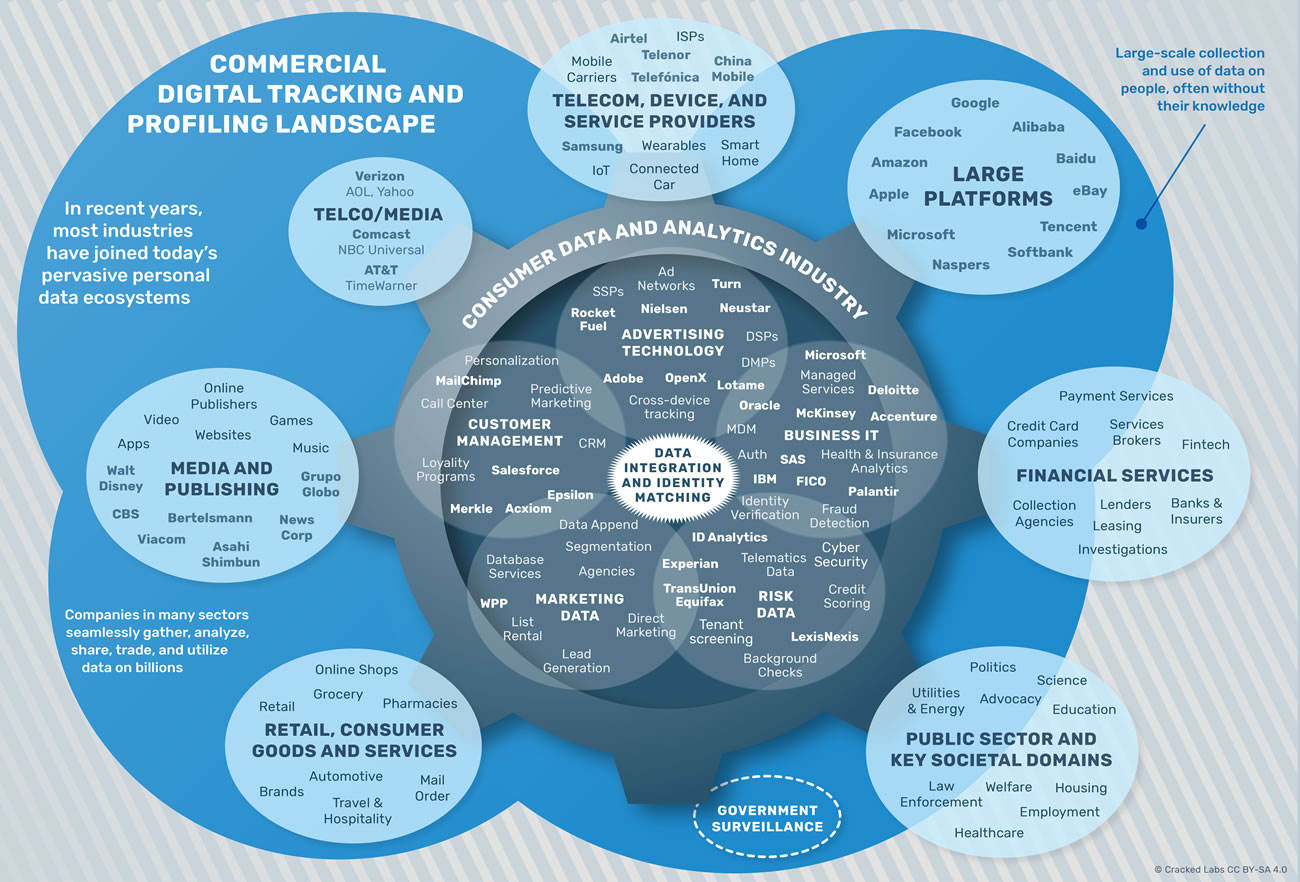
