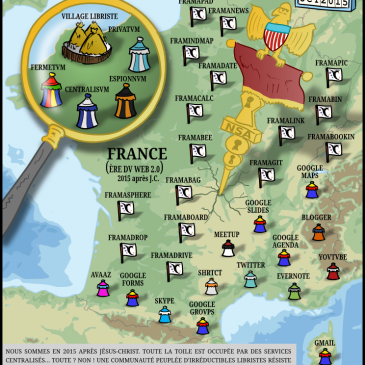
L’histoire d’un dessin animé libre
Vous l’avez sans doute vu passer à plusieurs reprises : notre dessinateur Gee nous a concocté cette année un petit GIF animé (avec variantes) pour illustrer les sorties de nos différents services et a même poussé le concept jusqu’à en faire … Lire la suite