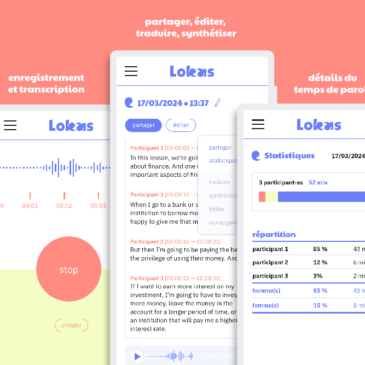
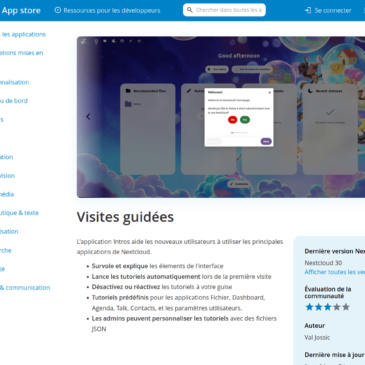
Framatoolbox, une boite à outils numérique pour les p’tits besoins du quotidien
Nous l’annoncions il y a quelques semaines, nous avons ouvert quatre nouveaux services ! La semaine dernière nous vous proposions de découvrir les coulisses du nouveau Framadate et aujourd’hui, nous souhaitons vous présenter le deuxième service de la liste : Framatoolbox. Pour … Lire la suite