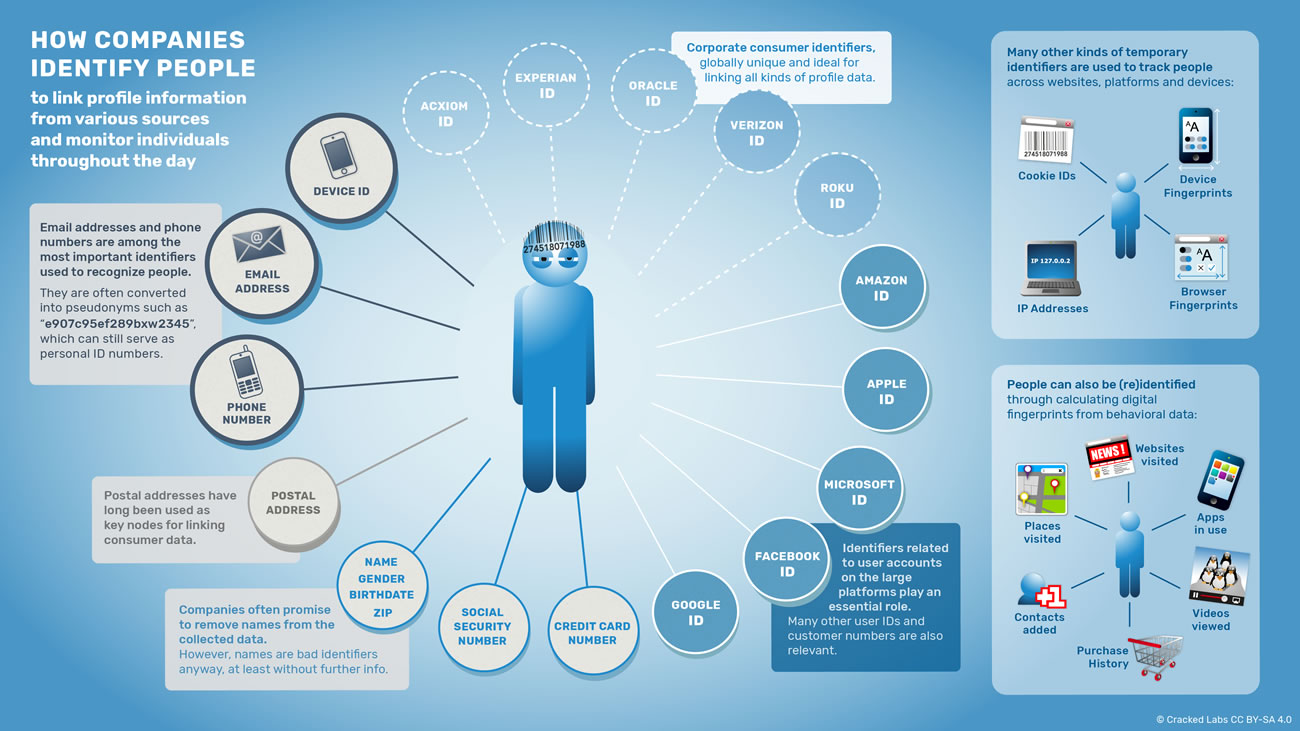
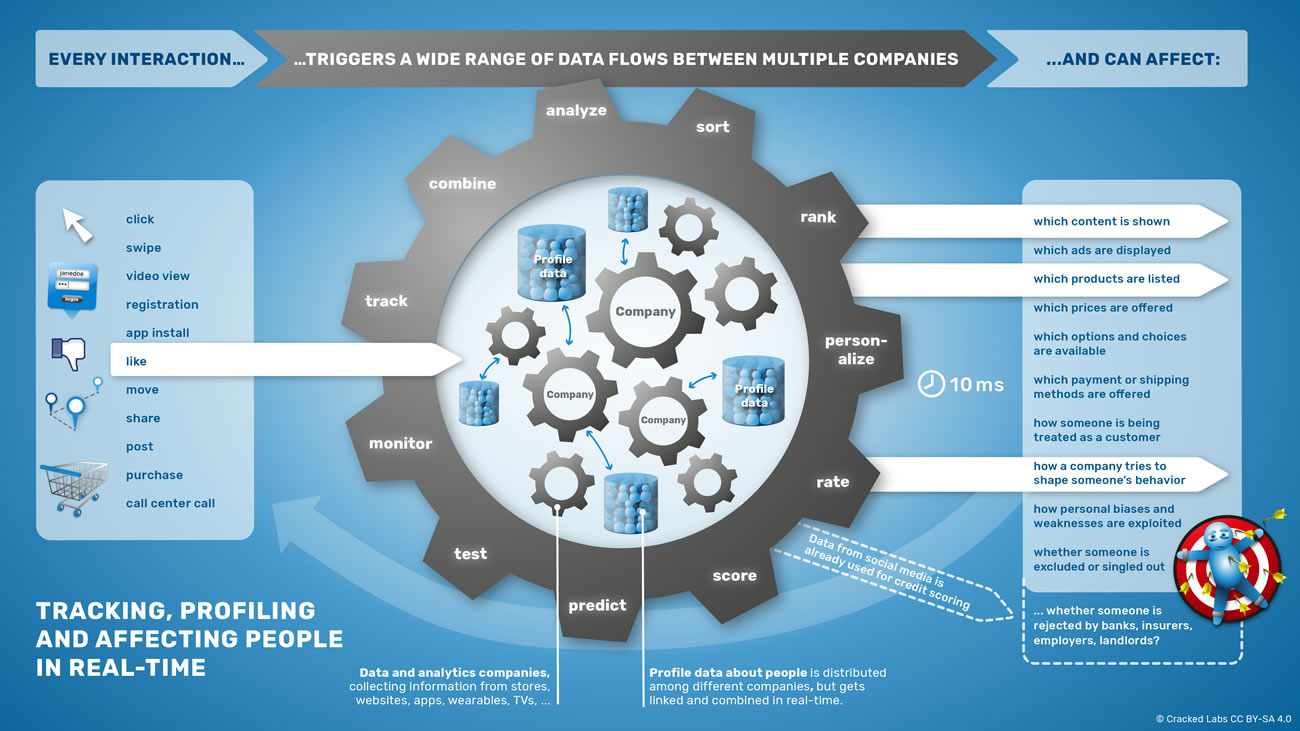
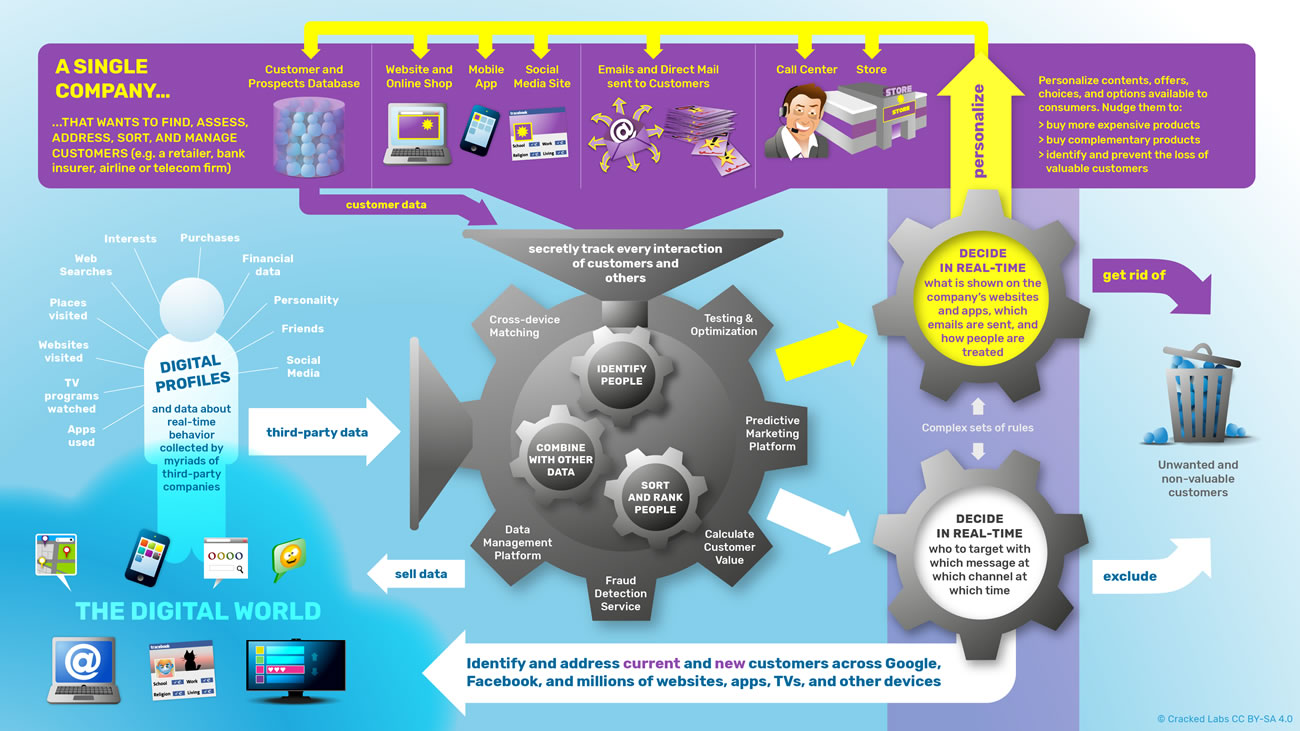
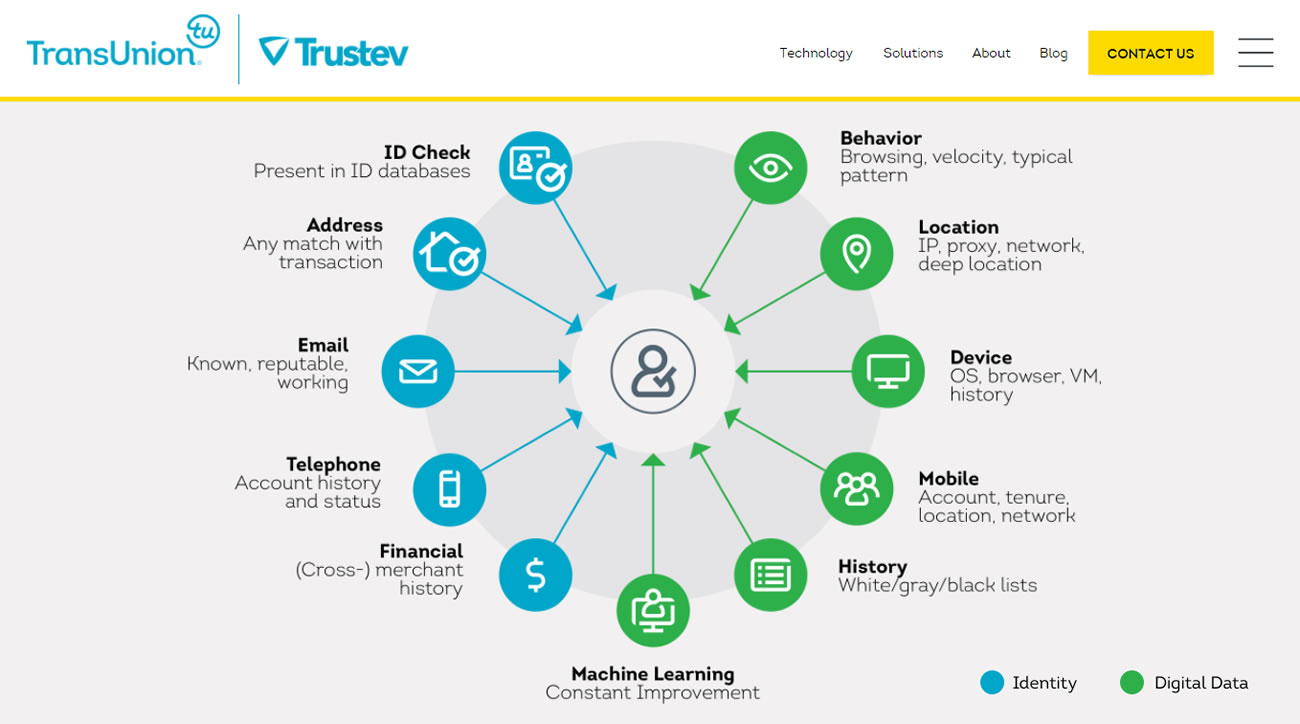
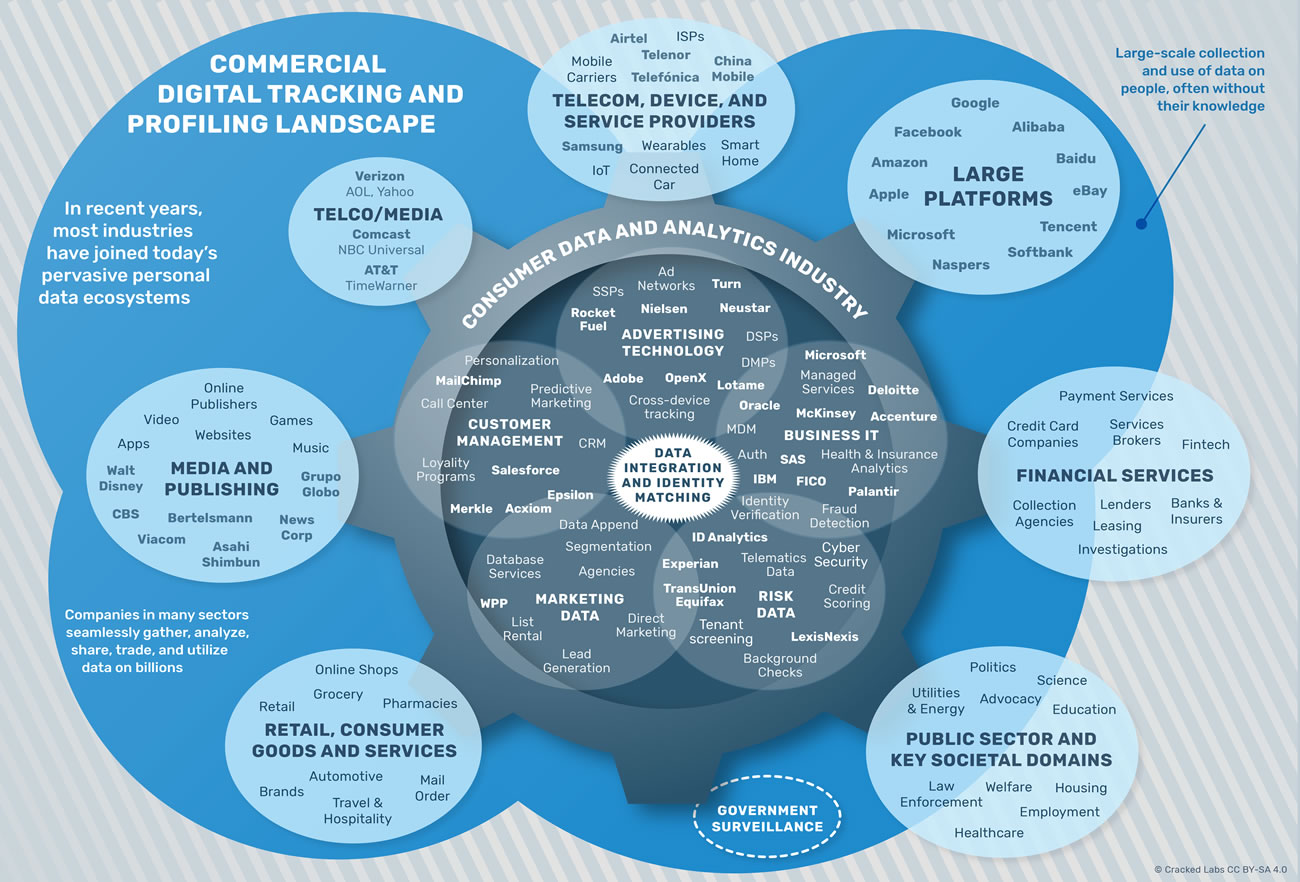
{kind=link}
{kind=link}
{kind=link}